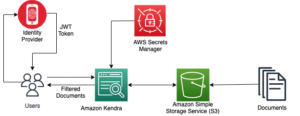
Kullanıcıların yeni içeriği keşfetme biçimini iyileştirmek, medya platformlarında kullanıcı katılımını ve memnuniyetini artırmak için kritik öneme sahiptir. Anahtar kelime arama tek başına anlambilimi ve kullanıcı amacını yakalama konusunda zorluklar barındırır ve bu da ilgili bağlamdan yoksun sonuçlara yol açar; örneğin randevu gecesi veya Noel temalı filmler bulmak. Bu, kullanıcıların istedikleri içeriği güvenilir bir şekilde bulamamaları durumunda elde tutma oranlarının düşmesine neden olabilir. Ancak büyük dil modelleri (LLM'ler), bu anlamsal ve kullanıcı amacına yönelik zorlukları çözme fırsatı vardır. Birleştirerek kalıplamaların adı verilen bir teknikle anlambilimi yakalayan Erişim Artırılmış Nesil (RAG), kendi veri kaynaklarınızdan alınan bağlama dayalı olarak daha alakalı yanıtlar oluşturabilirsiniz.
Bu yazıda, RAG'ı kendi verilerinizle uygulayarak güvenli bir şekilde film sohbet robotunu nasıl oluşturacağınızı gösteriyoruz. Bilgi Tabanı için Amazon Ana Kayası. Medya ve eğlence müşterilerine yönelik bir kataloğu simüle etmek ve yalnızca birkaç adımda kendi RAG çözümünüzü nasıl oluşturabileceğinizi göstermek için IMDb ve Box Office Mojo veri kümesini kullanıyoruz.
Çözüme genel bakış
The IMDb ve Gişe Mojo Filmleri/TV/OTT lisanslanabilir veri paketi, 1.6 milyardan fazla kullanıcı derecelendirmesi dahil olmak üzere çok çeşitli eğlence meta verileri sağlar; 13 milyondan fazla oyuncu ve ekip üyesi için kredi; 10 milyon film, TV ve eğlence başlığı; ve 60'tan fazla ülkeden küresel gişe raporlama verileri. Birçok AWS medya ve eğlence müşterisi, IMDb verilerini şu yollarla lisanslar: AWS Veri Değişimi içerik keşfini iyileştirmek ve müşteri katılımını ve elde tutmayı artırmak.
Amazon Bedrock için Bilgi Tabanlarına Giriş
Kuruluşlar, bir LLM'yi güncel özel bilgilerle donatmak için, şirket veri kaynaklarından veri almayı ve daha alakalı ve doğru yanıtlar sunmak üzere istemi bu verilerle zenginleştirmeyi içeren bir teknik olan RAG'ı kullanır. Amazon Bedrock için Bilgi Tabanları, LLM yanıtlarını bağlamsal ve ilgili şirket verileriyle özelleştirmenize olanak tanıyan, tam olarak yönetilen bir RAG özelliği sağlar. Bilgi Tabanları, veri kaynaklarını entegre etmek ve sorguları yönetmek için özel kod yazma gereksinimini ortadan kaldırarak, alma, alma, bilgi istemi artırma ve alıntılar dahil olmak üzere uçtan uca RAG iş akışını otomatikleştirir. Amazon Bedrock için Bilgi Tabanları ayrıca LLM'nin karmaşık kullanıcı sorgularına doğru yanıtla yanıt verebilmesi için çok yönlü konuşmalara da olanak tanır.
Bu çözümün bir parçası olarak aşağıdaki hizmetleri kullanıyoruz:
Aşağıdaki üst düzey adımlardan geçiyoruz:
- Her film kaydından belgeler oluşturmak ve verileri bir dosyaya yüklemek için IMDb verilerini ön işleme tabi tutun. Amazon Basit Depolama Hizmeti (Amazon S3) kovası.
- Bir bilgi tabanı oluşturun.
- Bilgi tabanınızı veri kaynağınızla senkronize edin.
- Film kataloğuyla ilgili anlamsal soruları yanıtlamak için bilgi tabanını kullanın.
Önkoşullar
Bu gönderide kullanılan IMDb verileri, ticari içerik lisansı ve AWS Data Exchange'deki IMDb ve Box Office Mojo Movies/TV/OTT lisanslama paketine ücretli abonelik gerektirir. Lisans hakkında bilgi almak ve örnek verilere erişmek için şu adresi ziyaret edin: geliştirici.imdb.com. Veri kümesine erişmek için bkz. Bir IMDb bilgi grafiği kullanarak güç önerisi ve arama – Bölüm 1 ve izleyin IMDb verilerine erişin Bölüm.
IMDb verilerini önceden işleyin
Bir bilgi tabanı oluşturmadan önce IMDb veri kümesini metin dosyaları halinde önceden işlememiz ve bunları bir S3 klasörüne yüklememiz gerekir. Bu yazıda IMDb veri kümesini kullanarak bir müşteri kataloğunun simülasyonunu yapıyoruz. Katalog için IMDb veri setinden 10,000 popüler filmi alıp veri setini oluşturuyoruz.
Aşağıdakileri kullanın defter aktörler, yönetmen ve yapımcı adları gibi ek bilgiler içeren veri kümesini oluşturmak için. Bir film için, dosyada saklanan tüm bilgilerin, Yüksek Lisans'ın anlayabileceği, yapılandırılmamış bir metin halinde olduğu tek bir dosya oluşturmak için aşağıdaki kodu kullanırız:
Verileri .txt biçiminde aldıktan sonra aşağıdaki komutu kullanarak verileri Amazon S3'e yükleyebilirsiniz:
IMDb Bilgi Tabanını Oluşturun
Bilgi tabanınızı oluşturmak için aşağıdaki adımları tamamlayın:
- Amazon Bedrock konsolunda şunu seçin: Bilgi tabanı Gezinti bölmesinde.
- Klinik Bilgi tabanı oluştur.
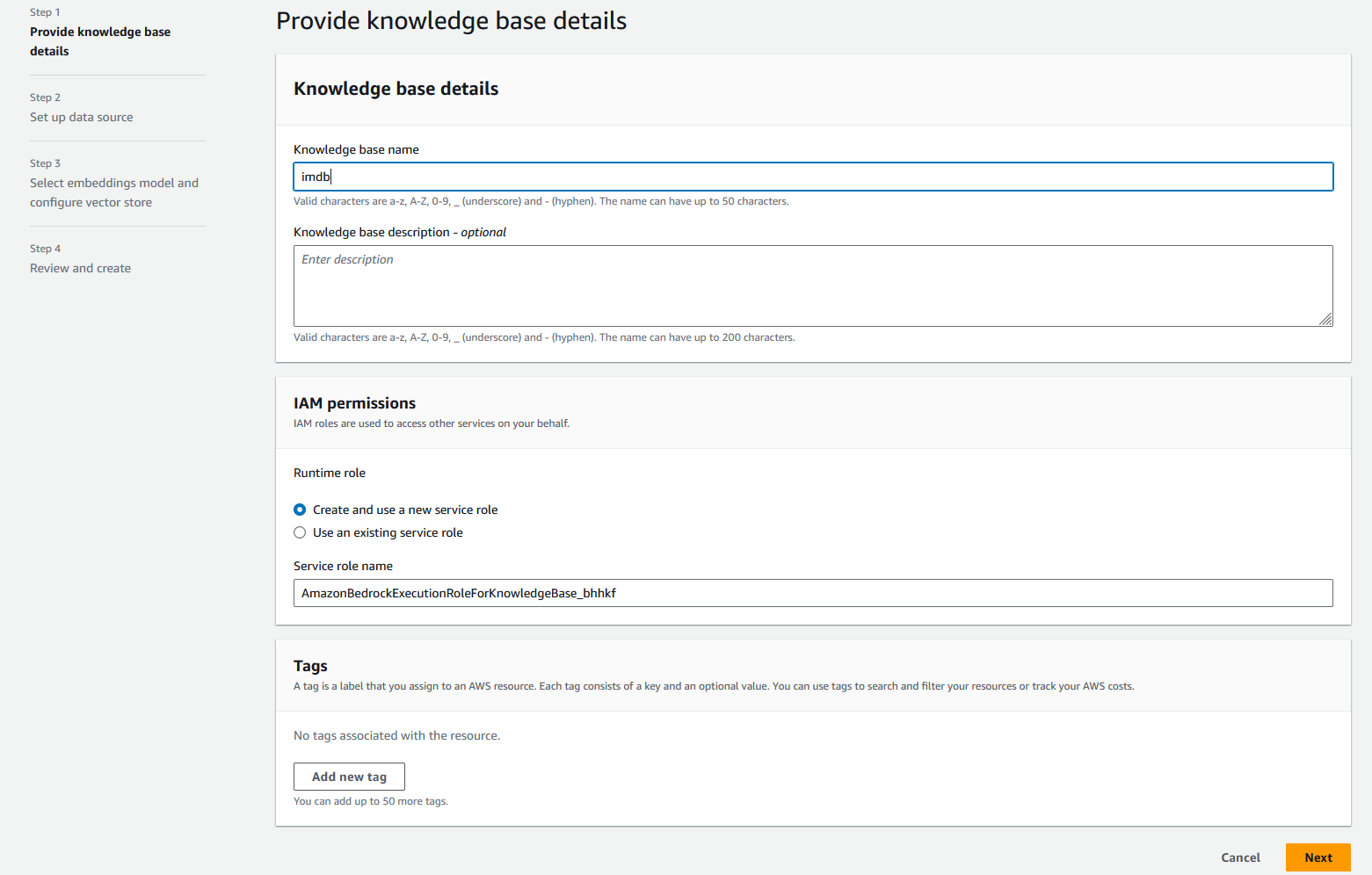
- İçin Bilgi tabanı adı, girmek
imdb. - İçin Bilgi tabanı açıklamasıimdb verilerini almak ve depolamak için Bilgi tabanı gibi isteğe bağlı bir açıklama girin.
- İçin IAM izinleriseçin Yeni bir hizmet rolü oluşturma ve kullanma, ardından yeni hizmet rolünüz için bir ad girin.
- Klinik Sonraki.
- İçin Veri kaynağı adı, girmek
imdb-s3. - İçin S3 URI'sı, verileri yüklediğiniz S3 URI'yi girin.
- içinde Gelişmiş ayarlar – isteğe bağlı bölümü Parçalama stratejisi, seçmek Parçalama yok.
- Klinik Sonraki.
Bilgi tabanları, büyük belgeleri işlemenizi kolaylaştırmak için belgelerinizi daha küçük bölümlere ayırmanıza olanak tanır. Bizim durumumuzda, verileri zaten daha küçük boyutlu bir belgeye (film başına bir tane) böldük.
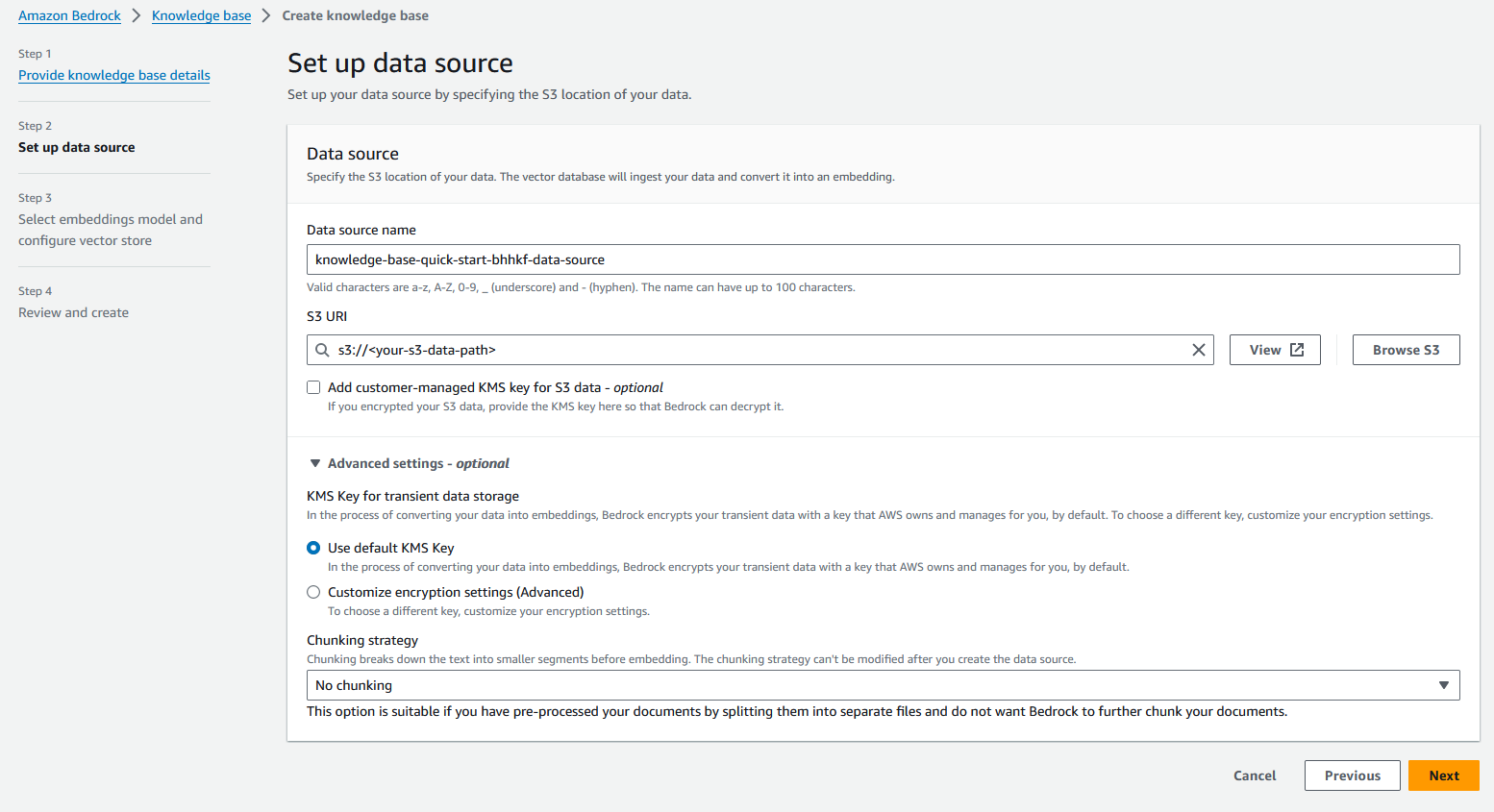
- içinde Vektör veritabanı bölümünde, seçin Hızlı bir şekilde yeni bir vektör mağazası oluşturun.
Amazon Bedrock otomatik olarak tam olarak yönetilen bir OpenSearch Sunucusuz vektör arama koleksiyonu oluşturacak ve seçilen Titan Embedding G1 – Metin yerleştirme modelini kullanarak veri kaynaklarınızı yerleştirmeye yönelik ayarları yapılandıracaktır.
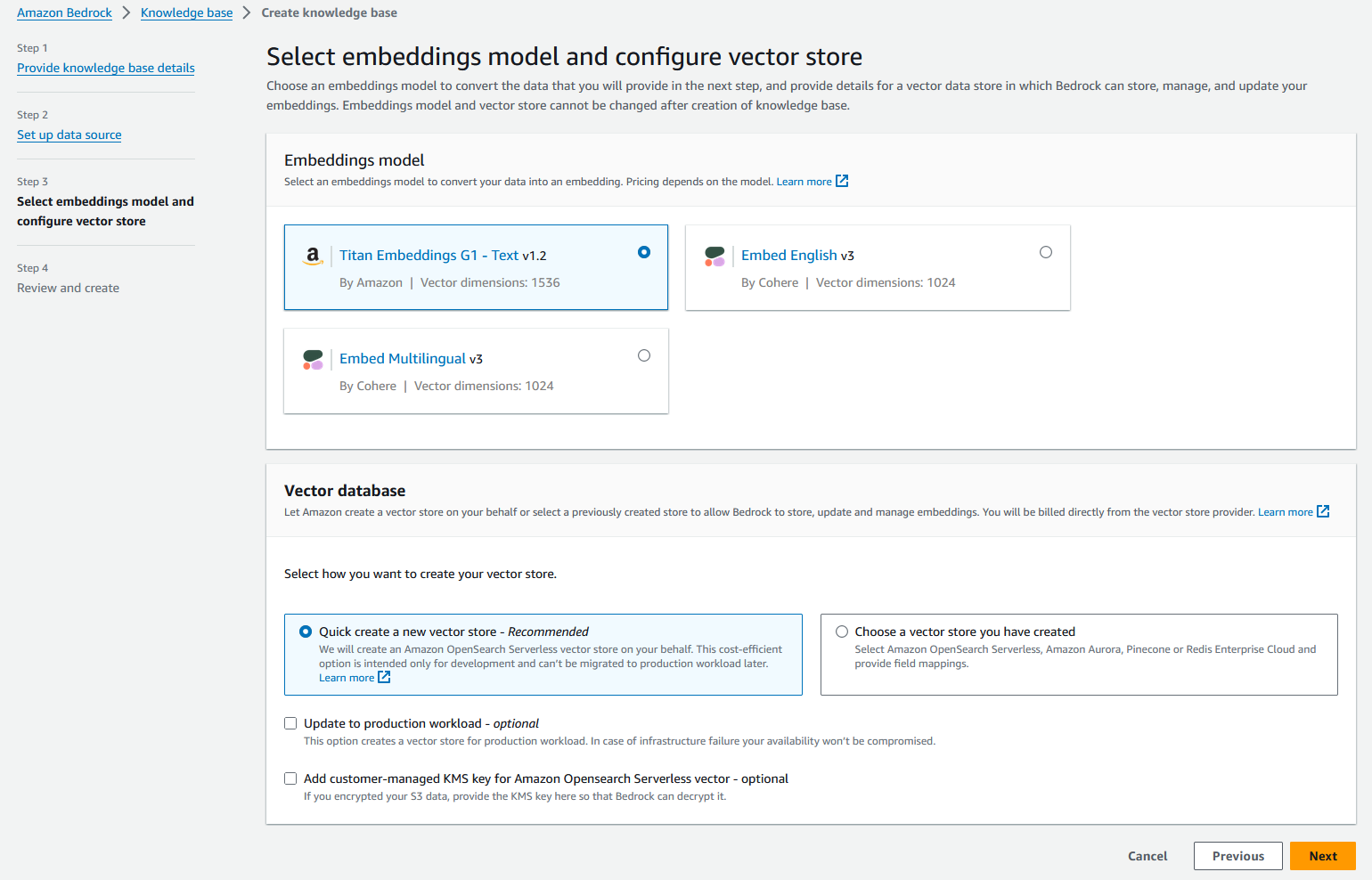
- Klinik Sonraki.
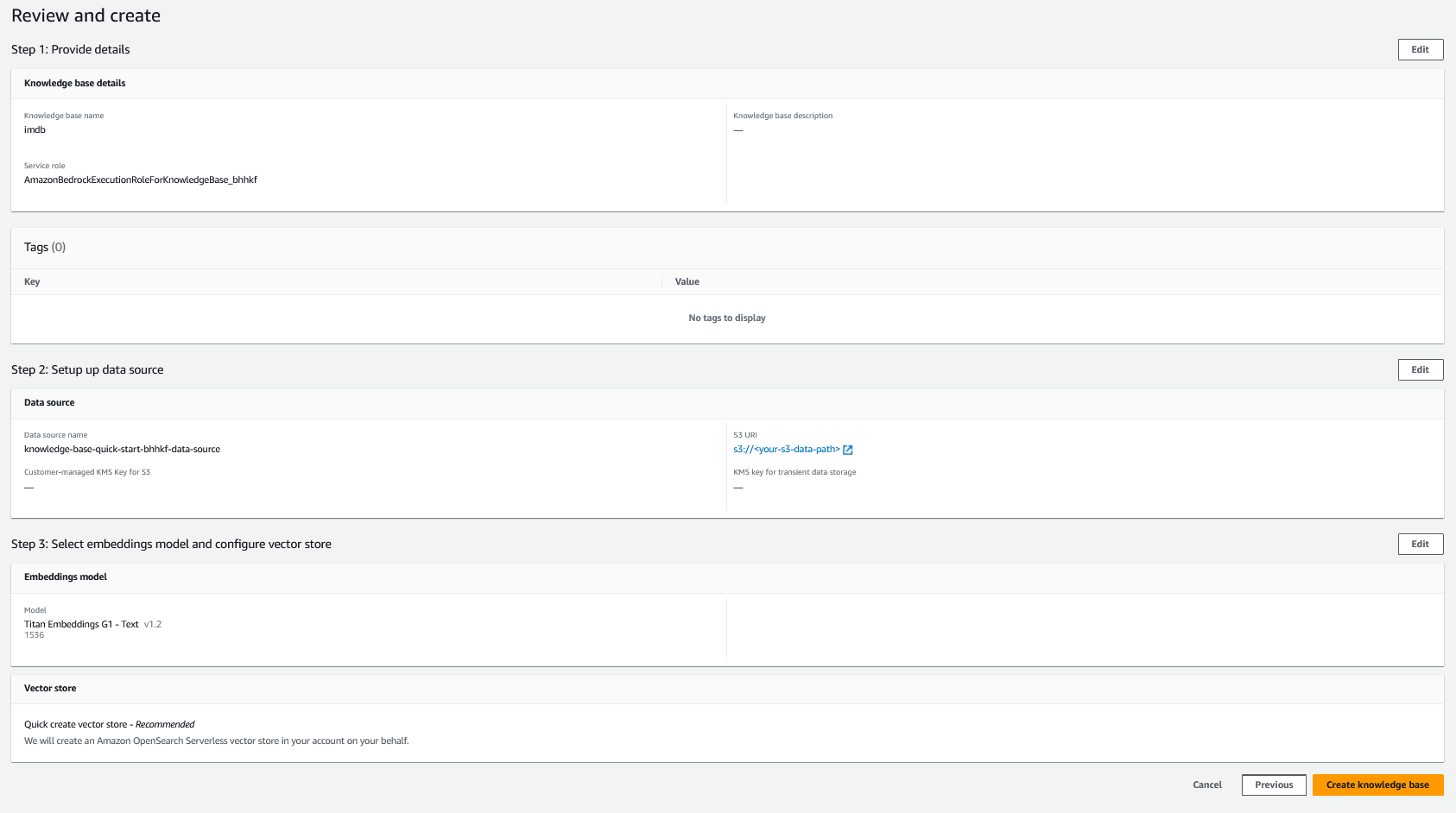
- Ayarlarınızı gözden geçirin ve seçin Bilgi tabanı oluştur.
Verilerinizi bilgi tabanıyla senkronize edin
Artık bilgi tabanınızı oluşturduğunuza göre bilgi tabanınızı verilerinizle senkronize edebilirsiniz.
- Amazon Bedrock konsolunda bilgi tabanınıza gidin.
- içinde Veri kaynağı bölümü, seçim Senkronizasyon.

Veri kaynağı senkronize edildikten sonra verileri sorgulamaya hazırsınız.
Anlamsal sonuçları kullanarak aramayı iyileştirin
Çözümü test etmek ve anlamsal sonuçları kullanarak aramanızı geliştirmek için aşağıdaki adımları tamamlayın:
- Amazon Bedrock konsolunda bilgi tabanınıza gidin.
- Bilgi tabanınızı seçin ve seçin Bilgi tabanını test edin.
- Klinik Model seç, ve Seç Antropik Claude v2.1.
- Klinik Tamam.
Artık verileri sorgulamaya hazırsınız.
“Bana Noel temalı birkaç film önerin” gibi bazı anlamsal sorular sorabiliriz.
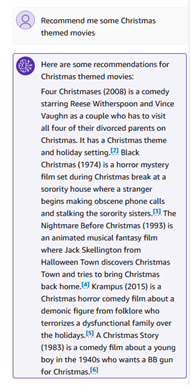
Bilgi tabanındaki yanıtlar, yanıtın doğruluğunu ve gerçekçiliğini araştırabileceğiniz alıntılar içerir.
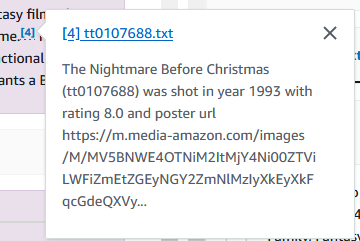
Ayrıca bu filmlerden ihtiyaç duyduğunuz bilgileri de inceleyebilirsiniz. Aşağıdaki örnekte “Noelden önce kabusu kim yönetti?” diye soruyoruz.

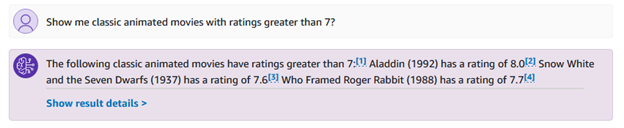
Ayrıca türler ve derecelendirmelerle ilgili "bana reytingi 7'den yüksek olan klasik animasyon filmleri göster?" gibi daha spesifik sorular da sorabilirsiniz.
Temsilcilerle bilgi tabanınızı genişletin
Amazon Bedrock Temsilcileri karmaşık görevleri otomatikleştirmenize yardımcı olur. Aracılar, kullanıcı sorgusunu daha küçük görevlere bölebilir ve yürütülen eylemlere yönelik bilgileri desteklemek üzere özel API'leri veya bilgi tabanlarını çağırabilir. Agents for Amazon Bedrock ile geliştiriciler, akıllı aracıları uygulamalarına entegre ederek yapay zeka destekli uygulamaların teslimini hızlandırabilir ve haftalarca süren geliştirme süresinden tasarruf edebilir. Temsilcilerle, tavsiyeler gibi daha fazla işlevsellik ekleyerek bilgi tabanınızı genişletebilirsiniz. Amazon Kişiselleştir kullanıcıya özel öneriler veya filmleri kullanıcı ihtiyaçlarına göre filtrelemek gibi eylemler gerçekleştirmek için.
Sonuç
Bu yazıda, kendi verilerinize ve IMDb ve Box Office Mojo Movies/TV/OTT lisanslı veri kümesine dayalı olarak anlamsal arama ve konuşma deneyimlerine yanıt vermek için Amazon Bedrock'u kullanarak birkaç adımda sohbete dayalı bir film sohbet robotunun nasıl oluşturulacağını gösterdik. Bir sonraki gönderide Agents for Amazon Bedrock kullanarak çözümünüze daha fazla işlevsellik ekleme sürecini ele alacağız. Amazon Bedrock'taki bilgi tabanlarını kullanmaya başlamak için bkz. Amazon Bedrock için Bilgi Tabanları.
Yazarlar Hakkında
 Gaurav Rele Üretken Yapay Zeka İnovasyon Merkezi'nde Kıdemli Veri Bilimcisi olarak görev yapıyor ve burada farklı sektörlerdeki AWS müşterileriyle birlikte çalışarak onların iş zorluklarını çözmek için üretken yapay zeka ve AWS Bulut hizmetlerini kullanmalarını hızlandırıyor.
Gaurav Rele Üretken Yapay Zeka İnovasyon Merkezi'nde Kıdemli Veri Bilimcisi olarak görev yapıyor ve burada farklı sektörlerdeki AWS müşterileriyle birlikte çalışarak onların iş zorluklarını çözmek için üretken yapay zeka ve AWS Bulut hizmetlerini kullanmalarını hızlandırıyor.
 Divya Bhargavi Üretken Yapay Zeka İnovasyon Merkezi'nde Kıdemli Uygulamalı Bilim Adamı Lideridir ve burada AWS müşterileri için yüksek değerli iş sorunlarını üretken yapay zeka yöntemlerini kullanarak çözmektedir. Görüntü/video anlama ve erişim, bilgi grafiğiyle zenginleştirilmiş büyük dil modelleri ve kişiselleştirilmiş reklamcılık kullanım örnekleri üzerinde çalışmaktadır.
Divya Bhargavi Üretken Yapay Zeka İnovasyon Merkezi'nde Kıdemli Uygulamalı Bilim Adamı Lideridir ve burada AWS müşterileri için yüksek değerli iş sorunlarını üretken yapay zeka yöntemlerini kullanarak çözmektedir. Görüntü/video anlama ve erişim, bilgi grafiğiyle zenginleştirilmiş büyük dil modelleri ve kişiselleştirilmiş reklamcılık kullanım örnekleri üzerinde çalışmaktadır.
 Suren Günturu Yüksek değerli iş sorunlarını çözmek için çeşitli AWS müşterileriyle birlikte çalıştığı Üretken Yapay Zeka İnovasyon Merkezi'nde çalışan bir Veri Bilimcisidir. Başta Amazon Bedrock ve diğer AWS Cloud hizmetleri olmak üzere Büyük Dil Modellerini kullanarak makine öğrenimi hatları oluşturma konusunda uzmanlaşmıştır.
Suren Günturu Yüksek değerli iş sorunlarını çözmek için çeşitli AWS müşterileriyle birlikte çalıştığı Üretken Yapay Zeka İnovasyon Merkezi'nde çalışan bir Veri Bilimcisidir. Başta Amazon Bedrock ve diğer AWS Cloud hizmetleri olmak üzere Büyük Dil Modellerini kullanarak makine öğrenimi hatları oluşturma konusunda uzmanlaşmıştır.
 Vidya Sagar Ravipati Generative AI İnovasyon Merkezi'nde Bilim Yöneticisi olarak görev yapıyor ve burada büyük ölçekli dağıtılmış sistemlerdeki engin deneyiminden ve makine öğrenimine olan tutkusundan yararlanarak farklı endüstri sektörlerindeki AWS müşterilerinin yapay zeka ve bulutu benimsemelerini hızlandırmasına yardımcı oluyor.
Vidya Sagar Ravipati Generative AI İnovasyon Merkezi'nde Bilim Yöneticisi olarak görev yapıyor ve burada büyük ölçekli dağıtılmış sistemlerdeki engin deneyiminden ve makine öğrenimine olan tutkusundan yararlanarak farklı endüstri sektörlerindeki AWS müşterilerinin yapay zeka ve bulutu benimsemelerini hızlandırmasına yardımcı oluyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/build-a-movie-chatbot-for-tv-ott-platforms-using-retrieval-augmented-generation-in-amazon-bedrock/
- :vardır
- :dır-dir
- :Neresi
- $ 10 milyon
- 000
- 1
- 10
- 100
- 11
- 118
- 12
- 13
- 360
- 385
- 60
- 7
- a
- Hakkımızda
- hızlandırmak
- hızlanan
- erişim
- doğru
- karşısında
- eylemler
- aktörler
- ekleme
- Ek
- Benimseme
- reklâm
- ajanları
- AI
- AI destekli
- Türkiye
- veriyor
- tek başına
- zaten
- Ayrıca
- Amazon
- Amazon Web Servisleri
- an
- ve
- cevap
- cevaplar
- herhangi
- API'ler
- uygulamaları
- uygulamalı
- uygulamalar
- ARE
- AS
- sormak
- At
- büyütme
- augmented
- otomatikleştirmek
- otomatik olarak
- AWS
- baz
- merkezli
- BE
- önce
- Milyar
- kutu
- gişe
- mola
- inşa etmek
- bina
- iş
- by
- çağrı
- denilen
- CAN
- kabiliyet
- ele geçirmek
- Yakalama
- dava
- durumlarda
- katalog
- Merkez
- zorluklar
- chatbot
- Klinik
- seçilmiş
- Noel
- klasik
- bulut
- bulut benimseme
- bulut hizmetleri
- kod
- Toplamak
- birleştirme
- ticari
- şirket
- karmaşık
- konsolos
- içermek
- içerik
- bağlam
- bağlamsal
- konuşkan
- konuşmaları
- doğru
- ülkeler
- Çift
- yaratmak
- çevrimiçi kurslar düzenliyorlar.
- Künye
- mürettebat
- kritik
- görenek
- müşteri
- Müşteri katılımı
- Müşteriler
- özelleştirmek
- veri
- Veri değişimi
- veri bilimcisi
- Tarih
- teslim etmek
- teslim
- tanım
- ayrıntılar
- geliştiriciler
- gelişme
- farklı
- yönlendirilmiş
- yönetmen
- Yönetmenler
- keşfetmek
- keşif
- dağıtıldı
- dağıtılmış sistemler
- belge
- evraklar
- aşağı
- sürücü
- ortadan
- katıştırma
- etkinleştirmek
- son uca
- nişan
- zenginleştirici
- Keşfet
- Entertainment
- Eter (ETH)
- Her
- örnek
- takas
- deneyim
- Deneyimler
- keşfetmek
- az
- fileto
- dosyalar
- süzme
- bulmak
- bulma
- takip et
- takip etme
- İçin
- biçim
- itibaren
- tamamen
- işlevsellik
- g1
- oluşturmak
- nesil
- üretken
- üretken yapay zeka
- türler
- almak
- Küresel
- Go
- grafik
- büyük
- Var
- he
- yardım et
- üst düzey
- onun
- Ne kadar
- Nasıl Yapılır
- Ancak
- HTML
- http
- HTTPS
- if
- uygulanması
- iyileştirmek
- in
- Dahil olmak üzere
- Artırmak
- sanayi
- bilgi
- bilgi
- Yenilikçilik
- sormak
- entegre
- Akıllı
- niyet
- içine
- içerir
- IT
- jpg
- sadece
- bilgi
- Eksiklik
- dil
- büyük
- büyük ölçekli
- öncülük etmek
- önemli
- öğrenme
- leverages
- Lisans
- ruhsatlı
- ruhsat verme
- sevmek
- lm
- yerel
- yer
- alt
- makine
- makine öğrenme
- yapmak
- yönetmek
- yönetilen
- müdür
- çok
- me
- medya
- Üyeler
- Metadata
- yöntemleri
- milyon
- ML
- model
- modelleri
- mojo
- Daha
- film
- filmler
- isim
- isimleri
- Gezin
- Navigasyon
- gerek
- ihtiyaçlar
- yeni
- sonraki
- gece
- of
- Office
- on
- ONE
- Fırsat
- or
- organizasyonlar
- Diğer
- bizim
- tekrar
- kendi
- paket
- Kanal
- ödenmiş
- bölmesi
- Bölüm
- tutku
- yol
- başına
- icra
- Kişiselleştirilmiş
- Platformlar
- Platon
- Plato Veri Zekası
- PlatoVeri
- arsa
- Popüler
- Çivi
- afiş
- öncelikle
- sorunlar
- süreç
- üretici
- Üreticileri
- özel
- sağlar
- sorgular
- sorgu
- Sorular
- paçavra
- menzil
- oranlar
- değerlendirme
- değerlendirme
- hazır
- tavsiye etmek
- Tavsiye
- tavsiyeler
- kayıt
- başvurmak
- ilgili
- uygun
- Raporlama
- gerektirir
- yanıt
- yanıtları
- Sonuçlar
- tutma
- geri alma
- dönüş
- Rol
- SIRA
- koşu
- memnuniyet
- tasarruf
- Bilim
- bilim adamı
- Ara
- Bölüm
- Güvenli
- segmentler
- seçmek
- anlamsal
- semantik
- kıdemli
- Serverless
- hizmet
- Hizmetler
- ayarlar
- o
- atış
- şov
- vitrin
- gösterdi
- Basit
- benzetmek
- tek
- beden
- daha küçük
- So
- çözüm
- ÇÖZMEK
- çözer
- biraz
- Kaynak
- kaynaklar
- uzmanlaşmış
- özel
- başladı
- Basamaklar
- hafızası
- mağaza
- saklı
- basit
- abone
- böyle
- tamamlamak
- senkron.
- Sistemler
- Bizi daha iyi tanımak için
- görevleri
- teknik
- test
- metin
- göre
- o
- The
- Bilgi
- ve bazı Asya
- Onları
- Temalı
- sonra
- Orada.
- Bunlar
- onlar
- Re-Tweet
- İçinden
- zaman
- titan
- başlıkları
- için
- tv
- anlayış
- anladım
- yapılandırılmamış
- aktüel
- Yüklenen
- URI
- URL
- kullanım
- Kullanılmış
- kullanıcı
- kullanıcılar
- kullanma
- çeşitli
- Geniş
- sektörler
- Türkiye Dental Sosyal Medya Hesaplarından bizi takip edebilirsiniz.
- W
- yürümek
- istemek
- oldu
- we
- ağ
- web hizmetleri
- Haftalar
- geniş
- Geniş ürün yelpazesi
- irade
- ile
- iş akışı
- çalışma
- çalışır
- yazmak
- X
- yıl
- sen
- zefirnet