องค์กรหลายแห่งทั้งขนาดเล็กและขนาดใหญ่กำลังทำงานเพื่อโยกย้ายและปรับปรุงปริมาณงานการวิเคราะห์บน Amazon Web Services (AWS) ให้ทันสมัย มีเหตุผลหลายประการที่ลูกค้าจะย้ายไปยัง AWS แต่เหตุผลหลักประการหนึ่งก็คือความสามารถในการใช้บริการที่มีการจัดการเต็มรูปแบบ แทนที่จะใช้เวลาไปกับการบำรุงรักษาโครงสร้างพื้นฐาน การแพตช์ การตรวจสอบ การสำรองข้อมูล และอื่นๆ ทีมผู้นำและการพัฒนาสามารถใช้เวลามากขึ้นในการเพิ่มประสิทธิภาพโซลูชันปัจจุบัน และแม้แต่การทดลองกับกรณีการใช้งานใหม่ แทนที่จะรักษาโครงสร้างพื้นฐานในปัจจุบัน
ด้วยความสามารถในการเคลื่อนที่อย่างรวดเร็วบน AWS คุณจะต้องรับผิดชอบต่อข้อมูลที่คุณได้รับและประมวลผลเมื่อคุณขยายขนาดต่อไป ความรับผิดชอบเหล่านี้รวมถึงการปฏิบัติตามกฎหมายและข้อบังคับความเป็นส่วนตัวของข้อมูล และไม่จัดเก็บหรือเปิดเผยข้อมูลที่ละเอียดอ่อน เช่น ข้อมูลที่สามารถระบุตัวบุคคลได้ (PII) หรือข้อมูลด้านสุขภาพที่ได้รับการคุ้มครอง (PHI) จากแหล่งที่มาต้นทาง
ในโพสต์นี้ เราจะอธิบายเกี่ยวกับสถาปัตยกรรมระดับสูงและกรณีการใช้งานเฉพาะที่แสดงให้เห็นว่าคุณสามารถปรับขนาดแพลตฟอร์มข้อมูลขององค์กรของคุณต่อไปได้อย่างไร โดยไม่จำเป็นต้องใช้เวลาในการพัฒนาจำนวนมากเพื่อจัดการกับข้อกังวลด้านความเป็นส่วนตัวของข้อมูล เราใช้ AWS กาว เพื่อตรวจจับ มาสก์ และตรวจทานข้อมูล PII ก่อนที่จะโหลดเข้าไป บริการ Amazon OpenSearch.
ภาพรวมโซลูชัน
แผนภาพต่อไปนี้แสดงสถาปัตยกรรมโซลูชันระดับสูง เราได้กำหนดเลเยอร์และส่วนประกอบทั้งหมดของการออกแบบของเราให้สอดคล้องกับ เลนส์วิเคราะห์ข้อมูลกรอบงาน AWS Well-Architected.
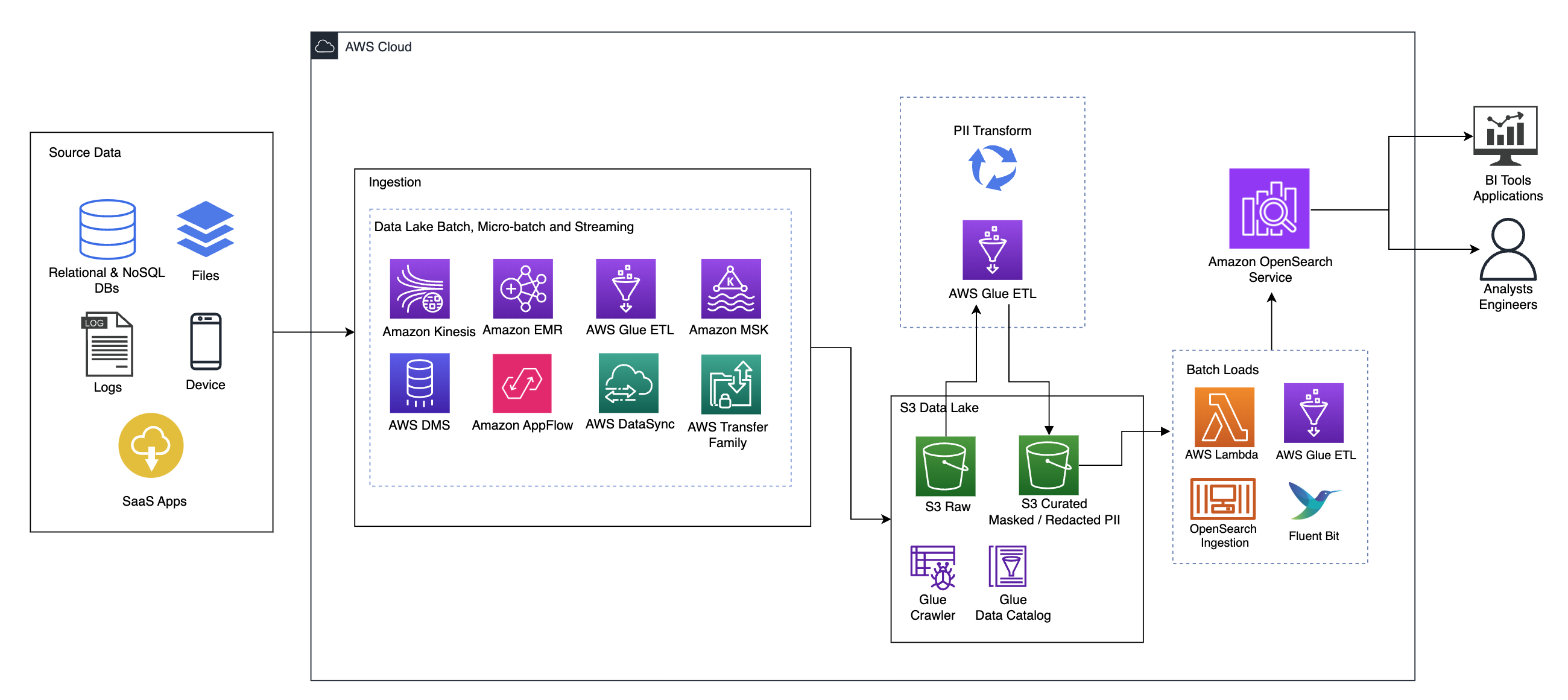
สถาปัตยกรรมประกอบด้วยองค์ประกอบหลายประการ:
แหล่งที่มาของข้อมูล
ข้อมูลอาจมาจากหลายสิบถึงหลายร้อยแหล่ง รวมถึงฐานข้อมูล การถ่ายโอนไฟล์ บันทึก แอปพลิเคชันซอฟต์แวร์เป็นบริการ (SaaS) และอื่นๆ องค์กรอาจไม่สามารถควบคุมข้อมูลที่ส่งผ่านช่องทางเหล่านี้และเข้าสู่พื้นที่จัดเก็บข้อมูลและแอปพลิเคชันดาวน์สตรีมได้เสมอไป
การกลืนกิน: แบทช์ Data Lake, ไมโครแบทช์ และการสตรีม
องค์กรหลายแห่งนำข้อมูลต้นฉบับไปไว้ใน Data Lake ด้วยวิธีต่างๆ มากมาย รวมถึงงานแบบแบตช์ ไมโครแบตช์ และงานสตรีมมิ่ง ตัวอย่างเช่น, อเมซอน EMR, AWS กาวและ บริการย้ายฐานข้อมูล AWS (AWS DMS) ทั้งหมดสามารถใช้เพื่อดำเนินการแบบแบตช์และหรือการสตรีมที่จมลงสู่ Data Lake บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (อเมซอน เอส3). Amazon App Flow สามารถใช้เพื่อถ่ายโอนข้อมูลจากแอปพลิเคชัน SaaS ต่างๆ ไปยัง Data Lake AWS DataSync และ กลุ่มการถ่ายโอน AWS สามารถช่วยในการย้ายไฟล์เข้าและออกจาก Data Lake ผ่านโปรโตคอลที่แตกต่างกันจำนวนหนึ่ง อเมซอน Kinesis และ Amazon MSK ยังมีความสามารถในการสตรีมข้อมูลโดยตรงไปยัง Data Lake บน Amazon S3
ทะเลสาบข้อมูล S3
การใช้ Amazon S3 สำหรับ Data Lake ของคุณสอดคล้องกับกลยุทธ์ข้อมูลสมัยใหม่ มอบพื้นที่จัดเก็บข้อมูลราคาประหยัดโดยไม่กระทบต่อประสิทธิภาพ ความน่าเชื่อถือ หรือความพร้อมใช้งาน ด้วยแนวทางนี้ คุณสามารถนำการประมวลผลมาสู่ข้อมูลของคุณได้ตามต้องการ และจ่ายเฉพาะความจุที่จำเป็นในการทำงานเท่านั้น
ในสถาปัตยกรรมนี้ ข้อมูลดิบสามารถมาจากแหล่งที่มาต่างๆ (ภายในและภายนอก) ซึ่งอาจมีข้อมูลที่ละเอียดอ่อน
ด้วยการใช้โปรแกรมรวบรวมข้อมูล AWS Glue เราสามารถค้นพบและจัดทำแคตตาล็อกข้อมูลซึ่งจะสร้างแผนตารางให้เรา และท้ายที่สุดทำให้การใช้ AWS Glue ETL กับการแปลง PII เป็นเรื่องง่ายเพื่อตรวจจับและปกปิดหรือแก้ไขข้อมูลที่ละเอียดอ่อนใด ๆ ที่อาจเข้ามา ในทะเลสาบข้อมูล
บริบททางธุรกิจและชุดข้อมูล
เพื่อแสดงให้เห็นถึงคุณค่าของแนวทางของเรา ลองจินตนาการว่าคุณเป็นส่วนหนึ่งของทีมวิศวกรรมข้อมูลสำหรับองค์กรที่ให้บริการทางการเงิน ข้อกำหนดของคุณคือการตรวจจับและปกปิดข้อมูลที่ละเอียดอ่อนในขณะที่ข้อมูลถูกนำเข้าในสภาพแวดล้อมคลาวด์ขององค์กรของคุณ ข้อมูลจะถูกใช้โดยกระบวนการวิเคราะห์ขั้นปลายน้ำ ในอนาคต ผู้ใช้ของคุณจะสามารถค้นหาธุรกรรมการชำระเงินในอดีตได้อย่างปลอดภัยโดยอิงตามสตรีมข้อมูลที่รวบรวมจากระบบธนาคารภายใน ผลการค้นหาจากทีมปฏิบัติการ ลูกค้า และแอปพลิเคชันที่เชื่อมต่อจะต้องถูกปกปิดในช่องที่ละเอียดอ่อน
ตารางต่อไปนี้แสดงโครงสร้างข้อมูลที่ใช้สำหรับโซลูชัน เพื่อความชัดเจน เราได้แมปชื่อคอลัมน์ดิบกับชื่อคอลัมน์ที่ได้รับการดูแลจัดการ คุณจะสังเกตเห็นว่าหลายช่องภายในสคีมานี้ถือเป็นข้อมูลที่ละเอียดอ่อน เช่น ชื่อ นามสกุล หมายเลขประกันสังคม (SSN) ที่อยู่ หมายเลขบัตรเครดิต หมายเลขโทรศัพท์ อีเมล และที่อยู่ IPv4
| ชื่อคอลัมน์ดิบ | ชื่อคอลัมน์ที่ดูแลจัดการ | ชนิดภาพเขียน |
| c0 | ชื่อจริง | เชือก |
| c1 | นามสกุล | เชือก |
| c2 | เอสเอสเอ็น | เชือก |
| c3 | ที่อยู่ | เชือก |
| c4 | รหัสไปรษณีย์ | เชือก |
| c5 | ประเทศ | เชือก |
| c6 | buy_site | เชือก |
| c7 | หมายเลขบัตรเครดิต | เชือก |
| c8 | credit_card_provider | เชือก |
| c9 | เงินตรา | เชือก |
| c10 | buy_value | จำนวนเต็ม |
| c11 | ธุรกรรม_วันที่ | ข้อมูล |
| c12 | หมายเลขโทรศัพท์ | เชือก |
| c13 | อีเมล | เชือก |
| c14 | ipv4 | เชือก |
กรณีการใช้งาน: การตรวจจับชุด PII ก่อนที่จะโหลดไปยัง OpenSearch Service
ลูกค้าที่ใช้สถาปัตยกรรมต่อไปนี้ได้สร้าง Data Lake ของตนบน Amazon S3 เพื่อเรียกใช้การวิเคราะห์ประเภทต่างๆ ในวงกว้าง โซลูชันนี้เหมาะสำหรับลูกค้าที่ไม่ต้องการนำเข้า OpenSearch Service แบบเรียลไทม์ และวางแผนที่จะใช้เครื่องมือบูรณาการข้อมูลที่ทำงานตามกำหนดเวลาหรือถูกทริกเกอร์ผ่านเหตุการณ์ต่างๆ
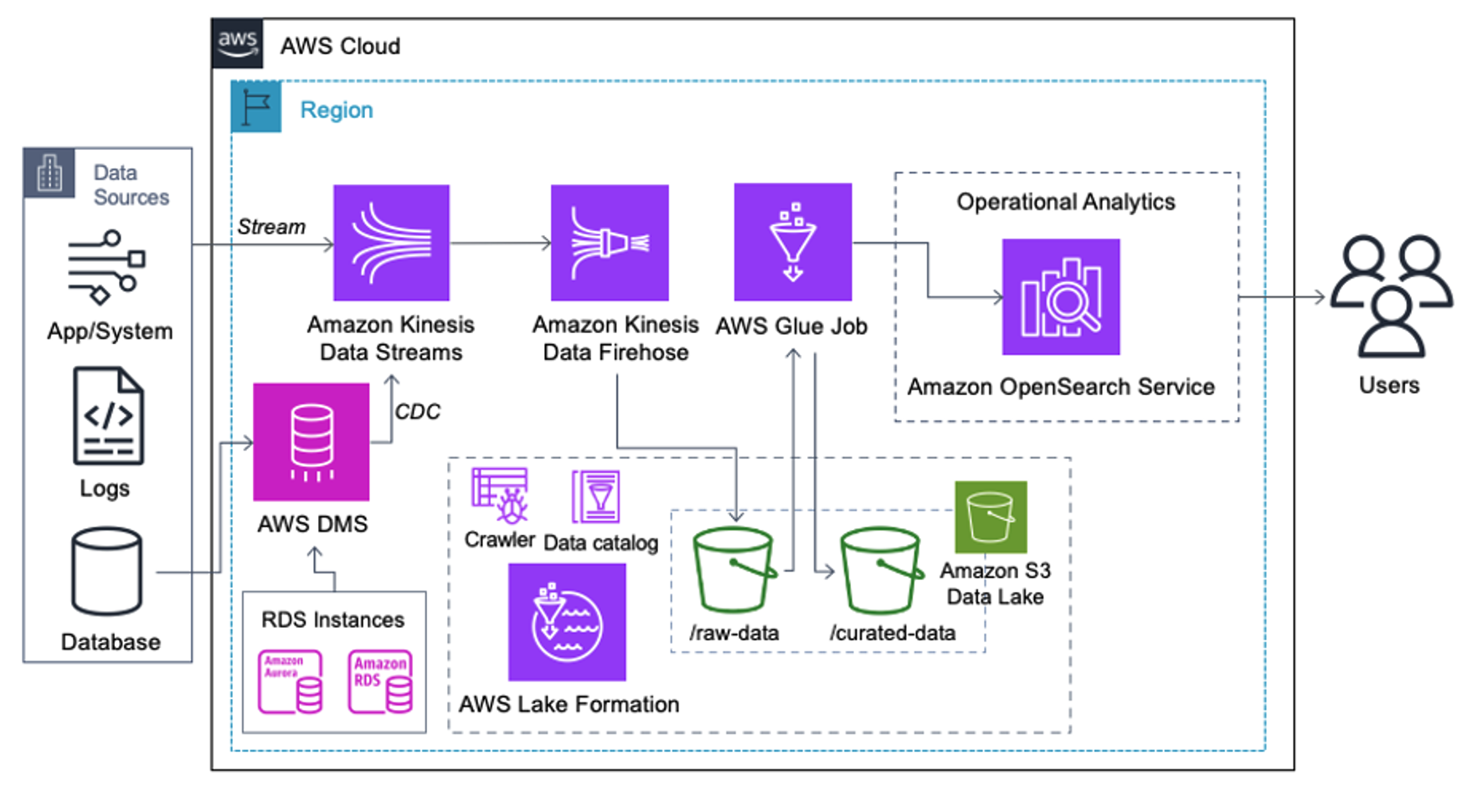
ก่อนที่บันทึกข้อมูลจะลงสู่ Amazon S3 เราจะใช้เลเยอร์การนำเข้าเพื่อนำสตรีมข้อมูลทั้งหมดไปยัง Data Lake อย่างเชื่อถือได้และปลอดภัย Kinesis Data Streams ได้รับการปรับใช้เป็นเลเยอร์การนำเข้าเพื่อเร่งการรับสตรีมข้อมูลที่มีโครงสร้างและกึ่งโครงสร้าง ตัวอย่างของสิ่งเหล่านี้คือการเปลี่ยนแปลงฐานข้อมูลเชิงสัมพันธ์ แอปพลิเคชัน บันทึกของระบบ หรือคลิกสตรีม สำหรับกรณีการใช้งาน Change Data Capture (CDC) คุณสามารถใช้ Kinesis Data Streams เป็นเป้าหมายสำหรับ AWS DMS ได้ แอปพลิเคชันหรือระบบที่สร้างสตรีมที่มีข้อมูลที่ละเอียดอ่อนจะถูกส่งไปยังสตรีมข้อมูล Kinesis ผ่านหนึ่งในสามวิธีที่รองรับ: Amazon Kinesis Agent, AWS SDK สำหรับ Java หรือ Kinesis Producer Library เป็นขั้นตอนสุดท้าย สายไฟ Amazon Kinesis Data ช่วยให้เราสามารถโหลดชุดข้อมูลแบบเกือบจะเรียลไทม์ไปยังปลายทาง Data Lake ของ S3 ของเราได้อย่างน่าเชื่อถือ
ภาพหน้าจอต่อไปนี้แสดงให้เห็นว่าข้อมูลไหลผ่าน Kinesis Data Streams ผ่านทาง โปรแกรมดูข้อมูล และดึงข้อมูลตัวอย่างที่อยู่บนคำนำหน้า Raw S3 สำหรับสถาปัตยกรรมนี้ เราได้ปฏิบัติตามวงจรการใช้งานข้อมูลสำหรับคำนำหน้า S3 ตามที่แนะนำใน มูลนิธิดาต้าเลค.
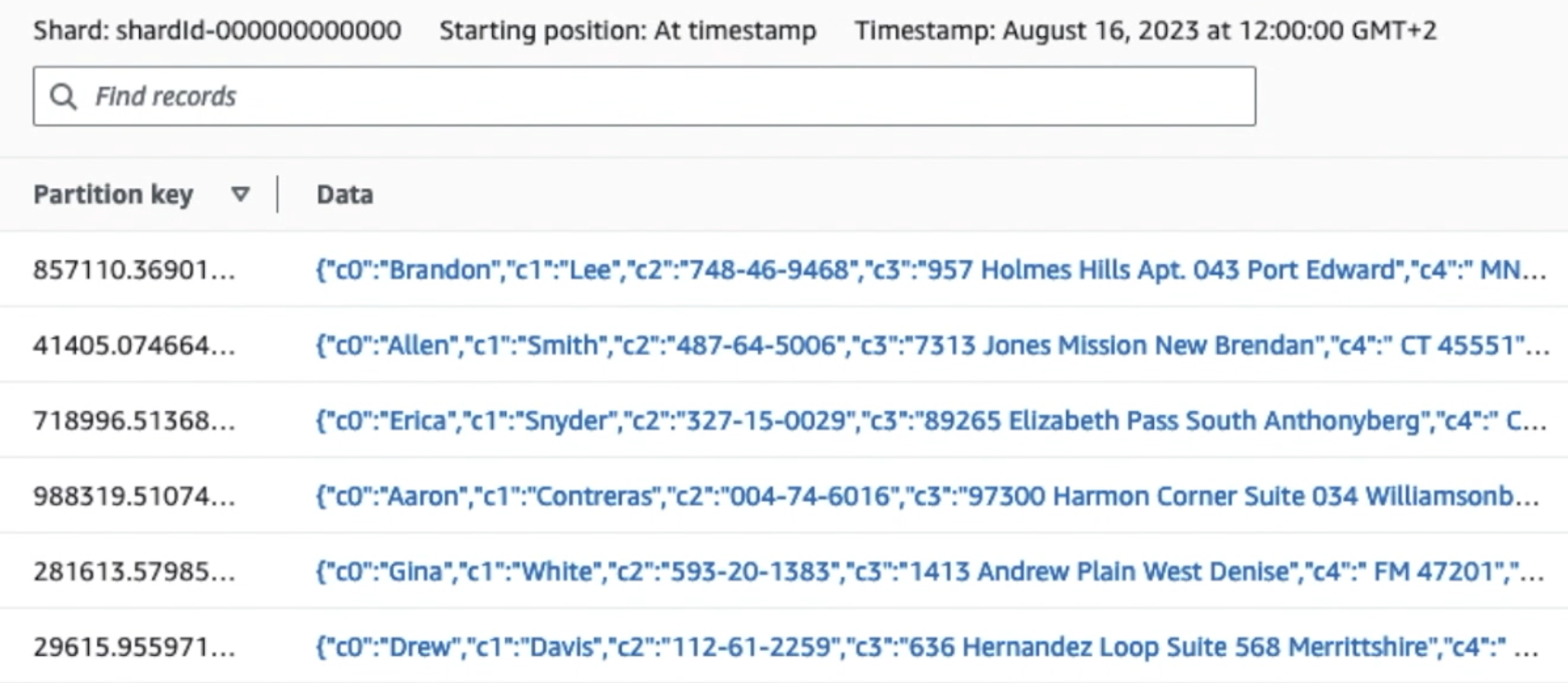
ดังที่คุณเห็นจากรายละเอียดของบันทึกแรกในภาพหน้าจอต่อไปนี้ เพย์โหลด JSON จะเป็นไปตามสคีมาเดียวกันกับในส่วนที่แล้ว คุณจะเห็นข้อมูลที่ยังไม่ได้แก้ไขไหลเข้าสู่สตรีมข้อมูล Kinesis ซึ่งจะถูกทำให้สับสนในภายหลังในระยะต่อๆ ไป
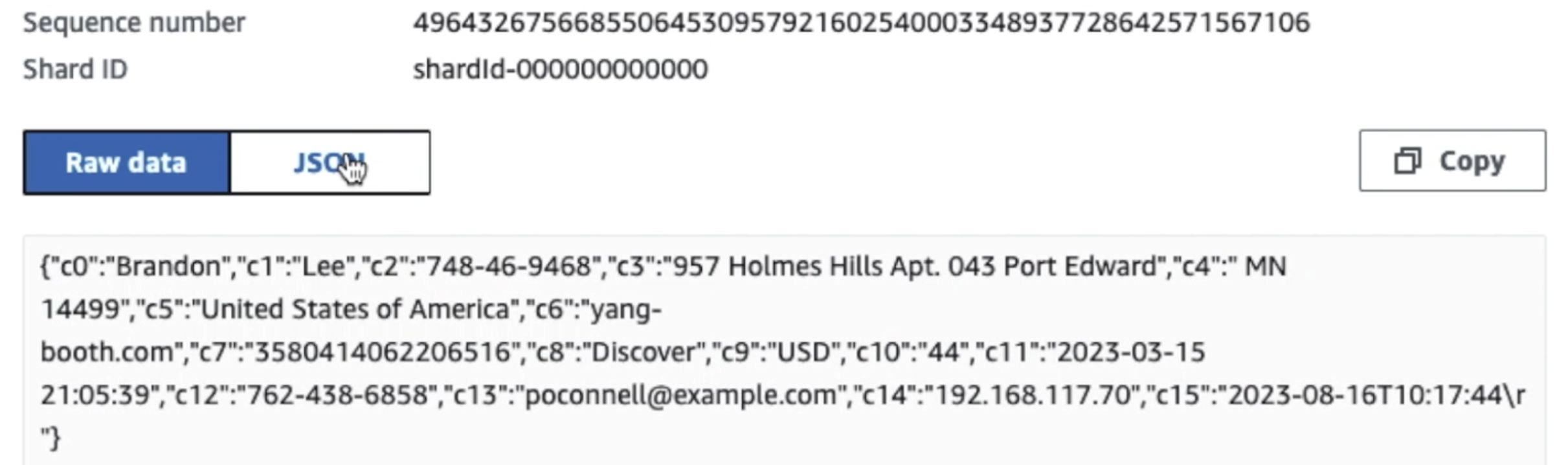
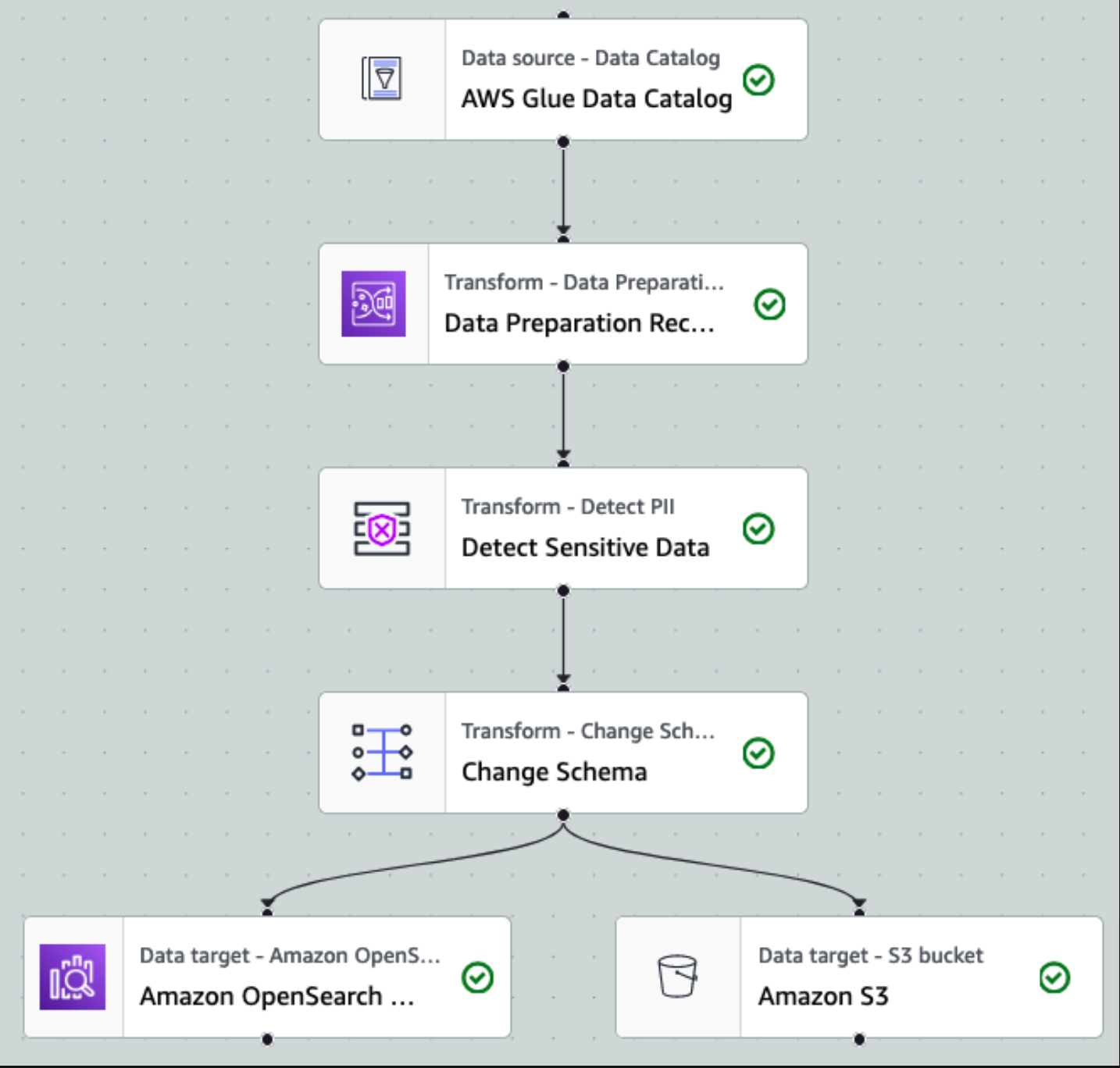
หลังจากที่ข้อมูลถูกรวบรวมและนำเข้าไปยัง Kinesis Data Streams และส่งมอบไปยังบัคเก็ต S3 โดยใช้ Kinesis Data Firehose เลเยอร์การประมวลผลของสถาปัตยกรรมจะเข้ามาแทนที่ เราใช้การแปลง AWS Glue PII เพื่อตรวจจับและมาสก์ข้อมูลที่ละเอียดอ่อนในไปป์ไลน์ของเราโดยอัตโนมัติ ดังที่แสดงในแผนภาพเวิร์กโฟลว์ต่อไปนี้ เราใช้แนวทาง ETL แบบเห็นภาพและไม่ต้องเขียนโค้ดเพื่อใช้งานการเปลี่ยนแปลงของเราใน AWS Glue Studio
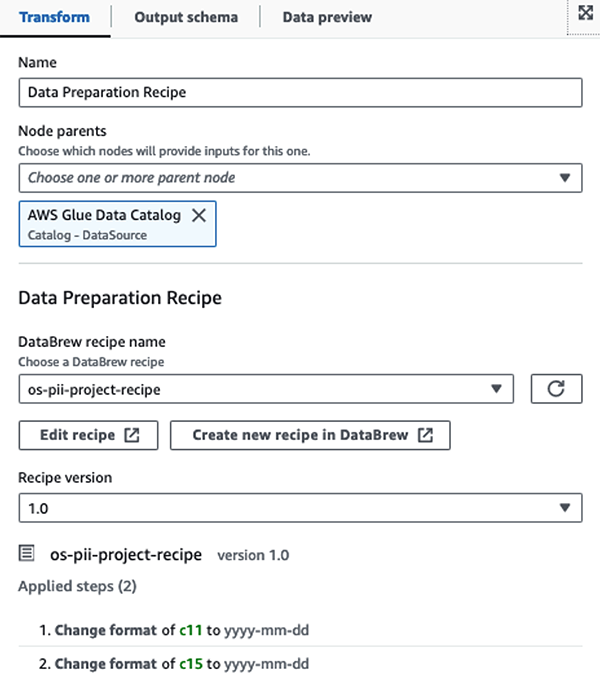
ขั้นแรก เราเข้าถึงตาราง Data Catalog ต้นฉบับจาก pii_data_db ฐานข้อมูล ตารางมีโครงสร้างสคีมาที่นำเสนอในส่วนก่อนหน้า เพื่อติดตามข้อมูลดิบที่ประมวลผล เราใช้ ที่คั่นหน้างาน.

เราใช้ สูตร AWS Glue DataBrew ในงาน ETL ภาพของ AWS Glue Studio เพื่อแปลงแอตทริบิวต์วันที่สองรายการให้เข้ากันได้กับ OpenSearch ที่คาดหวัง รูปแบบ. สิ่งนี้ทำให้เรามีประสบการณ์ที่ไม่มีโค้ดเต็มรูปแบบ
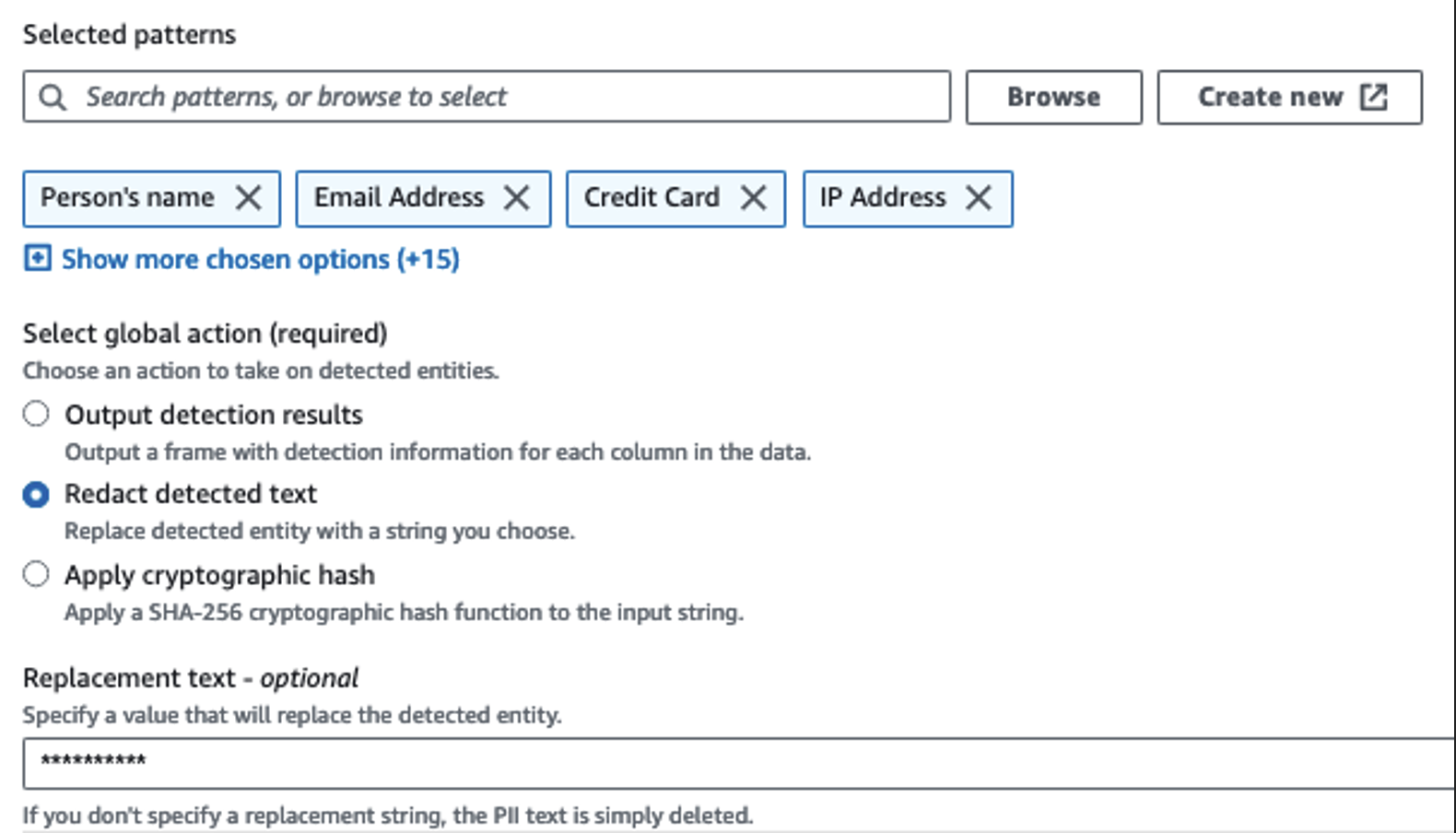
เราใช้การดำเนินการ Detect PII เพื่อระบุคอลัมน์ที่ละเอียดอ่อน เราปล่อยให้ AWS Glue พิจารณาสิ่งนี้ตามรูปแบบที่เลือก เกณฑ์การตรวจจับ และส่วนตัวอย่างของแถวจากชุดข้อมูล ในตัวอย่างของเรา เราใช้รูปแบบที่ใช้กับสหรัฐอเมริกาโดยเฉพาะ (เช่น SSN) และอาจตรวจไม่พบข้อมูลที่ละเอียดอ่อนจากประเทศอื่น คุณอาจค้นหาหมวดหมู่และตำแหน่งที่ใช้ได้กับกรณีการใช้งานของคุณ หรือใช้นิพจน์ทั่วไป (regex) ใน AWS Glue เพื่อสร้างเอนทิตีการตรวจจับสำหรับข้อมูลที่ละเอียดอ่อนจากประเทศอื่นๆ
สิ่งสำคัญคือต้องเลือกวิธีการสุ่มตัวอย่างที่ถูกต้องที่ AWS Glue นำเสนอ ในตัวอย่างนี้ เป็นที่ทราบกันว่าข้อมูลที่มาจากสตรีมมีข้อมูลที่ละเอียดอ่อนในทุกแถว ดังนั้นจึงไม่จำเป็นต้องสุ่มตัวอย่าง 100% ของแถวในชุดข้อมูล หากคุณมีข้อกำหนดที่ไม่อนุญาตข้อมูลที่ละเอียดอ่อนไปยังแหล่งที่มาดาวน์สตรีม ให้ลองสุ่มตัวอย่างข้อมูล 100% สำหรับรูปแบบที่คุณเลือก หรือสแกนชุดข้อมูลทั้งหมดและดำเนินการกับแต่ละเซลล์เพื่อให้แน่ใจว่าตรวจพบข้อมูลที่ละเอียดอ่อนทั้งหมด ประโยชน์ที่คุณได้รับจากการสุ่มตัวอย่างคือลดต้นทุน เนื่องจากคุณไม่จำเป็นต้องสแกนข้อมูลมากนัก

การดำเนินการตรวจหา PII ช่วยให้คุณสามารถเลือกสตริงเริ่มต้นเมื่อมาสก์ข้อมูลที่ละเอียดอ่อนได้ ในตัวอย่างของเรา เราใช้สตริง ********
เราใช้การดำเนินการใช้การแมปเพื่อเปลี่ยนชื่อและลบคอลัมน์ที่ไม่จำเป็นเช่น ingestion_year, ingestion_monthและ ingestion_day. ขั้นตอนนี้ยังช่วยให้เราสามารถเปลี่ยนประเภทข้อมูลของคอลัมน์ใดคอลัมน์หนึ่งได้ (purchase_value) จากสตริงเป็นจำนวนเต็ม

จากจุดนี้ไป งานจะแบ่งออกเป็นปลายทางเอาต์พุตสองปลายทาง: OpenSearch Service และ Amazon S3
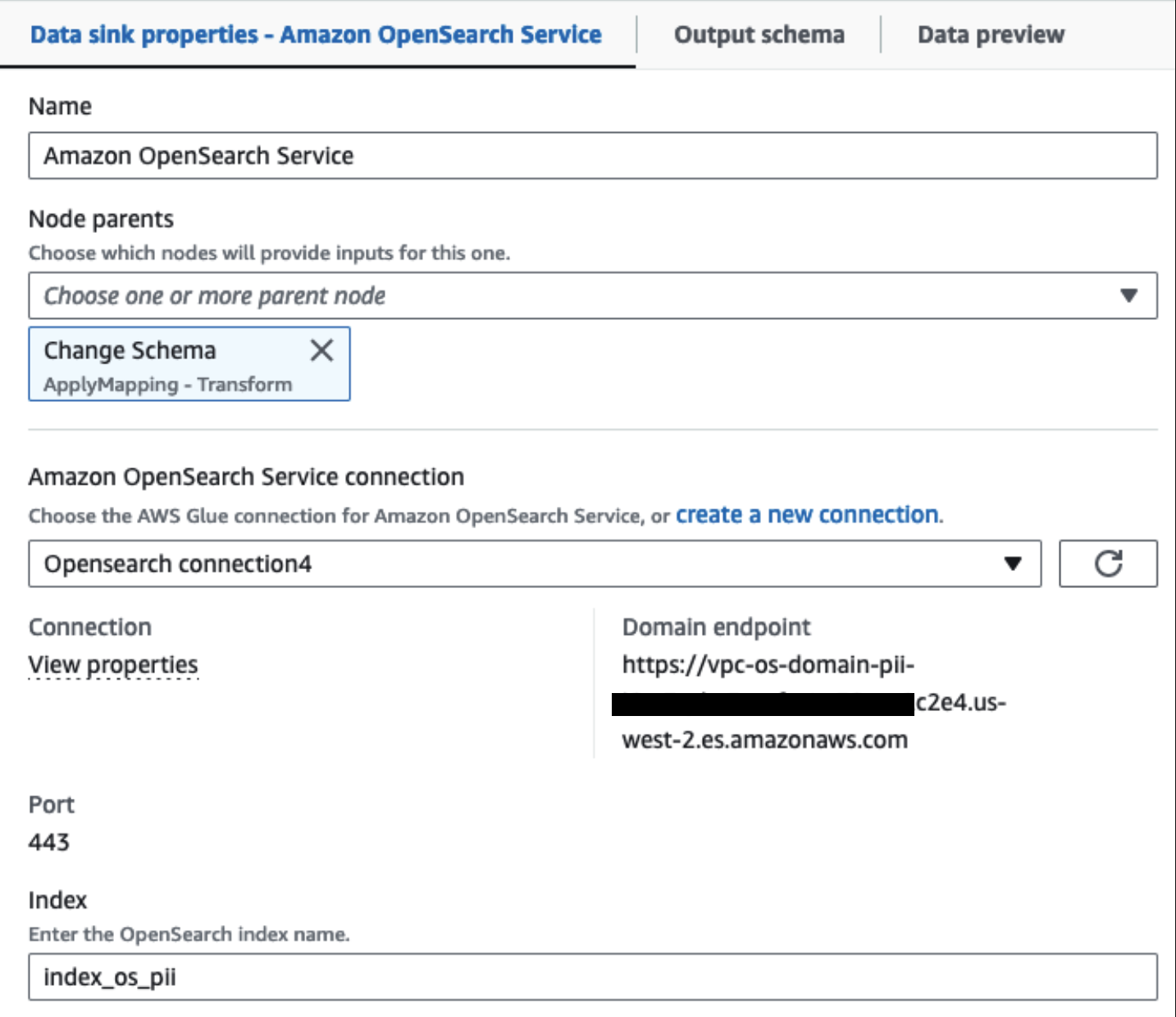
คลัสเตอร์บริการ OpenSearch ที่จัดเตรียมไว้ของเราเชื่อมต่อผ่าน ตัวเชื่อมต่อในตัว OpenSearch สำหรับกาว. เราระบุดัชนี OpenSearch ที่เราต้องการเขียน และตัวเชื่อมต่อจะจัดการข้อมูลรับรอง โดเมน และพอร์ต ในภาพหน้าจอด้านล่าง เราเขียนไปยังดัชนีที่ระบุ index_os_pii.
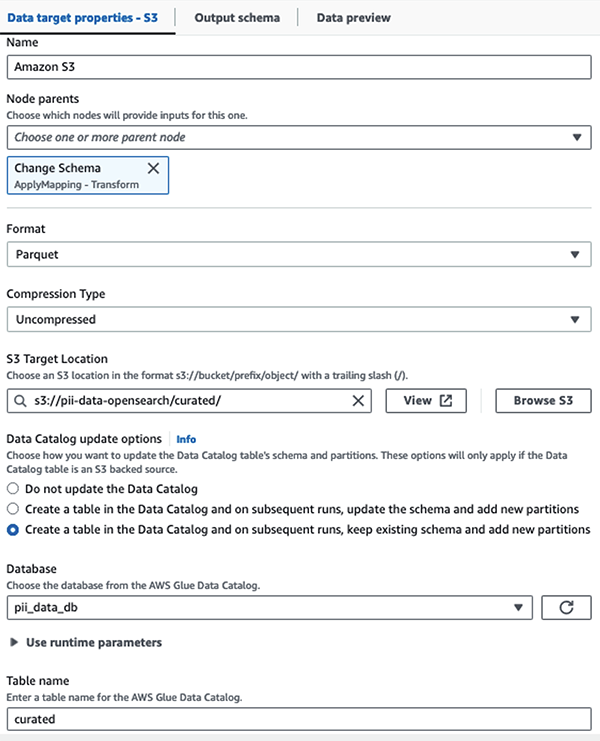
เราจัดเก็บชุดข้อมูลที่มาสก์ไว้ในคำนำหน้า S3 ที่ได้รับการดูแลจัดการ ที่นั่น เรามีข้อมูลที่ปรับให้เป็นมาตรฐานตามกรณีการใช้งานเฉพาะและการใช้งานอย่างปลอดภัยโดยนักวิทยาศาสตร์ข้อมูลหรือสำหรับความต้องการการรายงานเฉพาะกิจ
สำหรับการกำกับดูแลแบบรวมศูนย์ การควบคุมการเข้าถึง และเส้นทางการตรวจสอบของชุดข้อมูลและตาราง Data Catalog ทั้งหมด คุณสามารถใช้ได้ การก่อตัวของทะเลสาบ AWS. สิ่งนี้ช่วยให้คุณจำกัดการเข้าถึงตาราง AWS Glue Data Catalog และข้อมูลพื้นฐานเฉพาะผู้ใช้และบทบาทที่ได้รับสิทธิ์ที่จำเป็นในการดำเนินการดังกล่าว
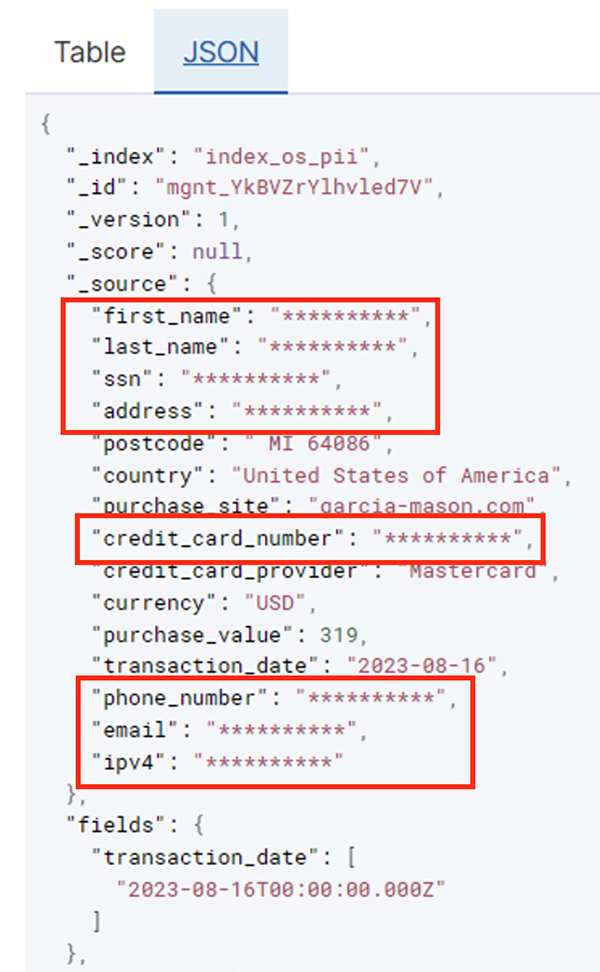
หลังจากที่งานแบตช์รันสำเร็จแล้ว คุณสามารถใช้ OpenSearch Service เพื่อเรียกใช้คำค้นหาหรือรายงานได้ ดังที่แสดงในภาพหน้าจอต่อไปนี้ ไปป์ไลน์จะปกปิดฟิลด์ที่ละเอียดอ่อนโดยอัตโนมัติโดยไม่ต้องพยายามพัฒนาโค้ด

คุณสามารถระบุแนวโน้มจากข้อมูลการดำเนินงาน เช่น จำนวนธุรกรรมต่อวันที่กรองโดยผู้ให้บริการบัตรเครดิต ดังที่แสดงในภาพหน้าจอก่อนหน้า คุณยังกำหนดสถานที่และโดเมนที่ผู้ใช้ทำการซื้อได้ด้วย ที่ transaction_date คุณลักษณะช่วยให้เราเห็นแนวโน้มเหล่านี้เมื่อเวลาผ่านไป ภาพหน้าจอต่อไปนี้แสดงบันทึกที่มีการแก้ไขข้อมูลธุรกรรมทั้งหมดอย่างเหมาะสม
สำหรับวิธีอื่นในการโหลดข้อมูลลงใน Amazon OpenSearch โปรดดูที่ กำลังโหลดข้อมูลการสตรีมลงใน Amazon OpenSearch Service.
นอกจากนี้ ข้อมูลที่ละเอียดอ่อนยังสามารถค้นพบและปกปิดได้โดยใช้โซลูชัน AWS อื่นๆ ตัวอย่างเช่น คุณสามารถใช้ อเมซอน แม็กกี้ เพื่อตรวจจับข้อมูลที่ละเอียดอ่อนภายในบัคเก็ต S3 จากนั้นจึงใช้งาน เข้าใจ Amazon เพื่อแก้ไขข้อมูลที่ละเอียดอ่อนที่ถูกตรวจพบ สำหรับข้อมูลเพิ่มเติม โปรดดูที่ เทคนิคทั่วไปในการตรวจจับข้อมูล PHI และ PII โดยใช้บริการของ AWS.
สรุป
โพสต์นี้กล่าวถึงความสำคัญของการจัดการข้อมูลที่ละเอียดอ่อนภายในสภาพแวดล้อมของคุณ ตลอดจนวิธีการและสถาปัตยกรรมต่างๆ เพื่อให้เป็นไปตามข้อกำหนด ในขณะเดียวกันก็ช่วยให้องค์กรของคุณสามารถปรับขนาดได้อย่างรวดเร็ว ตอนนี้คุณควรมีความเข้าใจเกี่ยวกับวิธีการตรวจจับ มาสก์ หรือแก้ไขและโหลดข้อมูลของคุณลงใน Amazon OpenSearch Service เป็นอย่างดี
เกี่ยวกับผู้แต่ง
 Michael Hamilton เป็นสถาปนิกโซลูชันการวิเคราะห์อาวุโสที่มุ่งเน้นที่การช่วยเหลือลูกค้าระดับองค์กรในการปรับให้ทันสมัยและลดความซับซ้อนของปริมาณงานการวิเคราะห์บน AWS เขาสนุกกับการปั่นจักรยานเสือภูเขาและใช้เวลากับภรรยาและลูกสามคนเมื่อไม่ได้ทำงาน
Michael Hamilton เป็นสถาปนิกโซลูชันการวิเคราะห์อาวุโสที่มุ่งเน้นที่การช่วยเหลือลูกค้าระดับองค์กรในการปรับให้ทันสมัยและลดความซับซ้อนของปริมาณงานการวิเคราะห์บน AWS เขาสนุกกับการปั่นจักรยานเสือภูเขาและใช้เวลากับภรรยาและลูกสามคนเมื่อไม่ได้ทำงาน
 แดเนียล โรโซ เป็นสถาปนิกโซลูชันอาวุโสที่มี AWS สนับสนุนลูกค้าในเนเธอร์แลนด์ ความหลงใหลของเขาคือวิศวกรรมข้อมูลและโซลูชันการวิเคราะห์ที่เรียบง่าย และช่วยให้ลูกค้าเปลี่ยนไปใช้สถาปัตยกรรมข้อมูลสมัยใหม่ นอกเหนือจากงาน เขาชอบเล่นเทนนิสและขี่จักรยาน
แดเนียล โรโซ เป็นสถาปนิกโซลูชันอาวุโสที่มี AWS สนับสนุนลูกค้าในเนเธอร์แลนด์ ความหลงใหลของเขาคือวิศวกรรมข้อมูลและโซลูชันการวิเคราะห์ที่เรียบง่าย และช่วยให้ลูกค้าเปลี่ยนไปใช้สถาปัตยกรรมข้อมูลสมัยใหม่ นอกเหนือจากงาน เขาชอบเล่นเทนนิสและขี่จักรยาน
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- 07
- 100
- 28
- 300
- 31
- 32
- 39
- 40
- 46
- 50
- 51
- 600
- 90
- 970
- a
- ความสามารถ
- สามารถ
- เร่ง
- เข้า
- กระทำ
- การกระทำ
- Ad
- ที่อยู่
- ตัวแทน
- ทั้งหมด
- อนุญาตให้
- การอนุญาต
- ช่วยให้
- ด้วย
- เสมอ
- อเมซอน
- อเมซอน Kinesis
- Amazon Web Services
- Amazon Web Services (AWS)
- จำนวน
- จำนวน
- an
- วิเคราะห์
- การวิเคราะห์
- และ
- ใด
- เหมาะสม
- การใช้งาน
- ใช้
- เข้าใกล้
- อย่างเหมาะสม
- สถาปัตยกรรม
- เป็น
- AS
- At
- แอตทริบิวต์
- การตรวจสอบบัญชี
- โดยอัตโนมัติ
- อัตโนมัติ
- ความพร้อมใช้งาน
- ใช้ได้
- AWS
- AWS กาว
- การสำรองข้อมูล
- การธนาคาร
- ระบบธนาคาร
- ตาม
- BE
- เพราะ
- รับ
- ก่อน
- กำลัง
- ด้านล่าง
- ประโยชน์
- นำมาซึ่ง
- สร้าง
- สร้าง
- built-in
- แต่
- by
- CAN
- ความสามารถในการ
- ความจุ
- จับ
- บัตร
- กรณี
- กรณี
- แค็ตตาล็อก
- หมวดหมู่
- CDC
- เซลล์
- เปลี่ยนแปลง
- การเปลี่ยนแปลง
- ช่อง
- เด็ก
- เลือก
- ความชัดเจน
- เมฆ
- Cluster
- รหัส
- คอลัมน์
- คอลัมน์
- อย่างไร
- มา
- มา
- เข้ากันได้
- ไม่ขัดขืน
- ส่วนประกอบ
- ประกอบด้วย
- คำนวณ
- ความกังวลเกี่ยวกับ
- งานที่เชื่อมต่อ
- พิจารณา
- ถือว่า
- ถูกใช้
- การบริโภค
- บรรจุ
- สิ่งแวดล้อม
- ต่อ
- ควบคุม
- แก้ไข
- ค่าใช้จ่าย
- ได้
- ประเทศ
- สร้าง
- หนังสือรับรอง
- เครดิต
- บัตรเครดิต
- curated
- ปัจจุบัน
- ลูกค้า
- ข้อมูล
- วิเคราะห์ข้อมูล
- การรวมข้อมูล
- ดาต้าเลค
- แพลตฟอร์มข้อมูล
- ความเป็นส่วนตัวของข้อมูล
- กลยุทธ์ข้อมูล
- ฐานข้อมูล
- ฐานข้อมูล
- ชุดข้อมูล
- วันที่
- วัน
- ค่าเริ่มต้น
- กำหนด
- ส่ง
- สาธิต
- แสดงให้เห็นถึง
- นำไปใช้
- ออกแบบ
- ปลายทาง
- สถานที่ท่องเที่ยว
- รายละเอียด
- ตรวจจับ
- ตรวจพบ
- การตรวจพบ
- กำหนด
- พัฒนาการ
- ทีมพัฒนา
- ต่าง
- โดยตรง
- ค้นพบ
- ค้นพบ
- กล่าวถึง
- do
- โดเมน
- โดเมน
- Dont
- แต่ละ
- ความพยายาม
- อีเมล
- ชั้นเยี่ยม
- ทำให้มั่นใจ
- Enterprise
- ลูกค้าองค์กร
- ทั้งหมด
- หน่วยงาน
- สิ่งแวดล้อม
- อีเธอร์ (ETH)
- แม้
- เหตุการณ์
- ทุกๆ
- ตัวอย่าง
- ตัวอย่าง
- ที่คาดหวัง
- ประสบการณ์
- การแสดงออก
- ภายนอก
- FAST
- สาขา
- เนื้อไม่มีมัน
- ไฟล์
- ทางการเงิน
- บริการทางการเงิน
- ชื่อจริง
- ที่ไหล
- กระแส
- โดยมุ่งเน้น
- ตาม
- ดังต่อไปนี้
- ดังต่อไปนี้
- สำหรับ
- กรอบ
- ราคาเริ่มต้นที่
- เต็ม
- อย่างเต็มที่
- อนาคต
- การสร้าง
- ได้รับ
- ดี
- การกำกับดูแล
- รับ
- จัดการ
- การจัดการ
- มี
- he
- สุขภาพ
- ข้อมูลสุขภาพ
- ช่วย
- การช่วยเหลือ
- จะช่วยให้
- ระดับสูง
- ของเขา
- ทางประวัติศาสตร์
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTML
- ที่ http
- HTTPS
- ร้อย
- แยกแยะ
- if
- แสดงให้เห็นถึง
- ภาพ
- การดำเนินการ
- ความสำคัญ
- สำคัญ
- in
- ประกอบด้วย
- รวมทั้ง
- ดัชนี
- เป็นรายบุคคล
- ข้อมูล
- โครงสร้างพื้นฐาน
- ภายใน
- บูรณาการ
- ภายใน
- เข้าไป
- IT
- ชวา
- การสัมภาษณ์
- งาน
- jpg
- JSON
- เก็บ
- ท่อดับเพลิง Kinesis Data
- สตรีมข้อมูล Kinesis
- ที่รู้จักกัน
- ทะเลสาบ
- ที่ดิน
- ดินแดน
- ใหญ่
- ชื่อสกุล
- ต่อมา
- กฎหมาย
- กฎหมายและข้อบังคับ
- ชั้น
- ชั้น
- ความเป็นผู้นำ
- ให้
- ห้องสมุด
- วงจรชีวิต
- กดไลก์
- Line
- โหลด
- โหลด
- วันหยุด
- ดู
- ที่มีราคาต่ำ
- หลัก
- การบำรุงรักษา
- ทำ
- การจัดการ
- หลาย
- การทำแผนที่
- หน้ากาก
- อาจ..
- วิธี
- วิธีการ
- อพยพ
- การโยกย้าย
- ทันสมัย
- ทันสมัย
- การตรวจสอบ
- ข้อมูลเพิ่มเติม
- ภูเขา
- ย้าย
- การย้าย
- มาก
- หลาย
- ต้อง
- ชื่อ
- ชื่อ
- จำเป็น
- จำเป็นต้อง
- จำเป็น
- ต้อง
- ความต้องการ
- เนเธอร์แลนด์
- ใหม่
- ไม่
- โหนด
- สังเกต..
- ตอนนี้
- จำนวน
- of
- เสนอ
- on
- ONE
- เพียง
- การดำเนินการ
- การดำเนินงาน
- การดำเนินการ
- การเพิ่มประสิทธิภาพ
- Options
- or
- organizacja
- องค์กร
- อื่นๆ
- ของเรา
- เอาท์พุต
- ด้านนอก
- เกิน
- ส่วนหนึ่ง
- กิเลส
- ปะ
- รูปแบบ
- ชำระ
- การชำระเงิน
- ต่อ
- ดำเนินการ
- การปฏิบัติ
- สิทธิ์
- ส่วนตัว
- โทรศัพท์
- PII
- ท่อ
- แผนการ
- เวที
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- เล่น
- จุด
- ส่วน
- โพสต์
- มาก่อน
- นำเสนอ
- ก่อน
- ความเป็นส่วนตัว
- กฎหมายความเป็นส่วนตัว
- การประมวลผล
- กระบวนการ
- การประมวลผล
- ผู้ผลิต
- การป้องกัน
- โปรโตคอล
- ผู้จัดหา
- ให้
- การซื้อสินค้า
- คำสั่ง
- อย่างรวดเร็ว
- ค่อนข้าง
- ดิบ
- ข้อมูลดิบ
- เรียลไทม์
- เหตุผล
- การได้รับ
- สูตรอาหาร
- แนะนำ
- ระเบียน
- บันทึก
- ลดลง
- อ้างอิง
- ปกติ
- กฎระเบียบ
- ความเชื่อถือได้
- ยังคง
- เอาออก
- การรายงาน
- รายงาน
- ต้องการ
- ความต้องการ
- ความต้องการ
- ความรับผิดชอบ
- รับผิดชอบ
- จำกัด
- ผลสอบ
- บทบาท
- แถว
- วิ่ง
- ทำงาน
- SaaS
- เสียสละ
- ปลอดภัย
- อย่างปลอดภัย
- เดียวกัน
- ขนาด
- การสแกน
- กำหนด
- นักวิทยาศาสตร์
- จอภาพ
- SDK
- ค้นหา
- Section
- อย่างปลอดภัย
- ความปลอดภัย
- เห็น
- เลือก
- เลือก
- ระดับอาวุโส
- มีความละเอียดอ่อน
- ส่ง
- บริการ
- บริการ
- การถ่ายภาพ
- น่า
- แสดง
- แสดงให้เห็นว่า
- ง่าย
- ลดความซับซ้อน
- เล็ก
- So
- สังคม
- ซอฟต์แวร์
- ซอฟต์แวร์เป็นบริการ
- ทางออก
- โซลูชัน
- แหล่ง
- แหล่งที่มา
- โดยเฉพาะ
- เฉพาะ
- ที่ระบุไว้
- ใช้จ่าย
- การใช้จ่าย
- แยก
- ขั้นตอน
- สหรัฐอเมริกา
- ขั้นตอน
- การเก็บรักษา
- จัดเก็บ
- ซื่อตรง
- กลยุทธ์
- กระแส
- ที่พริ้ว
- ลำธาร
- เชือก
- โครงสร้าง
- โครงสร้าง
- สตูดิโอ
- ภายหลัง
- ประสบความสำเร็จ
- อย่างเช่น
- เหมาะสม
- ที่สนับสนุน
- ที่สนับสนุน
- ระบบ
- ระบบ
- ตาราง
- ใช้เวลา
- เป้า
- ทีม
- ทีม
- เทคนิค
- เทนนิส
- เมตริกซ์
- กว่า
- ที่
- พื้นที่
- ก้าวสู่อนาคต
- เนเธอร์แลนด์
- ที่มา
- ของพวกเขา
- แล้วก็
- ที่นั่น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- นี้
- เหล่านั้น
- สาม
- ธรณีประตู
- ตลอด
- เวลา
- ไปยัง
- เอา
- เครื่องมือ
- ลู่
- การทำธุรกรรม
- โอน
- การถ่ายโอน
- แปลง
- การแปลง
- แนวโน้ม
- ทริกเกอร์
- สอง
- ชนิด
- ชนิด
- ในที่สุด
- พื้นฐาน
- ความเข้าใจ
- ปึกแผ่น
- พร้อมใจกัน
- ประเทศสหรัฐอเมริกา
- us
- ใช้
- ใช้กรณี
- มือสอง
- ผู้ใช้
- การใช้
- ความคุ้มค่า
- ความหลากหลาย
- ต่างๆ
- ผ่านทาง
- ภาพ
- เดิน
- คือ
- วิธี
- we
- เว็บ
- บริการเว็บ
- อะไร
- เมื่อ
- ที่
- ในขณะที่
- WHO
- ภรรยา
- จะ
- กับ
- ภายใน
- ไม่มี
- งาน
- เวิร์กโฟลว์
- การทำงาน
- เขียน
- เธอ
- ของคุณ
- ลมทะเล