
September 20, 2023
แบบจำลองพื้นฐาน (FMs) ถือเป็นการเริ่มต้นยุคใหม่ การเรียนรู้ของเครื่อง (ML) และ ปัญญาประดิษฐ์ (AI)ซึ่งนำไปสู่การพัฒนาที่เร็วขึ้นของ AI ซึ่งสามารถปรับให้เข้ากับงานดาวน์สตรีมที่หลากหลายและปรับแต่งให้เหมาะกับอาร์เรย์ของแอปพลิเคชัน
ด้วยความสำคัญที่เพิ่มขึ้นของการประมวลผลข้อมูลในสถานที่ทำงาน การให้บริการโมเดล AI ที่ Edge ขององค์กร ช่วยให้สามารถคาดการณ์ได้เกือบจะเรียลไทม์ ขณะเดียวกันก็ปฏิบัติตามข้อกำหนดด้านอธิปไตยของข้อมูลและความเป็นส่วนตัว โดยการผสมผสาน ไอบีเอ็ม วัตสัน ความสามารถด้านข้อมูลและแพลตฟอร์ม AI สำหรับ FM ที่มีการประมวลผลแบบเอดจ์ องค์กรต่างๆ สามารถเรียกใช้ปริมาณงาน AI สำหรับการปรับแต่ง FM แบบละเอียดและการอนุมานที่ขอบการปฏิบัติงาน ช่วยให้องค์กรต่างๆ สามารถปรับขนาดการใช้งาน AI ที่ Edge ได้ ซึ่งช่วยลดเวลาและค่าใช้จ่ายในการปรับใช้ด้วยเวลาตอบสนองที่เร็วขึ้น
โปรดตรวจสอบงวดทั้งหมดในบล็อกโพสต์ชุดนี้เกี่ยวกับ Edge Computing:
โมเดลพื้นฐานคืออะไร?
โมเดลพื้นฐาน (FM) ซึ่งได้รับการฝึกฝนเกี่ยวกับชุดข้อมูลที่ไม่มีป้ายกำกับจำนวนมาก กำลังขับเคลื่อนแอปพลิเคชันปัญญาประดิษฐ์ (AI) ที่ล้ำสมัย สามารถปรับให้เข้ากับงานดาวน์สตรีมได้หลากหลายและปรับแต่งอย่างละเอียดสำหรับแอปพลิเคชันต่างๆ โมเดล AI สมัยใหม่ซึ่งดำเนินงานเฉพาะเจาะจงในโดเมนเดียว กำลังเปิดทางให้กับ FM เพราะพวกเขาเรียนรู้โดยทั่วไปมากขึ้นและทำงานข้ามโดเมนและปัญหาต่างๆ ตามชื่อที่แสดง FM อาจเป็นรากฐานสำหรับการประยุกต์ใช้โมเดล AI มากมาย
FM จัดการกับความท้าทายสำคัญสองประการที่ทำให้องค์กรต่างๆ ไม่สามารถปรับขนาดการนำ AI มาใช้ ประการแรก องค์กรต่างๆ ผลิตข้อมูลที่ไม่มีป้ายกำกับจำนวนมหาศาล โดยมีเพียงบางส่วนเท่านั้นที่มีป้ายกำกับสำหรับการฝึกอบรมโมเดล AI ประการที่สอง งานการติดป้ายกำกับและคำอธิบายประกอบนี้เป็นงานที่ต้องใช้มนุษย์เป็นอย่างมาก โดยมักต้องใช้เวลาหลายร้อยชั่วโมงจากผู้เชี่ยวชาญเฉพาะเรื่อง (SME) ทำให้มีต้นทุนที่จำกัดในการปรับขนาดตามกรณีการใช้งาน เนื่องจากต้องใช้กองทัพของ SME และผู้เชี่ยวชาญด้านข้อมูล ด้วยการนำเข้าข้อมูลที่ไม่มีป้ายกำกับจำนวนมหาศาล และใช้เทคนิคที่มีการดูแลตนเองสำหรับการฝึกโมเดล FMs ได้ขจัดปัญหาคอขวดเหล่านี้ และเปิดช่องทางสำหรับการนำ AI มาใช้ทั่วทั้งองค์กรในวงกว้าง ข้อมูลจำนวนมหาศาลที่มีอยู่ในทุกธุรกิจกำลังรอการเผยแพร่เพื่อขับเคลื่อนข้อมูลเชิงลึก
โมเดลภาษาขนาดใหญ่คืออะไร?
โมเดลภาษาขนาดใหญ่ (LLM) เป็นคลาสของโมเดลพื้นฐาน (FM) ที่ประกอบด้วยชั้นของ เครือข่ายประสาทเทียม ที่ได้รับการฝึกอบรมเกี่ยวกับข้อมูลจำนวนมหาศาลที่ไม่มีป้ายกำกับเหล่านี้ พวกเขาใช้อัลกอริธึมการเรียนรู้ด้วยตนเองเพื่อดำเนินการต่างๆ การประมวลผลภาษาธรรมชาติ (NLP) งานในลักษณะที่คล้ายคลึงกับวิธีที่มนุษย์ใช้ภาษา (ดูรูปที่ 1)
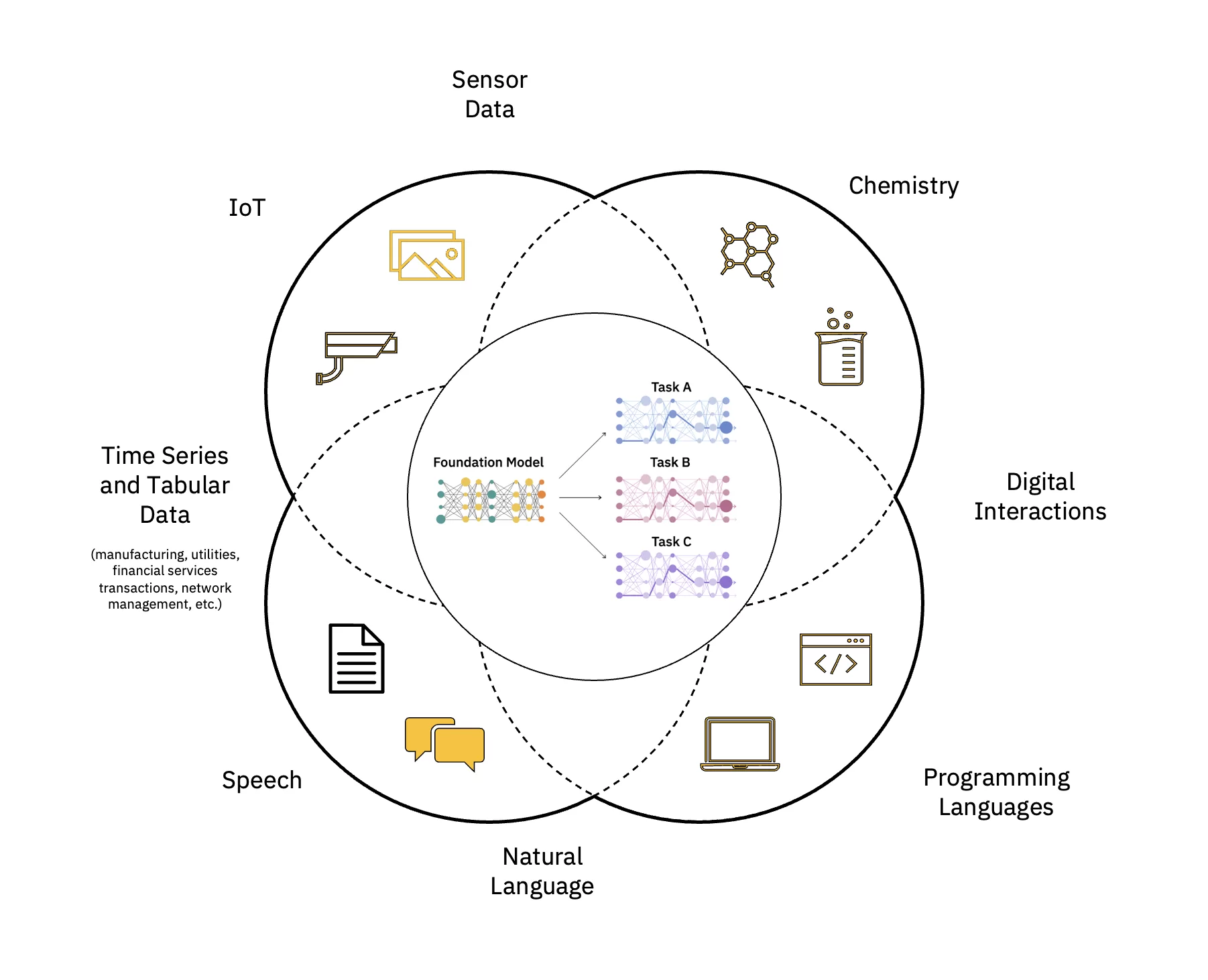
ปรับขนาดและเร่งผลกระทบของ AI
มีหลายขั้นตอนในการสร้างและปรับใช้โมเดลพื้นฐาน (FM) สิ่งเหล่านี้รวมถึงการนำเข้าข้อมูล การเลือกข้อมูล การประมวลผลข้อมูลล่วงหน้า การฝึกอบรม FM ล่วงหน้า การปรับแต่งโมเดลสำหรับงานดาวน์สตรีมหนึ่งงานขึ้นไป การให้บริการการอนุมาน และการกำกับดูแลโมเดลข้อมูลและ AI และการจัดการวงจรชีวิต ซึ่งทั้งหมดนี้สามารถอธิบายได้ว่าเป็น FMOPs.
เพื่อช่วยในเรื่องทั้งหมดนี้ IBM จึงนำเสนอเครื่องมือและความสามารถที่จำเป็นแก่องค์กรเพื่อใช้ประโยชน์จากพลังของ FM เหล่านี้ผ่านทาง ไอบีเอ็ม วัตสันซึ่งเป็นแพลตฟอร์ม AI และข้อมูลที่พร้อมใช้งานระดับองค์กร ซึ่งได้รับการออกแบบมาเพื่อเพิ่มผลกระทบของ AI ทั่วทั้งองค์กร IBM watsonx ประกอบด้วยสิ่งต่อไปนี้:
- ไอบีเอ็ม watsonx.ai นำมาซึ่งสิ่งใหม่ AI กำเนิด ความสามารถที่ขับเคลื่อนโดย FM และการเรียนรู้ของเครื่องแบบดั้งเดิม (ML) กลายเป็นสตูดิโออันทรงพลังที่ครอบคลุมวงจรชีวิต AI
- ไอบีเอ็ม watsonx.data เป็นที่จัดเก็บข้อมูลที่เหมาะกับวัตถุประสงค์ที่สร้างขึ้นบนสถาปัตยกรรมเลคเฮาส์แบบเปิดเพื่อปรับขนาดปริมาณงาน AI สำหรับข้อมูลทั้งหมดของคุณได้ทุกที่
- IBM watsonx.การกำกับดูแล คือชุดเครื่องมือกำกับดูแลวงจร AI อัตโนมัติแบบครบวงจรที่สร้างขึ้นเพื่อช่วยให้เวิร์กโฟลว์ AI มีความรับผิดชอบ โปร่งใส และอธิบายได้
เวกเตอร์ที่สำคัญอีกประการหนึ่งคือความสำคัญที่เพิ่มขึ้นของการประมวลผลที่ขอบองค์กร เช่น ที่ตั้งอุตสาหกรรม ชั้นการผลิต ร้านค้าปลีก ไซต์ขอบโทรคมนาคม ฯลฯ โดยเฉพาะอย่างยิ่ง AI ที่ขอบองค์กรช่วยให้สามารถประมวลผลข้อมูลที่มีการดำเนินงานสำหรับ การวิเคราะห์แบบใกล้เรียลไทม์ Edge ขององค์กรคือที่ซึ่งข้อมูลองค์กรจำนวนมหาศาลถูกสร้างขึ้น และที่ที่ AI สามารถให้ข้อมูลเชิงลึกทางธุรกิจที่มีคุณค่า ทันเวลา และนำไปปฏิบัติได้
การให้บริการโมเดล AI ที่ Edge ช่วยให้คาดการณ์ได้ใกล้เคียงเรียลไทม์ ในขณะเดียวกันก็ปฏิบัติตามข้อกำหนดด้านอธิปไตยของข้อมูลและความเป็นส่วนตัว ซึ่งช่วยลดเวลาแฝงซึ่งมักเกี่ยวข้องกับการได้มา การส่งผ่าน การเปลี่ยนแปลง และการประมวลผลข้อมูลการตรวจสอบได้อย่างมาก การทำงานที่ Edge ช่วยให้เราสามารถปกป้องข้อมูลองค์กรที่ละเอียดอ่อนและลดต้นทุนการถ่ายโอนข้อมูลด้วยเวลาตอบสนองที่เร็วขึ้น
อย่างไรก็ตาม การปรับขนาดการใช้งาน AI ที่ Edge นั้นไม่ใช่เรื่องง่าย ท่ามกลางความท้าทายที่เกี่ยวข้องกับข้อมูล (ความหลากหลาย ปริมาณ และกฎระเบียบ) และทรัพยากรที่มีข้อจำกัด (การประมวลผล การเชื่อมต่อเครือข่าย พื้นที่เก็บข้อมูล และแม้แต่ทักษะด้านไอที) สิ่งเหล่านี้สามารถอธิบายอย่างกว้าง ๆ ได้เป็นสองประเภท:
- เวลา/ค่าใช้จ่ายในการปรับใช้: การใช้งานแต่ละครั้งประกอบด้วยฮาร์ดแวร์และซอฟต์แวร์หลายชั้นที่จำเป็นต้องติดตั้ง กำหนดค่า และทดสอบก่อนใช้งาน ปัจจุบัน ผู้เชี่ยวชาญด้านบริการอาจใช้เวลาถึงหนึ่งหรือสองสัปดาห์ในการติดตั้ง ในแต่ละสถานที่ จำกัดอย่างรุนแรงถึงความรวดเร็วและคุ้มค่าขององค์กรในการขยายขนาดการใช้งานทั่วทั้งองค์กร
- การจัดการวันที่ 2: Edge ที่ใช้งานอยู่จำนวนมากและตำแหน่งทางภูมิศาสตร์ของการปรับใช้แต่ละครั้งมักจะทำให้การให้การสนับสนุนด้านไอทีในพื้นที่ในแต่ละสถานที่มีค่าใช้จ่ายสูง เพื่อตรวจสอบ บำรุงรักษา และอัปเดตการปรับใช้เหล่านี้
การปรับใช้ Edge AI
IBM พัฒนาสถาปัตยกรรม Edge ที่จัดการกับความท้าทายเหล่านี้โดยนำโมเดลอุปกรณ์ฮาร์ดแวร์/ซอฟต์แวร์ (HW/SW) แบบบูรณาการมาปรับใช้กับ Edge AI ประกอบด้วยกระบวนทัศน์หลักหลายประการที่ช่วยในการปรับขนาดการใช้งาน AI:
- การจัดสรรชุดซอฟต์แวร์แบบเต็มตามนโยบายและไม่ต้องสัมผัส
- การตรวจสอบความสมบูรณ์ของระบบ Edge อย่างต่อเนื่อง
- ความสามารถในการจัดการและผลักดันการอัปเดตซอฟต์แวร์/ความปลอดภัย/การกำหนดค่าไปยังตำแหน่ง Edge จำนวนมาก ทั้งหมดนี้มาจากตำแหน่งบนระบบคลาวด์ส่วนกลางสำหรับการจัดการวันที่ 2
สถาปัตยกรรมฮับและพูดแบบกระจายสามารถใช้เพื่อปรับขนาดการใช้งาน AI ขององค์กรที่ Edge โดยที่คลาวด์ส่วนกลางหรือศูนย์ข้อมูลขององค์กรทำหน้าที่เป็นฮับ และอุปกรณ์ Edge-in-a-box ทำหน้าที่เป็นซี่ที่ตำแหน่ง Edge. โมเดลฮับและซี่ล้อนี้ขยายไปทั่วสภาพแวดล้อมคลาวด์แบบไฮบริดและ Edge แสดงให้เห็นความสมดุลที่จำเป็นในการใช้ทรัพยากรที่จำเป็นสำหรับการดำเนินงาน FM ได้อย่างเหมาะสมที่สุด (ดูรูปที่ 2)
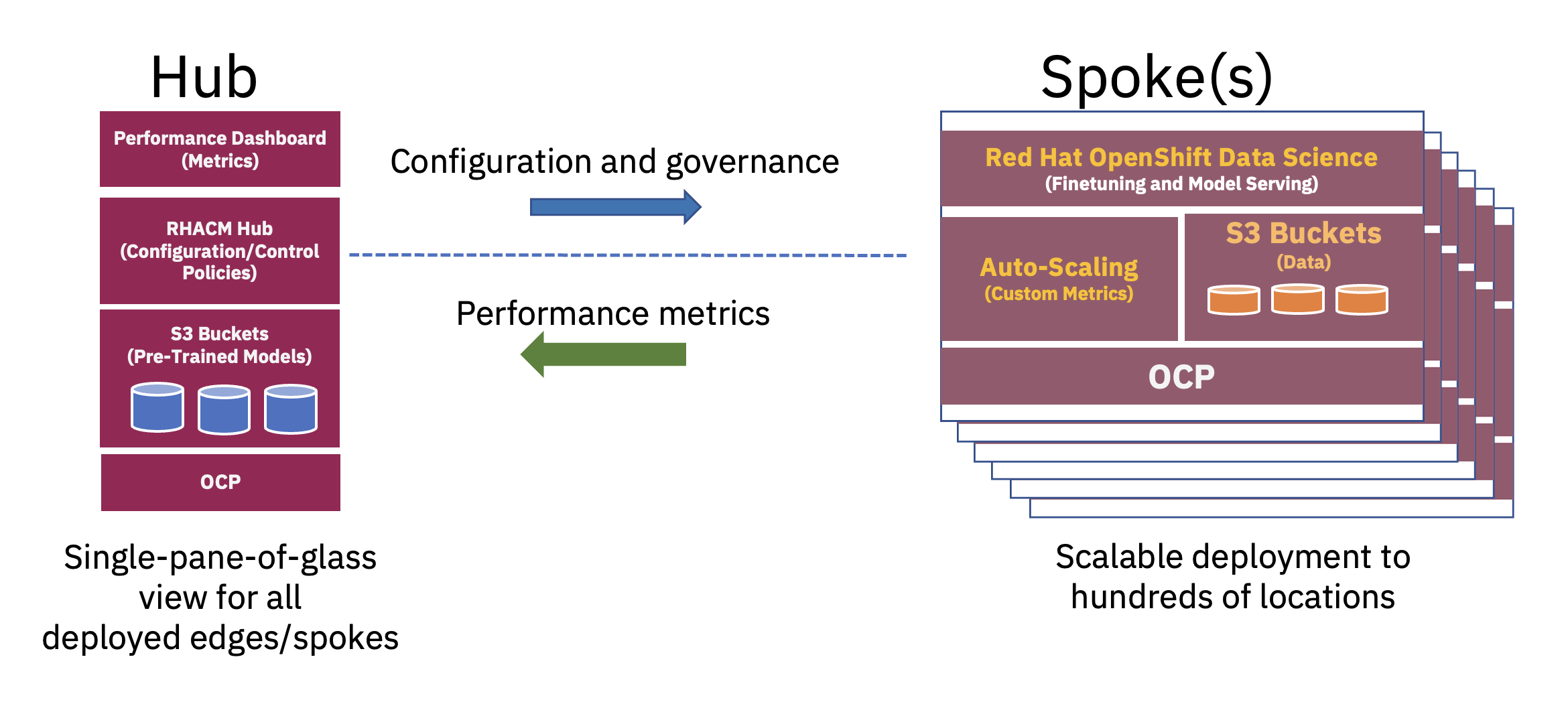
การฝึกอบรมล่วงหน้าสำหรับโมเดลภาษาขนาดใหญ่พื้นฐาน (LLM) และโมเดลพื้นฐานประเภทอื่นๆ โดยใช้เทคนิคที่มีการดูแลตนเองบนชุดข้อมูลขนาดใหญ่ที่ไม่มีป้ายกำกับ มักต้องการทรัพยากรการประมวลผล (GPU) จำนวนมาก และดำเนินการได้ดีที่สุดที่ฮับ ทรัพยากรการประมวลผลที่แทบไม่มีขีดจำกัดและกองข้อมูลขนาดใหญ่ที่มักจัดเก็บไว้ในระบบคลาวด์ช่วยให้สามารถฝึกอบรมโมเดลพารามิเตอร์ขนาดใหญ่ล่วงหน้าได้ และปรับปรุงความแม่นยำของโมเดลพื้นฐานเหล่านี้อย่างต่อเนื่อง
ในทางกลับกัน การปรับ FM ฐานเหล่านี้สำหรับงานดาวน์สตรีม ซึ่งต้องใช้ตัวอย่างข้อมูลที่ติดป้ายกำกับและการให้บริการการอนุมานเพียงไม่กี่สิบหรือหลายร้อยรายการ สามารถทำได้โดยใช้ GPU เพียงไม่กี่ตัวที่ Edge ระดับองค์กร ซึ่งช่วยให้ข้อมูลที่ติดป้ายกำกับละเอียดอ่อน (หรือข้อมูล Crown-Jewel ขององค์กร) ยังคงอยู่ในสภาพแวดล้อมการปฏิบัติงานขององค์กรได้อย่างปลอดภัย ในขณะเดียวกันก็ลดต้นทุนการถ่ายโอนข้อมูลอีกด้วย
ด้วยการใช้วิธีการแบบฟูลสแตกในการปรับใช้แอปพลิเคชันบน Edge นักวิทยาศาสตร์ด้านข้อมูลจึงสามารถดำเนินการปรับแต่ง ทดสอบ และปรับใช้โมเดลอย่างละเอียดได้ ซึ่งสามารถทำได้ในสภาพแวดล้อมเดียวในขณะที่ลดวงจรการพัฒนาเพื่อให้บริการโมเดล AI ใหม่แก่ผู้ใช้ปลายทาง แพลตฟอร์ม เช่น Red Hat OpenShift Data Science (RHODS) และ Red Hat OpenShift AI ที่เพิ่งประกาศไปเมื่อเร็ว ๆ นี้ มอบเครื่องมือในการพัฒนาและปรับใช้โมเดล AI ที่พร้อมสำหรับการผลิตอย่างรวดเร็วใน เมฆกระจาย และสภาพแวดล้อมที่ขอบ
สุดท้ายนี้ การให้บริการโมเดล AI ที่ได้รับการปรับแต่งอย่างละเอียดที่ Edge ขององค์กรจะช่วยลดเวลาแฝงซึ่งมักเกี่ยวข้องกับการได้มา การส่งข้อมูล การแปลง และการประมวลผลข้อมูลได้อย่างมาก การแยกการฝึกอบรมล่วงหน้าในระบบคลาวด์จากการปรับแต่งอย่างละเอียดและการอนุมานบน Edge จะช่วยลดต้นทุนการดำเนินงานโดยรวมโดยการลดเวลาที่ต้องใช้และต้นทุนการเคลื่อนย้ายข้อมูลที่เกี่ยวข้องกับงานการอนุมานใดๆ (ดูรูปที่ 3)
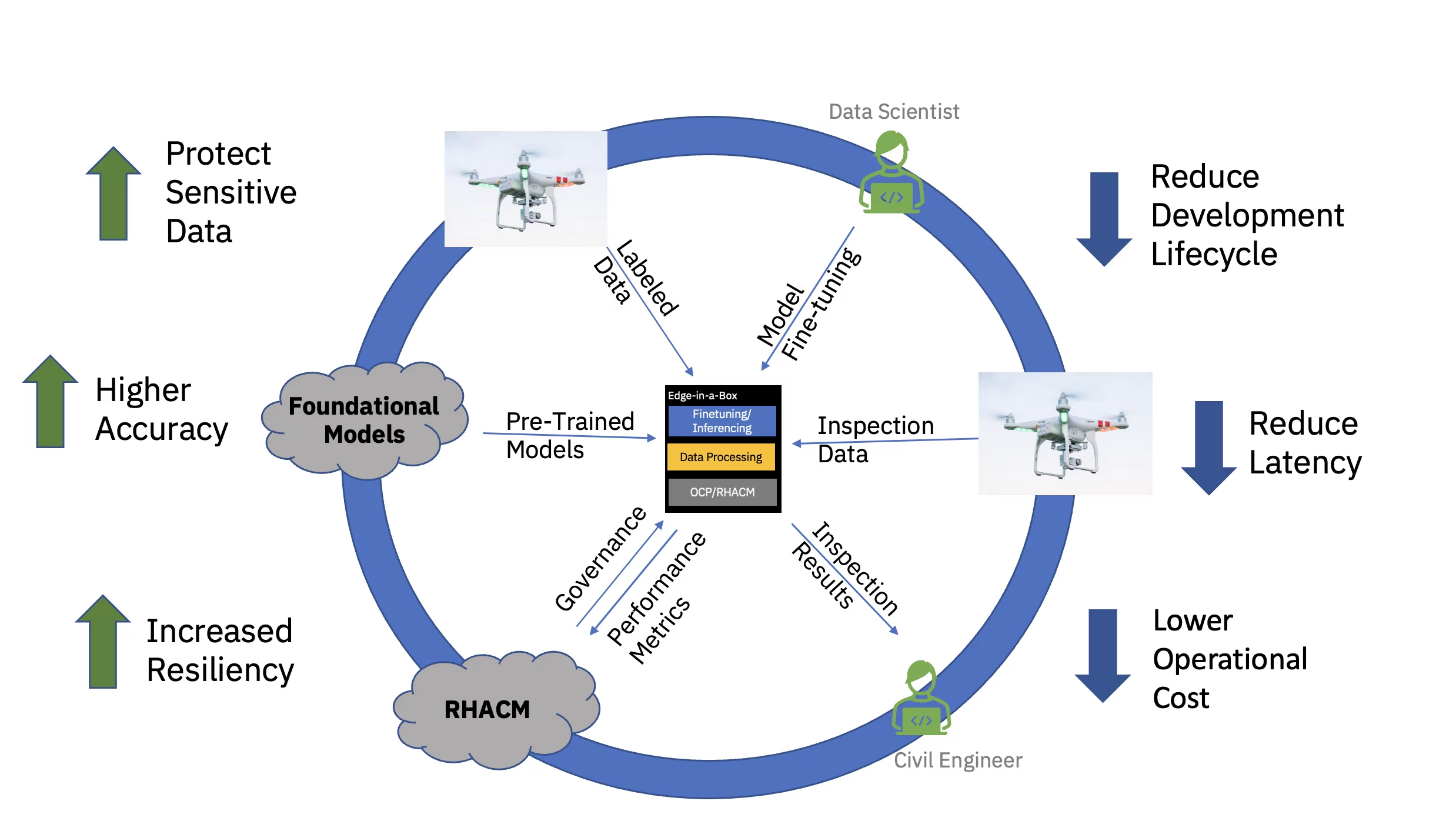
เพื่อแสดงให้เห็นถึงคุณค่าที่นำเสนอแบบ end-to-end นี้ โมเดลพื้นฐานที่อิงวิสัยทัศน์ของหม้อแปลงสำหรับโครงสร้างพื้นฐานทางแพ่ง (ได้รับการฝึกอบรมล่วงหน้าโดยใช้ชุดข้อมูลสาธารณะและเฉพาะอุตสาหกรรมที่กำหนดเอง) ได้รับการปรับแต่งอย่างละเอียดและปรับใช้สำหรับการอนุมานบนขอบสามโหนด (พูด) คลัสเตอร์ ชุดซอฟต์แวร์ประกอบด้วย Red Hat OpenShift Container Platform และ Red Hat OpenShift Data Science คลัสเตอร์ Edge นี้ยังเชื่อมต่อกับอินสแตนซ์ของ Red Hat Advanced Cluster Management สำหรับฮับ Kubernetes (RHACM) ที่ทำงานในระบบคลาวด์
การจัดเตรียมแบบไม่มีการสัมผัส
การจัดเตรียมแบบ Zero-Touch ตามนโยบายเสร็จสิ้นด้วย Red Hat Advanced Cluster Management for Kubernetes (RHACM) ผ่านนโยบายและแท็กตำแหน่ง ซึ่งเชื่อมโยงคลัสเตอร์ Edge เฉพาะกับชุดส่วนประกอบซอฟต์แวร์และการกำหนดค่า ส่วนประกอบซอฟต์แวร์เหล่านี้ซึ่งขยายทั่วทั้งสแตกและครอบคลุมการประมวลผล พื้นที่จัดเก็บ เครือข่าย และเวิร์กโหลด AI ได้รับการติดตั้งโดยใช้ตัวดำเนินการ OpenShift ต่างๆ การจัดเตรียมบริการแอปพลิเคชันที่จำเป็น และ S3 Bucket (พื้นที่เก็บข้อมูล)
โมเดลพื้นฐาน (FM) ที่ได้รับการฝึกอบรมล่วงหน้าสำหรับโครงสร้างพื้นฐานทางแพ่งได้รับการปรับแต่งอย่างละเอียดผ่าน Jupyter Notebook ภายใน Red Hat OpenShift Data Science (RHODS) โดยใช้ข้อมูลที่ติดป้ายกำกับเพื่อจำแนกข้อบกพร่อง XNUMX ประเภทที่พบในสะพานคอนกรีต การให้บริการอนุมานของ FM ที่ได้รับการปรับแต่งนี้ยังแสดงให้เห็นโดยใช้เซิร์ฟเวอร์ Triton นอกจากนี้ การตรวจสอบความสมบูรณ์ของระบบ Edge นี้เกิดขึ้นได้ด้วยการรวมตัววัดความสามารถในการสังเกตจากส่วนประกอบฮาร์ดแวร์และซอฟต์แวร์ผ่าน Prometheus ไปยังแดชบอร์ด RHACM ส่วนกลางในระบบคลาวด์ องค์กรด้านโครงสร้างพื้นฐานทางแพ่งสามารถติดตั้ง FM เหล่านี้ได้ที่ตำแหน่ง Edge ของตน และใช้ภาพถ่ายโดรนเพื่อตรวจจับข้อบกพร่องในแบบเรียลไทม์ ซึ่งช่วยเร่งเวลาในการทำความเข้าใจและลดค่าใช้จ่ายในการย้ายข้อมูลความละเอียดสูงปริมาณมากเข้าและออกจากระบบคลาวด์
สรุป
รวม ไอบีเอ็ม วัตสัน ความสามารถด้านข้อมูลและแพลตฟอร์ม AI สำหรับโมเดลพื้นฐาน (FM) พร้อมด้วยอุปกรณ์ Edge-in-a-Box ช่วยให้องค์กรต่างๆ สามารถรันเวิร์กโหลด AI สำหรับการปรับแต่ง FM อย่างละเอียดและการอนุมานที่ขอบการปฏิบัติงาน อุปกรณ์นี้สามารถจัดการกรณีการใช้งานที่ซับซ้อนได้ทันที และสร้างเฟรมเวิร์กแบบฮับและพูดสำหรับการจัดการแบบรวมศูนย์ ระบบอัตโนมัติ และการบริการตนเอง การใช้งาน Edge FM สามารถลดลงจากสัปดาห์เหลือเพียงไม่กี่ชั่วโมงโดยสามารถทำซ้ำได้ มีความยืดหยุ่นและความปลอดภัยสูงขึ้น
เรียนรู้เพิ่มเติมเกี่ยวกับโมเดลพื้นฐาน
โปรดตรวจสอบงวดทั้งหมดในบล็อกโพสต์ชุดนี้เกี่ยวกับ Edge Computing:
เพิ่มเติมจากคลาวด์




- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://www.ibm.com/blog/foundational-models-at-the-edge/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 08
- 1
- 10
- 13
- 15%
- 20
- 2023
- 22
- 28
- 29
- 30
- 300
- 39
- 400
- 41
- 7
- 70
- 9
- a
- เกี่ยวกับเรา
- เร่งความเร็ว
- เข้า
- คล่องแคล่ว
- ความถูกต้อง
- การครอบครอง
- ข้าม
- การกระทำ
- เหมาะ
- นอกจากนี้
- ที่อยู่
- ที่อยู่
- การนำมาใช้
- สูง
- ความก้าวหน้า
- การโฆษณา
- AI
- การรับเลี้ยงบุตรบุญธรรมของ AI
- โมเดล AI
- แพลตฟอร์ม AI
- ช่วย
- อัลกอริทึม
- ทั้งหมด
- อนุญาต
- ช่วยให้
- ด้วย
- ท่ามกลาง
- จำนวน
- จำนวน
- amp
- an
- การวิเคราะห์
- การวิเคราะห์
- และ
- ประกาศ
- ใด
- ทุกแห่ง
- การใช้งาน
- การใช้งาน
- เข้าใกล้
- สถาปัตยกรรม
- เป็น
- แถว
- บทความ
- เทียม
- ปัญญาประดิษฐ์
- ปัญญาประดิษฐ์ (AI)
- AS
- ที่เกี่ยวข้อง
- At
- ผู้เขียน
- อัตโนมัติ
- อัตโนมัติ
- ใช้ได้
- ถนน
- กลับ
- ยอดคงเหลือ
- ธนาคาร
- ธนาคาร
- ฐาน
- BE
- เพราะ
- กลายเป็น
- สมควร
- รับ
- การเริ่มต้น
- กำลัง
- เชื่อ
- ที่ดีที่สุด
- ผูก
- บล็อก
- บล็อกโพสต์
- Blog
- ทั้งสอง
- กล่อง
- สะพาน
- การนำ
- นำ
- กว้าง
- แต้
- การก่อสร้าง
- สร้าง
- สร้าง
- ธุรกิจ
- by
- CAN
- ความสามารถในการ
- เมืองหลวง
- จับ
- คาร์บอน
- บัตร
- การ์ด
- กรณี
- แมว
- หมวดหมู่
- ก่อให้เกิด
- ศูนย์
- ส่วนกลาง
- ธนาคารกลาง
- สกุลเงินดิจิทัลของธนาคารกลาง
- ส่วนกลาง
- โซ่
- ความท้าทาย
- เปลี่ยนแปลง
- เปลี่ยนแปลง
- ตรวจสอบ
- ทางเลือก
- วงกลม
- CIS
- พลเรือน
- ชั้น
- แยกประเภท
- ชัดเจน
- ลูกค้า
- อย่างใกล้ชิด
- เมฆ
- Cluster
- สี
- มีสีสัน
- การรวมกัน
- การแข่งขัน
- ซับซ้อน
- ความซับซ้อน
- การปฏิบัติตาม
- ส่วนประกอบ
- คำนวณ
- การคำนวณ
- องค์ประกอบ
- การกำหนดค่า
- งานที่เชื่อมต่อ
- การเชื่อมต่อ
- ประกอบ
- ภาชนะ
- ต่อ
- ควบคุม
- ราคา
- ค่าใช้จ่าย
- ได้
- ครอบคลุม
- cryptocurrency
- CSS
- สกุลเงิน
- ประเพณี
- ลูกค้า
- ประสบการณ์ของลูกค้า
- ลูกค้า
- หน้าปัด
- ข้อมูล
- ศูนย์ข้อมูล
- แพลตฟอร์มข้อมูล
- วิทยาศาสตร์ข้อมูล
- นักวิทยาศาสตร์ข้อมูล
- ชุดข้อมูล
- วันที่
- ทุ่มเท
- ค่าเริ่มต้น
- คำจำกัดความ
- ส่งมอบ
- สาธิต
- แสดงให้เห็นถึง
- ปรับใช้
- นำไปใช้
- ปรับใช้
- การใช้งาน
- การใช้งาน
- อธิบาย
- ลักษณะ
- ได้รับการออกแบบ
- พัฒนา
- พัฒนา
- พัฒนาการ
- ดิจิตอล
- สกุลเงินดิจิตอล
- แปลง
- การหยุดชะงัก
- ซึ่งทำให้ยุ่ง
- ผู้ก่อกวน
- กระจาย
- ตำบล
- โดเมน
- โดเมน
- ทำ
- ขับรถ
- การขับขี่
- เสียงหึ่งๆ
- แต่ละ
- ง่าย
- ระบบนิเวศ
- ขอบ
- การคำนวณที่ทันสมัย
- ยกระดับ
- สูง
- ทำให้สามารถ
- ช่วยให้
- ปลาย
- จบสิ้น
- วิศวกร
- ชั้นเยี่ยม
- เข้าสู่
- Enterprise
- ผู้ประกอบการ
- ขาเข้า
- สิ่งแวดล้อม
- สภาพแวดล้อม
- ยุค
- โดยเฉพาะอย่างยิ่ง
- ฯลฯ
- อีเธอร์ (ETH)
- แม้
- เหตุการณ์
- ทุกๆ
- วิวัฒน์
- การตรวจสอบ
- ตัวอย่าง
- ดำเนินการ
- มีอยู่
- ทางออก
- แพง
- ประสบการณ์
- ผู้เชี่ยวชาญ
- AI ที่อธิบายได้
- อธิบาย
- การขยาย
- อย่างยิ่ง
- ปัจจัย
- FAST
- เร็วขึ้น
- สองสาม
- สนาม
- รูป
- ทางการเงิน
- สถาบันการเงิน
- การจัดหาเงินทุน
- ชื่อจริง
- ชั้น
- ปฏิบัติตาม
- ดังต่อไปนี้
- แบบอักษร
- สำหรับ
- แถวหน้า
- พบ
- รากฐาน
- เศษ
- กรอบ
- ราคาเริ่มต้นที่
- เต็ม
- กองเต็ม
- นอกจากนี้
- โดยทั่วไป
- สร้าง
- เครื่องกำเนิดไฟฟ้า
- ตามภูมิศาสตร์
- ภูมิศาสตร์การเมือง
- ให้
- เหตุการณ์ที่
- การค้าโลก
- การกำกับดูแล
- GPU
- GPUs
- ตะแกรง
- มือ
- จัดการ
- ฮาร์ดแวร์
- หมวก
- มี
- สุขภาพ
- ความสูง
- ช่วย
- การช่วยเหลือ
- จะช่วยให้
- ความคมชัดสูง
- สูงกว่า
- อย่างสูง
- ประวัติ
- เจ้าภาพ
- ชั่วโมง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTTPS
- Hub
- มนุษย์
- ร้อย
- เป็นลูกผสม
- เมฆไฮบริด
- ไอบีเอ็ม
- IBM Cloud
- ICO
- ICON
- แสดงให้เห็นถึง
- ภาพ
- ส่งผลกระทบ
- ความสำคัญ
- การปรับปรุง
- in
- ประกอบด้วย
- รวม
- ที่เพิ่มขึ้น
- ขึ้น
- ดัชนี
- อุตสาหกรรม
- อุตสาหกรรม
- อุตสาหกรรม
- อุตสาหกรรมเฉพาะ
- เงินเฟ้อ
- โรคติดเชื้อ
- จุดสะท้อน
- อิทธิพล
- โครงสร้างพื้นฐาน
- Initiative
- นักวิเคราะห์ส่วนบุคคลที่หาโอกาสให้เป็นไปได้มากที่สุด
- นวัตกรรม
- ปัจจัยการผลิต
- ข้อมูลเชิงลึก
- ตัวอย่าง
- สถาบัน
- แบบบูรณาการ
- Intelligence
- แท้จริง
- แนะนำ
- IT
- IT Support
- เส้นทางท่องเที่ยว
- jpg
- กระโดด
- โน้ตบุ๊ค Jupyter
- เพียงแค่
- แค่หนึ่ง
- เก็บไว้
- คีย์
- Kubernetes
- การติดฉลาก
- ภาษา
- ใหญ่
- ส่วนใหญ่
- ความแอบแฝง
- ล่าสุด
- ชั้น
- ชั้นนำ
- เรียนรู้
- การเรียนรู้
- เลฟเวอเรจ
- วงจรชีวิต
- กดไลก์
- ไม่ จำกัด
- ลินุกซ์
- ในประเทศ
- ในประเทศ
- ที่ตั้ง
- วันหยุด
- นาน
- ดู
- เครื่อง
- เรียนรู้เครื่อง
- ทำ
- เก็บรักษา
- ทำ
- ทำให้
- จัดการ
- การจัดการ
- การผลิต
- หลาย
- เครื่องหมาย
- มาก
- เจ้านาย
- เรื่อง
- ความกว้างสูงสุด
- กลไก
- วิธีการ
- ตัวชี้วัด
- นาที
- การลด
- นาที
- ML
- โทรศัพท์มือถือ
- แบบ
- โมเดล
- ทันสมัย
- สร้างสรรค์สิ่งใหม่ ๆ
- ทันสมัย
- การตรวจสอบ
- การตรวจสอบ
- ข้อมูลเพิ่มเติม
- การเคลื่อนไหว
- การย้าย
- ชื่อ
- การเดินเรือ
- ใกล้
- จำเป็น
- จำเป็นต้อง
- จำเป็น
- ความต้องการ
- เครือข่าย
- ใหม่
- ถัดไป
- NLP
- สมุดบันทึก
- ไม่มีอะไร
- ตอนนี้
- จำนวน
- มากมาย
- of
- การเสนอ
- มักจะ
- on
- ONE
- เพียง
- เปิด
- เปิด
- การดำเนินงาน
- การดำเนินการ
- ผู้ประกอบการ
- การปรับให้เหมาะสม
- or
- organizacja
- อื่นๆ
- ของเรา
- ออก
- ทั้งหมด
- แพคเกจ
- หน้า
- พารามิเตอร์
- การชำระเงิน
- วิธีการชำระเงิน
- การชำระเงิน
- ดำเนินการ
- ดำเนินการ
- PHP
- การวาง
- เวที
- แพลตฟอร์ม
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- เสียบเข้าไป
- จุด
- นโยบาย
- นโยบาย
- ตำแหน่ง
- เป็นไปได้
- โพสต์
- โพสต์
- ที่มีศักยภาพ
- อำนาจ
- ที่มีประสิทธิภาพ
- การคาดการณ์
- ก่อน
- ความเป็นส่วนตัว
- ส่วนตัว
- ปัญหาที่เกิดขึ้น
- การประมวลผล
- ก่อ
- มืออาชีพ
- ประพจน์
- ให้
- สาธารณะ
- ผลัก
- พิสัย
- อย่างรวดเร็ว
- การอ่าน
- เรียลไทม์
- เมื่อเร็ว ๆ นี้
- ระเบียน
- การบันทึก
- สีแดง
- หมวกสีแดง
- ลด
- ลดลง
- ลด
- ลด
- กฎระเบียบ
- หน่วยงานกำกับดูแล
- หน่วยงานกำกับดูแล
- ที่เกี่ยวข้อง
- ลบออก
- ทำซ้ำได้
- ต้องการ
- จำเป็นต้องใช้
- ความต้องการ
- จำเป็น
- การวิจัย
- แหล่งข้อมูล
- คำตอบ
- รับผิดชอบ
- การตอบสนอง
- ค้าปลีก
- ขึ้น
- หุ่นยนต์
- วิ่ง
- วิ่ง
- อย่างปลอดภัย
- เดียวกัน
- scalability
- ขนาด
- ขนาดไอ
- ปรับ
- วิทยาศาสตร์
- นักวิทยาศาสตร์
- จอภาพ
- สคริปต์
- ที่สอง
- อย่างปลอดภัย
- ความปลอดภัย
- เห็น
- เห็น
- การเลือก
- บริการตัวเอง
- มีความละเอียดอ่อน
- SEO
- กันยายน
- ชุด
- เซิร์ฟเวอร์
- บริการ
- บริการ
- การให้บริการ
- เซสชั่น
- ครั้ง ราคา
- ชุด
- หลาย
- Share
- โชว์
- สำคัญ
- อย่างมีความหมาย
- คล้ายคลึงกัน
- ตั้งแต่
- สิงคโปร์
- เดียว
- สภาพแวดล้อมเดียว
- เว็บไซต์
- สถานที่ทำวิจัย
- หก
- ทักษะ
- เล็ก
- EMS
- SMEs
- ซอฟต์แวร์
- ส่วนประกอบซอฟต์แวร์
- ทางออก
- อธิปไตย
- ช่องว่าง
- ความตึงเครียด
- โดยเฉพาะ
- เฉพาะ
- ผู้ให้การสนับสนุน
- กอง
- เริ่มต้น
- รัฐของศิลปะ
- เข้าพัก
- ขั้นตอน
- การเก็บรักษา
- จัดเก็บ
- เก็บไว้
- ร้านค้า
- พายุ
- สตูดิโอ
- หรือ
- ความสำเร็จ
- อย่างเช่น
- ชี้ให้เห็นถึง
- จัดหาอุปกรณ์
- ห่วงโซ่อุปทาน
- สนับสนุน
- แน่ใจ
- ระบบ
- เอา
- นำ
- งาน
- งาน
- เทคนิค
- เทคโนโลยี
- Telco
- temenos
- เมตริกซ์
- terraform
- การทดสอบ
- การทดสอบ
- ที่
- พื้นที่
- ของพวกเขา
- ชุดรูปแบบ
- ที่นั่น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- นี้
- ตลอด
- เวลา
- ทันเวลา
- ครั้ง
- ชื่อหนังสือ
- ไปยัง
- ในวันนี้
- ร่วมกัน
- เครื่องมือ
- เครื่องมือ
- ด้านบน
- การค้า
- แบบดั้งเดิม
- รถไฟ
- ผ่านการฝึกอบรม
- การฝึกอบรม
- โอน
- แปลง
- การแปลง
- การแปลง
- โปร่งใส
- ไทรทัน
- พูดเบาและรวดเร็ว
- สอง
- ชนิด
- ชนิด
- ปลดปล่อย
- บันทึก
- การปรับปรุง
- URL
- us
- ใช้
- มือสอง
- ผู้ใช้
- การใช้
- นำไปใช้
- ใช้
- มีคุณค่า
- ความคุ้มค่า
- ข้อเสนอที่มีค่า
- ความหลากหลาย
- ต่างๆ
- กว้างใหญ่
- ผ่านทาง
- รายละเอียด
- จวน
- ปริมาณ
- ไดรฟ์
- W
- ที่รอ
- กระเป๋าสตางค์
- คือ
- คลื่น
- ทาง..
- วิธี
- we
- สัปดาห์
- สัปดาห์ที่ผ่านมา
- อะไร
- ความหมายของ
- เมื่อ
- ที่
- ในขณะที่
- WHO
- ทำไม
- กว้าง
- ช่วงกว้าง
- กับ
- ภายใน
- หญิง
- WordPress
- งาน
- ขั้นตอนการทำงาน
- การทำงาน
- จะ
- เขียน
- ของคุณ
- ลมทะเล











