ภาพโดยผู้เขียน
ในโพสต์นี้ เราจะสำรวจโมเดลโอเพ่นซอร์สล้ำสมัยใหม่ที่เรียกว่า Mixtral 8x7b นอกจากนี้เรายังจะได้เรียนรู้วิธีการเข้าถึงโดยใช้ไลบรารี LLaMA C++ และวิธีการเรียกใช้โมเดลภาษาขนาดใหญ่โดยใช้คอมพิวเตอร์และหน่วยความจำที่ลดลง
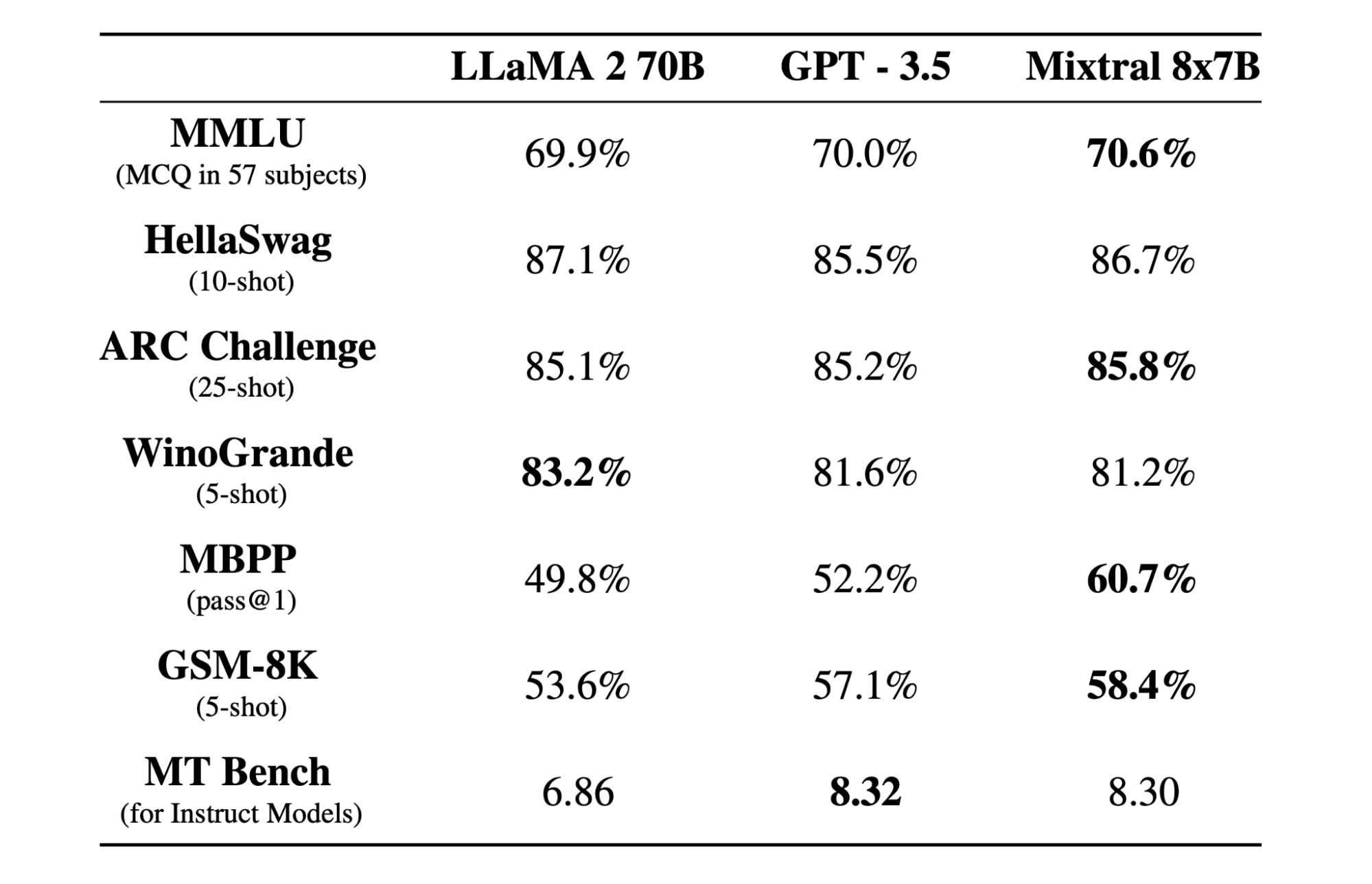
มิกซ์ทรัล 8x7b เป็นโมเดลผสมเบาบางคุณภาพสูงของผู้เชี่ยวชาญ (SMoE) ที่มีน้ำหนักเปิด สร้างขึ้นโดย Mistral AI ได้รับใบอนุญาตภายใต้ Apache 2.0 และมีประสิทธิภาพเหนือกว่า Llama 2 70B ในการวัดประสิทธิภาพส่วนใหญ่ ในขณะที่มีการอนุมานเร็วขึ้น 6 เท่า Mixtral จับคู่หรือเอาชนะ GPT3.5 ในการวัดประสิทธิภาพมาตรฐานส่วนใหญ่ และเป็นรุ่นน้ำหนักเปิดที่ดีที่สุดเกี่ยวกับต้นทุน/ประสิทธิภาพ
ภาพจาก การผสมผสานของผู้เชี่ยวชาญ
Mixtral 8x7B ใช้เครือข่ายผสมของผู้เชี่ยวชาญแบบกระจัดกระจายเท่านั้น สิ่งนี้เกี่ยวข้องกับการบล็อกฟีดฟอร์เวิร์ดที่เลือกจากกลุ่มพารามิเตอร์ 8 กลุ่ม โดยเครือข่ายเราเตอร์จะเลือกกลุ่มเหล่านี้สองกลุ่มสำหรับแต่ละโทเค็น รวมเอาต์พุตเข้าด้วยกัน วิธีการนี้ช่วยเพิ่มจำนวนพารามิเตอร์ของโมเดลไปพร้อมๆ กับการจัดการกับต้นทุนและเวลาแฝง ทำให้มีประสิทธิภาพเทียบเท่ากับโมเดล 12.9B แม้ว่าจะมีพารามิเตอร์ทั้งหมด 46.7B ก็ตาม
โมเดล Mixtral 8x7B เป็นเลิศในการจัดการบริบทที่กว้างของโทเค็น 32 และรองรับหลายภาษา รวมถึงอังกฤษ ฝรั่งเศส อิตาลี เยอรมัน และสเปน มันแสดงให้เห็นถึงประสิทธิภาพที่แข็งแกร่งในการสร้างโค้ด และสามารถปรับแต่งให้เป็นโมเดลตามคำสั่งได้อย่างละเอียด ซึ่งได้รับคะแนนสูงบนเกณฑ์มาตรฐาน เช่น MT-Bench
LLaMA.cpp เป็นไลบรารี C/C++ ที่ให้อินเทอร์เฟซประสิทธิภาพสูงสำหรับโมเดลภาษาขนาดใหญ่ (LLM) ตามสถาปัตยกรรม LLM ของ Facebook เป็นไลบรารีน้ำหนักเบาและมีประสิทธิภาพที่สามารถนำไปใช้งานได้หลากหลาย รวมถึงการสร้างข้อความ การแปล และการตอบคำถาม LLaMA.cpp รองรับ LLM ที่หลากหลาย รวมถึง LLaMA, LLaMA 2, Falcon, Alpaca, Mistral 7B, Mixtral 8x7B และ GPT4ALL มันเข้ากันได้กับระบบปฏิบัติการทั้งหมดและสามารถทำงานได้ทั้งบน CPU และ GPU
ในส่วนนี้ เราจะเรียกใช้เว็บแอปพลิเคชัน llama.cpp บน Colab ด้วยการเขียนโค้ดเพียงไม่กี่บรรทัด คุณจะได้สัมผัสกับประสิทธิภาพของโมเดลที่ล้ำสมัยใหม่บนพีซีของคุณหรือบน Google Colab
เริ่มต้นใช้งาน
ขั้นแรก เราจะดาวน์โหลดพื้นที่เก็บข้อมูล llama.cpp GitHub โดยใช้บรรทัดคำสั่งด้านล่าง:
!git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitหลังจากนั้น เราจะเปลี่ยนไดเรกทอรีเป็นพื้นที่เก็บข้อมูล และติดตั้ง llama.cpp โดยใช้คำสั่ง `make` เรากำลังติดตั้ง llama.cpp สำหรับ NVidia GPU ที่ติดตั้ง CUDA
%cd llama.cpp
!make LLAMA_CUBLAS=1ดาวน์โหลดโมเดล
เราสามารถดาวน์โหลดโมเดลได้จาก Hugging Face Hub โดยเลือกเวอร์ชันที่เหมาะสมของไฟล์โมเดล `.gguf` ข้อมูลเพิ่มเติมเกี่ยวกับเวอร์ชันต่างๆ สามารถพบได้ใน TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF.
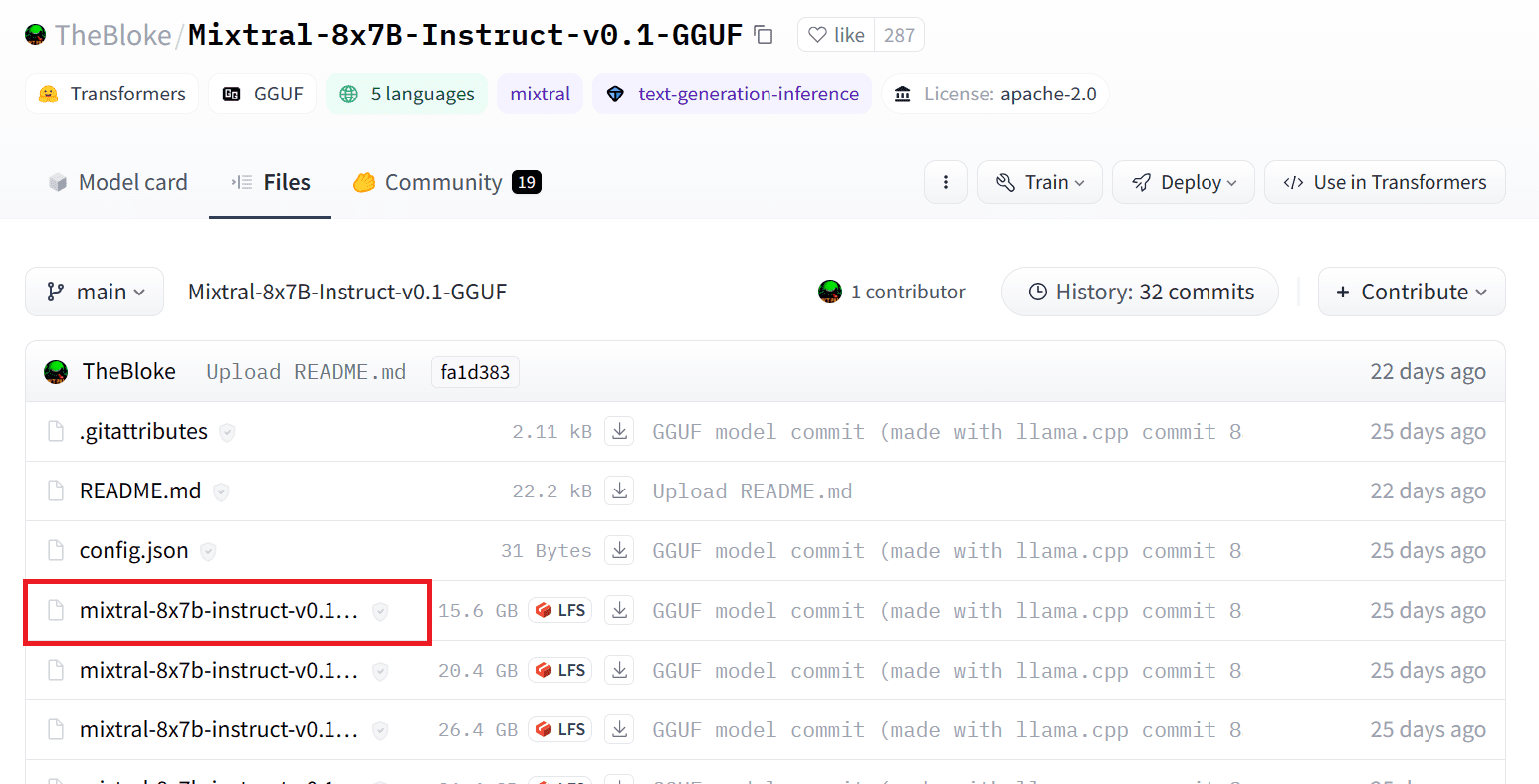
ภาพจาก TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
คุณสามารถใช้คำสั่ง `wget` เพื่อดาวน์โหลดโมเดลในไดเร็กทอรีปัจจุบัน
!wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q2_K.ggufที่อยู่ภายนอกสำหรับเซิร์ฟเวอร์ LLaMA
เมื่อเราเรียกใช้เซิร์ฟเวอร์ LLaMA มันจะให้ IP ของโฮสต์ในพื้นที่ซึ่งไม่มีประโยชน์สำหรับเราบน Colab เราต้องการเชื่อมต่อกับพร็อกซี localhost โดยใช้พอร์ตพร็อกซีเคอร์เนล Colab
หลังจากรันโค้ดด้านล่างแล้ว คุณจะได้รับไฮเปอร์ลิงก์ส่วนกลาง เราจะใช้ลิงก์นี้เพื่อเข้าถึงเว็บแอปของเราในภายหลัง
from google.colab.output import eval_js
print(eval_js("google.colab.kernel.proxyPort(6589)"))
https://8fx1nbkv1c8-496ff2e9c6d22116-6589-colab.googleusercontent.com/การรันเซิร์ฟเวอร์
ในการรันเซิร์ฟเวอร์ LLaMA C++ คุณจะต้องจัดเตรียมคำสั่งเซิร์ฟเวอร์พร้อมตำแหน่งของไฟล์โมเดลและหมายเลขพอร์ตที่ถูกต้อง สิ่งสำคัญคือต้องตรวจสอบให้แน่ใจว่าหมายเลขพอร์ตตรงกับที่เราเริ่มต้นในขั้นตอนก่อนหน้าสำหรับพอร์ตพร็อกซี
%cd /content/llama.cpp
!./server -m mixtral-8x7b-instruct-v0.1.Q2_K.gguf -ngl 27 -c 2048 --port 6589
สามารถเข้าถึงเว็บแอปแชทได้โดยการคลิกที่ไฮเปอร์ลิงก์พอร์ตพร็อกซีในขั้นตอนก่อนหน้า เนื่องจากเซิร์ฟเวอร์ไม่ได้ทำงานอยู่ในเครื่อง
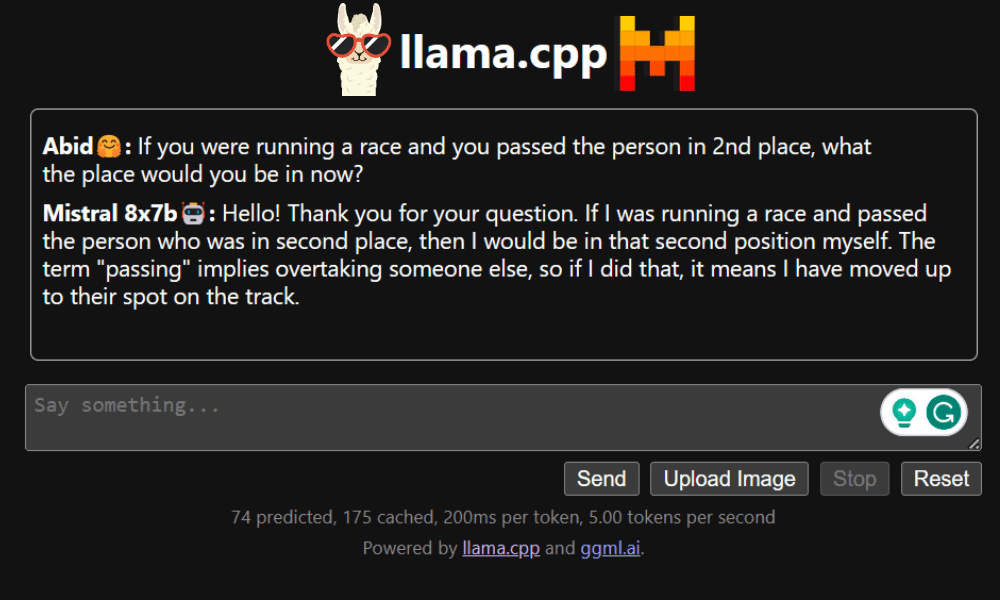
LLaMA C++ เว็บแอป
ก่อนที่เราจะเริ่มใช้แชทบอท เราจำเป็นต้องปรับแต่งมันก่อน แทนที่ “LLaMA” ด้วยชื่อรุ่นของคุณในส่วนข้อความแจ้ง นอกจากนี้ แก้ไขชื่อผู้ใช้และชื่อบอทเพื่อแยกความแตกต่างระหว่างการตอบสนองที่สร้างขึ้น
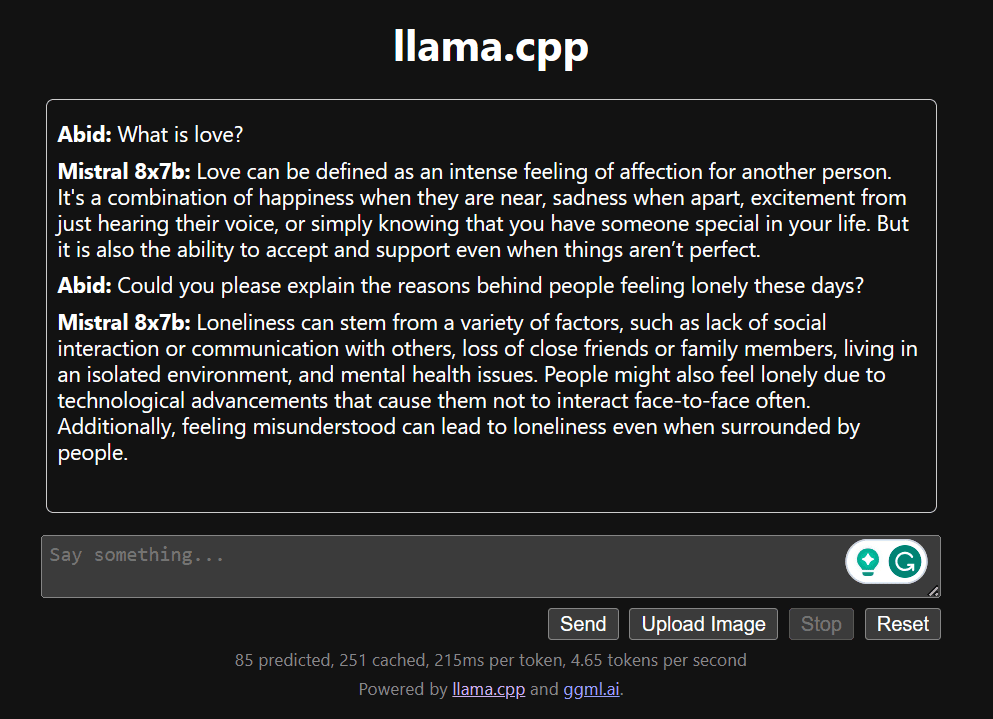
เริ่มแชทโดยเลื่อนลงและพิมพ์ในส่วนแชท อย่าลังเลที่จะถามคำถามทางเทคนิคที่โมเดลโอเพ่นซอร์สอื่นๆ ไม่สามารถตอบได้อย่างถูกต้อง
หากคุณประสบปัญหากับแอป คุณสามารถลองเรียกใช้ด้วยตัวเองโดยใช้ Google Colab ของฉัน: https://colab.research.google.com/drive/1gQ1lpSH-BhbKN-DdBmq5r8-8Rw8q1p9r?usp=sharing
บทช่วยสอนนี้ให้คำแนะนำที่ครอบคลุมเกี่ยวกับวิธีการเรียกใช้โมเดลโอเพ่นซอร์สขั้นสูง Mixtral 8x7b บน Google Colab โดยใช้ไลบรารี LLaMA C++ เมื่อเปรียบเทียบกับรุ่นอื่นๆ Mixtral 8x7b มอบประสิทธิภาพและประสิทธิภาพที่เหนือกว่า ทำให้เป็นโซลูชันที่ยอดเยี่ยมสำหรับผู้ที่ต้องการทดลองใช้โมเดลที่ใช้ภาษาขนาดใหญ่ แต่ไม่มีทรัพยากรในการคำนวณที่กว้างขวาง คุณสามารถเรียกใช้บนแล็ปท็อปของคุณหรือบนระบบคลาวด์ฟรีได้อย่างง่ายดาย มันใช้งานง่ายและคุณยังสามารถปรับใช้แอปแชทของคุณเพื่อให้ผู้อื่นใช้และทดลองด้วยได้
ฉันหวังว่าคุณจะพบว่าวิธีแก้ปัญหาง่ายๆ ในการรันโมเดลขนาดใหญ่นี้มีประโยชน์ ฉันมองหาตัวเลือกที่เรียบง่ายและดีกว่าอยู่เสมอ หากคุณมีวิธีแก้ปัญหาที่ดียิ่งขึ้น โปรดแจ้งให้เราทราบ และเราจะกล่าวถึงในครั้งต่อไป
อาบิด อาลี อาวัน (@1อบีดาลิวัน) เป็นนักวิทยาศาสตร์ข้อมูลที่ได้รับการรับรองมืออาชีพที่รักการสร้างแบบจำลองการเรียนรู้ของเครื่อง ปัจจุบันเขามุ่งเน้นไปที่การสร้างเนื้อหาและการเขียนบล็อกทางเทคนิคเกี่ยวกับการเรียนรู้ของเครื่องและเทคโนโลยีวิทยาศาสตร์ข้อมูล อาบิดสำเร็จการศึกษาระดับปริญญาโทด้านการจัดการเทคโนโลยีและปริญญาตรีสาขาวิศวกรรมโทรคมนาคม วิสัยทัศน์ของเขาคือการสร้างผลิตภัณฑ์ AI โดยใช้โครงข่ายประสาทเทียมแบบกราฟสำหรับนักเรียนที่ป่วยเป็นโรคทางจิต
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://www.kdnuggets.com/running-mixtral-8x7b-on-google-colab-for-free?utm_source=rss&utm_medium=rss&utm_campaign=running-mixtral-8x7b-on-google-colab-for-free
- :เป็น
- :ไม่
- 1
- 12
- 27
- 46
- 7
- 8
- a
- สามารถ
- เข้า
- Accessed
- การบรรลุ
- นอกจากนี้
- ที่อยู่
- สูง
- AI
- ทั้งหมด
- ด้วย
- เสมอ
- am
- an
- และ
- คำตอบ
- อาปาเช่
- app
- การใช้งาน
- เหมาะสม
- สถาปัตยกรรม
- เป็น
- AS
- ถาม
- ตาม
- BE
- เริ่ม
- ด้านล่าง
- มาตรฐาน
- ที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- ปิดกั้น
- Blog
- ธ ปท
- ทั้งสอง
- สร้าง
- การก่อสร้าง
- แต่
- by
- C + +
- ที่เรียกว่า
- CAN
- มีมาตรฐาน
- เปลี่ยนแปลง
- พูดคุย
- chatbot
- การพูดคุย
- เลือก
- เมฆ
- รหัส
- การรวมกัน
- เมื่อเทียบกับ
- เข้ากันได้
- ครอบคลุม
- การคำนวณ
- คำนวณ
- การคำนวณ
- การเชื่อมต่อ
- เนื้อหา
- การสร้างเนื้อหา
- สิ่งแวดล้อม
- แก้ไข
- ราคา
- หน้าปก
- ที่สร้างขึ้น
- การสร้าง
- ปัจจุบัน
- ขณะนี้
- ปรับแต่ง
- ข้อมูล
- วิทยาศาสตร์ข้อมูล
- นักวิทยาศาสตร์ข้อมูล
- องศา
- มอบ
- แสดงให้เห็นถึง
- ปรับใช้
- แม้จะมี
- เห็นความแตกต่าง
- do
- ลง
- ดาวน์โหลด
- แต่ละ
- อย่างง่ายดาย
- อย่างมีประสิทธิภาพ
- ที่มีประสิทธิภาพ
- พบ
- ชั้นเยี่ยม
- ภาษาอังกฤษ
- ช่วย
- แม้
- ยอดเยี่ยม
- ประสบการณ์
- การทดลอง
- ผู้เชี่ยวชาญ
- สำรวจ
- กว้างขวาง
- ใบหน้า
- ล้มเหลว
- เหยี่ยวนกเขา
- เร็วขึ้น
- รู้สึก
- สองสาม
- เนื้อไม่มีมัน
- โดยมุ่งเน้น
- สำหรับ
- พบ
- ฟรี
- ภาษาฝรั่งเศส
- ราคาเริ่มต้นที่
- ฟังก์ชัน
- สร้าง
- รุ่น
- ภาษาเยอรมัน
- ได้รับ
- GitHub
- ให้
- เหตุการณ์ที่
- GPU
- GPUs
- กราฟ
- กราฟโครงข่ายประสาท
- กลุ่ม
- ให้คำแนะนำ
- การจัดการ
- มี
- มี
- he
- เป็นประโยชน์
- จุดสูง
- ประสิทธิภาพสูง
- ที่มีคุณภาพสูง
- ของเขา
- ถือ
- ความหวัง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTTPS
- Hub
- i
- if
- การเจ็บป่วย
- นำเข้า
- สำคัญ
- in
- รวมทั้ง
- ข้อมูล
- ที่ริเริ่ม
- ติดตั้ง
- การติดตั้ง
- อินเตอร์เฟซ
- เข้าไป
- ที่เกี่ยวข้องกับการ
- IP
- ปัญหา
- IT
- ภาษาอิตาลี
- KD นักเก็ต
- ทราบ
- ภาษา
- ภาษา
- แล็ปท็อป
- ใหญ่
- ความแอบแฝง
- ต่อมา
- เรียนรู้
- การเรียนรู้
- ให้
- ห้องสมุด
- ได้รับใบอนุญาต
- มีน้ำหนักเบา
- กดไลก์
- Line
- เส้น
- LINK
- ดูรายละเอียด
- ในท้องถิ่น
- ที่ตั้ง
- ที่ต้องการหา
- รัก
- เครื่อง
- เรียนรู้เครื่อง
- ทำ
- การทำ
- การจัดการ
- การจัดการ
- เจ้านาย
- ที่ตรงกัน
- me
- หน่วยความจำ
- จิต
- จิตเภท
- วิธี
- สารผสม
- แบบ
- โมเดล
- แก้ไข
- ข้อมูลเพิ่มเติม
- มากที่สุด
- หลาย
- my
- ชื่อ
- จำเป็นต้อง
- เครือข่าย
- ประสาท
- เครือข่ายประสาท
- ใหม่
- ถัดไป
- จำนวน
- Nvidia
- of
- on
- ONE
- เปิด
- โอเพนซอร์ส
- การดำเนินงาน
- ระบบปฏิบัติการ
- Options
- or
- อื่นๆ
- ผลิตภัณฑ์อื่นๆ
- ของเรา
- ประสิทธิภาพเหนือกว่า
- เอาท์พุต
- เอาท์พุท
- ของตนเอง
- พารามิเตอร์
- พารามิเตอร์
- PC
- การปฏิบัติ
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- กรุณา
- โพสต์
- ก่อน
- ผลิตภัณฑ์
- มืออาชีพ
- อย่างถูกต้อง
- ให้
- ให้
- หนังสือมอบฉันทะ
- คำถาม
- คำถาม
- พิสัย
- ลดลง
- เกี่ยวกับ
- แทนที่
- กรุ
- การวิจัย
- แหล่งข้อมูล
- การตอบสนอง
- เราเตอร์
- วิ่ง
- วิ่ง
- s
- วิทยาศาสตร์
- นักวิทยาศาสตร์
- คะแนน
- การเลื่อน
- Section
- การเลือก
- เซิร์ฟเวอร์
- ง่าย
- ตั้งแต่
- ทางออก
- แหล่ง
- สเปน
- มาตรฐาน
- รัฐของศิลปะ
- ขั้นตอน
- แข็งแรง
- การดิ้นรน
- นักเรียน
- เหนือกว่า
- รองรับ
- แน่ใจ
- ระบบ
- งาน
- วิชาการ
- เทคโนโลยี
- เทคโนโลยี
- การสื่อสารโทรคมนาคม
- ข้อความ
- การสร้างข้อความ
- ที่
- พื้นที่
- ของพวกเขา
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- นี้
- เหล่านั้น
- เวลา
- ไปยัง
- โทเค็น
- ราชสกุล
- รวม
- การแปลภาษา
- ลอง
- เกี่ยวกับการสอน
- สอง
- ภายใต้
- us
- ใช้
- มือสอง
- ผู้ใช้งาน
- ที่ใช้งานง่าย
- ใช้
- การใช้
- ความหลากหลาย
- ต่างๆ
- รุ่น
- วิสัยทัศน์
- ต้องการ
- we
- เว็บ
- โปรแกรมประยุกต์บนเว็บ
- ที่
- ในขณะที่
- WHO
- กว้าง
- ช่วงกว้าง
- จะ
- กับ
- การเขียน
- เธอ
- ของคุณ
- ลมทะเล