Küçük ve büyük birçok kuruluş, analitik iş yüklerini Amazon Web Services'e (AWS) taşımak ve modernleştirmek için çalışıyor. Müşterilerin AWS'ye geçmesinin birçok nedeni vardır ancak ana nedenlerden biri, altyapı bakımı, yama uygulama, izleme, yedekleme ve daha fazlasına zaman harcamak yerine tam olarak yönetilen hizmetleri kullanabilme yeteneğidir. Liderlik ve geliştirme ekipleri, mevcut altyapıyı korumak yerine mevcut çözümleri optimize etmeye ve hatta yeni kullanım örneklerini denemeye daha fazla zaman harcayabilir.
AWS'de hızlı hareket edebilme yeteneği sayesinde, ölçeklendirmeye devam ederken aldığınız ve işlediğiniz verilerden de sorumlu olmanız gerekir. Bu sorumluluklar, veri gizliliği yasaları ve düzenlemelerine uymayı ve kişisel olarak tanımlanabilir bilgiler (PII) veya korunan sağlık bilgileri (PHI) gibi hassas verileri üst kaynaklardan saklamamayı veya ifşa etmemeyi içerir.
Bu yazıda, veri gizliliği endişelerini gidermek için büyük miktarda geliştirme süresi harcamanıza gerek kalmadan kuruluşunuzun veri platformunu nasıl ölçeklendirmeye devam edebileceğinizi gösteren üst düzey bir mimariyi ve özel bir kullanım senaryosunu ele alacağız. Kullanırız AWS Tutkal PII verilerini yüklemeden önce tespit etmek, maskelemek ve çıkarmak için Amazon Açık Arama Hizmeti.
Çözüme genel bakış
Aşağıdaki diyagram üst düzey çözüm mimarisini göstermektedir. Tasarımımızın tüm katmanlarını ve bileşenlerini standartlara uygun olarak tanımladık. AWS Well-Architected Framework Veri Analitiği Merceği.
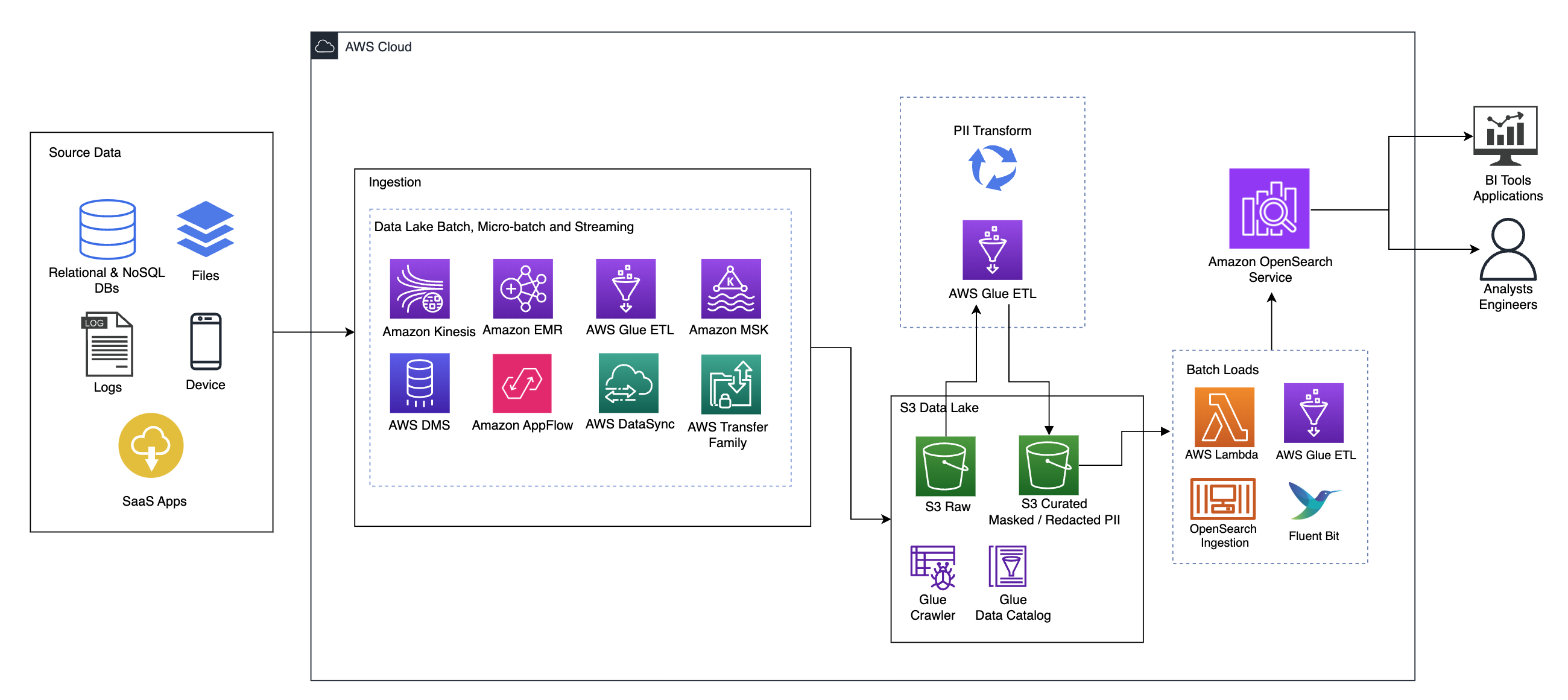
Mimari bir dizi bileşenden oluşur:
Kaynak verileri
Veriler, veritabanları, dosya aktarımları, günlükler, hizmet olarak yazılım (SaaS) uygulamaları ve daha fazlası dahil olmak üzere onlarca ila yüzlerce kaynaktan geliyor olabilir. Kuruluşlar, bu kanallardan hangi verilerin geldiği ve bunların alt depolama ve uygulamaları üzerinde her zaman kontrol sahibi olmayabilir.
Besleme: Veri gölü toplu işlemi, mikro toplu iş ve akış
Birçok kuruluş, kaynak verilerini toplu iş, mikro toplu iş ve akış işleri dahil olmak üzere çeşitli yollarla veri göllerine yerleştirir. Örneğin, Amazon EMR'si, AWS Tutkal, ve AWS Veritabanı Geçiş Hizmeti (AWS DMS) tümü, bir veri gölüne batan toplu ve/veya akış işlemlerini gerçekleştirmek için kullanılabilir. Amazon Basit Depolama Hizmeti (Amazon S3). Amazon Uygulama Akışı farklı SaaS uygulamalarından veri gölüne veri aktarmak için kullanılabilir. AWS Veri Eşzamanlama ve AWS Transfer Ailesi dosyaların bir dizi farklı protokol üzerinden veri gölüne ve veri gölünden taşınmasına yardımcı olabilir. Amazon Kinesis ve Amazon MSK, verileri doğrudan Amazon S3'teki bir veri gölüne aktarma yeteneklerine de sahiptir.
S3 veri gölü
Veri gölünüz için Amazon S3'ü kullanmak modern veri stratejisiyle uyumludur. Performanstan, güvenilirlikten veya kullanılabilirlikten ödün vermeden düşük maliyetli depolama sağlar. Bu yaklaşımla verilerinize gerektiği kadar bilgi işlem getirebilir ve yalnızca çalışması gereken kapasite için ödeme yapabilirsiniz.
Bu mimaride ham veriler, hassas veriler içerebilen çeşitli kaynaklardan (dahili ve harici) gelebilir.
AWS Glue tarayıcılarını kullanarak, bizim için tablo şemalarını oluşturacak verileri keşfedip kataloglayabiliriz ve sonuç olarak, gelmiş olabilecek hassas verileri tespit etmek, maskelemek veya düzenlemek için AWS Glue ETL'yi PII dönüşümüyle kullanmayı kolaylaştırabiliriz. veri gölünde.
İş bağlamı ve veri kümeleri
Yaklaşımımızın değerini göstermek için, bir finansal hizmetler kuruluşunun veri mühendisliği ekibinin parçası olduğunuzu varsayalım. Gereksinimleriniz, kuruluşunuzun bulut ortamına aktarılan hassas verileri tespit etmek ve maskelemektir. Veriler, aşağı yönlü analitik süreçler tarafından tüketilecektir. Gelecekte kullanıcılarınız, dahili bankacılık sistemlerinden toplanan veri akışlarına dayalı olarak geçmiş ödeme işlemlerini güvenli bir şekilde arayabilecek. Operasyon ekiplerinden, müşterilerden ve arayüz uygulamalarından gelen arama sonuçları hassas alanlarda maskelenmelidir.
Aşağıdaki tabloda çözüm için kullanılan veri yapısı gösterilmektedir. Açıklık sağlamak için ham sütun adlarını seçilmiş sütun adlarıyla eşleştirdik. Bu şemadaki ad, soyadı, Sosyal Güvenlik numarası (SSN), adres, kredi kartı numarası, telefon numarası, e-posta ve IPv4 adresi gibi birden fazla alanın hassas veri olarak kabul edildiğini fark edeceksiniz.
| Ham Sütun Adı | Seçilmiş Sütun Adı | Tip |
| c0 | İsim | dizi |
| c1 | soyadı | dizi |
| c2 | ssn | dizi |
| c3 | adres | dizi |
| c4 | posta kodu | dizi |
| c5 | ülke | dizi |
| c6 | satın alma sitesi | dizi |
| c7 | Kredi Kartı Numarası | dizi |
| c8 | kredi_kartı_sağlayıcı | dizi |
| c9 | para | dizi |
| c10 | alım değeri | tamsayı |
| c11 | İşlem Tarihi | tarih |
| c12 | telefon numarası | dizi |
| c13 | E-posta | dizi |
| c14 | ipv4 | dizi |
Kullanım örneği: OpenSearch Hizmetine yüklenmeden önce PII toplu tespiti
Aşağıdaki mimariyi uygulayan müşteriler, farklı analiz türlerini uygun ölçekte çalıştırmak için veri göllerini Amazon S3'te oluşturmuştur. Bu çözüm, OpenSearch Hizmetine gerçek zamanlı alım gerektirmeyen ve bir programa göre çalışan veya olaylar aracılığıyla tetiklenen veri entegrasyon araçlarını kullanmayı planlayan müşteriler için uygundur.
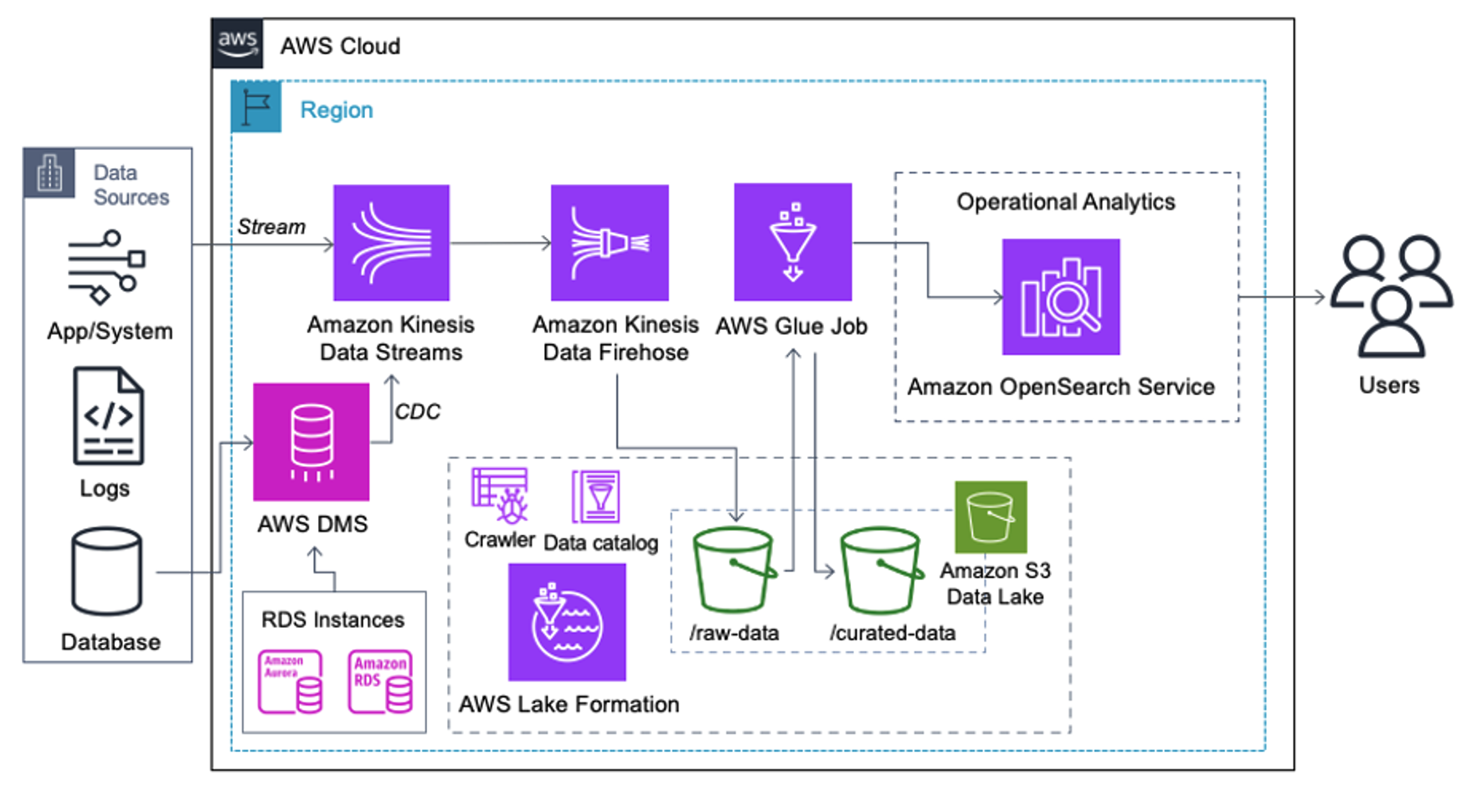
Veri kayıtları Amazon S3'e ulaşmadan önce, tüm veri akışlarını güvenilir ve emniyetli bir şekilde veri gölüne getirmek için bir alım katmanı uyguluyoruz. Kinesis Data Streams, yapılandırılmış ve yarı yapılandırılmış veri akışlarının hızlandırılmış alımı için bir alım katmanı olarak dağıtılır. Bunlara örnek olarak ilişkisel veritabanı değişiklikleri, uygulamalar, sistem günlükleri veya tıklama akışları verilebilir. Değişiklik verileri yakalama (CDC) kullanım senaryoları için Kinesis Veri Akışlarını AWS DMS hedefi olarak kullanabilirsiniz. Hassas veriler içeren akışlar oluşturan uygulamalar veya sistemler, desteklenen üç yöntemden biri aracılığıyla Kinesis veri akışına gönderilir: Amazon Kinesis Agent, Java için AWS SDK veya Kinesis Yapımcı Kitaplığı. Son adım olarak, Amazon Kinesis Veri İtfaiyesi gerçek zamanlıya yakın veri gruplarını S3 data lake hedefimize güvenilir bir şekilde yüklememize yardımcı olur.
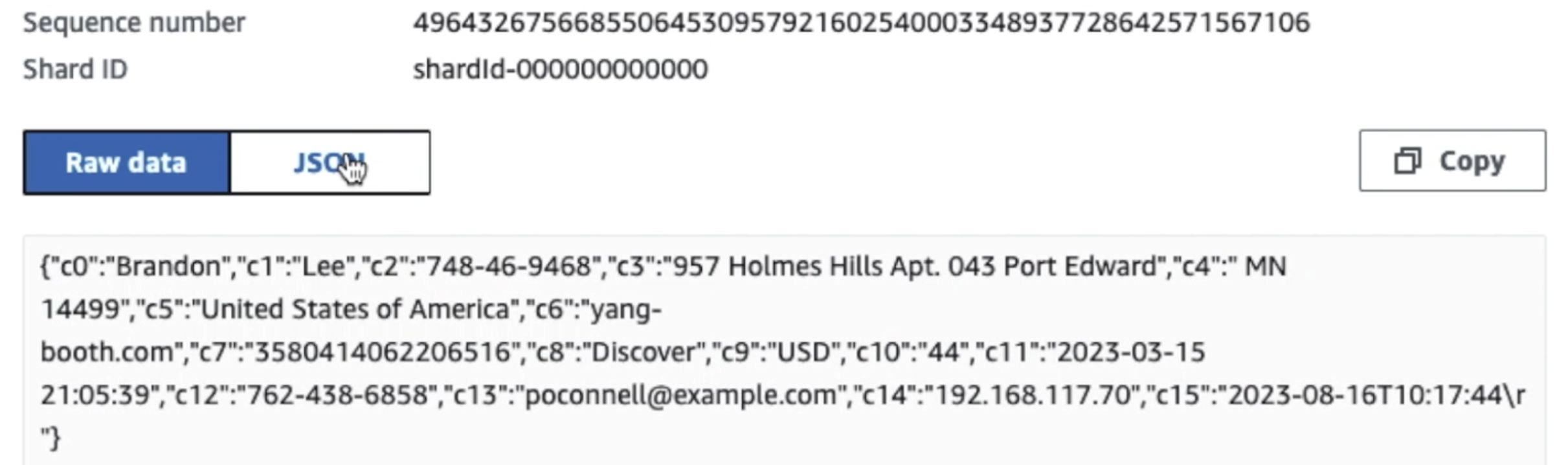
Aşağıdaki ekran görüntüsü, verilerin Kinesis Veri Akışları üzerinden nasıl aktığını göstermektedir. Veri Görüntüleyici ve ham S3 önekine ulaşan örnek verileri alır. Bu mimari için, S3 öneklerinin veri yaşam döngüsünü şurada önerildiği şekilde takip ettik. Veri gölü temeli.
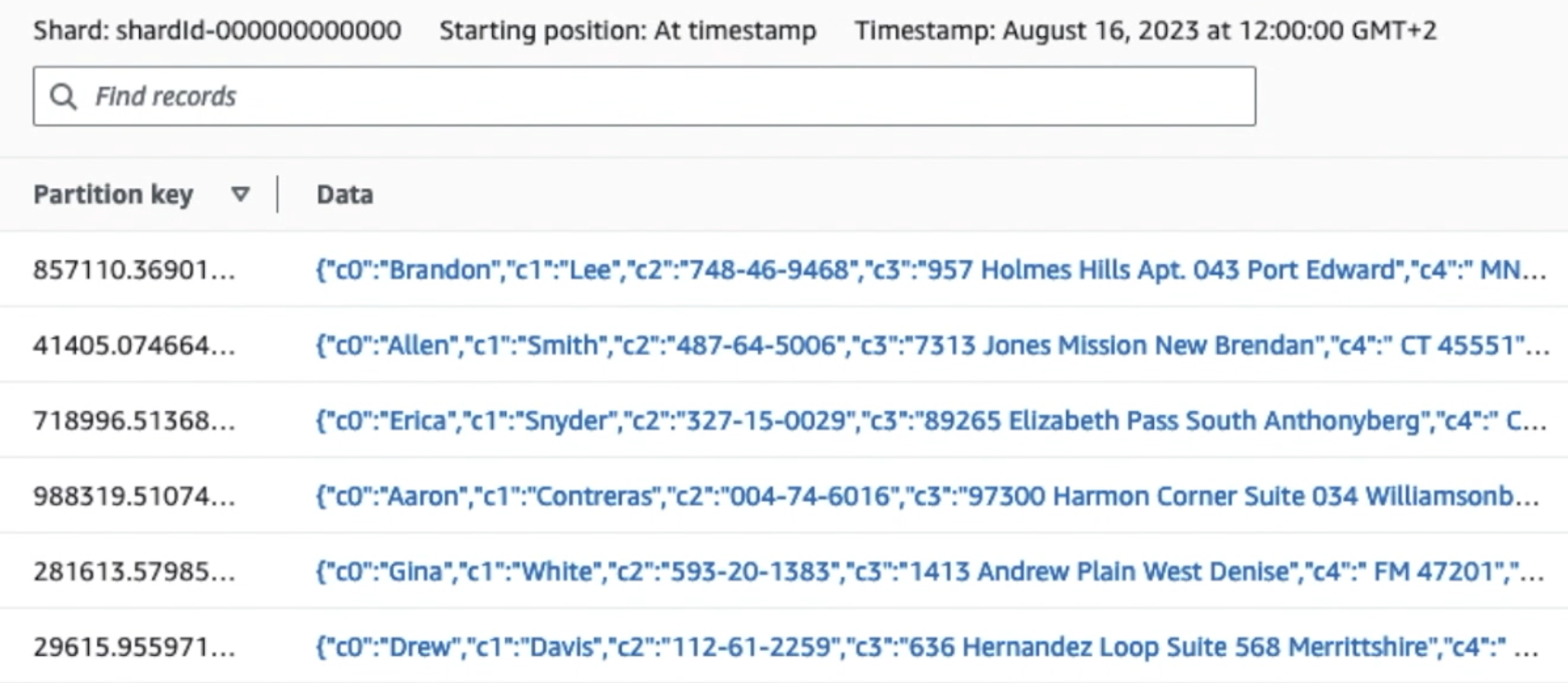
Aşağıdaki ekran görüntüsündeki ilk kaydın detaylarından da görebileceğiniz gibi JSON yükü, önceki bölümdeki şemanın aynısını takip ediyor. Düzenlenmemiş verilerin Kinesis veri akışına aktığını görebilirsiniz; bu veriler daha sonraki aşamalarda karartılacaktır.
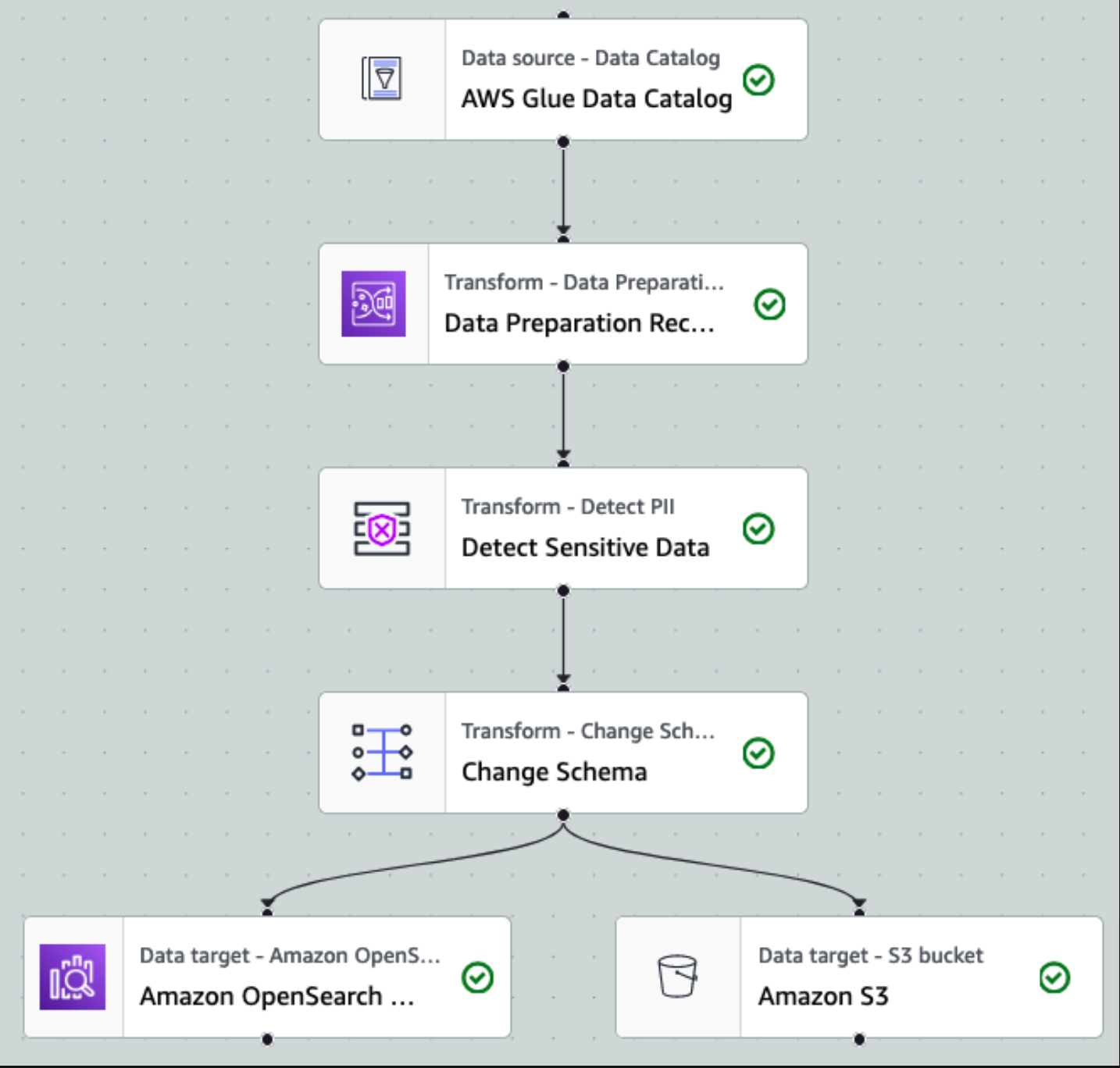
Veriler toplanıp Kinesis Data Streams'e alındıktan ve Kinesis Data Firehose kullanılarak S3 klasörüne iletildikten sonra mimarinin işleme katmanı görevi devralır. İşlem hattımızdaki hassas verilerin algılanmasını ve maskelenmesini otomatikleştirmek için AWS Glue PII dönüşümünü kullanıyoruz. Aşağıdaki iş akışı şemasında gösterildiği gibi, dönüşüm işimizi AWS Glue Studio'da uygulamak için kodsuz, görsel bir ETL yaklaşımını benimsedik.
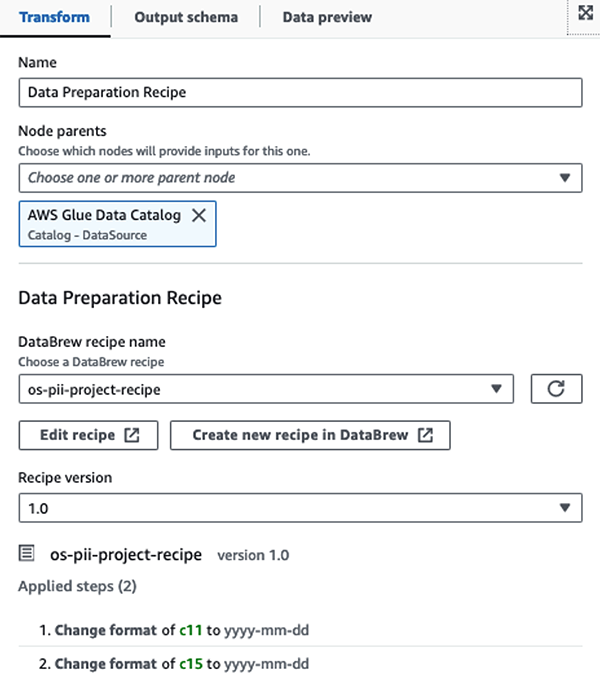
Öncelikle kaynak Data Catalog tablosuna ham olarak erişiyoruz. pii_data_db veri tabanı. Tablo önceki bölümde sunulan şema yapısına sahiptir. Ham işlenmiş verileri takip etmek için şunları kullandık: iş imleri.

Biz kullanın AWS Glue Studio görsel ETL işindeki AWS Glue DataBrew tarifleri iki tarih niteliğinin OpenSearch ile uyumlu olacak şekilde dönüştürülmesi bekleniyor formatları. Bu, tam bir kodsuz deneyim yaşamamızı sağlar.
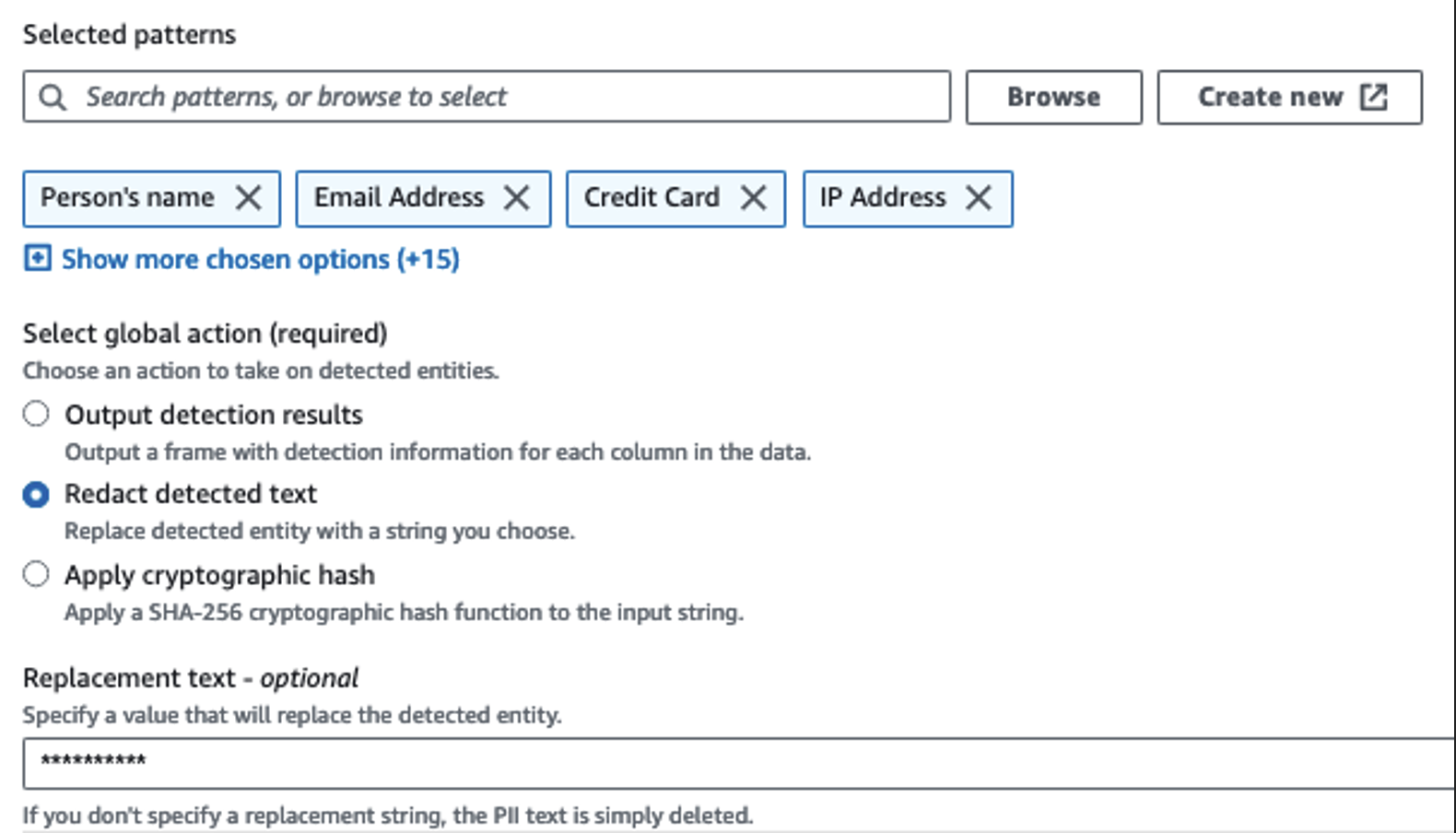
Hassas sütunları tanımlamak için Kimlik Bilgilerini Algıla eylemini kullanırız. AWS Glue'nun bunu seçilen kalıplara, algılama eşiğine ve veri kümesindeki satırların örnek kısmına göre belirlemesine izin veriyoruz. Örneğimizde, özellikle Amerika Birleşik Devletleri'ne (SSN'ler gibi) uygulanan ve diğer ülkelerden gelen hassas verileri tespit edemeyebilecek kalıplar kullandık. Kullanım durumunuza uygun mevcut kategorileri ve konumları arayabilir veya diğer ülkelerdeki hassas verilere yönelik algılama varlıkları oluşturmak için AWS Glue'da normal ifadeler (regex) kullanabilirsiniz.
AWS Glue'nun sunduğu doğru örnekleme yöntemini seçmek önemlidir. Bu örnekte, akıştan gelen verilerin her satırında hassas veriler bulunduğu bilindiğinden, veri kümesindeki satırların %100'ünün örneklenmesine gerek yoktur. Hiçbir hassas verinin alt kaynaklara gönderilmesine izin verilmeyen bir gereksiniminiz varsa, seçtiğiniz modeller için verilerin %100'ünü örneklemeyi düşünün veya veri kümesinin tamamını tarayın ve tüm hassas verilerin algılandığından emin olmak için her bir hücre üzerinde işlem yapın. Örneklemeden elde ettiğiniz fayda maliyetlerin azalmasıdır çünkü çok fazla veri taramanıza gerek kalmaz.

Kimlik Bilgilerini Algıla eylemi, hassas verileri maskelerken varsayılan bir dize seçmenize olanak tanır. Örneğimizde ********** dizesini kullanıyoruz.
Gibi gereksiz sütunları yeniden adlandırmak ve kaldırmak için uygulama eşleme işlemini kullanırız. ingestion_year, ingestion_month, ve ingestion_day. Bu adım aynı zamanda sütunlardan birinin veri türünü değiştirmemize de olanak tanır (purchase_value) dizeden tamsayıya.

Bu noktadan itibaren iş iki çıktı hedefine bölünür: OpenSearch Service ve Amazon S3.
Sağlanan OpenSearch Hizmet kümemiz, Tutkal için OpenSearch yerleşik bağlayıcı. Yazmak istediğimiz OpenSearch Index'i belirliyoruz ve bağlayıcı kimlik bilgilerini, etki alanını ve bağlantı noktasını yönetiyor. Aşağıdaki ekran görüntüsünde belirtilen indekse yazıyoruz index_os_pii.
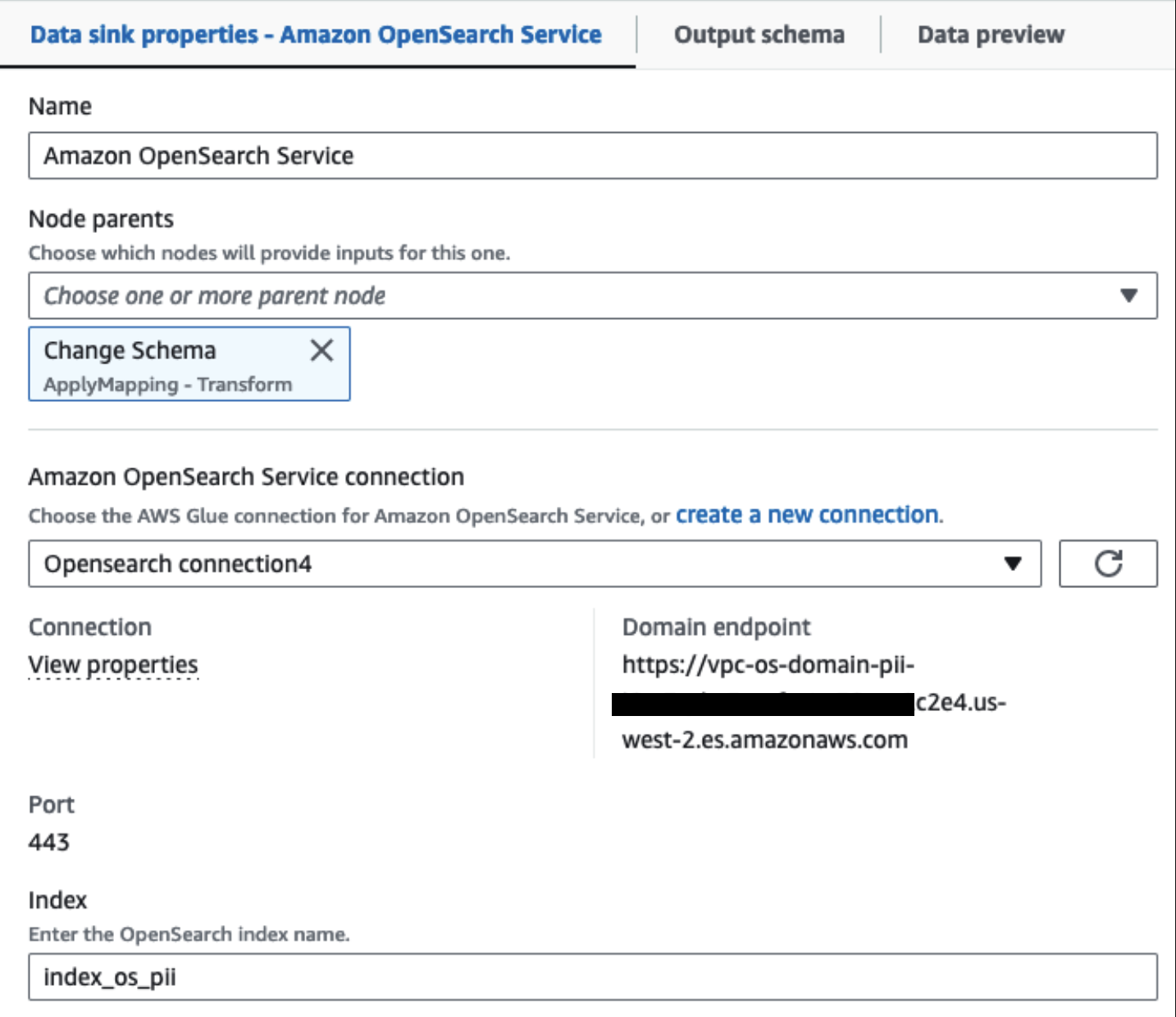
Maskelenmiş veri kümesini seçilmiş S3 önekinde saklıyoruz. Burada, belirli bir kullanım durumuna göre normalleştirilmiş ve veri bilimcileri tarafından veya geçici raporlama ihtiyaçları için güvenli bir şekilde tüketilen verilere sahibiz.
Tüm veri kümelerinin ve Data Catalog tablolarının birleşik yönetimi, erişim kontrolü ve denetim izleri için şunları kullanabilirsiniz: AWS Göl Oluşumu. Bu, AWS Glue Data Catalog tablolarına ve temel verilere erişimi yalnızca gerekli izinlerin verildiği kullanıcılar ve rollerle kısıtlamanıza yardımcı olur.
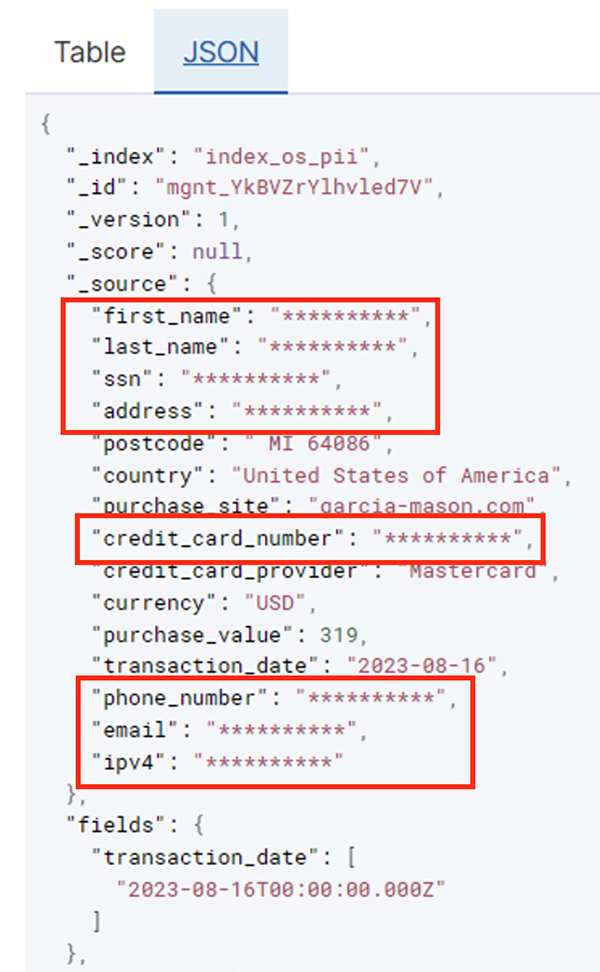
Toplu iş başarıyla çalıştırıldıktan sonra, arama sorgularını veya raporları çalıştırmak için OpenSearch Hizmetini kullanabilirsiniz. Aşağıdaki ekran görüntüsünde gösterildiği gibi, işlem hattı hassas alanları hiçbir kod geliştirme çabasına gerek kalmadan otomatik olarak maskeledi.

Önceki ekran görüntüsünde gösterildiği gibi, kredi kartı sağlayıcısına göre filtrelenen günlük işlem miktarı gibi operasyonel verilerden eğilimleri belirleyebilirsiniz. Ayrıca kullanıcıların alışveriş yaptığı konumları ve alanları da belirleyebilirsiniz. transaction_date özelliği zaman içindeki bu eğilimleri görmemize yardımcı olur. Aşağıdaki ekran görüntüsü, işlemin tüm bilgilerinin uygun şekilde düzenlendiği bir kaydı göstermektedir.
Amazon OpenSearch'e veri yüklemeye ilişkin alternatif yöntemler için bkz. Akış verilerini Amazon OpenSearch Service'e yükleme.
Ayrıca hassas veriler diğer AWS çözümleri kullanılarak da keşfedilebilir ve maskelenebilir. Örneğin, kullanabilirsiniz Amazon Macie'si S3 klasöründeki hassas verileri tespit etmek ve ardından kullanmak için Amazon Kavramak tespit edilen hassas verileri düzenlemek için. Daha fazla bilgi için bkz. AWS Hizmetlerini kullanarak PHI ve PII verilerini tespit etmeye yönelik yaygın teknikler.
Sonuç
Bu gönderide, ortamınızda hassas verilerin işlenmesinin önemi ve uyumlu kalmanın yanı sıra kuruluşunuzun hızlı bir şekilde ölçeklenmesine de olanak sağlamak için çeşitli yöntem ve mimariler tartışıldı. Artık verilerinizi nasıl tespit edeceğinizi, maskeleyeceğinizi veya düzelteceğinizi ve Amazon OpenSearch Service'e nasıl yükleyeceğinizi iyi anlamış olmalısınız.
yazarlar hakkında
 Michael Hamilton kurumsal müşterilerin AWS'deki analitik iş yüklerini modernleştirmelerine ve basitleştirmelerine yardımcı olmaya odaklanan bir Kıdemli Analitik Çözümleri Mimarıdır. Çalışmadığı zamanlarda dağ bisikletine binmeyi ve eşi ve üç çocuğuyla vakit geçirmeyi seviyor.
Michael Hamilton kurumsal müşterilerin AWS'deki analitik iş yüklerini modernleştirmelerine ve basitleştirmelerine yardımcı olmaya odaklanan bir Kıdemli Analitik Çözümleri Mimarıdır. Çalışmadığı zamanlarda dağ bisikletine binmeyi ve eşi ve üç çocuğuyla vakit geçirmeyi seviyor.
 daniel rozo AWS'nin Hollanda'daki müşterilerini destekleyen Kıdemli Çözüm Mimarıdır. Onun tutkusu basit veri ve analiz çözümleri tasarlamak ve müşterilerin modern veri mimarilerine geçmesine yardımcı olmaktır. İş dışında tenis oynamaktan ve bisiklete binmekten hoşlanıyor.
daniel rozo AWS'nin Hollanda'daki müşterilerini destekleyen Kıdemli Çözüm Mimarıdır. Onun tutkusu basit veri ve analiz çözümleri tasarlamak ve müşterilerin modern veri mimarilerine geçmesine yardımcı olmaktır. İş dışında tenis oynamaktan ve bisiklete binmekten hoşlanıyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- :vardır
- :dır-dir
- :olumsuzluk
- :Neresi
- 07
- 100
- 28
- 300
- 31
- 32
- 39
- 40
- 46
- 50
- 51
- 600
- 90
- 970
- a
- kabiliyet
- Yapabilmek
- hızlandırılmış
- erişim
- Hareket
- Action
- Ad
- adres
- Danışman
- Türkiye
- izin
- Izin
- veriyor
- Ayrıca
- her zaman
- Amazon
- Amazon Kinesis
- Amazon Web Servisleri
- Amazon Web Services (AWS)
- miktar
- tutarları
- an
- Analitik
- analytics
- ve
- herhangi
- uygulanabilir
- uygulamaları
- Tamam
- yaklaşım
- uygun olarak
- mimari
- ARE
- AS
- At
- öznitelikleri
- denetim
- otomatikleştirmek
- otomatik olarak
- kullanılabilirliği
- mevcut
- AWS
- AWS Tutkal
- yedekleme
- Bankacılık
- Bankacılık sistemleri
- merkezli
- BE
- Çünkü
- olmuştur
- önce
- olmak
- altında
- yarar
- getirmek
- inşa etmek
- yapılı
- yerleşik
- fakat
- by
- CAN
- yetenekleri
- Kapasite
- ele geçirmek
- kart
- dava
- durumlarda
- katalog
- kategoriler
- CDC)
- hücre
- değişiklik
- değişiklikler
- kanallar
- Çocuk
- seçti
- berraklık
- bulut
- Küme
- kod
- Sütun
- Sütunlar
- nasıl
- geliyor
- gelecek
- uyumlu
- uyumlu
- bileşenler
- oluşur
- hesaplamak
- Endişeler
- bağlı
- Düşünmek
- kabul
- tüketilen
- tüketim
- içermek
- bağlam
- devam etmek
- kontrol
- doğru
- maliyetler
- olabilir
- ülkeler
- yaratmak
- Tanıtım
- kredi
- kredi kartı
- küratörlüğünü
- akım
- Müşteriler
- veri
- Veri Analizi
- veri entegrasyonu
- Veri Gölü
- Veri Platformu
- veri gizliliği
- veri stratejisi
- veritabanı
- veritabanları
- veri kümeleri
- Tarih
- gün
- Varsayılan
- tanımlı
- teslim edilen
- göstermek
- gösteriyor
- konuşlandırılmış
- Dizayn
- hedef
- Destinasyon
- ayrıntılar
- belirlemek
- algılandı
- Bulma
- Belirlemek
- gelişme
- geliştirme ekipleri
- farklı
- direkt olarak
- keşfetmek
- keşfetti
- tartışılan
- do
- domain
- etki
- Dont
- her
- çabaları
- E-posta
- Mühendislik
- sağlamak
- kuruluş
- kurumsal müşteriler
- Tüm
- kişiler
- çevre
- Eter (ETH)
- Hatta
- olaylar
- Her
- örnek
- örnekler
- beklenen
- deneyim
- ifade
- dış
- HIZLI
- Alanlar
- fileto
- dosyalar
- mali
- finansal hizmetler
- Ad
- Akan
- Akışları
- odaklanma
- takip
- takip etme
- şu
- İçin
- iskelet
- itibaren
- tam
- tamamen
- gelecek
- üreten
- almak
- Tercih Etmenizin
- yönetim
- verilmiş
- Kolları
- kullanma
- Var
- he
- Sağlık
- sağlık Bilgisi
- yardım et
- yardım
- yardımcı olur
- üst düzey
- onun
- tarihsel
- Ne kadar
- Nasıl Yapılır
- HTML
- http
- HTTPS
- Yüzlerce
- belirlemek
- if
- göstermektedir
- resim
- uygulamak
- önem
- önemli
- in
- dahil
- Dahil olmak üzere
- indeks
- bireysel
- bilgi
- Altyapı
- içeride
- bütünleşme
- iç
- içine
- IT
- Java
- İş
- Mesleki Öğretiler
- jpg
- json
- tutmak
- Kinesis Veri Yangın Hortumu
- Kinesis Veri Akışları
- bilinen
- göl
- arazi
- topraklar
- büyük
- Soyad
- sonra
- Yasalar
- Yasalar ve düzenlemeler
- tabaka
- katmanları
- Liderlik
- izin
- Kütüphane
- yaşam döngüsü
- sevmek
- çizgi
- yük
- yükleme
- yerleri
- Bakın
- düşük maliyetli
- Ana
- sürdürmek
- yapmak
- yönetilen
- çok
- haritalama
- maske
- Mayıs..
- yöntem
- yöntemleri
- göç
- göç
- Modern
- modernleştirmek
- izleme
- Daha
- Dağ
- hareket
- hareketli
- çok
- çoklu
- şart
- isim
- isimleri
- gerekli
- gerek
- gerekli
- gerek
- ihtiyaçlar
- Hollanda
- yeni
- yok hayır
- düğümler
- Fark etme..
- şimdi
- numara
- of
- Teklifler
- on
- ONE
- bir tek
- operasyon
- işletme
- Operasyon
- optimize
- Opsiyonlar
- or
- kuruluşlar
- organizasyonlar
- Diğer
- bizim
- çıktı
- dışında
- tekrar
- Bölüm
- tutku
- Yama
- desen
- ödeme
- başına
- yapmak
- performans
- izinleri
- Şahsen
- telefon
- pii
- boru hattı
- plan
- platform
- Platon
- Plato Veri Zekası
- PlatoVeri
- oynama
- Nokta
- kısım
- Çivi
- önceki
- sundu
- önceki
- gizlilik
- gizlilik kanunları
- işlenmiş
- Süreçler
- işleme
- üretici
- korumalı
- protokolleri
- sağlayan
- sağlar
- alımları
- sorgular
- hızla
- daha doğrusu
- Çiğ
- işlenmemiş veri
- gerçek zaman
- nedenleri
- alma
- Tarifler
- Tavsiye edilen
- kayıt
- kayıtlar
- Indirimli
- başvurmak
- düzenli
- yönetmelik
- güvenilirlik
- kalmak
- Kaldır
- Raporlama
- Raporlar
- gerektirir
- gereklilik
- Yer Alan Kurallar
- sorumlulukları
- sorumlu
- kısıtlamak
- Sonuçlar
- rolleri
- SIRA
- koşmak
- ishal
- SaaS
- feda
- güvenli
- güvenli bir şekilde
- aynı
- ölçek
- taramak
- program
- bilim adamları
- Ekran
- sdk
- Ara
- Bölüm
- Güvenli
- güvenlik
- görmek
- seçmek
- seçilmiş
- kıdemli
- hassas
- gönderdi
- hizmet
- Hizmetler
- atış
- meli
- gösterilen
- Gösteriler
- Basit
- basitleştirmek
- küçük
- So
- Sosyal Medya
- Yazılım
- hizmet olarak yazılım
- çözüm
- Çözümler
- Kaynak
- kaynaklar
- özel
- özellikle
- Belirtilen
- geçirmek
- Harcama
- Splits
- aşamaları
- Devletler
- adım
- hafızası
- mağaza
- basit
- Stratejileri
- dere
- akış
- dere
- dizi
- yapı
- yapılandırılmış
- stüdyo
- sonraki
- Başarılı olarak
- böyle
- uygun
- destekli
- Destek
- sistem
- Sistemler
- tablo
- alır
- Hedef
- takım
- takım
- teknikleri
- tenis
- onlarca
- göre
- o
- The
- Gelecek
- Hollanda
- Kaynak
- ve bazı Asya
- sonra
- Orada.
- Bunlar
- Re-Tweet
- Bu
- üç
- eşik
- İçinden
- zaman
- için
- aldı
- araçlar
- iz
- işlemler
- transfer
- transferler
- Dönüştürmek
- Dönüşüm
- Trendler
- tetiklenir
- iki
- tip
- türleri
- eninde sonunda
- altında yatan
- anlayış
- birleşik
- Birleşik
- USA
- us
- kullanım
- kullanım durumu
- Kullanılmış
- kullanıcılar
- kullanma
- değer
- çeşitlilik
- çeşitli
- üzerinden
- görsel
- yürümek
- oldu
- yolları
- we
- ağ
- web hizmetleri
- Ne
- ne zaman
- hangi
- süre
- DSÖ
- eş
- irade
- ile
- içinde
- olmadan
- İş
- iş akışı
- çalışma
- yazmak
- sen
- zefirnet