ความหมายของ Amazon เป็นบริการคอมพิวเตอร์วิทัศน์ที่ช่วยให้เพิ่มการวิเคราะห์ภาพและวิดีโอลงในแอปพลิเคชันของคุณได้ง่ายโดยใช้เทคโนโลยีการเรียนรู้เชิงลึกที่ได้รับการพิสูจน์แล้ว ปรับขนาดได้สูง และไม่ต้องอาศัยความเชี่ยวชาญด้านแมชชีนเลิร์นนิง (ML) ในการใช้งาน ด้วย Amazon Rekognition คุณสามารถระบุวัตถุ บุคคล ข้อความ ฉาก และกิจกรรมในรูปภาพและวิดีโอ ตลอดจนตรวจจับเนื้อหาที่ไม่เหมาะสมได้ Amazon Rekognition ยังมีความสามารถในการวิเคราะห์ใบหน้าและการค้นหาใบหน้าที่แม่นยำสูง ซึ่งคุณสามารถใช้ตรวจจับ วิเคราะห์ และเปรียบเทียบใบหน้าสำหรับกรณีการใช้งานที่หลากหลาย
ป้ายกำกับที่กำหนดเองของ Amazon Rekognition ช่วยให้คุณระบุวัตถุและฉากในภาพที่เจาะจงกับความต้องการทางธุรกิจของคุณได้ ตัวอย่างเช่น คุณสามารถค้นหาโลโก้ของคุณในโพสต์โซเชียลมีเดีย ระบุผลิตภัณฑ์ของคุณบนชั้นวางสินค้า จำแนกชิ้นส่วนเครื่องจักรในสายการประกอบ แยกแยะพืชที่มีสุขภาพดีและที่ติดเชื้อ และอื่นๆ บล็อกโพสต์ สร้างการตรวจจับแบรนด์ของคุณเอง แสดงวิธีใช้ Amazon Rekognition Custom Labels เพื่อสร้างโซลูชันแบบ end-to-end เพื่อตรวจจับโลโก้แบรนด์ในรูปภาพและวิดีโอ
Amazon Rekognition Custom Labels มอบประสบการณ์การใช้งานแบบ end-to-end ที่เรียบง่าย โดยที่คุณเริ่มต้นด้วยการติดป้ายกำกับชุดข้อมูล และ Amazon Rekognition Custom Labels จะสร้างโมเดล ML แบบกำหนดเองให้กับคุณโดยตรวจสอบข้อมูลและเลือกอัลกอริทึม ML ที่เหมาะสม หลังจากที่แบบจำลองของคุณได้รับการฝึกอบรมแล้ว คุณสามารถเริ่มใช้งานแบบจำลองได้ทันทีสำหรับการวิเคราะห์ภาพ หากคุณต้องการประมวลผลรูปภาพเป็นชุด (เช่น วันละครั้งหรือสัปดาห์ หรือตามเวลาที่กำหนดไว้ในระหว่างวัน) คุณสามารถจัดเตรียมแบบจำลองที่กำหนดเองของคุณตามเวลาที่กำหนดได้
ในโพสต์นี้ เราจะแสดงวิธีที่คุณสามารถสร้างโซลูชันชุดงานที่เหมาะสมกับต้นทุนด้วย Amazon Rekognition Custom Labels ที่จัดเตรียมโมเดลแบบกำหนดเองของคุณตามเวลาที่กำหนด ประมวลผลภาพทั้งหมดของคุณ และยกเลิกการจัดสรรทรัพยากรของคุณเพื่อหลีกเลี่ยงค่าใช้จ่ายเพิ่มเติม
ภาพรวมของโซลูชัน
ไดอะแกรมสถาปัตยกรรมต่อไปนี้แสดงวิธีที่คุณสามารถออกแบบเวิร์กโฟลว์ที่คุ้มค่าและปรับขนาดได้สูงเพื่อประมวลผลภาพเป็นชุดด้วย Amazon Rekognition Custom Labels ใช้ประโยชน์จากบริการของ AWS เช่น อเมซอน EventBridge, ฟังก์ชันขั้นตอนของ AWS, บริการ Amazon Simple Queue (อเมซอน SQS) AWS แลมบ์ดาและ บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (อเมซอน เอส3).
โซลูชันนี้ใช้สถาปัตยกรรมแบบไร้เซิร์ฟเวอร์และบริการที่มีการจัดการ จึงสามารถปรับขนาดได้ตามความต้องการและไม่ต้องเตรียมใช้งานและจัดการเซิร์ฟเวอร์ใดๆ คิว Amazon SQS เพิ่มความทนทานต่อความผิดพลาดโดยรวมของโซลูชันโดยแยกการนำเข้ารูปภาพออกจากการประมวลผลรูปภาพ และเปิดใช้งานการส่งข้อความที่เชื่อถือได้สำหรับรูปภาพที่นำเข้าแต่ละรูป Step Functions ทำให้ง่ายต่อการสร้างเวิร์กโฟลว์แบบภาพเพื่อจัดเตรียมชุดของงานแต่ละอย่าง เช่น การตรวจสอบว่ามีอิมเมจพร้อมสำหรับการประมวลผลหรือไม่ และจัดการวงจรชีวิตสถานะของโปรเจ็กต์ Amazon Rekognition Custom Labels แม้ว่าสถาปัตยกรรมต่อไปนี้จะแสดงวิธีที่คุณสามารถสร้างโซลูชันการประมวลผลแบบกลุ่มสำหรับ Amazon Rekognition Custom Labels โดยใช้ AWS Lambda คุณสามารถสร้างสถาปัตยกรรมที่คล้ายกันได้โดยใช้บริการต่างๆ เช่น AWS ฟาร์เกต.
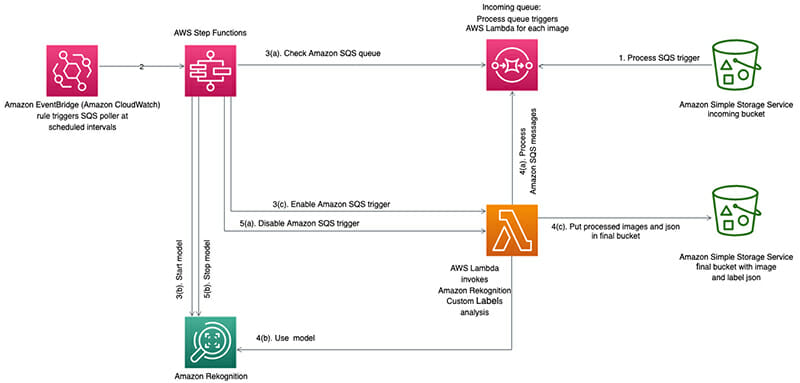
ขั้นตอนต่อไปนี้อธิบายเวิร์กโฟลว์โดยรวม:
- เนื่องจากรูปภาพถูกจัดเก็บไว้ในบัคเก็ต Amazon S3 จึงทริกเกอร์ข้อความที่จัดเก็บไว้ในคิว Amazon SQS
- Amazon EventBridge ได้รับการกำหนดค่าให้ทริกเกอร์เวิร์กโฟลว์ AWS Step Functions ที่ความถี่ที่แน่นอน (ค่าเริ่มต้น 1 ชั่วโมง)
- ขณะที่เวิร์กโฟลว์ทำงาน จะดำเนินการดังต่อไปนี้:
- จะตรวจสอบจำนวนรายการในคิว Amazon SQS หากไม่มีรายการให้ดำเนินการในคิว เวิร์กโฟลว์จะสิ้นสุดลง
- หากมีรายการที่ต้องดำเนินการในคิว เวิร์กโฟลว์จะเริ่มต้นโมเดล Amazon Rekognition Custom Labels
- เวิร์กโฟลว์ทำให้สามารถผสานรวม Amazon SQS กับฟังก์ชัน AWS Lambda เพื่อประมวลผลภาพเหล่านั้นได้
- เมื่อเปิดใช้งานการผสานระหว่างคิว Amazon SQS และ AWS Lambda เหตุการณ์ต่อไปนี้จะเกิดขึ้น:
- AWS Lambda เริ่มประมวลผลข้อความด้วยรายละเอียดรูปภาพจาก Amazon SQS
- ฟังก์ชัน AWS Lambda ใช้โปรเจ็กต์ Amazon Rekognition Custom Labels เพื่อประมวลผลอิมเมจ
- จากนั้นฟังก์ชัน AWS Lambda จะวางไฟล์ JSON ที่มีป้ายกำกับที่อนุมานไว้ในบัคเก็ตสุดท้าย รูปภาพจะถูกย้ายจากที่เก็บข้อมูลต้นทางไปยังที่เก็บข้อมูลสุดท้ายด้วย
- เมื่อภาพทั้งหมดได้รับการประมวลผล เวิร์กโฟลว์ AWS Step Functions จะทำสิ่งต่อไปนี้:
- จะหยุดโมเดล Amazon Rekognition Custom Labels
- ปิดใช้งานการผสานระหว่างคิว Amazon SQS และฟังก์ชัน AWS Lambda โดยการปิดใช้งานทริกเกอร์
ไดอะแกรมต่อไปนี้แสดงเครื่องสถานะ AWS Step Functions สำหรับโซลูชันนี้
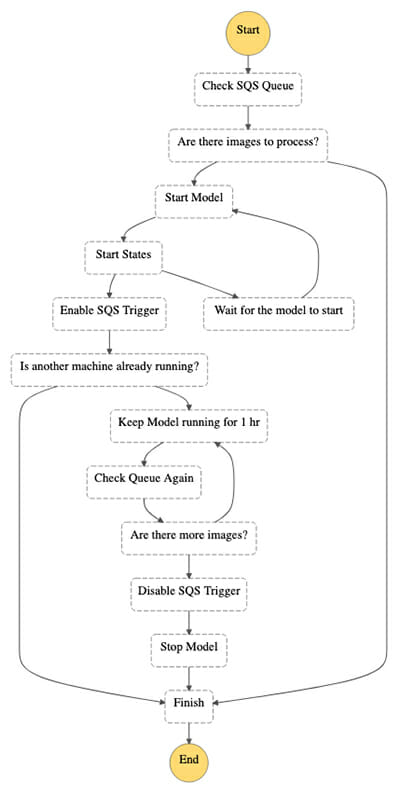
เบื้องต้น
ในการปรับใช้โซลูชันนี้ คุณต้องมีข้อกำหนดเบื้องต้นต่อไปนี้:
- บัญชี AWS ที่ได้รับอนุญาตให้ปรับใช้โซลูชันโดยใช้ การก่อตัวของ AWS Cloudซึ่งสร้าง AWS Identity และการจัดการการเข้าถึง (IAM) บทบาทและทรัพยากรอื่นๆ
- ชื่อทรัพยากร Amazon (ARN) ของโครงการ Amazon Rekognition Custom Labels (เรียกว่า โครงการArn) และชื่อทรัพยากรของ Amazon (ARN) ของรุ่นรุ่นที่สร้างขึ้นหลังจากการฝึกแบบจำลอง (อ้างอิงเป็น โปรเจ็กต์เวอร์ชันอาร์น). ค่าเหล่านี้จำเป็นสำหรับตรวจสอบสถานะของโมเดลและวิเคราะห์รูปภาพโดยใช้โมเดลด้วย
เรียนรู้วิธีฝึกโมเดลได้ที่ เริ่มต้นใช้งาน Amazon Rekognition Custom Labels.
การใช้งาน
ในการปรับใช้โซลูชันโดยใช้ AWS CloudFormation ในบัญชี AWS ของคุณ ให้ทำตามขั้นตอนใน repo GitHub. มันสร้างทรัพยากรดังต่อไปนี้:
- ถัง Amazon S3
- คิว Amazon SQS
- เวิร์กโฟลว์ AWS Step Function
- กฎ Amazon EventBridge เพื่อทริกเกอร์เวิร์กโฟลว์
- บทบาท IAM
- ฟังก์ชัน AWS Lambda
คุณสามารถดูชื่อของทรัพยากรต่างๆ ที่สร้างโดยโซลูชันได้ในส่วนผลลัพธ์ของ กอง CloudFormation.
การทดสอบเวิร์กโฟลว์
ในการทดสอบเวิร์กโฟลว์ของคุณ ให้ทำตามขั้นตอนต่อไปนี้:
- อัปโหลดภาพตัวอย่างไปยังบัคเก็ต S3 อินพุตที่สร้างโดยโซลูชัน (เช่น xxxx-sources3bucket-xxxx)
- บนคอนโซล Step Functions ให้เลือกเครื่องสถานะที่สร้างโดยโซลูชัน (เช่น CustomCVStateMachine-xxxx)
คุณควรเห็นว่าเครื่องสถานะถูกทริกเกอร์โดยกฎ Amazon EventBridge ทุกชั่วโมง
- คุณสามารถเริ่มเวิร์กโฟลว์ด้วยตนเองโดยเลือก เริ่มดำเนินการ.
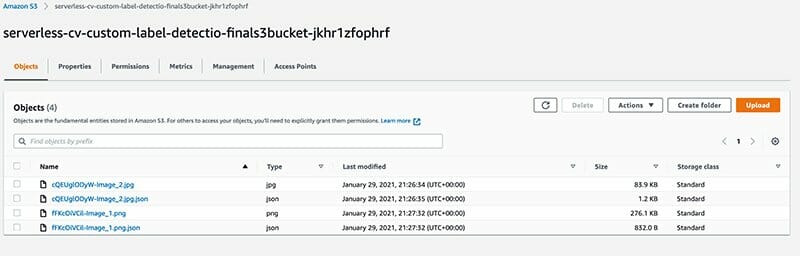
- ขณะประมวลผลรูปภาพ คุณสามารถไปที่บัคเก็ต S3 ของเอาต์พุต (เช่น xxxx-finals3bucket-xxxx) เพื่อดูเอาต์พุต JSON สำหรับแต่ละรูปภาพ
ภาพหน้าจอต่อไปนี้แสดงเนื้อหาของบัคเก็ต S3 สุดท้ายพร้อมรูปภาพ พร้อมด้วยเอาต์พุต JSON ที่เกี่ยวข้องจากป้ายกำกับที่กำหนดเองของ Amazon Rekognition
สรุป
ในโพสต์นี้ เราแสดงวิธีที่คุณสามารถสร้างโซลูชันแบบกลุ่มที่เหมาะสมกับต้นทุนด้วย Amazon Rekognition Custom Labels ที่สามารถจัดเตรียมโมเดลแบบกำหนดเองของคุณตามเวลาที่กำหนด ประมวลผลภาพทั้งหมดของคุณ และยกเลิกการจัดสรรทรัพยากรของคุณเพื่อหลีกเลี่ยงค่าใช้จ่ายเพิ่มเติม ขึ้นอยู่กับกรณีการใช้งานของคุณ คุณสามารถปรับกรอบเวลาตามกำหนดการที่โซลูชันควรประมวลผลชุดงานได้อย่างง่ายดาย สำหรับข้อมูลเพิ่มเติมเกี่ยวกับวิธีการสร้าง ฝึกฝน ประเมิน และใช้แบบจำลองที่ตรวจจับวัตถุ ฉาก และแนวคิดในภาพ โปรดดู เริ่มต้นใช้งาน Amazon Rekognition Custom Labels.
ในขณะที่โซลูชันที่อธิบายในโพสต์นี้แสดงให้เห็นว่าคุณสามารถประมวลผลภาพแบตช์ด้วย Amazon Rekognition Custom Labels ได้อย่างไร คุณสามารถปรับแต่งโซลูชันเพื่อประมวลผลภาพแบตช์ได้อย่างง่ายดายด้วย Amazon Lookout สำหรับวิสัยทัศน์ สำหรับข้อบกพร่องและการตรวจจับความผิดปกติ ด้วย Amazon Lookout for Vision บริษัทผู้ผลิตสามารถเพิ่มคุณภาพและลดต้นทุนการดำเนินงานโดยระบุความแตกต่างอย่างรวดเร็วในรูปภาพของวัตถุตามขนาด ตัวอย่างเช่น สามารถใช้ Amazon Lookout for Vision เพื่อระบุส่วนประกอบที่ขาดหายไปในผลิตภัณฑ์ ความเสียหายต่อยานพาหนะหรือโครงสร้าง ความผิดปกติในสายการผลิต ข้อบกพร่องเล็กน้อยในแผ่นเวเฟอร์ซิลิคอน และปัญหาอื่นๆ ที่คล้ายคลึงกัน หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ Amazon Lookout for Vision โปรดดูที่ คู่มือนักพัฒนา.
เกี่ยวกับผู้เขียน
 ราหุล ศรีวัฒวา เป็นสถาปนิกโซลูชันอาวุโสที่ Amazon Web Services และตั้งอยู่ในสหราชอาณาจักร เขามีประสบการณ์ด้านสถาปัตยกรรมที่กว้างขวางในการทำงานกับลูกค้าองค์กรขนาดใหญ่ เขากำลังช่วยเหลือลูกค้าของเราในด้านสถาปัตยกรรม การนำระบบคลาวด์มาใช้ พัฒนาผลิตภัณฑ์โดยมีจุดประสงค์ และใช้ประโยชน์จาก AI/ ML เพื่อแก้ปัญหาทางธุรกิจในโลกแห่งความเป็นจริง
ราหุล ศรีวัฒวา เป็นสถาปนิกโซลูชันอาวุโสที่ Amazon Web Services และตั้งอยู่ในสหราชอาณาจักร เขามีประสบการณ์ด้านสถาปัตยกรรมที่กว้างขวางในการทำงานกับลูกค้าองค์กรขนาดใหญ่ เขากำลังช่วยเหลือลูกค้าของเราในด้านสถาปัตยกรรม การนำระบบคลาวด์มาใช้ พัฒนาผลิตภัณฑ์โดยมีจุดประสงค์ และใช้ประโยชน์จาก AI/ ML เพื่อแก้ปัญหาทางธุรกิจในโลกแห่งความเป็นจริง
 คาชิฟ อิมราน เป็นสถาปนิกโซลูชั่นหลักที่ Amazon Web Services เขาทำงานร่วมกับลูกค้า AWS รายใหญ่ที่สุดบางรายที่กำลังใช้ประโยชน์จาก AI/ML เพื่อแก้ปัญหาทางธุรกิจที่ซับซ้อน เขาให้คำแนะนำด้านเทคนิคและคำแนะนำในการออกแบบเพื่อนำแอปพลิเคชันวิทัศน์คอมพิวเตอร์ไปใช้ในวงกว้าง ความเชี่ยวชาญของเขาครอบคลุมสถาปัตยกรรมแอปพลิเคชัน ไร้เซิร์ฟเวอร์ คอนเทนเนอร์ NoSQL และการเรียนรู้ของเครื่อง
คาชิฟ อิมราน เป็นสถาปนิกโซลูชั่นหลักที่ Amazon Web Services เขาทำงานร่วมกับลูกค้า AWS รายใหญ่ที่สุดบางรายที่กำลังใช้ประโยชน์จาก AI/ML เพื่อแก้ปัญหาทางธุรกิจที่ซับซ้อน เขาให้คำแนะนำด้านเทคนิคและคำแนะนำในการออกแบบเพื่อนำแอปพลิเคชันวิทัศน์คอมพิวเตอร์ไปใช้ในวงกว้าง ความเชี่ยวชาญของเขาครอบคลุมสถาปัตยกรรมแอปพลิเคชัน ไร้เซิร์ฟเวอร์ คอนเทนเนอร์ NoSQL และการเรียนรู้ของเครื่อง
