อเมซอน Redshiftซึ่งเป็นคลังข้อมูลบนคลาวด์ที่ใช้กันอย่างแพร่หลาย มีการพัฒนาอย่างมากเพื่อตอบสนองความต้องการด้านประสิทธิภาพของปริมาณงานที่มีความต้องการมากที่สุด โพสต์นี้ครอบคลุมถึงฟีเจอร์ใหม่อย่างหนึ่ง นั่นก็คือคีย์การเรียงลำดับเค้าโครงข้อมูลหลายมิติ
ตอนนี้ Amazon RedShift ปรับปรุงประสิทธิภาพการสืบค้นของคุณโดยรองรับคีย์การจัดเรียงเค้าโครงข้อมูลหลายมิติ ซึ่งเป็นคีย์การจัดเรียงประเภทใหม่ที่จัดเรียงข้อมูลของตารางตามเพรดิเคตตัวกรอง แทนที่จะเป็นคอลัมน์ทางกายภาพของตาราง คีย์การจัดเรียงเค้าโครงข้อมูลหลายมิติจะช่วยปรับปรุงประสิทธิภาพการสแกนตารางได้อย่างมาก โดยเฉพาะอย่างยิ่งเมื่อปริมาณงานการสืบค้นของคุณมีตัวกรองการสแกนซ้ำๆ
Amazon RedShift มีความสามารถด้าน การเพิ่มประสิทธิภาพตารางอัตโนมัติ (ATO) ซึ่งจะปรับการออกแบบตารางให้เหมาะสมโดยอัตโนมัติโดยใช้คีย์การเรียงลำดับและการแจกจ่ายโดยไม่จำเป็นต้องให้ผู้ดูแลระบบเข้าไปแทรกแซง ในโพสต์นี้ เราขอแนะนำคีย์การจัดเรียงเค้าโครงข้อมูลหลายมิติเป็นความสามารถเพิ่มเติมที่นำเสนอโดย ATO และเสริมด้วยอัลกอริธึมที่ปรึกษาคีย์การเรียงลำดับของ Amazon Redshift
คีย์การเรียงลำดับโครงร่างข้อมูลหลายมิติ
เมื่อคุณกำหนดตารางด้วยคีย์การจัดเรียงอัตโนมัติ Amazon RedShift ATO จะวิเคราะห์ประวัติการสืบค้นของคุณ และเลือกคีย์การจัดเรียงคอลัมน์เดียวหรือคีย์การจัดเรียงข้อมูลหลายมิติสำหรับตารางของคุณโดยอัตโนมัติ โดยขึ้นอยู่กับตัวเลือกที่เหมาะกับปริมาณงานของคุณมากกว่า เมื่อเลือกเค้าโครงข้อมูลแบบหลายมิติ Amazon RedShift จะสร้างฟังก์ชันการจัดเรียงแบบหลายมิติที่จัดตำแหน่งแถวที่โดยทั่วไปเข้าถึงได้ด้วยการสืบค้นเดียวกัน และฟังก์ชันการจัดเรียงจะใช้ในเวลาต่อมาในระหว่างการดำเนินการสืบค้นเพื่อข้ามบล็อกข้อมูลและแม้แต่ข้ามการสแกนภาคแสดงแต่ละรายการ คอลัมน์
พิจารณาแบบสอบถามผู้ใช้ต่อไปนี้ ซึ่งเป็นรูปแบบแบบสอบถามที่โดดเด่นในเวิร์กโหลดของผู้ใช้:
Amazon RedShift จัดเก็บข้อมูลสำหรับแต่ละคอลัมน์ในบล็อกดิสก์ขนาด 1 MB และจัดเก็บค่าต่ำสุดและสูงสุดในแต่ละบล็อกโดยเป็นส่วนหนึ่งของเมตาดาต้าของตาราง หากแบบสอบถามใช้ไฟล์ ภาคแสดงที่จำกัดช่วงAmazon RedShift สามารถใช้ค่าต่ำสุดและสูงสุดเพื่อข้ามบล็อกจำนวนมากอย่างรวดเร็วในระหว่างการสแกนตาราง อย่างไรก็ตาม ตัวกรองการสืบค้นนี้ในคอลัมน์ภูมิภาคย่อยไม่สามารถใช้เพื่อกำหนดบล็อกที่จะข้ามตามค่าต่ำสุดและสูงสุดได้ และด้วยเหตุนี้ Amazon RedShift จึงสแกนแถวทั้งหมดจากตารางชื่อ:
เมื่อแบบสอบถามของผู้ใช้ถูกเรียกใช้ด้วย titles โดยใช้คีย์การเรียงลำดับคอลัมน์เดียว subregionผลลัพธ์ของการสืบค้นก่อนหน้าจะเป็นดังนี้:
นี่แสดงว่าการสแกนตารางอ่านได้ 2,164,081,640 แถว
เพื่อปรับปรุงการสแกนบน titles ตาราง Amazon RedShift อาจตัดสินใจใช้คีย์การจัดเรียงเค้าโครงข้อมูลหลายมิติโดยอัตโนมัติ ทุกแถวที่ตรงใจ lower(subregion) like '%United States%' เพรดิเคตจะตั้งอยู่ร่วมกับภูมิภาคเฉพาะของตาราง ดังนั้น Amazon RedShift จะสแกนเฉพาะบล็อกข้อมูลที่ตรงตามเพรดิเคตเท่านั้น
เมื่อแบบสอบถามของผู้ใช้ถูกเรียกใช้ด้วย titles โดยใช้คีย์การเรียงลำดับเค้าโครงข้อมูลหลายมิติที่มี lower(subregion) like '%United States%' เป็นภาคแสดงผลลัพธ์ของ sys_query_detail แบบสอบถามมีดังนี้:
นี่แสดงให้เห็นว่าการสแกนตารางอ่านได้ 152,324,046 แถว ซึ่งเป็นเพียง 7% ของต้นฉบับ และใช้คีย์การเรียงลำดับเค้าโครงข้อมูลหลายมิติ
โปรดทราบว่าตัวอย่างนี้ใช้การสืบค้นเดียวเพื่อแสดงคุณสมบัติเค้าโครงข้อมูลหลายมิติ แต่ Amazon RedShift จะพิจารณาการสืบค้นทั้งหมดที่ทำงานเทียบกับตาราง และสามารถสร้างหลายขอบเขตเพื่อให้เป็นไปตามเพรดิเคตที่มีการรันบ่อยที่สุด
คราวนี้ลองมาดูอีกตัวอย่างหนึ่ง โดยมีภาคแสดงที่ซับซ้อนมากขึ้นและมีหลายคำถาม
ลองนึกภาพว่ามีโต๊ะ items (cost int, available int, demand int) มีสี่แถวดังแสดงในตัวอย่างต่อไปนี้
| #NS | ราคา | ใช้ได้ | ความต้องการ |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
ปริมาณงานหลักของคุณประกอบด้วยสองคำถาม:
- รูปแบบการสืบค้น 70%:
- รูปแบบการสืบค้น 20%:
ด้วยเทคนิคการเรียงลำดับแบบดั้งเดิม คุณอาจเลือกที่จะเรียงลำดับตารางตามคอลัมน์ต้นทุน เช่น การประเมิน cost > 3 จะได้ประโยชน์จากการเรียงลำดับ ดังนั้นตารางรายการหลังจากการเรียงลำดับโดยใช้รายการเดียว cost คอลัมน์จะมีลักษณะดังนี้
| #NS | ราคา | ใช้ได้ | ความต้องการ |
| ภูมิภาค #1 ด้วยราคา <= 3 | |||
| ภูมิภาค #2 โดยมีค่าใช้จ่าย > 3 | |||
| #NS | ราคา | ใช้ได้ | ความต้องการ |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
เมื่อใช้การเรียงลำดับแบบดั้งเดิมนี้ เราสามารถยกเว้นสองแถวบนสุด (สีน้ำเงิน) ที่มี ID 4 และ ID 2 ได้ทันที เนื่องจากไม่ตรงตามข้อกำหนด cost > 3.
ในทางกลับกัน ด้วยคีย์การเรียงลำดับโครงร่างข้อมูลหลายมิติ ตารางจะถูกจัดเรียงตามการรวมกันของสองภาคแสดงที่เกิดขึ้นโดยทั่วไปในปริมาณงานของผู้ใช้ ซึ่งก็คือ cost > 3 และ available < demand. ด้วยเหตุนี้ แถวของตารางจึงถูกจัดเรียงเป็นสี่ภูมิภาค
| #NS | ราคา | ใช้ได้ | ความต้องการ |
| ภูมิภาค #1 โดยมีต้นทุน <= 3 และพร้อมใช้งาน < ความต้องการ | |||
| ภูมิภาค #2 โดยมีต้นทุน <= 3 และพร้อมใช้งาน >= ความต้องการ | |||
| ภูมิภาค #3 โดยมีค่าใช้จ่าย > 3 และพร้อมใช้งาน < ความต้องการ | |||
| ภูมิภาค #4 ที่มีค่าใช้จ่าย > 3 และพร้อมใช้งาน >= ความต้องการ | |||
| #NS | ราคา | ใช้ได้ | ความต้องการ |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
แนวคิดนี้จะมีประสิทธิภาพมากยิ่งขึ้นเมื่อนำไปใช้กับบล็อกทั้งหมดแทนที่จะเป็นแถวเดียว เมื่อนำไปใช้กับเพรดิเคตที่ซับซ้อนซึ่งใช้ตัวดำเนินการที่ไม่เหมาะกับเทคนิคการเรียงลำดับแบบดั้งเดิม (เช่น like) และเมื่อนำไปใช้กับภาคแสดงมากกว่าสองภาค
ตารางระบบ
ตารางระบบ Amazon RedShift ต่อไปนี้จะแสดงให้ผู้ใช้เห็นว่ามีการใช้เค้าโครงข้อมูลหลายมิติในตารางและการสืบค้นหรือไม่:
- หากต้องการตรวจสอบว่าตารางใดใช้คีย์การเรียงลำดับเค้าโครงข้อมูลหลายมิติหรือไม่ คุณสามารถตรวจสอบได้ว่า
sortkey1in svv_table_info เท่ากับAUTO(SORTKEY(padb_internal_mddl_key_col)). - หากต้องการทราบว่าแบบสอบถามใดใช้เค้าโครงข้อมูลหลายมิติเพื่อเร่งการสแกนตารางหรือไม่ คุณสามารถตรวจสอบได้
step_attributeใน sys_query_detail ดู. จะได้ค่าเท่ากับmulti-dimensionalหากมีการใช้คีย์การเรียงลำดับเค้าโครงข้อมูลหลายมิติของตารางในระหว่างการสแกน
มาตรฐานประสิทธิภาพ
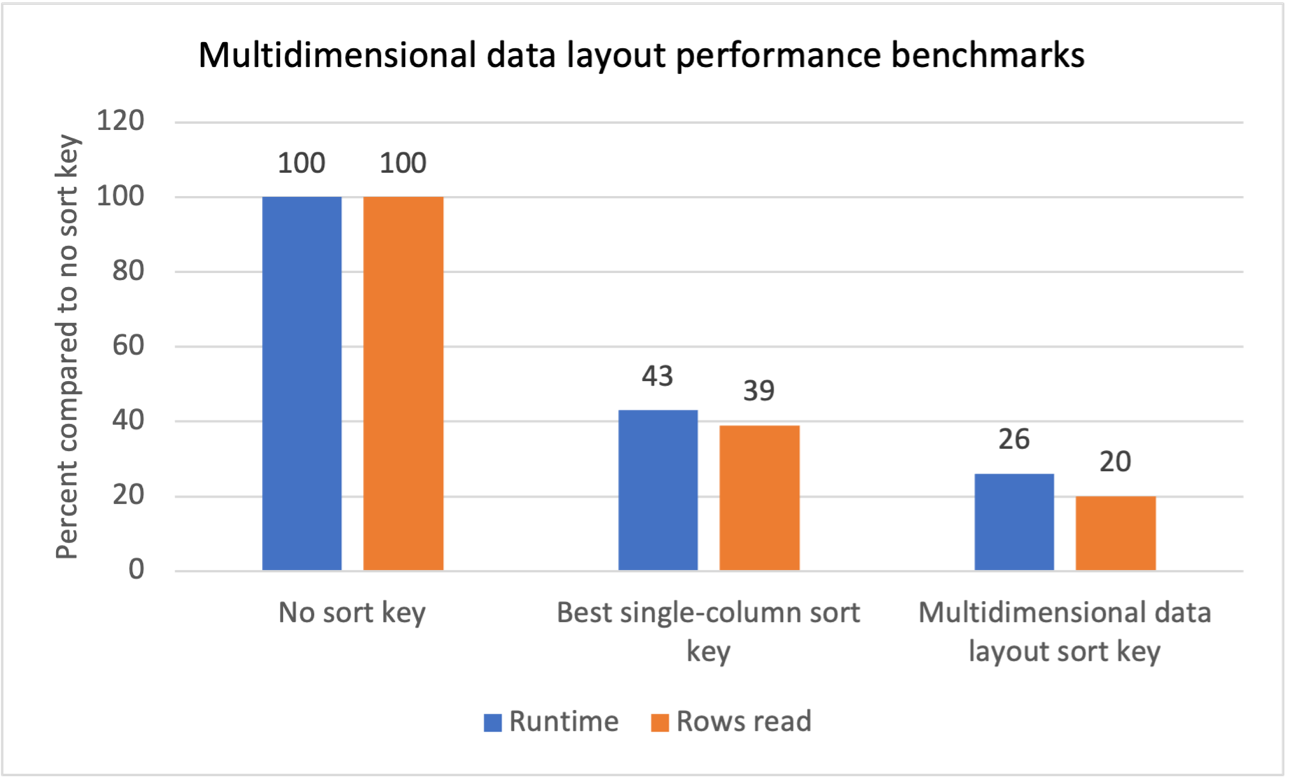
เราทำการทดสอบเกณฑ์มาตรฐานภายในสำหรับปริมาณงานหลายรายการด้วยตัวกรองการสแกนซ้ำๆ และพบว่าการใช้คีย์การจัดเรียงข้อมูลหลายมิติให้ผลลัพธ์ดังต่อไปนี้:
- ลดรันไทม์ทั้งหมด 74% เมื่อเทียบกับการไม่มีคีย์การเรียงลำดับ
- การลดรันไทม์ทั้งหมด 40% เมื่อเทียบกับการมีคีย์การเรียงลำดับคอลัมน์เดียวที่ดีที่สุดในแต่ละตาราง
- ลดจำนวนแถวทั้งหมดที่อ่านจากตารางลง 80% เมื่อเทียบกับการไม่มีคีย์การเรียงลำดับ
- แถวทั้งหมดที่อ่านจากตารางลดลง 47% เมื่อเทียบกับการมีคีย์การเรียงลำดับคอลัมน์เดียวที่ดีที่สุดในแต่ละตาราง
การเปรียบเทียบคุณสมบัติ
ด้วยการเปิดตัวคีย์การจัดเรียงเค้าโครงข้อมูลหลายมิติ ขณะนี้ตารางของคุณสามารถจัดเรียงตามนิพจน์โดยอิงจากเพรดิเคตตัวกรองที่เกิดขึ้นโดยทั่วไปในปริมาณงานของคุณ ตารางต่อไปนี้แสดงการเปรียบเทียบคุณสมบัติสำหรับ Amazon RedShift กับคู่แข่งสองราย
| ลักษณะ | อเมซอน Redshift | คู่แข่ง A | คู่แข่ง B |
| รองรับการเรียงลำดับคอลัมน์ | ใช่ | ใช่ | ใช่ |
| รองรับการจัดเรียงตามนิพจน์ | ใช่ | ใช่ | ไม่ |
| การเลือกคอลัมน์อัตโนมัติสำหรับการเรียงลำดับ | ใช่ | ไม่ | ใช่ |
| การเลือกนิพจน์อัตโนมัติสำหรับการเรียงลำดับ | ใช่ | ไม่ | ไม่ |
| การเลือกอัตโนมัติระหว่างการเรียงลำดับคอลัมน์หรือการเรียงลำดับนิพจน์ | ใช่ | ไม่ | ไม่ |
| การใช้คุณสมบัติการเรียงลำดับอัตโนมัติสำหรับนิพจน์ระหว่างการสแกน | ใช่ | ไม่ | ไม่ |
สิ่งที่ควรพิจารณา
โปรดคำนึงถึงสิ่งต่อไปนี้เมื่อใช้เค้าโครงข้อมูลหลายมิติ:
- เค้าโครงข้อมูลหลายมิติจะเปิดใช้งานเมื่อคุณตั้งค่าตารางเป็น SORTKEY AUTO
- Amazon Redshift Advisor จะเลือกคีย์การจัดเรียงคอลัมน์เดียวหรือเค้าโครงข้อมูลหลายมิติสำหรับตารางโดยอัตโนมัติโดยการวิเคราะห์ปริมาณงานในอดีตของคุณ
- Amazon Redshift ATO ปรับผลลัพธ์การจัดเรียงเค้าโครงข้อมูลหลายมิติตามลักษณะที่การสืบค้นอย่างต่อเนื่องโต้ตอบกับปริมาณงาน
- Amazon Redshift ATO จะรักษาคีย์การจัดเรียงเค้าโครงข้อมูลหลายมิติในลักษณะเดียวกับที่ทำกับคีย์การจัดเรียงที่มีอยู่ในปัจจุบัน อ้างถึง การทำงานกับการเพิ่มประสิทธิภาพตารางอัตโนมัติ สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับ ATO
- คีย์การจัดเรียงเค้าโครงข้อมูลหลายมิติจะทำงานร่วมกับทั้งคลัสเตอร์ที่จัดเตรียมไว้และกลุ่มงานแบบไร้เซิร์ฟเวอร์
- ปุ่มจัดเรียงเค้าโครงข้อมูลหลายมิติจะทำงานกับข้อมูลที่มีอยู่ของคุณตราบใดที่เปิดใช้งาน SORTKEY อัตโนมัติบนโต๊ะของคุณและตรวจพบภาระงานที่มีตัวกรองการสแกนซ้ำ ๆ ตารางจะถูกจัดระเบียบใหม่ตามผลลัพธ์ของฟังก์ชันการเรียงลำดับหลายมิติ
- หากต้องการปิดใช้งานคีย์การเรียงลำดับเค้าโครงข้อมูลหลายมิติสำหรับตาราง ให้ใช้ตารางแก้ไข:
ALTER TABLE table_name ALTER SORTKEY NONE. สิ่งนี้จะปิดการใช้งานคุณสมบัติคีย์การเรียงลำดับอัตโนมัติบนโต๊ะ - คีย์การจัดเรียงเค้าโครงข้อมูลหลายมิติจะถูกรักษาไว้เมื่อกู้คืนหรือย้ายคลัสเตอร์ที่จัดเตรียมไว้ไปยังคลัสเตอร์แบบไร้เซิร์ฟเวอร์หรือในทางกลับกัน
สรุป
ในโพสต์นี้ เราแสดงให้เห็นว่าคีย์การจัดเรียงเค้าโครงข้อมูลหลายมิติสามารถปรับปรุงประสิทธิภาพรันไทม์การสืบค้นสำหรับปริมาณงานได้อย่างมาก โดยที่การสืบค้นหลักมีตัวกรองการสแกนซ้ำ ๆ
หากต้องการสร้างคลัสเตอร์แสดงตัวอย่างจากคอนโซล Amazon RedShift ให้ไปที่ เครือข่ายวิสาหกิจ หน้าและเลือก สร้างตัวอย่างคลัสเตอร์. คุณสามารถสร้างคลัสเตอร์ในภูมิภาคสหรัฐอเมริกาฝั่งตะวันออก (โอไฮโอ) สหรัฐอเมริกาฝั่งตะวันออก (เวอร์จิเนียเหนือ) สหรัฐอเมริกาฝั่งตะวันตก (ออริกอน) เอเชียแปซิฟิก (โตเกียว) ยุโรป (ไอร์แลนด์) และยุโรป (สตอกโฮล์ม) และทดสอบปริมาณงานของคุณ
เรายินดีรับฟังความคิดเห็นของคุณเกี่ยวกับคุณลักษณะใหม่นี้ และหวังว่าจะได้รับความคิดเห็นของคุณในโพสต์นี้
เกี่ยวกับผู้แต่ง
 มิลิน โอเค เป็น Data Warehouse Specialist Solutions Architect ซึ่งตั้งอยู่ในนิวยอร์ก เขาได้สร้างโซลูชันคลังข้อมูลมานานกว่า 15 ปีและเชี่ยวชาญใน Amazon Redshift
มิลิน โอเค เป็น Data Warehouse Specialist Solutions Architect ซึ่งตั้งอยู่ในนิวยอร์ก เขาได้สร้างโซลูชันคลังข้อมูลมานานกว่า 15 ปีและเชี่ยวชาญใน Amazon Redshift
 เจียหลินติง เป็นนักวิทยาศาสตร์ประยุกต์ในกลุ่ม Learned Systems ซึ่งเชี่ยวชาญในการประยุกต์ใช้การเรียนรู้ของเครื่องและเทคนิคการปรับให้เหมาะสมเพื่อปรับปรุงประสิทธิภาพของระบบข้อมูล เช่น Amazon RedShift
เจียหลินติง เป็นนักวิทยาศาสตร์ประยุกต์ในกลุ่ม Learned Systems ซึ่งเชี่ยวชาญในการประยุกต์ใช้การเรียนรู้ของเครื่องและเทคนิคการปรับให้เหมาะสมเพื่อปรับปรุงประสิทธิภาพของระบบข้อมูล เช่น Amazon RedShift
 เหยียนจู จิ เป็นผู้จัดการผลิตภัณฑ์ในทีม Amazon Redshift เธอมีประสบการณ์ด้านการมองเห็นผลิตภัณฑ์และกลยุทธ์ในผลิตภัณฑ์ข้อมูลและแพลตฟอร์มชั้นนำของอุตสาหกรรม เธอมีทักษะที่โดดเด่นในการสร้างผลิตภัณฑ์ซอฟต์แวร์จำนวนมากโดยใช้การพัฒนาเว็บไซต์ การออกแบบระบบ ฐานข้อมูล และเทคนิคการเขียนโปรแกรมแบบกระจาย ในชีวิตส่วนตัวของเธอ Yanzhu ชอบวาดภาพ ถ่ายภาพ และเล่นเทนนิส
เหยียนจู จิ เป็นผู้จัดการผลิตภัณฑ์ในทีม Amazon Redshift เธอมีประสบการณ์ด้านการมองเห็นผลิตภัณฑ์และกลยุทธ์ในผลิตภัณฑ์ข้อมูลและแพลตฟอร์มชั้นนำของอุตสาหกรรม เธอมีทักษะที่โดดเด่นในการสร้างผลิตภัณฑ์ซอฟต์แวร์จำนวนมากโดยใช้การพัฒนาเว็บไซต์ การออกแบบระบบ ฐานข้อมูล และเทคนิคการเขียนโปรแกรมแบบกระจาย ในชีวิตส่วนตัวของเธอ Yanzhu ชอบวาดภาพ ถ่ายภาพ และเล่นเทนนิส
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- 1
- 100
- 15%
- 152
- 7
- 8
- 9
- a
- เร่งความเร็ว
- Accessed
- เพิ่มเติม
- กุนซือ
- หลังจาก
- กับ
- ขั้นตอนวิธี
- ทั้งหมด
- แล้ว
- อเมซอน
- Amazon Web Services
- an
- วิเคราะห์
- วิเคราะห์
- และ
- อื่น
- ประยุกต์
- การประยุกต์ใช้
- เป็น
- AS
- เอเชีย
- ในภูมิภาคเอเชียแปซิฟิก
- รถยนต์
- อัตโนมัติ
- อัตโนมัติ
- ใช้ได้
- AWS
- ตาม
- BE
- เพราะ
- รับ
- มาตรฐาน
- ประโยชน์
- ที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- ปิดกั้น
- Blocks
- สีน้ำเงิน
- ทั้งสอง
- การก่อสร้าง
- แต่
- by
- CAN
- ความสามารถ
- ตรวจสอบ
- Choose
- เมฆ
- Cluster
- คอลัมน์
- คอลัมน์
- การผสมผสาน
- ความคิดเห็น
- อย่างธรรมดา
- เมื่อเทียบกับ
- การเปรียบเทียบ
- คู่แข่ง
- ซับซ้อน
- แนวคิด
- พิจารณา
- ประกอบ
- ปลอบใจ
- สร้าง
- มี
- ราคา
- ครอบคลุม
- สร้าง
- ขณะนี้
- ข้อมูล
- คลังข้อมูล
- ฐานข้อมูล
- ตัดสินใจ
- ทุ่มเท
- กำหนด
- ความต้องการ
- เรียกร้อง
- ออกแบบ
- รายละเอียด
- ตรวจพบ
- กำหนด
- พัฒนาการ
- กระจาย
- การกระจาย
- ทำ
- เด่น
- Dont
- ในระหว่าง
- แต่ละ
- ตะวันออก
- ทั้ง
- เปิดการใช้งาน
- ทั้งหมด
- เท่ากัน
- โดยเฉพาะอย่างยิ่ง
- อีเธอร์ (ETH)
- ยุโรป
- การประเมินผล
- แม้
- วิวัฒน์
- ตัวอย่าง
- ที่มีอยู่
- ประสบการณ์
- การแสดงออก
- ลักษณะ
- ข้อเสนอแนะ
- กรอง
- ฟิลเตอร์
- ดังต่อไปนี้
- ดังต่อไปนี้
- สำหรับ
- ข้างหน้า
- สี่
- ราคาเริ่มต้นที่
- ฟังก์ชัน
- บัญชีกลุ่ม
- มือ
- มี
- มี
- he
- ได้ยิน
- เธอ
- ทางประวัติศาสตร์
- ประวัติ
- อย่างไรก็ตาม
- HTML
- HTTPS
- ID
- if
- ทันที
- ปรับปรุง
- ช่วยเพิ่ม
- in
- รวมถึง
- เป็นรายบุคคล
- ชั้นนำของอุตสาหกรรม
- แทน
- โต้ตอบ
- ภายใน
- การแทรกแซง
- เข้าไป
- แนะนำ
- แนะนำ
- บทนำ
- ไอร์แลนด์
- IT
- รายการ
- คีย์
- กุญแจ
- ใหญ่
- แบบ
- ได้เรียนรู้
- การเรียนรู้
- ชีวิต
- กดไลก์
- ยอดไลก์
- นาน
- ดู
- ดูเหมือน
- ความรัก
- เครื่อง
- เรียนรู้เครื่อง
- รักษา
- ผู้จัดการ
- ลักษณะ
- สูงสุด
- พบ
- เมตาดาต้า
- อาจ
- การโยกย้าย
- ใจ
- ขั้นต่ำ
- ข้อมูลเพิ่มเติม
- มากที่สุด
- หลาย
- นำทาง
- จำเป็นต้อง
- ใหม่
- คุณลักษณะใหม่
- นิวยอร์ก
- ไม่
- ตอนนี้
- ตัวเลข
- ที่เกิดขึ้น
- of
- ปิด
- เสนอ
- โอไฮโอ
- on
- ONE
- ต่อเนื่อง
- เพียง
- ผู้ประกอบการ
- การเพิ่มประสิทธิภาพ
- เพิ่มประสิทธิภาพ
- ตัวเลือกเสริม (Option)
- or
- ใบสั่ง
- ออริกอน
- เป็นต้นฉบับ
- อื่นๆ
- ออก
- โดดเด่น
- เกิน
- แปซิฟิก
- ภาพวาด
- ส่วนหนึ่ง
- ในสิ่งที่สนใจ
- แบบแผน
- การปฏิบัติ
- ดำเนินการ
- ส่วนบุคคล
- การถ่ายภาพ
- กายภาพ
- แพลตฟอร์ม
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- เล่น
- โพสต์
- ที่มีประสิทธิภาพ
- ดอง
- ดูตัวอย่าง
- ผลิต
- ผลิตภัณฑ์
- ผู้จัดการผลิตภัณฑ์
- ผลิตภัณฑ์
- การเขียนโปรแกรม
- คุณสมบัติ
- ให้
- คำสั่ง
- อย่างรวดเร็ว
- อ่าน
- การลดลง
- อ้างอิง
- ภูมิภาค
- ภูมิภาค
- ซ้ำ
- ความต้องการ
- การฟื้นฟู
- ผล
- ผลสอบ
- วิ่ง
- วิ่ง
- ทำงาน
- เดียวกัน
- การสแกน
- การสแกน
- สแกน
- นักวิทยาศาสตร์
- ฤดู
- เห็น
- เลือก
- เลือก
- การเลือก
- serverless
- บริการ
- ชุด
- เธอ
- โชว์
- แสดง
- แสดงให้เห็นว่า
- แสดง
- แสดงให้เห็นว่า
- อย่างมีความหมาย
- เดียว
- ความสามารถ
- So
- ซอฟต์แวร์
- โซลูชัน
- ผู้เชี่ยวชาญ
- ความเชี่ยวชาญ
- ความเชี่ยวชาญ
- ร้านค้า
- กลยุทธ์
- ต่อจากนั้น
- เป็นกอบเป็นกำ
- อย่างเช่น
- เหมาะสม
- ที่สนับสนุน
- ระบบ
- ระบบ
- ตาราง
- เอา
- ทีม
- เทคนิค
- เทนนิส
- ทดสอบ
- การทดสอบ
- กว่า
- ที่
- พื้นที่
- ของพวกเขา
- ดังนั้น
- พวกเขา
- นี้
- เวลา
- ชื่อ
- ไปยัง
- โตเกียว
- ด้านบน
- รวม
- แบบดั้งเดิม
- สอง
- ชนิด
- เป็นปกติ
- us
- ใช้
- มือสอง
- ผู้ใช้งาน
- ผู้ใช้
- ใช้
- การใช้
- ความคุ้มค่า
- ความคุ้มค่า
- รอง
- รายละเอียด
- virginia
- วิสัยทัศน์
- คลังสินค้า
- คือ
- ทาง..
- we
- เว็บ
- การพัฒนาเว็บ
- บริการเว็บ
- ตะวันตก
- เมื่อ
- ว่า
- ที่
- อย่างกว้างขวาง
- จะ
- กับ
- ไม่มี
- งาน
- จะ
- ปี
- นิวยอร์ก
- เธอ
- ของคุณ
- ลมทะเล