ทนายความ เครดิต: Midjourney
หากคุณอ่านงานของฉัน คุณอาจรู้ว่าฉันเผยแพร่บทความของฉันเป็นอันดับแรกและสำคัญที่สุดในจดหมายข่าว AI ของฉัน สะพานอัลกอริทึม. สิ่งที่คุณอาจไม่รู้คือทุกวันอาทิตย์ฉันจะเผยแพร่คอลัมน์พิเศษที่เรียกว่า "สิ่งที่คุณอาจพลาดไป" ซึ่งฉันจะทบทวนทุกสิ่งที่เกิดขึ้นในระหว่างสัปดาห์พร้อมบทวิเคราะห์ที่ช่วยให้คุณเข้าใจข่าวได้
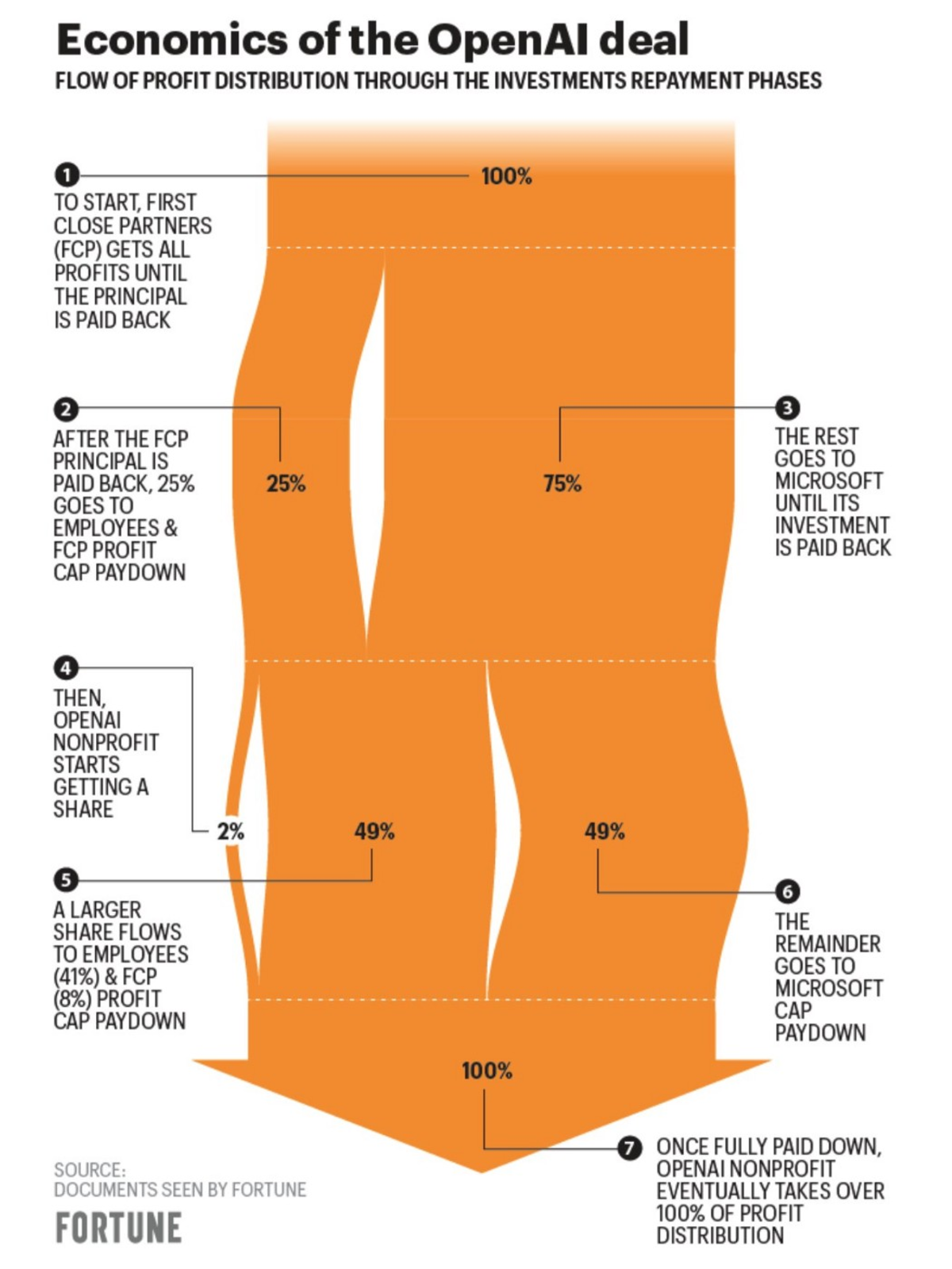
Microsoft-OpenAI ข้อตกลงมูลค่า 10 หมื่นล้านดอลลาร์
เซมาฟอร์รายงาน เมื่อสองสัปดาห์ที่แล้ว หากทุกอย่างเป็นไปตามแผน Microsoft จะปิดข้อตกลงการลงทุนมูลค่า 10 พันล้านดอลลาร์กับ OpenAI ก่อนสิ้นเดือนมกราคม (Satya Nadella, CEO ของ Microsoft ได้ประกาศ ขยายความร่วมมือ อย่างเป็นทางการในวันจันทร์)
มีข้อมูลที่ผิดเกี่ยวกับข้อตกลงซึ่งบอกเป็นนัยว่าผู้บริหารของ OpenAI ไม่แน่ใจเกี่ยวกับความเป็นไปได้ในระยะยาวของบริษัท อย่างไรก็ตาม, มันถูกชี้แจงในภายหลัง ข้อตกลงมีลักษณะดังนี้:
เครดิต: โชคลาภ
ลีโอ ลอเรนจ์ ผู้เขียน The Neuron อธิบาย ว่า “เมื่อกำไร 92 ล้านดอลลาร์ บวกกับเงินลงทุนเริ่มแรก 13 ล้านดอลลาร์ จะได้รับการชำระคืนให้กับ Microsoft และเมื่อนักลงทุนร่วมทุนรายอื่นได้รับ 150 ล้านดอลลาร์ ส่วนของทุนทั้งหมดก็จะกลับคืนสู่ OpenAI”
ผู้คนแตกแยก บางคนบอกว่าดีลนี้ “เจ๋ง” หรือ “น่าสนใจ” ในขณะที่บางคนบอกว่ามัน “แปลก” และ “บ้า” สิ่งที่ฉันรับรู้ด้วยสายตาที่ไม่ใช่ผู้เชี่ยวชาญคือ OpenAI และ Sam Altman do ความเชื่อใจ (บางคนบอกว่า ไว้ใจเกิน) ความสามารถระยะยาวของบริษัทในการบรรลุเป้าหมาย
อย่างไรก็ตามเนื่องจาก Will Knight เขียน สำหรับ WIRED “ยังไม่ชัดเจนว่าผลิตภัณฑ์ใดที่สามารถสร้างจากเทคโนโลยีได้” OpenAI ต้องหารูปแบบธุรกิจที่ทำงานได้ในไม่ช้า
การเปลี่ยนแปลงของ ChatGPT: ฟีเจอร์ใหม่และการสร้างรายได้
OpenAI อัปเดต ChatGPT ในวันที่ 9 ม.ค. (จากเดิมอัพเดทวันที่ 15 ธ.ค.) ตอนนี้แชทบอทได้ "ปรับปรุงข้อเท็จจริง" และคุณสามารถหยุดคนรุ่นกลางได้
พวกเขากำลังทำงานกับ "ChatGPT เวอร์ชันมืออาชีพ" (ซึ่งมีข่าวลือว่าจะเปิดตัวที่ $ 42 / เดือน) ในฐานะประธานของ OpenAI Greg Brockman ประกาศ ในวันที่ 11 ม.ค. คุณสมบัติหลัก XNUMX ประการ ได้แก่
“พร้อมใช้งานเสมอ (ไม่มีหน้าต่างปิดทึบ)
การตอบสนองที่รวดเร็วจาก ChatGPT (เช่น ไม่มีการควบคุมปริมาณ)
ข้อความได้มากเท่าที่คุณต้องการ (อย่างน้อย 2X ขีดจำกัดรายวันตามปกติ)”
ในการลงทะเบียนรายการรอคุณต้อง กรอกแบบฟอร์ม โดยพวกเขาจะถามคุณว่าคุณต้องการจ่ายเท่าไหร่ (และเท่าไหร่ที่จะมากเกินไป)
หากคุณวางแผนที่จะดำเนินการอย่างจริงจัง คุณควรพิจารณาลงลึกในกลุ่มผลิตภัณฑ์ของ OpenAI ด้วย ที่เก็บตำราอาหาร OpenAI. โบยาน ตุงกุซ กล่าวว่า "repo ที่ได้รับความนิยมสูงสุดบน GitHub ในเดือนนี้” เป็นสัญญาณที่ดีเสมอ
ChatGPT นักวิทยาศาสตร์ตัวปลอม
ChatGPT ได้เข้าสู่โดเมนทางวิทยาศาสตร์แล้ว คารีม คาร์ โพสต์ภาพหน้าจอในวันพฤหัสบดีของเอกสารที่ ChatGPT เป็นผู้เขียนร่วม
แต่ทำไม ChatGPT เป็นเครื่องมือ? “ผู้คนเริ่มปฏิบัติต่อ ChatGPT ราวกับว่ามันเป็นข้อมูลทางวิทยาศาสตร์ที่น่าเชื่อถือและได้รับการรับรองอย่างดี ผู้ประสานงานGary Marcus อธิบาย ในโพสต์ Substack. “นักวิทยาศาสตร์ โปรดอย่าปล่อยให้แชทบอทของคุณเติบโตขึ้นมาเป็นผู้เขียนร่วม” เขาขอร้อง
ที่น่าเป็นห่วงกว่านั้นคือกรณีที่ไม่มีการเปิดเผยการใช้ AI นักวิทยาศาสตร์ ได้พบ พวกเขาไม่สามารถระบุบทคัดย่อที่เขียนโดย ChatGPT ได้อย่างน่าเชื่อถือ — คำพูดพล่ามพล่ามของมันหลอกแม้กระทั่งผู้เชี่ยวชาญในสาขาของตน ดังที่ Sandra Wachter ผู้ซึ่ง “ศึกษาเทคโนโลยีและระเบียบข้อบังคับ” ที่ Oxford กล่าวกับ Holly Else สำหรับ ชิ้นส่วนเกี่ยวกับธรรมชาติ:
“หากตอนนี้เราอยู่ในสถานการณ์ที่ผู้เชี่ยวชาญไม่สามารถระบุได้ว่าสิ่งใดจริงหรือไม่จริง เราจะสูญเสียคนกลางที่เราจำเป็นอย่างยิ่งที่จะแนะนำเราผ่านหัวข้อที่ซับซ้อน”
ความท้าทายของ ChatGPT ต่อการศึกษา
ChatGPT ถูกแบนในศูนย์การศึกษาทั่วโลก (เช่น โรงเรียนของรัฐนิวยอร์ก, มหาวิทยาลัยในออสเตรเลียและ อาจารย์ในสหราชอาณาจักร กำลังคิดอยู่) อย่างที่ผมเถียงไป เรียงความก่อนหน้านี้ฉันไม่คิดว่านี่เป็นการตัดสินใจที่ฉลาดที่สุด แต่เป็นเพียงปฏิกิริยาเนื่องจากไม่ได้เตรียมพร้อมสำหรับการพัฒนาอย่างรวดเร็วของ AI เชิงกำเนิด
Kevin Roose จาก NYT โต้แย้ง ว่า “ศักยภาพของ [ChatGPT] ในฐานะเครื่องมือทางการศึกษานั้นมีมากกว่าความเสี่ยง” Terence Tao นักคณิตศาสตร์ผู้ยิ่งใหญ่ ตกลง: “ในระยะยาว ดูเหมือนว่าไร้ประโยชน์ที่จะต่อสู้กับสิ่งนี้ บางทีสิ่งที่เราในฐานะวิทยากรต้องทำคือเปลี่ยนไปใช้โหมดการสอบแบบ “open book, open AI””
จาดา พิสติลลี่นักจริยธรรมหลักของ Hugging Face อธิบายถึงความท้าทายที่โรงเรียนต้องเผชิญกับ ChatGPT:
“น่าเสียดายที่ระบบการศึกษาดูเหมือนจะถูกบังคับให้ต้องปรับตัวให้เข้ากับเทคโนโลยีใหม่เหล่านี้ ฉันคิดว่ามันเข้าใจได้ว่าเป็นปฏิกิริยา เนื่องจากไม่ค่อยมีใครทำเพื่อคาดการณ์ บรรเทา หรือแก้ปัญหาทางเลือกอย่างละเอียดเพื่อกำหนดขอบเขตของปัญหาที่อาจเกิดขึ้น เทคโนโลยีก่อกวนมักต้องการการศึกษาผู้ใช้เพราะไม่สามารถถูกโยนใส่ผู้คนอย่างควบคุมไม่ได้”
ประโยคสุดท้ายนั้นจับได้อย่างสมบูรณ์แบบว่าปัญหาเกิดขึ้นที่ใดและวิธีแก้ปัญหาที่เป็นไปได้ เราต้องพยายามเป็นพิเศษเพื่อให้ความรู้แก่ผู้ใช้เกี่ยวกับวิธีการทำงานของเทคโนโลยีนี้ และสิ่งที่เป็นไปได้และไม่ควรทำกับพวกเขา นั่นคือแนวทางที่ Catalonia ได้ดำเนินไป เช่น Francesc Bracero และ Carina Farreras รายงาน สำหรับ La Vanguardia:
“ในคาตาโลเนีย กระทรวงศึกษาธิการจะไม่ห้าม 'ทั้งระบบและสำหรับทุกคน เนื่องจากจะเป็นมาตรการที่ไม่ได้ผล' ตามแหล่งข่าวจากกระทรวง จะเป็นการดีกว่าหากขอให้ศูนย์ให้ความรู้ในการใช้ AI 'ซึ่งสามารถให้ความรู้และข้อดีมากมาย'”
เพื่อนที่ดีที่สุดของนักเรียน: ฐานข้อมูลข้อผิดพลาดของ ChatGPT
Gary Marcus และ Ernest Davis ได้จัดตั้ง “ตัวติดตามข้อผิดพลาด” เพื่อบันทึกและจัดประเภทรูปแบบภาษาที่มีข้อผิดพลาด เช่น ChatGPT make (นี่คือข้อมูลเพิ่มเติม เกี่ยวกับสาเหตุที่พวกเขารวบรวมเอกสารนี้และสิ่งที่พวกเขาวางแผนจะทำกับเอกสารนี้)
ฐานข้อมูลเป็นแบบสาธารณะและทุกคนสามารถเข้าร่วมได้ เป็นแหล่งข้อมูลที่ดีที่ช่วยให้สามารถศึกษาอย่างเข้มงวดว่าโมเดลเหล่านี้ทำงานผิดปกติอย่างไร และผู้คนจะหลีกเลี่ยงการใช้ผิดวิธีได้อย่างไร นี่คือตัวอย่างที่น่าขบขันว่าทำไมเรื่องนี้ถึงสำคัญ:
OpenAI ตระหนักถึงสิ่งนี้และต้องการต่อสู้กับข้อมูลที่ผิดและบิดเบือน: “การคาดการณ์การใช้รูปแบบภาษาในทางที่ผิดสำหรับแคมเปญที่บิดเบือนข้อมูล — และวิธีลดความเสี่ยง".
ข้อมูลใหม่
แซม อัลท์แมนพูดเป็นนัย ความล่าช้าในการเปิดตัว GPT-4 ในการสนทนากับ คอนนี่ ลอยซอสบรรณาธิการของ Silicon Valley ที่ TechCrunch Altman กล่าวว่า "โดยทั่วไปแล้ว เราจะปล่อยเทคโนโลยีช้ากว่าที่ผู้คนต้องการ เราจะนั่งกับมันอีกนาน…” นี่คือสิ่งที่ฉันใช้:
(Altman ยังบอกด้วยว่ากำลังมีโมเดลวิดีโออยู่ในผลงาน!)
ข้อมูลที่ไม่ถูกต้องเกี่ยวกับ GPT-4
มีการอ้างสิทธิ์ "GPT-4 = 100T" ที่กำลังแพร่ระบาดไปทั่วบนโซเชียลมีเดีย (ส่วนใหญ่ฉันเห็นใน Twitter และ LinkedIn) ในกรณีที่คุณไม่เห็น ดูเหมือนว่า:
หรือสิ่งนี้:
ทั้งหมดเป็นเวอร์ชันที่แตกต่างกันเล็กน้อยในสิ่งเดียวกัน: กราฟภาพที่น่าดึงดูดซึ่งดึงดูดความสนใจ และตะขอที่แข็งแกร่งด้วยการเปรียบเทียบ GPT-4/GPT-3 (พวกเขาใช้ GPT-3 เป็นพร็อกซีสำหรับ ChatGPT)
ฉันคิดว่าการแบ่งปันข่าวลือและการคาดเดาและตีกรอบให้เป็นเช่นนั้นไม่เป็นไร (ฉันรู้สึกมีส่วนรับผิดชอบในเรื่องนี้) แต่การโพสต์ข้อมูลที่ตรวจสอบไม่ได้ด้วยน้ำเสียงที่น่าเชื่อถือและไม่มีการอ้างอิงนั้นเป็นสิ่งที่น่ารังเกียจ
ผู้คนที่ทำเช่นนี้ไม่ได้ห่างไกลจากความไร้ประโยชน์และอันตรายเท่ากับ ChatGPT ที่เป็นแหล่งข้อมูล — และด้วยแรงจูงใจที่แข็งแกร่งกว่ามากให้ทำต่อไป ระวังสิ่งนี้เพราะจะทำให้ทุกช่องทางของข้อมูลเกี่ยวกับ AI เสียหายในอนาคต
ทนายความหุ่นยนต์
Joshua Browder ซีอีโอของ DoNotPay โพสต์เมื่อวันที่ 9 มกราคม:
จะเป็นอย่างอื่นไปไม่ได้ การอ้างสิทธิ์ที่กล้าได้กล้าเสียนี้เกิดขึ้น การถกเถียงกันมาก ถึงจุดที่ Twitter ตั้งค่าสถานะทวีตพร้อมลิงก์ไปยัง หน้าศาลฎีกาของต้องห้าม.
แม้ว่าในที่สุดพวกเขาจะไม่สามารถทำได้เนื่องจากเหตุผลทางกฎหมาย แต่ก็คุ้มค่าที่จะพิจารณาคำถามจากจุดยืนทางจริยธรรมและสังคม จะเกิดอะไรขึ้นหากระบบ AI ทำผิดพลาดอย่างร้ายแรง? สามารถ คนที่ไม่สามารถเข้าถึงได้ เพื่อให้ทนายความได้รับประโยชน์จากเทคโนโลยีนี้ในเวอร์ชันผู้ใหญ่
การฟ้องร้องต่อ Stable Diffusion ได้เริ่มขึ้นแล้ว
แมทธิว บัตเตอร์ริค เผยแพร่เมื่อวันที่ 13 มกราคม:
“ในนามของสามสิ่งที่ยอดเยี่ยม โจทก์ศิลปิน - ซาราห์ แอนเดอร์เซ็น, เคลลี่ แมคเคอร์แนนและ คาร์ลา ออร์ติซ — เราได้ยื่นฟ้องคดีแบบกลุ่มกับ AI เสถียรภาพ, จิตพิสัยและ กลางการเดินทาง สำหรับการใช้งานของพวกเขา การแพร่กระจายที่เสถียรซึ่งเป็นเครื่องมือคอลลาจแห่งศตวรรษที่ 21 ที่รีมิกซ์ผลงานที่มีลิขสิทธิ์ของศิลปินหลายล้านคน ซึ่งผลงานของเขาถูกใช้เป็นข้อมูลการฝึกอบรม”
เริ่มต้นขึ้น — ขั้นตอนแรกในสิ่งที่สัญญาว่าจะเป็นการต่อสู้ที่ยาวนานเพื่อกลั่นกรองการฝึกอบรมและการใช้ AI เชิงกำเนิด ฉันเห็นด้วยกับแรงจูงใจ: “AI จำเป็นต้องยุติธรรมและมีจริยธรรมสำหรับทุกคน”
แต่ เหมือนคนอื่นๆ อีกหลายคนฉันพบความไม่ถูกต้องในบล็อกโพสต์ มันลงลึกในด้านเทคนิคของ Stable Diffusion แต่ไม่สามารถอธิบายได้อย่างถูกต้อง ไม่ว่าจะเป็นความตั้งใจที่จะเชื่อมช่องว่างทางเทคนิคสำหรับผู้ที่ไม่ทราบ — และไม่มีเวลาที่จะเรียนรู้ — เกี่ยวกับวิธีการทำงานของเทคโนโลยีนี้ (หรือเป็นวิธีการระบุลักษณะของเทคโนโลยีในลักษณะที่เป็นประโยชน์ต่อพวกเขา ) หรือผิดพลาดเปิดให้เก็งกำไร
ฉันเถียง ในบทความก่อนหน้านี้ การปะทะกันระหว่างศิลปะ AI และศิลปินดั้งเดิมนั้นรุนแรงมากในตอนนี้ การตอบสนองต่อคดีนี้จะไม่แตกต่างกัน เราจะต้องรอกรรมการตัดสินผล
CNET เผยแพร่บทความที่สร้างโดย AI
รายงานลัทธิอนาคต เมื่อสองสามสัปดาห์ที่ผ่านมา:
"CNETสำนักข่าวเทคโนโลยีที่ได้รับความนิยมอย่างล้นหลาม ใช้ความช่วยเหลือจาก “เทคโนโลยีอัตโนมัติ” ซึ่งเป็นคำสละสลวยสำหรับ AI อย่างเงียบๆ ในบทความอธิบายทางการเงินคลื่นลูกใหม่”
Gael Breton ผู้พบเห็นสิ่งนี้เป็นคนแรก เขียนบทวิเคราะห์เชิงลึกเมื่อวันศุกร์. เขาอธิบายว่า Google ดูเหมือนจะไม่ขัดขวางการเข้าชมโพสต์เหล่านี้ “ตอนนี้เนื้อหา AI โอเคไหม” เขาถาม.
ฉันพบว่ามันเป็นการตัดสินใจของ CNET เพื่อเปิดเผยการใช้ AI อย่างครบถ้วน ในบทความของพวกเขาเป็นแบบอย่างที่ดี ตอนนี้มีคนกี่คนที่เผยแพร่เนื้อหาโดยใช้ AI โดยไม่เปิดเผย อย่างไรก็ตาม ผลที่ตามมาคือผู้คนอาจตกงานหากสิ่งนี้ได้ผล (เช่นฉันและคนอื่นๆ ที่คาดการณ์). มันกำลังเกิดขึ้นแล้ว:
ฉันเห็นด้วยอย่างยิ่งกับทวีตนี้จากซันติอาโก:
RLHF สำหรับการสร้างภาพ
หากการเรียนรู้แบบเสริมแรงผ่านคำติชมของมนุษย์ใช้ได้กับโมเดลภาษา ทำไมไม่ใช้กับการแปลงข้อความเป็นรูปภาพ นั่นคือสิ่งที่ PickaPic พยายามทำให้สำเร็จ
ตัวอย่าง มีไว้เพื่อวัตถุประสงค์ในการวิจัย แต่อาจเป็นส่วนเสริมที่น่าสนใจสำหรับ Stable Diffusion หรือ DALL-E (Midjourney ทำสิ่งที่คล้ายกัน — พวกเขาแนะนำโมเดลภายในเพื่อให้ได้ภาพที่สวยงามและเป็นศิลปะ)
สูตร "ทำให้ Siri/Alexa ดีขึ้น 10 เท่า"
สูตรอาหารที่ผสมโมเดล AI กำเนิดต่างๆ เพื่อสร้างบางอย่างที่ดีกว่าผลรวมของส่วนต่างๆ:
อัลแบร์โต โรเมโร เป็นนักเขียนอิสระที่เน้นเรื่องเทคโนโลยีและ AI เขาเขียน สะพานอัลกอริทึมจดหมายข่าวที่ช่วยให้ผู้ที่ไม่เชี่ยวชาญด้านเทคนิคเข้าใจข่าวสารและกิจกรรมเกี่ยวกับ AI เขายังเป็นนักวิเคราะห์เทคโนโลยีที่ CambrianAI ซึ่งเขาเชี่ยวชาญด้านโมเดลภาษาขนาดใหญ่
Original. โพสต์ใหม่โดยได้รับอนุญาต
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://www.kdnuggets.com/2023/02/chatgpt-gpt4-generative-ai-news.html?utm_source=rss&utm_medium=rss&utm_campaign=chatgpt-gpt-4-and-more-generative-ai-news
- 11
- 7
- 9
- a
- ความสามารถ
- สามารถ
- เกี่ยวกับเรา
- เกี่ยวกับมัน
- บทคัดย่อ
- ตาม
- บรรลุ
- ข้าม
- ปรับ
- นอกจากนี้
- ข้อได้เปรียบ
- กับ
- AI
- ไอ อาร์ต
- อัลกอริทึม
- ทั้งหมด
- ช่วยให้
- แล้ว
- ทางเลือก
- เสมอ
- ในหมู่
- การวิเคราะห์
- นักวิเคราะห์
- และ
- ประกาศ
- คาดหวัง
- ทุกคน
- อุทธรณ์
- เข้าใกล้
- ศิลปะ
- บทความ
- ศิลปะ
- ศิลปิน
- ความสนใจ
- ใช้ได้
- กลับ
- ห้าม
- สวยงาม
- เพราะ
- ก่อน
- กำลัง
- ประโยชน์
- ประโยชน์ที่ได้รับ
- ที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- ระวัง
- พันล้าน
- บล็อก
- กล้า
- ร้านหนังสือเกาหลี
- สะพาน
- สร้าง
- ธุรกิจ
- รูปแบบธุรกิจ
- โทรศัพท์
- แคมเปญ
- ไม่ได้
- จับ
- จับ
- กรณี
- กรณี
- ศูนย์
- ผู้บริหารสูงสุด
- ท้าทาย
- ช่อง
- สมบัติ
- chatbot
- chatbots
- ChatGPT
- ข้อเรียกร้อง
- การปะทะกัน
- แยกประเภท
- ปิดหน้านี้
- CNET
- ผู้เขียนร่วม
- คอลัมน์
- COM
- บริษัท
- การเปรียบเทียบ
- ซับซ้อน
- พิจารณา
- พิจารณา
- เนื้อหา
- การสนทนา
- ได้
- คู่
- ศาล
- สร้าง
- เครดิต
- ประจำวัน
- ดัล-อี
- Dangerous
- ข้อมูล
- ฐานข้อมูล
- เดวิส
- จัดการ
- การตัดสินใจ
- ลึก
- ลึก
- ความล่าช้า
- ความต้องการ
- แผนก
- กำหนด
- พัฒนาการ
- ต่าง
- การจัดจำหน่าย
- เปิดเผย
- การเปิดเผย
- การเปิดเผย
- บิดเบือน
- ซึ่งทำให้ยุ่ง
- แบ่งออก
- เอกสาร
- ไม่
- การทำ
- โดเมน
- Dont
- ในระหว่าง
- ได้รับ
- บรรณาธิการ
- สอน
- การศึกษา
- เกี่ยวกับการศึกษา
- ความพยายาม
- ทำอย่างละเอียด
- เข้า
- ทั้งหมด
- ส่วนได้เสีย
- ข้อผิดพลาด
- อีเธอร์ (ETH)
- ตามหลักจริยธรรม
- แม้
- เหตุการณ์
- ทุกๆ
- ทุกคน
- ทุกอย่าง
- ตัวอย่าง
- ผู้บริหาร
- ผู้เชี่ยวชาญ
- อธิบาย
- อธิบาย
- พิเศษ
- Eyes
- ใบหน้า
- ล้มเหลว
- ธรรม
- เทียม
- FAST
- คุณสมบัติ
- ข้อเสนอแนะ
- สนาม
- สู้
- รูป
- ในที่สุด
- ทางการเงิน
- หา
- ชื่อจริง
- ก้าวแรก
- ธง
- มุ่งเน้นไปที่
- สำคัญ
- ข้างหน้า
- พบ
- อาชีพอิสระ
- เพื่อน
- ราคาเริ่มต้นที่
- อย่างเต็มที่
- ช่องว่าง
- แกรี่
- General
- กำเนิด
- กำเนิด AI
- GitHub
- กำหนด
- โลก
- Go
- เป้าหมาย
- ไป
- ไป
- ดี
- กราฟ
- ยิ่งใหญ่
- ขึ้น
- ให้คำแนะนำ
- ที่เกิดขึ้น
- ที่เกิดขึ้น
- ช่วย
- จะช่วยให้
- เฮฮา
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTML
- HTTPS
- เป็นมนุษย์
- แยกแยะ
- ภาพ
- ภาพ
- โดยนัย
- in
- แรงจูงใจ
- ข้อมูล
- ข้อมูล
- แรกเริ่ม
- โดยเจตนา
- น่าสนใจ
- ภายใน
- การลงทุน
- นักลงทุน
- IT
- แจน
- มกราคม
- งาน
- KD นักเก็ต
- เก็บ
- อัศวิน
- ทราบ
- ความรู้
- ภาษา
- ใหญ่
- ชื่อสกุล
- คดีความ
- ทนายความ
- เรียนรู้
- การเรียนรู้
- กฎหมาย
- LIMIT
- LINK
- นาน
- ระยะยาว
- LOOKS
- สูญเสีย
- Lot
- หลัก
- ทำ
- ทำให้
- หลาย
- หลายคน
- มาร์คัส
- อย่างมากมาย
- เรื่อง
- เป็นผู้ใหญ่
- วิธี
- วัด
- ภาพบรรยากาศ
- กลาง
- แค่
- ข้อความ
- ไมโครซอฟท์
- กลางการเดินทาง
- กระทรวง
- ข้อมูลที่ผิด
- ข้อผิดพลาด
- บรรเทา
- โหมด
- แบบ
- โมเดล
- วันจันทร์
- ข้อมูลเพิ่มเติม
- แรงจูงใจ
- ย้าย
- ธรรมชาติ
- จำเป็นต้อง
- ความต้องการ
- ใหม่
- คุณสมบัติใหม่
- เทคโนโลยีใหม่ ๆ
- ข่าว
- ข่าวสารและกิจกรรม
- จดหมายข่าว
- ไม่ใช่เทคนิค
- อย่างเป็นทางการ
- ถูก
- เปิด
- OpenAI
- อื่นๆ
- ผลิตภัณฑ์อื่นๆ
- มิฉะนั้น
- ผล
- ฟอร์ด
- กระดาษ
- มีส่วนร่วม
- ส่วน
- ชำระ
- คน
- บางที
- การอนุญาต
- ชิ้น
- แผนการ
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- ขอร้อง
- กรุณา
- บวก
- จุด
- ยอดนิยม
- เป็นไปได้
- โพสต์
- โพสต์
- โพสต์
- ที่มีศักยภาพ
- แบบอย่าง
- ก่อน
- หลัก
- อาจ
- ปัญหา
- ปัญหาที่เกิดขึ้น
- ผลิตภัณฑ์
- ผลิตภัณฑ์
- กำไร
- ห้าม
- สัญญา
- ให้
- หนังสือมอบฉันทะ
- สาธารณะ
- ประกาศ
- การประกาศ
- วัตถุประสงค์
- คำถาม
- เงียบ ๆ
- ปฏิกิริยา
- อ่าน
- เหตุผล
- สูตร
- ลด
- การอ้างอิง
- ปกติ
- การเรียนรู้การเสริมแรง
- ปล่อย
- การวิจัย
- ทรัพยากร
- รับผิดชอบ
- ส่งผลให้
- ทบทวน
- เข้มงวด
- ความเสี่ยง
- หุ่นยนต์
- ข่าวเล่าลือ
- กล่าวว่า
- แซม
- เดียวกัน
- สัตยา Nadella
- โรงเรียน
- ดูเหมือนว่า
- สัญญาณ
- ความรู้สึก
- ประโยค
- ร้ายแรง
- ชุด
- ใช้งานร่วมกัน
- น่า
- ลงชื่อ
- ซิลิคอน
- หุบเขาซิลิคอน
- คล้ายคลึงกัน
- ง่ายดาย
- ตั้งแต่
- สถานการณ์
- แตกต่างกันเล็กน้อย
- ช้า
- สังคม
- โซเชียลมีเดีย
- ทางออก
- โซลูชัน
- บาง
- บางสิ่งบางอย่าง
- ในไม่ช้า
- แหล่งที่มา
- พิเศษ
- ความเชี่ยวชาญ
- การเก็งกำไร
- มั่นคง
- กอง
- ที่เริ่มต้น
- ขั้นตอน
- หยุด
- แข็งแรง
- แข็งแกร่ง
- เสถียร
- ศึกษา
- อย่างเช่น
- ระบบ
- เอา
- เทคโนโลยี
- ข่าวเทคโนโลยี
- TechCrunch
- วิชาการ
- เทคโนโลยี
- เทคโนโลยี
- พื้นที่
- ของพวกเขา
- สิ่ง
- สิ่ง
- คิด
- สาม
- ตลอด
- เวลา
- ไปยัง
- TONE
- เกินไป
- เครื่องมือ
- ด้านบน
- หัวข้อ
- แบบดั้งเดิม
- การจราจร
- การฝึกอบรม
- รักษา
- แนวโน้ม
- จริง
- วางใจ
- tweet
- พูดเบาและรวดเร็ว
- แบบฟอร์ม
- เข้าใจได้
- บันทึก
- ให้กับคุณ
- us
- ใช้
- ผู้ใช้งาน
- ผู้ใช้
- หุบเขา
- บริษัท ร่วมทุน
- รุ่น
- การทำงานได้
- ทำงานได้
- วีดีโอ
- รอ
- คลื่น
- สัปดาห์
- สัปดาห์ที่ผ่านมา
- อะไร
- ว่า
- ที่
- WHO
- จะ
- เต็มใจ
- หน้าต่าง
- ไม่มี
- งาน
- การทำงาน
- โรงงาน
- คุ้มค่า
- จะ
- นักเขียน
- เขียน
- ของคุณ
- ลมทะเล