
Yazara göre resim
Verileri analiz ederken aklımızdaki şey gizli kalıpları bulmak ve anlamlı içgörüler çıkarmaktır. Kümeleme görevlerini çözecek güçlü algoritmalardan birinin, veri anlamada devrim yaratan K-Means kümeleme algoritması olduğu ML tabanlı öğrenmenin yeni kategorisine yani Denetimsiz öğrenme kategorisine girelim.
K-Means has become a useful algorithm in machine learning and data mining applications. In this article, we will deep dive into the workings of K-Means, its implementation using Python, and exploring its principles, applications, etc. So, let’s start the journey to unlock the secret patterns and harness the potential of the K-Means clustering algorithm.
Denetimsiz öğrenme sınıfına ait kümeleme problemlerinin çözümünde K-Means algoritması kullanılmaktadır. Bu algoritmanın yardımıyla gözlem sayısını K kümesi halinde gruplandırabiliriz.
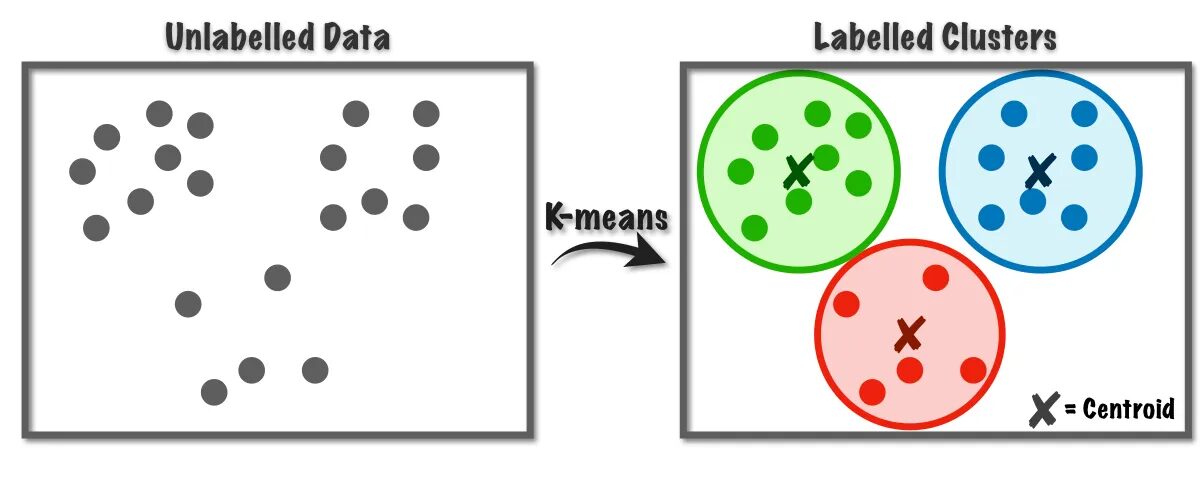
Şekil 1 K-Ortalama Algoritmasının Çalışması | Resim: Veri Bilimine Doğru
Bu algoritma dahili olarak vektör nicelemeyi kullanır; bu sayede veri kümesindeki her gözlemi kümeye minimum mesafeyle atayabiliriz, bu da kümeleme algoritmasının prototipidir. Bu kümeleme algoritması, Veri madenciliği ve makine öğreniminde, benzerlik ölçümlerine dayalı olarak verileri K kümelerine bölmek için yaygın olarak kullanılır. Bu nedenle, bu algoritmada, gözlemler ile onlara karşılık gelen merkezler arasındaki uzaklığın karelerinin toplamını en aza indirmemiz gerekir; bu da sonuçta farklı ve homojen kümelerle sonuçlanır.
K-ortalama Kümeleme Uygulamaları
İşte bu algoritmanın standart uygulamalarından bazıları. K-means algoritması, endüstriyel kullanım durumlarında kümeleme ile ilgili sorunların çözümü için yaygın olarak kullanılan bir tekniktir.
- Müşteri segmentasyonu: K-means kümelemesi, farklı müşterileri ilgi alanlarına göre segmentlere ayırabilir. Bankacılık, telekom, e-ticaret, spor, reklam, satış vb. alanlara uygulanabilir.
- Belge Kümeleme: Bu teknikte, benzer belgeleri bir dizi belgeden toplayacağız, böylece aynı kümelerde benzer belgeler elde edeceğiz.
- Öneri Motorları: Bazen öneri sistemleri oluşturmak için K-ortalama kümelemesi kullanılabilir. Örneğin arkadaşlarınıza şarkı önermek istiyorsunuz. Bu kişinin beğendiği şarkılara bakabilir ve ardından benzer şarkıları bulmak ve en benzer olanları önermek için kümelemeyi kullanabilirsiniz.
Daha önce düşündüğünüzden emin olduğum ve muhtemelen bu makalenin altındaki yorumlar bölümünde paylaşacağınız daha birçok uygulama var.
Bu bölümde ağırlıklı olarak Veri Bilimi projelerinde kullanılan Python kullanarak K-Means algoritmasını veri setlerinden biri üzerinde uygulamaya başlayacağız.
1. Gerekli Kütüphaneleri ve Bağımlılıkları İçe Aktarın
Öncelikle, NumPy, Pandas, Seaborn, Marplotlib vb. dahil olmak üzere K-means algoritmasını uygulamak için kullandığımız python kitaplıklarını içe aktaralım.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb2. Veri Kümesini Yükleyin ve Analiz Edin
Bu adımda öğrenci veri setini Pandas veri çerçevesinde saklayarak yükleyeceğiz. Veri setini indirmek için bağlantıya başvurabilirsiniz. okuyun.
Sorunun tam boru hattı aşağıda gösterilmiştir:

Şekil 2 Proje Boru Hattı | Yazara ait resim
df = pd.read_csv('student_clustering.csv')
print("The shape of data is",df.shape)
df.head()3. Veri Kümesinin Dağılım Grafiği
Şimdi modellemenin adımı verileri görselleştirmektir, bu nedenle kümeleme algoritmasının nasıl çalıştığını kontrol etmek ve farklı kümeler oluşturmak için dağılım grafiğini çizmek için matplotlib'i kullanırız.
# Scatter plot of the dataset
import matplotlib.pyplot as plt
plt.scatter(df['cgpa'],df['iq'])
Çıktı:
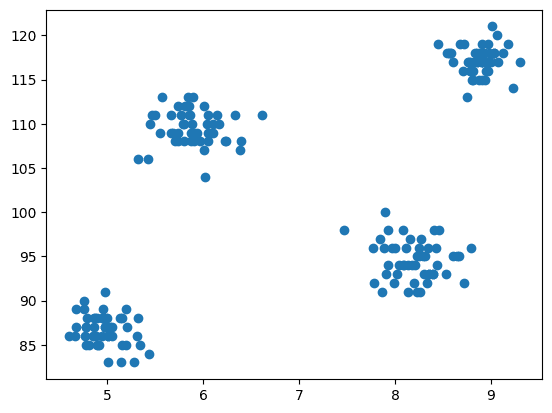
Şekil 3 Dağılım Grafiği | Yazara ait resim
4. Scikit-learn'in Küme Sınıfından K-Ortalamalarını İçe Aktarın
Artık K-Means kümelemesini uygulamamız gerektiğinden, önce küme sınıfını içe aktarıyoruz ve ardından bu sınıfın modülü olarak KMeans'e sahibiz.
from sklearn.cluster import KMeans5. Dirsek Yöntemini Kullanarak K'nın Optimum Değerini Bulma
Bu adımda algoritmayı uygularken hiperparametrelerden biri olan K'nın optimal değerini bulacağız. K değeri veri setimiz için kaç tane küme oluşturmamız gerektiğini ifade eder. Bu değeri sezgisel olarak bulmak mümkün değildir, dolayısıyla en uygun değeri bulmak için WCSS (küme içi kareler toplamı) ile farklı K değerleri arasında bir çizim oluşturacağız ve bu K'yı seçmeliyiz. bize WCSS'nin minimum değerini verir.
# create an empty list for store residuals
wcss = [] for i in range(1,11): # create an object of K-Means class km = KMeans(n_clusters=i) # pass the dataframe to fit the algorithm km.fit_predict(df) # append inertia value to wcss list wcss.append(km.inertia_)
Şimdi K'nin optimal değerini bulmak için dirsek grafiğini çizelim.
# Plot of WCSS vs. K to check the optimal value of K
plt.plot(range(1,11),wcss)
Çıktı:
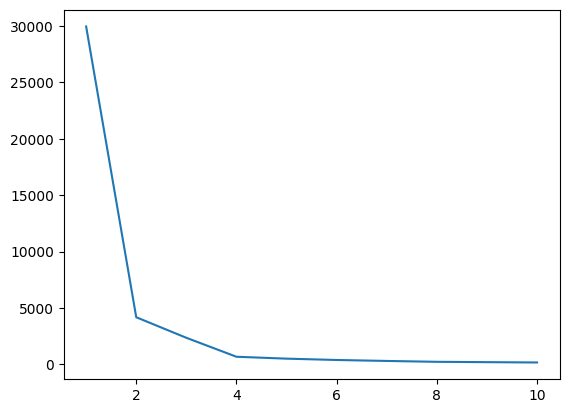
Şekil 4 Dirsek Grafiği | Yazara ait resim
Yukarıdaki dirsek grafiğinden K=4'ü görebiliriz; WCSS değerinde bir düşüş var yani eğer optimal değeri 4 olarak kullanırsak bu durumda kümeleme size iyi bir performans verecektir.
6. K-Ortalamalar Algoritmasını Optimum K değerine uydurun
K'nın optimal değerini bulmamız bitti. Şimdi tüm özelliklere sahip veri setinin tamamını saklayan bir X dizisi oluşturacağımız modellemeyi yapalım. Denetimsiz bir sorun olduğu için burada hedef ve özellik vektörünü ayırmaya gerek yoktur. Bundan sonra, seçilen K değerine sahip KMeans sınıfından bir nesne oluşturacağız ve bunu sağlanan veri kümesine sığdıracağız. Son olarak, oluşan farklı kümelerin ortalamalarını gösteren y_means'ı yazdırıyoruz.
X = df.iloc[:,:].values # complete data is used for model building
km = KMeans(n_clusters=4)
y_means = km.fit_predict(X)
y_means7. Her Kategorinin Küme Atamasını Kontrol Edin
Veri setindeki hangi noktaların hangi kümeye ait olduğunu kontrol edelim.
X[y_means == 3,1]
Şu ana kadar centroid başlatma için K-Means++ stratejisini kullandık, şimdi K-Means++ yerine rastgele centroidleri başlatalım ve aynı işlemi takip ederek sonuçları karşılaştıralım.
km_new = KMeans(n_clusters=4, init='random')
y_means_new = km_new.fit_predict(X)
y_means_new
Kaç değerin eşleştiğini kontrol edin.
sum(y_means == y_means_new)8. Kümeleri Görselleştirme
Her kümeyi görselleştirmek için onları eksenlere yerleştiririz ve 4 kümenin oluştuğunu kolayca görebileceğimiz farklı renkler atarız.
plt.scatter(X[y_means == 0,0],X[y_means == 0,1],color='blue')
plt.scatter(X[y_means == 1,0],X[y_means == 1,1],color='red') plt.scatter(X[y_means == 2,0],X[y_means == 2,1],color='green') plt.scatter(X[y_means == 3,0],X[y_means == 3,1],color='yellow')
Çıktı:
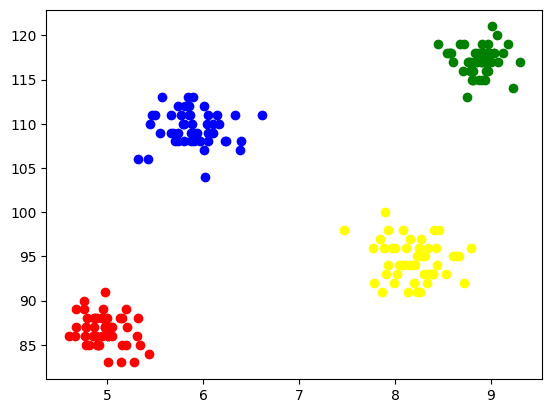
Şekil 5 Oluşan Kümelerin Görselleştirilmesi | Yazara ait resim
9. 3D Verilerde K-Araçları
Önceki veri kümesinde 2 sütun olduğundan 2 boyutlu bir sorunumuz var. Şimdi aynı adımları 3 boyutlu bir problem için kullanacağız ve n boyutlu veriler için kodun tekrarlanabilirliğini analiz etmeye çalışacağız.
# Create a synthetic dataset from sklearn
from sklearn.datasets import make_blobs # make synthetic dataset
centroids = [(-5,-5,5),(5,5,-5),(3.5,-2.5,4),(-2.5,2.5,-4)]
cluster_std = [1,1,1,1]
X,y = make_blobs(n_samples=200,cluster_std=cluster_std,centers=centroids,n_features=3,random_state=1)
# Scatter plot of the dataset
import plotly.express as px
fig = px.scatter_3d(x=X[:,0], y=X[:,1], z=X[:,2])
fig.show()
Çıktı:
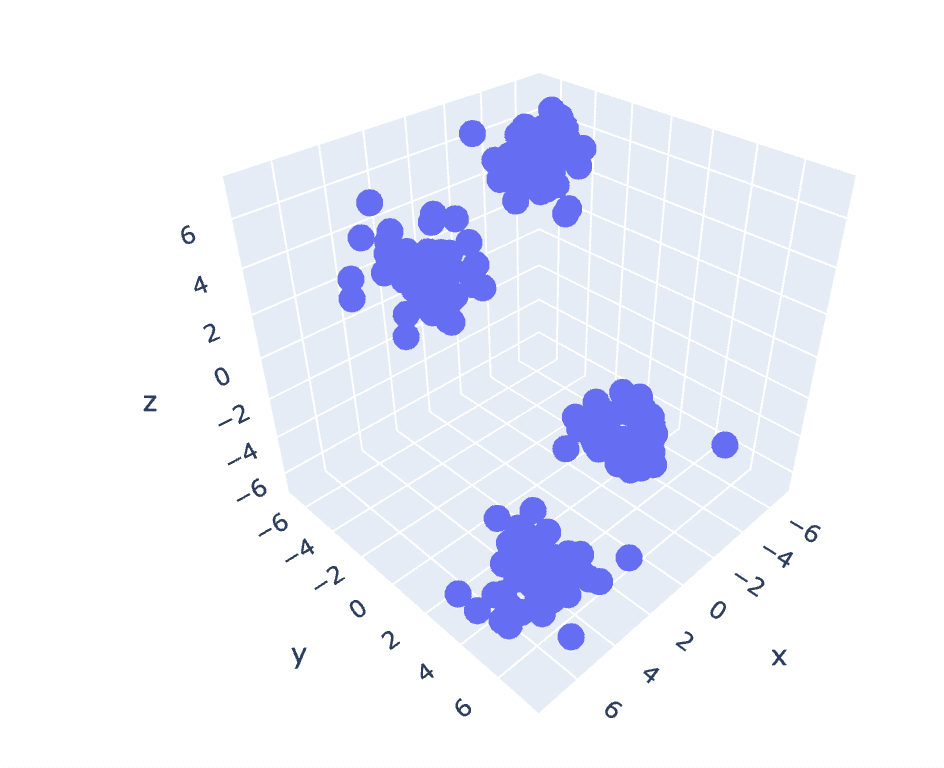
Şekil 6 3 Boyutlu Veri Kümesinin Dağılım Grafiği | Yazara ait resim
wcss = []
for i in range(1,21): km = KMeans(n_clusters=i) km.fit_predict(X) wcss.append(km.inertia_) plt.plot(range(1,21),wcss)
Çıktı:

Şekil 7 Dirsek Grafiği | Yazara ait resim
# Fit the K-Means algorithm with the optimal value of K
km = KMeans(n_clusters=4)
y_pred = km.fit_predict(X)
# Analyse the different clusters formed
df = pd.DataFrame()
df['col1'] = X[:,0]
df['col2'] = X[:,1]
df['col3'] = X[:,2]
df['label'] = y_pred fig = px.scatter_3d(df,x='col1', y='col2', z='col3',color='label')
fig.show()
Çıktı:
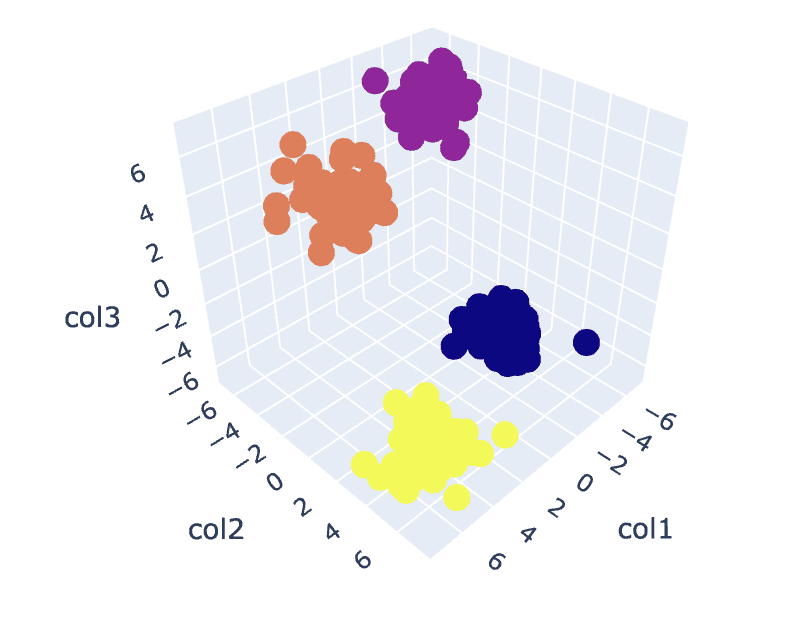
Şekil 8. Küme Görselleştirme | Yazara ait resim
You can find the complete code here – Colab Not Defteri
Bu tartışmamızı tamamlıyor. K-Means'in çalışmasını, uygulanmasını ve uygulamalarını tartıştık. Sonuç olarak, kümeleme görevlerinin uygulanması, bir veri kümesindeki gözlemlerin gruplandırılmasına yönelik basit ve sezgisel bir yaklaşım sağlayan, denetimsiz öğrenme sınıfından yaygın olarak kullanılan bir algoritmadır. Bu algoritmanın temel gücü, algoritmayı uygulayan kullanıcının yardımıyla gözlemleri seçilen benzerlik metriklerine dayalı olarak birden fazla kümeye bölmektir.
Ancak ilk adımda ağırlık merkezlerinin seçimine bağlı olarak algoritmamız farklı davranır ve yerel veya küresel optimuma yakınsar. Bu nedenle, algoritmayı uygulamak için küme sayısının seçilmesi, verilerin ön işlenmesi, aykırı değerlerin işlenmesi vb. iyi sonuçlar elde etmek için çok önemlidir. Ancak bu algoritmanın sınırlamaların ardındaki diğer tarafını gözlemlersek, K-Means, çeşitli alanlarda keşfedici veri analizi ve örüntü tanıma için yararlı bir tekniktir.
Aryan Garg bir B.Tech'tir. Elektrik Mühendisliği öğrencisi, şu anda lisans eğitiminin son yılında. İlgi alanı Web Geliştirme ve Makine Öğrenimi alanında yatmaktadır. Bu ilginin peşinden gitti ve bu yönlerde daha fazla çalışmak için can atıyorum.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. Otomotiv / EV'ler, karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- Blok Ofsetleri. Çevre Dengeleme Sahipliğini Modernleştirme. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/2023/07/clustering-unleashed-understanding-kmeans-clustering.html?utm_source=rss&utm_medium=rss&utm_campaign=clustering-unleashed-understanding-k-means-clustering
- :vardır
- :dır-dir
- :olumsuzluk
- :Neresi
- 1
- 10
- 11
- 13
- 16
- 25
- 28
- 7
- 8
- 9
- a
- yukarıdaki
- reklâm
- Sonra
- algoritma
- algoritmalar
- Türkiye
- zaten
- am
- an
- çözümlemek
- analiz
- çözümlemek
- analiz
- ve
- uygulamaları
- uygulamalı
- yaklaşım
- ARE
- Dizi
- göre
- AS
- At
- EKSENLER
- b
- Bankacılık
- merkezli
- BE
- müşterimiz
- arkasında
- altında
- arasında
- Mavi
- bina
- fakat
- by
- CAN
- dava
- durumlarda
- Kategoriler
- Kontrol
- Klinik
- sınıf
- kulüp
- Küme
- kümeleme
- kod
- Sütunlar
- geliyor
- yorumlar
- çoğunlukla
- karşılaştırmak
- tamamlamak
- Tamamladı
- sonuç
- uyan
- yaratmak
- çok önemli
- Şu anda
- müşteri
- Müşteriler
- veri
- veri analizi
- veri madenciliği
- veri bilimi
- veri kümeleri
- derin
- derin dalış
- gelişme
- farklı
- Dip
- yol tarifi
- tartışılan
- tartışma
- mesafe
- farklı
- do
- belge
- evraklar
- yapılmış
- indir
- çekmek
- e
- e-ticaret
- her
- istekli
- kolayca
- elektrik Mühendisliği
- Mühendislik
- Motorlar
- Keşfet
- vb
- sonunda
- örnek
- Açıklayıcı Veri Analizi
- Keşfetmek
- ekspres
- çıkarmak
- Özellikler(Hazırlık aşamasında)
- Özellikler
- alan
- Alanlar
- Incir
- son
- Nihayet
- bulmak
- bulma
- Ad
- uygun
- takip etme
- İçin
- oluşturulan
- arkadaşlar
- itibaren
- Vermek
- verir
- Küresel
- gidiş
- Tercih Etmenizin
- Yeşil
- grup
- kullanma
- koşum
- Var
- sahip olan
- he
- yardım et
- faydalı
- okuyun
- Gizli
- onun
- Ne kadar
- HTTPS
- i
- if
- görüntü
- uygulamak
- uygulama
- uygulanması
- ithalat
- in
- Dahil olmak üzere
- gösterir
- Sanayi
- süredurum
- anlayışlar
- yerine
- faiz
- ilgi alanları
- içten
- içine
- sezgisel
- IT
- ONUN
- seyahat
- jpg
- KDNuggets
- etiket
- öğrenme
- kütüphaneler
- yalan
- sınırlamaları
- LINK
- Liste
- yük
- yerel
- Bakın
- makine
- makine öğrenme
- Ana
- ağırlıklı olarak
- yapmak
- çok
- Maç
- matplotlib
- anlamlı
- anlamına geliyor
- Metrikleri
- akla
- asgari
- Madencilik
- model
- Modelleme
- modül
- Daha
- çoğu
- çoklu
- şart
- gerekli
- gerek
- yeni
- yok hayır
- şimdi
- numara
- dizi
- nesne
- gözlemek
- elde etmek
- of
- on
- ONE
- olanlar
- optimum
- or
- Diğer
- bizim
- pandalar
- geçmek
- model
- desen
- performans
- kişi
- boru hattı
- Platon
- Plato Veri Zekası
- PlatoVeri
- noktaları
- mümkün
- potansiyel
- güçlü
- önceki
- ilkeler
- muhtemelen
- Sorun
- sorunlar
- süreç
- proje
- Projeler
- prototip
- sağlanan
- sağlar
- Python
- rasgele
- tanıma
- tavsiye etmek
- Tavsiye
- Kırmızı
- araştırma
- Ortaya çıkan
- Sonuçlar
- devrim yapar
- s
- satış
- aynı
- Bilim
- Seaborn
- Gizli
- Bölüm
- görmek
- bölüm
- bölünme
- seçilmiş
- seçme
- seçim
- ayrı
- set
- Setleri
- Shape
- paylaş
- gösterilen
- yan
- anlamına gelir
- benzer
- Basit
- So
- ÇÖZMEK
- Çözme
- biraz
- Spor
- kareler
- standart
- başlama
- adım
- Basamaklar
- mağaza
- mağaza
- Stratejileri
- kuvvet
- Öğrenci
- elbette
- sentetik
- Sistemler
- Hedef
- görevleri
- teknoloji
- telekom
- o
- The
- ve bazı Asya
- Onları
- sonra
- Orada.
- bu nedenle
- Bunlar
- şey
- Re-Tweet
- düşünce
- İçinden
- için
- denemek
- anlayış
- dışarı çıktı
- kilidini açmak
- denetimsiz öğrenme
- us
- kullanım
- Kullanılmış
- kullanıcı
- kullanım
- kullanma
- kullanmak
- değer
- Değerler
- çeşitli
- görüntüleme
- vs
- istemek
- we
- ağ
- Web geliştirme
- hangi
- süre
- DSÖ
- geniş ölçüde
- irade
- ile
- İş
- çalışma
- kazı
- çalışır
- X
- yıl
- Sarı
- sen
- zefirnet








