สร้างด้วย Midjourney
การประชุม NeurIPS 2023 ซึ่งจัดขึ้นในเมืองนิวออร์ลีนส์อันมีชีวิตชีวา ระหว่างวันที่ 10 ถึง 16 ธันวาคม โดยเน้นไปที่ generative AI และโมเดลภาษาขนาดใหญ่ (LLM) เมื่อพิจารณาถึงความก้าวหน้าที่ก้าวล้ำล่าสุดในโดเมนนี้ จึงไม่น่าแปลกใจที่หัวข้อเหล่านี้ครอบงำการอภิปราย
หัวข้อหลักประการหนึ่งของการประชุมในปีนี้คือการแสวงหาระบบ AI ที่มีประสิทธิภาพมากขึ้น นักวิจัยและนักพัฒนาต่างกระตือรือร้นมองหาวิธีสร้าง AI ที่ไม่เพียงแต่เรียนรู้ได้เร็วกว่า LLM ในปัจจุบันเท่านั้น แต่ยังมีความสามารถในการให้เหตุผลที่ได้รับการปรับปรุงในขณะที่ใช้ทรัพยากรคอมพิวเตอร์น้อยลง การแสวงหานี้มีความสำคัญอย่างยิ่งในการแข่งขันเพื่อบรรลุปัญญาประดิษฐ์ทั่วไป (AGI) ซึ่งเป็นเป้าหมายที่ดูเหมือนจะบรรลุได้มากขึ้นในอนาคตอันใกล้
การเสวนาที่ได้รับเชิญที่ NeurIPS 2023 สะท้อนให้เห็นถึงความสนใจที่เปลี่ยนแปลงอย่างรวดเร็วและไม่หยุดนิ่งเหล่านี้ ผู้นำเสนอจากการวิจัย AI ในด้านต่างๆ แบ่งปันความสำเร็จล่าสุดของพวกเขา โดยนำเสนอช่องทางสู่การพัฒนา AI ที่ล้ำสมัย ในบทความนี้ เราจะเจาะลึกการเสวนาเหล่านี้ โดยแยกและอภิปรายประเด็นสำคัญและการเรียนรู้ ซึ่งจำเป็นสำหรับการทำความเข้าใจภูมิทัศน์ของนวัตกรรม AI ในปัจจุบันและอนาคต
NextGenAI: ความเข้าใจผิดของการปรับขนาดและอนาคตของ Generative AI
In คำพูดของเขาBjörn Ommer หัวหน้ากลุ่มคอมพิวเตอร์วิทัศน์และการเรียนรู้ที่ Ludwig Maximilian University of Munich เล่าว่าห้องทดลองของเขาพัฒนา Stable Diffusion ได้อย่างไร บทเรียนสองสามข้อที่พวกเขาเรียนรู้จากกระบวนการนี้ และการพัฒนาล่าสุด รวมถึงวิธีที่เราสามารถผสมผสานโมเดลการแพร่กระจายเข้ากับ การจับคู่โฟลว์ การเพิ่มการดึงข้อมูล และการประมาณ LoRA และอื่นๆ อีกมากมาย
ประเด็นที่สำคัญ:
- ในยุคของ Generative AI เราย้ายจากการมุ่งเน้นไปที่การรับรู้ในโมเดลการมองเห็น (เช่น การจดจำวัตถุ) ไปสู่การทำนายส่วนที่ขาดหายไป (เช่น การสร้างรูปภาพและวิดีโอด้วยโมเดลการแพร่กระจาย)
- เป็นเวลา 20 ปีแล้วที่คอมพิวเตอร์วิทัศน์มุ่งเน้นไปที่การวิจัยเกณฑ์มาตรฐาน ซึ่งช่วยให้มุ่งเน้นไปที่ปัญหาที่โดดเด่นที่สุด ใน Generative AI เราไม่มีเกณฑ์มาตรฐานใดๆ ที่ต้องปรับให้เหมาะสม ซึ่งเปิดช่องให้ทุกคนเดินไปในทิศทางของตนเอง
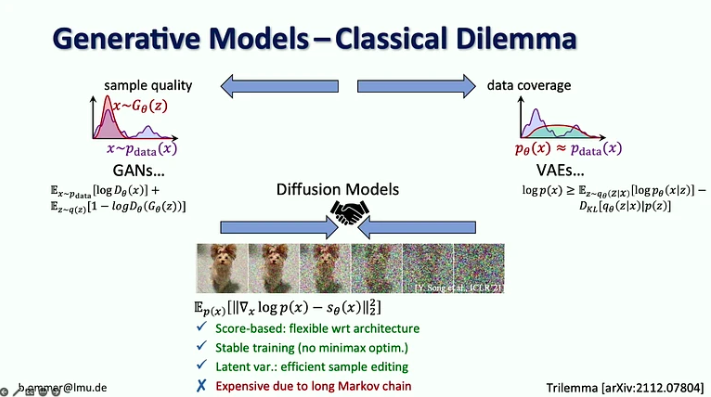
- แบบจำลองการแพร่กระจายรวมข้อดีของแบบจำลองกำเนิดก่อนหน้าโดยอิงตามคะแนน เข้ากับขั้นตอนการฝึกอบรมที่มั่นคงและการแก้ไขตัวอย่างที่มีประสิทธิภาพ แต่มีราคาแพงเนื่องจากมีสายโซ่ Markov ที่ยาว
- ความท้าทายที่มีโมเดลความเป็นไปได้สูงคือบิตส่วนใหญ่จะลงรายละเอียดที่ตามนุษย์แทบจะมองไม่เห็น ในขณะที่การเข้ารหัสความหมายซึ่งสำคัญที่สุดนั้นใช้เวลาเพียงไม่กี่บิตเท่านั้น การปรับขนาดเพียงอย่างเดียวไม่สามารถแก้ปัญหานี้ได้ เนื่องจากความต้องการทรัพยากรการประมวลผลเพิ่มขึ้นเร็วกว่าอุปทานของ GPU ถึง 9 เท่า
- วิธีแก้ปัญหาที่แนะนำคือการรวมจุดแข็งของแบบจำลองการแพร่กระจายและ ConvNets โดยเฉพาะอย่างยิ่งประสิทธิภาพของการโน้มน้าวใจในการแสดงรายละเอียดในท้องถิ่นและการแสดงออกของแบบจำลองการแพร่กระจายสำหรับบริบทระยะไกล
- Björn Ommer ยังแนะนำให้ใช้แนวทางการจับคู่การไหลเพื่อให้สามารถสังเคราะห์ภาพที่มีความละเอียดสูงจากแบบจำลองการแพร่กระจายแฝงขนาดเล็ก
- อีกวิธีหนึ่งในการเพิ่มประสิทธิภาพของการสังเคราะห์ภาพคือการมุ่งเน้นไปที่องค์ประกอบของฉากในขณะที่ใช้การเสริมการดึงข้อมูลเพื่อกรอกรายละเอียด
- ในที่สุด เขาได้แนะนำแนวทาง iPoke สำหรับการสังเคราะห์วิดีโอสุ่มแบบควบคุม
หากเนื้อหาเชิงลึกนี้มีประโยชน์สำหรับคุณ สมัครรับจดหมายข่าว AI ของเรา เพื่อรับการแจ้งเตือนเมื่อเราเผยแพร่เนื้อหาใหม่
ใบหน้าที่หลากหลายของ AI ที่มีความรับผิดชอบ
In การนำเสนอของเธอLora Aroyo นักวิทยาศาสตร์การวิจัยที่ Google Research เน้นย้ำถึงข้อจำกัดสำคัญในแนวทางการเรียนรู้ของเครื่องแบบดั้งเดิม นั่นคือ การพึ่งพาการจัดหมวดหมู่ข้อมูลแบบไบนารีเป็นตัวอย่างเชิงบวกหรือเชิงลบ เธอแย้งว่าการทำให้เข้าใจง่ายเกินไปนี้มองข้ามความเป็นส่วนตัวที่ซับซ้อนซึ่งมีอยู่ในสถานการณ์และเนื้อหาในโลกแห่งความเป็นจริง ด้วยกรณีการใช้งานต่างๆ Aroyo แสดงให้เห็นว่าความคลุมเครือของเนื้อหาและความแปรปรวนตามธรรมชาติในมุมมองของมนุษย์มักจะนำไปสู่ความขัดแย้งที่หลีกเลี่ยงไม่ได้ได้อย่างไร เธอเน้นย้ำถึงความสำคัญของการปฏิบัติต่อความขัดแย้งเหล่านี้เป็นสัญญาณที่มีความหมายมากกว่าเป็นเพียงเสียงรบกวน

ประเด็นสำคัญจากการเสวนามีดังนี้:
- ความขัดแย้งระหว่างคนงานที่เป็นมนุษย์อาจก่อให้เกิดผลได้ แทนที่จะปฏิบัติต่อคำตอบทั้งหมดว่าถูกหรือผิด Lora Aroyo ได้นำเสนอ "ความจริงโดยไม่เห็นด้วย" ซึ่งเป็นแนวทางการกระจายความจริงสำหรับการประเมินความน่าเชื่อถือของข้อมูลโดยควบคุมความขัดแย้งของผู้ประเมิน
- คุณภาพของข้อมูลยังทำได้ยากแม้กับผู้เชี่ยวชาญ เนื่องจากผู้เชี่ยวชาญไม่เห็นด้วยมากพอๆ กับเจ้าหน้าที่ฝูงชน ความขัดแย้งเหล่านี้ให้ความรู้มากกว่าคำตอบจากผู้เชี่ยวชาญเพียงคนเดียว
- ในงานประเมินความปลอดภัย ผู้เชี่ยวชาญไม่เห็นด้วยกับตัวอย่าง 40% แทนที่จะพยายามแก้ไขข้อขัดแย้งเหล่านี้ เราจำเป็นต้องรวบรวมตัวอย่างดังกล่าวเพิ่มเติม และใช้ตัวอย่างเหล่านั้นเพื่อปรับปรุงแบบจำลองและตัวชี้วัดการประเมิน
- ลอร่า อโรโย ก็ได้นำเสนอผลงานของพวกเขาด้วย ปลอดภัยกับความหลากหลาย วิธีการกลั่นกรองข้อมูลว่ามีอะไรอยู่ในนั้นและใครเป็นผู้ใส่คำอธิบายประกอบ
- วิธีการนี้สร้างชุดข้อมูลเกณฑ์มาตรฐานที่มีความแปรปรวนในการตัดสินด้านความปลอดภัยของ LLM ในกลุ่มผู้ประเมินทางประชากรศาสตร์ต่างๆ (คะแนนรวม 2.5 ล้านคะแนน)
- สำหรับ 20% ของการสนทนา เป็นการยากที่จะตัดสินว่าการตอบกลับแชทบอทนั้นปลอดภัยหรือไม่ปลอดภัย เนื่องจากมีผู้ตอบแบบสอบถามจำนวนเท่าๆ กันที่ติดป้ายกำกับว่าปลอดภัยหรือไม่ปลอดภัย
- ความหลากหลายของผู้ประเมินและข้อมูลมีบทบาทสำคัญในการประเมินแบบจำลอง การไม่ยอมรับมุมมองที่หลากหลายของมนุษย์และความคลุมเครือที่มีอยู่ในเนื้อหาสามารถขัดขวางการจัดประสิทธิภาพของการเรียนรู้ของเครื่องกับความคาดหวังในโลกแห่งความเป็นจริง
- 80% ของความพยายามด้านความปลอดภัยของ AI ค่อนข้างดีอยู่แล้ว แต่ 20% ที่เหลือจำเป็นต้องเพิ่มความพยายามเป็นสองเท่าเพื่อจัดการกับ Edge Cases และตัวแปรทั้งหมดในพื้นที่ความหลากหลายอันไม่มีที่สิ้นสุด
สถิติการเชื่อมโยงกัน ประสบการณ์ที่สร้างขึ้นเอง และเหตุใดมนุษย์รุ่นเยาว์จึงฉลาดกว่า AI ในปัจจุบันมาก
In คำพูดของเธอลินดา สมิธ ศาสตราจารย์พิเศษแห่งมหาวิทยาลัยอินเดียนา บลูมมิงตัน ได้สำรวจหัวข้อความกระจัดกระจายของข้อมูลในกระบวนการเรียนรู้ของทารกและเด็กเล็ก เธอมุ่งเน้นไปที่การรู้จำวัตถุและการเรียนรู้ชื่อโดยเฉพาะ โดยเจาะลึกว่าสถิติของประสบการณ์ที่เด็กทารกสร้างขึ้นเองนำเสนอวิธีแก้ปัญหาที่เป็นไปได้ต่อความท้าทายเรื่องความกระจัดกระจายของข้อมูลได้อย่างไร
ประเด็นที่สำคัญ:
- เมื่ออายุได้ 16,000 ขวบ เด็กๆ ได้พัฒนาความสามารถในการเป็นผู้เรียนแบบ one-shot ในขอบเขตต่างๆ ในเวลาไม่ถึง 1,000 ชั่วโมงก่อนจะถึงวันเกิดปีที่ XNUMX พวกเขาสามารถเรียนรู้หมวดหมู่ได้มากกว่า XNUMX หมวดหมู่ เชี่ยวชาญไวยากรณ์ของภาษาแม่ของตน และซึมซับความแตกต่างทางวัฒนธรรมและสังคมของสภาพแวดล้อมของพวกเขา
- ดร. ลินดา สมิธและทีมงานของเธอได้ค้นพบหลักการสามประการของการเรียนรู้ของมนุษย์ที่ช่วยให้เด็กๆ สามารถรวบรวมข้อมูลมากมายจากข้อมูลที่กระจัดกระจายดังกล่าว:
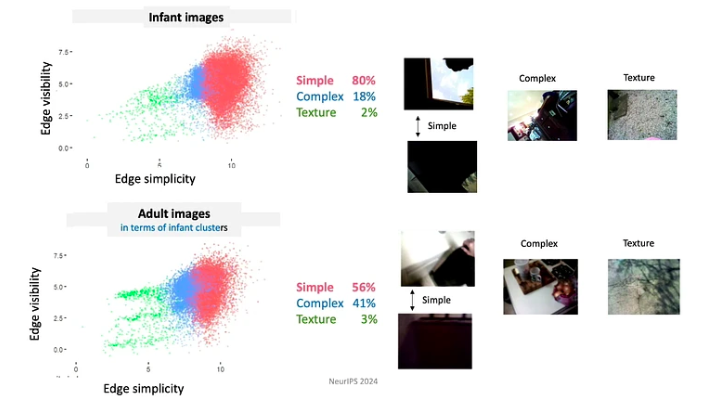
- ผู้เรียนควบคุมข้อมูลนำเข้า ขณะนั้นพวกเขากำลังกำหนดรูปแบบและจัดโครงสร้างข้อมูลนำเข้า ตัวอย่างเช่น ในช่วง XNUMX-XNUMX เดือนแรกของชีวิต เด็กทารกมักจะมองสิ่งของที่มีขอบเรียบๆ มากขึ้น
- เนื่องจากเด็กทารกมีการพัฒนาความรู้และความสามารถอย่างต่อเนื่อง พวกเขาจึงปฏิบัติตามหลักสูตรที่มีข้อจำกัดสูง ข้อมูลที่พวกเขาเปิดเผยได้รับการจัดระเบียบในลักษณะที่มีนัยสำคัญอย่างยิ่ง ตัวอย่างเช่น เด็กทารกอายุต่ำกว่า 4 เดือนใช้เวลาส่วนใหญ่ในการมองใบหน้า ประมาณ 15 นาทีต่อชั่วโมง ในขณะที่เด็กอายุมากกว่า 12 เดือนจะเน้นที่มือเป็นหลัก โดยสังเกตประมาณ 20 นาทีต่อชั่วโมง
- ตอนการเรียนรู้ประกอบด้วยชุดของประสบการณ์ที่เชื่อมโยงถึงกัน ความสัมพันธ์เชิงพื้นที่และเชิงเวลาจะสร้างการเชื่อมโยงกัน ซึ่งจะช่วยอำนวยความสะดวกในการก่อตัวของความทรงจำอันยาวนานจากเหตุการณ์ที่เกิดขึ้นเพียงครั้งเดียว ตัวอย่างเช่น เมื่อนำเสนอของเล่นแบบสุ่ม เด็กๆ มักจะมุ่งความสนใจไปที่ของเล่น 'ชิ้นโปรด' สองสามชิ้น พวกเขามีส่วนร่วมกับของเล่นเหล่านี้โดยใช้รูปแบบซ้ำๆ ซึ่งช่วยในการเรียนรู้วัตถุได้เร็วขึ้น
- ความทรงจำชั่วคราว (การทำงาน) ยังคงอยู่นานกว่าการรับความรู้สึก คุณสมบัติที่ส่งเสริมกระบวนการเรียนรู้ ได้แก่ ความหลากหลาย ความสัมพันธ์ ความสัมพันธ์เชิงทำนาย และการเปิดใช้งานความทรงจำในอดีต
- เพื่อการเรียนรู้ที่รวดเร็ว คุณต้องมีพันธมิตรระหว่างกลไกที่สร้างข้อมูลและกลไกที่เรียนรู้
การร่างภาพ: เครื่องมือหลัก การเพิ่มการเรียนรู้ และความทนทานในการปรับตัว
Jelani Nelson ศาสตราจารย์ด้านวิศวกรรมไฟฟ้าและวิทยาการคอมพิวเตอร์ที่ UC Berkeley นำเสนอแนวคิดข้อมูล 'ภาพร่าง' – การแสดงชุดข้อมูลที่บีบอัดด้วยหน่วยความจำซึ่งยังคงสามารถตอบคำถามที่เป็นประโยชน์ได้ แม้ว่าการพูดคุยจะค่อนข้างเป็นเทคนิค แต่ก็ให้ภาพรวมที่ยอดเยี่ยมของเครื่องมือการสเก็ตช์ภาพขั้นพื้นฐาน ซึ่งรวมถึงความก้าวหน้าล่าสุดด้วย
ประเด็นสำคัญ:
- CountSketch ซึ่งเป็นเครื่องมือหลักในการสเก็ตช์ภาพ เปิดตัวครั้งแรกในปี 2002 เพื่อแก้ไขปัญหา "ผู้ตีหนัก" โดยรายงานรายการเล็กๆ น้อยๆ ของรายการที่พบบ่อยที่สุดจากสตรีมรายการที่ระบุ CountSketch เป็นอัลกอริธึมซับลิเนียร์ตัวแรกที่รู้จักซึ่งใช้เพื่อจุดประสงค์นี้
- แอปพลิเคชั่นที่ไม่สตรีมมิ่งสองตัวของผู้ตีหนัก ได้แก่ :
- Interior point-based method (IPM) ที่ให้อัลกอริทึมที่รู้จักเร็วที่สุดสำหรับการเขียนโปรแกรมเชิงเส้น
- วิธีการ HyperAttention ที่จัดการกับความท้าทายด้านการคำนวณที่เกิดจากความซับซ้อนที่เพิ่มขึ้นของบริบทแบบยาวที่ใช้ใน LLM
- งานล่าสุดส่วนใหญ่มุ่งเน้นไปที่การออกแบบภาพร่างที่แข็งแกร่งต่อการโต้ตอบแบบปรับตัวได้ แนวคิดหลักคือการใช้ข้อมูลเชิงลึกจากการวิเคราะห์ข้อมูลแบบปรับเปลี่ยนได้
นอกเหนือจากแผงปรับขนาด
แผงที่ยอดเยี่ยมเกี่ยวกับโมเดลภาษาขนาดใหญ่ ดำเนินรายการโดย Alexander Rush รองศาสตราจารย์ที่ Cornell Tech และนักวิจัยที่ Hugging Face ผู้เข้าร่วมคนอื่นๆ ได้แก่:
- Aakanksha Chowdhery – นักวิทยาศาสตร์การวิจัยที่ Google DeepMind ที่มีความสนใจด้านการวิจัยเกี่ยวกับระบบ การฝึกอบรม LLM ล่วงหน้า และความหลากหลายทางรูปแบบ เธอเป็นส่วนหนึ่งของทีมพัฒนา PaLM, Gemini และ Pathways
- Angela Fan – นักวิทยาศาสตร์การวิจัยที่ Meta Generative AI ที่มีความสนใจด้านการวิจัยในการจัดตำแหน่ง ศูนย์ข้อมูล และการพูดได้หลายภาษา เธอเข้าร่วมในการพัฒนา Llama-2 และ Meta AI Assistant
- Percy Liang – ศาสตราจารย์ที่ Stanford ค้นคว้าเกี่ยวกับผู้สร้าง โอเพ่นซอร์ส และตัวแทนกำเนิด เขาเป็นผู้อำนวยการศูนย์วิจัยโมเดลพื้นฐาน (CRFM) ที่สแตนฟอร์ด และเป็นผู้ก่อตั้ง Together AI
การอภิปรายมุ่งเน้นไปที่สี่หัวข้อหลัก: (1) สถาปัตยกรรมและวิศวกรรม (2) ข้อมูลและการจัดตำแหน่ง (3) การประเมินและความโปร่งใส และ (4) ผู้สร้างและผู้มีส่วนร่วม
นี่คือประเด็นบางส่วนจากการสำรวจครั้งนี้:
- การฝึกอบรมโมเดลภาษาในปัจจุบันไม่ใช่เรื่องยาก ความท้าทายหลักในการฝึกฝนโมเดลอย่าง Llama-2-7b นั้นอยู่ที่ข้อกำหนดด้านโครงสร้างพื้นฐานและความจำเป็นในการประสานงานระหว่าง GPU หลายตัว ศูนย์ข้อมูล ฯลฯ อย่างไรก็ตาม หากจำนวนพารามิเตอร์น้อยพอที่จะทำให้สามารถฝึกฝนบน GPU ตัวเดียวได้ แม้แต่ระดับปริญญาตรีก็สามารถจัดการได้
- แม้ว่าโมเดลการถดถอยอัตโนมัติมักใช้สำหรับการสร้างข้อความและโมเดลการแพร่กระจายสำหรับการสร้างรูปภาพและวิดีโอ แต่ก็มีการทดลองด้วยการย้อนกลับแนวทางเหล่านี้ โดยเฉพาะในโครงการ Gemini แบบจำลองการถดถอยอัตโนมัติจะถูกนำมาใช้สำหรับการสร้างภาพ มีการสำรวจการใช้แบบจำลองการแพร่กระจายสำหรับการสร้างข้อความด้วย แต่สิ่งเหล่านี้ยังไม่ได้พิสูจน์ว่ามีประสิทธิภาพเพียงพอ
- เนื่องจากข้อมูลภาษาอังกฤษสำหรับแบบจำลองการฝึกอบรมมีจำกัด นักวิจัยจึงกำลังสำรวจแนวทางอื่น ความเป็นไปได้ประการหนึ่งคือการฝึกอบรมโมเดลหลายรูปแบบโดยใช้ข้อความ วิดีโอ รูปภาพ และเสียง โดยคาดหวังว่าทักษะที่เรียนรู้จากรูปแบบทางเลือกเหล่านี้อาจถ่ายโอนไปยังข้อความได้ อีกทางเลือกหนึ่งคือการใช้ข้อมูลสังเคราะห์ สิ่งสำคัญคือต้องทราบว่าข้อมูลสังเคราะห์มักจะผสมผสานเข้ากับข้อมูลจริง แต่การบูรณาการนี้ไม่ได้เกิดขึ้นแบบสุ่ม โดยทั่วไปข้อความที่เผยแพร่ทางออนไลน์จะต้องผ่านการดูแลจัดการและการแก้ไขโดยมนุษย์ ซึ่งอาจเพิ่มมูลค่าเพิ่มเติมให้กับการฝึกโมเดล
- โมเดล Open Foundation มักถูกมองว่าเป็นประโยชน์ต่อนวัตกรรม แต่อาจเป็นอันตรายต่อความปลอดภัยของ AI เนื่องจากโมเดลเหล่านี้สามารถถูกนำไปใช้โดยผู้ไม่ประสงค์ดีได้ อย่างไรก็ตาม ดร. เพอร์ซี เหลียง ให้เหตุผลว่าแบบจำลองแบบเปิดยังส่งผลดีต่อความปลอดภัยอีกด้วย เขาแย้งว่าการเข้าถึงได้ทำให้นักวิจัยมีโอกาสทำการวิจัยด้านความปลอดภัยของ AI มากขึ้นและทบทวนแบบจำลองเพื่อหาช่องโหว่ที่อาจเกิดขึ้น
- ทุกวันนี้ การใส่คำอธิบายประกอบข้อมูลต้องการความเชี่ยวชาญในโดเมนคำอธิบายประกอบมากขึ้นอย่างมาก เมื่อเทียบกับเมื่อห้าปีที่แล้ว อย่างไรก็ตาม หากผู้ช่วย AI ทำงานตามที่คาดหวังไว้ในอนาคต เราจะได้รับข้อมูลตอบรับอันมีค่าจากผู้ใช้มากขึ้น ซึ่งช่วยลดการพึ่งพาข้อมูลจำนวนมากจากผู้อธิบายประกอบ
ระบบสำหรับแบบจำลองฐานราก และแบบจำลองฐานรากสำหรับระบบ
In คำพูดนี้, Christopher Ré รองศาสตราจารย์ในภาควิชาวิทยาการคอมพิวเตอร์ที่มหาวิทยาลัยสแตนฟอร์ด แสดงให้เห็นว่าแบบจำลองพื้นฐานเปลี่ยนแปลงระบบที่เราสร้างอย่างไร นอกจากนี้เขายังสำรวจวิธีการสร้างโมเดลพื้นฐานอย่างมีประสิทธิภาพ ยืมข้อมูลเชิงลึกจากการวิจัยระบบฐานข้อมูล และอภิปรายการสถาปัตยกรรมที่อาจมีประสิทธิภาพมากกว่าสำหรับโมเดลพื้นฐานมากกว่า Transformer
ประเด็นสำคัญจากการพูดคุยครั้งนี้มีดังนี้:
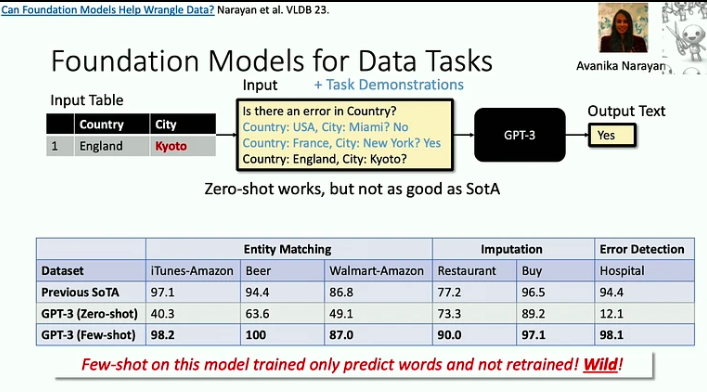
- แบบจำลองพื้นฐานมีประสิทธิภาพในการแก้ปัญหา 'การตายถึง 1000 ครั้ง' ซึ่งแต่ละงานอาจจะค่อนข้างง่าย แต่ความกว้างและความหลากหลายของงานถือเป็นความท้าทายที่สำคัญ ตัวอย่างที่ดีของปัญหานี้คือปัญหาการล้างข้อมูล ซึ่งขณะนี้ LLM สามารถช่วยแก้ไขได้อย่างมีประสิทธิภาพมากขึ้น
- เมื่อคันเร่งเร็วขึ้น หน่วยความจำมักจะกลายเป็นคอขวด นี่เป็นปัญหาที่นักวิจัยฐานข้อมูลจัดการมานานหลายทศวรรษ และเราสามารถนำกลยุทธ์บางอย่างของพวกเขาไปปรับใช้ได้ ตัวอย่างเช่น วิธีการ Flash Attention ช่วยลดกระแสอินพุต-เอาท์พุตผ่านการบล็อกและการรวมข้อมูลเชิงรุก: เมื่อใดก็ตามที่เราเข้าถึงข้อมูลชิ้นหนึ่ง เราจะดำเนินการกับข้อมูลนั้นให้มากที่สุดเท่าที่จะเป็นไปได้
- มีสถาปัตยกรรมคลาสใหม่ซึ่งมีรากฐานมาจากการประมวลผลสัญญาณ ซึ่งอาจมีประสิทธิภาพมากกว่ารุ่น Transformer โดยเฉพาะอย่างยิ่งในการจัดการลำดับที่ยาว การประมวลผลสัญญาณให้ความเสถียรและประสิทธิภาพ โดยวางรากฐานสำหรับโมเดลที่เป็นนวัตกรรมใหม่ เช่น S4
การเรียนรู้การเสริมกำลังออนไลน์ในการแทรกแซงด้านสุขภาพดิจิทัล
In คำพูดของเธอSusan Murphy ศาสตราจารย์ด้านสถิติและวิทยาการคอมพิวเตอร์ที่ Harvard University ได้แบ่งปันวิธีแก้ปัญหาแรกๆ ให้กับความท้าทายที่พวกเขาเผชิญในการพัฒนาอัลกอริทึม RL ออนไลน์เพื่อใช้ในการแทรกแซงด้านสุขภาพดิจิทัล
ต่อไปนี้เป็นประเด็นเล็กๆ น้อยๆ จากการนำเสนอ:
- ดร.ซูซาน เมอร์ฟีย์กล่าวถึงสองโครงการที่เธอกำลังทำอยู่:
- HeartStep ซึ่งมีการแนะนำกิจกรรมตามข้อมูลจากสมาร์ทโฟนและอุปกรณ์ติดตามที่สวมใส่ได้ และ
- การบำบัดช่องปากสำหรับการฝึกสอนด้านสุขภาพช่องปาก โดยการแทรกแซงจะขึ้นอยู่กับข้อมูลการมีส่วนร่วมที่ได้รับจากแปรงสีฟันไฟฟ้า
- ในการพัฒนานโยบายพฤติกรรมสำหรับตัวแทน AI นักวิจัยจะต้องตรวจสอบให้แน่ใจว่านโยบายดังกล่าวเป็นแบบอัตโนมัติและสามารถนำไปใช้ในระบบการดูแลสุขภาพในวงกว้างได้อย่างเป็นไปได้ สิ่งนี้ทำให้มั่นใจได้ว่าเวลาที่ต้องใช้ในการมีส่วนร่วมของแต่ละบุคคลนั้นสมเหตุสมผล และการดำเนินการที่แนะนำนั้นมีความถูกต้องตามหลักจริยธรรมและเป็นไปได้ทางวิทยาศาสตร์
- ความท้าทายหลักในการพัฒนาตัวแทน RL สำหรับการแทรกแซงด้านสุขภาพดิจิทัล ได้แก่ การจัดการกับระดับเสียงที่สูง เนื่องจากผู้คนดำเนินชีวิตและอาจไม่สามารถตอบสนองต่อข้อความได้เสมอไป แม้ว่าพวกเขาต้องการ เช่นเดียวกับการจัดการผลกระทบด้านลบที่รุนแรงและล่าช้า .
อย่างที่คุณเห็น NeurIPS 2023 ได้ให้ข้อมูลเชิงลึกเกี่ยวกับอนาคตของ AI การเสวนาที่ได้รับเชิญเน้นย้ำถึงแนวโน้มไปสู่แบบจำลองที่มีประสิทธิภาพและคำนึงถึงทรัพยากรมากขึ้น และการสำรวจสถาปัตยกรรมใหม่ๆ ที่นอกเหนือไปจากกระบวนทัศน์แบบดั้งเดิม
สนุกกับบทความนี้? ลงทะเบียนเพื่อรับการอัปเดตการวิจัย AI เพิ่มเติม
เราจะแจ้งให้คุณทราบเมื่อเราเผยแพร่บทความสรุปเพิ่มเติมเช่นนี้
ที่เกี่ยวข้อง
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://www.topbots.com/neurips-2023-invited-talks/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 000
- 1
- 10
- 10th
- 11
- 110
- 12
- 12 เดือน
- 125
- 13
- 14
- ลด 15%
- 154
- 16
- 16th
- 17
- 20
- 2023
- 32
- ลด 35%
- 41
- 58
- 65
- 7
- 70
- 710
- 8
- 9
- a
- ความสามารถ
- สามารถ
- เกี่ยวกับเรา
- เร่ง
- เข้า
- สามารถเข้าถึงได้
- ความสำเร็จ
- การบรรลุ
- รับทราบ
- ข้าม
- การปฏิบัติ
- การกระตุ้น
- อย่างกระตือรือร้น
- กิจกรรม
- นักแสดง
- ปรับได้
- เพิ่ม
- เพิ่มเติม
- ที่อยู่
- ที่อยู่
- ที่อยู่
- นำมาใช้
- ความก้าวหน้า
- ข้อได้เปรียบ
- อายุ
- ตัวแทน
- ตัวแทน
- ก้าวร้าว
- AGI
- มาแล้ว
- AI
- ผู้ช่วย AI
- วิจัยไอ
- ระบบ AI
- เอดส์
- อเล็กซานเด
- ขั้นตอนวิธี
- อัลกอริทึม
- การวางแนว
- ทั้งหมด
- พันธมิตร
- อนุญาต
- คนเดียว
- แล้ว
- ด้วย
- ทางเลือก
- แม้ว่า
- เสมอ
- ความคลุมเครือ
- ในหมู่
- an
- การวิเคราะห์
- และ
- อื่น
- ใด
- การใช้งาน
- เข้าใกล้
- วิธีการ
- ประมาณ
- เป็น
- ที่ถกเถียงกันอยู่
- ระบุ
- บทความ
- บทความ
- เทียม
- ปัญญาประดิษฐ์ทั่วไป
- AS
- การประเมิน
- ผู้ช่วย
- ผู้ช่วย
- ภาคี
- สมาคม
- การแบ่งประเภท
- At
- สำเร็จได้
- ความสนใจ
- เสียง
- อิสระ
- ความพร้อมใช้งาน
- ตาม
- BE
- เพราะ
- กลายเป็น
- รับ
- พฤติกรรม
- กำลัง
- มาตรฐาน
- มาตรฐาน
- เป็นประโยชน์
- เบิร์กลีย์
- ระหว่าง
- เกิน
- การผสมผสาน
- ผสม
- การปิดกั้น
- การยืม
- ทั้งสอง
- ความกว้าง
- ที่กว้างขึ้น
- สร้าง
- แต่
- by
- มา
- CAN
- ความสามารถในการ
- จับ
- กรณี
- หมวดหมู่
- ศูนย์
- ศูนย์
- โซ่
- ท้าทาย
- ความท้าทาย
- การเปลี่ยนแปลง
- chatbot
- เด็ก
- คริส
- เมือง
- ชั้น
- การทำความสะอาด
- การฝึก
- รวบรวม
- การผสมผสาน
- รวมกัน
- เมื่อเทียบกับ
- ซับซ้อน
- ความซับซ้อน
- ส่วนประกอบ
- การคำนวณ
- คอมพิวเตอร์
- วิทยาการคอมพิวเตอร์
- วิสัยทัศน์คอมพิวเตอร์
- การคำนวณ
- แนวคิด
- ความประพฤติ
- การประชุม
- สร้าง
- เนื้อหา
- สิ่งแวดล้อม
- บริบท
- เรื่อย
- สนับสนุน
- ผู้ให้
- ควบคุม
- การควบคุม
- การสนทนา
- ประสานงาน
- แกน
- คอร์เนลล์
- แก้ไข
- ความสัมพันธ์
- ได้
- สร้าง
- ผู้สร้าง
- ฝูงชน
- สำคัญมาก
- ด้านวัฒนธรรม
- curation
- ปัจจุบัน
- หลักสูตร
- ตัดขอบ
- ข้อมูล
- การวิเคราะห์ข้อมูล
- ศูนย์ข้อมูล
- ฐานข้อมูล
- การซื้อขาย
- ทศวรรษที่ผ่านมา
- ธันวาคม
- ตัดสินใจ
- Deepmind
- ล่าช้า
- คุ้ย
- ความต้องการ
- ความต้องการ
- ประชากรศาสตร์
- แสดงให้เห็นถึง
- แผนก
- การออกแบบ
- รายละเอียด
- รายละเอียด
- พัฒนา
- พัฒนา
- นักพัฒนา
- ที่กำลังพัฒนา
- พัฒนาการ
- การพัฒนา
- ยาก
- การจัดจำหน่าย
- ดิจิตอล
- สุขภาพดิจิทัล
- ทิศทาง
- ผู้อำนวยการ
- ค้นพบ
- กล่าวถึง
- พูดคุย
- การสนทนา
- การอภิปราย
- โดดเด่น
- ความหลากหลาย
- โดเมน
- โดเมน
- ครอบงำ
- Dont
- การเสแสร้ง
- dr
- สอง
- ในระหว่าง
- พลวัต
- e
- แต่ละ
- ขอบ
- การแก้ไข
- มีประสิทธิภาพ
- ผลกระทบ
- อย่างมีประสิทธิภาพ
- ที่มีประสิทธิภาพ
- อย่างมีประสิทธิภาพ
- ความพยายาม
- ความพยายาม
- ทั้ง
- วิศวกรรมไฟฟ้า
- อิเล็กทรอนิกส์
- โผล่ออกมา
- ความสำคัญ
- เน้น
- ทำให้สามารถ
- ช่วยให้
- การเข้ารหัส
- ว่าจ้าง
- มีส่วนร่วม
- ชั้นเยี่ยม
- เสริม
- ที่เพิ่มขึ้น
- พอ
- ทำให้มั่นใจ
- การสร้างความมั่นใจ
- สิ่งแวดล้อม
- ตอน
- เท่ากัน
- โดยเฉพาะอย่างยิ่ง
- จำเป็น
- ฯลฯ
- อีเธอร์ (ETH)
- การประเมินการ
- การประเมินผล
- แม้
- เหตุการณ์
- ทุกคน
- คาย
- การพัฒนา
- ตัวอย่าง
- ตัวอย่าง
- ยอดเยี่ยม
- ความคาดหวัง
- ความคาดหวัง
- ที่คาดหวัง
- แพง
- ประสบการณ์
- ประสบการณ์
- การทดลอง
- ชำนาญ
- ความชำนาญ
- ผู้เชี่ยวชาญ
- ใช้ประโยชน์
- การสำรวจ
- สำรวจ
- สำรวจ
- สำรวจ
- ที่เปิดเผย
- กว้างขวาง
- ตา
- ใบหน้า
- ใบหน้า
- อำนวยความสะดวก
- ความล้มเหลว
- แฟน
- เร็วขึ้น
- ที่เร็วที่สุด
- ข้อเสนอแนะ
- สองสาม
- น้อยลง
- สนาม
- ใส่
- ชื่อจริง
- ห้า
- แฟลช
- ไหล
- กระแส
- โฟกัส
- มุ่งเน้น
- ปฏิบัติตาม
- สำหรับ
- มองไกลได้
- การสร้าง
- รากฐาน
- ผู้สร้าง
- สี่
- ที่สี่
- บ่อย
- มัก
- ราคาเริ่มต้นที่
- พื้นฐาน
- การผสม
- อนาคต
- อนาคตของ AI
- เมถุน
- General
- ปัญญาทั่วไป
- สร้าง
- การสร้าง
- รุ่น
- กำเนิด
- กำเนิด AI
- กำหนด
- จะช่วยให้
- เหลือบ
- Go
- เป้าหมาย
- ดี
- GPU
- GPUs
- แหวกแนว
- บัญชีกลุ่ม
- กลุ่ม
- การเจริญเติบโต
- มี
- การจัดการ
- มือ
- เป็นอันตราย
- การควบคุม
- ฮาร์วาร์
- มหาวิทยาลัยฮาร์วาร์ด
- มี
- he
- หัว
- สุขภาพ
- การดูแลสุขภาพ
- หนัก
- จัดขึ้น
- ช่วย
- ช่วย
- เธอ
- จุดสูง
- ความละเอียดสูง
- ไฮไลต์
- อย่างสูง
- ขัดขวาง
- ของเขา
- ชั่วโมง
- ชั่วโมง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- ที่ http
- HTTPS
- เป็นมนุษย์
- มนุษย์
- i
- ความคิด
- if
- การส่องสว่าง
- ภาพ
- การสร้างภาพ
- ภาพ
- การดำเนินการ
- ความสำคัญ
- สำคัญ
- ปรับปรุง
- in
- ลึกซึ้ง
- ประกอบด้วย
- รวม
- รวมทั้ง
- ที่เพิ่มขึ้น
- ขึ้น
- อินดีแอนา
- เป็นรายบุคคล
- หลีกเลี่ยงไม่ได้
- ข้อมูล
- ให้ข้อมูล
- โครงสร้างพื้นฐาน
- โดยธรรมชาติ
- อย่างโดยเนื้อแท้
- นักวิเคราะห์ส่วนบุคคลที่หาโอกาสให้เป็นไปได้มากที่สุด
- นวัตกรรม
- อินพุต
- ข้อมูลเชิงลึก
- ตัวอย่าง
- แทน
- บูรณาการ
- Intelligence
- ปฏิสัมพันธ์
- เชื่อมต่อถึงกัน
- ผลประโยชน์
- การแทรกแซง
- เข้าไป
- แนะนำ
- เชิญ
- IT
- รายการ
- jpg
- คำตัดสิน
- คีย์
- ทราบ
- ความรู้
- ที่รู้จักกัน
- ห้องปฏิบัติการ
- การติดฉลาก
- ภาษา
- ใหญ่
- ทน
- ล่าสุด
- การวาง
- นำ
- ชั้นนำ
- เรียนรู้
- ได้เรียนรู้
- ผู้เรียน
- การเรียนรู้
- มรดก
- น้อยลง
- บทเรียน
- ให้
- ระดับ
- ตั้งอยู่
- เบา
- กดไลก์
- ความเป็นไปได้
- การ จำกัด
- ถูก จำกัด
- ลินดา
- รายการ
- ชีวิต
- ในประเทศ
- นาน
- อีกต่อไป
- ดู
- ที่ต้องการหา
- เครื่อง
- เรียนรู้เครื่อง
- ทางไปรษณีย์
- หลัก
- จัดการ
- การจัดการ
- หลาย
- เจ้านาย
- การจับคู่
- วัสดุ
- เรื่อง
- ความกว้างสูงสุด
- อาจ..
- มีความหมาย
- กลไก
- ความทรงจำ
- หน่วยความจำ
- Mers
- ข้อความ
- Meta
- วิธี
- ตัวชี้วัด
- อาจ
- ล้าน
- ย่อขนาด
- นาที
- หายไป
- กิริยา
- แบบ
- โมเดล
- ขณะ
- เดือน
- ข้อมูลเพิ่มเติม
- มีประสิทธิภาพมากขึ้น
- มากที่สุด
- ย้าย
- มาก
- หลาย
- มิวนิค
- ต้อง
- ชื่อ
- พื้นเมือง
- โดยธรรมชาติ
- จำเป็นต้อง
- เชิงลบ
- ประสาทไอพีเอส
- ใหม่
- นิวออร์ลี
- ไม่
- สัญญาณรบกวน
- ไม่มี
- หมายเหตุ
- นวนิยาย
- ตอนนี้
- ความแตกต่าง
- จำนวน
- วัตถุ
- วัตถุ
- of
- เสนอ
- การเสนอ
- เสนอ
- มักจะ
- เก่ากว่า
- on
- ONE
- ออนไลน์
- เพียง
- เปิด
- โอเพนซอร์ส
- เปิด
- การดำเนินการ
- โอกาส
- เพิ่มประสิทธิภาพ
- ตัวเลือกเสริม (Option)
- or
- ทางปาก
- สุขภาพช่องปาก
- Organized
- เมืองออเลียนส
- อื่นๆ
- ผู้เข้าร่วมอื่น ๆ
- ผลิตภัณฑ์อื่นๆ
- ของเรา
- เกิน
- ภาพรวม
- ของตนเอง
- ปาล์ม
- แผง
- กระบวนทัศน์
- พารามิเตอร์
- ส่วนหนึ่ง
- ผู้เข้าร่วม
- เข้าร่วม
- ในสิ่งที่สนใจ
- โดยเฉพาะ
- ส่วน
- อดีต
- อย่างทุลักทุเล
- รูปแบบ
- คน
- ต่อ
- ความเข้าใจ
- ดำเนินการ
- การปฏิบัติ
- มุมมอง
- ชิ้น
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- น่าเชื่อถือ
- เล่น
- นโยบาย
- ถูกวาง
- บวก
- บวก
- ครอบครอง
- ความเป็นไปได้
- เป็นไปได้
- ที่มีศักยภาพ
- ที่อาจเกิดขึ้น
- ทำนาย
- ทำนาย
- นำเสนอ
- การเสนอ
- นำเสนอ
- ก่อน
- ส่วนใหญ่
- ประถม
- หลักการ
- ปัญหา
- ปัญหาที่เกิดขึ้น
- ขั้นตอนการ
- กระบวนการ
- กระบวนการ
- การประมวลผล
- ผลิต
- ประสิทธิผล
- ศาสตราจารย์
- อย่างสุดซึ้ง
- การเขียนโปรแกรม
- โครงการ
- โครงการ
- โดดเด่น
- คุณสมบัติ
- ที่พิสูจน์แล้ว
- ให้
- ให้
- การตีพิมพ์
- วัตถุประสงค์
- การแสวงหา
- คุณภาพ
- คำสั่ง
- การแสวงหา
- ทีเดียว
- เชื่อชาติ
- สุ่ม
- พิสัย
- รวดเร็ว
- อย่างรวดเร็ว
- ค่อนข้าง
- การให้คะแนน
- จริง
- โลกแห่งความจริง
- เหมาะสม
- รับ
- ที่ได้รับ
- เมื่อเร็ว ๆ นี้
- การรับรู้
- แนะนำ
- ลด
- สะท้อน
- การเรียนรู้การเสริมแรง
- ความสัมพันธ์
- สัมพัทธ์
- ปล่อย
- ความเชื่อถือได้
- ความเชื่อมั่น
- ที่เหลืออยู่
- ซ้ำ
- การรายงาน
- การแสดง
- เป็นตัวแทนของ
- ต้องการ
- จำเป็นต้องใช้
- ความต้องการ
- การวิจัย
- นักวิจัย
- นักวิจัย
- แก้ไข
- แหล่งข้อมูล
- ตอบสนอง
- ผู้ตอบแบบสอบถาม
- คำตอบ
- การตอบสนอง
- รับผิดชอบ
- ทบทวน
- แข็งแรง
- บทบาท
- ซึ่งได้หยั่งราก
- ลวก
- รีบเร่ง
- ปลอดภัย
- ความปลอดภัย
- ปรับ
- สถานการณ์
- ฉาก
- วิทยาศาสตร์
- วิทยาศาสตร์
- นักวิทยาศาสตร์
- เห็น
- ที่กำลังมองหา
- ดูเหมือนว่า
- เห็น
- อรรถศาสตร์
- ชุด
- การสร้าง
- ที่ใช้ร่วมกัน
- เธอ
- แสดงให้เห็นว่า
- ลงชื่อ
- สัญญาณ
- สัญญาณ
- สำคัญ
- อย่างมีความหมาย
- ง่าย
- เดียว
- ทักษะ
- เล็ก
- อย่างชาญฉลาด
- มาร์ทโฟน
- สมิ ธ
- So
- สังคม
- ทางออก
- โซลูชัน
- แก้
- บาง
- เสียง
- แหล่ง
- ช่องว่าง
- เกี่ยวกับอวกาศ
- เฉพาะ
- ใช้จ่าย
- Stability
- มั่นคง
- Stanford
- มหาวิทยาลัยสแตนฟอร์ด
- สถิติ
- ยังคง
- กลยุทธ์
- กระแส
- จุดแข็ง
- แข็งแรง
- การจัดโครงสร้าง
- อย่างเช่น
- ชี้ให้เห็นถึง
- สรุป
- จัดหาอุปกรณ์
- แปลกใจ
- ซูซาน
- วากยสัมพันธ์
- การสังเคราะห์
- สังเคราะห์
- ข้อมูลสังเคราะห์
- ระบบ
- ระบบ
- Takeaways
- ใช้เวลา
- คุย
- พูดคุย
- งาน
- งาน
- ทีม
- เทคโนโลยี
- วิชาการ
- มีแนวโน้ม
- เงื่อนไขการใช้บริการ
- ข้อความ
- การสร้างข้อความ
- กว่า
- ที่
- พื้นที่
- ก้าวสู่อนาคต
- ของพวกเขา
- พวกเขา
- ธีม
- ที่นั่น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- นี้
- เหล่านั้น
- สาม
- ตลอด
- เวลา
- ไปยัง
- ร่วมกัน
- เครื่องมือ
- เครื่องมือ
- ท็อปบอท
- หัวข้อ
- หัวข้อ
- รวม
- ไปทาง
- ติดตาม
- แบบดั้งเดิม
- การฝึกอบรม
- โอน
- หม้อแปลงไฟฟ้า
- ความโปร่งใส
- การรักษาเยียวยา
- เทรนด์
- ความจริง
- พยายาม
- กลับ
- สอง
- เป็นปกติ
- ภายใต้
- ผ่านการ
- ความเข้าใจ
- มหาวิทยาลัย
- การปรับปรุง
- ใช้
- มือสอง
- ผู้ใช้
- การใช้
- มักจะ
- ใช้
- มีคุณค่า
- ความคุ้มค่า
- ความหลากหลาย
- ต่างๆ
- สั่นสะเทือน
- วีดีโอ
- วิดีโอ
- มุมมอง
- วิสัยทัศน์
- ช่องโหว่
- W3
- คือ
- วิธี
- we
- เครื่องแต่งตัว
- ดี
- คือ
- อะไร
- เมื่อ
- เมื่อไรก็ตาม
- แต่ทว่า
- ว่า
- ที่
- ในขณะที่
- WHO
- ทำไม
- กว้าง
- ช่วงกว้าง
- จะ
- หน้าต่าง
- กับ
- งาน
- การทำงาน
- ผิด
- ปี
- ยัง
- เธอ
- หนุ่มสาว
- ลมทะเล