Bu, AWS ve Voxel51 tarafından ortak yazılan ortak bir yazıdır. Voxel51, yüksek kaliteli veri kümeleri ve bilgisayarla görme modelleri oluşturmaya yönelik açık kaynaklı araç seti olan FiftyOne'ın arkasındaki şirkettir.
Bir perakende şirketi, müşterilerin kıyafet satın almasına yardımcı olacak bir mobil uygulama geliştiriyor. Bu uygulamayı oluşturmak için farklı kategorilerle etiketlenmiş giyim resimlerini içeren yüksek kaliteli bir veri kümesine ihtiyaçları var. Bu yazıda, mevcut bir veri kümesini veri temizleme, ön işleme ve ön etiketleme yoluyla sıfır vuruşlu bir sınıflandırma modeliyle nasıl yeniden kullanacağımızı gösteriyoruz. Elli birve bu etiketlerin ayarlanması Amazon SageMaker Yer Gerçeği.
Veri etiketleme projenizi hızlandırmak için Ground Truth ve FiftyOne'ı kullanabilirsiniz. Yüksek kaliteli etiketli veri kümeleri oluşturmak için iki uygulamayı birlikte sorunsuz bir şekilde nasıl kullanacağınızı gösteriyoruz. Örnek kullanım durumumuz için, Fashion200K veri kümesi, ICCV 2017'de yayınlandı.
Çözüme genel bakış
Ground Truth, veri bilimcileri, makine öğrenimi (ML) mühendislerini ve araştırmacıları yüksek kaliteli veri kümeleri oluşturma konusunda destekleyen, tamamen kendi kendine hizmet veren ve yönetilen bir veri etiketleme hizmetidir. Elli bir by Voxel51 kullanım durumlarınızı hızlandırarak daha iyi modelleri eğitebilmeniz ve analiz edebilmeniz için bilgisayarla görme veri kümelerini düzenlemeye, görselleştirmeye ve değerlendirmeye yönelik açık kaynaklı bir araç setidir.
Aşağıdaki bölümlerde, aşağıdakilerin nasıl yapıldığını gösteriyoruz:
- Veri kümesini FiftyOne'da görselleştirin
- FiftyOne'da filtreleme ve görüntü tekilleştirme ile veri kümesini temizleyin
- FiftyOne'da sıfır vuruşlu sınıflandırma ile temizlenmiş verileri önceden etiketleyin
- Daha küçük derlenmiş veri kümesini Ground Truth ile etiketleyin
- Ground Truth'tan etiketli sonuçları FiftyOne'a enjekte edin ve etiketli sonuçları FiftyOne'da gözden geçirin
Kullanım örneğine genel bakış
Bir perakende şirketiniz olduğunu ve kullanıcıların ne giyeceklerine karar vermelerine yardımcı olacak kişiselleştirilmiş öneriler sunan bir mobil uygulama oluşturmak istediğinizi varsayalım. Potansiyel kullanıcılarınız, dolaplarındaki hangi giyim parçalarının birlikte iyi çalıştığını söyleyen bir uygulama arıyor. Burada bir fırsat görüyorsunuz: İyi kıyafetler belirleyebilirseniz, bunu müşterinin zaten sahip olduğu kıyafetleri tamamlayan yeni kıyafetler önermek için kullanabilirsiniz.
Son kullanıcı için işleri olabildiğince kolaylaştırmak istiyorsunuz. İdeal olarak, uygulamanızı kullanan birinin yalnızca gardırobundaki kıyafetlerin fotoğraflarını çekmesi yeterlidir ve makine öğrenimi modelleriniz perde arkasında sihirlerini gerçekleştirir. Genel amaçlı bir model eğitebilir veya bir tür geri bildirimle her kullanıcının benzersiz stiline göre bir modelde ince ayar yapabilirsiniz.
Ancak öncelikle, kullanıcının ne tür bir giysiyi yakaladığını belirlemeniz gerekir. gömlek mi Bir çift pantolon? Veya başka bir şey? Ne de olsa, birden çok elbisesi veya birden çok şapkası olan bir kıyafeti önermek istemezsiniz.
Bu ilk zorluğun üstesinden gelmek için, çeşitli desen ve tarzlara sahip çeşitli giyim eşyalarının resimlerinden oluşan bir eğitim veri seti oluşturmak istiyorsunuz. Sınırlı bir bütçeyle prototip oluşturmak için mevcut bir veri kümesini kullanarak önyükleme yapmak istiyorsunuz.
Bu gönderideki süreci göstermek ve size yol göstermek için, ICCV 200'de yayınlanan Fashion2017K veri kümesini kullanıyoruz. Yerleşik ve iyi alıntılanmış bir veri kümesidir, ancak kullanım durumunuz için doğrudan uygun değildir.
Giyim eşyaları kategorilerle (ve alt kategorilerle) etiketlenmiş ve orijinal ürün açıklamalarından çıkarılan çeşitli faydalı etiketler içerse de, veriler sistematik olarak model veya stil bilgileriyle etiketlenmez. Amacınız, bu mevcut veri setini giyim sınıflandırma modelleriniz için sağlam bir eğitim veri setine dönüştürmektir. Etiketleme şemasını stil etiketleriyle zenginleştirerek verileri temizlemeniz gerekir. Ve bunu olabildiğince hızlı ve mümkün olduğunca az harcamayla yapmak istiyorsunuz.
Verileri yerel olarak indirin
Öncelikle, aşağıda verilen talimatları izleyerek women.tar zip dosyasını ve etiketler klasörünü (tüm alt klasörleriyle birlikte) indirin. Fashion200K veri kümesi GitHub deposu. İkisini de açtıktan sonra, bir üst dizin fashion200k oluşturun ve etiketleri ve kadın klasörlerini buna taşıyın. Neyse ki, bu görüntüler zaten nesne algılama sınırlayıcı kutularına kırpılmıştır, böylece nesne algılama konusunda endişelenmek yerine sınıflandırmaya odaklanabiliriz.
Takma adındaki “200K”ya rağmen, çıkardığımız kadın dizini 338,339 resim içeriyor. Resmi Fashion200K veri setini oluşturmak için, veri setinin yazarları çevrimiçi olarak 300,000'den fazla ürünü taradı ve yalnızca dört kelimeden fazla açıklama içeren ürünler kesinti yaptı. Ürün açıklamasının zorunlu olmadığı amaçlarımız için, taranan tüm resimleri kullanabiliriz.
Bu verilerin nasıl organize edildiğine bir göz atalım: kadınlar klasöründe, resimler üst düzey eşya türüne (etekler, üstler, pantolonlar, ceketler ve elbiseler) ve eşya türü alt kategorisine (bluzlar, tişörtler, uzun kollular) göre düzenlenir. üstleri).
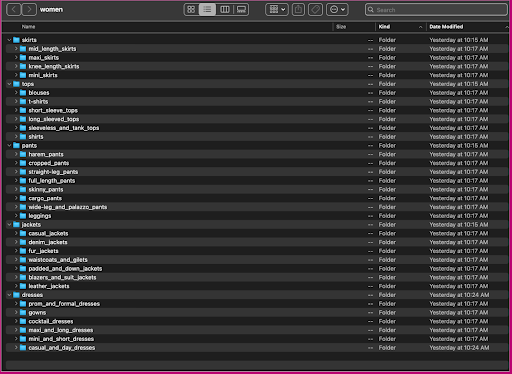
Alt kategori dizinleri içinde, her ürün listesi için bir alt dizin bulunur. Bunların her biri değişken sayıda görüntü içerir. Örneğin, kırpılmış_pantolon alt kategorisi, aşağıdaki ürün listelemelerini ve ilişkili görselleri içerir.
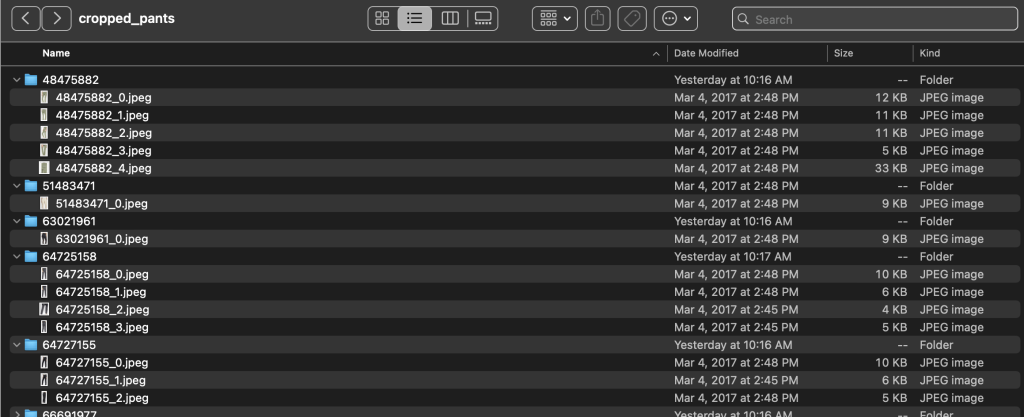
Etiketler klasörü, hem eğitim hem de test bölümleri için her üst düzey makale türü için bir metin dosyası içerir. Bu metin dosyalarının her birinde, her görüntü için ilgili dosya yolunu, bir puanı ve ürün açıklamasından etiketleri belirten ayrı bir satır bulunur.
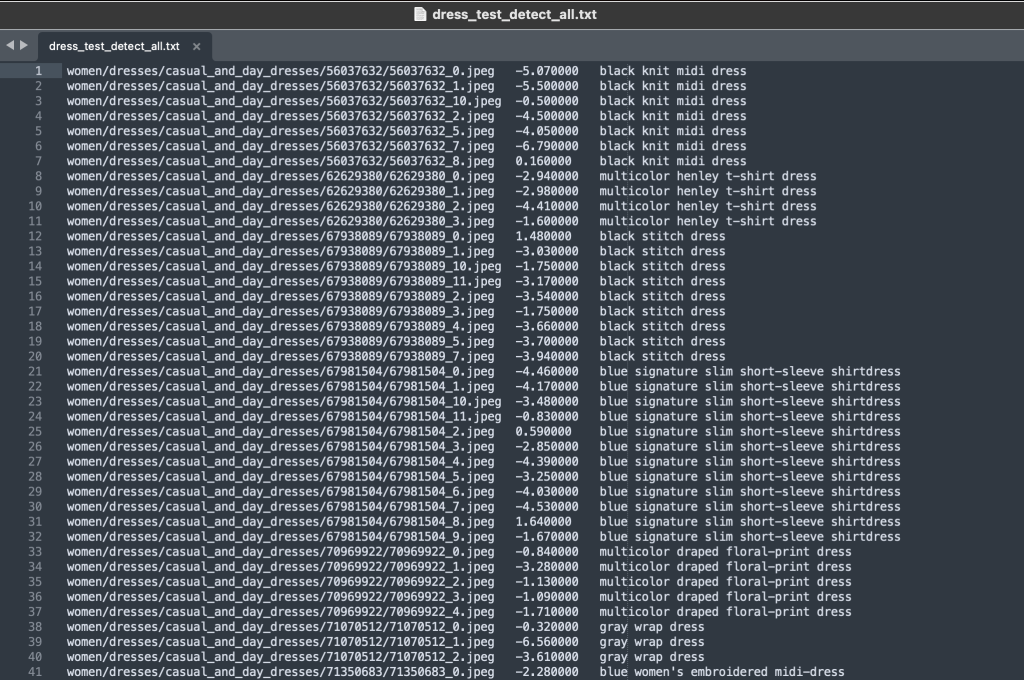
Veri kümesini yeniden tasarladığımız için tüm tren ve test görüntülerini birleştiriyoruz. Bunları, uygulamaya özel yüksek kaliteli bir veri kümesi oluşturmak için kullanıyoruz. Bu işlemi tamamladıktan sonra, ortaya çıkan veri setini rastgele yeni tren ve test bölmelerine bölebiliriz.
FiftyOne'da bir veri kümesini enjekte edin, görüntüleyin ve düzenleyin
Henüz yapmadıysanız, açık kaynaklı FiftyOne'ı pip kullanarak kurun:
En iyi uygulama, bunu yeni bir sanal (venv veya conda) ortam içinde yapmaktır. Ardından ilgili modülleri içe aktarın. Elli bir numaralı temel kitaplığı, yerleşik ML yöntemlerine sahip FiftyOne Brain'i, bizim için sıfır vuruşlu etiketler oluşturacak bir modeli yükleyeceğimiz FiftyOne Zoo'yu ve verimli bir şekilde filtrelememizi sağlayan ViewField'i içe aktarın. veri kümemizdeki veriler:
Ayrıca, dizin içerikleri üzerinde yollar ve kalıp eşleşmesi ile çalışmamıza yardımcı olacak glob ve os Python modüllerini de içe aktarmak istiyorsunuz:
Artık veri setini FiftyOne'a yüklemeye hazırız. İlk önce fashion200k adında bir veri seti oluşturuyoruz ve kalıcı hale getiriyoruz, bu da hesaplama açısından yoğun işlemlerin sonuçlarını kaydetmemizi sağlıyor, bu nedenle söz konusu miktarları yalnızca bir kez hesaplamamız gerekiyor.
Artık tüm alt kategori dizinlerini, ürün dizinlerindeki tüm görselleri ekleyerek yineleyebiliriz. Görüntünün en üst düzey makale kategorisi tarafından doldurulan makale_türü alan adıyla her örneğe bir FiftyOne sınıflandırma etiketi ekleriz. Ayrıca hem kategori hem de alt kategori bilgilerini etiket olarak ekliyoruz:
Bu noktada, bir oturum başlatarak veri kümemizi FiftyOne uygulamasında görselleştirebiliriz:
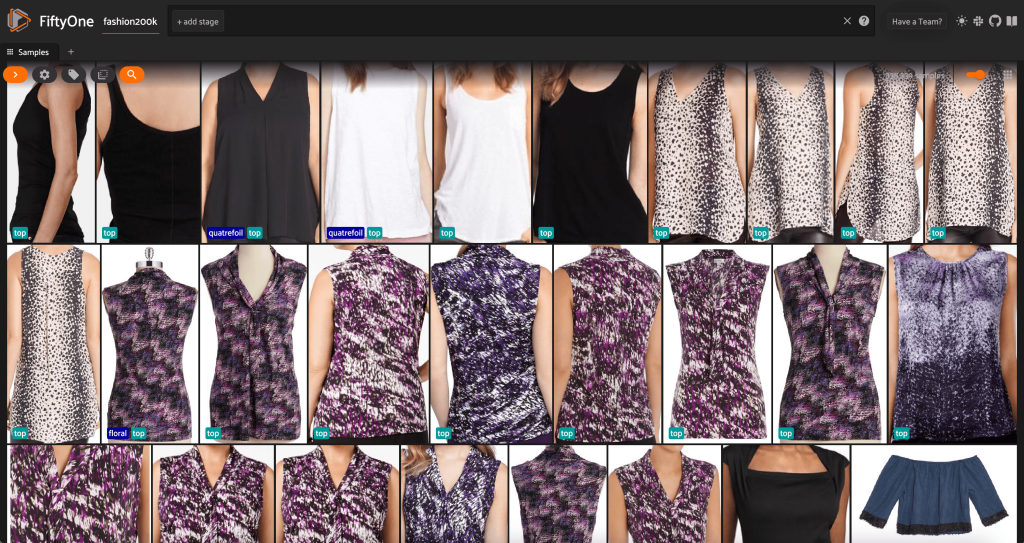
Çalıştırarak Python'daki veri kümesinin bir özetini de yazdırabiliriz. print(dataset):
Etiketleri şu adresten de ekleyebiliriz: labels veri kümemizdeki örnekler dizini:
Verilere bakıldığında, birkaç şey netleşiyor:
- Görüntülerin bazıları oldukça grenli ve düşük çözünürlüklü. Bunun nedeni, bu görüntülerin, nesne algılama sınırlama kutularındaki ilk görüntülerin kırpılmasıyla oluşturulmuş olmasıdır.
- Bazı kıyafetler bir kişi tarafından giyilir, bazıları ise kendi başına fotoğraflanır. Bu ayrıntılar kapsüllenmiş
viewpointözelliği. - Aynı ürünün birçok görseli birbirine çok benzer, bu nedenle en azından başlangıçta, ürün başına birden fazla görselin dahil edilmesi çok fazla tahmin gücü sağlamayabilir. Çoğunlukla, her ürünün ilk görseli (sonunda
_0.jpeg) en temizidir.
Başlangıçta, giyim tarzı sınıflandırma modelimizi bu görüntülerin kontrollü bir alt kümesi üzerinde eğitmek isteyebiliriz. Bu amaçla, ürünlerimizin yüksek çözünürlüklü resimlerini kullanıyoruz ve görüşümüzü ürün başına bir temsili numune ile sınırlıyoruz.
İlk olarak, düşük çözünürlüklü görüntüleri filtreliyoruz. biz kullanıyoruz compute_metadata() veri kümesindeki her görüntü için görüntü genişliğini ve yüksekliğini piksel cinsinden hesaplamak ve depolamak için yöntem. Daha sonra FiftyOne'ı kullanırız ViewField izin verilen minimum genişlik ve yükseklik değerlerine göre görüntüleri filtrelemek için. Aşağıdaki koda bakın:
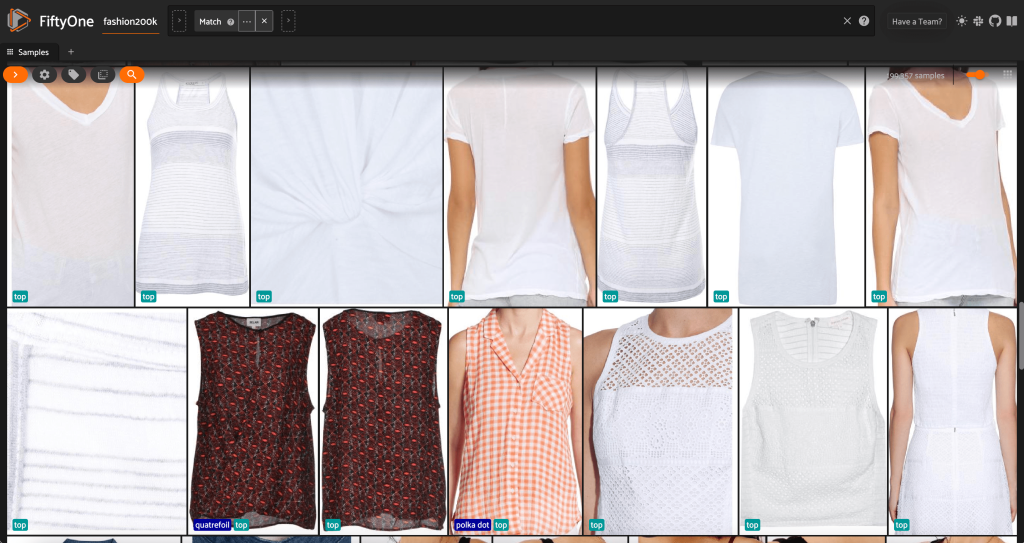
Bu yüksek çözünürlüklü alt küme, 200,000'in biraz altında örneğe sahiptir.
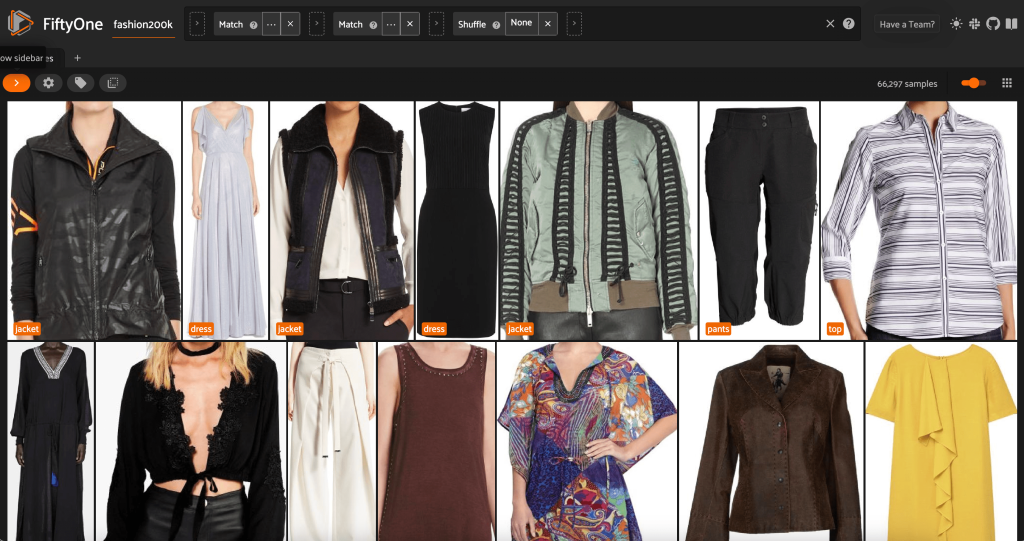
Bu görünümden, her ürün için (en fazla) yalnızca bir temsili örnek içeren veri kümemizde yeni bir görünüm oluşturabiliriz. biz kullanıyoruz ViewField bir kez daha, ile biten dosya yolları için kalıp eşleştirme _0.jpeg:
Bu alt kümedeki görüntülerin rastgele karıştırılmış sıralamasını görelim:
Veri kümesindeki gereksiz görüntüleri kaldırın
Bu görünüm 66,297 resim veya orijinal veri setinin %19'undan biraz fazlasını içerir. Ancak manzaraya baktığımızda birbirine çok benzeyen birçok ürün olduğunu görüyoruz. Tüm bu kopyaları saklamak, performansı fark edilir şekilde artırmadan, muhtemelen yalnızca etiketleme ve model eğitimimize maliyet katacaktır. Bunun yerine, yine aynı etkiyi taşıyan daha küçük bir veri kümesi oluşturmak için yakın kopyalardan kurtulalım.
Bu görüntüler tam kopya olmadığından, piksel bazında eşitliği kontrol edemiyoruz. Neyse ki, veri kümemizi temizlememize yardımcı olması için FiftyOne Brain'i kullanabiliriz. Özellikle, her görüntü için bir katıştırmayı (görüntüyü temsil eden daha düşük boyutlu bir vektör) hesaplayacağız ve ardından katıştırma vektörleri birbirine yakın olan görüntüleri arayacağız. Vektörler ne kadar yakınsa, görüntüler o kadar benzerdir.
Her görüntü için 512 boyutlu bir katıştırma vektörü oluşturmak için bir CLIP modeli kullanıyoruz ve bu katıştırmaları veri kümemizdeki örneklerdeki alan katıştırmalarında saklıyoruz:
Ardından, gömmeler arasındaki yakınlığı hesaplıyoruz. kosinüs benzerliği, ve benzerliği bazı eşik değerlerinden daha büyük olan herhangi iki vektörün muhtemelen kopyalara yakın olduğunu iddia edin. Kosinüs benzerlik skorları [0, 1] aralığındadır ve verilere bakıldığında, eşik değeri = 0.5'lik bir eşik skoru yaklaşık doğru gibi görünmektedir. Yine, bunun mükemmel olması gerekmez. Neredeyse yinelenen birkaç görüntünün tahmin gücümüzü bozması pek olası değildir ve yinelenmeyen birkaç görüntünün atılması, model performansını önemli ölçüde etkilemez.
Gerçekten gereksiz olduklarını doğrulamak için sözde kopyaları görüntüleyebiliriz:
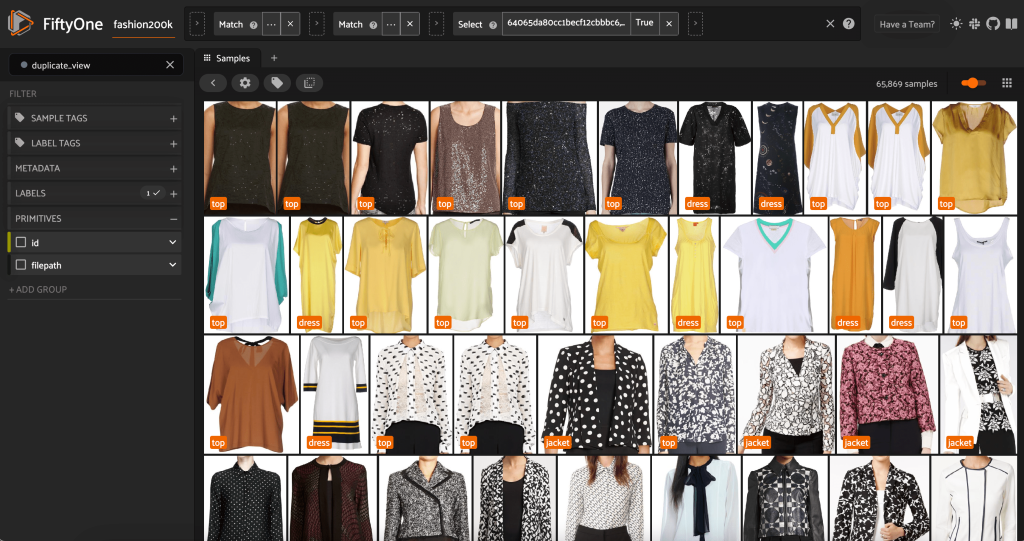
Sonuçtan memnun kaldığımızda ve bu görüntülerin gerçekten de neredeyse kopyalar olduğuna inandığımızda, saklamak için her bir benzer örnek grubundan bir örnek seçebilir ve diğerlerini göz ardı edebiliriz:
Şimdi bu görünümde 3,729 resim var. FiftyOne, verileri temizleyerek ve Fashion200K veri kümesinin yüksek kaliteli bir alt kümesini tanımlayarak, odağımızı 300,000'den fazla görüntüden 4,000'in biraz altına sınırlamamıza olanak tanıyor ve bu da %98'lik bir azalmayı temsil ediyor. Tek başına neredeyse yinelenen görüntüleri kaldırmak için yerleştirmeleri kullanmak, incelenmekte olan toplam görüntü sayımızı %90'dan fazla azalttı ve bu veriler üzerinde eğitilecek herhangi bir model üzerinde çok az veya hiç etkisi olmadı.
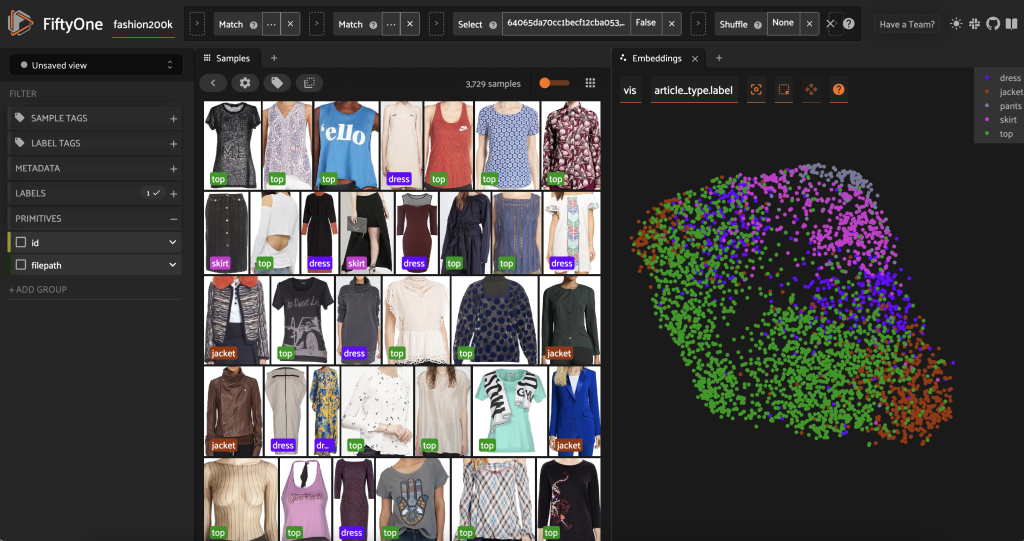
Bu alt kümeyi önceden etiketlemeden önce, önceden hesaplamış olduğumuz yerleştirmeleri görselleştirerek verileri daha iyi anlayabiliriz. FiftyOne Brain'in yerleşik özelliklerini kullanabiliriz. compute_visualization() yöntemi, 512 boyutlu gömme vektörlerini iki boyutlu uzaya yansıtmak için tekdüze manifold yaklaşımı (UMAP) tekniğini kullanır, böylece onları görselleştirebiliriz:
yeni açıyoruz Gömmeler paneli FiftyOne uygulamasında ve makale türüne göre renklendirmede ve bu yerleştirmelerin kabaca bir makale türü kavramını (diğer şeylerin yanı sıra!) kodladığını görebiliriz.
Artık bu verileri önceden etiketlemeye hazırız.
Bu son derece benzersiz, yüksek çözünürlüklü görüntüleri inceleyerek, ön etiketleme sıfır atış sınıflandırmamızda sınıflar olarak kullanmak için uygun bir başlangıç stilleri listesi oluşturabiliriz. Bu görüntüleri önceden etiketlemedeki amacımız, her görüntüyü mutlaka doğru şekilde etiketlemek değildir. Bunun yerine amacımız, etiketleme süresini ve maliyetini azaltabilmemiz için insan açıklama yapanlar için iyi bir başlangıç noktası sağlamaktır.
Daha sonra bu uygulama için sıfır atışlı bir sınıflandırma modeli başlatabiliriz. Hem görseller hem de doğal dil üzerine eğitilmiş genel amaçlı bir model olan CLIP modelini kullanıyoruz. "Tarzda Giyim" metin istemiyle bir CLIP modelini başlatıyoruz, böylece bir görüntü verildiğinde model, "Stilde [sınıf] Giyimde" en uygun sınıfın çıktısını verecektir. CLIP perakende veya modaya özgü veriler konusunda eğitimli değildir, bu nedenle bu mükemmel olmayacaktır, ancak etiketleme ve ek açıklama maliyetlerinden tasarruf etmenizi sağlayabilir.
Daha sonra bu modeli indirgenmiş alt kümemize uygularız ve sonuçları bir article_style alan:
FiftyOne Uygulamasını bir kez daha başlatarak, görüntüleri bu tahmin edilen stil etiketleriyle görselleştirebiliriz. Tahmin güvenilirliğine göre sıralarız, böylece önce en güvenilir stil tahminlerini görürüz:
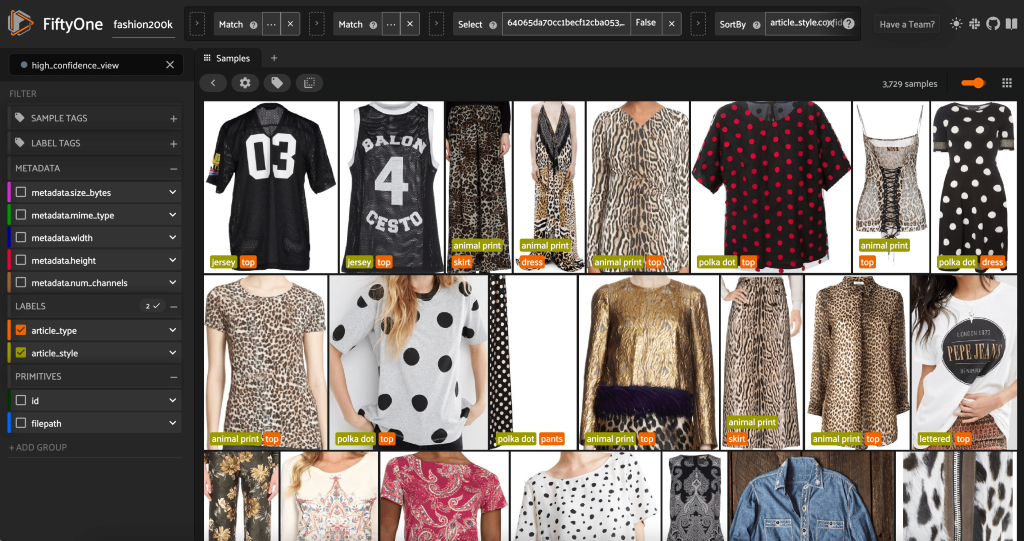
En yüksek güven tahminlerinin "jarse", "hayvan desenli", "polka noktalı" ve "harfli" stiller için göründüğünü görebiliriz. Bu mantıklı, çünkü bu stiller nispeten farklı. Tahmin edilen stil etiketleri de çoğunlukla doğru gibi görünüyor.
Ayrıca en düşük güven düzeyine sahip stil tahminlerine de bakabiliriz:
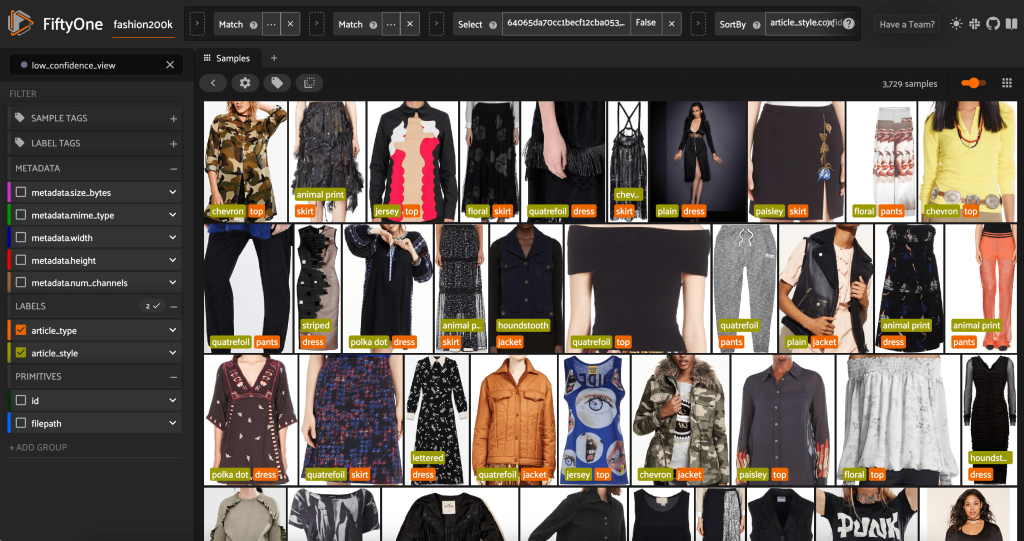
Bu resimlerin bazıları için uygun stil kategorisi verilen listede yer alıyor ve giyim eşyası yanlış etiketlenmiş. Örneğin, tablodaki ilk resim "şerit" değil, açıkça "kamuflaj" olmalıdır. Ancak diğer durumlarda, ürünler stil kategorilerine tam olarak uymaz. Örneğin, ikinci sıradaki ikinci görüntüdeki elbise tam olarak "çizgili" değildir, ancak aynı etiketleme seçenekleri göz önüne alındığında, bir insan açıklamacı da çelişmiş olabilir. Veri kümemizi oluştururken, bunun gibi uç durumları kaldırmaya, yeni stil kategorileri eklemeye veya veri kümesini artırmaya karar vermemiz gerekir.
Son veri kümesini FiftyOne'dan dışa aktarın
Son veri kümesini aşağıdaki kodla dışa aktarın:
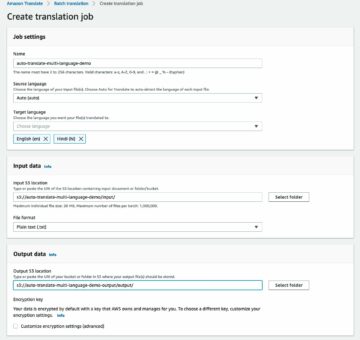
Daha küçük bir veri kümesini, örneğin 16 görüntüyü klasöre aktarabiliriz. 200kFashionDatasetExportResult-16Images. Bunu kullanarak bir Zemin Gerçeği ayarlama işi yaratıyoruz:
Düzeltilen veri kümesini yükleyin, etiket biçimini Ground Truth'a dönüştürün, Amazon S3'e yükleyin ve ayarlama işi için bir bildirim dosyası oluşturun
Veri kümesindeki etiketleri, eşleşecek şekilde dönüştürebiliriz. çıktı bildirim şeması bir Ground Truth sınırlayıcı kutu işine ait ve görüntüleri bir Amazon Basit Depolama Hizmeti (Amazon S3) paketi başlatmak için Zemin Gerçeği ayarlama işi:
Manifest dosyasını aşağıdaki kodla Amazon S3'e yükleyin:
Ground Truth ile düzeltilmiş tarza sahip etiketler oluşturun
Verilerinize Ground Truth'u kullanarak stil etiketleriyle açıklama eklemek için, aşağıda belirtilen prosedürü izleyerek bir sınırlayıcı kutu etiketleme işi başlatmak için gerekli adımları tamamlayın. Ground Truth'a Başlarken veri kümesini aynı S3 klasöründe olacak şekilde yönlendirin.
- SageMaker konsolunda bir Ground Truth etiketleme işi oluşturun.
- Yı kur Giriş veri kümesi konumu önceki adımlarda oluşturduğumuz manifesto olmak.
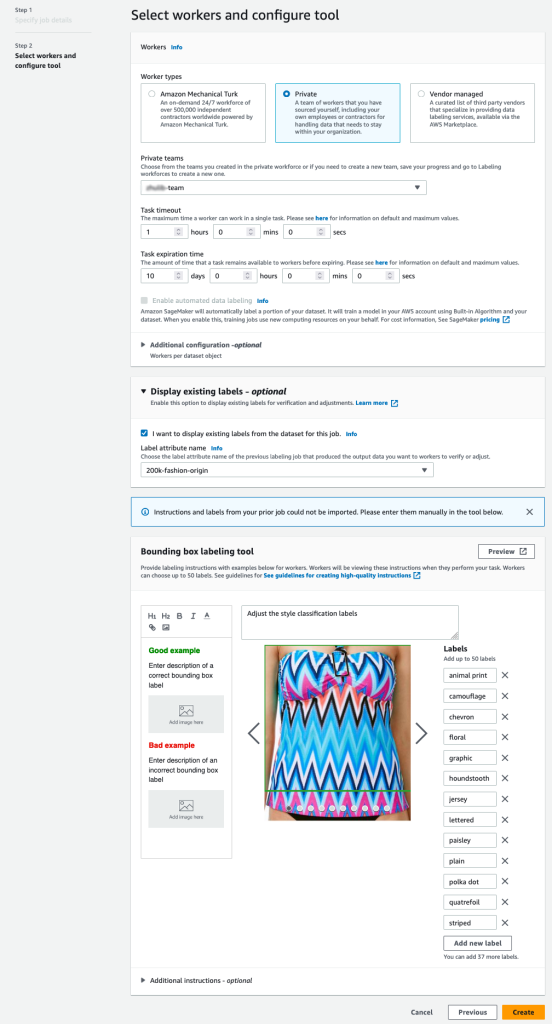
- Şunun için bir S3 yolu belirtin: Çıktı veri kümesi konumu.
- İçin IAM Rolü, seçmek Özel bir IAM rolü girin RNA, ardından ARN rolünü girin.
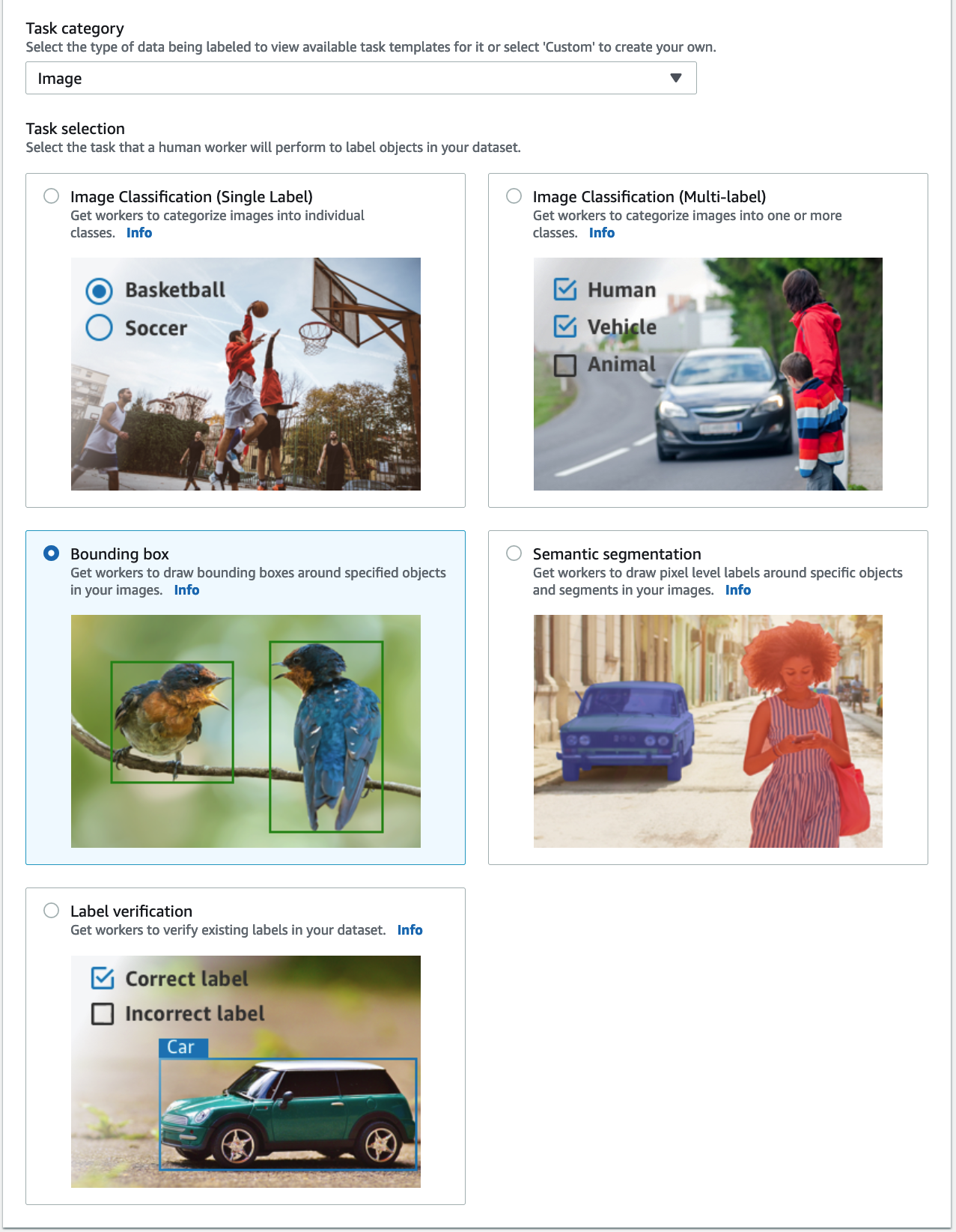
- İçin Görev kategorisi, seçmek Resim seçin Sınırlayıcı kutu.
- Klinik Sonraki.
- içinde Işçiler bölümünde, kullanmak istediğiniz işgücü türünü seçin.
aracılığıyla bir iş gücü seçebilirsiniz. Amazon Mekanik Türk, üçüncü taraf satıcılar veya kendi özel iş gücünüz. İş gücü seçenekleriniz hakkında daha fazla ayrıntı için bkz. İş Gücü Oluşturun ve Yönetin. - Genişletmek Mevcut etiket görüntüleme seçenekleri seçin Bu iş için veri kümesindeki mevcut etiketleri görüntülemek istiyorum.
- İçin Etiket özelliği ad, bildiriminizden ayarlama için görüntülemek istediğiniz etiketlere karşılık gelen adı seçin.
Yalnızca önceki adımlarda seçtiğiniz görev türüyle eşleşen etiketler için etiket öznitelik adlarını göreceksiniz. - Şunun için etiketleri manuel olarak girin: Sınırlayıcı kutu etiketleme aracı.
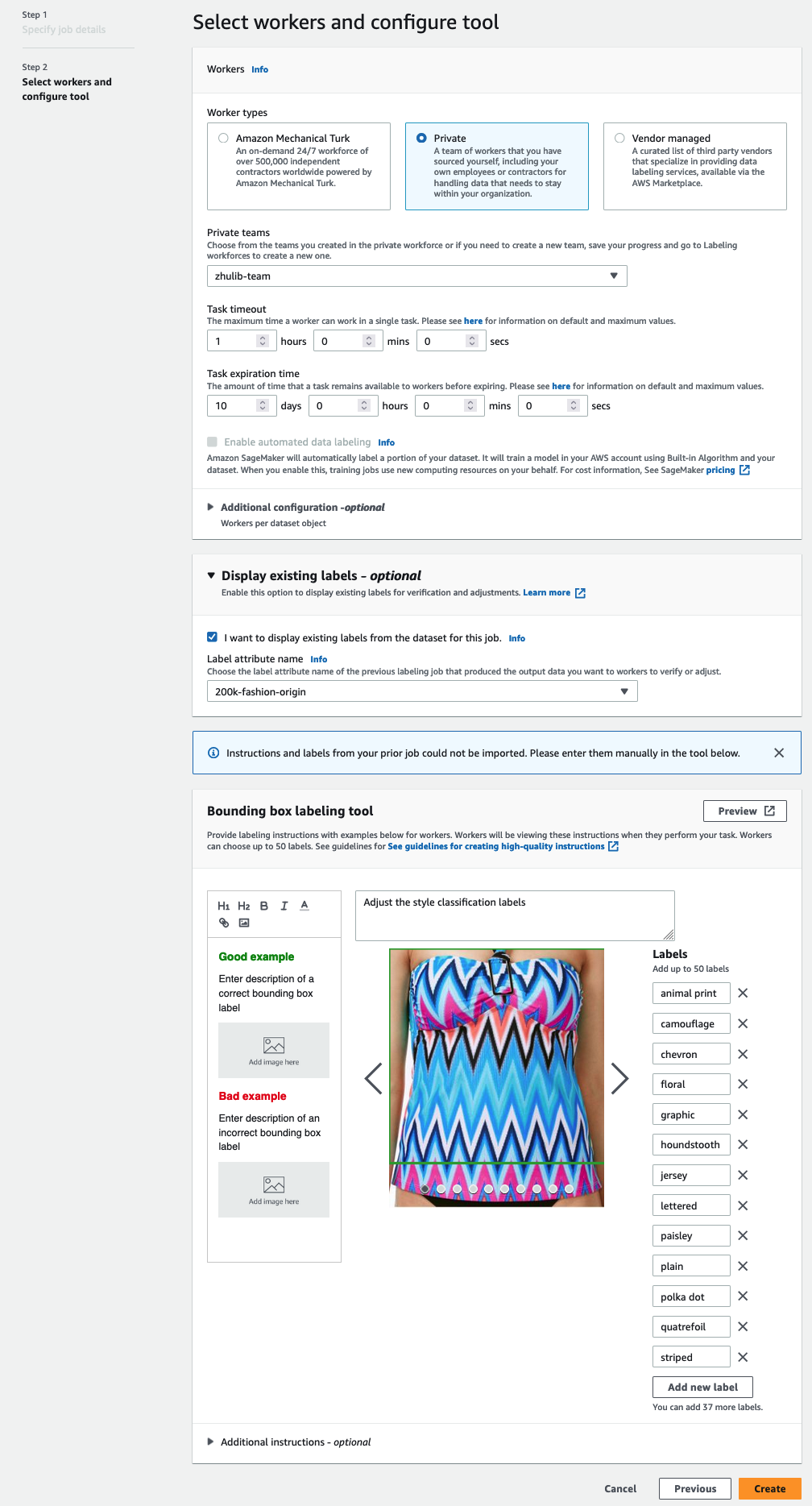 Etiketler, genel veri kümesinde kullanılan etiketlerin aynısını içermelidir. Yeni etiketler ekleyebilirsiniz. Aşağıdaki ekran görüntüsü, etiketleme işiniz için çalışanları nasıl seçebileceğinizi ve aracı nasıl yapılandırabileceğinizi gösterir.
Etiketler, genel veri kümesinde kullanılan etiketlerin aynısını içermelidir. Yeni etiketler ekleyebilirsiniz. Aşağıdaki ekran görüntüsü, etiketleme işiniz için çalışanları nasıl seçebileceğinizi ve aracı nasıl yapılandırabileceğinizi gösterir.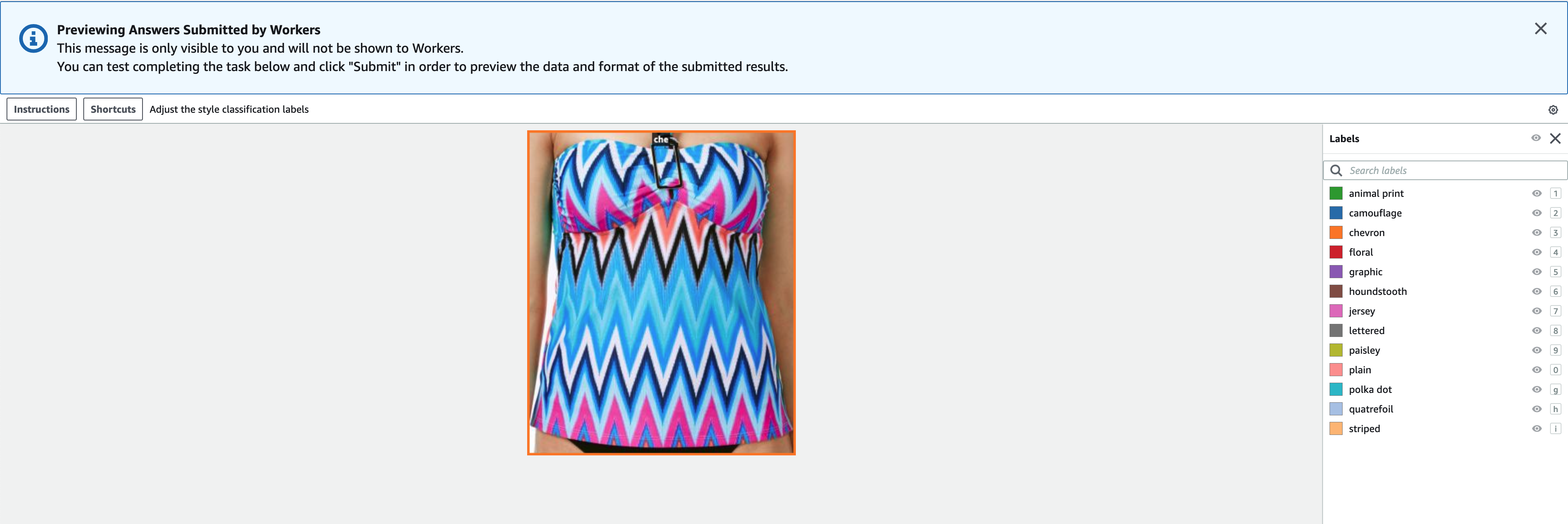
- Klinik Önizleme görüntüyü ve orijinal ek açıklamaları önizlemek için.
Artık Ground Truth'ta bir etiketleme işi oluşturduk. İşimiz tamamlandıktan sonra, yeni oluşturulan etiketli verileri FiftyOne'a yükleyebiliriz. Temel Gerçeği, bir Temel Gerçeği çıktı bildiriminde çıktı verileri üretir. Çıktı bildirim dosyası hakkında daha fazla ayrıntı için bkz. Sınırlandırıcı Kutu İş Çıkışı. Aşağıdaki kod, bu çıktı bildirim biçiminin bir örneğini gösterir:
FiftyOne'daki Ground Truth'un etiketli sonuçlarını inceleyin
İş tamamlandıktan sonra etiketleme işinin çıktı bildirimini Amazon S3'ten indirin.
Çıktı bildirim dosyasını okuyun:
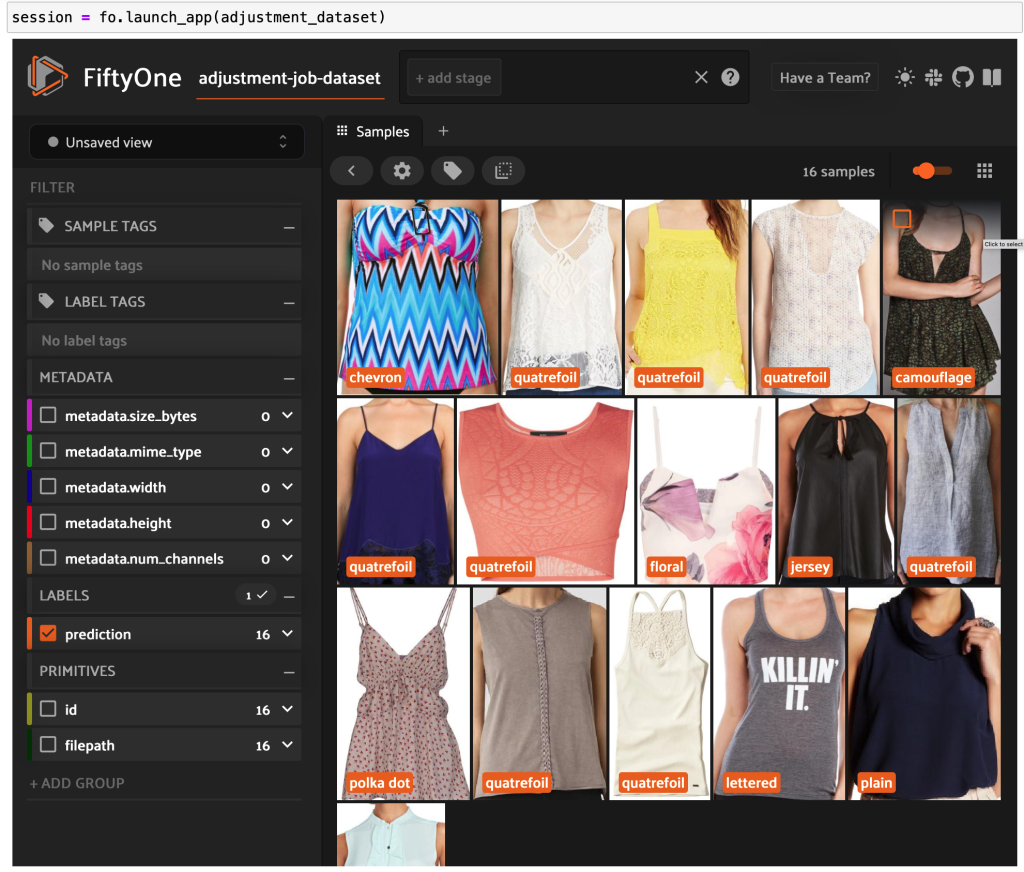
Bir FiftyOne veri kümesi oluşturun ve bildirim satırlarını veri kümesindeki örneklere dönüştürün:
Artık FiftyOne'da Ground Truth'tan yüksek kaliteli etiketlenmiş verileri görebilirsiniz.
Sonuç
Bu yazıda, gücü birleştirerek yüksek kaliteli veri kümelerinin nasıl oluşturulacağını gösterdik. Elli bir by Voxel51, veri kümenizi yönetmenize, izlemenize, görselleştirmenize ve iyileştirmenize olanak tanıyan açık kaynaklı bir araç seti ve birden fazla yerleşik veri setine erişim sağlayarak makine öğrenimi sistemlerini eğitmek için gereken veri kümelerini verimli ve doğru bir şekilde etiketlemenize olanak tanıyan bir veri etiketleme hizmeti olan Ground Truth - görev şablonlarında ve Mechanical Turk, üçüncü taraf satıcılar veya kendi özel iş gücünüz aracılığıyla çeşitli iş gücüne erişim.
Başlamak için bir FiftyOne bulut sunucusu kurarak ve Ground Truth konsolunu kullanarak bu yeni işlevi denemenizi öneririz. Ground Truth hakkında daha fazla bilgi edinmek için bkz. Etiket Verileri, Amazon SageMaker Veri Etiketleme SSS, Ve AWS Makine Öğrenimi Blogu.
ile bağlanın Makine Öğrenimi ve Yapay Zeka topluluğu herhangi bir sorunuz veya geri bildiriminiz varsa!
FiftyOne topluluğuna katılın!
Bugün bilgisayarlı görü alanındaki en zorlu sorunlardan bazılarını çözmek için FiftyOne'ı kullanan binlerce mühendis ve veri bilimciye katılın!
Yazarlar Hakkında
Shalendra Çabra şu anda Amazon SageMaker Human-in-the-Loop (HIL) Hizmetleri için Ürün Yönetimi Başkanıdır. Daha önce Shalendra, Microsoft Teams Meetings için Dil ve Konuşma Zekası kuluçkası yaptı ve liderliğini yaptı, Amazon Alexa Techstars Startup Accelerator'da EIR, Ürün ve Pazarlamadan Sorumlu Başkan Yardımcısıydı. Tartışma.io, Clipboard'da Ürün ve Pazarlama Başkanı (Salesforce tarafından satın alındı) ve Swype'ta Baş Ürün Yöneticisi (Nuance tarafından satın alındı). Toplamda, Shalendra bir milyardan fazla yaşama dokunan ürünlerin inşa edilmesine, sevk edilmesine ve pazarlanmasına yardımcı oldu.
Yakup İşaretleri Voxel51'de bir Makine Öğrenimi Mühendisi ve Geliştirici Evanjelistidir ve burada dünyanın verilerine şeffaflık ve netlik getirmeye yardımcı olur. Jacob, Voxel51'e katılmadan önce, gelişmekte olan müzisyenlerin hayranlarla bağlantı kurmasına ve yaratıcı içerikleri paylaşmasına yardımcı olmak için bir girişim kurdu. Bundan önce Google X, Samsung Research ve Wolfram Research'te çalıştı. Geçmiş yaşamında Jacob, maddenin kuantum fazlarını araştırdığı Stanford'da doktorasını tamamlayan teorik bir fizikçiydi. Jacob boş zamanlarında tırmanmaktan, koşmaktan ve bilim kurgu romanları okumaktan hoşlanır.
jason corso Voxel51'in kurucu ortağı ve CEO'sudur ve burada son teknoloji esnek yazılım aracılığıyla dünya verilerine şeffaflık ve netlik getirmeye yardımcı olacak stratejiyi yönlendirmektedir. Aynı zamanda Michigan Üniversitesi'nde Robotik, Elektrik Mühendisliği ve Bilgisayar Bilimleri profesörüdür ve burada bilgisayar görüşü, doğal dil ve fiziksel platformların kesişimindeki en son problemlere odaklanmaktadır. Jason boş zamanlarında ailesiyle vakit geçirmekten, kitap okumaktan, doğada olmaktan, masa oyunları oynamaktan ve her türlü yaratıcı aktiviteden hoşlanır.
Brian Moore teknik strateji ve vizyona liderlik ettiği Voxel51'in kurucu ortağı ve CTO'sudur. Michigan Üniversitesi'nden Elektrik Mühendisliği alanında doktora derecesine sahiptir ve burada araştırması, bilgisayarla görme uygulamalarına özel bir vurgu yaparak, büyük ölçekli makine öğrenimi sorunları için verimli algoritmalara odaklanmıştır. Boş zamanlarında badminton, golf, doğa yürüyüşü ve ikiz Yorkshire Teriyerleri ile oynamayı seviyor.
Zhuling Bai Amazon Web Services'ta Yazılım Geliştirme Mühendisi. Makine öğrenimi sorunlarını çözmek için büyük ölçekli dağıtık sistemler geliştirmeye çalışıyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoAiStream. Web3 Veri Zekası. Bilgi Genişletildi. Buradan Erişin.
- Adryenn Ashley ile Geleceği Basmak. Buradan Erişin.
- PREIPO® ile PRE-IPO Şirketlerinde Hisse Al ve Sat. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- :vardır
- :dır-dir
- :olumsuzluk
- :Neresi
- $UP
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- Hakkımızda
- hızlandırmak
- hızlanan
- hızlandırıcı
- erişim
- doğru
- tam olarak
- edinilen
- faaliyetler
- eklemek
- ekleme
- adres
- Düzeltilmiş
- Ayar
- Sonra
- tekrar
- AI
- Alexa
- algoritmalar
- Türkiye
- veriyor
- tek başına
- zaten
- Ayrıca
- Amazon
- amazon alexa
- Amazon Adaçayı Yapıcı
- Amazon SageMaker Yer Gerçeği
- Amazon Web Servisleri
- arasında
- an
- çözümlemek
- ve
- hayvan
- herhangi
- uygulamayı yükleyeceğiz
- Uygulama
- uygulamaları
- Tamam
- uygun
- ARE
- düzenlenmiş
- göre
- mal
- AS
- ilişkili
- At
- Yazarlar
- uzakta
- AWS
- baz
- merkezli
- BE
- Çünkü
- müşterimiz
- olmuştur
- önce
- arkasında
- kamera ARKASI
- olmak
- Inanmak
- İYİ
- Daha iyi
- arasında
- Milyar
- yazı tahtası
- Masa Oyunları
- KEMİK
- Çizme atkısı
- her ikisi de
- kutu
- kutular
- Beyin
- mola
- getirmek
- getirdi
- bütçe
- inşa etmek
- bina
- yerleşik
- fakat
- satın almak
- by
- CAN
- Yakalama
- dava
- durumlarda
- kategoriler
- Kategoriler
- ceo
- meydan okuma
- zor
- Kontrol
- Klinik
- berraklık
- sınıf
- sınıflar
- sınıflandırma
- Temizlik
- açık
- Açıkça
- müşteri
- Tırmanma
- Kapanış
- yakın
- çamaşırlar
- Giyim
- Kurucu
- kod
- birleştirmek
- birleştirme
- şirket
- Tamamlayıcı
- tamamlamak
- tamamladıktan
- hesaplamak
- bilgisayar
- Bilgisayar Bilimleri
- Bilgisayar görüşü
- Bilgisayarla Görme Uygulamaları
- güven
- emin
- Sosyal medya
- dikkate
- oluşan
- konsolos
- içeren
- içerik
- içindekiler
- kontrollü
- konuşkan
- dönüştürmek
- kopyalar
- çekirdek
- düzeltilmiş
- tekabül
- Ücret
- maliyetler
- yaratmak
- çevrimiçi kurslar düzenliyorlar.
- Yaratıcı
- Tanıtım
- CTO
- küratörlüğünü
- küratörlük
- Şu anda
- görenek
- müşteri
- Müşteriler
- kesim
- keskin kenar
- veri
- veri kümeleri
- karar vermek
- göstermek
- Denim
- derinlik
- tanım
- ayrıntılar
- Bulma
- Geliştirici
- gelişen
- gelişme
- farklı
- direkt olarak
- dizinleri
- ekran
- farklı
- dağıtıldı
- dağıtılmış sistemler
- çeşitli
- do
- Değil
- Köpek
- yapıyor
- yapılmış
- Dont
- DOT
- aşağı
- indir
- çiftleri
- e
- her
- kolay
- kenar
- Efekt
- verimli
- verimli biçimde
- elektrik Mühendisliği
- katıştırma
- ortaya çıkan
- vurgu
- istihdam
- olarak güçlendiriyor
- kapsüllü
- teşvik etmek
- son
- mühendis
- Mühendislik
- Mühendisler
- Keşfet
- çevre
- eşitlik
- gerekli
- kurulmuş
- Eter (ETH)
- değerlendirilmesi
- Gezici vaiz
- kesinlikle
- örnek
- mevcut
- ihracat
- oldukça
- aile
- fanlar
- geribesleme
- az
- Kurgu
- alan
- Alanlar
- fileto
- dosyalar
- filtre
- süzme
- son
- Ad
- uygun
- esnek
- odak
- odaklanmış
- odaklanır
- takip etme
- İçin
- Airdrop Formu
- biçim
- iyi ki
- Kurulmuş
- dört
- Ücretsiz
- itibaren
- tamamen
- işlevsellik
- Games
- genel amaçlı
- oluşturmak
- oluşturulan
- almak
- GitHub
- Vermek
- verilmiş
- gol
- golf
- Tercih Etmenizin
- büyük
- Grid
- Zemin
- grup
- rehberlik
- mutlu
- Var
- he
- baş
- yükseklik
- yardım et
- yardım
- faydalı
- yardımcı olur
- okuyun
- Yüksek kaliteli
- yüksek çözünürlük
- en yüksek
- büyük ölçüde
- yürüyüş
- onun
- tutar
- Ne kadar
- Nasıl Yapılır
- Ancak
- HTML
- http
- HTTPS
- insan
- i
- IAM
- ID
- belirlemek
- belirlenmesi
- kimlikleri
- if
- görüntü
- görüntüleri
- darbe
- ithalat
- geliştirme
- in
- Diğer
- Dahil olmak üzere
- hatalı olarak
- inkübe
- bilgi
- ilk
- başlangıçta
- kurmak
- yükleme
- örnek
- yerine
- talimatlar
- İstihbarat
- kavşak
- içine
- IT
- ONUN
- Jersey
- İş
- birleştirme
- ortak
- json
- sadece
- tutmak
- koruma
- etiket
- etiketleme
- Etiketler
- dil
- büyük ölçekli
- başlatmak
- fırlatma
- öncülük etmek
- İlanlar
- ÖĞRENİN
- öğrenme
- en az
- Led
- sol
- Lets
- Kütüphane
- hayat
- sevmek
- Muhtemelen
- LİMİT
- Sınırlı
- çizgi
- hatları
- Liste
- listeleme
- Deneyimler
- küçük
- Yaşıyor
- yük
- Bakın
- bakıyor
- Çok
- Düşük
- makine
- makine öğrenme
- yapılmış
- sihirli
- yapmak
- YAPAR
- yönetmek
- yönetilen
- yönetim
- müdür
- çok
- harita
- pazar
- Pazarlama
- Maç
- uygun
- maddi olarak
- Mesele
- Mayıs..
- mekanik
- medya
- toplantılar
- Meta
- Metadata
- yöntem
- yöntemleri
- Michigan
- Microsoft
- microsoft takımları
- olabilir
- asgari
- ML
- Telefon
- Mobil uygulama
- model
- modelleri
- Modüller
- Daha
- çoğu
- hareket
- çok
- çoklu
- müzisyenler
- şart
- isim
- adlı
- isimleri
- Doğal (Madenden)
- Doğal lisan
- Tabiat
- yakın
- zorunlu olarak
- gerekli
- gerek
- ihtiyaçlar
- yeni
- fark
- kavram
- şimdi
- nüans
- numara
- nesne
- Nesne algılama
- nesneler
- of
- resmi
- on
- bir Zamanlar
- ONE
- Online
- bir tek
- açık
- açık kaynak
- Operasyon
- Fırsat
- Opsiyonlar
- or
- Düzenlenmiş
- orijinal
- OS
- Diğer
- Diğer
- bizim
- dışarı
- özetlenen
- çıktı
- tekrar
- kendi
- sahibi
- Paketleri
- eşleştirilmiş
- Bölüm
- belirli
- geçmiş
- yol
- model
- desen
- MÜKEMMEL OLAN YERİ BULUN
- performans
- kişi
- Kişiselleştirilmiş
- Maddenin Evreleri
- fiziksel
- seçmek
- Fotoğraf Galerisi
- EKOSE
- Sade
- Platformlar
- Platon
- Plato Veri Zekası
- PlatoVeri
- oynama
- Nokta
- nüfuslu
- mümkün
- Çivi
- güç kelimesini seçerim
- uygulama
- tahmin
- tahmin
- Tahminler
- Önizleme
- önceki
- Önceden
- Önceki
- özel
- muhtemelen
- sorunlar
- süreç
- PLATFORM
- ürün Yönetimi
- ürün müdürü
- Ürünler
- profesör
- proje
- özellik
- muhtemel
- prototip
- sağlamak
- sağlanan
- sağlama
- halka açık
- yumruk
- amaçlı
- Python
- Kuantum
- Sorular
- hızla
- menzil
- daha doğrusu
- Okuma
- hazır
- tavsiye etmek
- tavsiyeler
- azaltmak
- Indirimli
- azalma
- Nispeten
- serbest
- uygun
- Kaldır
- temsilci
- temsil
- gereklidir
- araştırma
- Araştırmacılar
- çözüm
- kısıtlamak
- sonuç
- Ortaya çıkan
- Sonuçlar
- perakende
- dönüş
- yorum
- Kurtulmak
- robotik
- gürbüz
- Rol
- kabaca
- SIRA
- harabe
- koşu
- sagemaker
- Adı geçen
- satış ekibi
- aynı
- Samsung
- İndirim
- Sahneler
- Bilim
- Bilimkurgu
- bilim adamları
- Gol
- sorunsuz
- İkinci
- Bölüm
- bölümler
- görmek
- görünmek
- görünüyor
- seçilmiş
- duyu
- ayrı
- hizmet
- Hizmetler
- Oturum
- set
- paylaş
- o
- meli
- şov
- Gösteriler
- SIM
- benzer
- Basit
- daha küçük
- So
- Yazılım
- yazılım geliştirme
- ÇÖZMEK
- biraz
- Birisi
- bir şey
- uzay
- geçirmek
- Harcama
- bölmek
- Splits
- stanford
- başlama
- başladı
- XNUMX dakika içinde!
- başlangıç
- başlangıç hızlandırıcı
- state-of-the-art
- Basamaklar
- Yine
- hafızası
- mağaza
- Stratejileri
- stil
- stilleri
- ÖZET
- destekli
- Sistemler
- Bizi daha iyi tanımak için
- Görev
- takım
- Teknik
- Techstars
- anlatır
- şablonları
- test
- göre
- o
- The
- ve bazı Asya
- Onları
- sonra
- teorik
- Orada.
- Bunlar
- onlar
- işler
- düşünmek
- üçüncü şahıslara ait
- Re-Tweet
- Binlerce
- eşik
- İçinden
- Atma
- zaman
- için
- birlikte
- araç
- araç
- üst
- Üst düzey
- tops
- Toplam
- müteessir
- iz
- Tren
- eğitilmiş
- Eğitim
- Dönüştürmek
- Şeffaflık
- gerçek
- Hakikat
- DÖNÜŞ
- iki
- tip
- türleri
- altında
- anlamak
- benzersiz
- üniversite
- Michigan Üniversitesi
- Güncelleme
- us
- kullanım
- kullanım durumu
- Kullanılmış
- kullanıcı
- kullanıcılar
- kullanma
- Değerler
- çeşitlilik
- çeşitli
- satıcıları
- doğrulamak
- çok
- üzerinden
- Görüntüle
- Sanal
- vizyonumuz
- istemek
- oldu
- we
- ağ
- web hizmetleri
- İYİ
- vardı
- Ne
- ne zaman
- olup olmadığını
- hangi
- Vikipedi
- irade
- ile
- içinde
- olmadan
- Kadın
- sözler
- İş
- işlenmiş
- işçiler
- işgücü
- çalışır
- Dünyanın en
- endişe
- olur
- yazmak
- X
- sen
- zefirnet
- zip
- ZOO