ในโพสต์นี้ เราจะสาธิตวิธีใช้การตัดแต่งโครงสร้างตามการค้นหาสถาปัตยกรรมประสาท (NAS) เพื่อบีบอัดโมเดล BERT ที่ปรับแต่งอย่างละเอียด เพื่อปรับปรุงประสิทธิภาพของโมเดลและลดเวลาในการอนุมาน โมเดลภาษาที่ได้รับการฝึกอบรมล่วงหน้า (PLM) กำลังอยู่ระหว่างการนำเชิงพาณิชย์และองค์กรไปใช้อย่างรวดเร็ว ในด้านเครื่องมือเพิ่มประสิทธิภาพการทำงาน การบริการลูกค้า การค้นหาและคำแนะนำ กระบวนการทางธุรกิจอัตโนมัติ และการสร้างเนื้อหา โดยทั่วไปการนำจุดสิ้นสุดการอนุมาน PLM ไปใช้มักเกี่ยวข้องกับเวลาแฝงที่สูงขึ้นและต้นทุนโครงสร้างพื้นฐานที่สูงขึ้น เนื่องจากข้อกำหนดในการประมวลผล และลดประสิทธิภาพในการคำนวณเนื่องจากมีพารามิเตอร์จำนวนมาก การตัด PLM ช่วยลดขนาดและความซับซ้อนของแบบจำลองในขณะที่ยังคงความสามารถในการคาดการณ์ไว้ PLM ที่ถูกตัดออกทำให้ได้พื้นที่หน่วยความจำน้อยลงและมีเวลาแฝงน้อยลง เราแสดงให้เห็นโดยการตัด PLM และแลกกับจำนวนพารามิเตอร์และข้อผิดพลาดในการตรวจสอบความถูกต้องสำหรับงานเป้าหมายเฉพาะ และสามารถบรรลุเวลาตอบสนองที่เร็วขึ้นเมื่อเปรียบเทียบกับโมเดล PLM พื้นฐาน
การเพิ่มประสิทธิภาพหลายวัตถุประสงค์เป็นขอบเขตของการตัดสินใจที่จะปรับฟังก์ชันวัตถุประสงค์มากกว่าหนึ่งฟังก์ชัน เช่น การใช้หน่วยความจำ เวลาการฝึกอบรม และทรัพยากรการประมวลผล ที่จะปรับให้เหมาะสมพร้อมกัน การตัดแต่งกิ่งโครงสร้างเป็นเทคนิคในการลดขนาดและข้อกำหนดในการคำนวณของ PLM โดยการตัดแต่งเลเยอร์หรือเซลล์ประสาท/โหนดในขณะที่พยายามรักษาความแม่นยำของแบบจำลอง การลบเลเยอร์ออกทำให้การตัดโครงสร้างทำให้ได้รับอัตราการบีบอัดที่สูงขึ้น ซึ่งนำไปสู่ความกระจัดกระจายที่มีโครงสร้างเป็นมิตรกับฮาร์ดแวร์ ซึ่งจะช่วยลดรันไทม์และเวลาตอบสนอง การใช้เทคนิคการตัดโครงสร้างกับโมเดล PLM ส่งผลให้โมเดลมีน้ำหนักเบากว่าและมีหน่วยความจำน้อยกว่า ซึ่งเมื่อโฮสต์เป็นจุดสิ้นสุดการอนุมานใน SageMaker จะช่วยปรับปรุงประสิทธิภาพของทรัพยากรและลดต้นทุนเมื่อเปรียบเทียบกับ PLM ที่ปรับแต่งแบบละเอียดดั้งเดิม
แนวคิดที่แสดงในโพสต์นี้สามารถนำไปใช้กับแอปพลิเคชันที่ใช้คุณสมบัติ PLM เช่น ระบบการแนะนำ การวิเคราะห์ความรู้สึก และเครื่องมือค้นหา โดยเฉพาะอย่างยิ่ง คุณสามารถใช้แนวทางนี้ได้หากคุณมีทีมแมชชีนเลิร์นนิ่ง (ML) และทีมวิทยาศาสตร์ข้อมูลที่ปรับแต่งโมเดล PLM ของตนเองอย่างละเอียดโดยใช้ชุดข้อมูลเฉพาะโดเมน และปรับใช้ตำแหน่งข้อมูลการอนุมานจำนวนมากโดยใช้ อเมซอน SageMaker. ตัวอย่างหนึ่งคือผู้ค้าปลีกออนไลน์ที่ใช้จุดสิ้นสุดการอนุมานจำนวนมากสำหรับการสรุปข้อความ การจำแนกประเภทแค็ตตาล็อกผลิตภัณฑ์ และการจัดประเภทความคิดเห็นเกี่ยวกับผลตอบรับผลิตภัณฑ์ อีกตัวอย่างหนึ่งอาจเป็นผู้ให้บริการด้านการดูแลสุขภาพที่ใช้ตำแหน่งข้อมูลการอนุมาน PLM สำหรับการจำแนกประเภทเอกสารทางคลินิก การระบุชื่อการรับรู้เอนทิตีจากรายงานทางการแพทย์ แชทบอททางการแพทย์ และการแบ่งชั้นความเสี่ยงของผู้ป่วย
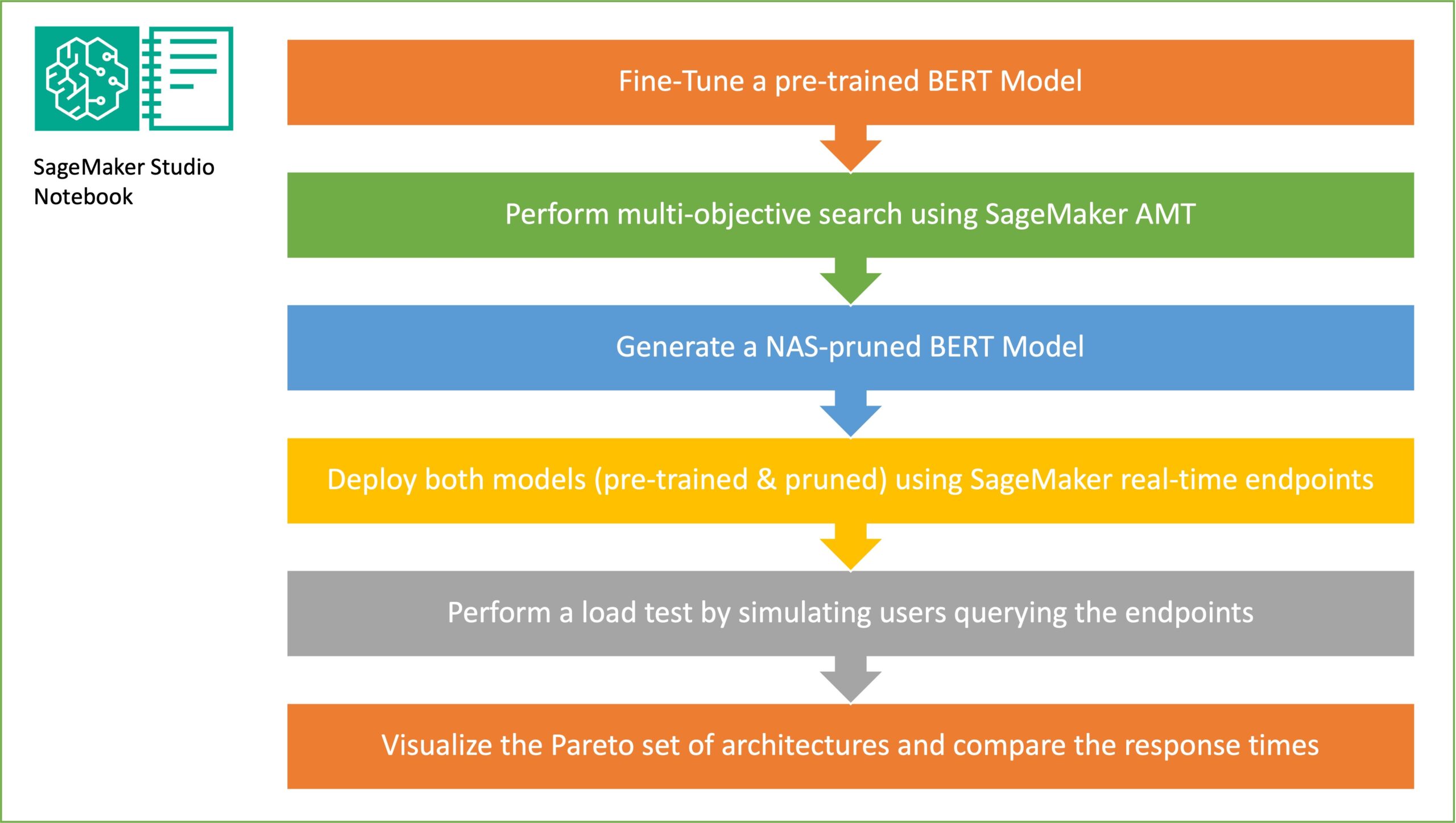
ภาพรวมโซลูชัน
ในส่วนนี้ เราจะนำเสนอขั้นตอนการทำงานโดยรวมและอธิบายแนวทาง ขั้นแรกเราใช้ an สตูดิโอ Amazon SageMaker สมุดบันทึก เพื่อปรับแต่งโมเดล BERT ที่ได้รับการฝึกอบรมล่วงหน้าในงานเป้าหมายโดยใช้ชุดข้อมูลเฉพาะโดเมน BERT (BiDirectional Encoder Representations จาก Transformers) เป็นรูปแบบภาษาที่ได้รับการฝึกอบรมล่วงหน้าโดยยึดตาม สถาปัตยกรรมหม้อแปลงไฟฟ้า ใช้สำหรับงานการประมวลผลภาษาธรรมชาติ (NLP) การค้นหาสถาปัตยกรรมประสาท (NAS) เป็นแนวทางในการออกแบบเครือข่ายประสาทเทียมโดยอัตโนมัติ และเกี่ยวข้องอย่างใกล้ชิดกับการเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์ ซึ่งเป็นแนวทางที่ใช้กันอย่างแพร่หลายในด้านการเรียนรู้ของเครื่อง เป้าหมายของ NAS คือการค้นหาสถาปัตยกรรมที่เหมาะสมที่สุดสำหรับปัญหาที่กำหนดโดยการค้นหาสถาปัตยกรรมที่เป็นตัวเลือกจำนวนมากโดยใช้เทคนิค เช่น การเพิ่มประสิทธิภาพที่ไม่มีการไล่ระดับสี หรือโดยการปรับหน่วยวัดที่ต้องการให้เหมาะสม โดยทั่วไปประสิทธิภาพของสถาปัตยกรรมจะวัดโดยใช้หน่วยเมตริก เช่น การสูญเสียการตรวจสอบ การปรับโมเดลอัตโนมัติของ SageMaker (AMT) ทำให้กระบวนการที่น่าเบื่อและซับซ้อนเป็นอัตโนมัติในการค้นหาชุดค่าผสมที่เหมาะสมที่สุดของไฮเปอร์พารามิเตอร์ของโมเดล ML ที่ให้ประสิทธิภาพของโมเดลที่ดีที่สุด AMT ใช้อัลกอริธึมการค้นหาอัจฉริยะและการประเมินซ้ำโดยใช้ช่วงของไฮเปอร์พารามิเตอร์ที่คุณระบุ โดยจะเลือกค่าไฮเปอร์พารามิเตอร์ที่สร้างแบบจำลองที่ทำงานได้ดีที่สุด โดยวัดจากตัวชี้วัดประสิทธิภาพ เช่น ความแม่นยำ และคะแนน F-1
วิธีการปรับแต่งอย่างละเอียดที่อธิบายไว้ในโพสต์นี้เป็นแนวทางทั่วไปและสามารถนำไปใช้กับชุดข้อมูลแบบข้อความใดก็ได้ งานที่มอบหมายให้กับ BERT PLM อาจเป็นงานแบบข้อความ เช่น การวิเคราะห์ความรู้สึก การจัดประเภทข้อความ หรือการถามตอบ ในการสาธิตนี้ งานเป้าหมายคือปัญหาการจำแนกประเภทไบนารี โดยที่ BERT ใช้ในการระบุ จากชุดข้อมูลที่ประกอบด้วยชุดของคู่ของส่วนของข้อความ ว่าความหมายของส่วนของข้อความหนึ่งสามารถอนุมานจากอีกส่วนของข้อความได้หรือไม่ เราใช้ การรับรู้ชุดข้อมูล Textual Entailment จากชุดการเปรียบเทียบ GLUE เราทำการค้นหาแบบหลายวัตถุประสงค์โดยใช้ SageMaker AMT เพื่อระบุเครือข่ายย่อยที่ให้การแลกเปลี่ยนที่เหมาะสมที่สุดระหว่างการนับพารามิเตอร์และความแม่นยำในการคาดการณ์สำหรับงานเป้าหมาย เมื่อทำการค้นหาหลายวัตถุประสงค์ เราจะเริ่มต้นด้วยการกำหนดความแม่นยำและจำนวนพารามิเตอร์เป็นวัตถุประสงค์ที่เรามุ่งหมายที่จะเพิ่มประสิทธิภาพ
ภายในเครือข่าย BERT PLM สามารถมีเครือข่ายย่อยแบบโมดูลาร์ในตัวเอง ซึ่งช่วยให้โมเดลมีความสามารถพิเศษ เช่น ความเข้าใจภาษา และการนำเสนอความรู้ BERT PLM ใช้เครือข่ายย่อยการเอาใจใส่ตนเองแบบหลายหัวและเครือข่ายย่อยการส่งต่อฟีด เลเยอร์การเอาใจใส่ตนเองแบบหลายหัวช่วยให้ BERT เชื่อมโยงตำแหน่งที่แตกต่างกันของลำดับเดียวเพื่อคำนวณการเป็นตัวแทนของลำดับโดยอนุญาตให้หลายหัวเข้าร่วมกับสัญญาณบริบทหลายรายการ ข้อมูลเข้าจะถูกแบ่งออกเป็นหลายพื้นที่ย่อยและมีการใช้การเอาใจใส่ตนเองกับแต่ละพื้นที่ย่อยแยกกัน หัวหลายหัวในหม้อแปลง PLM ช่วยให้โมเดลสามารถร่วมรับข้อมูลจากพื้นที่ย่อยการเป็นตัวแทนที่แตกต่างกันได้ เครือข่ายย่อยการส่งต่อฟีดเป็นเครือข่ายประสาทอย่างง่ายที่รับเอาต์พุตจากเครือข่ายย่อยการเอาใจใส่ตนเองแบบหลายหัว ประมวลผลข้อมูล และส่งคืนการแสดงตัวเข้ารหัสขั้นสุดท้าย
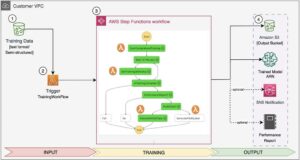
เป้าหมายของการสุ่มตัวอย่างเครือข่ายย่อยคือการฝึกโมเดล BERT ขนาดเล็กที่สามารถทำงานได้ดีเพียงพอกับงานเป้าหมาย เราสุ่มตัวอย่างเครือข่ายย่อยแบบสุ่ม 100 รายการจากโมเดล BERT พื้นฐานที่ได้รับการปรับแต่ง และประเมิน 10 เครือข่ายพร้อมกัน เครือข่ายย่อยที่ได้รับการฝึกอบรมจะได้รับการประเมินสำหรับตัวชี้วัดตามวัตถุประสงค์ และเลือกแบบจำลองสุดท้ายโดยพิจารณาจากข้อดีข้อเสียที่พบระหว่างตัวชี้วัดตามวัตถุประสงค์ เราเห็นภาพ ปาเรโต้ด้านหน้า สำหรับเครือข่ายย่อยตัวอย่าง ซึ่งมีโมเดลที่ถูกตัดออกซึ่งให้การแลกเปลี่ยนที่เหมาะสมที่สุดระหว่างความแม่นยำของโมเดลและขนาดของโมเดล เราเลือกเครือข่ายย่อยที่เป็นตัวเลือก (โมเดล BERT ที่ตัด NAS) ตามขนาดโมเดลและความแม่นยำของโมเดลที่เรายินดีจะแลก ต่อไป เราจะโฮสต์ตำแหน่งข้อมูล โมเดลพื้นฐาน BERT ที่ได้รับการฝึกอบรมล่วงหน้า และโมเดล BERT ที่ตัดแต่ง NAS โดยใช้ SageMaker ในการทำการทดสอบโหลดเราใช้ ปาทังกาซึ่งเป็นเครื่องมือทดสอบโหลดโอเพ่นซอร์สที่คุณนำไปใช้ได้โดยใช้ Python เราทำการทดสอบโหลดบนตำแหน่งข้อมูลทั้งสองโดยใช้ Locust และแสดงภาพผลลัพธ์โดยใช้ส่วนหน้า Pareto เพื่อแสดงให้เห็นถึงข้อดีข้อเสียระหว่างเวลาตอบสนองและความแม่นยำของทั้งสองรุ่น ไดอะแกรมต่อไปนี้แสดงภาพรวมของเวิร์กโฟลว์ที่อธิบายไว้ในโพสต์นี้
เบื้องต้น
สำหรับโพสต์นี้ จำเป็นต้องมีข้อกำหนดเบื้องต้นต่อไปนี้:
คุณยังต้องเพิ่ม โควต้าการบริการ เพื่อเข้าถึงอินสแตนซ์ ml.g4dn.xlarge อย่างน้อยสามอินสแตนซ์ใน SageMaker ประเภทอินสแตนซ์ ml.g4dn.xlarge เป็นอินสแตนซ์ GPU ที่คุ้มต้นทุนซึ่งช่วยให้คุณเรียกใช้ PyTorch ได้แบบเนทีฟ หากต้องการเพิ่มโควต้าการบริการ ให้ทำตามขั้นตอนต่อไปนี้:
- บนคอนโซล ให้ไปที่โควต้าบริการ
- สำหรับ จัดการโควต้าเลือก อเมซอน SageMakerแล้วเลือก ดูโควต้า.

- ค้นหา "ml-g4dn.xlarge สำหรับการใช้งานการฝึกอบรม" และเลือกรายการโควต้า
- Choose ขอเพิ่มในระดับบัญชี.
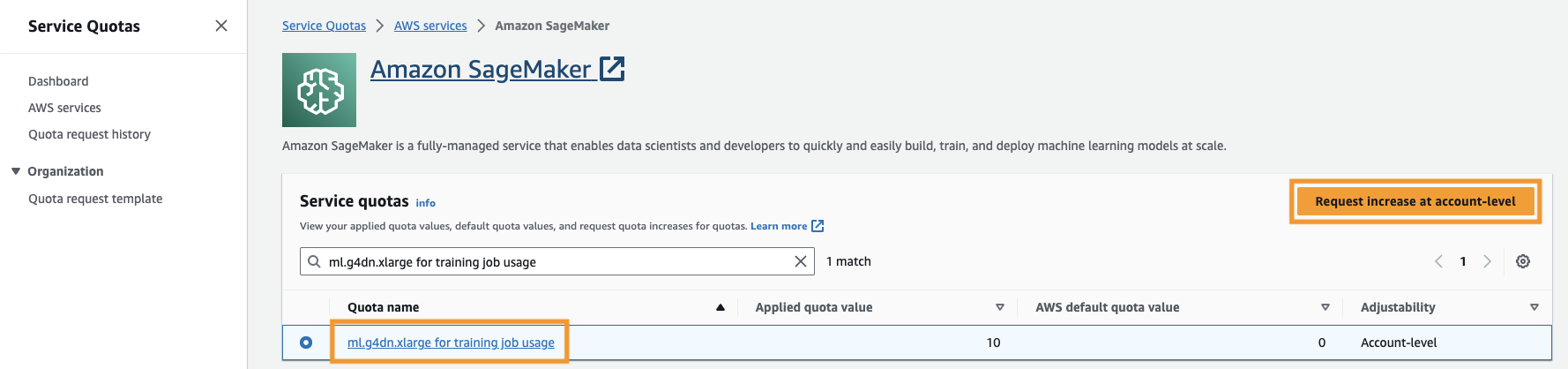
- สำหรับ เพิ่มมูลค่าโควต้าให้ป้อนค่า 5 หรือสูงกว่า
- Choose ขอร้อง.
การอนุมัติโควต้าที่ร้องขออาจใช้เวลาพอสมควรจึงจะเสร็จสมบูรณ์ ขึ้นอยู่กับสิทธิ์ของบัญชี

- เปิด SageMaker Studio จากคอนโซล SageMaker

- Choose เทอร์มินัลระบบ ภายใต้ ยูทิลิตี้และไฟล์.

- เรียกใช้คำสั่งต่อไปนี้เพื่อโคลนไฟล์ repo GitHub ไปยังอินสแตนซ์ SageMaker Studio:
- นำทางไปยัง
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - เปิดไฟล์
nas_for_llm_with_amt.ipynb. - กำหนดสภาพแวดล้อมด้วยการ
ml.g4dn.xlargeตัวอย่างและเลือก เลือก.

ตั้งค่าโมเดล BERT ที่ได้รับการฝึกอบรมล่วงหน้า
ในส่วนนี้ เรานำเข้าชุดข้อมูล Recognizing Textual Entailment จากไลบรารีชุดข้อมูล และแยกชุดข้อมูลออกเป็นชุดการฝึกอบรมและการตรวจสอบความถูกต้อง ชุดข้อมูลนี้ประกอบด้วยคู่ประโยค หน้าที่ของ BERT PLM คือการจดจำด้วยแฟรกเมนต์ข้อความสองส่วน ไม่ว่าความหมายของแฟรกเมนต์ข้อความหนึ่งสามารถอนุมานจากอีกแฟรกเมนต์อื่นได้หรือไม่ ในตัวอย่างต่อไปนี้ เราสามารถสรุปความหมายของวลีแรกจากวลีที่สองได้:
เราโหลดชุดข้อมูลที่เกี่ยวข้องกับการจดจำข้อความจาก กาว ชุดการเปรียบเทียบผ่านทาง ไลบรารีชุดข้อมูล จาก Hugging Face ภายในสคริปต์การฝึกอบรมของเรา (./training.py). เราแยกชุดข้อมูลการฝึกอบรมดั้งเดิมจาก GLUE ออกเป็นชุดการฝึกอบรมและการตรวจสอบ ในแนวทางของเรา เราปรับแต่งโมเดล BERT พื้นฐานโดยใช้ชุดข้อมูลการฝึกอบรม จากนั้นเราทำการค้นหาแบบหลายวัตถุประสงค์เพื่อระบุชุดของเครือข่ายย่อยที่สร้างสมดุลระหว่างตัวชี้วัดวัตถุประสงค์อย่างเหมาะสมที่สุด เราใช้ชุดข้อมูลการฝึกอบรมเพื่อการปรับแต่งโมเดล BERT โดยเฉพาะ อย่างไรก็ตาม เราใช้ข้อมูลการตรวจสอบความถูกต้องสำหรับการค้นหาหลายวัตถุประสงค์โดยการวัดความแม่นยำบนชุดข้อมูลการตรวจสอบความถูกต้องของการระงับ
ปรับแต่ง BERT PLM โดยใช้ชุดข้อมูลเฉพาะโดเมน
กรณีการใช้งานทั่วไปสำหรับโมเดล BERT แบบดิบรวมถึงการคาดเดาประโยคถัดไปหรือการสร้างแบบจำลองภาษาที่สวมหน้ากาก หากต้องการใช้โมเดล BERT พื้นฐานสำหรับงานดาวน์สตรีม เช่น การจดจำข้อความ เราต้องปรับแต่งโมเดลเพิ่มเติมโดยใช้ชุดข้อมูลเฉพาะโดเมน คุณสามารถใช้โมเดล BERT ที่ปรับแต่งแล้วสำหรับงานต่างๆ เช่น การจำแนกลำดับ การตอบคำถาม และการจัดประเภทโทเค็น อย่างไรก็ตาม เพื่อวัตถุประสงค์ของการสาธิตนี้ เราใช้แบบจำลองที่ได้รับการปรับแต่งสำหรับการจำแนกไบนารี เราปรับแต่งโมเดล BERT ที่ได้รับการฝึกล่วงหน้าอย่างละเอียดด้วยชุดข้อมูลการฝึกที่เราเตรียมไว้ก่อนหน้านี้ โดยใช้ไฮเปอร์พารามิเตอร์ต่อไปนี้:
เราบันทึกจุดตรวจของการฝึกโมเดลไว้ที่ บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (Amazon S3) เพื่อให้สามารถโหลดแบบจำลองได้ระหว่างการค้นหาหลายวัตถุประสงค์บน NAS ก่อนที่เราจะฝึกโมเดล เราจะกำหนดตัวชี้วัด เช่น ยุค การสูญเสียการฝึก จำนวนพารามิเตอร์ และข้อผิดพลาดในการตรวจสอบ:
หลังจากกระบวนการปรับแต่งอย่างละเอียดเริ่มต้นขึ้น งานการฝึกอบรมจะใช้เวลาประมาณ 15 นาทีจึงจะเสร็จสมบูรณ์
ทำการค้นหาแบบหลายวัตถุประสงค์เพื่อเลือกเครือข่ายย่อยและแสดงภาพผลลัพธ์
ในขั้นตอนถัดไป เราทำการค้นหาแบบหลายวัตถุประสงค์ในโมเดล BERT พื้นฐานที่ได้รับการปรับแต่งอย่างละเอียด โดยการสุ่มตัวอย่างเครือข่ายย่อยแบบสุ่มโดยใช้ SageMaker AMT ในการเข้าถึงเครือข่ายย่อยภายในเครือข่ายซุปเปอร์ (โมเดล BERT ที่ได้รับการปรับแต่งอย่างละเอียด) เราจะปกปิดส่วนประกอบทั้งหมดของ PLM ที่ไม่ได้เป็นส่วนหนึ่งของเครือข่ายย่อย การมาสก์เครือข่ายขั้นสูงเพื่อค้นหาเครือข่ายย่อยใน PLM เป็นเทคนิคที่ใช้ในการแยกและระบุรูปแบบของพฤติกรรมของแบบจำลอง โปรดทราบว่าหม้อแปลง Hugging Face ต้องใช้ขนาดที่ซ่อนอยู่เพื่อให้เป็นผลคูณของจำนวนหัว ขนาดที่ซ่อนอยู่ใน Transformer PLM จะควบคุมขนาดของปริภูมิเวกเตอร์สถานะที่ซ่อนอยู่ ซึ่งส่งผลต่อความสามารถของโมเดลในการเรียนรู้การนำเสนอและรูปแบบที่ซับซ้อนในข้อมูล ใน BERT PLM เวกเตอร์สถานะที่ซ่อนอยู่จะมีขนาดคงที่ (768) เราไม่สามารถเปลี่ยนขนาดที่ซ่อนอยู่ได้ ดังนั้นจำนวนหัวจึงต้องอยู่ใน [1, 3, 6, 12]
ตรงกันข้ามกับการเพิ่มประสิทธิภาพวัตถุประสงค์เดียว ในการตั้งค่าหลายวัตถุประสงค์ โดยทั่วไปเราไม่มีโซลูชันเดียวที่จะปรับวัตถุประสงค์ทั้งหมดให้เหมาะสมพร้อมกัน แต่เรามุ่งมั่นที่จะรวบรวมชุดโซลูชันที่ครอบงำโซลูชันอื่นๆ ทั้งหมดโดยมีวัตถุประสงค์อย่างน้อยหนึ่งประการ (เช่น ข้อผิดพลาดในการตรวจสอบความถูกต้อง) ตอนนี้เราสามารถเริ่มการค้นหาแบบหลายวัตถุประสงค์ผ่าน AMT ได้โดยการตั้งค่าหน่วยเมตริกที่เราต้องการลด (ข้อผิดพลาดในการตรวจสอบความถูกต้องและจำนวนพารามิเตอร์) เครือข่ายย่อยแบบสุ่มถูกกำหนดโดยพารามิเตอร์ max_jobs และจำนวนงานพร้อมกันถูกกำหนดโดยพารามิเตอร์ max_parallel_jobs. รหัสสำหรับโหลดจุดตรวจสอบโมเดลและประเมินเครือข่ายย่อยมีอยู่ใน evaluate_subnetwork.py ต้นฉบับ
งานปรับแต่ง AMT ใช้เวลาประมาณ 2 ชั่วโมง 20 นาทีในการรัน หลังจากที่งานปรับแต่ง AMT รันสำเร็จ เราจะแยกวิเคราะห์ประวัติของงานและรวบรวมการกำหนดค่าของเครือข่ายย่อย เช่น จำนวนหัว จำนวนเลเยอร์ จำนวนหน่วย และหน่วยวัดที่เกี่ยวข้อง เช่น ข้อผิดพลาดในการตรวจสอบความถูกต้อง และจำนวนพารามิเตอร์ ภาพหน้าจอต่อไปนี้แสดงข้อมูลสรุปของงานเครื่องรับ AMT ที่ประสบความสำเร็จ
ต่อไป เราจะแสดงภาพผลลัพธ์โดยใช้ชุด Pareto (หรือที่เรียกว่า Pareto frontier หรือชุดที่เหมาะสมที่สุดของ Pareto) ซึ่งช่วยให้เราระบุชุดเครือข่ายย่อยที่เหมาะสมที่สุดที่ครอบงำเครือข่ายย่อยอื่น ๆ ทั้งหมดในตัวชี้วัดวัตถุประสงค์ (ข้อผิดพลาดในการตรวจสอบ):
ขั้นแรก เรารวบรวมข้อมูลจากงานปรับแต่ง AMT จากนั้นเราก็พล็อตชุด Pareto โดยใช้ matplotlob.pyplot ด้วยจำนวนพารามิเตอร์ในแกน x และข้อผิดพลาดในการตรวจสอบความถูกต้องในแกน y นี่หมายความว่าเมื่อเราย้ายจากเครือข่ายย่อยหนึ่งของ Pareto ที่ตั้งค่าไปยังอีกเครือข่ายหนึ่ง เราต้องเสียสละประสิทธิภาพหรือขนาดโมเดล แต่ปรับปรุงอีกเครือข่ายหนึ่ง ท้ายที่สุด ชุด Pareto ให้ความยืดหยุ่นในการเลือกเครือข่ายย่อยที่เหมาะกับความต้องการของเรามากที่สุด เราสามารถตัดสินใจได้ว่าเราต้องการลดขนาดเครือข่ายของเรามากเพียงใด และเราจะยอมเสียสละประสิทธิภาพมากเพียงใด

ปรับใช้โมเดล BERT ที่ได้รับการปรับแต่งอย่างละเอียดและโมเดลเครือข่ายย่อยที่เพิ่มประสิทธิภาพ NAS โดยใช้ SageMaker
ต่อไป เราจะปรับใช้โมเดลที่ใหญ่ที่สุดในชุด Pareto ของเรา ซึ่งส่งผลให้ประสิทธิภาพการทำงานลดลงน้อยที่สุดใน a ปลายทาง SageMaker. โมเดลที่ดีที่สุดคือโมเดลที่ให้การแลกเปลี่ยนที่เหมาะสมที่สุดระหว่างข้อผิดพลาดในการตรวจสอบและจำนวนพารามิเตอร์สำหรับกรณีการใช้งานของเรา
เปรียบเทียบแบบจำลอง
เราใช้โมเดล BERT พื้นฐานที่ได้รับการฝึกอบรมมาล่วงหน้า ปรับแต่งอย่างละเอียดโดยใช้ชุดข้อมูลเฉพาะโดเมน รันการค้นหา NAS เพื่อระบุเครือข่ายย่อยที่โดดเด่นตามเกณฑ์ชี้วัดวัตถุประสงค์ และปรับใช้โมเดลที่ตัดทอนแล้วบนตำแหน่งข้อมูล SageMaker นอกจากนี้ เรายังนำโมเดล BERT พื้นฐานที่ได้รับการฝึกอบรมมาล่วงหน้า และปรับใช้โมเดลพื้นฐานบนตำแหน่งข้อมูล SageMaker ที่สอง ต่อไปเราก็วิ่ง การทดสอบโหลด ใช้ Locust บนจุดสิ้นสุดการอนุมานและประเมินประสิทธิภาพในแง่ของเวลาตอบสนอง
ขั้นแรก เรานำเข้าไลบรารี Locust และ Boto3 ที่จำเป็น จากนั้น เราจะสร้างข้อมูลเมตาของคำขอและบันทึกเวลาเริ่มต้นที่จะใช้สำหรับการทดสอบโหลด จากนั้นเพย์โหลดจะถูกส่งไปยังตำแหน่งข้อมูล SageMaker ที่เรียกใช้ API ผ่าน BotoClient เพื่อจำลองคำขอของผู้ใช้จริง เราใช้ Locust เพื่อวางไข่ผู้ใช้เสมือนหลายรายเพื่อส่งคำขอแบบขนานและวัดประสิทธิภาพของอุปกรณ์ปลายทางภายใต้โหลด การทดสอบจะดำเนินการโดยการเพิ่มจำนวนผู้ใช้สำหรับแต่ละปลายทางทั้งสองตามลำดับ หลังจากการทดสอบเสร็จสิ้น Locust จะส่งไฟล์ CSV สถิติคำขอสำหรับแต่ละรุ่นที่ปรับใช้
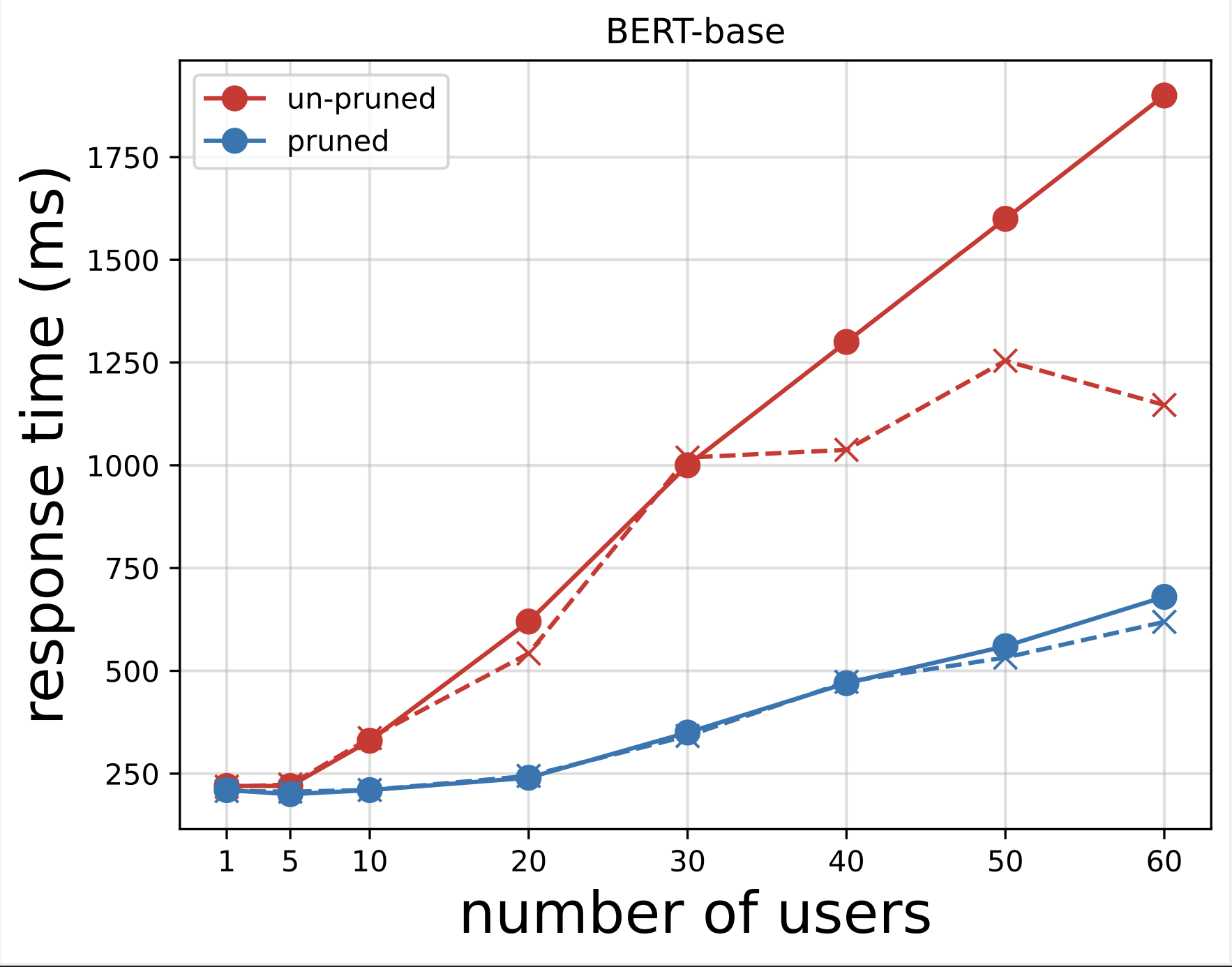
ต่อไป เราจะสร้างแผนเวลาตอบสนองจากไฟล์ CSV ที่ดาวน์โหลดหลังจากรันการทดสอบด้วย Locust วัตถุประสงค์ของการวางแผนเวลาตอบสนองเทียบกับจำนวนผู้ใช้คือเพื่อวิเคราะห์ผลการทดสอบโหลดโดยการแสดงภาพผลกระทบของเวลาตอบสนองของจุดสิ้นสุดของโมเดล ในแผนภูมิต่อไปนี้ เราจะเห็นว่าจุดสิ้นสุดของโมเดล NAS-pruned มีเวลาตอบสนองที่ต่ำกว่าเมื่อเปรียบเทียบกับจุดสิ้นสุดของโมเดล BERT พื้นฐาน
ในแผนภูมิที่สอง ซึ่งเป็นส่วนขยายของแผนภูมิแรก เราสังเกตว่าหลังจากผู้ใช้ประมาณ 70 ราย SageMaker จะเริ่มควบคุมจุดสิ้นสุดโมเดล BERT พื้นฐานและส่งข้อยกเว้น อย่างไรก็ตาม สำหรับตำแหน่งข้อมูลโมเดลที่ตัดแต่งโดย NAS การควบคุมปริมาณจะเกิดขึ้นระหว่างผู้ใช้ 90–100 รายและมีเวลาตอบสนองน้อยกว่า

จากแผนภูมิทั้งสอง เราสังเกตว่าแบบจำลองที่ถูกตัดออกมีเวลาตอบสนองที่เร็วกว่าและปรับขนาดได้ดีกว่าเมื่อเปรียบเทียบกับแบบจำลองที่ถูกตัดออก ขณะที่เราขยายจำนวนตำแหน่งข้อมูลการอนุมาน เช่นเดียวกับกรณีผู้ใช้ที่ปรับใช้ตำแหน่งข้อมูลการอนุมานจำนวนมากสำหรับแอปพลิเคชัน PLM ผลประโยชน์ด้านต้นทุนและการปรับปรุงประสิทธิภาพก็เริ่มมีความสำคัญมากขึ้น
ทำความสะอาด
หากต้องการลบตำแหน่งข้อมูล SageMaker สำหรับโมเดล BERT พื้นฐานที่ได้รับการปรับแต่งและโมเดล NAS-pruned ให้ทำตามขั้นตอนต่อไปนี้:
- บนคอนโซล SageMaker ให้เลือก การอนุมาน และ ปลายทาง ในบานหน้าต่างนำทาง
- เลือกปลายทางและลบออก
หรืออีกทางหนึ่ง จากสมุดบันทึก SageMaker Studio ให้รันคำสั่งต่อไปนี้โดยระบุชื่อตำแหน่งข้อมูล:
สรุป
ในโพสต์นี้ เราได้พูดคุยถึงวิธีใช้ NAS เพื่อตัดโมเดล BERT ที่ปรับแต่งอย่างละเอียด ขั้นแรกเราได้ฝึกโมเดล BERT พื้นฐานโดยใช้ข้อมูลเฉพาะโดเมนและปรับใช้กับตำแหน่งข้อมูล SageMaker เราทำการค้นหาแบบหลายวัตถุประสงค์ในโมเดล BERT พื้นฐานที่ได้รับการปรับแต่งอย่างละเอียดโดยใช้ SageMaker AMT สำหรับงานเป้าหมาย เราแสดงภาพด้านหน้า Pareto และเลือกโมเดล BERT ที่ตัดแต่ง NAS ที่เหมาะสมที่สุดของ Pareto และปรับใช้โมเดลกับตำแหน่งข้อมูล SageMaker ที่สอง เราทำการทดสอบโหลดโดยใช้ Locust เพื่อจำลองผู้ใช้ที่สอบถามทั้งปลายทาง และวัดและบันทึกเวลาตอบสนองในไฟล์ CSV เราวางแผนเวลาตอบสนองเทียบกับจำนวนผู้ใช้สำหรับทั้งสองรุ่น
เราสังเกตเห็นว่าโมเดล BERT ที่ถูกตัดออกนั้นทำงานได้ดีขึ้นอย่างมากทั้งในด้านเวลาตอบสนองและขีดจำกัดการควบคุมอินสแตนซ์ เราสรุปได้ว่าโมเดล NAS-pruned มีความยืดหยุ่นมากกว่าต่อโหลดที่เพิ่มขึ้นที่ปลายทาง โดยรักษาเวลาตอบสนองที่ต่ำกว่า แม้ว่าผู้ใช้จะเน้นระบบมากขึ้นเมื่อเทียบกับโมเดล BERT พื้นฐาน คุณสามารถใช้เทคนิค NAS ที่อธิบายไว้ในโพสต์นี้กับโมเดลภาษาขนาดใหญ่ใดๆ เพื่อค้นหาโมเดลแบบตัดทอนที่สามารถทำงานเป้าหมายด้วยเวลาตอบสนองที่ลดลงอย่างมาก คุณสามารถปรับแนวทางให้เหมาะสมเพิ่มเติมได้โดยใช้เวลาแฝงเป็นพารามิเตอร์ นอกเหนือจากการสูญเสียการตรวจสอบ
แม้ว่าเราจะใช้ NAS ในโพสต์นี้ การหาปริมาณเป็นอีกแนวทางหนึ่งที่ใช้ในการปรับให้เหมาะสมและบีบอัดโมเดล PLM การหาปริมาณจะลดความแม่นยำของน้ำหนักและการเปิดใช้งานในเครือข่ายที่ผ่านการฝึกอบรมจากจุดลอยตัว 32 บิตไปจนถึงความกว้างบิตที่ต่ำกว่า เช่น จำนวนเต็ม 8 บิตหรือ 16 บิต ซึ่งส่งผลให้เกิดแบบจำลองที่บีบอัดซึ่งสร้างการอนุมานที่เร็วขึ้น การหาปริมาณไม่ได้ลดจำนวนพารามิเตอร์ แต่จะลดความแม่นยำของพารามิเตอร์ที่มีอยู่แทนเพื่อให้ได้โมเดลที่บีบอัด การตัด NAS จะลบเครือข่ายที่ซ้ำซ้อนใน PLM ซึ่งจะสร้างแบบจำลองแบบกระจายที่มีพารามิเตอร์น้อยลง โดยทั่วไปแล้ว การตัด NAS และการหาปริมาณจะถูกใช้ร่วมกันเพื่อบีบอัด PLM ขนาดใหญ่เพื่อรักษาความแม่นยำของโมเดล ลดการสูญเสียการตรวจสอบในขณะที่ปรับปรุงประสิทธิภาพ และลดขนาดโมเดล เทคนิคอื่นๆ ที่ใช้กันทั่วไปในการลดขนาดของ PLM ได้แก่ การกลั่นความรู้, ตัวประกอบเมทริกซ์และ น้ำตกกลั่น.
แนวทางที่เสนอในบล็อกโพสต์เหมาะสำหรับทีมที่ใช้ SageMaker เพื่อฝึกฝนและปรับแต่งโมเดลโดยใช้ข้อมูลเฉพาะโดเมน และปรับใช้ตำแหน่งข้อมูลเพื่อสร้างการอนุมาน หากคุณกำลังมองหาบริการที่มีการจัดการเต็มรูปแบบซึ่งเสนอตัวเลือกโมเดลพื้นฐานประสิทธิภาพสูงซึ่งจำเป็นต่อการสร้างแอปพลิเคชัน AI ทั่วไป ให้พิจารณาใช้ อเมซอน เบดร็อค. หากคุณกำลังมองหาโมเดลโอเพ่นซอร์สที่ได้รับการฝึกอบรมล่วงหน้าสำหรับกรณีการใช้งานทางธุรกิจที่หลากหลาย และต้องการเข้าถึงเทมเพลตโซลูชันและสมุดบันทึกตัวอย่าง ให้พิจารณาใช้ Amazon SageMaker JumpStart. เวอร์ชันก่อนการฝึกของโมเดลฐาน Hugging Face BERT ที่เราใช้ในโพสต์นี้มีให้ใช้งานจาก SageMaker JumpStart เช่นกัน
เกี่ยวกับผู้เขียน
 อุปราจิตธาน ไวยานาธาน เป็น Principal Enterprise Solutions Architect ที่ AWS เขาเป็นสถาปนิกระบบคลาวด์ที่มีประสบการณ์มากกว่า 24 ปีในการออกแบบและพัฒนาระบบซอฟต์แวร์ระดับองค์กรขนาดใหญ่และแบบกระจาย เขาเชี่ยวชาญด้านวิศวกรรมข้อมูลเจเนอเรทีฟ AI และการเรียนรู้ของเครื่อง เขาเป็นนักวิ่งมาราธอนที่มีความมุ่งมั่นและมีงานอดิเรก ได้แก่ เดินป่า ขี่จักรยาน และใช้เวลากับภรรยาและลูกชายสองคน
อุปราจิตธาน ไวยานาธาน เป็น Principal Enterprise Solutions Architect ที่ AWS เขาเป็นสถาปนิกระบบคลาวด์ที่มีประสบการณ์มากกว่า 24 ปีในการออกแบบและพัฒนาระบบซอฟต์แวร์ระดับองค์กรขนาดใหญ่และแบบกระจาย เขาเชี่ยวชาญด้านวิศวกรรมข้อมูลเจเนอเรทีฟ AI และการเรียนรู้ของเครื่อง เขาเป็นนักวิ่งมาราธอนที่มีความมุ่งมั่นและมีงานอดิเรก ได้แก่ เดินป่า ขี่จักรยาน และใช้เวลากับภรรยาและลูกชายสองคน
 แอรอนไคลน์ เป็นนักวิทยาศาสตร์ประยุกต์อาวุโสที่ AWS ที่ทำงานเกี่ยวกับวิธีการเรียนรู้ของเครื่องอัตโนมัติสำหรับโครงข่ายประสาทเชิงลึก
แอรอนไคลน์ เป็นนักวิทยาศาสตร์ประยุกต์อาวุโสที่ AWS ที่ทำงานเกี่ยวกับวิธีการเรียนรู้ของเครื่องอัตโนมัติสำหรับโครงข่ายประสาทเชิงลึก
 ยาเซค โกเลเบียสกี้ เป็น Sr Applied Scientist ที่ AWS
ยาเซค โกเลเบียสกี้ เป็น Sr Applied Scientist ที่ AWS
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- ][หน้า
- $ ขึ้น
- 1
- 10
- 100
- 11
- 12
- 13
- 15%
- 17
- 19
- 20
- 26
- 30
- 31
- 320
- 7
- 70
- 72
- 8
- 9
- a
- ความสามารถ
- สามารถ
- เข้า
- ลงชื่อเข้าใช้
- ความถูกต้อง
- บรรลุ
- ประสบความสำเร็จ
- การเปิดใช้งาน
- นอกจากนี้
- การนำมาใช้
- หลังจาก
- AI
- จุดมุ่งหมาย
- การเล็ง
- อัลกอริทึม
- ทั้งหมด
- อนุญาต
- การอนุญาต
- ช่วยให้
- ด้วย
- อเมซอน
- Amazon Web Services
- จำนวน
- an
- การวิเคราะห์
- การวิเคราะห์
- วิเคราะห์
- และ
- อื่น
- ตอบ
- ใด
- API
- การใช้งาน
- ประยุกต์
- ใช้
- การประยุกต์ใช้
- เข้าใกล้
- การอนุมัติ
- ประมาณ
- สถาปัตยกรรม
- เป็น
- AREA
- พื้นที่
- ข้อโต้แย้ง
- รอบ
- เทียม
- โครงข่ายประสาทเทียม
- AS
- ที่ต้องการ
- ที่ได้รับมอบหมาย
- ที่เกี่ยวข้อง
- At
- พยายาม
- ที่คาดหวัง
- อัตโนมัติ
- การเรียนรู้ของเครื่องอัตโนมัติ
- โดยอัตโนมัติ
- อัตโนมัติ
- โดยอัตโนมัติ
- อัตโนมัติ
- ใช้ได้
- AWS
- แกน
- ยอดคงเหลือ
- ฐาน
- ตาม
- BE
- กลายเป็น
- ก่อน
- พฤติกรรม
- การเปรียบเทียบ
- ประโยชน์ที่ได้รับ
- ที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- บิต
- ร่างกาย
- ทั้งสอง
- สร้าง
- ธุรกิจ
- กระบวนการทางธุรกิจ
- ระบบอัตโนมัติของกระบวนการทางธุรกิจ
- แต่
- by
- CAN
- ผู้สมัคร
- ความสามารถในการ
- กรณี
- กรณี
- แค็ตตาล็อก
- เปลี่ยนแปลง
- แผนภูมิ
- ชาร์ต
- chatbots
- ทางเลือก
- Choose
- เลือก
- ชั้น
- การจัดหมวดหมู่
- คลินิก
- อย่างใกล้ชิด
- เมฆ
- รหัส
- รวบรวม
- ชุด
- รวม
- เชิงพาณิชย์
- ร่วมกัน
- อย่างธรรมดา
- เมื่อเทียบกับ
- สมบูรณ์
- เสร็จ
- ซับซ้อน
- ความซับซ้อน
- ส่วนประกอบ
- การคำนวณ
- คำนวณ
- แนวความคิด
- สรุป
- พิจารณา
- ประกอบ
- ปลอบใจ
- ข้อ จำกัด
- สร้าง
- การบริโภค
- มี
- เนื้อหา
- การสร้างเนื้อหา
- สิ่งแวดล้อม
- ต่อ
- ตรงกันข้าม
- การควบคุม
- ตรงกัน
- ราคา
- ค่าใช้จ่าย
- นับ
- สร้าง
- สร้าง
- การสร้าง
- ลูกค้า
- บริการลูกค้า
- ข้อมูล
- วิทยาศาสตร์ข้อมูล
- ชุดข้อมูล
- วันเวลา
- ตัดสินใจ
- การตัดสินใจ
- ทุ่มเท
- ลึก
- เครือข่ายประสาทลึก
- กำหนด
- กำหนด
- การกำหนด
- ทดลอง
- สาธิต
- ทั้งนี้ขึ้นอยู่กับ
- ปรับใช้
- นำไปใช้
- ปรับใช้
- Deploys
- อธิบาย
- ออกแบบ
- การออกแบบ
- ที่ต้องการ
- ที่กำลังพัฒนา
- ต่าง
- กล่าวถึง
- กระจาย
- เอกสาร
- ไม่
- เด่น
- ครอบงำ
- Dont
- สอง
- ในระหว่าง
- e
- แต่ละ
- อย่างมีประสิทธิภาพ
- ที่มีประสิทธิภาพ
- ทั้ง
- ปลายทาง
- ปลายทาง
- ชั้นเยี่ยม
- เครื่องยนต์
- พอ
- เข้าสู่
- Enterprise
- การรับเลี้ยงบุตรบุญธรรม
- โซลูชั่นองค์กร
- เอกลักษณ์
- การเข้า
- สิ่งแวดล้อม
- ยุค
- ความผิดพลาด
- อีเธอร์ (ETH)
- ประเมินค่า
- ประเมิน
- การประเมินผล
- แม้
- เหตุการณ์
- ตัวอย่าง
- ยกเว้น
- ข้อยกเว้น
- โดยเฉพาะ
- ที่มีอยู่
- ประสบการณ์
- อธิบาย
- อธิบาย
- นามสกุล
- ใบหน้า
- เท็จ
- เร็วขึ้น
- คุณสมบัติ
- ข้อเสนอแนะ
- น้อยลง
- สนาม
- เนื้อไม่มีมัน
- ไฟล์
- สุดท้าย
- หา
- หา
- ชื่อจริง
- การแก้ไข
- ความยืดหยุ่น
- ที่ลอย
- ดังต่อไปนี้
- รอยพระบาท
- สำหรับ
- พบ
- รากฐาน
- ราคาเริ่มต้นที่
- ด้านหน้า
- ชายแดน
- อย่างเต็มที่
- ฟังก์ชัน
- ต่อไป
- สร้าง
- สร้าง
- กำเนิด
- กำเนิด AI
- ได้รับ
- กำหนด
- เป้าหมาย
- GPU
- สีเทา
- ที่เกิดขึ้น
- มี
- he
- หัว
- หัว
- การดูแลสุขภาพ
- จะช่วยให้
- ซ่อนเร้น
- ที่มีประสิทธิภาพสูง
- สูงกว่า
- การธุดงค์
- ของเขา
- ประวัติ
- งานอดิเรก
- เจ้าภาพ
- เป็นเจ้าภาพ
- ชั่วโมง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTML
- ที่ http
- HTTPS
- กอดใบหน้า
- การเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์
- การปรับแต่งไฮเปอร์พารามิเตอร์
- i
- แยกแยะ
- IDX
- if
- แสดง
- ส่งผลกระทบ
- ผลกระทบ
- การดำเนินการ
- นำเข้า
- ปรับปรุง
- การปรับปรุง
- การปรับปรุง
- การปรับปรุง
- in
- ประกอบด้วย
- เพิ่ม
- เพิ่มขึ้น
- ที่เพิ่มขึ้น
- ข้อมูล
- โครงสร้างพื้นฐาน
- อินพุต
- ตัวอย่าง
- อินสแตนซ์
- แทน
- ฉลาด
- เข้าไป
- IT
- ITS
- การสัมภาษณ์
- งาน
- jpg
- JSON
- ความรู้
- ที่รู้จักกัน
- ภาษา
- ใหญ่
- ขนาดใหญ่
- ใหญ่ที่สุด
- ความแอบแฝง
- ชั้น
- ชั้น
- นำไปสู่
- เรียนรู้
- การเรียนรู้
- น้อยที่สุด
- ให้
- ห้องสมุด
- ห้องสมุด
- Line
- โหลด
- เข้าสู่ระบบ
- การเข้าสู่ระบบ
- ที่ต้องการหา
- ปิด
- การสูญเสีย
- ลด
- เครื่อง
- เรียนรู้เครื่อง
- เก็บรักษา
- การบำรุงรักษา
- มนุษย์
- การจัดการ
- มาราธอน
- หน้ากาก
- matplotlib
- สูงสุด
- อาจ..
- ความหมาย
- วัด
- วัด
- การวัด
- ทางการแพทย์
- พบ
- หน่วยความจำ
- เมตาดาต้า
- วิธีการ
- เมตริก
- ตัวชี้วัด
- อาจ
- ลด
- นาที
- ML
- แบบ
- การสร้างแบบจำลอง
- โมเดล
- โมดูลาร์
- ข้อมูลเพิ่มเติม
- ย้าย
- มาก
- หลาย
- ต้อง
- ชื่อ
- ที่มีชื่อ
- ชื่อ
- ที่
- โดยธรรมชาติ
- ภาษาธรรมชาติ
- ประมวลผลภาษาธรรมชาติ
- นำทาง
- การเดินเรือ
- จำเป็น
- จำเป็นต้อง
- จำเป็น
- ความต้องการ
- เครือข่าย
- เครือข่าย
- ประสาท
- เครือข่ายประสาท
- เครือข่ายประสาทเทียม
- ถัดไป
- NLP
- ไม่มี
- หมายเหตุ
- สมุดบันทึก
- โน๊ตบุ๊ค
- ตอนนี้
- จำนวน
- วัตถุ
- วัตถุประสงค์
- วัตถุประสงค์
- สังเกต
- ตั้งข้อสังเกต
- of
- ปิด
- เสนอ
- เสนอ
- on
- ONE
- ออนไลน์
- ผู้ค้าปลีกออนไลน์
- เพียง
- เปิด
- โอเพนซอร์ส
- ดีที่สุด
- การเพิ่มประสิทธิภาพ
- เพิ่มประสิทธิภาพ
- การปรับให้เหมาะสม
- เพิ่มประสิทธิภาพ
- การเพิ่มประสิทธิภาพ
- or
- ใบสั่ง
- เป็นต้นฉบับ
- อื่นๆ
- ของเรา
- ออก
- เอาท์พุต
- เอาท์พุท
- เกิน
- ทั้งหมด
- ภาพรวม
- ของตนเอง
- คู่
- บานหน้าต่าง
- Parallel
- พารามิเตอร์
- พารามิเตอร์
- Pareto
- ส่วนหนึ่ง
- ผ่าน
- เส้นทาง
- ผู้ป่วย
- รูปแบบ
- ดำเนินการ
- การปฏิบัติ
- ดำเนินการ
- ที่มีประสิทธิภาพ
- ดำเนินการ
- สิทธิ์
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- จุด
- จุด
- ตำแหน่ง
- โพสต์
- ความแม่นยำ
- คำทำนาย
- ทำนาย
- Predictor
- การตั้งค่า
- เตรียม
- ข้อกำหนดเบื้องต้น
- นำเสนอ
- ก่อนหน้านี้
- หลัก
- ปัญหา
- กระบวนการ
- กระบวนการอัตโนมัติ
- กระบวนการ
- การประมวลผล
- ผลิตภัณฑ์
- ผลผลิต
- ผลผลิต
- เสนอ
- ผู้จัดหา
- ให้
- การให้
- การดึง
- ดึง
- วัตถุประสงค์
- วัตถุประสงค์
- หลาม
- ไฟฉาย
- Q & A
- คำถาม
- ทีเดียว
- สุ่ม
- พิสัย
- รวดเร็ว
- ราคา
- ดิบ
- จริง
- การรับรู้
- รับรู้
- ตระหนักถึง
- แนะนำ
- แนะนำ
- ระเบียน
- บันทึก
- สีแดง
- ลด
- ลดลง
- ลด
- ถดถอย
- ที่เกี่ยวข้อง
- ลบ
- ลบ
- รายงาน
- การแสดง
- ขอ
- ร้องขอ
- การร้องขอ
- จำเป็นต้องใช้
- ความต้องการ
- ยืดหยุ่น
- ทรัพยากร
- แหล่งข้อมูล
- ตามลำดับ
- คำตอบ
- ผลสอบ
- ร้านค้าปลีก
- การรักษา
- รับคืน
- การขี่
- ความเสี่ยง
- แถว
- วิ่ง
- ทางวิ่ง
- วิ่ง
- ทำงาน
- s
- เสียสละ
- sagemaker
- การอนุมาน SageMaker
- ลด
- ขนาด
- ตาชั่ง
- วิทยาศาสตร์
- นักวิทยาศาสตร์
- คะแนน
- ต้นฉบับ
- ค้นหา
- เครื่องมือค้นหา
- ค้นหา
- ที่สอง
- Section
- เห็น
- เลือก
- เลือก
- ตนเอง
- ส่ง
- ประโยค
- ความรู้สึก
- ลำดับ
- บริการ
- บริการ
- เซสชั่น
- ชุด
- ชุดอุปกรณ์
- การตั้งค่า
- แสดงให้เห็นว่า
- สัญญาณ
- อย่างมีความหมาย
- ง่าย
- พร้อมกัน
- พร้อมกัน
- เดียว
- ขนาด
- มีขนาดเล็กกว่า
- So
- ซอฟต์แวร์
- ทางออก
- โซลูชัน
- บาง
- แหล่ง
- ช่องว่าง
- วางไข่
- เฉพาะ
- ความเชี่ยวชาญ
- โดยเฉพาะ
- เฉพาะ
- การใช้จ่าย
- แยก
- เริ่มต้น
- เริ่มต้น
- สถานะ
- สถิติ
- ขั้นตอน
- ขั้นตอน
- การเก็บรักษา
- โครงสร้าง
- โครงสร้าง
- สตูดิโอ
- เป็นกอบเป็นกำ
- ที่ประสบความสำเร็จ
- ประสบความสำเร็จ
- อย่างเช่น
- เหมาะสม
- ชุด
- สรุป
- ระบบ
- ระบบ
- T
- เอา
- ใช้เวลา
- เป้า
- งาน
- งาน
- ทีม
- เทคนิค
- เทคนิค
- แม่แบบ
- เงื่อนไขการใช้บริการ
- การทดสอบ
- การทดสอบ
- ข้อความ
- การจัดประเภทข้อความ
- เกี่ยวกับใจความ
- กว่า
- ที่
- พื้นที่
- ของพวกเขา
- แล้วก็
- ที่นั่น
- ดังนั้น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- นี้
- สาม
- ธรณีประตู
- ตลอด
- เวลา
- ครั้ง
- ไปยัง
- ร่วมกัน
- โทเค็น
- เอา
- เครื่องมือ
- เครื่องมือ
- การค้า
- เทรด
- รถไฟ
- ผ่านการฝึกอบรม
- การฝึกอบรม
- หม้อแปลงไฟฟ้า
- หม้อแปลง
- จริง
- ลอง
- สอง
- ชนิด
- ชนิด
- ตามแบบฉบับ
- เป็นปกติ
- ในที่สุด
- ภายใต้
- กำลังดำเนินการ
- ความเข้าใจ
- หน่วย
- us
- ใช้
- ใช้กรณี
- มือสอง
- ผู้ใช้งาน
- ผู้ใช้
- ใช้
- การใช้
- การตรวจสอบ
- ความคุ้มค่า
- ความคุ้มค่า
- รุ่น
- ผ่านทาง
- เสมือน
- เห็นภาพ
- vs
- ต้องการ
- คือ
- we
- เว็บ
- บริการเว็บ
- ดี
- เมื่อ
- ว่า
- ที่
- ในขณะที่
- WHO
- กว้าง
- ช่วงกว้าง
- อย่างกว้างขวาง
- ภรรยา
- วิกิพีเดีย
- จะ
- เต็มใจ
- กับ
- ภายใน
- งาน
- เวิร์กโฟลว์
- การทำงาน
- X
- ปี
- ผล
- เธอ
- ของคุณ
- ลมทะเล