บทนำ
การควบรวมกิจการของ ปัญญาประดิษฐ์ (AI) และศิลปะเผยให้เห็นช่องทางใหม่ในงานศิลปะดิจิทัลเชิงสร้างสรรค์ โดยโดดเด่นผ่านโมเดลการแพร่กระจาย โมเดลเหล่านี้โดดเด่นในการสร้างงานศิลปะ AI ที่สร้างสรรค์ โดยนำเสนอแนวทางที่แตกต่างจากโครงข่ายประสาทเทียมทั่วไป บทความนี้จะพาคุณเดินทางสำรวจไปสู่ส่วนลึกของแบบจำลองการแพร่กระจาย โดยอธิบายกลไกที่เป็นเอกลักษณ์ของแบบจำลองเหล่านี้ในการสร้างสรรค์ผลงานศิลปะที่มีรูปลักษณ์สวยงามและสร้างสรรค์ ทำความเข้าใจความแตกต่างของโมเดลการแพร่กระจายและรับข้อมูลเชิงลึกเกี่ยวกับบทบาทของพวกเขาในการกำหนดนิยามใหม่ของการแสดงออกทางศิลปะผ่านเลนส์ของเทคโนโลยี AI ขั้นสูง

วัตถุประสงค์การเรียนรู้
- ทำความเข้าใจแนวคิดพื้นฐานของแบบจำลองการแพร่กระจายใน AI
- สำรวจความแตกต่างระหว่างโมเดลการแพร่กระจายและโครงข่ายประสาทเทียมแบบดั้งเดิมในการสร้างงานศิลปะ
- วิเคราะห์กระบวนการสร้างสรรค์งานศิลปะโดยใช้แบบจำลองการแพร่กระจาย
- ประเมินความหมายเชิงสร้างสรรค์และสุนทรียะของ AI ในงานศิลปะดิจิทัล
- อภิปรายข้อพิจารณาด้านจริยธรรมในงานศิลปะที่สร้างโดย AI
บทความนี้เผยแพร่โดยเป็นส่วนหนึ่งของไฟล์ Blogathon วิทยาศาสตร์ข้อมูล
สารบัญ
ทำความเข้าใจกับแบบจำลองการแพร่กระจาย

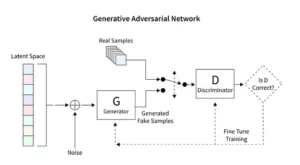
โมเดลการแพร่กระจายปฏิวัติ generative AI โดยนำเสนอวิธีการสร้างภาพที่ไม่เหมือนใคร แตกต่างจากเทคนิคทั่วไป เช่น Generative Adversarial Networks (GANs) เริ่มต้นด้วยสัญญาณรบกวนแบบสุ่ม โมเดลเหล่านี้จะค่อยๆ ปรับแต่ง คล้ายกับศิลปินที่ปรับแต่งภาพวาดอย่างละเอียด ส่งผลให้ได้ภาพที่สลับซับซ้อนและสอดคล้องกัน
กระบวนการปรับแต่งแบบค่อยเป็นค่อยไปนี้สะท้อนให้เห็นถึงธรรมชาติของการแพร่กระจายที่มีระเบียบวิธี การวนซ้ำแต่ละครั้งในที่นี้จะเปลี่ยนเสียงรบกวนอย่างละเอียด ทำให้ใกล้เคียงกับวิสัยทัศน์ทางศิลปะขั้นสุดท้ายมากขึ้น ผลงานที่ออกมาไม่ได้เป็นเพียงผลผลิตของการสุ่มเท่านั้น แต่ยังเป็นผลงานศิลปะที่ได้รับการพัฒนาขึ้น มีความแตกต่างในด้านความก้าวหน้าและความสมบูรณ์ของมัน
การเขียนโค้ดสำหรับโมเดลการแพร่กระจายจำเป็นต้องมีความเข้าใจอย่างลึกซึ้งเกี่ยวกับโครงข่ายประสาทเทียมและเฟรมเวิร์กการเรียนรู้ของเครื่อง เช่น TensorFlow หรือ PyTorch โค้ดผลลัพธ์มีความซับซ้อน โดยต้องมีการฝึกอบรมอย่างกว้างขวางเกี่ยวกับชุดข้อมูลที่กว้างขวางเพื่อให้ได้เอฟเฟกต์ที่เหมาะสมยิ่งที่พบในงานศิลปะที่สร้างโดย AI
การประยุกต์การแพร่กระจายที่เสถียรในงานศิลปะ
การกำเนิดของเครื่องกำเนิดงานศิลปะ AI เช่น โมเดลการแพร่กระจายที่เสถียร จำเป็นต้องมีการเขียนโค้ดที่ซับซ้อนภายในแพลตฟอร์ม เช่น TensorFlow หรือ PyTorch โมเดลเหล่านี้โดดเด่นด้วยความสามารถในการแปลงความสุ่มให้เป็นโครงสร้างอย่างมีระบบ เหมือนกับศิลปินที่ขัดเกลาภาพร่างเบื้องต้นให้เป็นผลงานชิ้นเอกที่สดใส
โมเดลการแพร่กระจายที่เสถียรเปลี่ยนโฉมฉากศิลปะ AI โดยการสร้างภาพที่เป็นระเบียบจากการสุ่ม โดยละทิ้งลักษณะเฉพาะด้านการแข่งขันของ GAN พวกเขาเป็นเลิศในการตีความแนวคิดที่เกิดขึ้นในทัศนศิลป์ ส่งเสริมการเต้นที่ประสานกันระหว่างความสามารถของ AI และความเฉลียวฉลาดของมนุษย์ ด้วยการควบคุม PyTorch เราจะสังเกตว่าโมเดลเหล่านี้ปรับแต่งความสับสนวุ่นวายให้กลายเป็นความชัดเจนได้อย่างไร โดยสะท้อนการเดินทางของศิลปินตั้งแต่แนวคิดใหม่ไปจนถึงการสร้างสรรค์ที่ขัดเกลา
การทดลองกับงานศิลปะที่สร้างโดย AI
การสาธิตนี้จะเจาะลึกโลกอันน่าทึ่งของงานศิลปะที่สร้างโดย AI โดยใช้โครงข่ายประสาทเทียมที่เรียกว่า Convการแพร่กระจายแบบจำลอง. โมเดลนี้ได้รับการฝึกฝนเกี่ยวกับภาพศิลปะที่หลากหลาย ครอบคลุมภาพวาด ภาพวาด ประติมากรรม และการแกะสลัก ซึ่งมีที่มาจาก ชุดข้อมูล Kaggle นี้. เป้าหมายของเราคือการสำรวจความสามารถของโมเดลในการจับภาพและทำซ้ำความสวยงามที่ซับซ้อนของงานศิลปะเหล่านี้
สถาปัตยกรรมแบบจำลองและการฝึกอบรม
การออกแบบสถาปัตยกรรม
ConvDiffusionModel เป็นแกนหลักคือความมหัศจรรย์ของวิศวกรรมประสาท โดยมีสถาปัตยกรรมตัวเข้ารหัส-ตัวถอดรหัสที่ซับซ้อนซึ่งปรับให้เหมาะกับความต้องการของการสร้างงานศิลปะ โครงสร้างของแบบจำลองนั้นเป็นโครงข่ายประสาทเทียมที่ซับซ้อน ซึ่งรวมเอากลไกตัวเข้ารหัส-ตัวถอดรหัสที่ได้รับการปรับปรุงซึ่งได้รับการฝึกฝนมาโดยเฉพาะสำหรับการสร้างงานศิลปะ ด้วยเลเยอร์การบิดเพิ่มเติมและการข้ามการเชื่อมต่อที่เลียนแบบสัญชาตญาณทางศิลปะ โมเดลสามารถแยกและประกอบงานศิลปะอีกครั้งด้วยความเข้าใจอันชาญฉลาดในองค์ประกอบและสไตล์
- Encoder: ตัวเข้ารหัสคือดวงตาแห่งการวิเคราะห์ของโมเดล โดยพิจารณารายละเอียดเล็กๆ น้อยๆ ของภาพที่ป้อนทุกภาพ เมื่อรูปภาพผ่านเลเยอร์ที่ซับซ้อนของตัวเข้ารหัส รูปภาพเหล่านั้นก็จะถูกบีบอัดลงในพื้นที่แฝงอย่างต่อเนื่อง ซึ่งเป็นการแสดงอาร์ตเวิร์คต้นฉบับที่มีการเข้ารหัสขนาดกะทัดรัด ตัวเข้ารหัสของเราไม่เพียงแต่ตรวจสอบภาพที่อินพุตอย่างละเอียดเท่านั้น แต่ขณะนี้ทำได้ด้วยการรับรู้เชิงลึกที่เพิ่มมากขึ้น โดยได้รับความอนุเคราะห์จากเลเยอร์เพิ่มเติมและเทคนิคการทำให้เป็นมาตรฐานแบบกลุ่ม การตรวจสอบแบบขยายนี้ช่วยให้สามารถนำเสนอเนื้อหาที่เข้มข้นและเข้มข้นยิ่งขึ้นภายในพื้นที่แฝง สะท้อนการไตร่ตรองอย่างลึกซึ้งของศิลปินในเรื่องใดเรื่องหนึ่ง
- ถอดรหัส: ในทางตรงกันข้าม ตัวถอดรหัสทำหน้าที่เป็นมือสร้างสรรค์ของโมเดล โดยนำภาพร่างนามธรรมจากตัวเข้ารหัสและเติมชีวิตชีวาให้กับโมเดล โดยสร้างงานศิลปะขึ้นมาใหม่จากพื้นที่ที่ซ่อนอยู่ ทีละชั้น รายละเอียดทีละรายละเอียด จนกระทั่งได้ภาพที่สมบูรณ์ออกมา ตัวถอดรหัสของเราได้รับประโยชน์จากการเชื่อมต่อแบบข้ามและสามารถสร้างอาร์ตเวิร์คขึ้นมาใหม่ได้อย่างแม่นยำยิ่งขึ้น โดยจะทบทวนสาระสำคัญที่เป็นนามธรรมของข้อมูลนำเข้าและตกแต่งอย่างต่อเนื่อง เพื่อให้ได้การตีความที่ตรงกับเนื้อหาต้นฉบับมากขึ้น เลเยอร์ที่ได้รับการปรับปรุงทำงานร่วมกันเพื่อให้แน่ใจว่าภาพสุดท้ายเป็นชิ้นงานที่สดใสและซับซ้อนซึ่งสะท้อนถึงศิลปะของอินพุต
กระบวนการฝึกอบรม
การฝึกอบรม ConvDiffusionModel คือการเดินทางผ่านภูมิทัศน์ทางศิลปะที่ครอบคลุม 150 ยุค แต่ละยุคแสดงถึงการส่งผ่านชุดข้อมูลทั้งหมดโดยสมบูรณ์ โดยแบบจำลองมุ่งมั่นที่จะปรับแต่งความเข้าใจและปรับปรุงความถูกต้องของรูปภาพที่สร้างขึ้น
- ฟังก์ชั่นการสูญเสียแบบไฮบริด: หัวใจสำคัญของการฝึกอบรมคือฟังก์ชันการสูญเสียค่าความคลาดเคลื่อนกำลังสองเฉลี่ย (MSE) ฟังก์ชันนี้จะวัดปริมาณความแตกต่างระหว่างผลงานชิ้นเอกดั้งเดิมกับการสร้างโมเดลขึ้นมาใหม่ โดยให้ตัวชี้วัดที่ชัดเจนในการลดให้เหลือน้อยที่สุด เราจะแนะนำองค์ประกอบการสูญเสียการรับรู้ที่ได้มาจากเครือข่าย VGG ที่ได้รับการฝึกอบรมล่วงหน้า ซึ่งจะช่วยเสริมเมตริก Mean Squared Error (MSE) กลยุทธ์การสูญเสียแบบคู่นี้ขับเคลื่อนแบบจำลองให้ยกย่องความสมบูรณ์ทางศิลปะของต้นฉบับ ในขณะเดียวกันก็สร้างรายละเอียดทางเทคนิคที่สมบูรณ์แบบ
- เครื่องมือเพิ่มประสิทธิภาพ: ด้วยอัตราการเรียนรู้ที่ปรับแบบไดนามิกโดยตัวกำหนดเวลา เครื่องมือเพิ่มประสิทธิภาพ Adam จะนำทางการเรียนรู้ของโมเดลด้วยความรอบรู้ที่เพิ่มขึ้น แนวทางการปรับตัวนี้ช่วยให้แน่ใจว่าความก้าวหน้าของแบบจำลองในการเรียนรู้ที่จะทำซ้ำและสร้างสรรค์งานศิลปะนั้นมีทั้งความมั่นคงและแข็งแกร่ง
- การทำซ้ำและการปรับแต่ง: การฝึกซ้ำเป็นการเต้นรำระหว่างการรักษาสาระสำคัญทางศิลปะและการจำลองทางเทคนิค ในทุกรอบ โมเดลจะเข้าใกล้การสังเคราะห์ความเที่ยงตรงและความคิดสร้างสรรค์มากขึ้น
- การแสดงภาพความคืบหน้า: รูปภาพจะถูกบันทึกตามช่วงเวลาปกติระหว่างการฝึกเพื่อให้เห็นภาพความคืบหน้าของโมเดล. สแน็ปช็อตเหล่านี้ช่วยให้มองเห็นช่วงการเรียนรู้ของโมเดล โดยแสดงให้เห็นว่างานศิลปะที่สร้างขึ้นมีวิวัฒนาการ มีความชัดเจนมากขึ้น มีรายละเอียดมากขึ้น และมีความสอดคล้องทางศิลปะมากขึ้นในแต่ละยุคสมัยอย่างไร



ข้างต้นแสดงผ่านโค้ดต่อไปนี้:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision.models import vgg16
from PIL import Image
# Defining a function to check for valid images
def is_valid_image(image_path):
try:
with Image.open(image_path) as img:
img.verify()
return True
except (IOError, SyntaxError) as e:
# Printing out the names of all corrupt files
print(f'Bad file:', image_path)
return False
# Defining the neural network
class ConvDiffusionModel(nn.Module):
def __init__(self):
super(ConvDiffusionModel, self).__init__()
# Encoder
self.enc1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc2 = nn.Sequential(nn.Conv2d(64, 128,
kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3,
padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2,
stride=2))
# Decoder
self.dec1 = nn.Sequential(nn.ConvTranspose2d(256, 128,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(128))
self.dec2 = nn.Sequential(nn.ConvTranspose2d(128, 64,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(64))
self.dec3 = nn.Sequential(nn.ConvTranspose2d(64, 3,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid())
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
# Decoder with skip connections
dec1 = self.dec1(enc3) + enc2
dec2 = self.dec2(dec1) + enc1
dec3 = self.dec3(dec2)
return dec3
# Using a pre-trained VGG16 model to compute perceptual loss
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
self.vgg = vgg16(pretrained=True).features[:16].cuda()
.eval() # Only the first 16 layers
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, input, target):
input_vgg = self.vgg(input)
target_vgg = self.vgg(target)
loss = torch.nn.functional.mse_loss(input_vgg,
target_vgg)
return loss
# Checking if CUDA is available and set device to GPU if it is.
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# Initializing the model and perceptual loss
model = ConvDiffusionModel().to(device)
vgg_loss = VGGLoss().to(device)
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30,
gamma=0.1)
# Dataset and DataLoader setup
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(root='/content/Images',
transform=transform, is_valid_file=is_valid_image)
dataloader = DataLoader(dataset, batch_size=32,
shuffle=True)
# Training loop
num_epochs = 150
for epoch in range(num_epochs):
for i, (inputs, _) in enumerate(dataloader):
inputs = inputs.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Calculate losses
mse = mse_loss(outputs, inputs)
perceptual = vgg_loss(outputs, inputs)
loss = mse + perceptual
# Backward pass and optimize
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}],
Step [{i+1}/{len(dataloader)}], Loss: {loss.item()},
Perceptual Loss: {perceptual.item()}, MSE Loss:
{mse.item()}')
# Saving the generated image for visualization
save_image(outputs, f'output_epoch_{epoch+1}
_step_{i+1}.png')
# Updating the learning rate
scheduler.step()
# Saving model checkpoints
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(),
f'/content/model_epoch_{epoch+1}.pth')
print('Training Complete')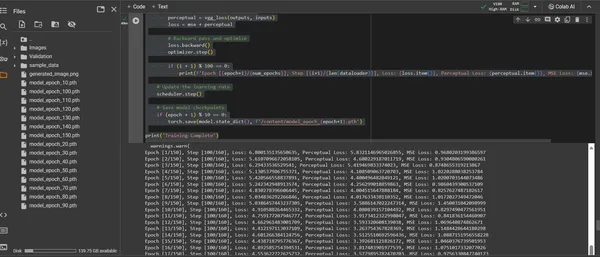
การแสดงภาพงานศิลปะที่สร้างขึ้น
แสดงให้เห็นถึงศิลปะที่สร้างขึ้นโดย AI
เมื่อ ConvDiffusionModel ได้รับการฝึกฝนอย่างเต็มที่แล้ว จุดสนใจจะเปลี่ยนจากนามธรรมไปเป็นรูปธรรม จากศักยภาพไปสู่การนำงานศิลปะที่ประดิษฐ์ด้วย AI มาใช้จริง ข้อมูลโค้ดที่ตามมาจะทำให้ความสามารถทางศิลปะที่เรียนรู้ของโมเดลเป็นรูปธรรม โดยเปลี่ยนข้อมูลอินพุตให้เป็นผืนผ้าใบแห่งการแสดงออกทางดิจิทัล
import os
import matplotlib.pyplot as plt
# Loading the trained model
model = ConvDiffusionModel().to(device)
model.load_state_dict(torch.load('/content/model_epoch_150.pth'))
model.eval() # Set the model to evaluation mode
# Transforming for the input image
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Function to de-normalize the image for viewing
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).
to(device).view(-1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).
to(device).view(-1, 1, 1)
tensor = tensor * std + mean # De-normalize
tensor = tensor.clamp(0, 1) # Clamp to the valid image range
return tensor
# Loading and transforming the image
input_image_path = '/content/Validation/0006.jpg'
input_image = Image.open(input_image_path).convert('RGB')
input_tensor = transform(input_image).unsqueeze(0).to(device)
# Adding a batch dimension
# Generating the image
with torch.no_grad():
generated_tensor = model(input_tensor)
# Converting the generated image tensor to an image
generated_image = denormalize(generated_tensor.squeeze(0))
# Removing the batch dimension and de-normalizing
generated_image = generated_image.cpu() # Move to CPU
# Saving the generated image
save_image(generated_image, '/content/generated_image.png')
print("Generated image saved to '/content/generated_image.png'")
# Displaying the generated image using matplotlib
plt.figure(figsize=(8, 8))
plt.imshow(generated_image.permute(1, 2, 0))
# Rearrange the channels for plotting
plt.axis('off') # Hide the axes
plt.show()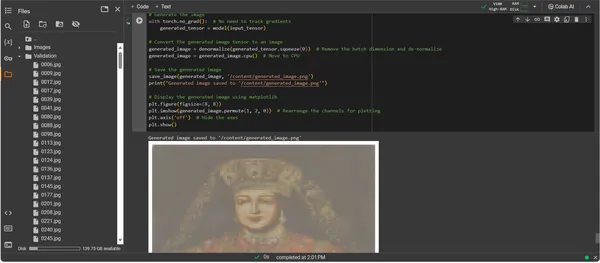

คำแนะนำการสร้างรหัสงานศิลปะ
- การฟื้นคืนชีพของแบบจำลอง: ขั้นตอนแรกในการสร้างอาร์ตเวิร์คคือการฟื้นฟู ConvDiffusionModel ที่ผ่านการฝึกอบรมของเรา น้ำหนักที่เรียนรู้ของแบบจำลองจะถูกโหลดและนำเข้าสู่โหมดการประเมิน ซึ่งเป็นการกำหนดขั้นตอนสำหรับการสร้างโดยไม่ต้องเปลี่ยนแปลงพารามิเตอร์เพิ่มเติม
- การแปลงภาพ: เพื่อให้มั่นใจว่าสอดคล้องกับระบบการฝึกอบรม รูปภาพอินพุตจะถูกประมวลผลผ่านลำดับการแปลงแบบเดียวกัน ซึ่งรวมถึงการปรับขนาดเพื่อให้ตรงกับขนาดอินพุตของโมเดล การแปลงเทนเซอร์สำหรับความเข้ากันได้ของ PyTorch และการทำให้เป็นมาตรฐานตามโปรไฟล์ทางสถิติของข้อมูลการฝึก
- ยูทิลิตี้การทำให้เป็นมาตรฐาน: ฟังก์ชันแบบกำหนดเองจะกลับเอฟเฟกต์ที่ประมวลผลล่วงหน้า โดยปรับขนาดเทนเซอร์ใหม่ให้เป็นช่วงสีของภาพต้นฉบับ ขั้นตอนนี้จำเป็นสำหรับการเรนเดอร์เอาต์พุตที่สร้างขึ้นให้เป็นการแสดงภาพที่แม่นยำ
- การเตรียมอินพุต: รูปภาพถูกโหลดและอยู่ภายใต้การเปลี่ยนแปลงดังกล่าวข้างต้น สิ่งสำคัญที่ควรทราบคือรูปภาพนี้ทำหน้าที่เป็นแรงบันดาลใจให้ AI ดึงแรงบันดาลใจ เสียงกระซิบอันเงียบงันจุดประกายจินตนาการสังเคราะห์ของโมเดล
- การสังเคราะห์งานศิลปะ: ในการเต้นที่ละเอียดอ่อนของการแพร่กระจายไปข้างหน้า โมเดลจะตีความเทนเซอร์อินพุต ซึ่งช่วยให้เลเยอร์สามารถทำงานร่วมกันเพื่อสร้างวิสัยทัศน์ทางศิลปะใหม่ ดำเนินการตามขั้นตอนนี้โดยไม่ต้องติดตามการไล่ระดับสี เนื่องจากตอนนี้เราอยู่ในขอบเขตของการใช้งาน ไม่ใช่การฝึกอบรม
- การแปลงรูปภาพ: เทนเซอร์เอาท์พุตของโมเดลซึ่งขณะนี้เก็บงานศิลปะที่เกิดในรูปแบบดิจิทัลนั้นถูกทำให้เป็นมาตรฐาน โดยแปลการสร้างสรรค์ของโมเดลกลับไปสู่พื้นที่แห่งสีและแสงที่คุ้นเคยซึ่งดวงตาของเราสามารถชื่นชมได้
- วิวรณ์งานศิลปะ: เทนเซอร์ที่แปลงแล้วจะถูกจัดวางบนผืนผ้าใบดิจิทัล และปิดท้ายด้วยไฟล์ภาพที่บันทึกไว้ ไฟล์นี้เป็นหน้าต่างสู่จิตวิญญาณแห่งการสร้างสรรค์ของ AI ซึ่งเป็นเสียงสะท้อนคงที่ของกระบวนการไดนามิกที่ทำให้ AI มีชีวิตชีวา
- การเรียกค้นงานศิลปะ: สคริปต์จะสรุปโดยการบันทึกรูปภาพที่สร้างขึ้นไปยังเส้นทางที่กำหนดและประกาศให้ทราบว่าเสร็จสิ้นแล้ว ภาพที่บันทึกไว้เป็นการสังเคราะห์หลักการทางศิลปะที่เรียนรู้และความคิดสร้างสรรค์ที่เกิดขึ้น พร้อมสำหรับการจัดแสดงและการไตร่ตรอง
การวิเคราะห์ผลลัพธ์
ผลลัพธ์ของ ConvDiffusionModel นำเสนอรูปร่างที่สนับสนุนศิลปะทางประวัติศาสตร์อย่างชัดเจน ภาพที่เรนเดอร์ด้วย AI แต่งกายด้วยเสื้อผ้าที่ประณีต สะท้อนความยิ่งใหญ่ของภาพถ่ายบุคคลคลาสสิกแต่ยังคงความทันสมัยและแตกต่าง เครื่องแต่งกายของตัวแบบเต็มไปด้วยเนื้อผ้า โดยผสมผสานรูปแบบที่เรียนรู้ของนางแบบเข้ากับการตีความแบบใหม่ ใบหน้าที่ละเอียดอ่อนและแสงและเงาที่เชื่อมโยงกันอย่างละเอียดอ่อน แสดงให้เห็นถึงความเข้าใจอันละเอียดอ่อนของ AI เกี่ยวกับเทคนิคศิลปะแบบดั้งเดิม งานศิลปะชิ้นนี้เป็นข้อพิสูจน์ถึงการฝึกฝนอันซับซ้อนของโมเดล ซึ่งสะท้อนถึงการสังเคราะห์อันสง่างามของศิลปะเชิงประวัติศาสตร์ผ่านปริซึมของการเรียนรู้ของเครื่องขั้นสูง โดยพื้นฐานแล้ว มันเป็นการแสดงความเคารพต่ออดีตแบบดิจิทัลซึ่งสร้างขึ้นด้วยอัลกอริธึมของปัจจุบัน
ความท้าทายและข้อพิจารณาด้านจริยธรรม
การใช้โมเดลการแพร่กระจายสำหรับการสร้างงานศิลปะนำมาซึ่งความท้าทายและข้อพิจารณาด้านจริยธรรมหลายประการที่คุณควรพิจารณา:
- แหล่งที่มาของข้อมูล: ชุดข้อมูลการฝึกอบรมจะต้องได้รับการดูแลจัดการอย่างมีความรับผิดชอบ การตรวจสอบว่าข้อมูลที่ใช้ในการฝึกอบรมโมเดลการแพร่กระจายไม่มีงานที่มีลิขสิทธิ์หรือได้รับการคุ้มครองโดยไม่ได้รับอนุญาตอย่างเหมาะสมถือเป็นสิ่งสำคัญ
- อคติและการเป็นตัวแทน: โมเดล AI สามารถขยายเวลาอคติในข้อมูลการฝึกได้ การรับรองชุดข้อมูลที่หลากหลายและครอบคลุมเป็นสิ่งสำคัญเพื่อหลีกเลี่ยงการตอกย้ำทัศนคติแบบเหมารวมในงานศิลปะที่สร้างโดย AI
- ควบคุมเอาท์พุต: เนื่องจากโมเดลการแพร่กระจายสามารถสร้างผลลัพธ์ได้หลากหลาย การกำหนดขอบเขตเพื่อป้องกันการสร้างเนื้อหาที่ไม่เหมาะสมหรือไม่เหมาะสมจึงเป็นสิ่งจำเป็น
- กรอบกฎหมาย: การขาดกรอบทางกฎหมายที่แข็งแกร่งในการจัดการกับความแตกต่างของ AI ในกระบวนการสร้างสรรค์ถือเป็นความท้าทาย กฎหมายจำเป็นต้องพัฒนาเพื่อปกป้องสิทธิของทุกฝ่ายที่เกี่ยวข้อง
สรุป
การเพิ่มขึ้นของโมเดลการแพร่กระจายใน AI และงานศิลปะถือเป็นยุคแห่งการเปลี่ยนแปลง โดยผสานความแม่นยำในการคำนวณเข้ากับการสำรวจเชิงสุนทรีย์ การเดินทางในโลกศิลปะของพวกเขาเน้นย้ำถึงศักยภาพด้านนวัตกรรมที่สำคัญแต่กลับมาพร้อมกับความซับซ้อน การสร้างความสมดุลระหว่างความคิดริเริ่ม อิทธิพล การสร้างสรรค์อย่างมีจริยธรรม และการเคารพผลงานที่มีอยู่ เป็นส่วนสำคัญในกระบวนการทางศิลปะ
ประเด็นที่สำคัญ
- โมเดลการแพร่กระจายถือเป็นแนวหน้าของการเปลี่ยนแปลงในการสร้างสรรค์งานศิลปะ พวกเขานำเสนอเครื่องมือดิจิทัลใหม่ๆ ที่ขยายขอบเขตการแสดงออกทางศิลปะให้ก้าวข้ามขอบเขตแบบเดิมๆ
- ในงานศิลปะที่ปรับปรุงด้วย AI การจัดลำดับความสำคัญของการรวบรวมข้อมูลการฝึกอบรมอย่างมีจริยธรรมและการเคารพทรัพย์สินทางปัญญาของผู้สร้างเป็นสิ่งจำเป็นในการรักษาความสมบูรณ์ในงานศิลปะดิจิทัล
- การบรรจบกันของวิสัยทัศน์ทางศิลปะและนวัตกรรมทางเทคโนโลยีเปิดประตูสู่ความสัมพันธ์ทางชีวภาพระหว่างศิลปินและนักพัฒนา AI ส่งเสริมสภาพแวดล้อมการทำงานร่วมกันที่สามารถก่อให้เกิดงานศิลปะที่ก้าวล้ำ
- การดูแลให้งานศิลปะที่สร้างโดย AI นำเสนอมุมมองที่หลากหลายถือเป็นสิ่งสำคัญ รวบรวมข้อมูลที่หลากหลายซึ่งสะท้อนถึงความสมบูรณ์ของวัฒนธรรมและมุมมองที่แตกต่างกัน ซึ่งจะช่วยส่งเสริมความไม่แบ่งแยก
- ความสนใจที่เพิ่มขึ้นในงานศิลปะที่ประดิษฐ์ด้วย AI จำเป็นต้องสร้างกรอบกฎหมายที่แข็งแกร่ง กรอบงานเหล่านี้ควรชี้แจงประเด็นลิขสิทธิ์ รับรู้ถึงการมีส่วนร่วม และควบคุมการใช้งานเชิงพาณิชย์ของงานศิลปะที่สร้างโดย AI
รุ่งอรุณของวิวัฒนาการทางศิลปะนี้นำเสนอเส้นทางที่เต็มไปด้วยศักยภาพในการสร้างสรรค์ แต่ต้องอาศัยการดูแลเอาใจใส่ เป็นหน้าที่ของเราที่จะต้องปลูกฝังภูมิทัศน์ที่การผสมผสานระหว่าง AI และศิลปะเจริญรุ่งเรือง โดยได้รับคำแนะนำจากแนวทางปฏิบัติที่มีความรับผิดชอบและละเอียดอ่อนทางวัฒนธรรม
คำถามที่พบบ่อย
A. โมเดลการแพร่กระจายเป็นอัลกอริธึม ML แบบเจนเนอเรชั่นที่สร้างภาพโดยเริ่มต้นด้วยรูปแบบของสัญญาณรบกวนแบบสุ่ม และค่อยๆ สร้างเป็นภาพที่สอดคล้องกัน กระบวนการนี้คล้ายกับศิลปินที่เริ่มต้นด้วยผืนผ้าใบเปล่าๆ และค่อย ๆ เพิ่มรายละเอียดเป็นชั้นๆ
A. GAN โมเดลการแพร่กระจายไม่จำเป็นต้องมีเครือข่ายแยกต่างหากเพื่อตัดสินเอาท์พุต ทำงานโดยการเพิ่มและลบจุดรบกวนซ้ำๆ ซึ่งมักจะส่งผลให้ได้ภาพที่ละเอียดและเหมาะสมยิ่งขึ้น
ตอบ ใช่ โมเดลการแพร่กระจายสามารถสร้างผลงานศิลปะต้นฉบับโดยการเรียนรู้จากชุดข้อมูลของรูปภาพ อย่างไรก็ตาม ความคิดริเริ่มได้รับอิทธิพลจากความหลากหลายและขอบเขตของข้อมูลการฝึกอบรม มีการถกเถียงกันอย่างต่อเนื่องเกี่ยวกับหลักจริยธรรมในการใช้งานศิลปะที่มีอยู่เพื่อฝึกโมเดลเหล่านี้
A. ข้อกังวลด้านจริยธรรมรวมถึงการหลีกเลี่ยงการละเมิดลิขสิทธิ์งานศิลปะที่สร้างโดย AI เคารพในความคิดริเริ่มของศิลปินที่เป็นมนุษย์ ป้องกันอคติที่คงอยู่ และรับรองความโปร่งใสในกระบวนการสร้างสรรค์ของ AI
A. อนาคตของงานศิลปะที่สร้างโดย AI ดูสดใส ด้วยโมเดลการแพร่กระจายที่นำเสนอเครื่องมือใหม่สำหรับศิลปินและนักสร้างสรรค์ เราคาดหวังที่จะได้เห็นงานศิลปะที่ซับซ้อนและซับซ้อนมากขึ้นตามความก้าวหน้าทางเทคโนโลยี อย่างไรก็ตาม ชุมชนสร้างสรรค์จะต้องคำนึงถึงหลักจริยธรรมและทำงานไปสู่แนวทางที่ชัดเจนและแนวปฏิบัติที่ดีที่สุด
สื่อที่แสดงในบทความนี้ไม่ได้เป็นของ Analytics Vidhya และถูกใช้ตามดุลยพินิจของผู้เขียน
ที่เกี่ยวข้อง
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://www.analyticsvidhya.com/blog/2023/12/implementing-diffusion-models-for-creative-ai-art-generation/
- :เป็น
- :ไม่
- :ที่ไหน
- 001
- 1
- 10
- 100
- 11
- 12
- 15%
- 150
- 16
- 19
- 224
- 225
- 8
- 9
- a
- ความสามารถ
- เกี่ยวกับเรา
- ข้างบน
- บทคัดย่อ
- ถูกต้อง
- บรรลุ
- การบรรลุ
- อาดัม
- ปรับได้
- เพิ่ม
- เพิ่มเติม
- ที่อยู่
- ปรับ
- สูง
- ความก้าวหน้า
- การกำเนิด
- ขัดแย้ง
- AI
- ไอ อาร์ต
- คล้ายกัน
- อัลกอริทึม
- ทั้งหมด
- การอนุญาต
- ช่วยให้
- an
- วิเคราะห์
- การวิเคราะห์
- การวิเคราะห์ วิทยา
- และ
- ประกาศ
- การใช้งาน
- ขอขอบคุณ
- เข้าใกล้
- สถาปัตยกรรม
- เป็น
- ศิลปะ
- บทความ
- ศิลปิน
- ศิลปะ
- อย่างมีศิลปะ
- งานศิลป์
- ศิลปิน
- งานศิลปะ
- งานศิลปะ
- AS
- At
- เติม
- การอนุญาต
- ใช้ได้
- ลู่ทาง
- หลีกเลี่ยง
- หลีกเลี่ยง
- แกน
- กลับ
- ไม่ดี
- สมดุล
- ตาม
- BE
- สมควร
- ประโยชน์ที่ได้รับ
- ที่ดีที่สุด
- ปฏิบัติที่ดีที่สุด
- ระหว่าง
- เกิน
- อคติ
- อคติ
- ว่างเปล่า
- การผสม
- บล็อกกาธอน
- เกิด
- ทั้งสอง
- เขตแดน
- การหายใจ
- เต็มไปด้วย
- นำ
- กว้าง
- นำ
- ที่กำลังบูม
- แต่
- by
- คำนวณ
- ที่เรียกว่า
- CAN
- ผ้าใบ
- ความสามารถในการ
- ความสามารถ
- จับ
- ท้าทาย
- ความท้าทาย
- ช่อง
- ความสับสนวุ่นวาย
- ลักษณะเฉพาะ
- ตรวจสอบ
- การตรวจสอบ
- ที่หนีบ
- ความชัดเจน
- ชั้น
- ชัดเจน
- ชัดเจนขึ้น
- ใกล้ชิด
- รหัส
- การเข้ารหัส
- สอดคล้องกัน
- ร่วมมือ
- การทำงานร่วมกัน
- สี
- มา
- เชิงพาณิชย์
- ชุมชน
- กะทัดรัด
- ความเข้ากันได้
- การแข่งขัน
- สมบูรณ์
- เสร็จสิ้น
- ซับซ้อน
- ความซับซ้อน
- ส่วนประกอบ
- ส่วนประกอบ
- การคำนวณ
- คำนวณ
- แนวความคิด
- เกี่ยวกับความคิดเห็น
- ความกังวลเกี่ยวกับ
- คอนเสิร์ต
- สรุป
- การเชื่อมต่อ
- พิจารณา
- การพิจารณา
- บรรจุ
- เนื้อหา
- ตรงกันข้าม
- ผลงาน
- ตามธรรมเนียม
- การลู่เข้า
- การแปลง
- การแปลง
- เครือข่ายประสาทเทียม
- ลิขสิทธิ์
- การละเมิดลิขสิทธิ์
- แกน
- ทุจริต
- ซีพียู
- ที่สร้างขึ้น
- สร้าง
- การสร้าง
- การสร้าง
- ความคิดสร้างสรรค์
- อย่างสร้างสรรค์
- ความคิดสร้างสรรค์
- ผู้สร้าง
- สำคัญมาก
- สุดยอด
- ปลูกฝัง
- ในเชิงวัฒนธรรม
- curated
- เส้นโค้ง
- ประเพณี
- วงจร
- เต้นรำ
- ข้อมูล
- ชุดข้อมูล
- การอภิปราย
- ลึก
- การกำหนด
- ความต้องการ
- แสดงให้เห็นถึง
- ความลึก
- ระดับความลึก
- ที่ได้มา
- กำหนด
- รายละเอียด
- รายละเอียด
- รายละเอียด
- นักพัฒนา
- เครื่อง
- แตกต่าง
- ความแตกต่าง
- ต่าง
- การจัดจำหน่าย
- ดิจิตอล
- ศิลปะดิจิตอล
- ดิจิทัล
- Dimension
- มิติ
- ดุลพินิจ
- แสดง
- แสดง
- แตกต่าง
- ความแตกต่าง
- หลาย
- ความหลากหลาย
- do
- ทำ
- ประตู
- วาด
- ภาพวาด
- ในระหว่าง
- พลวัต
- แบบไดนามิก
- พลศาสตร์
- e
- แต่ละ
- เสียงสะท้อน
- ก้อง
- ผลกระทบ
- ทำอย่างละเอียด
- อื่น
- โผล่ออกมา
- เข้ารหัส
- ห้อมล้อม
- ห้อมล้อม
- ชั้นเยี่ยม
- ที่เพิ่มขึ้น
- ทำให้มั่นใจ
- เพื่อให้แน่ใจ
- การสร้างความมั่นใจ
- ทั้งหมด
- สิ่งแวดล้อม
- ยุค
- ยุค
- ยุค
- ความผิดพลาด
- แก่นแท้
- จำเป็น
- สถานประกอบการ
- อีเธอร์ (ETH)
- ตามหลักจริยธรรม
- จริยธรรม
- การประเมินผล
- ทุกๆ
- วิวัฒนาการ
- คาย
- วิวัฒน์
- วิวัฒนาการ
- การตรวจสอบ
- Excel
- ยกเว้น
- ที่มีอยู่
- แสดง
- ไพศาล
- คาดหวัง
- การสำรวจ
- สำรวจ
- การแสดงออก
- ขยาย
- กว้างขวาง
- ตา
- Eyes
- ที่หน้า
- ซื่อสัตย์
- เท็จ
- คุ้นเคย
- ที่น่าสนใจ
- คุณสมบัติ
- ที่มีคุณสมบัติ
- ความจงรักภักดี
- รูป
- เนื้อไม่มีมัน
- ไฟล์
- สุดท้าย
- เสร็จสิ้น
- ชื่อจริง
- โฟกัส
- ดังต่อไปนี้
- สำหรับ
- แถวหน้า
- ข้างหน้า
- อุปถัมภ์
- อุปถัมภ์
- กรอบ
- กรอบ
- ราคาเริ่มต้นที่
- อย่างเต็มที่
- ฟังก์ชัน
- การทำงาน
- พื้นฐาน
- ต่อไป
- การผสม
- อนาคต
- ได้รับ
- GAN
- การรวบรวม
- ให้
- สร้าง
- สร้าง
- การสร้าง
- รุ่น
- กำเนิด
- เครือข่ายปฏิปักษ์โดยกำเนิด
- กำเนิด AI
- เครื่องกำเนิดไฟฟ้า
- ให้
- เป้าหมาย
- GPU
- การไล่ระดับสี
- ค่อยๆ
- ความยิ่งใหญ่
- เข้าใจ
- มากขึ้น
- แหวกแนว
- แนะนำ
- แนวทาง
- คู่มือ
- มือ
- การควบคุม
- หัวใจสำคัญ
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- ซ่อน
- ไฮไลท์
- ทางประวัติศาสตร์
- โฮลดิ้ง
- ความเคารพ
- เกียรติ
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- อย่างไรก็ตาม
- HTTPS
- เป็นมนุษย์
- i
- ความคิด
- if
- จี้ใจดำ
- ภาพ
- ภาพ
- จินตนาการ
- ความจำเป็น
- การดำเนินการ
- ผลกระทบ
- นำเข้า
- สำคัญ
- ปรับปรุง
- in
- รวมถึง
- รวมทั้ง
- inclusivity
- รวมเข้าด้วยกัน
- เพิ่มขึ้น
- ที่เพิ่มขึ้น
- เป็นหน้าที่
- มีอิทธิพล
- อิทธิพล
- การละเมิด
- ความฉลาด
- เราสร้างสรรค์สิ่งใหม่ ๆ
- นักวิเคราะห์ส่วนบุคคลที่หาโอกาสให้เป็นไปได้มากที่สุด
- อินพุต
- ปัจจัยการผลิต
- ความเข้าใจ
- สำคัญ
- การบูรณาการ
- ความสมบูรณ์
- ทางปัญญา
- ทรัพย์สินทางปัญญา
- อยากเรียนรู้
- การตีความ
- เข้าไป
- ซับซ้อน
- แนะนำ
- ปรีชา
- ร่วมมือ
- ปัญหา
- IT
- การย้ำ
- ซ้ำ
- ITS
- การเดินทาง
- jpg
- ผู้พิพากษา
- ไม่มี
- ภูมิประเทศ
- ชั้น
- ชั้น
- ได้เรียนรู้
- การเรียนรู้
- กฎหมาย
- กรอบกฎหมาย
- กฎหมาย
- เลนส์
- ตั้งอยู่
- ชีวิต
- เบา
- กดไลก์
- โหลด
- LOOKS
- ปิด
- การสูญเสีย
- เครื่อง
- เรียนรู้เครื่อง
- เก็บรักษา
- ประหลาดใจ
- ผลงานชิ้นเอก
- การจับคู่
- วัสดุ
- matplotlib
- หมายความ
- กลไก
- กลไก
- ภาพบรรยากาศ
- แค่
- การผสม
- วิธี
- มีระเบียบ
- เมตริก
- ลด
- นาที
- มิเรอร์
- ML
- อัลกอริทึม ML
- โหมด
- แบบ
- โมเดล
- ทันสมัย
- โมดูล
- ข้อมูลเพิ่มเติม
- ย้าย
- มาก
- รำพึง
- ต้อง
- ชื่อ
- ตั้งไข่
- ธรรมชาติ
- นำทาง
- จำเป็น
- ความต้องการ
- เครือข่าย
- เครือข่าย
- ประสาท
- วิศวกรรมประสาท
- เครือข่ายประสาท
- เครือข่ายประสาทเทียม
- ใหม่
- สัญญาณรบกวน
- หมายเหตุ
- นวนิยาย
- ตอนนี้
- ความแตกต่าง
- สังเกต
- ตั้งข้อสังเกต
- of
- ปิด
- น่ารังเกียจ
- เสนอ
- การเสนอ
- เสนอ
- มักจะ
- on
- ต่อเนื่อง
- เพียง
- เปิด
- เพิ่มประสิทธิภาพ
- or
- เป็นต้นฉบับ
- ความคิดริเริ่ม
- ต้นฉบับ
- OS
- อื่นๆ
- ของเรา
- ออก
- เอาท์พุต
- เอาท์พุท
- เกิน
- เป็นเจ้าของ
- ภาพวาด
- ภาพวาด
- พารามิเตอร์
- พารามิเตอร์
- ส่วนหนึ่ง
- คู่กรณี
- ส่ง
- อดีต
- เส้นทาง
- แบบแผน
- รูปแบบ
- ความเข้าใจ
- สมบูรณ์แบบ
- ดำเนินการ
- มุมมอง
- ภาพ
- ชิ้น
- ชิ้น
- แพลตฟอร์ม
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- การถ่ายภาพบุคคล
- ที่มีศักยภาพ
- การปฏิบัติ
- ความแม่นยำ
- เบื้องต้น
- นำเสนอ
- นำเสนอ
- การรักษา
- ป้องกัน
- การป้องกัน
- หลักการ
- การพิมพ์
- จัดลำดับความสำคัญ
- กระบวนการ
- การประมวลผล
- การผลิต
- ผลิตภัณฑ์
- โปรไฟล์
- ลึกซึ้ง
- ความคืบหน้า
- ในอาชีพ
- ก้าวหน้า
- แวว
- การส่งเสริม
- แจ้ง
- การเผยแผ่
- เหมาะสม
- คุณสมบัติ
- ป้องกัน
- การป้องกัน
- ราก
- การให้
- การตีพิมพ์
- การใฝ่หา
- ไฟฉาย
- วัดปริมาณ
- สุ่ม
- สุ่ม
- พิสัย
- คะแนน
- พร้อม
- ดินแดน
- รับรู้
- Redefining
- ปรับแต่ง
- กลั่น
- สะท้อนให้เห็นถึง
- สะท้อนให้เห็นถึง
- ระบบการปกครอง
- ปกติ
- ความสัมพันธ์
- ลบ
- การแสดงผล
- การทำซ้ำ
- การแสดง
- แสดงให้เห็นถึง
- การทำสำเนา
- ต้องการ
- ต้อง
- คล้าย
- Reshape
- เคารพ
- ในกรณี
- รับผิดชอบ
- อย่างรับผิดชอบ
- ส่งผลให้
- กลับ
- การเปิดเผย
- ฟื้น
- ปฏิวัติ
- RGB
- รวย
- สิทธิ
- ขึ้น
- แข็งแรง
- บทบาท
- เดียวกัน
- ที่บันทึกไว้
- ประหยัด
- ฉาก
- วิทยาศาสตร์
- ขอบเขต
- ต้นฉบับ
- เห็น
- ตนเอง
- มีความละเอียดอ่อน
- แยก
- ลำดับ
- ให้บริการอาหาร
- ชุด
- การตั้งค่า
- การติดตั้ง
- หลาย
- เงา
- การสร้าง
- เปลี่ยน
- กะ
- น่า
- แสดง
- การจัดแสดง
- แสดง
- สำคัญ
- ตั้งแต่
- ช้า
- เศษเล็กเศษน้อย
- So
- ซับซ้อน
- จิตวิญญาณ
- แหล่ง
- ที่มา
- ช่องว่าง
- ความตึงเครียด
- เฉพาะ
- สเปกตรัม
- squared
- มั่นคง
- ระยะ
- ยืน
- ที่เริ่มต้น
- ทางสถิติ
- คงที่
- ขั้นตอน
- กลยุทธ์
- มุ่งมั่น
- โครงสร้าง
- ทำให้งงงวย
- สไตล์
- หรือ
- ภายหลัง
- อย่างเช่น
- ชีวภาพ
- การทำงานร่วมกัน
- การสังเคราะห์
- สังเคราะห์
- ปรับปรุง
- ใช้เวลา
- การ
- เป้า
- วิชาการ
- เทคนิค
- เทคโนโลยี
- เทคโนโลยี
- เทคโนโลยี
- tensorflow
- จะ
- ที่
- พื้นที่
- ก้าวสู่อนาคต
- ที่มา
- ของพวกเขา
- พวกเขา
- ที่นั่น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- นี้
- thrives
- ตลอด
- ดังนั้น
- ไปยัง
- เครื่องมือ
- ไฟฉาย
- คบเพลิง
- แตะ
- ไปทาง
- การติดตาม
- แบบดั้งเดิม
- รถไฟ
- ผ่านการฝึกอบรม
- การฝึกอบรม
- แปลง
- การแปลง
- การแปลง
- กระแส
- เปลี่ยน
- การเปลี่ยนแปลง
- การแปลง
- ความโปร่งใส
- จริง
- ลอง
- เข้าใจ
- ความเข้าใจ
- เป็นเอกลักษณ์
- จนกระทั่ง
- เปิดตัว
- การปรับปรุง
- เมื่อ
- us
- ใช้
- มือสอง
- การใช้
- ประโยชน์
- ถูกต้อง
- การตรวจสอบ
- ผ่านทาง
- การดู
- มุมมอง
- วิสัยทัศน์
- ภาพ
- ทัศนศิลป์
- การสร้างภาพ
- เห็นภาพ
- สายตา
- จำเป็น
- คือ
- we
- webp
- อะไร
- ความหมายของ
- ที่
- ในขณะที่
- กระซิบ
- WHO
- กว้าง
- ช่วงกว้าง
- จะ
- หน้าต่าง
- กับ
- ภายใน
- ไม่มี
- งาน
- โรงงาน
- โลก
- X
- ใช่
- ยัง
- เธอ
- ลมทะเล
- เป็นศูนย์