ในบทความนี้เราจะได้เรียนรู้ วิธีปรับใช้และใช้งาน GPT4All model บนคอมพิวเตอร์ที่ใช้ CPU เท่านั้น (ผมใช้ a โปร Macbook ไม่มี GPU!)

ใช้ GPT4All บนคอมพิวเตอร์ของคุณ — รูปภาพโดยผู้เขียน
ในบทความนี้ เราจะติดตั้ง GPT4All บนเครื่องคอมพิวเตอร์ของเรา (LLM ที่ทรงพลัง) และเราจะค้นพบวิธีโต้ตอบกับเอกสารของเราด้วยไพธอน การรวบรวม PDF หรือบทความออนไลน์จะเป็นฐานความรู้สำหรับคำถาม/คำตอบของเรา
จาก เว็บไซต์อย่างเป็นทางการ GPT4All มันถูกอธิบายว่าเป็น แชทบ็อตที่ทำงานในเครื่องที่ใช้งานได้ฟรีและตระหนักถึงความเป็นส่วนตัว ไม่จำเป็นต้องใช้ GPU หรืออินเทอร์เน็ต
GTP4All เป็นระบบนิเวศสำหรับฝึกอบรมและปรับใช้ ที่มีประสิทธิภาพ และ การปรับแต่ง โมเดลภาษาขนาดใหญ่ที่เรียกใช้ ในท้องถิ่น บนซีพียูระดับผู้บริโภค
รุ่น GPT4All ของเราเป็นไฟล์ขนาด 4GB ที่คุณสามารถดาวน์โหลดและเสียบเข้ากับซอฟต์แวร์ระบบนิเวศแบบโอเพนซอร์ส GPT4All AI ธรรมดา อำนวยความสะดวกในระบบนิเวศซอฟต์แวร์คุณภาพสูงและปลอดภัย ขับเคลื่อนความพยายามเพื่อให้บุคคลและองค์กรสามารถฝึกอบรมและนำโมเดลภาษาขนาดใหญ่ของตนเองไปใช้ในพื้นที่ได้อย่างง่ายดาย
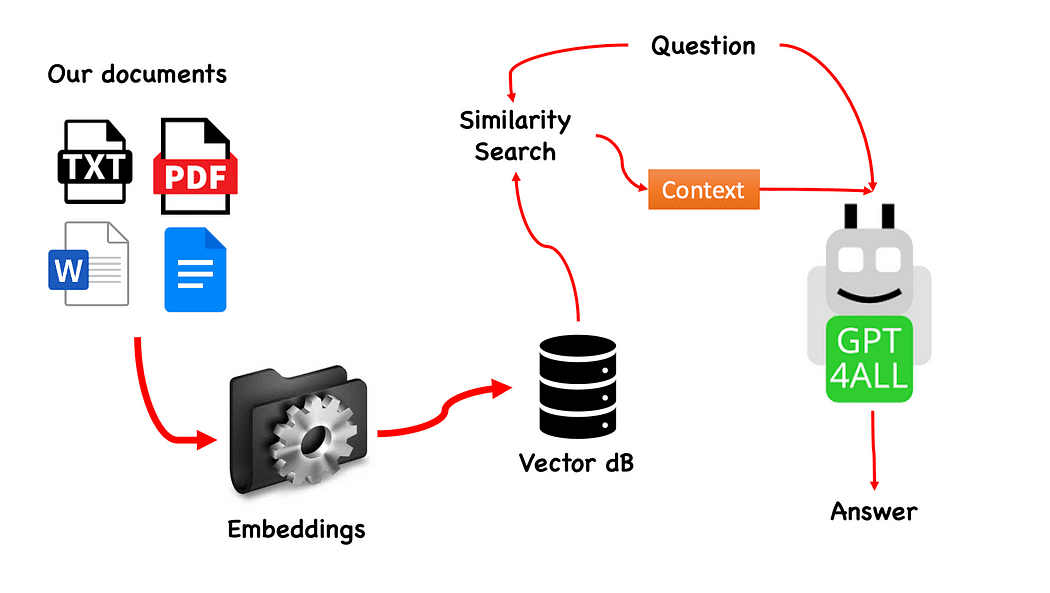
ขั้นตอนการทำงานของ QnA ด้วย GPT4All — สร้างโดยผู้เขียน
กระบวนการนี้ง่ายมาก (เมื่อคุณรู้) และสามารถทำซ้ำกับรุ่นอื่นได้เช่นกัน ขั้นตอนมีดังนี้:
- โหลดรุ่น GPT4All
- ใช้ หลังโซ่ เพื่อรับเอกสารของเราและโหลด
- แบ่งเอกสารเป็นชิ้นเล็ก ๆ ที่ย่อยได้โดยการฝัง
- ใช้ FAISS เพื่อสร้างฐานข้อมูลเวกเตอร์ของเราด้วยการฝัง
- ทำการค้นหาความคล้ายคลึงกัน (การค้นหาความหมาย) บนฐานข้อมูลเวกเตอร์ของเราตามคำถามที่เราต้องการส่งไปยัง GPT4All ซึ่งจะใช้เป็น สิ่งแวดล้อม สำหรับคำถามของเรา
- ป้อนคำถามและบริบทให้ GPT4All ด้วย หลังโซ่ และรอคำตอบ
ดังนั้นสิ่งที่เราต้องการคือการฝัง การฝังคือการแสดงตัวเลขของชิ้นส่วนของข้อมูล ตัวอย่างเช่น ข้อความ เอกสาร รูปภาพ เสียง ฯลฯ การแสดงจะจับความหมายเชิงความหมายของสิ่งที่กำลังฝัง และนี่คือสิ่งที่เราต้องการ สำหรับโปรเจกต์นี้ เราไม่สามารถพึ่งพาโมเดล GPU จำนวนมากได้ ดังนั้นเราจะดาวน์โหลดโมเดลดั้งเดิมของ Alpaca และใช้งานจาก หลังโซ่ การฝัง LlamaCpp. ไม่ต้องกังวล! ทุกอย่างอธิบายทีละขั้นตอน
สร้างสภาพแวดล้อมเสมือนจริง
สร้างโฟลเดอร์ใหม่สำหรับโครงการ Python ใหม่ของคุณ เช่น GPT4ALL_Fabio (ใส่ชื่อของคุณ…):
mkdir GPT4ALL_Fabio
cd GPT4ALL_Fabioจากนั้น สร้างสภาพแวดล้อมเสมือน Python ใหม่ หากคุณติดตั้ง python มากกว่าหนึ่งเวอร์ชัน ให้ระบุเวอร์ชันที่คุณต้องการ: ในกรณีนี้ ฉันจะใช้การติดตั้งหลักของฉัน ซึ่งเชื่อมโยงกับ python 3.10
python3 -m venv .venvคำสั่ง python3 -m venv .venv สร้างสภาพแวดล้อมเสมือนใหม่ชื่อ .venv (จุดจะสร้างไดเรกทอรีที่ซ่อนอยู่ที่เรียกว่า venv)
สภาพแวดล้อมเสมือนจัดเตรียมการติดตั้ง Python แบบแยก ซึ่งอนุญาตให้คุณติดตั้งแพ็คเกจและการอ้างอิงเฉพาะสำหรับโครงการเฉพาะ โดยไม่ส่งผลกระทบต่อการติดตั้ง Python ทั่วทั้งระบบหรือโครงการอื่นๆ การแยกนี้ช่วยรักษาความสม่ำเสมอและป้องกันความขัดแย้งที่อาจเกิดขึ้นระหว่างข้อกำหนดต่างๆ ของโครงการ
เมื่อสร้างสภาพแวดล้อมเสมือนจริงแล้ว คุณสามารถเปิดใช้งานได้โดยใช้คำสั่งต่อไปนี้:
source .venv/bin/activate 
เปิดใช้งานสภาพแวดล้อมเสมือนจริง
ไลบรารีที่จะติดตั้ง
สำหรับโครงการที่เรากำลังสร้าง เราไม่ต้องการแพ็คเกจมากเกินไป เราต้องการเพียง:
- การผูกไพ ธ อนสำหรับ GPT4All
- Langchain เพื่อโต้ตอบกับเอกสารของเรา
LangChain เป็นเฟรมเวิร์คสำหรับการพัฒนาแอพพลิเคชั่นที่ขับเคลื่อนโดยโมเดลภาษา ซึ่งไม่เพียงแต่ช่วยให้คุณเรียกใช้โมเดลภาษาผ่าน API ได้ แต่ยังเชื่อมต่อโมเดลภาษากับแหล่งข้อมูลอื่นๆ และอนุญาตให้โมเดลภาษาโต้ตอบกับสภาพแวดล้อมได้
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4สำหรับ LangChain คุณจะเห็นว่าเราได้ระบุเวอร์ชันด้วย ไลบรารีนี้ได้รับการอัปเดตจำนวนมากเมื่อเร็วๆ นี้ ดังนั้นเพื่อให้มั่นใจว่าการตั้งค่าของเราจะใช้งานได้ในวันพรุ่งนี้ จะเป็นการดีกว่าหากระบุเวอร์ชันที่เราทราบว่าใช้งานได้ดี ไม่มีโครงสร้างเป็นการพึ่งพาที่จำเป็นสำหรับตัวโหลด pdf และ ไพเทสเซอแรค และ pdf2 ภาพ เช่นกัน
หมายเหตุ: บนที่เก็บ GitHub มีไฟล์ specification.txt (แนะนำโดย เจแอล แอดซีอาร์) กับเวอร์ชันทั้งหมดที่เกี่ยวข้องกับโครงการนี้ คุณสามารถทำการติดตั้งได้ในครั้งเดียว หลังจากดาวน์โหลดลงในไดเร็กทอรีไฟล์หลักของโปรเจ็กต์ด้วยคำสั่งต่อไปนี้:
pip install -r requirements.txtในตอนท้ายของบทความฉันสร้าง ส่วนสำหรับการแก้ปัญหา. GitHub repo ยังมี READ.ME ที่อัปเดตพร้อมข้อมูลเหล่านี้ทั้งหมด
จำไว้ว่าบางอย่าง ไลบรารีมีเวอร์ชันที่พร้อมใช้งานโดยขึ้นอยู่กับเวอร์ชันของไพธอน คุณกำลังทำงานบนสภาพแวดล้อมเสมือนจริงของคุณ
ดาวน์โหลดโมเดลบนพีซีของคุณ
นี่เป็นขั้นตอนที่สำคัญจริงๆ
สำหรับโครงการเราต้องการ GPT4All อย่างแน่นอน กระบวนการที่อธิบายไว้ใน Nomic AI นั้นซับซ้อนมากและต้องใช้ฮาร์ดแวร์ที่พวกเราทุกคนมี (เช่นฉัน) ดังนั้น นี่คือลิงค์ไปยังรุ่น แปลงแล้วพร้อมใช้งานได้เลย เพียงคลิกที่ดาวน์โหลด
ดาวน์โหลดโมเดล GPT4All
ตามที่อธิบายไว้สั้นๆ ในบทนำ เราต้องการโมเดลสำหรับการฝังด้วย ซึ่งเป็นโมเดลที่เราสามารถเรียกใช้บน CPU ของเราโดยไม่บีบอัด คลิก ลิงค์ที่นี่เพื่อดาวน์โหลด alpaca-native-7B-ggml แปลงเป็น 4 บิตแล้วและพร้อมที่จะใช้เป็นแบบจำลองของเราสำหรับการฝัง

คลิกลูกศรดาวน์โหลดถัดจาก ggml-model-q4_0.bin
ทำไมเราต้องฝัง? หากคุณจำได้จากไดอะแกรมโฟลว์ ขั้นตอนแรกที่จำเป็นหลังจากที่เรารวบรวมเอกสารสำหรับฐานความรู้ของเราคือ ฝัง พวกเขา. การฝัง LLamaCPP จากรุ่น Alpaca นี้เข้ากับงานได้อย่างสมบูรณ์แบบ และรุ่นนี้ก็ค่อนข้างเล็กเช่นกัน (4 Gb) นอกจากนี้ คุณยังสามารถใช้โมเดล Alpaca สำหรับ QnA ของคุณได้!
อัปเดต 2023.05.25: ผู้ใช้ Mani Windows กำลังประสบปัญหาในการใช้การฝัง llamaCPP สิ่งนี้ส่วนใหญ่เกิดขึ้นเนื่องจากระหว่างการติดตั้งแพ็คเกจ python llama-cpp-python ด้วย:
pip install llama-cpp-pythonแพ็คเกจ pip กำลังจะรวบรวมจากแหล่งไลบรารี Windows มักจะไม่ได้ติดตั้งคอมไพเลอร์ CMake หรือ C เป็นค่าเริ่มต้นในเครื่อง แต่ไม่ต้องกังวลว่าจะมีวิธีแก้ไข
การรันการติดตั้ง llama-cpp-python ซึ่งจำเป็นต้องใช้โดย LangChain ที่มี llamaEmbeddings บน windows CMake C complier จะไม่ถูกติดตั้งตามค่าเริ่มต้น ดังนั้นคุณจึงไม่สามารถสร้างจากแหล่งที่มาได้
สำหรับผู้ใช้ Mac ที่มี Xtools และบน Linux โดยปกติแล้ว C complier จะมีอยู่ในระบบปฏิบัติการอยู่แล้ว
เพื่อหลีกเลี่ยงปัญหา คุณต้องใช้ล้อที่ผ่านเกณฑ์มาตรฐาน.
ไปที่นี่ https://github.com/abetlen/llama-cpp-python/releases
และมองหาวงล้อที่สอดคล้องกับสถาปัตยกรรมและเวอร์ชันไพธอนของคุณ — คุณต้องใช้ Weels เวอร์ชัน 0.1.49 เนื่องจากรุ่นที่สูงกว่าไม่รองรับ
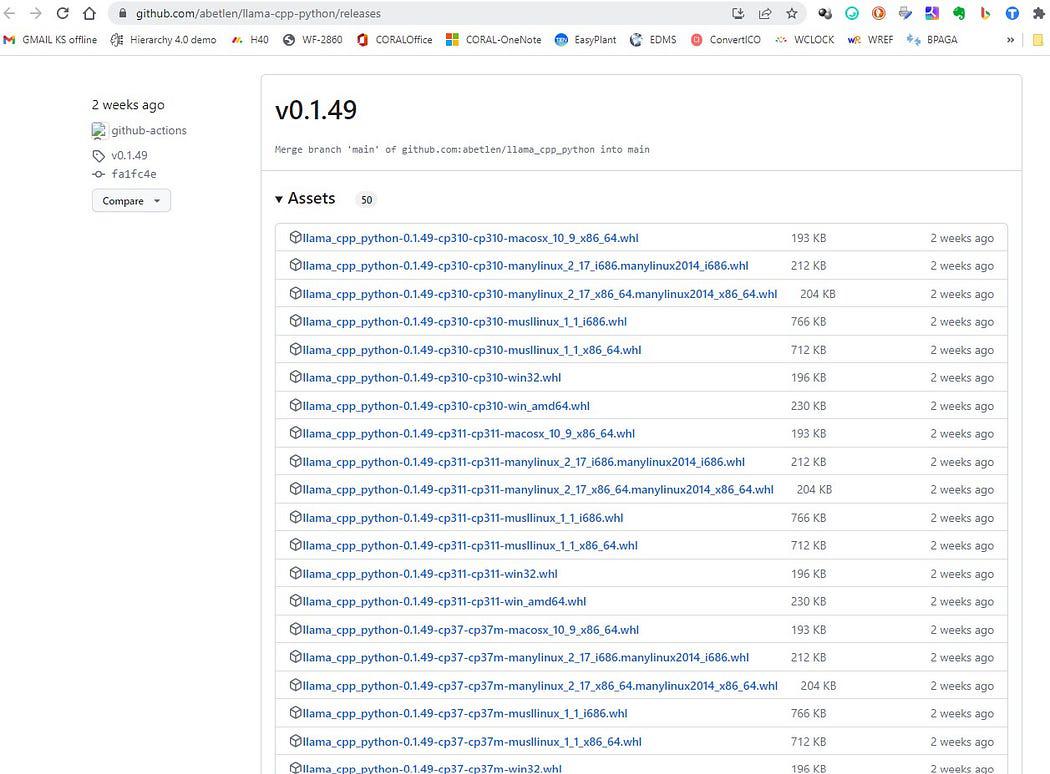
ภาพหน้าจอจาก https://github.com/abetlen/llama-cpp-python/releases
ในกรณีของฉัน ฉันมี Windows 10, 64 บิต, python 3.10
ดังนั้นไฟล์ของฉันคือ llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl
มีการติดตามปัญหาในที่เก็บ GitHub
หลังจากดาวน์โหลด คุณต้องใส่โมเดลทั้งสองในไดเร็กทอรีโมเดล ดังที่แสดงด้านล่าง

โครงสร้างไดเร็กทอรีและตำแหน่งที่จะวางไฟล์โมเดล
เนื่องจากเราต้องการควบคุมการโต้ตอบของเราในรูปแบบ GPT เราจึงต้องสร้างไฟล์ python (ขอเรียกมันว่า pygpt4all_test.py) นำเข้าการอ้างอิงและให้คำแนะนำกับโมเดล คุณจะเห็นว่ามันค่อนข้างง่าย
from pygpt4all.models.gpt4all import GPT4Allนี่คือการเชื่อมโยงหลามสำหรับโมเดลของเรา ตอนนี้เราสามารถโทรหาและเริ่มถามได้ มาลองสร้างสรรค์กัน
เราสร้างฟังก์ชันที่อ่านการเรียกกลับจากโมเดล และขอให้ GPT4All เติมประโยคให้สมบูรณ์
def new_text_callback(text): print(text, end="") model = GPT4All('./models/gpt4all-converted.bin')
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)คำสั่งแรกเป็นการบอกโปรแกรมของเราว่าจะหาโมเดลได้ที่ไหน (จำสิ่งที่เราทำในส่วนด้านบน)
คำสั่งที่สองขอให้โมเดลสร้างการตอบสนองและทำตามข้อความแจ้ง "กาลครั้งหนึ่งนานมาแล้ว" ของเรา
ในการเรียกใช้งาน ตรวจสอบให้แน่ใจว่าสภาพแวดล้อมเสมือนยังคงเปิดใช้งานอยู่ และเพียงแค่เรียกใช้ :
python3 pygpt4all_test.pyคุณควรดูข้อความโหลดของโมเดลและประโยคที่สมบูรณ์ อาจใช้เวลาเล็กน้อยทั้งนี้ขึ้นอยู่กับทรัพยากรฮาร์ดแวร์ของคุณ
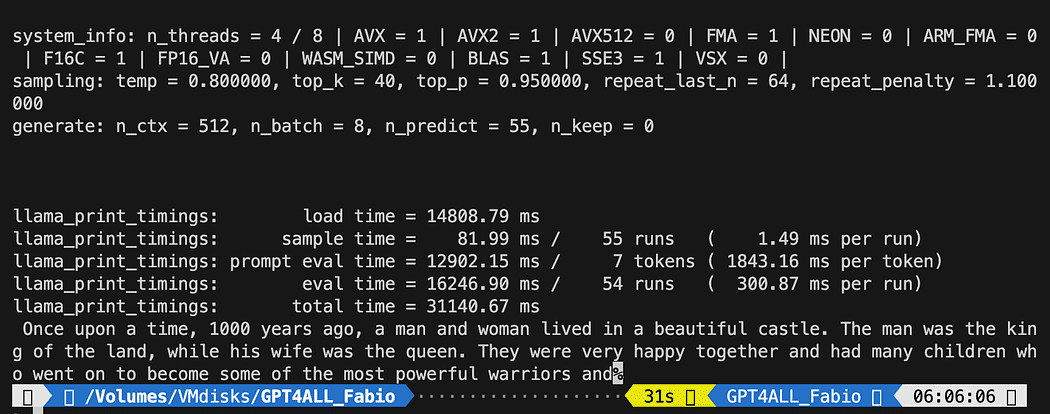
ผลลัพธ์อาจแตกต่างจากของคุณ… แต่สำหรับเรา สิ่งสำคัญคือมันใช้งานได้ และเราสามารถดำเนินการกับ LangChain เพื่อสร้างบางสิ่งขั้นสูงได้
หมายเหตุ (อัปเดต 2023.05.23): หากคุณพบข้อผิดพลาดเกี่ยวกับ pygpt4all ให้ตรวจสอบส่วนการแก้ไขปัญหาในหัวข้อนี้ด้วยวิธีการแก้ไขที่กำหนดโดย ราชนีช อัคการ์วาล or โดย Oscar Jeong
LangChain framework เป็นไลบรารีที่น่าทึ่งจริงๆ มันให้ ส่วนประกอบ เพื่อทำงานกับโมเดลภาษาด้วยวิธีที่ใช้งานง่าย และยังมี โซ่. โซ่สามารถถูกมองว่าเป็นการประกอบส่วนประกอบเหล่านี้ด้วยวิธีเฉพาะเพื่อให้บรรลุกรณีการใช้งานเฉพาะอย่างดีที่สุด สิ่งเหล่านี้มีวัตถุประสงค์เพื่อเป็นอินเทอร์เฟซในระดับที่สูงขึ้นซึ่งผู้คนสามารถเริ่มต้นใช้งานกรณีการใช้งานเฉพาะได้อย่างง่ายดาย โซ่เหล่านี้ได้รับการออกแบบให้ปรับแต่งได้
ในการทดสอบ Python ครั้งต่อไป เราจะใช้ a เทมเพลตพรอมต์. โมเดลภาษาใช้ข้อความเป็นอินพุต — ข้อความนั้นโดยทั่วไปเรียกว่าพรอมต์ โดยทั่วไปแล้ว นี่ไม่ใช่แค่สตริงฮาร์ดโค้ด แต่เป็นการรวมกันของเทมเพลต ตัวอย่างบางส่วน และการป้อนข้อมูลของผู้ใช้ LangChain มีคลาสและฟังก์ชันมากมายเพื่อให้การสร้างและการทำงานกับพรอมต์เป็นเรื่องง่าย เรามาดูกันดีกว่าว่าเราจะทำได้อย่างไร
สร้างไฟล์ python ใหม่และเรียกมันว่า my_langchain.py
# Import of langchain Prompt Template and Chain
from langchain import PromptTemplate, LLMChain # Import llm to be able to interact with GPT4All directly from langchain
from langchain.llms import GPT4All # Callbacks manager is required for the response handling from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler local_path = './models/gpt4all-converted.bin' callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])เรานำเข้าจาก LangChain the Prompt Template and Chain และ GPT4All llm class เพื่อให้สามารถโต้ตอบโดยตรงกับโมเดล GPT ของเรา
จากนั้น หลังจากตั้งค่าเส้นทาง llm ของเราแล้ว (เหมือนที่เราเคยทำมาก่อน) เราจะสร้างอินสแตนซ์ของผู้จัดการการโทรกลับ เพื่อให้เราสามารถรับคำตอบสำหรับคำถามของเราได้
การสร้างเทมเพลตนั้นง่ายมาก: ทำตาม กวดวิชาเอกสาร เราสามารถใช้สิ่งนี้ ...
template = """Question: {question} Answer: Let's think step by step on it. """
prompt = PromptTemplate(template=template, input_variables=["question"])พื้นที่ เทมเพลต ตัวแปรคือสตริงหลายบรรทัดที่มีโครงสร้างการโต้ตอบของเรากับโมเดล: ในวงเล็บปีกกาเราใส่ตัวแปรภายนอกลงในเทมเพลต ในสถานการณ์ของเราคือ คำถาม.
เนื่องจากเป็นตัวแปร คุณจึงสามารถตัดสินใจได้ว่าจะเป็นคำถามแบบฮาร์ดโค้ดหรือคำถามที่ผู้ใช้ป้อน: นี่คือตัวอย่างสองตัวอย่าง
# Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User input question...
question = input("Enter your question: ")สำหรับการทดสอบการทำงาน เราจะแสดงความคิดเห็นที่ผู้ใช้ป้อนเข้ามา ตอนนี้เราต้องเชื่อมโยงเทมเพลต คำถาม และโมเดลภาษาของเราเข้าด้วยกันเท่านั้น
template = """Question: {question}
Answer: Let's think step by step on it. """ prompt = PromptTemplate(template=template, input_variables=["question"]) # initialize the GPT4All instance
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True) # link the language model with our prompt template
llm_chain = LLMChain(prompt=prompt, llm=llm) # Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User imput question...
# question = input("Enter your question: ") #Run the query and get the results
llm_chain.run(question)อย่าลืมตรวจสอบว่าสภาพแวดล้อมเสมือนของคุณยังคงเปิดใช้งานอยู่และเรียกใช้คำสั่ง:
python3 my_langchain.pyคุณอาจได้รับผลลัพธ์ที่แตกต่างจากของฉัน สิ่งที่น่าทึ่งคือคุณสามารถเห็นเหตุผลทั้งหมดตามด้วย GPT4All ที่พยายามหาคำตอบให้คุณ การปรับคำถามอาจทำให้คุณได้ผลลัพธ์ที่ดีขึ้นด้วย
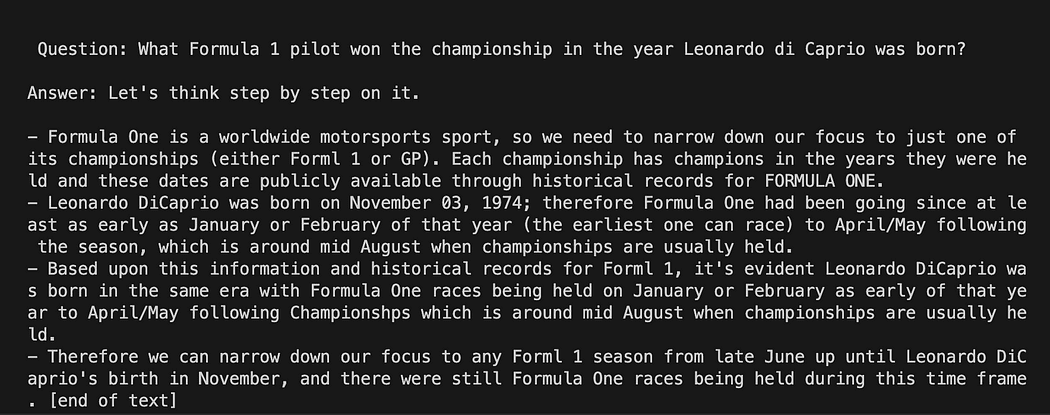
Langchain พร้อมเทมเพลตพรอมต์บน GPT4All
เรามาเริ่มส่วนที่น่าทึ่งกันที่นี่ เพราะเราจะพูดคุยกับเอกสารของเราโดยใช้ GPT4All เป็นแชทบอทที่ตอบคำถามของเรา
ลำดับขั้นตอน หมายถึง ขั้นตอนการทำงานของ QnA ด้วย GPT4Allคือการโหลดไฟล์ pdf ของเรา ทำให้มันเป็นชิ้นๆ หลังจากนั้นเราจะต้องใช้ Vector Store สำหรับการฝังของเรา เราจำเป็นต้องป้อนเอกสารย่อยของเราในร้านค้าเวกเตอร์เพื่อดึงข้อมูล จากนั้นเราจะฝังเอกสารเหล่านี้พร้อมกับการค้นหาความคล้ายคลึงกันในฐานข้อมูลนี้เพื่อเป็นบริบทสำหรับการสืบค้น LLM ของเรา
เพื่อจุดประสงค์นี้ เราจะใช้ FAISS โดยตรงจาก หลังโซ่ ห้องสมุด. FAISS เป็นไลบรารีโอเพ่นซอร์สจาก Facebook AI Research ซึ่งออกแบบมาเพื่อค้นหารายการที่คล้ายกันอย่างรวดเร็วในคอลเล็กชันข้อมูลขนาดใหญ่ที่มีมิติสูง มีวิธีการจัดทำดัชนีและการค้นหาเพื่อให้มองเห็นรายการที่คล้ายคลึงกันมากที่สุดในชุดข้อมูลได้ง่ายและรวดเร็วขึ้น มันสะดวกสำหรับเราเป็นพิเศษเพราะมันทำให้ง่ายขึ้น การดึงข้อมูล และทำให้เราสามารถบันทึกฐานข้อมูลที่สร้างขึ้นในเครื่องได้ ซึ่งหมายความว่าหลังจากการสร้างครั้งแรก ฐานข้อมูลจะถูกโหลดเร็วมากสำหรับการใช้งานต่อไป
การสร้างดัชนีเวกเตอร์ db
สร้างไฟล์ใหม่และเรียกมันว่า my_knowledge_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # function for loading only TXT files
from langchain.document_loaders import TextLoader # text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter # to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader # Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator # LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings # FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS import os #for interaaction with the files
import datetimeห้องสมุดแรกเหมือนกับที่เราเคยใช้มาก่อน นอกจากนี้ เรากำลังใช้อยู่ หลังโซ่ สำหรับการสร้างดัชนีร้านค้าเวกเตอร์ การฝัง LlamaCpp เพื่อโต้ตอบกับโมเดล Alpaca ของเรา (ปรับขนาดเป็น 4 บิตและคอมไพล์ด้วยไลบรารี cpp) และตัวโหลด PDF
เรามาโหลด LLM ของเราด้วยเส้นทางของตัวเอง: หนึ่งสำหรับการฝังและอีกอันสำหรับการสร้างข้อความ
# assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)สำหรับการทดสอบ มาดูกันว่าเราจัดการอ่านไฟล์ pfd ทั้งหมดหรือไม่ ขั้นตอนแรกคือประกาศ 3 ฟังก์ชันที่จะใช้ในเอกสารแต่ละฉบับ อย่างแรกคือการแยกข้อความที่แยกออกเป็นส่วนๆ อย่างที่สองคือการสร้างดัชนีเวกเตอร์ด้วยข้อมูลเมตา (เช่น หมายเลขหน้า ฯลฯ …) และอันสุดท้ายคือการทดสอบการค้นหาความคล้ายคลึงกัน (ฉันจะอธิบายให้ดีขึ้นในภายหลัง)
# Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sourcesตอนนี้ เราสามารถทดสอบการสร้างดัชนีสำหรับเอกสารใน เอกสาร ไดเร็กทอรี: เราต้องใส่ไฟล์ PDF ทั้งหมดของเราไว้ที่นั่น หลังโซ่ ยังมีวิธีการโหลดทั้งโฟลเดอร์ โดยไม่คำนึงถึงไฟล์ประเภทใด: เนื่องจากกระบวนการโพสต์มีความซับซ้อน ฉันจะกล่าวถึงในบทความถัดไปเกี่ยวกับรุ่น LaMini

ไดเร็กทอรีเอกสารของฉันมีไฟล์ pdf 4 ไฟล์
เราจะใช้ฟังก์ชันของเรากับเอกสารแรกในรายการ
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# load the documents with Langchain
docs = loader.load()
# Split in chunks
chunks = split_chunks(docs)
# create the db vector index
db0 = create_index(chunks)ในบรรทัดแรกเราใช้ os library เพื่อรับ รายชื่อไฟล์ pdf ภายในไดเร็กทอรีเอกสาร จากนั้นเราโหลดเอกสารแรก (doc_list[0]) จากโฟลเดอร์เอกสารด้วย หลังโซ่แยกเป็นชิ้นๆ แล้วเราก็สร้างฐานข้อมูลเวกเตอร์ด้วย ลามะ การฝัง
อย่างที่คุณเห็นเรากำลังใช้ วิธี pyPDF. อันนี้ใช้นานหน่อยเพราะต้องโหลดทีละไฟล์ แต่โหลด PDF โดยใช้ pypdf ลงในอาร์เรย์ของเอกสาร ช่วยให้คุณมีอาร์เรย์ที่แต่ละเอกสารมีเนื้อหาของหน้าและข้อมูลเมตาด้วย page ตัวเลข. สิ่งนี้สะดวกมากเมื่อคุณต้องการทราบแหล่งที่มาของบริบทที่เราจะมอบให้กับ GPT4All ด้วยข้อความค้นหาของเรา นี่คือตัวอย่างจาก readthedocs:
ภาพหน้าจอจาก เอกสารแลงเชน
เราสามารถเรียกใช้ไฟล์ python ด้วยคำสั่งจากเทอร์มินัล:
python3 my_knowledge_qna.pyหลังจากการโหลดโมเดลสำหรับการฝัง คุณจะเห็นโทเค็นที่ทำงานสำหรับการจัดทำดัชนี: อย่าตกใจเพราะมันต้องใช้เวลา โดยเฉพาะอย่างยิ่งถ้าคุณทำงานบน CPU เท่านั้น เช่นฉัน (ใช้เวลา 8 นาที)
เสร็จสิ้นเวกเตอร์ db ตัวแรก
ขณะที่ฉันอธิบายวิธี pyPDF นั้นช้ากว่า แต่ให้ข้อมูลเพิ่มเติมสำหรับการค้นหาความคล้ายคลึงกัน ในการวนซ้ำไฟล์ทั้งหมดของเรา เราจะใช้วิธีการที่สะดวกจาก FAISS ที่ช่วยให้เราสามารถผสานฐานข้อมูลต่างๆ เข้าด้วยกัน สิ่งที่เราทำตอนนี้คือเราใช้โค้ดด้านบนเพื่อสร้าง db แรก (เราจะเรียกว่า db0) และด้วย for วนซ้ำ เราสร้างดัชนีของไฟล์ถัดไปในรายการและรวมเข้าด้วยกันทันที db0.
นี่คือรหัส: โปรดทราบว่าฉันได้เพิ่มบันทึกบางส่วนเพื่อให้คุณทราบสถานะของความคืบหน้าโดยใช้ datetime.datetime.now() และพิมพ์เดลต้าของเวลาสิ้นสุดและเวลาเริ่มต้นเพื่อคำนวณระยะเวลาการดำเนินการ (คุณสามารถลบออกได้หากไม่ต้องการ)
คำแนะนำในการรวมเป็นเช่นนี้
# merge dbi with the existing db0
db0.merge_from(dbi)หนึ่งในคำแนะนำสุดท้ายคือการบันทึกฐานข้อมูลของเราในเครื่อง การสร้างทั้งรุ่นอาจใช้เวลาหลายชั่วโมงด้วยซ้ำ (ขึ้นอยู่กับจำนวนเอกสารที่คุณมี) ดังนั้นจึงเป็นเรื่องดีที่เราต้องทำเพียงครั้งเดียว!
# Save the databasae locally
db0.save_local("my_faiss_index")นี่คือรหัสทั้งหมด เราจะแสดงความคิดเห็นหลายส่วนเมื่อเราโต้ตอบกับ GPT4All ที่โหลดดัชนีโดยตรงจากโฟลเดอร์ของเรา
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
general_start = datetime.datetime.now() #not used now but useful
print("starting the loop...")
loop_start = datetime.datetime.now() #not used now but useful
print("generating fist vector database and then iterate with .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Main Vector database created. Start iteration and merging...")
for i in range(1,num_of_docs): print(doc_list[i]) print(f"loop position {i}") loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i])) start = datetime.datetime.now() #not used now but useful docs = loader.load() chunks = split_chunks(docs) dbi = create_index(chunks) print("start merging with db0...") db0.merge_from(dbi) end = datetime.datetime.now() #not used now but useful elapsed = end - start #not used now but useful #total time print(f"completed in {elapsed}") print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now but useful
loop_elapsed = loop_end - loop_start #not used now but useful
print(f"All documents processed in {loop_elapsed}")
print(f"the daatabase is done with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging completed")
print("-----------------------------------")
print("Saving Merged Database Locally")
# Save the databasae locally
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now but useful
general_elapsed = general_end - general_start #not used now but useful
print(f"All indexing completed in {general_elapsed}")
print("-----------------------------------")  การรันไฟล์ python ใช้เวลา 22 นาที
การรันไฟล์ python ใช้เวลา 22 นาที
ถามคำถามกับ GPT4All ในเอกสารของคุณ
ตอนนี้เราอยู่ที่นี่ เรามีดัชนีของเรา เราสามารถโหลดได้ และด้วยเทมเพลตพรอมต์ เราสามารถขอให้ GPT4All ตอบคำถามของเราได้ เราเริ่มต้นด้วยคำถามแบบฮาร์ดโค้ด จากนั้นเราจะวนซ้ำคำถามป้อนเข้าของเรา
ใส่รหัสต่อไปนี้ในไฟล์ python db_loading.py และเรียกใช้ด้วยคำสั่งจากเทอร์มินัล python3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime # TEST FOR SIMILARITY SEARCH # assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True) # Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources # Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded question
query = "What is a PLC and what is the difference with a PC"
docs = index.similarity_search(query)
# Get the matches best 3 results - defined in the function k=3
print(f"The question is: {query}")
print("Here the result of the semantic search on the index, without GPT4All..")
print(docs[0])ข้อความที่พิมพ์คือรายการของแหล่งข้อมูล 3 แหล่งที่ตรงกับข้อความค้นหามากที่สุด โดยระบุชื่อเอกสารและหมายเลขหน้าด้วย
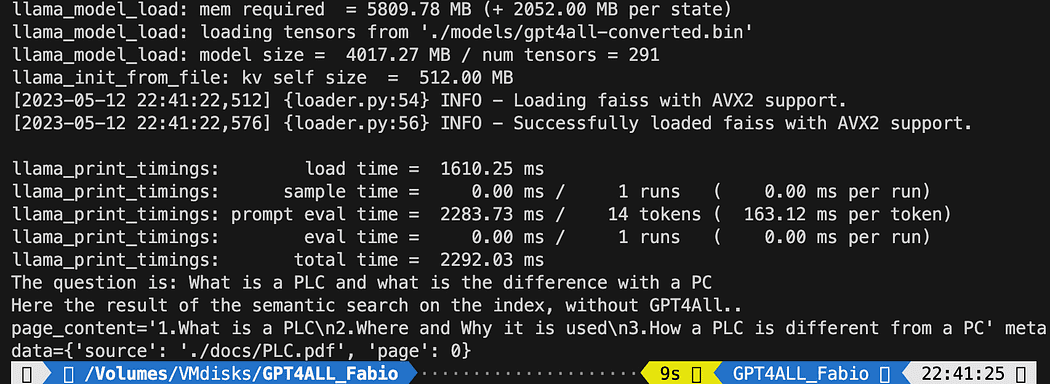
ผลลัพธ์ของการค้นหาความหมายที่เรียกใช้ไฟล์ db_loading.py
ตอนนี้เราสามารถใช้การค้นหาความคล้ายคลึงกันเป็นบริบทสำหรับการค้นหาของเราโดยใช้เทมเพลตพรอมต์ หลังจาก 3 ฟังก์ชัน ให้แทนที่โค้ดทั้งหมดด้วยสิ่งต่อไปนี้:
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings) # create the prompt template
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step.""" # Hardcoded question
question = "What is a PLC and what is the difference with a PC"
matched_docs, sources = similarity_search(question, index)
# Creating the context
context = "n".join([doc.page_content for doc in matched_docs])
# instantiating the prompt template and the GPT4All chain
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Print the result
print(llm_chain.run(question))หลังจากเรียกใช้คุณจะได้ผลลัพธ์เช่นนี้ (แต่อาจแตกต่างกันไป) น่าทึ่งไม่!?!?
Please use the following context to answer questions.
Context: 1.What is a PLC
2.Where and Why it is used
3.How a PLC is different from a PC
PLC is especially important in industries where safety and reliability are
critical, such as manufacturing plants, chemical plants, and power plants.
How a PLC is different from a PC
Because a PLC is a specialized computer used in industrial and
manufacturing applications to control machinery and processes.,the
hardware components of a typical PLC must be able to interact with
industrial device. So a typical PLC hardware include:
---
Question: What is a PLC and what is the difference with a PC
Answer: Let's think step by step. 1) A Programmable Logic Controller (PLC), also called Industrial Control System or ICS, refers to an industrial computer that controls various automated processes such as manufacturing machines/assembly lines etcetera through sensors and actuators connected with it via inputs & outputs. It is a form of digital computers which has the ability for multiple instruction execution (MIE), built-in memory registers used by software routines, Input Output interface cards(IOC) to communicate with other devices electronically/digitally over networks or buses etcetera
2). A Programmable Logic Controller is widely utilized in industrial automation as it has the ability for more than one instruction execution. It can perform tasks automatically and programmed instructions, which allows it to carry out complex operations that are beyond a Personal Computer (PC) capacity. So an ICS/PLC contains built-in memory registers used by software routines or firmware codes etcetera but PC doesn't contain them so they need external interfaces such as hard disks drives(HDD), USB ports, serial and parallel communication protocols to store data for further analysis or report generation.หากคุณต้องการให้ผู้ใช้ป้อนคำถามเพื่อแทนที่บรรทัด
question = "What is a PLC and what is the difference with a PC"ด้วยสิ่งนี้:
question = input("Your question: ")ถึงเวลาที่คุณจะทดลอง ถามคำถามต่างๆ ในหัวข้อทั้งหมดที่เกี่ยวข้องกับเอกสารของคุณ แล้วดูผลลัพธ์ มีช่องว่างขนาดใหญ่สำหรับการปรับปรุง แน่นอนว่าต้องพร้อมท์และเทมเพลต: คุณสามารถดูได้ ที่นี่เพื่อหาแรงบันดาลใจ. แต่ หลังโซ่ เอกสารน่าทึ่งจริงๆ (ฉันทำตามได้ !!)
สามารถติดตามโค้ดได้จากบทความหรือตรวจสอบได้ที่ repo GitHub ของฉัน.
ฟาบิโอ มาตริคาร์ดี้ นักการศึกษา ครู วิศวกร และผู้ใฝ่เรียนรู้ เขาสอนนักเรียนรุ่นเยาว์มาเป็นเวลา 15 ปี และตอนนี้เขาฝึกสอนพนักงานใหม่ที่ Key Solution Srl เขาเริ่มอาชีพของฉันในฐานะวิศวกรระบบอัตโนมัติทางอุตสาหกรรมในปี 2010 เขาหลงใหลในการเขียนโปรแกรมตั้งแต่ยังเป็นวัยรุ่น เขาค้นพบความสวยงามของซอฟต์แวร์สำหรับสร้างและส่วนต่อประสานระหว่างเครื่องจักรกับมนุษย์เพื่อทำให้บางสิ่งมีชีวิตขึ้นมา การสอนและการฝึกสอนเป็นส่วนหนึ่งของกิจวัตรประจำวันของฉัน เช่นเดียวกับการศึกษาและเรียนรู้วิธีการเป็นผู้นำที่กระตือรือร้นด้วยทักษะการจัดการที่ทันสมัย เข้าร่วมกับฉันในการเดินทางสู่การออกแบบที่ดีขึ้น การรวมระบบการคาดการณ์โดยใช้การเรียนรู้ของเครื่องและปัญญาประดิษฐ์ตลอดวงจรชีวิตทางวิศวกรรมทั้งหมด
Original. โพสต์ใหม่โดยได้รับอนุญาต
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- การเงิน EVM ส่วนต่อประสานแบบครบวงจรสำหรับการเงินแบบกระจายอำนาจ เข้าถึงได้ที่นี่.
- กลุ่มสื่อควอนตัม IR/PR ขยาย เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. ข้อมูลอัจฉริยะ Web3 ขยายความรู้ เข้าถึงได้ที่นี่.
- ที่มา: https://www.kdnuggets.com/2023/06/gpt4all-local-chatgpt-documents-free.html?utm_source=rss&utm_medium=rss&utm_campaign=gpt4all-is-the-local-chatgpt-for-your-documents-and-it-is-free
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 1
- 10
- 11
- 12
- 13
- 14
- ลด 15%
- 16
- 2023
- 22
- 23
- 25
- 420
- 7
- 8
- 9
- a
- ความสามารถ
- สามารถ
- เกี่ยวกับเรา
- ข้างบน
- บรรลุผล
- กระทำ
- เปิดใช้งาน
- ที่เพิ่ม
- นอกจากนี้
- เพิ่มเติม
- สูง
- น่าสงสาร
- หลังจาก
- AI
- วิจัยไอ
- ทั้งหมด
- อนุญาต
- ช่วยให้
- แล้ว
- ด้วย
- am
- น่าอัศจรรย์
- an
- การวิเคราะห์
- และ
- คำตอบ
- ใด
- API
- การใช้งาน
- ใช้
- สถาปัตยกรรม
- เป็น
- แถว
- บทความ
- บทความ
- เทียม
- ปัญญาประดิษฐ์
- AS
- ที่เกี่ยวข้อง
- At
- เสียง
- อัตโนมัติ
- อัตโนมัติ
- อัตโนมัติ
- ใช้ได้
- หลีกเลี่ยง
- ฐาน
- ตาม
- BE
- ร้านเสริมสวยเกาหลี
- เพราะ
- รับ
- ก่อน
- กำลัง
- ด้านล่าง
- ที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- เกิน
- ใหญ่
- BIN
- ผูกพัน
- บิต
- เกิด
- สั้น
- นำมาซึ่ง
- สร้าง
- การก่อสร้าง
- built-in
- รถบัส
- แต่
- by
- คำนวณ
- โทรศัพท์
- ที่เรียกว่า
- โทร
- CAN
- ไม่ได้
- ความจุ
- จับ
- ความก้าวหน้า
- พกพา
- กรณี
- จับ
- CD
- บาง
- อย่างแน่นอน
- โซ่
- ห่วงโซ่
- แชมป์
- chatbot
- ChatGPT
- ตรวจสอบ
- สารเคมี
- ชั้น
- ชั้นเรียน
- คลิก
- การฝึก
- รหัส
- รหัส
- รวบรวม
- ชุด
- คอลเลกชัน
- การผสมผสาน
- ความเห็น
- อย่างธรรมดา
- สื่อสาร
- การสื่อสาร
- เข้ากันได้
- สมบูรณ์
- เสร็จ
- เสร็จสิ้น
- ซับซ้อน
- ซับซ้อน
- ส่วนประกอบ
- คอมพิวเตอร์
- คอมพิวเตอร์
- เชื่อมต่อ
- งานที่เชื่อมต่อ
- ก่อสร้าง
- ผู้บริโภค
- มี
- เนื้อหา
- สิ่งแวดล้อม
- ควบคุม
- ตัวควบคุม
- การควบคุม
- สะดวกสบาย
- แปลง
- ได้
- หน้าปก
- ซีพียู
- สร้าง
- ที่สร้างขึ้น
- สร้าง
- การสร้าง
- การสร้าง
- ความคิดสร้างสรรค์
- วิกฤติ
- ปรับแต่งได้
- ประจำวัน
- ข้อมูล
- ฐานข้อมูล
- ฐานข้อมูล
- วันที่
- วันเวลา
- ตัดสินใจ
- ค่าเริ่มต้น
- กำหนด
- สันดอน
- การอยู่ที่
- ทั้งนี้ขึ้นอยู่กับ
- ขึ้นอยู่กับ
- ปรับใช้
- อธิบาย
- ออกแบบ
- ได้รับการออกแบบ
- ที่ต้องการ
- ที่กำลังพัฒนา
- เครื่อง
- อุปกรณ์
- DID
- ความแตกต่าง
- ต่าง
- ย่อยได้
- ดิจิตอล
- โดยตรง
- ค้นพบ
- ค้นพบ
- do
- เอกสาร
- เอกสาร
- เอกสาร
- ทำ
- doesn
- ทำ
- Dont
- DOT
- ดาวน์โหลด
- การขับขี่
- ในระหว่าง
- แต่ละ
- ง่ายดาย
- อย่างง่ายดาย
- ง่าย
- ระบบนิเวศ
- ระบบนิเวศ
- ความพยายาม
- ฝัง
- ที่ฝัง
- การฝัง
- พนักงาน
- ทำให้สามารถ
- ปลาย
- วิศวกร
- ชั้นเยี่ยม
- เข้าสู่
- คนที่กระตือรือร้น
- ทั้งหมด
- สิ่งแวดล้อม
- ความผิดพลาด
- โดยเฉพาะอย่างยิ่ง
- ฯลฯ
- อีเธอร์ (ETH)
- แม้
- ทุกอย่าง
- เผง
- ตัวอย่าง
- ตัวอย่าง
- การปฏิบัติ
- ที่มีอยู่
- การทดลอง
- อธิบาย
- อธิบาย
- อธิบาย
- ภายนอก
- ใบหน้า
- อำนวยความสะดวก
- หันหน้าไปทาง
- FAST
- เร็วขึ้น
- เนื้อไม่มีมัน
- ไฟล์
- หา
- ปลาย
- ชื่อจริง
- พอดี
- ไหล
- ปฏิบัติตาม
- ตาม
- ดังต่อไปนี้
- ดังต่อไปนี้
- สำหรับ
- ฟอร์ม
- รูป
- สูตร
- 1 สูตร
- กรอบ
- ราคาเริ่มต้นที่
- ฟังก์ชัน
- ฟังก์ชั่น
- ต่อไป
- สร้าง
- การสร้าง
- รุ่น
- ได้รับ
- GitHub
- ให้
- กำหนด
- จะช่วยให้
- ให้
- ไป
- ดี
- GPU
- เกรด
- การจัดการ
- ที่เกิดขึ้น
- ยาก
- ฮาร์ดแวร์
- มี
- he
- หนัก
- จะช่วยให้
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- ซ่อนเร้น
- จุดสูง
- สูงกว่า
- ชั่วโมง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTML
- ที่ http
- HTTPS
- เป็นมนุษย์
- i
- ICS
- if
- ภาพ
- ทันที
- การดำเนินการ
- นำเข้า
- สำคัญ
- การปรับปรุง
- in
- ประกอบด้วย
- ดัชนี
- ดัชนี
- บุคคล
- อุตสาหกรรม
- ระบบอัตโนมัติอุตสาหกรรม
- อุตสาหกรรม
- ข้อมูล
- อินพุต
- อินพุตเอาต์พุต
- ปัจจัยการผลิต
- ติดตั้ง
- การติดตั้ง
- ตัวอย่าง
- คำแนะนำการใช้
- บูรณาการ
- Intelligence
- ตั้งใจว่า
- โต้ตอบ
- ปฏิสัมพันธ์
- อินเตอร์เฟซ
- อินเตอร์เฟซ
- อินเทอร์เน็ต
- เข้าไป
- บทนำ
- เปลี่ยว
- ความเหงา
- IT
- รายการ
- การย้ำ
- ITS
- การสัมภาษณ์
- ร่วม
- การเดินทาง
- เพียงแค่
- KD นักเก็ต
- คีย์
- ทราบ
- ความรู้
- ภาษา
- ใหญ่
- ชื่อสกุล
- ต่อมา
- ผู้นำ
- การเรียนรู้
- ชั้น
- ห้องสมุด
- ห้องสมุด
- ชีวิต
- วงจรชีวิต
- กดไลก์
- เส้น
- LINK
- ลินุกซ์
- รายการ
- น้อย
- โหลด
- loader
- โหลด
- ในประเทศ
- ในท้องถิ่น
- ตรรกะ
- นาน
- อีกต่อไป
- ดู
- Lot
- Mac
- เครื่อง
- เรียนรู้เครื่อง
- เครื่องจักรกล
- หลัก
- ส่วนใหญ่
- เก็บรักษา
- ทำ
- การจัดการ
- การจัดการ
- ผู้จัดการ
- ผู้จัดการ
- การผลิต
- หลาย
- อาจ..
- ความหมาย
- วิธี
- หน่วยความจำ
- ผสาน
- การผสม
- เมตาดาต้า
- วิธี
- วิธีการ
- ใจ
- นาที
- แบบ
- โมเดล
- ข้อมูลเพิ่มเติม
- มากที่สุด
- หลาย
- ต้อง
- my
- ชื่อ
- พื้นเมือง
- จำเป็นต้อง
- เครือข่าย
- ใหม่
- ถัดไป
- ตอนนี้
- จำนวน
- ตัวเลข
- วัตถุ
- of
- เสนอ
- on
- ครั้งเดียว
- ONE
- ออนไลน์
- เพียง
- โอเพนซอร์ส
- การดำเนินการ
- การดำเนินการ
- or
- ใบสั่ง
- องค์กร
- OS
- อื่นๆ
- ของเรา
- ออก
- เอาท์พุต
- เกิน
- ของตนเอง
- แพ็คเกจ
- แพคเกจ
- หน้า
- Parallel
- ส่วนหนึ่ง
- ในสิ่งที่สนใจ
- โดยเฉพาะ
- ส่ง
- หลงใหล
- เส้นทาง
- PC
- รูปแบบไฟล์ PDF
- คน
- ดำเนินการ
- การอนุญาต
- ส่วนบุคคล
- ภาพ
- ชิ้น
- นักบิน
- พืช
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- บมจ.
- กรุณา
- ปลั๊ก
- พอร์ต
- ตำแหน่ง
- โพสต์
- ที่มีศักยภาพ
- อำนาจ
- โรงไฟฟ้า
- ขับเคลื่อน
- ที่มีประสิทธิภาพ
- ก่อน
- ป้องกัน
- พิมพ์
- การพิมพ์
- ปัญหาที่เกิดขึ้น
- กระบวนการ
- การประมวลผล
- กระบวนการ
- โครงการ
- โปรแกรม
- การเขียนโปรแกรม
- ความคืบหน้า
- โครงการ
- โครงการ
- โปรโตคอล
- ให้
- วัตถุประสงค์
- ใส่
- หลาม
- คุณภาพ
- คำถาม
- คำถาม
- อย่างรวดเร็ว
- ค่อนข้าง
- อ่าน
- พร้อม
- จริงๆ
- การได้รับ
- เมื่อเร็ว ๆ นี้
- เรียกว่า
- หมายถึง
- ไม่คำนึงถึง
- ลงทะเบียน
- ที่เกี่ยวข้อง
- ความเชื่อถือได้
- วางใจ
- จำ
- เอาออก
- ซ้ำแล้วซ้ำอีก
- แทนที่
- รายงาน
- กรุ
- การแสดง
- จำเป็นต้องใช้
- ความต้องการ
- ต้อง
- การวิจัย
- แหล่งข้อมูล
- คำตอบ
- การตอบสนอง
- ผล
- ผลสอบ
- กลับ
- ห้อง
- วิ่ง
- วิ่ง
- s
- ความปลอดภัย
- เดียวกัน
- ลด
- ประหยัด
- สถานการณ์
- ค้นหา
- ค้นหา
- ที่สอง
- Section
- ปลอดภัย
- เห็น
- เซ็นเซอร์
- ประโยค
- ลำดับ
- อนุกรม
- การตั้งค่า
- การติดตั้ง
- หลาย
- การถ่ายภาพ
- น่า
- แสดง
- คล้ายคลึงกัน
- ง่าย
- ง่ายดาย
- ตั้งแต่
- เดียว
- ทักษะ
- เล็ก
- So
- ซอฟต์แวร์
- ทางออก
- บาง
- บางสิ่งบางอย่าง
- แหล่ง
- แหล่งที่มา
- เฉพาะ
- พิเศษ
- โดยเฉพาะ
- ที่ระบุไว้
- แยก
- จุด
- เริ่มต้น
- ข้อความที่เริ่ม
- ที่เริ่มต้น
- คำแถลง
- Status
- ขั้นตอน
- ขั้นตอน
- ยังคง
- จัดเก็บ
- เชือก
- โครงสร้าง
- นักเรียน
- การศึกษา
- อย่างเช่น
- ระบบ
- เอา
- คุย
- งาน
- ครู
- การเรียนการสอน
- ขบเผาะ
- เทมเพลต
- สถานีปลายทาง
- ทดสอบ
- การทดสอบทำงาน
- การทดสอบ
- การสร้างข้อความ
- กว่า
- ที่
- พื้นที่
- ของพวกเขา
- พวกเขา
- แล้วก็
- ที่นั่น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- คิด
- นี้
- คิดว่า
- ตลอด
- ตลอด
- เวลา
- ไปยัง
- ร่วมกัน
- ราชสกุล
- วันพรุ่งนี้
- เกินไป
- เอา
- หัวข้อ
- หัวข้อ
- ไปทาง
- รถไฟ
- ลอง
- สอง
- ชนิด
- ตามแบบฉบับ
- เป็นปกติ
- ให้กับคุณ
- การปรับปรุง
- เมื่อ
- us
- การใช้
- USB
- ใช้
- ใช้กรณี
- มือสอง
- ผู้ใช้งาน
- ผู้ใช้
- การใช้
- มักจะ
- ใช้
- ต่างๆ
- ตรวจสอบ
- รุ่น
- มาก
- ผ่านทาง
- เสมือน
- W3
- รอ
- ต้องการ
- คือ
- ทาง..
- วิธี
- we
- Website
- ดี
- อะไร
- ความหมายของ
- ล้อ
- เมื่อ
- ที่
- WHO
- ทำไม
- อย่างกว้างขวาง
- จะ
- หน้าต่าง
- ผู้ใช้ Windows
- กับ
- ภายใน
- ไม่มี
- วอน
- งาน
- การทำงาน
- ปี
- ปี
- เธอ
- หนุ่มสาว
- ของคุณ
- ลมทะเล










