ข้อมูลเชิงพื้นที่คือข้อมูลเกี่ยวกับตำแหน่งเฉพาะบนพื้นผิวโลก สามารถแสดงถึงพื้นที่ทางภูมิศาสตร์โดยรวมหรืออาจเป็นตัวแทนของเหตุการณ์ที่เกี่ยวข้องกับพื้นที่ทางภูมิศาสตร์ก็ได้ การวิเคราะห์ข้อมูลเชิงพื้นที่เป็นที่ต้องการในอุตสาหกรรมไม่กี่แห่ง มันเกี่ยวข้องกับการทำความเข้าใจว่าข้อมูลอยู่ที่ไหนจากมุมมองเชิงพื้นที่และเหตุใดจึงมีข้อมูลอยู่ที่นั่น
ข้อมูลเชิงพื้นที่มีสองประเภท: ข้อมูลเวกเตอร์และข้อมูลแรสเตอร์ ข้อมูลแรสเตอร์เป็นเมทริกซ์ของเซลล์ที่แสดงเป็นตาราง ซึ่งส่วนใหญ่เป็นตัวแทนภาพถ่ายและภาพถ่ายดาวเทียม ในโพสต์นี้ เรามุ่งเน้นไปที่ข้อมูลเวกเตอร์ ซึ่งแสดงเป็นพิกัดทางภูมิศาสตร์ของละติจูดและลองจิจูด ตลอดจนเส้นและรูปหลายเหลี่ยม (พื้นที่) ที่เชื่อมต่อหรือล้อมรอบพวกมัน ข้อมูลเวกเตอร์มีกรณีการใช้งานมากมายในการรับข้อมูลเชิงลึกด้านการเคลื่อนไหว ข้อมูลมือถือของผู้ใช้เป็นส่วนประกอบหนึ่ง และส่วนใหญ่มาจากตำแหน่งทางภูมิศาสตร์ของอุปกรณ์มือถือที่ใช้ GPS หรือผู้เผยแพร่แอปที่ใช้ SDK หรือการผสานรวมที่คล้ายกัน เพื่อวัตถุประสงค์ของโพสต์นี้ เราเรียกข้อมูลนี้ว่า ข้อมูลการเคลื่อนไหว.
นี่เป็นซีรีส์สองตอน ในโพสต์แรกนี้ เราจะแนะนำข้อมูลการเคลื่อนไหว แหล่งที่มา และสคีมาทั่วไปของข้อมูลนี้ จากนั้นเราจะหารือเกี่ยวกับกรณีการใช้งานต่างๆ และสำรวจวิธีที่คุณสามารถใช้บริการของ AWS เพื่อล้างข้อมูล วิธีที่ Machine Learning (ML) สามารถช่วยในความพยายามนี้ และวิธีที่คุณสามารถใช้ข้อมูลอย่างมีจริยธรรมในการสร้างภาพและข้อมูลเชิงลึก โพสต์ที่สองจะมีลักษณะทางเทคนิคมากกว่า และครอบคลุมขั้นตอนเหล่านี้โดยละเอียดควบคู่ไปกับโค้ดตัวอย่าง โพสต์นี้ไม่มีชุดข้อมูลตัวอย่างหรือโค้ดตัวอย่าง แต่จะครอบคลุมวิธีการใช้ข้อมูลหลังจากที่ซื้อจากผู้รวบรวมข้อมูลแล้ว
คุณสามารถใช้ได้ ความสามารถเชิงพื้นที่ของ Amazon SageMaker เพื่อซ้อนทับข้อมูลการเคลื่อนที่บนแผนที่ฐาน และจัดเตรียมการแสดงภาพแบบเลเยอร์เพื่อทำให้การทำงานร่วมกันง่ายขึ้น โปรแกรมสร้างภาพเชิงโต้ตอบที่ขับเคลื่อนด้วย GPU และโน้ตบุ๊ก Python มอบวิธีที่ราบรื่นในการสำรวจจุดข้อมูลนับล้านในหน้าต่างเดียวและแบ่งปันข้อมูลเชิงลึกและผลลัพธ์
แหล่งที่มาและสคีมา
มีแหล่งข้อมูลการเคลื่อนไหวเพียงไม่กี่แหล่ง นอกเหนือจากการปิงของ GPS และผู้เผยแพร่แอปแล้ว ยังมีการใช้แหล่งข้อมูลอื่นๆ เพื่อเพิ่มชุดข้อมูล เช่น จุดเข้าใช้งาน Wi-Fi ข้อมูลสตรีมราคาเสนอที่ได้รับผ่านการแสดงโฆษณาบนอุปกรณ์เคลื่อนที่ และตัวส่งสัญญาณฮาร์ดแวร์เฉพาะที่ธุรกิจวางไว้ (เช่น ในร้านค้าจริง ). มักเป็นเรื่องยากสำหรับธุรกิจที่จะรวบรวมข้อมูลนี้ด้วยตนเอง ดังนั้นพวกเขาจึงอาจซื้อข้อมูลจากผู้รวบรวมข้อมูล ผู้รวบรวมข้อมูลรวบรวมข้อมูลการเคลื่อนไหวจากแหล่งต่างๆ ทำความสะอาด เพิ่มสัญญาณรบกวน และทำให้ข้อมูลพร้อมใช้งานทุกวันสำหรับภูมิภาคทางภูมิศาสตร์ที่เฉพาะเจาะจง เนื่องจากลักษณะของข้อมูลเองและเนื่องจากเป็นการยากที่จะได้รับ ความถูกต้องและคุณภาพของข้อมูลนี้จึงอาจแตกต่างกันอย่างมาก และขึ้นอยู่กับธุรกิจที่จะประเมินและตรวจสอบสิ่งนี้โดยใช้ตัวชี้วัด เช่น ผู้ใช้ที่ใช้งานรายวัน, Ping รายวันทั้งหมด, และ Ping รายวันโดยเฉลี่ยต่ออุปกรณ์ ตารางต่อไปนี้แสดงให้เห็นว่าสคีมาทั่วไปของฟีดข้อมูลรายวันที่ส่งโดยผู้รวบรวมข้อมูลอาจมีหน้าตาเป็นอย่างไร
| คุณลักษณะ | รายละเอียด |
| ไอดีหรือมายด์ | รหัสโฆษณาบนมือถือ (MAID) ของอุปกรณ์ (แฮช) |
| ลาดพร้าว | ละติจูดของอุปกรณ์ |
| ก๊าซหุงต้ม | ลองจิจูดของอุปกรณ์ |
| จีโอแฮช | ตำแหน่ง Geohash ของอุปกรณ์ |
| ประเภทอุปกรณ์ | ระบบปฏิบัติการของอุปกรณ์ = IDFA หรือ GAID |
| แนวนอน_ความแม่นยำ | ความแม่นยำของพิกัด GPS แนวนอน (หน่วยเป็นเมตร) |
| การประทับเวลา | การประทับเวลาของเหตุการณ์ |
| ip | ที่อยู่ IP |
| ทั้งหมด | ความสูงของอุปกรณ์ (หน่วยเป็นเมตร) |
| ความเร็ว | ความเร็วของอุปกรณ์ (เมตร/วินาที) |
| ประเทศ | รหัส ISO สองหลักสำหรับประเทศต้นทาง |
| รัฐ | รหัสที่แสดงถึงรัฐ |
| เมือง | รหัสที่แสดงถึงเมือง |
| รหัสไปรษณีย์ | รหัสไปรษณีย์ของที่เห็นรหัสอุปกรณ์ |
| พาหะ | ผู้ให้บริการอุปกรณ์ |
| อุปกรณ์_ผู้ผลิต | ผู้ผลิตอุปกรณ์ |
ใช้กรณี
ข้อมูลการเคลื่อนไหวมีการใช้งานอย่างแพร่หลายในอุตสาหกรรมต่างๆ ต่อไปนี้คือกรณีการใช้งานที่พบบ่อยที่สุดบางส่วน:
- การวัดความหนาแน่น – การวิเคราะห์ปริมาณการเดินเท้าสามารถใช้ร่วมกับความหนาแน่นของประชากรเพื่อสังเกตกิจกรรมและการเยี่ยมชมจุดสนใจ (POI) ตัวชี้วัดเหล่านี้แสดงภาพจำนวนอุปกรณ์หรือผู้ใช้ที่กำลังหยุดและมีส่วนร่วมกับธุรกิจ ซึ่งสามารถนำไปใช้เพิ่มเติมในการเลือกสถานที่ หรือแม้แต่การวิเคราะห์รูปแบบการเคลื่อนไหวรอบๆ กิจกรรม (เช่น ผู้คนที่เดินทางเพื่อเล่นเกม) เพื่อให้ได้ข้อมูลเชิงลึกดังกล่าว ข้อมูลดิบที่เข้ามาจะต้องผ่านกระบวนการแยก แปลง และโหลด (ETL) เพื่อระบุกิจกรรมหรือการมีส่วนร่วมจากการส่ง Ping ตำแหน่งอุปกรณ์อย่างต่อเนื่อง เราสามารถวิเคราะห์กิจกรรมได้โดยการระบุจุดหยุดที่ทำโดยผู้ใช้หรืออุปกรณ์มือถือโดยการจัดกลุ่ม Ping โดยใช้โมเดล ML อเมซอน SageMaker.
- การเดินทางและวิถี – ฟีดตำแหน่งรายวันของอุปกรณ์สามารถแสดงเป็นชุดของกิจกรรม (การหยุด) และการเดินทาง (การเคลื่อนไหว) กิจกรรมคู่หนึ่งสามารถแสดงถึงการเดินทางระหว่างกิจกรรมเหล่านั้น และการติดตามการเดินทางโดยอุปกรณ์ที่เคลื่อนที่ในพื้นที่ทางภูมิศาสตร์สามารถนำไปสู่การสร้างแผนที่วิถีที่แท้จริง รูปแบบการเคลื่อนที่ของผู้ใช้สามารถนำไปสู่ข้อมูลเชิงลึกที่น่าสนใจ เช่น รูปแบบการจราจร ปริมาณการใช้เชื้อเพลิง การวางผังเมือง และอื่นๆ นอกจากนี้ยังสามารถให้ข้อมูลเพื่อวิเคราะห์เส้นทางที่นำมาจากจุดโฆษณา เช่น ป้ายโฆษณา ระบุเส้นทางการจัดส่งที่มีประสิทธิภาพสูงสุดเพื่อเพิ่มประสิทธิภาพการดำเนินงานของห่วงโซ่อุปทาน หรือวิเคราะห์เส้นทางอพยพในภัยพิบัติทางธรรมชาติ (เช่น การอพยพพายุเฮอริเคน)
- การวิเคราะห์พื้นที่รับน้ำ - พื้นที่รับน้ำ หมายถึงสถานที่ที่พื้นที่หนึ่งๆ ดึงดูดผู้มาเยือน ซึ่งอาจเป็นลูกค้าหรือผู้ที่มีแนวโน้มจะเป็นลูกค้า ธุรกิจค้าปลีกสามารถใช้ข้อมูลนี้เพื่อระบุตำแหน่งที่เหมาะสมที่สุดในการเปิดร้านใหม่ หรือพิจารณาว่าที่ตั้งร้านค้าสองแห่งอยู่ใกล้กันมากเกินไปโดยมีพื้นที่รับน้ำที่ทับซ้อนกันและเป็นอุปสรรคต่อธุรกิจของกันและกันหรือไม่ พวกเขายังสามารถค้นหาว่าลูกค้าที่แท้จริงมาจากไหน ระบุผู้มีโอกาสเป็นลูกค้าที่ผ่านพื้นที่ที่เดินทางไปทำงานหรือที่บ้าน วิเคราะห์ตัวชี้วัดการเยี่ยมชมที่คล้ายกันสำหรับคู่แข่ง และอื่นๆ บริษัทเทคโนโลยีการตลาด (MarTech) และบริษัทเทคโนโลยีโฆษณา (AdTech) สามารถใช้การวิเคราะห์นี้เพื่อเพิ่มประสิทธิภาพแคมเปญการตลาดโดยการระบุผู้ชมที่อยู่ใกล้กับร้านค้าของแบรนด์ หรือเพื่อจัดอันดับร้านค้าตามประสิทธิภาพสำหรับการโฆษณานอกบ้าน
มีกรณีการใช้งานอื่นๆ อีกหลายกรณี รวมถึงการสร้างข้อมูลตำแหน่งอัจฉริยะสำหรับอสังหาริมทรัพย์เชิงพาณิชย์ การเพิ่มข้อมูลภาพถ่ายดาวเทียมด้วยจำนวนก้าว การระบุศูนย์กลางการจัดส่งสำหรับร้านอาหาร การพิจารณาความเป็นไปได้ในการอพยพในบริเวณใกล้เคียง การค้นพบรูปแบบการเคลื่อนไหวของผู้คนในระหว่างการระบาดใหญ่ และอื่นๆ
ความท้าทายและการใช้อย่างมีจริยธรรม
การใช้ข้อมูลการเคลื่อนที่อย่างมีจริยธรรมสามารถนำไปสู่ข้อมูลเชิงลึกที่น่าสนใจมากมาย ซึ่งสามารถช่วยองค์กรปรับปรุงการดำเนินงาน ทำการตลาดอย่างมีประสิทธิผล หรือแม้แต่บรรลุความได้เปรียบทางการแข่งขัน หากต้องการใช้ข้อมูลนี้อย่างมีจริยธรรม จำเป็นต้องปฏิบัติตามหลายขั้นตอน
มันเริ่มต้นด้วยการรวบรวมข้อมูลเอง แม้ว่าข้อมูลการเคลื่อนที่ส่วนใหญ่จะไม่มีข้อมูลส่วนบุคคลที่สามารถระบุตัวตนได้ (PII) เช่น ชื่อและที่อยู่ ผู้รวบรวมข้อมูลและผู้รวบรวมข้อมูลจะต้องได้รับความยินยอมจากผู้ใช้ในการรวบรวม ใช้ จัดเก็บ และแบ่งปันข้อมูลของตน กฎหมายความเป็นส่วนตัวของข้อมูล เช่น GDPR และ CCPA จำเป็นต้องปฏิบัติตาม เนื่องจากกฎหมายเหล่านี้ให้อำนาจผู้ใช้สามารถกำหนดวิธีที่ธุรกิจต่างๆ สามารถใช้ข้อมูลของตนได้ ขั้นตอนแรกนี้เป็นก้าวสำคัญไปสู่การใช้ข้อมูลการเดินทางอย่างมีจริยธรรมและความรับผิดชอบ แต่ยังสามารถทำได้มากกว่านี้
อุปกรณ์แต่ละเครื่องจะได้รับรหัสโฆษณาบนมือถือ (MAID) ที่แฮช ซึ่งใช้ในการยึดคำสั่ง Ping แต่ละรายการ สิ่งนี้สามารถทำให้สับสนได้อีกโดยใช้ อเมซอน แม็กกี้, ออบเจ็กต์ Amazon S3 Lambda, เข้าใจ Amazonหรือแม้แต่ไฟล์ AWS กาวสตูดิโอ ตรวจจับการแปลง PII สำหรับข้อมูลเพิ่มเติม โปรดดูที่ เทคนิคทั่วไปในการตรวจจับข้อมูล PHI และ PII โดยใช้บริการของ AWS.
นอกเหนือจาก PII แล้ว ควรพิจารณาเพื่อปกปิดตำแหน่งบ้านของผู้ใช้ตลอดจนสถานที่ที่ละเอียดอ่อนอื่นๆ เช่น ฐานทัพทหารหรือสถานที่สักการะ
ขั้นตอนสุดท้ายสำหรับการใช้งานอย่างมีจริยธรรมคือการรับและส่งออกเฉพาะตัววัดรวมออกจาก Amazon SageMaker ซึ่งหมายถึงการรับตัวชี้วัด เช่น จำนวนเฉลี่ยหรือจำนวนผู้เข้าชมทั้งหมด เมื่อเทียบกับรูปแบบการเดินทางของแต่ละบุคคล รับแนวโน้มรายวัน รายสัปดาห์ รายเดือนหรือรายปี หรือการจัดทำดัชนีรูปแบบการเคลื่อนย้ายเหนือข้อมูลที่เปิดเผยต่อสาธารณะ เช่น ข้อมูลการสำรวจสำมะโนประชากร
ภาพรวมโซลูชัน
ดังที่กล่าวไว้ก่อนหน้านี้ บริการของ AWS ที่คุณสามารถใช้เพื่อวิเคราะห์ข้อมูลการเคลื่อนที่ ได้แก่ ความสามารถเชิงพื้นที่ของ Amazon S3, Amazon Macie, AWS Glue, S3 Object Lambda, Amazon Comprehend และ Amazon SageMaker ความสามารถเชิงพื้นที่ของ Amazon SageMaker ช่วยให้นักวิทยาศาสตร์ข้อมูลและวิศวกร ML สร้าง ฝึก และปรับใช้โมเดลโดยใช้ข้อมูลเชิงพื้นที่ได้อย่างง่ายดาย คุณสามารถแปลงหรือเพิ่มชุดข้อมูลภูมิสารสนเทศขนาดใหญ่ได้อย่างมีประสิทธิภาพ เร่งการสร้างแบบจำลองด้วยโมเดล ML ที่ได้รับการฝึกล่วงหน้า และสำรวจการคาดการณ์แบบจำลองและข้อมูลเชิงพื้นที่บนแผนที่เชิงโต้ตอบโดยใช้กราฟิกเร่งความเร็ว 3 มิติและเครื่องมือแสดงภาพในตัว
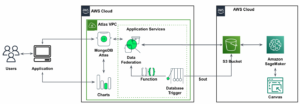
สถาปัตยกรรมอ้างอิงต่อไปนี้แสดงขั้นตอนการทำงานโดยใช้ ML พร้อมข้อมูลเชิงพื้นที่
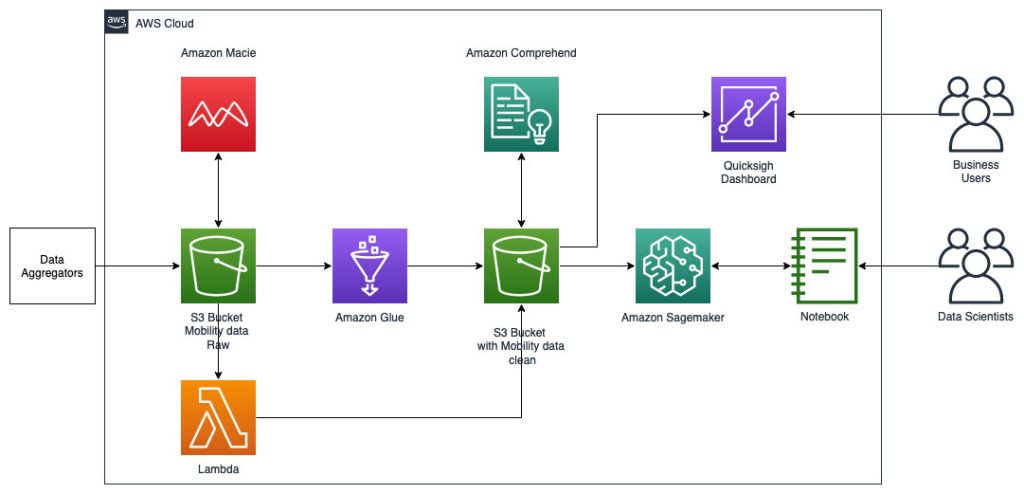
ในเวิร์กโฟลว์นี้ ข้อมูลดิบจะถูกรวบรวมจากแหล่งข้อมูลต่างๆ และจัดเก็บไว้ใน บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (S3) ถัง Amazon Macie ใช้ในบัคเก็ต S3 นี้เพื่อระบุและแก้ไขและ PII จากนั้น AWS Glue จะใช้ในการล้างและแปลงข้อมูลดิบเป็นรูปแบบที่ต้องการ จากนั้นข้อมูลที่แก้ไขและล้างจะถูกจัดเก็บไว้ในบัคเก็ต S3 แยกต่างหาก สำหรับการแปลงข้อมูลที่ไม่สามารถทำได้ผ่าน AWS Glue คุณใช้ AWS แลมบ์ดา เพื่อแก้ไขและล้างข้อมูลดิบ เมื่อล้างข้อมูลแล้ว คุณสามารถใช้ Amazon SageMaker เพื่อสร้าง ฝึก และปรับใช้โมเดล ML บนข้อมูลภูมิสารสนเทศที่เตรียมไว้ได้ คุณยังสามารถใช้ งานการประมวลผลเชิงพื้นที่ คุณลักษณะของความสามารถเชิงพื้นที่ของ Amazon SageMaker ในการประมวลผลข้อมูลล่วงหน้า เช่น การใช้ฟังก์ชัน Python และคำสั่ง SQL เพื่อระบุกิจกรรมจากข้อมูลการเคลื่อนที่แบบ Raw นักวิทยาศาสตร์ข้อมูลสามารถทำกระบวนการนี้ให้สำเร็จได้โดยการเชื่อมต่อผ่านสมุดบันทึก Amazon SageMaker คุณยังสามารถใช้ อเมซอน QuickSight เพื่อแสดงภาพผลลัพธ์ทางธุรกิจและตัวชี้วัดที่สำคัญอื่นๆ จากข้อมูล
ความสามารถเชิงพื้นที่ของ Amazon SageMaker และงานการประมวลผลเชิงพื้นที่
หลังจากที่ข้อมูลได้รับและป้อนเข้าสู่ Amazon S3 ด้วยฟีดรายวัน และล้างข้อมูลที่ละเอียดอ่อนแล้ว ก็สามารถนำเข้าสู่ Amazon SageMaker ได้โดยใช้ สตูดิโอ Amazon SageMaker สมุดบันทึกที่มีภาพภูมิสารสนเทศ ภาพหน้าจอต่อไปนี้แสดงตัวอย่างการ Ping ของอุปกรณ์รายวันที่อัปโหลดไปยัง Amazon S3 เป็นไฟล์ CSV จากนั้นโหลดในกรอบข้อมูล Pandas สมุดบันทึก Amazon SageMaker Studio ที่มีรูปภาพเชิงพื้นที่มาพร้อมกับไลบรารีเชิงพื้นที่ เช่น GDAL, GeoPandas, Fiona และ Shapely ที่โหลดไว้ล่วงหน้า และทำให้การประมวลผลและวิเคราะห์ข้อมูลนี้ตรงไปตรงมา
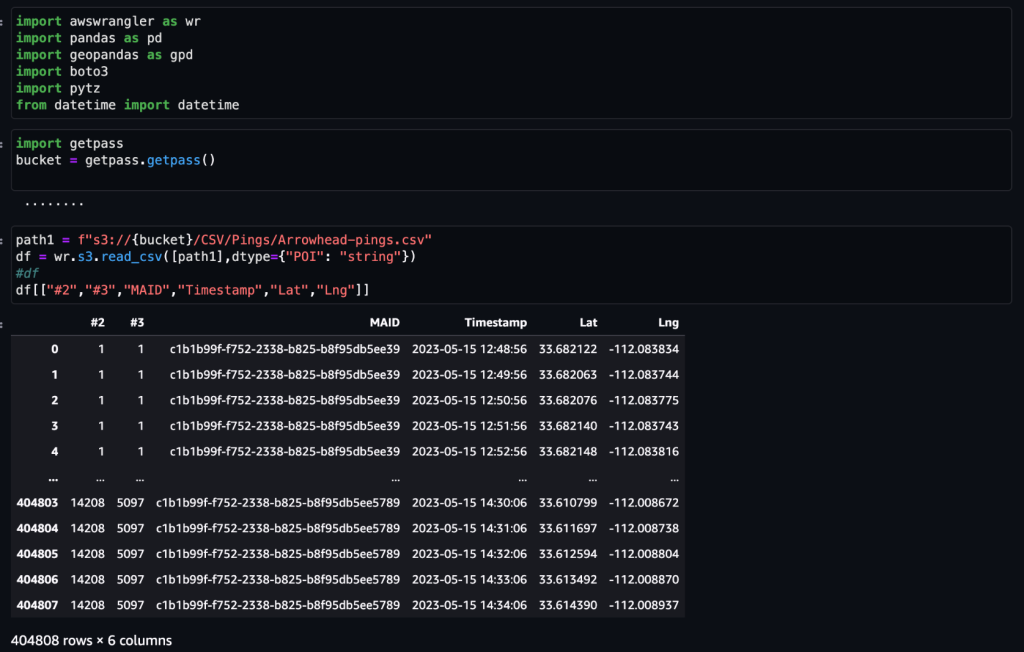
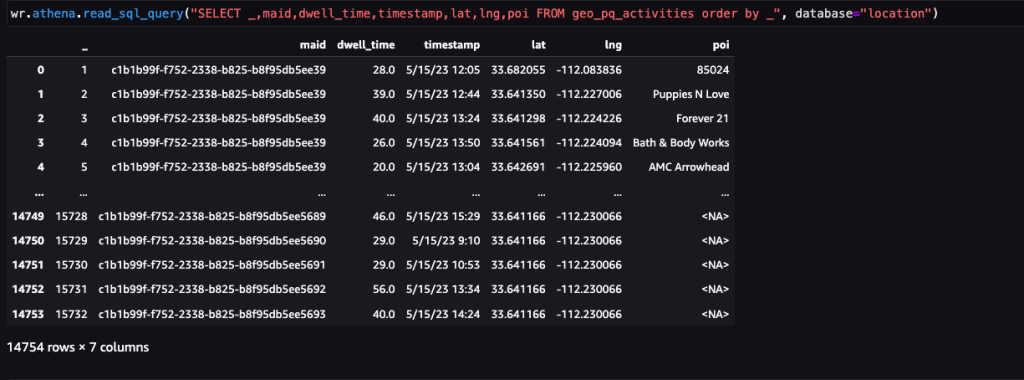
ชุดข้อมูลตัวอย่างนี้มีการปิงอุปกรณ์ประมาณ 400,000 รายการต่อวันจากอุปกรณ์ 5,000 เครื่องจากสถานที่ที่ไม่ซ้ำกัน 14,000 แห่งที่บันทึกจากผู้ใช้ที่เยี่ยมชม Arrowhead Mall ห้างสรรพสินค้ายอดนิยมในฟีนิกซ์ รัฐแอริโซนา เมื่อวันที่ 15 พฤษภาคม 2023 ภาพหน้าจอก่อนหน้านี้แสดงชุดย่อยของคอลัมน์ใน สคีมาข้อมูล ที่ MAID คอลัมน์แสดงถึง ID อุปกรณ์ และ MAID แต่ละตัวจะสร้าง Ping ทุกนาทีโดยถ่ายทอดละติจูดและลองจิจูดของอุปกรณ์ บันทึกในไฟล์ตัวอย่างเป็น Lat และ Lng คอลัมน์
ต่อไปนี้เป็นภาพหน้าจอจากเครื่องมือแสดงภาพแผนที่ของความสามารถเชิงพื้นที่ของ Amazon SageMaker ที่ขับเคลื่อนโดย Foursquare Studio ซึ่งแสดงเค้าโครงของการส่ง Ping จากอุปกรณ์ที่เยี่ยมชมห้างสรรพสินค้าระหว่างเวลา 7 น. ถึง 00 น.
ภาพหน้าจอต่อไปนี้แสดงการ Ping จากห้างสรรพสินค้าและพื้นที่โดยรอบ

ต่อไปนี้จะแสดงการ Ping จากภายในร้านค้าต่างๆ ในห้างสรรพสินค้า
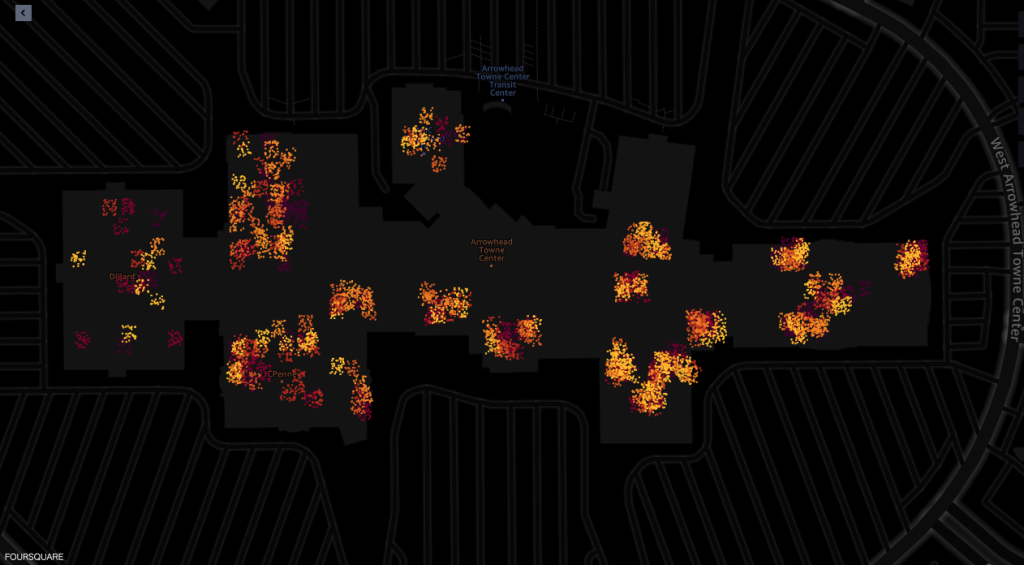
แต่ละจุดในภาพหน้าจอแสดงถึงการ ping จากอุปกรณ์ที่กำหนด ณ เวลาที่กำหนด กลุ่มของการส่ง Ping หมายถึงจุดยอดนิยมที่อุปกรณ์มารวมตัวกันหรือหยุด เช่น ร้านค้าหรือร้านอาหาร
เนื่องจากเป็นส่วนหนึ่งของ ETL เริ่มต้น ข้อมูลดิบนี้สามารถโหลดลงตารางได้โดยใช้ AWS Glue คุณสามารถสร้างโปรแกรมรวบรวมข้อมูล AWS Glue เพื่อระบุสคีมาของข้อมูลและตารางฟอร์มโดยชี้ไปที่ตำแหน่งข้อมูลดิบใน Amazon S3 เป็นแหล่งข้อมูล

ตามที่กล่าวไว้ข้างต้น ข้อมูลดิบ (การส่ง Ping ของอุปกรณ์รายวัน) แม้หลังจาก ETL เริ่มต้นแล้ว จะแสดงสตรีม GPS Ping อย่างต่อเนื่องเพื่อระบุตำแหน่งของอุปกรณ์ เพื่อดึงข้อมูลเชิงลึกที่สามารถนำไปปฏิบัติได้จากข้อมูลนี้ เราจำเป็นต้องระบุจุดแวะพักและการเดินทาง (วิถี) ซึ่งสามารถทำได้โดยใช้ งานการประมวลผลเชิงพื้นที่ คุณลักษณะของความสามารถเชิงพื้นที่ของ SageMaker การประมวลผล Amazon SageMaker ใช้ประสบการณ์การจัดการที่เรียบง่ายบน SageMaker เพื่อรันปริมาณงานการประมวลผลข้อมูลด้วยคอนเทนเนอร์ภูมิสารสนเทศที่สร้างขึ้นตามวัตถุประสงค์ โครงสร้างพื้นฐานที่สำคัญสำหรับงานการประมวลผลของ SageMaker ได้รับการจัดการโดย SageMaker อย่างเต็มรูปแบบ คุณสมบัตินี้ช่วยให้โค้ดที่กำหนดเองสามารถรันบนข้อมูลเชิงพื้นที่ที่จัดเก็บไว้ใน Amazon S3 โดยการเรียกใช้คอนเทนเนอร์ ML เชิงพื้นที่ในงานประมวลผล SageMaker คุณสามารถดำเนินการแบบกำหนดเองกับข้อมูลเชิงพื้นที่แบบเปิดหรือส่วนตัวได้โดยการเขียนโค้ดแบบกำหนดเองด้วยไลบรารีโอเพ่นซอร์ส และดำเนินการตามขนาดโดยใช้งาน SageMaker Processing วิธีการแบบอิงคอนเทนเนอร์ช่วยแก้ปัญหาความต้องการในการสร้างมาตรฐานของสภาพแวดล้อมการพัฒนาด้วยไลบรารีโอเพ่นซอร์สที่ใช้กันทั่วไป
หากต้องการรันปริมาณงานขนาดใหญ่ คุณต้องมีคลัสเตอร์การประมวลผลที่ยืดหยุ่นซึ่งสามารถปรับขนาดได้ตั้งแต่อินสแตนซ์หลายสิบอินสแตนซ์เพื่อประมวลผลบล็อกเมือง ไปจนถึงอินสแตนซ์หลายพันอินสแตนซ์สำหรับการประมวลผลระดับดาวเคราะห์ การจัดการคลัสเตอร์การประมวลผล DIY ด้วยตนเองนั้นช้าและมีราคาแพง คุณลักษณะนี้มีประโยชน์อย่างยิ่งเมื่อชุดข้อมูลการเคลื่อนที่เกี่ยวข้องกับเมืองมากกว่าสองสามเมืองไปยังหลายรัฐหรือแม้แต่ประเทศ และสามารถใช้เพื่อดำเนินการแนวทาง ML สองขั้นตอนได้
ขั้นตอนแรกคือการใช้การจัดกลุ่มเชิงพื้นที่ตามความหนาแน่นของอัลกอริทึมเสียงรบกวน (DBSCAN) เพื่อหยุดคลัสเตอร์จากการปิง ขั้นตอนต่อไปคือการใช้วิธี Support Vector Machine (SVM) เพื่อปรับปรุงความแม่นยำของการหยุดที่ระบุ และยังแยกความแตกต่างระหว่างการหยุดที่มีการนัดหมายกับ POI กับการหยุดที่ไม่มีจุดแวะ (เช่น บ้านหรือที่ทำงาน) คุณยังสามารถใช้งานการประมวลผลของ SageMaker เพื่อสร้างการเดินทางและวิถีจากการส่ง Ping ของอุปกรณ์ในแต่ละวันโดยการระบุจุดหยุดที่ต่อเนื่องกันและจับคู่เส้นทางระหว่างจุดหยุดต้นทางและปลายทาง
หลังจากประมวลผลข้อมูลดิบ (การปิงอุปกรณ์รายวัน) ในวงกว้างด้วยงานการประมวลผลเชิงพื้นที่ ชุดข้อมูลใหม่ที่เรียกว่าหยุดควรมีสคีมาต่อไปนี้
| คุณลักษณะ | รายละเอียด |
| ไอดีหรือมายด์ | รหัสโฆษณาบนมือถือของอุปกรณ์ (แฮช) |
| ลาดพร้าว | ละติจูดของจุดศูนย์กลางของคลัสเตอร์หยุด |
| ก๊าซหุงต้ม | ลองจิจูดของจุดศูนย์กลางของคลัสเตอร์หยุด |
| จีโอแฮช | ตำแหน่ง Geohash ของ POI |
| ประเภทอุปกรณ์ | ระบบปฏิบัติการของอุปกรณ์ (IDFA หรือ GAID) |
| การประทับเวลา | เวลาเริ่มต้นของการหยุด |
| อยู่_เวลา | เวลาหยุดนิ่ง (เป็นวินาที) |
| ip | ที่อยู่ IP |
| ทั้งหมด | ความสูงของอุปกรณ์ (หน่วยเป็นเมตร) |
| ประเทศ | รหัส ISO สองหลักสำหรับประเทศต้นทาง |
| รัฐ | รหัสที่แสดงถึงรัฐ |
| เมือง | รหัสที่แสดงถึงเมือง |
| รหัสไปรษณีย์ | รหัสไปรษณีย์ที่แสดงรหัสอุปกรณ์ |
| พาหะ | ผู้ให้บริการอุปกรณ์ |
| อุปกรณ์_ผู้ผลิต | ผู้ผลิตอุปกรณ์ |
การหยุดจะถูกรวมเข้าด้วยกันโดยการจัดกลุ่มการส่ง Ping ต่ออุปกรณ์ การจัดกลุ่มตามความหนาแน่นจะรวมกับพารามิเตอร์ เช่น เกณฑ์การหยุดคือ 300 วินาที และระยะห่างขั้นต่ำระหว่างจุดหยุดคือ 50 เมตร พารามิเตอร์เหล่านี้สามารถปรับได้ตามกรณีการใช้งานของคุณ
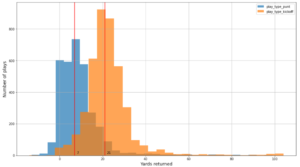
ภาพหน้าจอต่อไปนี้แสดงประมาณ 15,000 หยุดที่ระบุจาก 400,000 ping มีชุดย่อยของสคีมาก่อนหน้านี้ด้วย โดยที่คอลัมน์ Dwell Time แสดงถึงระยะเวลาหยุด และ Lat และ Lng คอลัมน์แสดงถึงละติจูดและลองจิจูดของเซนทรอยด์ของคลัสเตอร์หยุดต่ออุปกรณ์ต่อสถานที่
Post-ETL ข้อมูลจะถูกจัดเก็บในรูปแบบไฟล์ Parquet ซึ่งเป็นรูปแบบการจัดเก็บแบบเรียงเป็นแนวซึ่งช่วยให้ประมวลผลข้อมูลจำนวนมากได้ง่ายขึ้น
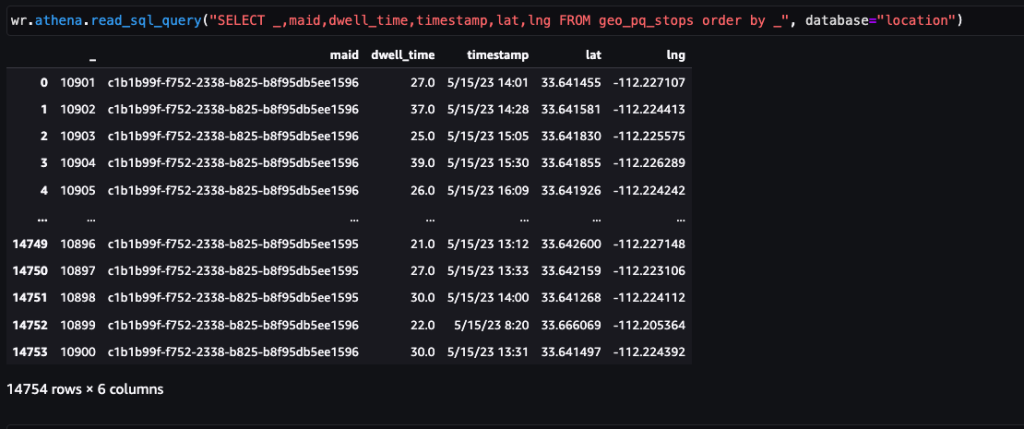
ภาพหน้าจอต่อไปนี้แสดงจุดหยุดที่รวบรวมจากการส่ง Ping ต่ออุปกรณ์ภายในห้างสรรพสินค้าและพื้นที่โดยรอบ

หลังจากระบุจุดหยุดแล้ว ชุดข้อมูลนี้สามารถรวมกับข้อมูล POI ที่เปิดเผยต่อสาธารณะหรือข้อมูล POI ที่กำหนดเองสำหรับกรณีการใช้งานโดยเฉพาะ เพื่อระบุกิจกรรม เช่น การมีส่วนร่วมกับแบรนด์
ภาพหน้าจอต่อไปนี้แสดงจุดจอดที่ระบุใน POI หลัก (ร้านค้าและแบรนด์) ภายใน Arrowhead Mall
รหัสไปรษณีย์ของบ้านถูกนำมาใช้เพื่อปกปิดตำแหน่งบ้านของผู้เยี่ยมชมแต่ละคนเพื่อรักษาความเป็นส่วนตัวในกรณีที่เป็นส่วนหนึ่งของการเดินทางในชุดข้อมูล ละติจูดและลองจิจูดในกรณีดังกล่าวจะเป็นพิกัดตามลำดับของจุดศูนย์กลางของรหัสไปรษณีย์
ภาพหน้าจอต่อไปนี้เป็นการแสดงภาพของกิจกรรมดังกล่าว ภาพด้านซ้ายแสดงแผนที่ป้ายหยุดไปยังร้านค้าต่างๆ และภาพด้านขวาให้แนวคิดเกี่ยวกับแผนผังของห้างสรรพสินค้า

ชุดข้อมูลผลลัพธ์นี้สามารถแสดงภาพได้หลายวิธี ซึ่งเราจะกล่าวถึงในส่วนต่อไปนี้
การวัดความหนาแน่น
เราสามารถคำนวณและแสดงภาพความหนาแน่นของกิจกรรมและการเข้าชมได้
1 ตัวอย่าง – ภาพหน้าจอต่อไปนี้แสดงร้านค้าที่มีผู้เข้าชมสูงสุด 15 อันดับแรกในห้างสรรพสินค้า
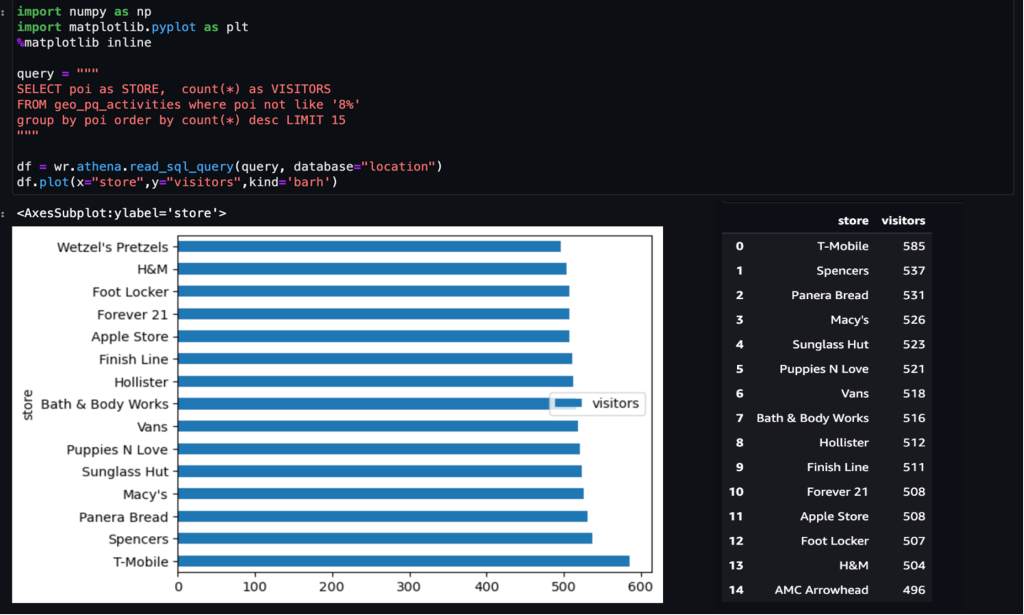
2 ตัวอย่าง – ภาพหน้าจอต่อไปนี้แสดงจำนวนการเข้าชม Apple Store ในแต่ละชั่วโมง

การเดินทางและวิถี
ดังที่ได้กล่าวไว้ข้างต้น กิจกรรมคู่ที่ต่อเนื่องกันหมายถึงการเดินทาง เราสามารถใช้แนวทางต่อไปนี้เพื่อรับการเดินทางจากข้อมูลกิจกรรม ในที่นี้ ฟังก์ชันหน้าต่างจะถูกนำมาใช้กับ SQL เพื่อสร้าง trips ตารางดังที่แสดงในภาพหน้าจอ

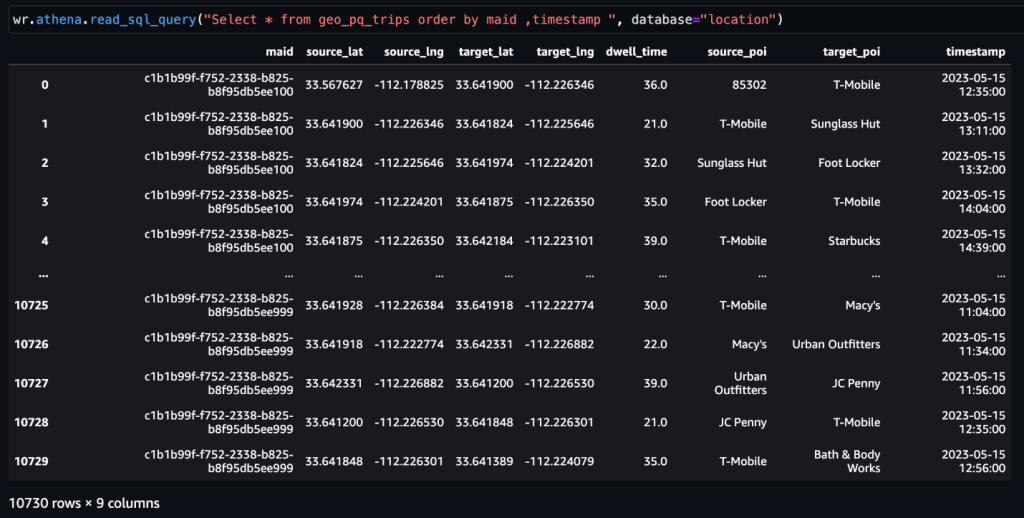
หลังจาก trips ตารางถูกสร้างขึ้น สามารถกำหนดการเดินทางไปยัง POI ได้
ตัวอย่างที่ 1 – ภาพหน้าจอต่อไปนี้แสดงร้านค้า 10 อันดับแรกที่นำลูกค้าเข้า Apple Store

2 ตัวอย่าง – ภาพหน้าจอต่อไปนี้แสดงการเดินทางทั้งหมดไปยัง Arrowhead Mall

3 ตัวอย่าง – วิดีโอต่อไปนี้แสดงรูปแบบการเคลื่อนไหวภายในห้างสรรพสินค้า

4 ตัวอย่าง – วิดีโอต่อไปนี้แสดงรูปแบบการเคลื่อนไหวภายนอกห้างสรรพสินค้า
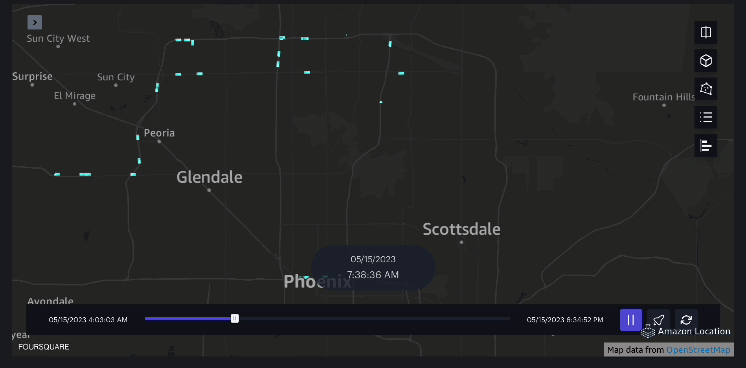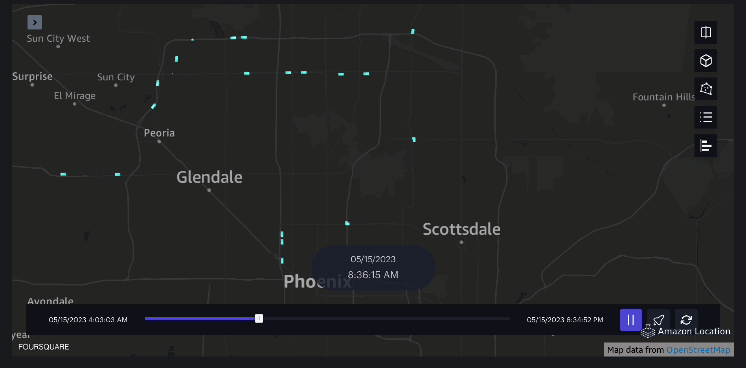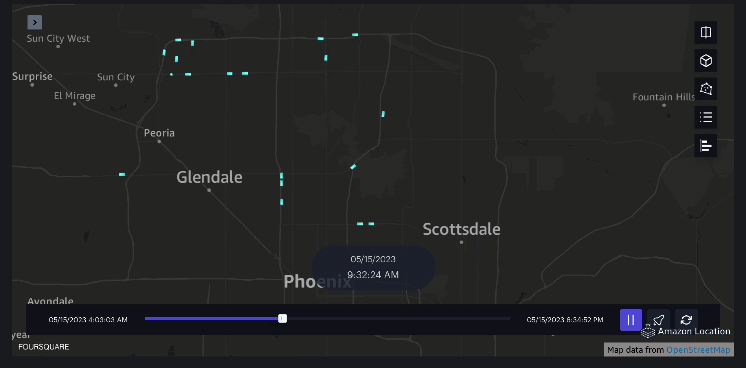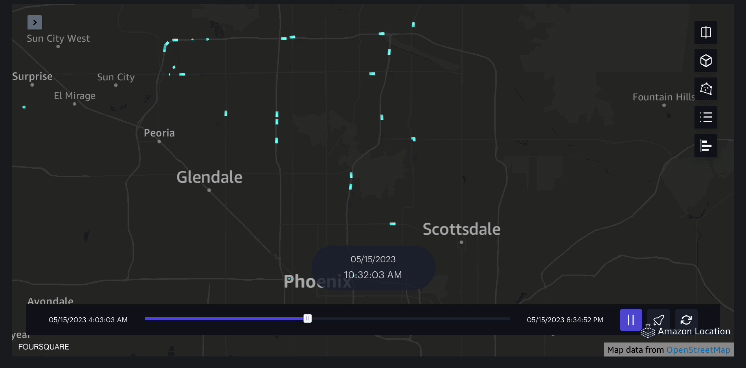
การวิเคราะห์พื้นที่รับน้ำ
เราสามารถวิเคราะห์การเยี่ยมชม POI ทั้งหมดและกำหนดพื้นที่รับน้ำได้
ตัวอย่างที่ 1 – ภาพหน้าจอต่อไปนี้แสดงการเข้าชมร้านค้าของ Macy ทั้งหมด

2 ตัวอย่าง – ภาพหน้าจอต่อไปนี้แสดงรหัสไปรษณีย์ในพื้นที่บ้าน 10 อันดับแรก (เน้นขอบเขต) จากสถานที่ที่มีการเยี่ยมชม

การตรวจสอบคุณภาพข้อมูล
เราสามารถตรวจสอบคุณภาพฟีดข้อมูลขาเข้ารายวันและตรวจจับความผิดปกติโดยใช้แดชบอร์ด QuickSight และการวิเคราะห์ข้อมูล ภาพหน้าจอต่อไปนี้แสดงตัวอย่างแดชบอร์ด

สรุป
ข้อมูลการเคลื่อนไหวและการวิเคราะห์เพื่อรับข้อมูลเชิงลึกของลูกค้าและความได้เปรียบทางการแข่งขันยังคงเป็นพื้นที่เฉพาะเนื่องจากเป็นการยากที่จะได้รับชุดข้อมูลที่สอดคล้องกันและแม่นยำ อย่างไรก็ตาม ข้อมูลนี้สามารถช่วยให้องค์กรเพิ่มบริบทให้กับการวิเคราะห์ที่มีอยู่ และแม้แต่สร้างข้อมูลเชิงลึกใหม่เกี่ยวกับรูปแบบการเคลื่อนไหวของลูกค้า ความสามารถเชิงพื้นที่ของ Amazon SageMaker และงานการประมวลผลเชิงพื้นที่สามารถช่วยปรับใช้กรณีการใช้งานเหล่านี้และรับข้อมูลเชิงลึกด้วยวิธีที่ใช้งานง่ายและเข้าถึงได้
ในโพสต์นี้ เราได้สาธิตวิธีใช้บริการของ AWS เพื่อล้างข้อมูลการเคลื่อนที่ จากนั้นใช้ความสามารถเชิงพื้นที่ของ Amazon SageMaker เพื่อสร้างชุดข้อมูลอนุพันธ์ เช่น การหยุด กิจกรรม และการเดินทางโดยใช้โมเดล ML จากนั้นเราใช้ชุดข้อมูลอนุพันธ์เพื่อแสดงภาพรูปแบบการเคลื่อนไหวและสร้างข้อมูลเชิงลึก
คุณสามารถเริ่มต้นใช้งานความสามารถเชิงพื้นที่ของ Amazon SageMaker ได้สองวิธี:
ต้องการเรียนรู้เพิ่มเติมโปรดเยี่ยมชม ความสามารถเชิงพื้นที่ของ Amazon SageMaker และ เริ่มต้นใช้งานภูมิสารสนเทศของ Amazon SageMaker. นอกจากนี้ยังเยี่ยมชมของเรา repo GitHubซึ่งมีสมุดบันทึกตัวอย่างหลายตัวอย่างเกี่ยวกับความสามารถเชิงพื้นที่ของ Amazon SageMaker
เกี่ยวกับผู้เขียน
 จิมมี่ แมทธิวส์ เป็นสถาปนิกโซลูชัน AWS ที่มีความเชี่ยวชาญด้านเทคโนโลยี AI/ML Jimy มีสำนักงานใหญ่ในบอสตันและทำงานร่วมกับลูกค้าระดับองค์กรในขณะที่พวกเขาเปลี่ยนแปลงธุรกิจของตนโดยการนำระบบคลาวด์มาใช้และช่วยให้พวกเขาสร้างโซลูชันที่มีประสิทธิภาพและยั่งยืน เขาหลงใหลในครอบครัว รถยนต์ และศิลปะการต่อสู้แบบผสมผสาน
จิมมี่ แมทธิวส์ เป็นสถาปนิกโซลูชัน AWS ที่มีความเชี่ยวชาญด้านเทคโนโลยี AI/ML Jimy มีสำนักงานใหญ่ในบอสตันและทำงานร่วมกับลูกค้าระดับองค์กรในขณะที่พวกเขาเปลี่ยนแปลงธุรกิจของตนโดยการนำระบบคลาวด์มาใช้และช่วยให้พวกเขาสร้างโซลูชันที่มีประสิทธิภาพและยั่งยืน เขาหลงใหลในครอบครัว รถยนต์ และศิลปะการต่อสู้แบบผสมผสาน
 กริช เคชาฟ เป็นสถาปนิกโซลูชันที่ AWS ซึ่งช่วยเหลือลูกค้าในเส้นทางการโยกย้ายระบบคลาวด์เพื่อปรับปรุงและรันปริมาณงานอย่างปลอดภัยและมีประสิทธิภาพ เขาทำงานร่วมกับผู้นำทีมเทคโนโลยีเพื่อให้คำแนะนำเกี่ยวกับความปลอดภัยของแอปพลิเคชัน การเรียนรู้ของเครื่อง การเพิ่มประสิทธิภาพต้นทุน และความยั่งยืน เขาอาศัยอยู่ในซานฟรานซิสโก และชอบการเดินทาง เดินป่า ดูกีฬา และสำรวจโรงเบียร์คราฟต์
กริช เคชาฟ เป็นสถาปนิกโซลูชันที่ AWS ซึ่งช่วยเหลือลูกค้าในเส้นทางการโยกย้ายระบบคลาวด์เพื่อปรับปรุงและรันปริมาณงานอย่างปลอดภัยและมีประสิทธิภาพ เขาทำงานร่วมกับผู้นำทีมเทคโนโลยีเพื่อให้คำแนะนำเกี่ยวกับความปลอดภัยของแอปพลิเคชัน การเรียนรู้ของเครื่อง การเพิ่มประสิทธิภาพต้นทุน และความยั่งยืน เขาอาศัยอยู่ในซานฟรานซิสโก และชอบการเดินทาง เดินป่า ดูกีฬา และสำรวจโรงเบียร์คราฟต์
 ท่าเรือราเมช เป็นผู้นำอาวุโสด้านสถาปัตยกรรมโซลูชันที่มุ่งเน้นการช่วยเหลือลูกค้าองค์กร AWS สร้างรายได้จากสินทรัพย์ข้อมูลของตน เขาแนะนำให้ผู้บริหารและวิศวกรออกแบบและสร้างโซลูชันคลาวด์ที่ปรับขนาดได้สูง เชื่อถือได้ และคุ้มค่า โดยเฉพาะอย่างยิ่งที่เน้นไปที่การเรียนรู้ของเครื่อง ข้อมูล และการวิเคราะห์ ในเวลาว่าง เขาชอบกิจกรรมกลางแจ้ง ปั่นจักรยาน และเดินป่ากับครอบครัว
ท่าเรือราเมช เป็นผู้นำอาวุโสด้านสถาปัตยกรรมโซลูชันที่มุ่งเน้นการช่วยเหลือลูกค้าองค์กร AWS สร้างรายได้จากสินทรัพย์ข้อมูลของตน เขาแนะนำให้ผู้บริหารและวิศวกรออกแบบและสร้างโซลูชันคลาวด์ที่ปรับขนาดได้สูง เชื่อถือได้ และคุ้มค่า โดยเฉพาะอย่างยิ่งที่เน้นไปที่การเรียนรู้ของเครื่อง ข้อมูล และการวิเคราะห์ ในเวลาว่าง เขาชอบกิจกรรมกลางแจ้ง ปั่นจักรยาน และเดินป่ากับครอบครัว
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/use-mobility-data-to-derive-insights-using-amazon-sagemaker-geospatial-capabilities/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 000
- 1
- 10
- 100
- 14
- ลด 15%
- 2023
- 300
- 361
- 3d
- 400
- 50
- 7
- 9
- a
- เกี่ยวกับเรา
- ข้างบน
- เร่งความเร็ว
- เร่ง
- เข้า
- สามารถเข้าถึงได้
- บรรลุผล
- ความถูกต้อง
- ถูกต้อง
- ประสบความสำเร็จ
- คล่องแคล่ว
- อย่างกระตือรือร้น
- กิจกรรม
- ที่เกิดขึ้นจริง
- เพิ่ม
- ที่อยู่
- ยึดมั่น
- ปรับ
- การนำ
- โฆษณา
- ความได้เปรียบ
- โฆษณา
- การโฆษณา
- หลังจาก
- รวบรวม
- รวบรวม
- AI / ML
- ช่วย
- ขั้นตอนวิธี
- ทั้งหมด
- คู่ขนาน
- ด้วย
- แม้ว่า
- am
- อเมซอน
- เข้าใจ Amazon
- อเมซอน SageMaker
- Amazon SageMaker เชิงพื้นที่
- สตูดิโอ Amazon SageMaker
- Amazon Web Services
- จำนวน
- an
- วิเคราะห์
- การวิเคราะห์
- การวิเคราะห์
- วิเคราะห์
- วิเคราะห์
- สมอ
- และ
- ใด
- นอกเหนือ
- app
- Apple
- การใช้งาน
- ความปลอดภัยของแอปพลิเคชัน
- การใช้งาน
- เข้าใกล้
- ประมาณ
- สถาปัตยกรรม
- เป็น
- AREA
- พื้นที่
- อาริโซน่า
- รอบ
- ศิลปะ
- AS
- สินทรัพย์
- ที่ได้รับมอบหมาย
- ที่เกี่ยวข้อง
- At
- บรรลุ
- ผู้ฟัง
- เสริม
- ใช้ได้
- เฉลี่ย
- AWS
- AWS กาว
- ฐาน
- ตาม
- รากฐาน
- BE
- เพราะ
- รับ
- กำลัง
- ระหว่าง
- สั่ง
- ปิดกั้น
- บอสตัน
- เขตแดน
- แบรนด์
- สร้าง
- การก่อสร้าง
- built-in
- ธุรกิจ
- ธุรกิจ
- แต่
- by
- คำนวณ
- ที่เรียกว่า
- แคมเปญ
- CAN
- สามารถรับ
- ความสามารถในการ
- รถยนต์
- กรณี
- กรณี
- CCPA
- เซลล์
- การสำรวจสำมะโนประชากร
- ข้อมูลสำมะโน
- โซ่
- ตรวจสอบ
- เมือง
- เมือง
- ปลาเดยส์
- ปิดหน้านี้
- เมฆ
- Cluster
- การจัดกลุ่ม
- รหัส
- รหัส
- การทำงานร่วมกัน
- รวบรวม
- ชุด
- นักสะสม
- คอลัมน์
- คอลัมน์
- รวม
- มา
- มา
- เชิงพาณิชย์
- อสังหาริมทรัพย์เชิงพาณิชย์
- ร่วมกัน
- อย่างธรรมดา
- บริษัท
- การแข่งขัน
- คู่แข่ง
- ซับซ้อน
- ส่วนประกอบ
- เข้าใจ
- คำนวณ
- การเชื่อมต่อ
- ติดต่อกัน
- ความยินยอม
- การพิจารณา
- คงเส้นคงวา
- การบริโภค
- ภาชนะ
- มี
- สิ่งแวดล้อม
- ต่อเนื่องกัน
- ราคา
- ประเทศ
- ประเทศ
- หน้าปก
- ครอบคลุม
- หัตถกรรม
- ไม้เลื้อย
- สร้าง
- ประเพณี
- ลูกค้า
- ลูกค้า
- ประจำวัน
- หน้าปัด
- แดชบอร์ด
- ข้อมูล
- จุดข้อมูล
- ความเป็นส่วนตัวของข้อมูล
- การประมวลผล
- ชุดข้อมูล
- วัน
- การจัดส่ง
- แสดงให้เห็นถึง
- ภาพวาด
- ปรับใช้
- ตราสารอนุพันธ์
- ได้มา
- ที่ได้มา
- ออกแบบ
- สถานที่ท่องเที่ยว
- รายละเอียด
- ตรวจจับ
- กำหนด
- แน่นอน
- การกำหนด
- พัฒนาการ
- เครื่อง
- อุปกรณ์
- ยาก
- โดยตรง
- ภัยพิบัติ
- การค้นพบ
- สนทนา
- ระยะทาง
- เห็นความแตกต่าง
- DIY
- ทำ
- ทำ
- DOT
- ดึง
- สอง
- ระยะเวลา
- ในระหว่าง
- แต่ละ
- ก่อน
- ง่ายดาย
- ง่าย
- มีประสิทธิภาพ
- ที่มีประสิทธิภาพ
- อย่างมีประสิทธิภาพ
- ความพยายาม
- ให้อำนาจ
- ช่วยให้
- ห้อมล้อม
- มีส่วนร่วม
- การนัดหมาย
- น่าสนใจ
- วิศวกร
- ประเทือง
- Enterprise
- ลูกค้าองค์กร
- สิ่งแวดล้อม
- โดยเฉพาะอย่างยิ่ง
- ที่ดิน
- อีเธอร์ (ETH)
- ตามหลักจริยธรรม
- แม้
- เหตุการณ์
- ทุกๆ
- ตัวอย่าง
- ผู้บริหารระดับสูง
- ที่มีอยู่
- ที่มีอยู่
- แพง
- ประสบการณ์
- ความชำนาญ
- สำรวจ
- สำรวจ
- ส่งออก
- แสดง
- สารสกัด
- ครอบครัว
- ลักษณะ
- เฟด
- สองสาม
- เนื้อไม่มีมัน
- สุดท้าย
- หา
- fiona
- ชื่อจริง
- มีความยืดหยุ่น
- โฟกัส
- มุ่งเน้น
- ตาม
- ดังต่อไปนี้
- เท้า
- สำหรับ
- ฟอร์ม
- รูป
- foursquare
- FRAME
- ฟรานซิส
- ฟรี
- ราคาเริ่มต้นที่
- เชื้อเพลิง
- อย่างเต็มที่
- ฟังก์ชัน
- ฟังก์ชั่น
- ต่อไป
- ดึงดูด
- เกม
- รวมตัวกัน
- GDPR
- สร้าง
- สร้าง
- สร้าง
- การสร้าง
- ในทางภูมิศาสตร์
- ตามภูมิศาสตร์
- ML เชิงพื้นที่
- ได้รับ
- ได้รับ
- GIF
- กำหนด
- จะช่วยให้
- ไป
- จีพีเอส
- กราฟิก
- ยิ่งใหญ่
- กลางแจ้งที่ดี
- ตะแกรง
- ให้คำแนะนำ
- ฮาร์ดแวร์
- แฮช
- มี
- he
- ช่วย
- เป็นประโยชน์
- การช่วยเหลือ
- จะช่วยให้
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- ไฮไลต์
- อย่างสูง
- การธุดงค์
- ของเขา
- หน้าแรก
- ตามแนวนอน
- ชั่วโมง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTML
- ที่ http
- HTTPS
- ฮับ
- พายุเฮอริเคน
- ID
- ความคิด
- ระบุ
- แยกแยะ
- ระบุ
- สสส
- if
- ภาพ
- การดำเนินการ
- สำคัญ
- ปรับปรุง
- in
- รวมทั้ง
- ขาเข้า
- การแสดง
- เป็นรายบุคคล
- อุตสาหกรรม
- ข้อมูล
- โครงสร้างพื้นฐาน
- แรกเริ่ม
- ภายใน
- ข้อมูลเชิงลึก
- อินสแตนซ์
- การผสานรวม
- Intelligence
- การโต้ตอบ
- อยากเรียนรู้
- น่าสนใจ
- เข้าไป
- แนะนำ
- ใช้งานง่าย
- ที่เกี่ยวข้องกับการ
- IT
- ITS
- ตัวเอง
- การสัมภาษณ์
- งาน
- เข้าร่วม
- การเดินทาง
- jpg
- ใหญ่
- ขนาดใหญ่
- ละติจูด
- กฎหมาย
- ชั้น
- แบบ
- นำ
- ผู้นำ
- ผู้นำ
- เรียนรู้
- การเรียนรู้
- ซ้าย
- ห้องสมุด
- กดไลก์
- ความเป็นไปได้
- เส้น
- โหลด
- ที่ตั้ง
- วันหยุด
- ดู
- ดูเหมือน
- รัก
- เครื่อง
- เรียนรู้เครื่อง
- เครื่อง
- ทำ
- เก็บรักษา
- สำคัญ
- ทำ
- ทำให้
- การจัดการ
- การจัดการ
- ด้วยมือ
- หลาย
- แผนที่
- การทำแผนที่
- แผนที่
- การตลาด
- แคมเปญการตลาด
- เทคโนโลยีการตลาด
- มาร์เทค
- การต่อสู้
- หน้ากาก
- มดลูก
- อาจ..
- วิธี
- กล่าวถึง
- วิธี
- ตัวชี้วัด
- การโยกย้าย
- ทหาร
- ล้าน
- ขั้นต่ำ
- นาที
- ผสม
- ML
- โทรศัพท์มือถือ
- โทรศัพท์มือถือ
- อุปกรณ์มือถือ
- การเคลื่อนย้าย
- แบบ
- โมเดล
- ทันสมัย
- การแก้ไข
- แก้ไข
- สร้างรายได้
- รายเดือน
- ข้อมูลเพิ่มเติม
- มากที่สุด
- ส่วนใหญ่
- ย้าย
- การเคลื่อนไหว
- การเคลื่อนไหว
- การย้าย
- หลาย
- ฝูง
- ต้อง
- ชื่อ
- โดยธรรมชาติ
- ธรรมชาติ
- จำเป็นต้อง
- ความต้องการ
- ใหม่
- ถัดไป
- ช่อง
- สัญญาณรบกวน
- สมุดบันทึก
- โน๊ตบุ๊ค
- จำนวน
- ตัวเลข
- วัตถุ
- สังเกต
- ได้รับ
- ที่ได้รับ
- การได้รับ
- ที่เกิดขึ้น
- of
- มักจะ
- on
- ONE
- เพียง
- เปิด
- โอเพนซอร์ส
- การดำเนินการ
- การดำเนินการ
- ตรงข้าม
- ดีที่สุด
- การเพิ่มประสิทธิภาพ
- เพิ่มประสิทธิภาพ
- or
- องค์กร
- อื่นๆ
- ของเรา
- ออก
- ผลลัพธ์
- กลางแจ้ง
- ด้านนอก
- เกิน
- คู่
- หมีแพนด้า
- การระบาดกระจายทั่ว
- พารามิเตอร์
- ส่วนหนึ่ง
- โดยเฉพาะ
- ส่ง
- หลงใหล
- เส้นทาง
- รูปแบบ
- คน
- ต่อ
- ดำเนินการ
- การปฏิบัติ
- ส่วนตัว
- มุมมอง
- ต้นอินทผลัม
- ภาพ
- กายภาพ
- ภาพ
- PII
- ปิง
- วางไว้
- สถานที่
- การวางแผน
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- pm
- จุด
- จุด
- ยอดนิยม
- ประชากร
- ตำแหน่ง
- เป็นไปได้
- โพสต์
- ที่มีศักยภาพ
- ผู้มีโอกาสเป็นลูกค้า
- ขับเคลื่อน
- มาก่อน
- การคาดการณ์
- นำเสนอ
- ความเป็นส่วนตัว
- กฎหมายความเป็นส่วนตัว
- ส่วนตัว
- กระบวนการ
- การประมวลผล
- ก่อ
- ให้
- สาธารณชน
- สำนักพิมพ์
- ซื้อ
- ซื้อ
- วัตถุประสงค์
- หลาม
- คุณภาพ
- อันดับ
- ค่อนข้าง
- ดิบ
- ข้อมูลดิบ
- จริง
- อสังหาริมทรัพย์
- บันทึก
- อ้างอิง
- การอ้างอิง
- หมายถึง
- ภูมิภาค
- น่าเชื่อถือ
- ซากศพ
- แสดง
- การแสดง
- เป็นตัวแทนของ
- เป็นตัวแทนของ
- แสดงให้เห็นถึง
- จำเป็นต้องใช้
- ว่า
- รับผิดชอบ
- ร้านอาหาร
- ส่งผลให้
- ผลสอบ
- ค้าปลีก
- ขวา
- เส้นทาง
- เส้นทาง
- วิ่ง
- วิ่ง
- sagemaker
- ตัวอย่างชุดข้อมูล
- ซาน
- ซานฟรานซิสโก
- ดาวเทียม
- ภาพจากดาวเทียม
- ที่ปรับขนาดได้
- ขนาด
- นักวิทยาศาสตร์
- ภาพหน้าจอ
- sdks
- ไร้รอยต่อ
- ที่สอง
- วินาที
- ส่วน
- อย่างปลอดภัย
- ความปลอดภัย
- การเลือก
- ระดับอาวุโส
- มีความละเอียดอ่อน
- ส่ง
- แยก
- ชุด
- บริการ
- การให้บริการ
- หลาย
- Share
- ช้อปปิ้ง
- น่า
- แสดง
- แสดงให้เห็นว่า
- คล้ายคลึงกัน
- ง่าย
- ที่เรียบง่าย
- เดียว
- เว็บไซต์
- ช้า
- So
- โซลูชัน
- แก้ปัญหา
- บาง
- แสวงหา
- แหล่ง
- แหล่งที่มา
- ช่องว่าง
- เกี่ยวกับอวกาศ
- โดยเฉพาะ
- กีฬา
- จุด
- SQL
- มาตรฐาน
- ข้อความที่เริ่ม
- เริ่มต้น
- งบ
- สหรัฐอเมริกา
- ขั้นตอน
- ขั้นตอน
- หยุด
- หยุด
- การหยุด
- หยุด
- การเก็บรักษา
- จัดเก็บ
- เก็บไว้
- ร้านค้า
- ซื่อตรง
- กระแส
- สตูดิโอ
- เป็นกอบเป็นกำ
- อย่างเช่น
- จัดหาอุปกรณ์
- ห่วงโซ่อุปทาน
- สนับสนุน
- พื้นผิว
- ที่ล้อมรอบ
- การพัฒนาอย่างยั่งยืน
- ที่ยั่งยืน
- ระบบ
- ตาราง
- นำ
- ทีม
- เทคโนโลยี
- วิชาการ
- เทคนิค
- เทคโนโลยี
- เมตริกซ์
- กว่า
- ที่
- พื้นที่
- พื้นที่
- ที่มา
- ของพวกเขา
- พวกเขา
- ตัวเอง
- แล้วก็
- ที่นั่น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- นี้
- เหล่านั้น
- พัน
- ธรณีประตู
- ตลอด
- เวลา
- ไปยัง
- เกินไป
- เครื่องมือ
- เครื่องมือ
- ด้านบน
- สูงสุด 10
- รวม
- ไปทาง
- การติดตาม
- การจราจร
- รถไฟ
- เส้นโคจร
- แปลง
- การแปลง
- เครื่องส่งสัญญาณ
- การเดินทาง
- การเดินทาง
- แนวโน้ม
- การเดินทาง
- สอง
- ชนิด
- ตามแบบฉบับ
- พื้นฐาน
- ความเข้าใจ
- เป็นเอกลักษณ์
- อัปโหลด
- ใช้
- ใช้กรณี
- มือสอง
- ผู้ใช้งาน
- ผู้ใช้
- ใช้
- การใช้
- นำไปใช้
- ต่างๆ
- ตรวจสอบ
- ผ่านทาง
- วีดีโอ
- เยี่ยมชมร้านค้า
- เข้าเยี่ยมชม
- ผู้เข้าชม
- จำนวนการเข้าชม
- ภาพ
- การสร้างภาพ
- เห็นภาพ
- ภาพ
- vs
- ชม
- ทาง..
- วิธี
- we
- เว็บ
- บริการเว็บ
- รายสัปดาห์
- ดี
- อะไร
- เมื่อ
- ที่
- WHO
- ทั้งหมด
- ทำไม
- Wi-Fi
- แพร่หลาย
- จะ
- หน้าต่าง
- กับ
- ไม่มี
- งาน
- เวิร์กโฟลว์
- โรงงาน
- การเขียน
- ประจำปี
- เธอ
- ของคุณ
- ลมทะเล
- รหัสไปรษณีย์