Benzer sütunları bulma Data Lake birden çok veri kaynağında veri temizleme ve ek açıklama, şema eşleştirme, veri keşfi ve analitikte önemli uygulamalara sahiptir. Farklı kaynaklardan gelen verileri doğru bir şekilde bulup analiz edememe, veri bilimcilerden, tıp araştırmacılarına, akademisyenlere, finans ve devlet analistlerine kadar herkes için potansiyel bir verimlilik öldürücüdür.
Geleneksel çözümler, sütun adlarının olmaması veya farklı veri kümelerinde farklı sütun adlandırma kuralları (örneğin, zip_code, zcode, postalcode).
Bu gönderide, sütun adına, sütun içeriğine veya her ikisine göre benzer sütunları aramak için bir çözüm gösteriyoruz. Çözüm kullanır yaklaşık en yakın komşu algoritmaları uygun Amazon Açık Arama Hizmeti anlamsal olarak benzer sütunları aramak için. Aramayı kolaylaştırmak için, önceden eğitilmiş Transformer modellerini kullanarak veri gölündeki ayrı sütunlar için özellik temsilleri (gömmeler) oluşturuyoruz. cümle dönüştürücüler kitaplığı in Amazon Adaçayı Yapıcı. Son olarak, çözümümüzle etkileşime geçmek ve çözümümüzün sonuçlarını görselleştirmek için etkileşimli bir Akışlı çalışan web uygulaması AWS Fargate.
Biz bir kod eğitimi çözümü örnek veriler veya kendi verileriniz üzerinde çalıştırmak için kaynakları devreye almanız için.
Çözüme genel bakış
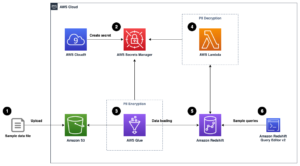
Aşağıdaki mimari diyagram, anlamsal olarak benzer sütunları bulmak için iki aşamalı iş akışını göstermektedir. İlk aşama bir çalışır AWS Basamak İşlevleri tablo sütunlarından yerleştirmeler oluşturan ve OpenSearch Service arama dizinini oluşturan iş akışı. İkinci aşama veya çevrimiçi çıkarım aşaması, Fargate üzerinden bir Streamlit uygulaması çalıştırır. Web uygulaması girdi arama sorgularını toplar ve OpenSearch Service dizininden sorguya en çok benzeyen yaklaşık k sütunu alır.

Şekil 1. Çözüm mimarisi
Otomatik iş akışı aşağıdaki adımlarda ilerler:
- Kullanıcı, tablo veri kümelerini bir Amazon Basit Depolama Hizmeti çağıran (Amazon S3) grubu AWS Lambda Adım İşlevleri iş akışını başlatan işlev.
- İş akışı bir ile başlar AWS Tutkal CSV dosyalarını dönüştüren iş Apache Parke veri formatı.
- Bir SageMaker İşleme işi, önceden eğitilmiş modeller veya özel sütun gömme modelleri kullanarak her sütun için yerleştirmeler oluşturur. SageMaker İşleme işi, Amazon S3'teki her tablo için sütun yerleştirmelerini kaydeder.
- Bir Lambda işlevi, önceki adımda üretilen sütun gömmelerini dizine eklemek için OpenSearch Hizmeti etki alanını ve kümesini oluşturur.
- Son olarak, etkileşimli bir Streamlit web uygulaması Fargate ile dağıtılır. Web uygulaması, kullanıcının benzer sütunlar için OpenSearch Service alanında arama yapmak üzere sorgu girmesi için bir arayüz sağlar.
Kod eğitimini adresinden indirebilirsiniz. GitHub bu çözümü örnek veriler veya kendi verileriniz üzerinde denemek için. Bu eğitim için gerekli kaynakların nasıl dağıtılacağına ilişkin talimatlar şu adreste mevcuttur: Github.
Önkoşullar
Bu çözümü uygulamak için şunlara ihtiyacınız var:
- An AWS hesabı.
- gibi AWS hizmetleriyle ilgili temel aşinalık AWS Bulut Geliştirme Kiti (AWS CDK), Lambda, OpenSearch Hizmeti ve SageMaker İşleme.
- Arama dizini oluşturmak için tablolu bir veri kümesi. Kendi tablo verilerinizi getirebilir veya örnek veri setlerini adresinden indirebilirsiniz. GitHub.
Bir arama dizini oluşturun
İlk aşama, sütun arama motoru dizini oluşturur. Aşağıdaki şekilde, bu aşamayı çalıştıran Adım İşlevleri iş akışı gösterilmektedir.

Şekil 2 - Adım işlevleri iş akışı - birden fazla gömme modeli
Veri Setleri
Bu gönderide, 400'ten fazla tablo veri kümesinden 25'den fazla sütun içerecek bir arama dizini oluşturuyoruz. Veri kümeleri aşağıdaki genel kaynaklardan gelmektedir:
Dizinde yer alan tabloların tam listesi için, adresindeki kod eğitimine bakın. GitHub.
Örnek verileri artırmak veya kendi arama dizininizi oluşturmak için kendi tablo veri kümenizi getirebilirsiniz. Sırasıyla tek tek CSV dosyaları veya toplu CSV dosyaları için arama dizini oluşturmak üzere Adım İşlevleri iş akışını başlatan iki Lambda işlevi dahil ediyoruz.
CSV'yi Parkeye Dönüştür
Ham CSV dosyaları, AWS Glue ile Parquet veri biçimine dönüştürülür. Parquet, verimli sıkıştırma ve kodlama sağlayan, büyük veri analitiğinde tercih edilen, sütun yönelimli formatta bir dosya formatıdır. Deneylerimizde, Parquet veri formatı, ham CSV dosyalarına kıyasla depolama boyutunda önemli ölçüde azalma sağladı. Gelişmiş iç içe veri yapılarını desteklediğinden, diğer veri biçimlerini (örneğin JSON ve NDJSON) dönüştürmek için ortak bir veri biçimi olarak Parquet'i de kullandık.
Sekmeli sütun yerleştirmeleri oluşturma
Bu gönderideki örnek tablo veri kümelerindeki tek tek tablo sütunları için katıştırmaları ayıklamak için aşağıdaki önceden eğitilmiş modelleri kullanıyoruz. sentence-transformers kütüphane. Ek modeller için bkz. Önceden eğitilmiş modeller.
SageMaker İşleme işi çalışır create_embeddings.py(kod) tek bir model için. Birden çok modelden yerleştirmeleri ayıklamak için iş akışı, Step Functions iş akışında gösterildiği gibi paralel SageMaker Processing işlerini çalıştırır. Modeli iki set yerleştirme oluşturmak için kullanıyoruz:
- sütun_adı_yerleştirmeler – Sütun adlarının gömülmesi (başlıklar)
- sütun_içeriği_yerleştirmeler – Sütundaki tüm satırların ortalama gömülmesi
Sütun gömme işlemi hakkında daha fazla bilgi için, adresindeki kod eğitimine bakın. GitHub.
SageMaker İşleme adımına bir alternatif, büyük veri kümelerinde sütun katıştırmaları elde etmek için bir SageMaker toplu dönüşümü oluşturmaktır. Bu, modelin bir SageMaker uç noktasına dağıtılmasını gerektirir. Daha fazla bilgi için bakınız Toplu Dönüştürmeyi Kullan.
OpenSearch Hizmeti ile indeks yerleştirmeleri
Bu aşamanın son adımında, bir Lambda işlevi sütun yerleştirmelerini bir OpenSearch Service yaklaşık k-En Yakın-Komşu'ya ekler (kNN) arama dizini. Her modele kendi arama indeksi atanır. Yaklaşık kNN arama dizini parametreleri hakkında daha fazla bilgi için bkz. k-NN.
Bir web uygulamasıyla çevrimiçi çıkarım ve anlamsal arama
İş akışının ikinci aşaması bir Akışlı Girdi sağlayabileceğiniz ve OpenSearch Hizmetinde dizinlenmiş semantik olarak benzer sütunları arayabileceğiniz web uygulaması. Uygulama katmanı bir Uygulama Yük Dengeleyici, Fargate ve Lambda. Uygulama altyapısı, çözümün bir parçası olarak otomatik olarak devreye alınır.
Uygulama, bir girdi sağlamanıza ve anlamsal olarak benzer sütun adlarını, sütun içeriğini veya her ikisini aramanıza olanak tanır. Ek olarak, aramadan dönmek için katıştırma modelini ve en yakın komşu sayısını seçebilirsiniz. Uygulama girdileri alır, girdiyi belirtilen modele yerleştirir ve kullanır OpenSearch Hizmetinde kNN araması dizinlenmiş sütun yerleşimlerini aramak ve verilen girdiye en çok benzeyen sütunları bulmak için. Görüntülenen arama sonuçları, tanımlanan sütunlar için tablo adlarını, sütun adlarını ve benzerlik puanlarının yanı sıra daha fazla araştırma için Amazon S3'teki verilerin konumlarını içerir.
Aşağıdaki şekil web uygulamasının bir örneğini göstermektedir. Bu örnekte, veri gölümüzde benzer özelliklere sahip sütunları aradık. Column Names (yük tipi) Ile district (yük). Kullanılan uygulama all-MiniLM-L6-v2 gibi gömme modeli ve geri döndü 10 (k) OpenSearch Hizmet dizinimizden en yakın komşular.
Uygulama geri döndü transit_district, city, borough, ve location OpenSearch Hizmetinde indekslenen verilere dayalı olarak en benzer dört sütun olarak. Bu örnek, arama yaklaşımının veri kümeleri arasında anlamsal olarak benzer sütunları belirleme yeteneğini gösterir.

Şekil 3: Web uygulaması kullanıcı arabirimi
Temizlemek
Bu öğreticide AWS CDK tarafından oluşturulan kaynakları silmek için aşağıdaki komutu çalıştırın:
cdk destroy --allSonuç
Bu gönderide, tablo sütunları için semantik bir arama motoru oluşturmaya yönelik uçtan uca bir iş akışı sunduk.
Şu adreste bulunan kod öğreticimizle bugün kendi verilerinizle başlayın: GitHub. Ürünlerinizde ve süreçlerinizde makine öğrenimi kullanımınızı hızlandırmak için yardıma ihtiyacınız varsa, lütfen Amazon Makine Öğrenimi Çözümleri Laboratuvarı.
Yazarlar Hakkında
![]() Kachi Odoemene AWS AI'da bir Uygulamalı Bilim Adamıdır. AWS müşterileri için iş sorunlarını çözmek için AI/ML çözümleri geliştiriyor.
Kachi Odoemene AWS AI'da bir Uygulamalı Bilim Adamıdır. AWS müşterileri için iş sorunlarını çözmek için AI/ML çözümleri geliştiriyor.
![]() Taylor McNally Amazon Machine Learning Solutions Lab'de Derin Öğrenme Mimarıdır. Çeşitli sektörlerden müşterilerin AWS'de AI/ML'den yararlanan çözümler oluşturmasına yardımcı olur. İyi bir fincan kahveden, açık havada ve ailesi ve enerjik köpeğiyle vakit geçirmekten hoşlanıyor.
Taylor McNally Amazon Machine Learning Solutions Lab'de Derin Öğrenme Mimarıdır. Çeşitli sektörlerden müşterilerin AWS'de AI/ML'den yararlanan çözümler oluşturmasına yardımcı olur. İyi bir fincan kahveden, açık havada ve ailesi ve enerjik köpeğiyle vakit geçirmekten hoşlanıyor.
![]() austin welch Amazon ML Solutions Lab'de Veri Bilimcisidir. AWS kamu sektörü müşterilerinin yapay zekayı ve bulutu benimseme sürecini hızlandırmasına yardımcı olmak için özel derin öğrenme modelleri geliştiriyor. Boş zamanlarında kitap okumaktan, seyahat etmekten ve jiu-jitsu yapmaktan hoşlanır.
austin welch Amazon ML Solutions Lab'de Veri Bilimcisidir. AWS kamu sektörü müşterilerinin yapay zekayı ve bulutu benimseme sürecini hızlandırmasına yardımcı olmak için özel derin öğrenme modelleri geliştiriyor. Boş zamanlarında kitap okumaktan, seyahat etmekten ve jiu-jitsu yapmaktan hoşlanır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- kabiliyet
- Hakkımızda
- yok
- hızlandırmak
- hızlanan
- tam olarak
- karşısında
- Ek
- Ayrıca
- Ekler
- Benimseme
- ileri
- AI
- AI / ML
- Türkiye
- veriyor
- alternatif
- Amazon
- Amazon Makine Öğrenimi
- Amazon ML Çözümleri Laboratuvarı
- Analistler
- analytics
- çözümlemek
- ve
- Apache
- Uygulama
- uygulamaları
- uygulamalı
- yaklaşım
- mimari
- atanmış
- Otomatik
- otomatik olarak
- mevcut
- ortalama
- AWS
- AWS Tutkal
- merkezli
- Çünkü
- Büyük
- büyük Veri
- getirmek
- inşa etmek
- bina
- inşa
- iş
- Temizlik
- bulut
- bulut benimseme
- Küme
- kod
- Kahve
- toplar
- Sütun
- Sütunlar
- ortak
- karşılaştırıldığında
- UAF ile
- içerik
- konvansiyonlar
- dönüştürmek
- dönüştürülmüş
- yaratmak
- çevrimiçi kurslar düzenliyorlar.
- oluşturur
- Fincan
- görenek
- Müşteriler
- veri
- Veri Analizi
- Veri Gölü
- veri kalitesi
- veri bilimcisi
- veri kümeleri
- derin
- derin öğrenme
- göstermek
- gösteriyor
- dağıtmak
- konuşlandırılmış
- dağıtma
- yıkmak
- gelişme
- geliştirir
- farklı
- keşif
- çılgınlık
- çeşitli
- Köpek
- domain
- indir
- her
- verim
- verimli
- son uca
- Son nokta
- Motor
- Eter (ETH)
- herkes
- örnek
- keşif
- çıkarmak
- kolaylaştırmak
- Aşinalık
- aile
- Özellikler
- şekil
- fileto
- dosyalar
- son
- Nihayet
- mali
- bulmak
- bulma
- Ad
- takip etme
- biçim
- itibaren
- tam
- işlev
- fonksiyonlar
- daha fazla
- almak
- verilmiş
- Tercih Etmenizin
- Hükümet
- başlıkları
- yardım et
- yardımcı olur
- Ne kadar
- Nasıl Yapılır
- HTML
- HTTPS
- tespit
- belirlemek
- uygulamak
- önemli
- in
- yetersizlik
- dahil
- dahil
- indeks
- bireysel
- Endüstri
- bilgi
- Altyapı
- başlatmak
- Başlattı
- giriş
- talimatlar
- etkileşim
- interaktif
- arayüzey
- çağırır
- dahil
- sorunlar
- IT
- İş
- Mesleki Öğretiler
- json
- laboratuvar
- göl
- büyük
- tabaka
- öğrenme
- kaldıraç
- Kütüphane
- Liste
- yük
- yerleri
- makine
- makine öğrenme
- uygun
- tıbbi
- ML
- model
- modelleri
- Daha
- çoğu
- çoklu
- isim
- isimleri
- adlandırma
- gerek
- komşular
- numara
- sunulan
- Online
- Diğer
- açık havada
- kendi
- Paralel
- parametreler
- Bölüm
- Platon
- Plato Veri Zekası
- PlatoVeri
- Lütfen
- Çivi
- potansiyel
- tercihli
- sundu
- önceki
- sorunlar
- gelir
- süreç
- Süreçler
- işleme
- Üretilmiş
- Ürünler
- sağlamak
- sağlar
- halka açık
- kalite
- Çiğ
- Okuma
- alır
- düzenli
- temsil
- gerektirir
- gereklidir
- Araştırmacılar
- Kaynaklar
- sırasıyla
- Sonuçlar
- dönüş
- koşmak
- koşu
- sagemaker
- bilim adamı
- bilim adamları
- Ara
- arama motoru
- arama
- İkinci
- sektör
- hizmet
- Hizmetler
- Setleri
- gösterilen
- Gösteriler
- önemli
- benzer
- Basit
- tek
- beden
- çözüm
- Çözümler
- ÇÖZMEK
- kaynaklar
- Belirtilen
- Aşama
- başladı
- adım
- Basamaklar
- hafızası
- böyle
- Destekler
- eğilimli
- tablo
- The
- ve bazı Asya
- İçinden
- zaman
- için
- bugün
- Dönüştürmek
- transformatörler
- Seyahat
- öğretici
- kullanım
- kullanıcı
- Kullanıcı Arayüzü
- çeşitli
- ağ
- Web uygulaması
- hangi
- iş akışı
- olur
- zefirnet