Apaçi Hudi veri göllerine veritabanı ve veri ambarı yeteneklerini getiren açık tablo formatıdır. Apache Hudi, veri mühendislerinin sorgu performansını korurken sürekli gelişen veri kümelerini işlemlerle yönetme gibi karmaşık zorlukları yönetmelerine yardımcı olur. Veri mühendisleri Apache Hudi'yi iş yüklerinin akışının yanı sıra verimli artımlı veri hatları oluşturmak için kullanıyor. Hudi sağlar tablolar, işlemler, verimli yükseltmeler ve silmeler, gelişmiş indeksler, akış alma hizmetleri, veri kümeleme ve sıkıştırma optimizasyonlar ve eşzamanlılık kontrolü, verilerinizi açık kaynaklı dosya formatlarında tutarken. Hudi'nin gelişmiş performans optimizasyonları, Apache Spark, Presto, Trino, Hive ve benzeri popüler sorgu motorlarından herhangi biriyle analitik iş yüklerini daha hızlı hale getirir.
Birçok AWS müşterisi, Amazon S3 üzerine inşa edilen veri göllerinde Apache Hudi'yi kullanmaya başladı. AWS Tutkalanaliz, makine öğrenimi (ML) ve uygulama geliştirme için birden fazla kaynaktan gelen verileri keşfetmeyi, hazırlamayı, taşımayı ve entegre etmeyi kolaylaştıran sunucusuz bir veri entegrasyon hizmeti. AWS Tutkal Paletli AWS Glue'un bir bileşenidir ve meta verilerin manuel olarak tanımlanmasına gerek kalmadan veri içeriğinden otomatik olarak tablo meta verileri oluşturmanıza olanak tanır.
AWS Glue tarayıcıları artık Apache Hudi tablolarını destekliyorbenimsenmesini basitleştirerek AWS Tutkal Veri Kataloğu Hudi tabloları kataloğu olarak. Tipik bir kullanım durumu, katalog tablosu tanımı olmayan Hudi tablolarının kaydedilmesidir. Diğer bir tipik kullanım durumu ise Hive metastore gibi diğer Hudi kataloglarından geçiştir. Diğer Hudi Kataloglarından geçiş yaparken bir AWS Glue tarayıcısı oluşturup planlayabilir ve Hudi tablo dosyalarının bulunduğu bir veya daha fazla Amazon S3 yolu sağlayabilirsiniz. AWS Glue tarayıcısının geçebileceği maksimum Amazon S3 yolu derinliğini sağlama seçeneğiniz vardır. AWS Glue tarayıcıları her çalıştırmada şema ve bölüm bilgilerini çıkaracak ve AWS Glue Data Catalog'u şema ve bölüm değişiklikleriyle güncelleyecektir. AWS Glue tarayıcıları, AWS analitik motorlarının doğrudan kullanabileceği AWS Glue Veri Kataloğu'ndaki en son meta veri dosyası konumunu günceller.
Bu lansmanla birlikte, Hudi tablolarını AWS Glue Veri Kataloğuna kaydetmek için bir AWS Glue tarayıcısı oluşturabilir ve planlayabilirsiniz. Daha sonra Hudi tablolarının bulunduğu bir veya daha fazla Amazon S3 yolu sağlayabilirsiniz. Tarayıcıların geçebileceği maksimum Amazon S3 yolu derinliğini sağlama seçeneğiniz vardır. Her tarayıcı çalıştırmasında, tarayıcı S3 yollarının her birini inceler ve yeni tablolar, silmeler ve şema güncellemeleri gibi şema bilgilerini AWS Glue Data Catalog'da kataloglar. Tarayıcılar bölüm bilgilerini inceler ve yeni eklenen bölümleri AWS Glue Data Catalog'a ekler. Tarayıcılar ayrıca AWS analitik motorlarının doğrudan kullanabileceği AWS Glue Data Catalog'daki en son meta veri dosyası konumunu da günceller.
Bu gönderi, Hudi tablolarını taramaya yönelik bu yeni yeteneğin nasıl çalıştığını göstermektedir.
AWS Glue tarayıcısı Hudi tablolarıyla nasıl çalışır?
Hudi tablolarının her biri için özel anlamlara sahip iki kategorisi vardır:
- Yazarken kopyalama (CoW) – Veriler sütunlu bir biçimde (Parke) depolanır ve her güncelleme, yazma sırasında dosyaların yeni bir sürümünü oluşturur.
- Okuma sırasında birleştirme (MoR) – Veriler, sütunlu (Parke) ve satır tabanlı (Avro) formatların bir kombinasyonu kullanılarak depolanır. Güncellemeler satır tabanlı olarak günlüğe kaydedilir
deltasütunlu dosyaların yeni sürümlerini oluşturmak için gerektiği şekilde sıkıştırılır.
CoW veri kümelerinde, bir kayıtta her güncelleme yapıldığında, kaydı içeren dosya güncellenen değerlerle yeniden yazılır. Bir MoR veri kümesinde, her güncelleme olduğunda Hudi yalnızca değiştirilen kaydın satırını yazar. MoR, daha az okuma gerektiren, yazma veya değişiklik ağırlıklı iş yükleri için daha uygundur. CoW, daha az sıklıkta değişen veriler üzerindeki okuma ağırlıklı iş yükleri için daha uygundur.
Hudi, verilere erişim için üç sorgu türü sağlar:
- Anlık görüntü sorguları – Belirli bir işleme veya sıkıştırma işlemine göre tablonun en son anlık görüntüsünü gören sorgular. MoR tabloları için anlık görüntü sorguları, sorgu anındaki en son dosya diliminin temel ve delta dosyalarını birleştirerek tablonun en son durumunu ortaya çıkarır.
- Artımlı sorgular – Sorgular, belirli bir taahhüt veya sıkıştırmadan bu yana yalnızca tabloya yazılan yeni verileri görür. Bu, artımlı veri ardışık düzenlerini etkinleştirmek için etkili bir şekilde değişiklik akışları sağlar.
- Optimize edilmiş sorguları okuyun – MoR tabloları için sorgular sıkıştırılmış en son verileri görür. CoW tabloları için sorgular, kaydedilen en son verileri görür.
Yazma sırasında kopyalama tabloları için tarayıcılar, AWS Glue Data Catalog'da ReadOptimized Serde ile tek bir tablo oluşturur org.apache.hudi.hadoop.HoodieParquetInputFormat.
Okuma sırasında birleştirme tabloları için tarayıcılar, aynı tablo konumu için AWS Glue Data Catalog'da iki tablo oluşturur:
- Sonek içeren bir tablo
_roReadOptimized Serde'yi kullananorg.apache.hudi.hadoop.HoodieParquetInputFormat - Sonek içeren bir tablo
_rtAnlık Görüntü sorgularına izin veren RealTime Serde'yi kullanan:org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
Her tarama sırasında, sağlanan her Hudi yolu için tarayıcılar bir Amazon S3 listesi API çağrısı yapar ve .hoodie klasörleri açın ve bu Hudi tablo meta veri klasörü altında en yeni meta veri dosyasını bulun.
AWS Glue tarayıcısını kullanarak Hudi CoW tablosunu tarayın
Bu bölümde, AWS Glue tarayıcılarını kullanarak bir Hudi CoW'un nasıl taranacağını inceleyelim.
Önkoşullar
Bu eğitimin önkoşulları şunlardır:
- Yükle ve yapılandır AWS Komut Satırı Arayüzü (AWS CLI).
- S3 klasörünüz yoksa oluşturun.
- AWS Glue için IAM rolünüzü oluşturun eğer sende yoksa. ihtiyacın var
s3:GetObjectiçins3://your_s3_bucket/data/sample_hudi_cow_table/. - Örnek Hudi tablosunu S3 klasörünüze kopyalamak için aşağıdaki komutu çalıştırın. (Yer değiştirmek
your_s3_bucketS3 grup adınızla.)
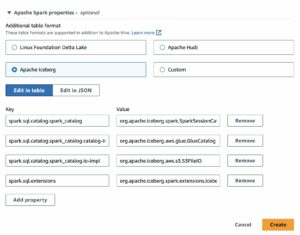
Bu talimat, örnek verileri kopyalamanız için size yol gösterir ancak AWS Glue'yu kullanarak herhangi bir Hudi tablosunu kolayca oluşturabilirsiniz. Daha fazla bilgi edinin AWS Glue for Apache Spark, Bölüm 2'de Apache Hudi, Delta Lake ve Apache Iceberg için yerel destekle tanışın: AWS Glue Studio Visual Editor.
Hudi tarayıcısı oluşturun
Bu talimatta tarayıcıyı konsol aracılığıyla oluşturun. Hudi tarayıcısı oluşturmak için aşağıdaki adımları tamamlayın:
- AWS Glue konsolunda seçin Tarayıcıları.
- Klinik tarayıcı oluştur.
- İçin Name, girmek
hudi_cow_crawler. Seçin Sonraki. - Altında Veri kaynağı yapılandırması, seçmek Veri kaynağı ekleyin.
- İçin Veri kaynağı, seçmek hudi.
- İçin Hudi tablosu yollarını dahil et, girmek
s3://your_s3_bucket/data/sample_hudi_cow_table/. (Yer değiştirmekyour_s3_bucketS3 grup adınızla.) - Klinik Hudi veri kaynağı ekle.
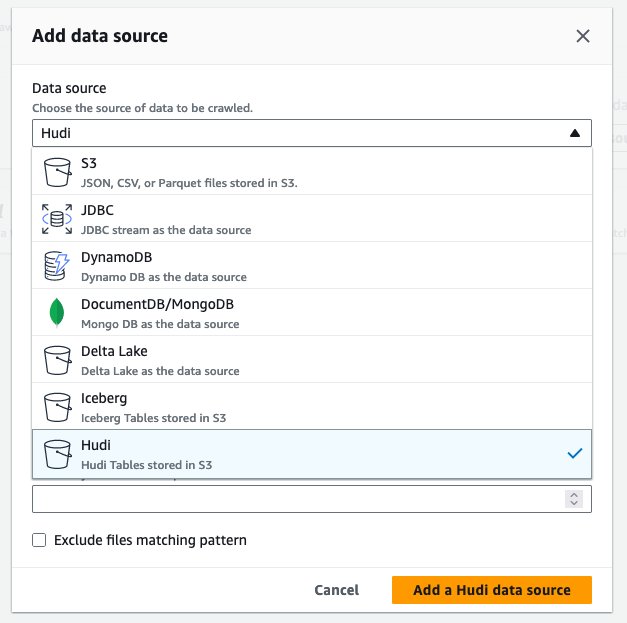
- Klinik Sonraki.
- İçin Mevcut IAM rolü, IAM rolünüzü seçin, ardından Sonraki.
- İçin Hedef veritabanı, seçmek Veritabanı ekle, sonra Veritabanı ekle iletişim kutusu görünür. İçin Veri tabanı ismi, girmek
hudi_crawler_blog, Daha sonra seçmek oluşturmak. Seçin Sonraki. - Klinik tarayıcı oluştur.
Artık yeni bir Hudi tarayıcısı başarıyla oluşturuldu. Tarayıcı, konsol aracılığıyla veya SDK ya da AWS CLI aracılığıyla çalışacak şekilde tetiklenebilir. StartCrawl API. Tarayıcıları belirli zamanlarda tetiklemek için konsol aracılığıyla da planlanabilir. Bu talimatta, tarayıcıyı konsol üzerinden çalıştırın.
- Klinik Tarayıcıyı çalıştırın.
- Tarayıcının tamamlanmasını bekleyin.
Tarayıcı çalıştırıldıktan sonra AWS Glue konsolunda Hudi tablosu tanımını görebilirsiniz:
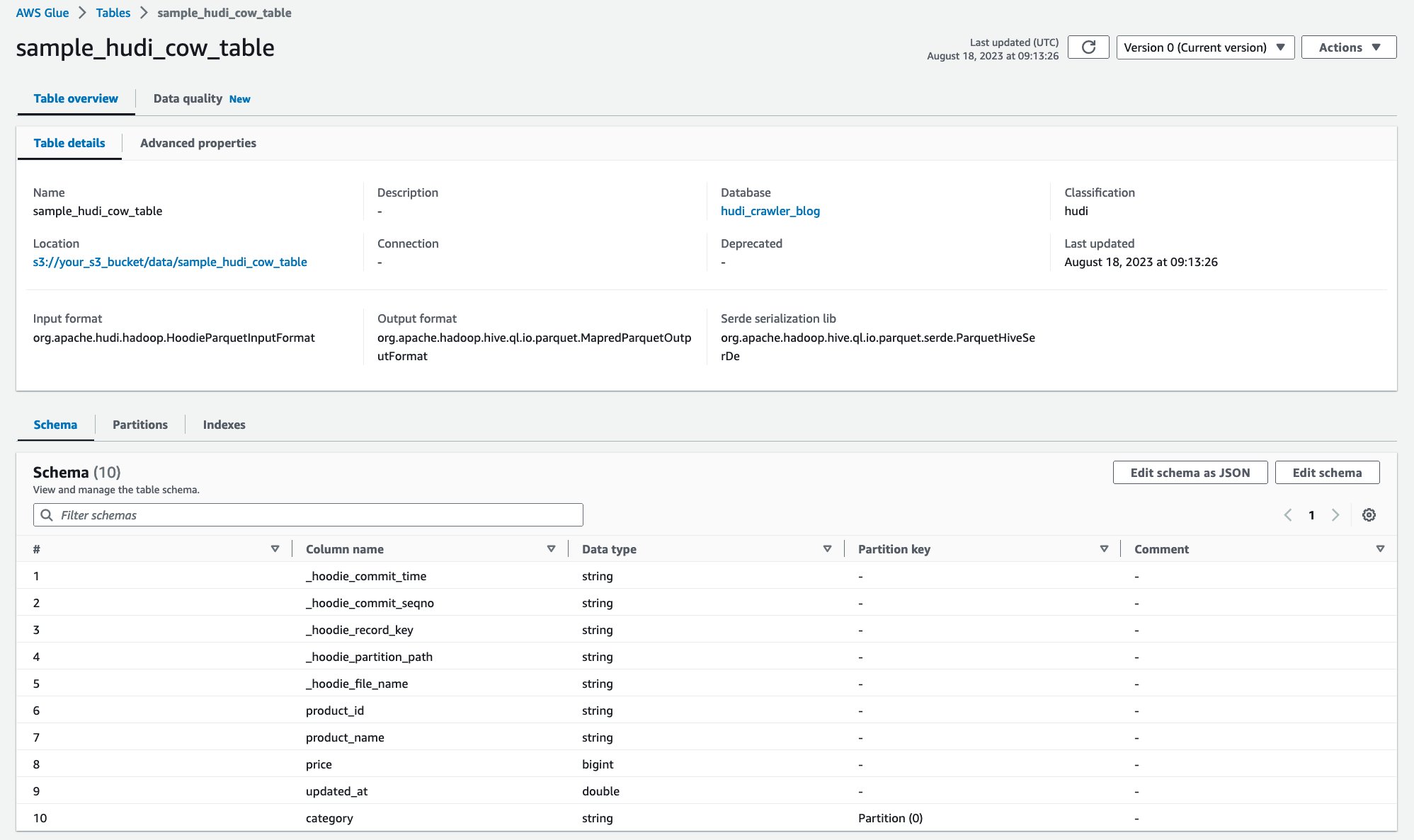
Amazon S3'teki verileri içeren Hudi CoR tablosunu başarıyla taradınız ve şema doldurulmuş bir AWS Glue Data Catalog tablosu oluşturdunuz. AWS Glue Data Catalog'da tablo tanımını oluşturduktan sonra Amazon Athena gibi AWS analiz hizmetleri Hudi tablosunu sorgulayabilir.
Athena'da sorgulama başlatmak için aşağıdaki adımları tamamlayın:
- Amazon Athena konsolunu açın.
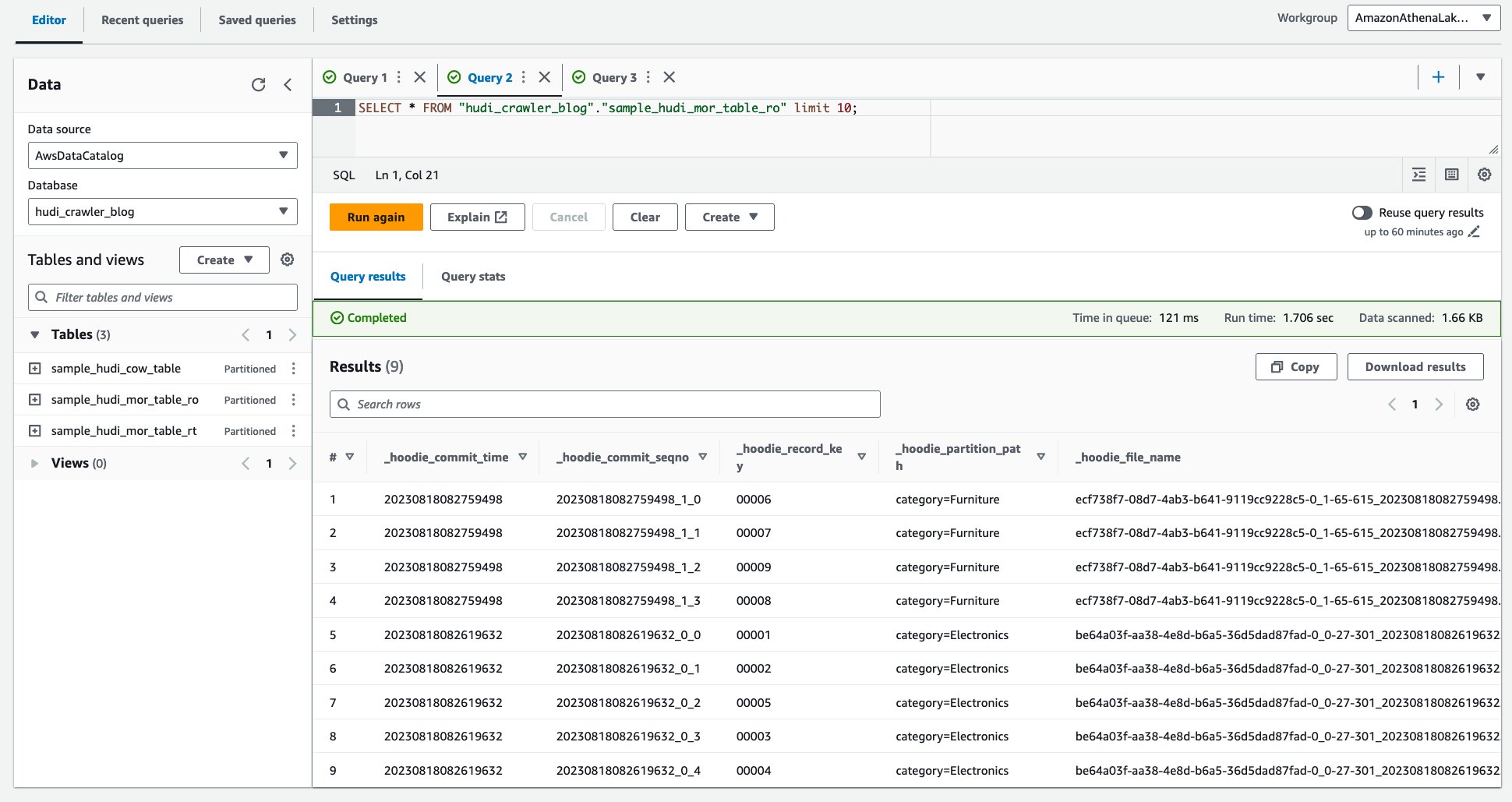
- Aşağıdaki sorguyu çalıştırın.
Aşağıdaki ekran görüntüsü çıktımızı göstermektedir:
AWS Lake Formation veri izinlerine sahip AWS Glue tarayıcısını kullanarak Hudi MoR tablosunu tarayın
Bu bölümde AWS Glue kullanarak bir Hudi MoR tablosunun nasıl taranacağını inceleyelim. Bu sefer Amazon S3 veri kaynaklarını taramak için IAM ve Amazon S3 izni yerine AWS Lake Formation veri iznini kullanırsınız. Bu isteğe bağlıdır ancak veri gölünüz AWS Lake Formation izinleri tarafından yönetildiğinde izin yapılandırmalarını basitleştirir.
Önkoşullar
Bu eğitimin önkoşulları şunlardır:
- Yükle ve yapılandır AWS Komut Satırı Arayüzü (AWS CLI).
- S3 klasörünüz yoksa oluşturun.
- AWS Glue için IAM rolünüzü oluşturun eğer sende yoksa. ihtiyacın var
lakeformation:GetDataAccess. Ama ihtiyacın yoks3:GetObjectiçins3://your_s3_bucket/data/sample_hudi_mor_table/çünkü dosyalara erişmek için Lake Formation veri iznini kullanıyoruz. - Örnek Hudi tablosunu S3 klasörünüze kopyalamak için aşağıdaki komutu çalıştırın. (Yer değiştirmek
your_s3_bucketS3 grup adınızla.)
İşleme adımlarına ek olarak, AWS Glue Data Catalog ayarlarını, katalog kaynaklarını kontrol etmek amacıyla IAM tabanlı erişim kontrolü yerine Lake Formation izinlerini kullanacak şekilde güncellemek için aşağıdaki adımları tamamlayın:
- Lake Formation konsolunda veri gölü yöneticisi olarak oturum açın.
- Lake Formation konsoluna ilk kez erişiyorsanız, kendinizi data lake yöneticisi olarak ekleyin.
- Altında Yönetim, seçmek Veri kataloğu ayarları.
- İçin Yeni oluşturulan veritabanları ve tablolar için varsayılan izinler, seçimi kaldır Yeni veritabanları için yalnızca IAM erişim kontrolünü kullanın ve Yeni veritabanlarındaki yeni tablolar için yalnızca IAM erişim kontrolünü kullanın.
- İçin Hesaplar arası sürüm ayarı, seçmek Sürüm 3.
- Klinik İndirim.
Bir sonraki adım, S3 klasörünüzü Lake Formation veri gölü konumlarına kaydetmektir:
- Göl Oluşumu konsolunda seçin Veri gölü konumları, ve Seç Konumu kaydet.
- İçin Amazon S3 yolu, girmek
s3://your_s3_bucket/. (Yer değiştirmekyour_s3_bucketS3 grup adınızla.) - Klinik Konumu kaydet.
Ardından, tarayıcının verilere erişmek ve konumda tablolar oluşturmak için Göl Oluşumu iznini kullanabilmesi için Glue tarayıcı rolüne veri konumuna erişim izni verin:
- Göl Oluşumu konsolunda seçin Veri konumları Ve seç Hibe.
- İçin IAM kullanıcıları ve rolleritarayıcı için kullandığınız IAM rolünü seçin.
- İçin Depolama yeri, girmek
s3://your_s3_bucket/data/. (Yer değiştirmekyour_s3_bucketS3 grup adınızla.) - Klinik Hibe.
Daha sonra veritabanı altında tablolar oluşturmak için tarayıcı rolü verin hudi_crawler_blog:
- Göl Oluşumu konsolunda seçin Veri gölü izinleri.
- Klinik Hibe.
- İçin müdürler, seçmek IAM kullanıcıları ve rollerive tarayıcı rolünü seçin.
- İçin LF etiketleri veya katalog kaynakları, seçmek Adlandırılmış veri kataloğu kaynakları.
- İçin veritabanı, veritabanını seçin
hudi_crawler_blog. - Altında Veritabanı izinleriseçin Tablo oluştur.
- Klinik Hibe.
Lake Formation veri izinlerine sahip bir Hudi tarayıcısı oluşturun
Hudi tarayıcısı oluşturmak için aşağıdaki adımları tamamlayın:
- AWS Glue konsolunda seçin Tarayıcıları.
- Klinik tarayıcı oluştur.
- İçin Name, girmek
hudi_mor_crawler. Seçin Sonraki. - Altında Veri kaynağı yapılandırması, seçmek Veri kaynağı ekleyin.
- İçin Veri kaynağı, seçmek hudi.
- İçin Hudi tablosu yollarını dahil et, girmek
s3://your_s3_bucket/data/sample_hudi_mor_table/. (Yer değiştirmekyour_s3_bucketS3 grup adınızla.) - Klinik Hudi veri kaynağı ekle.
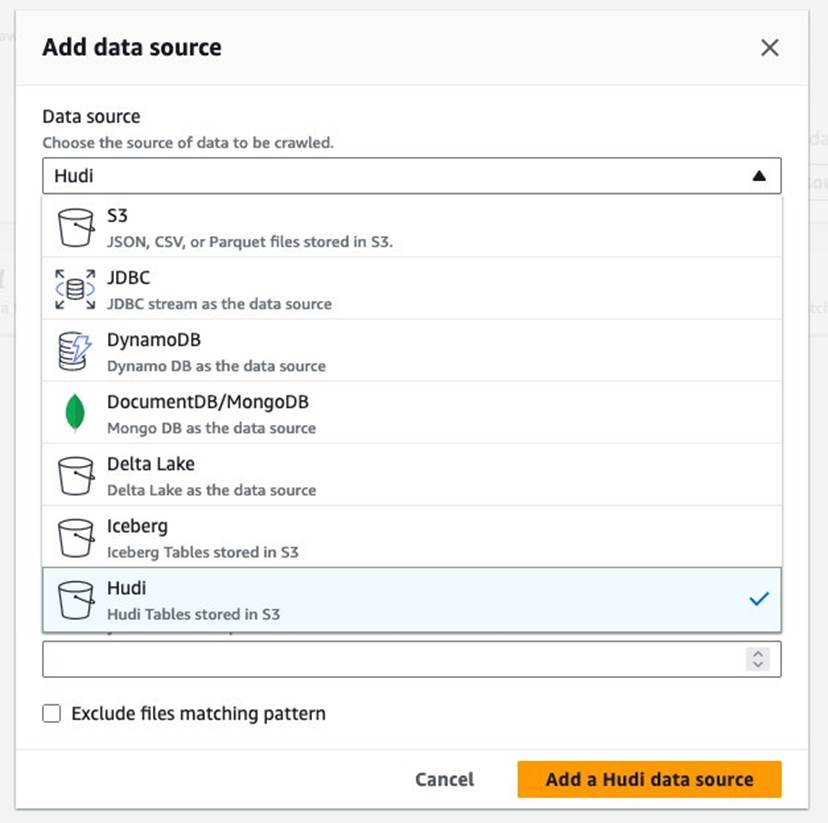
- Klinik Sonraki.
- İçin Mevcut IAM rolü, IAM rolünüzü seçin.
- Altında Göl Oluşumu konfigürasyonu – isteğe bağlıseçin S3 veri kaynağını taramak için Lake Formation kimlik bilgilerini kullanın.
- Klinik Sonraki.
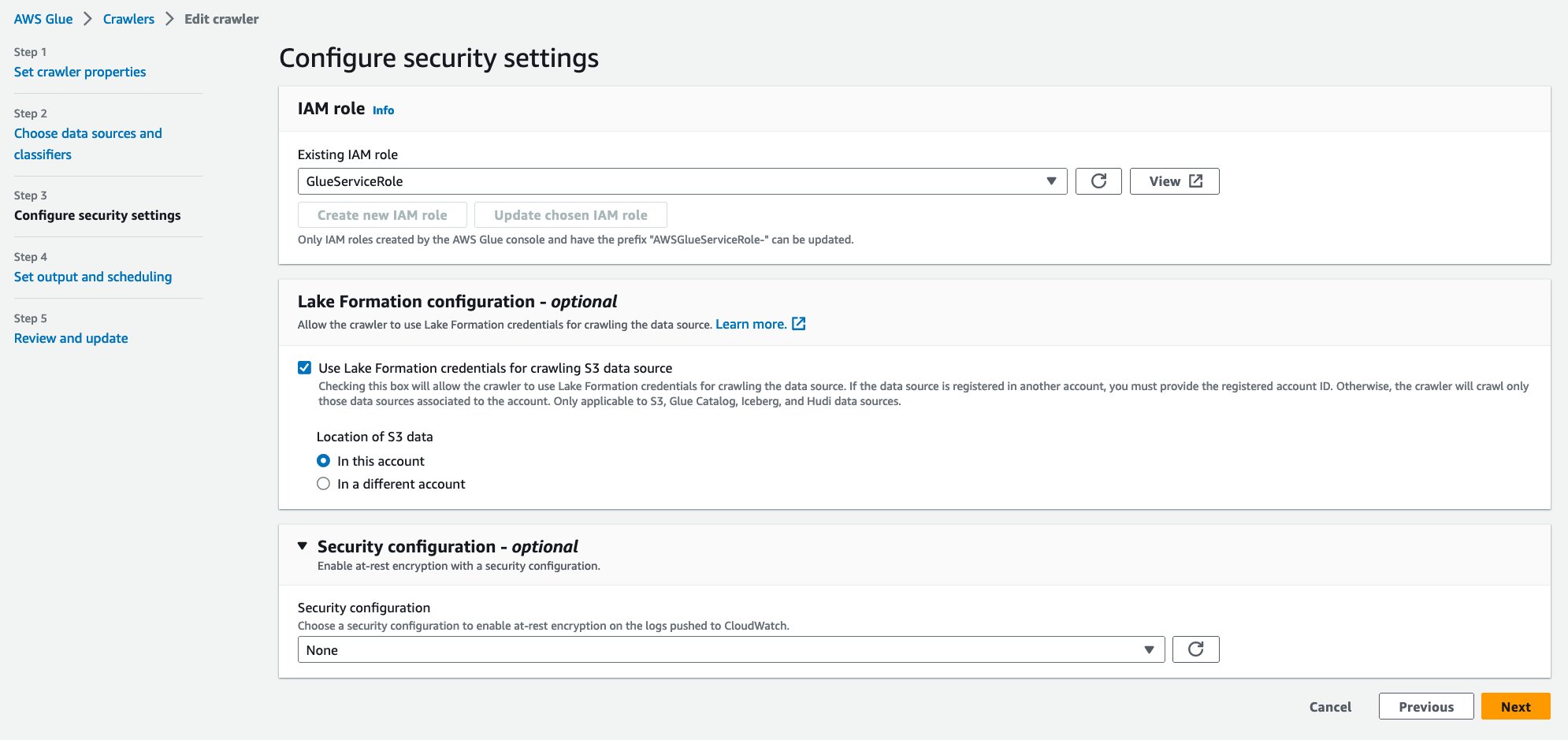
- İçin Hedef veritabanı, seçmek
hudi_crawler_blog. Seçin Sonraki. - Klinik tarayıcı oluştur.
Artık yeni bir Hudi tarayıcısı başarıyla oluşturuldu. Tarayıcı, Amazon S3 dosyalarını taramak için Lake Formation kimlik bilgilerini kullanır. Yeni tarayıcıyı çalıştıralım:
- Klinik Tarayıcıyı çalıştırın.
- Tarayıcının tamamlanmasını bekleyin.
Tarayıcı çalıştırıldıktan sonra AWS Glue konsolunda Hudi tablo tanımının iki tablosunu görebilirsiniz:
sample_hudi_mor_table_ro(optimize edilmiş tabloyu okuyun)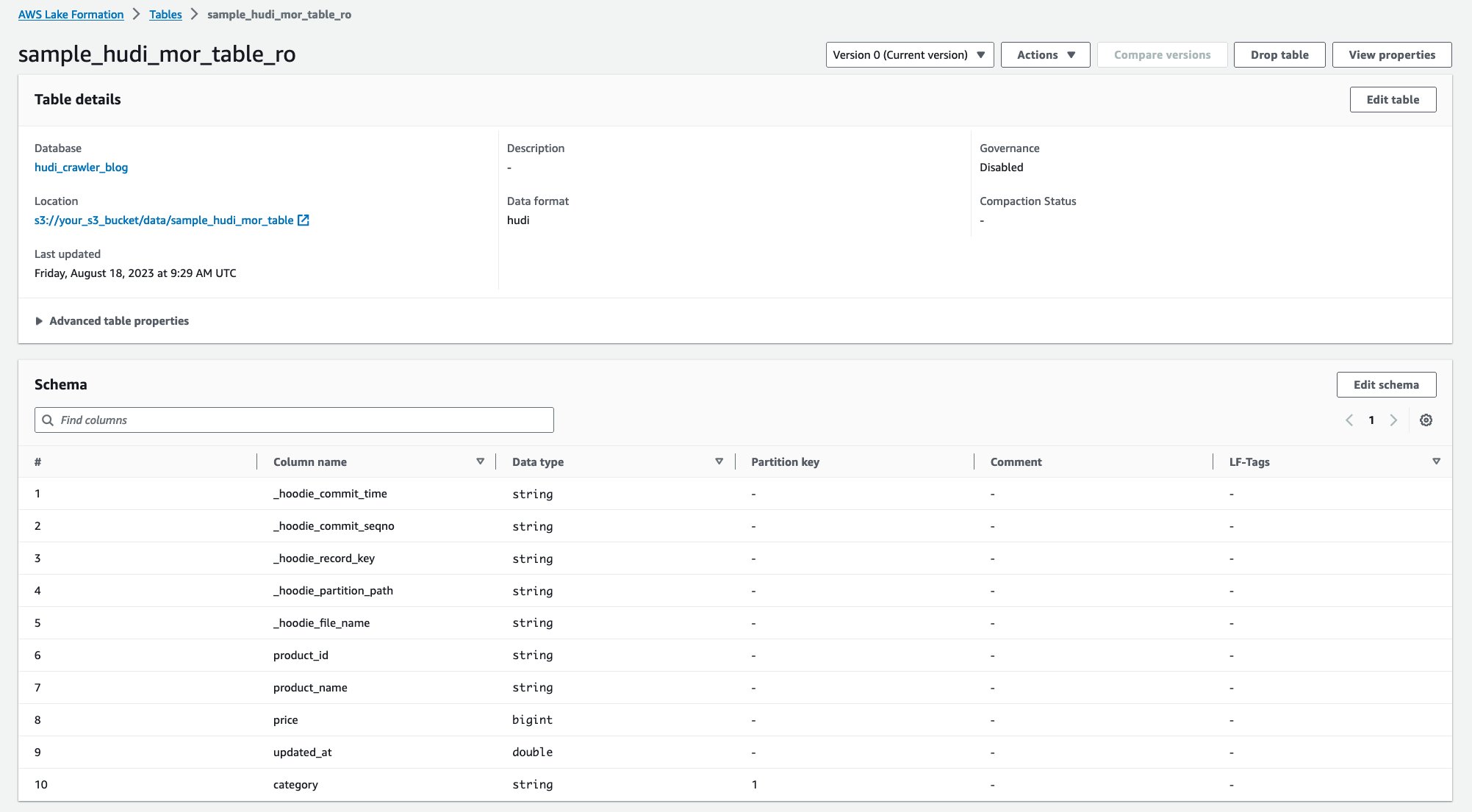
sample_hudi_mor_table_rt(gerçek zamanlı tablo)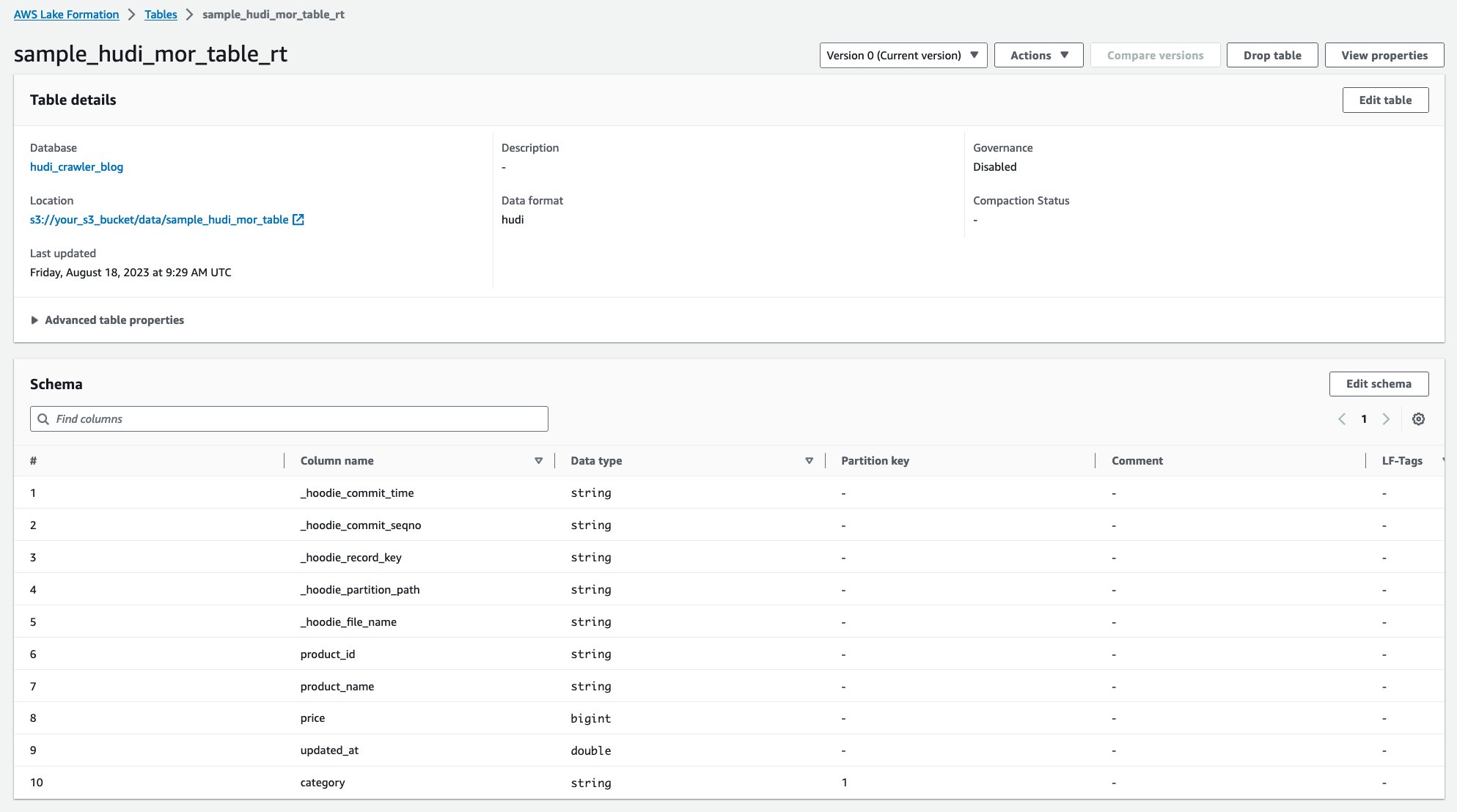
Veri gölü grubunu Lake Formation'a kaydettiniz ve Lake Formation izinlerini kullanarak veri gölüne tarama erişimini etkinleştirdiniz. Amazon S3'teki verileri içeren Hudi MoR tablosunu başarıyla taradınız ve şema doldurulmuş bir AWS Glue Data Catalog tablosu oluşturdunuz. AWS Glue Data Catalog'da tablo tanımlarını oluşturduktan sonra Amazon Athena gibi AWS analiz hizmetleri Hudi tablosunu sorgulayabilir.
Athena'da sorgulama başlatmak için aşağıdaki adımları tamamlayın:
- Amazon Athena konsolunu açın.
- Aşağıdaki sorguyu çalıştırın.
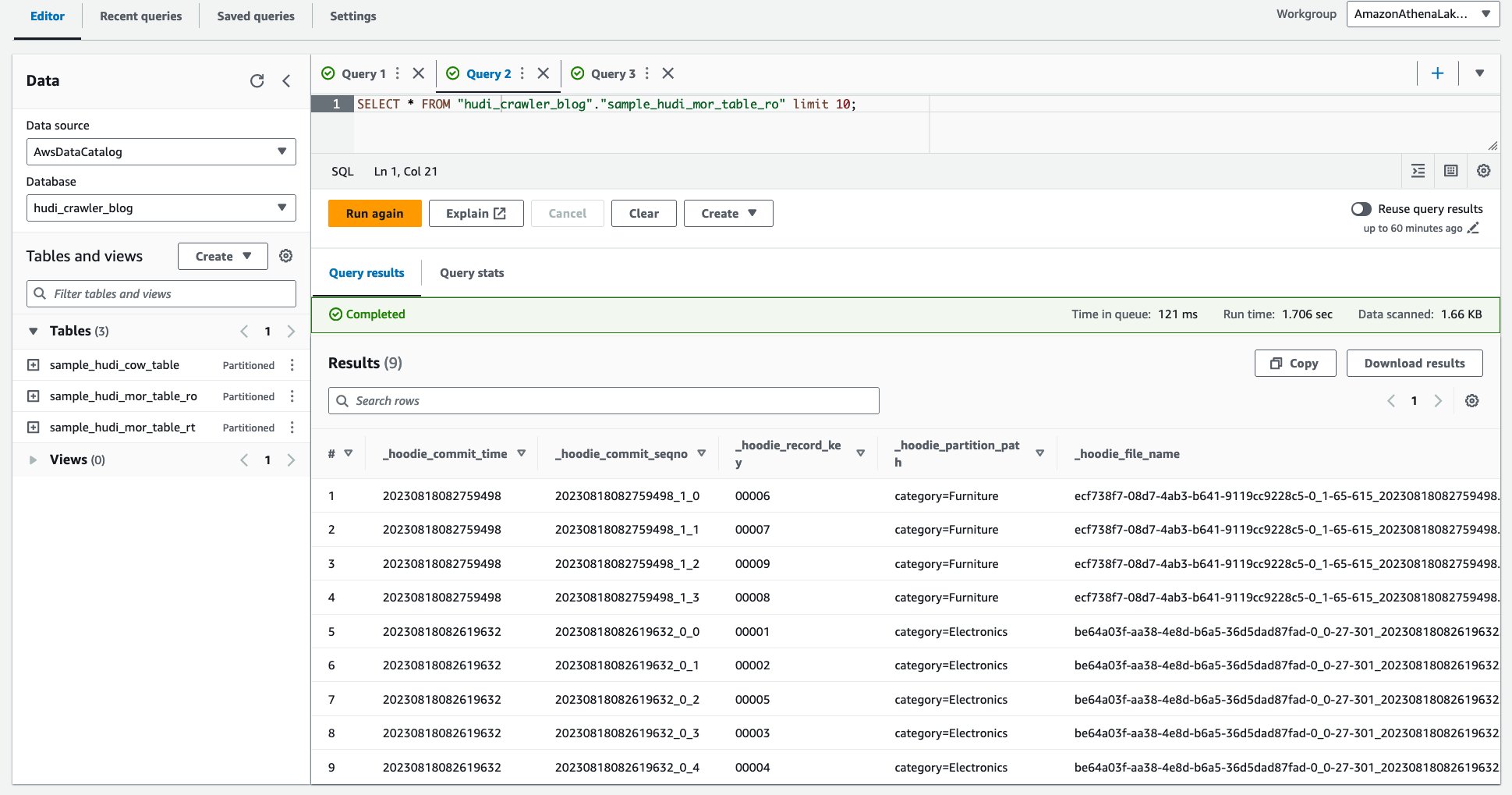
Aşağıdaki ekran görüntüsü çıktımızı göstermektedir:
- Aşağıdaki sorguyu çalıştırın.
Aşağıdaki ekran görüntüsü çıktımızı göstermektedir:
AWS Lake Formation izinlerini kullanan ayrıntılı erişim kontrolü
Hudi tablosunda ayrıntılı erişim kontrolü uygulamak için AWS Lake Formation izinlerinden yararlanabilirsiniz. Göl Oluşumu izinleri, belirli tablolara, sütunlara veya satırlara erişimi kısıtlamanıza ve ardından ayrıntılı erişim kontrolüyle Amazon Athena aracılığıyla Hudi tablolarını sorgulamanıza olanak tanır. Hudi MoR tablosu için Göl Oluşumu iznini yapılandıralım.
Önkoşullar
Bu eğitimin önkoşulları şunlardır:
- Önceki bölümü tamamlayın AWS Lake Formation veri izinlerine sahip AWS Glue tarayıcısını kullanarak Hudi MoR tablosunu tarayın.
- AWS tarafından yönetilen politikaya sahip bir IAM kullanıcısı DataAnalyst oluşturun AmazonAthenaTam Erişim.
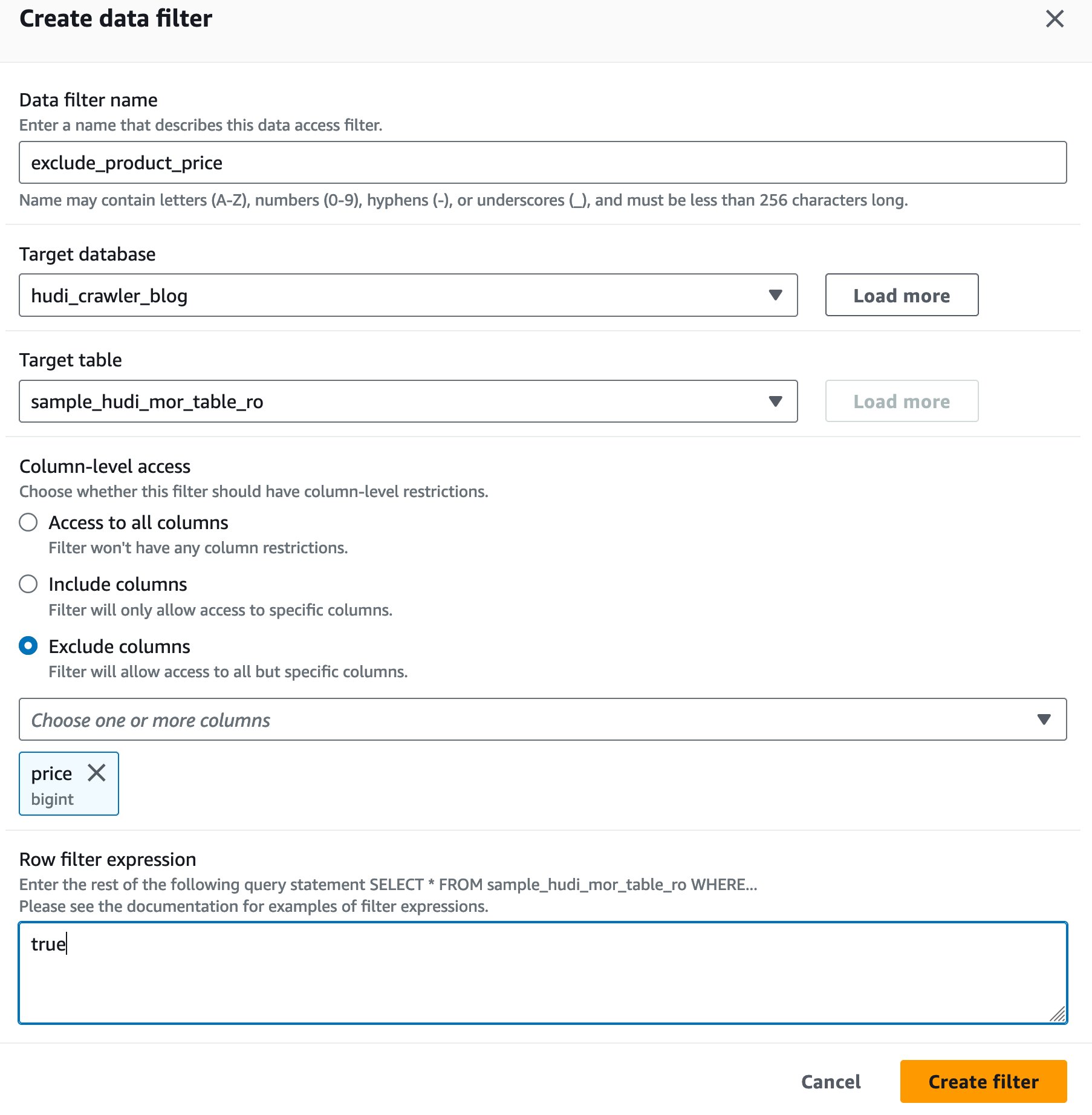
Göl Oluşumu veri hücresi filtresi oluşturma
Öncelikle MoR okuma optimizasyonlu tablosu için bir filtre ayarlayalım.
- Lake Formation konsolunda veri gölü yöneticisi olarak oturum açın.
- Klinik Veri filtreleri.
- Klinik Yeni filtre oluştur.
- İçin Veri filtresi adı, girmek
exclude_product_price. - İçin Hedef veritabanı, veritabanını seçin
hudi_crawler_blog. - İçin Hedef tablo, masayı seç
sample_hudi_mor_table_ro. - İçin sütun düzeyi erişim, seç Sütunları hariç tutve sütun fiyatını seçin.
- İçin Satır filtresi ifadesi, girmek
true. - Klinik Filtre oluştur.
DataAnalyst kullanıcısına Lake Formation izinleri verme
Göl Oluşumu iznini vermek için aşağıdaki adımları tamamlayın. DataAnalyst kullanıcı
- Göl Oluşumu konsolunda seçin Veri gölü izinleri.
- Klinik Hibe.
- İçin müdürler, seçmek IAM kullanıcıları ve rollerive kullanıcıyı seçin
DataAnalyst. - İçin LF etiketleri veya katalog kaynakları, seçmek Adlandırılmış veri kataloğu kaynakları.
- İçin veritabanı, veritabanını seçin
hudi_crawler_blog. - İçin Tablo – isteğe bağlı, masayı seç
sample_hudi_mor_table_ro. - İçin Veri filtreleri – isteğe bağlı, seçin
exclude_product_price. - İçin Veri filtresi izinleriseçin seç.
- Klinik Hibe.
Veritabanında Göl Oluşumu izni verdiniz hudi_crawler_blog ve masa sample_hudi_mor_table_ro, sütun hariç price DataAnalyst kullanıcısına. Şimdi Athena'yı kullanarak verilere kullanıcı erişimini doğrulayalım.
- Athena konsolunda DataAnalyst kullanıcısı olarak oturum açın.
- Sorgu düzenleyicisinde aşağıdaki sorguyu çalıştırın:
Aşağıdaki ekran görüntüsü çıktımızı göstermektedir:
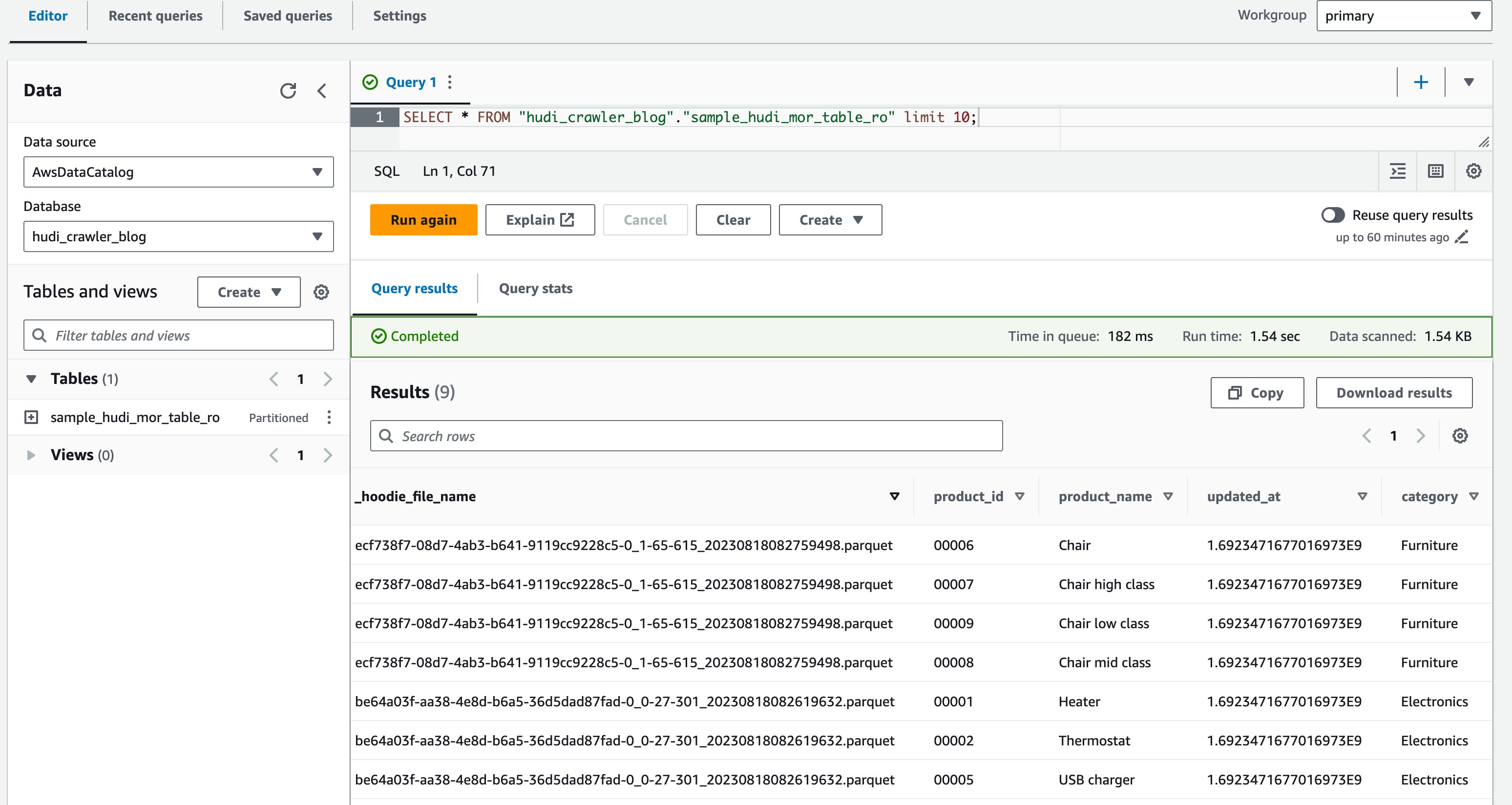
Artık sütunun olduğunu doğruladınız price gösterilmiyor ancak diğer sütunlar product_id, product_name, update_at, ve category gösterilir.
Temizlemek
AWS hesabınıza istenmeyen ödemelerin yapılmasını önlemek için aşağıdaki AWS kaynaklarını silin:
- AWS Glue veritabanını silin
hudi_crawler_blog. - AWS Glue tarayıcılarını silin
hudi_cow_crawlervehudi_mor_crawler. - Amazon S3 dosyalarını silin
s3://your_s3_bucket/data/sample_hudi_cow_table/ves3://your_s3_bucket/data/sample_hudi_mor_table/.
Sonuç
Bu gönderi, AWS Glue tarayıcılarının Hudi tabloları için nasıl çalıştığını gösterdi. Hudi tarayıcısı desteği sayesinde, AWS Glue Data Catalog'u birincil Hudi tablo kataloğunuz olarak kullanmaya hızlı bir şekilde geçebilirsiniz. AWS analitik motorları tarafından desteklenen tablolar ve formatlar için AWS Glue, AWS Glue Data Catalog ve Lake Formation ayrıntılı erişim kontrollerini kullanarak AWS'de Hudi'yi kullanarak sunucusuz işlemsel veri gölünüzü oluşturmaya başlayabilirsiniz.
yazarlar hakkında
 Noritaka Sekiyama AWS Glue ekibinde Baş Büyük Veri Mimarıdır. Tokyo, Japonya merkezli çalışıyor. Müşterilere yardımcı olmak için yazılım yapıları oluşturmaktan sorumludur. Boş zamanlarında yol bisikleti ile bisiklet sürmekten keyif alıyor.
Noritaka Sekiyama AWS Glue ekibinde Baş Büyük Veri Mimarıdır. Tokyo, Japonya merkezli çalışıyor. Müşterilere yardımcı olmak için yazılım yapıları oluşturmaktan sorumludur. Boş zamanlarında yol bisikleti ile bisiklet sürmekten keyif alıyor.
 Kyle Duong AWS Glue and Lake Formation ekibinde Yazılım Geliştirme Mühendisidir. Büyük veri teknolojileri ve dağıtılmış sistemler oluşturma konusunda tutkulu.
Kyle Duong AWS Glue and Lake Formation ekibinde Yazılım Geliştirme Mühendisidir. Büyük veri teknolojileri ve dağıtılmış sistemler oluşturma konusunda tutkulu.
 Sandeep Adwankar AWS'de Kıdemli Teknik Ürün Müdürüdür. California Bay Area'da yerleşik olarak, iş ve teknik gereksinimleri, müşterilerin verileri yönetme, güvenlik altına alma ve verilere erişme yöntemlerini geliştirmelerini sağlayan ürünlere dönüştürmek için dünyanın dört bir yanındaki müşterilerle birlikte çalışır.
Sandeep Adwankar AWS'de Kıdemli Teknik Ürün Müdürüdür. California Bay Area'da yerleşik olarak, iş ve teknik gereksinimleri, müşterilerin verileri yönetme, güvenlik altına alma ve verilere erişme yöntemlerini geliştirmelerini sağlayan ürünlere dönüştürmek için dünyanın dört bir yanındaki müşterilerle birlikte çalışır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- :vardır
- :dır-dir
- :olumsuzluk
- :Neresi
- $UP
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- Yapabilmek
- Hakkımızda
- erişim
- Verilere erişim
- erişme
- Hesap
- Action
- eklemek
- katma
- ilave
- benimsenen
- Benimseme
- ileri
- Sonra
- Türkiye
- izin vermek
- Izin
- veriyor
- Ayrıca
- Amazon
- Amazon Atina
- Amazon Web Servisleri
- an
- Analitik
- analytics
- ve
- Başka
- herhangi
- Apache
- Apache Spark
- api
- belirir
- Uygulama
- Uygulama Geliştirme
- Tamam
- ARE
- ALAN
- etrafında
- AS
- At
- otomatik olarak
- önlemek
- AWS
- AWS Tutkal
- AWS Göl Oluşumu
- baz
- merkezli
- Defne
- BE
- Çünkü
- olmuştur
- yarar
- Daha iyi
- Büyük
- büyük Veri
- Getiriyor
- bina
- yapılı
- iş
- fakat
- by
- Kaliforniya
- çağrı
- CAN
- yetenekleri
- kabiliyet
- dava
- katalog
- kataloglar
- kategoriler
- hücre
- zorluklar
- değişiklik
- değişmiş
- değişiklikler
- yükler
- Klinik
- Sütun
- Sütunlar
- kombinasyon
- işlemek
- taahhüt
- tamamlamak
- karmaşık
- bileşen
- yapılandırma
- konsolos
- içeren
- içerik
- devamlı olarak
- kontrol
- kontroller
- olabilir
- paletli
- yaratmak
- çevrimiçi kurslar düzenliyorlar.
- oluşturur
- Tanıtım
- Müşteriler
- veri
- veri entegrasyonu
- Veri Gölü
- veri ambarı
- veritabanı
- veritabanları
- veri kümeleri
- tanım
- tanımları
- Delta
- gösterdi
- gösteriyor
- derinlik
- gelişme
- direkt olarak
- keşfetmek
- dağıtıldı
- dağıtılmış sistemler
- do
- yok
- sırasında
- her
- kolay
- kolayca
- editör
- etkili bir şekilde
- verimli
- etkinleştirmek
- etkin
- mühendis
- Mühendisler
- Motorlar
- Keşfet
- Eter (ETH)
- gelişen
- hariç
- çıkarmak
- Daha hızlı
- daha az
- fileto
- dosyalar
- filtre
- filtreler
- bulmak
- Ad
- ilk kez
- takip etme
- İçin
- biçim
- oluşum
- sık sık
- itibaren
- verilmiş
- dünya
- Go
- vermek
- verilmiş
- Rehberler
- Hadoop'un
- Var
- he
- yardım et
- yardımcı olur
- onun
- kovan
- Ne kadar
- Nasıl Yapılır
- HTML
- HTTPS
- IAM
- if
- etkileri
- iyileştirmek
- in
- Dahil olmak üzere
- artımlı
- bilgi
- yerine
- entegre
- bütünleşme
- arayüzey
- içine
- tanıtım
- IT
- Japonya
- jpg
- koruma
- göl
- göller
- son
- başlatmak
- ÖĞRENİN
- öğrenme
- az
- LİMİT
- çizgi
- Liste
- bulunan
- yer
- yerleri
- giriş
- makine
- makine öğrenme
- sürdürmek
- yapmak
- YAPAR
- yönetmek
- yönetilen
- müdür
- yönetme
- Manuel
- maksimum
- birleştirme
- Metadata
- göç
- göç
- ML
- Daha
- çoğu
- hareket
- çoklu
- isim
- yerli
- gerek
- gerekli
- yeni
- yeni
- sonraki
- şimdi
- of
- on
- ONE
- bir tek
- açık
- açık kaynak
- optimize
- seçenek
- or
- Diğer
- bizim
- çıktı
- Bölüm
- tutkulu
- yol
- yolları
- performans
- izin
- izinleri
- Platon
- Plato Veri Zekası
- PlatoVeri
- Popüler
- nüfuslu
- Çivi
- Hazırlamak
- önkoşullar
- önceki
- fiyat
- birincil
- Anapara
- işleme
- PLATFORM
- ürün müdürü
- Ürünler
- sağlamak
- sağlanan
- sağlar
- sorgular
- hızla
- Okumak
- gerçek
- gerçek zaman
- realtime
- son
- kayıt
- kayıt olmak
- kayıtlı
- değiştirmek
- Yer Alan Kurallar
- Kaynaklar
- sorumlu
- kısıtlamak
- yol
- Rol
- SIRA
- koşmak
- aynı
- program
- tarifeli
- sdk
- Bölüm
- güvenli
- görmek
- seçmek
- kıdemli
- Serverless
- hizmet
- Hizmetler
- set
- ayarlar
- gösterilen
- Gösteriler
- basitleştirir
- beri
- tek
- Dilim
- Enstantane fotoğraf
- So
- Yazılım
- yazılım geliştirme
- Kaynak
- kaynaklar
- Kıvılcım
- özel
- başlama
- Eyalet
- adım
- Basamaklar
- saklı
- akış
- dere
- stüdyo
- Başarılı olarak
- böyle
- destek
- destekli
- senkron.
- Sistemler
- tablo
- takım
- Teknik
- Teknolojileri
- o
- The
- ve bazı Asya
- sonra
- Orada.
- onlar
- Re-Tweet
- üç
- İçinden
- zaman
- zamanlar
- için
- Tokyo
- üst
- işlemsel
- işlemler
- çevirmek
- çapraz
- tetikleyebilir
- tetiklenir
- öğretici
- iki
- türleri
- tipik
- altında
- istenmeyen
- Güncelleme
- güncellenmiş
- Güncellemeler
- kullanım
- kullanım durumu
- Kullanılmış
- kullanıcı
- kullanıcılar
- kullanım
- kullanma
- DOĞRULA
- valide
- Değerler
- versiyon
- görsel
- depo
- we
- ağ
- web hizmetleri
- İYİ
- ne zaman
- hangi
- süre
- DSÖ
- irade
- ile
- olmadan
- İş
- çalışır
- yazmak
- yazılı
- sen
- kendiniz
- zefirnet