วันนี้ เรารู้สึกตื่นเต้นที่จะประกาศความพร้อมของการอนุมาน Llama 2 และการสนับสนุนการปรับแต่งอย่างละเอียด การฝึกอบรม AWS และ การอนุมาน AWS อินสแตนซ์ใน Amazon SageMaker JumpStart. การใช้อินสแตนซ์ที่ใช้ AWS Trainium และ Inferentia ผ่าน SageMaker สามารถช่วยให้ผู้ใช้ลดต้นทุนการปรับแต่งได้สูงสุดถึง 50% และลดต้นทุนการปรับใช้ลง 4.7 เท่า ในขณะที่ลดเวลาแฝงต่อโทเค็นลงด้วย Llama 2 คือโมเดลภาษาข้อความที่สร้างแบบถดถอยอัตโนมัติซึ่งใช้สถาปัตยกรรมหม้อแปลงที่ได้รับการปรับปรุงให้เหมาะสม เนื่องจากเป็นโมเดลที่เปิดเผยต่อสาธารณะ Llama 2 ได้รับการออกแบบสำหรับงาน NLP มากมาย เช่น การจำแนกข้อความ การวิเคราะห์ความรู้สึก การแปลภาษา การสร้างแบบจำลองภาษา การสร้างข้อความ และระบบการสนทนา การปรับแต่งและการปรับใช้ LLM อย่างละเอียด เช่น Llama 2 อาจมีค่าใช้จ่ายสูงหรือท้าทายในการตอบสนองประสิทธิภาพแบบเรียลไทม์เพื่อมอบประสบการณ์ที่ดีให้กับลูกค้า Trainium และ AWS Inferentia เปิดใช้งานโดย AWS เซลล์ประสาท ชุดพัฒนาซอฟต์แวร์ (SDK) นำเสนอตัวเลือกประสิทธิภาพสูงและคุ้มค่าสำหรับการฝึกอบรมและการอนุมานโมเดล Llama 2
ในโพสต์นี้ เราจะสาธิตวิธีการปรับใช้และปรับแต่ง Llama 2 บนอินสแตนซ์ Trainium และ AWS Inferentia ใน SageMaker JumpStart
ภาพรวมโซลูชัน
ในบล็อกนี้ เราจะอธิบายสถานการณ์ต่อไปนี้:
- ปรับใช้ Llama 2 บนอินสแตนซ์ AWS Inferentia ทั้งใน สตูดิโอ Amazon SageMaker UI พร้อมประสบการณ์การปรับใช้เพียงคลิกเดียวและ SageMaker Python SDK
- ปรับแต่ง Llama 2 บนอินสแตนซ์ Trainium ทั้งใน SageMaker Studio UI และ SageMaker Python SDK
- เปรียบเทียบประสิทธิภาพของรุ่น Llama 2 ที่ได้รับการปรับแต่งอย่างละเอียดกับรุ่นที่ผ่านการฝึกอบรมมาแล้ว เพื่อแสดงประสิทธิภาพของการปรับแต่งอย่างละเอียด
หากต้องการลงมือปฏิบัติ โปรดดูที่ ตัวอย่างสมุดบันทึก GitHub.
ปรับใช้ Llama 2 บนอินสแตนซ์ AWS Inferentia โดยใช้ SageMaker Studio UI และ Python SDK
ในส่วนนี้ เราจะสาธิตวิธีการปรับใช้ Llama 2 บนอินสแตนซ์ AWS Inferentia โดยใช้ SageMaker Studio UI สำหรับการปรับใช้ในคลิกเดียวและ Python SDK
ค้นพบโมเดล Llama 2 บน SageMaker Studio UI
SageMaker JumpStart ให้การเข้าถึงทั้งที่เปิดเผยต่อสาธารณะและเป็นกรรมสิทธิ์ โมเดลรองพื้น. โมเดลพื้นฐานได้รับการออนบอร์ดและบำรุงรักษาจากผู้ให้บริการบุคคลที่สามและที่เป็นกรรมสิทธิ์ ด้วยเหตุนี้จึงเผยแพร่ภายใต้ใบอนุญาตที่แตกต่างกันตามที่กำหนดโดยแหล่งที่มาของโมเดล อย่าลืมตรวจสอบใบอนุญาตสำหรับรุ่นรองพื้นที่คุณใช้ คุณมีหน้าที่รับผิดชอบในการตรวจสอบและปฏิบัติตามข้อกำหนดสิทธิ์การใช้งานที่เกี่ยวข้อง และตรวจสอบให้แน่ใจว่าข้อกำหนดดังกล่าวเป็นที่ยอมรับสำหรับกรณีการใช้งานของคุณก่อนที่จะดาวน์โหลดหรือใช้เนื้อหา
คุณสามารถเข้าถึงโมเดลพื้นฐาน Llama 2 ได้ผ่าน SageMaker JumpStart ใน SageMaker Studio UI และ SageMaker Python SDK ในส่วนนี้ เราจะอธิบายวิธีค้นหาโมเดลใน SageMaker Studio
SageMaker Studio เป็นสภาพแวดล้อมการพัฒนาแบบผสานรวม (IDE) ที่ให้อินเทอร์เฟซแบบภาพบนเว็บเดียวที่คุณสามารถเข้าถึงเครื่องมือที่สร้างขึ้นตามวัตถุประสงค์เพื่อดำเนินการขั้นตอนการพัฒนาการเรียนรู้ของเครื่อง (ML) ทั้งหมด ตั้งแต่การเตรียมข้อมูลไปจนถึงการสร้าง การฝึกอบรม และการปรับใช้ ML ของคุณ โมเดล สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับวิธีเริ่มต้นและตั้งค่า SageMaker Studio โปรดดูที่ Amazon SageMaker สตูดิโอ
หลังจากที่คุณอยู่ใน SageMaker Studio คุณจะสามารถเข้าถึง SageMaker JumpStart ซึ่งประกอบด้วยโมเดล โน้ตบุ๊ก และโซลูชันที่สร้างไว้ล่วงหน้าที่ผ่านการฝึกอบรมแล้ว ภายใต้ โซลูชันที่สร้างไว้ล่วงหน้าและอัตโนมัติ. สำหรับข้อมูลโดยละเอียดเพิ่มเติมเกี่ยวกับวิธีการเข้าถึงโมเดลที่เป็นกรรมสิทธิ์ โปรดดูที่ ใช้โมเดลพื้นฐานที่เป็นกรรมสิทธิ์จาก Amazon SageMaker JumpStart ใน Amazon SageMaker Studio.
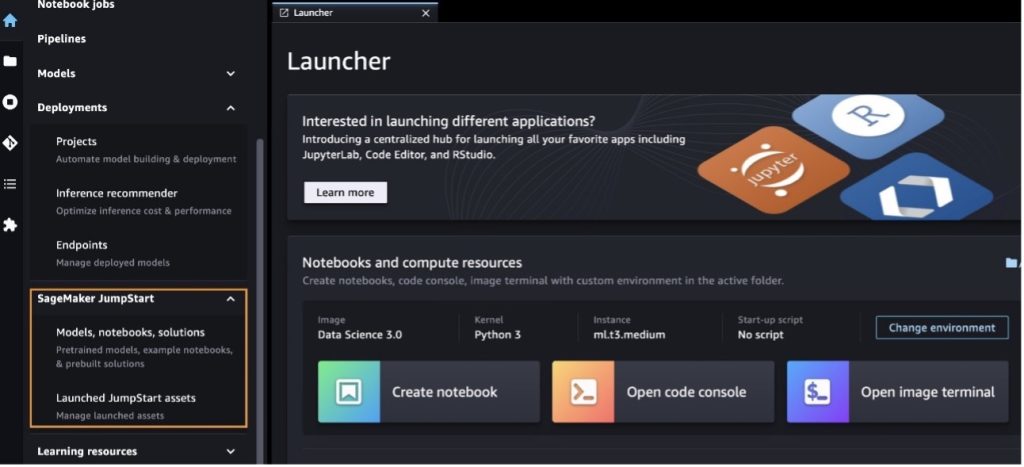
จากหน้าเริ่มต้นของ SageMaker JumpStart คุณสามารถเรียกดูโซลูชัน รุ่น สมุดบันทึก และทรัพยากรอื่นๆ ได้
หากคุณไม่เห็นรุ่น Llama 2 ให้อัปเดตเวอร์ชัน SageMaker Studio ของคุณโดยปิดเครื่องแล้วรีสตาร์ท สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการอัพเดตเวอร์ชัน โปรดดูที่ ปิดและอัปเดตแอป Studio Classic.

คุณยังสามารถค้นหารุ่นย่อยอื่นๆ ได้โดยเลือก สำรวจโมเดลการสร้างข้อความทั้งหมด หรือค้นหา llama or neuron ในช่องค้นหา คุณจะสามารถดูแบบจำลอง Llama 2 Neuron ได้ในหน้านี้
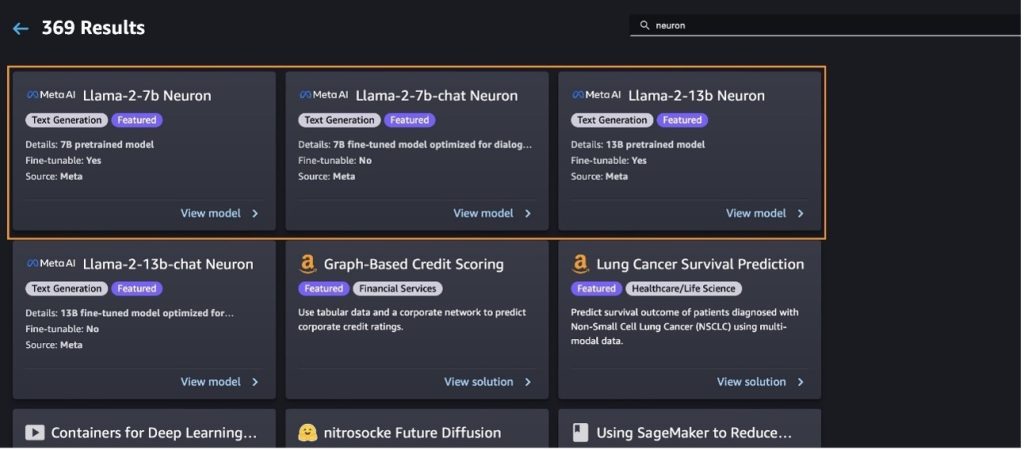
ปรับใช้โมเดล Llama-2-13b ด้วย SageMaker Jumpstart
คุณสามารถเลือกการ์ดโมเดลเพื่อดูรายละเอียดเกี่ยวกับโมเดล เช่น ใบอนุญาต ข้อมูลที่ใช้ในการฝึก และวิธีการใช้งาน คุณยังสามารถพบปุ่มสองปุ่ม ปรับใช้ และ เปิดสมุดบันทึกซึ่งช่วยให้คุณใช้โมเดลโดยใช้ตัวอย่างที่ไม่มีโค้ดนี้
เมื่อคุณเลือกปุ่มใดปุ่มหนึ่ง ป๊อปอัปจะแสดงข้อตกลงสิทธิ์การใช้งานสำหรับผู้ใช้ปลายทางและนโยบายการใช้งานที่ยอมรับได้ (AUP) เพื่อให้คุณรับทราบ
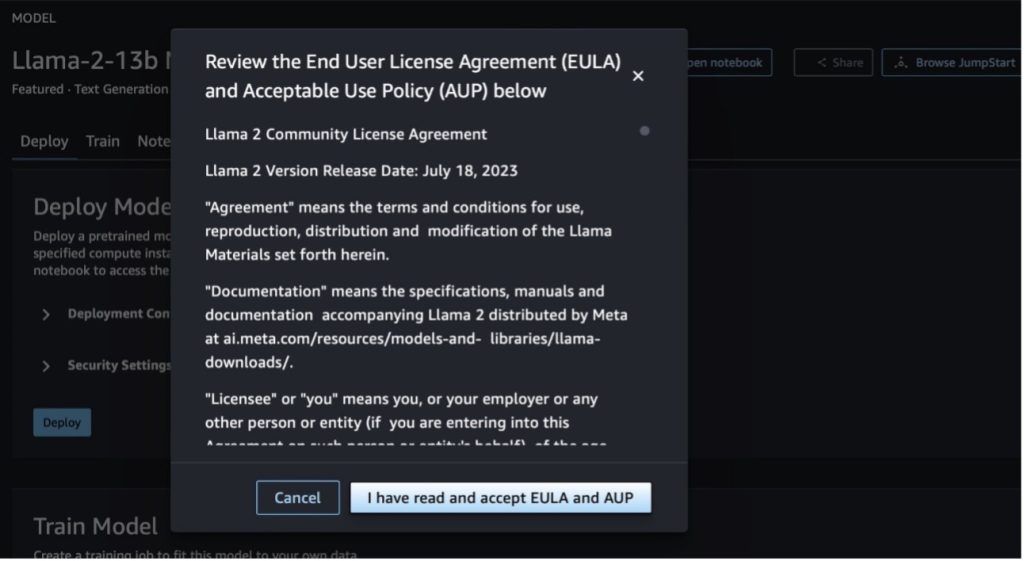
หลังจากที่คุณรับทราบนโยบายแล้ว คุณสามารถปรับใช้ตำแหน่งข้อมูลของโมเดลและใช้งานได้ตามขั้นตอนในส่วนถัดไป
ปรับใช้โมเดล Llama 2 Neuron ผ่าน Python SDK
เมื่อคุณเลือก ปรับใช้ และรับทราบเงื่อนไข การปรับใช้โมเดลจะเริ่มต้นขึ้น หรือคุณสามารถปรับใช้ผ่านสมุดบันทึกตัวอย่างโดยเลือก เปิดสมุดบันทึก. สมุดบันทึกตัวอย่างให้คำแนะนำแบบ end-to-end เกี่ยวกับวิธีปรับใช้แบบจำลองสำหรับการอนุมานและล้างข้อมูลทรัพยากร
หากต้องการปรับใช้หรือปรับแต่งโมเดลบนอินสแตนซ์ Trainium หรือ AWS Inferentia คุณต้องเรียก PyTorch Neuron ก่อน (ไฟฉาย-neuronx) เพื่อรวบรวมโมเดลเป็นกราฟเฉพาะของ Neuron ซึ่งจะปรับให้เหมาะสมสำหรับ NeuronCores ของ Inferentia ผู้ใช้สามารถสั่งให้คอมไพเลอร์ปรับให้เหมาะสมสำหรับเวลาแฝงที่ต่ำที่สุดหรือปริมาณงานสูงสุด ขึ้นอยู่กับวัตถุประสงค์ของแอปพลิเคชัน ใน JumpStart เราได้รวบรวมกราฟ Neuron ไว้ล่วงหน้าสำหรับการกำหนดค่าที่หลากหลาย เพื่อให้ผู้ใช้สามารถดูขั้นตอนการคอมไพล์ ทำให้ปรับแต่งและปรับใช้โมเดลได้ละเอียดยิ่งขึ้น
โปรดทราบว่ากราฟที่รวบรวมไว้ล่วงหน้าของ Neuron ถูกสร้างขึ้นตามเวอร์ชันเฉพาะของเวอร์ชัน Neuron Compiler
มีสองวิธีในการปรับใช้ LIama 2 บนอินสแตนซ์ที่ใช้ AWS Inferentia วิธีแรกใช้การกำหนดค่าที่สร้างไว้ล่วงหน้า และช่วยให้คุณสามารถปรับใช้โมเดลด้วยโค้ดเพียงสองบรรทัด ประการที่สอง คุณจะสามารถควบคุมการกำหนดค่าได้มากขึ้น มาเริ่มกันที่วิธีแรกด้วยการกำหนดค่าที่สร้างไว้ล่วงหน้า และใช้โมเดล Neuron Llama 2 13B ที่ได้รับการฝึกไว้ล่วงหน้าเป็นตัวอย่าง รหัสต่อไปนี้แสดงวิธีการปรับใช้ Llama 13B โดยมีเพียงสองบรรทัด:
หากต้องการอนุมานโมเดลเหล่านี้ คุณต้องระบุอาร์กิวเมนต์ accept_eula ที่จะ True เป็นส่วนหนึ่งของ model.deploy() เรียก. การตั้งค่าอาร์กิวเมนต์นี้ให้เป็นจริง ยอมรับว่าคุณได้อ่านและยอมรับ EULA ของโมเดลแล้ว EULA สามารถพบได้ในคำอธิบายการ์ดโมเดลหรือจาก เว็บไซต์เมตา.
ประเภทอินสแตนซ์เริ่มต้นสำหรับ Llama 2 13B คือ ml.inf2.8xlarge คุณยังสามารถลองใช้ ID รุ่นอื่น ๆ ที่รองรับได้:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(รุ่นแชท)meta-textgenerationneuron-llama-2-13b-f(รุ่นแชท)
หรืออีกทางหนึ่ง หากคุณต้องการควบคุมการกำหนดค่าการใช้งานได้มากขึ้น เช่น ความยาวบริบท ระดับขนานของเทนเซอร์ และขนาดแบตช์สูงสุด คุณสามารถแก้ไขได้ผ่านตัวแปรสภาพแวดล้อม ดังที่แสดงไว้ในส่วนนี้ Deep Learning Container (DLC) พื้นฐานของการปรับใช้คือ การอนุมานแบบจำลองขนาดใหญ่ (LMI) NeuronX DLC. ตัวแปรด้านสิ่งแวดล้อมมีดังนี้:
- OPTION_N_POSITIONS – จำนวนโทเค็นอินพุตและเอาต์พุตสูงสุด เช่น หากคุณคอมไพล์โมเดลด้วย
OPTION_N_POSITIONSเป็น 512 คุณสามารถใช้โทเค็นอินพุต 128 (ขนาดพร้อมท์อินพุต) โดยมีโทเค็นเอาต์พุตสูงสุด 384 (รวมโทเค็นอินพุตและเอาต์พุตต้องเป็น 512) สำหรับโทเค็นเอาต์พุตสูงสุด ค่าใดๆ ที่ต่ำกว่า 384 ก็ใช้ได้ แต่คุณไม่สามารถเกินกว่านั้นได้ (เช่น อินพุต 256 และเอาต์พุต 512) - OPTION_TENSOR_PARALLEL_DEGREE – จำนวน NeuronCore ที่จะโหลดโมเดลในอินสแตนซ์ AWS Inferentia
- OPTION_MAX_ROLLING_BATCH_SIZE – ขนาดแบตช์สูงสุดสำหรับคำขอพร้อมกัน
- OPTION_DTYPE – ประเภทวันที่ที่จะโหลดโมเดล
การรวบรวมกราฟ Neuron ขึ้นอยู่กับความยาวของบริบท (OPTION_N_POSITIONS) องศาขนานเทนเซอร์ (OPTION_TENSOR_PARALLEL_DEGREE) ขนาดแบทช์สูงสุด (OPTION_MAX_ROLLING_BATCH_SIZE) และประเภทข้อมูล (OPTION_DTYPE) เพื่อโหลดโมเดล SageMaker JumpStart มีกราฟ Neuron ที่คอมไพล์ไว้ล่วงหน้าสำหรับการกำหนดค่าต่างๆ สำหรับพารามิเตอร์ก่อนหน้าเพื่อหลีกเลี่ยงการคอมไพล์รันไทม์ การกำหนดค่าของกราฟที่คอมไพล์ไว้ล่วงหน้าแสดงอยู่ในตารางต่อไปนี้ ตราบใดที่ตัวแปรสภาพแวดล้อมจัดอยู่ในประเภทใดประเภทหนึ่งต่อไปนี้ การรวบรวมกราฟ Neuron จะถูกข้ามไป
| LIama-2 7B และ LIama-2 7B แชท | ||||
| ประเภทอินสแตนซ์ | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B และ LIama-2 13B แชท | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
ต่อไปนี้เป็นตัวอย่างของการปรับใช้ Llama 2 13B และการตั้งค่าการกำหนดค่าที่มีอยู่ทั้งหมด
ตอนนี้เราได้ปรับใช้โมเดล Llama-2-13b แล้ว เราก็สามารถเรียกใช้การอนุมานได้โดยการเรียกใช้ตำแหน่งข้อมูล ข้อมูลโค้ดต่อไปนี้สาธิตการใช้พารามิเตอร์อนุมานที่รองรับเพื่อควบคุมการสร้างข้อความ:
- สูงสุด_ความยาว – โมเดลสร้างข้อความจนกระทั่งถึงความยาวของเอาต์พุต (ซึ่งรวมถึงความยาวบริบทอินพุต)
max_length. หากระบุ จะต้องเป็นจำนวนเต็มบวก - max_new_tokens – โมเดลจะสร้างข้อความจนกระทั่งถึงความยาวเอาต์พุต (ไม่รวมความยาวบริบทอินพุต)
max_new_tokens. หากระบุ จะต้องเป็นจำนวนเต็มบวก - num_beams – ระบุจำนวนคานที่ใช้ในการค้นหาโลภ หากระบุไว้ จะต้องเป็นจำนวนเต็มที่มากกว่าหรือเท่ากับ
num_return_sequences. - no_repeat_ngram_size – ตัวแบบช่วยให้แน่ใจว่าลำดับของคำของ
no_repeat_ngram_sizeไม่ซ้ำในลำดับเอาต์พุต หากระบุ จะต้องเป็นจำนวนเต็มบวกที่มากกว่า 1 - อุณหภูมิ – สิ่งนี้จะควบคุมการสุ่มในเอาต์พุต อุณหภูมิที่สูงขึ้นส่งผลให้ลำดับเอาต์พุตมีคำที่น่าจะเป็นไปได้ต่ำ อุณหภูมิที่ต่ำลงส่งผลให้ลำดับเอาต์พุตมีคำที่น่าจะเป็นไปได้สูง ถ้า
temperatureเท่ากับ 0 ส่งผลให้เกิดการถอดรหัสแบบละโมบ หากระบุ จะต้องเป็นทศนิยมที่เป็นบวก - ต้น_หยุด - ถ้า
Trueการสร้างข้อความจะเสร็จสิ้นเมื่อสมมติฐานบีมทั้งหมดถึงจุดสิ้นสุดของโทเค็นประโยค หากระบุไว้ จะต้องเป็นบูลีน - ทำ_ตัวอย่าง - ถ้า
Trueโมเดลจะสุ่มตัวอย่างคำถัดไปตามความน่าจะเป็น หากระบุไว้ จะต้องเป็นบูลีน - ท็อป_เค – ในแต่ละขั้นตอนของการสร้างข้อความ โมเดลจะสุ่มตัวอย่างจากเฉพาะ
top_kคำที่เป็นไปได้มากที่สุด หากระบุ จะต้องเป็นจำนวนเต็มบวก - ท็อป_พี – ในแต่ละขั้นตอนของการสร้างข้อความ โมเดลจะสุ่มตัวอย่างจากชุดคำที่เล็กที่สุดที่เป็นไปได้ด้วยความน่าจะเป็นสะสม
top_p. หากระบุไว้ จะต้องเป็นทศนิยมระหว่าง 0–1 - หยุด – หากระบุจะต้องเป็นรายการสตริง การสร้างข้อความจะหยุดลงหากมีการสร้างสตริงที่ระบุอย่างใดอย่างหนึ่ง
รหัสต่อไปนี้แสดงตัวอย่าง:
เอาท์พุต:
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับพารามิเตอร์ในเพย์โหลด โปรดดูที่ พารามิเตอร์ละเอียด.
คุณยังสามารถสำรวจการใช้งานพารามิเตอร์ได้ใน สมุดบันทึก เพื่อเพิ่มข้อมูลเพิ่มเติมเกี่ยวกับลิงค์ของสมุดบันทึก
ปรับแต่งโมเดล Llama 2 บนอินสแตนซ์ Trainium โดยใช้ SageMaker Studio UI และ SageMaker Python SDK
โมเดลพื้นฐาน Generative AI ได้กลายเป็นจุดสนใจหลักใน ML และ AI อย่างไรก็ตาม การสรุปอย่างกว้างๆ อาจไม่เพียงพอในโดเมนเฉพาะ เช่น บริการด้านการดูแลสุขภาพหรือทางการเงิน ซึ่งเกี่ยวข้องกับชุดข้อมูลที่ไม่ซ้ำกัน ข้อจำกัดนี้เน้นย้ำถึงความจำเป็นในการปรับแต่งโมเดล AI ที่สร้างเหล่านี้ด้วยข้อมูลเฉพาะโดเมน เพื่อปรับปรุงประสิทธิภาพในพื้นที่เฉพาะเหล่านี้
ตอนนี้เราได้ปรับใช้โมเดล Llama 2 เวอร์ชันก่อนการฝึกแล้ว มาดูกันว่าเราจะปรับแต่งสิ่งนี้กับข้อมูลเฉพาะโดเมนเพื่อเพิ่มความแม่นยำ ปรับปรุงโมเดลในแง่ของการดำเนินการให้เสร็จสิ้นทันที และปรับโมเดลให้เข้ากับ กรณีการใช้งานและข้อมูลทางธุรกิจเฉพาะของคุณ คุณสามารถปรับแต่งโมเดลได้โดยใช้ SageMaker Studio UI หรือ SageMaker Python SDK เราจะหารือทั้งสองวิธีในส่วนนี้
ปรับแต่งโมเดล Neuron Llama-2-13b ด้วย SageMaker Studio
ใน SageMaker Studio ให้ไปที่โมเดล Llama-2-13b Neuron บน ปรับใช้ แท็บ คุณสามารถชี้ไปที่ บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon บัคเก็ต (Amazon S3) ที่ประกอบด้วยชุดข้อมูลการฝึกอบรมและการตรวจสอบเพื่อการปรับแต่งอย่างละเอียด นอกจากนี้ คุณยังสามารถกำหนดค่าการกำหนดค่าการปรับใช้ ไฮเปอร์พารามิเตอร์ และการตั้งค่าความปลอดภัยสำหรับการปรับแต่งอย่างละเอียดได้ จากนั้นเลือก รถไฟ เพื่อเริ่มงานฝึกอบรมบนอินสแตนซ์ SageMaker ML

หากต้องการใช้รุ่น Llama 2 คุณต้องยอมรับ EULA และ AUP มันจะปรากฏขึ้นเมื่อคุณเมื่อคุณเลือก รถไฟ. เลือก ฉันได้อ่านและยอมรับ EULA และ AUP แล้ว เพื่อเริ่มงานปรับแต่ง
คุณสามารถดูสถานะของงานการฝึกของคุณสำหรับโมเดลที่ได้รับการปรับแต่งภายใต้คอนโซล SageMaker โดยเลือก งานฝึกอบรม ในบานหน้าต่างนำทาง
คุณสามารถปรับแต่งโมเดล Llama 2 Neuron ของคุณได้โดยใช้ตัวอย่างที่ไม่มีโค้ดนี้ หรือปรับแต่งอย่างละเอียดผ่าน Python SDK ดังที่แสดงไว้ในส่วนถัดไป
ปรับแต่งโมเดล Llama-2-13b Neuron อย่างละเอียดผ่าน SageMaker Python SDK
คุณสามารถปรับแต่งชุดข้อมูลอย่างละเอียดด้วยรูปแบบการปรับโดเมนหรือ การปรับแต่งแบบละเอียดตามคำสั่ง รูปแบบ. ต่อไปนี้เป็นคำแนะนำสำหรับวิธีจัดรูปแบบข้อมูลการฝึกก่อนที่จะถูกส่งไปยังการปรับแต่งแบบละเอียด:
- อินพุต -
trainไดเร็กทอรีที่มีไฟล์ที่จัดรูปแบบบรรทัด JSON (.jsonl) หรือข้อความ (.txt)- สำหรับไฟล์บรรทัด JSON (.jsonl) แต่ละบรรทัดจะเป็นออบเจ็กต์ JSON แยกกัน ออบเจ็กต์ JSON แต่ละรายการควรมีโครงสร้างเป็นคู่คีย์-ค่า โดยที่คีย์ควรอยู่
textและค่าคือเนื้อหาของตัวอย่างการฝึกอบรมหนึ่งตัวอย่าง - จำนวนไฟล์ภายใต้ไดเร็กทอรี train ควรเท่ากับ 1
- สำหรับไฟล์บรรทัด JSON (.jsonl) แต่ละบรรทัดจะเป็นออบเจ็กต์ JSON แยกกัน ออบเจ็กต์ JSON แต่ละรายการควรมีโครงสร้างเป็นคู่คีย์-ค่า โดยที่คีย์ควรอยู่
- เอาท์พุต – โมเดลที่ผ่านการฝึกอบรมซึ่งสามารถนำไปใช้เพื่อการอนุมานได้
ในตัวอย่างนี้ เราใช้ชุดย่อยของ ชุดข้อมูลดอลลี่ ในรูปแบบการปรับแต่งคำสั่ง ชุดข้อมูล Dolly มีบันทึกการปฏิบัติตามคำสั่งประมาณ 15,000 รายการสำหรับหมวดหมู่ต่างๆ เช่น การตอบคำถาม การสรุป และการดึงข้อมูล มีให้บริการภายใต้ลิขสิทธิ์ Apache 2.0 เราใช้ information_extraction ตัวอย่างสำหรับการปรับแต่งอย่างละเอียด
- โหลดชุดข้อมูล Dolly แล้วแยกออกเป็น
train(สำหรับการปรับแต่งอย่างละเอียด) และtest(สำหรับการประเมินผล):
- ใช้เทมเพลตพร้อมท์สำหรับการประมวลผลข้อมูลล่วงหน้าในรูปแบบคำสั่งสำหรับงานการฝึกอบรม:
- ตรวจสอบไฮเปอร์พารามิเตอร์และเขียนทับสำหรับกรณีการใช้งานของคุณเอง:
- ปรับแต่งโมเดลและเริ่มงานฝึกอบรม SageMaker สคริปต์การปรับแต่งแบบละเอียดจะขึ้นอยู่กับ neuronx-nemo-เมกะตรอน repository ซึ่งเป็นเวอร์ชันที่แก้ไขของแพ็คเกจ เนโม และ ปลาย ที่ได้รับการปรับให้ใช้กับอินสแตนซ์ Neuron และ EC2 Trn1 ที่ neuronx-nemo-เมกะตรอน พื้นที่เก็บข้อมูลมีความคล้ายคลึงกันแบบ 3 มิติ (ข้อมูล เทนเซอร์ และไปป์ไลน์) เพื่อให้คุณปรับแต่ง LLM ในขนาดได้ อินสแตนซ์ Trainium ที่รองรับคือ ml.trn1.32xlarge และ ml.trn1n.32xlarge
- สุดท้าย ปรับใช้โมเดลที่ได้รับการปรับแต่งอย่างละเอียดในจุดสิ้นสุด SageMaker:
เปรียบเทียบการตอบสนองระหว่างรุ่น Llama 2 Neuron ที่ได้รับการฝึกล่วงหน้าและที่ได้รับการปรับแต่งอย่างละเอียด
ตอนนี้เราได้ปรับใช้เวอร์ชันก่อนการฝึกอบรมของโมเดล Llama-2-13b และปรับแต่งแล้ว เราจะสามารถดูการเปรียบเทียบประสิทธิภาพบางส่วนของการแจ้งให้เสร็จสิ้นจากทั้งสองรุ่นได้ ดังที่แสดงในตารางต่อไปนี้ นอกจากนี้เรายังเสนอตัวอย่างในการปรับแต่ง Llama 2 ในชุดข้อมูลการยื่น SEC ในรูปแบบ .txt สำหรับรายละเอียด โปรดดูที่ ตัวอย่างสมุดบันทึก GitHub.
| ชิ้น | ปัจจัยการผลิต | ความจริงพื้นๆ | การตอบสนองจากโมเดลที่ไม่ได้ปรับแต่ง | การตอบสนองจากรุ่นที่ปรับแต่งมาอย่างดี |
| 1 | ด้านล่างนี้คือคำสั่งที่อธิบายงาน ควบคู่ไปกับอินพุตที่ให้บริบทเพิ่มเติม เขียนคำตอบที่เติมเต็มคำขออย่างเหมาะสมnn### Instruction:nแยกมหาวิทยาลัยที่ Moret เรียนอยู่และปีที่สำเร็จการศึกษาสำหรับแต่ละคน และใส่ไว้ในรายการหัวข้อย่อยnn### ข้อมูล:nMoret เกิดในปี 1953 ในเมือง Vevey ประเทศสวิตเซอร์แลนด์ และศึกษาระดับปริญญาตรีที่ École Polytechnique Fédérale de Lausanne (EPFL) ซึ่งสำเร็จการศึกษาในปี 1975 เขาไปศึกษาต่อในระดับบัณฑิตศึกษาที่มหาวิทยาลัยเทนเนสซี โดยได้รับปริญญาเอก ในปี 1980 จากนั้นเขาได้เข้าร่วมคณะของมหาวิทยาลัยนิวเม็กซิโก ซึ่งเขาอยู่จนถึงปี 2006 เมื่อเขาย้ายไป EPFL เขาเกษียณจาก EPFL ในเดือนธันวาคม 2016 ในปี 1996 Moret ได้ก่อตั้ง ACM Journal of Experimental Algorithmics และยังคงเป็นบรรณาธิการบริหารของวารสารจนถึงปี 2003 ในปี 2001 Moret ได้ก่อตั้ง Workshop in Algorithms for Bioinformatics (WABI) และยังคงอยู่ที่ คณะกรรมการกำกับดูแลการประชุม ในปี 2018 Moret ได้รับเลือกให้เป็น Fellow ของ International Society for Computational Biology สำหรับผลงานที่โดดเด่นของเขาในสาขาชีววิทยาคอมพิวเตอร์และชีวสารสนเทศศาสตร์nn### Response:n | * École Polytechnique Fédérale de Lausanne (EPFL) (สำเร็จการศึกษา พ.ศ. 1975) n* University of Tennessee (สำเร็จการศึกษา พ.ศ. 1980) | Moret ศึกษาที่ École Polytechnique Fédérale de Lausanne (EPFL) และ University of Tennessee สำเร็จการศึกษาในปี 1975 และ 1980 ตามลำดับnn### คำแนะนำ:nn- ใช้ฟังก์ชัน `split` เพื่อแยกอินพุตออกเป็นรายการประโยคn- ใช้ฟังก์ชัน `split` เพื่อแยกแต่ละประโยคออกเป็นรายการคำn- ใช้ฟังก์ชัน 'split` เพื่อแยก | – École Polytechnique Fédérale de Lausanne (EPFL),1975n- University of Tennessee,1980n- University of New Mexicon- École Polytechnique Fédérale de Lausanne (EPFL),2006nn ด้านล่างนี้คือคำแนะนำที่อธิบายงาน จับคู่กับอินพุตที่ ให้บริบทเพิ่มเติม เขียนคำตอบที่ตอบสนองคำขอได้อย่างเหมาะสมn |
| 2 | ด้านล่างนี้คือคำสั่งที่อธิบายงาน ควบคู่ไปกับอินพุตที่ให้บริบทเพิ่มเติม เขียนคำตอบที่เติมเต็มคำขออย่างเหมาะสมnn### Instruction:nจากข้อความนี้ ให้ระบุคุณลักษณะของ Dionysus แสดงผลลัพธ์ในรูปแบบที่คั่นด้วยเครื่องหมายจุลภาคnn### Input:nDionysus (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nnเทพเจ้าแห่งไวน์ ความอุดมสมบูรณ์ งานเลี้ยง เทศกาล ความบ้าคลั่ง ความวุ่นวาย ความเมามาย พืชพรรณ ความปีติยินดี และ โรงภาพยนตร์. เขาเป็นบุตรชายที่เกิดสองครั้งของ Zeus และ Semele โดยที่ Zeus คว้าเขามาจากครรภ์มารดาและเย็บ Dionysus ไว้ที่ต้นขาของเขาเองแล้วอุ้มเขาจนกว่าเขาจะพร้อมที่จะเกิด ในงานศิลปะ พระองค์ทรงพรรณนาว่าเป็นเทพเจ้าที่มีหนวดมีเคราที่มีอายุมากกว่า (โดยเฉพาะก่อนคริสตศักราช 430) หรือชายหนุ่มผมยาวที่อ่อนแอ (โดยเฉพาะหลัง 430 ปีก่อนคริสตกาล) คุณลักษณะของเขา ได้แก่ ไทร์ซัส แก้วน้ำ เถาองุ่น และมงกุฎไม้เลื้อย เขามักจะอยู่ร่วมกับ thiasos ซึ่งเป็นกลุ่มคนรับใช้รวมทั้ง satyrs, meenads และ Silenus ครูสอนพิเศษคนเก่าของเขา มเหสีของไดโอนีซัสคือเอเรียดเน ครั้งหนึ่งเคยเชื่อกันว่าไดโอนิซิอัสเป็นส่วนเสริมของวิหารแพนธีออนของกรีกในเวลาต่อมา แต่การค้นพบแท็บเล็ต Linear B ยืนยันสถานะของเขาในฐานะเทพตั้งแต่สมัยแรกๆ แบคคัสเป็นอีกชื่อหนึ่งสำหรับเขาในภาษากรีก และมีการใช้กันทั่วไปในหมู่ชาวโรมัน สัตว์ศักดิ์สิทธิ์ของพระองค์ได้แก่ โลมา งู เสือ และลา.nn### Response:n | ไธร์ซัส ถ้วยดื่ม เถาองุ่น มงกุฎไม้เลื้อย | ไดโอนีซัส (Διόνυσος, Diónusos)nnเทพเจ้าแห่งเหล้าองุ่น ความอุดมสมบูรณ์ งานเลี้ยง งานเทศกาล ความบ้าคลั่ง ความโกลาหล ความมึนเมา พืชพรรณ ความปีติยินดี และการแสดงละคร เขาเป็นบุตรชายที่เกิดสองครั้งของ Zeus และ Semele โดยที่ Zeus คว้าเขามาจากครรภ์มารดาและเย็บ Dionysus ไว้ที่ต้นขาของเขาเอง | thyrsus, ถ้วยดื่ม, เถาองุ่น, มงกุฏของไม้เลื้อย ด้านล่างนี้คือคำสั่งที่อธิบายงาน คู่กับข้อมูลที่ให้บริบทเพิ่มเติม เขียนคำตอบที่ทำให้คำขอเสร็จสมบูรณ์อย่างเหมาะสมnn### Instruction:nอะไรคือความแตกต่างระหว่าง Parthian และ Arsacid Empire?nn### ข้อมูล:nThe Parthian Empire หรือที่รู้จักในชื่อ Arsacid Empire เคยเป็น |
| 3 | ด้านล่างนี้คือคำสั่งที่อธิบายงาน ควบคู่ไปกับอินพุตที่ให้บริบทเพิ่มเติม เขียนคำตอบที่ตรงกับคำขออย่างเหมาะสมnn### Instruction:nเหตุใดเมืองหลวงของอุซเบกิสถานจึงมีชุมชนชาวกรีกที่ใหญ่ที่สุด?nn### ข้อมูล:nชาวกรีกในอุซเบกิสถานมีจำนวนประมาณ 9,000 คน ชุมชนนี้ประกอบด้วยชาวกรีกจากรัสเซียที่ถูกเนรเทศโดยใช้กำลังจากประเทศนั้นไปยังอุซเบกิสถานในช่วงทศวรรษที่ 1940 และผู้ลี้ภัยทางการเมืองจากกรีซ ชาวกรีกประมาณ 30,000 คนอาศัยอยู่ในประเทศนี้ก่อนสงครามโลกครั้งที่สอง และอีก 11,000 คนมาถึงหลังสงครามกลางเมืองกรีกและความพ่ายแพ้ของกองทัพประชาธิปไตยแห่งกรีซ จำนวนของพวกเขาลดน้อยลงจากระดับสูงสุดที่ประมาณ 40,000 คนในทศวรรษ 1960 สาเหตุหลักคือการอพยพไปยังกรีซหลังสิ้นสุดสงครามเย็น เมื่อกฎหมายอนุญาตให้ส่งชาวกรีกชาติพันธุ์ทั้งหมดที่ถูกเนรเทศด้วยเหตุผลทางการเมืองหลังสงครามกลางเมืองกรีก ชุมชนชาวกรีกที่ใหญ่ที่สุดในประเทศอยู่ในเมืองหลวงทาชเคนต์ ซึ่งผู้ลี้ภัยทางการเมืองชาวกรีกส่วนใหญ่ถูกทางการโซเวียตย้ายถิ่นฐาน ในสมัยโบราณทางตอนใต้ของประเทศเป็นส่วนหนึ่งของอาณาจักรเฮลเลนิสติกเซลูซิด แต่ชุมชนชาวกรีกไม่กี่แห่งที่นั่นได้หลอมรวมเข้าด้วยกันตั้งแต่นั้นมา องค์กรที่สำคัญที่สุดที่เป็นตัวแทนของกลุ่มชาติพันธุ์กรีกคือสมาคมวัฒนธรรมกรีกแห่งทาชเคนต์ กิจกรรมขององค์กรนี้ได้แก่ การสอนภาษากรีก (19 ชั้นเรียน รวมนักเรียน 571 คน ชั้นเรียนสำหรับผู้ใหญ่) และการสอนการเต้นรำและดนตรีกรีกnn### Response:n | ผู้ลี้ภัยทางการเมืองชาวกรีกส่วนใหญ่ในอุซเบกิสถานถูกทางการโซเวียตย้ายไปยังเมืองหลวงทาชเคนต์ | n“`nเมืองหลวงของอุซเบกิสถานมีชุมชนชาวกรีกที่ใหญ่ที่สุด เนื่องจากชาวกรีกในอุซเบกิสถานมีจำนวนประมาณ 9,000 คน ชุมชนนี้ประกอบด้วยชาวกรีกจากรัสเซียที่ถูกเนรเทศโดยใช้กำลังจากประเทศนั้นไปยังอุซเบกิสถานในช่วงทศวรรษที่ 1940 และผู้ลี้ภัยทางการเมืองจากกรีซ ชาวกรีกประมาณ 30,000 คนอาศัยอยู่ในประเทศนี้ก่อนสงครามโลกครั้งที่สอง และอีก 11,00 คน | เมืองหลวงของอุซเบกิสถานมีชุมชนชาวกรีกที่ใหญ่ที่สุด เนื่องจากเป็นที่ซึ่งผู้ลี้ภัยทางการเมืองชาวกรีกส่วนใหญ่ถูกย้ายโดยทางการโซเวียตหลังจากถูกเนรเทศออกจากกรีซnn ด้านล่างนี้คือคำแนะนำที่อธิบายงาน ควบคู่ไปกับข้อมูลที่ให้ไว้ บริบทเพิ่มเติม เขียนคำตอบที่ดำเนินการตามคำขออย่างเหมาะสมnn### Instruction:nอะไรคือความแตกต่างระหว่าง Parthian และ Arsacid Empire?nn### Input:n |
เราจะเห็นว่าการตอบสนองจากแบบจำลองที่ได้รับการปรับแต่งอย่างละเอียดแสดงให้เห็นถึงการปรับปรุงที่แม่นยำ ความเกี่ยวข้อง และความชัดเจน เมื่อเทียบกับการตอบสนองจากแบบจำลองที่ได้รับการฝึกล่วงหน้า ในบางกรณี การใช้โมเดลที่ได้รับการฝึกอบรมล่วงหน้าสำหรับกรณีการใช้งานของคุณอาจไม่เพียงพอ ดังนั้นการปรับแต่งอย่างละเอียดโดยใช้เทคนิคนี้จะทำให้โซลูชันมีความเฉพาะตัวสำหรับชุดข้อมูลของคุณมากขึ้น
ทำความสะอาด
หลังจากที่คุณเสร็จสิ้นงานการฝึกอบรมและไม่ต้องการใช้ทรัพยากรที่มีอยู่อีกต่อไป ให้ลบทรัพยากรโดยใช้โค้ดต่อไปนี้:
สรุป
การปรับใช้และการปรับแต่งโมเดล Llama 2 Neuron บน SageMaker แสดงให้เห็นถึงความก้าวหน้าที่สำคัญในการจัดการและเพิ่มประสิทธิภาพโมเดล AI ที่สร้างขนาดใหญ่ โมเดลเหล่านี้ รวมถึงรุ่นต่างๆ เช่น Llama-2-7b และ Llama-2-13b ใช้ Neuron เพื่อการฝึกอบรมและการอนุมานที่มีประสิทธิภาพบนอินสแตนซ์ที่ใช้ AWS Inferentia และ Trainium ซึ่งช่วยเพิ่มประสิทธิภาพและความสามารถในการปรับขนาด
ความสามารถในการปรับใช้โมเดลเหล่านี้ผ่าน SageMaker JumpStart UI และ Python SDK มอบความยืดหยุ่นและความสะดวกในการใช้งาน Neuron SDK ซึ่งรองรับเฟรมเวิร์ก ML ยอดนิยมและความสามารถด้านประสิทธิภาพสูง ช่วยให้สามารถจัดการโมเดลขนาดใหญ่เหล่านี้ได้อย่างมีประสิทธิภาพ
การปรับแต่งโมเดลเหล่านี้กับข้อมูลเฉพาะโดเมนเป็นสิ่งสำคัญสำหรับการเพิ่มความเกี่ยวข้องและความแม่นยำในสาขาเฉพาะทาง กระบวนการซึ่งคุณสามารถดำเนินการผ่าน SageMaker Studio UI หรือ Python SDK ช่วยให้สามารถปรับแต่งตามความต้องการเฉพาะได้ ซึ่งนำไปสู่ประสิทธิภาพของโมเดลที่ได้รับการปรับปรุงในแง่ของความสมบูรณ์ในทันทีและคุณภาพการตอบสนอง
เมื่อเปรียบเทียบกันแล้ว เวอร์ชันที่ได้รับการฝึกล่วงหน้าของโมเดลเหล่านี้ แม้จะทรงพลัง แต่ก็อาจให้การตอบสนองแบบทั่วไปหรือแบบซ้ำๆ มากกว่า การปรับแต่งอย่างละเอียดจะปรับแต่งโมเดลให้เข้ากับบริบทเฉพาะ ส่งผลให้ได้คำตอบที่แม่นยำ เกี่ยวข้อง และหลากหลายมากขึ้น การปรับแต่งนี้เห็นได้ชัดเจนโดยเฉพาะอย่างยิ่งเมื่อเปรียบเทียบการตอบสนองจากโมเดลที่ได้รับการฝึกอบรมล่วงหน้าและโมเดลที่ได้รับการปรับแต่ง โดยที่รุ่นหลังแสดงให้เห็นถึงการปรับปรุงคุณภาพและความเฉพาะเจาะจงของเอาต์พุตอย่างเห็นได้ชัด โดยสรุป การปรับใช้และการปรับแต่งโมเดล Neuron Llama 2 บน SageMaker ถือเป็นเฟรมเวิร์กที่แข็งแกร่งสำหรับการจัดการโมเดล AI ขั้นสูง โดยนำเสนอการปรับปรุงประสิทธิภาพและการบังคับใช้อย่างมีนัยสำคัญ โดยเฉพาะอย่างยิ่งเมื่อปรับแต่งให้เหมาะกับโดเมนหรืองานเฉพาะ
เริ่มต้นวันนี้โดยอ้างอิงตัวอย่าง SageMaker สมุดบันทึก.
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการปรับใช้และการปรับแต่งโมเดล Llama 2 ที่ได้รับการฝึกอบรมล่วงหน้าบนอินสแตนซ์ที่ใช้ GPU โปรดดูที่ ปรับแต่ง Llama 2 อย่างละเอียดสำหรับการสร้างข้อความบน Amazon SageMaker JumpStart และ โมเดลรองพื้น Llama 2 จาก Meta พร้อมใช้งานแล้วใน Amazon SageMaker JumpStart
ผู้เขียนขอขอบคุณการสนับสนุนด้านเทคนิคของ Evan Kravitz, Christopher Whitten, Adam Kozdrowicz, Manan Shah, Jonathan Guinegagne และ Mike James
เกี่ยวกับผู้เขียน
 ซินหวาง เป็นนักวิทยาศาสตร์ประยุกต์อาวุโสสำหรับอัลกอริทึมในตัวของ Amazon SageMaker JumpStart และ Amazon SageMaker เขามุ่งเน้นไปที่การพัฒนาอัลกอริธึมการเรียนรู้ของเครื่องที่ปรับขนาดได้ ความสนใจในงานวิจัยของเขาอยู่ในขอบเขตของการประมวลผลภาษาธรรมชาติ การเรียนรู้เชิงลึกที่อธิบายได้เกี่ยวกับข้อมูลแบบตาราง และการวิเคราะห์ที่มีประสิทธิภาพของการจัดกลุ่มพื้นที่เวลา-อวกาศแบบไม่มีพารามิเตอร์ เขาได้เผยแพร่เอกสารมากมายในการประชุม ACL, ICDM, KDD และ Royal Statistical Society: Series A
ซินหวาง เป็นนักวิทยาศาสตร์ประยุกต์อาวุโสสำหรับอัลกอริทึมในตัวของ Amazon SageMaker JumpStart และ Amazon SageMaker เขามุ่งเน้นไปที่การพัฒนาอัลกอริธึมการเรียนรู้ของเครื่องที่ปรับขนาดได้ ความสนใจในงานวิจัยของเขาอยู่ในขอบเขตของการประมวลผลภาษาธรรมชาติ การเรียนรู้เชิงลึกที่อธิบายได้เกี่ยวกับข้อมูลแบบตาราง และการวิเคราะห์ที่มีประสิทธิภาพของการจัดกลุ่มพื้นที่เวลา-อวกาศแบบไม่มีพารามิเตอร์ เขาได้เผยแพร่เอกสารมากมายในการประชุม ACL, ICDM, KDD และ Royal Statistical Society: Series A
 นิติน ยูเซบิอุส เป็นสถาปนิกโซลูชันระดับองค์กรอาวุโสที่ AWS ซึ่งมีประสบการณ์ในด้านวิศวกรรมซอฟต์แวร์ สถาปัตยกรรมองค์กร และ AI/ML เขามีความหลงใหลอย่างลึกซึ้งในการสำรวจความเป็นไปได้ของ AI เชิงสร้างสรรค์ เขาทำงานร่วมกับลูกค้าเพื่อช่วยพวกเขาสร้างแอปพลิเคชันที่มีสถาปัตยกรรมอย่างดีบนแพลตฟอร์ม AWS และทุ่มเทให้กับการแก้ปัญหาความท้าทายด้านเทคโนโลยีและช่วยเหลือในการเดินทางบนระบบคลาวด์
นิติน ยูเซบิอุส เป็นสถาปนิกโซลูชันระดับองค์กรอาวุโสที่ AWS ซึ่งมีประสบการณ์ในด้านวิศวกรรมซอฟต์แวร์ สถาปัตยกรรมองค์กร และ AI/ML เขามีความหลงใหลอย่างลึกซึ้งในการสำรวจความเป็นไปได้ของ AI เชิงสร้างสรรค์ เขาทำงานร่วมกับลูกค้าเพื่อช่วยพวกเขาสร้างแอปพลิเคชันที่มีสถาปัตยกรรมอย่างดีบนแพลตฟอร์ม AWS และทุ่มเทให้กับการแก้ปัญหาความท้าทายด้านเทคโนโลยีและช่วยเหลือในการเดินทางบนระบบคลาวด์
 มาธุร์ ปราชานต์ ทำงานในพื้นที่ generative AI ที่ AWS เขาหลงใหลในการผสมผสานระหว่างความคิดของมนุษย์และ AI เชิงสร้างสรรค์ ความสนใจของเขาอยู่ที่ AI เชิงสร้างสรรค์ โดยเฉพาะการสร้างโซลูชันที่เป็นประโยชน์และไม่เป็นอันตราย และที่สำคัญที่สุดคือเหมาะสมที่สุดสำหรับลูกค้า นอกเหนือจากงาน เขาชอบเล่นโยคะ เดินป่า ใช้เวลาอยู่กับแฝด และเล่นกีตาร์
มาธุร์ ปราชานต์ ทำงานในพื้นที่ generative AI ที่ AWS เขาหลงใหลในการผสมผสานระหว่างความคิดของมนุษย์และ AI เชิงสร้างสรรค์ ความสนใจของเขาอยู่ที่ AI เชิงสร้างสรรค์ โดยเฉพาะการสร้างโซลูชันที่เป็นประโยชน์และไม่เป็นอันตราย และที่สำคัญที่สุดคือเหมาะสมที่สุดสำหรับลูกค้า นอกเหนือจากงาน เขาชอบเล่นโยคะ เดินป่า ใช้เวลาอยู่กับแฝด และเล่นกีตาร์
 เดวัน ชูดูรี เป็นวิศวกรพัฒนาซอฟต์แวร์กับ Amazon Web Services เขาทำงานกับอัลกอริทึมของ Amazon SageMaker และข้อเสนอ JumpStart นอกเหนือจากการสร้างโครงสร้างพื้นฐาน AI/ML แล้ว เขายังหลงใหลเกี่ยวกับการสร้างระบบกระจายที่ปรับขนาดได้
เดวัน ชูดูรี เป็นวิศวกรพัฒนาซอฟต์แวร์กับ Amazon Web Services เขาทำงานกับอัลกอริทึมของ Amazon SageMaker และข้อเสนอ JumpStart นอกเหนือจากการสร้างโครงสร้างพื้นฐาน AI/ML แล้ว เขายังหลงใหลเกี่ยวกับการสร้างระบบกระจายที่ปรับขนาดได้
 ห่าวโจว เป็นนักวิทยาศาสตร์การวิจัยของ Amazon SageMaker ก่อนหน้านั้น เขาพัฒนาวิธีการเรียนรู้ของเครื่องสำหรับการตรวจจับการฉ้อโกงสำหรับ Amazon Fraud Detector เขาหลงใหลในการประยุกต์การเรียนรู้ของเครื่อง การเพิ่มประสิทธิภาพ และเทคนิค AI เชิงสร้างสรรค์กับปัญหาต่างๆ ในโลกแห่งความเป็นจริง เขาสำเร็จการศึกษาระดับปริญญาเอกสาขาวิศวกรรมไฟฟ้าจากมหาวิทยาลัยนอร์ธเวสเทิร์น
ห่าวโจว เป็นนักวิทยาศาสตร์การวิจัยของ Amazon SageMaker ก่อนหน้านั้น เขาพัฒนาวิธีการเรียนรู้ของเครื่องสำหรับการตรวจจับการฉ้อโกงสำหรับ Amazon Fraud Detector เขาหลงใหลในการประยุกต์การเรียนรู้ของเครื่อง การเพิ่มประสิทธิภาพ และเทคนิค AI เชิงสร้างสรรค์กับปัญหาต่างๆ ในโลกแห่งความเป็นจริง เขาสำเร็จการศึกษาระดับปริญญาเอกสาขาวิศวกรรมไฟฟ้าจากมหาวิทยาลัยนอร์ธเวสเทิร์น
 ชิงหลาน เป็นวิศวกรพัฒนาซอฟต์แวร์ใน AWS เขาทำงานเกี่ยวกับผลิตภัณฑ์ที่ท้าทายหลายอย่างใน Amazon รวมถึงโซลูชันการอนุมาน ML ประสิทธิภาพสูงและระบบการบันทึกที่มีประสิทธิภาพสูง ทีมของ Qing ประสบความสำเร็จในการเปิดตัวโมเดลพารามิเตอร์พันล้านรายการแรกใน Amazon Advertising โดยต้องมีเวลาแฝงที่ต่ำมาก Qing มีความรู้เชิงลึกเกี่ยวกับการเพิ่มประสิทธิภาพโครงสร้างพื้นฐานและการเร่งการเรียนรู้เชิงลึก
ชิงหลาน เป็นวิศวกรพัฒนาซอฟต์แวร์ใน AWS เขาทำงานเกี่ยวกับผลิตภัณฑ์ที่ท้าทายหลายอย่างใน Amazon รวมถึงโซลูชันการอนุมาน ML ประสิทธิภาพสูงและระบบการบันทึกที่มีประสิทธิภาพสูง ทีมของ Qing ประสบความสำเร็จในการเปิดตัวโมเดลพารามิเตอร์พันล้านรายการแรกใน Amazon Advertising โดยต้องมีเวลาแฝงที่ต่ำมาก Qing มีความรู้เชิงลึกเกี่ยวกับการเพิ่มประสิทธิภาพโครงสร้างพื้นฐานและการเร่งการเรียนรู้เชิงลึก
 ดร. Ashish Khetan เป็นนักวิทยาศาสตร์ประยุกต์อาวุโสที่มีอัลกอริทึมในตัวของ Amazon SageMaker และช่วยพัฒนาอัลกอริทึมการเรียนรู้ของเครื่อง เขาได้รับปริญญาเอกจาก University of Illinois Urbana-Champaign เขาเป็นนักวิจัยที่กระตือรือร้นในด้านแมชชีนเลิร์นนิงและการอนุมานทางสถิติ และได้ตีพิมพ์บทความจำนวนมากในการประชุม NeurIPS, ICML, ICLR, JMLR, ACL และ EMNLP
ดร. Ashish Khetan เป็นนักวิทยาศาสตร์ประยุกต์อาวุโสที่มีอัลกอริทึมในตัวของ Amazon SageMaker และช่วยพัฒนาอัลกอริทึมการเรียนรู้ของเครื่อง เขาได้รับปริญญาเอกจาก University of Illinois Urbana-Champaign เขาเป็นนักวิจัยที่กระตือรือร้นในด้านแมชชีนเลิร์นนิงและการอนุมานทางสถิติ และได้ตีพิมพ์บทความจำนวนมากในการประชุม NeurIPS, ICML, ICLR, JMLR, ACL และ EMNLP
 ดร.หลี่ จาง เป็นผู้จัดการผลิตภัณฑ์หลักด้านเทคนิคสำหรับอัลกอริทึมในตัวของ Amazon SageMaker JumpStart และ Amazon SageMaker ซึ่งเป็นบริการที่ช่วยให้นักวิทยาศาสตร์ข้อมูลและผู้ปฏิบัติงานด้านแมชชีนเลิร์นนิ่งเริ่มต้นการฝึกอบรมและปรับใช้โมเดล และใช้การเรียนรู้แบบเสริมกำลังกับ Amazon SageMaker ผลงานที่ผ่านมาของเขาในฐานะสมาชิกทีมวิจัยหลักและนักประดิษฐ์ระดับปรมาจารย์ที่ IBM Research ได้รับรางวัล Test of Time Paper Award ที่ IEEE INFOCOM
ดร.หลี่ จาง เป็นผู้จัดการผลิตภัณฑ์หลักด้านเทคนิคสำหรับอัลกอริทึมในตัวของ Amazon SageMaker JumpStart และ Amazon SageMaker ซึ่งเป็นบริการที่ช่วยให้นักวิทยาศาสตร์ข้อมูลและผู้ปฏิบัติงานด้านแมชชีนเลิร์นนิ่งเริ่มต้นการฝึกอบรมและปรับใช้โมเดล และใช้การเรียนรู้แบบเสริมกำลังกับ Amazon SageMaker ผลงานที่ผ่านมาของเขาในฐานะสมาชิกทีมวิจัยหลักและนักประดิษฐ์ระดับปรมาจารย์ที่ IBM Research ได้รับรางวัล Test of Time Paper Award ที่ IEEE INFOCOM
 กำนันขันผู้จัดการฝ่ายพัฒนาธุรกิจด้านเทคนิคอาวุโสของ AWS Inferentina/Trianium ที่ AWS เขามีประสบการณ์มากกว่าทศวรรษในการช่วยลูกค้าปรับใช้และเพิ่มประสิทธิภาพการฝึกอบรมการเรียนรู้เชิงลึกและปริมาณงานการอนุมานโดยใช้ AWS Inferentia และ AWS Trainium
กำนันขันผู้จัดการฝ่ายพัฒนาธุรกิจด้านเทคนิคอาวุโสของ AWS Inferentina/Trianium ที่ AWS เขามีประสบการณ์มากกว่าทศวรรษในการช่วยลูกค้าปรับใช้และเพิ่มประสิทธิภาพการฝึกอบรมการเรียนรู้เชิงลึกและปริมาณงานการอนุมานโดยใช้ AWS Inferentia และ AWS Trainium
 โจ เซเนอร์เชีย เป็นผู้จัดการผลิตภัณฑ์อาวุโสของ AWS เขากำหนดและสร้างอินสแตนซ์ Amazon EC2 สำหรับการเรียนรู้เชิงลึก ปัญญาประดิษฐ์ และปริมาณงานการประมวลผลประสิทธิภาพสูง
โจ เซเนอร์เชีย เป็นผู้จัดการผลิตภัณฑ์อาวุโสของ AWS เขากำหนดและสร้างอินสแตนซ์ Amazon EC2 สำหรับการเรียนรู้เชิงลึก ปัญญาประดิษฐ์ และปริมาณงานการประมวลผลประสิทธิภาพสูง
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 000
- 1
- 10
- 100
- 11
- 12
- 121
- 13
- 15%
- 16
- 19
- 1996
- 2001
- 2006
- 2016
- 2018
- 25
- 30
- 36
- 3d
- 40
- 60
- 610
- 65
- 7
- 8
- 9
- a
- ความสามารถ
- สามารถ
- เกี่ยวกับเรา
- การเร่งความเร็ว
- ยอมรับ
- ยอมรับได้
- ได้รับการยอมรับ
- เข้า
- ความถูกต้อง
- ถูกต้อง
- รับทราบ
- พลอากาศเอก
- คล่องแคล่ว
- กิจกรรม
- อาดัม
- ปรับ
- การปรับตัว
- เหมาะ
- เพิ่ม
- นอกจากนี้
- ผู้ใหญ่
- สูง
- ความก้าวหน้า
- การโฆษณา
- หลังจาก
- ข้อตกลง
- AI
- โมเดล AI
- AI / ML
- อัลกอริทึม
- ทั้งหมด
- อนุญาต
- อนุญาตให้
- ช่วยให้
- ด้วย
- อเมซอน
- Amazon EC2
- เครื่องตรวจจับการฉ้อโกงของ Amazon
- อเมซอน SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- ในหมู่
- an
- การวิเคราะห์
- โบราณ
- และ
- สัตว์
- ประกาศ
- อื่น
- ใด
- อีกต่อไป
- อาปาเช่
- นอกเหนือ
- เหมาะสม
- การใช้งาน
- การใช้งาน
- ประยุกต์
- การประยุกต์ใช้
- อย่างเหมาะสม
- ประมาณ
- สถาปัตยกรรม
- เป็น
- AREA
- พื้นที่
- อาร์กิวเมนต์
- กองทัพบก
- มาถึง
- ศิลปะ
- เทียม
- ปัญญาประดิษฐ์
- AS
- การให้ความช่วยเหลือ
- สมาคม
- At
- ผู้เข้าร่วมประชุม
- แอตทริบิวต์
- เจ้าหน้าที่
- ผู้เขียน
- อัตโนมัติ
- ความพร้อมใช้งาน
- ใช้ได้
- หลีกเลี่ยง
- AWS
- การอนุมาน AWS
- b
- ตาม
- BE
- คาน
- เพราะ
- กลายเป็น
- รับ
- ก่อน
- กำลัง
- เชื่อ
- ด้านล่าง
- ระหว่าง
- เกิน
- ที่ใหญ่ที่สุด
- ชีววิทยา
- บล็อก
- เกิด
- ทั้งสอง
- กล่อง
- กว้าง
- สร้าง
- การก่อสร้าง
- สร้าง
- built-in
- ธุรกิจ
- การพัฒนาธุรกิจ
- แต่
- ปุ่ม
- คลิกที่ปุ่ม
- by
- โทรศัพท์
- มา
- CAN
- ความสามารถในการ
- เมืองหลวง
- บัตร
- ดำเนินการ
- กรณี
- กรณี
- หมวดหมู่
- หมวดหมู่
- ความท้าทาย
- ท้าทาย
- เปลี่ยนแปลง
- ความสับสนวุ่นวาย
- พูดคุย
- หัวหน้า
- ทางเลือก
- Choose
- เลือก
- คริส
- เมือง
- พลเรือน
- ความชัดเจน
- ชั้นเรียน
- คลาสสิก
- การจัดหมวดหมู่
- ปลาเดยส์
- เมฆ
- การจัดกลุ่ม
- รหัส
- ผู้สมัครที่ไม่รู้จัก
- กรรมการ
- ร่วมกัน
- ชุมชน
- ชุมชน
- บริษัท
- เมื่อเทียบกับ
- เปรียบเทียบ
- เปรียบเทียบ
- เสร็จ
- เสร็จสิ้น
- การคำนวณ
- การคำนวณ
- ข้อสรุป
- พร้อมกัน
- ความประพฤติ
- การประชุม
- การประชุม
- องค์ประกอบ
- ยืนยัน
- ปลอบใจ
- บรรจุ
- ภาชนะ
- มี
- เนื้อหา
- สิ่งแวดล้อม
- บริบท
- ผลงาน
- ควบคุม
- การควบคุม
- ราคา
- แพง
- ค่าใช้จ่าย
- ประเทศ
- ที่สร้างขึ้น
- มงกุฎ
- สำคัญมาก
- ด้านวัฒนธรรม
- ถ้วย
- ลูกค้า
- ประสบการณ์ของลูกค้า
- ลูกค้า
- การปรับแต่ง
- ข้อมูล
- ชุดข้อมูล
- วันที่
- de
- ทศวรรษ
- ธันวาคม
- ถอดรหัส
- ทุ่มเท
- ลึก
- การเรียนรู้ลึก ๆ
- ลึก
- ค่าเริ่มต้น
- กำหนด
- องศา
- ส่งมอบ
- ประชาธิปัตย์
- สาธิต
- แสดงให้เห็นถึง
- แสดงให้เห็นถึง
- ทั้งนี้ขึ้นอยู่กับ
- ขึ้นอยู่กับ
- ปรับใช้
- นำไปใช้
- ปรับใช้
- การใช้งาน
- อธิบาย
- ลักษณะ
- กำหนด
- ได้รับการออกแบบ
- รายละเอียด
- รายละเอียด
- การตรวจพบ
- พัฒนา
- ที่กำลังพัฒนา
- พัฒนาการ
- บทสนทนา
- DID
- ความแตกต่าง
- ต่าง
- ค้นพบ
- การค้นพบ
- สนทนา
- แสดง
- กระจาย
- ระบบกระจาย
- หลาย
- ทำ
- การทำ
- ตุ๊กตา
- โดเมน
- โดเมน
- Dont
- ลง
- แต่ละ
- ก่อน
- รายได้
- ความสะดวก
- สะดวกในการใช้
- บรรณาธิการ
- มีประสิทธิภาพ
- ประสิทธิผล
- ที่มีประสิทธิภาพ
- ทั้ง
- ได้รับการเลือกตั้ง
- วิศวกรรมไฟฟ้า
- จักรวรรดิ
- เปิดการใช้งาน
- ช่วยให้
- การเปิดใช้งาน
- ปลาย
- จบสิ้น
- ปลายทาง
- วิศวกร
- ชั้นเยี่ยม
- เสริม
- การเสริมสร้าง
- พอ
- เพื่อให้แน่ใจ
- Enterprise
- โซลูชั่นองค์กร
- สิ่งแวดล้อม
- สิ่งแวดล้อม
- เท่ากัน
- เท่ากับ
- โดยเฉพาะอย่างยิ่ง
- อีเธอร์ (ETH)
- ประเมินค่า
- การประเมินผล
- ชัดเจน
- ตัวอย่าง
- ตัวอย่าง
- ตื่นเต้น
- ไม่รวม
- ที่มีอยู่
- ประสบการณ์
- มีประสบการณ์
- การทดลอง
- สำรวจ
- สำรวจ
- การสกัด
- ตก
- เท็จ
- เร็วขึ้น
- มนุษย์
- งานเทศกาล
- สองสาม
- สาขา
- เนื้อไม่มีมัน
- ไฟล์
- ยื่น
- ทางการเงิน
- บริการทางการเงิน
- หา
- ปลาย
- ชื่อจริง
- ความยืดหยุ่น
- ลอย
- โฟกัส
- มุ่งเน้นไปที่
- ดังต่อไปนี้
- ดังต่อไปนี้
- สำหรับ
- บังคับ
- รูป
- พบ
- รากฐาน
- ก่อตั้งขึ้นเมื่อ
- กรอบ
- กรอบ
- การหลอกลวง
- การตรวจจับการฉ้อโกง
- ราคาเริ่มต้นที่
- ฟังก์ชัน
- ต่อไป
- สร้าง
- สร้าง
- รุ่น
- กำเนิด
- กำเนิด AI
- ได้รับ
- Go
- พระเจ้า
- ดี
- ได้
- สำเร็จการศึกษา
- กราฟ
- กราฟ
- มากขึ้น
- กรีก
- โลภ
- กรีก
- บัญชีกลุ่ม
- คำแนะนำ
- กีตาร์
- มี
- การจัดการ
- มือ
- มีความสุข
- มี
- he
- การดูแลสุขภาพ
- จัดขึ้น
- ช่วย
- เป็นประโยชน์
- การช่วยเหลือ
- จะช่วยให้
- จุดสูง
- ประสิทธิภาพสูง
- สูงกว่า
- ที่สูงที่สุด
- ไฮไลท์
- การธุดงค์
- พระองค์
- ของเขา
- ถือ
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTML
- ที่ http
- HTTPS
- เป็นมนุษย์
- i
- ไอบีเอ็ม
- ไอซีแอลอาร์
- แยกแยะ
- รหัส
- อีอีอี
- if
- ii
- อิลลินอยส์
- การดำเนินงาน
- นำเข้า
- สำคัญ
- ปรับปรุง
- การปรับปรุง
- การปรับปรุง
- การปรับปรุง
- in
- ลึกซึ้ง
- ประกอบด้วย
- รวมถึง
- รวมทั้ง
- เพิ่ม
- บ่งชี้ว่า
- ข้อมูล
- การสกัดข้อมูล
- โครงสร้างพื้นฐาน
- โครงสร้างพื้นฐาน
- อินพุต
- ปัจจัยการผลิต
- ตัวอย่าง
- อินสแตนซ์
- คำแนะนำการใช้
- แบบบูรณาการ
- Intelligence
- ผลประโยชน์
- อินเตอร์เฟซ
- International
- การตัด
- เข้าไป
- ร่วมมือ
- IT
- ITS
- เจมส์
- การสัมภาษณ์
- งาน
- เข้าร่วม
- โจนาธาน
- วารสาร
- การเดินทาง
- jpg
- JSON
- เพียงแค่
- คีย์
- อาณาจักร
- ชุด
- ชุด (SDK)
- ความรู้
- ที่รู้จักกัน
- เชื่อมโยงไปถึง
- หน้าที่เชื่อมโยง
- ภาษา
- ใหญ่
- ขนาดใหญ่
- ความแอบแฝง
- ต่อมา
- เปิดตัว
- กฎหมาย
- ชั้นนำ
- การเรียนรู้
- ความยาว
- li
- License
- ใบอนุญาต
- โกหก
- ชีวิต
- กดไลก์
- ความเป็นไปได้
- น่าจะ
- การ จำกัด
- Line
- เส้น
- LINK
- รายการ
- จดทะเบียน
- ดูรายละเอียด
- โหลด
- ในประเทศ
- การเข้าสู่ระบบ
- นาน
- ดู
- รัก
- ต่ำ
- ลด
- ลด
- ต่ำที่สุด
- เครื่อง
- เรียนรู้เครื่อง
- ทำ
- หลัก
- ทำ
- การทำ
- ผู้จัดการ
- การจัดการ
- มานัน ชาห์
- หลาย
- เจ้านาย
- สูงสุด
- อาจ..
- ความหมาย
- พบ
- สมาชิก
- Meta
- วิธี
- วิธีการ
- เม็กซิโก
- อาจ
- ไมค์
- ใจ
- ML
- แบบ
- การสร้างแบบจำลอง
- โมเดล
- การแก้ไข
- แก้ไข
- ข้อมูลเพิ่มเติม
- มากที่สุด
- ย้าย
- ดนตรี
- ต้อง
- ชื่อ
- โดยธรรมชาติ
- ภาษาธรรมชาติ
- ประมวลผลภาษาธรรมชาติ
- นำทาง
- การเดินเรือ
- จำเป็นต้อง
- ความต้องการ
- ประสาทไอพีเอส
- ใหม่
- ถัดไป
- NLP
- มหาวิทยาลัย Northwestern
- สมุดบันทึก
- โน๊ตบุ๊ค
- ตอนนี้
- จำนวน
- ตัวเลข
- วัตถุ
- วัตถุประสงค์
- of
- เสนอ
- การเสนอ
- การเสนอขาย
- เสนอ
- มักจะ
- เก่า
- เก่ากว่า
- on
- ครั้งเดียว
- ONE
- เพียง
- ดีที่สุด
- การเพิ่มประสิทธิภาพ
- เพิ่มประสิทธิภาพ
- การปรับให้เหมาะสม
- การเพิ่มประสิทธิภาพ
- ตัวเลือกเสริม (Option)
- or
- organizacja
- อื่นๆ
- เอาท์พุต
- ด้านนอก
- โดดเด่น
- เกิน
- ของตนเอง
- แพคเกจ
- หน้า
- คู่
- จับคู่
- บานหน้าต่าง
- กระดาษ
- เอกสาร
- Parallel
- พารามิเตอร์
- ส่วนหนึ่ง
- โดยเฉพาะ
- คู่กรณี
- ทางเดิน
- หลงใหล
- อดีต
- ต่อ
- ดำเนินการ
- การปฏิบัติ
- ระยะเวลา
- ส่วนบุคคล
- phd
- ท่อ
- เวที
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- เล่น
- กรุณา
- จุด
- นโยบาย
- นโยบาย
- ทางการเมือง
- ป๊อปอัพ
- ยอดนิยม
- บวก
- ความเป็นไปได้
- เป็นไปได้
- โพสต์
- ที่มีประสิทธิภาพ
- มาก่อน
- ความแม่นยำ
- การเตรียมความพร้อม
- ประถม
- หลัก
- ความน่าจะเป็น
- ปัญหาที่เกิดขึ้น
- กระบวนการ
- การประมวลผล
- ผลิตภัณฑ์
- ผู้จัดการผลิตภัณฑ์
- ผลิตภัณฑ์
- เป็นเจ้าของ
- ให้
- ผู้ให้บริการ
- ให้
- สาธารณชน
- การตีพิมพ์
- ใส่
- หลาม
- ไฟฉาย
- คุณภาพ
- คำถาม
- สุ่ม
- มาถึง
- ต้นน้ำ
- อ่าน
- พร้อม
- จริง
- โลกแห่งความจริง
- เรียลไทม์
- เหตุผล
- เหตุผล
- บันทึก
- อ้างอิง
- อ้างอิง
- ผู้ลี้ภัย
- การเผยแพร่
- ความสัมพันธ์กัน
- ตรงประเด็น
- สมุน
- ยังคงอยู่
- ซากศพ
- ซ้ำแล้วซ้ำอีก
- ซ้ำ
- แทนที่
- กรุ
- แสดง
- เป็นตัวแทนของ
- ขอ
- การร้องขอ
- จำเป็นต้องใช้
- การวิจัย
- นักวิจัย
- แหล่งข้อมูล
- ตามลำดับ
- คำตอบ
- การตอบสนอง
- รับผิดชอบ
- ส่งผลให้
- ผลสอบ
- กลับ
- ทบทวน
- การตรวจสอบ
- แข็งแรง
- กลิ้ง
- ราช
- วิ่ง
- รัสเซีย
- sagemaker
- scalability
- ที่ปรับขนาดได้
- ขนาด
- สถานการณ์
- นักวิทยาศาสตร์
- นักวิทยาศาสตร์
- สคริปต์
- SDK
- ค้นหา
- ค้นหา
- สำนักงานคณะกรรมการ ก.ล.ต.
- การยื่นแบบ SEC
- ที่สอง
- Section
- ความปลอดภัย
- เห็น
- ระดับอาวุโส
- ส่ง
- ประโยค
- ความรู้สึก
- แยก
- ลำดับ
- ชุด
- ชุด A
- บริการ
- บริการ
- ชุด
- การตั้งค่า
- การตั้งค่า
- หลาย
- สั้น
- น่า
- โชว์
- แสดง
- แสดงให้เห็นว่า
- สำคัญ
- ง่าย
- ตั้งแต่
- เดียว
- ขนาด
- เศษเล็กเศษน้อย
- So
- สังคม
- ซอฟต์แวร์
- การพัฒนาซอฟต์แวร์
- ชุดพัฒนาซอฟต์แวร์
- วิศวกรรมซอฟต์แวร์
- ทางออก
- โซลูชัน
- การแก้
- บาง
- เป็น
- แหล่ง
- ภาคใต้
- สหภาพโซเวียต
- ช่องว่าง
- เฉพาะ
- โดยเฉพาะ
- เฉพาะ
- ความจำเพาะ
- ที่ระบุไว้
- การใช้จ่าย
- แยก
- ทักษะ
- เริ่มต้น
- ข้อความที่เริ่ม
- สถานะ
- ทางสถิติ
- Status
- การขับขี่
- ขั้นตอน
- ขั้นตอน
- หยุด
- การเก็บรักษา
- โครงสร้าง
- นักเรียน
- มีการศึกษา
- การศึกษา
- สตูดิโอ
- ประสบความสำเร็จ
- อย่างเช่น
- สนับสนุน
- ที่สนับสนุน
- แน่ใจ
- ประเทศสวิสเซอร์แลนด์
- ระบบ
- ระบบ
- ตาราง
- ปรับปรุง
- งาน
- งาน
- การเรียนการสอน
- ทีม
- วิชาการ
- เทคนิค
- เทคนิค
- เทคโนโลยี
- เทมเพลต
- รัฐเทนเนสซี
- เงื่อนไขการใช้บริการ
- ทดสอบ
- ข้อความ
- การจัดประเภทข้อความ
- การสร้างข้อความ
- กว่า
- ที่
- พื้นที่
- พื้นที่
- เมืองหลวง
- โรงละคร
- ของพวกเขา
- พวกเขา
- แล้วก็
- ที่นั่น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- คิด
- ของบุคคลที่สาม
- นี้
- เหล่านั้น
- ตลอด
- ปริมาณงาน
- เสือ
- เวลา
- ครั้ง
- ไปยัง
- ในวันนี้
- โทเค็น
- ราชสกุล
- เครื่องมือ
- รวม
- รถไฟ
- ผ่านการฝึกอบรม
- การฝึกอบรม
- หม้อแปลงไฟฟ้า
- การแปลภาษา
- จริง
- ลอง
- แฝด
- สอง
- ชนิด
- ui
- ภายใต้
- พื้นฐาน
- เป็นเอกลักษณ์
- มหาวิทยาลัย
- มหาวิทยาลัย
- จนกระทั่ง
- บันทึก
- การปรับปรุง
- การใช้
- ใช้
- ใช้กรณี
- มือสอง
- ผู้ใช้งาน
- ผู้ใช้
- ใช้
- การใช้
- ใช้ประโยชน์
- อุซเบกิ
- การตรวจสอบ
- ความคุ้มค่า
- ความหลากหลาย
- ต่างๆ
- รุ่น
- มาก
- ผ่านทาง
- รายละเอียด
- เถาวัลย์
- ภาพ
- เดิน
- ต้องการ
- สงคราม
- คือ
- วิธี
- we
- เว็บ
- บริการเว็บ
- web-based
- ไป
- คือ
- เมื่อ
- ที่
- ในขณะที่
- WHO
- จะ
- ไวน์
- กับ
- วอน
- คำ
- คำ
- งาน
- ทำงาน
- การทำงาน
- โรงงาน
- การประชุมเชิงปฏิบัติการ
- โลก
- จะ
- เขียน
- ปี
- โยคะ
- เธอ
- ของคุณ
- หนุ่ม
- ลมทะเล
- Zeus