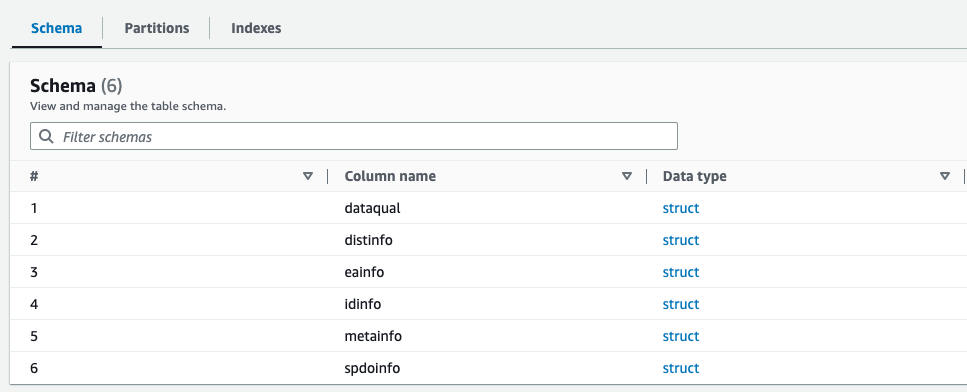
ในยุคดิจิทัลปัจจุบัน ข้อมูลถือเป็นหัวใจสำคัญของความสำเร็จของทุกองค์กร รูปแบบหนึ่งที่ใช้กันมากที่สุดสำหรับการแลกเปลี่ยนข้อมูลคือ XML การวิเคราะห์ไฟล์ XML มีความสำคัญด้วยเหตุผลหลายประการ ประการแรก ไฟล์ XML ถูกใช้ในหลายอุตสาหกรรม รวมถึงการเงิน การดูแลสุขภาพ และภาครัฐ การวิเคราะห์ไฟล์ XML สามารถช่วยให้องค์กรได้รับข้อมูลเชิงลึกเกี่ยวกับข้อมูล ทำให้พวกเขาสามารถตัดสินใจได้ดีขึ้นและปรับปรุงการดำเนินงานของพวกเขา การวิเคราะห์ไฟล์ XML ยังช่วยในการรวมข้อมูลได้ เนื่องจากแอปพลิเคชันและระบบจำนวนมากใช้ XML เป็นรูปแบบข้อมูลมาตรฐาน ด้วยการวิเคราะห์ไฟล์ XML องค์กรต่างๆ สามารถรวมข้อมูลจากแหล่งต่างๆ ได้อย่างง่ายดายและรับประกันความสอดคล้องกันทั่วทั้งระบบ อย่างไรก็ตาม ไฟล์ XML มีข้อมูลที่ซ้อนกันแบบกึ่งมีโครงสร้างสูง ทำให้ยากต่อการเข้าถึงและวิเคราะห์ข้อมูล โดยเฉพาะอย่างยิ่งหากไฟล์มีขนาดใหญ่และมี สคีมาที่ซับซ้อนและซ้อนกันสูง
ไฟล์ XML เหมาะสำหรับแอปพลิเคชัน แต่อาจไม่เหมาะสำหรับเครื่องมือวิเคราะห์ เพื่อเพิ่มประสิทธิภาพในการสืบค้นและช่วยให้เข้าถึงได้ง่ายในเครื่องมือวิเคราะห์ดาวน์สตรีมเช่น อเมซอน อาเธน่าการประมวลผลไฟล์ XML ล่วงหน้าให้อยู่ในรูปแบบแนวคอลัมน์ เช่น Parquet ถือเป็นสิ่งสำคัญ การเปลี่ยนแปลงนี้ช่วยปรับปรุงประสิทธิภาพและการใช้งานในเวิร์กโฟลว์การวิเคราะห์ ในโพสต์นี้ เราจะแสดงวิธีการประมวลผลข้อมูล XML โดยใช้ AWS กาว และเอเธน่า
ภาพรวมโซลูชัน
เราสำรวจเทคนิคที่แตกต่างกันสองประการซึ่งสามารถปรับปรุงขั้นตอนการประมวลผลไฟล์ XML ของคุณได้:
- เทคนิคที่ 1: ใช้โปรแกรมรวบรวมข้อมูล AWS Glue และโปรแกรมแก้ไขภาพ AWS Glue – คุณสามารถใช้อินเทอร์เฟซผู้ใช้ AWS Glue ร่วมกับซอฟต์แวร์รวบรวมข้อมูลเพื่อกำหนดโครงสร้างตารางสำหรับไฟล์ XML ของคุณได้ แนวทางนี้มีอินเทอร์เฟซที่เป็นมิตรต่อผู้ใช้ และเหมาะอย่างยิ่งสำหรับบุคคลที่ชอบวิธีการจัดการข้อมูลแบบกราฟิก
- เทคนิคที่ 2: ใช้ AWS Glue DynamicFrames กับสคีมาแบบสรุปและแบบคงที่ – โปรแกรมรวบรวมข้อมูลมีข้อจำกัดในการประมวลผลแถวเดียวในไฟล์ XML ที่มีขนาดใหญ่กว่า 1 MB. เพื่อเอาชนะข้อจำกัดนี้ เราใช้สมุดบันทึก AWS Glue เพื่อสร้าง AWS Glue
DynamicFramesโดยใช้ทั้งสคีมาแบบอนุมานและแบบคงที่ วิธีการนี้ช่วยให้มั่นใจในการจัดการไฟล์ XML ที่มีแถวขนาดเกิน 1 MB ได้อย่างมีประสิทธิภาพ
ในทั้งสองแนวทาง เป้าหมายสูงสุดของเราคือการแปลงไฟล์ XML เป็นรูปแบบ Apache Parquet ทำให้พร้อมสำหรับการสืบค้นโดยใช้ Athena ด้วยเทคนิคเหล่านี้ คุณสามารถเพิ่มความเร็วในการประมวลผลและการเข้าถึงข้อมูล XML ของคุณได้ ทำให้คุณได้รับข้อมูลเชิงลึกอันมีค่าได้อย่างง่ายดาย
เบื้องต้น
ก่อนที่คุณจะเริ่มบทช่วยสอนนี้ ให้ทำตามข้อกำหนดเบื้องต้นต่อไปนี้ให้ครบถ้วน (ใช้ได้กับทั้งสองเทคนิค):
- ดาวน์โหลดไฟล์ XML เทคนิค1.xml และ เทคนิค2.xml.
- อัพโหลดไฟล์ไปที่ บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (อเมซอน S3) ที่เก็บข้อมูล คุณสามารถอัปโหลดไปยังบัคเก็ต S3 เดียวกันในโฟลเดอร์ที่แตกต่างกันหรือไปยังบัคเก็ต S3 ที่แตกต่างกันได้
- สร้าง AWS Identity และการจัดการการเข้าถึง บทบาท (IAM) สำหรับงาน ETL หรือสมุดบันทึกของคุณตามคำแนะนำใน ตั้งค่าการอนุญาต IAM สำหรับ AWS Glue Studio.
- เพิ่มนโยบายอินไลน์ให้กับบทบาทของคุณด้วย แล้ว: PassRole หนังบู๊:
- เพิ่มนโยบายการอนุญาตให้กับบทบาทที่มีสิทธิ์เข้าถึงบัคเก็ต S3 ของคุณ
ตอนนี้เราเสร็จสิ้นตามข้อกำหนดเบื้องต้นแล้ว มาดูการนำเทคนิคแรกไปใช้กันดีกว่า
เทคนิคที่ 1: ใช้โปรแกรมรวบรวมข้อมูล AWS Glue และโปรแกรมแก้ไขภาพ
ไดอะแกรมต่อไปนี้แสดงสถาปัตยกรรมอย่างง่ายที่คุณสามารถใช้เพื่อนำโซลูชันไปใช้
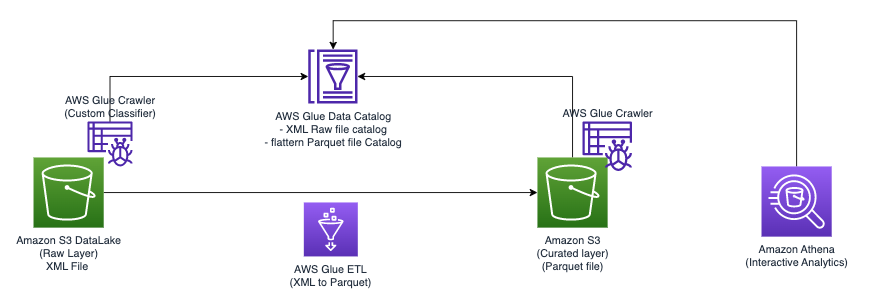
เพื่อวิเคราะห์ไฟล์ XML ที่จัดเก็บไว้ใน Amazon S3 โดยใช้ AWS Glue และ Athena เราได้ทำตามขั้นตอนระดับสูงต่อไปนี้:
- สร้างโปรแกรมรวบรวมข้อมูล AWS Glue เพื่อแยกข้อมูลเมตา XML และสร้างตารางใน AWS Glue Data Catalog
- ประมวลผลและแปลงข้อมูล XML เป็นรูปแบบ (เช่น Parquet) ที่เหมาะสำหรับ Athena โดยใช้งานการแยก แปลง และโหลด (ETL) ของ AWS Glue
- ตั้งค่าและรันงาน AWS Glue ผ่านคอนโซล AWS Glue หรือ อินเทอร์เฟซบรรทัดคำสั่ง AWS AWS (AWS CLI)
- ใช้ข้อมูลที่ประมวลผล (ในรูปแบบ Parquet) กับตาราง Athena เพื่อเปิดใช้งานการสืบค้น SQL
- ใช้อินเทอร์เฟซที่เป็นมิตรต่อผู้ใช้ใน Athena เพื่อวิเคราะห์ข้อมูล XML ด้วยการสืบค้น SQL เกี่ยวกับข้อมูลของคุณที่จัดเก็บไว้ใน Amazon S3
สถาปัตยกรรมนี้เป็นโซลูชันที่ปรับขนาดได้และคุ้มค่าสำหรับการวิเคราะห์ข้อมูล XML บน Amazon S3 โดยใช้ AWS Glue และ Athena คุณสามารถวิเคราะห์ชุดข้อมูลขนาดใหญ่ได้โดยไม่ต้องมีการจัดการโครงสร้างพื้นฐานที่ซับซ้อน
เราใช้โปรแกรมรวบรวมข้อมูล AWS Glue เพื่อแยกข้อมูลเมตาของไฟล์ XML คุณสามารถเลือกตัวแยกประเภท AWS Glue เริ่มต้นสำหรับการจัดประเภท XML วัตถุประสงค์ทั่วไปได้ โดยจะตรวจจับโครงสร้างข้อมูลและสคีมา XML โดยอัตโนมัติ ซึ่งมีประโยชน์สำหรับรูปแบบทั่วไป
เรายังใช้ตัวแยกประเภท XML แบบกำหนดเองในโซลูชันนี้ ได้รับการออกแบบมาสำหรับสคีมาหรือรูปแบบ XML ที่เฉพาะเจาะจง ช่วยให้สามารถแยกข้อมูลเมตาได้อย่างแม่นยำ เหมาะอย่างยิ่งสำหรับรูปแบบ XML ที่ไม่ได้มาตรฐาน หรือเมื่อคุณต้องการการควบคุมการจัดประเภทอย่างละเอียด ตัวแยกประเภทที่กำหนดเองช่วยให้มั่นใจได้ว่าจะแยกเฉพาะข้อมูลเมตาที่จำเป็นเท่านั้น ซึ่งช่วยให้การประมวลผลและการวิเคราะห์ดาวน์สตรีมง่ายขึ้น วิธีการนี้จะเพิ่มประสิทธิภาพการใช้ไฟล์ XML ของคุณ
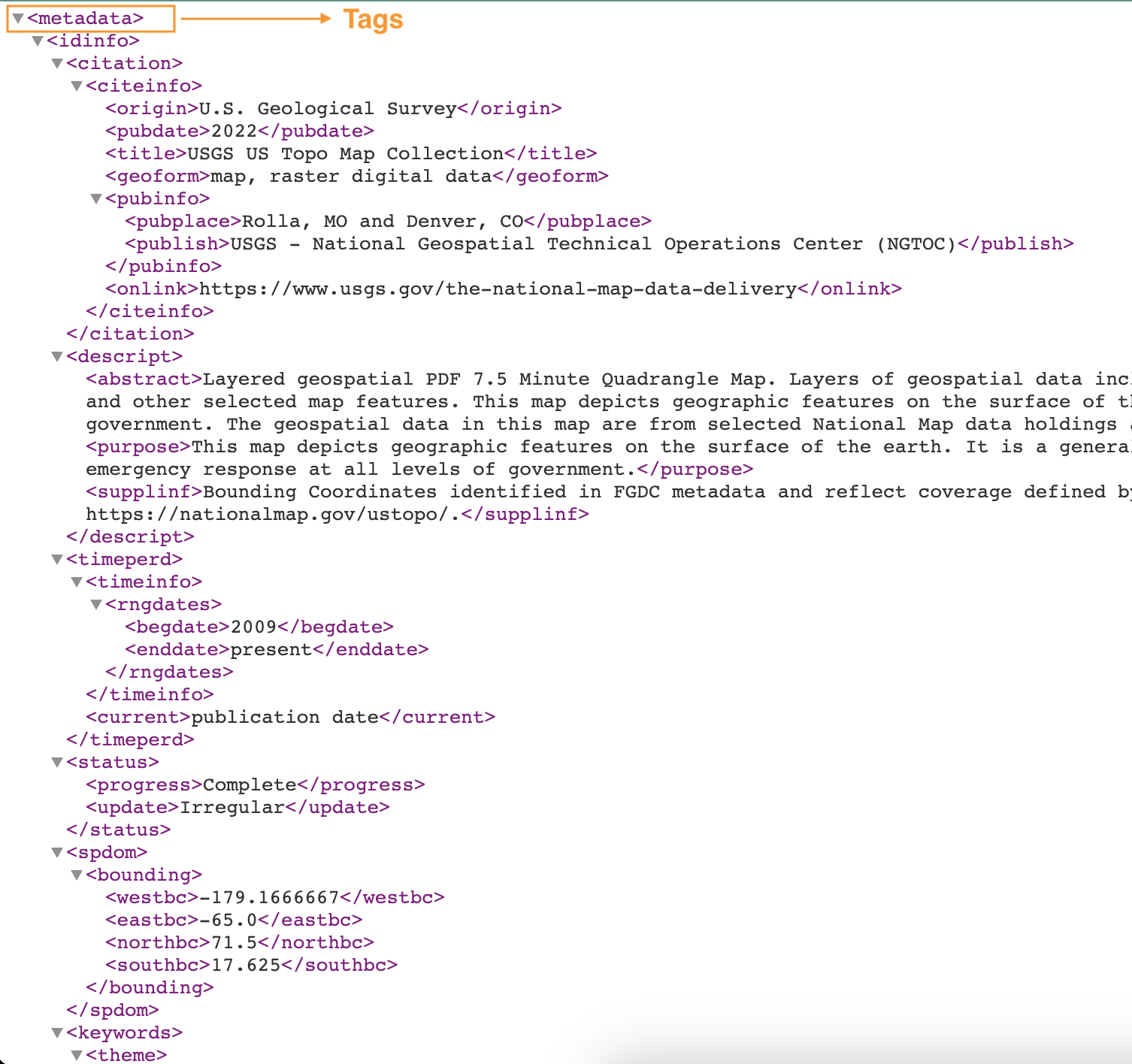
ภาพหน้าจอต่อไปนี้แสดงตัวอย่างไฟล์ XML พร้อมแท็ก
สร้างตัวแยกประเภทที่กำหนดเอง
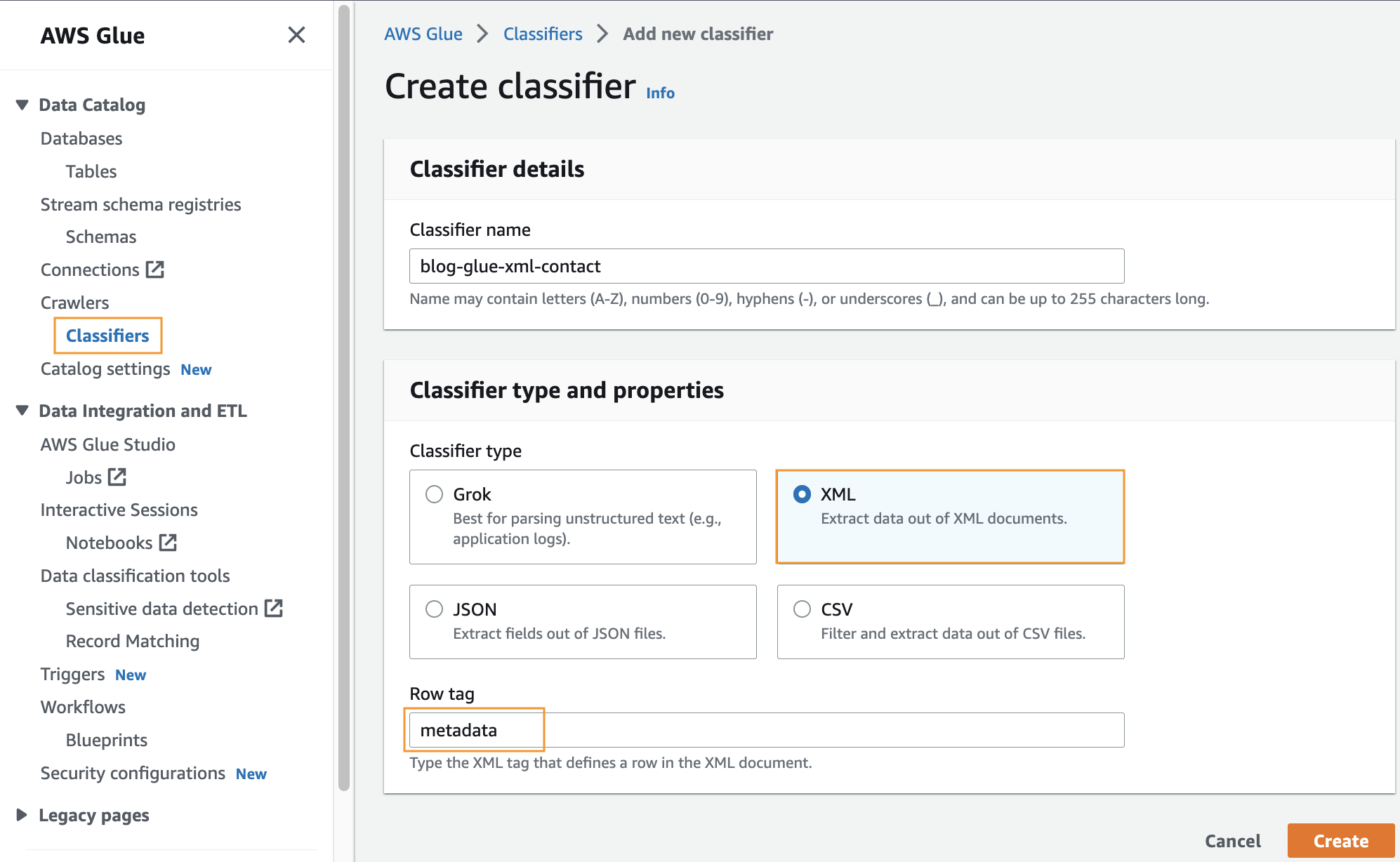
ในขั้นตอนนี้ คุณจะสร้างตัวแยกประเภท AWS Glue แบบกำหนดเองเพื่อดึงข้อมูลเมตาจากไฟล์ XML ทำตามขั้นตอนต่อไปนี้:
- บนคอนโซล AWS Glue ภายใต้ โปรแกรมรวบรวมข้อมูล ในบานหน้าต่างนำทาง ให้เลือก ลักษณนาม.
- Choose เพิ่มตัวแยกประเภท.
- เลือก XML เป็นประเภทลักษณนาม
- ป้อนชื่อสำหรับตัวแยกประเภท เช่น
blog-glue-xml-contact. - สำหรับ แท็กแถวให้ป้อนชื่อของแท็กรูทที่มีข้อมูลเมตา (เช่น
metadata). - Choose สร้างบัญชีตัวแทน.
สร้าง AWS Glue Crawler เพื่อรวบรวมข้อมูลไฟล์ xml
ในส่วนนี้ เรากำลังสร้าง Glue Crawler เพื่อแยกข้อมูลเมตาจากไฟล์ XML โดยใช้ตัวแยกประเภทลูกค้าที่สร้างขึ้นในขั้นตอนก่อนหน้า
สร้างฐานข้อมูล
- ไปที่ คอนโซลกาว AWSเลือก ฐานข้อมูล ในบานหน้าต่างนำทาง
- คลิกที่ เพิ่มฐานข้อมูล
- ระบุชื่อ เช่น
blog_glue_xml - Choose สร้างบัญชีตัวแทน ฐานข้อมูล
สร้างโปรแกรมรวบรวมข้อมูล
ทำตามขั้นตอนต่อไปนี้เพื่อสร้างโปรแกรมรวบรวมข้อมูลแรกของคุณ:
- บนคอนโซล AWS Glue ให้เลือก โปรแกรมรวบรวมข้อมูล ในบานหน้าต่างนำทาง
- Choose สร้างโปรแกรมรวบรวมข้อมูล.
- เกี่ยวกับ ตั้งค่าคุณสมบัติของโปรแกรมรวบรวมข้อมูล ระบุชื่อสำหรับโปรแกรมรวบรวมข้อมูลใหม่ (เช่น
blog-glue-parquet) จากนั้นเลือก ถัดไป. - เกี่ยวกับ เลือกแหล่งข้อมูลและตัวแยกประเภท ใหเลือก ยัง ภายใต้ การกำหนดค่าแหล่งข้อมูล.
- Choose เพิ่มที่เก็บข้อมูล.
- สำหรับ เส้นทาง S3เรียกดูไปที่
s3://${BUCKET_NAME}/input/geologicalsurvey/.
ตรวจสอบให้แน่ใจว่าคุณเลือกโฟลเดอร์ XML แทนที่จะเป็นไฟล์ภายในโฟลเดอร์
- ปล่อยให้ตัวเลือกที่เหลือเป็นค่าเริ่มต้นและเลือก เพิ่มแหล่งข้อมูล S3.
- แสดง ตัวแยกประเภทที่กำหนดเอง – ไม่จำเป็นให้เลือก blog-glue-xml-contact จากนั้นเลือก ถัดไป และเก็บตัวเลือกที่เหลือไว้เป็นค่าเริ่มต้น
- เลือกบทบาท IAM ของคุณหรือเลือก สร้างบทบาท IAM ใหม่ให้เพิ่มส่วนต่อท้าย
glue-xml-contact(ตัวอย่างเช่น,AWSGlueServiceNotebookRoleBlog) และเลือก ถัดไป. - เกี่ยวกับ ตั้งค่าเอาต์พุตและการจัดตารางเวลา หน้าภายใต้ การกำหนดค่าเอาต์พุตเลือก
blog_glue_xmlfor ฐานข้อมูลเป้าหมาย. - เข้าสู่
console_เป็นคำนำหน้าที่ถูกเพิ่มลงในตาราง (ไม่บังคับ) และต่ำกว่า ตารางโปรแกรมรวบรวมข้อมูลให้ตั้งความถี่ไว้ที่ ตามความต้องการ. - Choose ถัดไป.
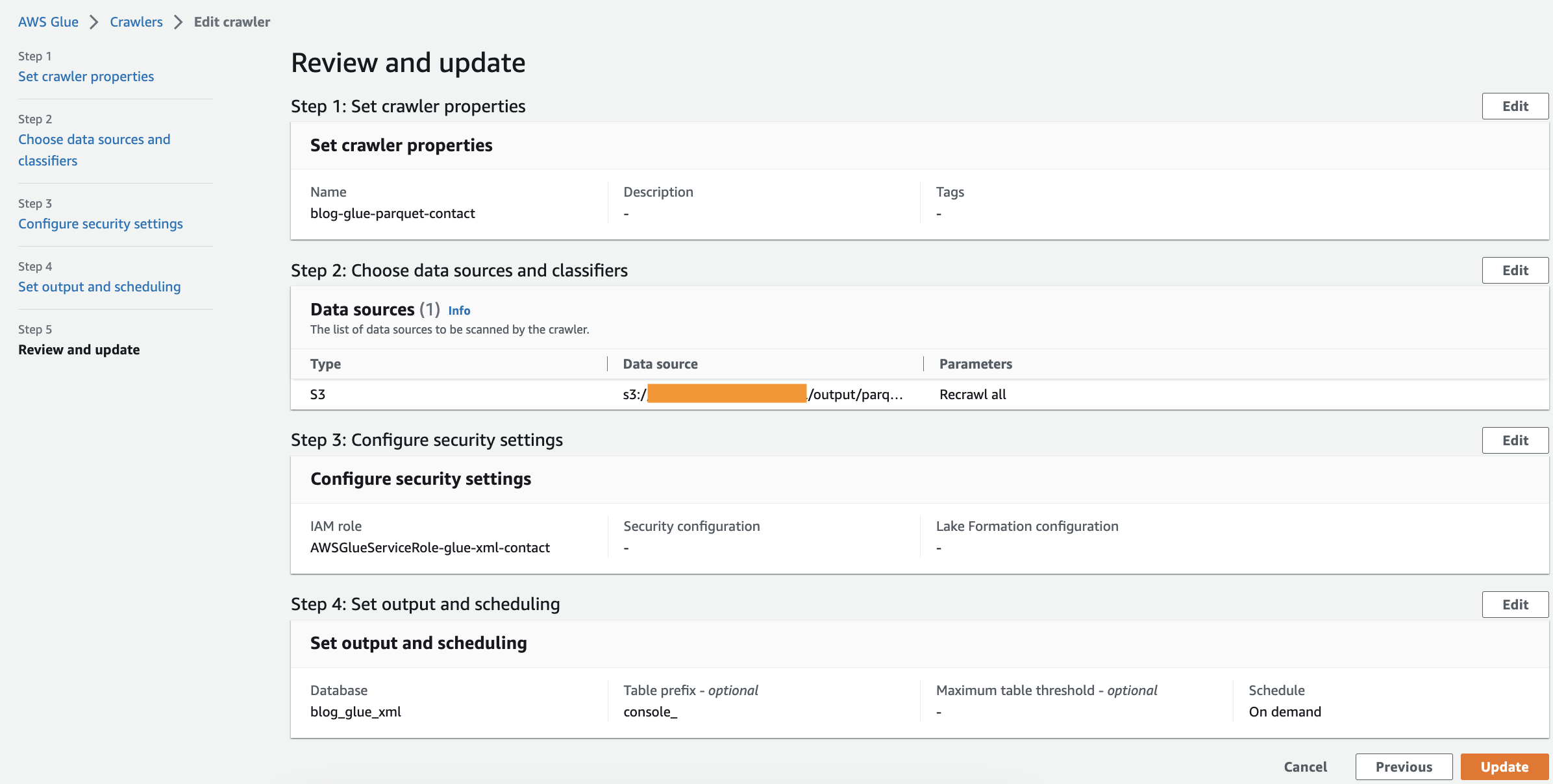
- ตรวจสอบพารามิเตอร์ทั้งหมดแล้วเลือก สร้างโปรแกรมรวบรวมข้อมูล.
เรียกใช้โปรแกรมรวบรวมข้อมูล
หลังจากที่คุณสร้างโปรแกรมรวบรวมข้อมูลแล้ว ให้ทำตามขั้นตอนต่อไปนี้เพื่อเรียกใช้โปรแกรมรวบรวมข้อมูล:
- บนคอนโซล AWS Glue ให้เลือก โปรแกรมรวบรวมข้อมูล ในบานหน้าต่างนำทาง
- เปิดโปรแกรมรวบรวมข้อมูลที่คุณสร้างและเลือก วิ่ง.
โปรแกรมรวบรวมข้อมูลจะใช้เวลา 1-2 นาทีจึงจะเสร็จสิ้น
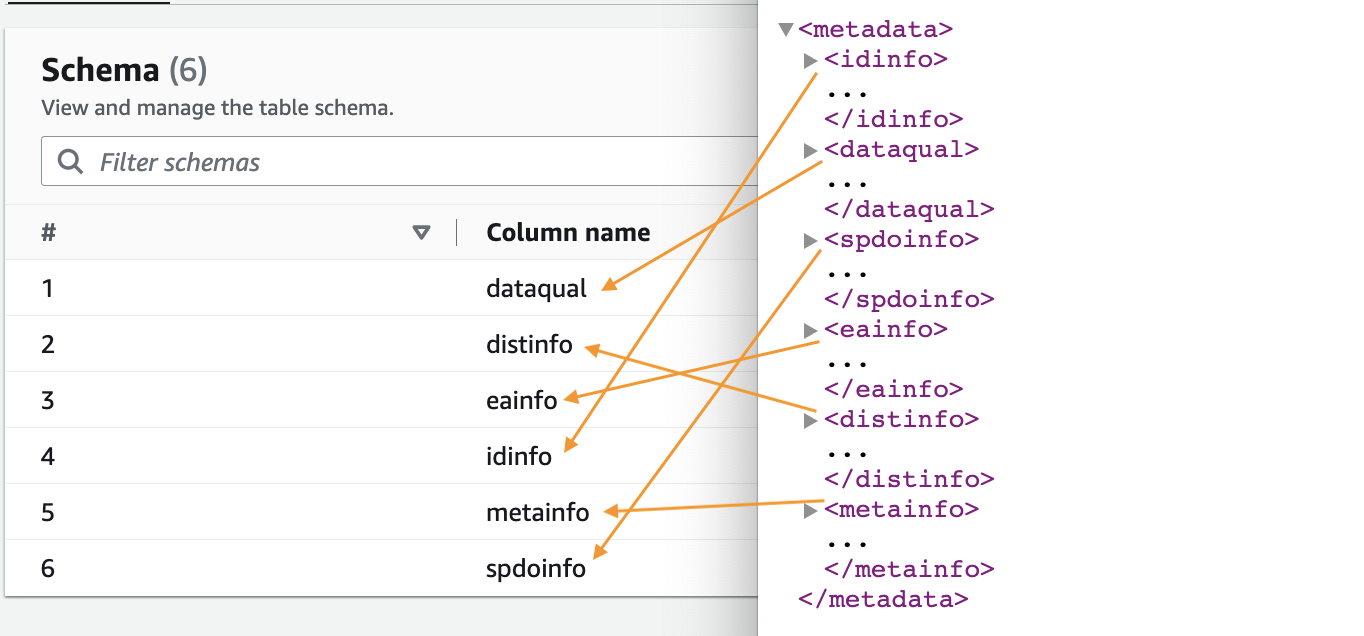
- เมื่อโปรแกรมรวบรวมข้อมูลเสร็จสิ้น ให้เลือก ฐานข้อมูล ในบานหน้าต่างนำทาง
- เลือกฐานข้อมูลที่คุณสร้าง และเลือกชื่อตารางเพื่อดูสคีมาที่แยกโดยโปรแกรมรวบรวมข้อมูล
สร้างงาน AWS Glue เพื่อแปลง XML เป็นรูปแบบ Parquet
ในขั้นตอนนี้ คุณจะสร้างงาน AWS Glue Studio เพื่อแปลงไฟล์ XML เป็นไฟล์ Parquet ทำตามขั้นตอนต่อไปนี้:
- บนคอนโซล AWS Glue ให้เลือก งาน ในบานหน้าต่างนำทาง
- ภายใต้ สร้างงานให้เลือก ภาพด้วยผ้าใบเปล่า.
- Choose สร้างบัญชีตัวแทน.
- เปลี่ยนชื่องานเป็น
blog_glue_xml_job.
ตอนนี้คุณมีตัวแก้ไขงานภาพ AWS Glue Studio ที่ว่างเปล่าแล้ว ที่ด้านบนของตัวแก้ไขคือแท็บสำหรับมุมมองต่างๆ
- เลือก ต้นฉบับ เพื่อดูเชลล์ว่างของสคริปต์ AWS Glue ETL
ขณะที่เราเพิ่มขั้นตอนใหม่ในตัวแก้ไขภาพ สคริปต์จะได้รับการอัปเดตโดยอัตโนมัติ
- เลือก รายละเอียดงาน เพื่อดูการกำหนดค่างานทั้งหมด
- สำหรับ บทบาท IAMเลือก
AWSGlueServiceNotebookRoleBlog. - สำหรับ รุ่นกาวเลือก Glue 4.0 – รองรับ Spark 3.3, Scala 2, Python 3.
- ชุด ขอจำนวนคนงาน เพื่อ 2
- ชุด จำนวนครั้งในการลองใหม่ เพื่อ 0
- เลือก ของ Visual แท็บเพื่อกลับไปที่โปรแกรมแก้ไขภาพ
- เกี่ยวกับ แหล่ง เลือกเมนูแบบเลื่อนลง แคตตาล็อกข้อมูลกาว AWS Data.
- เกี่ยวกับ คุณสมบัติแหล่งข้อมูล – แค็ตตาล็อกข้อมูล แท็บ ระบุข้อมูลต่อไปนี้:
- สำหรับ ฐานข้อมูลเลือก
blog_glue_xml. - สำหรับ ตารางให้เลือกตารางที่ขึ้นต้นด้วยชื่อ console_ ที่โปรแกรมรวบรวมข้อมูลสร้างขึ้น (เช่น
console_geologicalsurvey).
- สำหรับ ฐานข้อมูลเลือก
- เกี่ยวกับ คุณสมบัติโหนด แท็บ ระบุข้อมูลต่อไปนี้:
- เปลี่ยนแปลง Name ไปยัง
geologicalsurveyชุดข้อมูล - Choose การกระทำ และการเปลี่ยนแปลง เปลี่ยนสคีมา (ใช้การแมป).
- Choose คุณสมบัติโหนด และเปลี่ยนชื่อการแปลงจาก Change Schema (Apply Mapping) เป็น
ApplyMapping. - เกี่ยวกับ เป้า เมนูให้เลือก S3.
- เปลี่ยนแปลง Name ไปยัง
- เกี่ยวกับ คุณสมบัติแหล่งข้อมูล – S3 แท็บ ระบุข้อมูลต่อไปนี้:
- สำหรับ รูปแบบให้เลือก ปาร์เกต์.
- สำหรับ ประเภทการบีบอัดให้เลือก ไม่บีบอัด.
- สำหรับ ประเภทแหล่งที่มา S3ให้เลือก ที่ตั้ง S3.
- สำหรับ URL S3ป้อน
s3://${BUCKET_NAME}/output/parquet/. - Choose คุณสมบัติโหนด และเปลี่ยนชื่อเป็น
Output.
- Choose ลด เพื่อบันทึกงาน
- Choose วิ่ง เพื่อเรียกใช้งาน
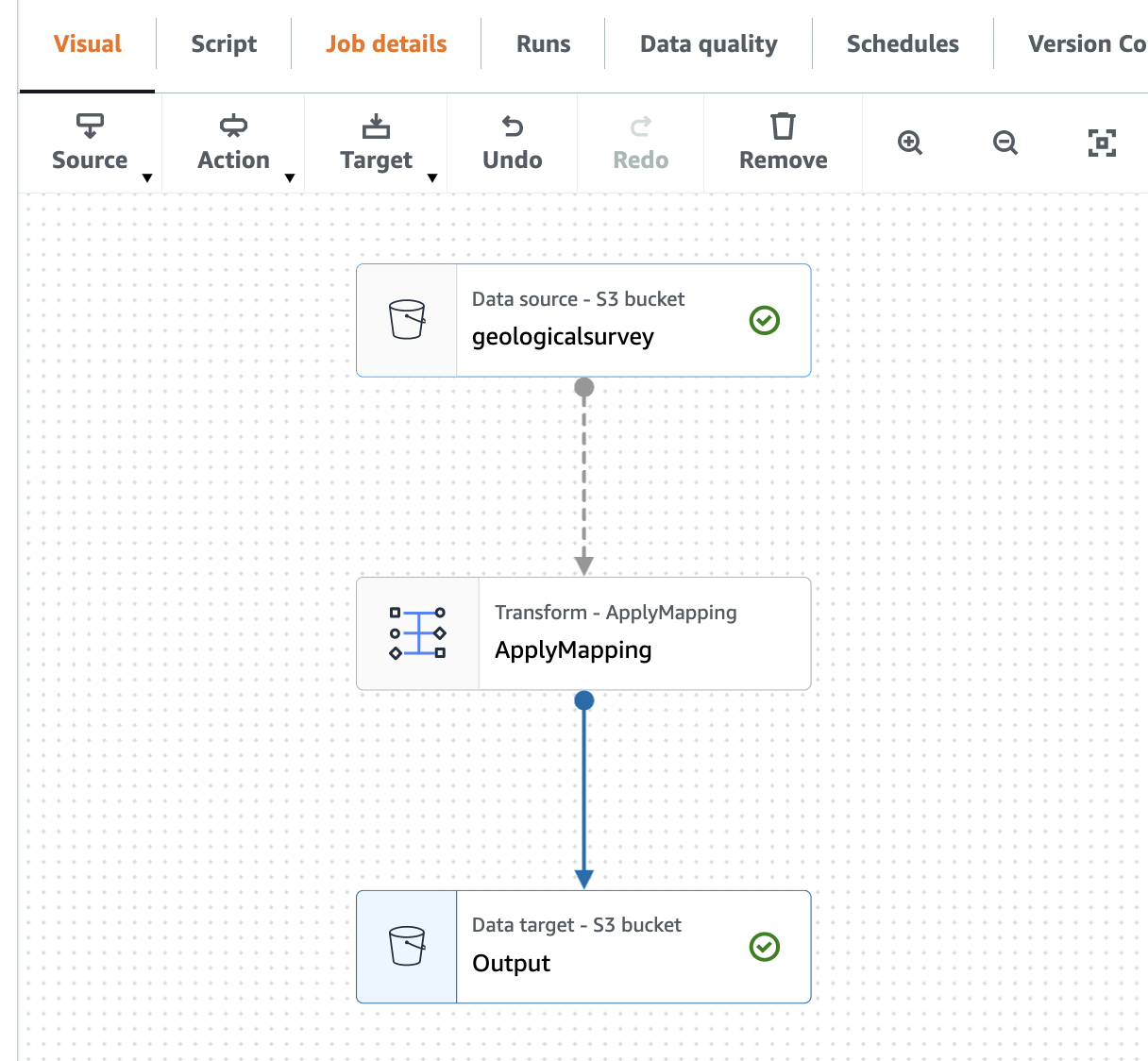
ภาพหน้าจอต่อไปนี้แสดงงานในตัวแก้ไขภาพ
สร้าง AWS Gue Crawler เพื่อรวบรวมข้อมูลไฟล์ Parquet
ในขั้นตอนนี้ คุณจะสร้างโปรแกรมรวบรวมข้อมูล AWS Glue เพื่อดึงข้อมูลเมตาจากไฟล์ Parquet ที่คุณสร้างขึ้นโดยใช้งาน AWS Glue Studio คราวนี้ คุณใช้ตัวแยกประเภทเริ่มต้น ทำตามขั้นตอนต่อไปนี้:
- บนคอนโซล AWS Glue ให้เลือก โปรแกรมรวบรวมข้อมูล ในบานหน้าต่างนำทาง
- Choose สร้างโปรแกรมรวบรวมข้อมูล.
- เกี่ยวกับ ตั้งค่าคุณสมบัติของโปรแกรมรวบรวมข้อมูล ระบุชื่อสำหรับซอฟต์แวร์รวบรวมข้อมูลใหม่ เช่น blog-glue-parquet-contact จากนั้นเลือก ถัดไป.
- เกี่ยวกับ เลือกแหล่งข้อมูลและตัวแยกประเภท ใหเลือก ยัง for การกำหนดค่าแหล่งข้อมูล.
- Choose เพิ่มที่เก็บข้อมูล.
- สำหรับ เส้นทาง S3เรียกดูไปที่
s3://${BUCKET_NAME}/output/parquet/.
ตรวจสอบให้แน่ใจว่าคุณเลือก parquet แทนที่จะเป็นไฟล์ที่อยู่ในโฟลเดอร์
- เลือกบทบาท IAM ของคุณที่สร้างขึ้นในระหว่างส่วนข้อกำหนดเบื้องต้นหรือเลือก สร้างบทบาท IAM ใหม่ (ตัวอย่างเช่น,
AWSGlueServiceNotebookRoleBlog) และเลือก ถัดไป. - เกี่ยวกับ ตั้งค่าเอาต์พุตและการจัดตารางเวลา หน้าภายใต้ การกำหนดค่าเอาต์พุตเลือก
blog_glue_xmlfor ฐานข้อมูล. - เข้าสู่
parquet_เป็นคำนำหน้าที่ถูกเพิ่มลงในตาราง (ไม่บังคับ) และต่ำกว่า ตารางโปรแกรมรวบรวมข้อมูลให้ตั้งความถี่ไว้ที่ ตามความต้องการ. - Choose ถัดไป.
- ตรวจสอบพารามิเตอร์ทั้งหมดแล้วเลือก สร้างโปรแกรมรวบรวมข้อมูล.
ตอนนี้คุณสามารถเรียกใช้โปรแกรมรวบรวมข้อมูลได้ ซึ่งจะใช้เวลา 1-2 นาทีจึงจะเสร็จสมบูรณ์

คุณสามารถดูตัวอย่างสคีมาที่สร้างขึ้นใหม่สำหรับไฟล์ Parquet ได้ใน AWS Glue Data Catalog ซึ่งคล้ายกับสคีมาของไฟล์ XML
ตอนนี้เรามีข้อมูลที่เหมาะกับการใช้งานกับเอเธน่าแล้ว ในส่วนถัดไป เราจะทำการสืบค้นข้อมูลโดยใช้ Athena
ค้นหาไฟล์ Parquet โดยใช้ Athena
Athena ไม่รองรับการสืบค้น รูปแบบไฟล์ XMLซึ่งเป็นสาเหตุที่ทำให้คุณแปลงไฟล์ XML เป็น Parquet เพื่อการสืบค้นและใช้งานข้อมูลที่มีประสิทธิภาพมากขึ้น สัญกรณ์จุด เพื่อค้นหาประเภทที่ซับซ้อนและโครงสร้างที่ซ้อนกัน
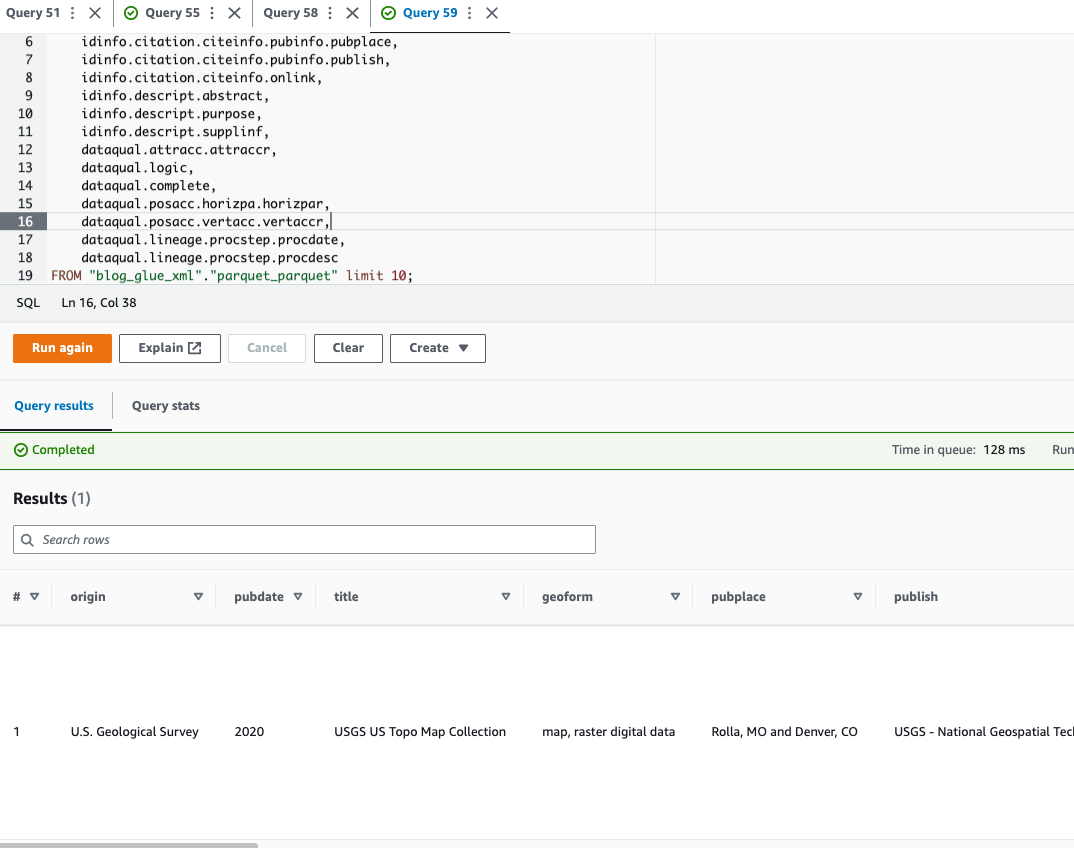
โค้ดตัวอย่างต่อไปนี้ใช้เครื่องหมายจุดเพื่อสอบถามข้อมูลที่ซ้อนกัน:
หลังจากที่เราเสร็จสิ้นเทคนิคที่ 1 แล้ว เรามาเรียนรู้เกี่ยวกับเทคนิคที่ 2 กันต่อ
เทคนิคที่ 2: ใช้ AWS Glue DynamicFrames กับสคีมาแบบสรุปและแบบคงที่
ในส่วนก่อนหน้านี้ เราได้กล่าวถึงกระบวนการจัดการไฟล์ XML ขนาดเล็กโดยใช้โปรแกรมรวบรวมข้อมูล AWS Glue เพื่อสร้างตาราง งาน AWS Glue เพื่อแปลงไฟล์เป็นรูปแบบ Parquet และ Athena เพื่อเข้าถึงข้อมูล Parquet อย่างไรก็ตาม โปรแกรมรวบรวมข้อมูลพบข้อจำกัดในการประมวลผลไฟล์ XML ที่เกิน ขนาด 1 MB. ในส่วนนี้ เราจะเจาะลึกหัวข้อการประมวลผลไฟล์ XML ขนาดใหญ่เป็นชุด ซึ่งจำเป็นต้องมีการแยกวิเคราะห์เพิ่มเติมเพื่อแยกแต่ละเหตุการณ์และดำเนินการวิเคราะห์โดยใช้ Athena
แนวทางของเราเกี่ยวข้องกับการอ่านไฟล์ XML ผ่าน AWS Glue ไดนามิกเฟรมโดยใช้สกีมาทั้งแบบอนุมานและแบบตายตัว จากนั้นเราจะแยกแต่ละเหตุการณ์ในรูปแบบ Parquet โดยใช้ สัมพันธ์กัน การเปลี่ยนแปลงทำให้เราสามารถสืบค้นและวิเคราะห์ได้อย่างราบรื่นโดยใช้ Athena
เมื่อต้องการใช้โซลูชันนี้ คุณต้องทำตามขั้นตอนระดับสูงต่อไปนี้:
- สร้างสมุดบันทึก AWS Glue เพื่ออ่านและวิเคราะห์ไฟล์ XML
- ใช้
DynamicFramesกับInferSchemaเพื่ออ่านไฟล์ XML - ใช้ฟังก์ชันความสัมพันธ์เพื่อแยกอาร์เรย์ใดๆ
- แปลงข้อมูลเป็นรูปแบบไม้ปาร์เก้
- ค้นหาข้อมูล Parquet โดยใช้ Athena
- ทำซ้ำขั้นตอนก่อนหน้า แต่คราวนี้ส่งสคีมาไป
DynamicFramesแทนการใช้InferSchema.
ไฟล์ XML ข้อมูลประชากรรถยนต์ไฟฟ้ามีรูปแบบ response แท็กที่ระดับราก แท็กนี้มีอาร์เรย์ของ row แท็กที่ซ้อนกันอยู่ภายใน แท็กแถวคืออาร์เรย์ที่ประกอบด้วยชุดของแท็กแถวอื่น ซึ่งให้ข้อมูลเกี่ยวกับยานพาหนะ รวมถึงยี่ห้อ รุ่น และรายละเอียดอื่นๆ ที่เกี่ยวข้อง ภาพหน้าจอต่อไปนี้แสดงตัวอย่าง

สร้างสมุดบันทึก AWS Glue
หากต้องการสร้างสมุดบันทึก AWS Glue ให้ทำตามขั้นตอนต่อไปนี้:
- เปิด AWS กาวสตูดิโอ คอนโซล เลือก งาน ในบานหน้าต่างนำทาง
- เลือก โน้ตบุ๊ค Jupyter และเลือก สร้างบัญชีตัวแทน.
- ป้อนชื่อสำหรับงาน AWS Glue ของคุณ เช่น
blog_glue_xml_job_Jupyter. - เลือกบทบาทที่คุณสร้างในข้อกำหนดเบื้องต้น (
AWSGlueServiceNotebookRoleBlog).
สมุดบันทึก AWS Glue มาพร้อมกับตัวอย่างที่มีอยู่แล้วซึ่งสาธิตวิธีการสืบค้นฐานข้อมูลและเขียนเอาต์พุตไปยัง Amazon S3
- ปรับการหมดเวลา (เป็นนาที) ดังที่แสดงในภาพหน้าจอต่อไปนี้ และเรียกใช้เซลล์เพื่อสร้างเซสชันแบบโต้ตอบ AWS Glue
สร้างตัวแปรพื้นฐาน
หลังจากที่คุณสร้างเซสชันแบบโต้ตอบแล้ว ที่ส่วนท้ายของสมุดบันทึก ให้สร้างเซลล์ใหม่ด้วยตัวแปรต่อไปนี้ (ระบุชื่อบัคเก็ตของคุณเอง):
อ่านไฟล์ XML ที่อนุมานสคีมา
หากคุณไม่ส่งสคีมาไปที่ DynamicFrameมันจะอนุมานสคีมาของไฟล์ หากต้องการอ่านข้อมูลโดยใช้เฟรมไดนามิก คุณสามารถใช้คำสั่งต่อไปนี้:
พิมพ์ DynamicFrame Schema
พิมพ์สคีมาด้วยรหัสต่อไปนี้:
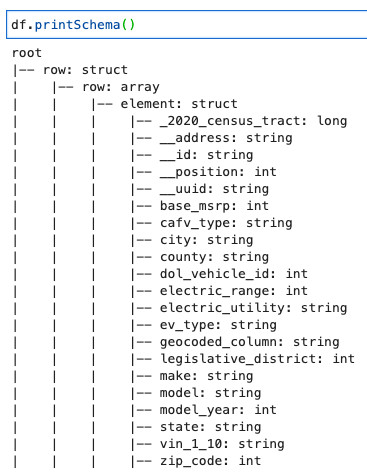
สคีมาแสดงโครงสร้างที่ซ้อนกันด้วย row อาร์เรย์ที่มีหลายองค์ประกอบ หากต้องการแยกโครงสร้างนี้เป็นเส้น คุณสามารถใช้ AWS Glue สัมพันธ์กัน การเปลี่ยนแปลง:
เราสนใจเฉพาะข้อมูลที่มีอยู่ในแถวอาร์เรย์เท่านั้น และเราสามารถดูสคีมาได้โดยใช้คำสั่งต่อไปนี้:
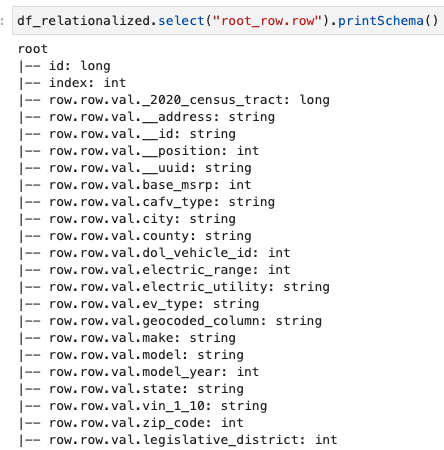
ชื่อคอลัมน์ประกอบด้วย row.rowซึ่งสอดคล้องกับโครงสร้างอาร์เรย์และคอลัมน์อาร์เรย์ในชุดข้อมูล เราไม่เปลี่ยนชื่อคอลัมน์ในโพสต์นี้ สำหรับคำแนะนำในการดำเนินการดังกล่าว โปรดดูที่ ทำการแมปแบบไดนามิกและการเปลี่ยนชื่อคอลัมน์ในไฟล์ข้อมูลโดยอัตโนมัติโดยใช้ AWS Glue: ตอนที่ 1. จากนั้น คุณสามารถแปลงข้อมูลเป็นรูปแบบ Parquet และสร้างตาราง AWS Glue ได้โดยใช้คำสั่งต่อไปนี้:
AWS กาว DynamicFrame มีคุณสมบัติที่คุณสามารถใช้ในสคริปต์ ETL ของคุณเพื่อสร้างและอัปเดตสคีมาใน Data Catalog เราใช้ updateBehavior พารามิเตอร์เพื่อสร้างตารางโดยตรงใน Data Catalog ด้วยแนวทางนี้ เราไม่จำเป็นต้องเรียกใช้โปรแกรมรวบรวมข้อมูล AWS Glue หลังจากที่งาน AWS Glue เสร็จสมบูรณ์

อ่านไฟล์ XML โดยการตั้งค่าสคีมา
อีกวิธีหนึ่งในการอ่านไฟล์คือการกำหนดสคีมาล่วงหน้า เมื่อต้องการทำเช่นนี้ ให้ทำตามขั้นตอนต่อไปนี้:
- นำเข้าประเภทข้อมูล AWS Glue:
- สร้างสคีมาสำหรับไฟล์ XML:
- ส่งสคีมาเมื่ออ่านไฟล์ XML:
- ยกเลิกชุดข้อมูลเหมือนเมื่อก่อน:
- แปลงชุดข้อมูลเป็น Parquet และสร้างตาราง AWS Glue:
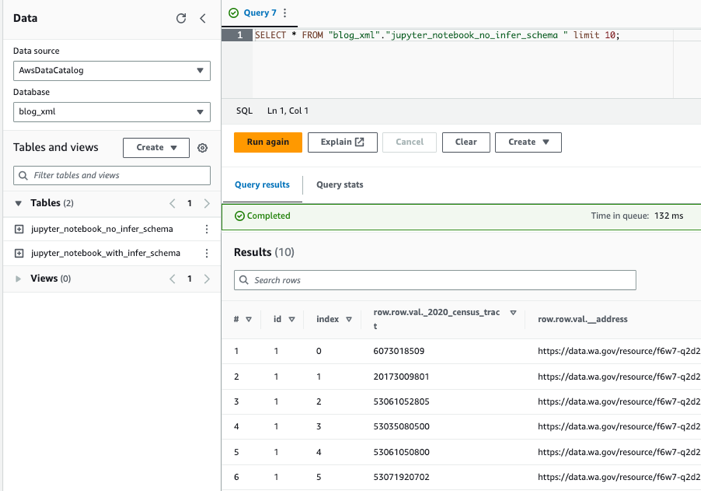
สอบถามตารางโดยใช้ Athena
ตอนนี้เราได้สร้างทั้งสองตารางแล้ว เราสามารถสืบค้นตารางโดยใช้ Athena ได้ ตัวอย่างเช่น เราสามารถใช้แบบสอบถามต่อไปนี้:
ทำความสะอาดขึ้น
ในโพสต์นี้ เราได้สร้างบทบาท IAM, สมุดบันทึก AWS Glue Jupyter และตารางสองตารางใน AWS Glue Data Catalog เรายังอัปโหลดไฟล์บางไฟล์ไปยังบัคเก็ต S3 ด้วย หากต้องการล้างข้อมูลอ็อบเจ็กต์เหล่านี้ ให้ทำตามขั้นตอนต่อไปนี้:
- บนคอนโซล IAM ให้ลบบทบาทที่คุณสร้างขึ้น
- บนคอนโซล AWS Glue Studio ให้ลบตัวแยกประเภทที่กำหนดเอง โปรแกรมรวบรวมข้อมูล งาน ETL และสมุดบันทึก Jupyter
- ไปที่ AWS Glue Data Catalog และลบตารางที่คุณสร้างขึ้น
- บนคอนโซล Amazon S3 ให้นำทางไปยังบัคเก็ตที่คุณสร้างและลบโฟลเดอร์ที่มีชื่อ
temp,infer_schemaและno_infer_schema.
ประเด็นที่สำคัญ
ใน AWS Glue มีคุณสมบัติที่เรียกว่า InferSchema ใน AWS Glue DynamicFrames. มันจะระบุโครงสร้างของกรอบข้อมูลโดยอัตโนมัติตามข้อมูลที่มีอยู่ ในทางตรงกันข้าม การกำหนดสคีมาหมายถึงการระบุอย่างชัดเจนว่าโครงสร้างของกรอบข้อมูลควรเป็นอย่างไรก่อนที่จะโหลดข้อมูล
XML ซึ่งเป็นรูปแบบข้อความไม่ได้จำกัดประเภทข้อมูลของคอลัมน์ ซึ่งอาจทำให้เกิดปัญหากับฟังก์ชัน InferSchema ตัวอย่างเช่น ในการรันครั้งแรก ไฟล์ที่มีคอลัมน์ A มีค่า 2 จะส่งผลให้ไฟล์ Parquet มีคอลัมน์ A เป็นจำนวนเต็ม ในการรันครั้งที่สอง ไฟล์ใหม่มีคอลัมน์ A ที่มีค่า C ซึ่งนำไปสู่ไฟล์ Parquet ที่มีคอลัมน์ A เป็นสตริง ขณะนี้มีไฟล์สองไฟล์บน S3 โดยแต่ละไฟล์มีคอลัมน์ A ที่มีประเภทข้อมูลต่างกัน ซึ่งสามารถสร้างปัญหาดาวน์สตรีมได้
สิ่งเดียวกันนี้เกิดขึ้นกับประเภทข้อมูลที่ซับซ้อน เช่น โครงสร้างหรืออาร์เรย์ที่ซ้อนกัน ตัวอย่างเช่น หากไฟล์มีรายการแท็กหนึ่งรายการที่เรียกว่า transactionมันถูกอนุมานว่าเป็นโครงสร้าง แต่ถ้าไฟล์อื่นมีแท็กเดียวกัน ไฟล์นั้นจะอนุมานเป็นอาร์เรย์
แม้จะมีปัญหาประเภทข้อมูลเหล่านี้ InferSchema มีประโยชน์เมื่อคุณไม่ทราบสคีมาหรือการกำหนดสคีมาด้วยตนเองนั้นไม่สามารถทำได้ อย่างไรก็ตาม ไม่เหมาะสำหรับชุดข้อมูลขนาดใหญ่หรือมีการเปลี่ยนแปลงอยู่ตลอดเวลา การกำหนดสคีมามีความแม่นยำมากขึ้น โดยเฉพาะอย่างยิ่งกับประเภทข้อมูลที่ซับซ้อน แต่มีปัญหาในตัวเอง เช่น ต้องใช้ความพยายามด้วยตนเอง และไม่ยืดหยุ่นต่อการเปลี่ยนแปลงข้อมูล
InferSchema มีข้อจำกัด เช่น การอนุมานประเภทข้อมูลที่ไม่ถูกต้อง และปัญหาในการจัดการค่า Null การกำหนดสคีมายังมีข้อจำกัด เช่น การดำเนินการด้วยตนเองและข้อผิดพลาดที่อาจเกิดขึ้น
การเลือกระหว่างการอนุมานและการกำหนดสคีมาขึ้นอยู่กับความต้องการของโปรเจ็กต์ InferSchema เหมาะอย่างยิ่งสำหรับการสำรวจชุดข้อมูลขนาดเล็กอย่างรวดเร็ว ในขณะที่การกำหนดสคีมาจะดีกว่าสำหรับชุดข้อมูลขนาดใหญ่และซับซ้อนซึ่งต้องการความแม่นยำและความสม่ำเสมอ พิจารณาข้อดีข้อเสียและข้อจำกัดของแต่ละวิธีเพื่อเลือกสิ่งที่เหมาะสมกับโครงการของคุณที่สุด
สรุป
ในโพสต์นี้ เราได้สำรวจเทคนิคสองประการในการจัดการข้อมูล XML โดยใช้ AWS Glue ซึ่งแต่ละเทคนิคได้รับการออกแบบมาเพื่อตอบสนองความต้องการและความท้าทายเฉพาะที่คุณอาจเผชิญ
เทคนิคที่ 1 นำเสนอเส้นทางที่เป็นมิตรต่อผู้ใช้สำหรับผู้ที่ชื่นชอบอินเทอร์เฟซแบบกราฟิก คุณสามารถใช้โปรแกรมรวบรวมข้อมูล AWS Glue และโปรแกรมแก้ไขภาพเพื่อกำหนดโครงสร้างตารางสำหรับไฟล์ XML ของคุณได้อย่างง่ายดาย แนวทางนี้ทำให้กระบวนการจัดการข้อมูลง่ายขึ้น และน่าสนใจเป็นพิเศษสำหรับผู้ที่มองหาวิธีที่ตรงไปตรงมาในการจัดการข้อมูลของตน
อย่างไรก็ตาม เราทราบดีว่าโปรแกรมรวบรวมข้อมูลมีข้อจำกัด โดยเฉพาะเมื่อต้องจัดการกับไฟล์ XML ที่มีแถวขนาดใหญ่กว่า 1 MB นี่คือจุดที่เทคนิค 2 มาช่วยเหลือ โดยการควบคุม AWS Glue DynamicFrames ด้วยสคีมาทั้งแบบสรุปและแบบคงที่ และการใช้สมุดบันทึก AWS Glue คุณสามารถจัดการไฟล์ XML ทุกขนาดได้อย่างมีประสิทธิภาพ วิธีนี้เป็นโซลูชันที่มีประสิทธิภาพซึ่งช่วยให้การประมวลผลราบรื่นแม้กระทั่งไฟล์ XML ที่มีแถวเกินข้อจำกัด 1 MB
ในขณะที่คุณสำรวจโลกแห่งการจัดการข้อมูล การมีเทคนิคเหล่านี้ในชุดเครื่องมือของคุณจะช่วยให้คุณตัดสินใจโดยมีข้อมูลครบถ้วนตามความต้องการเฉพาะของโครงการของคุณ ไม่ว่าคุณจะชอบความเรียบง่ายของเทคนิค 1 หรือความสามารถในการปรับขนาดของเทคนิค 2 AWS Glue มอบความยืดหยุ่นที่คุณต้องการในการจัดการข้อมูล XML อย่างมีประสิทธิภาพ
เกี่ยวกับผู้เขียน
 นวนิต ชุกลาทำหน้าที่เป็นสถาปนิกโซลูชันผู้เชี่ยวชาญ AWS โดยมุ่งเน้นที่การวิเคราะห์ เขามีความกระตือรือร้นอย่างมากในการช่วยเหลือลูกค้าในการค้นพบข้อมูลเชิงลึกอันมีค่าจากข้อมูลของพวกเขา ด้วยความเชี่ยวชาญของเขา เขาสร้างโซลูชั่นที่เป็นนวัตกรรมที่ช่วยให้ธุรกิจต่างๆ มีตัวเลือกที่ขับเคลื่อนด้วยข้อมูลและชาญฉลาด โดยเฉพาะอย่างยิ่ง Navnit Shukla เป็นผู้แต่งหนังสือชื่อ “Data Wrangling on AWS” ที่ประสบความสำเร็จ
นวนิต ชุกลาทำหน้าที่เป็นสถาปนิกโซลูชันผู้เชี่ยวชาญ AWS โดยมุ่งเน้นที่การวิเคราะห์ เขามีความกระตือรือร้นอย่างมากในการช่วยเหลือลูกค้าในการค้นพบข้อมูลเชิงลึกอันมีค่าจากข้อมูลของพวกเขา ด้วยความเชี่ยวชาญของเขา เขาสร้างโซลูชั่นที่เป็นนวัตกรรมที่ช่วยให้ธุรกิจต่างๆ มีตัวเลือกที่ขับเคลื่อนด้วยข้อมูลและชาญฉลาด โดยเฉพาะอย่างยิ่ง Navnit Shukla เป็นผู้แต่งหนังสือชื่อ “Data Wrangling on AWS” ที่ประสบความสำเร็จ
 แพทริก มุลเลอร์ ทำงานเป็นสถาปนิก Data Lab อาวุโสที่ AWS ความรับผิดชอบหลักของเขาคือการช่วยเหลือลูกค้าในการเปลี่ยนความคิดของตนให้เป็นผลิตภัณฑ์ข้อมูลที่พร้อมสำหรับการผลิต ในเวลาว่าง แพทริคชอบเล่นฟุตบอล ดูหนัง และท่องเที่ยว
แพทริก มุลเลอร์ ทำงานเป็นสถาปนิก Data Lab อาวุโสที่ AWS ความรับผิดชอบหลักของเขาคือการช่วยเหลือลูกค้าในการเปลี่ยนความคิดของตนให้เป็นผลิตภัณฑ์ข้อมูลที่พร้อมสำหรับการผลิต ในเวลาว่าง แพทริคชอบเล่นฟุตบอล ดูหนัง และท่องเที่ยว
 อาโมก ไกวาด เป็นนักพัฒนาโซลูชันอาวุโสที่ Amazon Web Services เขาช่วยลูกค้าทั่วโลกสร้างและปรับใช้โซลูชัน AI/ML บน AWS งานของเขามุ่งเน้นไปที่คอมพิวเตอร์วิทัศน์และการประมวลผลภาษาธรรมชาติเป็นหลัก และช่วยเหลือลูกค้าในการเพิ่มประสิทธิภาพปริมาณงาน AI/ML เพื่อความยั่งยืน Amogh สำเร็จการศึกษาระดับปริญญาโทสาขาวิทยาการคอมพิวเตอร์ที่เชี่ยวชาญด้านการเรียนรู้ของเครื่อง
อาโมก ไกวาด เป็นนักพัฒนาโซลูชันอาวุโสที่ Amazon Web Services เขาช่วยลูกค้าทั่วโลกสร้างและปรับใช้โซลูชัน AI/ML บน AWS งานของเขามุ่งเน้นไปที่คอมพิวเตอร์วิทัศน์และการประมวลผลภาษาธรรมชาติเป็นหลัก และช่วยเหลือลูกค้าในการเพิ่มประสิทธิภาพปริมาณงาน AI/ML เพื่อความยั่งยืน Amogh สำเร็จการศึกษาระดับปริญญาโทสาขาวิทยาการคอมพิวเตอร์ที่เชี่ยวชาญด้านการเรียนรู้ของเครื่อง
 ชีล่า โซโนน เป็นสถาปนิกอาวุโสประจำที่ AWS เธอช่วยให้ลูกค้า AWS ตัดสินใจอย่างมีข้อมูลและแลกเปลี่ยนกับการเร่งความเร็วข้อมูล การวิเคราะห์ รวมถึงปริมาณงานและการใช้งาน AI/ML ในเวลาว่าง เธอสนุกกับการใช้เวลาอยู่กับครอบครัว ซึ่งโดยปกติแล้วจะอยู่บนสนามเทนนิส
ชีล่า โซโนน เป็นสถาปนิกอาวุโสประจำที่ AWS เธอช่วยให้ลูกค้า AWS ตัดสินใจอย่างมีข้อมูลและแลกเปลี่ยนกับการเร่งความเร็วข้อมูล การวิเคราะห์ รวมถึงปริมาณงานและการใช้งาน AI/ML ในเวลาว่าง เธอสนุกกับการใช้เวลาอยู่กับครอบครัว ซึ่งโดยปกติแล้วจะอยู่บนสนามเทนนิส
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- เกี่ยวกับเรา
- บทคัดย่อ
- เร่ง
- เข้า
- การเข้าถึง
- คล่องแคล่ว
- ความถูกต้อง
- ข้าม
- การกระทำ
- เพิ่ม
- ที่เพิ่ม
- เพิ่มเติม
- ที่อยู่
- หลังจาก
- อายุ
- AI / ML
- ทั้งหมด
- อนุญาต
- การอนุญาต
- ช่วยให้
- ด้วย
- ทางเลือก
- อเมซอน
- อเมซอน อาเธน่า
- Amazon Web Services
- an
- การวิเคราะห์
- การวิเคราะห์
- วิเคราะห์
- วิเคราะห์
- และ
- อื่น
- ใด
- อาปาเช่
- อุทธรณ์
- การใช้งาน
- ใช้
- เข้าใกล้
- วิธีการ
- สถาปัตยกรรม
- เป็น
- แถว
- AS
- ช่วยเหลือ
- การให้ความช่วยเหลือ
- At
- ผู้เขียน
- อัตโนมัติ
- ใช้ได้
- AWS
- AWS กาว
- กลับ
- ตาม
- ขั้นพื้นฐาน
- BE
- เพราะ
- ก่อน
- เริ่ม
- กำลัง
- ที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- ว่างเปล่า
- หนังสือ
- ทั้งสอง
- สร้าง
- ธุรกิจ
- แต่
- by
- ที่เรียกว่า
- CAN
- แค็ตตาล็อก
- ก่อให้เกิด
- เซลล์
- ความท้าทาย
- เปลี่ยนแปลง
- การเปลี่ยนแปลง
- เปลี่ยนแปลง
- ทางเลือก
- Choose
- เมือง
- การจัดหมวดหมู่
- ลูกค้า
- รหัส
- คอลัมน์
- คอลัมน์
- COM
- มา
- ร่วมกัน
- อย่างธรรมดา
- สมบูรณ์
- เสร็จ
- ซับซ้อน
- คอมพิวเตอร์
- วิทยาการคอมพิวเตอร์
- วิสัยทัศน์คอมพิวเตอร์
- สภาพ
- ความประพฤติ
- ร่วม
- พิจารณา
- ปลอบใจ
- ไม่หยุดหย่อน
- ข้อ จำกัด
- สร้าง
- บรรจุ
- ที่มีอยู่
- มี
- ตรงกันข้าม
- ควบคุม
- แปลง
- แปลง
- ค่าใช้จ่ายที่มีประสิทธิภาพ
- โซลูชันที่คุ้มค่า
- มณฑล
- ศาล
- ปกคลุม
- ไม้เลื้อย
- สร้าง
- ที่สร้างขึ้น
- การสร้าง
- สำคัญมาก
- ประเพณี
- ลูกค้า
- ลูกค้า
- ข้อมูล
- การรวมข้อมูล
- การจัดการข้อมูล
- ที่ขับเคลื่อนด้วยข้อมูล
- ฐานข้อมูล
- ชุดข้อมูล
- การซื้อขาย
- การตัดสินใจ
- ค่าเริ่มต้น
- กำหนด
- การกำหนด
- คุ้ย
- แสดงให้เห็นถึง
- ขึ้นอยู่กับ
- ปรับใช้
- ได้รับการออกแบบ
- รายละเอียด
- รายละเอียด
- ผู้พัฒนา
- ต่าง
- ยาก
- ดิจิตอล
- ยุคดิจิตอล
- โดยตรง
- การค้นพบ
- แตกต่าง
- do
- ไม่
- ทำ
- Dont
- DOT
- ในระหว่าง
- พลวัต
- แต่ละ
- ความสะดวก
- อย่างง่ายดาย
- ง่าย
- บรรณาธิการ
- ผล
- มีประสิทธิภาพ
- อย่างมีประสิทธิภาพ
- ที่มีประสิทธิภาพ
- อย่างมีประสิทธิภาพ
- ความพยายาม
- ง่าย
- ติดตั้งระบบไฟฟ้า
- ยานพาหนะไฟฟ้า
- องค์ประกอบ
- จ้าง
- ให้อำนาจ
- ให้อำนาจ
- ไม่มีข้อมูล
- ทำให้สามารถ
- การเปิดใช้งาน
- พบ
- ปลาย
- เครื่องยนต์
- เสริม
- ทำให้มั่นใจ
- เพื่อให้แน่ใจ
- เข้าสู่
- ความกระตือรือร้น
- การเข้า
- ข้อผิดพลาด
- โดยเฉพาะอย่างยิ่ง
- อีเธอร์ (ETH)
- แม้
- เหตุการณ์
- ทุกๆ
- ตัวอย่าง
- เกินกว่า
- การแลกเปลี่ยน
- ความชำนาญ
- การสำรวจ
- สำรวจ
- สำรวจ
- สารสกัด
- การสกัด
- ครอบครัว
- ลักษณะ
- คุณสมบัติ
- ตัวเลข
- เนื้อไม่มีมัน
- ไฟล์
- เงินทุน
- ชื่อจริง
- การแก้ไข
- ความยืดหยุ่น
- โฟกัส
- มุ่งเน้น
- ดังต่อไปนี้
- สำหรับ
- รูป
- FRAME
- ฟรี
- เวลา
- ราคาเริ่มต้นที่
- ฟังก์ชัน
- ได้รับ
- จุดประสงค์ทั่วไป
- สร้าง
- เหตุการณ์ที่
- Go
- เป้าหมาย
- รัฐบาล
- ยิ่งใหญ่
- จัดการ
- การจัดการ
- ที่เกิดขึ้น
- การควบคุม
- มี
- มี
- he
- การดูแลสุขภาพ
- หัวใจสำคัญ
- ช่วย
- การช่วยเหลือ
- จะช่วยให้
- เธอ
- ระดับสูง
- อย่างสูง
- ของเขา
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTML
- ที่ http
- HTTPS
- AMI
- ในอุดมคติ
- ความคิด
- เอกลักษณ์
- if
- แสดงให้เห็นถึง
- การดำเนินการ
- การใช้งาน
- การดำเนินการ
- นำเข้า
- ปรับปรุง
- การปรับปรุง
- in
- รวมทั้ง
- เป็นรายบุคคล
- บุคคล
- อุตสาหกรรม
- ข้อมูล
- แจ้ง
- โครงสร้างพื้นฐาน
- นวัตกรรม
- ภายใน
- ข้อมูลเชิงลึก
- แทน
- คำแนะนำการใช้
- รวบรวม
- บูรณาการ
- การโต้ตอบ
- สนใจ
- อินเตอร์เฟซ
- เข้าไป
- ที่เกี่ยวข้องกับการ
- ปัญหา
- IT
- ITS
- การสัมภาษณ์
- งาน
- jpg
- JSON
- โน้ตบุ๊ค Jupyter
- เก็บ
- ทราบ
- ห้องปฏิบัติการ
- ภาษา
- ใหญ่
- ที่มีขนาดใหญ่
- ชั้นนำ
- เรียนรู้
- การเรียนรู้
- ชั้น
- กดไลก์
- LIMIT
- การ จำกัด
- ข้อ จำกัด
- Line
- เส้น
- โหลด
- โหลด
- ตรรกะ
- ที่ต้องการหา
- เครื่อง
- เรียนรู้เครื่อง
- หลัก
- ส่วนใหญ่
- ทำ
- การทำ
- การจัดการ
- การจัดการ
- คู่มือ
- ด้วยมือ
- หลาย
- การทำแผนที่
- ปริญญาโท
- อาจ..
- วิธี
- เมนู
- เมตาดาต้า
- วิธี
- นาที
- แบบ
- ข้อมูลเพิ่มเติม
- มีประสิทธิภาพมากขึ้น
- มากที่สุด
- ย้าย
- Movies
- หลาย
- ชื่อ
- ที่มีชื่อ
- ชื่อ
- โดยธรรมชาติ
- ภาษาธรรมชาติ
- ประมวลผลภาษาธรรมชาติ
- นำทาง
- การเดินเรือ
- จำเป็น
- จำเป็นต้อง
- ความต้องการ
- ใหม่
- ใหม่
- ถัดไป
- ยวด
- สมุดบันทึก
- ตอนนี้
- จำนวน
- วัตถุ
- of
- เสนอ
- on
- ONE
- เพียง
- การดำเนินการ
- ดีที่สุด
- เพิ่มประสิทธิภาพ
- เพิ่มประสิทธิภาพ
- Options
- or
- ใบสั่ง
- องค์กร
- ที่มา
- อื่นๆ
- ของเรา
- ออก
- เอาท์พุต
- เกิน
- เอาชนะ
- ของตนเอง
- หน้า
- บานหน้าต่าง
- พารามิเตอร์
- พารามิเตอร์
- ส่วนหนึ่ง
- โดยเฉพาะ
- ส่ง
- เส้นทาง
- แพทริค
- ดำเนินการ
- การปฏิบัติ
- สิทธิ์
- เลือก
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- เล่น
- นโยบาย
- ประชากร
- มี
- โพสต์
- ที่มีศักยภาพ
- จำเป็นต้อง
- ชอบ
- ข้อกำหนดเบื้องต้น
- ดูตัวอย่าง
- ก่อน
- ปัญหาที่เกิดขึ้น
- กระบวนการ
- การประมวลผล
- การประมวลผล
- ผลิตภัณฑ์
- โครงการ
- โครงการ
- คุณสมบัติ
- ให้
- ให้
- ประกาศ
- วัตถุประสงค์
- หลาม
- คำสั่ง
- รวดเร็ว
- ค่อนข้าง
- อ่าน
- อย่างง่ายดาย
- การอ่าน
- เหตุผล
- ที่ได้รับ
- รับรู้
- อ้างอิง
- ตรงประเด็น
- ความต้องการ
- ช่วยเหลือ
- ทรัพยากร
- คำตอบ
- ความรับผิดชอบ
- REST
- จำกัด
- การ จำกัด
- ผลสอบ
- แข็งแรง
- บทบาท
- ราก
- แถว
- วิ่ง
- เดียวกัน
- ลด
- สกาล่า
- scalability
- ที่ปรับขนาดได้
- วิทยาศาสตร์
- ต้นฉบับ
- ไร้รอยต่อ
- ได้อย่างลงตัว
- ที่สอง
- Section
- เห็น
- ระดับอาวุโส
- บริการ
- เซสชั่น
- ชุด
- การตั้งค่า
- หลาย
- เธอ
- เปลือก
- น่า
- โชว์
- แสดง
- แสดงให้เห็นว่า
- คล้ายคลึงกัน
- ง่าย
- ความง่าย
- ลดความซับซ้อน
- เดียว
- ขนาด
- เล็ก
- So
- ฟุตบอล
- ทางออก
- โซลูชัน
- บาง
- แหล่ง
- แหล่งที่มา
- จุดประกาย
- ผู้เชี่ยวชาญ
- ความเชี่ยวชาญ
- โดยเฉพาะ
- เฉพาะ
- ความเร็ว
- การใช้จ่าย
- SQL
- มาตรฐาน
- เริ่มต้น
- สถานะ
- คำแถลง
- เซน
- ขั้นตอน
- ขั้นตอน
- การเก็บรักษา
- เก็บไว้
- ซื่อตรง
- เพรียวลม
- เชือก
- แข็งแรง
- โครงสร้าง
- โครงสร้าง
- สตูดิโอ
- ความสำเร็จ
- อย่างเช่น
- เหมาะสม
- สนับสนุน
- แน่ใจ
- การพัฒนาอย่างยั่งยืน
- ระบบ
- ตาราง
- TAG
- ปรับปรุง
- เอา
- ใช้เวลา
- งาน
- เทคนิค
- เทนนิส
- กว่า
- ที่
- พื้นที่
- ข้อมูล
- โลก
- ของพวกเขา
- พวกเขา
- แล้วก็
- ที่นั่น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- นี้
- เหล่านั้น
- ตลอด
- เวลา
- ชื่อหนังสือ
- หัวข้อ
- ไปยัง
- วันนี้
- เครื่องมือ
- ด้านบน
- หัวข้อ
- แปลง
- การแปลง
- การเดินทาง
- การหมุน
- เกี่ยวกับการสอน
- สอง
- ชนิด
- ชนิด
- ที่สุด
- ภายใต้
- บันทึก
- ให้กับคุณ
- อัปโหลด
- us
- การใช้งาน
- ใช้
- มือสอง
- ผู้ใช้งาน
- ส่วนติดต่อผู้ใช้
- ที่ใช้งานง่าย
- ใช้
- การใช้
- มักจะ
- การใช้ประโยชน์
- มีคุณค่า
- ความคุ้มค่า
- ความคุ้มค่า
- พาหนะ
- รุ่น
- ผ่านทาง
- รายละเอียด
- ยอดวิว
- วิสัยทัศน์
- ชม
- ทาง..
- we
- เว็บ
- บริการเว็บ
- อะไร
- เมื่อ
- แต่ทว่า
- ว่า
- ที่
- WHO
- ทำไม
- จะ
- กับ
- ภายใน
- ไม่มี
- งาน
- เวิร์กโฟลว์
- ขั้นตอนการทำงาน
- โรงงาน
- โลก
- เขียน
- XML
- เธอ
- ของคุณ
- ลมทะเล