Amazon Kırmızıya Kaydırma analitik iş yüklerini güçlendirmek için her gün eksabaytlarca veriyi işlemek için on binlerce müşteri tarafından kullanılan, tam olarak yönetilen ve petabayt ölçeğinde bir bulut veri ambarıdır. Boyutlu bir model kullanarak verilerinizi yapılandırabilir, iş süreçlerini ölçebilir ve hızlı bir şekilde değerli içgörüler elde edebilirsiniz. Amazon Redshift, boyutlu bir modelden modelleme, düzenleme ve raporlama sürecini hızlandırmak için yerleşik özellikler sağlar.
Bu yazıda, boyutlu bir modelin nasıl uygulanacağını, özellikle de Kimball metodolojisi. Amazon Redshift'te boyutları ve gerçekleri uygulamayı tartışıyoruz. Modellemeyi gerçekleştirmek için ham verileri bir veri gölünden bir hazırlama katmanına almaya odaklanan bir entegrasyon süreci olan ayıklama, dönüştürme ve yüklemenin (ELT) nasıl gerçekleştirileceğini gösteriyoruz. Genel olarak gönderi, Amazon Redshift'te boyutsal modellemenin nasıl kullanılacağına dair net bir anlayış sağlayacaktır.
Çözüme genel bakış
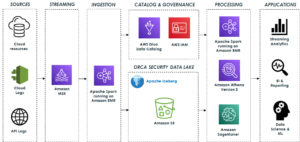
Aşağıdaki şemada çözüm mimarisi gösterilmektedir.

Aşağıdaki bölümlerde, öncelikle boyutsal modelin temel özelliklerini tartışıyor ve gösteriyoruz. Ardından, Amazon Redshift'i kullanarak boyut ve olgu tablolarını içeren boyutlu bir veri modeliyle bir data mart oluşturuyoruz. Veriler kullanılarak yüklenir ve hazırlanır. KOPYA komutu kullanılarak boyutlardaki veriler yüklenir. BİRLEŞTİRMEK ifade ve gerçekler, içgörülerin türetildiği boyutlarla birleştirilecektir. Kullanarak boyutların ve gerçeklerin yüklenmesini planlıyoruz. Amazon Redshift Sorgu Düzenleyicisi V2. Son olarak, kullandığımız Amazon QuickSight QuickSight panosu biçiminde modellenen veriler hakkında içgörüler elde etmek için.
Bu çözüm için, etkinlik bileti satışları için Amazon Redshift tarafından sağlanan örnek bir veri kümesi (normalleştirilmiş) kullanıyoruz. Bu gönderi için, basitlik ve tanıtım amacıyla veri kümesini daralttık. Aşağıdaki tablolar, bilet satışları ve mekanlara ilişkin veri örneklerini göstermektedir.


Göre Kimball boyutlu modelleme metodolojisi, boyutlu bir model tasarlamanın dört temel adımı vardır:
- İş sürecini tanımlayın.
- Verilerinizin tanesini beyan edin.
- Boyutları belirleyin ve uygulayın.
- Gerçekleri belirleyin ve uygulayın.
Ek olarak, gösteri amaçlı olarak iş olaylarını raporlamak ve analiz etmek için beşinci bir adım ekledik.
Önkoşullar
Bu izlenecek yol için aşağıdaki ön koşullara sahip olmalısınız:
İş sürecini tanımlayın
Basit bir ifadeyle, iş sürecini tanımlamak, bir kuruluş içinde veri üreten ölçülebilir bir olayı tanımlamaktır. Genellikle şirketler, verilerini ham biçiminde üreten bir tür operasyonel kaynak sistemine sahiptir. Bu, bir iş süreci için çeşitli kaynakları belirlemek için iyi bir başlangıç noktasıdır.
İş süreci daha sonra bir mart tarihi boyutlar ve gerçekler şeklinde. Daha önce bahsedilen örnek veri kümemize baktığımızda, iş sürecinin belirli bir etkinlik için yapılan satışlar olduğunu açıkça görebiliriz.
Yapılan yaygın bir hata, bir şirketin departmanlarını iş süreci olarak kullanmaktır. Verilerin (iş süreci) çeşitli departmanlar arasında entegre edilmesi gerekir, bu durumda pazarlama, satış verilerine erişebilir. Doğru iş sürecini belirlemek çok önemlidir; bu adımı yanlış yapmak, tüm veri pazarını etkileyebilir (tanenin yinelenmesine ve nihai raporlarda yanlış ölçümlere neden olabilir).
Verilerinizin tanesini beyan edin
Taneyi bildirmek, veri kaynağınızdaki bir kaydı benzersiz bir şekilde tanımlama eylemidir. Tahıl, verileri doğru bir şekilde ölçmek ve daha fazla toparlama yapmanızı sağlamak için olgu tablosunda kullanılır. Örneğimizde bu, satış iş sürecindeki bir kalem olabilir.
Bizim kullanım durumumuzda, bir satış, satışın gerçekleştiği işlem zamanına bakılarak benzersiz bir şekilde tanımlanabilir; bu en atomik seviye olacak.

Boyutları tanımlayın ve uygulayın
Boyut tablonuz, olgu tablonuzu ve niteliklerini açıklar. İş sürecinizin tanımlayıcı bağlamını belirlerken, olgu tablosunu göz önünde bulundurarak metni ayrı bir tabloda saklarsınız. Boyutlar tablosunu olgu tablosuyla birleştirirken, olgu tablosuyla ilişkili yalnızca tek bir satır olmalıdır. Örneğimizde, bir boyut tablosuna ayırmak için aşağıdaki tabloyu kullanıyoruz; bu alanlar ölçeceğimiz gerçekleri tanımlar.
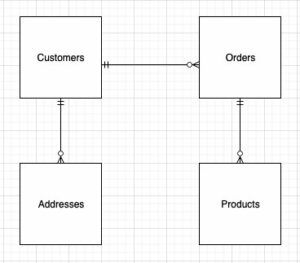
Boyutlu modelin (şema) yapısını tasarlarken, bir star or kar taneciği şema. Yapı, iş süreciyle yakından uyumlu olmalıdır; bu nedenle, bir yıldız şeması örneğimiz için en uygun olanıdır. Aşağıdaki şekilde Varlık İlişki Şemamız (ERD) gösterilmektedir.

Aşağıdaki bölümlerde, boyutları uygulama adımlarını ayrıntılarıyla açıklıyoruz.
Kaynak verileri hazırlama
Boyutlar tablosunu oluşturmadan ve yüklemeden önce kaynak verilere ihtiyacımız var. Bu nedenle, kaynak verileri bir aşamalandırma veya geçici tabloya yerleştiririz. Bu genellikle şu şekilde adlandırılır: evreleme katmanı, kaynak verilerin ham kopyasıdır. Amazon Redshift'te bunu yapmak için KOPYALA komutu Amazon redshift'te boyutsal modelleme genel S3 klasöründeki verileri yüklemek için us-east-1 Bölge. COPY komutunun bir AWS Kimlik ve Erişim Yönetimi (IAM) rolü ile Amazon S3'e erişim. Rol olması gereken küme ile ilişkili. Kaynak verileri hazırlamak için aşağıdaki adımları tamamlayın:
- oluşturmak
venuekaynak tablosu:
- Mekan verilerini yükleyin:
- oluşturmak
saleskaynak tablosu:
- Satış kaynağı verilerini yükleyin:
- oluşturmak
calendartablosu:
- Takvim verilerini yükleyin:
Boyutlar tablosunu oluşturun
Boyutlar tablosunu tasarlamak, iş gereksinimlerinize bağlı olabilir; örneğin, zaman içinde verilerde meydana gelen değişiklikleri izlemeniz gerekiyor mu? Var yedi farklı boyut türü. Örneğimiz için, kullandığımız 1 yazın çünkü tarihsel değişiklikleri takip etmemize gerek yok. Tip 2 hakkında daha fazla bilgi için bkz. Amazon Redshift'te yavaşça değişen boyutlar olan Tip 2'ye veri yüklemeyi basitleştirin. Boyutlar tablosu, tablodaki değişiklikleri belirtmek için bir birincil anahtar, vekil anahtar ve birkaç ek alanla normalleştirilecektir. Aşağıdaki koda bakın:
Boyut tablosu oluşturma hakkında birkaç not:
- Alan adları iş dostu adlara dönüştürülür
- Birincil anahtarımız
VenueID, satışın gerçekleştiği yeri benzersiz bir şekilde tanımlamak için kullandığımız - Bir kaydın ne zaman eklendiğini ve güncellendiğini gösteren iki ek satır eklenecektir (değişiklikleri izlemek için)
- biz kullanıyoruz OTO dağıtım stili dağıtım stilini seçme ve düzenleme sorumluluğunu Amazon Redshift'e vermek
Boyutsal modellemede dikkate alınması gereken bir diğer önemli faktör, yedek anahtarlar. Yedek anahtarlar, bir boyut tablosundaki her bir kaydı benzersiz şekilde tanımlamak için boyutsal modellemede kullanılan yapay anahtarlardır. Tipik olarak sıralı bir tamsayı olarak üretilirler ve iş alanında herhangi bir anlamları yoktur. Tipik olarak doğal anahtarlardan daha küçük olduklarından ve vekil anahtarlar olarak zamanla değişmediklerinden, birleştirmelerde benzersizliği sağlamak ve performansı artırmak gibi çeşitli avantajlar sunarlar. Bu, tutarlı olmamızı ve gerçekleri ve boyutları daha kolay birleştirmemizi sağlar.
Amazon Redshift'te yedek anahtarlar genellikle IDENTITY anahtar sözcüğü kullanılarak oluşturulur. Örneğin, önceki CREATE deyimi, bir boyut tablosu oluşturur. VenueSkey Vekil anahtarı. bu VenueSkey sütun, tabloya yeni satırlar eklendikçe benzersiz değerlerle otomatik olarak doldurulur. Bu sütun daha sonra mekan tablosunu aşağıdakilerle birleştirmek için kullanılabilir: FactSaleTransactions tablo.
Vekil anahtarlar tasarlamak için birkaç ipucu:
- Yedek anahtar için küçük, sabit genişlikli bir veri türü kullanın. Bu, performansı artıracak ve depolama alanını azaltacaktır.
- KİMLİK anahtar sözcüğünü kullanın veya bir sıralı ya da GUID değeri kullanarak vekil anahtarı oluşturun. Bu, vekil anahtarın benzersiz olmasını ve değiştirilememesini sağlayacaktır.
MERGE kullanarak dim tablosunu yükleyin
Dim tablonuzu yüklemenin çok sayıda yolu vardır. Performans, veri hacmi ve belki de SLA yükleme süreleri gibi belirli faktörlerin dikkate alınması gerekir. İle BİRLEŞTİRMEK ifadesinde, birden çok ekleme ve güncelleme komutu belirtmeye gerek kalmadan bir upsert gerçekleştiriyoruz. ayarlayabilirsiniz BİRLEŞTİRMEK bir ifadede saklı yordam verileri doldurmak için. Daha sonra saklı yordamı, gönderide daha sonra göstereceğimiz sorgu düzenleyici aracılığıyla programlı olarak çalışacak şekilde planlarsınız. Aşağıdaki kod, adlı bir saklı yordam oluşturur. SalesMart.DimVenueLoad:
Boyut yüklemesi hakkında birkaç not:
- İlk kez bir kayıt girildiğinde, girilen tarih ve güncellenen tarih doldurulacaktır. Herhangi bir değer değiştiğinde, veriler güncellenir ve güncellenen tarih değiştirildiği tarihi yansıtır. Girilen tarih kalır.
- Veriler iş kullanıcıları tarafından kullanılacağından, varsa NULL değerleri iş için daha uygun değerlerle değiştirmemiz gerekir.
Gerçekleri belirle ve uygula
Tahılımızın belirli bir zamanda gerçekleşen bir satış olayı olduğunu ilan ettiğimize göre, olgu tablomuz iş sürecimiz için sayısal gerçekleri saklayacaktır.
Ölçmek için aşağıdaki sayısal gerçekleri belirledik:
- Satış başına satılan bilet miktarı
- satış komisyonu
Gerçeği Uygulamak
Var üç tür bilgi tablosu (işlem olgu tablosu, periyodik anlık görüntü olgu tablosu ve biriken anlık görüntü olgu tablosu). Her biri, iş sürecinin farklı bir görünümüne hizmet eder. Örneğimiz için, bir işlem olgu tablosu kullanıyoruz. Aşağıdaki adımları tamamlayın:
- Olgu tablosunu oluşturun
Bir kaydın yüklenip yüklenmediğini ve ne zaman yüklendiğini gösteren, varsayılan değere sahip bir girilen tarih eklenir. Yinelemeleri önlemek için önceden yüklenmiş verileri kaldırmak için olgu tablosunu yeniden yüklerken bunu kullanabilirsiniz.
Olgu tablosunu yüklemek, ilişkili boyutlarınızı birleştiren basit bir ekleme ifadesinden oluşur. dan katılıyoruz DimVenue gerçeklerimizi açıklayan oluşturulan tablo. En iyi uygulamadır, ancak sahip olmak isteğe bağlıdır takvim tarihi son kullanıcının olgu tablosunda gezinmesine izin veren boyutlar. Veriler, yeni bir satış olduğunda veya günlük olarak yüklenebilir; girilen tarihin veya yükleme tarihinin kullanışlı olduğu yer burasıdır.
Olgu tablosunu bir saklı yordam kullanarak yüklüyoruz ve bir tarih parametresi kullanıyoruz.
- Saklı yordamı aşağıdaki kodla oluşturun. Boyut yükünde uyguladığımız aynı veri bütünlüğünü korumak için, varsa NULL değerleri daha iş için uygun değerlerle değiştiririz:
- Aşağıdaki komutla yordamı çağırarak verileri yükleyin:
Veri yüklemesini planlayın
Artık Amazon Redshift Query Editor V2'de saklı yordamları planlayarak modelleme sürecini otomatik hale getirebiliriz. Aşağıdaki adımları tamamlayın:
- Önce Dimension Load diyoruz ve Dimension Load başarılı bir şekilde çalıştıktan sonra, fact load başlıyor:
Boyut yüklemesi başarısız olursa, olgu yüklemesi çalışmaz. Olgu tablosunu eski boyutlarla yüklemek istemediğimizden bu, verilerde tutarlılık sağlar.
- Yükü planlamak için seçin Çizelge Sorgu Düzenleyicisi V2'de.

- Sorguyu her gün saat 5:00'te çalışacak şekilde planlıyoruz.
- İsteğe bağlı olarak, etkinleştirerek arıza bildirimleri ekleyebilirsiniz. Amazon Basit Bildirim Servisi (Amazon SNS) bildirimleri.

Amazon Quicksight'ta verileri raporlayın ve analiz edin
QuickSight, içgörü sağlamayı kolaylaştıran bir iş zekası hizmetidir. Tamamen yönetilen bir hizmet olarak QuickSight, daha sonra herhangi bir cihazdan erişilebilen ve uygulamalarınıza, portallarınıza ve web sitelerinize yerleştirilebilen etkileşimli panoları kolayca oluşturmanıza ve yayınlamanıza olanak tanır.
Gerçekleri bir pano biçiminde görsel olarak sunmak için data mart'ımızı kullanıyoruz. QuickSight'ı başlatmak ve kurmak için bkz. Otomatik olarak keşfedilmemiş bir veritabanı kullanarak veri kümesi oluşturma.
QuickSight'ta veri kaynağınızı oluşturduktan sonra, yedek anahtarımıza dayalı olarak modellenen verileri (data mart) birleştiririz. skey. Data mart'ı görselleştirmek için bu veri setini kullanıyoruz.

Son kontrol panelimiz, veri pazarının içgörülerini içerecek ve mekan başına toplam komisyon ve en yüksek satışın olduğu tarihler gibi kritik işle ilgili soruları yanıtlayacaktır. Aşağıdaki ekran görüntüsü, data mart'ın nihai ürününü göstermektedir.

Temizlemek
İleride ücret ödemekten kaçınmak için bu gönderinin bir parçası olarak oluşturduğunuz tüm kaynakları silin.
Sonuç
Artık başarıyla bir data mart'ı uyguladık. DimVenue, DimCalendar, ve FactSaleTransactions tablolar. Depomuz tamamlanmadı; veri pazarını daha fazla gerçekle genişletebildiğimiz ve daha fazla pazar uygulayabildiğimiz için ve iş süreci ve gereksinimler zaman içinde büyüdükçe, veri ambarı da büyüyecektir. Bu gönderide, Amazon Redshift'te boyutsal modellemeyi anlama ve uygulamaya ilişkin uçtan uca bir bakış açısı sunduk.
Seninle başla Amazon Kırmızıya Kaydırma boyutlu model bugün.
Yazarlar Hakkında
 bernard verster ölçeklenebilir ve verimli veri modelleri oluşturma, veri entegrasyon stratejilerini tanımlama ve veri yönetişimi ile güvenliğini sağlama konularında yıllarca deneyime sahip deneyimli bir bulut mühendisidir. İş gereklilikleri ve hedefleriyle uyumlu hale gelirken içgörüleri yönlendirmek için verileri kullanma konusunda tutkulu.
bernard verster ölçeklenebilir ve verimli veri modelleri oluşturma, veri entegrasyon stratejilerini tanımlama ve veri yönetişimi ile güvenliğini sağlama konularında yıllarca deneyime sahip deneyimli bir bulut mühendisidir. İş gereklilikleri ve hedefleriyle uyumlu hale gelirken içgörüleri yönlendirmek için verileri kullanma konusunda tutkulu.
 Abhishek Tavası AWS Hindistan Kamu sektörü müşterileriyle çalışan bir WWSO Uzmanı SA-Analytics'tir. Veriye dayalı stratejiyi tanımlamak, analitik kullanım durumlarıyla ilgili ayrıntılı oturumlar sağlamak ve ölçeklenebilir ve yüksek performanslı analitik uygulamalar tasarlamak için müşterilerle iletişim kurar. 12 yıllık deneyime sahiptir ve veritabanları, analitik ve AI/ML konusunda tutkuludur. Hevesli bir gezgin ve kamera merceğinden dünyayı yakalamaya çalışıyor.
Abhishek Tavası AWS Hindistan Kamu sektörü müşterileriyle çalışan bir WWSO Uzmanı SA-Analytics'tir. Veriye dayalı stratejiyi tanımlamak, analitik kullanım durumlarıyla ilgili ayrıntılı oturumlar sağlamak ve ölçeklenebilir ve yüksek performanslı analitik uygulamalar tasarlamak için müşterilerle iletişim kurar. 12 yıllık deneyime sahiptir ve veritabanları, analitik ve AI/ML konusunda tutkuludur. Hevesli bir gezgin ve kamera merceğinden dünyayı yakalamaya çalışıyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. Otomotiv / EV'ler, karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- Blok Ofsetleri. Çevre Dengeleme Sahipliğini Modernleştirme. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- :vardır
- :dır-dir
- :olumsuzluk
- :Neresi
- $UP
- 1
- 100
- 12
- %15
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- Hakkımızda
- hızlandırmak
- erişim
- erişilen
- tam olarak
- karşısında
- Hareket
- eklemek
- katma
- Ek
- Sonra
- AI / ML
- hizalamak
- dizme
- izin vermek
- veriyor
- zaten
- am
- Amazon
- Amazon Web Servisleri
- an
- analiz
- Analitik
- analytics
- çözümlemek
- ve
- cevap
- herhangi
- uygulamaları
- uygulamalı
- uygun
- mimari
- ARE
- yapay
- AS
- yönleri
- ilişkili
- At
- öznitelikleri
- Oto
- otomatikleştirmek
- otomatik olarak
- önlemek
- AWS
- b
- merkezli
- BE
- Çünkü
- başlamak
- faydaları
- İYİ
- yerleşik
- iş
- iş zekası
- İş süreci
- Iş süreçleri
- fakat
- by
- Takvim
- çağrı
- denilen
- çağrı
- kamera
- CAN
- ele geçirmek
- dava
- durumlarda
- Sebeb olmak
- belli
- değişiklik
- değişmiş
- değişiklikler
- değiştirme
- karakter
- yükler
- Klinik
- açık
- Açıkça
- yakından
- bulut
- kod
- Sütun
- geliyor
- alın
- ortak
- Şirketler
- şirket
- tamamlamak
- Düşünmek
- tutarlı
- oluşur
- bağlam
- doğru
- olabilir
- yaratmak
- çevrimiçi kurslar düzenliyorlar.
- oluşturur
- Oluşturma
- oluşturma
- kritik
- Müşteriler
- günlük
- gösterge paneli
- gösterge tabloları
- veri
- veri entegrasyonu
- Veri Gölü
- veri ambarı
- veri-güdümlü
- Veriye Dayalı Strateji
- veritabanı
- veritabanları
- Tarih
- Tarih
- datetime
- gün
- derin
- derin dalış
- Varsayılan
- tanımlarken
- teslim etmek
- göstermek
- bölümler
- Türetilmiş
- tanımlamak
- Dizayn
- tasarım
- ayrıntı
- cihaz
- farklı
- Boyut
- boyutlar
- tartışmak
- farklı
- dağıtım
- do
- domain
- yapılmış
- Dont
- aşağı
- sürücü
- çiftleri
- her
- Daha erken
- kolayca
- kolay
- editör
- verimli
- ya
- gömülü
- etkinleştirmek
- etkinleştirme
- son
- son uca
- meşgul
- mühendis
- sağlamak
- olmasını sağlar
- sağlanması
- Tüm
- varlık
- Eter (ETH)
- Etkinlikler
- olaylar
- Her
- her gün
- örnek
- örnekler
- Genişletmek
- deneyim
- deneyimli
- Maruz kalma
- çıkarmak
- gerçek
- faktör
- faktörler
- gerçekler
- başarısız
- Başarısızlık
- Özellikler
- az
- alan
- Alanlar
- beşinci
- şekil
- filtre
- son
- Ad
- ilk kez
- uygun
- odaklanmış
- takip etme
- İçin
- Airdrop Formu
- biçim
- dört
- itibaren
- tamamen
- daha fazla
- gelecek
- Kazanç
- oluşturmak
- oluşturulan
- üretir
- almak
- alma
- Vermek
- verilmiş
- Tercih Etmenizin
- yönetim
- Büyümek
- kullanışlı
- Var
- he
- en yüksek
- onun
- tarihsel
- Tatil
- Ne kadar
- Nasıl Yapılır
- HTML
- http
- HTTPS
- IAM
- tespit
- belirlemek
- belirlenmesi
- Kimlik
- if
- göstermektedir
- darbe
- uygulamak
- uygulanan
- uygulanması
- önemli
- iyileştirmek
- geliştirme
- in
- Dahil olmak üzere
- Hindistan
- belirtmek
- belirten
- bilgi
- anlayışlar
- entegre
- bütünleşme
- bütünlük
- İstihbarat
- interaktif
- içine
- IT
- ONUN
- kaydol
- katıldı
- birleştirme
- Katıldı
- jpg
- tutmak
- koruma
- anahtar
- anahtarlar
- göl
- dil
- sonra
- son
- tabaka
- sol
- Lens
- Lets
- seviye
- çizgi
- yük
- yükleme
- yükler
- bulunan
- bakıyor
- yapılmış
- YAPAR
- yönetilen
- Pazarlama
- eşleşti
- anlam
- ölçmek
- adı geçen
- gitmek
- Metrikleri
- akla
- hata
- model
- Modelleme
- modelleme
- modelleri
- Ay
- Daha
- çoğu
- çoklu
- isimleri
- Doğal (Madenden)
- Gezin
- gerek
- gerek
- ihtiyaçlar
- yeni
- notlar
- tebliğ
- bildirimleri
- şimdi
- sayısız
- hedefleri
- of
- teklif
- sık sık
- on
- bir tek
- işletme
- or
- kuruluşlar
- bizim
- tekrar
- tüm
- parametre
- Bölüm
- tutkulu
- başına
- yapmak
- performans
- belki
- periyodik
- yer
- Platon
- Plato Veri Zekası
- PlatoVeri
- Nokta
- nüfuslu
- Çivi
- güç kelimesini seçerim
- uygulama
- önkoşullar
- mevcut
- birincil
- prosedür
- prosedürler
- süreç
- Süreçler
- PLATFORM
- sağlamak
- sağlanan
- sağlar
- halka açık
- yayınlamak
- amaçlı
- Sorular
- hızla
- yükseltmek
- Çiğ
- işlenmemiş veri
- kayıt
- kayıtlar
- azaltmak
- Referans
- yansıtır
- bölge
- ilişki
- kalıntılar
- Kaldır
- değiştirmek
- rapor
- Raporlama
- Raporlar
- Yer Alan Kurallar
- Kaynaklar
- sorumluluk
- Rol
- Rulo
- SIRA
- koşmak
- ishal
- satış
- satış
- aynı
- Örnek veri kümesi
- ölçeklenebilir
- program
- çizelgeleme
- bölümler
- sektör
- güvenlik
- görmek
- ayrı
- vermektedir
- hizmet
- Hizmetler
- oturumları
- set
- birkaç
- meli
- şov
- Gösteriler
- Basit
- basitlik
- tek
- Yavaş yavaş
- küçük
- daha küçük
- Enstantane fotoğraf
- So
- satılan
- çözüm
- biraz
- Kaynak
- kaynaklar
- uzay
- uzman
- özel
- özellikle
- Aşama
- sahneleme
- Star
- başladı
- XNUMX dakika içinde!
- Açıklama
- adım
- Basamaklar
- hafızası
- mağaza
- saklı
- stratejileri
- Stratejileri
- yapı
- başarılı
- Başarılı olarak
- böyle
- sistem
- tablo
- geçici
- onlarca
- şartlar
- göre
- o
- The
- Kaynak
- Dünya
- ve bazı Asya
- sonra
- Orada.
- bu nedenle
- Bunlar
- onlar
- Re-Tweet
- Binlerce
- İçinden
- bilet
- bilet satışı
- bilet
- zaman
- zamanlar
- zaman damgası
- ipuçları
- için
- bugün
- birlikte
- aldı
- Toplam
- iz
- işlem
- Dönüştürmek
- transforme
- gezgin
- tip
- türleri
- tipik
- anlayış
- benzersiz
- benzersiz
- benzersizlik
- bilinmeyen
- Güncelleme
- güncellenmiş
- us
- kullanım
- kullanım
- kullanım durumu
- Kullanılmış
- kullanıcılar
- kullanım
- kullanma
- genellikle
- Değerli
- değer
- Değerler
- çeşitli
- Yer
- mekanları
- üzerinden
- Görüntüle
- hacim
- örneklerde
- istemek
- depo
- oldu
- yolları
- we
- ağ
- web hizmetleri
- web siteleri
- hafta
- ne zaman
- hangi
- süre
- irade
- ile
- içinde
- olmadan
- çalışma
- Dünya
- Yanlış
- yıl
- yıl
- sen
- zefirnet