ประเด็นที่สำคัญ
- การขยายพันธุ์ทางความคิด (TP) เป็นวิธีการใหม่ที่ช่วยเพิ่มความสามารถในการให้เหตุผลที่ซับซ้อนของโมเดลภาษาขนาดใหญ่ (LLM)
- TP ใช้ประโยชน์จากปัญหาที่คล้ายคลึงกันและวิธีแก้ปัญหาเพื่อปรับปรุงการใช้เหตุผล แทนที่จะสร้างเหตุผลของ LLM ตั้งแต่เริ่มต้น
- การทดลองในงานต่างๆ แสดงให้เห็นว่า TP มีประสิทธิภาพเหนือกว่าวิธีพื้นฐานอย่างมาก โดยมีการปรับปรุงตั้งแต่ 12% ถึง 15%
ขั้นแรก TP จะแจ้งให้ LLM เสนอและแก้ไขปัญหาชุดหนึ่งที่เกี่ยวข้องกับอินพุต จากนั้น TP จะนำผลลัพธ์ของปัญหาที่คล้ายกันกลับมาใช้ใหม่เพื่อให้ได้วิธีแก้ปัญหาใหม่โดยตรง หรือจัดทำแผนงานที่ต้องใช้ความรู้จำนวนมากสำหรับการดำเนินการเพื่อแก้ไขวิธีแก้ปัญหาเบื้องต้นที่ได้รับตั้งแต่เริ่มต้น
ความเก่งกาจและพลังในการคำนวณของ Large Language Models (LLM) นั้นไม่อาจปฏิเสธได้ แต่ก็ไม่ได้ไร้ขีดจำกัด หนึ่งในความท้าทายที่สำคัญและสม่ำเสมอที่สุดสำหรับ LLM คือแนวทางทั่วไปในการแก้ปัญหา ซึ่งประกอบด้วยการให้เหตุผลจากหลักการแรกๆ สำหรับงานใหม่ทุกงานที่ต้องเผชิญ นี่เป็นปัญหา เนื่องจากช่วยให้สามารถปรับตัวได้ในระดับสูง แต่ยังเพิ่มโอกาสที่จะเกิดข้อผิดพลาด โดยเฉพาะอย่างยิ่งในงานที่ต้องใช้เหตุผลหลายขั้นตอน
ความท้าทายของ "การใช้เหตุผลตั้งแต่เริ่มต้น" เด่นชัดเป็นพิเศษในงานที่ซับซ้อนซึ่งต้องใช้ตรรกะและการอนุมานหลายขั้นตอน ตัวอย่างเช่น หาก LLM ถูกขอให้ค้นหาเส้นทางที่สั้นที่สุดในเครือข่ายของจุดที่เชื่อมต่อถึงกัน โดยทั่วไปแล้วจะไม่ใช้ประโยชน์จากความรู้เดิมหรือปัญหาที่คล้ายคลึงกันในการค้นหาวิธีแก้ไข แต่จะพยายามแก้ไขปัญหาแบบแยกส่วน ซึ่งอาจนำไปสู่ผลลัพธ์ที่ต่ำกว่ามาตรฐานหรือแม้แต่ข้อผิดพลาดโดยสิ้นเชิงได้ เข้า การเผยแพร่ความคิด (TP) วิธีการที่ออกแบบมาเพื่อเพิ่มความสามารถในการให้เหตุผลของ LLM TP มุ่งหวังที่จะเอาชนะข้อจำกัดโดยธรรมชาติของ LLM โดยปล่อยให้พวกเขาดึงเอาปัญหาที่คล้ายคลึงกันและแนวทางแก้ไขที่เกี่ยวข้องออกจากแหล่งกักเก็บ วิธีการที่เป็นนวัตกรรมนี้ไม่เพียงแต่ปรับปรุงความแม่นยำของโซลูชันที่สร้างโดย LLM เท่านั้น แต่ยังช่วยเพิ่มความสามารถในการจัดการกับงานการให้เหตุผลที่ซับซ้อนหลายขั้นตอนอีกด้วย ด้วยการใช้ประโยชน์จากพลังแห่งการเปรียบเทียบ TP ได้จัดเตรียมกรอบการทำงานที่ขยายความสามารถในการให้เหตุผลโดยธรรมชาติของ LLM ซึ่งนำเราเข้าใกล้การตระหนักถึงระบบประดิษฐ์ที่ชาญฉลาดอย่างแท้จริงอีกก้าวหนึ่ง
การเผยแพร่ความคิดประกอบด้วยสองขั้นตอนหลัก:
- ขั้นแรก LLM จะได้รับแจ้งให้เสนอและแก้ไขปัญหาที่คล้ายกันที่เกี่ยวข้องกับปัญหาอินพุต
- ขั้นต่อไป วิธีแก้ปัญหาของปัญหาคล้ายคลึงเหล่านี้ถูกใช้เพื่อให้เกิดวิธีแก้ปัญหาใหม่โดยตรงหรือเพื่อแก้ไขวิธีแก้ปัญหาเบื้องต้น
กระบวนการระบุปัญหาที่คล้ายคลึงกันทำให้ LLM สามารถใช้กลยุทธ์และวิธีแก้ไขปัญหาซ้ำได้ ซึ่งจะเป็นการปรับปรุงความสามารถในการให้เหตุผล TP เข้ากันได้กับวิธีการแจ้งที่มีอยู่ โดยให้โซลูชันทั่วไปที่สามารถรวมเข้ากับงานต่างๆ ได้โดยไม่ต้องมีวิศวกรรมเฉพาะงานที่สำคัญ
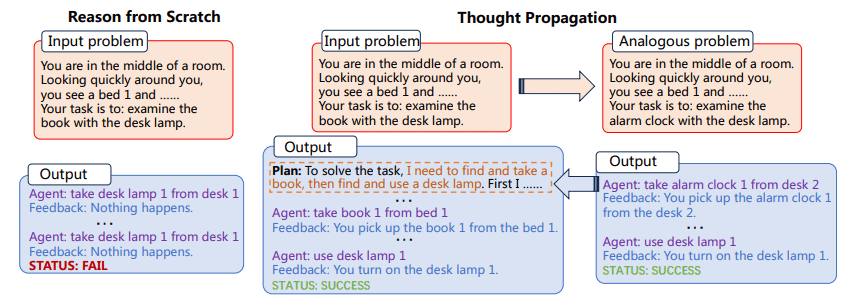
รูป 1: กระบวนการเผยแพร่ความคิด (ภาพจากกระดาษ)
นอกจากนี้ไม่ควรประเมินความสามารถในการปรับตัวของ TP ต่ำไป ความเข้ากันได้กับวิธีการแจ้งที่มีอยู่ทำให้เป็นเครื่องมือที่หลากหลายมาก ซึ่งหมายความว่า TP ไม่ได้จำกัดอยู่เพียงโดเมนการแก้ปัญหาประเภทใดโดยเฉพาะ นี่เป็นการเปิดช่องทางที่น่าตื่นเต้นสำหรับการปรับแต่งและการเพิ่มประสิทธิภาพเฉพาะงาน ซึ่งจะช่วยยกระดับอรรถประโยชน์และประสิทธิภาพของ LLM ในแอพพลิเคชั่นที่หลากหลาย
การนำการเผยแพร่ทางความคิดไปใช้สามารถบูรณาการเข้ากับขั้นตอนการทำงานของ LLM ที่มีอยู่ได้ ตัวอย่างเช่น ในงานการใช้เหตุผลเส้นทางที่สั้นที่สุด TP สามารถแก้ชุดปัญหาที่ง่ายกว่าและคล้ายคลึงกันก่อนเพื่อทำความเข้าใจเส้นทางต่างๆ ที่เป็นไปได้ จากนั้นจะใช้ข้อมูลเชิงลึกเหล่านี้ในการแก้ปัญหาที่ซับซ้อน ซึ่งจะเป็นการเพิ่มโอกาสในการค้นหาวิธีแก้ปัญหาที่ดีที่สุด
1 ตัวอย่าง
- งาน: การใช้เหตุผลเส้นทางที่สั้นที่สุด
- ปัญหาที่คล้ายคลึงกัน: เส้นทางที่สั้นที่สุดระหว่างจุด A และ B, เส้นทางที่สั้นที่สุดระหว่างจุด B และ C
- ทางออกสุดท้าย: เส้นทางที่เหมาะสมที่สุดจากจุด A ถึง C โดยพิจารณาวิธีแก้ปัญหาที่คล้ายคลึงกัน
2 ตัวอย่าง
- งาน: การเขียนเชิงสร้างสรรค์
- ปัญหาที่คล้ายคลึงกัน: เขียนเรื่องสั้นเกี่ยวกับมิตรภาพ เขียนเรื่องสั้นเกี่ยวกับความไว้วางใจ
- ทางออกสุดท้าย: เขียนเรื่องสั้นที่ซับซ้อนซึ่งผสมผสานธีมของมิตรภาพและความไว้วางใจ
กระบวนการนี้เกี่ยวข้องกับการแก้ปัญหาที่คล้ายคลึงกันเหล่านี้ก่อน จากนั้นจึงใช้ข้อมูลเชิงลึกที่ได้รับเพื่อจัดการกับงานที่ซับซ้อนที่มีอยู่ วิธีการนี้ได้แสดงให้เห็นถึงประสิทธิผลในงานต่างๆ มากมาย โดยแสดงให้เห็นการปรับปรุงที่สำคัญในการวัดประสิทธิภาพ
ผลกระทบของการเผยแพร่ทางความคิดมีมากกว่าแค่การปรับปรุงตัวชี้วัดที่มีอยู่เท่านั้น เทคนิคการกระตุ้นเตือนนี้มีศักยภาพในการเปลี่ยนแปลงวิธีที่เราเข้าใจและปรับใช้ LLM ระเบียบวิธีเน้นย้ำถึงการเปลี่ยนแปลงจากการแก้ปัญหาแบบอะตอมมิกแบบแยกเดี่ยวไปสู่แนวทางแบบองค์รวมและเชื่อมโยงถึงกันมากขึ้น มันเตือนให้เราพิจารณาว่า LLM สามารถเรียนรู้ไม่เพียงแต่จากข้อมูลเท่านั้น แต่จากกระบวนการแก้ไขปัญหาด้วยตัวมันเอง ด้วยการอัปเดตความเข้าใจอย่างต่อเนื่องผ่านแนวทางแก้ไขปัญหาที่คล้ายกัน LLM ที่ติดตั้ง TP จึงเตรียมพร้อมรับมือกับความท้าทายที่ไม่คาดฝันได้ดีขึ้น ทำให้มีความยืดหยุ่นและปรับตัวได้มากขึ้นในสภาพแวดล้อมที่พัฒนาอย่างรวดเร็ว
การขยายพันธุ์ทางความคิดเป็นส่วนเสริมที่น่าหวังในกล่องเครื่องมือของวิธีการกระตุ้นที่มีจุดมุ่งหมายเพื่อเพิ่มขีดความสามารถของ LLM ด้วยการอนุญาตให้ LLM ใช้ประโยชน์จากปัญหาที่คล้ายคลึงกันและวิธีแก้ไข TP จึงมีวิธีการให้เหตุผลที่เหมาะสมและมีประสิทธิภาพมากขึ้น การทดลองยืนยันประสิทธิภาพ ทำให้เป็นกลยุทธ์ในการปรับปรุงประสิทธิภาพของ LLM ในงานต่างๆ ในที่สุด TP อาจเป็นตัวแทนของก้าวสำคัญในการค้นหาระบบ AI ที่มีความสามารถมากขึ้น
Matthew Mayo May (@แมตต์มาโย13) สำเร็จการศึกษาระดับปริญญาโทสาขาวิทยาการคอมพิวเตอร์และประกาศนียบัตรบัณฑิตสาขาการทำเหมืองข้อมูล ในฐานะบรรณาธิการบริหารของ KDnuggets Matthew ตั้งเป้าที่จะทำให้แนวคิดด้านวิทยาศาสตร์ข้อมูลที่ซับซ้อนเข้าถึงได้ ความสนใจทางวิชาชีพของเขา ได้แก่ การประมวลผลภาษาธรรมชาติ อัลกอริธึมการเรียนรู้ของเครื่อง และการสำรวจ AI ที่เกิดขึ้นใหม่ เขาขับเคลื่อนด้วยภารกิจในการทำให้ความรู้เป็นประชาธิปไตยในชุมชนวิทยาศาสตร์ข้อมูล Matthew เขียนโค้ดตั้งแต่อายุ 6 ขวบ
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://www.kdnuggets.com/thought-propagation-an-analogical-approach-to-complex-reasoning-with-large-language-models?utm_source=rss&utm_medium=rss&utm_campaign=thought-propagation-an-analogical-approach-to-complex-reasoning-with-large-language-models
- :มี
- :เป็น
- :ไม่
- $ ขึ้น
- 15%
- 8
- a
- ความสามารถ
- ความสามารถ
- เกี่ยวกับเรา
- สามารถเข้าถึงได้
- ความถูกต้อง
- ข้าม
- นอกจากนี้
- AI
- ระบบ AI
- มีวัตถุประสงค์เพื่อ
- จุดมุ่งหมาย
- อัลกอริทึม
- การอนุญาต
- ช่วยให้
- ด้วย
- amplifies
- an
- และ
- ใด
- การใช้งาน
- เข้าใกล้
- เป็น
- เทียม
- AS
- At
- ความพยายาม
- เสริม
- ลู่ทาง
- b
- baseline
- BE
- รับ
- ดีกว่า
- ระหว่าง
- เกิน
- การนำ
- กว้าง
- แต่
- by
- CAN
- ผู้สมัคร
- ความสามารถในการ
- สามารถ
- ท้าทาย
- ความท้าทาย
- ใกล้ชิด
- การเข้ารหัส
- ชุมชน
- ความเข้ากันได้
- เข้ากันได้
- ซับซ้อน
- การคำนวณ
- พลังการคำนวณ
- คอมพิวเตอร์
- วิทยาการคอมพิวเตอร์
- แนวความคิด
- ยืนยัน
- พิจารณา
- พิจารณา
- คงเส้นคงวา
- ประกอบด้วย
- อย่างต่อเนื่อง
- ตรงกัน
- ได้
- ความคิดสร้างสรรค์
- ข้อมูล
- การทำเหมืองข้อมูล
- วิทยาศาสตร์ข้อมูล
- องศา
- ความต้องการ
- ทำให้เป็นประชาธิปไตย
- แสดงให้เห็นถึง
- ปรับใช้
- ได้รับการออกแบบ
- โดยตรง
- โดเมน
- วาด
- ขับเคลื่อน
- บรรณาธิการ
- มีประสิทธิภาพ
- ประสิทธิผล
- ประสิทธิภาพ
- ทั้ง
- การยกขึ้น
- กากกะรุน
- ชั้นเยี่ยม
- ช่วย
- การเสริมสร้าง
- เข้าสู่
- สภาพแวดล้อม
- พร้อม
- ข้อผิดพลาด
- โดยเฉพาะอย่างยิ่ง
- แม้
- ทุกๆ
- การพัฒนา
- ตัวอย่าง
- น่าตื่นเต้น
- การปฏิบัติ
- ที่มีอยู่
- การทดลอง
- สำรวจ
- หา
- หา
- ชื่อจริง
- สำหรับ
- ข้างหน้า
- กรอบ
- มิตรภาพ
- ราคาเริ่มต้นที่
- ที่ได้รับ
- General
- Go
- สำเร็จการศึกษา
- มือ
- he
- จุดสูง
- อย่างสูง
- ของเขา
- ถือ
- แบบองค์รวม
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- HTTPS
- ระบุ
- if
- ภาพ
- การดำเนินงาน
- ผลกระทบ
- ปรับปรุง
- การปรับปรุง
- ช่วยเพิ่ม
- การปรับปรุง
- in
- ประกอบด้วย
- Incorporated
- เพิ่มขึ้น
- ที่เพิ่มขึ้น
- โดยธรรมชาติ
- แรกเริ่ม
- โดยธรรมชาติ
- นวัตกรรม
- อินพุต
- ข้อมูลเชิงลึก
- แทน
- แบบบูรณาการ
- รวม
- ฉลาด
- เชื่อมต่อถึงกัน
- ผลประโยชน์
- เข้าไป
- ที่เกี่ยวข้องกับการ
- เปลี่ยว
- ความเหงา
- IT
- ITS
- ตัวเอง
- jpg
- เพียงแค่
- KD นักเก็ต
- ชนิด
- ความรู้
- ภาษา
- ใหญ่
- นำ
- เรียนรู้
- การเรียนรู้
- เลฟเวอเรจ
- ยกระดับ
- การใช้ประโยชน์
- ความเป็นไปได้
- LIMIT
- ข้อ จำกัด
- ถูก จำกัด
- ตรรกะ
- เครื่อง
- เรียนรู้เครื่อง
- หลัก
- ทำ
- ทำให้
- การทำ
- เจ้านาย
- แมทธิว
- อาจ..
- วิธี
- แค่
- วิธี
- ระเบียบวิธี
- วิธีการ
- ตัวชี้วัด
- การทำเหมืองแร่
- ภารกิจ
- โมเดล
- ข้อมูลเพิ่มเติม
- มากที่สุด
- หลาย
- โดยธรรมชาติ
- ภาษาธรรมชาติ
- ประมวลผลภาษาธรรมชาติ
- เครือข่าย
- ใหม่
- โซลูชั่นใหม่
- นวนิยาย
- ที่ได้รับ
- of
- เก่า
- on
- ONE
- เพียง
- เปิด
- ดีที่สุด
- การเพิ่มประสิทธิภาพ
- or
- ประสิทธิภาพเหนือกว่า
- ทันที
- เอาชนะ
- กระดาษ
- โดยเฉพาะ
- เส้นทาง
- การปฏิบัติ
- แผนการ
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- จุด
- จุด
- เป็นไปได้
- ที่มีศักยภาพ
- อำนาจ
- เตรียม
- หลักการ
- ก่อน
- ปัญหา
- การแก้ปัญหา
- ปัญหาที่เกิดขึ้น
- กระบวนการ
- การประมวลผล
- มืออาชีพ
- แวว
- เด่นชัด
- การเผยแผ่
- เสนอ
- ให้
- การให้
- ตั้งแต่
- อย่างรวดเร็ว
- ค่อนข้าง
- สำนึก
- เหตุผล
- ที่เกี่ยวข้อง
- การแสดงผล
- แสดง
- ต้องการ
- ยืดหยุ่น
- ผลสอบ
- นำมาใช้ใหม่
- s
- วิทยาศาสตร์
- รอยขีดข่วน
- ค้นหา
- ชุด
- เปลี่ยน
- สั้น
- น่า
- โชว์
- การจัดแสดง
- สำคัญ
- อย่างมีความหมาย
- ตั้งแต่
- ทางออก
- โซลูชัน
- แก้
- การแก้
- โดยเฉพาะ
- สเปกตรัม
- ขั้นตอน
- ขั้นตอน
- เรื่องราว
- กลยุทธ์
- กลยุทธ์
- เป็นกอบเป็นกำ
- อย่างเป็นจริงเป็นจัง
- ระบบ
- ต่อสู้
- งาน
- งาน
- เทคนิค
- กว่า
- ที่
- พื้นที่
- ของพวกเขา
- พวกเขา
- ธีม
- แล้วก็
- ดังนั้น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- นี้
- คิดว่า
- ตลอด
- ไปยัง
- เครื่องมือ
- กล่องเครื่องมือ
- ไปทาง
- tp
- อย่างแท้จริง
- วางใจ
- สอง
- เป็นปกติ
- ในที่สุด
- ปฏิเสธไม่ได้
- ขีด
- เข้าใจ
- ความเข้าใจ
- คาดไม่ถึง
- การปรับปรุง
- us
- ใช้
- มือสอง
- การใช้
- ประโยชน์
- ความหลากหลาย
- ต่างๆ
- อเนกประสงค์
- ความเก่งกาจ
- คือ
- we
- ที่
- กับ
- ไม่มี
- เวิร์กโฟลว์
- จะ
- เขียน
- การเขียน
- ปี
- ยัง
- ผล
- ลมทะเล