ภาพที่สร้างด้วย DALL-E3
ปัญญาประดิษฐ์ถือเป็นการปฏิวัติครั้งยิ่งใหญ่ในโลกเทคโนโลยี
ความสามารถในการเลียนแบบสติปัญญาของมนุษย์และทำงานที่ครั้งหนึ่งเคยถูกพิจารณาว่าเป็นเพียงโดเมนของมนุษย์ยังคงสร้างความประหลาดใจให้กับพวกเราส่วนใหญ่
อย่างไรก็ตาม ไม่ว่าการก้าวกระโดดของ AI ในช่วงท้ายๆ เหล่านี้จะดีแค่ไหน แต่ก็ยังมีช่องว่างให้ปรับปรุงได้เสมอ
และนี่คือจุดเริ่มต้นของวิศวกรรมที่รวดเร็ว!
ป้อนข้อมูลในช่องนี้ซึ่งสามารถเพิ่มประสิทธิภาพการทำงานของโมเดล AI ได้อย่างมาก
มาค้นพบมันด้วยกันเถอะ!
Prompt Engineering เป็นโดเมนที่เติบโตอย่างรวดเร็วภายใน AI ซึ่งมุ่งเน้นไปที่การปรับปรุงประสิทธิภาพและประสิทธิผลของโมเดลภาษา มันคือทั้งหมดที่เกี่ยวกับการสร้างคำแนะนำที่สมบูรณ์แบบเพื่อเป็นแนวทางให้กับโมเดล AI เพื่อสร้างผลลัพธ์ที่เราต้องการ
คิดว่าเป็นการเรียนรู้วิธีให้คำแนะนำที่ดีขึ้นแก่ผู้อื่นเพื่อให้แน่ใจว่าพวกเขาเข้าใจและปฏิบัติงานได้อย่างถูกต้อง
เหตุใดจึงต้องคำนึงถึงวิศวกรรมพร้อมท์
- เพิ่มผลผลิต: ด้วยการใช้พร้อมท์คุณภาพสูง โมเดล AI สามารถสร้างการตอบสนองที่แม่นยำและเกี่ยวข้องมากขึ้น ซึ่งหมายความว่าจะใช้เวลาในการแก้ไขน้อยลง และมีเวลามากขึ้นในการใช้ประโยชน์จากความสามารถของ AI
- ประสิทธิภาพต้นทุน: การฝึกอบรมโมเดล AI ต้องใช้ทรัพยากรมาก วิศวกรรมพร้อมท์สามารถลดความจำเป็นในการฝึกอบรมใหม่ได้โดยการเพิ่มประสิทธิภาพโมเดลด้วยการแจ้งเตือนที่ดีขึ้น
- เก่งกาจ: ข้อความแจ้งที่ออกแบบมาอย่างดีสามารถทำให้โมเดล AI มีความหลากหลายมากขึ้น ช่วยให้สามารถรับมือกับงานและความท้าทายที่หลากหลายยิ่งขึ้น
ก่อนที่จะเจาะลึกเทคนิคขั้นสูงสุด เรามาดูเทคนิคทางวิศวกรรมที่เป็นประโยชน์ที่สุด (และเป็นพื้นฐาน) สองข้อก่อน
การคิดตามลำดับด้วย “คิดทีละขั้นตอน”
ปัจจุบันเป็นที่ทราบกันดีว่าความแม่นยำของแบบจำลอง LLM ได้รับการปรับปรุงอย่างมากเมื่อเพิ่มลำดับคำ "ลองคิดดูทีละขั้นตอน"
ทำไม…คุณอาจถาม?
นี่เป็นเพราะว่าเรากำลังบังคับให้โมเดลแบ่งงานใดๆ ออกเป็นหลายขั้นตอน เพื่อให้แน่ใจว่าโมเดลมีเวลาเพียงพอในการประมวลผลแต่ละงาน
ตัวอย่างเช่น ฉันสามารถท้าทาย GPT3.5 ด้วยข้อความแจ้งต่อไปนี้:
ถ้าจอห์นมีลูกแพร์ 5 ลูก แล้วกิน 2 ลูก ซื้อเพิ่มอีก 5 ลูก แล้วให้เพื่อน 3 ลูก เขามีลูกแพร์กี่ลูก?
นางแบบจะตอบให้ทันที อย่างไรก็ตาม หากฉันเพิ่มส่วนสุดท้าย “มาคิดกันทีละขั้นตอน” ฉันกำลังบังคับให้โมเดลสร้างกระบวนการคิดที่มีหลายขั้นตอน
ไม่กี่ Shot Prompting
แม้ว่าการพร้อมท์แบบ Zero-shot หมายถึงการขอให้โมเดลทำงานโดยไม่ต้องให้บริบทหรือความรู้เดิม เทคนิคการพร้อมท์แบบไม่กี่ช็อตก็หมายความว่าเรานำเสนอ LLM พร้อมด้วยตัวอย่างผลลัพธ์ที่เราต้องการบางส่วนพร้อมกับคำถามเฉพาะบางข้อ
ตัวอย่างเช่น หากเราต้องการสร้างแบบจำลองที่กำหนดคำใดๆ โดยใช้น้ำเสียงเชิงกวี ก็อาจจะค่อนข้างอธิบายได้ยาก ขวา?
อย่างไรก็ตาม เราสามารถใช้คำแนะนำสั้นๆ ต่อไปนี้เพื่อบังคับโมเดลไปในทิศทางที่เราต้องการ
งานของคุณคือตอบในรูปแบบที่สอดคล้องกันซึ่งสอดคล้องกับสไตล์ต่อไปนี้
: สอนฉันเรื่องความยืดหยุ่น
: ความยืดหยุ่นก็เหมือนต้นไม้ที่โค้งตามลมแต่ไม่เคยหัก
มันคือความสามารถในการฟื้นตัวจากความยากลำบากและก้าวไปข้างหน้า
: ข้อมูลของคุณที่นี่
หากคุณยังไม่ได้ลองใช้คุณสามารถไปท้าทาย GPT ได้
อย่างไรก็ตาม เนื่องจากฉันค่อนข้างแน่ใจว่าพวกคุณส่วนใหญ่รู้เทคนิคพื้นฐานเหล่านี้อยู่แล้ว ฉันจะพยายามท้าทายคุณด้วยเทคนิคขั้นสูงบางอย่าง
1. การกระตุ้นด้วยห่วงโซ่แห่งความคิด (CoT)
แนะนำโดย Google ในปี 2022วิธีนี้เกี่ยวข้องกับการสั่งแบบจำลองให้ผ่านขั้นตอนการให้เหตุผลหลายขั้นตอนก่อนที่จะให้การตอบสนองขั้นสุดท้าย
ฟังดูคุ้นเคยใช่ไหม? ถ้าเป็นเช่นนั้นคุณก็พูดถูก
มันเหมือนกับการผสมผสานทั้งการคิดตามลำดับและการเตือนใจแบบ Few-Shot
ได้อย่างไร
โดยพื้นฐานแล้ว CoT prompting จะสั่งให้ LLM ประมวลผลข้อมูลตามลำดับ ซึ่งหมายความว่าเรายกตัวอย่างวิธีแก้ปัญหาแรกด้วยการให้เหตุผลหลายขั้นตอน จากนั้นส่งงานจริงของเราไปยังโมเดล โดยคาดหวังว่ามันจะจำลองห่วงโซ่ความคิดที่เทียบเคียงได้เมื่อตอบคำถามจริงที่เราต้องการให้แก้ไข
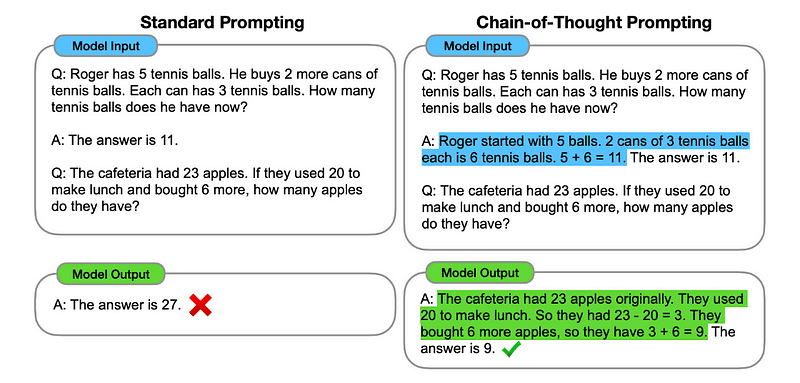
ภาพที่นำมาจาก กระดาษ.
ดังนั้น จากตัวอย่างแรกสุด เราสามารถให้ข้อมูลปัญหาแรกพร้อมทั้งคำอธิบายวิธีแก้ปัญหาตามลำดับได้ จากนั้นเราสามารถส่งข้อมูลของเราและดูว่าความมหัศจรรย์เกิดขึ้นได้อย่างไร!
ถ้าจอห์นมีลูกแพร์ 5 ลูก แล้วกิน 2 ลูก ซื้อเพิ่มอีก 5 ลูก แล้วให้เพื่อน 3 ลูก เขามีลูกแพร์กี่ลูก? ลองคิดทีละขั้นตอน
เราไปทีละขั้นตอนกัน จอห์นเริ่มต้นด้วยลูกแพร์ 5 ลูก เขากินลูกแพร์ 2 ลูก ดังนั้นเขาจึงเหลือลูกแพร์ 5–2 = 3 ลูก จากนั้นเขาก็ซื้อลูกแพร์เพิ่มอีก 5 ลูก ตอนนี้เขามีลูกแพร์ 3 + 5 = 8 ลูก ในที่สุดเขาก็มอบลูกแพร์ 3 ลูกให้เพื่อน ดังนั้นเขาจึงเหลือลูกแพร์ 8–3 = 5 ลูก หลังจากทำตามขั้นตอนทั้งหมดนี้ จอห์นก็มีลูกแพร์ 5 ลูก
ข้อมูลของคุณที่นี่
อย่างไรก็ตาม พวกคุณส่วนใหญ่คงกำลังคิดว่า... ทุกครั้งที่ฉันต้องการถามอะไรใน ChatGPT ฉันจะต้องคิดวิธีแก้ปัญหาตามลำดับหรือไม่?
ก็…คุณไม่ใช่คนแรก! และสิ่งนี้นำเราไปสู่...
2. ห่วงโซ่แห่งความคิดอัตโนมัติ (Auto-CoT)
ใน 2022, เหวย และเพื่อนร่วมงานได้แนะนำวิธีการหลีกเลี่ยงกระบวนการที่ต้องดำเนินการด้วยตนเองนี้ มีเหตุผลหลักสองประการที่ควรหลีกเลี่ยงงานที่ต้องทำเอง:
- มันอาจจะน่าเบื่อ
- มันสามารถให้ผลลัพธ์ที่ไม่ดีได้ เช่น เมื่อกระบวนการทางจิตของเราผิดไป
พวกเขาแนะนำให้ใช้ LLM ร่วมกับข้อความ "ลองคิดดูทีละขั้นตอน" เพื่อสร้างห่วงโซ่การให้เหตุผลตามลำดับสำหรับการสาธิตแต่ละครั้ง
นี่หมายถึงการถาม ChatGPT ถึงวิธีแก้ปัญหาตามลำดับ จากนั้นใช้ตัวอย่างเดียวกันนี้เพื่อฝึกให้ ChatGPT ทราบวิธีแก้ปัญหาอื่นๆ
3. ความสม่ำเสมอในตนเอง
ความสม่ำเสมอในตนเองเป็นอีกเทคนิคการกระตุ้นเตือนที่น่าสนใจซึ่งมีจุดมุ่งหมายเพื่อปรับปรุงห่วงโซ่แห่งความคิดที่กระตุ้นให้เกิดปัญหาการใช้เหตุผลที่ซับซ้อนมากขึ้น
ดังนั้น… อะไรคือความแตกต่างที่สำคัญ?
แนวคิดหลักภายใต้ Self-Consistency คือการตระหนักว่าเราสามารถฝึกโมเดลด้วยตัวอย่างที่ไม่ถูกต้องได้ ลองจินตนาการว่าฉันแก้ไขปัญหาก่อนหน้านี้ด้วยกระบวนการทางจิตที่ผิด:
ถ้าจอห์นมีลูกแพร์ 5 ลูก แล้วกิน 2 ลูก ซื้อเพิ่มอีก 5 ลูก แล้วให้เพื่อน 3 ลูก เขามีลูกแพร์กี่ลูก? ลองคิดทีละขั้นตอน
เริ่มต้นด้วย 5 ลูกแพร์ จอห์นกินลูกแพร์ 2 ลูก จากนั้นเขาก็มอบลูกแพร์ 3 ลูกให้เพื่อน การกระทำเหล่านี้สามารถรวมกันได้: 2 (กิน) + 3 (ให้) = ผลรวมลูกแพร์ 5 ลูก ตอนนี้ ลบลูกแพร์ทั้งหมดที่ได้รับผลกระทบจากลูกแพร์ 5 ลูกเริ่มต้น: 5 (เริ่มต้น) – 5 (ได้รับผลกระทบ) = เหลือลูกแพร์ 0 ลูก
จากนั้นงานอื่นๆ ที่ฉันส่งไปยังโมเดลก็จะผิดพลาด
นี่คือเหตุผลว่าทำไมความสม่ำเสมอในตนเองจึงเกี่ยวข้องกับการสุ่มตัวอย่างจากเส้นทางการให้เหตุผลต่างๆ ซึ่งแต่ละเส้นทางมีสายโซ่แห่งความคิด จากนั้นให้ LLM เลือกเส้นทางที่ดีที่สุดและสม่ำเสมอที่สุดในการแก้ปัญหา
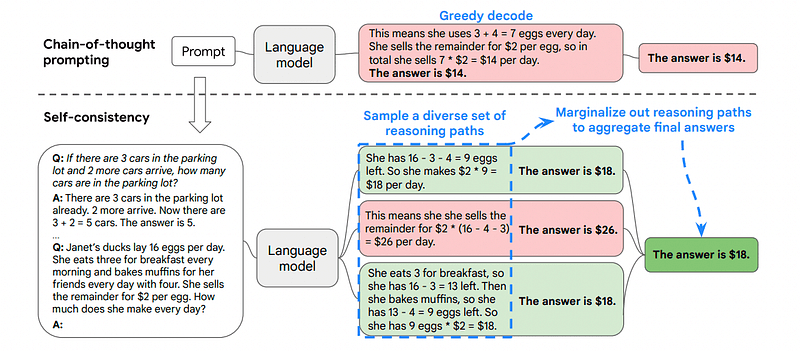
ภาพที่นำมาจาก กระดาษ
ในกรณีนี้ และทำตามตัวอย่างแรกอีกครั้ง เราสามารถแสดงแบบจำลองวิธีแก้ปัญหาต่างๆ ได้
ถ้าจอห์นมีลูกแพร์ 5 ลูก แล้วกิน 2 ลูก ซื้อเพิ่มอีก 5 ลูก แล้วให้เพื่อน 3 ลูก เขามีลูกแพร์กี่ลูก?
เริ่มต้นด้วย 5 ลูกแพร์ จอห์นกินลูกแพร์ 2 ลูก เหลือลูกแพร์ 5–2 = 3 ลูก เขาซื้อลูกแพร์เพิ่ม 5 ลูก รวมเป็น 3 + 5 = 8 ลูกแพร์ ในที่สุด เขาให้ลูกแพร์ 3 ลูกกับเพื่อน ดังนั้นเขาจึงเหลือลูกแพร์ 8–3 = 5 ลูก
ถ้าจอห์นมีลูกแพร์ 5 ลูก แล้วกิน 2 ลูก ซื้อเพิ่มอีก 5 ลูก แล้วให้เพื่อน 3 ลูก เขามีลูกแพร์กี่ลูก?
เริ่มต้นด้วย 5 ลูกแพร์ จากนั้นเขาก็ซื้อลูกแพร์เพิ่มอีก 5 ลูก ตอนนี้จอห์นกินลูกแพร์ 2 ลูก การกระทำเหล่านี้สามารถรวมกันได้: 2 (กิน) + 5 (ซื้อ) = รวมลูกแพร์ 7 ลูก ลบลูกแพร์ที่จอนกินออกจากจำนวนลูกแพร์ทั้งหมด 7 (จำนวนทั้งหมด) – 2 (กินแล้ว) = เหลือลูกแพร์ 5 ลูก
ข้อมูลของคุณที่นี่
และมาถึงเทคนิคสุดท้าย
4. การแจ้งความรู้ทั่วไป
แนวทางปฏิบัติทั่วไปของวิศวกรรมพร้อมท์คือการเพิ่มการค้นหาด้วยความรู้เพิ่มเติม ก่อนที่จะส่งการเรียก API สุดท้ายไปยัง GPT-3 หรือ GPT-4
ตามที่ เจียเฉิง หลิว แอนด์ โคเราสามารถเพิ่มความรู้ให้กับคำขอใดๆ ได้เสมอ เพื่อให้ LLM รู้ดีเกี่ยวกับคำถามนั้น
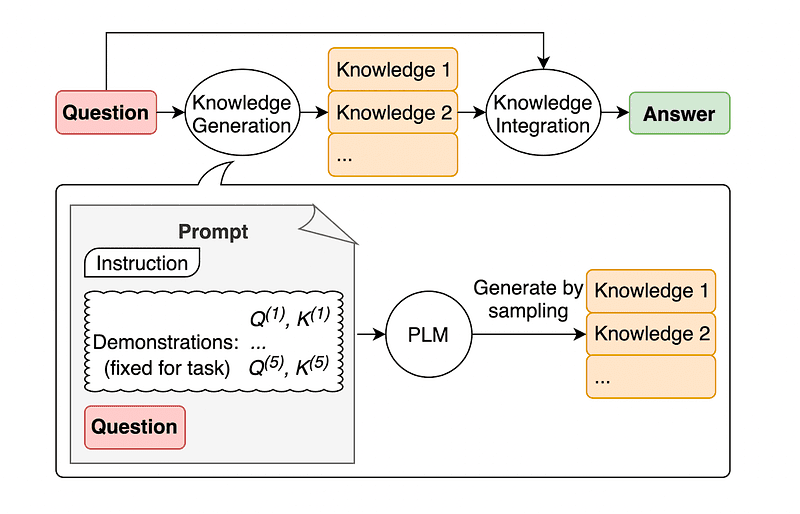
ภาพที่นำมาจาก กระดาษ.
ตัวอย่างเช่น เมื่อถาม ChatGPT ว่าส่วนหนึ่งของกอล์ฟพยายามทำคะแนนรวมให้สูงกว่าส่วนอื่นหรือไม่ จะเป็นการยืนยันเรา แต่เป้าหมายหลักของการเล่นกอล์ฟกลับตรงกันข้าม นี่คือเหตุผลที่เราสามารถเพิ่มความรู้ก่อนหน้านี้โดยบอกว่า "ผู้เล่นที่มีคะแนนต่ำกว่าจะเป็นผู้ชนะ"

แล้ว.. อะไรคือส่วนที่ตลกหากเราบอกแบบจำลองให้ทราบคำตอบอย่างชัดเจน?
ในกรณีนี้ เทคนิคนี้ใช้เพื่อปรับปรุงวิธีที่ LLM โต้ตอบกับเรา
ดังนั้น แทนที่จะดึงบริบทเสริมจากฐานข้อมูลภายนอก ผู้เขียนรายงานแนะนำให้ LLM สร้างความรู้ของตนเอง ความรู้ที่สร้างขึ้นเองนี้จะถูกรวมเข้ากับพรอมต์เพื่อสนับสนุนการใช้เหตุผลทั่วไปและให้ผลลัพธ์ที่ดีกว่า
นี่คือวิธีที่สามารถปรับปรุง LLM ได้โดยไม่ต้องเพิ่มชุดข้อมูลการฝึกอบรม!
วิศวกรรมพร้อมท์กลายเป็นเทคนิคสำคัญในการเสริมสร้างขีดความสามารถของ LLM ด้วยการทำซ้ำและปรับปรุงการแจ้งเตือน เราสามารถสื่อสารกับโมเดล AI ได้โดยตรงมากขึ้น และทำให้ได้รับผลลัพธ์ที่แม่นยำและเกี่ยวข้องกับบริบทมากขึ้น ซึ่งช่วยประหยัดทั้งเวลาและทรัพยากร
สำหรับผู้ที่ชื่นชอบเทคโนโลยี นักวิทยาศาสตร์ข้อมูล และผู้สร้างเนื้อหา การทำความเข้าใจและความเชี่ยวชาญด้านวิศวกรรมที่รวดเร็วสามารถเป็นทรัพย์สินที่มีค่าในการควบคุมศักยภาพของ AI ได้อย่างเต็มที่
ด้วยการรวมอินพุตที่ออกแบบอย่างพิถีพิถันเข้ากับเทคนิคขั้นสูงเหล่านี้ การมีชุดทักษะด้านวิศวกรรมพร้อมท์จะทำให้คุณได้เปรียบในปีต่อๆ ไปอย่างไม่ต้องสงสัย
โจเซป เฟอร์เรอร์ เป็นวิศวกรวิเคราะห์จากบาร์เซโลนา เขาสำเร็จการศึกษาด้านวิศวกรรมฟิสิกส์และกำลังทำงานในสาขาวิทยาศาสตร์ข้อมูลที่ประยุกต์ใช้กับการเคลื่อนที่ของมนุษย์ เขาเป็นผู้สร้างเนื้อหานอกเวลาที่มุ่งเน้นด้านวิทยาศาสตร์ข้อมูลและเทคโนโลยี สามารถติดต่อเขาได้ที่ LinkedIn, Twitter or กลาง.
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://www.kdnuggets.com/some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models?utm_source=rss&utm_medium=rss&utm_campaign=some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 10
- 11
- 2022
- 29
- 7
- 8
- a
- ความสามารถ
- เกี่ยวกับเรา
- ความถูกต้อง
- ถูกต้อง
- การปฏิบัติ
- ที่เกิดขึ้นจริง
- เพิ่ม
- เพิ่ม
- เพิ่มเติม
- สูง
- หลังจาก
- อีกครั้ง
- AI
- โมเดล AI
- จุดมุ่งหมาย
- ชิด
- เหมือนกัน
- ทั้งหมด
- การอนุญาต
- ตาม
- แล้ว
- เสมอ
- am
- จำนวน
- an
- การวิเคราะห์
- และ
- อื่น
- คำตอบ
- ใด
- API
- ประยุกต์
- เป็น
- AS
- ถาม
- ขอให้
- สินทรัพย์
- ผู้เขียน
- อัตโนมัติ
- หลีกเลี่ยง
- ทราบ
- ไป
- กลับ
- ไม่ดี
- บาร์เซโลนา
- ขั้นพื้นฐาน
- BE
- เพราะ
- รับ
- ก่อน
- กำลัง
- ที่ดีที่สุด
- ดีกว่า
- หนุน
- เพิ่ม
- เจาะ
- ทั้งสอง
- ซื้อ
- เด้ง
- ทำลาย
- แบ่ง
- นำ
- ที่กว้างขึ้น
- แต่
- ซื้อ
- by
- โทรศัพท์
- CAN
- ความสามารถในการ
- รอบคอบ
- กรณี
- โซ่
- ห่วงโซ่
- ท้าทาย
- ความท้าทาย
- ChatGPT
- Choose
- เพื่อนร่วมงาน
- รวม
- การรวมกัน
- อย่างไร
- มา
- มา
- ร่วมกัน
- สื่อสาร
- เทียบเคียง
- สมบูรณ์
- ซับซ้อน
- ถือว่า
- คงเส้นคงวา
- ติดต่อเรา
- เนื้อหา
- ผู้สร้างเนื้อหา
- สิ่งแวดล้อม
- การแก้ไข
- ได้อย่างถูกต้อง
- ได้
- ที่สร้างขึ้น
- ผู้สร้าง
- ผู้สร้าง
- ขณะนี้
- ข้อมูล
- วิทยาศาสตร์ข้อมูล
- ฐานข้อมูล
- กำหนด
- การส่งมอบ
- ได้รับการออกแบบ
- ที่ต้องการ
- ความแตกต่าง
- ต่าง
- โดยตรง
- ทิศทาง
- ค้นพบ
- การดำน้ำ
- do
- ทำ
- โดเมน
- โดเมน
- ลง
- แต่ละ
- ขอบ
- ประสิทธิผล
- อย่างมีประสิทธิภาพ
- โผล่ออกมา
- วิศวกร
- ชั้นเยี่ยม
- เสริม
- การเสริมสร้าง
- พอ
- ทำให้มั่นใจ
- ผู้ที่ชื่นชอบ
- เผง
- ตัวอย่าง
- ตัวอย่าง
- ดำเนินการ
- คาดหวังว่า
- อธิบาย
- คำอธิบาย
- คุ้นเคย
- สองสาม
- สนาม
- สุดท้าย
- ในที่สุด
- ชื่อจริง
- มุ่งเน้น
- มุ่งเน้นไปที่
- ดังต่อไปนี้
- สำหรับ
- พระเดช
- ข้างหน้า
- เพื่อน
- ราคาเริ่มต้นที่
- เต็ม
- ตลก
- General
- สร้าง
- ได้รับ
- ให้
- กำหนด
- จะช่วยให้
- Go
- เป้าหมาย
- กอล์ฟ
- ดี
- ให้คำแนะนำ
- ยาก
- การควบคุม
- มี
- มี
- he
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- ที่มีคุณภาพสูง
- สูงกว่า
- พระองค์
- ของเขา
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTTPS
- เป็นมนุษย์
- สติปัญญาของมนุษย์
- i
- ความคิด
- if
- ภาพ
- ปรับปรุง
- การปรับปรุง
- การปรับปรุง
- การปรับปรุง
- in
- ที่เพิ่มขึ้น
- ข้อมูล
- แรกเริ่ม
- อินพุต
- ตัวอย่าง
- คำแนะนำการใช้
- แบบบูรณาการ
- Intelligence
- เชิงโต้ตอบ
- น่าสนใจ
- เข้าไป
- แนะนำ
- ที่เกี่ยวข้องกับการ
- IT
- ITS
- จอห์น
- จอน
- เพียงแค่
- KD นักเก็ต
- เก็บ
- เตะ
- kicks
- ทราบ
- ความรู้
- รู้
- ภาษา
- ชื่อสกุล
- ปลาย
- นำไปสู่
- กระโดด
- การเรียนรู้
- การออกจาก
- ซ้าย
- น้อยลง
- ให้
- การให้
- การใช้ประโยชน์
- กดไลก์
- ลด
- มายากล
- หลัก
- ทำ
- การทำ
- ลักษณะ
- คู่มือ
- หลาย
- Mastering
- เรื่อง
- me
- วิธี
- จิต
- การผสม
- วิธี
- อาจ
- การเคลื่อนย้าย
- แบบ
- โมเดล
- ข้อมูลเพิ่มเติม
- มากที่สุด
- การย้าย
- หลาย
- ต้อง
- จำเป็นต้อง
- ไม่เคย
- ไม่
- ตอนนี้
- ได้รับ
- of
- on
- ครั้งเดียว
- ตรงข้าม
- การเพิ่มประสิทธิภาพ
- or
- อื่นๆ
- ผลิตภัณฑ์อื่นๆ
- ของเรา
- ออก
- เอาท์พุต
- เอาท์พุท
- ด้านนอก
- ของตนเอง
- กระดาษ
- ส่วนหนึ่ง
- เส้นทาง
- รูปแบบไฟล์ PDF
- สมบูรณ์
- ดำเนินการ
- การปฏิบัติ
- ฟิสิกส์
- เป็นจุดสำคัญ
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- ผู้เล่น
- จุด
- ที่มีศักยภาพ
- การปฏิบัติ
- อย่างแม่นยำ
- นำเสนอ
- สวย
- ก่อน
- ปัญหา
- ปัญหาที่เกิดขึ้น
- กระบวนการ
- ก่อ
- ผลผลิต
- ให้
- การให้
- การดึง
- คำถาม
- ทีเดียว
- พิสัย
- ค่อนข้าง
- จริง
- เหตุผล
- แนะนำ
- ลด
- หมายถึง
- ตรงประเด็น
- ขอ
- ความยืดหยุ่น
- ใช้ทรัพยากรมาก
- แหล่งข้อมูล
- การตอบสนอง
- คำตอบ
- การตอบสนอง
- ผลสอบ
- การอบรมขึ้นใหม่
- การปฏิวัติ
- ขวา
- ห้อง
- s
- เดียวกัน
- ประหยัด
- วิทยาศาสตร์
- วิทยาศาสตร์และเทคโนโลยี
- นักวิทยาศาสตร์
- คะแนน
- เห็น
- ส่ง
- การส่ง
- ลำดับ
- ชุด
- หลาย
- โชว์
- อย่างมีความหมาย
- ความสามารถ
- So
- เพียงผู้เดียว
- แก้
- การแก้
- บาง
- บางคน
- บางสิ่งบางอย่าง
- โดยเฉพาะ
- การใช้จ่าย
- ขั้นตอน
- เริ่มต้น
- เริ่มต้น
- คัดท้าย
- ขั้นตอน
- ขั้นตอน
- ยังคง
- สไตล์
- แน่ใจ
- ต่อสู้
- นำ
- งาน
- งาน
- เทคโนโลยี
- เทคนิค
- เทคนิค
- เทคโนโลยี
- บอก
- ระยะ
- กว่า
- ที่
- พื้นที่
- พวกเขา
- แล้วก็
- ที่นั่น
- ดังนั้น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- คิด
- คิด
- นี้
- คิดว่า
- ตลอด
- ดังนั้น
- เวลา
- ไปยัง
- TONE
- รวม
- โดยสิ้นเชิง
- รถไฟ
- การฝึกอบรม
- ต้นไม้
- พยายาม
- ลอง
- พยายาม
- สอง
- ที่สุด
- ภายใต้
- ได้รับ
- เข้าใจ
- ความเข้าใจ
- ไม่ต้องสงสัย
- us
- ใช้
- มือสอง
- การใช้
- ตรวจสอบความถูกต้อง
- มีคุณค่า
- ต่างๆ
- อเนกประสงค์
- มาก
- ต้องการ
- ทาง..
- วิธี
- we
- โด่งดัง
- คือ
- เมื่อ
- ที่
- ทำไม
- จะ
- ลม
- กับ
- ภายใน
- ไม่มี
- คำ
- การทำงาน
- โลก
- ผิด
- ปี
- ยัง
- ผล
- เธอ
- ของคุณ
- ลมทะเล