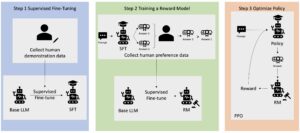
นี่คือโพสต์ร่วมที่เขียนร่วมกันโดย AWS และ Voxel51 Voxel51 เป็นบริษัทที่อยู่เบื้องหลัง FiftyOne ซึ่งเป็นชุดเครื่องมือโอเพ่นซอร์สสำหรับการสร้างชุดข้อมูลคุณภาพสูงและโมเดลการมองเห็นด้วยคอมพิวเตอร์
บริษัทค้าปลีกแห่งหนึ่งกำลังสร้างแอปบนอุปกรณ์เคลื่อนที่เพื่อช่วยลูกค้าซื้อเสื้อผ้า ในการสร้างแอปนี้ พวกเขาต้องการชุดข้อมูลคุณภาพสูงที่มีรูปภาพเสื้อผ้า ซึ่งมีป้ายกำกับตามหมวดหมู่ต่างๆ ในโพสต์นี้ เราจะแสดงวิธีการเปลี่ยนวัตถุประสงค์ของชุดข้อมูลที่มีอยู่ผ่านการล้างข้อมูล การประมวลผลล่วงหน้า และการติดฉลากล่วงหน้าด้วยโมเดลการจัดประเภทแบบ Zero-shot ใน ห้าสิบเอ็ดและปรับป้ายกำกับเหล่านี้ด้วย ความจริงของ Amazon SageMaker.
คุณสามารถใช้ Ground Truth และ FiftyOne เพื่อเร่งโครงการติดฉลากข้อมูลของคุณ เราแสดงวิธีใช้แอปพลิเคชันทั้งสองอย่างราบรื่นร่วมกันเพื่อสร้างชุดข้อมูลที่มีป้ายกำกับคุณภาพสูง สำหรับกรณีการใช้งานตัวอย่างของเรา เราทำงานร่วมกับ ชุดข้อมูล Fashion200Kเปิดตัวที่ ICCV 2017
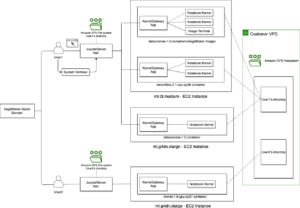
ภาพรวมโซลูชัน
Ground Truth คือบริการจัดการฉลากข้อมูลแบบบริการตนเองและจัดการโดยสมบูรณ์ ซึ่งช่วยให้นักวิทยาศาสตร์ข้อมูล วิศวกรแมชชีนเลิร์นนิง (ML) และนักวิจัยสามารถสร้างชุดข้อมูลคุณภาพสูงได้ ห้าสิบเอ็ด by วอกเซล 51 เป็นชุดเครื่องมือโอเพ่นซอร์สสำหรับการดูแลจัดการ แสดงภาพ และประเมินชุดข้อมูลการมองเห็นด้วยคอมพิวเตอร์ เพื่อให้คุณสามารถฝึกฝนและวิเคราะห์โมเดลที่ดีขึ้นโดยเร่งกรณีการใช้งานของคุณ
ในส่วนต่อไปนี้ เราสาธิตวิธีดำเนินการต่อไปนี้:
- เห็นภาพชุดข้อมูลใน FiftyOne
- ทำความสะอาดชุดข้อมูลด้วยการกรองและการขจัดข้อมูลซ้ำซ้อนใน FiftyOne
- ติดฉลากล่วงหน้าข้อมูลที่สะอาดด้วยการจัดประเภทแบบ Zero-shot ใน FiftyOne
- ติดป้ายกำกับชุดข้อมูลที่รวบรวมไว้ขนาดเล็กกว่าด้วย Ground Truth
- ใส่ผลลัพธ์ที่มีป้ายกำกับจาก Ground Truth ลงใน FiftyOne และตรวจสอบผลลัพธ์ที่มีป้ายกำกับใน FiftyOne
ภาพรวมกรณีใช้งาน
สมมติว่าคุณเป็นเจ้าของบริษัทค้าปลีกและต้องการสร้างแอปพลิเคชันมือถือเพื่อให้คำแนะนำส่วนบุคคลเพื่อช่วยให้ผู้ใช้ตัดสินใจว่าจะสวมใส่อะไร ผู้ใช้ที่คาดหวังของคุณกำลังมองหาแอปพลิเคชันที่บอกว่าเสื้อผ้าชิ้นใดในตู้เสื้อผ้าของพวกเขาเข้ากันได้ดี คุณเห็นโอกาสที่นี่: หากคุณสามารถระบุเครื่องแต่งกายที่ดีได้ คุณสามารถใช้สิ่งนี้เพื่อแนะนำบทความใหม่ๆ เกี่ยวกับเสื้อผ้าที่เสริมเสื้อผ้าที่ลูกค้ามีอยู่แล้ว
คุณต้องการทำสิ่งต่าง ๆ ให้ง่ายที่สุดสำหรับผู้ใช้ปลายทาง ตามหลักการแล้ว คนที่ใช้แอปพลิเคชันของคุณจะต้องถ่ายภาพเสื้อผ้าในตู้เสื้อผ้าของตนเท่านั้น และนางแบบ ML ของคุณจะใช้เวทมนตร์อยู่เบื้องหลัง คุณอาจฝึกโมเดลสำหรับวัตถุประสงค์ทั่วไปหรือปรับแต่งโมเดลให้เหมาะกับสไตล์เฉพาะของผู้ใช้แต่ละคนด้วยความคิดเห็นบางรูปแบบ
อย่างไรก็ตาม ขั้นแรก คุณต้องระบุว่าผู้ใช้กำลังถ่ายภาพเสื้อผ้าประเภทใด มันเป็นเสื้อ? คู่ของกางเกง? หรืออย่างอื่น? ท้ายที่สุด คุณคงไม่อยากแนะนำชุดที่มีเดรสหลายตัวหรือหมวกหลายใบ
ในการรับมือกับความท้าทายเบื้องต้นนี้ คุณต้องการสร้างชุดข้อมูลการฝึกอบรมซึ่งประกอบด้วยรูปภาพของเสื้อผ้าประเภทต่างๆ ที่มีรูปแบบและสไตล์ต่างๆ หากต้องการสร้างต้นแบบด้วยงบประมาณที่จำกัด คุณต้องการเริ่มต้นระบบโดยใช้ชุดข้อมูลที่มีอยู่
เพื่อแสดงให้เห็นและนำคุณสู่ขั้นตอนต่างๆ ในโพสต์นี้ เราใช้ชุดข้อมูล Fashion200K ที่เผยแพร่ที่ ICCV 2017 ซึ่งเป็นชุดข้อมูลที่สร้างขึ้นและได้รับการอ้างถึงอย่างดี แต่ไม่เหมาะกับกรณีการใช้งานของคุณโดยตรง
แม้ว่าบทความเกี่ยวกับเสื้อผ้าจะมีป้ายกำกับเป็นหมวดหมู่ (และหมวดหมู่ย่อย) และมีแท็กที่เป็นประโยชน์มากมายซึ่งดึงมาจากคำอธิบายผลิตภัณฑ์ดั้งเดิม แต่ข้อมูลดังกล่าวไม่ได้ติดป้ายกำกับอย่างเป็นระบบด้วยข้อมูลรูปแบบหรือสไตล์ เป้าหมายของคุณคือเปลี่ยนชุดข้อมูลที่มีอยู่นี้เป็นชุดข้อมูลการฝึกอบรมที่มีประสิทธิภาพสำหรับโมเดลการจัดประเภทเสื้อผ้าของคุณ คุณต้องล้างข้อมูล โดยเพิ่มสคีมาฉลากด้วยสไตล์เลเบล และคุณต้องการดำเนินการอย่างรวดเร็วและใช้จ่ายให้น้อยที่สุดเท่าที่จะเป็นไปได้
ดาวน์โหลดข้อมูลในเครื่อง
ขั้นแรก ให้ดาวน์โหลดไฟล์ zip ของ women.tar และโฟลเดอร์ป้ายกำกับ (พร้อมโฟลเดอร์ย่อยทั้งหมด) ตามคำแนะนำที่ให้ไว้ใน ที่เก็บ GitHub ชุดข้อมูล Fashion200K. หลังจากที่คุณแตกไฟล์ทั้งสองแล้ว ให้สร้างไดเร็กทอรีหลัก fashion200k และย้ายป้ายกำกับและโฟลเดอร์ women ไปไว้ที่นี่ โชคดีที่รูปภาพเหล่านี้ถูกครอบตัดไปยังกรอบขอบเขตการตรวจจับวัตถุแล้ว ดังนั้น เราจึงสามารถมุ่งเน้นไปที่การจัดประเภท แทนที่จะกังวลเกี่ยวกับการตรวจจับวัตถุ
แม้จะมีชื่อเล่นว่า “200K” แต่ไดเร็กทอรีผู้หญิงที่เราดึงข้อมูลออกมามีรูปภาพ 338,339 ภาพ ในการสร้างชุดข้อมูล Fashion200K อย่างเป็นทางการ ผู้เขียนชุดข้อมูลรวบรวมข้อมูลผลิตภัณฑ์มากกว่า 300,000 รายการทางออนไลน์ และเฉพาะผลิตภัณฑ์ที่มีคำอธิบายที่มีมากกว่าสี่คำเท่านั้นที่ตัดออก เพื่อจุดประสงค์ของเรา โดยที่คำอธิบายผลิตภัณฑ์ไม่จำเป็น เราสามารถใช้รูปภาพที่รวบรวมข้อมูลทั้งหมดได้
ลองดูวิธีการจัดระเบียบข้อมูลนี้: ภายในโฟลเดอร์ผู้หญิง รูปภาพจะถูกจัดเรียงตามประเภทบทความระดับบนสุด (กระโปรง เสื้อ กางเกง แจ็กเก็ต และเดรส) และหมวดหมู่ย่อยของประเภทบทความ (เสื้อเบลาส์ เสื้อยืด แขนยาว ท็อปส์ซู).
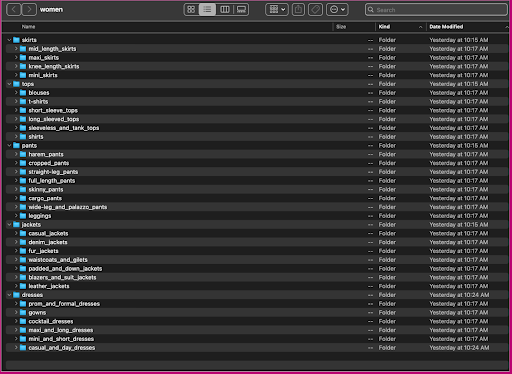
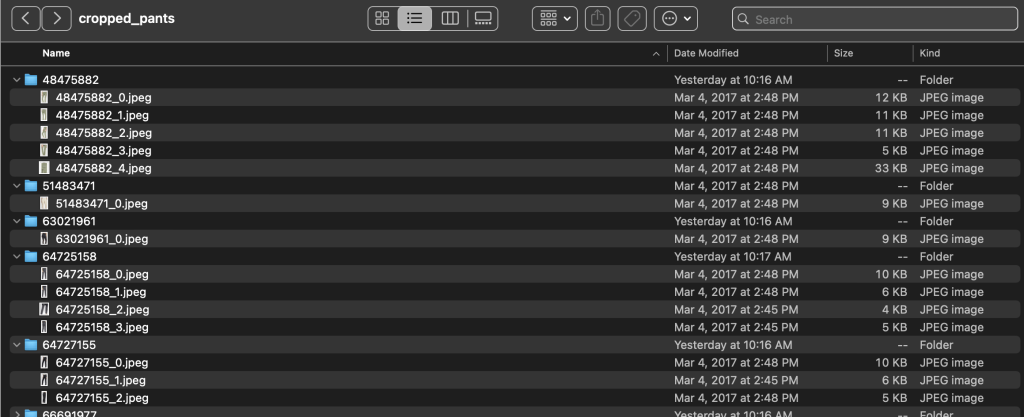
ภายในไดเร็กทอรีหมวดหมู่ย่อย จะมีไดเร็กทอรีย่อยสำหรับรายการสินค้าแต่ละรายการ แต่ละสิ่งเหล่านี้มีจำนวนภาพที่ผันแปร ตัวอย่างเช่น หมวดหมู่ย่อย cropped_pants มีรายการผลิตภัณฑ์ต่อไปนี้และรูปภาพที่เกี่ยวข้อง
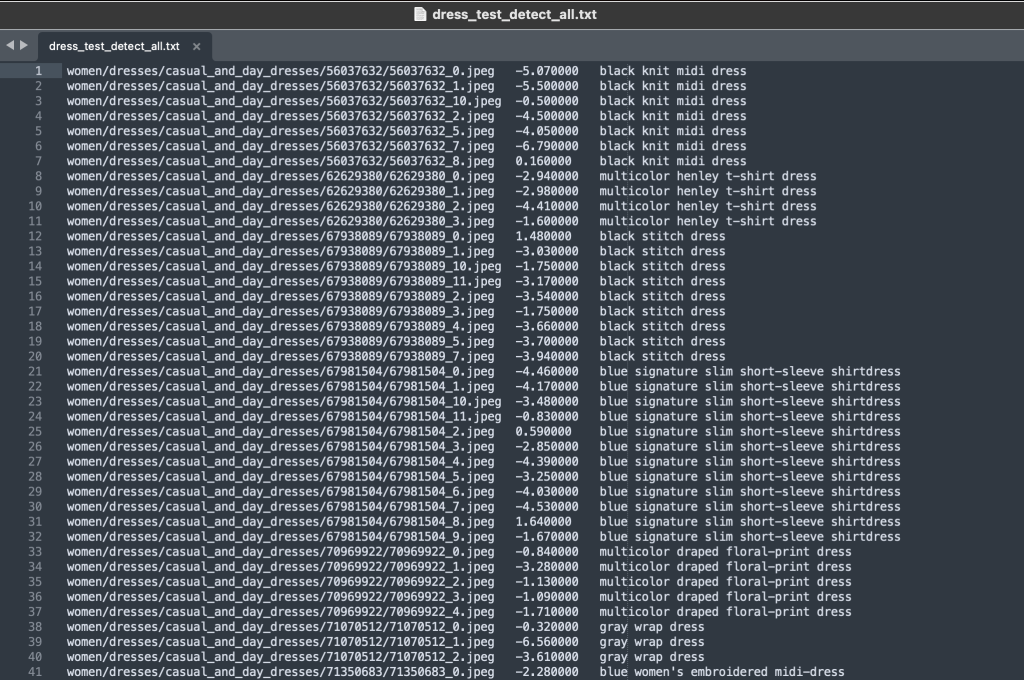
โฟลเดอร์ป้ายกำกับมีไฟล์ข้อความสำหรับบทความระดับบนสุดแต่ละประเภท สำหรับทั้งการฝึกและการทดสอบ ภายในแต่ละไฟล์ข้อความเหล่านี้มีบรรทัดแยกต่างหากสำหรับแต่ละภาพ ซึ่งระบุเส้นทางไฟล์ที่เกี่ยวข้อง คะแนน และแท็กจากรายละเอียดสินค้า
เนื่องจากเรากำลังเปลี่ยนชุดข้อมูลใหม่ เราจึงรวมภาพรถไฟและภาพทดสอบทั้งหมดเข้าด้วยกัน เราใช้สิ่งเหล่านี้เพื่อสร้างชุดข้อมูลเฉพาะแอปพลิเคชันคุณภาพสูง หลังจากที่เราทำขั้นตอนนี้เสร็จแล้ว เราสามารถสุ่มแยกชุดข้อมูลผลลัพธ์ออกเป็นชุดฝึกใหม่และชุดทดสอบ
ใส่ ดู และจัดการชุดข้อมูลใน FiftyOne
หากคุณยังไม่ได้ติดตั้ง ให้ติดตั้งโอเพ่นซอร์ส FiftyOne โดยใช้ pip:
แนวทางปฏิบัติที่ดีที่สุดคือการทำเช่นนั้นในสภาพแวดล้อมเสมือนใหม่ (venv หรือ conda) จากนั้นนำเข้าโมดูลที่เกี่ยวข้อง นำเข้าไลบรารีฐาน, ห้าสิบเอ็ด, FiftyOne Brain ซึ่งมีเมธอด ML ในตัว, FiftyOne Zoo ซึ่งเราจะโหลดโมเดลที่จะสร้างป้ายกำกับแบบ zero-shot สำหรับเรา และ ViewField ซึ่งช่วยให้เรากรองได้อย่างมีประสิทธิภาพ ข้อมูลในชุดข้อมูลของเรา:
คุณต้องการนำเข้าโมดูล glob และ os Python ซึ่งจะช่วยให้เราทำงานกับเส้นทางและรูปแบบที่ตรงกันในเนื้อหาไดเร็กทอรี:
ตอนนี้เราพร้อมที่จะโหลดชุดข้อมูลลงใน FiftyOne แล้ว ขั้นแรก เราสร้างชุดข้อมูลที่ชื่อ fashion200k และทำให้มันคงอยู่ ซึ่งช่วยให้เราสามารถบันทึกผลลัพธ์ของการดำเนินการที่ต้องใช้การคำนวณมาก ดังนั้น เราจำเป็นต้องคำนวณปริมาณดังกล่าวเพียงครั้งเดียว
ขณะนี้เราสามารถวนซ้ำผ่านไดเร็กทอรีหมวดหมู่ย่อยทั้งหมด โดยเพิ่มรูปภาพทั้งหมดภายในไดเร็กทอรีผลิตภัณฑ์ เราเพิ่มป้ายกำกับการจัดหมวดหมู่ FiftyOne ให้กับแต่ละตัวอย่างด้วยชื่อช่อง article_type ซึ่งบรรจุตามหมวดหมู่บทความระดับบนสุดของรูปภาพ เรายังเพิ่มทั้งข้อมูลหมวดหมู่และหมวดหมู่ย่อยเป็นแท็ก:
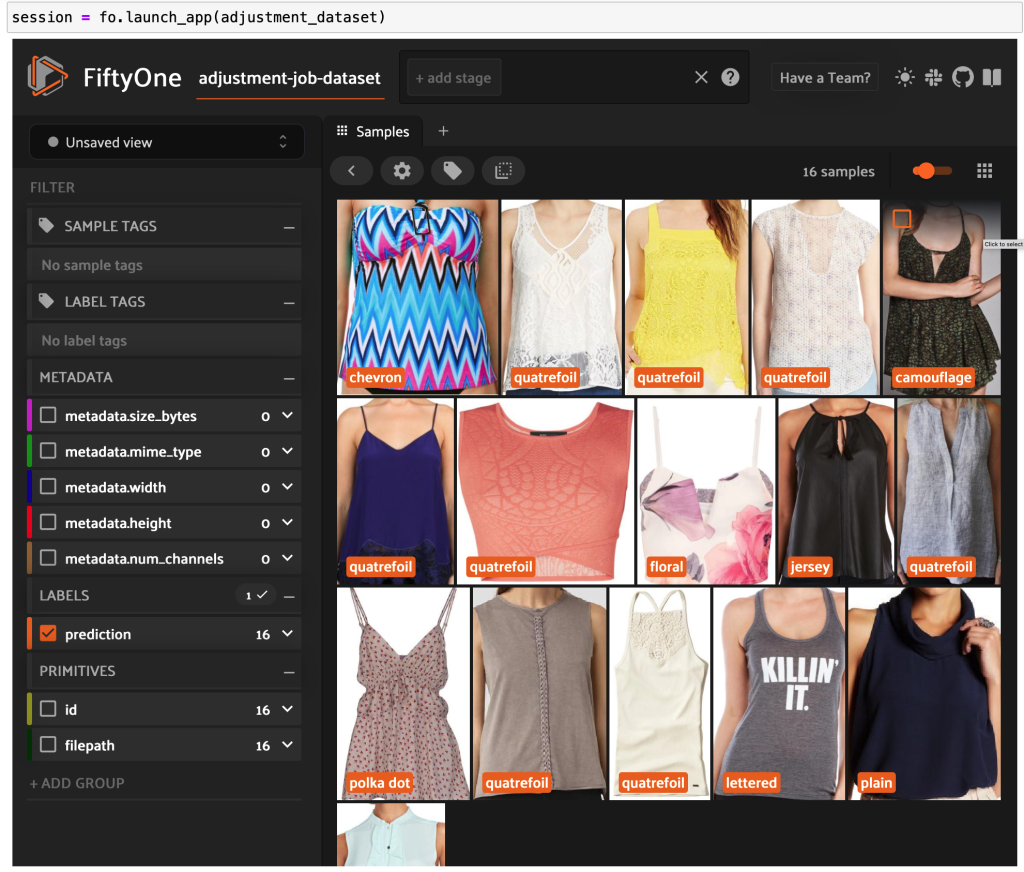
ณ จุดนี้ เราสามารถแสดงภาพชุดข้อมูลของเราในแอป FiftyOne โดยเปิดใช้เซสชัน:
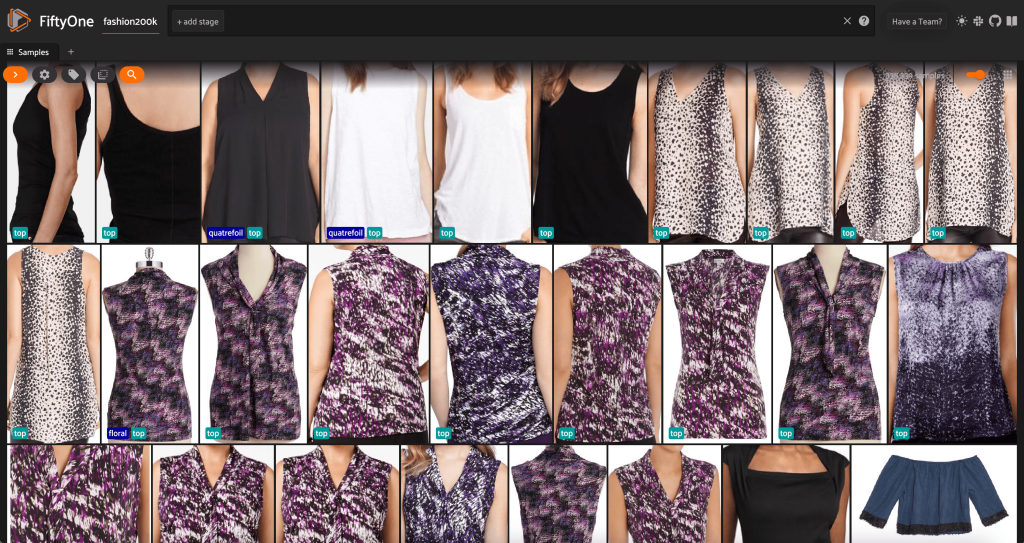
เรายังสามารถพิมพ์สรุปชุดข้อมูลใน Python ได้ด้วยการเรียกใช้ print(dataset):
เรายังสามารถเพิ่มแท็กจาก labels ไดเรกทอรีไปยังตัวอย่างในชุดข้อมูลของเรา:
เมื่อดูข้อมูล มีบางสิ่งที่ชัดเจน:
- ภาพบางภาพค่อนข้างหยาบและมีความละเอียดต่ำ อาจเป็นเพราะภาพเหล่านี้สร้างขึ้นโดยการครอบตัดภาพเริ่มต้นในกล่องขอบเขตการตรวจหาวัตถุ
- เสื้อผ้าบางชิ้นสวมใส่โดยบุคคลและบางส่วนถูกถ่ายภาพด้วยตัวเอง รายละเอียดเหล่านี้สรุปโดย
viewpointคุณสมบัติ - รูปภาพจำนวนมากของผลิตภัณฑ์ชนิดเดียวกันมีความคล้ายคลึงกันมาก ดังนั้นอย่างน้อยในขั้นต้น การรวมรูปภาพมากกว่าหนึ่งรูปต่อผลิตภัณฑ์หนึ่งรายการอาจไม่เพิ่มพลังในการคาดเดามากนัก ส่วนใหญ่แล้ว ภาพแรกของแต่ละผลิตภัณฑ์ (ลงท้ายด้วย
_0.jpeg) สะอาดที่สุด
ในขั้นต้น เราอาจต้องการฝึกแบบจำลองการจัดประเภทเสื้อผ้าของเราบนชุดย่อยที่มีการควบคุมของรูปภาพเหล่านี้ ด้วยเหตุนี้ เราจึงใช้ภาพความละเอียดสูงของผลิตภัณฑ์ของเรา และจำกัดมุมมองของเราไว้เพียงหนึ่งตัวอย่างต่อหนึ่งผลิตภัณฑ์
ขั้นแรก เรากรองภาพที่มีความละเอียดต่ำออก เราใช้ compute_metadata() วิธีคำนวณและจัดเก็บความกว้างและความสูงของภาพเป็นพิกเซลสำหรับแต่ละภาพในชุดข้อมูล จากนั้นเราก็จ้าง FiftyOne ViewField เพื่อกรองภาพตามค่าความกว้างและความสูงขั้นต่ำที่อนุญาต ดูรหัสต่อไปนี้:
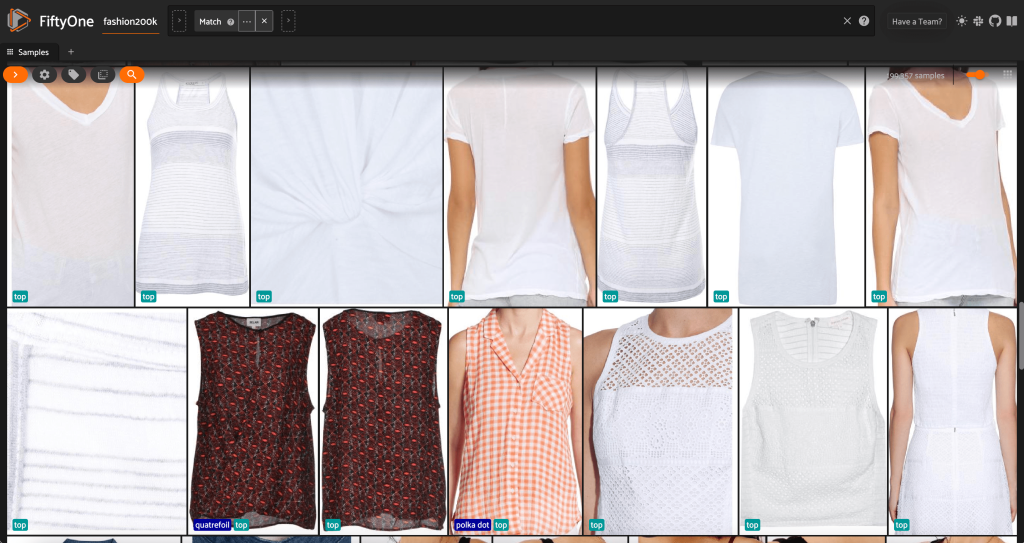
ชุดย่อยความละเอียดสูงนี้มีตัวอย่างน้อยกว่า 200,000 ตัวอย่าง
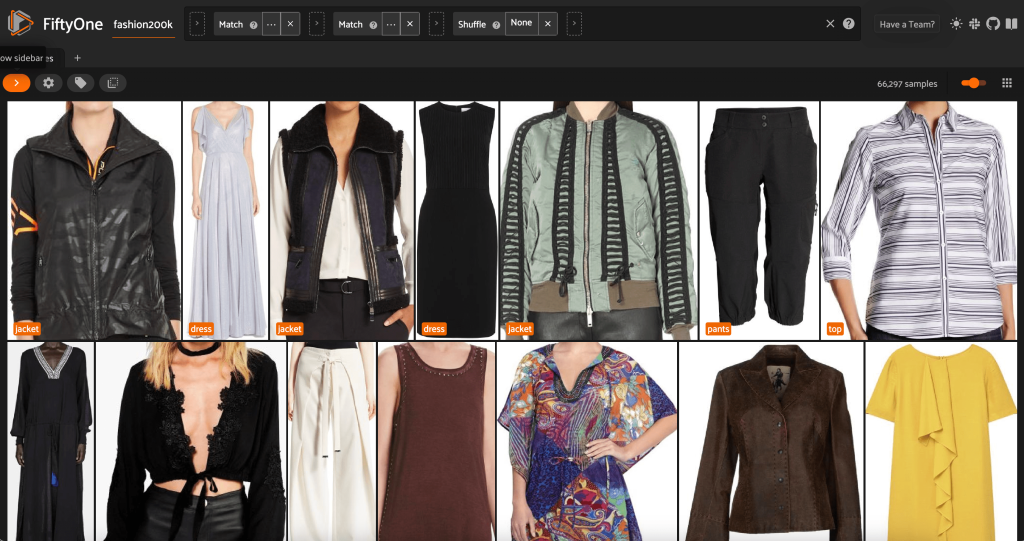
จากมุมมองนี้ เราสามารถสร้างมุมมองใหม่ในชุดข้อมูลของเราที่มีตัวอย่างตัวแทนเพียงหนึ่งตัวอย่าง (มากที่สุด) สำหรับแต่ละผลิตภัณฑ์ เราใช้ ViewField อีกครั้ง การจับคู่รูปแบบสำหรับเส้นทางไฟล์ที่ลงท้ายด้วย _0.jpeg:
มาดูการเรียงลำดับภาพแบบสุ่มในชุดย่อยนี้:
ลบภาพที่ซ้ำซ้อนในชุดข้อมูล
มุมมองนี้มีรูปภาพ 66,297 รูป หรือมากกว่า 19% ของชุดข้อมูลดั้งเดิม แต่เมื่อเราดูในมุมมองเราจะเห็นว่ามีผลิตภัณฑ์ที่คล้ายกันมาก การเก็บสำเนาทั้งหมดเหล่านี้มีแนวโน้มที่จะเพิ่มต้นทุนให้กับการติดฉลากและการฝึกอบรมแบบจำลองของเราเท่านั้น โดยไม่ได้ปรับปรุงประสิทธิภาพอย่างเห็นได้ชัด เรามากำจัดข้อมูลที่ซ้ำกันออกไปเพื่อสร้างชุดข้อมูลที่มีขนาดเล็กลงซึ่งยังคงอัดแน่นไปด้วยสิ่งเดียวกัน
เนื่องจากรูปภาพเหล่านี้ไม่ได้ซ้ำกันทั้งหมด เราจึงไม่สามารถตรวจสอบความเท่าเทียมกันของพิกเซลได้ โชคดีที่เราสามารถใช้ FiftyOne Brain เพื่อช่วยเราทำความสะอาดชุดข้อมูลของเรา โดยเฉพาะอย่างยิ่ง เราจะคำนวณการฝังสำหรับแต่ละภาพ ซึ่งเป็นเวกเตอร์ที่มีมิติต่ำกว่าซึ่งเป็นตัวแทนของภาพ จากนั้นมองหาภาพที่เวกเตอร์ฝังอยู่ใกล้กัน ยิ่งเวกเตอร์อยู่ใกล้กันมากเท่าใด ภาพก็จะยิ่งคล้ายกันมากขึ้นเท่านั้น
เราใช้โมเดล CLIP เพื่อสร้างเวกเตอร์การฝัง 512 มิติสำหรับแต่ละภาพ และจัดเก็บการฝังเหล่านี้ในฟิลด์การฝังบนตัวอย่างในชุดข้อมูลของเรา:
จากนั้นเราจะคำนวณความใกล้ชิดระหว่างการฝังโดยใช้ ความคล้ายคลึงของโคไซน์และยืนยันว่าเวกเตอร์สองตัวใด ๆ ที่มีความคล้ายคลึงกันมากกว่าเกณฑ์บางอย่างมีแนวโน้มที่จะใกล้เคียงกัน คะแนนความคล้ายคลึงกันของโคไซน์อยู่ในช่วง [0, 1] และเมื่อดูข้อมูลแล้ว คะแนนเกณฑ์ของ thresh=0.5 ดูเหมือนจะถูกต้อง ย้ำอีกครั้งว่าสิ่งนี้ไม่จำเป็นต้องสมบูรณ์แบบ รูปภาพที่เกือบจะซ้ำกันสองสามภาพไม่น่าจะทำลายความสามารถในการคาดการณ์ของเรา และการทิ้งรูปภาพที่ไม่ซ้ำสองสามภาพออกไปจะไม่ส่งผลกระทบอย่างมีนัยสำคัญต่อประสิทธิภาพของโมเดล
เราสามารถดูสำเนาที่อ้างว่าอ้างว่าซ้ำซ้อนจริง ๆ ได้:
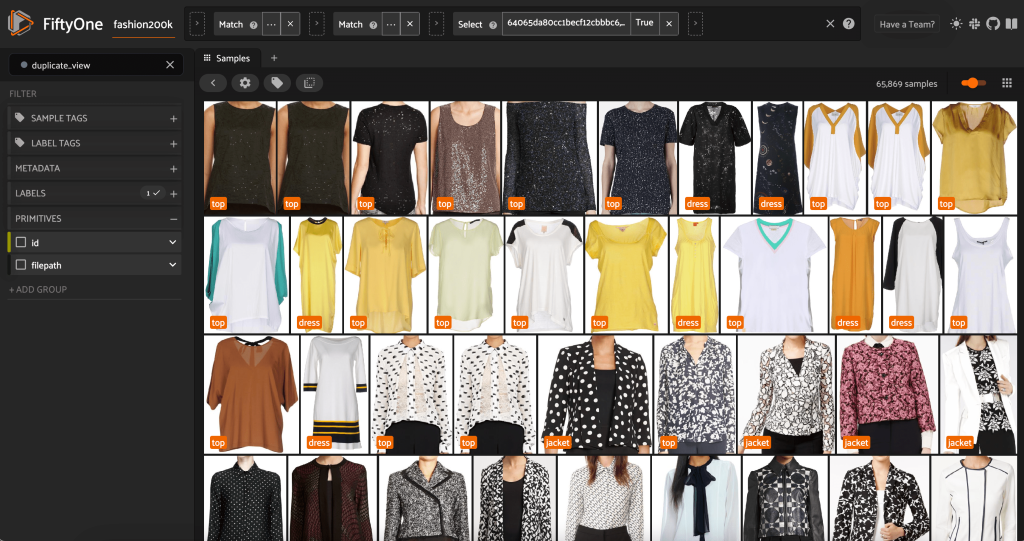
เมื่อเราพอใจกับผลลัพธ์และเชื่อว่าภาพเหล่านี้เกือบจะซ้ำกันจริงๆ เราสามารถเลือกตัวอย่างหนึ่งชุดจากตัวอย่างที่คล้ายกันแต่ละชุดเพื่อเก็บไว้ และไม่ต้องสนใจภาพอื่นๆ:
ตอนนี้มุมมองนี้มี 3,729 ภาพ ด้วยการล้างข้อมูลและระบุชุดย่อยคุณภาพสูงของชุดข้อมูล Fashion200K ทำให้ FiftyOne ช่วยให้เราจำกัดโฟกัสของเราจากภาพมากกว่า 300,000 ภาพให้เหลือต่ำกว่า 4,000 ภาพ ซึ่งลดลงถึง 98% การใช้การฝังเพื่อลบรูปภาพที่เกือบซ้ำเพียงอย่างเดียวทำให้จำนวนรูปภาพทั้งหมดของเราภายใต้การพิจารณาลดลงมากกว่า 90% โดยมีผลกระทบเล็กน้อยต่อโมเดลใดๆ ที่จะฝึกกับข้อมูลนี้
ก่อนที่จะติดป้ายชุดย่อยนี้ล่วงหน้า เราสามารถเข้าใจข้อมูลได้ดีขึ้นโดยการแสดงภาพการฝังที่เราได้คำนวณไว้แล้ว เราสามารถใช้ FiftyOne Brain ในตัวได้ compute_visualization() วิธีการซึ่งใช้เทคนิคการประมาณค่าแบบสม่ำเสมอ (UMAP) เพื่อฉายภาพเวกเตอร์แบบฝัง 512 มิติในพื้นที่สองมิติ เพื่อให้เราเห็นภาพ:
เราเปิดใหม่ แผงฝัง ในแอป FiftyOne และระบายสีตามประเภทบทความ และเราจะเห็นว่าการฝังเหล่านี้เข้ารหัสแนวคิดของประเภทบทความอย่างคร่าว ๆ (เหนือสิ่งอื่นใด!)
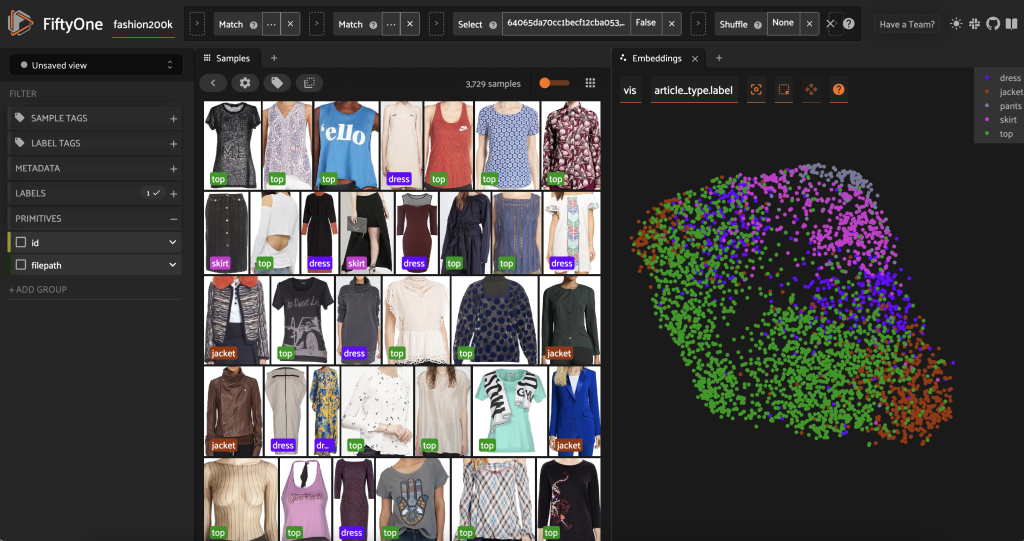
ตอนนี้เราพร้อมที่จะติดป้ายข้อมูลนี้ล่วงหน้าแล้ว
การตรวจสอบภาพความละเอียดสูงที่ไม่ซ้ำใครเหล่านี้ เราสามารถสร้างรายการสไตล์เริ่มต้นที่เหมาะสมเพื่อใช้เป็นคลาสในการจำแนกประเภท Zero-shot ที่ติดฉลากล่วงหน้าของเรา เป้าหมายของเราในการติดป้ายกำกับรูปภาพเหล่านี้ล่วงหน้าไม่จำเป็นต้องติดป้ายกำกับแต่ละภาพให้ถูกต้องเสมอไป แต่เป้าหมายของเราคือการจัดเตรียมจุดเริ่มต้นที่ดีสำหรับผู้ทำหมายเหตุประกอบ เพื่อให้เราสามารถลดเวลาและต้นทุนในการติดฉลากได้
จากนั้นเราสามารถสร้างแบบจำลองการจัดหมวดหมู่แบบ Zero-shot สำหรับแอปพลิเคชันนี้ได้ เราใช้โมเดล CLIP ซึ่งเป็นโมเดลสำหรับวัตถุประสงค์ทั่วไปที่ฝึกทั้งภาพและภาษาธรรมชาติ เราจำลองแบบจำลอง CLIP ด้วยข้อความแจ้ง "เสื้อผ้าในสไตล์" เพื่อให้ได้รับภาพ นางแบบจะแสดงคลาสที่ "เสื้อผ้าในสไตล์ [คลาส]" เหมาะสมที่สุด CLIP ไม่ได้รับการฝึกอบรมเกี่ยวกับข้อมูลการค้าปลีกหรือแฟชั่นโดยเฉพาะ ดังนั้นสิ่งนี้จะไม่สมบูรณ์แบบ แต่สามารถช่วยให้คุณประหยัดค่าใช้จ่ายในการติดฉลากและคำอธิบายประกอบ
จากนั้นเราใช้โมเดลนี้กับเซ็ตย่อยที่ลดลงและเก็บผลลัพธ์ไว้ใน article_style สนาม:
การเปิดตัวแอป FiftyOne อีกครั้ง เราสามารถแสดงภาพด้วยป้ายกำกับสไตล์ที่คาดการณ์ไว้เหล่านี้ เราจัดเรียงตามความมั่นใจในการคาดคะเน ดังนั้น เราจึงดูการคาดคะเนสไตล์ที่มีความมั่นใจมากที่สุดก่อน:
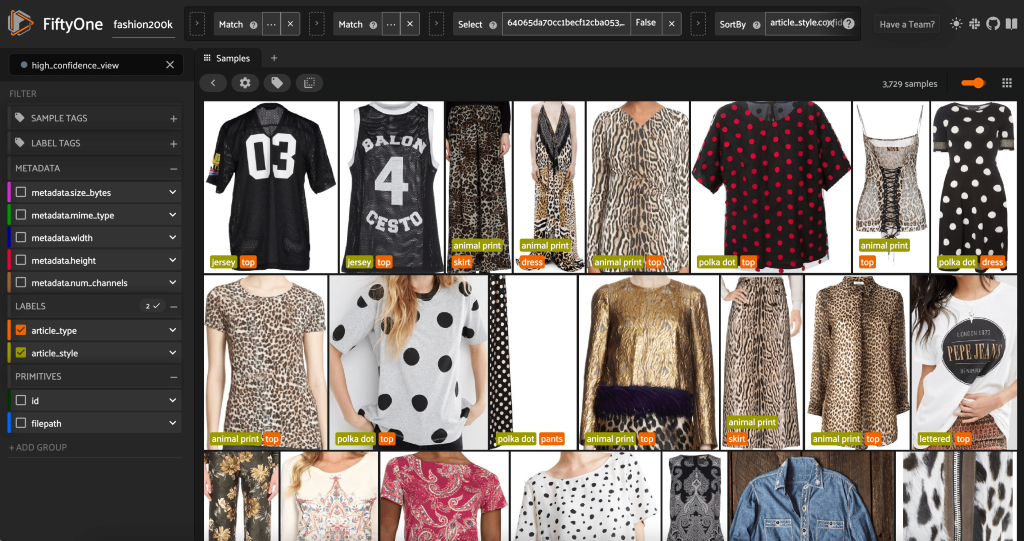
เราจะเห็นว่าการคาดคะเนที่มีความมั่นใจสูงสุดน่าจะเป็นสำหรับสไตล์ "เจอร์ซีย์" "ลายพิมพ์สัตว์" "ลายจุด" และ "ตัวอักษร" สิ่งนี้สมเหตุสมผลเพราะสไตล์เหล่านี้ค่อนข้างแตกต่าง นอกจากนี้ ดูเหมือนว่าป้ายสไตล์ที่คาดการณ์ไว้ส่วนใหญ่จะแม่นยำ
เรายังสามารถดูการคาดคะเนรูปแบบที่มีความเชื่อมั่นต่ำที่สุด:
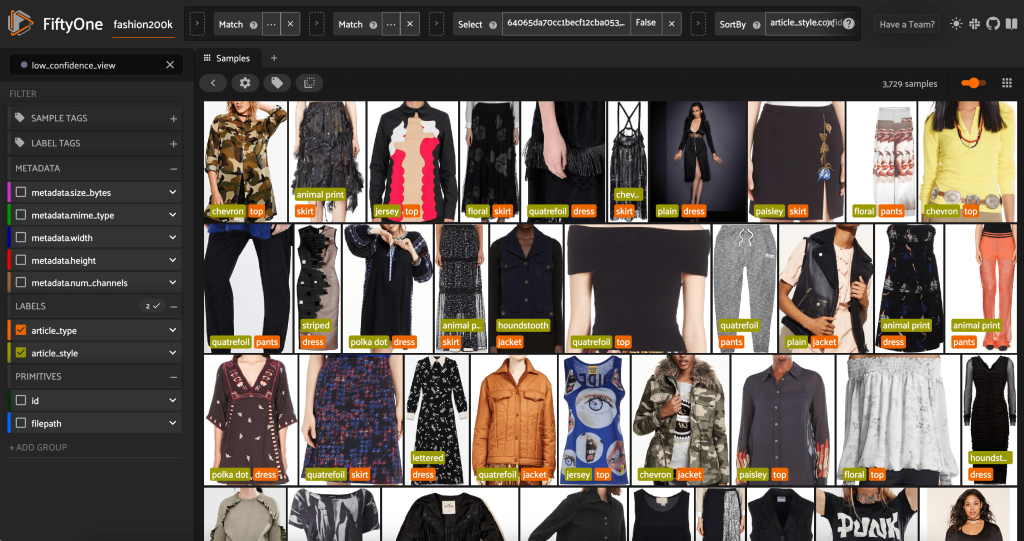
สำหรับรูปภาพบางรูปเหล่านี้ หมวดหมู่สไตล์ที่เหมาะสมอยู่ในรายการที่จัดเตรียมไว้ และบทความเกี่ยวกับเสื้อผ้ามีป้ายกำกับไม่ถูกต้อง ตัวอย่างเช่น ภาพแรกในตารางควรเป็น "ลายพราง" ไม่ใช่ "บั้ง" อย่างไรก็ตาม ในกรณีอื่นๆ ผลิตภัณฑ์ไม่เข้ากับหมวดหมู่สไตล์อย่างลงตัว ตัวอย่างเช่น เครื่องแต่งกายในภาพที่สองในแถวที่สองนั้นไม่ใช่ "ลายทาง" ทุกประการ แต่เมื่อมีตัวเลือกการติดฉลากแบบเดียวกัน ผู้ใช้อาจขัดแย้งกับคำอธิบายประกอบ ขณะที่เราสร้างชุดข้อมูลของเรา เราจำเป็นต้องตัดสินใจว่าจะลบขอบเคสเช่นนี้ เพิ่มหมวดหมู่สไตล์ใหม่ หรือเสริมชุดข้อมูล
ส่งออกชุดข้อมูลสุดท้ายจาก FiftyOne
ส่งออกชุดข้อมูลสุดท้ายด้วยรหัสต่อไปนี้:
เราสามารถส่งออกชุดข้อมูลขนาดเล็กลง เช่น รูปภาพ 16 ภาพ ไปยังโฟลเดอร์ 200kFashionDatasetExportResult-16Images. เราสร้างงานปรับ Ground Truth โดยใช้:
อัปโหลดชุดข้อมูลที่แก้ไข แปลงรูปแบบฉลากเป็น Ground Truth อัปโหลดไปยัง Amazon S3 และสร้างไฟล์รายการสำหรับงานปรับแต่ง
เราสามารถแปลงฉลากในชุดข้อมูลให้ตรงกับ สคีมารายการผลลัพธ์ ของงานกล่องขอบเขต Ground Truth และอัปโหลดภาพไปยัง บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (Amazon S3) ที่ฝากข้อมูลเพื่อเปิดตัว งานปรับพื้นความจริง:
อัปโหลดไฟล์รายการไปยัง Amazon S3 ด้วยรหัสต่อไปนี้:
สร้างฉลากสไตล์ที่ถูกต้องด้วย Ground Truth
เมื่อต้องการใส่คำอธิบายประกอบข้อมูลของคุณด้วยป้ายสไตล์โดยใช้ Ground Truth ให้ทำตามขั้นตอนที่จำเป็นเพื่อเริ่มงานการติดป้ายขอบกล่องโดยปฏิบัติตามขั้นตอนที่แสดงไว้ใน เริ่มต้นด้วยความจริงพื้นฐาน คำแนะนำด้วยชุดข้อมูลในบัคเก็ต S3 เดียวกัน
- บนคอนโซล SageMaker ให้สร้างงานการติดฉลาก Ground Truth
- ตั้ง ใส่ตำแหน่งชุดข้อมูล เพื่อเป็นรายการที่เราสร้างในขั้นตอนก่อนหน้านี้
- ระบุเส้นทาง S3 สำหรับ ตำแหน่งชุดข้อมูลเอาต์พุต.
- สำหรับ บทบาท IAMเลือก ป้อนบทบาท IAM ที่กำหนดเอง อาร์เอ็นเอจากนั้นป้อนบทบาท ARN
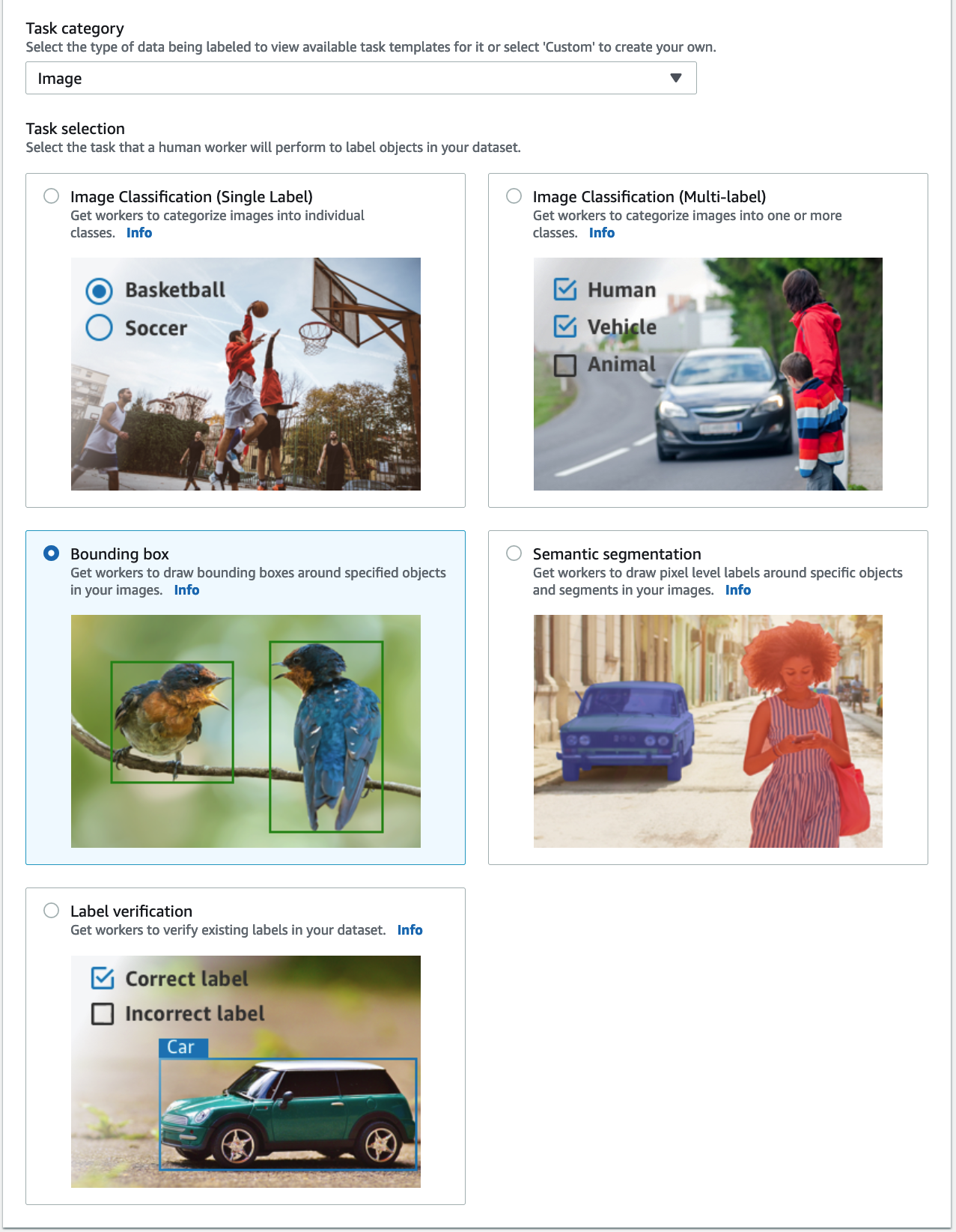
- สำหรับ หมวดหมู่งานเลือก ภาพ และเลือก กล่องกั้น.
- Choose ถัดไป.
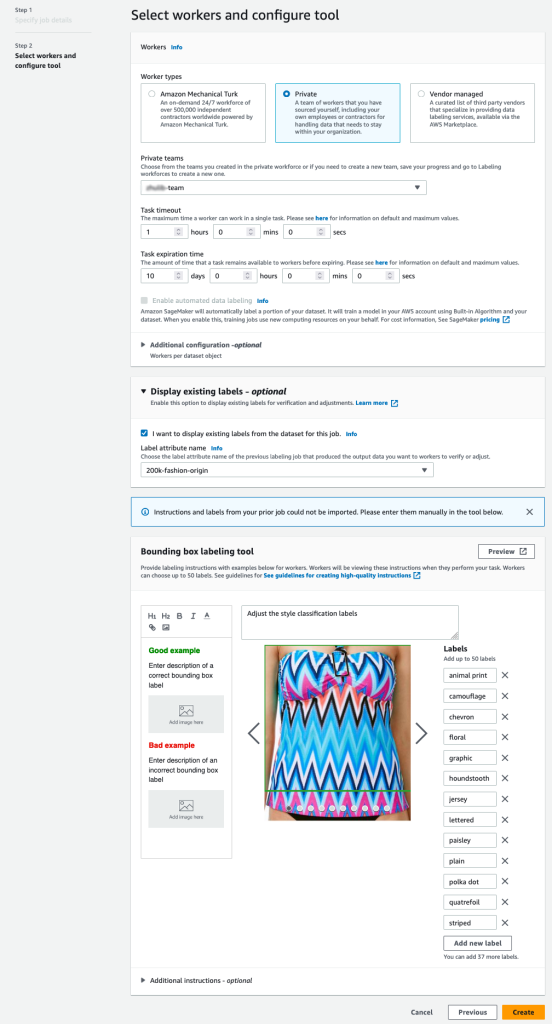
- ตัว Vortex Indicator ได้ถูกนำเสนอลงในนิตยสาร แรงงาน เลือกประเภทของพนักงานที่คุณต้องการใช้
คุณสามารถเลือกลูกทีมได้ผ่าน อังคารเครื่องกลเติร์กผู้ขายบุคคลที่สาม หรือพนักงานส่วนตัวของคุณเอง สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับตัวเลือกพนักงานของคุณ โปรดดูที่ สร้างและจัดการแรงงาน. - แสดง ตัวเลือกการแสดงฉลากที่มีอยู่ และเลือก ฉันต้องการแสดงป้ายกำกับที่มีอยู่จากชุดข้อมูลสำหรับงานนี้
- สำหรับ แอตทริบิวต์ป้ายกำกับ ชื่อ ให้เลือกชื่อจากรายการของคุณที่สอดคล้องกับป้ายกำกับที่คุณต้องการแสดงสำหรับการปรับเปลี่ยน
คุณจะเห็นเฉพาะชื่อแอตทริบิวต์ของป้ายกำกับสำหรับป้ายกำกับที่ตรงกับประเภทงานที่คุณเลือกในขั้นตอนก่อนหน้า - ป้อนป้ายกำกับด้วยตนเองสำหรับ เครื่องมือติดฉลากกล่องขอบ.
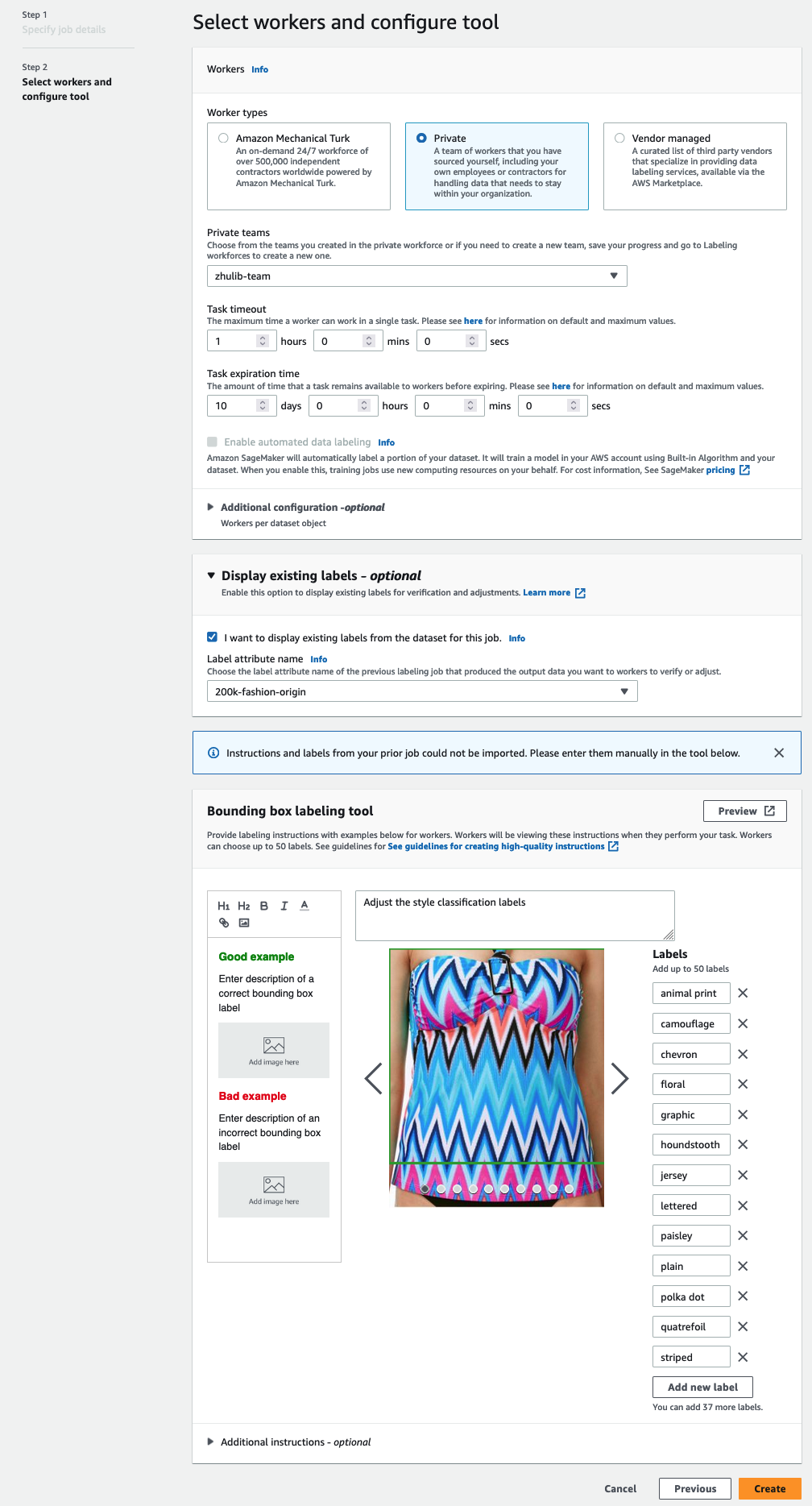 ป้ายกำกับต้องมีป้ายกำกับเดียวกันกับที่ใช้ในชุดข้อมูลสาธารณะ คุณสามารถเพิ่มป้ายกำกับใหม่ได้ ภาพหน้าจอต่อไปนี้แสดงวิธีที่คุณสามารถเลือกผู้ปฏิบัติงานและกำหนดค่าเครื่องมือสำหรับงานติดฉลากของคุณ
ป้ายกำกับต้องมีป้ายกำกับเดียวกันกับที่ใช้ในชุดข้อมูลสาธารณะ คุณสามารถเพิ่มป้ายกำกับใหม่ได้ ภาพหน้าจอต่อไปนี้แสดงวิธีที่คุณสามารถเลือกผู้ปฏิบัติงานและกำหนดค่าเครื่องมือสำหรับงานติดฉลากของคุณ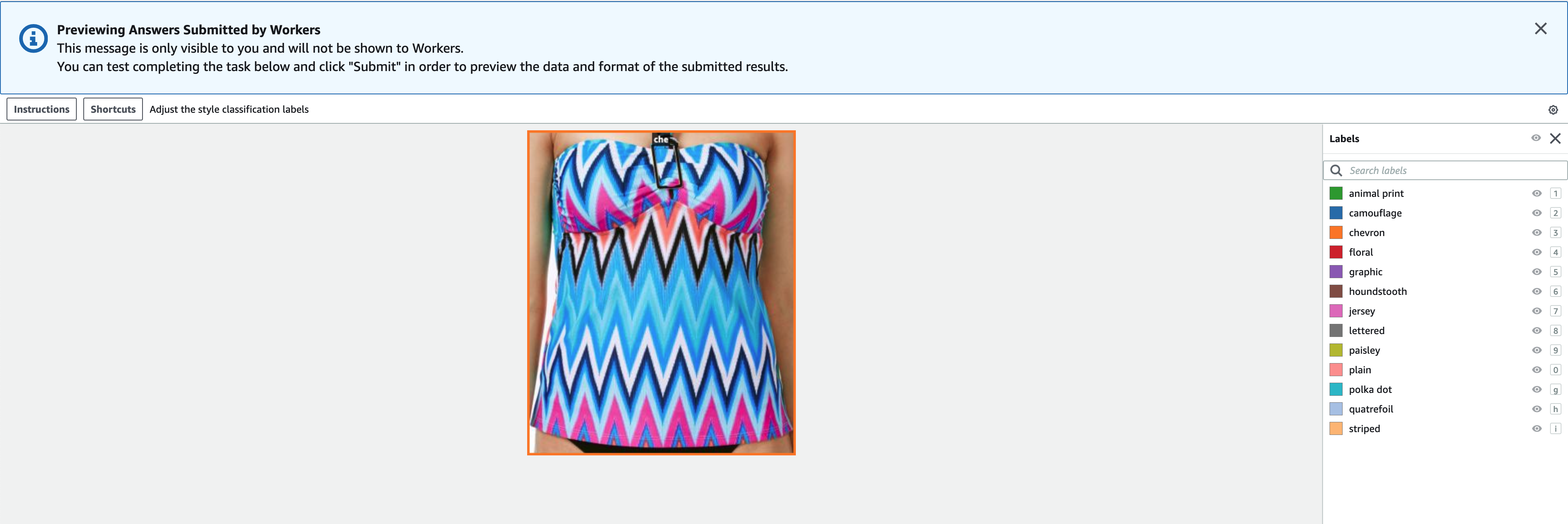
- Choose ดูตัวอย่าง เพื่อดูตัวอย่างรูปภาพและคำอธิบายประกอบต้นฉบับ
ตอนนี้เราได้สร้างงานการติดฉลากใน Ground Truth หลังจากงานของเราเสร็จสิ้น เราสามารถโหลดข้อมูลป้ายกำกับที่สร้างขึ้นใหม่ลงใน FiftyOne Ground Truth สร้างข้อมูลเอาต์พุตในรายการเอาต์พุต Ground Truth สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับไฟล์รายการเอาต์พุต โปรดดูที่ เอาต์พุตงานกล่องขอบเขต. รหัสต่อไปนี้แสดงตัวอย่างรูปแบบรายการผลลัพธ์นี้:
ตรวจสอบผลลัพธ์ที่มีป้ายกำกับจาก Ground Truth ใน FiftyOne
หลังจากงานเสร็จสิ้น ให้ดาวน์โหลดไฟล์ Manifest ของงานการติดฉลากจาก Amazon S3
อ่านไฟล์รายการผลลัพธ์:
สร้างชุดข้อมูล FiftyOne และแปลงรายการรายการเป็นตัวอย่างในชุดข้อมูล:
ตอนนี้คุณสามารถดูข้อมูลที่มีป้ายกำกับคุณภาพสูงจาก Ground Truth ใน FiftyOne
สรุป
ในโพสต์นี้ เราได้แสดงวิธีสร้างชุดข้อมูลคุณภาพสูงโดยการรวมพลังของ ห้าสิบเอ็ด by วอกเซล 51ซึ่งเป็นชุดเครื่องมือโอเพ่นซอร์สที่ให้คุณจัดการ ติดตาม แสดงภาพ และดูแลชุดข้อมูลของคุณ และ Ground Truth ซึ่งเป็นบริการติดป้ายข้อมูลที่ช่วยให้คุณติดป้ายชุดข้อมูลที่จำเป็นสำหรับการฝึกอบรมระบบ ML ได้อย่างมีประสิทธิภาพและแม่นยำโดยให้สิทธิ์เข้าถึงชุดเครื่องมือที่สร้างขึ้นหลายชุด -ในเทมเพลตงานและการเข้าถึงพนักงานที่หลากหลายผ่าน Mechanical Turk ผู้จำหน่ายบุคคลที่สาม หรือพนักงานส่วนตัวของคุณเอง
เราขอแนะนำให้คุณลองใช้ฟังก์ชันใหม่นี้โดยการติดตั้งอินสแตนซ์ FiftyOne และใช้คอนโซล Ground Truth เพื่อเริ่มต้น หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับความจริงพื้นฐาน โปรดดูที่ ข้อมูลป้ายกำกับ, คำถามที่พบบ่อยเกี่ยวกับการติดฉลากข้อมูลของ Amazon SageMakerและ บล็อก AWS Machine Learning.
เชื่อมต่อกับ การเรียนรู้ของเครื่องและชุมชน AI หากคุณมีคำถามหรือข้อเสนอแนะ!
เข้าร่วมชุมชน FiftyOne!
เข้าร่วมกับวิศวกรและนักวิทยาศาสตร์ข้อมูลหลายพันคนที่ใช้ FiftyOne เพื่อแก้ปัญหาที่ท้าทายที่สุดในการมองเห็นของคอมพิวเตอร์ในวันนี้!
เกี่ยวกับผู้เขียน
ชาเลนดรา ชาบรา ปัจจุบันเป็นหัวหน้าฝ่ายการจัดการผลิตภัณฑ์สำหรับบริการ Amazon SageMaker Human-in-the-Loop (HIL) ก่อนหน้านี้ Shalendra บ่มเพาะและเป็นผู้นำด้านภาษาและการสนทนาอัจฉริยะสำหรับการประชุม Microsoft Teams เป็น EIR ที่ Amazon Alexa Techstars Startup Accelerator รองประธานฝ่ายผลิตภัณฑ์และการตลาดที่ Discus.io, หัวหน้าฝ่ายผลิตภัณฑ์และการตลาดที่ Clipboard (ซื้อกิจการโดย Salesforce) และเป็นหัวหน้าผู้จัดการผลิตภัณฑ์ที่ Swype (ซื้อกิจการโดย Nuance) โดยรวมแล้ว ชาเลนดราได้ช่วยสร้าง จัดส่ง และทำการตลาดผลิตภัณฑ์ที่สัมผัสชีวิตคนมาแล้วกว่าพันล้านคน
เจคอบ มาร์ค เป็นวิศวกรการเรียนรู้ของเครื่องและผู้เผยแพร่ศาสนานักพัฒนาที่ Voxel51 ซึ่งเขาช่วยนำความโปร่งใสและความชัดเจนมาสู่ข้อมูลของโลก ก่อนที่จะเข้าร่วม Voxel51 Jacob ได้ก่อตั้งบริษัทสตาร์ทอัพเพื่อช่วยให้นักดนตรีหน้าใหม่เชื่อมต่อและแบ่งปันเนื้อหาที่สร้างสรรค์กับแฟนๆ ก่อนหน้านั้นเขาทำงานที่ Google X, Samsung Research และ Wolfram Research ในชีวิตที่แล้ว เจคอบเป็นนักฟิสิกส์เชิงทฤษฎี สำเร็จการศึกษาระดับปริญญาเอกที่มหาวิทยาลัยสแตนฟอร์ด ซึ่งเขาได้สำรวจขั้นตอนควอนตัมของสสาร ในเวลาว่าง เจคอบชอบปีนเขา วิ่ง และอ่านนิยายวิทยาศาสตร์
เจสัน คอร์โซ เป็นผู้ร่วมก่อตั้งและซีอีโอของ Voxel51 ซึ่งเขาเป็นผู้กำหนดกลยุทธ์ที่จะช่วยนำความโปร่งใสและความชัดเจนมาสู่ข้อมูลของโลกผ่านซอฟต์แวร์ที่ยืดหยุ่นล้ำสมัย เขายังเป็นศาสตราจารย์ด้านวิทยาการหุ่นยนต์ วิศวกรรมไฟฟ้า และวิทยาการคอมพิวเตอร์ที่มหาวิทยาลัยมิชิแกน ซึ่งเขามุ่งเน้นไปที่ปัญหาที่ล้ำสมัยที่จุดบรรจบของการมองเห็นคอมพิวเตอร์ ภาษาธรรมชาติ และแพลตฟอร์มทางกายภาพ ในเวลาว่าง Jason ชอบใช้เวลากับครอบครัว อ่านหนังสือ อยู่กับธรรมชาติ เล่นเกมกระดาน และกิจกรรมสร้างสรรค์ทุกประเภท
Brian Moore เป็นผู้ร่วมก่อตั้งและซีทีโอของ Voxel51 ซึ่งเขาเป็นผู้นำด้านกลยุทธ์และวิสัยทัศน์ทางเทคนิค เขาสำเร็จการศึกษาระดับปริญญาเอกสาขาวิศวกรรมไฟฟ้าจากมหาวิทยาลัยมิชิแกน ซึ่งงานวิจัยของเขามุ่งเน้นไปที่อัลกอริธึมที่มีประสิทธิภาพสำหรับปัญหาการเรียนรู้ของเครื่องขนาดใหญ่ โดยเน้นเป็นพิเศษเกี่ยวกับแอปพลิเคชันการมองเห็นด้วยคอมพิวเตอร์ ในเวลาว่าง เขาชอบเล่นแบดมินตัน ตีกอล์ฟ เดินป่า และเล่นกับยอร์คเชียร์เทอร์เรียร์ฝาแฝดของเขา
จูหลิงไป๋ เป็นวิศวกรพัฒนาซอฟต์แวร์ที่ Amazon Web Services เธอทำงานเกี่ยวกับการพัฒนาระบบกระจายขนาดใหญ่เพื่อแก้ปัญหาการเรียนรู้ของเครื่อง
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตไอสตรีม. ข้อมูลอัจฉริยะ Web3 ขยายความรู้ เข้าถึงได้ที่นี่.
- การสร้างอนาคตโดย Adryenn Ashley เข้าถึงได้ที่นี่.
- ซื้อและขายหุ้นในบริษัท PRE-IPO ด้วย PREIPO® เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- เกี่ยวกับเรา
- เร่งความเร็ว
- เร่ง
- คันเร่ง
- เข้า
- ถูกต้อง
- แม่นยำ
- ที่ได้มา
- กิจกรรม
- เพิ่ม
- เพิ่ม
- ที่อยู่
- ปรับ
- การปรับ
- หลังจาก
- อีกครั้ง
- AI
- Alexa
- อัลกอริทึม
- ทั้งหมด
- ช่วยให้
- คนเดียว
- แล้ว
- ด้วย
- อเมซอน
- amazon alexa
- อเมซอน SageMaker
- ความจริงของ Amazon SageMaker
- Amazon Web Services
- ในหมู่
- an
- วิเคราะห์
- และ
- สัตว์
- ใด
- app
- การใช้งาน
- การใช้งาน
- ใช้
- เหมาะสม
- เป็น
- จัด
- บทความ
- บทความ
- AS
- ที่เกี่ยวข้อง
- At
- ผู้เขียน
- ไป
- AWS
- ฐาน
- ตาม
- BE
- เพราะ
- กลายเป็น
- รับ
- ก่อน
- หลัง
- เบื้องหลัง
- กำลัง
- เชื่อ
- ที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- พันล้าน
- คณะกรรมการ
- เกมกระดาน
- กระดูก
- บูต
- ทั้งสอง
- กล่อง
- ในกล่องสี่เหลี่ยม
- ของเล่นเพิ่มพัฒนาสมอง
- ทำลาย
- นำมาซึ่ง
- นำ
- งบ
- สร้าง
- การก่อสร้าง
- built-in
- แต่
- ซื้อ
- by
- CAN
- จับ
- กรณี
- กรณี
- หมวดหมู่
- หมวดหมู่
- ผู้บริหารสูงสุด
- ท้าทาย
- ท้าทาย
- ตรวจสอบ
- Choose
- ความชัดเจน
- ชั้น
- ชั้นเรียน
- การจัดหมวดหมู่
- การทำความสะอาด
- ชัดเจน
- อย่างเห็นได้ชัด
- ไคลเอนต์
- ปีนเขา
- ปิดหน้านี้
- ใกล้ชิด
- เสื้อผ้า
- เสื้อผ้า
- ผู้ร่วมก่อตั้ง
- รหัส
- รวมกัน
- การรวมกัน
- บริษัท
- ส่วนประกอบ
- สมบูรณ์
- เสร็จสิ้น
- คำนวณ
- คอมพิวเตอร์
- วิทยาการคอมพิวเตอร์
- วิสัยทัศน์คอมพิวเตอร์
- แอพพลิเคชั่นคอมพิวเตอร์วิชั่น
- ความมั่นใจ
- มั่นใจ
- เชื่อมต่อ
- การพิจารณา
- ประกอบด้วย
- ปลอบใจ
- มี
- เนื้อหา
- เนื้อหา
- การควบคุม
- การสนทนา
- แปลง
- สำเนา
- แกน
- การแก้ไข
- สอดคล้อง
- ราคา
- ค่าใช้จ่าย
- สร้าง
- ที่สร้างขึ้น
- ความคิดสร้างสรรค์
- หนังสือรับรอง
- CTO
- curated
- curating
- ขณะนี้
- ประเพณี
- ลูกค้า
- ลูกค้า
- ตัด
- ตัดขอบ
- ข้อมูล
- ชุดข้อมูล
- ตัดสินใจ
- สาธิต
- กางเกงยีนส์
- ความลึก
- ลักษณะ
- รายละเอียด
- การตรวจพบ
- ผู้พัฒนา
- ที่กำลังพัฒนา
- พัฒนาการ
- ต่าง
- โดยตรง
- ไดเรกทอรี
- แสดง
- แตกต่าง
- กระจาย
- ระบบกระจาย
- หลาย
- do
- ไม่
- สุนัข
- การทำ
- ทำ
- Dont
- DOT
- ลง
- ดาวน์โหลด
- ที่ซ้ำกัน
- e
- แต่ละ
- ง่าย
- ขอบ
- ผล
- ที่มีประสิทธิภาพ
- อย่างมีประสิทธิภาพ
- วิศวกรรมไฟฟ้า
- การฝัง
- กากกะรุน
- ความสำคัญ
- พนักงาน
- ให้อำนาจ
- ห่อหุ้ม
- ส่งเสริม
- ปลาย
- วิศวกร
- ชั้นเยี่ยม
- วิศวกร
- เข้าสู่
- สิ่งแวดล้อม
- ความเสมอภาค
- จำเป็น
- ที่จัดตั้งขึ้น
- อีเธอร์ (ETH)
- การประเมินการ
- ผู้สอนศาสนา
- เผง
- ตัวอย่าง
- ที่มีอยู่
- ส่งออก
- อย่างเป็นธรรม
- ครอบครัว
- แฟน ๆ
- ข้อเสนอแนะ
- สองสาม
- นิยาย
- สนาม
- สาขา
- เนื้อไม่มีมัน
- ไฟล์
- กรอง
- กรอง
- สุดท้าย
- ชื่อจริง
- พอดี
- มีความยืดหยุ่น
- โฟกัส
- มุ่งเน้น
- มุ่งเน้นไปที่
- ดังต่อไปนี้
- สำหรับ
- ฟอร์ม
- รูป
- โชคดี
- ก่อตั้งขึ้นเมื่อ
- สี่
- ฟรี
- ราคาเริ่มต้นที่
- อย่างเต็มที่
- ฟังก์ชั่น
- เกม
- จุดประสงค์ทั่วไป
- สร้าง
- สร้าง
- ได้รับ
- GitHub
- ให้
- กำหนด
- เป้าหมาย
- กอล์ฟ
- ดี
- มากขึ้น
- ตะแกรง
- พื้น
- บัญชีกลุ่ม
- ให้คำแนะนำ
- มีความสุข
- มี
- he
- หัว
- ความสูง
- ช่วย
- ช่วย
- เป็นประโยชน์
- จะช่วยให้
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- ที่มีคุณภาพสูง
- ความละเอียดสูง
- ที่สูงที่สุด
- อย่างสูง
- การธุดงค์
- ของเขา
- ถือ
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTML
- ที่ http
- HTTPS
- เป็นมนุษย์
- i
- AMI
- ID
- แยกแยะ
- ระบุ
- รหัส
- if
- ภาพ
- ภาพ
- ส่งผลกระทบ
- นำเข้า
- การปรับปรุง
- in
- ในอื่น ๆ
- รวมทั้ง
- อย่างไม่ถูกต้อง
- ฟักไข่
- ข้อมูล
- แรกเริ่ม
- ในขั้นต้น
- ติดตั้ง
- การติดตั้ง
- ตัวอย่าง
- แทน
- คำแนะนำการใช้
- Intelligence
- การตัด
- เข้าไป
- IT
- ITS
- นิวเจอร์ซีย์
- การสัมภาษณ์
- การร่วม
- ร่วมกัน
- JSON
- เพียงแค่
- เก็บ
- การเก็บรักษา
- ฉลาก
- การติดฉลาก
- ป้ายกำกับ
- ภาษา
- ขนาดใหญ่
- เปิดตัว
- การเปิดตัว
- นำ
- นำไปสู่
- เรียนรู้
- การเรียนรู้
- น้อยที่สุด
- นำ
- ซ้าย
- ช่วยให้
- ห้องสมุด
- ชีวิต
- กดไลก์
- น่าจะ
- LIMIT
- ถูก จำกัด
- Line
- เส้น
- รายการ
- รายการ
- รายชื่อ
- น้อย
- ชีวิต
- โหลด
- ดู
- ที่ต้องการหา
- Lot
- ต่ำ
- เครื่อง
- เรียนรู้เครื่อง
- ทำ
- มายากล
- ทำ
- ทำให้
- จัดการ
- การจัดการ
- การจัดการ
- ผู้จัดการ
- หลาย
- แผนที่
- ตลาด
- การตลาด
- การจับคู่
- การจับคู่
- อย่างเป็นรูปธรรม
- เรื่อง
- อาจ..
- เชิงกล
- ภาพบรรยากาศ
- การประชุม
- Meta
- เมตาดาต้า
- วิธี
- วิธีการ
- มิชิแกน
- ไมโครซอฟท์
- ทีมไมโครซอฟท์
- อาจ
- ขั้นต่ำ
- ML
- โทรศัพท์มือถือ
- app มือถือ
- แบบ
- โมเดล
- โมดูล
- ข้อมูลเพิ่มเติม
- มากที่สุด
- ย้าย
- มาก
- หลาย
- นักดนตรี
- ต้อง
- ชื่อ
- ที่มีชื่อ
- ชื่อ
- โดยธรรมชาติ
- ภาษาธรรมชาติ
- ธรรมชาติ
- ใกล้
- จำเป็นต้อง
- จำเป็น
- จำเป็นต้อง
- ความต้องการ
- ใหม่
- อย่างเห็นได้ชัด
- ความคิด
- ตอนนี้
- นวงของภาษา
- จำนวน
- วัตถุ
- การตรวจจับวัตถุ
- วัตถุ
- of
- เป็นทางการ
- on
- ครั้งเดียว
- ONE
- ออนไลน์
- เพียง
- เปิด
- โอเพนซอร์ส
- การดำเนินการ
- โอกาส
- Options
- or
- Organized
- เป็นต้นฉบับ
- OS
- อื่นๆ
- ผลิตภัณฑ์อื่นๆ
- ของเรา
- ออก
- ที่ระบุไว้
- เอาท์พุต
- เกิน
- ของตนเอง
- เป็นเจ้าของ
- แพ็ค
- จับคู่
- ส่วนหนึ่ง
- ในสิ่งที่สนใจ
- อดีต
- เส้นทาง
- แบบแผน
- รูปแบบ
- สมบูรณ์
- การปฏิบัติ
- คน
- ส่วนบุคคล
- เฟสของสสาร
- กายภาพ
- เลือก
- ภาพ
- ผ้าตาหมากรุก
- ที่ราบ
- แพลตฟอร์ม
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- เล่น
- จุด
- ประชากร
- เป็นไปได้
- โพสต์
- อำนาจ
- การปฏิบัติ
- ที่คาดการณ์
- คำทำนาย
- การคาดการณ์
- ดูตัวอย่าง
- ก่อน
- ก่อนหน้านี้
- พิมพ์
- ก่อน
- ส่วนตัว
- อาจ
- ปัญหาที่เกิดขึ้น
- กระบวนการ
- ผลิตภัณฑ์
- การจัดการผลิตภัณฑ์
- ผู้จัดการผลิตภัณฑ์
- ผลิตภัณฑ์
- ศาสตราจารย์
- โครงการ
- คุณสมบัติ
- ที่คาดหวัง
- ต้นแบบ
- ให้
- ให้
- การให้
- สาธารณะ
- หมัด
- วัตถุประสงค์
- หลาม
- ควอนตัม
- คำถาม
- อย่างรวดเร็ว
- พิสัย
- ค่อนข้าง
- การอ่าน
- พร้อม
- แนะนำ
- แนะนำ
- ลด
- ลดลง
- การลดลง
- สัมพัทธ์
- การเผยแพร่
- ตรงประเด็น
- เอาออก
- ตัวแทน
- เป็นตัวแทนของ
- จำเป็นต้องใช้
- การวิจัย
- นักวิจัย
- ความละเอียด
- จำกัด
- ผล
- ส่งผลให้
- ผลสอบ
- ค้าปลีก
- กลับ
- ทบทวน
- กำจัด
- หุ่นยนต์
- แข็งแรง
- บทบาท
- ลวก
- แถว
- ทำลาย
- วิ่ง
- sagemaker
- กล่าวว่า
- Salesforce
- เดียวกัน
- ซัมซุง
- ลด
- ฉาก
- วิทยาศาสตร์
- นิยายวิทยาศาสตร์
- นักวิทยาศาสตร์
- คะแนน
- ได้อย่างลงตัว
- ที่สอง
- Section
- ส่วน
- เห็น
- ดูเหมือน
- ดูเหมือนว่า
- เลือก
- ความรู้สึก
- แยก
- บริการ
- บริการ
- เซสชั่น
- ชุด
- Share
- เธอ
- น่า
- โชว์
- แสดงให้เห็นว่า
- YES
- คล้ายคลึงกัน
- ง่าย
- มีขนาดเล็กกว่า
- So
- ซอฟต์แวร์
- การพัฒนาซอฟต์แวร์
- แก้
- บาง
- บางคน
- บางสิ่งบางอย่าง
- ช่องว่าง
- ใช้จ่าย
- การใช้จ่าย
- แยก
- แยก
- Stanford
- เริ่มต้น
- ข้อความที่เริ่ม
- ที่เริ่มต้น
- การเริ่มต้น
- ตัวเร่งการเริ่มต้น
- รัฐของศิลปะ
- ขั้นตอน
- ยังคง
- การเก็บรักษา
- จัดเก็บ
- กลยุทธ์
- สไตล์
- รูปแบบ
- สรุป
- ที่สนับสนุน
- ระบบ
- เอา
- งาน
- ทีม
- วิชาการ
- เทคสตาร์ส
- บอก
- แม่แบบ
- ทดสอบ
- กว่า
- ที่
- พื้นที่
- ของพวกเขา
- พวกเขา
- แล้วก็
- ตามทฤษฎี
- ที่นั่น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- สิ่ง
- คิด
- ของบุคคลที่สาม
- นี้
- พัน
- ธรณีประตู
- ตลอด
- การขว้างปา
- เวลา
- ไปยัง
- ร่วมกัน
- เครื่องมือ
- เครื่องมือ
- ด้านบน
- ระดับบนสุด
- ท็อปส์ซู
- รวม
- สัมผัส
- ลู่
- รถไฟ
- ผ่านการฝึกอบรม
- การฝึกอบรม
- แปลง
- ความโปร่งใส
- จริง
- ความจริง
- กลับ
- สอง
- ชนิด
- ชนิด
- ภายใต้
- เข้าใจ
- เป็นเอกลักษณ์
- มหาวิทยาลัย
- มหาวิทยาลัยมิชิแกน
- บันทึก
- us
- ใช้
- ใช้กรณี
- มือสอง
- ผู้ใช้งาน
- ผู้ใช้
- การใช้
- ความคุ้มค่า
- ความหลากหลาย
- ต่างๆ
- ผู้ขาย
- ตรวจสอบ
- มาก
- ผ่านทาง
- รายละเอียด
- เสมือน
- วิสัยทัศน์
- ต้องการ
- คือ
- we
- เว็บ
- บริการเว็บ
- ดี
- คือ
- อะไร
- เมื่อ
- ว่า
- ที่
- วิกิพีเดีย
- จะ
- กับ
- ภายใน
- ไม่มี
- ผู้หญิง
- คำ
- งาน
- ทำงาน
- แรงงาน
- กำลังแรงงาน
- โรงงาน
- ของโลก
- กังวล
- จะ
- เขียน
- X
- เธอ
- ของคุณ
- ลมทะเล
- รหัสไปรษณีย์
- สวนสัตว์