The University of Maryland, Baltimore County's Bina lab เป็นห้องปฏิบัติการวิจัยสหสาขาวิชาชีพสำหรับการใช้คอมพิวเตอร์วิทัศน์ขั้นสูง แมชชีนเลิร์นนิง (ML) และเทคนิคการสำรวจระยะไกลเพื่อค้นหาความรู้ใหม่เกี่ยวกับสภาพแวดล้อมของเรา โดยเฉพาะอย่างยิ่งในภูมิภาคอาร์กติกและแอนตาร์กติก งานของห้องปฏิบัติการได้รับการสนับสนุนโดยรางวัล NSF BIGDATA (IIS-1947584, IIS-1838230), รางวัลสถาบัน NSF HDR (OAC-2118285) และ การวิจัย Amazon ML รางวัลสำหรับการเปลี่ยนแปลงสภาพภูมิอากาศ เมื่อเร็ว ๆ นี้ Bina Lab ได้รับรางวัลจาก Harnessing the Data Revolution (NSF HDR) ของ National Science Foundation เพื่อสนับสนุนสถาบันสำหรับการควบคุมข้อมูลและการปฏิวัติแบบจำลองในภูมิภาคขั้วโลก (เรียกว่า iHARP) หากต้องการเรียนรู้เพิ่มเติมและมีส่วนร่วมในกิจกรรมการวิจัย ML โปรดเยี่ยมชมเว็บไซต์ของ iHARP ที่ i-harp.org.
iHARP ร่วมมือกับ NASA, Amazon Research และ AWS อย่างจริงจังเพื่อดำเนินการวิจัยขั้นสูงในการวิเคราะห์ข้อมูลและการสร้างแบบจำลองในภูมิภาคอาร์กติกและแอนตาร์กติกโดยใช้วิทยาศาสตร์ข้อมูล ML และ AI ทีมนักวิทยาศาสตร์ที่ iHARP ภายใต้การนำของ Dr. Maryam Rahnemoonfar และ Dr. Masoud Yari กำลังทำงานเพื่อค้นหาข้อมูลเชิงลึกเกี่ยวกับแนวโน้มที่เกี่ยวข้องกับความหนาของแผ่นน้ำแข็ง ระดับของการสะสมของหิมะ และความเร็วในการหลอมเหลว ปัจจัยทั้งหมดเหล่านี้เป็นตัวบ่งชี้ที่สำคัญเกี่ยวกับรูปแบบการเปลี่ยนแปลงสภาพภูมิอากาศ กระบวนการรวบรวมและเตรียมข้อมูลยังคงต้องใช้แรงงานจำนวนมาก แม้ว่าจะมีความก้าวหน้าทางเทคโนโลยีที่สำคัญในเทคนิคการสำรวจระยะไกล ความท้าทายทวีความรุนแรงขึ้นจากความจำเป็นในการกลั่นกรองรูปภาพจำนวนมหาศาลที่รวบรวมมาหลายปีเพื่อตรวจจับการเปลี่ยนแปลงรูปแบบที่มีความหมาย นอกจากนี้ รูปภาพที่มีคุณภาพแตกต่างกันยังทำให้เกิดความเสื่อมในกระบวนการวิเคราะห์ ขณะฝึกโมเดลการแบ่งส่วนความหมายเชิงความหมายและการตรวจจับรูปร่าง นักวิจัย iHARP ไม่สามารถแยกขอบเขตของเลเยอร์และการคาดการณ์รูปร่างด้วยความแม่นยำที่ต้องการ แม้ว่าจะมีงานประมวลผลล่วงหน้าของรูปภาพที่ครอบคลุม
ด้วยความเป็นประชาธิปไตยของเทคโนโลยีทำให้สามารถดำเนินการฝึกอบรมการเรียนรู้เชิงลึกในระบบคลาวด์ด้วยค่าใช้จ่ายและเวลาเพียงเล็กน้อยเมื่อเทียบกับในสถานที่ นักวิจัย iHARP ตัดสินใจสร้างเวิร์กโฟลว์ ML บน อเมซอน SageMaker. ซึ่งช่วยให้ทีมสามารถตอบสนองข้อกำหนดด้านความสามารถในการปรับขนาด ปรับปรุงโมเดลการติดฉลากอัตโนมัติที่มีอยู่ และเร่งการเรียนรู้เชิงรุกกับมนุษย์ในวง ซึ่งช่วยให้เกิดการทำงานร่วมกันระหว่างนักวิทยาศาสตร์โดเมนและนักวิทยาศาสตร์ข้อมูล เป้าหมายสุดท้ายคือการทำให้การติดตามชั้นน้ำแข็งขั้วโลกมีความแม่นยำมากขึ้นและใช้เวลาน้อยลง ในโพสต์นี้ เราบันทึกผลลัพธ์ของการทำงานร่วมกันระหว่างนักวิจัยที่ iHARP และ AWS เพื่อแก้ปัญหากรณีการใช้งานการวิเคราะห์น้ำแข็งอาร์กติก โดยเฉพาะอย่างยิ่ง เราจะแนะนำคุณในหัวข้อต่อไปนี้:
- การวิเคราะห์น้ำแข็งอาร์กติกคืออะไร?
- แนวทางการใช้ ML สำหรับการวิเคราะห์น้ำแข็งอาร์กติก
- ML ที่ปรับขนาดได้ด้วย SageMaker
- เวิร์กโฟลว์การเรียนรู้เชิงรุกกับ อเมซอน เสริม AI (Amazon A2I) และ SageMaker
การวิเคราะห์น้ำแข็งอาร์กติกคืออะไร?
วิทยาวิทยา เป็นสาขาวิชาวิทยาศาสตร์สิ่งแวดล้อมที่เน้นน้ำแข็งและคุณสมบัติของน้ำแข็ง 71% ของโลกของเราประกอบด้วยน้ำ ดังนั้นน้ำแข็งจึงมีบทบาทสำคัญในการส่งผลกระทบต่อสภาพอากาศโลก (อ่านเพิ่มเติมในหัวข้อนี้ใน หกวิธีการสูญเสียน้ำแข็งอาร์กติกส่งผลกระทบต่อทุกคน). การละลายของน้ำแข็งขั้วโลก (อาร์กติกและแอนตาร์กติก) ทำให้โลกของเราได้รับความร้อนที่เพิ่มขึ้น เพราะตอนนี้เรามีน้ำแข็งน้อยลงเพื่อสะท้อนความร้อนกลับเข้าสู่อวกาศ เมื่อน้ำแข็งละลาย จะทำให้ระดับน้ำทะเลสูงขึ้น (SLR) ซึ่งเป็นปัญหาระดับโลก ระดับน้ำที่สูงขึ้นสามารถนำไปสู่อุทกภัยโดยเฉพาะอย่างยิ่งในพื้นที่ชายฝั่งทะเลและหมู่เกาะ
จากการศึกษาขององค์การสหประชาชาติปี 2019 ผู้คนมีอายุขัยเฉลี่ย 72.6 ปี เวลาของเราบนโลกใบนี้มีจำกัด ตามบทความ พื้นฐานแกนน้ำแข็งเราสามารถเข้าถึงแกนน้ำแข็ง (บล็อกทรงกระบอกเจาะผ่านแผ่นน้ำแข็ง โดยมีชั้นน้ำแข็งที่อายุน้อยที่สุดอยู่ด้านบนและชั้นที่เก่าที่สุดอยู่ที่ด้านล่าง) บันทึกที่ย้อนหลังไปอย่างน้อย 800,000 ปี เพื่อให้การวิจัยมีประสิทธิภาพ เราจำเป็นต้องเข้าถึงและวิเคราะห์ข้อมูลให้มากที่สุดเพื่อเปิดเผยความสัมพันธ์ระหว่างการเปลี่ยนแปลงรูปแบบชั้นน้ำแข็งและเหตุการณ์ภูมิอากาศในอดีต อย่างไรก็ตาม เป็นไปไม่ได้ทางคณิตศาสตร์ที่เราจะวิเคราะห์ข้อมูลทั้งหมดที่มี นี่คือจุดที่ ML และ AI เข้ามาเพื่อยืมโครงข่ายประสาทเทียมเพื่อเพิ่มความเร็ว!
แล้วการวิเคราะห์ข้อมูลน้ำแข็งเราหมายความว่าอย่างไร? เป็นกระบวนการที่ใช้แรงงานมากในการเคลื่อนผ่านเรดาร์ สเปกโตรสโคปี ภาพถ่าย ข้อมูลแบบตาราง และข้อมูลภูมิอากาศวิทยา หลายล้านหรือแม้กระทั่งพันล้านรายการเพื่อสร้างแผนที่ชั้นน้ำแข็ง ค้นหาการเปลี่ยนแปลงของชั้นน้ำแข็งเมื่อเวลาผ่านไป ระบุเหตุการณ์ภูมิอากาศ และค้นหารูปแบบ ที่พิสูจน์ความสัมพันธ์ระหว่างสิ่งที่เกิดขึ้นกับน้ำแข็งและผลกระทบต่อสภาพอากาศ ในการเร่งงานนี้ เราจำเป็นต้องมีคอมพิวเตอร์ที่ทรงพลัง ความสามารถในการอ่าน ทำความเข้าใจ และตีความรูปภาพ ความสามารถในการค้นหาการเปลี่ยนแปลงที่ดูเหมือนเล็กน้อยในรูปภาพเหล่านี้ซึ่งค่อยๆ เกิดขึ้นผ่านรูปภาพนับพัน ความสามารถในการเชื่อมโยงการเปลี่ยนแปลงเหล่านี้กับเหตุการณ์ที่เห็นได้ชัดเจน ในการอ่านค่าทางคณิตศาสตร์ ตาราง และเซ็นเซอร์ และอื่นๆ ด้วยความก้าวหน้าล่าสุดในอัลกอริธึมและเทคนิค ML และความพร้อมใช้งานของซูเปอร์คอมพิวเตอร์โดยมีค่าใช้จ่ายเพียงเล็กน้อยด้วยการประมวลผลแบบคลาวด์ นักวิทยาศาสตร์จึงกระตือรือร้นที่จะใช้ประโยชน์จาก ML ที่ใช้ระบบคลาวด์เพื่อสำรวจและขุดข้อมูลอาร์กติกและแอนตาร์กติก
ขั้นตอนแรกและอาจสำคัญที่สุดในกระบวนการวิเคราะห์น้ำแข็งอาร์กติกคือการแยกแยะชั้นน้ำแข็งต่างๆ ที่มีความแม่นยำมาก เนื่องจากขั้นตอนนี้แจ้งขั้นตอนที่เหลือในกระบวนการ เราสามารถทำได้โดยการฝึกโมเดล ML โดยใช้ การเรียนรู้ภายใต้การดูแล เพื่อตรวจจับชั้นน้ำแข็งจากภาพเรดาร์ เป็นต้น เพื่อให้ได้ความแม่นยำที่เราต้องการ เราต้องการข้อมูลที่มีคำอธิบายประกอบจำนวนมาก ความท้าทายไม่ใช่ความพร้อมของข้อมูล มีข้อมูลเรดาร์ที่ต่างกันจำนวนมากจากบริเวณขั้วโลกที่รวบรวมผ่านภารกิจราคาแพง อย่างไรก็ตาม ระหว่างการทดลอง เราพบว่าคุณภาพของคำอธิบายประกอบสำหรับข้อมูลนี้ไม่เพียงพอที่จะฝึกแบบจำลองด้วยความแม่นยำที่เราต้องการ ในตอนต่อไป เราจะแนะนำวิธีการแก้ปัญหานี้
แนวทางสำหรับการวิเคราะห์น้ำแข็งอาร์กติกโดยใช้ ML
ในการประชุม IEEE Big Data ในปี 2019 นักวิจัยของเรา Dr. Maryam และ Dr. Masoud พร้อมด้วยเพื่อนร่วมงานจาก University of Kansas และ University of Colorado ได้ตีพิมพ์บทความ การติดตามอย่างชาญฉลาดของชั้นน้ำแข็งภายในในข้อมูลเรดาร์ผ่านการเรียนรู้แบบหลายสเกล. เอกสารนี้ให้รายละเอียดการทดลองโดยใช้ ML โดยเฉพาะโมเดลการตรวจจับขอบโดยใช้แบบจำลองการเรียนรู้เชิงลึกหลายสเกล (เช่น Holistically-Nested Edge Detection (HED)) เพื่อติดตามขอบเขตของเลเยอร์ในภาพเรดาร์ของชั้นน้ำแข็ง งานวิจัยฉบับขยายนี้เผยแพร่ใน การเรียนรู้แบบหลายสเกลเชิงลึกสำหรับการติดตามชั้นน้ำแข็งภายในอัตโนมัติในข้อมูลเรดาร์ ในวารสาร Glaciology ในปี 2020
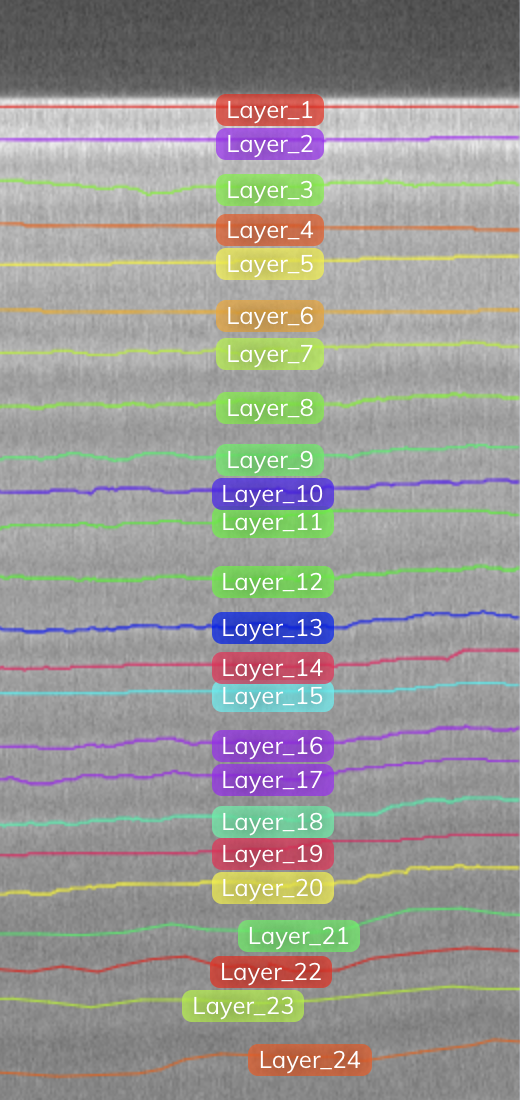
NASA ได้รวบรวมข้อมูลจากบริเวณขั้วโลกมาหลายทศวรรษแล้ว ของนาซ่า ICESat และ ICESat-2 และ การดำเนินงาน IceBridge เป็นตัวอย่างที่ชัดเจนของความพยายามเหล่านั้น ปฏิบัติการ IceBridge เป็นสะพานเชื่อมระหว่างภารกิจ ICESat ทั้งสองภารกิจเป็นเวลา 11 ปี เพื่อรวบรวมการสำรวจขั้วโลกโดยใช้เซ็นเซอร์ในอากาศ เช่น เรดาร์ ประโยชน์ของการใช้เซ็นเซอร์เรดาร์คือคลื่นของมันสามารถทะลุผ่านใต้พื้นผิวน้ำแข็งได้ อย่างไรก็ตาม ข้อมูลนี้แสดงถึงสแนปชอตในเวลา และเชื่อมโยงกับพิกัดเชิงพื้นที่ Operation IceBridge ให้ข้อมูลดิบที่เปิดเผยต่อสาธารณะในระดับเพทาไบต์ และการวิเคราะห์ด้วยตนเองถือเป็นความท้าทายครั้งใหญ่ ตัวอย่างเช่น รูปภาพต่อไปนี้แสดงส่วนภาพเรดาร์ที่รวบรวมในกรีนแลนด์ในปี 2012 ทิศทางแนวนอนคือเส้นทางการบิน และทิศทางแนวตั้งคือความลึกของหิมะ หน่วยต่อพิกเซลของภาพจะแสดงบนภาพ

รูปภาพต่อไปนี้แสดงรูปภาพเดียวกันกับคำอธิบายประกอบของเลเยอร์ที่วาดด้วยตนเอง เส้นแบ่งเขตแรก (ทำเครื่องหมายเป็น Layer-1) คือพื้นผิวหิมะ แต่ละชั้นที่อยู่ติดกันด้านล่างแสดงถึงการสะสมของหิมะประจำปีในปีก่อนหน้า เป้าหมายของเราคือตรวจจับเลเยอร์และคำนวณความหนาของเลเยอร์ในที่สุด แต่นี่เป็นเพียงส่วนหนึ่งของเฟรมเดียวเท่านั้น! เราต้องการที่จะสามารถปรับขนาดและทำแผนที่ชั้นน้ำแข็งทั่วเกาะกรีนแลนด์ได้!

โดยพื้นฐานแล้ว เราต้องการให้โมเดลของเราสามารถทำนายเลเยอร์ทั้งหมดได้ ดังที่แสดงในรูปต่อไปนี้ (ซึ่งรวมถึงรูปภาพต้นฉบับและรูปภาพที่มีคำอธิบายประกอบของเลเยอร์ทั้งหมด) นี่คือตัวอย่างรูปภาพที่มีเลเยอร์ที่แน่นและซีดจางมาก อย่างไรก็ตาม ยังมีปัญหาอื่นๆ ที่ต้องระวัง เช่น เสียงและสิ่งประดิษฐ์ ซึ่งการอภิปรายอยู่นอกขอบเขตของโพสต์นี้
 |
 |
โดยสรุปใน .ของพวกเขา กระดาษ IEEE 2019 และ JOG 2020นักวิจัยได้บันทึกข้อสังเกตต่อไปนี้จากการทดลองเกี่ยวกับประสิทธิภาพของการใช้การเรียนรู้เชิงลึกสำหรับการติดฉลากภาพเรดาร์:
- วิธีการเรียนรู้เชิงลึกที่เป็นที่รู้จักกันดีส่วนใหญ่ทำงานได้ดีกับภาพปกติ แต่ไม่พบว่าให้ผลลัพธ์ที่ยอมรับได้เมื่อมีสัญญาณรบกวน ข้อเท็จจริงที่ว่าโมเดลการเรียนรู้เชิงลึกนั้นไม่แข็งแกร่งในแง่ของเสียงรบกวน มีการกล่าวถึงในงานต่างๆ
- วิธีการโอนย้ายการเรียนรู้ไม่ได้ผลดีกับภาพเรดาร์ ในขณะที่การฝึกตั้งแต่เริ่มต้นจะให้ผลลัพธ์ที่ดีกว่ามาก
- การฝึกอบรมตั้งแต่เริ่มต้นต้องใช้ข้อมูลที่มีคำอธิบายประกอบโดยผู้เชี่ยวชาญของโดเมน การสร้างข้อมูลสังเคราะห์ที่ดีอาจเป็นวิธีแก้ปัญหาการขาดข้อมูลที่มีคำอธิบายประกอบ
จากการสังเกตเหล่านี้ เราตระหนักว่าเราจำเป็นต้องพิจารณาข้อควรพิจารณาบางประการ:
- ชุดข้อมูลของเราระหว่างการทดลองจะมีขนาดต่ำ (ประมาณ 5,000 ภาพ) อย่างไรก็ตาม เราจำเป็นต้องพิสูจน์สถาปัตยกรรมในอนาคตเพื่อปรับขนาดตามความต้องการ
- เราจำเป็นต้องสานในโซลูชันกึ่งอัตโนมัติที่มีอยู่ของเราสำหรับการติดตามเลเยอร์ (โดยใช้แบบจำลองที่กล่าวถึงในเอกสาร IEEE)
- แนวทางนี้ควรใช้ชุดข้อมูลที่มีคำอธิบายประกอบบางส่วนที่เรามี (เราไม่มีเวลาหรือทรัพยากรที่จะอธิบายชุดข้อมูลให้สมบูรณ์โดยมนุษย์)
- เราต้องการความสามารถในการปรับใช้เฟรมเวิร์กการเรียนรู้เชิงรุก เพื่อให้โมเดลสามารถพัฒนาได้โดยใช้คำติชมจากผู้ตรวจสอบที่เป็นมนุษย์ วิธีการเรียนรู้เชิงรุกจะพบจุดกึ่งกลางที่ช่วยให้นักวิทยาศาสตร์โดเมนสามารถปรับเปลี่ยนการคาดการณ์ของแบบจำลองได้
เป้าหมายสุดท้ายคือการเพิ่มความแม่นยำของแบบจำลองให้สูงสุดในการทำนายเลเยอร์
ML ที่ปรับขนาดได้ด้วย SageMaker
SageMaker เป็นบริการ ML ที่มีการจัดการเต็มรูปแบบ SageMaker จัดเตรียมสภาพแวดล้อม Jupyter แบบบูรณาการสำหรับการสร้างและการทดลอง และอินเทอร์เฟซแบบภาพบนเว็บที่เรียกว่า SageMaker สตูดิโอที่ซึ่งคุณสามารถดำเนินการตามขั้นตอนการพัฒนา ML ทั้งหมดด้วยการเข้าถึง การควบคุม และการมองเห็นที่สมบูรณ์ SageMaker จัดเตรียมและจัดการโครงสร้างพื้นฐานที่จำเป็นสำหรับการฝึกอบรมและการโฮสต์ SageMaker ยังมีอัลกอริธึม ML ทั่วไปที่ได้รับการปรับแต่งให้ทำงานอย่างมีประสิทธิภาพกับข้อมูลขนาดใหญ่มากในสภาพแวดล้อมแบบกระจาย ด้วยการสนับสนุนดั้งเดิมสำหรับอัลกอริทึมและเฟรมเวิร์กที่นำมาเอง SageMaker เสนอตัวเลือกการฝึกอบรมแบบกระจายที่ยืดหยุ่นซึ่งปรับให้เข้ากับเวิร์กโฟลว์ที่กำหนดเอง การฝึกอบรมและโฮสติ้งจะเรียกเก็บเงินเป็นนาทีของการใช้งาน โดยไม่มีค่าธรรมเนียมขั้นต่ำและไม่มีข้อผูกมัดล่วงหน้า
เราพบว่า SageMaker เหมาะสมกับความต้องการของเราเป็นอย่างดีเนื่องจากความสามารถในการปรับขนาด ความยืดหยุ่นในการรองรับอัลกอริธึม ML แบบกำหนดเองของเรา การที่เราสามารถเริ่มต้นได้อย่างรวดเร็วเนื่องจากการใช้งานง่าย และที่สำคัญกว่านั้นคือความสามารถในการตั้งค่าการเรียนรู้เชิงรุกโดยใช้ Amazon เอ2ไอ. เพื่อดำเนินการทดลองกับโมเดลการแบ่งส่วนความหมายของเราต่อไปโดยใช้ SageMaker เราได้ออกแบบสถาปัตยกรรมต่อไปนี้

ดาวน์โหลดและประมวลผลภาพล่วงหน้า
เราใช้ข้อมูลที่เปิดเผยต่อสาธารณะ สำหรับการฝึกโมเดลของเรา เราใช้ข้อมูลเรดาร์ที่มีอยู่ใน ศูนย์ข้อมูลหิมะและน้ำแข็งแห่งชาติ. มีคำอธิบายประกอบบางส่วนของชั้นน้ำแข็งให้ใช้งาน อย่างไรก็ตาม ไม่ใช่ทุกเลเยอร์ที่มีอยู่ในคำอธิบายประกอบ ซึ่งอาจบิดเบือนผลลัพธ์ ในขั้นแรก เราดาวน์โหลดชุดข้อมูลดิบลงใน an บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (Amazon S3) ถัง เราจัดเตรียมโน้ตบุ๊ก SageMaker Jupyter ซึ่งเราดึงข้อมูลภาพและแปลงเป็น บันทึกIO ซึ่งปรับพื้นที่จัดเก็บให้เหมาะสมและเปิดใช้งานการสตรีมข้อมูลในโหมดไปป์เพื่อการฝึกอบรมที่รวดเร็วยิ่งขึ้น จากนั้นไฟล์ RecordIO จะถูกอัปโหลดกลับไปที่ Amazon S3 เป็นชุดข้อมูลฝึกและทดสอบ
ฝึกโมเดลการติดตามเลเยอร์แบบหลายสเกลบน SageMaker
เราสร้างไฟล์ Python เป็นจุดเริ่มต้นที่มีโค้ดสำหรับอัลกอริธึมการติดตามเลเยอร์แบบหลายสเกลของเรา เราใช้ SageMaker ตัวประมาณ MXNet เป็นเสื้อคลุมสำหรับซีเอ็นเอ็นของเรา และเราใช้ SageMaker Python SDK สำหรับการเริ่มต้นตัวประมาณ การกำหนดค่าไฮเปอร์พารามิเตอร์ และดำเนินการฝึกอบรม เราทำการเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์ด้วย SageMaker จูนเนอร์รุ่นอัตโนมัติ เพื่อกำหนดการตั้งค่าที่เหมาะสมที่สุดซึ่งให้ผลลัพธ์ที่ดีที่สุดแก่เรา
โฮสต์โมเดลบน SageMaker และเรียกใช้การคาดคะเน
เมื่อการฝึกโมเดลเสร็จสิ้น SageMaker จะส่งสิ่งประดิษฐ์ไปยังบัคเก็ต S3 โดยอัตโนมัติ ก่อนที่เราจะสามารถเรียกใช้การคาดการณ์จำนวนมากของคำอธิบายประกอบสำหรับรูปภาพของเรา ในขั้นตอนการทดลอง เราต้องการตั้งค่าปลายทางแบบเรียลไทม์ เรียกใช้การทดสอบคุณภาพการทำนาย และเปิดใช้งานการเรียนรู้เชิงรุก ในการตั้งค่าการอนุมานตามเวลาจริง อันดับแรกเรา สร้างแพ็คเกจโมเดลแล้ว สร้างการกำหนดค่าปลายทาง ที่ระบุประเภทอินสแตนซ์ที่เราต้องการสำหรับการโฮสต์ พร้อมด้วยรายละเอียดว่าเราต้องการเรียกใช้หลายเวอร์ชันพร้อมกันหรือไม่ เราไม่ได้เลือกตัวเลือกนี้เนื่องจากเราอยู่ในขั้นตอนทดลอง แต่สำหรับรายละเอียดเพิ่มเติม โปรดดูที่ ปรับใช้โมเดลใน Amazon SageMaker. ในที่สุด เราก็ สร้างจุดสิ้นสุด. สำหรับการรันการคาดการณ์ เราใช้ชุดข้อมูลทดสอบที่ประมวลผลล่วงหน้าของอิมเมจที่เราส่งไปยังปลายทางที่โฮสต์ โมเดลส่งคืนคำอธิบายประกอบ JSON สำหรับขอบเขตเลเยอร์จากอิมเมจอินพุต และเรายืนยันพิกัดของคำอธิบายประกอบและอิมเมจลงในบัคเก็ต S3
แน่นอนว่าการนำแบบจำลองของเราไปใช้ SageMaker เป็นขั้นตอนแรก แต่สิ่งนี้ทำให้เรามีพื้นฐานที่จำเป็นในการสร้างสรรค์และเร่งการทดลองอย่างรวดเร็ว ในส่วนถัดไป เราจะแนะนำวิธีที่เราใช้ Amazon A2I กับ SageMaker เพื่อสร้างเวิร์กโฟลว์การเรียนรู้ที่ใช้งานได้เต็มรูปแบบ
ตั้งค่าเวิร์กโฟลว์การเรียนรู้เชิงรุกด้วย Amazon A2I
Amazon A2I ทำให้ง่ายต่อการเพิ่มการตรวจสอบจากเจ้าหน้าที่ลงในเวิร์กโฟลว์ ML ของคุณ Amazon A2I มีเวิร์กโฟลว์การตรวจสอบโดยเจ้าหน้าที่ในตัวสำหรับกรณีการใช้งาน ML ทั่วไป เช่น การควบคุมเนื้อหาและการแยกข้อความจากเอกสาร คุณยังสามารถสร้างเวิร์กโฟลว์ของคุณเองสำหรับโมเดล ML ที่สร้างบน SageMaker หรือเครื่องมืออื่นๆ ด้วย Amazon A2I คุณสามารถอนุญาตให้ผู้ตรวจสอบที่เป็นมนุษย์เข้ามามีส่วนร่วมเมื่อโมเดลไม่สามารถคาดการณ์ที่มีความมั่นใจสูงหรือตรวจสอบการคาดการณ์ได้อย่างต่อเนื่อง Amazon A2I มีให้ แม่แบบที่สร้างไว้ล่วงหน้า เพื่อสร้างหน้า UI ของงานสำหรับตรวจสอบเสียง รูปภาพ ข้อความ และวิดีโอ และคุณปรับแต่งเทมเพลตได้ตามความต้องการ สำหรับกรณีการใช้งานของเรา เราได้สร้างเทมเพลตของเหลวแบบกำหนดเองโดยใช้a ฝูงชน-polyline ธาตุ. การเปิดใช้งานการเรียนรู้เชิงรุกนี้ทำให้ผู้ตรวจสอบที่เป็นมนุษย์ (นักวิจัยของเรา) สามารถโต้ตอบกับ UI ของงาน (หน้าเว็บ) เพื่อทำตามขั้นตอนต่อไปนี้:
- ประเมินภาพต้นฉบับที่มีการใส่คำอธิบายประกอบบางส่วน
- เปรียบเทียบคำอธิบายประกอบที่คาดคะเนจากแบบจำลองกับรูปภาพต้นฉบับที่มีการใส่คำอธิบายประกอบบางส่วน
- ใช้ UI งานแบบโต้ตอบเพื่ออัปเดตหรือแก้ไขคำอธิบายประกอบและรูปภาพที่คาดคะเน และส่งสำหรับการฝึกใหม่
ขั้นแรก เราจะแนะนำคุณเกี่ยวกับวิธีตั้งค่าการตรวจสอบโดยเจ้าหน้าที่กับ Amazon A2I จากนั้นเราจะแสดงวิธีเปิดใช้การฝึกซ้ำและเวิร์กโฟลว์การเรียนรู้เชิงรุกให้เสร็จสมบูรณ์
สร้างเทมเพลตงานของผู้ปฏิบัติงาน
ก่อนอื่นให้แน่ใจทั้งหมด ข้อกำหนดเบื้องต้นของ Amazon A2I จะได้พบกับ ซึ่งรวมถึงการตั้งค่าบัคเก็ต S3 สำหรับอินพุตและเอาต์พุต AWS Identity และการจัดการการเข้าถึง บทบาท (IAM) และพนักงานสำหรับเวิร์กโฟลว์การตรวจทานโดยเจ้าหน้าที่
ต่อไป เราสร้าง UI งานโดยใช้เทมเพลตงานของผู้ปฏิบัติงานใน SageMaker เทมเพลตงานของผู้ปฏิบัติงานเป็นไฟล์ HTML ที่อนุญาตให้ปรับแต่ง UI ให้เหมาะสมกับกรณีการใช้งานการตรวจสอบโดยเจ้าหน้าที่ ในการเริ่มต้น SageMaker มี . มากมาย ส่วนประกอบ HTML สำหรับการสร้าง UI ของผู้ปฏิบัติงานแบบกำหนดเอง สำหรับกรณีการใช้งานนี้ เราต้องการให้ผู้ตรวจสอบสามารถอัปเดตส่วนของเส้นบน UI ที่สอดคล้องกับเลเยอร์หิมะในรูปภาพ เราเลือกใช้องค์ประกอบรูปแบบฝูงชนและองค์ประกอบกลุ่มเส้น องค์ประกอบแบบฟอร์มฝูงชนให้การควบคุมพื้นฐานสำหรับ UI เช่นการส่งผล องค์ประกอบ crowd-polyline ช่วยให้ผู้ใช้สามารถโต้ตอบกับส่วนของเส้นบน UI ซึ่งใช้เพื่อให้พอดีกับเส้นบนชั้นหิมะแต่ละชั้น
ตอนนี้เราได้ระบุส่วนประกอบ UI ที่จะใช้แล้ว เราจำเป็นต้องรวมข้อมูลโมเดลเพื่อโต้ตอบด้วยผ่าน UI คอมโพเนนต์ crowd-polyline ประกอบด้วยช่องสำหรับใส่ค่าเริ่มต้น ป้ายกำกับ และรูปภาพต้นฉบับ ช่องเหล่านี้ใช้เพื่อเติมข้อมูลชั้นหิมะและรูปภาพของชั้นหิมะ หลังจากที่แสดงผล UI ของผู้ปฏิบัติงานแล้ว ผู้ตรวจทานสามารถแก้ไขและเพิ่มกลุ่มบรรทัดเพิ่มเติมได้ เพื่อช่วยผู้ตรวจทาน เรายังรวมเอาท์พุตโมเดลดั้งเดิมและอิมเมจอินพุตที่ติดป้ายกำกับไว้ข้างๆ ตัวแก้ไข crowd-polyline
ภาพหน้าจอต่อไปนี้แสดง UI ของงานเมื่อเปิดใช้งาน

ต่อไปนี้เป็นข้อมูลโค้ดของเทมเพลต:
สร้างเวิร์กโฟลว์การตรวจสอบโดยเจ้าหน้าที่
เมื่อเทมเพลตงานเสร็จสมบูรณ์ เราจะเริ่มสร้างเวิร์กโฟลว์การตรวจทานโดยเจ้าหน้าที่ สิ่งนี้ระบุสิ่งต่อไปนี้:
- พนักงานที่งานถูกส่งไปยัง
- เทมเพลตงานที่สร้างในขั้นตอนก่อนหน้า
- ตำแหน่งผลลัพธ์ผลลัพธ์
เราสามารถสร้างเวิร์กโฟลว์ผ่าน API หรือคอนโซล Amazon A2I ดู สร้างเวิร์กโฟลว์การตรวจทานโดยเจ้าหน้าที่ เพื่อดูรายละเอียด
เริ่มรอบการตรวจสอบโดยเจ้าหน้าที่
ณ จุดนี้ เรามีเทมเพลตงานและเวิร์กโฟลว์การตรวจสอบโดยเจ้าหน้าที่ ซึ่งกำหนดวิธีที่เราต้องการให้ UI การตรวจสอบของเรามีหน้าตาและการทำงาน การเริ่มวนรอบการตรวจสอบโดยเจ้าหน้าที่เป็นขั้นตอนสุดท้ายในกระบวนการ Amazon A2I สำหรับชุดข้อมูลและภาพที่ติดป้ายกำกับแต่ละชุด เราสร้างวงจรการตรวจสอบโดยเจ้าหน้าที่เพื่อสร้างสภาพแวดล้อมสำหรับผู้ตรวจสอบบุคลากรของเรา ดู สร้างและเริ่มต้น Human Loop สำหรับประเภทงานที่กำหนดเอง เพื่อดูรายละเอียด
ผู้ตรวจสอบแต่ละคนสร้างบัญชีและเข้าสู่ระบบเพื่อดำเนินการตรวจสอบที่สร้างขึ้น จากนั้นพวกเขาเลือกจากรายการงานที่ได้รับมอบหมาย ดังที่เห็นในภาพหน้าจอต่อไปนี้

หลังจากเลือกงานแล้ว พวกเขาจะเห็น UI ของงานที่สร้างขึ้นโดยใช้ส่วนประกอบ HTML ที่กำหนดเอง สุดท้าย ผู้ใช้ส่งการอัปเดตหลังจากติดตั้งโพลิไลน์กับเลเยอร์หิมะแล้ว

เปิดใช้งานการฝึกขึ้นใหม่
ไดอะแกรมต่อไปนี้แสดงสถาปัตยกรรมที่อัปเดตพร้อมการเรียนรู้เชิงรุกที่นำไปใช้

ขณะนี้ วนรอบการตรวจสอบโดยเจ้าหน้าที่พร้อมแล้วเพื่อแก้ไขคำอธิบายประกอบ เราจำเป็นต้องส่งผลกลับไปยังกระบวนการดำเนินการฝึกอบรมซ้ำอัตโนมัติหลังจากที่ผู้ตรวจสอบได้แก้ไขรูปภาพจำนวนมาก เมื่อเราทำตามขั้นตอนนี้จนเสร็จสิ้น สถาปัตยกรรมของเราจะเปิดใช้งานการเรียนรู้เชิงรุกอย่างเต็มที่ ในกรณีของเรา เราตัดสินใจว่าควรเริ่มการฝึกใหม่หลังจากการแก้ไขภาพทุกๆ 100 ครั้ง รูปภาพที่มีการซ้อนทับคำอธิบายประกอบที่แก้ไขแล้วจะถูกจัดเก็บไว้ในบัคเก็ต S3 และเรายังจัดเก็บพิกัดของคำอธิบายประกอบพร้อมกับคำนำหน้ารูปภาพ S3 ที่เกี่ยวข้องใน อเมซอน ไดนาโมดีบี ตารางสำหรับการดึงและจัดทำดัชนีได้ง่าย
บทสรุปและขั้นตอนต่อไป
ในโพสต์นี้ เราอธิบายวิธีที่เราใช้ SageMaker และ Amazon A2I เพื่อตั้งค่าเวิร์กโฟลว์การเรียนรู้ ML ที่ใช้งานอยู่เพื่อปรับปรุงความถูกต้องของคำอธิบายประกอบของการติดตามชั้นน้ำแข็งอาร์กติก นี่เป็นการทดลองอย่างต่อเนื่องสำหรับเรา และเราวางแผนที่จะเผยแพร่โพสต์ร่วมเพื่อแบ่งปันผลลัพธ์ในรูปแบบของชุดข้อมูลชั้นน้ำแข็งขั้วโลกที่มีคำอธิบายประกอบที่มีความแม่นยำสูง เรามองหาผู้ทำงานร่วมกันอยู่เสมอ ดังนั้นหากฟังดูน่าสนใจ มองหาเราที่ i-HARP.org หรือแสดงความคิดเห็นในความคิดเห็น
เกี่ยวกับผู้เขียน
 เปรม รังสิต เชี่ยวชาญด้าน ML และ AI ที่ AWS ด้วยความกระตือรือร้นในการช่วยลูกค้าแก้ปัญหา NLP, CV และปัญหาการเรียนรู้เชิงลึก เปรมสร้างสถานีเบียร์ควบคุมของ Alexa ในฮูสตันและที่อื่นๆ เปรมเป็นผู้เขียน Packt คุณสามารถอ่านเกี่ยวกับเรื่องนี้และสิ่งพิมพ์อื่น ๆ ได้ที่ https://www.linkedin.com/in/premkr/
เปรม รังสิต เชี่ยวชาญด้าน ML และ AI ที่ AWS ด้วยความกระตือรือร้นในการช่วยลูกค้าแก้ปัญหา NLP, CV และปัญหาการเรียนรู้เชิงลึก เปรมสร้างสถานีเบียร์ควบคุมของ Alexa ในฮูสตันและที่อื่นๆ เปรมเป็นผู้เขียน Packt คุณสามารถอ่านเกี่ยวกับเรื่องนี้และสิ่งพิมพ์อื่น ๆ ได้ที่ https://www.linkedin.com/in/premkr/
 ดร.มาสุด ยารี เป็นศาสตราจารย์ด้านการวิจัยที่สถาบัน iHARP Data Science และห้องปฏิบัติการ Bina ที่ College of Engineering and Information Technology, University of Maryland, Baltimore County, MD ความสนใจในงานวิจัยของเขา ได้แก่ แมชชีนเลิร์นนิง, คอมพิวเตอร์วิทัศน์, การสำรวจระยะไกล, การสร้างแบบจำลองทางคณิตศาสตร์ และระบบไดนามิก เขาหลงใหลในการค้นหาข้อมูลเชิงลึกที่สามารถนำไปปฏิบัติได้จริงในข้อมูลและนำทีมวิจัยและโครงการวิจัยสหวิทยาการชั้นนำเพื่อแก้ไขปัญหาสิ่งแวดล้อมและมนุษยธรรม
ดร.มาสุด ยารี เป็นศาสตราจารย์ด้านการวิจัยที่สถาบัน iHARP Data Science และห้องปฏิบัติการ Bina ที่ College of Engineering and Information Technology, University of Maryland, Baltimore County, MD ความสนใจในงานวิจัยของเขา ได้แก่ แมชชีนเลิร์นนิง, คอมพิวเตอร์วิทัศน์, การสำรวจระยะไกล, การสร้างแบบจำลองทางคณิตศาสตร์ และระบบไดนามิก เขาหลงใหลในการค้นหาข้อมูลเชิงลึกที่สามารถนำไปปฏิบัติได้จริงในข้อมูลและนำทีมวิจัยและโครงการวิจัยสหวิทยาการชั้นนำเพื่อแก้ไขปัญหาสิ่งแวดล้อมและมนุษยธรรม
 Brett Seib เป็นสถาปนิก AWS Enterprise Solutions ซึ่งตั้งอยู่ในเมืองออสติน รัฐเท็กซัส เขาหลงใหลในการสร้างสรรค์และแก้ไขปัญหาทางธุรกิจกับลูกค้า Brett มีประสบการณ์หลายปีในอุตสาหกรรม IoT และ Data Analytics ที่ช่วยลูกค้าสร้างสรรค์นวัตกรรมด้วยข้อมูล
Brett Seib เป็นสถาปนิก AWS Enterprise Solutions ซึ่งตั้งอยู่ในเมืองออสติน รัฐเท็กซัส เขาหลงใหลในการสร้างสรรค์และแก้ไขปัญหาทางธุรกิจกับลูกค้า Brett มีประสบการณ์หลายปีในอุตสาหกรรม IoT และ Data Analytics ที่ช่วยลูกค้าสร้างสรรค์นวัตกรรมด้วยข้อมูล
 มอร์แกน ดัตตัน เป็นผู้จัดการโปรแกรมด้านเทคนิคของ AWS กับทีม Amazon Augmented AI และ Mechanical Turk ที่ตั้งอยู่ในเมืองซีแอตเทิล รัฐวอชิงตัน เธอทำงานร่วมกับลูกค้าด้านวิชาการและภาครัฐเพื่อเร่งการใช้บริการ ML แบบมนุษย์ในวงกว้าง มอร์แกนสนใจเป็นพิเศษที่จะร่วมมือกับลูกค้าที่เป็นนักวิชาการเพื่อสนับสนุนการนำเทคโนโลยี ML มาใช้โดยนักวิจัย นักศึกษา และนักการศึกษา
มอร์แกน ดัตตัน เป็นผู้จัดการโปรแกรมด้านเทคนิคของ AWS กับทีม Amazon Augmented AI และ Mechanical Turk ที่ตั้งอยู่ในเมืองซีแอตเทิล รัฐวอชิงตัน เธอทำงานร่วมกับลูกค้าด้านวิชาการและภาครัฐเพื่อเร่งการใช้บริการ ML แบบมนุษย์ในวงกว้าง มอร์แกนสนใจเป็นพิเศษที่จะร่วมมือกับลูกค้าที่เป็นนักวิชาการเพื่อสนับสนุนการนำเทคโนโลยี ML มาใช้โดยนักวิจัย นักศึกษา และนักการศึกษา
 มัรยัม ราห์เนมูนฟาร์ปริญญาเอก เป็น PI และผู้อำนวยการสถาบันวิทยาศาสตร์ข้อมูล NSF-iHARP ผู้อำนวยการ Computer Vision and Remote Sensing Laboratory (Bina lab) และรองศาสตราจารย์ด้าน AI และ Data Science ที่วิทยาลัยวิศวกรรมศาสตร์และเทคโนโลยีสารสนเทศ UMBC ความสนใจในงานวิจัยของเธอ ได้แก่ Deep Learning, Computer Vision, Data Science, AI for Social Good, Remote Sensing และ Document Image Analysis โครงการวิจัยของเธอได้รับทุนสนับสนุนจากหลายรางวัล เช่น รางวัลสถาบัน NSF HDR, รางวัล NSF BIGDATA, รางวัลการวิจัยทางวิชาการของ Amazon, รางวัลการเรียนรู้ของเครื่อง Amazon, Microsoft และ IBM
มัรยัม ราห์เนมูนฟาร์ปริญญาเอก เป็น PI และผู้อำนวยการสถาบันวิทยาศาสตร์ข้อมูล NSF-iHARP ผู้อำนวยการ Computer Vision and Remote Sensing Laboratory (Bina lab) และรองศาสตราจารย์ด้าน AI และ Data Science ที่วิทยาลัยวิศวกรรมศาสตร์และเทคโนโลยีสารสนเทศ UMBC ความสนใจในงานวิจัยของเธอ ได้แก่ Deep Learning, Computer Vision, Data Science, AI for Social Good, Remote Sensing และ Document Image Analysis โครงการวิจัยของเธอได้รับทุนสนับสนุนจากหลายรางวัล เช่น รางวัลสถาบัน NSF HDR, รางวัล NSF BIGDATA, รางวัลการวิจัยทางวิชาการของ Amazon, รางวัลการเรียนรู้ของเครื่อง Amazon, Microsoft และ IBM
- '
- &
- 000
- 100
- 11
- 2019
- 2020
- 98
- เข้า
- ลงชื่อเข้าใช้
- คล่องแคล่ว
- กิจกรรม
- เพิ่มเติม
- การนำมาใช้
- ความได้เปรียบ
- AI
- Alexa
- ขั้นตอนวิธี
- อัลกอริทึม
- ทั้งหมด
- การอนุญาต
- อเมซอน
- อเมซอน แมชชีนเลิร์นนิง
- อเมซอน SageMaker
- ในหมู่
- การวิเคราะห์
- การวิเคราะห์
- อาปาเช่
- API
- สถาปัตยกรรม
- อาร์คติก
- บทความ
- เสียง
- การตรวจสอบบัญชี
- ออสติน
- อัตโนมัติ
- ความพร้อมใช้งาน
- AWS
- บัลติมอร์
- เบียร์
- ที่ดีที่สุด
- ข้อมูลขนาดใหญ่
- BigData
- สะพาน
- สร้าง
- การก่อสร้าง
- ธุรกิจ
- เคมบริดจ์
- กรณี
- ท้าทาย
- เปลี่ยนแปลง
- อากาศเปลี่ยนแปลง
- เมฆ
- คอมพิวเตอร์เมฆ
- ซีเอ็นเอ็น
- รหัส
- การทำงานร่วมกัน
- วิทยาลัย
- โคโลราโด
- ความคิดเห็น
- ร่วมกัน
- ส่วนประกอบ
- วิสัยทัศน์คอมพิวเตอร์
- การคำนวณ
- การประชุม
- เนื้อหา
- การควบคุมเนื้อหา
- ต่อ
- อย่างต่อเนื่อง
- การแก้ไข
- มณฑล
- การสร้าง
- ลูกค้า
- ข้อมูล
- การวิเคราะห์ข้อมูล
- วิเคราะห์ข้อมูล
- วิทยาศาสตร์ข้อมูล
- การเรียนรู้ลึก ๆ
- ความต้องการ
- การตรวจพบ
- พัฒนาการ
- ผู้อำนวยการ
- เอกสาร
- ขอบ
- บรรณาธิการ
- มีประสิทธิภาพ
- ปลายทาง
- ชั้นเยี่ยม
- Enterprise
- โซลูชั่นองค์กร
- สิ่งแวดล้อม
- สิ่งแวดล้อม
- เหตุการณ์
- ประสบการณ์
- ผู้เชี่ยวชาญ
- การสกัด
- ค่าธรรมเนียม
- สาขา
- รูป
- ในที่สุด
- ชื่อจริง
- พอดี
- ความยืดหยุ่น
- เที่ยวบิน
- ฟอร์ม
- รูป
- รากฐาน
- กรอบ
- ฟังก์ชัน
- ได้รับทุนสนับสนุน
- อนาคต
- เหตุการณ์ที่
- ดี
- โฮสติ้ง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTTPS
- ใหญ่
- มนุษย์ในวง
- มีมนุษยธรรม
- AMI
- ไอบีเอ็ม
- ICE
- แยกแยะ
- เอกลักษณ์
- อีอีอี
- ภาพ
- การวิเคราะห์ภาพ
- รวมทั้ง
- เพิ่ม
- อุตสาหกรรม
- ข้อมูล
- เทคโนโลยีสารสนเทศ
- โครงสร้างพื้นฐาน
- ข้อมูลเชิงลึก
- การโต้ตอบ
- IOT
- IT
- โน้ตบุ๊ค Jupyter
- แคนซัส
- ความรู้
- การติดฉลาก
- ป้ายกำกับ
- แรงงาน
- ใหญ่
- นำ
- ความเป็นผู้นำ
- ชั้นนำ
- เรียนรู้
- การเรียนรู้
- ยืม
- ชั้น
- ถูก จำกัด
- Line
- ของเหลว
- รายการ
- ในประเทศ
- เรียนรู้เครื่อง
- การทำ
- แผนที่
- แมรี่แลนด์
- ไมโครซอฟท์
- ML
- อัลกอริทึม ML
- แบบ
- การสร้างแบบจำลอง
- ย้าย
- นาซา
- สุทธิ
- ประสาท
- NLP
- สัญญาณรบกวน
- เสนอ
- ตัวเลือกเสริม (Option)
- Options
- อื่นๆ
- กระดาษ
- แบบแผน
- รูปแบบไฟล์ PDF
- คน
- ท่อ
- พิกเซล
- ดาวเคราะห์
- คำทำนาย
- การคาดการณ์
- นำเสนอ
- โครงการ
- โครงการ
- พิสูจน์
- สาธารณะ
- ภาครัฐ
- สิ่งพิมพ์
- ประกาศ
- หลาม
- คุณภาพ
- เรดาร์
- พิสัย
- ดิบ
- ข้อมูลดิบ
- เรียลไทม์
- บันทึก
- ความสัมพันธ์
- ความต้องการ
- การวิจัย
- แหล่งข้อมูล
- REST
- ผลสอบ
- การอบรมขึ้นใหม่
- ทบทวน
- รีวิว
- วิ่ง
- วิ่ง
- sagemaker
- scalability
- ขนาด
- วิทยาศาสตร์
- นักวิทยาศาสตร์
- เอเชียตะวันออกเฉียงใต้
- ระดับน้ำทะเล
- ซีแอตเทิ
- เซ็นเซอร์
- บริการ
- ชุด
- การตั้งค่า
- Share
- ง่าย
- ขนาด
- ภาพย่อ
- หิมะ
- So
- สังคม
- สังคมดี
- โซลูชัน
- แก้
- ช่องว่าง
- ความเชี่ยวชาญ
- ความเร็ว
- ระยะ
- เริ่มต้น
- ข้อความที่เริ่ม
- การเก็บรักษา
- จัดเก็บ
- ที่พริ้ว
- ศึกษา
- ซูเปอร์
- สนับสนุน
- ที่สนับสนุน
- พื้นผิว
- ข้อมูลสังเคราะห์
- ระบบ
- วิชาการ
- เทคนิค
- เทคโนโลยี
- เทคโนโลยี
- ทดสอบ
- การทดสอบ
- เวลา
- ด้านบน
- หัวข้อ
- ลู่
- การติดตาม
- การฝึกอบรม
- แนวโน้ม
- ui
- เปิดเผย
- พร้อมใจกัน
- สหประชาชาติ
- มหาวิทยาลัย
- มหาวิทยาลัยแมริแลนด์
- บันทึก
- การปรับปรุง
- us
- ความคุ้มค่า
- ความเร็ว
- วีดีโอ
- ความชัดเจน
- วิสัยทัศน์
- นาฬิกา
- น้ำดื่ม
- คลื่น
- สาน
- Website
- งาน
- เวิร์กโฟลว์
- กำลังแรงงาน
- โรงงาน
- ปี


