ค้นหาคอลัมน์ที่คล้ายกันใน ทะเลสาบข้อมูล มีแอปพลิเคชันที่สำคัญในการทำความสะอาดข้อมูลและการเพิ่มความคิดเห็น การจับคู่สคีมา การค้นหาข้อมูล และการวิเคราะห์จากแหล่งข้อมูลต่างๆ การไม่สามารถค้นหาและวิเคราะห์ข้อมูลได้อย่างแม่นยำจากแหล่งข้อมูลที่แตกต่างกันแสดงถึงศักยภาพในการลดประสิทธิภาพสำหรับทุกคน ตั้งแต่นักวิทยาศาสตร์ข้อมูล นักวิจัยทางการแพทย์ นักวิชาการ ไปจนถึงนักวิเคราะห์ทางการเงินและรัฐบาล
โซลูชันทั่วไปเกี่ยวข้องกับการค้นหาคำหลักที่เป็นคำศัพท์หรือการจับคู่นิพจน์ทั่วไป ซึ่งมีความเสี่ยงต่อปัญหาด้านคุณภาพของข้อมูล เช่น ไม่มีชื่อคอลัมน์หรือหลักการตั้งชื่อคอลัมน์ที่แตกต่างกันในชุดข้อมูลที่หลากหลาย (ตัวอย่างเช่น zip_code, zcode, postalcode).
ในโพสต์นี้ เราสาธิตวิธีแก้ปัญหาสำหรับการค้นหาคอลัมน์ที่คล้ายกันตามชื่อคอลัมน์ เนื้อหาคอลัมน์ หรือทั้งสองอย่าง วิธีการแก้ปัญหาใช้ อัลกอริทึมเพื่อนบ้านที่ใกล้ที่สุดโดยประมาณ พร้อมใช้งานใน บริการ Amazon OpenSearch เพื่อค้นหาคอลัมน์ที่มีความหมายคล้ายกัน เพื่ออำนวยความสะดวกในการค้นหา เราสร้างการแสดงคุณลักษณะ (การฝัง) สำหรับแต่ละคอลัมน์ใน Data Lake โดยใช้แบบจำลอง Transformer ที่ผ่านการฝึกอบรมล่วงหน้าจาก ไลบรารีตัวแปลงประโยค in อเมซอน SageMaker. สุดท้าย ในการโต้ตอบและแสดงภาพผลลัพธ์จากโซลูชันของเรา เราสร้างการโต้ตอบ สตรีมไลท์ เว็บแอปพลิเคชันทำงานอยู่ AWS ฟาร์เกต.
เรารวมก กวดวิชารหัส เพื่อให้คุณปรับใช้ทรัพยากรเพื่อเรียกใช้โซลูชันกับข้อมูลตัวอย่างหรือข้อมูลของคุณเอง
ภาพรวมโซลูชัน
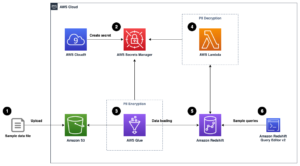
แผนภาพสถาปัตยกรรมต่อไปนี้แสดงเวิร์กโฟลว์สองขั้นตอนสำหรับการค้นหาคอลัมน์ที่มีความหมายคล้ายกัน ด่านแรกดำเนินการ ฟังก์ชันขั้นตอนของ AWS เวิร์กโฟลว์ที่สร้างการฝังจากคอลัมน์ตารางและสร้างดัชนีการค้นหา OpenSearch Service ขั้นตอนที่สองหรือขั้นตอนการอนุมานออนไลน์ เรียกใช้แอปพลิเคชัน Streamlit ผ่าน Fargate เว็บแอปพลิเคชันรวบรวมคำค้นหาอินพุตและดึงข้อมูลจากดัชนี OpenSearch Service คอลัมน์ที่คล้ายกันมากที่สุดโดยประมาณกับคำค้นหา

รูปที่ 1 สถาปัตยกรรมโซลูชัน
เวิร์กโฟลว์อัตโนมัติดำเนินการตามขั้นตอนต่อไปนี้:
- ผู้ใช้อัปโหลดชุดข้อมูลแบบตารางลงใน บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon บัคเก็ต (Amazon S3) ซึ่งเรียกใช้ไฟล์ AWS แลมบ์ดา ฟังก์ชันที่เริ่มต้นเวิร์กโฟลว์ของ Step Functions
- เวิร์กโฟลว์เริ่มต้นด้วย AWS กาว งานที่แปลงไฟล์ CSV เป็น อาปาเช่ปาร์เก้ รูปแบบข้อมูล
- งาน SageMaker Processing สร้างการฝังสำหรับแต่ละคอลัมน์โดยใช้โมเดลที่ผ่านการฝึกอบรมมาแล้วหรือโมเดลการฝังคอลัมน์แบบกำหนดเอง งานการประมวลผล SageMaker จะบันทึกการฝังคอลัมน์สำหรับแต่ละตารางใน Amazon S3
- ฟังก์ชัน Lambda สร้างโดเมน OpenSearch Service และคลัสเตอร์เพื่อจัดทำดัชนีการฝังคอลัมน์ที่สร้างในขั้นตอนก่อนหน้า
- ในที่สุด เว็บแอปพลิเคชัน Streamlit แบบอินเทอร์แอกทีฟจะถูกปรับใช้กับ Fargate เว็บแอ็พพลิเคชันมีส่วนต่อประสานสำหรับผู้ใช้ในการป้อนข้อความค้นหาเพื่อค้นหาโดเมน OpenSearch Service สำหรับคอลัมน์ที่คล้ายกัน
คุณสามารถดาวน์โหลดบทช่วยสอนโค้ดได้จาก GitHub เพื่อลองใช้วิธีแก้ปัญหานี้กับข้อมูลตัวอย่างหรือข้อมูลของคุณเอง คำแนะนำเกี่ยวกับวิธีปรับใช้ทรัพยากรที่จำเป็นสำหรับบทช่วยสอนนี้มีอยู่ใน Github.
ข้อกำหนดเบื้องต้น
ในการใช้โซลูชันนี้ คุณต้องมีสิ่งต่อไปนี้:
- An บัญชี AWS.
- ความคุ้นเคยเบื้องต้นกับบริการของ AWS เช่น ชุดพัฒนา AWS Cloud (AWS CDK), Lambda, OpenSearch Service และ SageMaker Processing
- ชุดข้อมูลแบบตารางเพื่อสร้างดัชนีการค้นหา คุณสามารถนำข้อมูลแบบตารางมาเองหรือดาวน์โหลดชุดข้อมูลตัวอย่างได้ GitHub.
สร้างดัชนีการค้นหา
ขั้นตอนแรกสร้างดัชนีเครื่องมือค้นหาของคอลัมน์ รูปต่อไปนี้แสดงเวิร์กโฟลว์ของ Step Functions ที่รันสเตจนี้

รูปที่ 2 – เวิร์กโฟลว์ของฟังก์ชันขั้นตอน – โมเดลการฝังหลายตัว
ชุดข้อมูล
ในโพสต์นี้ เราสร้างดัชนีการค้นหาเพื่อรวมกว่า 400 คอลัมน์จากชุดข้อมูลแบบตารางกว่า 25 ชุด ชุดข้อมูลมาจากแหล่งสาธารณะต่อไปนี้:
สำหรับรายการทั้งหมดของตารางที่รวมอยู่ในดัชนี โปรดดูบทช่วยสอนเกี่ยวกับโค้ด GitHub.
คุณสามารถนำชุดข้อมูลแบบตารางของคุณเองมาเสริมข้อมูลตัวอย่างหรือสร้างดัชนีการค้นหาของคุณเองได้ เรามีฟังก์ชัน Lambda สองฟังก์ชันที่เริ่มต้นเวิร์กโฟลว์ของ Step Functions เพื่อสร้างดัชนีการค้นหาสำหรับไฟล์ CSV แต่ละไฟล์หรือชุดไฟล์ CSV ตามลำดับ
แปลง CSV เป็น Parquet
ไฟล์ Raw CSV จะถูกแปลงเป็นรูปแบบข้อมูล Parquet ด้วย AWS Glue Parquet เป็นรูปแบบไฟล์รูปแบบคอลัมน์ที่ต้องการในการวิเคราะห์ข้อมูลขนาดใหญ่ที่ให้การบีบอัดและการเข้ารหัสที่มีประสิทธิภาพ ในการทดลองของเรา รูปแบบข้อมูล Parquet มีขนาดพื้นที่จัดเก็บลดลงอย่างมากเมื่อเทียบกับไฟล์ CSV ดิบ นอกจากนี้ เรายังใช้ Parquet เป็นรูปแบบข้อมูลทั่วไปในการแปลงรูปแบบข้อมูลอื่นๆ (เช่น JSON และ NDJSON) เนื่องจากสนับสนุนโครงสร้างข้อมูลที่ซ้อนกันขั้นสูง
สร้างการฝังคอลัมน์แบบตาราง
ในการแยกการฝังสำหรับแต่ละคอลัมน์ของตารางในชุดข้อมูลตารางตัวอย่างในโพสต์นี้ เราใช้โมเดลที่ผ่านการฝึกอบรมมาแล้วต่อไปนี้จาก sentence-transformers ห้องสมุด. สำหรับรุ่นเพิ่มเติม โปรดดูที่ โมเดลสำเร็จรูป.
งานประมวลผล SageMaker กำลังทำงาน create_embeddings.py(รหัส) สำหรับรุ่นเดียว สำหรับการแยกการฝังจากหลายรุ่น เวิร์กโฟลว์จะรันงาน SageMaker Processing แบบคู่ขนานตามที่แสดงในเวิร์กโฟลว์ Step Functions เราใช้แบบจำลองเพื่อสร้างการฝังสองชุด:
- column_name_embeddings – การฝังชื่อคอลัมน์ (ส่วนหัว)
- column_content_embeddings – การฝังเฉลี่ยของแถวทั้งหมดในคอลัมน์
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับกระบวนการฝังคอลัมน์ โปรดดูบทช่วยสอนเกี่ยวกับโค้ด GitHub.
อีกทางเลือกหนึ่งสำหรับขั้นตอนการประมวลผล SageMaker คือการสร้างการแปลงเป็นชุดของ SageMaker เพื่อรับการฝังคอลัมน์ในชุดข้อมูลขนาดใหญ่ ซึ่งจำเป็นต้องปรับใช้โมเดลกับตำแหน่งข้อมูล SageMaker สำหรับข้อมูลเพิ่มเติม โปรดดูที่ ใช้การแปลงเป็นชุด.
การฝังดัชนีด้วยบริการ OpenSearch
ในขั้นตอนสุดท้ายของขั้นตอนนี้ ฟังก์ชัน Lambda จะเพิ่มการฝังคอลัมน์ในบริการ OpenSearch โดยประมาณ k-Nearest-Neighbor (kNN) ดัชนีการค้นหา. แต่ละรุ่นได้รับการกำหนดดัชนีการค้นหาของตัวเอง สำหรับข้อมูลเพิ่มเติมเกี่ยวกับพารามิเตอร์ดัชนีการค้นหา kNN โดยประมาณ โปรดดูที่ เค-เอ็น.
การอนุมานออนไลน์และการค้นหาความหมายด้วยเว็บแอป
ขั้นตอนที่สองของเวิร์กโฟลว์เรียกใช้ สตรีมไลท์ เว็บแอปพลิเคชันที่คุณสามารถป้อนข้อมูลและค้นหาคอลัมน์ที่มีความหมายคล้ายกันซึ่งจัดทำดัชนีใน OpenSearch Service ชั้นแอปพลิเคชันใช้ไฟล์ แอปพลิเคชัน Load Balancerฟาร์เกตและแลมบ์ดา โครงสร้างพื้นฐานของแอปพลิเคชันจะถูกปรับใช้โดยอัตโนมัติโดยเป็นส่วนหนึ่งของโซลูชัน
แอปพลิเคชันอนุญาตให้คุณป้อนข้อมูลและค้นหาชื่อคอลัมน์ที่มีความหมายคล้ายกัน เนื้อหาคอลัมน์ หรือทั้งสองอย่าง นอกจากนี้ คุณสามารถเลือกรูปแบบการฝังและจำนวนเพื่อนบ้านที่ใกล้ที่สุดเพื่อส่งคืนจากการค้นหา แอปพลิเคชันรับอินพุต ฝังอินพุตด้วยโมเดลที่ระบุ และใช้งาน การค้นหา kNN ใน OpenSearch Service เพื่อค้นหาการฝังคอลัมน์ที่จัดทำดัชนีและค้นหาคอลัมน์ที่คล้ายกันมากที่สุดกับอินพุตที่กำหนด ผลการค้นหาที่แสดงประกอบด้วยชื่อตาราง ชื่อคอลัมน์ และคะแนนความคล้ายคลึงกันสำหรับคอลัมน์ที่ระบุ ตลอดจนตำแหน่งของข้อมูลใน Amazon S3 สำหรับการสำรวจเพิ่มเติม
รูปภาพต่อไปนี้แสดงตัวอย่างเว็บแอปพลิเคชัน ในตัวอย่างนี้ เราค้นหาคอลัมน์ใน Data Lake ของเราที่มีลักษณะคล้ายกัน Column Names (ประเภทน้ำหนักบรรทุก) มัน district (น้ำหนักบรรทุก). แอพพลิเคชั่นที่ใช้ all-MiniLM-L6-v2 เป็น รูปแบบการฝัง และกลับมา 10 (k) เพื่อนบ้านที่ใกล้ที่สุดจากดัชนี OpenSearch Service ของเรา
แอปพลิเคชันกลับมา transit_district, city, boroughและ location เป็นสี่คอลัมน์ที่คล้ายกันมากที่สุดตามข้อมูลที่จัดทำดัชนีใน OpenSearch Service ตัวอย่างนี้แสดงให้เห็นถึงความสามารถของแนวทางการค้นหาในการระบุคอลัมน์ที่มีความหมายคล้ายกันในชุดข้อมูลต่างๆ

รูปที่ 3: ส่วนติดต่อผู้ใช้เว็บแอปพลิเคชัน
ทำความสะอาด
หากต้องการลบทรัพยากรที่สร้างโดย AWS CDK ในบทช่วยสอนนี้ ให้เรียกใช้คำสั่งต่อไปนี้:
cdk destroy --allสรุป
ในโพสต์นี้ เรานำเสนอเวิร์กโฟลว์แบบ end-to-end สำหรับการสร้างเครื่องมือค้นหาความหมายสำหรับคอลัมน์แบบตาราง
เริ่มต้นวันนี้ด้วยข้อมูลของคุณเองด้วยการสอนโค้ดของเราที่มีอยู่บน GitHub. หากคุณต้องการความช่วยเหลือในการเร่งการใช้ ML ในผลิตภัณฑ์และกระบวนการของคุณ โปรดติดต่อ ห้องปฏิบัติการโซลูชันแมชชีนเลิร์นนิงของ Amazon.
เกี่ยวกับผู้เขียน
![]() คาจิ โอโดเมเนะ เป็นนักวิทยาศาสตร์ประยุกต์ที่ AWS AI เขาสร้างโซลูชัน AI/ML เพื่อแก้ปัญหาทางธุรกิจให้กับลูกค้า AWS
คาจิ โอโดเมเนะ เป็นนักวิทยาศาสตร์ประยุกต์ที่ AWS AI เขาสร้างโซลูชัน AI/ML เพื่อแก้ปัญหาทางธุรกิจให้กับลูกค้า AWS
![]() เทย์เลอร์ แมคแนลลี่ เป็นสถาปนิก Deep Learning ที่ Amazon Machine Learning Solutions Lab เขาช่วยลูกค้าจากอุตสาหกรรมต่างๆ สร้างโซลูชันที่ใช้ประโยชน์จาก AI/ML บน AWS เขาเพลิดเพลินกับกาแฟดีๆ สักถ้วย กลางแจ้ง และมีเวลาอยู่กับครอบครัวและสุนัขที่กระฉับกระเฉง
เทย์เลอร์ แมคแนลลี่ เป็นสถาปนิก Deep Learning ที่ Amazon Machine Learning Solutions Lab เขาช่วยลูกค้าจากอุตสาหกรรมต่างๆ สร้างโซลูชันที่ใช้ประโยชน์จาก AI/ML บน AWS เขาเพลิดเพลินกับกาแฟดีๆ สักถ้วย กลางแจ้ง และมีเวลาอยู่กับครอบครัวและสุนัขที่กระฉับกระเฉง
![]() ออสติน เวลช์ เป็นนักวิทยาศาสตร์ข้อมูลใน Amazon ML Solutions Lab เขาพัฒนาโมเดลการเรียนรู้เชิงลึกแบบกำหนดเองเพื่อช่วยให้ลูกค้าภาครัฐของ AWS เร่งการนำ AI และระบบคลาวด์ไปใช้ ในเวลาว่าง เขาชอบอ่านหนังสือ เดินทาง และยิวยิตสู
ออสติน เวลช์ เป็นนักวิทยาศาสตร์ข้อมูลใน Amazon ML Solutions Lab เขาพัฒนาโมเดลการเรียนรู้เชิงลึกแบบกำหนดเองเพื่อช่วยให้ลูกค้าภาครัฐของ AWS เร่งการนำ AI และระบบคลาวด์ไปใช้ ในเวลาว่าง เขาชอบอ่านหนังสือ เดินทาง และยิวยิตสู
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- ความสามารถ
- เกี่ยวกับเรา
- ไม่อยู่
- เร่งความเร็ว
- เร่ง
- แม่นยำ
- ข้าม
- เพิ่มเติม
- นอกจากนี้
- เพิ่ม
- การนำมาใช้
- สูง
- AI
- AI / ML
- ทั้งหมด
- ช่วยให้
- ทางเลือก
- อเมซอน
- อเมซอน แมชชีนเลิร์นนิง
- ห้องปฏิบัติการโซลูชัน Amazon ML
- นักวิเคราะห์
- การวิเคราะห์
- วิเคราะห์
- และ
- อาปาเช่
- การใช้งาน
- การใช้งาน
- ประยุกต์
- เข้าใกล้
- สถาปัตยกรรม
- ที่ได้รับมอบหมาย
- อัตโนมัติ
- อัตโนมัติ
- ใช้ได้
- เฉลี่ย
- AWS
- AWS กาว
- ตาม
- เพราะ
- ใหญ่
- ข้อมูลขนาดใหญ่
- นำมาซึ่ง
- สร้าง
- การก่อสร้าง
- สร้าง
- ธุรกิจ
- การทำความสะอาด
- เมฆ
- การยอมรับระบบคลาวด์
- Cluster
- รหัส
- กาแฟ
- เก็บรวบรวม
- คอลัมน์
- คอลัมน์
- ร่วมกัน
- เมื่อเทียบกับ
- ติดต่อเรา
- เนื้อหา
- การประชุม
- แปลง
- แปลง
- สร้าง
- ที่สร้างขึ้น
- สร้าง
- ถ้วย
- ประเพณี
- ลูกค้า
- ข้อมูล
- วิเคราะห์ข้อมูล
- ดาต้าเลค
- คุณภาพของข้อมูล
- นักวิทยาศาสตร์ข้อมูล
- ชุดข้อมูล
- ลึก
- การเรียนรู้ลึก ๆ
- สาธิต
- แสดงให้เห็นถึง
- ปรับใช้
- นำไปใช้
- ปรับใช้
- ทำลาย
- พัฒนาการ
- พัฒนา
- ต่าง
- การค้นพบ
- ต่างกัน
- หลาย
- สุนัข
- โดเมน
- ดาวน์โหลด
- แต่ละ
- อย่างมีประสิทธิภาพ
- ที่มีประสิทธิภาพ
- จบสิ้น
- ปลายทาง
- เครื่องยนต์
- อีเธอร์ (ETH)
- ทุกคน
- ตัวอย่าง
- การสำรวจ
- สารสกัด
- อำนวยความสะดวก
- ความคุ้นเคย
- ครอบครัว
- คุณสมบัติ
- รูป
- เนื้อไม่มีมัน
- ไฟล์
- สุดท้าย
- ในที่สุด
- ทางการเงิน
- หา
- หา
- ชื่อจริง
- ดังต่อไปนี้
- รูป
- ราคาเริ่มต้นที่
- เต็ม
- ฟังก์ชัน
- ฟังก์ชั่น
- ต่อไป
- ได้รับ
- กำหนด
- ดี
- รัฐบาล
- ส่วนหัว
- ช่วย
- จะช่วยให้
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTML
- HTTPS
- ระบุ
- แยกแยะ
- การดำเนินการ
- สำคัญ
- in
- การไร้ความสามารถ
- ประกอบด้วย
- รวม
- ดัชนี
- เป็นรายบุคคล
- อุตสาหกรรม
- ข้อมูล
- โครงสร้างพื้นฐาน
- เริ่มต้น
- ประทับจิต
- อินพุต
- คำแนะนำการใช้
- โต้ตอบ
- การโต้ตอบ
- อินเตอร์เฟซ
- จะเรียก
- รวมถึง
- ปัญหา
- IT
- การสัมภาษณ์
- งาน
- JSON
- ห้องปฏิบัติการ
- ทะเลสาบ
- ใหญ่
- ชั้น
- การเรียนรู้
- การใช้ประโยชน์
- ห้องสมุด
- รายการ
- โหลด
- วันหยุด
- เครื่อง
- เรียนรู้เครื่อง
- การจับคู่
- ทางการแพทย์
- ML
- แบบ
- โมเดล
- ข้อมูลเพิ่มเติม
- มากที่สุด
- หลาย
- ชื่อ
- ชื่อ
- การตั้งชื่อ
- จำเป็นต้อง
- เพื่อนบ้าน
- จำนวน
- เสนอ
- ออนไลน์
- อื่นๆ
- กลางแจ้ง
- ของตนเอง
- Parallel
- พารามิเตอร์
- ส่วนหนึ่ง
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- กรุณา
- โพสต์
- ที่มีศักยภาพ
- ที่ต้องการ
- นำเสนอ
- ก่อน
- ปัญหาที่เกิดขึ้น
- เงินที่ได้
- กระบวนการ
- กระบวนการ
- การประมวลผล
- ผลิต
- ผลิตภัณฑ์
- ให้
- ให้
- สาธารณะ
- คุณภาพ
- ดิบ
- การอ่าน
- ที่ได้รับ
- ปกติ
- แสดงให้เห็นถึง
- ต้องการ
- จำเป็นต้องใช้
- นักวิจัย
- แหล่งข้อมูล
- ตามลำดับ
- ผลสอบ
- กลับ
- วิ่ง
- วิ่ง
- sagemaker
- นักวิทยาศาสตร์
- นักวิทยาศาสตร์
- ค้นหา
- เครื่องมือค้นหา
- ค้นหา
- ที่สอง
- ภาค
- บริการ
- บริการ
- ชุดอุปกรณ์
- แสดง
- แสดงให้เห็นว่า
- สำคัญ
- คล้ายคลึงกัน
- ง่าย
- เดียว
- ขนาด
- ทางออก
- โซลูชัน
- แก้
- แหล่งที่มา
- ที่ระบุไว้
- ระยะ
- ข้อความที่เริ่ม
- ขั้นตอน
- ขั้นตอน
- การเก็บรักษา
- อย่างเช่น
- รองรับ
- ฉลาด
- ตาราง
- พื้นที่
- ของพวกเขา
- ตลอด
- เวลา
- ไปยัง
- ในวันนี้
- แปลง
- หม้อแปลง
- การเดินทาง
- เกี่ยวกับการสอน
- ใช้
- ผู้ใช้งาน
- ส่วนติดต่อผู้ใช้
- ต่างๆ
- เว็บ
- โปรแกรมประยุกต์บนเว็บ
- ที่
- เวิร์กโฟลว์
- จะ
- ของคุณ
- ลมทะเล