Automated Data Analytics (ADA) on AWS is an AWS solution that enables you to derive meaningful insights from data in a matter of minutes through a simple and intuitive user interface. ADA offers an AWS-native data analytics platform that is ready to use out of the box by data analysts for a variety of use cases. With ADA, teams can ingest, transform, govern, and query diverse datasets from a range of data sources without requiring specialist technical skills. ADA provides a set of ตัวเชื่อมต่อที่สร้างไว้ล่วงหน้า to ingest data from a wide range of sources including บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (อเมซอน เอส3) สตรีมข้อมูล Amazon Kinesis, อเมซอน คลาวด์วอตช์, อเมซอน CloudTrailและ อเมซอน ไดนาโมดีบี เช่นเดียวกับคนอื่น ๆ อีกมากมาย
ADA provides a foundational platform that can be used by data analysts in a diverse set of use cases including IT, finance, marketing, sales, and security. ADA’s out-of-the-box CloudWatch data connector allows data ingestion from CloudWatch logs in the same AWS account in which ADA has been deployed, or from a different AWS account.
In this post, we demonstrate how an application developer or application tester is able to use ADA to derive operational insights of applications running in AWS. We also demonstrate how you can use the ADA solution to connect to different data sources in AWS. We first deploy the ADA solution into an AWS account and set up the ADA solution โดยการสร้าง ข้อมูลผลิตภัณฑ์ using data connectors. We then use the ADA Query Workbench to join the separate datasets and query the correlated data, using familiar Structured Query Language (SQL), to gain insights. We also demonstrate how ADA can be integrated with business intelligence (BI) tools such as Tableau to visualize the data and to build reports.
ภาพรวมโซลูชัน
In this section, we present the solution architecture for the demo and explain the workflow. For the purposes of demonstration, the bespoke application is simulated using an AWS แลมบ์ดา function that emits logs in รูปแบบบันทึก Apache at a preset interval using อเมซอน EventBridge. This standard format can be produced by many different web servers and be read by many log analysis programs. The application (Lambda function) logs are sent to a CloudWatch log group. The historical application logs are stored in an S3 bucket for reference and for querying purposes. A lookup table with a list of รหัสสถานะ HTTP along with the descriptions is stored in a DynamoDB table. These three serve as sources from which data is ingested into ADA for correlation, query, and analysis. We deploy the ADA solution into an AWS account and set up ADA. We then create the ข้อมูลผลิตภัณฑ์ within ADA for the กลุ่มบันทึก CloudWatch, ถัง S3และ DynamoDB. As the data products are configured, ADA provisions data pipelines to ingest the data from the sources. With the ADA Query Workbench, you can query the ingested data using plain SQL for application troubleshooting or issue diagnosis.
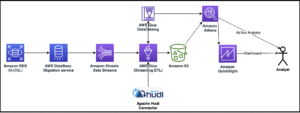
The following diagram provides an overview of the architecture and workflow of using ADA to gain insights into application logs.
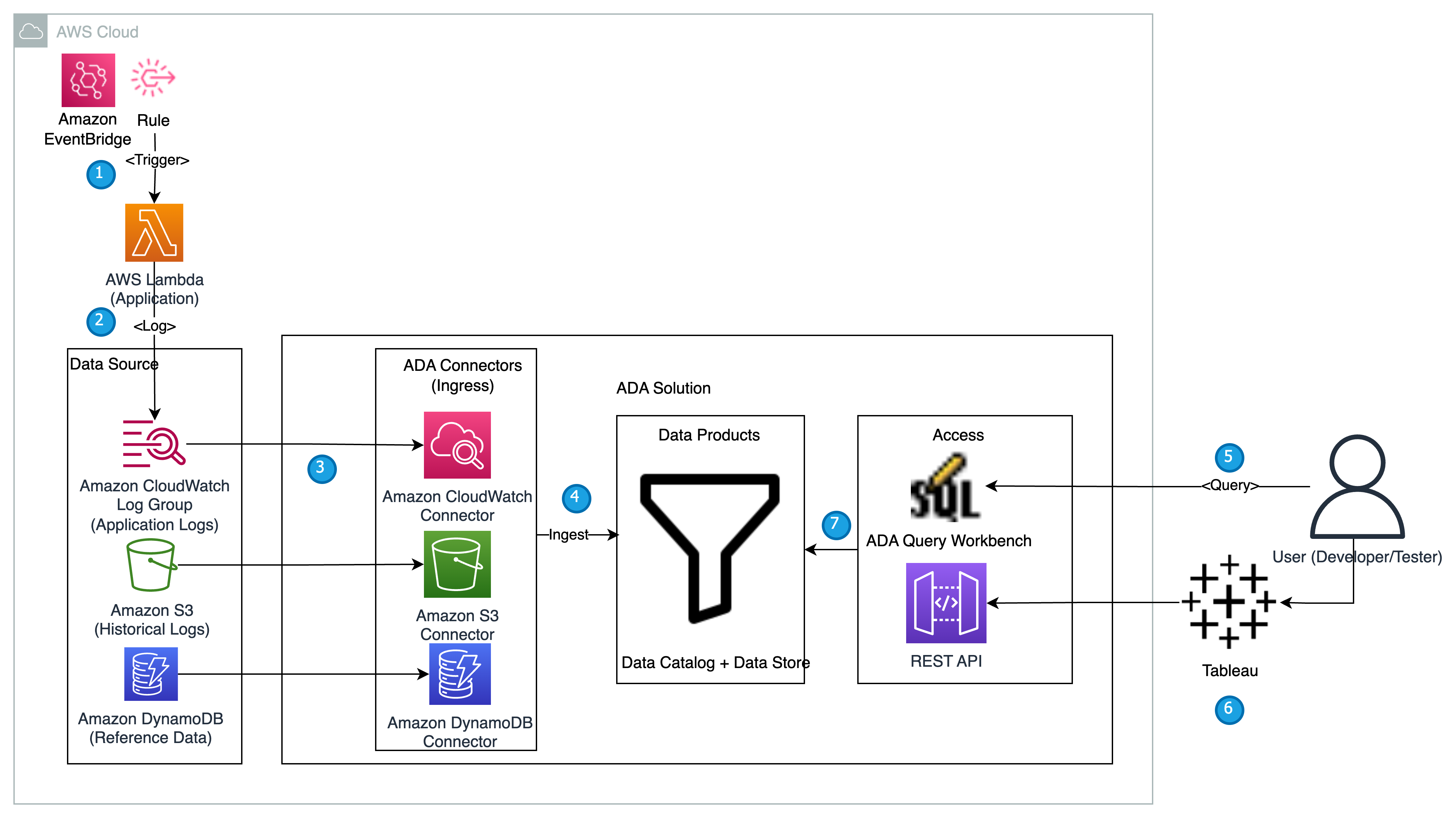
เวิร์กโฟลว์ประกอบด้วยขั้นตอนต่อไปนี้:
- A Lambda function is scheduled to be triggered at 2-minute intervals using EventBridge.
- The Lambda function emits logs that are stored at a specified CloudWatch log group under
/aws/lambda/CdkStack-AdaLogGenLambdaFunction. The application logs are generated using the Apache Log Format schema but stored in the CloudWatch log group in JSON format. - The data products for CloudWatch, Amazon S3, and DynamoDB are created in ADA. The CloudWatch data product connects to the CloudWatch log group where the application (Lambda function) logs are stored. The Amazon S3 connector connects to an S3 bucket folder where the historical logs are stored. The DynamoDB connector connects to a DynamoDB table where the status codes that are referred by the application and historical logs are stored.
- For each of the data products, ADA deploys the data pipeline infrastructure to ingest data from the sources. When the data ingestion is complete, you can write queries using SQL via the ADA Query Workbench.
- You can log in to the ADA portal and compose SQL queries from the Query Workbench to gain insights in to the application logs. You can optionally save the query and share the query with other ADA users in the same domain. The ADA query feature is powered by อเมซอน อาเธน่า, which is a serverless, interactive analytics service that provides a simplified, flexible way to analyze petabytes of data.
- Tableau is configured to access the ADA data products via ADA egress endpoints. You then create a dashboard with two charts. The first chart is a heat map that shows the prevalence of HTTP error codes correlated with the application API endpoints. The second chart is a bar chart that shows the top 10 application APIs with a total count of HTTP error codes from the historical data.
เบื้องต้น
For this post, you need to complete the following prerequisites:
- ติดตั้ง อินเทอร์เฟซบรรทัดคำสั่ง AWS AWS (AWS CLI) ชุดพัฒนา AWS Cloud (AWS ซีดีเค) ข้อกำหนดเบื้องต้น, TypeScript-specific ข้อกำหนดเบื้องต้นและ คอมไพล์.
- ปรับใช้ the ADA solution in your AWS account in the
us-east-1ภูมิภาค.- Provide an admin email while launching the ADA การก่อตัวของ AWS Cloud stack. This is needed for ADA to send the root user password. An admin phone number is required to receive a one-time password message if multi-factor authentication (MFA) is enabled. For this demo, MFA is not enabled.
- Build and deploy the sample application (available on the repo GitHub) solution so that the following resources can be provisioned in your account in the
us-east-1ภาค:- A Lambda function that simulates the logging application and an EventBridge rule that invokes the application function at 2-minute intervals.
- An S3 bucket with the relevant bucket policies and a CSV file that contains the historical application logs.
- A DynamoDB table with the lookup data.
- ที่เกี่ยวข้อง AWS Identity และการจัดการการเข้าถึง (IAM) roles and permissions required for the services.
- Optionally, install Tableau เดสก์ท็อป, a third-party BI provider. For this post, we use Tableau Desktop version 2021.2. There is a cost involved in using a licensed version of the Tableau Desktop application. For additional details, refer to the Tableau licensing ข้อมูล
Deploy and set up ADA
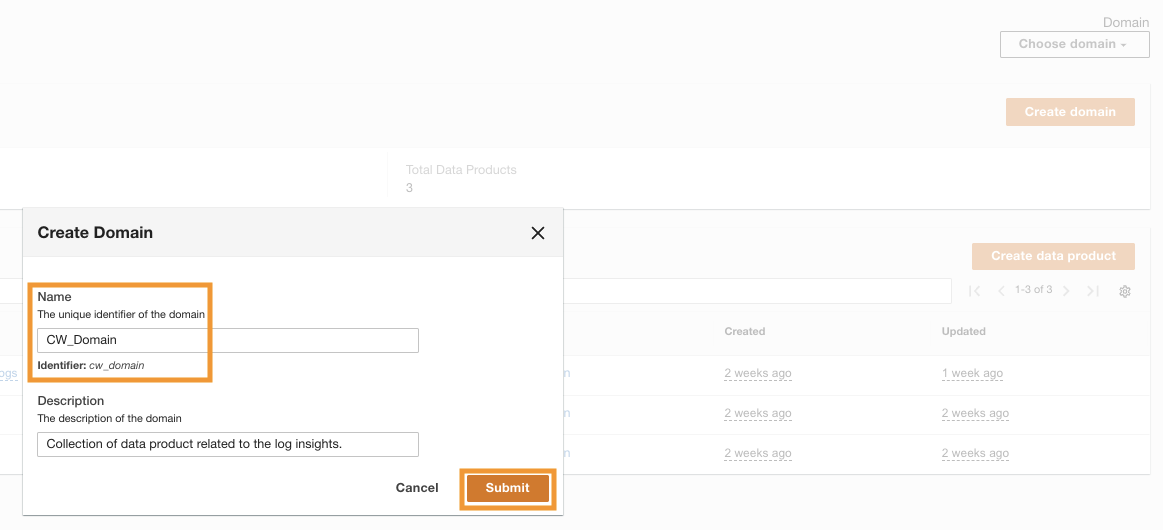
After ADA is deployed successfully, you can เข้าสู่ระบบ using the admin email provided during the installation. You then create a โดเมน ชื่อ CW_Domain. A domain is a user-defined collection of data products. For example, a domain might be a team or a project. Domains provide a structured way for users to organize their data products and manage access permissions.
- On the ADA console, choose โดเมน ในบานหน้าต่างนำทาง
- Choose สร้างโดเมน.
- ป้อนชื่อ (
CW_Domain) and description, then choose ส่ง.
Set up the sample application infrastructure using AWS CDK
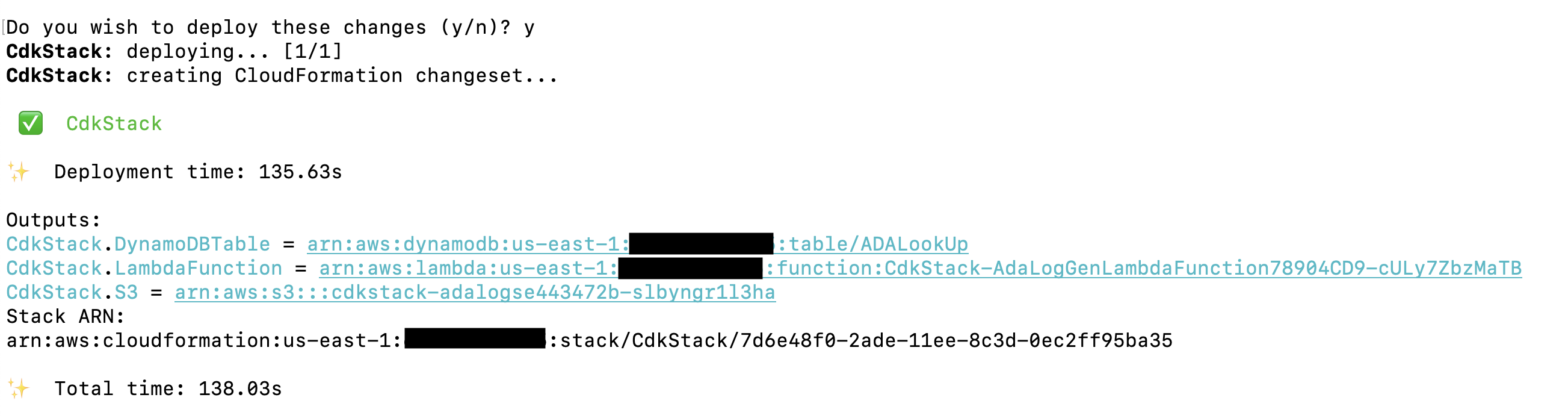
The AWS CDK solution that deploys the demo application is hosted on GitHub. The steps to clone the repo and to set up the AWS CDK project are detailed in this section. Before you run these commands, be sure to กำหนดค่า your AWS credentials. Create a folder, open the terminal, and navigate to the folder where the AWS CDK solution needs to be installed. Run the following code:
These steps perform the following actions:
- Install the library dependencies
- สร้างโครงการ
- Generate a valid CloudFormation template
- Deploy the stack using AWS CloudFormation in your AWS account
The deployment takes about 1–2 minutes and creates the DynamoDB lookup table, Lambda function, and S3 bucket containing the historical log files as outputs. Copy these values to a text editing application, such as Notepad.
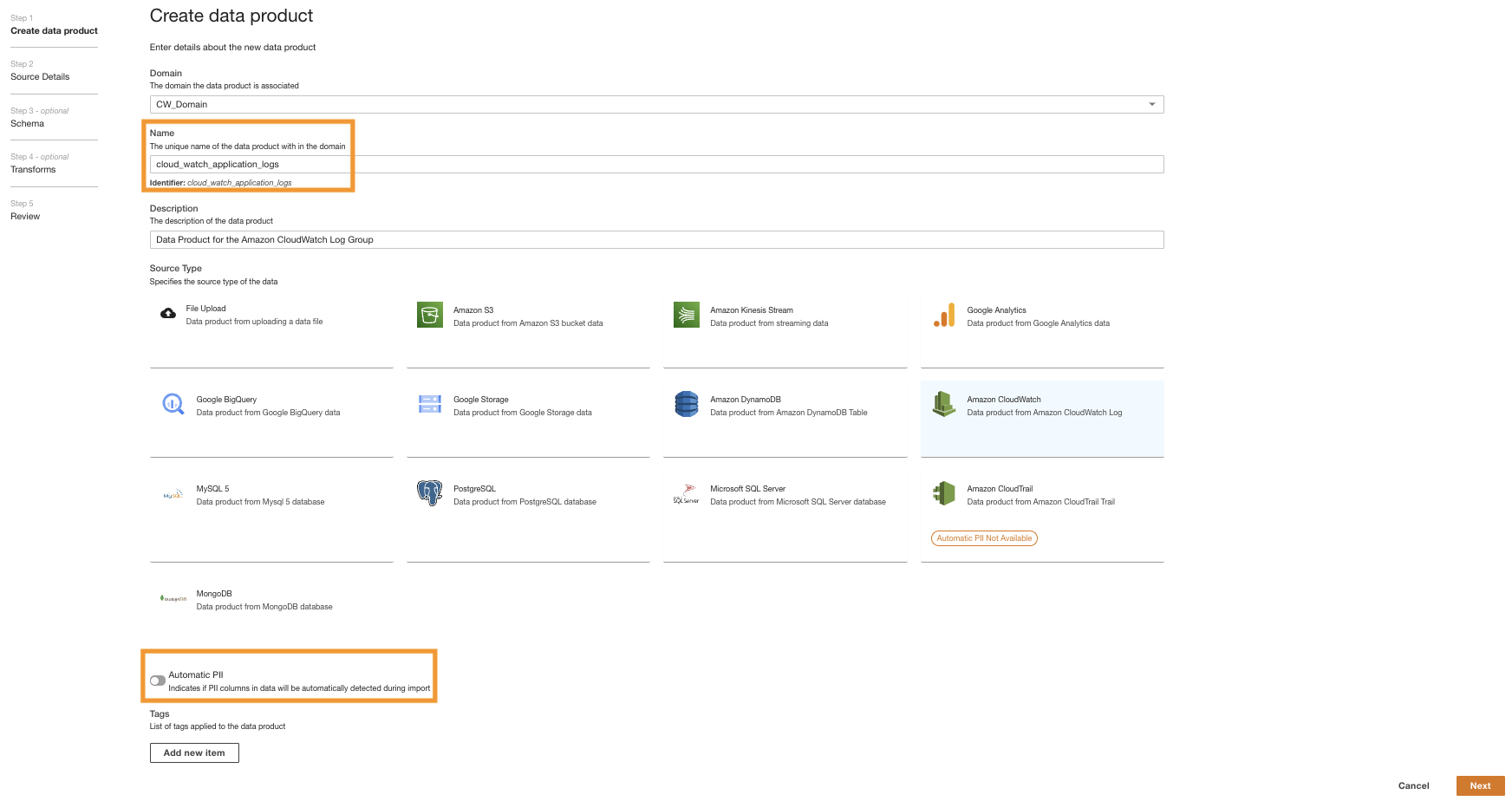
Create ADA data products
We create three different data products for this demo, one for each data source that you’ll be querying to gain operational insights. A data product is a dataset (a collection of data such as a table or a CSV file) that has been successfully imported into ADA and that can be queried.
Create a CloudWatch data product
First, we create a data product for the application logs by setting up ADA to ingest the CloudWatch log group for the sample application (Lambda function). Use the CdkStack.LambdaFunction output to get the Lambda function ARN and locate the corresponding CloudWatch log group ARN on the CloudWatch console.
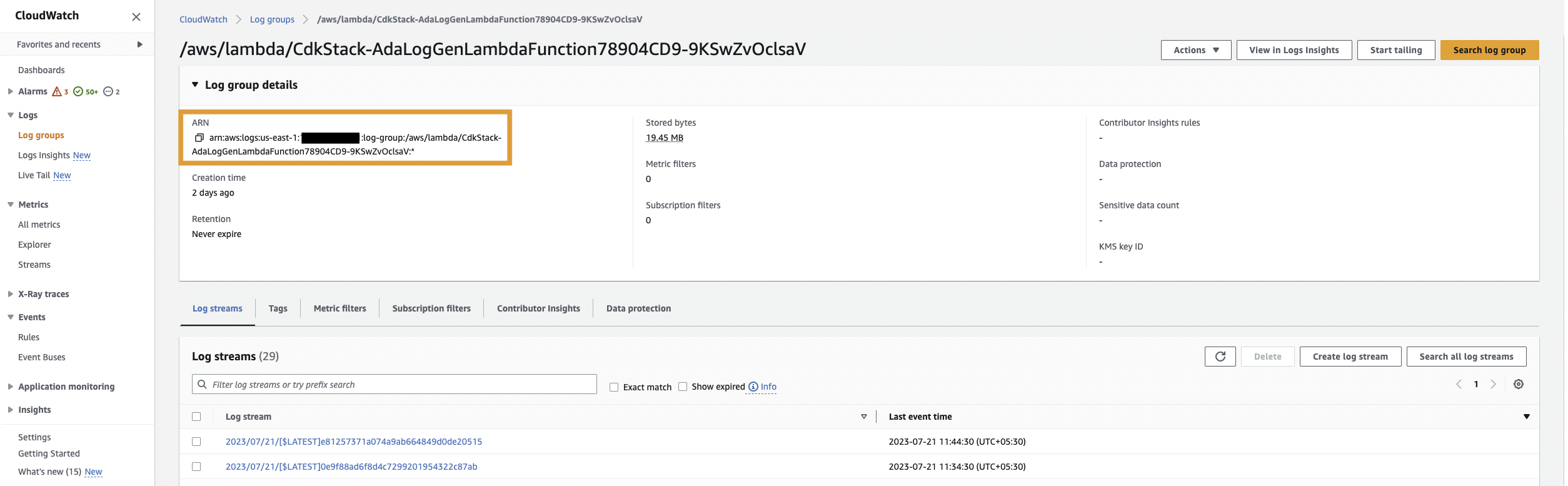
จากนั้นทำตามขั้นตอนต่อไปนี้:
- On the ADA console, navigate to the ADA domain and create a CloudWatch data product.
- สำหรับ Name¸ ใส่ชื่อ.
- สำหรับ Source type, เลือก อเมซอน คลาวด์วอตช์.
- ปิดการใช้งาน Automatic PII.
ADA has a feature that automatically detects personally identifiable information (PII) data during import that is enabled by default. For this demo, we disable this option for the data product because the discovery of PII data is not in the scope of this demo.
- Choose ถัดไป.
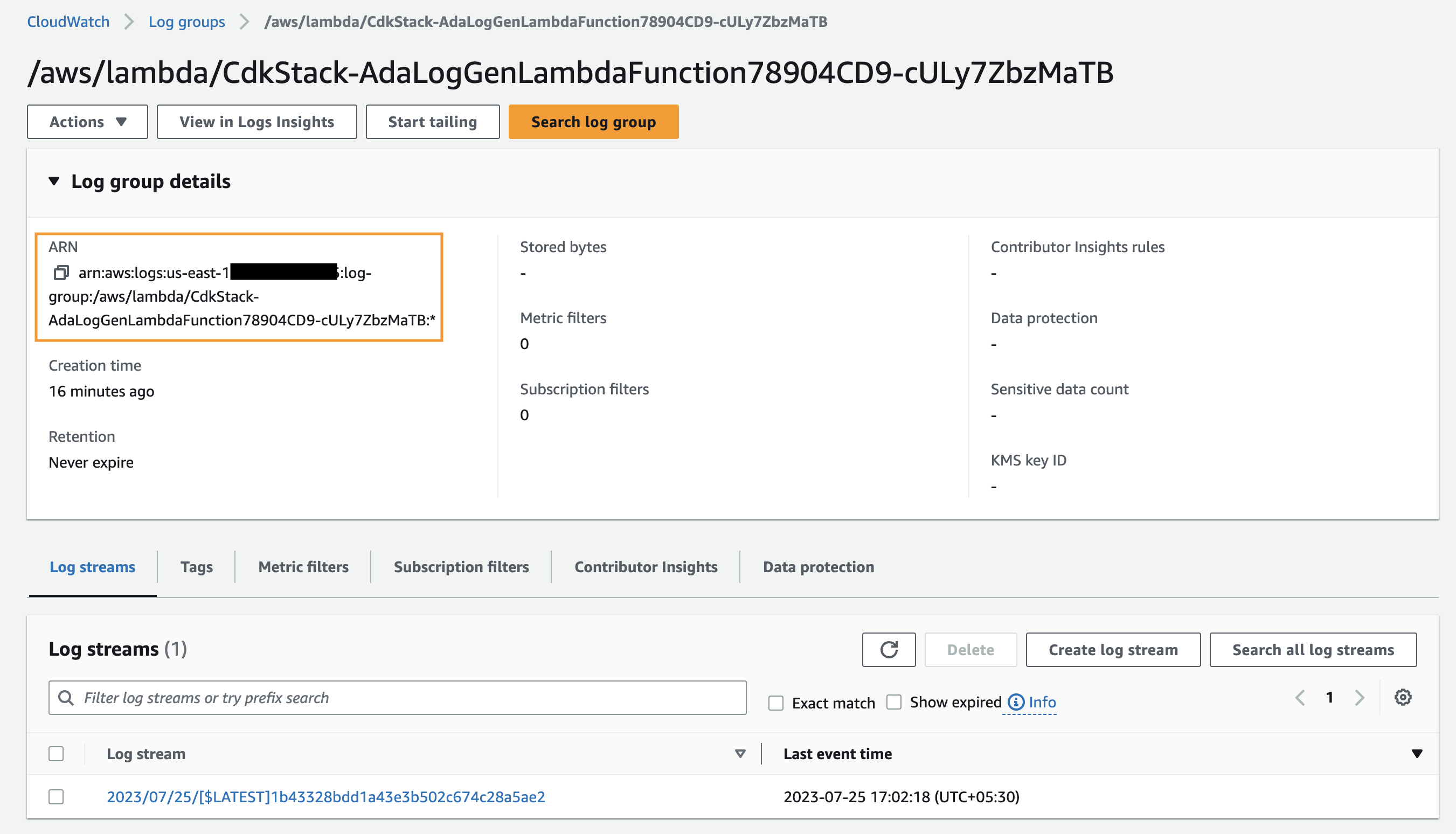
- Search for and choose the CloudWatch log group ARN copied from the previous step.

- Copy the log group ARN.
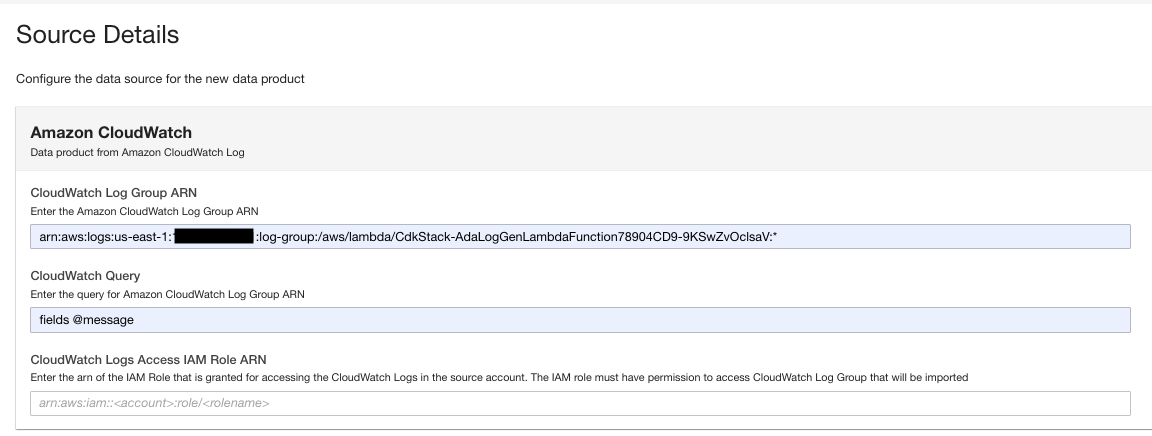
- On the data product page, enter the log group ARN.
- สำหรับ CloudWatch Query, enter a query that you want ADA to get from the log group.
In this demo, we query the @message field because we’re interested in getting the application logs from the log group.
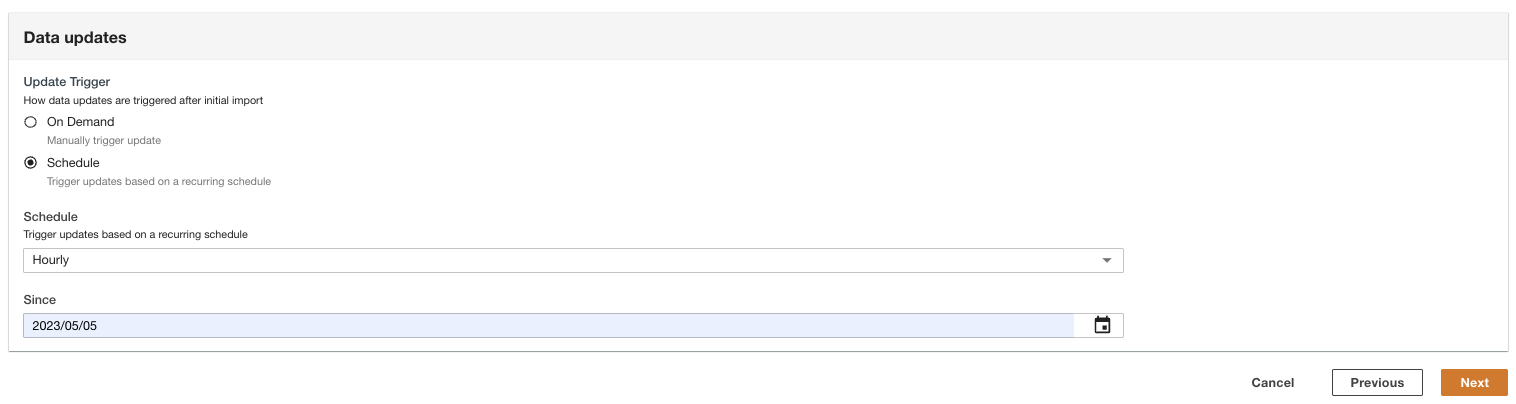
- Select how the data updates are triggered after initial import.
ADA can be configured to ingest the data from the source at flexible intervals (up to 15 minutes or later) or on demand. For the demo, we set the data updates to run hourly.
- Choose ถัดไป.
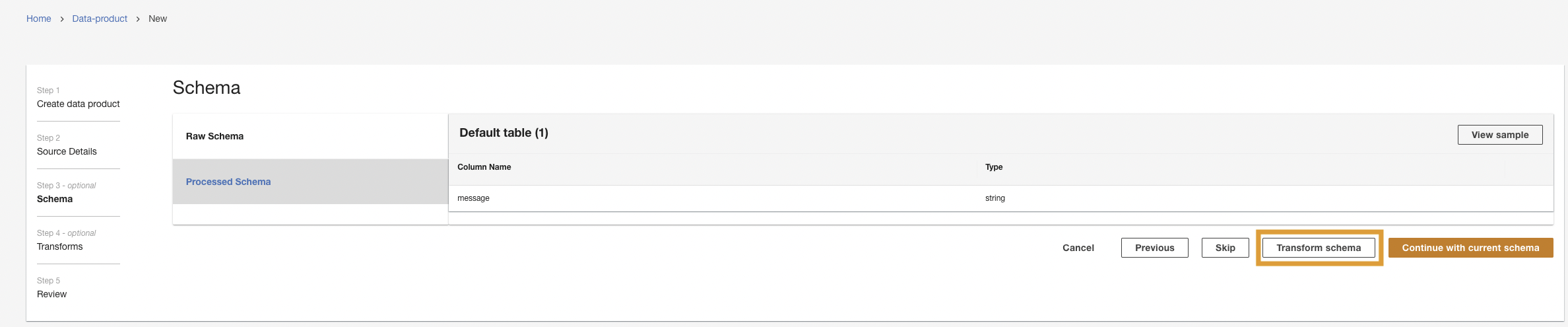
Next, ADA will connect to the log group and query the schema. Because the logs are in Apache Log Format, we transform the logs into separate fields so that we can run queries on the specific log fields. ADA provides four ผิดนัด transformations and supports custom transformation through a Python script. In this demo, we run a custom Python script to transform the JSON message field into Apache Log Format fields.
- Choose Transform schema.
- Choose Create new transform.
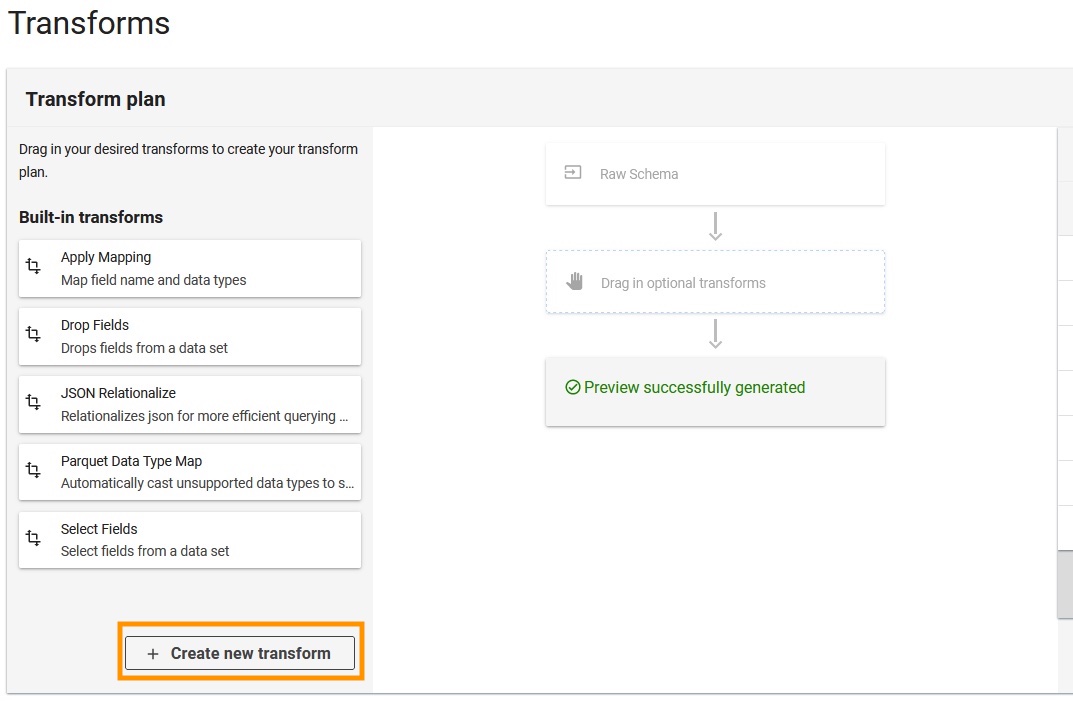
- อัปโหลดไฟล์
apache-log-extractor-transform.pyscript from the/asset/transform_logs/โฟลเดอร์ - Choose ส่ง.
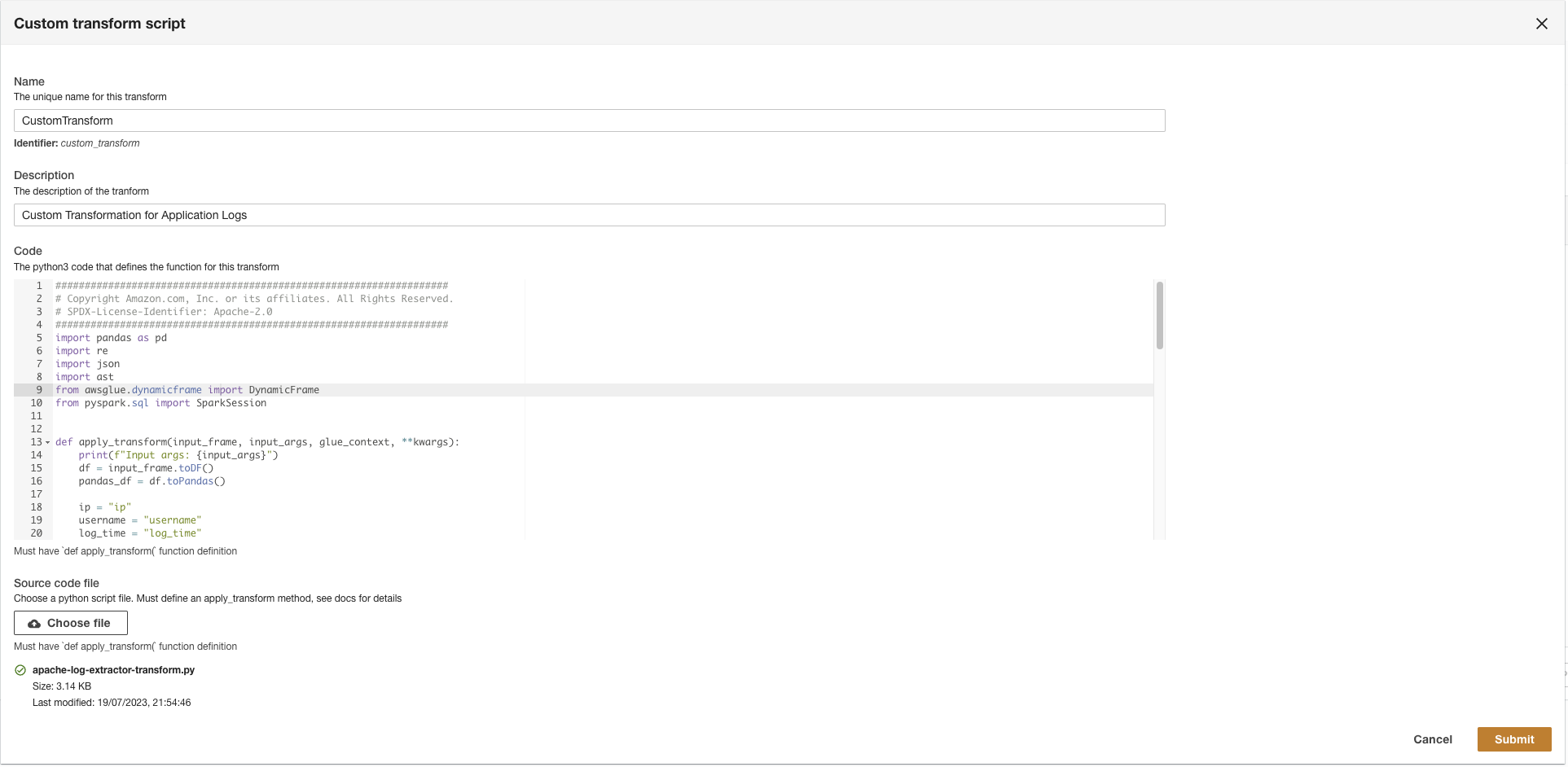
ADA will transform the CloudWatch logs using the script and present the processed schema.
- Choose ถัดไป.
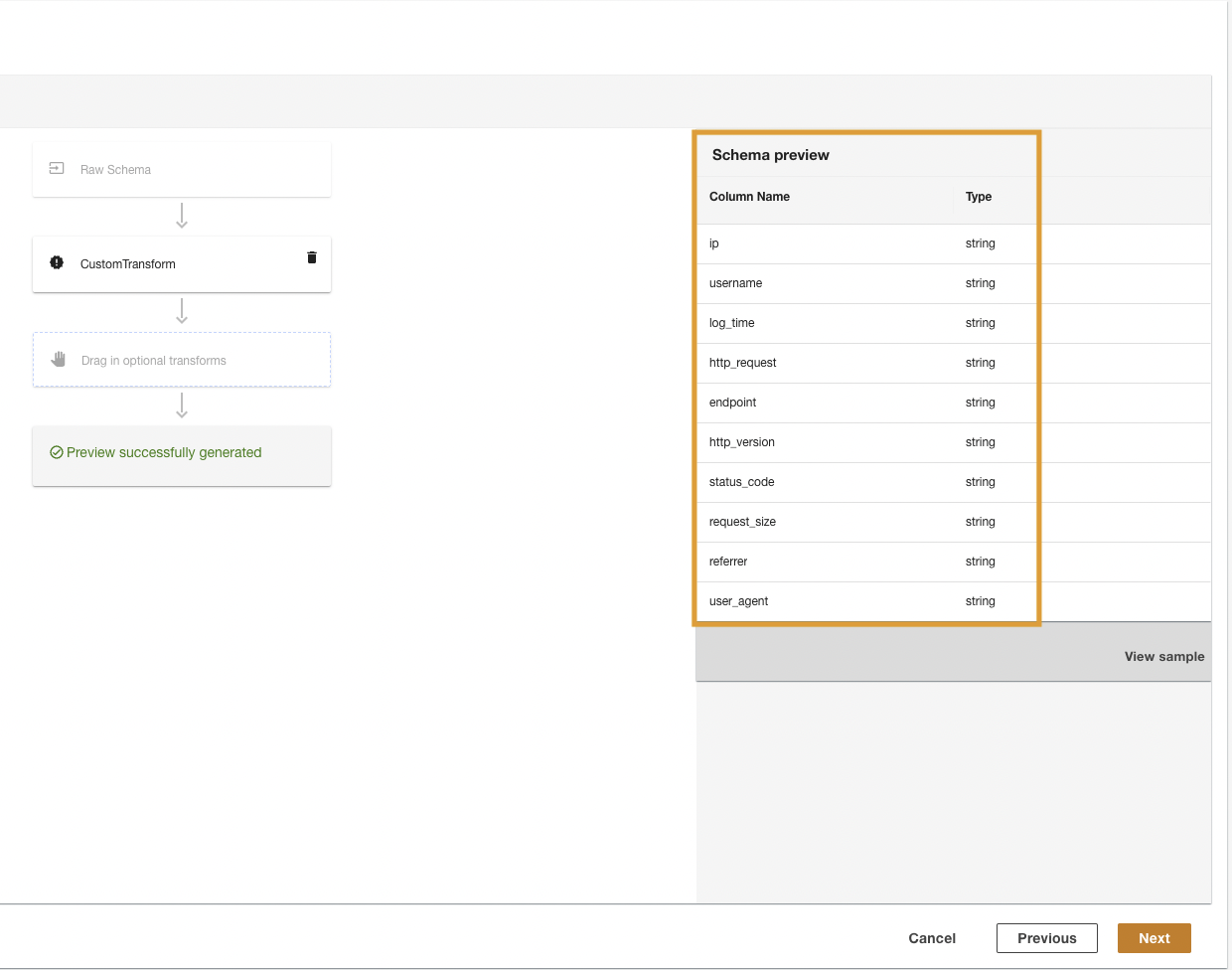
- In the last step, review the steps and choose ส่ง.
ADA will start the data processing, create the data pipelines, and prepare the CloudWatch log groups to be queried from the Query Workbench. This process will take a few minutes to complete and will be shown on the ADA console under ผลิตภัณฑ์ข้อมูล.
Create an Amazon S3 data product
We repeat the steps to add the historical logs from the Amazon S3 data source and look up reference data from the DynamoDB table. For these two data sources, we don’t create custom transforms because the data formats are in CSV (for historical logs) and key attributes (for reference lookup data).
- On the ADA console, create a new data product.
- ป้อนชื่อ (
hist_logs) และเลือก Amazon S3.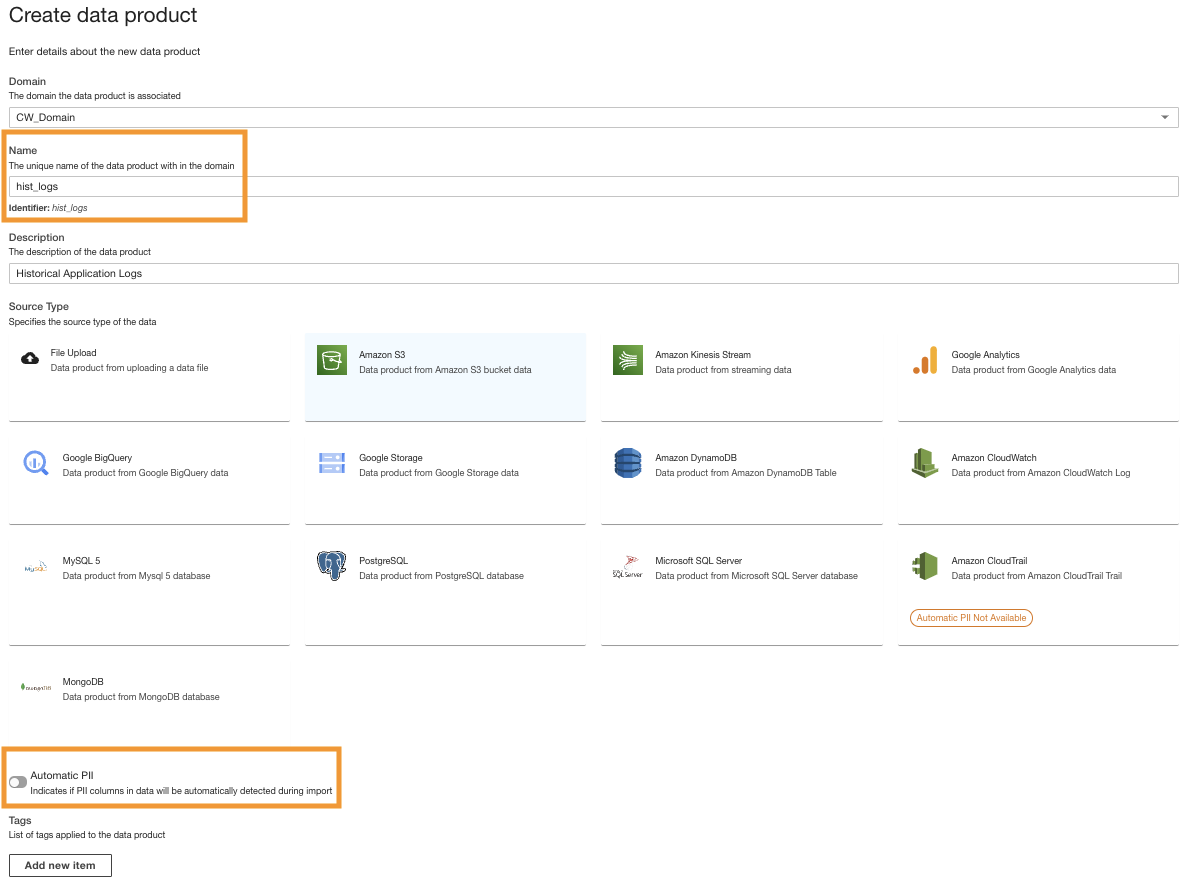
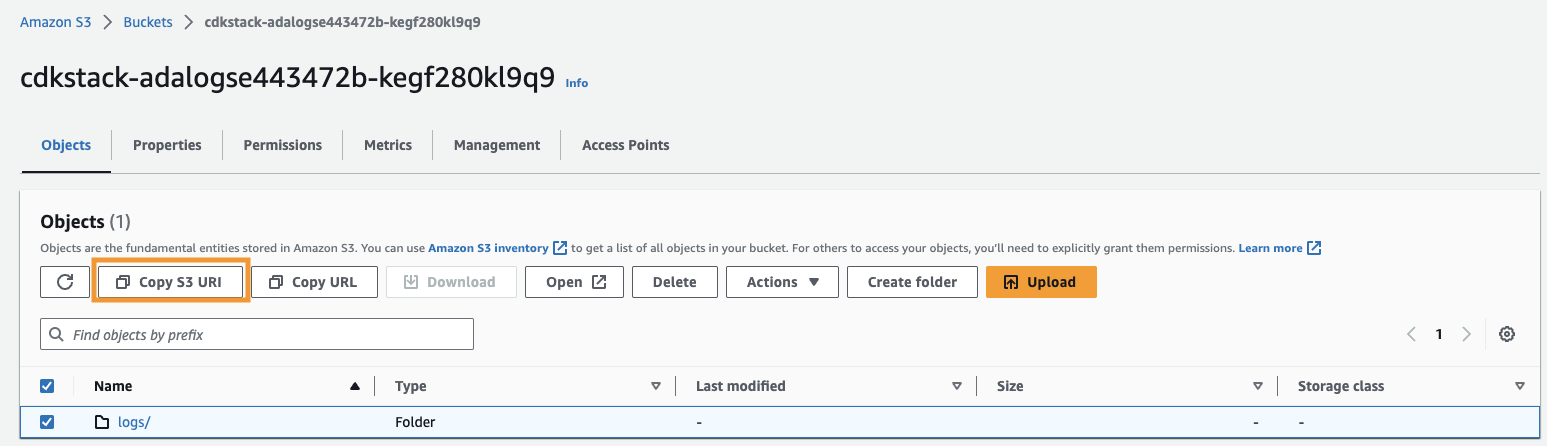
- Copy the Amazon S3 URI (the text after
arn:aws:s3:::) จากCdkStack.S3output variable and navigate to the Amazon S3 console. - In the search box, enter the copied text, open the S3 bucket, select the
/logsfolder, and choose Copy S3 URI.
The historical logs are stored in this path.
- Navigate back to the ADA console and enter the copied S3 URI for ที่ตั้ง S3.
- สำหรับ อัปเดตทริกเกอร์ให้เลือก ตามความต้องการ because the historical logs are updated at an unspecified frequency.
- สำหรับ อัปเดตนโยบายให้เลือก ผนวก to append newly imported data to the existing data.
- Choose ถัดไป.
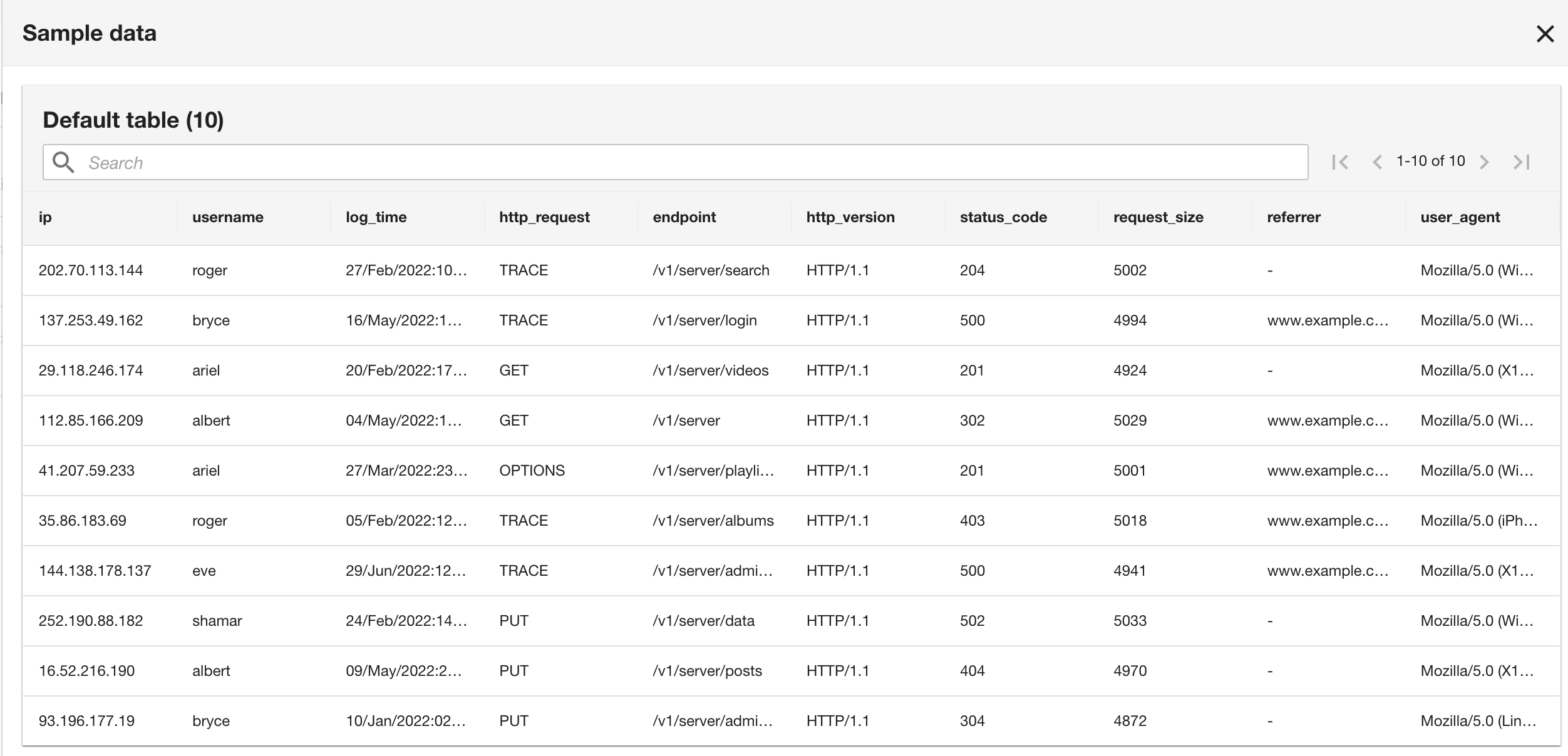
ADA processes the schema for the files in the selected folder path. Because the logs are in CSV format, ADA is able to read the column names without requiring additional transformations. However, the columns status_code และ request_size are inferred as long type by ADA. We want to keep the column data types consistent among the data products so that we can join the data tables and query the data. The column status_code will be used to create joins across the data tables.
- Choose Transform schema to change the data types of the two columns to string data type.
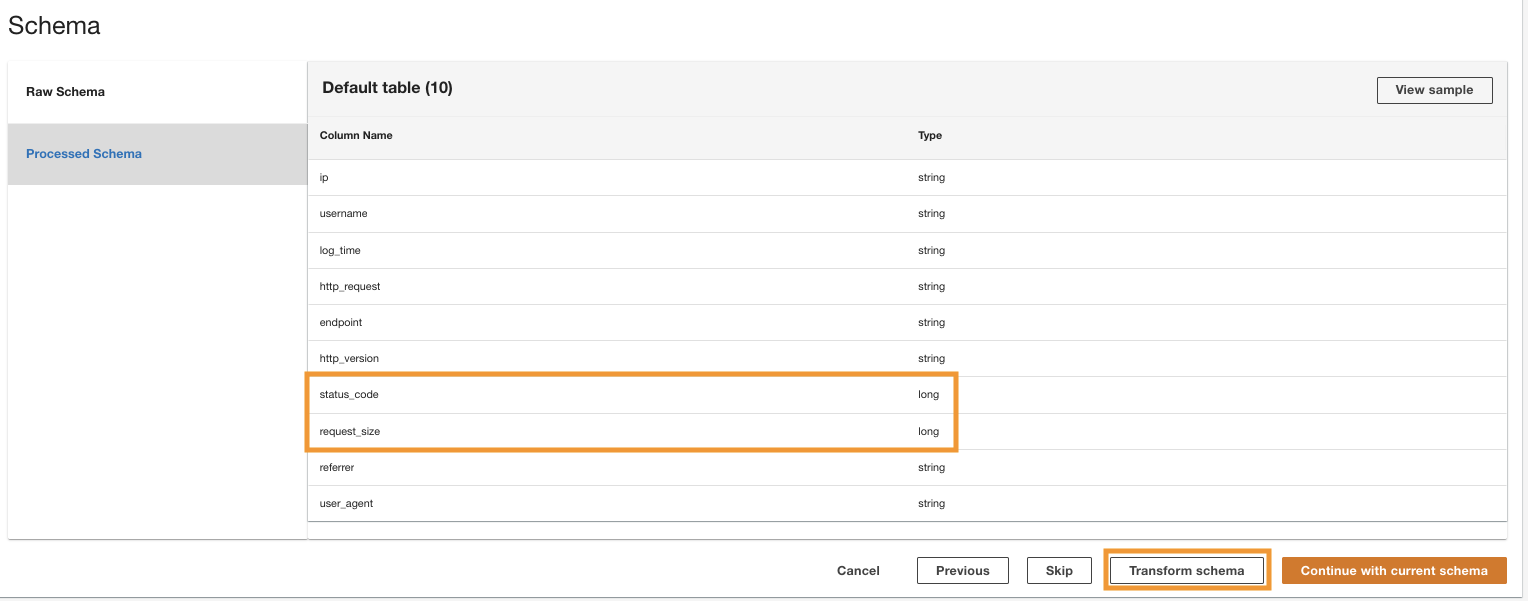
Note the highlighted column names in the Schema preview pane prior to applying the data type transformations.
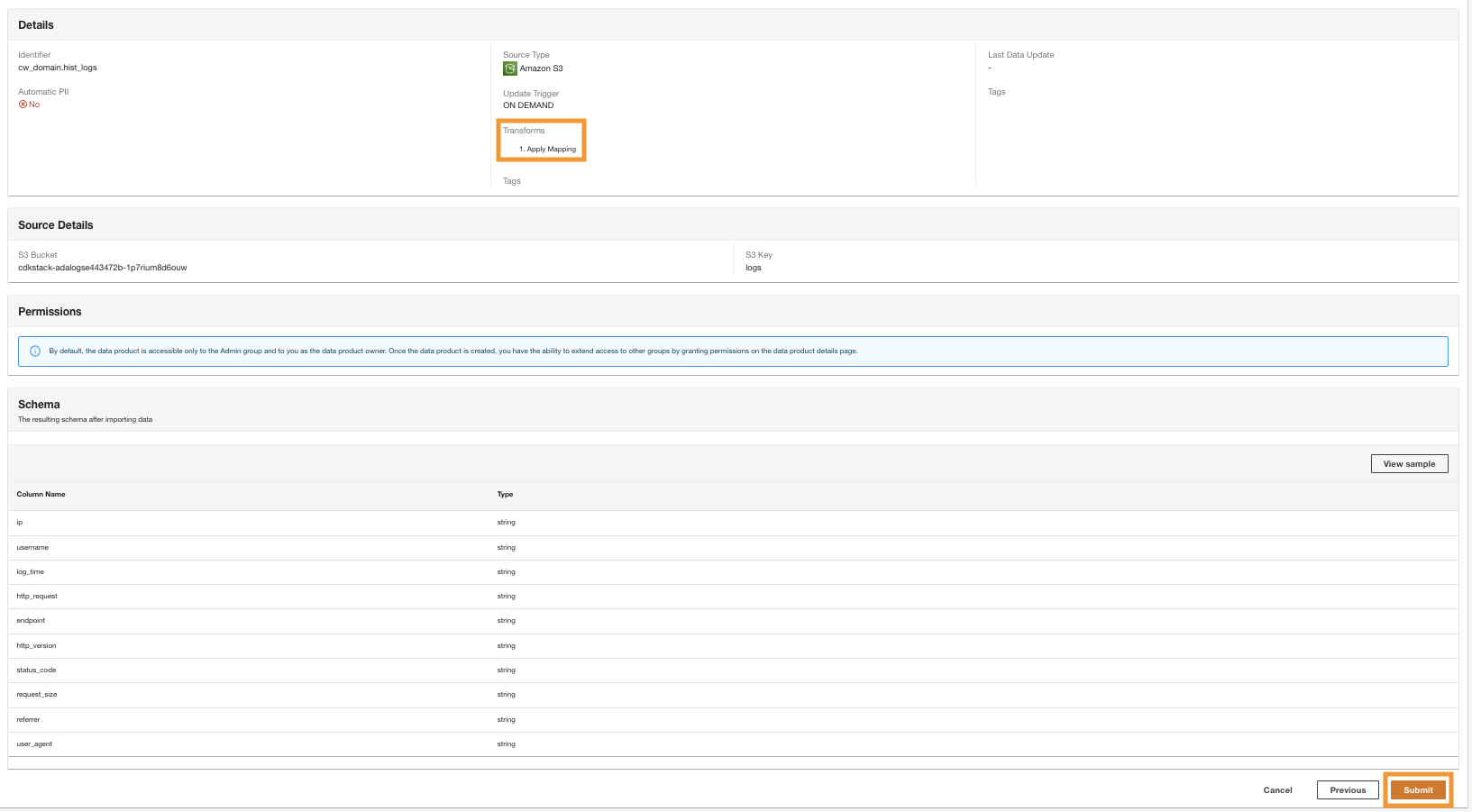
- ตัว Vortex Indicator ได้ถูกนำเสนอลงในนิตยสาร Transform plan บานหน้าต่างด้านล่าง Built-in transformsเลือก Apply Mapping.
This option allows you to change the data type from one type to another.
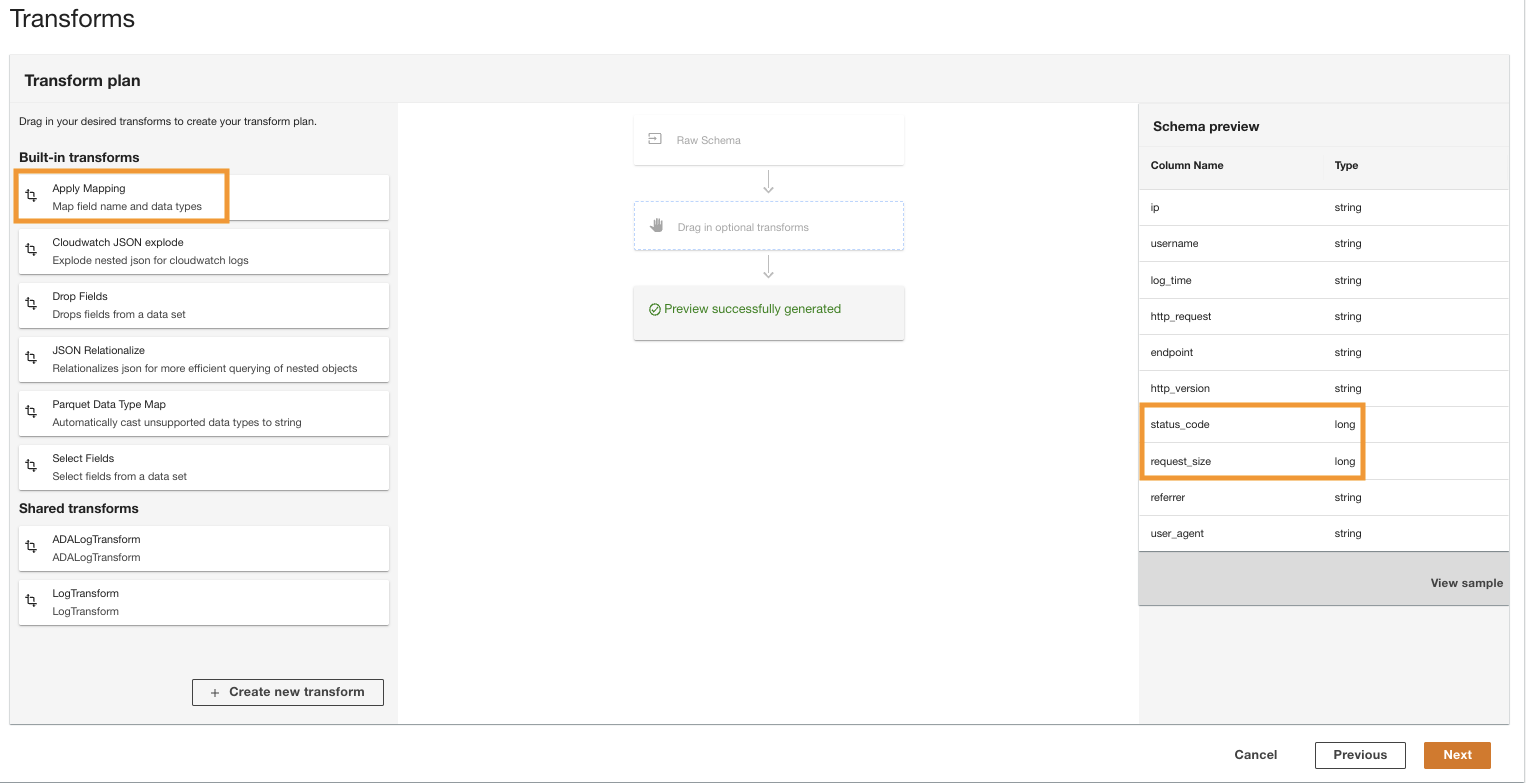
- ตัว Vortex Indicator ได้ถูกนำเสนอลงในนิตยสาร Apply Mapping ส่วน ยกเลิกการเลือก Drop other fields.
If this option is not disabled, only the transformed columns will be preserved and all other columns will be dropped. Because we want to retain all the columns, we disable this option.
- ภายใต้ การแมปฟิลด์¸ สำหรับ ชื่อเก่า และ ชื่อใหม่ป้อน
status_codeและสำหรับ ประเภทใหม่ป้อนstring.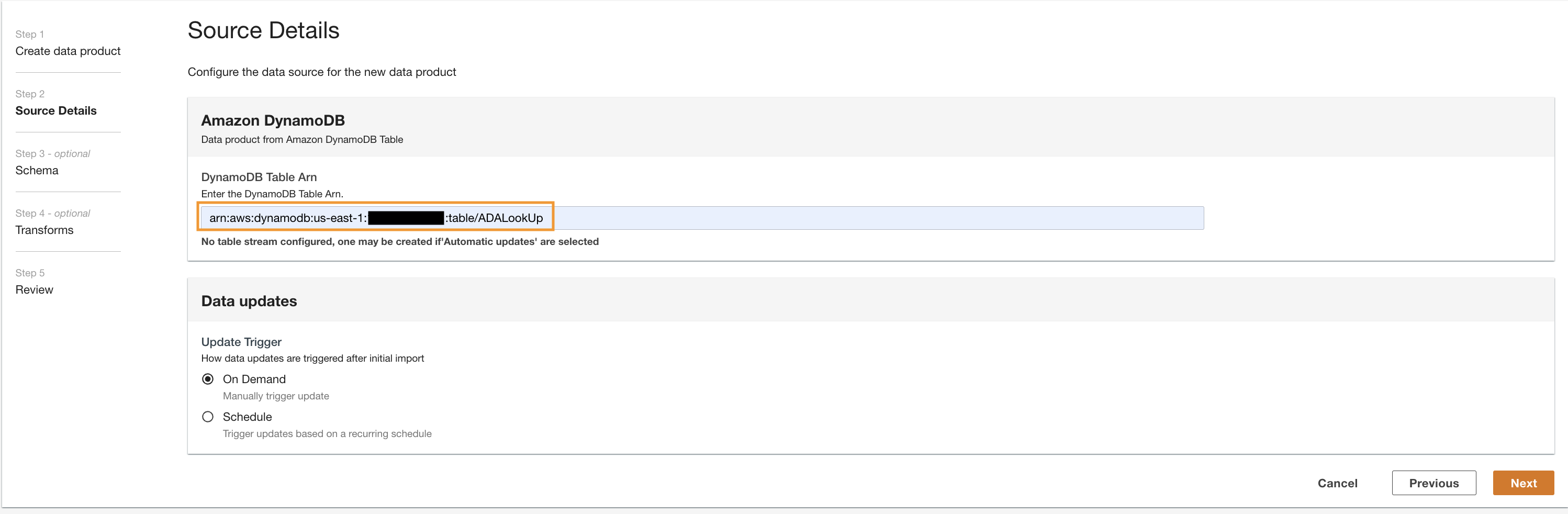
- Choose เพิ่มรายการ.
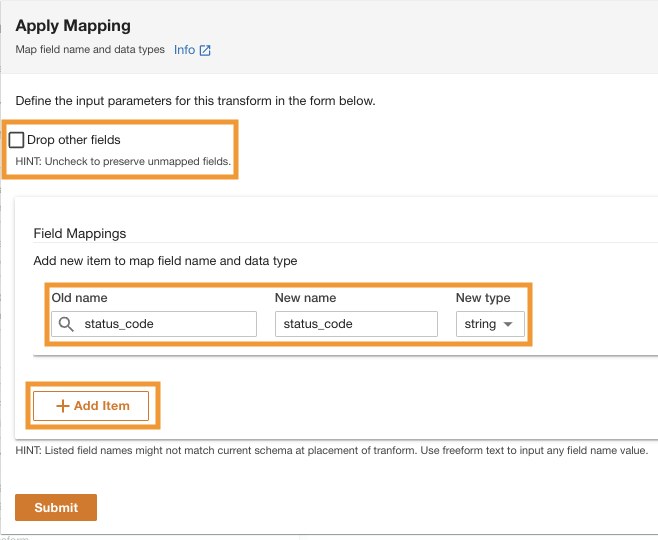
- สำหรับ ชื่อเก่า และ ชื่อใหม่¸ enter request_size and for New data type, enter string.
- Choose ส่ง.
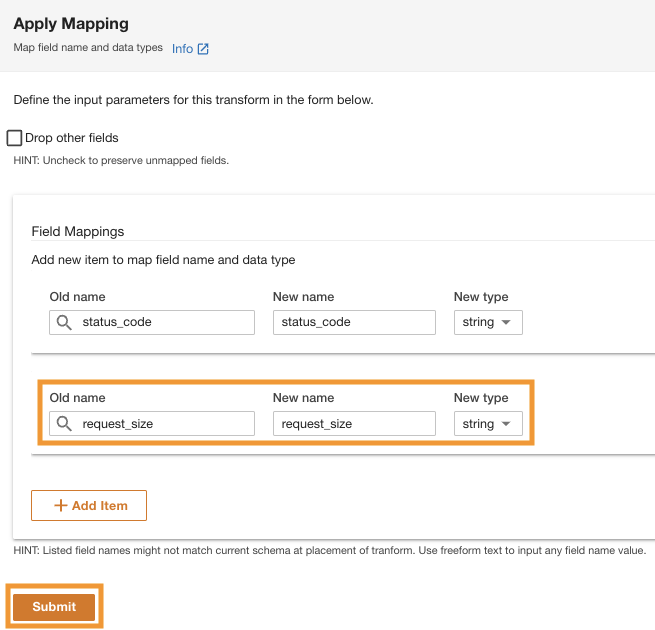
ADA will apply the mapping transformation on the Amazon S3 data source. Note the column types in the Schema preview บานหน้าต่าง
- Choose View sample to preview the data with the transformation applied.
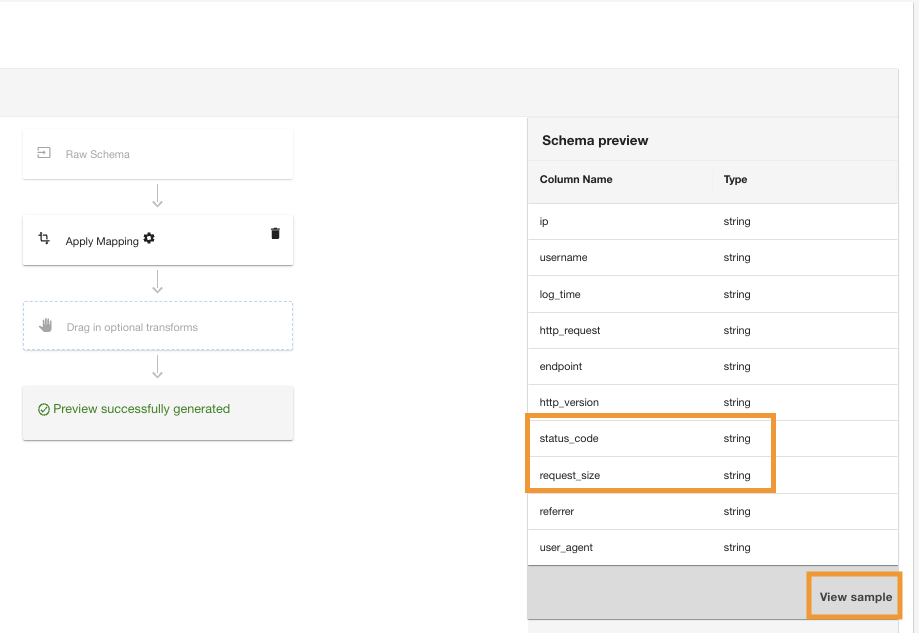
ADA will display the PII data acknowledgement to ensure that either only authorized users can view the data or that the dataset doesn’t contain any PII data.
- Choose เห็นด้วย to continue to view the sample data.
Note that the schema is identical to the CloudWatch log group schema because both the current application and historical application logs are in Apache Log Format.
- In the final step, review the configuration and choose ส่ง.
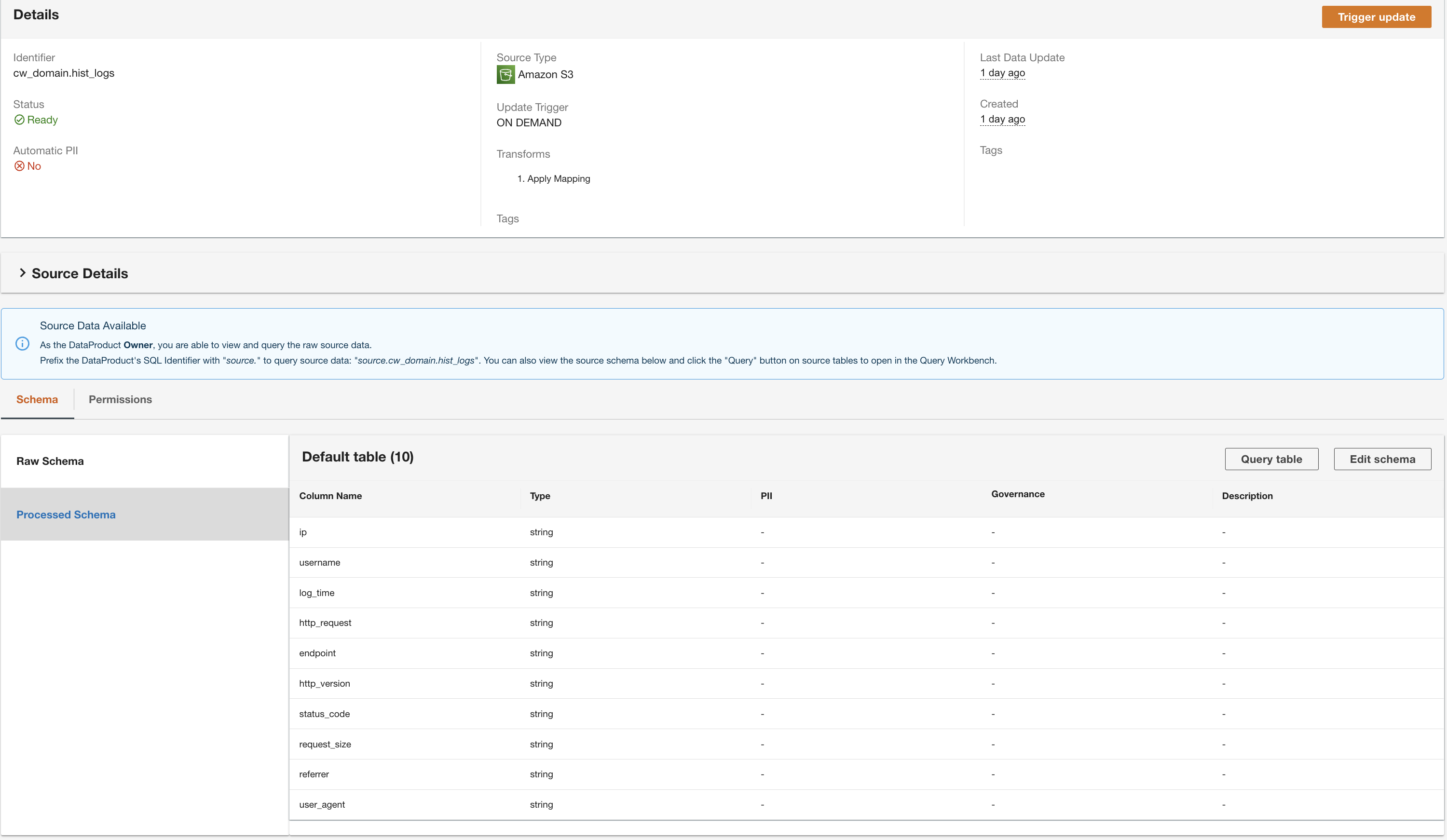
ADA starts processing the data from the Amazon S3 source, creates the backend infrastructure, and prepares the data product. This process takes a few minutes depending upon the size of the data.
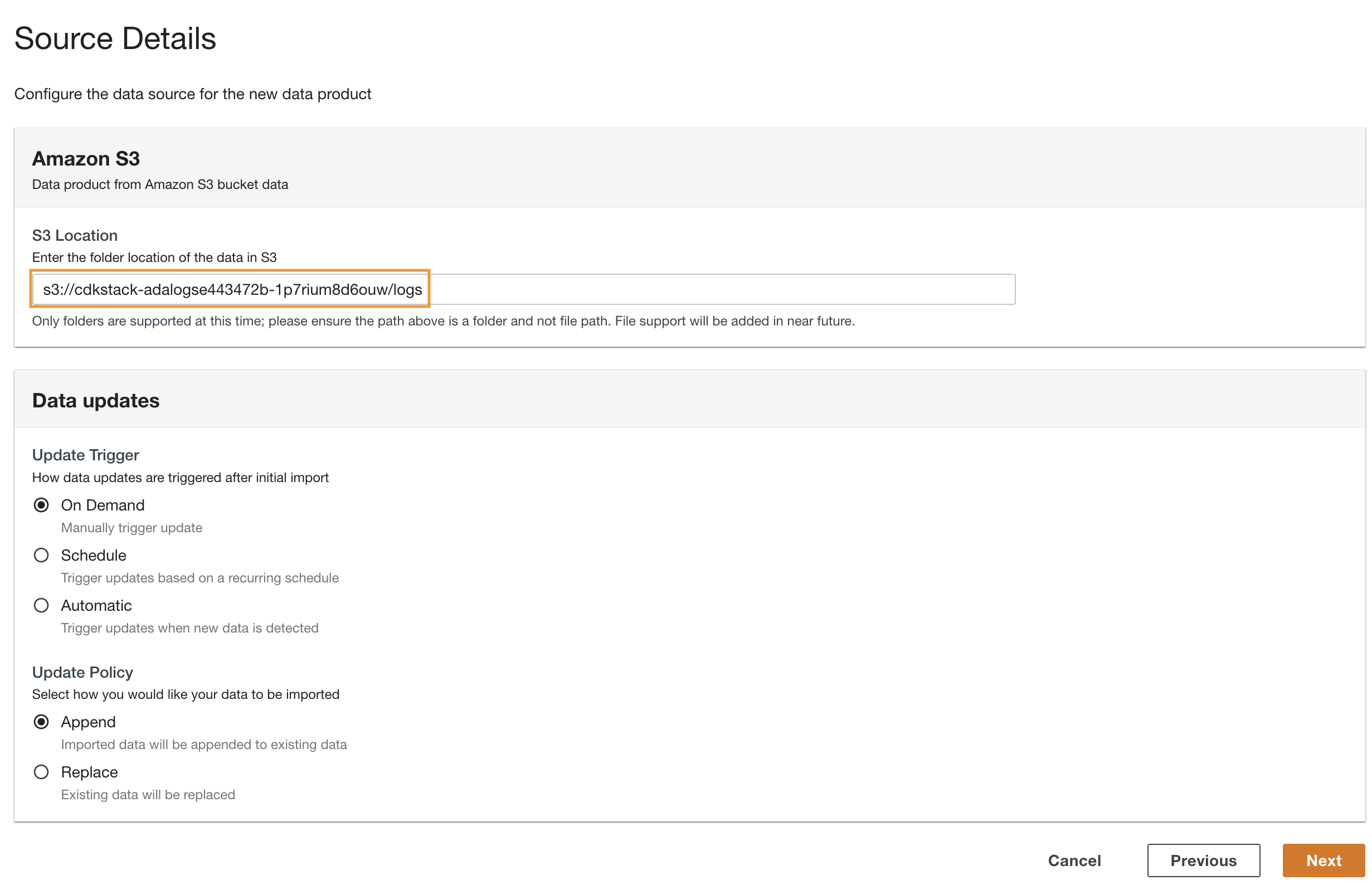
Create a DynamoDB data product
Lastly, we create a DynamoDB data product. Complete the following steps:
- On the ADA console, create a new data product.
- ป้อนชื่อ (
lookup) และเลือก อเมซอน ไดนาโมดีบี.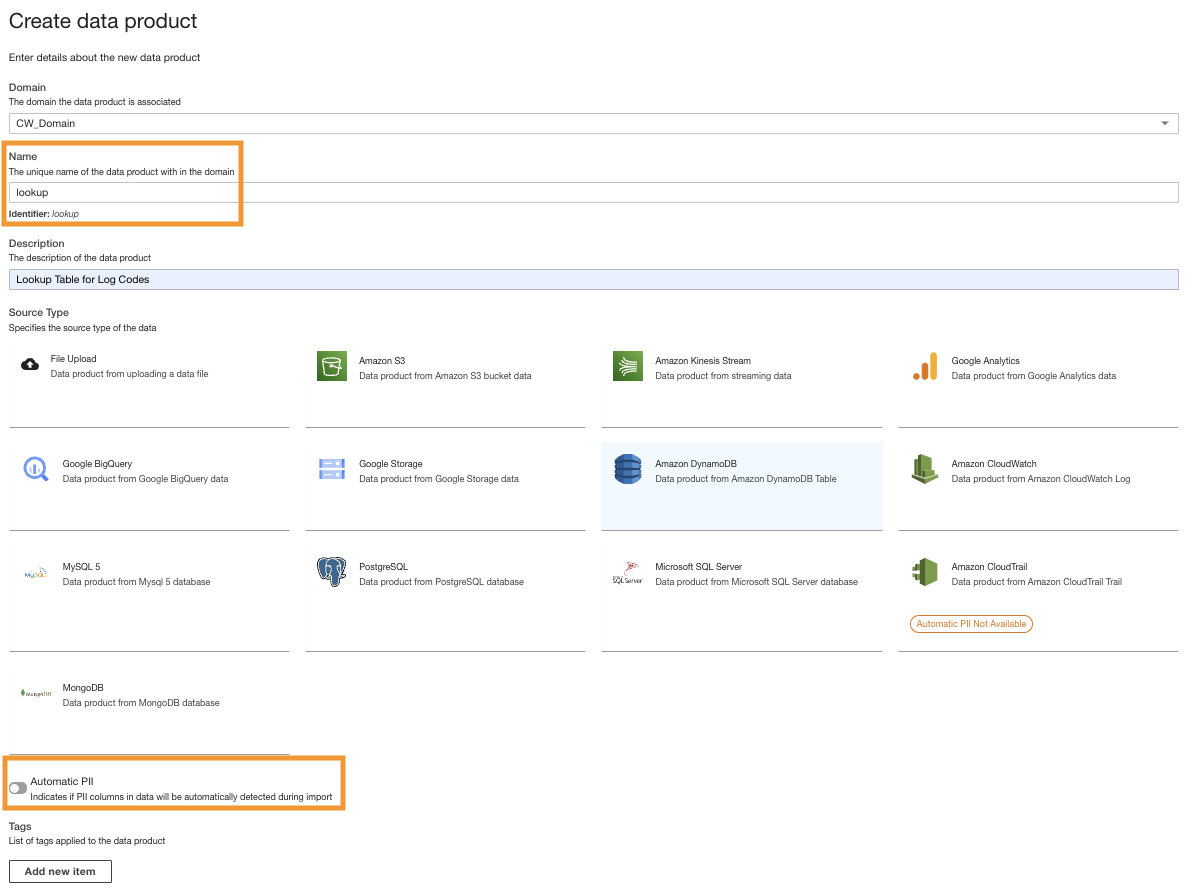
- ป้อน
Cdk.DynamoDBTableoutput variable for DynamoDB Table ARN.
This table contains key attributes that will be used as a lookup table in this demo. For the lookup data, we are using the HTTP codes and long and short descriptions of the codes. You can also use PostgreSQL, MySQL, or a CSV file source as an alternative.
- สำหรับ อัปเดตทริกเกอร์ให้เลือก ตามความต้องการ.
The updates will be on demand because the lookup is mostly for reference purpose while querying and any updates to the lookup data can be updated in ADA using on-demand triggers.
- Choose ถัดไป.
ADA reads the schema from the underlying DynamoDB schema and presents the column name and type for optional transformation. We will proceed with the default schema selection because the column types are consistent with the types from the CloudWatch log group and Amazon S3 CSV data source. Having data types that are consistent across the data sources allows us to write queries to fetch records by joining the tables using the column fields. For example, the column key in the DynamoDB schema corresponds to the status_code in the Amazon S3 and CloudWatch data products. We can write queries that can join the three tables using the column name key. An example is shown in the next section.
- Choose Continue with current schema.
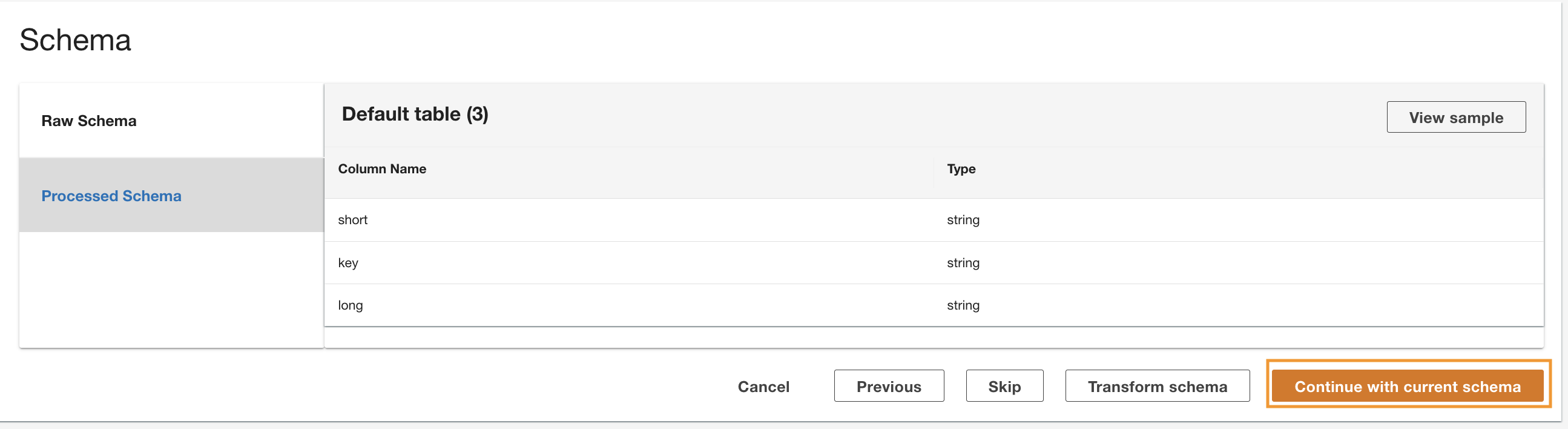
- ตรวจสอบการกำหนดค่าและเลือก ส่ง.
ADA will process the data from the DynamoDB table data source and prepare the data product. Depending upon the size of the data, this process takes a few minutes.
Now we have all the three data products processed by ADA and available for you to run queries.

Use the Query Workbench to query the data
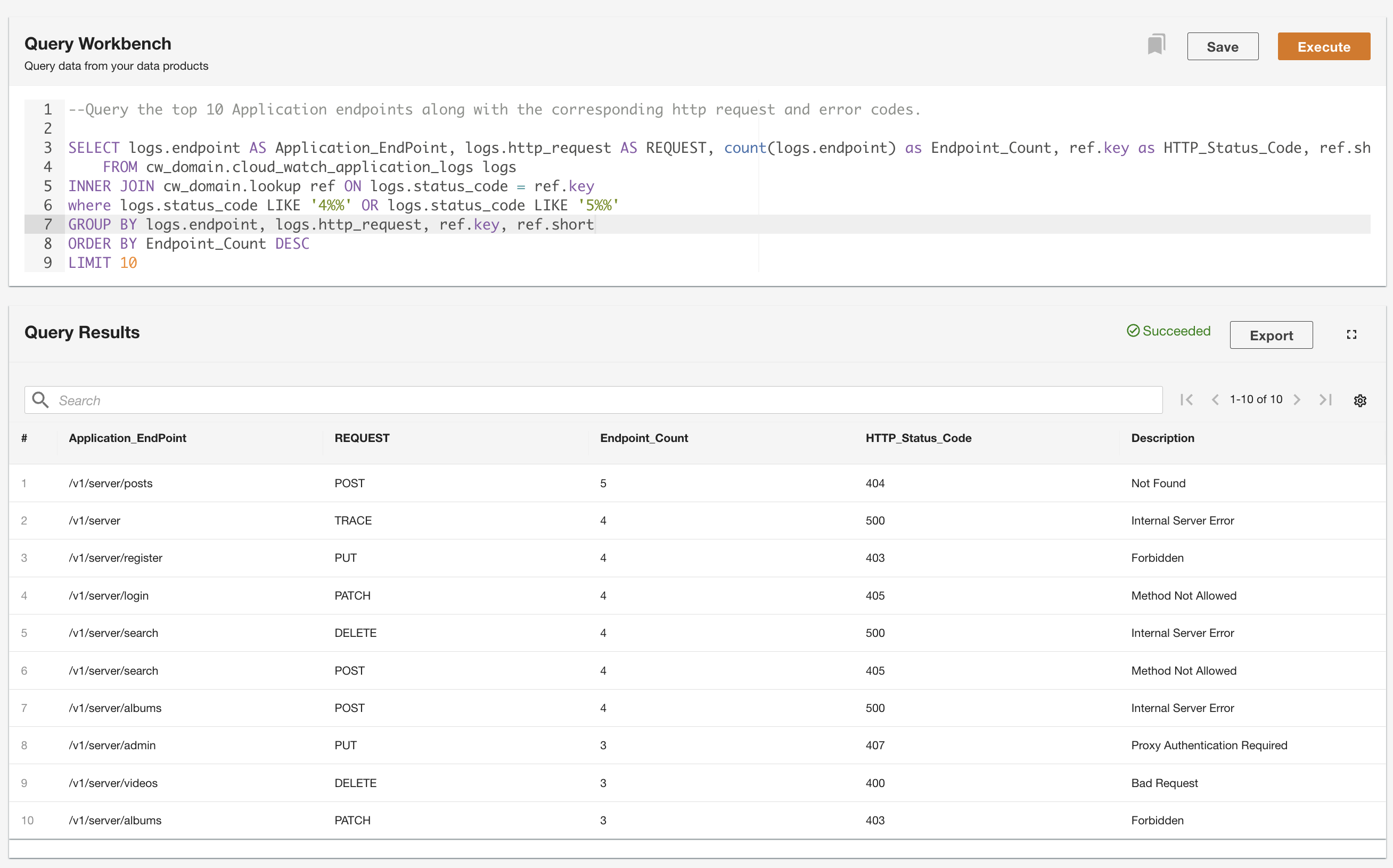
ADA allows you to run queries against the data products while abstracting the data source and making it accessible using SQL (Structured Query Language). You can write queries and join the tables just as you would query against tables in a relational database. We demonstrate ADA’s querying capability via two user scenarios. In both the scenarios, we join an application log dataset to the error codes lookup table. In the first use case, we query the current application logs to identify the top 10 most accessed application endpoints along with the corresponding HTTP status codes:
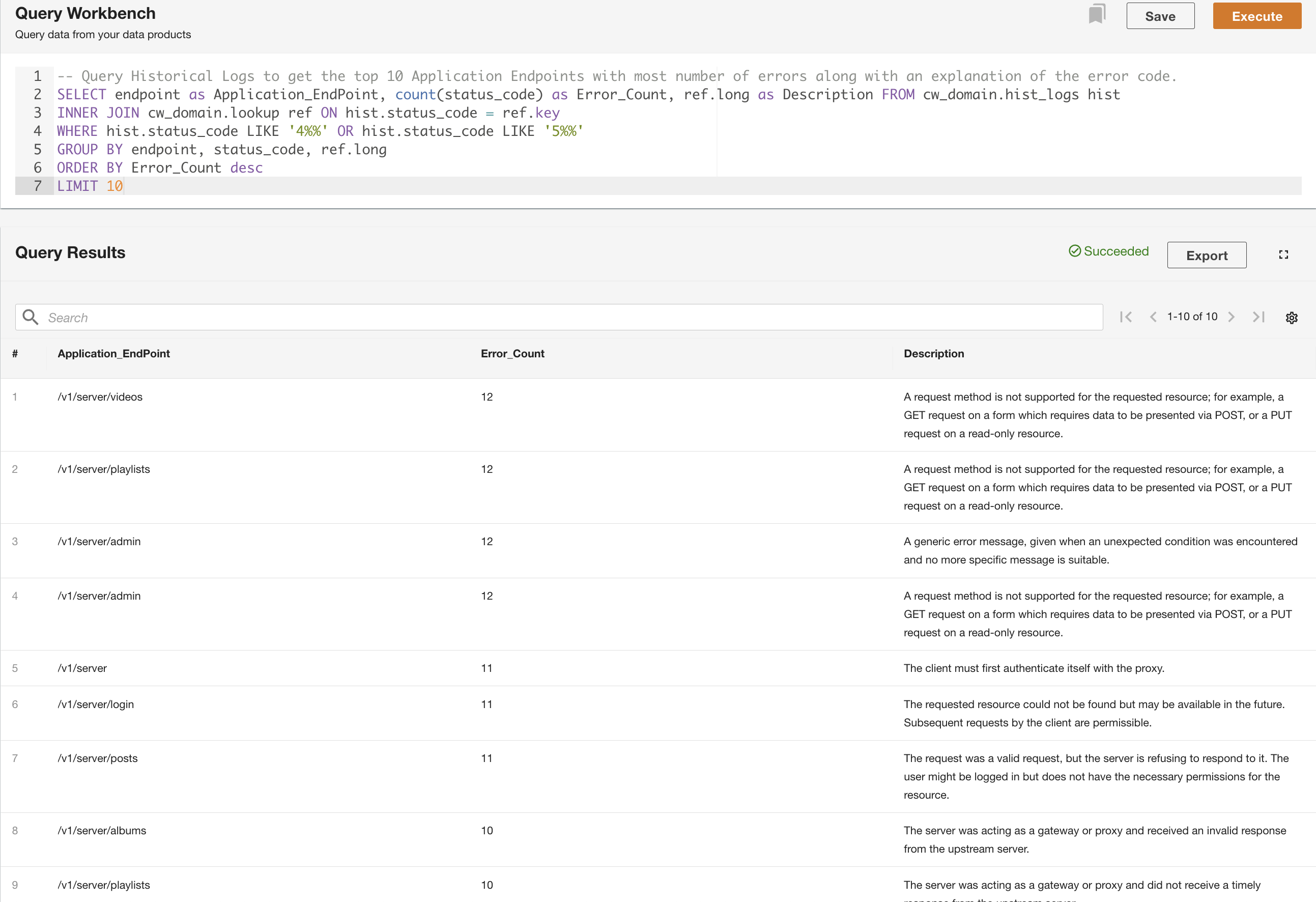
In the second example, we query the historical logs table to get the top 10 application endpoints with the most errors to understand the endpoint call pattern:
In addition to querying, you can optionally save the query and share the saved query with other users in the same domain. The shared queries are accessible directly from the Query Workbench. The query results can also be exported to CSV format.
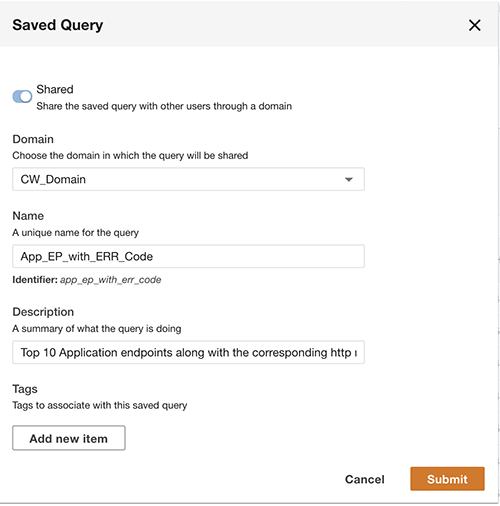
Visualize ADA data products in Tableau
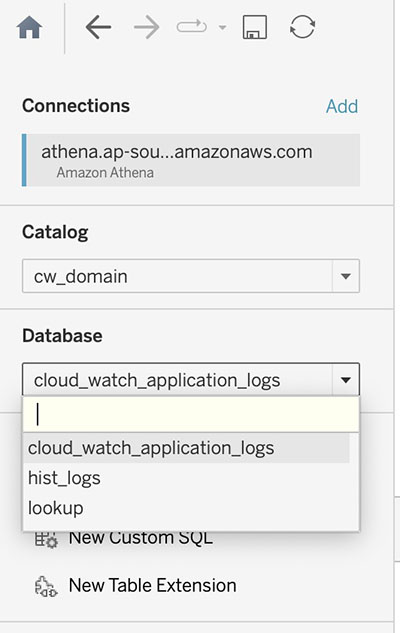
ADA offers the ability to ต่อ to third-party BI tools to visualize data and create reports from the ADA data products. In this demo, we use ADA’s native integration with Tableau to visualize the data from the three data products we configured earlier. Using Tableau’s Athena connector and following the steps in Tableau configuration, you can configure ADA as a data source in Tableau. After a successful connection has been established between Tableau and ADA, Tableau will populate the three data products under the Tableau catalog cw_domain.
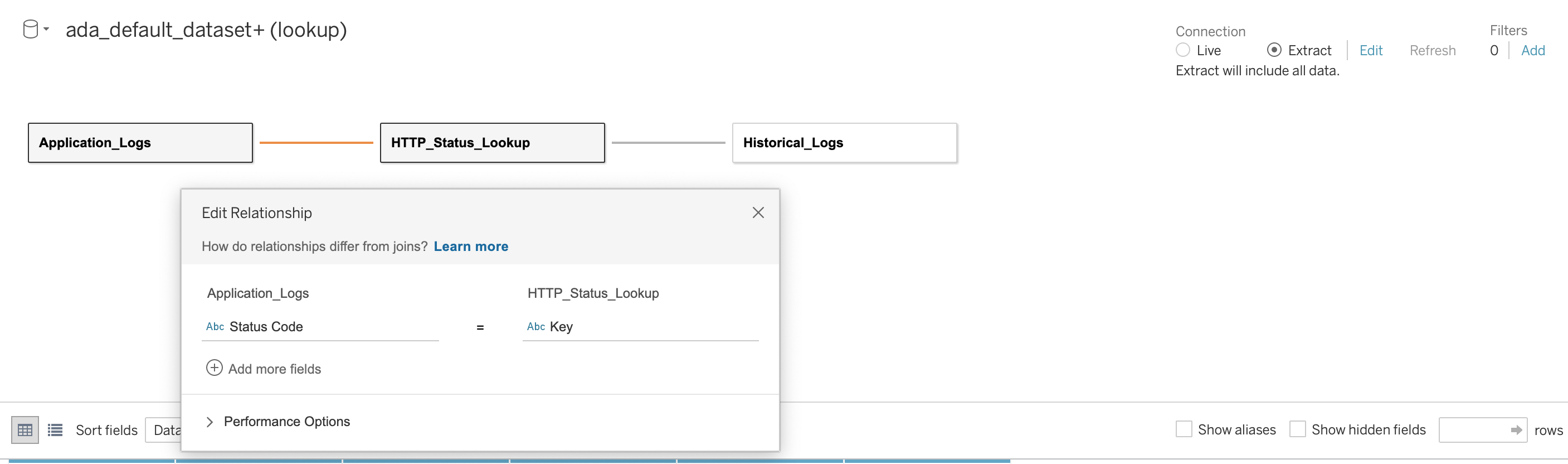
We then establish a relationship across the three databases using the HTTP status code as the joining column, as shown in the following screenshot. Tableau allows us to work in online and offline mode with the data sources. In online mode, Tableau will connect to ADA and query the data products live. In offline mode, we can use the สารสกัด option to extract the data from ADA and import the data in to Tableau. In this demo, we import the data in to Tableau to make the querying more responsive. We then save the Tableau workbook. We can inspect the data from the data sources by choosing the database and อัปเดตทันที.
With the data source configurations in place in Tableau, we can create custom reports, charts, and visualizations on the ADA data products. Let’s consider two use cases for visualizations.
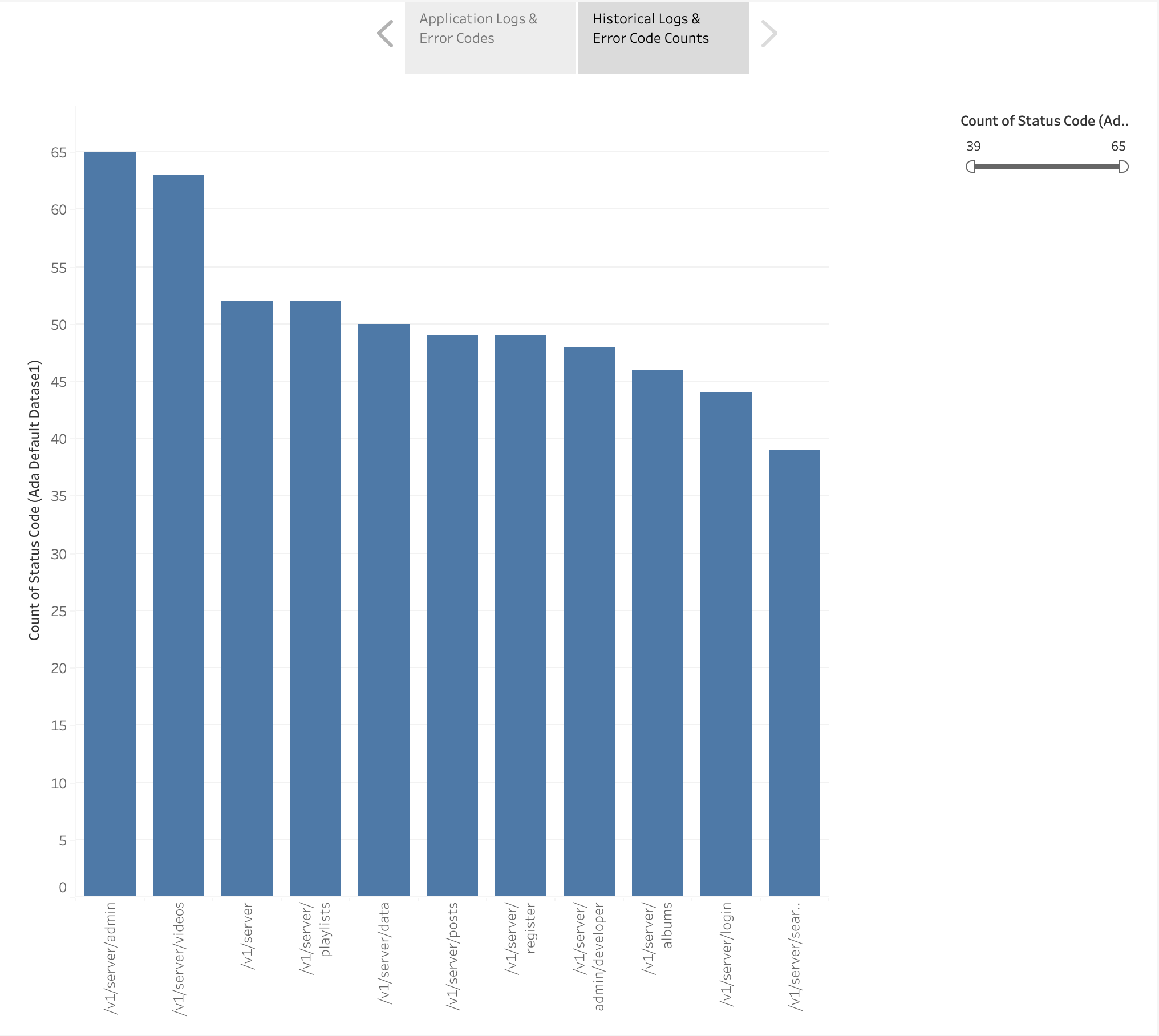
As shown in the following figure, we visualized the frequency of the HTTP errors by application endpoints using Tableau’s built-in แผนที่ความร้อน chart. We filtered out the HTTP status codes to only include error codes in the 4xx and 5xx range.
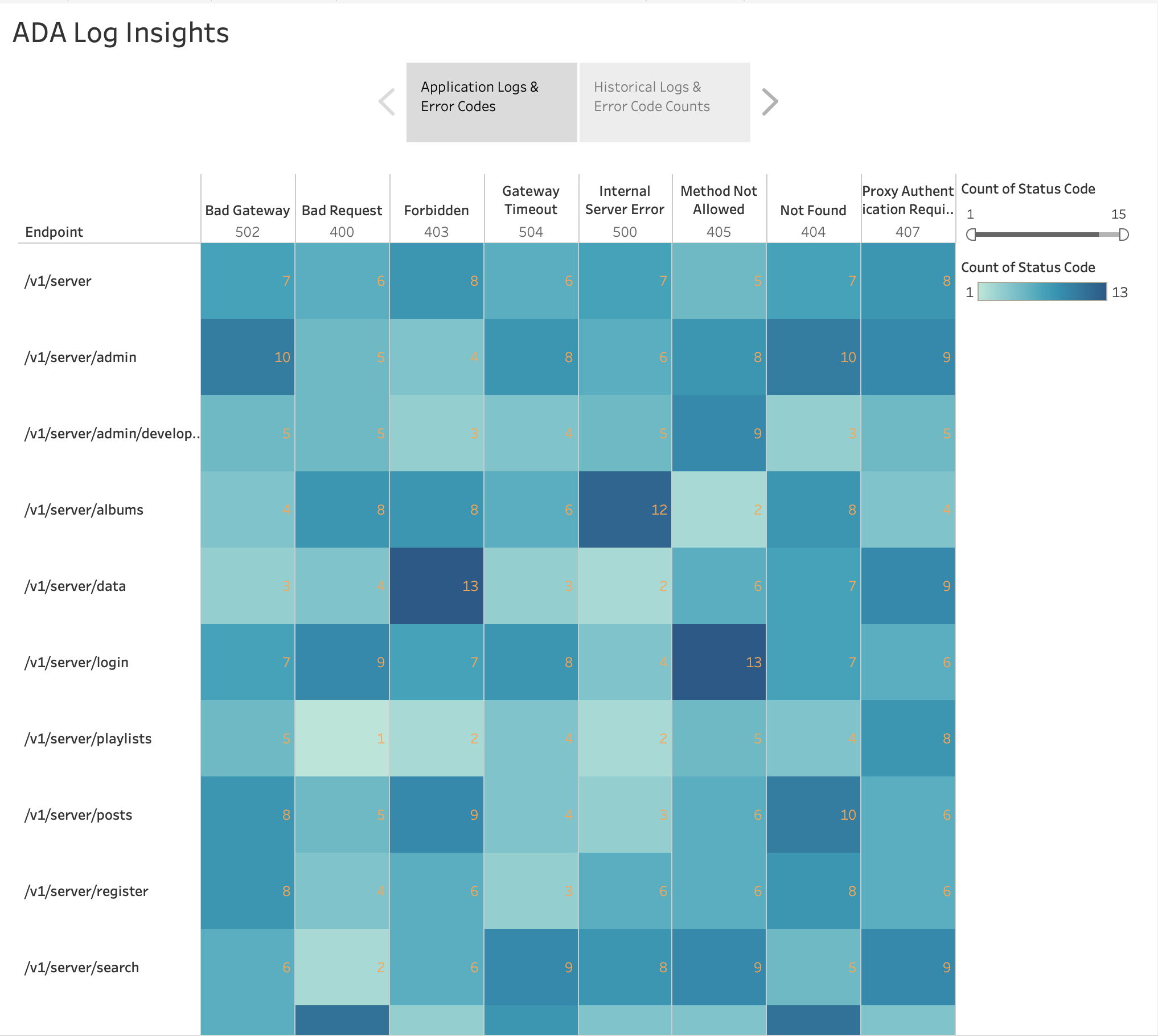
We also created a bar chart to depict the application endpoints from the historical logs ordered by the count of HTTP error codes. In this chart, we can see that the /v1/server/admin endpoint has generated the most HTTP error status codes.
ทำความสะอาด
Cleaning up the sample application infrastructure is a two-step process. First, to remove the infrastructure provisioned for the purposes of this demo, run the following command in the terminal:
For the following question, enter y and AWS CDK will delete the resources deployed for the demo:
Alternatively, you can remove the resources via the AWS CloudFormation console by navigating to the CdkStack stack and choosing ลบ.
The second step is to uninstall ADA. For instructions, refer to ถอนการติดตั้งโซลูชัน.
สรุป
In this post, we demonstrated how to use the ADA solution to derive insights from application logs stored across two different data sources. We demonstrated how to install ADA on an AWS account and deploy the demo components using AWS CDK. We created data products in ADA and configured the data products with the respective data sources using the ADA’s built-in data connectors. We demonstrated how to query the data products using standard SQL queries and generate insights on the log data. We also connected the Tableau Desktop client, a third-party BI product, to ADA and demonstrated how to build visualizations against the data products.
ADA automates the process of ingesting, transforming, governing, and querying diverse datasets and simplifying the lifecycle management of data. ADA’s pre-built connectors allow you to ingest data from diverse data sources. Software teams with basic knowledge of AWS products and services will be able to set up an operational data analytics platform in a few hours and provide secure access to the data. The data can then be easily and quickly queried using an intuitive and standalone web user interface.
Try out ADA today to easily manage and gain insights from data.
เกี่ยวกับผู้แต่ง
 อุปราจิตธาน ไวยานาธาน เป็น Principal Enterprise Solutions Architect ที่ AWS เขาสนับสนุนลูกค้าระดับองค์กรในการโยกย้ายและปรับปรุงปริมาณงานให้ทันสมัยบน AWS Cloud เขาเป็นสถาปนิกระบบคลาวด์ที่มีประสบการณ์มากกว่า 23 ปีในการออกแบบและพัฒนาระบบซอฟต์แวร์ระดับองค์กรขนาดใหญ่และแบบกระจาย เขาเชี่ยวชาญด้าน Machine Learning & Data Analytics โดยเน้นที่โดเมน Data and Feature Engineering เขาเป็นนักวิ่งมาราธอนที่มีความทะเยอทะยาน และงานอดิเรกของเขาคือการปีนเขา ขี่จักรยาน และใช้เวลากับภรรยาและลูกชายสองคน
อุปราจิตธาน ไวยานาธาน เป็น Principal Enterprise Solutions Architect ที่ AWS เขาสนับสนุนลูกค้าระดับองค์กรในการโยกย้ายและปรับปรุงปริมาณงานให้ทันสมัยบน AWS Cloud เขาเป็นสถาปนิกระบบคลาวด์ที่มีประสบการณ์มากกว่า 23 ปีในการออกแบบและพัฒนาระบบซอฟต์แวร์ระดับองค์กรขนาดใหญ่และแบบกระจาย เขาเชี่ยวชาญด้าน Machine Learning & Data Analytics โดยเน้นที่โดเมน Data and Feature Engineering เขาเป็นนักวิ่งมาราธอนที่มีความทะเยอทะยาน และงานอดิเรกของเขาคือการปีนเขา ขี่จักรยาน และใช้เวลากับภรรยาและลูกชายสองคน
 Rashim Rahman is a Software Developer based out of Sydney, Australia with 10+ years of experience in software development and architecture. He works primarily on building large scale open-source AWS solutions for common customer use cases and business problems. In his spare time, he enjoys sports and spending time with friends and family.
Rashim Rahman is a Software Developer based out of Sydney, Australia with 10+ years of experience in software development and architecture. He works primarily on building large scale open-source AWS solutions for common customer use cases and business problems. In his spare time, he enjoys sports and spending time with friends and family.
 Hafiz Saadullah is a Principal Technical Product Manager at Amazon Web Services. Hafiz focuses on AWS Solutions, designed to help customers by addressing common business problems and use cases.
Hafiz Saadullah is a Principal Technical Product Manager at Amazon Web Services. Hafiz focuses on AWS Solutions, designed to help customers by addressing common business problems and use cases.
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. ยานยนต์ / EVs, คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ChartPrime. ยกระดับเกมการซื้อขายของคุณด้วย ChartPrime เข้าถึงได้ที่นี่.
- BlockOffsets การปรับปรุงการเป็นเจ้าของออฟเซ็ตด้านสิ่งแวดล้อมให้ทันสมัย เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/derive-operational-insights-from-application-logs-using-automated-data-analytics-on-aws/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 10
- 11
- 12
- 14
- 15%
- 16
- 160
- 17
- 2021
- 3000
- 500
- 7
- 8
- 9
- a
- ความสามารถ
- สามารถ
- เกี่ยวกับเรา
- เข้า
- Accessed
- สามารถเข้าถึงได้
- ลงชื่อเข้าใช้
- ข้าม
- การปฏิบัติ
- ADA
- เพิ่ม
- นอกจากนี้
- เพิ่มเติม
- ที่อยู่
- ผู้ดูแลระบบ
- หลังจาก
- กับ
- ทั้งหมด
- อนุญาต
- ช่วยให้
- ตาม
- ด้วย
- ทางเลือก
- อเมซอน
- Amazon Web Services
- ในหมู่
- an
- การวิเคราะห์
- นักวิเคราะห์
- การวิเคราะห์
- วิเคราะห์
- และ
- อื่น
- ใด
- อาปาเช่
- API
- APIs
- การใช้งาน
- การใช้งาน
- ประยุกต์
- ใช้
- การประยุกต์ใช้
- สถาปัตยกรรม
- เป็น
- AS
- ที่ต้องการ
- At
- แอตทริบิวต์
- ออสเตรเลีย
- การยืนยันตัวตน
- มีอำนาจ
- อัตโนมัติ
- โดยอัตโนมัติ
- อัตโนมัติ
- ใช้ได้
- AWS
- การก่อตัวของ AWS Cloud
- กลับ
- แบ็กเอนด์
- บาร์
- ตาม
- ขั้นพื้นฐาน
- BE
- เพราะ
- รับ
- ก่อน
- bespoke
- ระหว่าง
- ทั้งสอง
- กล่อง
- สร้าง
- การก่อสร้าง
- built-in
- ธุรกิจ
- ระบบธุรกิจอัจฉริยะ
- แต่
- by
- โทรศัพท์
- CAN
- ความสามารถ
- กรณี
- กรณี
- แค็ตตาล็อก
- CD
- เปลี่ยนแปลง
- แผนภูมิ
- ชาร์ต
- Choose
- เลือก
- ไคลเอนต์
- เมฆ
- รหัส
- รหัส
- ชุด
- คอลัมน์
- คอลัมน์
- ร่วมกัน
- สมบูรณ์
- ส่วนประกอบ
- องค์ประกอบ
- การกำหนดค่า
- เชื่อมต่อ
- งานที่เชื่อมต่อ
- การเชื่อมต่อ
- เชื่อมต่อ
- พิจารณา
- คงเส้นคงวา
- ปลอบใจ
- มี
- ต่อ
- มีความสัมพันธ์
- ความสัมพันธ์
- ตรงกัน
- สอดคล้อง
- ราคา
- สร้าง
- ที่สร้างขึ้น
- สร้าง
- การสร้าง
- หนังสือรับรอง
- ปัจจุบัน
- ประเพณี
- ลูกค้า
- ลูกค้า
- หน้าปัด
- ข้อมูล
- วิเคราะห์ข้อมูล
- การประมวลผล
- ฐานข้อมูล
- ฐานข้อมูล
- ชุดข้อมูล
- ค่าเริ่มต้น
- ความต้องการ
- ทดลอง
- สาธิต
- แสดงให้เห็นถึง
- ทั้งนี้ขึ้นอยู่กับ
- ปรับใช้
- นำไปใช้
- การใช้งาน
- Deploys
- ลักษณะ
- ได้รับการออกแบบ
- การออกแบบ
- เดสก์ท็อป
- รายละเอียด
- รายละเอียด
- ผู้พัฒนา
- ที่กำลังพัฒนา
- พัฒนาการ
- การวินิจฉัยโรค
- ต่าง
- โดยตรง
- พิการ
- การค้นพบ
- แสดง
- กระจาย
- หลาย
- ไม่
- โดเมน
- โดเมน
- Dont
- ปรับตัวลดลง
- ในระหว่าง
- แต่ละ
- ก่อน
- อย่างง่ายดาย
- การแก้ไข
- ทั้ง
- อีเมล
- เปิดการใช้งาน
- ช่วยให้
- ปลายทาง
- ปลายทาง
- ชั้นเยี่ยม
- ทำให้มั่นใจ
- เข้าสู่
- Enterprise
- ลูกค้าองค์กร
- โซลูชั่นองค์กร
- ความผิดพลาด
- ข้อผิดพลาด
- สร้าง
- ที่จัดตั้งขึ้น
- อีเธอร์ (ETH)
- ตัวอย่าง
- ที่มีอยู่
- ประสบการณ์
- อธิบาย
- คำอธิบาย
- สารสกัด
- ดึงข้อมูล
- คุ้นเคย
- ครอบครัว
- ลักษณะ
- สองสาม
- สนาม
- สาขา
- รูป
- เนื้อไม่มีมัน
- ไฟล์
- สุดท้าย
- เงินทุน
- ชื่อจริง
- มีความยืดหยุ่น
- โฟกัส
- มุ่งเน้นไปที่
- ดังต่อไปนี้
- สำหรับ
- รูป
- สี่
- เวลา
- เพื่อน
- ราคาเริ่มต้นที่
- ฟังก์ชัน
- ได้รับ
- สร้าง
- สร้าง
- ได้รับ
- ได้รับ
- การปกครอง
- บัญชีกลุ่ม
- กลุ่ม
- มี
- มี
- he
- ช่วย
- ไฮไลต์
- การธุดงค์
- ของเขา
- ทางประวัติศาสตร์
- งานอดิเรก
- เป็นเจ้าภาพ
- ชั่วโมง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTML
- ที่ http
- HTTPS
- AMI
- identiques
- แยกแยะ
- เอกลักษณ์
- if
- นำเข้า
- in
- ประกอบด้วย
- รวมถึง
- รวมทั้ง
- ข้อมูล
- โครงสร้างพื้นฐาน
- แรกเริ่ม
- ข้อมูลเชิงลึก
- ติดตั้ง
- การติดตั้ง
- คำแนะนำการใช้
- แบบบูรณาการ
- บูรณาการ
- Intelligence
- การโต้ตอบ
- สนใจ
- อินเตอร์เฟซ
- เข้าไป
- ใช้งานง่าย
- จะเรียก
- ร่วมมือ
- ปัญหา
- IT
- ร่วม
- การร่วม
- ร่วม
- jpg
- JSON
- เพียงแค่
- เก็บ
- คีย์
- ความรู้
- ภาษา
- ใหญ่
- ขนาดใหญ่
- ชื่อสกุล
- ต่อมา
- การเปิดตัว
- การเรียนรู้
- ห้องสมุด
- ได้รับใบอนุญาต
- วงจรชีวิต
- กดไลก์
- LIMIT
- Line
- รายการ
- สด
- เข้าสู่ระบบ
- การเข้าสู่ระบบ
- นาน
- ดู
- ค้นหา
- เครื่อง
- เรียนรู้เครื่อง
- ทำ
- การทำ
- จัดการ
- การจัดการ
- ผู้จัดการ
- หลาย
- แผนที่
- การทำแผนที่
- มาราธอน
- การตลาด
- เรื่อง
- มีความหมาย
- ข่าวสาร
- ไอ้เวรตะไล
- อาจ
- อพยพ
- นาที
- โหมด
- ทันสมัย
- ข้อมูลเพิ่มเติม
- มากที่สุด
- ส่วนใหญ่
- Mozilla
- การตรวจสอบหลายปัจจัย
- MySQL
- ชื่อ
- ที่มีชื่อ
- ชื่อ
- พื้นเมือง
- นำทาง
- การนำทาง
- การเดินเรือ
- จำเป็นต้อง
- จำเป็น
- ความต้องการ
- ใหม่
- ใหม่
- ถัดไป
- จำนวน
- of
- เสนอ
- ออฟไลน์
- เก่า
- on
- ตามความต้องการ
- ONE
- ออนไลน์
- เพียง
- เปิด
- โอเพนซอร์ส
- การดำเนินงาน
- ตัวเลือกเสริม (Option)
- or
- ใบสั่ง
- อื่นๆ
- ผลิตภัณฑ์อื่นๆ
- ออก
- เอาท์พุต
- ภาพรวม
- หน้า
- บานหน้าต่าง
- รหัสผ่าน
- เส้นทาง
- แบบแผน
- ดำเนินการ
- สิทธิ์
- ส่วนตัว
- โทรศัพท์
- PII
- ท่อ
- สถานที่
- ที่ราบ
- แผนการ
- เวที
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- นโยบาย
- พอร์ทัล
- โพสต์
- postgresql
- ขับเคลื่อน
- เตรียมการ
- เตรียมความพร้อม
- ข้อกำหนดเบื้องต้น
- นำเสนอ
- นำเสนอ
- ดูตัวอย่าง
- ก่อน
- ส่วนใหญ่
- หลัก
- ก่อน
- ปัญหาที่เกิดขึ้น
- ดำเนิน
- กระบวนการ
- การประมวลผล
- กระบวนการ
- การประมวลผล
- ผลิต
- ผลิตภัณฑ์
- ผู้จัดการผลิตภัณฑ์
- ผลิตภัณฑ์
- สินค้าและบริการ
- โปรแกรม
- โครงการ
- ให้
- ให้
- ผู้จัดหา
- ให้
- วัตถุประสงค์
- วัตถุประสงค์
- หลาม
- คำสั่ง
- คำถาม
- อย่างรวดเร็ว
- พิสัย
- อ่าน
- พร้อม
- รับ
- บันทึก
- เรียกว่า
- ภูมิภาค
- ความสัมพันธ์
- ตรงประเด็น
- เอาออก
- ทำซ้ำ
- รายงาน
- ขอ
- จำเป็นต้องใช้
- แหล่งข้อมูล
- ว่า
- การตอบสนอง
- ผลสอบ
- รักษา
- ทบทวน
- การขี่
- บทบาท
- ราก
- กฎ
- วิ่ง
- ทางวิ่ง
- วิ่ง
- ขาย
- เดียวกัน
- ลด
- ขนาด
- สถานการณ์
- ที่กำหนดไว้
- ขอบเขต
- ค้นหา
- ที่สอง
- Section
- ปลอดภัย
- ความปลอดภัย
- เห็น
- เลือก
- การเลือก
- ส่ง
- ส่ง
- แยก
- ให้บริการ
- serverless
- บริการ
- บริการ
- ชุด
- การตั้งค่า
- Share
- ที่ใช้ร่วมกัน
- สั้น
- แสดง
- แสดงให้เห็นว่า
- ง่าย
- ที่เรียบง่าย
- ลดความซับซ้อน
- ขนาด
- ทักษะ
- So
- ซอฟต์แวร์
- การพัฒนาซอฟต์แวร์
- ทางออก
- โซลูชัน
- แหล่ง
- แหล่งที่มา
- ผู้เชี่ยวชาญ
- ความเชี่ยวชาญ
- โดยเฉพาะ
- ที่ระบุไว้
- การใช้จ่าย
- กีฬา
- SQL
- กอง
- สแตนด์อโลน
- มาตรฐาน
- เริ่มต้น
- เริ่มต้น
- Status
- ขั้นตอน
- ขั้นตอน
- การเก็บรักษา
- เก็บไว้
- เชือก
- โครงสร้าง
- ที่ประสบความสำเร็จ
- ประสบความสำเร็จ
- อย่างเช่น
- รองรับ
- แน่ใจ
- ซิดนีย์
- ระบบ
- ตาราง
- ฉาก
- เอา
- ใช้เวลา
- ทีม
- ทีม
- วิชาการ
- ทักษะทางเทคนิค
- สถานีปลายทาง
- ที่
- พื้นที่
- ที่มา
- ของพวกเขา
- แล้วก็
- ที่นั่น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- ของบุคคลที่สาม
- นี้
- สาม
- ตลอด
- เวลา
- ไปยัง
- ในวันนี้
- เครื่องมือ
- ด้านบน
- สูงสุด 10
- รวม
- แปลง
- การแปลง
- การแปลง
- เปลี่ยน
- การเปลี่ยนแปลง
- การแปลง
- ทริกเกอร์
- สอง
- ชนิด
- ชนิด
- ภายใต้
- พื้นฐาน
- เข้าใจ
- ให้กับคุณ
- การปรับปรุง
- เมื่อ
- URI
- us
- ใช้
- ใช้กรณี
- มือสอง
- ผู้ใช้งาน
- ส่วนติดต่อผู้ใช้
- ผู้ใช้
- การใช้
- ความคุ้มค่า
- ตัวแปร
- ความหลากหลาย
- รุ่น
- ผ่านทาง
- รายละเอียด
- ต้องการ
- ทาง..
- we
- เว็บ
- บริการเว็บ
- ดี
- เมื่อ
- ที่
- ในขณะที่
- กว้าง
- ช่วงกว้าง
- ภรรยา
- จะ
- กับ
- ภายใน
- ไม่มี
- งาน
- เวิร์กโฟลว์
- โรงงาน
- จะ
- เขียน
- ปี
- เธอ
- ของคุณ
- ลมทะเล