
ภาพจากผู้เขียน | ผู้สร้างรูปภาพ Bing
ดอลลี่ 2.0 เป็นโมเดลภาษาขนาดใหญ่ (LLM) แบบโอเพ่นซอร์สที่ทำตามคำสั่งซึ่งได้รับการปรับแต่งอย่างละเอียดบนชุดข้อมูลที่มนุษย์สร้างขึ้น สามารถใช้เพื่อวัตถุประสงค์ในการวิจัยและการค้า
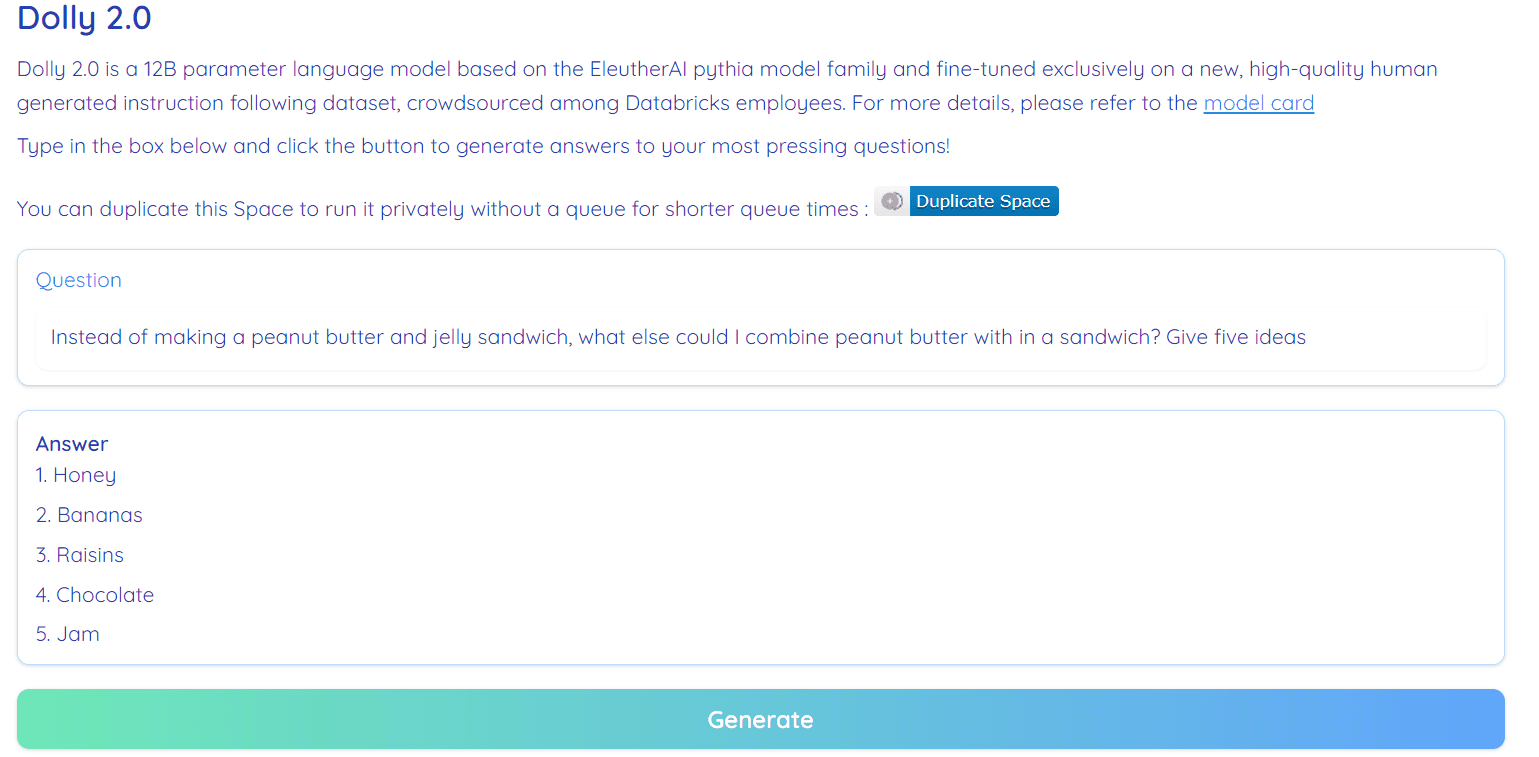
ภาพจาก Hugging Face Space โดย รามอนันธ์1
ก่อนหน้านี้ทีมงาน Databricks ได้ปล่อย ดอลลี่ 1.0, LLM ซึ่งแสดงคำสั่งเหมือน ChatGPT ตามความสามารถและมีค่าใช้จ่ายน้อยกว่า $30 ในการฝึกอบรม มันใช้ชุดข้อมูลของทีม Stanford Alpaca ซึ่งอยู่ภายใต้ใบอนุญาตแบบจำกัด (การวิจัยเท่านั้น)
Dolly 2.0 ได้แก้ไขปัญหานี้โดยการปรับโมเดลภาษาพารามิเตอร์ 12B แบบละเอียด (พีเธีย) ในคำแนะนำคุณภาพสูงที่มนุษย์สร้างขึ้นในชุดข้อมูลต่อไปนี้ ซึ่งระบุโดยพนักงานของ Datbricks ทั้งโมเดลและชุดข้อมูลพร้อมใช้งานในเชิงพาณิชย์
Dolly 1.0 ได้รับการฝึกอบรมเกี่ยวกับชุดข้อมูล Stanford Alpaca ซึ่งสร้างขึ้นโดยใช้ OpenAI API ชุดข้อมูลมีผลลัพธ์จาก ChatGPT และป้องกันไม่ให้ใครก็ตามใช้มันเพื่อแข่งขันกับ OpenAI กล่าวโดยย่อ คุณไม่สามารถสร้างแชทบอทเชิงพาณิชย์หรือแอปพลิเคชันภาษาตามชุดข้อมูลนี้ได้
รุ่นล่าสุดส่วนใหญ่ที่เปิดตัวในช่วงสองสามสัปดาห์ที่ผ่านมาประสบปัญหาเดียวกัน เช่น รุ่นต่างๆ สัตว์ขนยาวในอเมริกาคล้ายแกะ, หมีโคอาล่า, GPT4 ทั้งหมดและ วิคูนา. ในการหลีกเลี่ยง เราจำเป็นต้องสร้างชุดข้อมูลใหม่ที่มีคุณภาพสูงซึ่งสามารถนำไปใช้ในเชิงพาณิชย์ได้ และนั่นคือสิ่งที่ทีม Databricks ทำกับชุดข้อมูล databricks-dolly-15k
ชุดข้อมูลใหม่ประกอบด้วยคู่พรอมต์/การตอบสนองที่มีป้ายกำกับโดยมนุษย์คุณภาพสูง 15,000 คู่ ซึ่งสามารถใช้ในการออกแบบคำสั่งปรับแต่งโมเดลภาษาขนาดใหญ่ เดอะ databricks-ดอลลี่-15k ชุดข้อมูลมาพร้อมกับ Creative Commons Attribution-ShareAlike 3.0 ใบอนุญาตที่ไม่ได้รับอนุญาตซึ่งอนุญาตให้ทุกคนใช้ แก้ไข และสร้างแอปพลิเคชันเชิงพาณิชย์ได้
พวกเขาสร้างชุดข้อมูล databricks-dolly-15k ได้อย่างไร
การวิจัย OpenAI กระดาษ ระบุว่าโมเดล InstructGPT ดั้งเดิมได้รับการฝึกอบรมเกี่ยวกับข้อความแจ้งและการตอบสนอง 13,000 รายการ ด้วยการใช้ข้อมูลนี้ ทีม Databricks เริ่มทำงานกับข้อมูลนี้ และกลายเป็นว่าการสร้างคำถามและคำตอบ 13 ข้อเป็นงานที่ยาก พวกเขาไม่สามารถใช้ข้อมูลสังเคราะห์หรือข้อมูลกำเนิด AI และพวกเขาต้องสร้างคำตอบดั้งเดิมสำหรับทุกคำถาม นี่คือจุดที่พวกเขาตัดสินใจใช้พนักงาน 5,000 คนของ Databricks เพื่อสร้างข้อมูลที่มนุษย์สร้างขึ้น
Databricks ได้จัดการแข่งขันซึ่งผู้ติดฉลาก 20 อันดับแรกจะได้รับรางวัลใหญ่ ในการแข่งขันครั้งนี้ มีพนักงาน Databricks 5,000 คนที่มีความสนใจใน LLM เป็นอย่างมาก
Dolly-v2-12b ไม่ใช่รุ่นที่ล้ำสมัย มันมีประสิทธิภาพต่ำกว่า dolly-v1-6b ในเกณฑ์มาตรฐานการประเมินบางรายการ อาจเป็นเพราะองค์ประกอบและขนาดของชุดข้อมูลที่ปรับแต่งอย่างละเอียด ตระกูลรุ่น Dolly อยู่ระหว่างการพัฒนา ดังนั้นคุณอาจเห็นรุ่นอัปเดตที่มีประสิทธิภาพดีกว่าในอนาคต
กล่าวโดยย่อ โมเดล dolly-v2-12b ทำงานได้ดีกว่า EleutherAI/gpt-neox-20b และ EleutherAI/pythia-6.9b

ภาพจาก ฟรีดอลลี่
Dolly 2.0 เป็นโอเพ่นซอร์ส 100% มันมาพร้อมกับรหัสการฝึกอบรม ชุดข้อมูล น้ำหนักแบบจำลอง และไปป์ไลน์การอนุมาน ส่วนประกอบทั้งหมดเหมาะสำหรับใช้ในเชิงพาณิชย์ คุณสามารถลองใช้โมเดลได้ที่ Hugging Face Spaces ดอลลี่ V2 โดย รามอนันท์1.
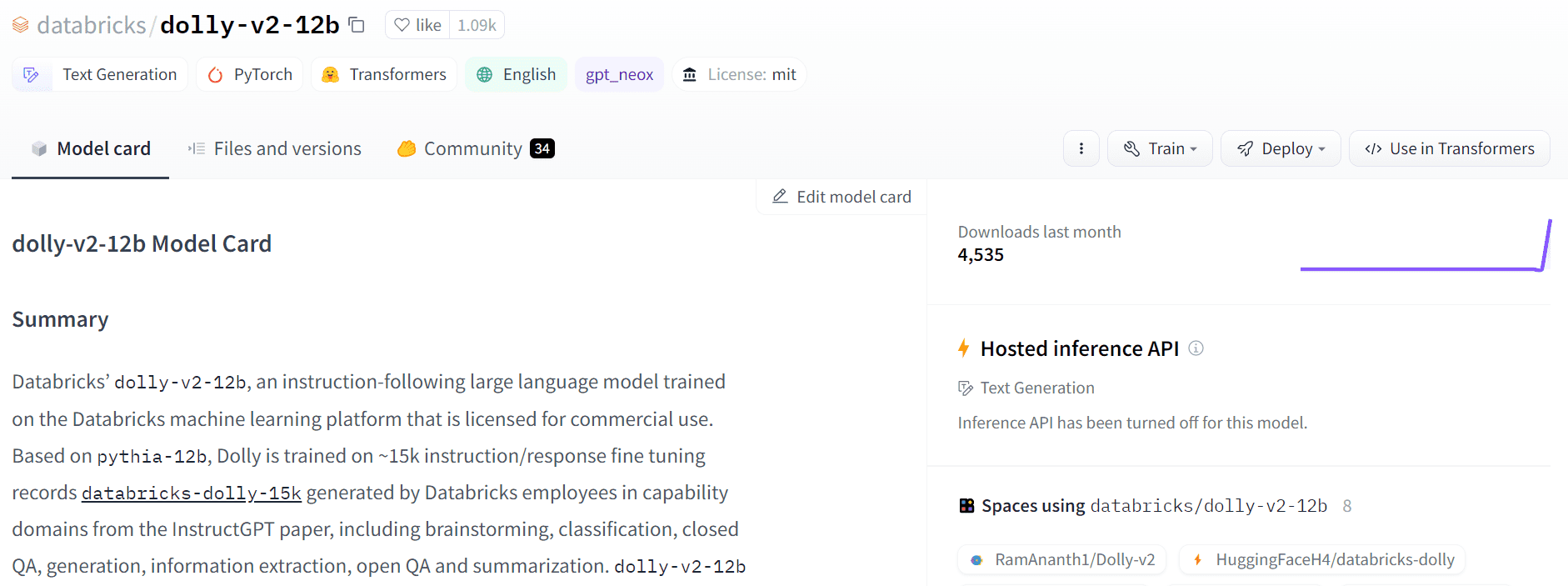
ภาพจาก กอดหน้า
ทรัพยากร:
ดอลลี่ 2.0 การสาธิต: ดอลลี่ V2 โดย รามอนันท์1
อาบิด อาลี อาวัน (@1อบีดาลิวัน) เป็นนักวิทยาศาสตร์ข้อมูลที่ได้รับการรับรองมืออาชีพที่รักการสร้างแบบจำลองการเรียนรู้ของเครื่อง ปัจจุบันเขามุ่งเน้นไปที่การสร้างเนื้อหาและการเขียนบล็อกทางเทคนิคเกี่ยวกับการเรียนรู้ของเครื่องและเทคโนโลยีวิทยาศาสตร์ข้อมูล อาบิดสำเร็จการศึกษาระดับปริญญาโทด้านการจัดการเทคโนโลยีและปริญญาตรีสาขาวิศวกรรมโทรคมนาคม วิสัยทัศน์ของเขาคือการสร้างผลิตภัณฑ์ AI โดยใช้โครงข่ายประสาทเทียมแบบกราฟสำหรับนักเรียนที่ป่วยเป็นโรคทางจิต
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- การสร้างอนาคตโดย Adryenn Ashley เข้าถึงได้ที่นี่.
- ที่มา: https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- :มี
- :เป็น
- :ไม่
- $ ขึ้น
- 000
- 1
- 20
- a
- ความสามารถ
- คล่องแคล่ว
- AI
- ทั้งหมด
- ช่วยให้
- ทางเลือก
- an
- และ
- คำตอบ
- ทุกคน
- API
- การใช้งาน
- เป็น
- รอบ
- ผู้เขียน
- ใช้ได้
- รางวัล
- ตาม
- BE
- มาตรฐาน
- เบิร์กลีย์
- ดีกว่า
- ใหญ่
- Bing
- Blog
- ทั้งสอง
- สร้าง
- การก่อสร้าง
- by
- CAN
- ไม่ได้
- มีมาตรฐาน
- chatbot
- ChatGPT
- รหัส
- เชิงพาณิชย์
- สภาสามัญ
- แข่งขัน
- ส่วนประกอบ
- มี
- เนื้อหา
- การสร้างเนื้อหา
- การประกวด
- ค่าใช้จ่าย
- สร้าง
- ที่สร้างขึ้น
- การสร้าง
- ขณะนี้
- ข้อมูล
- วิทยาศาสตร์ข้อมูล
- นักวิทยาศาสตร์ข้อมูล
- อิฐข้อมูล
- ชุดข้อมูล
- ตัดสินใจ
- องศา
- ทดลอง
- ออกแบบ
- พัฒนาการ
- DID
- ยาก
- ตุ๊กตา
- ลูกจ้าง
- พนักงาน
- ชั้นเยี่ยม
- การประเมินผล
- ทุกๆ
- การจัดแสดงนิทรรศการ
- ใบหน้า
- ครอบครัว
- สองสาม
- โดยมุ่งเน้น
- ดังต่อไปนี้
- สำหรับ
- ราคาเริ่มต้นที่
- อนาคต
- สร้าง
- การสร้าง
- กำเนิด
- ได้รับ
- กราฟ
- กราฟโครงข่ายประสาท
- มี
- he
- ที่มีคุณภาพสูง
- ถือ
- HTML
- HTTPS
- การเจ็บป่วย
- ภาพ
- in
- ข้อมูล
- สนใจ
- ปัญหา
- ปัญหา
- IT
- jpg
- KD นักเก็ต
- ภาษา
- ใหญ่
- ชื่อสกุล
- ล่าสุด
- การเรียนรู้
- License
- กดไลก์
- เครื่อง
- เรียนรู้เครื่อง
- การจัดการ
- เจ้านาย
- จิต
- จิตเภท
- อาจ
- แบบ
- โมเดล
- แก้ไข
- จำเป็นต้อง
- เครือข่าย
- ประสาท
- เครือข่ายประสาท
- ใหม่
- of
- on
- เพียง
- เปิด
- โอเพนซอร์ส
- OpenAI
- or
- เป็นต้นฉบับ
- เอาท์พุต
- คู่
- พารามิเตอร์
- เข้าร่วม
- รูปแบบไฟล์ PDF
- การปฏิบัติ
- ท่อ
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- ผลิตภัณฑ์
- มืออาชีพ
- วัตถุประสงค์
- คำถาม
- คำถาม
- การเผยแพร่
- การวิจัย
- ได้รับการแก้ไข
- หวงห้าม
- s
- เดียวกัน
- วิทยาศาสตร์
- นักวิทยาศาสตร์
- ชุด
- สั้น
- ขนาด
- So
- บาง
- แหล่ง
- ช่องว่าง
- ช่องว่าง
- Stanford
- ข้อความที่เริ่ม
- รัฐของศิลปะ
- สหรัฐอเมริกา
- การดิ้นรน
- นักเรียน
- เหมาะสม
- สังเคราะห์
- ข้อมูลสังเคราะห์
- งาน
- ทีม
- วิชาการ
- เทคโนโลยี
- เทคโนโลยี
- การสื่อสารโทรคมนาคม
- กว่า
- ที่
- พื้นที่
- ก้าวสู่อนาคต
- พวกเขา
- นี้
- ไปยัง
- ด้านบน
- รถไฟ
- ผ่านการฝึกอบรม
- การฝึกอบรม
- ภายใต้
- พื้นฐาน
- ให้กับคุณ
- ใช้
- มือสอง
- การใช้
- รุ่น
- วิสัยทัศน์
- คือ
- we
- สัปดาห์ที่ผ่านมา
- คือ
- อะไร
- ที่
- WHO
- กับ
- งาน
- จะ
- การเขียน
- เธอ
- ลมทะเล










