อาปาเช่ ฮูดี เป็นรูปแบบตารางแบบเปิดที่นำความสามารถของฐานข้อมูลและคลังข้อมูลมาสู่ Data Lake Apache Hudi ช่วยให้วิศวกรข้อมูลจัดการความท้าทายที่ซับซ้อน เช่น การจัดการชุดข้อมูลที่พัฒนาอย่างต่อเนื่องพร้อมธุรกรรมในขณะที่ยังคงรักษาประสิทธิภาพการสืบค้น วิศวกรข้อมูลใช้ Apache Hudi สำหรับการสตรีมปริมาณงาน รวมถึงสร้างไปป์ไลน์ข้อมูลส่วนเพิ่มที่มีประสิทธิภาพ หุดีจัดให้ ตาราง, การทำธุรกรรม, อัพและลบที่มีประสิทธิภาพ, ดัชนีขั้นสูง, บริการส่งผ่านข้อมูลสตรีมมิ่ง, ข้อมูล การจัดกลุ่ม และ การบดอัด การเพิ่มประสิทธิภาพและ การควบคุมภาวะพร้อมกันทั้งหมดนี้ในขณะเดียวกันก็เก็บข้อมูลของคุณในรูปแบบไฟล์โอเพ่นซอร์ส การเพิ่มประสิทธิภาพขั้นสูงของ Hudi ทำให้ปริมาณงานการวิเคราะห์เร็วขึ้นด้วยกลไกสืบค้นข้อมูลยอดนิยม เช่น Apache Spark, Presto, Trino, Hive และอื่นๆ
ลูกค้า AWS จำนวนมากนำ Apache Hudi มาใช้กับ Data Lake ของตนซึ่งสร้างบน Amazon S3 โดยใช้ AWS กาวซึ่งเป็นบริการผสานรวมข้อมูลแบบไร้เซิร์ฟเวอร์ที่ช่วยให้ค้นหา จัดเตรียม ย้าย และผสานข้อมูลจากแหล่งต่างๆ ได้ง่ายขึ้นสำหรับการวิเคราะห์ การเรียนรู้ของเครื่อง (ML) และการพัฒนาแอปพลิเคชัน โปรแกรมรวบรวมข้อมูล AWS Glue เป็นส่วนประกอบของ AWS Glue ซึ่งช่วยให้คุณสามารถสร้างข้อมูลเมตาของตารางจากเนื้อหาข้อมูลได้โดยอัตโนมัติ โดยไม่ต้องใช้คำจำกัดความของข้อมูลเมตาด้วยตนเอง
โปรแกรมรวบรวมข้อมูล AWS Glue รองรับตาราง Apache Hudi แล้วทำให้การรับเลี้ยงบุตรบุญธรรมง่ายขึ้น แคตตาล็อกข้อมูลกาว AWS Data เป็นแค็ตตาล็อกสำหรับตาราง Hudi กรณีการใช้งานทั่วไปกรณีหนึ่งคือการลงทะเบียนตาราง Hudi ซึ่งไม่มีคำจำกัดความของตารางแค็ตตาล็อก กรณีการใช้งานทั่วไปอีกกรณีหนึ่งคือการโยกย้ายจากแค็ตตาล็อก Hudi อื่นๆ เช่น Hive metastore เมื่อย้ายจาก Hudi Catalogs อื่น คุณสามารถสร้างและกำหนดเวลาโปรแกรมรวบรวมข้อมูล AWS Glue และจัดเตรียมเส้นทาง Amazon S3 อย่างน้อย 3 เส้นทางที่มีไฟล์ตาราง Hudi อยู่ คุณมีตัวเลือกในการจัดเตรียมเส้นทาง Amazon SXNUMX ที่มีความลึกสูงสุดที่โปรแกรมรวบรวมข้อมูล AWS Glue สามารถสำรวจได้ ในแต่ละรัน โปรแกรมรวบรวมข้อมูล AWS Glue จะแยกข้อมูลสคีมาและพาร์ติชัน และอัปเดต AWS Glue Data Catalog ด้วยการเปลี่ยนแปลงสคีมาและพาร์ติชัน โปรแกรมรวบรวมข้อมูล AWS Glue อัปเดตตำแหน่งไฟล์ข้อมูลเมตาล่าสุดใน AWS Glue Data Catalog ที่กลไกการวิเคราะห์ AWS สามารถใช้ได้โดยตรง
ด้วยการเปิดตัวนี้ คุณสามารถสร้างและกำหนดเวลาโปรแกรมรวบรวมข้อมูล AWS Glue เพื่อลงทะเบียนตาราง Hudi ใน AWS Glue Data Catalog จากนั้นคุณสามารถระบุเส้นทาง Amazon S3 หนึ่งหรือหลายเส้นทางที่มีตาราง Hudi ตั้งอยู่ได้ คุณมีตัวเลือกในการจัดเตรียมเส้นทาง Amazon S3 ที่มีความลึกสูงสุดที่โปรแกรมรวบรวมข้อมูลสามารถสำรวจได้ ทุกครั้งที่รันโปรแกรมรวบรวมข้อมูล โปรแกรมรวบรวมข้อมูลจะตรวจสอบแต่ละเส้นทาง S3 และจัดทำแคตตาล็อกข้อมูลสคีมา เช่น ตารางใหม่ การลบ และการอัปเดตสคีมาใน AWS Glue Data Catalog โปรแกรมรวบรวมข้อมูลตรวจสอบข้อมูลพาร์ติชันและเพิ่มพาร์ติชันที่เพิ่มใหม่ลงใน AWS Glue Data Catalog โปรแกรมรวบรวมข้อมูลยังอัปเดตตำแหน่งไฟล์ข้อมูลเมตาล่าสุดใน AWS Glue Data Catalog ที่กลไกการวิเคราะห์ AWS สามารถใช้ได้โดยตรง
โพสต์นี้สาธิตวิธีการทำงานของความสามารถใหม่ในการรวบรวมข้อมูลตาราง Hudi
โปรแกรมรวบรวมข้อมูล AWS Glue ทำงานอย่างไรกับตาราง Hudi
ตาราง Hudi มีสองประเภท โดยมีความหมายเฉพาะสำหรับแต่ละประเภท:
- คัดลอกเมื่อเขียน (CoW) – ข้อมูลจะถูกจัดเก็บในรูปแบบเรียงเป็นแนว (Parquet) และการอัปเดตแต่ละครั้งจะสร้างไฟล์เวอร์ชันใหม่ในระหว่างการเขียน
- ผสานเมื่ออ่าน (MoR) – ข้อมูลจะถูกจัดเก็บโดยใช้รูปแบบเรียงเป็นแนว (Parquet) และรูปแบบแถว (Avro) การอัปเดตจะถูกบันทึกตามแถว
deltaและถูกบีบอัดตามความจำเป็นเพื่อสร้างไฟล์เรียงเป็นแนวเวอร์ชันใหม่
ด้วยชุดข้อมูล CoW แต่ละครั้งที่มีการอัพเดตเรคคอร์ด ไฟล์ที่มีเรคคอร์ดจะถูกเขียนใหม่ด้วยค่าที่อัพเดต ด้วยชุดข้อมูล MoR ทุกครั้งที่มีการอัปเดต Hudi จะเขียนเฉพาะแถวสำหรับเรกคอร์ดที่เปลี่ยนแปลง MoR เหมาะกว่าสำหรับเวิร์กโหลดที่มีการเขียนหรือการเปลี่ยนแปลงจำนวนมากโดยมีการอ่านน้อยลง CoW เหมาะกว่าสำหรับปริมาณงานที่มีการอ่านข้อมูลจำนวนมากซึ่งมีการเปลี่ยนแปลงไม่บ่อยนัก
Hudi มีประเภทการสืบค้นสามประเภทสำหรับการเข้าถึงข้อมูล:
- แบบสอบถามภาพรวม – ข้อความค้นหาที่เห็นสแน็ปช็อตล่าสุดของตาราง ณ การดำเนินการที่กำหนดหรือการบีบอัดข้อมูล สำหรับตาราง MoR การสืบค้นสแนปช็อตจะแสดงสถานะล่าสุดของตารางโดยการผสานไฟล์ฐานและเดลต้าของไฟล์สไลซ์ล่าสุด ณ เวลาที่ทำการสืบค้น
- แบบสอบถามที่เพิ่มขึ้น – การสืบค้นจะเห็นเฉพาะข้อมูลใหม่ที่เขียนลงในตาราง นับตั้งแต่คอมมิตหรือการบีบอัดที่กำหนด สิ่งนี้ทำให้เกิดกระแสการเปลี่ยนแปลงอย่างมีประสิทธิภาพเพื่อเปิดใช้งานไปป์ไลน์ข้อมูลที่เพิ่มขึ้น
- อ่านแบบสอบถามที่ปรับให้เหมาะสม – สำหรับตาราง MoR แบบสอบถามจะเห็นข้อมูลล่าสุดที่กระชับ สำหรับตาราง CoW การค้นหาจะเห็นข้อมูลล่าสุดที่คอมมิต
สำหรับตารางการคัดลอกเมื่อเขียน โปรแกรมรวบรวมข้อมูลจะสร้างตารางเดียวใน AWS Glue Data Catalog พร้อมด้วย ReadOptimized Serde org.apache.hudi.hadoop.HoodieParquetInputFormat.
สำหรับตารางผสานเมื่ออ่าน โปรแกรมรวบรวมข้อมูลจะสร้างตารางสองตารางใน AWS Glue Data Catalog สำหรับตำแหน่งตารางเดียวกัน:
- ตารางที่มีส่วนต่อท้าย
_roซึ่งใช้ ReadOptimized Serdeorg.apache.hudi.hadoop.HoodieParquetInputFormat - ตารางที่มีส่วนต่อท้าย
_rtซึ่งใช้ RealTime Serde ที่อนุญาตให้มีการสืบค้น Snapshot:org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
ในระหว่างการรวบรวมข้อมูลแต่ละครั้ง สำหรับแต่ละเส้นทาง Hudi ที่ระบุ โปรแกรมรวบรวมข้อมูลจะทำการเรียก API รายการ Amazon S3 โดยกรองตาม .hoodie โฟลเดอร์และค้นหาไฟล์ข้อมูลเมตาล่าสุดภายใต้โฟลเดอร์ข้อมูลเมตาของตาราง Hudi นั้น
รวบรวมข้อมูลตาราง Hudi CoW โดยใช้โปรแกรมรวบรวมข้อมูล AWS Glue
ในส่วนนี้ มาดูวิธีการรวบรวมข้อมูล Hudi CoW โดยใช้โปรแกรมรวบรวมข้อมูล AWS Glue กัน
เบื้องต้น
ข้อกำหนดเบื้องต้นสำหรับบทช่วยสอนนี้มีดังนี้:
- ติดตั้งและกำหนดค่า อินเทอร์เฟซบรรทัดคำสั่ง AWS (AWS CLI).
- สร้างบัคเก็ต S3 ของคุณหากคุณไม่มี
- สร้างบทบาท IAM ของคุณสำหรับ AWS Glue ถ้าคุณไม่มีมัน คุณต้องการ
s3:GetObjectfors3://your_s3_bucket/data/sample_hudi_cow_table/. - รันคำสั่งต่อไปนี้เพื่อคัดลอกตาราง Hudi ตัวอย่างลงในบัคเก็ต S3 ของคุณ (แทนที่
your_s3_bucketด้วยชื่อบัคเก็ต S3 ของคุณ)
คำแนะนำนี้จะแนะนำให้คุณคัดลอกข้อมูลตัวอย่าง แต่คุณสามารถสร้างตาราง Hudi ได้อย่างง่ายดายโดยใช้ AWS Glue เรียนรู้เพิ่มเติมใน ขอแนะนำการสนับสนุนดั้งเดิมสำหรับ Apache Hudi, Delta Lake และ Apache Iceberg บน AWS Glue สำหรับ Apache Spark ตอนที่ 2: AWS Glue Studio Visual Editor.
สร้างโปรแกรมรวบรวมข้อมูล Hudi
ในคำสั่งนี้ ให้สร้างโปรแกรมรวบรวมข้อมูลผ่านคอนโซล ทำตามขั้นตอนต่อไปนี้เพื่อสร้างโปรแกรมรวบรวมข้อมูล Hudi:
- บนคอนโซล AWS Glue ให้เลือก โปรแกรมรวบรวมข้อมูล.
- Choose สร้างโปรแกรมรวบรวมข้อมูล.
- สำหรับ Nameป้อน
hudi_cow_crawler. เลือก ถัดไป. - ภายใต้ การกำหนดค่าแหล่งข้อมูล, เลือก เพิ่มแหล่งข้อมูล.
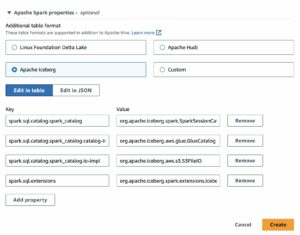
- สำหรับ แหล่งข้อมูลเลือก ฮูดิ.
- สำหรับ รวมเส้นทางตาราง hudiป้อน
s3://your_s3_bucket/data/sample_hudi_cow_table/. (แทนที่your_s3_bucketด้วยชื่อบัคเก็ต S3 ของคุณ) - Choose เพิ่มแหล่งข้อมูล Hudi.
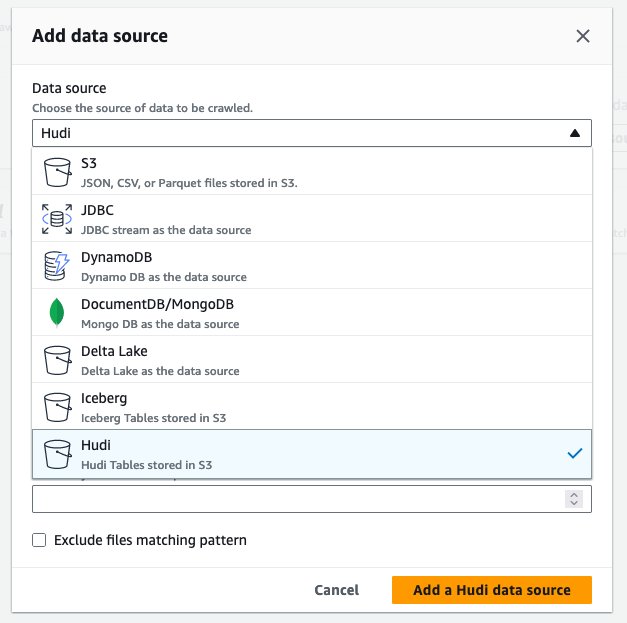
- Choose ถัดไป.
- สำหรับ บทบาท IAM ที่มีอยู่เลือกบทบาท IAM ของคุณ แล้วเลือก ถัดไป.
- สำหรับ ฐานข้อมูลเป้าหมายเลือก เพิ่มฐานข้อมูลแล้ว เพิ่มฐานข้อมูล กล่องโต้ตอบปรากฏขึ้น สำหรับ ชื่อฐานข้อมูลป้อน
hudi_crawler_blogแล้วเลือก สร้างบัญชีตัวแทน. เลือก ถัดไป. - Choose สร้างโปรแกรมรวบรวมข้อมูล.
ตอนนี้สร้างโปรแกรมรวบรวมข้อมูล Hudi ใหม่เรียบร้อยแล้ว โปรแกรมรวบรวมข้อมูลสามารถทริกเกอร์ให้ทำงานผ่านคอนโซลหรือผ่าน SDK หรือ AWS CLI ได้โดยใช้ StartCrawl เอพีไอ นอกจากนี้ยังสามารถกำหนดเวลาผ่านคอนโซลเพื่อเรียกใช้โปรแกรมรวบรวมข้อมูลตามเวลาที่กำหนด ในคำสั่งนี้ ให้รันโปรแกรมรวบรวมข้อมูลผ่านคอนโซล
- Choose เรียกใช้โปรแกรมรวบรวมข้อมูล.
- รอให้โปรแกรมรวบรวมข้อมูลเสร็จสิ้น
หลังจากรันโปรแกรมรวบรวมข้อมูลแล้ว คุณสามารถดูคำจำกัดความของตาราง Hudi ได้ในคอนโซล AWS Glue:
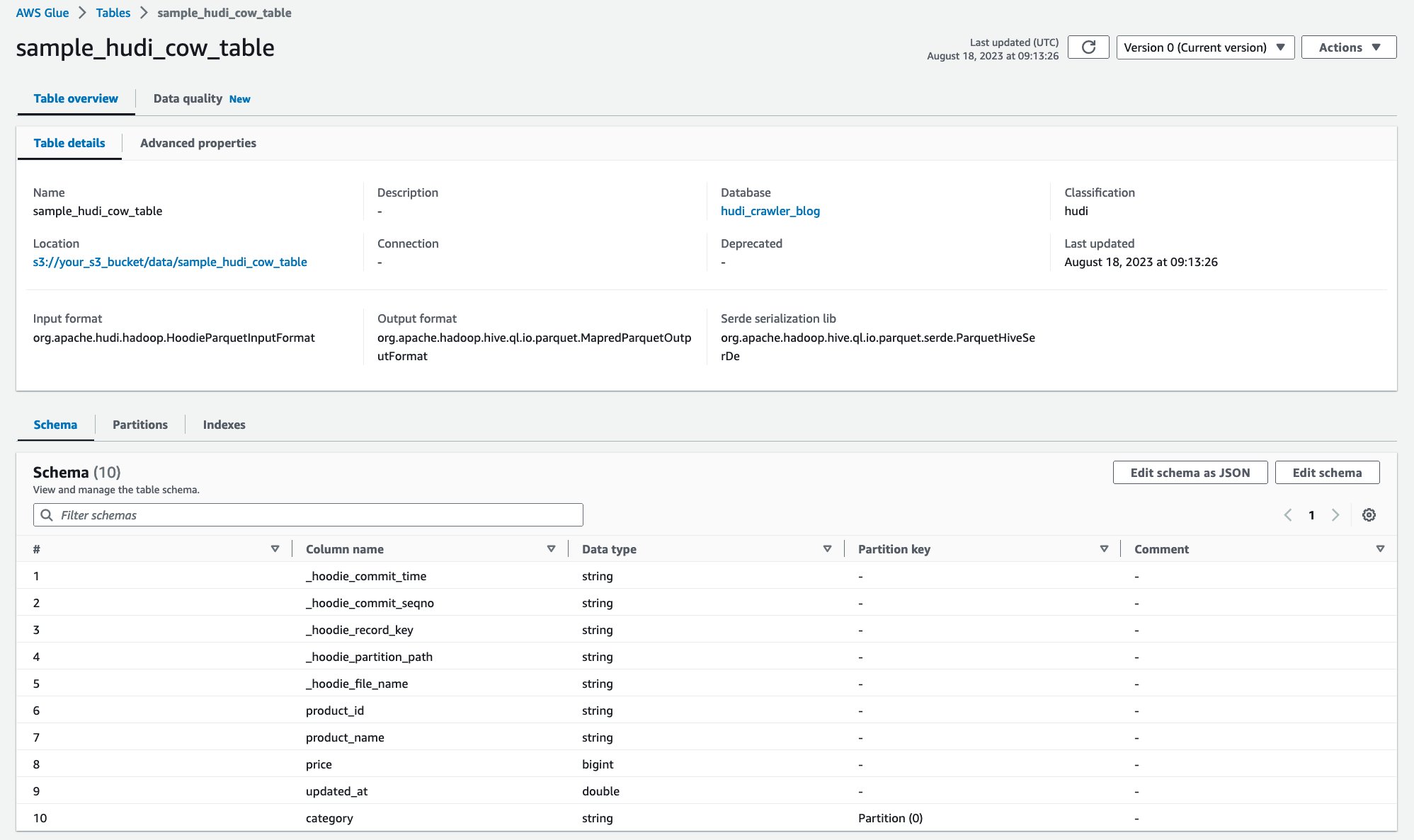
คุณได้รวบรวมข้อมูลตาราง Hudi CoR พร้อมข้อมูลบน Amazon S3 สำเร็จแล้ว และสร้างตาราง AWS Glue Data Catalog พร้อมข้อมูลสคีมา หลังจากที่คุณสร้างคำจำกัดความของตารางบน AWS Glue Data Catalog แล้ว บริการวิเคราะห์ของ AWS เช่น Amazon Athena จะสามารถสืบค้นตาราง Hudi ได้
ทำตามขั้นตอนต่อไปนี้เพื่อเริ่มการสืบค้นเกี่ยวกับ Athena:
- เปิดคอนโซล Amazon Athena
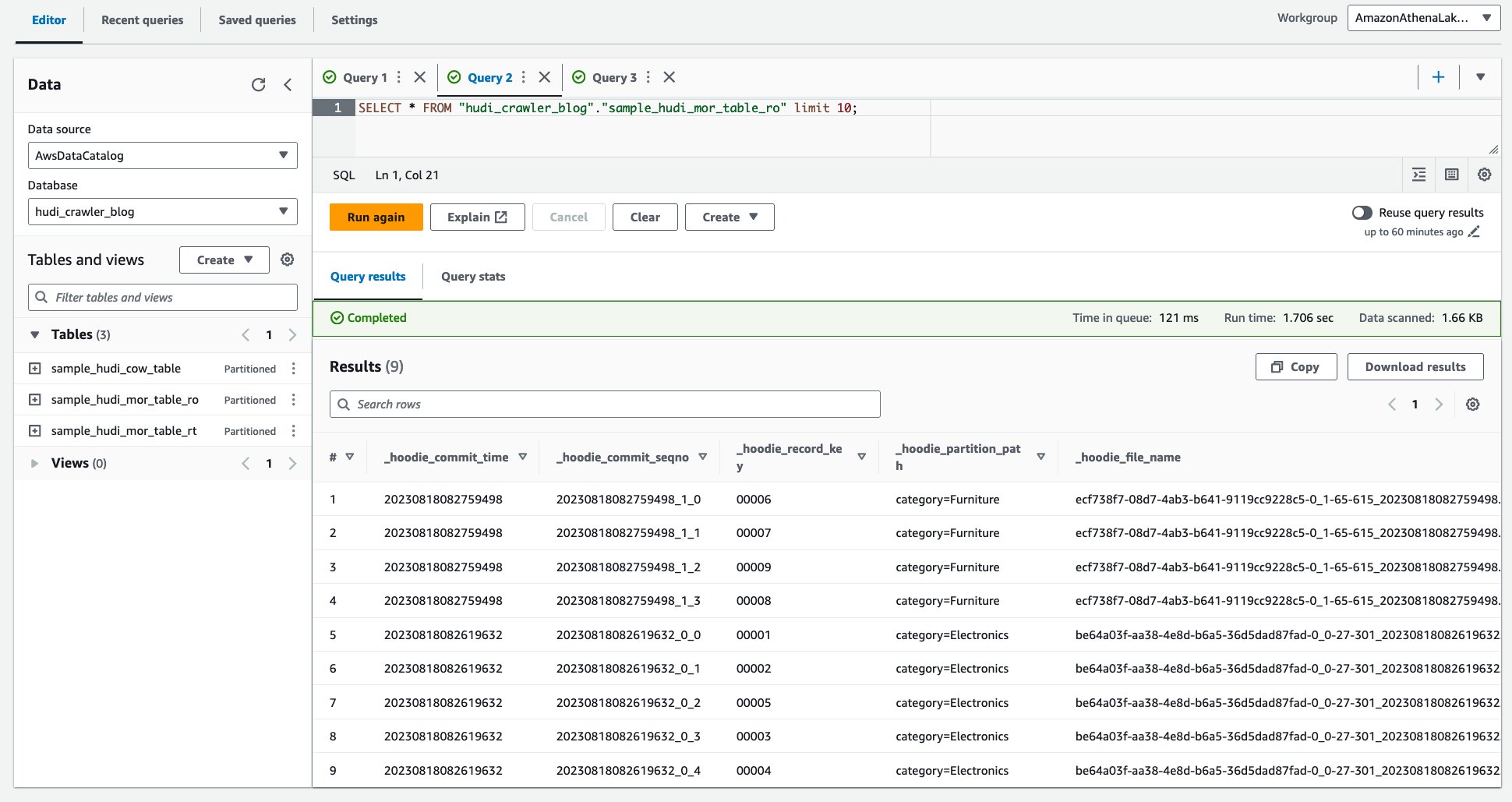
- เรียกใช้แบบสอบถามต่อไปนี้
ภาพหน้าจอต่อไปนี้แสดงผลลัพธ์ของเรา:
รวบรวมข้อมูลตาราง Hudi MoR โดยใช้โปรแกรมรวบรวมข้อมูล AWS Glue ที่มีสิทธิ์ข้อมูล AWS Lake Formation
ในส่วนนี้ มาดูวิธีการรวบรวมข้อมูลตาราง Hudi MoR โดยใช้ AWS Glue กัน ในครั้งนี้ คุณใช้สิทธิ์อนุญาตข้อมูล AWS Lake Formation สำหรับการรวบรวมข้อมูลแหล่งข้อมูล Amazon S3 แทนสิทธิ์ IAM และ Amazon S3 นี่เป็นทางเลือก แต่จะช่วยลดความยุ่งยากในการกำหนดค่าสิทธิ์เมื่อ Data Lake ของคุณได้รับการจัดการโดยสิทธิ์ AWS Lake Formation
เบื้องต้น
ข้อกำหนดเบื้องต้นสำหรับบทช่วยสอนนี้มีดังนี้:
- ติดตั้งและกำหนดค่า อินเทอร์เฟซบรรทัดคำสั่ง AWS (AWS CLI).
- สร้างบัคเก็ต S3 ของคุณหากคุณไม่มี
- สร้างบทบาท IAM ของคุณสำหรับ AWS Glue ถ้าคุณไม่มีมัน คุณต้องการ
lakeformation:GetDataAccess. แต่คุณไม่จำเป็นต้องs3:GetObjectfors3://your_s3_bucket/data/sample_hudi_mor_table/เนื่องจากเราใช้การอนุญาตข้อมูล Lake Formation เพื่อเข้าถึงไฟล์ - รันคำสั่งต่อไปนี้เพื่อคัดลอกตาราง Hudi ตัวอย่างลงในบัคเก็ต S3 ของคุณ (แทนที่
your_s3_bucketด้วยชื่อบัคเก็ต S3 ของคุณ)
นอกเหนือจากขั้นตอนการประมวลผล ให้ทำตามขั้นตอนต่อไปนี้เพื่ออัปเดตการตั้งค่า AWS Glue Data Catalog เพื่อใช้สิทธิ์ Lake Formation เพื่อควบคุมทรัพยากรแคตตาล็อกแทนการควบคุมการเข้าถึงตาม IAM:
- ลงชื่อเข้าใช้คอนโซล Lake Formation ในฐานะผู้ดูแลระบบ Data Lake
- หากนี่เป็นครั้งแรกที่เข้าถึงคอนโซล Lake Formation เพิ่มตัวคุณเองเป็นผู้ดูแล Data Lake
- ภายใต้ การบริหารจัดการเลือก การตั้งค่าแคตตาล็อกข้อมูล.
- สำหรับ สิทธิ์เริ่มต้นสำหรับฐานข้อมูลและตารางที่สร้างขึ้นใหม่, ยกเลิกการเลือก ใช้เฉพาะการควบคุมการเข้าถึง IAM สำหรับฐานข้อมูลใหม่ และ ใช้เฉพาะการควบคุมการเข้าถึง IAM สำหรับตารางใหม่ในฐานข้อมูลใหม่.
- สำหรับ การตั้งค่าเวอร์ชันข้ามบัญชีเลือก 3 เวอร์ชัน.
- Choose ลด.
ขั้นตอนต่อไปคือการลงทะเบียนบัคเก็ต S3 ของคุณในสถานที่ตั้ง Data Lake ของ Lake Formation:
- บนคอนโซล Lake Formation เลือก ที่ตั้งของ Data Lakeและเลือก ลงทะเบียนสถานที่.
- สำหรับ เส้นทาง Amazon S3ป้อน
s3://your_s3_bucket/. (แทนที่your_s3_bucketด้วยชื่อบัคเก็ต S3 ของคุณ) - Choose ลงทะเบียนสถานที่.
จากนั้น ให้สิทธิ์การเข้าถึงบทบาทโปรแกรมรวบรวมข้อมูลของ Glue ไปยังตำแหน่งข้อมูล เพื่อให้โปรแกรมรวบรวมข้อมูลสามารถใช้สิทธิ์ Lake Formation เพื่อเข้าถึงข้อมูลและสร้างตารางในตำแหน่งนั้น:
- บนคอนโซล Lake Formation เลือก ตำแหน่งข้อมูล และเลือก ให้.
- สำหรับ ผู้ใช้และบทบาท IAMให้เลือกบทบาท IAM ที่คุณใช้สำหรับโปรแกรมรวบรวมข้อมูล
- สำหรับ ที่เก็บสินค้าป้อน
s3://your_s3_bucket/data/. (แทนที่your_s3_bucketด้วยชื่อบัคเก็ต S3 ของคุณ) - Choose ให้.
จากนั้น ให้สิทธิ์บทบาทโปรแกรมรวบรวมข้อมูลเพื่อสร้างตารางภายใต้ฐานข้อมูล hudi_crawler_blog:
- บนคอนโซล Lake Formation เลือก สิทธิ์ในทะเลสาบข้อมูล.
- Choose ให้.
- สำหรับ ครูใหญ่เลือก ผู้ใช้และบทบาท IAMและเลือกบทบาทของโปรแกรมรวบรวมข้อมูล
- สำหรับ แท็ก LF หรือทรัพยากรแค็ตตาล็อกเลือก แหล่งข้อมูลแคตตาล็อกข้อมูลที่มีชื่อ.
- สำหรับ ฐานข้อมูล, เลือกฐานข้อมูล
hudi_crawler_blog. - ภายใต้ สิทธิ์ของฐานข้อมูลให้เลือก สร้างตาราง.
- Choose ให้.
สร้างโปรแกรมรวบรวมข้อมูล Hudi ที่มีสิทธิ์ข้อมูล Lake Formation
ทำตามขั้นตอนต่อไปนี้เพื่อสร้างโปรแกรมรวบรวมข้อมูล Hudi:
- บนคอนโซล AWS Glue ให้เลือก โปรแกรมรวบรวมข้อมูล.
- Choose สร้างโปรแกรมรวบรวมข้อมูล.
- สำหรับ Nameป้อน
hudi_mor_crawler. เลือก ถัดไป. - ภายใต้ การกำหนดค่าแหล่งข้อมูล, เลือก เพิ่มแหล่งข้อมูล.
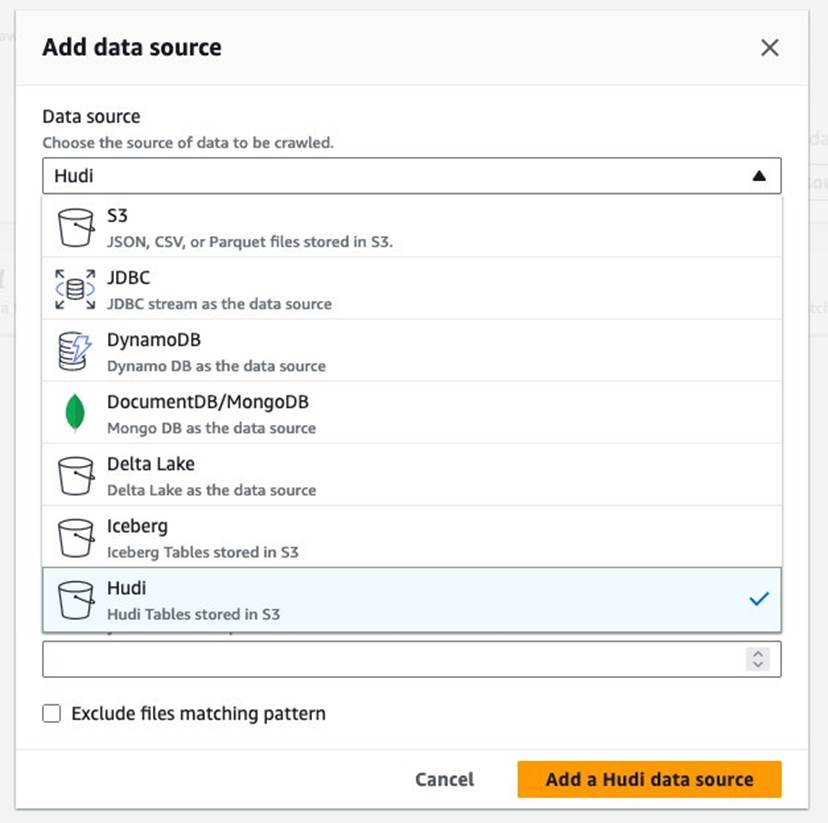
- สำหรับ แหล่งข้อมูลเลือก ฮูดิ.
- สำหรับ รวมเส้นทางตาราง hudiป้อน
s3://your_s3_bucket/data/sample_hudi_mor_table/. (แทนที่your_s3_bucketด้วยชื่อบัคเก็ต S3 ของคุณ) - Choose เพิ่มแหล่งข้อมูล Hudi.
- Choose ถัดไป.
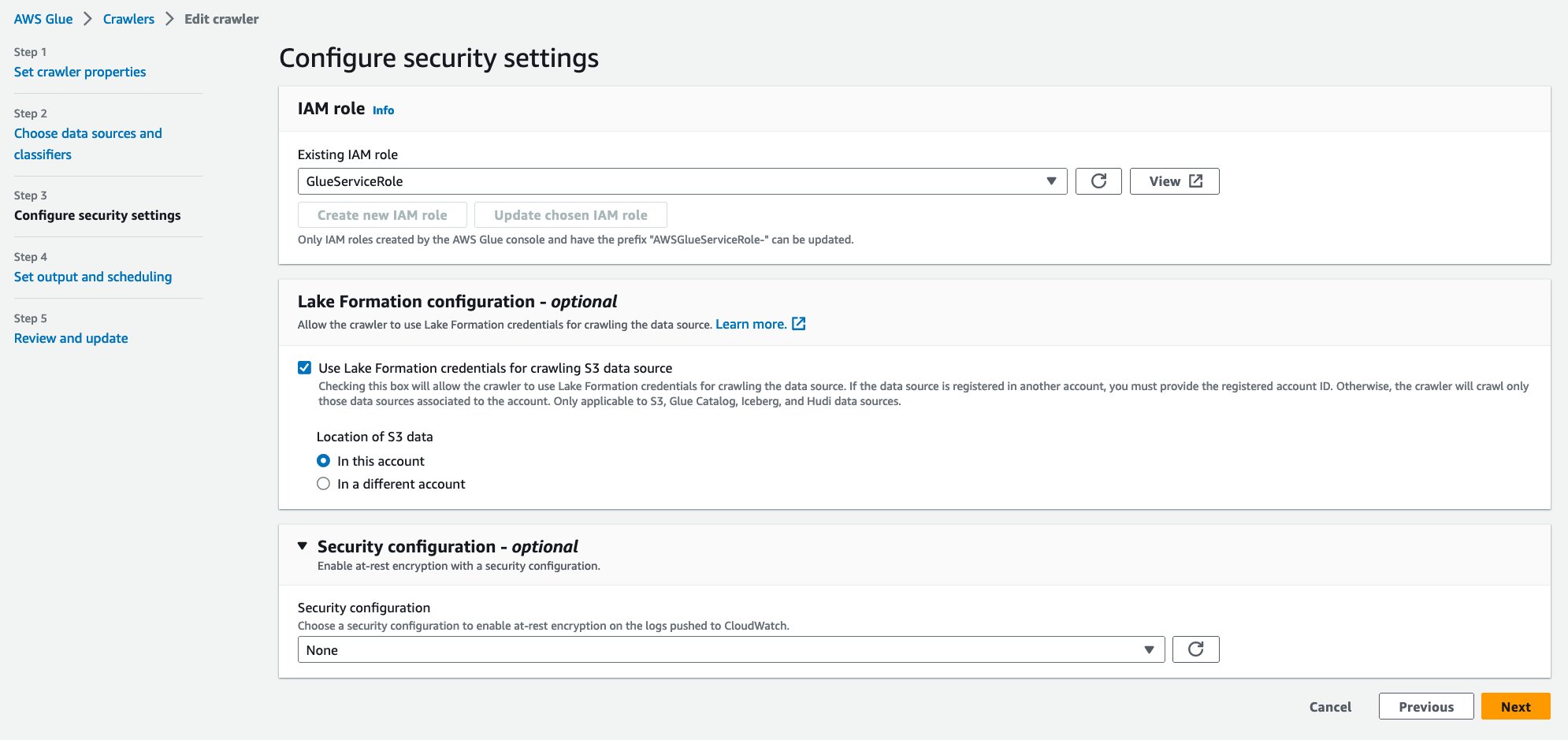
- สำหรับ บทบาท IAM ที่มีอยู่เลือกบทบาท IAM ของคุณ
- ภายใต้ การกำหนดค่าการก่อตัวของทะเลสาบ – ไม่จำเป็นให้เลือก ใช้ข้อมูลประจำตัวของ Lake Formation เพื่อรวบรวมข้อมูลแหล่งข้อมูล S3.
- Choose ถัดไป.
- สำหรับ ฐานข้อมูลเป้าหมายเลือก
hudi_crawler_blog. เลือก ถัดไป. - Choose สร้างโปรแกรมรวบรวมข้อมูล.
ตอนนี้สร้างโปรแกรมรวบรวมข้อมูล Hudi ใหม่เรียบร้อยแล้ว โปรแกรมรวบรวมข้อมูลใช้ข้อมูลรับรอง Lake Formation สำหรับการรวบรวมข้อมูลไฟล์ Amazon S3 มาเรียกใช้โปรแกรมรวบรวมข้อมูลใหม่:
- Choose เรียกใช้โปรแกรมรวบรวมข้อมูล.
- รอให้โปรแกรมรวบรวมข้อมูลเสร็จสิ้น
หลังจากรันโปรแกรมรวบรวมข้อมูลแล้ว คุณจะเห็นตารางสองตารางของคำจำกัดความของตาราง Hudi ในคอนโซล AWS Glue:
sample_hudi_mor_table_ro(อ่านตารางที่ปรับให้เหมาะสม)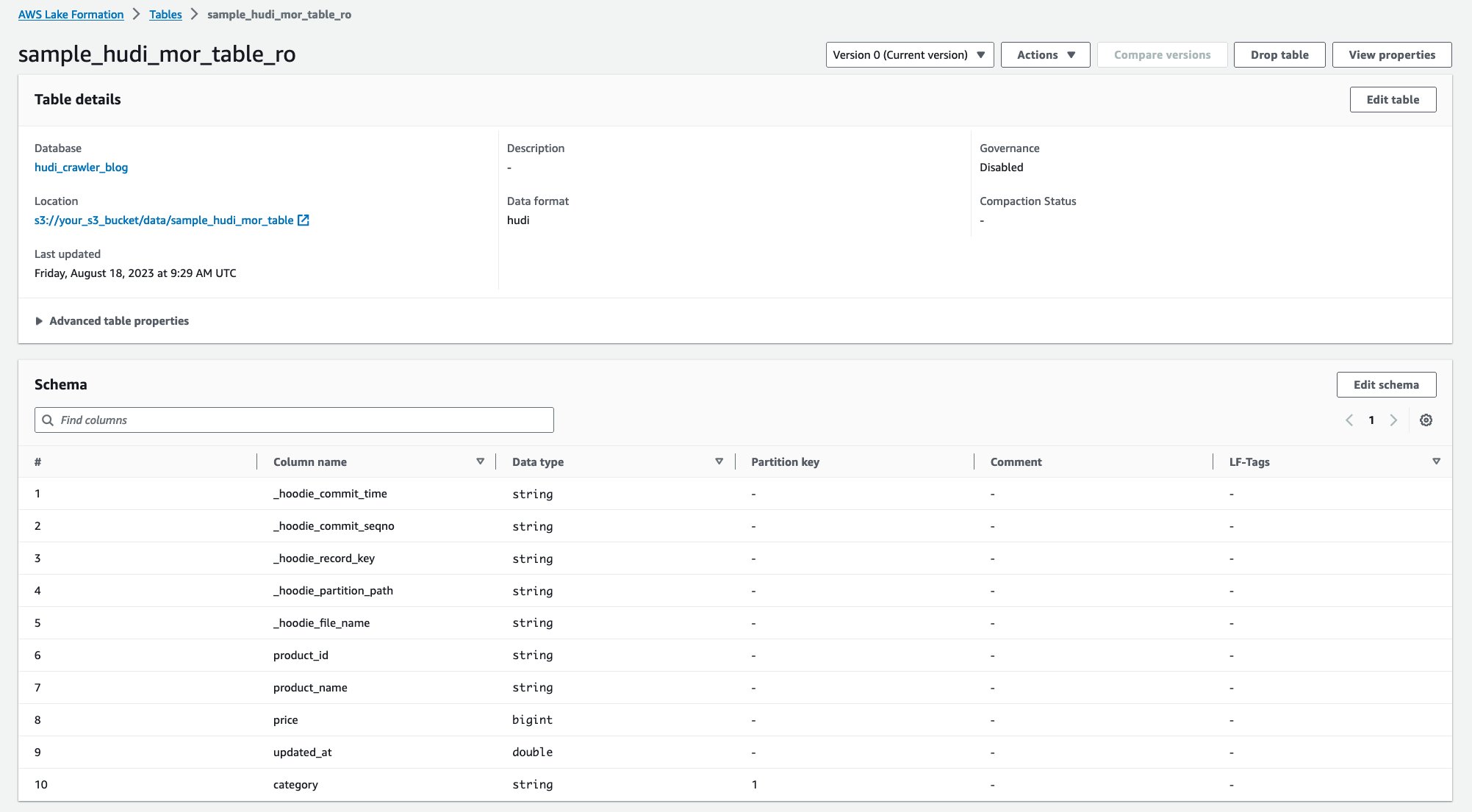
sample_hudi_mor_table_rt(ตารางเวลาจริง)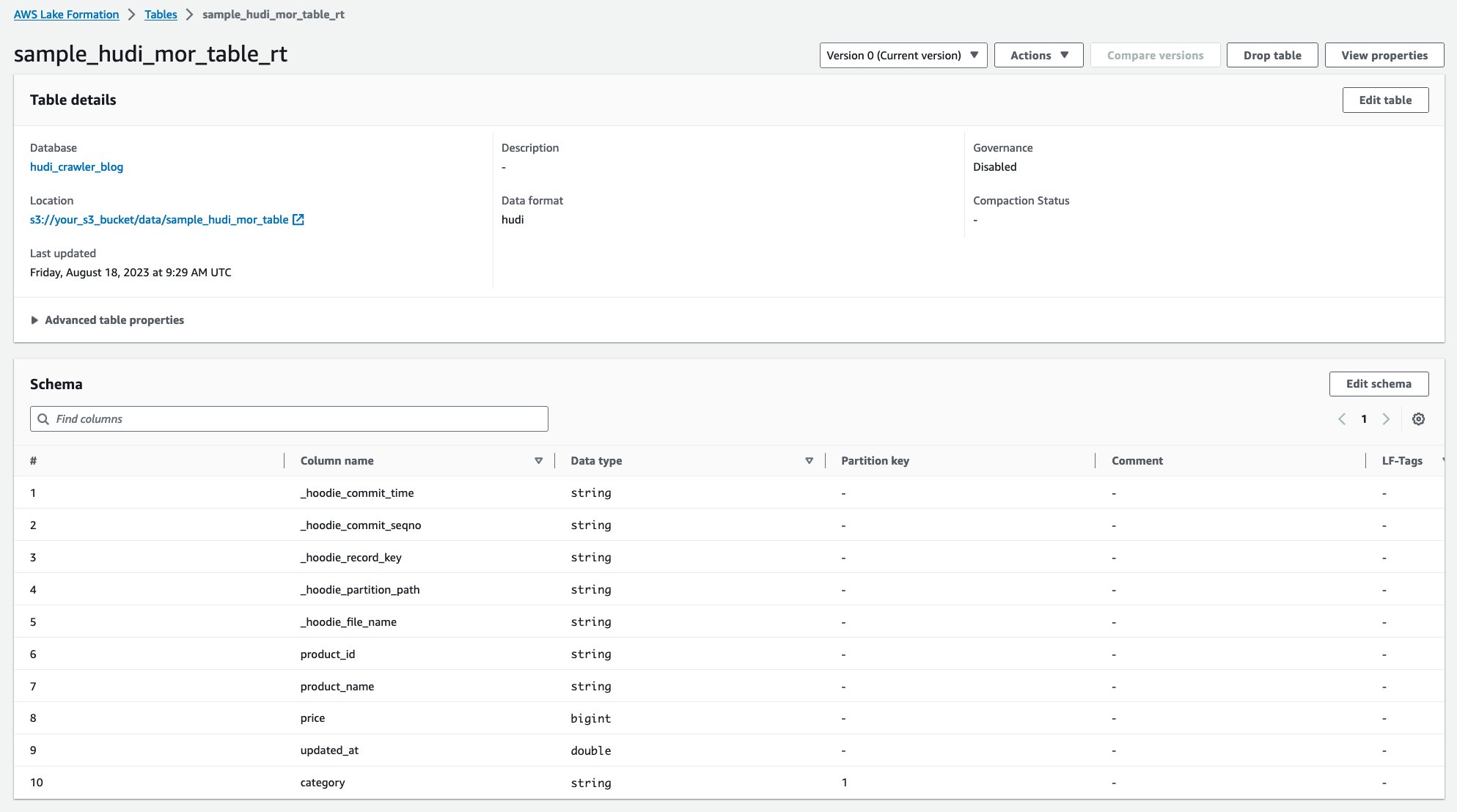
คุณได้ลงทะเบียนที่เก็บข้อมูล Data Lake ด้วย Lake Formation และเปิดใช้งานการรวบรวมข้อมูลการเข้าถึง Data Lake โดยใช้สิทธิ์ Lake Formation คุณได้รวบรวมข้อมูลตาราง Hudi MoR พร้อมข้อมูลบน Amazon S3 สำเร็จแล้ว และสร้างตาราง AWS Glue Data Catalog พร้อมข้อมูลสคีมา หลังจากที่คุณสร้างคำจำกัดความของตารางบน AWS Glue Data Catalog แล้ว บริการวิเคราะห์ของ AWS เช่น Amazon Athena จะสามารถสืบค้นตาราง Hudi ได้
ทำตามขั้นตอนต่อไปนี้เพื่อเริ่มการสืบค้นเกี่ยวกับ Athena:
- เปิดคอนโซล Amazon Athena
- เรียกใช้แบบสอบถามต่อไปนี้
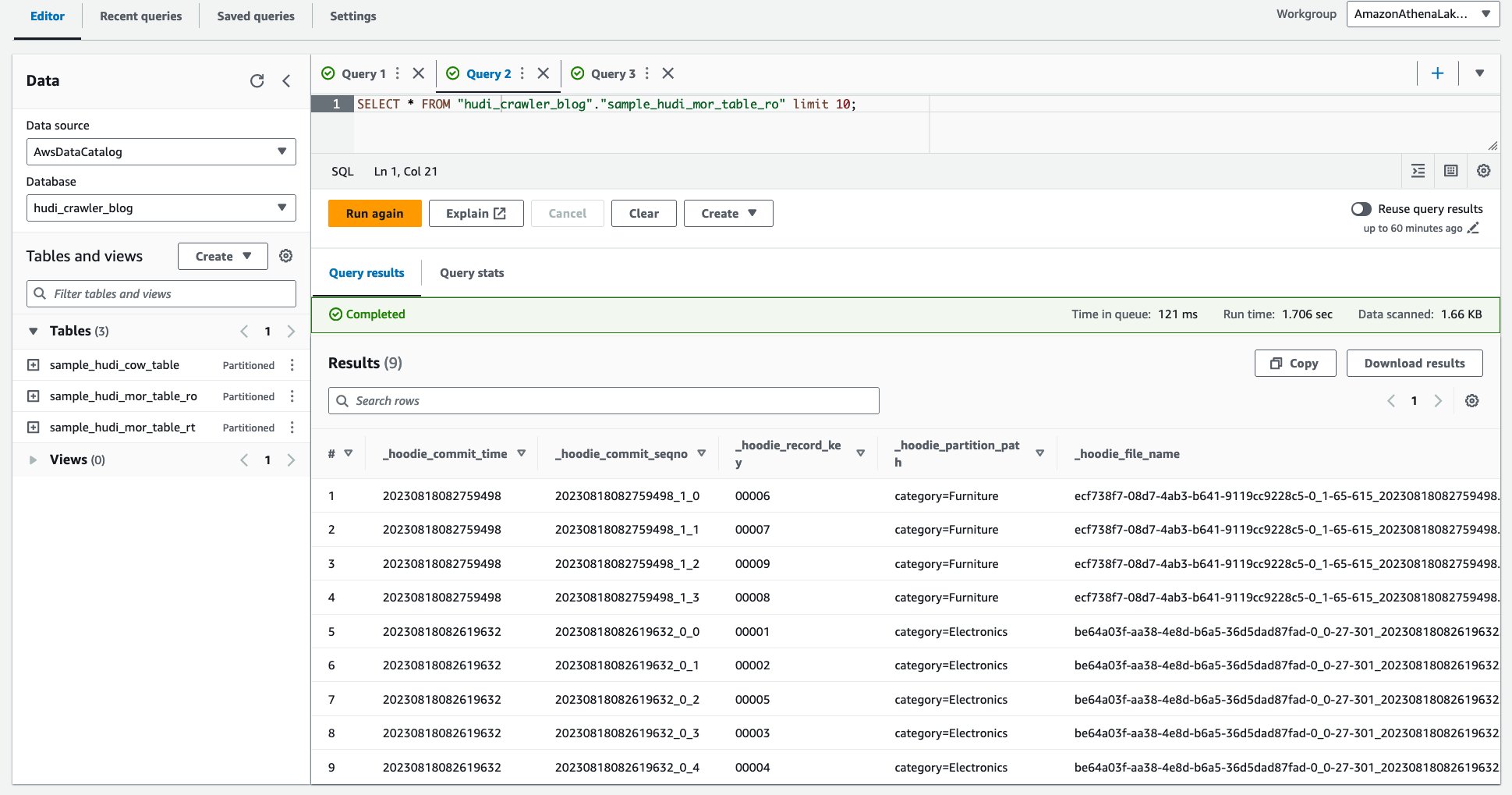
ภาพหน้าจอต่อไปนี้แสดงผลลัพธ์ของเรา:
- เรียกใช้แบบสอบถามต่อไปนี้
ภาพหน้าจอต่อไปนี้แสดงผลลัพธ์ของเรา:
การควบคุมการเข้าถึงอย่างละเอียดโดยใช้สิทธิ์ AWS Lake Formation
หากต้องการใช้การควบคุมการเข้าถึงแบบละเอียดบนตาราง Hudi คุณจะได้รับประโยชน์จากสิทธิ์ AWS Lake Formation สิทธิ์การสร้าง Lake ช่วยให้คุณสามารถจำกัดการเข้าถึงตาราง คอลัมน์ หรือแถวที่เฉพาะเจาะจง จากนั้นสืบค้นตาราง Hudi ผ่าน Amazon Athena ด้วยการควบคุมการเข้าถึงแบบละเอียด มากำหนดค่าสิทธิ์ Lake Formation สำหรับตาราง Hudi MoR กัน
เบื้องต้น
ข้อกำหนดเบื้องต้นสำหรับบทช่วยสอนนี้มีดังนี้:
- กรอกส่วนก่อนหน้าให้สมบูรณ์ รวบรวมข้อมูลตาราง Hudi MoR โดยใช้โปรแกรมรวบรวมข้อมูล AWS Glue ที่มีสิทธิ์ข้อมูล AWS Lake Formation.
- สร้าง DataAnalyst ผู้ใช้ IAM ซึ่งมีนโยบายที่ AWS จัดการ AmazonAthenaFullAccess.
สร้างตัวกรองเซลล์ข้อมูล Lake Formation
ก่อนอื่นมาตั้งค่าตัวกรองสำหรับตารางที่ปรับให้เหมาะสมสำหรับการอ่าน MoR
- ลงชื่อเข้าใช้คอนโซล Lake Formation ในฐานะผู้ดูแลระบบ Data Lake
- Choose ตัวกรองข้อมูล.
- Choose สร้างตัวกรองใหม่.
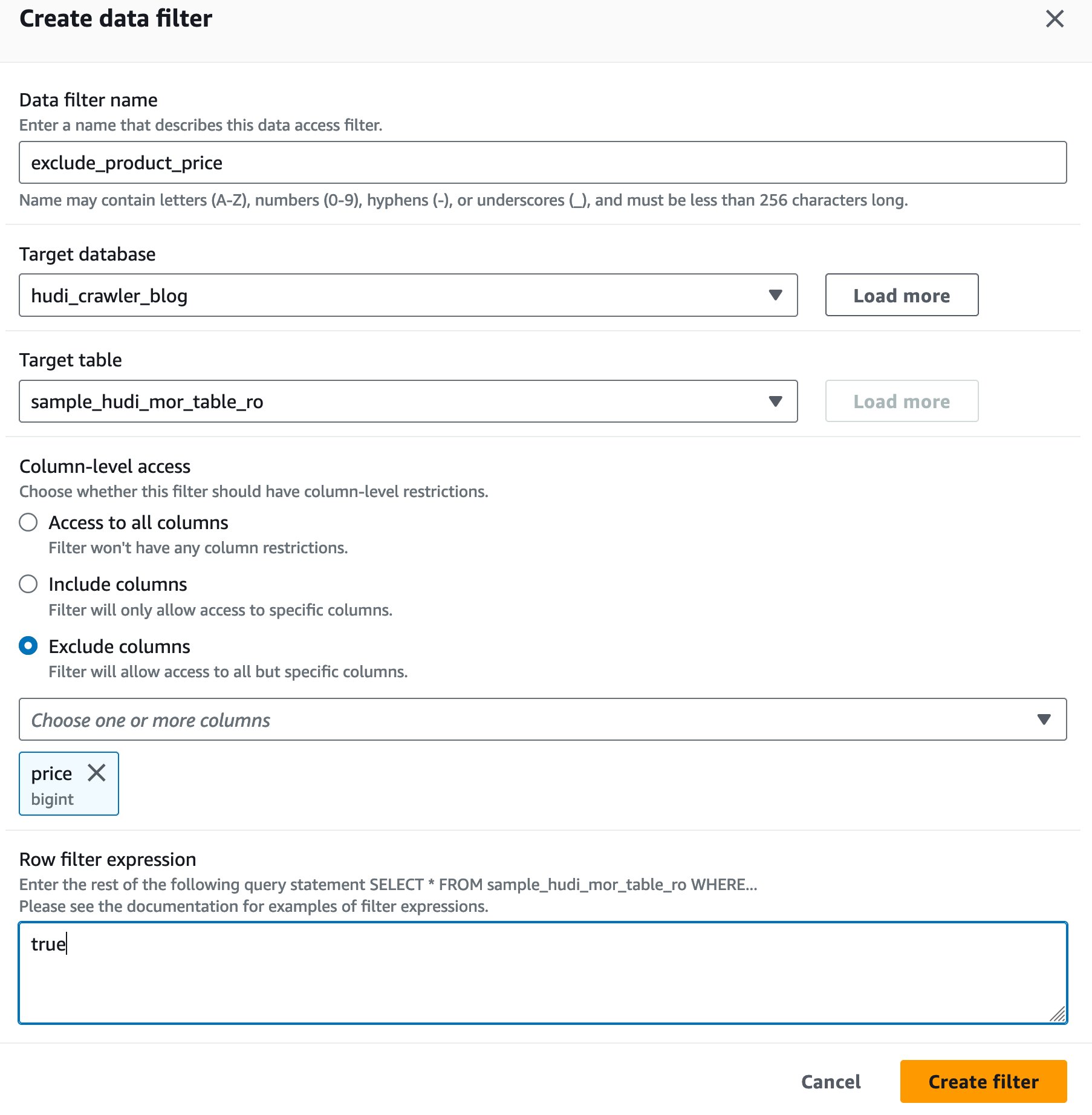
- สำหรับ ชื่อตัวกรองข้อมูลป้อน
exclude_product_price. - สำหรับ ฐานข้อมูลเป้าหมาย, เลือกฐานข้อมูล
hudi_crawler_blog. - สำหรับ ตารางเป้าหมาย, เลือกโต๊ะ
sample_hudi_mor_table_ro. - สำหรับ ระดับคอลัมน์ เข้าถึง เลือก ไม่รวมคอลัมน์และเลือกราคาคอลัมน์
- สำหรับ นิพจน์ตัวกรองแถวป้อน
true. - Choose สร้างตัวกรอง.
ให้สิทธิ์การสร้าง Lake แก่ผู้ใช้ DataAnalyst
ทำตามขั้นตอนต่อไปนี้เพื่อให้สิทธิ์ Lake Formation แก่ DataAnalyst ผู้ใช้งาน
- บนคอนโซล Lake Formation เลือก สิทธิ์ในทะเลสาบข้อมูล.
- Choose ให้.
- สำหรับ ครูใหญ่เลือก ผู้ใช้และบทบาท IAMและเลือกผู้ใช้
DataAnalyst. - สำหรับ แท็ก LF หรือทรัพยากรแค็ตตาล็อกเลือก แหล่งข้อมูลแคตตาล็อกข้อมูลที่มีชื่อ.
- สำหรับ ฐานข้อมูล, เลือกฐานข้อมูล
hudi_crawler_blog. - สำหรับ ตาราง – ไม่จำเป็น, เลือกโต๊ะ
sample_hudi_mor_table_ro. - สำหรับ ตัวกรองข้อมูล - ไม่จำเป็น, เลือก
exclude_product_price. - สำหรับ สิทธิ์การกรองข้อมูลให้เลือก เลือก.
- Choose ให้.
คุณได้รับสิทธิ์ในการสร้างทะเลสาบในฐานข้อมูล hudi_crawler_blog และโต๊ะ sample_hudi_mor_table_roไม่รวมคอลัมน์ price ให้กับผู้ใช้ DataAnalyst ตอนนี้เรามาตรวจสอบการเข้าถึงข้อมูลของผู้ใช้โดยใช้ Athena กันดีกว่า
- ลงชื่อเข้าใช้คอนโซล Athena ในฐานะผู้ใช้ DataAnalyst
- บนตัวแก้ไขแบบสอบถาม ให้รันแบบสอบถามต่อไปนี้:
ภาพหน้าจอต่อไปนี้แสดงผลลัพธ์ของเรา:
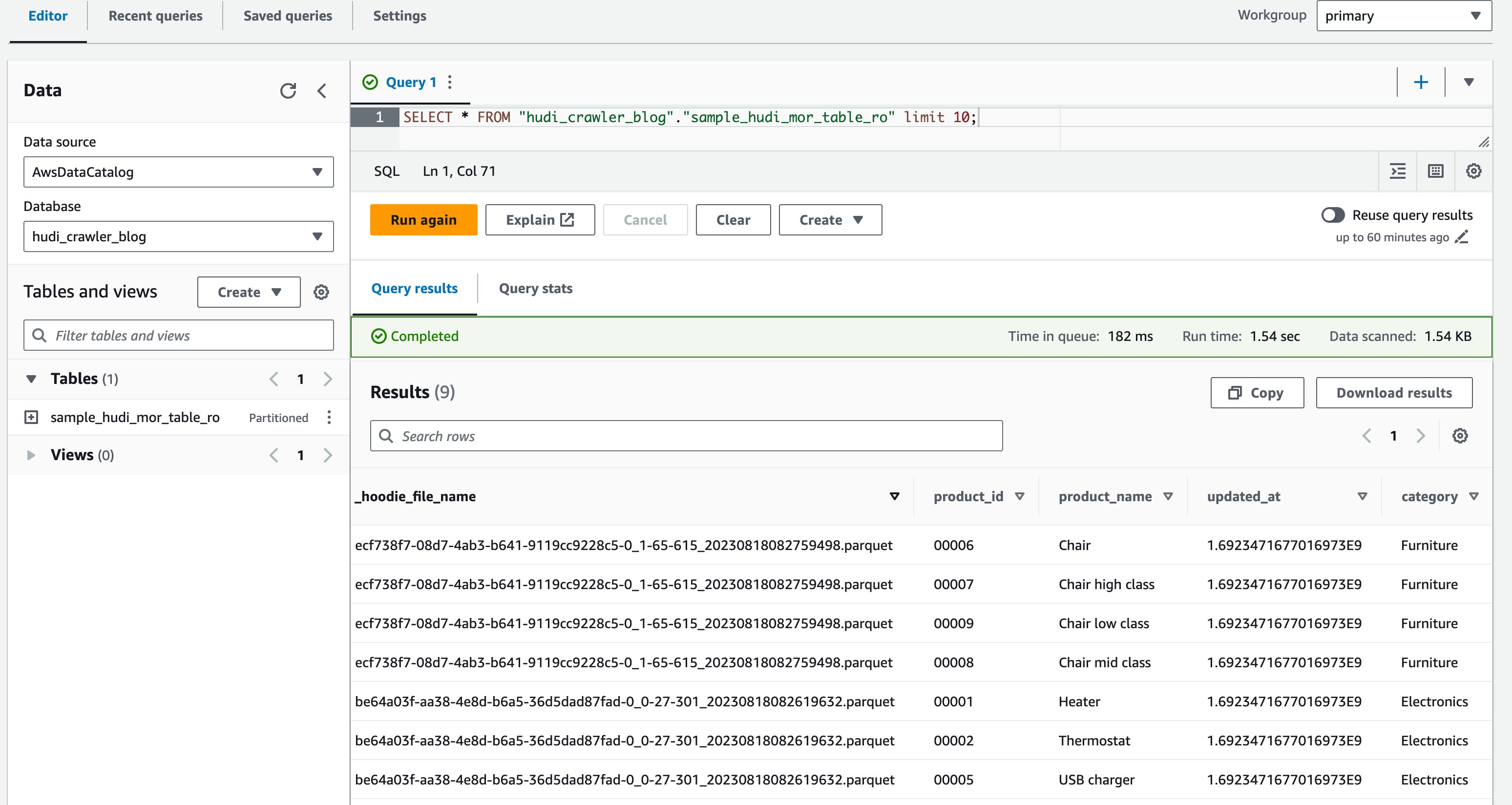
ตอนนี้คุณได้ตรวจสอบว่าคอลัมน์แล้ว price ไม่แสดงแต่คอลัมน์อื่นๆ product_id, product_name, update_atและ category ถูกแสดง.
ทำความสะอาด
เพื่อหลีกเลี่ยงการเรียกเก็บเงินที่ไม่ต้องการไปยังบัญชี AWS ของคุณ ให้ลบทรัพยากร AWS ต่อไปนี้:
- ลบฐานข้อมูล AWS Glue
hudi_crawler_blog. - ลบโปรแกรมรวบรวมข้อมูล AWS Glue
hudi_cow_crawlerและhudi_mor_crawler. - ลบไฟล์ Amazon S3 ที่อยู่ด้านล่าง
s3://your_s3_bucket/data/sample_hudi_cow_table/และs3://your_s3_bucket/data/sample_hudi_mor_table/.
สรุป
โพสต์นี้สาธิตวิธีการทำงานของโปรแกรมรวบรวมข้อมูล AWS Glue สำหรับตาราง Hudi ด้วยการรองรับโปรแกรมรวบรวมข้อมูล Hudi คุณสามารถเปลี่ยนไปใช้ AWS Glue Data Catalog เป็นแค็ตตาล็อกตาราง Hudi หลักของคุณได้อย่างรวดเร็ว คุณสามารถเริ่มสร้าง Data Lake ธุรกรรมแบบไร้เซิร์ฟเวอร์ได้โดยใช้ Hudi บน AWS โดยใช้ AWS Glue, AWS Glue Data Catalog และการควบคุมการเข้าถึงแบบละเอียดของ Lake Formation สำหรับตารางและรูปแบบที่รองรับโดยกลไกการวิเคราะห์ของ AWS
เกี่ยวกับผู้แต่ง
 โนริทากะ เซกิยามะ เป็น Principal Big Data Architect ในทีม AWS Glue เขาทำงานในโตเกียว ประเทศญี่ปุ่น เขามีหน้าที่รับผิดชอบในการสร้างสิ่งประดิษฐ์ซอฟต์แวร์เพื่อช่วยเหลือลูกค้า ในเวลาว่างเขาชอบปั่นจักรยานเสือหมอบ
โนริทากะ เซกิยามะ เป็น Principal Big Data Architect ในทีม AWS Glue เขาทำงานในโตเกียว ประเทศญี่ปุ่น เขามีหน้าที่รับผิดชอบในการสร้างสิ่งประดิษฐ์ซอฟต์แวร์เพื่อช่วยเหลือลูกค้า ในเวลาว่างเขาชอบปั่นจักรยานเสือหมอบ
 ไคล์ ดูง เป็นวิศวกรพัฒนาซอฟต์แวร์ในทีม AWS Glue and Lake Formation เขามีความหลงใหลในการสร้างเทคโนโลยีข้อมูลขนาดใหญ่และระบบแบบกระจาย
ไคล์ ดูง เป็นวิศวกรพัฒนาซอฟต์แวร์ในทีม AWS Glue and Lake Formation เขามีความหลงใหลในการสร้างเทคโนโลยีข้อมูลขนาดใหญ่และระบบแบบกระจาย
 ซานดีป แอดวานการ์ เป็นผู้จัดการผลิตภัณฑ์ด้านเทคนิคอาวุโสของ AWS ในแคลิฟอร์เนียเบย์แอเรีย เขาทำงานร่วมกับลูกค้าทั่วโลกเพื่อแปลข้อกำหนดทางธุรกิจและทางเทคนิคเป็นผลิตภัณฑ์ที่ช่วยให้ลูกค้าสามารถปรับปรุงวิธีจัดการ รักษาความปลอดภัย และเข้าถึงข้อมูลได้
ซานดีป แอดวานการ์ เป็นผู้จัดการผลิตภัณฑ์ด้านเทคนิคอาวุโสของ AWS ในแคลิฟอร์เนียเบย์แอเรีย เขาทำงานร่วมกับลูกค้าทั่วโลกเพื่อแปลข้อกำหนดทางธุรกิจและทางเทคนิคเป็นผลิตภัณฑ์ที่ช่วยให้ลูกค้าสามารถปรับปรุงวิธีจัดการ รักษาความปลอดภัย และเข้าถึงข้อมูลได้
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- สามารถ
- เกี่ยวกับเรา
- เข้า
- การเข้าถึงข้อมูล
- การเข้าถึง
- ลงชื่อเข้าใช้
- การกระทำ
- เพิ่ม
- ที่เพิ่ม
- นอกจากนี้
- บุญธรรม
- การนำมาใช้
- สูง
- หลังจาก
- ทั้งหมด
- อนุญาต
- การอนุญาต
- ช่วยให้
- ด้วย
- อเมซอน
- อเมซอน อาเธน่า
- Amazon Web Services
- an
- วิเคราะห์
- การวิเคราะห์
- และ
- อื่น
- ใด
- อาปาเช่
- Apache Spark
- API
- ปรากฏ
- การใช้งาน
- การพัฒนาโปรแกรมประยุกต์
- ใช้
- เป็น
- AREA
- รอบ
- AS
- At
- อัตโนมัติ
- หลีกเลี่ยง
- AWS
- AWS กาว
- การก่อตัวของทะเลสาบ AWS
- ฐาน
- ตาม
- อ่าว
- BE
- เพราะ
- รับ
- ประโยชน์
- ดีกว่า
- ใหญ่
- ข้อมูลขนาดใหญ่
- นำ
- การก่อสร้าง
- สร้าง
- ธุรกิจ
- แต่
- by
- แคลิฟอร์เนีย
- โทรศัพท์
- CAN
- ความสามารถในการ
- ความสามารถ
- กรณี
- แค็ตตาล็อก
- แคตตาล็อก
- หมวดหมู่
- เซลล์
- ความท้าทาย
- เปลี่ยนแปลง
- การเปลี่ยนแปลง
- การเปลี่ยนแปลง
- โหลด
- Choose
- คอลัมน์
- คอลัมน์
- การผสมผสาน
- ผูกมัด
- มุ่งมั่น
- สมบูรณ์
- ซับซ้อน
- ส่วนประกอบ
- องค์ประกอบ
- ปลอบใจ
- มี
- เนื้อหา
- อย่างต่อเนื่อง
- ควบคุม
- การควบคุม
- ได้
- ไม้เลื้อย
- สร้าง
- ที่สร้างขึ้น
- สร้าง
- หนังสือรับรอง
- ลูกค้า
- ข้อมูล
- การรวมข้อมูล
- ดาต้าเลค
- คลังข้อมูล
- ฐานข้อมูล
- ฐานข้อมูล
- ชุดข้อมูล
- คำนิยาม
- คำจำกัดความ
- สันดอน
- แสดงให้เห็นถึง
- แสดงให้เห็นถึง
- ความลึก
- พัฒนาการ
- โดยตรง
- ค้นพบ
- กระจาย
- ระบบกระจาย
- do
- ทำ
- ในระหว่าง
- แต่ละ
- ง่ายดาย
- อย่างง่ายดาย
- บรรณาธิการ
- มีประสิทธิภาพ
- ที่มีประสิทธิภาพ
- ทำให้สามารถ
- เปิดการใช้งาน
- วิศวกร
- วิศวกร
- เครื่องยนต์
- เข้าสู่
- อีเธอร์ (ETH)
- การพัฒนา
- ไม่รวม
- สารสกัด
- เร็วขึ้น
- น้อยลง
- เนื้อไม่มีมัน
- ไฟล์
- กรอง
- ฟิลเตอร์
- หา
- ชื่อจริง
- ครั้งแรก
- ดังต่อไปนี้
- สำหรับ
- รูป
- การสร้าง
- มัก
- ราคาเริ่มต้นที่
- กำหนด
- โลก
- Go
- ให้
- รับ
- คู่มือ
- Hadoop
- มี
- he
- ช่วย
- จะช่วยให้
- ของเขา
- รัง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTML
- HTTPS
- AMI
- if
- ผลกระทบ
- ปรับปรุง
- in
- รวมทั้ง
- ที่เพิ่มขึ้น
- ข้อมูล
- แทน
- รวบรวม
- บูรณาการ
- อินเตอร์เฟซ
- เข้าไป
- แนะนำ
- IT
- ประเทศญี่ปุ่น
- jpg
- การเก็บรักษา
- ทะเลสาบ
- ชล
- ล่าสุด
- เปิดตัว
- เรียนรู้
- การเรียนรู้
- น้อยลง
- LIMIT
- Line
- รายการ
- ที่ตั้งอยู่
- ที่ตั้ง
- วันหยุด
- เข้า
- เครื่อง
- เรียนรู้เครื่อง
- การบำรุงรักษา
- ทำ
- ทำให้
- จัดการ
- การจัดการ
- ผู้จัดการ
- การจัดการ
- คู่มือ
- สูงสุด
- การผสม
- เมตาดาต้า
- การโยกย้าย
- การโยกย้าย
- ML
- ข้อมูลเพิ่มเติม
- มากที่สุด
- ย้าย
- หลาย
- ชื่อ
- พื้นเมือง
- จำเป็นต้อง
- จำเป็น
- ใหม่
- ใหม่
- ถัดไป
- ตอนนี้
- of
- on
- ONE
- เพียง
- เปิด
- โอเพนซอร์ส
- การปรับให้เหมาะสม
- ตัวเลือกเสริม (Option)
- or
- อื่นๆ
- ของเรา
- เอาท์พุต
- ส่วนหนึ่ง
- หลงใหล
- เส้นทาง
- เส้นทาง
- การปฏิบัติ
- การอนุญาต
- สิทธิ์
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- ยอดนิยม
- ประชากร
- โพสต์
- เตรียมการ
- ข้อกำหนดเบื้องต้น
- ก่อน
- ราคา
- ประถม
- หลัก
- การประมวลผล
- ผลิตภัณฑ์
- ผู้จัดการผลิตภัณฑ์
- ผลิตภัณฑ์
- ให้
- ให้
- ให้
- คำสั่ง
- อย่างรวดเร็ว
- อ่าน
- จริง
- เรียลไทม์
- เรียลไทม์
- เมื่อเร็ว ๆ นี้
- ระเบียน
- ทะเบียน
- ลงทะเบียน
- แทนที่
- ความต้องการ
- แหล่งข้อมูล
- รับผิดชอบ
- จำกัด
- ถนน
- บทบาท
- แถว
- วิ่ง
- เดียวกัน
- กำหนด
- ที่กำหนดไว้
- SDK
- Section
- ปลอดภัย
- เห็น
- เลือก
- ระดับอาวุโส
- serverless
- บริการ
- บริการ
- ชุด
- การตั้งค่า
- แสดง
- แสดงให้เห็นว่า
- ช่วยลดความยุ่งยาก
- ตั้งแต่
- เดียว
- ชิ้น
- ภาพย่อ
- So
- ซอฟต์แวร์
- การพัฒนาซอฟต์แวร์
- แหล่ง
- แหล่งที่มา
- จุดประกาย
- โดยเฉพาะ
- เริ่มต้น
- สถานะ
- ขั้นตอน
- ขั้นตอน
- เก็บไว้
- ที่พริ้ว
- ลำธาร
- สตูดิโอ
- ประสบความสำเร็จ
- อย่างเช่น
- สนับสนุน
- ที่สนับสนุน
- ซิงค์.
- ระบบ
- ตาราง
- ทีม
- วิชาการ
- เทคโนโลยี
- ที่
- พื้นที่
- ของพวกเขา
- แล้วก็
- ที่นั่น
- พวกเขา
- นี้
- สาม
- ตลอด
- เวลา
- ครั้ง
- ไปยัง
- โตเกียว
- ด้านบน
- ธุรกรรม
- การทำธุรกรรม
- แปลความ
- สำรวจ
- เรียก
- ทริกเกอร์
- เกี่ยวกับการสอน
- สอง
- ชนิด
- ตามแบบฉบับ
- ภายใต้
- ที่ไม่พึงประสงค์
- บันทึก
- ให้กับคุณ
- การปรับปรุง
- ใช้
- ใช้กรณี
- มือสอง
- ผู้ใช้งาน
- ผู้ใช้
- ใช้
- การใช้
- ตรวจสอบความถูกต้อง
- การตรวจสอบ
- ความคุ้มค่า
- รุ่น
- ภาพ
- คลังสินค้า
- we
- เว็บ
- บริการเว็บ
- ดี
- เมื่อ
- ที่
- ในขณะที่
- WHO
- จะ
- กับ
- ไม่มี
- งาน
- โรงงาน
- เขียน
- เขียน
- เธอ
- ของคุณ
- ด้วยตัวคุณเอง
- ลมทะเล