ภาพโดย เจคอม on Freepik
อนุกรมเวลาเป็นชุดข้อมูลเฉพาะในสาขาวิทยาศาสตร์ข้อมูล ข้อมูลจะถูกบันทึกตามความถี่ของเวลา (เช่น รายวัน รายสัปดาห์ รายเดือน เป็นต้น) และการสังเกตแต่ละครั้งจะสัมพันธ์กัน ข้อมูลอนุกรมเวลามีค่าเมื่อคุณต้องการวิเคราะห์สิ่งที่เกิดขึ้นกับข้อมูลของคุณเมื่อเวลาผ่านไปและสร้างการคาดการณ์ในอนาคต
การพยากรณ์อนุกรมเวลาเป็นวิธีการสร้างการคาดคะเนในอนาคตตามข้อมูลอนุกรมเวลาในอดีต วิธีการทางสถิติสำหรับการพยากรณ์อนุกรมเวลามีหลายวิธี เช่น อาริมะ or การทำให้เรียบแบบเอ็กซ์โปเนนเชียล.
การพยากรณ์อนุกรมเวลามักพบในธุรกิจ ดังนั้นจึงเป็นประโยชน์สำหรับนักวิทยาศาสตร์ข้อมูลที่จะทราบวิธีพัฒนาแบบจำลองอนุกรมเวลา ในบทความนี้ เราจะเรียนรู้วิธีการคาดการณ์อนุกรมเวลาโดยใช้แพ็คเกจ Python สำหรับการพยากรณ์ยอดนิยมสองแพ็คเกจ statsmodels และศาสดา เข้าเรื่องกันเลย
พื้นที่ สถิติโมเดล แพ็คเกจ Python เป็นแพ็คเกจโอเพ่นซอร์สที่นำเสนอโมเดลทางสถิติที่หลากหลาย รวมถึงโมเดลการคาดการณ์อนุกรมเวลา มาลองแพ็คเกจกับชุดข้อมูลตัวอย่างกัน บทความนี้จะใช้ อนุกรมเวลาสกุลเงินดิจิทัล ข้อมูลจาก Kaggle (CC0: Public Domain)
มาทำความสะอาดข้อมูลและดูชุดข้อมูลที่เรามี
import pandas as pd df = pd.read_csv('dc.csv') df = df.rename(columns = {'Unnamed: 0' : 'Time'})
df['Time'] = pd.to_datetime(df['Time'])
df = df.iloc[::-1].set_index('Time') df.head()
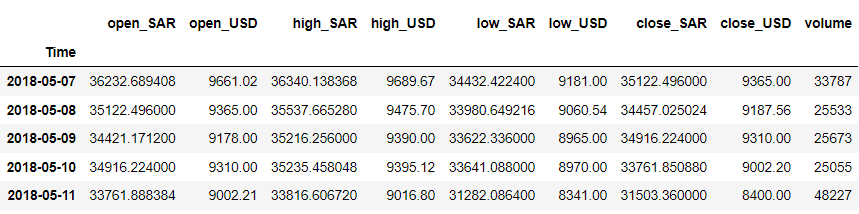
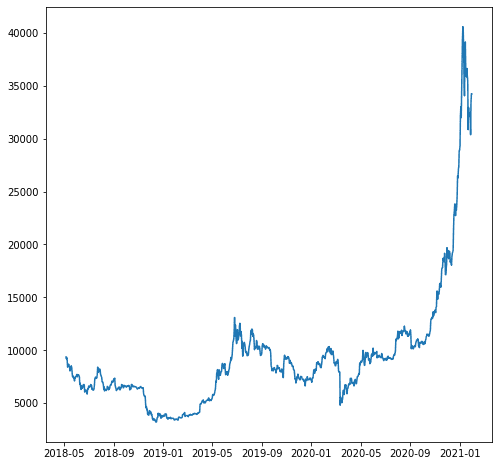
สำหรับตัวอย่างของเรา สมมติว่าเราต้องการคาดการณ์ตัวแปร 'close_USD' มาดูกันว่ารูปแบบข้อมูลเมื่อเวลาผ่านไปเป็นอย่างไร
import matplotlib.pyplot as plt plt.plot(df['close_USD'])
plt.show()
มาสร้างแบบจำลองการคาดการณ์ตามข้อมูลข้างต้นของเรา ก่อนสร้างโมเดล ให้แบ่งข้อมูลออกเป็นข้อมูลรถไฟและข้อมูลทดสอบ
# Split the data
train = df.iloc[:-200] test = df.iloc[-200:]
เราไม่แบ่งข้อมูลแบบสุ่มเนื่องจากเป็นข้อมูลอนุกรมเวลา และเราจำเป็นต้องรักษาลำดับไว้ แต่เราพยายามที่จะมีข้อมูลรถไฟจากก่อนหน้านี้และข้อมูลการทดสอบจากข้อมูลล่าสุด
ลองใช้ statsmodels เพื่อสร้างแบบจำลองการคาดการณ์ เดอะ โมเดลสถิติ มี API โมเดลอนุกรมเวลามากมาย แต่เราจะใช้โมเดล ARIMA เป็นตัวอย่างของเรา
from statsmodels.tsa.arima.model import ARIMA #sample parameters
model = ARIMA(train, order=(2, 1, 0)) results = model.fit() # Make predictions for the test set
forecast = results.forecast(steps=200)
forecast
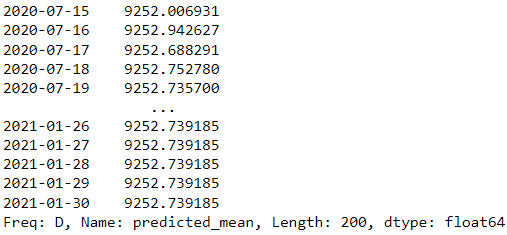
ในตัวอย่างด้านบน เราใช้แบบจำลอง ARIMA จากแบบจำลองสถิติเป็นแบบจำลองการคาดการณ์ และพยายามทำนายในอีก 200 วันข้างหน้า
ผลลัพธ์ของโมเดลดีหรือไม่? ลองประเมินพวกเขา การประเมินแบบจำลองอนุกรมเวลามักใช้กราฟการแสดงภาพเพื่อเปรียบเทียบข้อมูลจริงและการคาดคะเนด้วยเมตริกการถดถอย เช่น Mean Absolute Error (MAE), Root Mean Square Error (RMSE) และ MAPE (Mean Absolute Percentage Error)
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as np #mean absolute error
mae = mean_absolute_error(test, forecast) #root mean square error
mse = mean_squared_error(test, forecast)
rmse = np.sqrt(mse) #mean absolute percentage error
mape = (forecast - test).abs().div(test).mean() print(f"MAE: {mae:.2f}")
print(f"RMSE: {rmse:.2f}")
print(f"MAPE: {mape:.2f}%")
MAE: 7956.23 RMSE: 11705.11 MAPE: 0.35%
คะแนนด้านบนดูดี แต่มาดูกันว่าจะเป็นอย่างไรเมื่อเรานึกภาพออก
plt.plot(train.index, train, label='Train')
plt.plot(test.index, test, label='Test')
plt.plot(forecast.index, forecast, label='Forecast')
plt.legend()
plt.show()
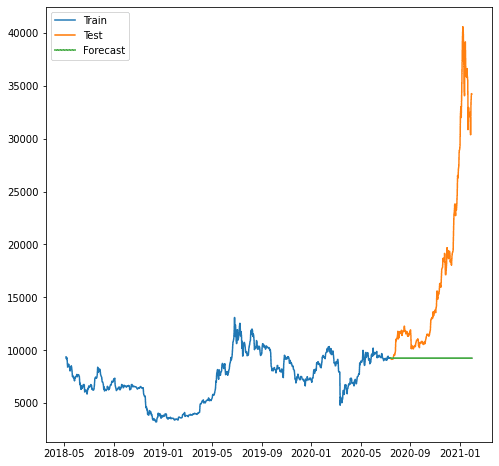
อย่างที่เราเห็น การคาดการณ์แย่ลงเนื่องจากแบบจำลองของเราไม่สามารถคาดการณ์แนวโน้มที่เพิ่มขึ้นได้ โมเดล ARIMA ที่เราใช้ดูเหมือนง่ายเกินไปสำหรับการคาดการณ์
อาจจะดีกว่าหากเราลองใช้โมเดลอื่นนอกโมเดลสถิติ มาลองแพ็กเกจนักพยากรณ์ชื่อดังจาก Facebook กัน
ศาสดา เป็นแพ็คเกจแบบจำลองการคาดการณ์อนุกรมเวลาที่ทำงานได้ดีที่สุดกับข้อมูลที่มีผลกระทบตามฤดูกาล ศาสดาได้รับการพิจารณาว่าเป็นแบบจำลองการคาดการณ์ที่มีประสิทธิภาพเนื่องจากสามารถจัดการกับข้อมูลที่ขาดหายไปและค่าผิดปกติได้
มาลองแพ็คเกจศาสดากันเถอะ ก่อนอื่นเราต้องติดตั้งแพ็คเกจ
pip install prophet
หลังจากนั้น เราต้องเตรียมชุดข้อมูลของเราสำหรับการฝึกอบรมแบบจำลองการคาดการณ์ ศาสดามีข้อกำหนดเฉพาะ: คอลัมน์เวลาต้องตั้งชื่อเป็น 'ds' และค่าเป็น 'y'
df_p = df.reset_index()[["Time", "close_USD"]].rename( columns={"Time": "ds", "close_USD": "y"}
)
เมื่อข้อมูลของเราพร้อมแล้ว มาลองสร้างการคาดการณ์ตามข้อมูลกัน
import pandas as pd
from prophet import Prophet model = Prophet() # Fit the model
model.fit(df_p) # create date to predict
future_dates = model.make_future_dataframe(periods=365) # Make predictions
predictions = model.predict(future_dates) predictions.head()
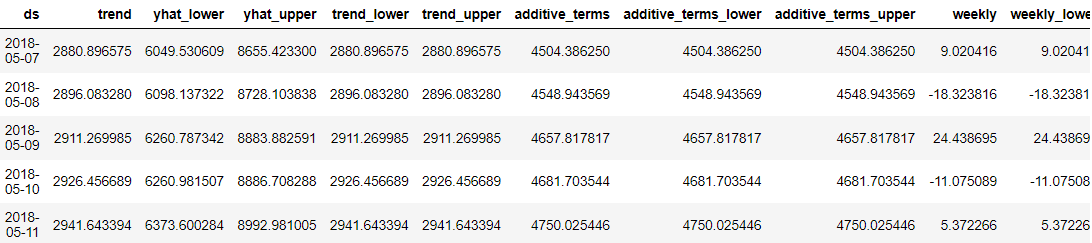
สิ่งที่ยอดเยี่ยมเกี่ยวกับศาสดาคือทุกจุดข้อมูลการคาดการณ์มีรายละเอียดเพื่อให้ผู้ใช้เข้าใจ อย่างไรก็ตาม ยากที่จะเข้าใจผลลัพธ์จากข้อมูลเพียงอย่างเดียว ดังนั้นเราจึงสามารถลองนึกภาพพวกเขาโดยใช้ผู้เผยพระวจนะ
model.plot(predictions)
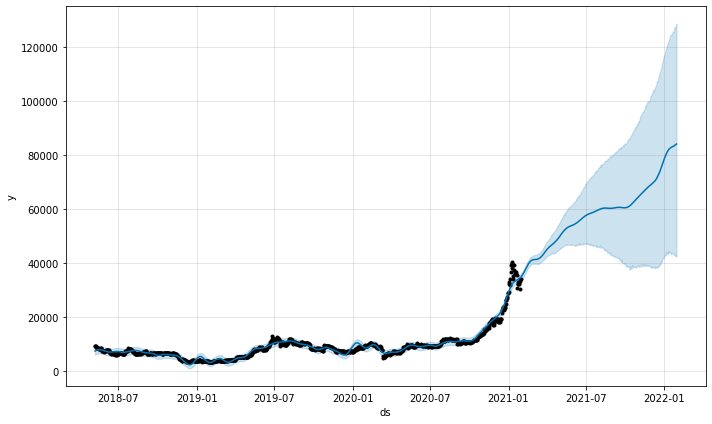
ฟังก์ชันพล็อตการคาดการณ์จากแบบจำลองจะช่วยให้เรามั่นใจว่าการคาดการณ์นั้นเป็นอย่างไร จากแผนภาพด้านบน เราจะเห็นว่าการคาดการณ์มีแนวโน้มสูงขึ้น แต่ด้วยความไม่แน่นอนที่เพิ่มขึ้น ยิ่งการคาดการณ์นานขึ้นเท่าใด
นอกจากนี้ยังสามารถตรวจสอบองค์ประกอบการคาดการณ์ด้วยฟังก์ชันต่อไปนี้
model.plot_components(predictions)
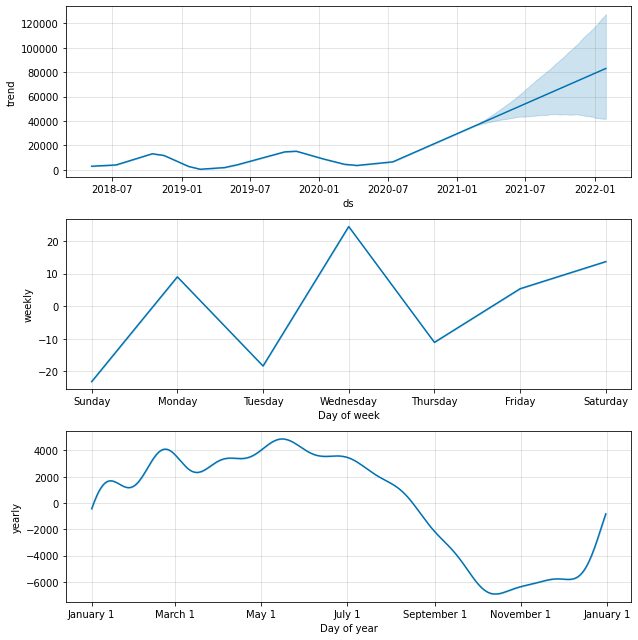
ตามค่าเริ่มต้น เราจะได้รับแนวโน้มข้อมูลตามฤดูกาลทั้งปีและรายสัปดาห์ เป็นวิธีที่ดีในการอธิบายว่าเกิดอะไรขึ้นกับข้อมูลของเรา
เป็นไปได้ไหมที่จะประเมินแบบจำลองศาสดาด้วย? อย่างแน่นอน. ศาสดารวมถึงการวัดการวินิจฉัยที่เราสามารถใช้ได้: การตรวจสอบข้ามอนุกรมเวลา. วิธีการนี้ใช้ส่วนหนึ่งของข้อมูลในอดีตและเหมาะกับโมเดลในแต่ละครั้งโดยใช้ข้อมูลจนถึงจุดตัด แล้วท่านนบีก็จะเอาคำทำนายมาเทียบเคียงกับของจริง มาลองใช้โค้ดกัน
from prophet.diagnostics import cross_validation, performance_metrics # Perform cross-validation with initial 365 days for the first training data and the cut-off for every 180 days. df_cv = cross_validation(model, initial='365 days', period='180 days', horizon = '365 days') # Calculate evaluation metrics
res = performance_metrics(df_cv) res
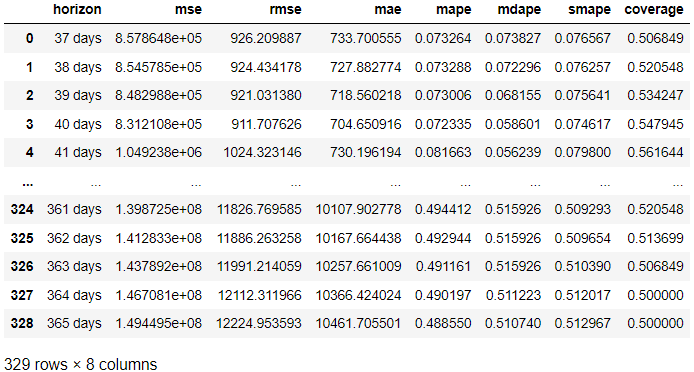
จากผลลัพธ์ข้างต้น เราได้รับผลการประเมินจากผลลัพธ์จริงเมื่อเปรียบเทียบกับการคาดการณ์ในแต่ละวันที่คาดการณ์ นอกจากนี้ยังเป็นไปได้ที่จะเห็นภาพผลลัพธ์ด้วยรหัสต่อไปนี้
from prophet.plot import plot_cross_validation_metric
#choose between 'mse', 'rmse', 'mae', 'mape', 'coverage' plot_cross_validation_metric(df_cv, metric= 'mape')
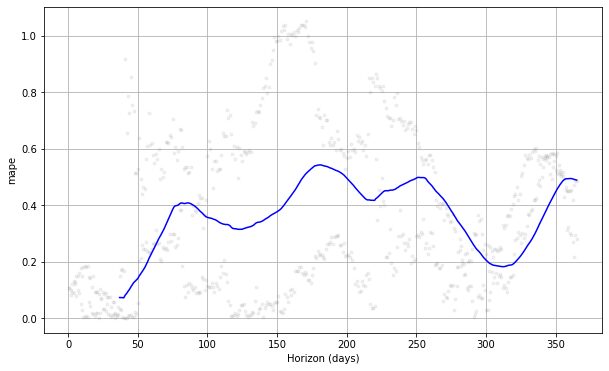
หากเราเห็นโครงเรื่องด้านบน เราจะเห็นว่าข้อผิดพลาดในการคาดคะเนนั้นแปรเปลี่ยนไปตามวัน และอาจมีข้อผิดพลาดถึง 50% ในบางจุด ด้วยวิธีนี้ เราอาจต้องการปรับแต่งโมเดลเพิ่มเติมเพื่อแก้ไขข้อผิดพลาด คุณสามารถตรวจสอบ เอกสาร เพื่อการสำรวจต่อไป
การพยากรณ์เป็นหนึ่งในกรณีทั่วไปที่เกิดขึ้นในธุรกิจ วิธีง่ายๆ วิธีหนึ่งในการพัฒนาแบบจำลองการคาดการณ์คือการใช้แพ็คเกจ statsforecast และ Prophet Python ในบทความนี้ เราเรียนรู้วิธีสร้างแบบจำลองการคาดการณ์และประเมินผลด้วย statsforecast และ Prophet
คอร์เนลเลียส ยุธา วิชายา เป็นผู้ช่วยผู้จัดการด้านวิทยาศาสตร์ข้อมูลและผู้เขียนข้อมูล ในขณะที่ทำงานเต็มเวลาที่ Allianz Indonesia เขาชอบแบ่งปันเคล็ดลับ Python และ Data ผ่านโซเชียลมีเดียและสื่อการเขียน
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://www.kdnuggets.com/2023/03/time-series-forecasting-statsmodels-prophet.html?utm_source=rss&utm_medium=rss&utm_campaign=time-series-forecasting-with-statsmodels-and-prophet
- :เป็น
- $ ขึ้น
- 1
- 11
- 7
- 8
- 9
- a
- เกี่ยวกับเรา
- ข้างบน
- แน่นอน
- อย่างแน่นอน
- บรรลุ
- ที่ได้มา
- อลิอันซ์
- วิเคราะห์
- และ
- อื่น
- APIs
- เป็น
- บทความ
- AS
- ผู้ช่วย
- At
- ตาม
- BE
- เพราะ
- ก่อน
- เป็นประโยชน์
- ที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- สร้าง
- ธุรกิจ
- by
- คำนวณ
- CAN
- กรณี
- CC0
- ตรวจสอบ
- รหัส
- คอลัมน์
- คอลัมน์
- ร่วมกัน
- เปรียบเทียบ
- เมื่อเทียบกับ
- ส่วนประกอบ
- มั่นใจ
- ถือว่า
- ได้
- ความคุ้มครอง
- สร้าง
- เงินตรา
- ประจำวัน
- ข้อมูล
- วิทยาศาสตร์ข้อมูล
- นักวิทยาศาสตร์ข้อมูล
- วันที่
- วัน
- วัน
- dc
- ค่าเริ่มต้น
- รายละเอียด
- พัฒนา
- โดเมน
- Dont
- e
- แต่ละ
- ก่อน
- ผลกระทบ
- ความผิดพลาด
- ฯลฯ
- ประเมินค่า
- การประเมินผล
- ทุกๆ
- ตัวอย่าง
- อธิบาย
- การสำรวจ
- มีชื่อเสียง
- สนาม
- ปลาย
- ชื่อจริง
- พอดี
- แก้ไขปัญหา
- ดังต่อไปนี้
- สำหรับ
- พยากรณ์
- ราคาเริ่มต้นที่
- ฟังก์ชัน
- ต่อไป
- อนาคต
- ได้รับ
- GitHub
- ดี
- กราฟ
- ยิ่งใหญ่
- จัดการ
- ที่เกิดขึ้น
- ยาก
- มี
- ทางประวัติศาสตร์
- ขอบฟ้า
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTML
- HTTPS
- นำเข้า
- in
- รวมถึง
- รวมทั้ง
- เพิ่มขึ้น
- ที่เพิ่มขึ้น
- ดัชนี
- อินโดนีเซีย
- แรกเริ่ม
- ติดตั้ง
- แทน
- IT
- jpg
- KD นักเก็ต
- ทราบ
- ล่าสุด
- เรียนรู้
- อีกต่อไป
- ดู
- LOOKS
- ทำ
- ผู้จัดการ
- หลาย
- matplotlib
- ภาพบรรยากาศ
- วิธี
- วิธีการ
- ตัวชี้วัด
- อาจ
- หายไป
- แบบ
- การสร้างแบบจำลอง
- โมเดล
- รายเดือน
- ที่มีชื่อ
- จำเป็นต้อง
- ความต้องการ
- ถัดไป
- มึน
- ได้รับ
- of
- การเสนอ
- on
- ONE
- โอเพนซอร์ส
- ใบสั่ง
- อื่นๆ
- ด้านนอก
- แพ็คเกจ
- แพคเกจ
- หมีแพนด้า
- พารามิเตอร์
- ส่วนหนึ่ง
- แบบแผน
- เปอร์เซ็นต์
- ดำเนินการ
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- จุด
- จุด
- ยอดนิยม
- เป็นไปได้
- คาดการณ์
- คำทำนาย
- การคาดการณ์
- เตรียมการ
- ให้
- ให้
- สาธารณะ
- หลาม
- พร้อม
- บันทึก
- ถดถอย
- ที่เกี่ยวข้อง
- ความต้องการ
- ผล
- ผลสอบ
- แข็งแรง
- ราก
- วิทยาศาสตร์
- นักวิทยาศาสตร์
- ดูเหมือนว่า
- ชุด
- ชุด
- Share
- ง่าย
- So
- สังคม
- โซเชียลมีเดีย
- บาง
- โดยเฉพาะ
- แยก
- สี่เหลี่ยม
- ทางสถิติ
- อย่างเช่น
- เอา
- ทดสอบ
- ที่
- พื้นที่
- พวกเขา
- เวลา
- อนุกรมเวลา
- เคล็ดลับ
- ไปยัง
- เกินไป
- รถไฟ
- การฝึกอบรม
- เทรนด์
- ความไม่แน่นอน
- เข้าใจ
- เป็นเอกลักษณ์
- ไม่มีชื่อ
- ขึ้นไปข้างบน
- us
- ใช้
- ผู้ใช้
- มักจะ
- มีคุณค่า
- ความคุ้มค่า
- ต่างๆ
- ผ่านทาง
- การสร้างภาพ
- ทาง..
- รายสัปดาห์
- ดี
- อะไร
- ในขณะที่
- วิกิพีเดีย
- จะ
- กับ
- ภายใน
- การทำงาน
- โรงงาน
- จะ
- นักเขียน
- การเขียน
- ของคุณ
- ลมทะเล