ระบบปัญญาประดิษฐ์ (AI) ที่สร้างขึ้นใหม่โดยอิงจากการเรียนรู้เชิงลึก (DRL) สามารถตอบสนองต่อผู้โจมตีในสภาพแวดล้อมจำลองและบล็อก 95% ของการโจมตีทางไซเบอร์ก่อนที่จะบานปลาย
นั่นเป็นไปตามที่นักวิจัยจากห้องทดลองแห่งชาติแปซิฟิกตะวันตกเฉียงเหนือของกระทรวงพลังงาน ซึ่งสร้างการจำลองเชิงนามธรรมของความขัดแย้งทางดิจิทัลระหว่างผู้โจมตีและผู้ปกป้องในเครือข่าย และฝึกเครือข่ายประสาท DRL ที่แตกต่างกันสี่เครือข่ายเพื่อเพิ่มผลตอบแทนสูงสุดโดยพิจารณาจากการป้องกันการประนีประนอมและลดการหยุดชะงักของเครือข่าย
ผู้โจมตีจำลองใช้ชุดกลยุทธ์ตาม MITER ATT&CK การจำแนกประเภทของเฟรมเวิร์กเพื่อย้ายจากระยะการเข้าถึงเริ่มต้นและการลาดตระเวนไปยังระยะการโจมตีอื่น ๆ จนกว่าจะบรรลุเป้าหมาย: ระยะผลกระทบและการกรอง
การฝึกอบรมระบบ AI ที่ประสบความสำเร็จในสภาพแวดล้อมการโจมตีแบบง่ายแสดงให้เห็นว่าการตอบสนองเชิงป้องกันต่อการโจมตีแบบเรียลไทม์สามารถจัดการได้ด้วยแบบจำลอง AI กล่าว Samrat Chatterjee นักวิทยาศาสตร์ข้อมูลที่นำเสนอผลงานของทีมในการประชุมประจำปีของสมาคมเพื่อ ความก้าวหน้าของปัญญาประดิษฐ์ในกรุงวอชิงตัน ดีซี เมื่อวันที่ 14 กุมภาพันธ์
“คุณคงไม่อยากเปลี่ยนไปใช้สถาปัตยกรรมที่ซับซ้อนกว่านี้ ถ้าคุณไม่สามารถแสดงเทคนิคเหล่านี้ให้เป็นจริงได้” เขากล่าว “เราต้องการแสดงให้เห็นว่าเราสามารถฝึก DRL ได้สำเร็จและแสดงผลการทดสอบที่ดีก่อนที่จะดำเนินการต่อ”
การประยุกต์ใช้เทคนิคแมชชีนเลิร์นนิงและปัญญาประดิษฐ์กับสาขาต่างๆ ภายในความปลอดภัยทางไซเบอร์ได้กลายเป็นเทรนด์ร้อนแรงในช่วงทศวรรษที่ผ่านมา ตั้งแต่การรวมการเรียนรู้ของเครื่องเข้ากับเกตเวย์ความปลอดภัยอีเมลในช่วงแรกๆ ในช่วงต้น 2010 เพื่อความพยายามล่าสุดที่จะ ใช้ ChatGPT เพื่อวิเคราะห์โค้ด หรือทำการวิเคราะห์ทางนิติวิทยาศาสตร์ ตอนนี้, ผลิตภัณฑ์รักษาความปลอดภัยส่วนใหญ่มี — หรืออ้างว่ามี — คุณลักษณะบางอย่างที่ขับเคลื่อนโดยอัลกอริทึมการเรียนรู้ของเครื่องที่ได้รับการฝึกฝนในชุดข้อมูลขนาดใหญ่
อย่างไรก็ตาม การสร้างระบบ AI ที่สามารถป้องกันเชิงรุกยังคงเป็นแรงบันดาลใจมากกว่าที่จะนำไปใช้ได้จริง ในขณะที่นักวิจัยยังคงมีอุปสรรคมากมาย แต่การวิจัยของ PNNL แสดงให้เห็นว่าผู้พิทักษ์ AI อาจเป็นไปได้ในอนาคต
“การประเมินอัลกอริธึม DRL หลายชุดที่ได้รับการฝึกฝนภายใต้การตั้งค่าของฝ่ายตรงข้ามที่หลากหลายเป็นขั้นตอนสำคัญสู่โซลูชันการป้องกันทางไซเบอร์แบบอัตโนมัติที่ใช้งานได้จริง” ทีมวิจัย PNNL ระบุไว้ในเอกสารของพวกเขา. “การทดลองของเราชี้ให้เห็นว่าอัลกอริธึม DRL แบบไม่มีโมเดลสามารถฝึกฝนได้อย่างมีประสิทธิภาพภายใต้โปรไฟล์การโจมตีหลายขั้นตอนด้วยทักษะและระดับความคงทนที่แตกต่างกัน ทำให้ได้ผลลัพธ์การป้องกันที่ดีในสภาพแวดล้อมที่มีการแข่งขัน”
ระบบใช้ MITER ATT&CK อย่างไร
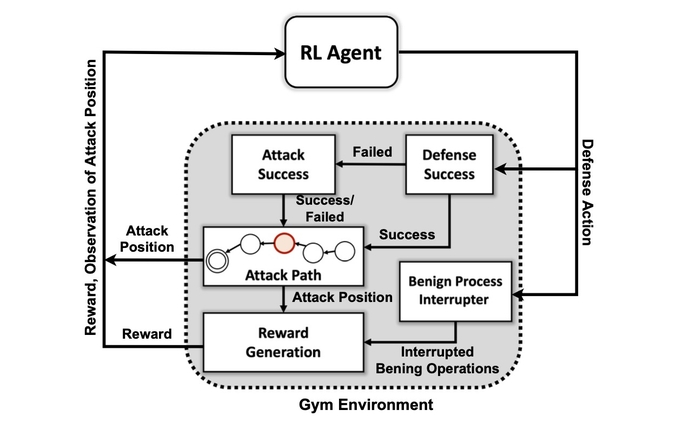
เป้าหมายแรกของทีมวิจัยคือการสร้างสภาพแวดล้อมการจำลองแบบกำหนดเองโดยใช้ชุดเครื่องมือโอเพ่นซอร์สที่รู้จักกันในชื่อ เปิด AI ยิม. เมื่อใช้สภาพแวดล้อมดังกล่าว นักวิจัยได้สร้างตัวตนของผู้โจมตีที่มีทักษะและระดับความคงอยู่ที่แตกต่างกัน พร้อมด้วยความสามารถในการใช้ชุดย่อยของ 7 กลยุทธ์และ 15 เทคนิคจากกรอบ MITER ATT&CK
เป้าหมายของเจ้าหน้าที่ผู้โจมตีคือการก้าวผ่านเจ็ดขั้นตอนของห่วงโซ่การโจมตี ตั้งแต่การเข้าถึงเริ่มต้นไปจนถึงการดำเนินการ จากการคงอยู่ไปจนถึงคำสั่งและการควบคุม และจากการรวบรวมไปจนถึงผลกระทบ
Chatterjee จาก PNNL กล่าวว่าสำหรับผู้โจมตี การปรับกลยุทธ์ให้เข้ากับสภาพแวดล้อมและการกระทำในปัจจุบันของผู้ป้องกันอาจมีความซับซ้อน
“ฝ่ายตรงข้ามต้องนำทางจากสถานะการลาดตระเวนเริ่มต้นไปจนถึงสถานะการสกัดกั้นหรือผลกระทบ” เขากล่าว “เราไม่ได้พยายามสร้างแบบจำลองเพื่อหยุดยั้งศัตรูก่อนที่พวกมันจะเข้าสู่สภาพแวดล้อม — เราคิดว่าระบบถูกบุกรุกแล้ว”
นักวิจัยใช้วิธีสี่วิธีในการสร้างโครงข่ายประสาทเทียมโดยอาศัยการเรียนรู้แบบเสริมแรง Reinforcement Learning (RL) เป็นวิธีการเรียนรู้ของเครื่องที่เลียนแบบระบบการให้รางวัลของสมองมนุษย์ โครงข่ายประสาทเทียมเรียนรู้โดยการเพิ่มหรือลดค่าพารามิเตอร์บางอย่างสำหรับเซลล์ประสาทแต่ละตัวเพื่อให้รางวัลแก่โซลูชันที่ดีกว่า โดยวัดจากคะแนนที่บ่งชี้ว่าระบบทำงานได้ดีเพียงใด
Mahantesh Halappanavar นักวิจัยของ PNNL และผู้เขียนบทความกล่าวว่า การเรียนรู้แบบเสริมแรงจะช่วยให้คอมพิวเตอร์สร้างแนวทางที่ดี แต่ไม่สมบูรณ์แบบ
“โดยไม่ต้องใช้การเรียนรู้เสริมแรง เรายังคงทำได้ แต่มันจะเป็นปัญหาใหญ่ที่จะไม่มีเวลาพอที่จะคิดหากลไกที่ดี” เขากล่าว “การวิจัยของเรา … ให้กลไกนี้แก่เราซึ่งการเรียนรู้แบบเสริมแรงในเชิงลึกเป็นการเลียนแบบพฤติกรรมของมนุษย์ในระดับหนึ่ง และสามารถสำรวจพื้นที่อันกว้างใหญ่นี้ได้อย่างมีประสิทธิภาพมาก”
ไม่พร้อมสำหรับไพรม์ไทม์
การทดลองพบว่าวิธีการเรียนรู้แบบเสริมกำลังเฉพาะที่เรียกว่า Deep Q Network ได้สร้างวิธีแก้ปัญหาที่แข็งแกร่งสำหรับปัญหาการป้องกัน จับผู้โจมตีได้ 97% ในชุดข้อมูลการทดสอบ การวิจัยยังเป็นเพียงจุดเริ่มต้นเท่านั้น ผู้เชี่ยวชาญด้านความปลอดภัยไม่ควรมองหาเพื่อน AI เพื่อช่วยพวกเขาในการตอบสนองต่อเหตุการณ์และนิติเวชในเร็ว ๆ นี้
ในบรรดาปัญหามากมายที่ยังคงต้องแก้ไขคือการได้รับการเรียนรู้แบบเสริมแรงและโครงข่ายประสาทเทียมเชิงลึกเพื่ออธิบายปัจจัยที่มีอิทธิพลต่อการตัดสินใจของพวกเขา ซึ่งเป็นงานวิจัยที่เรียกว่าการเรียนรู้การเสริมแรงแบบอธิบายได้ (XRL)
นอกจากนี้ ความแข็งแกร่งของอัลกอริทึม AI และการค้นหาวิธีที่มีประสิทธิภาพในการฝึกอบรมโครงข่ายประสาทเทียมต่างก็เป็นปัญหาที่ต้องแก้ไขเช่นกัน Chatterjee จาก PNNL กล่าว
“การสร้างผลิตภัณฑ์—นั่นไม่ใช่แรงจูงใจหลักสำหรับการวิจัยนี้” เขากล่าว "นี่เป็นเรื่องเกี่ยวกับการทดลองทางวิทยาศาสตร์และการค้นพบอัลกอริทึม"
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://www.darkreading.com/emerging-tech/researchers-create-ai-cyber-defender-that-reacts-to-attackers
- 7
- 95%
- a
- ความสามารถ
- เกี่ยวกับเรา
- บทคัดย่อ
- เข้า
- ตาม
- การปฏิบัติ
- จริง
- นอกจากนี้
- ความก้าวหน้า
- ขัดแย้ง
- ตัวแทน
- AI
- ขับเคลื่อนด้วย AI
- อัลกอริทึม
- อัลกอริทึม
- ทั้งหมด
- ช่วยให้
- แล้ว
- การวิเคราะห์
- วิเคราะห์
- และ
- ประจำปี
- การใช้งาน
- เข้าใกล้
- วิธีการ
- AREA
- เทียม
- ปัญญาประดิษฐ์
- ปัญญาประดิษฐ์ (AI)
- สมาคม
- โจมตี
- การโจมตี
- ผู้เขียน
- อิสระ
- ตาม
- กลายเป็น
- ก่อน
- ดีกว่า
- ระหว่าง
- ใหญ่
- ปิดกั้น
- ของเล่นเพิ่มพัฒนาสมอง
- สร้าง
- ที่เรียกว่า
- ไม่ได้
- สามารถ
- บาง
- โซ่
- ChatGPT
- ข้อเรียกร้อง
- การจัดหมวดหมู่
- ชุด
- อย่างไร
- ซับซ้อน
- ที่ถูกบุกรุก
- คอมพิวเตอร์
- ความประพฤติ
- ขัดกัน
- อย่างต่อเนื่อง
- ควบคุม
- ได้
- สร้าง
- ที่สร้างขึ้น
- การสร้าง
- ปัจจุบัน
- ประเพณี
- ไซเบอร์
- cyberattacks
- cybersecurity
- ข้อมูล
- นักวิทยาศาสตร์ข้อมูล
- ชุดข้อมูล
- ชุดข้อมูล
- dc
- ทศวรรษ
- การตัดสินใจ
- การตัดสินใจ
- ลึก
- เครือข่ายประสาทลึก
- Defenders
- ป้องกัน
- การป้องกัน
- สาธิต
- แสดงให้เห็นถึง
- แผนก
- กระทรวงพลังงาน
- ต่าง
- ดิจิตอล
- การค้นพบ
- การหยุดชะงัก
- หลาย
- DOE
- ก่อน
- มีประสิทธิภาพ
- ที่มีประสิทธิภาพ
- อย่างมีประสิทธิภาพ
- ความพยายาม
- อีเมล
- ความปลอดภัยของอีเมล
- พลังงาน
- พอ
- หน่วยงาน
- สิ่งแวดล้อม
- เป็นหลัก
- อีเธอร์ (ETH)
- การประเมินการ
- แม้
- การปฏิบัติ
- การกรอง
- อธิบาย
- สำรวจ
- ปัจจัย
- คุณสมบัติ
- สองสาม
- สาขา
- หา
- ชื่อจริง
- ไหล
- ทางกฎหมาย
- นิติ
- ข้างหน้า
- พบ
- กรอบ
- ราคาเริ่มต้นที่
- อนาคต
- ได้รับ
- ได้รับ
- จะช่วยให้
- เป้าหมาย
- เป้าหมาย
- ดี
- มือ
- ช่วย
- ร้อน
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- HTTPS
- เป็นมนุษย์
- วิ่งกระโดดข้ามรั้ว
- ส่งผลกระทบ
- สำคัญ
- in
- อุบัติการณ์
- การตอบสนองต่อเหตุการณ์
- การแสดง
- เป็นรายบุคคล
- อิทธิพล
- แรกเริ่ม
- บูรณาการ
- Intelligence
- IT
- ตัวเอง
- ชนิด
- ที่รู้จักกัน
- ห้องปฏิบัติการ
- ใหญ่
- การเรียนรู้
- ระดับ
- ดู
- เครื่อง
- เรียนรู้เครื่อง
- หลัก
- หลาย
- ความกว้างสูงสุด
- เพิ่ม
- กลไก
- ที่ประชุม
- วิธี
- การลด
- แบบ
- ข้อมูลเพิ่มเติม
- แรงจูงใจ
- ย้าย
- การย้าย
- หลาย
- แห่งชาติ
- นำทาง
- จำเป็นต้อง
- เครือข่าย
- เครือข่าย
- ประสาท
- เครือข่ายประสาท
- เครือข่ายประสาทเทียม
- เซลล์ประสาท
- เปิด
- โอเพนซอร์ส
- อื่นๆ
- แปซิฟิก
- กระดาษ
- พารามิเตอร์
- อดีต
- สมบูรณ์
- ดำเนินการ
- วิริยะ
- ระยะ
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- เป็นไปได้
- ขับเคลื่อน
- ประยุกต์
- นำเสนอ
- การป้องกัน
- สำคัญ
- เชิงรุก
- ปัญหา
- ปัญหาที่เกิดขึ้น
- ผลิตภัณฑ์
- มืออาชีพ
- ดูรายละเอียด
- คำมั่นสัญญา
- RE
- ถึง
- เกิดปฏิกิริยา
- ตอบสนอง
- พร้อม
- จริง
- เรียลไทม์
- เมื่อเร็ว ๆ นี้
- การเรียนรู้การเสริมแรง
- ยังคง
- การวิจัย
- นักวิจัย
- นักวิจัย
- คำตอบ
- รางวัล
- รางวัล
- ความแข็งแรง
- พูดว่า
- นักวิทยาศาสตร์
- ความปลอดภัย
- ชุด
- ชุด
- การตั้งค่า
- เจ็ด
- น่า
- โชว์
- แสดงให้เห็นว่า
- ที่เรียบง่าย
- จำลอง
- ความสามารถ
- ทางออก
- โซลูชัน
- บาง
- ในไม่ช้า
- แหล่ง
- ช่องว่าง
- โดยเฉพาะ
- เริ่มต้น
- สถานะ
- ขั้นตอน
- ขั้นตอน
- ยังคง
- หยุด
- เสริมสร้างความเข้มแข็ง
- แข็งแรง
- ที่ประสบความสำเร็จ
- ประสบความสำเร็จ
- ระบบ
- กลยุทธ์
- ทีม
- เทคนิค
- การทดสอบ
- พื้นที่
- ก้าวสู่อนาคต
- รัฐ
- ของพวกเขา
- ตลอด
- เวลา
- ไปยัง
- เครื่องมือ
- ไปทาง
- รถไฟ
- ผ่านการฝึกอบรม
- การฝึกอบรม
- เทรนด์
- ภายใต้
- us
- ใช้
- ความหลากหลาย
- กว้างใหญ่
- อยาก
- วอชิงตัน
- วิธี
- ในขณะที่
- WHO
- จะ
- ภายใน
- ไม่มี
- งาน
- จะ
- ยอมให้
- ลมทะเล











