รันไทม์ Amazon EMR สำหรับ Apache Spark เป็นรันไทม์ที่เพิ่มประสิทธิภาพสำหรับ Apache Spark ที่เข้ากันได้กับ API 100% กับ Apache Spark แบบโอเพ่นซอร์ส กับ อเมซอน EMR รีลีส 6.9.0 รันไทม์ EMR สำหรับ Apache Spark รองรับ Spark เวอร์ชัน 3.3.0 ที่เทียบเท่า
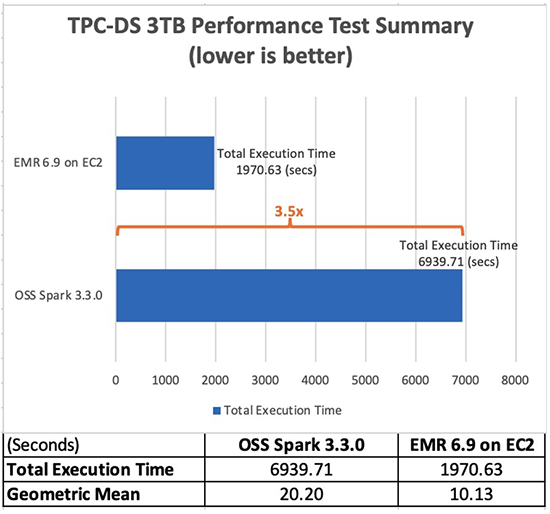
ด้วย Amazon EMR 6.9.0 ตอนนี้คุณสามารถเรียกใช้แอปพลิเคชัน Apache Spark 3.x ได้เร็วขึ้นและมีค่าใช้จ่ายน้อยลงโดยไม่ต้องทำการเปลี่ยนแปลงใดๆ กับแอปพลิเคชันของคุณ ในการทดสอบมาตรฐานประสิทธิภาพของเรา ซึ่งได้มาจากการทดสอบประสิทธิภาพ TPC-DS ที่ระดับ 3 TB เราพบว่ารันไทม์ EMR สำหรับ Apache Spark 3.3.0 ให้การปรับปรุงประสิทธิภาพโดยเฉลี่ย 3.5 เท่า (โดยใช้รันไทม์ทั้งหมด) เมื่อเทียบกับ Apache Spark 3.3.0 แบบโอเพ่นซอร์ส XNUMX.
ในโพสต์นี้ เราวิเคราะห์ผลลัพธ์จากการทดสอบเกณฑ์มาตรฐานของเราที่รันแอปพลิเคชัน TPC-DS Apache Spark แบบโอเพ่นซอร์ส จากนั้นใน Amazon EMR 6.9 ซึ่งมาพร้อมกับรันไทม์ Spark ที่ได้รับการปรับปรุงซึ่งเข้ากันได้กับ Spark แบบโอเพ่นซอร์ส เราดำเนินการวิเคราะห์ต้นทุนโดยละเอียด และสุดท้ายให้คำแนะนำแบบทีละขั้นตอนเพื่อเรียกใช้เกณฑ์มาตรฐาน
ผลลัพธ์ที่สังเกตได้
ในการประเมินการปรับปรุงประสิทธิภาพ เราใช้ยูทิลิตีการทดสอบประสิทธิภาพ Spark แบบโอเพ่นซอร์สซึ่งได้รับมาจากชุดเครื่องมือทดสอบประสิทธิภาพ TPC-DS เราทำการทดสอบบนคลัสเตอร์ EMR c5d.9xlarge XNUMX โหนด (XNUMX โหนดหลักและ XNUMX โหนดหลัก) พร้อมรันไทม์ EMR สำหรับ Apache Spark และคลัสเตอร์จัดการตัวเอง XNUMX โหนดที่สองบน อเมซอน อีลาสติก คอมพิวท์ คลาวด์ (Amazon EC2) ที่มี Spark เวอร์ชันโอเพ่นซอร์สเทียบเท่า เราทำการทดสอบทั้งสองแบบด้วยข้อมูลใน บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (อเมซอน เอส3).
การจัดสรรทรัพยากรแบบไดนามิก (DRA) เป็นคุณลักษณะที่ยอดเยี่ยมสำหรับใช้กับปริมาณงานที่แตกต่างกัน อย่างไรก็ตาม สำหรับแบบฝึกหัดเปรียบเทียบที่เราเปรียบเทียบสองแพลตฟอร์มเฉพาะในด้านประสิทธิภาพ และปริมาณข้อมูลทดสอบไม่เปลี่ยนแปลง (ในกรณีของเราคือ 3 TB) เราเชื่อว่าเป็นการดีที่สุดที่จะหลีกเลี่ยงความแปรปรวนเพื่อเรียกใช้การเปรียบเทียบระหว่างแอปเปิลกับแอปเปิล ในการทดสอบของเราทั้งใน Spark แบบโอเพ่นซอร์สและ Amazon EMR เราได้ปิดใช้งาน DRA ขณะเรียกใช้แอปพลิเคชันการเปรียบเทียบ
ตารางต่อไปนี้แสดงรันไทม์งานทั้งหมดสำหรับการสืบค้นทั้งหมด (เป็นวินาที) ในชุดข้อมูลการสืบค้น 3 TB ระหว่าง Amazon EMR เวอร์ชัน 6.9.0 และ Spark แบบโอเพ่นซอร์สเวอร์ชัน 3.3.0 เราสังเกตเห็นว่าการทดสอบ TPC-DS ของเรามีรันไทม์งานทั้งหมดบน Amazon EMR บน Amazon EC2 ซึ่งเร็วกว่าการใช้คลัสเตอร์ Spark แบบโอเพ่นซอร์สที่มีการกำหนดค่าเดียวกันถึง 3.5 เท่า
การเร่งความเร็วต่อการค้นหาบน Amazon EMR 6.9 ที่มีและไม่มีรันไทม์ EMR สำหรับ Apache Spark แสดงไว้ในแผนภูมิต่อไปนี้ แกนแนวนอนแสดงข้อความค้นหาแต่ละรายการในเกณฑ์มาตรฐานขนาด 3 TB แกนตั้งแสดงการเร่งความเร็วของข้อความค้นหาแต่ละรายการเนื่องจากรันไทม์ EMR การเพิ่มประสิทธิภาพที่โดดเด่นนั้นเร็วขึ้นกว่า 10 เท่าสำหรับการค้นหา TPC-DS 24b, 72, 95 และ 96

การวิเคราะห์ต้นทุน
การปรับปรุงประสิทธิภาพของรันไทม์ EMR สำหรับ Apache Spark ทำให้ต้นทุนลดลงโดยตรง เราสามารถประหยัดต้นทุนได้ 67% ในการเรียกใช้แอปพลิเคชันเกณฑ์มาตรฐานบน Amazon EMR เมื่อเปรียบเทียบกับต้นทุนที่เกิดขึ้นในการเรียกใช้แอปพลิเคชันเดียวกันบน Spark แบบโอเพ่นซอร์สบน Amazon EC2 ด้วยขนาดคลัสเตอร์เดียวกันเนื่องจาก Amazon EMR และ Amazon มีชั่วโมงที่ลดลง การใช้งาน EC2 ราคา Amazon EMR สำหรับแอปพลิเคชัน EMR ที่ทำงานบนคลัสเตอร์ EMR ที่มีอินสแตนซ์ EC2 ราคา Amazon EMR จะเพิ่มให้กับราคาการประมวลผลและพื้นที่จัดเก็บพื้นฐาน เช่น ราคาอินสแตนซ์ EC2 และ ร้านค้า Amazon Elastic Block ค่าใช้จ่าย (Amazon EBS) (หากแนบไดรฟ์ข้อมูล EBS) โดยรวมแล้ว ค่าใช้จ่ายเปรียบเทียบโดยประมาณในสหรัฐอเมริกาฝั่งตะวันออก (เวอร์จิเนียเหนือ) คือ 27.01 ดอลลาร์ต่อการเรียกใช้ Spark แบบโอเพ่นซอร์สบน Amazon EC2 และ 8.82 ดอลลาร์ต่อการเรียกใช้สำหรับ Amazon EMR
| เกณฑ์มาตรฐานงาน | รันไทม์ (ชั่วโมง) | ค่าใช้จ่ายโดยประมาณ | อินสแตนซ์ EC2 ทั้งหมด | รวม vCPU | หน่วยความจำทั้งหมด (GiB) | อุปกรณ์รูท (Amazon EBS) |
|
Spark แบบโอเพ่นซอร์สบน Amazon EC2 (1 โหนดหลักและ 6 โหนดหลัก) |
2.23 | $27.01 | 7 | 252 | 504 | 20 กิกะไบต์ gp2 |
|
Amazon EMR บน Amazon EC2 (1 โหนดหลักและ 6 โหนดหลัก) |
0.63 | $8.82 | 7 | 252 | 504 | 20 กิกะไบต์ gp2 |
การวิเคราะห์ต้นทุน
ต่อไปนี้คือรายละเอียดค่าใช้จ่ายสำหรับงาน Open-source Spark บน Amazon EC2 ($27.01):
- ค่าใช้จ่ายทั้งหมดของ Amazon EC2 – (7 * $1.728 * 2.23) = (จำนวนอินสแตนซ์ * อัตรารายชั่วโมง c5d.9xlarge * รันไทม์งานเป็นชั่วโมง) = 26.97 ดอลลาร์
- ค่าใช้จ่ายของ Amazon EBS – (0.1 USD/730 * 20 * 7 * 2.23) = (Amazon EBS ต่ออัตรา GB ต่อชั่วโมง * ขนาดรูท EBS * จำนวนอินสแตนซ์ * รันไทม์งานเป็นชั่วโมง) = 0.042 USD
ต่อไปนี้คือรายละเอียดค่าใช้จ่ายสำหรับ Amazon EMR ในงาน Amazon EC2 ($8.82):
- ค่าใช้จ่ายทั้งหมดของ Amazon EMR – (7 * 0.27 USD * 0.63) = ((จำนวนโหนดหลัก + จำนวนโหนดหลัก)* ราคา Amazon EMR c5d.9xlarge * รันไทม์งานเป็นชั่วโมง) = 1.19 USD
- ค่าใช้จ่ายทั้งหมดของ Amazon EC2 – (7 * 1.728 USD * 0.63) = ((จำนวนโหนดหลัก + จำนวนโหนดหลัก)* ราคาอินสแตนซ์ c5d.9xlarge * รันไทม์งานเป็นชั่วโมง) = 7.62 USD
- ค่าใช้จ่ายของ Amazon EBS – (0.1 USD/730 * 20 GiB * 7 * 0.63) = (Amazon EBS ต่อ GB ต่อชั่วโมง * ขนาด EBS * จำนวนอินสแตนซ์ * รันไทม์งานเป็นชั่วโมง) = 0.012 USD
ตั้งค่าการเปรียบเทียบ OSS Spark
ในส่วนต่อไปนี้ เราได้จัดเตรียมโครงร่างโดยย่อของขั้นตอนที่เกี่ยวข้องในการตั้งค่าการเปรียบเทียบ สำหรับคำแนะนำโดยละเอียดพร้อมตัวอย่าง โปรดดูที่ repo GitHub.
สำหรับการวัดประสิทธิภาพ OSS Spark เราใช้เครื่องมือโอเพ่นซอร์ส ฟลินท์ร็อค เพื่อเปิดตัวบนพื้นฐาน Amazon EC2 ของเรา Apache Spark กลุ่ม. Flintrock มีวิธีที่รวดเร็วในการเปิดใช้คลัสเตอร์ Apache Spark บน Amazon EC2 โดยใช้บรรทัดคำสั่ง
เบื้องต้น
ทำตามขั้นตอนข้อกำหนดเบื้องต้นต่อไปนี้:
- มี Python 3.7.x ขึ้นไป
- มี Pip3 22.2.2 ขึ้นไป
- เพิ่มไดเร็กทอรี Python bin ไปยังเส้นทางสภาพแวดล้อมของคุณ ไบนารี Flintrock จะถูกติดตั้งในเส้นทางนี้
- วิ่ง
aws configureเพื่อกำหนดค่าของคุณ อินเทอร์เฟซบรรทัดคำสั่ง AWS AWS (AWS CLI) เชลล์เพื่อชี้ไปที่บัญชีการเปรียบเทียบ อ้างถึง การกำหนดค่าอย่างรวดเร็วด้วย aws configuration สำหรับคำแนะนำ - มี คู่กุญแจ ด้วยสิทธิ์ไฟล์ที่จำกัดในการเข้าถึงโหนดหลัก OSS Spark
- สร้างบัคเก็ต S3 ใหม่ในบัญชีทดสอบของคุณ หากจำเป็น
- คัดลอกข้อมูลต้นทาง TPC-DS เป็นอินพุตไปยังบัคเก็ต S3 ของคุณ
- สร้างแอปพลิเคชันเกณฑ์มาตรฐานตามขั้นตอนที่ให้ไว้ใน ขั้นตอนในการสร้างแอปพลิเคชันชุดประกอบมาตรฐานจุดประกาย. หรือคุณสามารถดาวน์โหลดที่สร้างไว้ล่วงหน้า spark-benchmark-assembly-3.3.0.jar หากคุณต้องการแอปพลิเคชันที่ใช้ Spark 3.3.0
ปรับใช้คลัสเตอร์ Spark และเรียกใช้งานเกณฑ์มาตรฐาน
ทำตามขั้นตอนต่อไปนี้:
- ติดตั้งเครื่องมือ Flintrock ผ่าน pip ตามที่แสดงใน ขั้นตอนในการตั้งค่า OSS Spark Benchmarking.
- เรียกใช้คำสั่ง flintrock configuration ซึ่งจะแสดงไฟล์การกำหนดค่าเริ่มต้นขึ้นมา
- แก้ไขค่าเริ่มต้น
config.yamlไฟล์ตามความต้องการของคุณ หรือคัดลอกและวาง ไฟล์ config.yaml เนื้อหาไปยังไฟล์กำหนดค่าเริ่มต้น จากนั้นบันทึกไฟล์ไว้ที่เดิม - สุดท้าย เปิดใช้งานคลัสเตอร์ Spark 7 โหนดบน Amazon EC2 ผ่าน Flintrock
สิ่งนี้ควรสร้างคลัสเตอร์ Spark ที่มีโหนดหลักหนึ่งโหนดและโหนดผู้ปฏิบัติงานหกโหนด หากคุณเห็นข้อความแสดงข้อผิดพลาด ให้ตรวจสอบค่าไฟล์กำหนดค่าอีกครั้ง โดยเฉพาะเวอร์ชัน Spark และ Hadoop และแอตทริบิวต์ของแหล่งดาวน์โหลดและ AMI
คลัสเตอร์ OSS Spark ไม่ได้มาพร้อมกับตัวจัดการทรัพยากร YARN ในการเปิดใช้งาน เราจำเป็นต้องกำหนดค่าคลัสเตอร์
- ดาวน์โหลด เส้นด้าย-site.xml และ เปิดใช้งาน-yarn.sh ไฟล์จาก repo GitHub
- แทนที่ ด้วยที่อยู่ IP ของโหนดหลักในคลัสเตอร์ Flintrock ของคุณ
คุณสามารถเรียกที่อยู่ IP ได้จากคอนโซล Amazon EC2
- อัปโหลดไฟล์ไปยังโหนดทั้งหมดของคลัสเตอร์ Spark
- รันสคริปต์ enable-yarn
- เปิดใช้งานการสนับสนุน Snappy ใน Hadoop (งานเกณฑ์มาตรฐานอ่านข้อมูลที่บีบอัดของ Snappy)
- ดาวน์โหลดไฟล์ JAR ของแอปพลิเคชันยูทิลิตีเกณฑ์มาตรฐาน spark-benchmark-assembly-3.3.0.jar ไปยังเครื่องท้องถิ่นของคุณ
- คัดลอกไฟล์นี้ไปยังคลัสเตอร์
- ล็อกอินเข้าสู่โหนดหลักและเริ่ม YARN
- ส่งงานเกณฑ์มาตรฐานบนคลัสเตอร์ Spark แบบโอเพ่นซอร์สตามที่แสดงใน ส่งงานเกณฑ์มาตรฐาน.
สรุปผล
ดาวน์โหลดไฟล์ผลการทดสอบจากบัคเก็ต S3 เอาต์พุต s3://$YOUR_S3_BUCKET/EC2_TPCDS-TEST-3T-RESULT/timestamp=xxxx/summary.csv/xxx.csv. (แทนที่ $YOUR_S3_BUCKET ด้วยชื่อบัคเก็ต S3 ของคุณ) คุณสามารถใช้คอนโซล Amazon S3 และนำทางไปยังตำแหน่งเอาต์พุต S3 หรือใช้ AWS CLI
แอปพลิเคชันเกณฑ์มาตรฐาน Spark สร้างโฟลเดอร์ประทับเวลาและเขียนไฟล์สรุปภายในคำนำหน้า summary.csv การประทับเวลาและชื่อไฟล์ของคุณจะแตกต่างจากที่แสดงในตัวอย่างก่อนหน้านี้
ไฟล์ CSV เอาต์พุตมีสี่คอลัมน์โดยไม่มีชื่อส่วนหัว พวกเขาคือ:
- ชื่อแบบสอบถาม
- เวลามัธยฐาน
- เวลาขั้นต่ำ
- เวลาสูงสุด
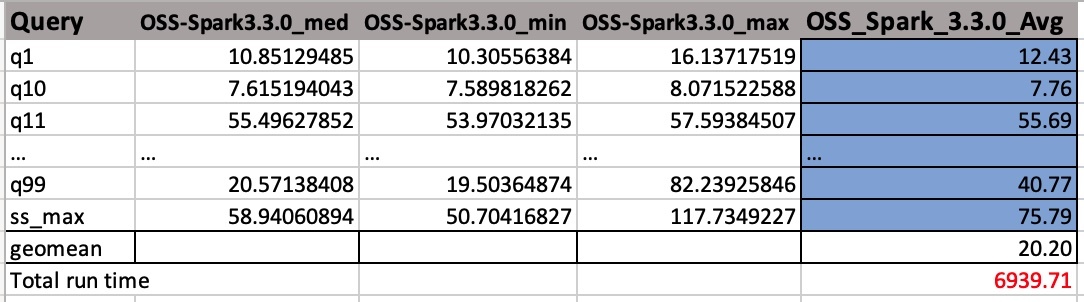
ภาพหน้าจอต่อไปนี้แสดงผลลัพธ์ตัวอย่าง เราได้เพิ่มชื่อคอลัมน์ด้วยตนเอง วิธีที่เราคำนวณค่าเฉลี่ยทางภูมิศาสตร์และรันไทม์ของงานทั้งหมดนั้นขึ้นอยู่กับค่าเฉลี่ยเลขคณิต ก่อนอื่นเราจะหาค่าเฉลี่ยของค่า med, min และ max โดยใช้สูตร AVERAGE(B2:D2) จากนั้นเราจะหาค่าเฉลี่ยทางเรขาคณิตของคอลัมน์ Avg โดยใช้สูตร GEOMEAN(E2:E105)
ตั้งค่าการเปรียบเทียบ Amazon EMR
สำหรับคำแนะนำโดยละเอียด โปรดดูที่ ขั้นตอนในการตั้งค่าการเปรียบเทียบ EMR.
เบื้องต้น
ทำตามขั้นตอนข้อกำหนดเบื้องต้นต่อไปนี้:
- วิ่ง
aws configureเพื่อกำหนดค่าเชลล์ AWS CLI ของคุณให้ชี้ไปที่บัญชีการเปรียบเทียบ อ้างถึง การกำหนดค่าอย่างรวดเร็วด้วย aws configuration สำหรับคำแนะนำ - อัปโหลดแอปพลิเคชันเกณฑ์มาตรฐานไปยัง Amazon S3
ปรับใช้คลัสเตอร์ EMR และเรียกใช้งานการวัดประสิทธิภาพ
ทำตามขั้นตอนต่อไปนี้:
- หมุน Amazon EMR ในเชลล์ AWS CLI ของคุณโดยใช้บรรทัดคำสั่งตามที่แสดงใน ปรับใช้ EMR Cluster และเรียกใช้งานเกณฑ์มาตรฐาน.
- กำหนดค่า Amazon EMR ด้วยโหนดหลักหนึ่งโหนด (c5d.9xlarge) และหกคอร์ (c5d.9xlarge) อ้างถึง สร้างคลัสเตอร์ สำหรับคำอธิบายโดยละเอียดของตัวเลือก AWS CLI
- เก็บ ID คลัสเตอร์จากการตอบกลับ คุณต้องการสิ่งนี้ในขั้นตอนถัดไป
- ส่งงานเปรียบเทียบใน Amazon EMR โดยใช้ขั้นตอนเพิ่มเติมใน AWS CLI
สรุปผล
สรุปผลลัพธ์จากที่ฝากข้อมูลเอาต์พุต s3://$YOUR_S3_BUCKET/blog/EMRONEC2_TPCDS-TEST-3T-RESULT ในลักษณะเดียวกับที่เราทำสำหรับผลลัพธ์ OSS และเปรียบเทียบ
ทำความสะอาด
เพื่อหลีกเลี่ยงค่าใช้จ่ายในอนาคต ให้ลบทรัพยากรที่คุณสร้างขึ้นโดยใช้คำแนะนำใน ส่วนการล้างข้อมูลของ repo GitHub.
- หยุดคลัสเตอร์ EMR และ OSS Spark คุณสามารถลบออกได้หากคุณไม่ต้องการเก็บรักษาเนื้อหาไว้ คุณสามารถลบทรัพยากรเหล่านี้ได้โดยการเรียกใช้สคริปต์ การล้างเกณฑ์มาตรฐาน env.sh จากเทอร์มินัลในสภาพแวดล้อมมาตรฐานของคุณ
- ถ้าคุณใช้ AWS Cloud9 เป็น IDE ของคุณสำหรับสร้างไฟล์ JAR ของแอปพลิเคชันเกณฑ์มาตรฐานโดยใช้ ขั้นตอนในการสร้างแอปพลิเคชันชุดประกอบมาตรฐานจุดประกายคุณอาจต้องการลบสภาพแวดล้อมด้วย
สรุป
คุณสามารถเรียกใช้ปริมาณงาน Apache Spark ได้ 3.5 เท่า (ขึ้นอยู่กับรันไทม์ทั้งหมด) เร็วขึ้นและมีค่าใช้จ่ายที่ต่ำลงโดยไม่ต้องทำการเปลี่ยนแปลงใดๆ กับแอปพลิเคชันของคุณโดยใช้ Amazon EMR 6.9.0
เพื่อให้ทันสมัย สมัครสมาชิกบล็อกข้อมูลขนาดใหญ่ ฟีด RSS เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับรันไทม์ EMR สำหรับ Apache Spark แนวทางปฏิบัติที่ดีที่สุดในการกำหนดค่า และคำแนะนำในการปรับแต่ง
สำหรับการทดสอบเกณฑ์มาตรฐานที่ผ่านมา โปรดดูที่ เรียกใช้ปริมาณงาน Apache Spark 3.0 เร็วขึ้น 1.7 เท่าด้วยรันไทม์ Amazon EMR สำหรับ Apache Spark. โปรดทราบว่าผลการเปรียบเทียบประสิทธิภาพที่ผ่านมา 1.7 เท่านั้นขึ้นอยู่กับค่าเฉลี่ยทางเรขาคณิต ตามค่าเฉลี่ยเรขาคณิต ประสิทธิภาพใน Amazon EMR 6.9 เร็วขึ้นสองเท่า
เกี่ยวกับผู้แต่ง
 เสการ์ ศรีนิวาสัน เป็น Sr. Specialist Solutions Architect ที่ AWS ที่เน้นเรื่อง Big Data และ Analytics Sekar มีประสบการณ์มากกว่า 20 ปีในการทำงานกับข้อมูล เขาหลงใหลในการช่วยลูกค้าสร้างโซลูชันที่ปรับขนาดได้ซึ่งปรับปรุงสถาปัตยกรรมของพวกเขาให้ทันสมัยและสร้างข้อมูลเชิงลึกจากข้อมูลของพวกเขา ในเวลาว่าง เขาชอบทำงานในโครงการที่ไม่แสวงหาผลกำไร โดยเฉพาะอย่างยิ่งโครงการที่เน้นการศึกษาของเด็กด้อยโอกาส
เสการ์ ศรีนิวาสัน เป็น Sr. Specialist Solutions Architect ที่ AWS ที่เน้นเรื่อง Big Data และ Analytics Sekar มีประสบการณ์มากกว่า 20 ปีในการทำงานกับข้อมูล เขาหลงใหลในการช่วยลูกค้าสร้างโซลูชันที่ปรับขนาดได้ซึ่งปรับปรุงสถาปัตยกรรมของพวกเขาให้ทันสมัยและสร้างข้อมูลเชิงลึกจากข้อมูลของพวกเขา ในเวลาว่าง เขาชอบทำงานในโครงการที่ไม่แสวงหาผลกำไร โดยเฉพาะอย่างยิ่งโครงการที่เน้นการศึกษาของเด็กด้อยโอกาส
 พระบุระวิจันทร์ เป็นสถาปนิกข้อมูลอาวุโสของ Amazon Web Services โดยมุ่งเน้นที่ Analytics สถาปัตยกรรม data Lake และการนำไปใช้งาน เขาช่วยลูกค้าออกแบบและสร้างโซลูชันที่ปรับขนาดได้และแข็งแกร่งโดยใช้บริการของ AWS ในเวลาว่าง ปราบูชอบท่องเที่ยวและใช้เวลากับครอบครัว
พระบุระวิจันทร์ เป็นสถาปนิกข้อมูลอาวุโสของ Amazon Web Services โดยมุ่งเน้นที่ Analytics สถาปัตยกรรม data Lake และการนำไปใช้งาน เขาช่วยลูกค้าออกแบบและสร้างโซลูชันที่ปรับขนาดได้และแข็งแกร่งโดยใช้บริการของ AWS ในเวลาว่าง ปราบูชอบท่องเที่ยวและใช้เวลากับครอบครัว
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/run-apache-spark-workloads-3-5-times-faster-with-amazon-emr-6-9/
- 1
- 10
- 100
- 1040
- 7
- 9
- a
- สามารถ
- เกี่ยวกับเรา
- ข้างบน
- เข้า
- ลงชื่อเข้าใช้
- ที่เพิ่ม
- ที่อยู่
- คำแนะนำ
- ทั้งหมด
- การจัดสรร
- อเมซอน
- Amazon EC2
- อเมซอน EMR
- Amazon Web Services
- การวิเคราะห์
- การวิเคราะห์
- วิเคราะห์
- และ
- อาปาเช่
- Apache Spark
- API
- การใช้งาน
- การใช้งาน
- สถาปัตยกรรม
- แอตทริบิวต์
- เฉลี่ย
- AVG
- AWS
- แกน
- ตาม
- เชื่อ
- มาตรฐาน
- ที่ดีที่สุด
- ปฏิบัติที่ดีที่สุด
- ระหว่าง
- ใหญ่
- ข้อมูลขนาดใหญ่
- ปิดกั้น
- รายละเอียด
- สร้าง
- การก่อสร้าง
- กรณี
- เปลี่ยนแปลง
- การเปลี่ยนแปลง
- โหลด
- แผนภูมิ
- Cluster
- คอลัมน์
- คอลัมน์
- อย่างไร
- เปรียบเทียบ
- การเปรียบเทียบ
- เข้ากันได้
- คำนวณ
- องค์ประกอบ
- ปลอบใจ
- เนื้อหา
- แกน
- ราคา
- ประหยัดค่าใช้จ่าย
- ค่าใช้จ่าย
- สร้าง
- ที่สร้างขึ้น
- สร้าง
- ลูกค้า
- ข้อมูล
- ดาต้าเลค
- วันที่
- ค่าเริ่มต้น
- ที่ได้มา
- ลักษณะ
- รายละเอียด
- เครื่อง
- DID
- ต่าง
- โดยตรง
- พิการ
- ไม่
- Dont
- ดาวน์โหลด
- แต่ละ
- ตะวันออก
- EBS
- การศึกษา
- ทำให้สามารถ
- สิ่งแวดล้อม
- เท่ากัน
- ความผิดพลาด
- โดยเฉพาะอย่างยิ่ง
- ประมาณ
- อีเธอร์ (ETH)
- ประเมินค่า
- ตัวอย่าง
- ตัวอย่าง
- การออกกำลังกาย
- ประสบการณ์
- ครอบครัว
- เร็วขึ้น
- ลักษณะ
- เนื้อไม่มีมัน
- ไฟล์
- ในที่สุด
- ชื่อจริง
- มุ่งเน้น
- เน้น
- ดังต่อไปนี้
- สูตร
- พบ
- ฟรี
- ราคาเริ่มต้นที่
- อนาคต
- กําไร
- การสร้าง
- GitHub
- ยิ่งใหญ่
- Hadoop
- การช่วยเหลือ
- จะช่วยให้
- ตามแนวนอน
- ชั่วโมง
- อย่างไรก็ตาม
- HTML
- HTTPS
- การดำเนินงาน
- การปรับปรุง
- การปรับปรุง
- in
- อินพุต
- ข้อมูลเชิงลึก
- ตัวอย่าง
- คำแนะนำการใช้
- ร่วมมือ
- IP
- ที่อยู่ IP
- IT
- การสัมภาษณ์
- เก็บ
- ทะเลสาบ
- เปิดตัว
- เรียนรู้
- Line
- ในประเทศ
- ที่ตั้ง
- เครื่อง
- การทำ
- ผู้จัดการ
- ลักษณะ
- ด้วยมือ
- แม็กซ์
- วิธี
- หน่วยความจำ
- ข้อความ
- ข้อมูลเพิ่มเติม
- ชื่อ
- ชื่อ
- นำทาง
- จำเป็นต้อง
- จำเป็น
- ความต้องการ
- ใหม่
- ถัดไป
- ปม
- โหนด
- ไม่แสวงหาผลกำไร
- โดดเด่น
- จำนวน
- ONE
- โอเพนซอร์ส
- การปรับให้เหมาะสม
- Options
- ใบสั่ง
- เรา
- เค้าโครง
- ทั้งหมด
- หลงใหล
- อดีต
- เส้นทาง
- การปฏิบัติ
- สิทธิ์
- แพลตฟอร์ม
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- จุด
- Pops
- โพสต์
- การปฏิบัติ
- ราคา
- ราคา
- การตั้งราคา
- ประถม
- ส่วนตัว
- โครงการ
- ให้
- ให้
- ให้
- หมดจด
- หลาม
- รวดเร็ว
- คะแนน
- ตระหนักถึง
- ลดลง
- ภูมิภาค
- ปล่อย
- แทนที่
- ทรัพยากร
- แหล่งข้อมูล
- คำตอบ
- คับแคบ
- ผล
- ผลสอบ
- แข็งแรง
- ราก
- วิ่ง
- วิ่ง
- เดียวกัน
- ลด
- เงินออม
- ที่ปรับขนาดได้
- ขนาด
- ที่สอง
- วินาที
- Section
- ส่วน
- ระดับอาวุโส
- บริการ
- การตั้งค่า
- การติดตั้ง
- เปลือก
- น่า
- แสดง
- แสดงให้เห็นว่า
- ง่าย
- หก
- ขนาด
- โซลูชัน
- แหล่ง
- จุดประกาย
- ผู้เชี่ยวชาญ
- การใช้จ่าย
- เริ่มต้น
- ขั้นตอน
- ขั้นตอน
- การเก็บรักษา
- สมัครเป็นสมาชิก
- อย่างเช่น
- สรุป
- สนับสนุน
- รองรับ
- ตาราง
- เอา
- สถานีปลายทาง
- ทดสอบ
- การทดสอบ
- พื้นที่
- ของพวกเขา
- ตลอด
- เวลา
- ครั้ง
- การประทับเวลา
- ไปยัง
- เครื่องมือ
- เครื่องมือ
- รวม
- แปลความ
- การเดินทาง
- พื้นฐาน
- ผู้ด้อยโอกาส
- us
- การใช้
- ใช้
- ประโยชน์
- ความคุ้มค่า
- รุ่น
- ผ่านทาง
- virginia
- ไดรฟ์
- เว็บ
- บริการเว็บ
- ที่
- ในขณะที่
- จะ
- ไม่มี
- งาน
- ผู้ปฏิบัติงาน
- การทำงาน
- X
- XML
- มันแกว
- ปี
- ของคุณ
- ลมทะเล