
ภาพโดยผู้เขียน
การเรียนรู้ของเครื่องถือเป็นดาวเด่นแห่งยุคใหม่อย่างปฏิเสธไม่ได้ โดยเป็นแกนหลักของเทคโนโลยีสำคัญต่างๆ ที่กลายมาเป็นส่วนสำคัญในชีวิตประจำวันของเรา เช่น การจดจำใบหน้า (สนับสนุนโดย Convolutional Neural Networks หรือ CNN) การรู้จำเสียงพูด (ใช้ประโยชน์จาก CNN และ Recurrent Neural Networks หรือ RNN) และแชทบอทที่ได้รับความนิยมมากขึ้นเรื่อยๆ เช่น ChatGPT (ขับเคลื่อนโดยการเรียนรู้การเสริมกำลังจากผลตอบรับของมนุษย์, RLHF)
ปัจจุบันมีวิธีการมากมายเพื่อปรับปรุงประสิทธิภาพของโมเดลการเรียนรู้ของเครื่อง วิธีการเหล่านี้สามารถทำให้โครงการของคุณมีความได้เปรียบในการแข่งขันโดยมอบประสิทธิภาพที่เหนือกว่า
ในการสนทนานี้ เราจะเจาะลึกขอบเขตของเทคนิคการเลือกคุณลักษณะ แต่ก่อนที่เราจะดำเนินการต่อไป เรามาทำความเข้าใจกันดีกว่า: การเลือกคุณสมบัติคืออะไรกันแน่?
การเลือกคุณสมบัติเป็นกระบวนการในการเลือกคุณสมบัติที่ดีที่สุดสำหรับโมเดลของคุณ กระบวนการนี้อาจแตกต่างกันไปในแต่ละเทคนิค แต่เป้าหมายหลักคือการค้นหาว่าคุณลักษณะใดมีผลกระทบต่อโมเดลของคุณมากกว่า
เพราะบางครั้งการมีฟีเจอร์มากเกินไปอาจส่งผลเสียต่อโมเดลแมชชีนเลิร์นนิงของคุณ ยังไง?
อาจมีสาเหตุที่แตกต่างกันมากเกินไป ตัวอย่างเช่น คุณลักษณะเหล่านี้อาจเกี่ยวข้องกัน ซึ่งอาจก่อให้เกิดความเชื่อมโยงหลายส่วน ส่งผลเสียต่อประสิทธิภาพของโมเดลของคุณ
ปัญหาที่อาจเกิดขึ้นอีกประการหนึ่งเกี่ยวข้องกับพลังการคำนวณ การมีคุณสมบัติมากเกินไปทำให้จำเป็นต้องใช้พลังในการคำนวณมากขึ้นเพื่อดำเนินงานไปพร้อมๆ กัน ซึ่งอาจต้องใช้ทรัพยากรมากขึ้น และส่งผลให้ต้นทุนเพิ่มขึ้นด้วย
แน่นอนว่าอาจมีสาเหตุอื่นเช่นกัน แต่ตัวอย่างเหล่านี้ควรช่วยให้คุณเข้าใจถึงปัญหาที่อาจเกิดขึ้นได้โดยทั่วไป อย่างไรก็ตาม มีสิ่งสำคัญอีกประการหนึ่งที่ต้องทำความเข้าใจก่อนที่เราจะเจาะลึกในหัวข้อนี้เพิ่มเติม
ใช่ นั่นเป็นคำถามที่ดีและควรตอบก่อนเริ่มโครงการ แต่มันไม่ง่ายเลยที่จะให้คำตอบทั่วไป
ทางเลือกของรูปแบบการเลือกคุณลักษณะจะขึ้นอยู่กับประเภทของข้อมูลที่คุณมีและเป้าหมายของโครงการของคุณ
ตัวอย่างเช่น วิธีการที่ใช้ตัวกรอง เช่น การทดสอบไคสแควร์หรือการรับข้อมูลร่วมกัน โดยทั่วไปจะใช้สำหรับการเลือกคุณลักษณะในข้อมูลหมวดหมู่ วิธีการที่ใช้ Wrapper เช่น การเลือกไปข้างหน้าหรือข้างหลัง เหมาะสำหรับข้อมูลตัวเลข
อย่างไรก็ตาม เป็นเรื่องดีที่ทราบว่าวิธีการเลือกคุณลักษณะหลายวิธีสามารถจัดการข้อมูลทั้งเชิงหมวดหมู่และข้อมูลเชิงตัวเลขได้
ตัวอย่างเช่น การถดถอยแบบ Lasso แผนผังการตัดสินใจ และฟอเรสต์แบบสุ่ม สามารถจัดการข้อมูลทั้งสองประเภทได้ค่อนข้างดี
ในแง่ของการเลือกคุณสมบัติแบบมีผู้ดูแลและไม่ได้รับการดูแล วิธีการที่มีการดูแล เช่น การกำจัดคุณสมบัติแบบเรียกซ้ำหรือแผนผังการตัดสินใจนั้นดีสำหรับข้อมูลที่ติดป้ายกำกับ วิธีการที่ไม่มีผู้ดูแล เช่น การวิเคราะห์องค์ประกอบหลัก (PCA) หรือการวิเคราะห์องค์ประกอบอิสระ (ICA) จะถูกนำมาใช้กับข้อมูลที่ไม่มีป้ายกำกับ
ท้ายที่สุดแล้ว การเลือกวิธีการเลือกคุณลักษณะควรขึ้นอยู่กับลักษณะเฉพาะของข้อมูลและเป้าหมายของโครงการของคุณ
ดูภาพรวมของหัวข้อที่เราจะกล่าวถึงในบทความ ทำความคุ้นเคยกับคุณลักษณะนี้ และมาเริ่มด้วยเทคนิคการเลือกคุณลักษณะภายใต้การดูแลกัน
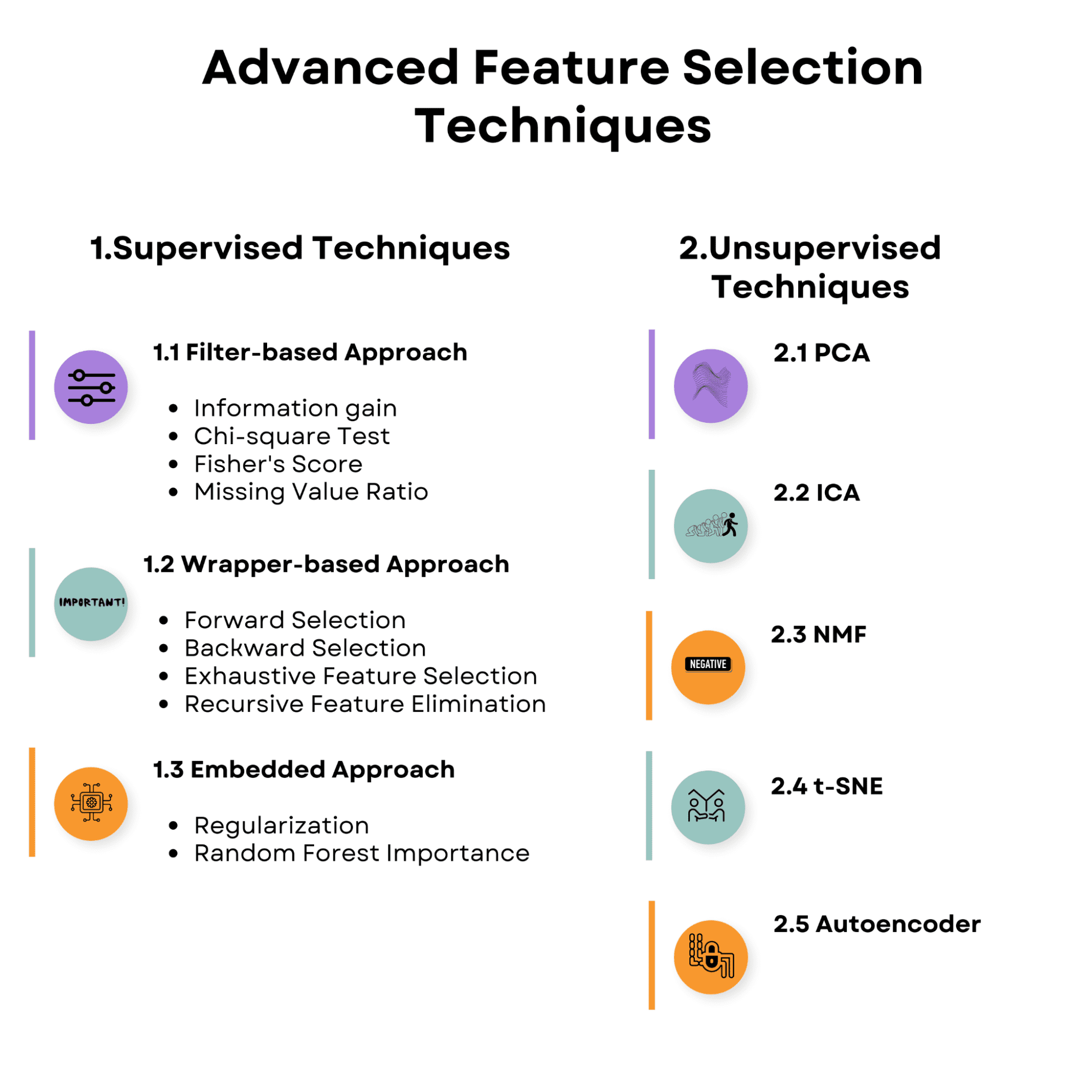
ภาพโดยผู้เขียน
กลยุทธ์การเลือกคุณลักษณะในการเรียนรู้แบบมีผู้สอนมีจุดมุ่งหมายเพื่อค้นหาคุณลักษณะที่เกี่ยวข้องมากที่สุดสำหรับการทำนายตัวแปรเป้าหมายโดยใช้ความสัมพันธ์ระหว่างคุณลักษณะอินพุตและตัวแปรเป้าหมาย กลยุทธ์เหล่านี้อาจช่วยปรับปรุงประสิทธิภาพของโมเดล ลดการติดตั้งมากเกินไป และลดต้นทุนการคำนวณในการฝึกโมเดล
ต่อไปนี้เป็นภาพรวมของเทคนิคการเลือกคุณสมบัติภายใต้การดูแลที่เราจะพูดถึง
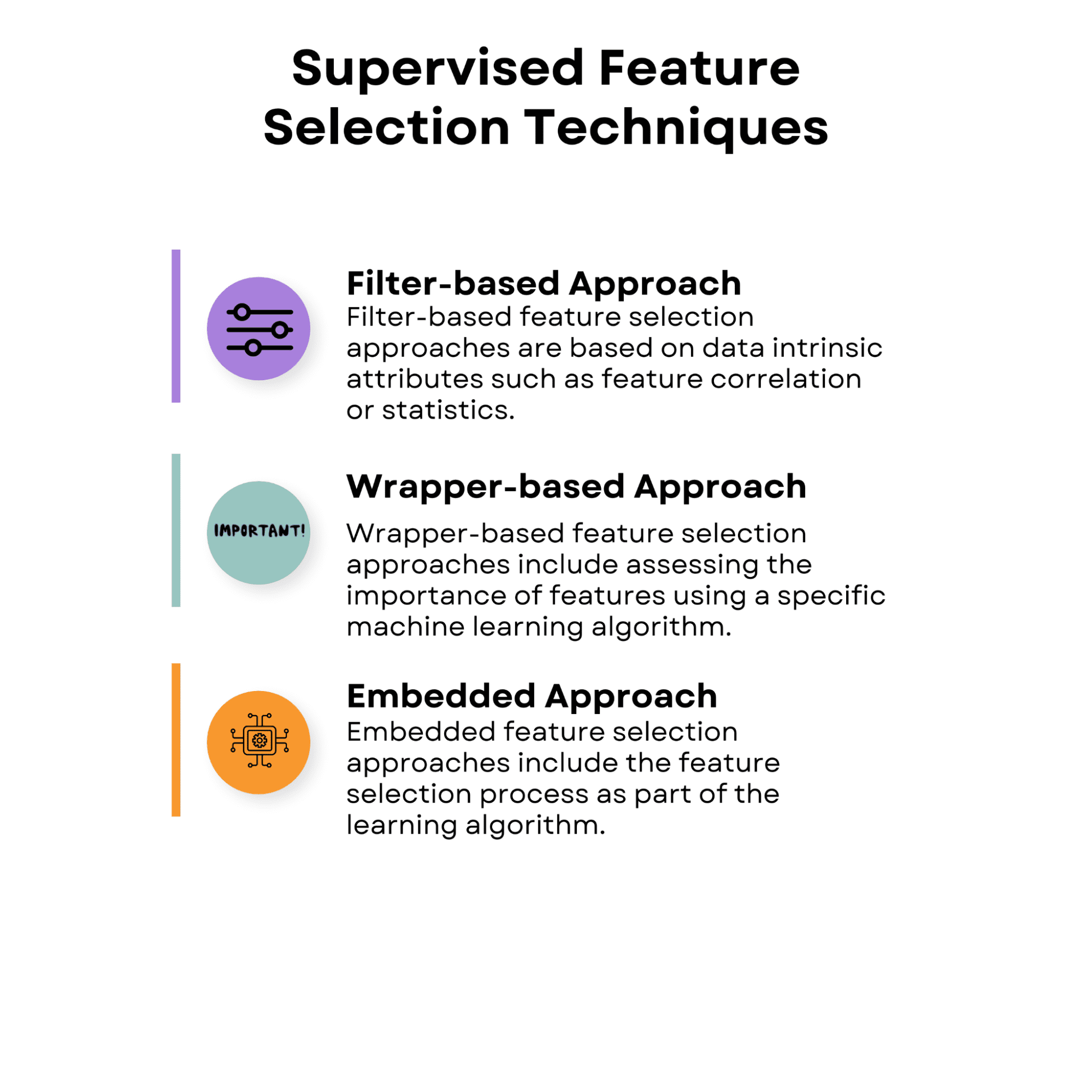
ภาพโดยผู้เขียน
1.1 แนวทางที่อิงตัวกรอง
วิธีการเลือกคุณลักษณะตามตัวกรองจะขึ้นอยู่กับคุณลักษณะภายในของข้อมูล เช่น ความสัมพันธ์ของคุณลักษณะหรือสถิติ วิธีการเหล่านี้จะประเมินคุณค่าของแต่ละคุณลักษณะเพียงอย่างเดียวหรือเป็นคู่โดยไม่คำนึงถึงประสิทธิภาพของอัลกอริทึมการเรียนรู้เฉพาะ
วิธีการที่ใช้ตัวกรองนั้นมีประสิทธิภาพในการคำนวณและอาจใช้กับอัลกอริธึมการเรียนรู้ที่หลากหลาย อย่างไรก็ตาม เนื่องจากไม่ได้คำนึงถึงปฏิสัมพันธ์ระหว่างคุณลักษณะและวิธีการเรียนรู้ จึงอาจไม่ได้บันทึกชุดย่อยของคุณลักษณะในอุดมคติสำหรับอัลกอริทึมบางอย่างเสมอไป
ดูภาพรวมของแนวทางที่ใช้ตัวกรอง แล้วเราจะหารือแต่ละข้อ

ภาพโดยผู้เขียน
ข้อมูลที่ได้รับ
Information Gain คือสถิติที่ใช้วัดการลดลงของเอนโทรปี (ความไม่แน่นอน) สำหรับคุณลักษณะเฉพาะโดยการแบ่งข้อมูลตามคุณลักษณะนั้น มักใช้ในอัลกอริทึมแผนผังการตัดสินใจ และยังมีคุณสมบัติที่มีประโยชน์อีกด้วย ยิ่งได้รับข้อมูลของคุณลักษณะสูงเท่าใดก็ยิ่งมีประโยชน์ในการตัดสินใจมากขึ้นเท่านั้น
ตอนนี้ เรามาประยุกต์ใช้ข้อมูลที่ได้รับโดยใช้ชุดข้อมูลโรคเบาหวานที่สร้างไว้ล่วงหน้า
ชุดข้อมูลโรคเบาหวานประกอบด้วยคุณลักษณะทางสรีรวิทยาที่เกี่ยวข้องกับการทำนายการลุกลามของโรคเบาหวาน
- อายุ: อายุเป็นปี
- เพศ: เพศ (1 = ชาย 0 = หญิง)
- BMI: ดัชนีมวลกาย คำนวณโดยน้ำหนักเป็นกิโลกรัมหารด้วยส่วนสูงยกกำลังสองเป็นเมตร
- bp: ความดันโลหิตเฉลี่ย (มม.ปรอท)
- s1, s2, s3, s4, s5, s6: การตรวจวัดระดับซีรั่มในเลือดของสารเคมีในเลือดที่แตกต่างกัน XNUMX ชนิด (รวมถึงกลูโคส)
รหัสต่อไปนี้สาธิตวิธีการใช้วิธีการรับข้อมูล โค้ดนี้ใช้ชุดข้อมูลโรคเบาหวานจากไลบรารี sklearn เป็นตัวอย่าง
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.feature_selection import mutual_info_regression # Load the diabetes dataset
data = load_diabetes() # Split the dataset into features and target
X = data.data
y = data.target
วัตถุประสงค์หลักของโค้ดนี้คือการคำนวณคะแนนความสำคัญของคุณลักษณะตามการได้รับข้อมูล ซึ่งจะช่วยระบุคุณลักษณะที่เกี่ยวข้องมากที่สุดสำหรับแบบจำลองการคาดการณ์ ด้วยการพิจารณาคะแนนเหล่านี้ คุณสามารถตัดสินใจได้อย่างชาญฉลาดว่าคุณสมบัติใดที่จะรวมหรือแยกออกจากการวิเคราะห์ของคุณ ซึ่งท้ายที่สุดจะนำไปสู่ประสิทธิภาพของโมเดลที่ได้รับการปรับปรุง ลดการติดตั้งมากเกินไป และเวลาการฝึกอบรมที่เร็วขึ้น
เพื่อให้บรรลุเป้าหมายนี้ โค้ดนี้จะคำนวณคะแนนการรับข้อมูลสำหรับแต่ละคุณลักษณะในชุดข้อมูลและจัดเก็บไว้ในพจนานุกรม
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.feature_selection import mutual_info_regression # Load the diabetes dataset
data = load_diabetes() # Split the dataset into features and target
X = data.data
y = data.target # Apply Information Gain
ig = mutual_info_regression(X, y) # Create a dictionary of feature importance scores
feature_scores = {}
for i in range(len(data.feature_names)): feature_scores[data.feature_names[i]] = ig[i]
คุณสมบัติต่างๆ จะถูกจัดเรียงตามลำดับจากมากไปน้อยตามคะแนน
# Sort the features by importance score in descending order
sorted_features = sorted(feature_scores.items(), key=lambda x: x[1], reverse=True) # Print the feature importance scores and the sorted features
for feature, score in sorted_features: print('Feature:', feature, 'Score:', score)
เราจะแสดงภาพคะแนนความสำคัญของคุณลักษณะที่จัดเรียงเป็นแผนภูมิแท่งแนวนอน ช่วยให้คุณสามารถเปรียบเทียบความเกี่ยวข้องของคุณลักษณะต่างๆ สำหรับงานที่กำหนดได้อย่างง่ายดาย
การแสดงภาพนี้มีประโยชน์อย่างยิ่งในการตัดสินใจว่าจะเก็บหรือละทิ้งฟีเจอร์ใดในขณะที่สร้างโมเดลแมชชีนเลิร์นนิง
# Plot a horizontal bar chart of the feature importance scores
fig, ax = plt.subplots()
y_pos = np.arange(len(sorted_features))
ax.barh(y_pos, [score for feature, score in sorted_features], align="center")
ax.set_yticks(y_pos)
ax.set_yticklabels([feature for feature, score in sorted_features])
ax.invert_yaxis() # Labels read top-to-bottom
ax.set_xlabel("Importance Score")
ax.set_title("Feature Importance Scores (Information Gain)") # Add importance scores as labels on the horizontal bar chart
for i, v in enumerate([score for feature, score in sorted_features]): ax.text(v + 0.01, i, str(round(v, 3)), color="black", fontweight="bold")
plt.show()
มาดูโค้ดทั้งหมดกัน
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.feature_selection import mutual_info_regression # Load the diabetes dataset
data = load_diabetes() # Split the dataset into features and target
X = data.data
y = data.target # Apply Information Gain
ig = mutual_info_regression(X, y) # Create a dictionary of feature importance scores
feature_scores = {}
for i in range(len(data.feature_names)): feature_scores[data.feature_names[i]] = ig[i]
# Sort the features by importance score in descending order
sorted_features = sorted(feature_scores.items(), key=lambda x: x[1], reverse=True) # Print the feature importance scores and the sorted features
for feature, score in sorted_features: print("Feature:", feature, "Score:", score)
# Plot a horizontal bar chart of the feature importance scores
fig, ax = plt.subplots()
y_pos = np.arange(len(sorted_features))
ax.barh(y_pos, [score for feature, score in sorted_features], align="center")
ax.set_yticks(y_pos)
ax.set_yticklabels([feature for feature, score in sorted_features])
ax.invert_yaxis() # Labels read top-to-bottom
ax.set_xlabel("Importance Score")
ax.set_title("Feature Importance Scores (Information Gain)") # Add importance scores as labels on the horizontal bar chart
for i, v in enumerate([score for feature, score in sorted_features]): ax.text(v + 0.01, i, str(round(v, 3)), color="black", fontweight="bold")
plt.show()
นี่คือผลลัพธ์
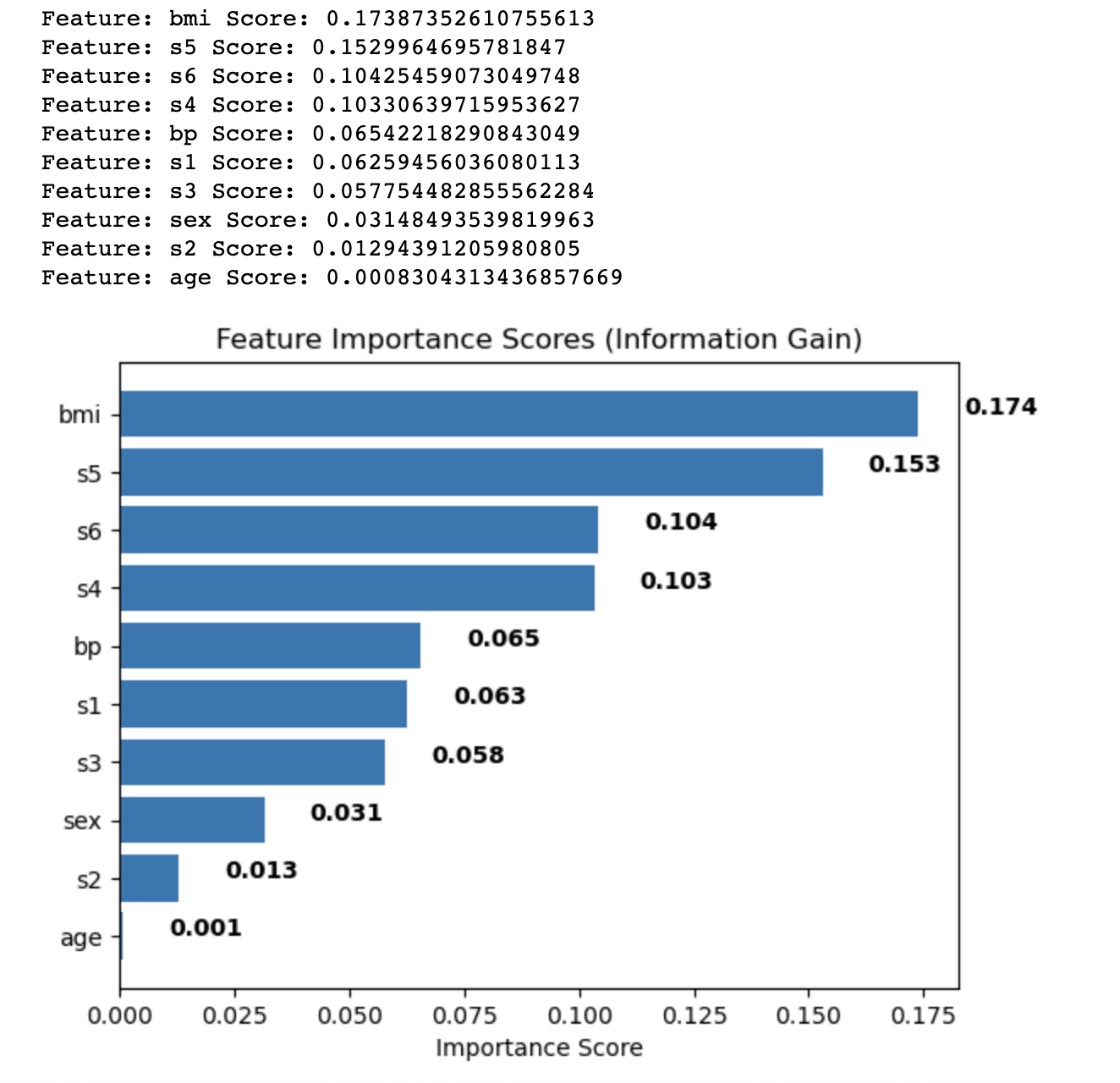
ผลลัพธ์จะแสดงคะแนนความสำคัญของฟีเจอร์ที่คำนวณโดยใช้วิธี Information Gain สำหรับแต่ละฟีเจอร์ในชุดข้อมูลโรคเบาหวาน คุณลักษณะต่างๆ จะถูกจัดเรียงตามลำดับจากมากไปน้อยตามคะแนน ซึ่งบ่งบอกถึงความสำคัญสัมพัทธ์ในการทำนายตัวแปรเป้าหมาย
ผลลัพธ์มีดังนี้:
- ดัชนีมวลกาย (bmi) มีคะแนนความสำคัญสูงสุด (0.174) ซึ่งบ่งชี้ว่าดัชนีนี้มีอิทธิพลที่สำคัญที่สุดต่อตัวแปรเป้าหมายในชุดข้อมูลโรคเบาหวาน
- การตรวจวัดระดับเซรั่ม 5 (s5) ตามมาด้วยคะแนน 0.153 ทำให้เป็นคุณลักษณะที่สำคัญที่สุดเป็นอันดับสอง
- การตรวจวัดในซีรั่ม 6 (s6), การวัดในซีรั่ม 4 (s4) และความดันโลหิต (bp) มีคะแนนความสำคัญปานกลาง ตั้งแต่ 0.104 ถึง 0.065
- คุณลักษณะที่เหลือ เช่น การวัดซีรั่ม 1, 2 และ 3 (s1, s2, s3) เพศ และอายุ มีคะแนนความสำคัญค่อนข้างต่ำกว่า ซึ่งบ่งชี้ว่าสิ่งเหล่านี้มีส่วนช่วยน้อยกว่าในพลังการทำนายของแบบจำลอง
ด้วยการวิเคราะห์คะแนนความสำคัญของคุณลักษณะเหล่านี้ คุณสามารถตัดสินใจได้ว่าคุณลักษณะใดที่จะรวมหรือแยกออกจากการวิเคราะห์ของคุณ เพื่อปรับปรุงประสิทธิภาพของโมเดล Machine Learning ของคุณ ในกรณีนี้ คุณอาจพิจารณารักษาคุณลักษณะที่มีคะแนนความสำคัญสูงกว่า เช่น bmi และ s5 ในขณะที่อาจลบหรือตรวจสอบคุณลักษณะที่มีคะแนนต่ำกว่า เช่น อายุและ s2 ต่อไป
การทดสอบไคสแควร์
การทดสอบไคสแควร์เป็นการทดสอบทางสถิติที่ใช้ในการประเมินความสัมพันธ์ระหว่างตัวแปรเด็ดขาดสองตัว ใช้ในการเลือกคุณลักษณะเพื่อวิเคราะห์ความสัมพันธ์ระหว่างคุณลักษณะที่เป็นหมวดหมู่และตัวแปรเป้าหมาย คะแนนไคสแควร์ที่มากขึ้นจะแสดงความเชื่อมโยงที่แน่นแฟ้นมากขึ้นระหว่างจุดสนใจและเป้าหมาย ซึ่งแสดงว่าจุดสนใจมีความสำคัญมากกว่าสำหรับงานจำแนกประเภท
แม้ว่าการทดสอบไคสแควร์เป็นวิธีการเลือกคุณสมบัติที่ใช้กันทั่วไป แต่โดยทั่วไปจะใช้สำหรับข้อมูลเชิงหมวดหมู่ โดยที่คุณสมบัติและตัวแปรเป้าหมายไม่ต่อเนื่องกัน
คะแนนของฟิชเชอร์
Fisher's Discriminant Ratio หรือที่เรียกกันทั่วไปว่า Fisher's Score เป็นวิธีการเลือกคุณสมบัติที่จัดอันดับคุณสมบัติต่างๆ ตามความสามารถในการแยกความแตกต่างของคลาสต่างๆ ในชุดข้อมูล อาจใช้สำหรับคุณลักษณะต่อเนื่องในปัญหาการจำแนกประเภท
คะแนนฟิชเชอร์คำนวณเป็นอัตราส่วนของความแปรปรวนระหว่างคลาสและความแปรปรวนภายในคลาส คะแนนฟิชเชอร์ที่สูงกว่าแสดงว่าคุณลักษณะนี้แยกแยะได้มากกว่าและมีคุณค่าในการจำแนกประเภท
หากต้องการใช้คะแนนของฟิชเชอร์ในการเลือกคุณลักษณะ ให้คำนวณคะแนนสำหรับคุณลักษณะต่อเนื่องแต่ละรายการและจัดอันดับตามคะแนน แบบจำลองนี้ถือว่าคุณลักษณะที่มีคะแนนฟิชเชอร์สูงกว่ามีความสำคัญมากกว่า
อัตราส่วนมูลค่าที่ขาดหายไป
อัตราส่วนมูลค่าที่ขาดหายไปเป็นวิธีการเลือกคุณลักษณะที่ไม่ซับซ้อน ซึ่งจะทำการตัดสินใจโดยพิจารณาจากจำนวนค่าที่หายไปในคุณลักษณะหนึ่งๆ
คุณลักษณะที่มีสัดส่วนที่มีนัยสำคัญของค่าที่หายไปอาจไม่ให้ข้อมูลและอาจเป็นอันตรายต่อประสิทธิภาพของแบบจำลอง คุณสามารถกรองฟีเจอร์ที่มีค่าที่ขาดหายไปมากเกินไปได้โดยการระบุเกณฑ์สำหรับอัตราส่วนมูลค่าที่หายไปที่ยอมรับได้
เมื่อต้องการใช้อัตราส่วนมูลค่าที่ขาดหายไปสำหรับการเลือกคุณลักษณะ ให้ทำตามขั้นตอนเหล่านี้:
- คำนวณอัตราส่วนมูลค่าที่หายไปสำหรับแต่ละฟีเจอร์โดยการหารจำนวนค่าที่หายไปด้วยจำนวนอินสแตนซ์ทั้งหมดในชุดข้อมูล
- กำหนดเกณฑ์สำหรับอัตราส่วนค่าที่หายไปที่ยอมรับได้ (เช่น 0.8 ซึ่งหมายความว่าจุดสนใจควรมีค่าที่ขาดหายไปไม่เกิน 80% เพื่อนำมาพิจารณา)
- กรองฟีเจอร์ที่มีอัตราส่วนมูลค่าที่ขาดหายไปเกินเกณฑ์ออก
1.2 แนวทางที่ใช้ Wrapper
วิธีการเลือกฟีเจอร์ที่ใช้ Wrapper รวมถึงการประเมินความสำคัญของฟีเจอร์โดยใช้อัลกอริธึมการเรียนรู้ของเครื่องเฉพาะ พวกเขาค้นหาชุดย่อยของคุณลักษณะที่ดีที่สุดโดยการทดลองกับชุดคุณลักษณะต่างๆ และประเมินประสิทธิภาพด้วยวิธีที่เลือก
เนื่องจากมีชุดย่อยคุณลักษณะที่มีอยู่จำนวนมาก วิธีการแบบ Wrapper อาจมีต้นทุนในการคำนวณสูง โดยเฉพาะอย่างยิ่งเมื่อทำงานกับชุดข้อมูลที่มีมิติสูง
อย่างไรก็ตาม พวกเขามักจะมีประสิทธิภาพเหนือกว่าแนวทางที่ใช้ตัวกรอง เนื่องจากพิจารณาความสัมพันธ์ระหว่างฟีเจอร์และอัลกอริธึมการเรียนรู้
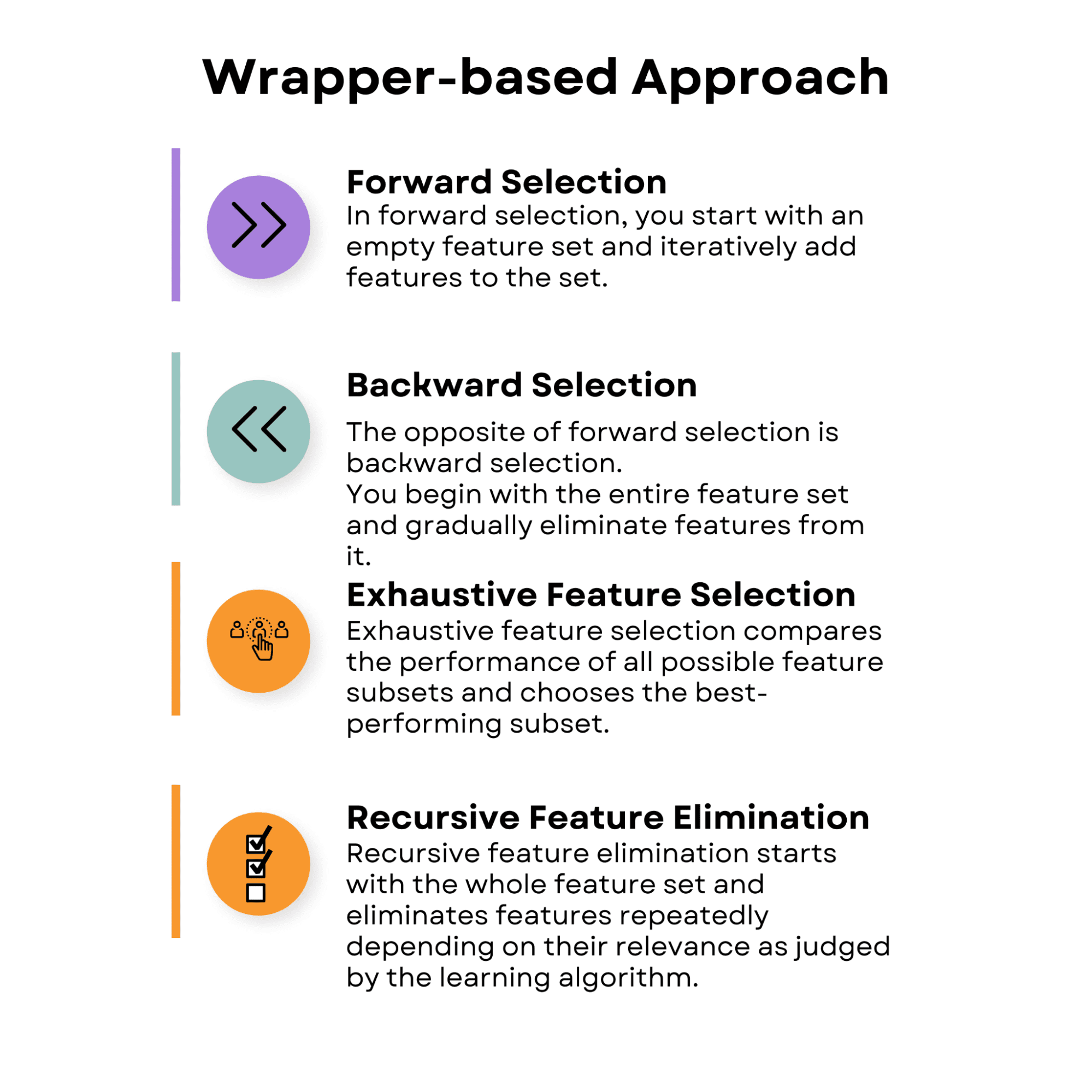
ภาพโดยผู้เขียน
การเลือกไปข้างหน้า
ในการเลือกไปข้างหน้า คุณจะเริ่มต้นด้วยชุดคุณสมบัติที่ว่างเปล่าและเพิ่มคุณสมบัติซ้ำๆ ให้กับชุด ในแต่ละขั้นตอน คุณจะประเมินประสิทธิภาพของโมเดลด้วยชุดคุณลักษณะปัจจุบันและคุณลักษณะเพิ่มเติม มีการเพิ่มคุณสมบัติที่ส่งผลให้มีการปรับปรุงประสิทธิภาพที่ดีที่สุดให้กับชุด
กระบวนการนี้จะดำเนินต่อไปจนกว่าจะไม่มีการปรับปรุงประสิทธิภาพอย่างมีนัยสำคัญ หรือมีคุณลักษณะถึงจำนวนที่กำหนดไว้ล่วงหน้า
รหัสต่อไปนี้แสดงให้เห็นถึงการประยุกต์ใช้การเลือกไปข้างหน้า ซึ่งเป็นเทคนิคการเลือกคุณลักษณะที่มีการดูแลแบบ wrapper
ตัวอย่างนี้ใช้ชุดข้อมูลมะเร็งเต้านมจากไลบรารี sklearn ชุดข้อมูลมะเร็งเต้านมหรือที่เรียกว่าชุดข้อมูล Wisconsin Diagnostic Breast Cancer (WDBC) เป็นชุดข้อมูลที่สร้างไว้ล่วงหน้าที่ใช้กันทั่วไปสำหรับการจำแนกประเภท และที่นี่ วัตถุประสงค์หลักคือการสร้างแบบจำลองการพยากรณ์สำหรับการวินิจฉัยมะเร็งเต้านมว่าเป็นมะเร็ง (เป็นมะเร็ง) หรือไม่ร้ายแรง (ไม่เป็นมะเร็ง)
เพื่อประโยชน์ของโมเดลของเรา เราจะเลือกคุณสมบัติจำนวนหนึ่งเพื่อดูว่าประสิทธิภาพเปลี่ยนแปลงไปอย่างไร แต่ก่อนอื่น มาโหลดไลบรารี ชุดข้อมูล และตัวแปรกันก่อน
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlxtend.feature_selection import SequentialFeatureSelector as SFS # Load the breast cancer dataset
data = load_breast_cancer() # Split the dataset into features and target
X = data.data
y = data.target
วัตถุประสงค์ของโค้ดคือการระบุชุดย่อยที่เหมาะสมที่สุดของคุณลักษณะสำหรับแบบจำลองการถดถอยโลจิสติกโดยใช้การเลือกไปข้างหน้า เทคนิคนี้เริ่มต้นด้วยชุดคุณสมบัติที่ว่างเปล่าและเพิ่มคุณสมบัติซ้ำ ๆ ที่ช่วยปรับปรุงประสิทธิภาพของแบบจำลองตามตัวชี้วัดการประเมินที่ระบุ ในกรณีนี้ เมตริกที่ใช้คือความแม่นยำ
ส่วนถัดไปของโค้ดใช้ SequentialFeatureSelector จากไลบรารี mlxtend เพื่อทำการเลือกไปข้างหน้า ได้รับการกำหนดค่าด้วยแบบจำลองการถดถอยโลจิสติก จำนวนคุณลักษณะที่ต้องการ และการตรวจสอบข้าม 5 เท่า ออบเจ็กต์การเลือกไปข้างหน้าจะพอดีกับข้อมูลการฝึก และคุณสมบัติที่เลือกจะถูกพิมพ์
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlxtend.feature_selection import SequentialFeatureSelector as SFS # Load the breast cancer dataset
data = load_breast_cancer() # Split the dataset into features and target
X = data.data
y = data.target # Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # Define the logistic regression model
model = LogisticRegression() # Define the forward selection object
sfs = SFS(model, k_features=5, forward=True, floating=False, scoring='accuracy', cv=5) # Perform forward selection on the training set
sfs.fit(X_train, y_train)
นอกจากนี้ เราจำเป็นต้องประเมินประสิทธิภาพของคุณลักษณะที่เลือกในชุดการทดสอบ และแสดงภาพประสิทธิภาพของแบบจำลองด้วยคุณลักษณะย่อยต่างๆ ในแผนภูมิเส้น
แผนภูมิจะแสดงความแม่นยำที่ผ่านการตรวจสอบข้ามเป็นฟังก์ชันของคุณสมบัติจำนวนหนึ่ง โดยให้ข้อมูลเชิงลึกเกี่ยวกับข้อดีข้อเสียระหว่างความซับซ้อนของโมเดลและประสิทธิภาพเชิงคาดการณ์
ด้วยการวิเคราะห์ผลลัพธ์และแผนภูมิ คุณสามารถกำหนดจำนวนคุณลักษณะที่เหมาะสมที่สุดที่จะรวมไว้ในโมเดลของคุณได้ ซึ่งจะช่วยปรับปรุงประสิทธิภาพและลดการติดตั้งมากเกินไปในท้ายที่สุด
# Print the selected features
print('Selected Features:', sfs.k_feature_names_) # Evaluate the performance of the selected features on the testing set
accuracy = sfs.k_score_
print('Accuracy:', accuracy) # Plot the performance of the model with different feature subsets
sfs_df = pd.DataFrame.from_dict(sfs.get_metric_dict()).T
sfs_df['avg_score'] = sfs_df['avg_score'].astype(float)
fig, ax = plt.subplots()
sfs_df.plot(kind='line', y='avg_score', ax=ax)
ax.set_xlabel('Number of Features')
ax.set_ylabel('Accuracy')
ax.set_title('Forward Selection Performance')
plt.show()
นี่คือรหัสทั้งหมด
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlxtend.feature_selection import SequentialFeatureSelector as SFS # Load the breast cancer dataset
data = load_breast_cancer() # Split the dataset into features and target
X = data.data
y = data.target # Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # Define the logistic regression model
model = LogisticRegression() # Define the forward selection object
sfs = SFS(model, k_features=5, forward=True, floating=False, scoring="accuracy", cv=5) # Perform forward selection on the training set
sfs.fit(X_train, y_train) # Print the selected features
print("Selected Features:", sfs.k_feature_names_) # Evaluate the performance of the selected features on the testing set
accuracy = sfs.k_score_
print("Accuracy:", accuracy) # Plot the performance of the model with different feature subsets
sfs_df = pd.DataFrame.from_dict(sfs.get_metric_dict()).T
sfs_df["avg_score"] = sfs_df["avg_score"].astype(float)
fig, ax = plt.subplots()
sfs_df.plot(kind="line", y="avg_score", ax=ax)
ax.set_xlabel("Number of Features")
ax.set_ylabel("Accuracy")
ax.set_title("Forward Selection Performance")
plt.show()
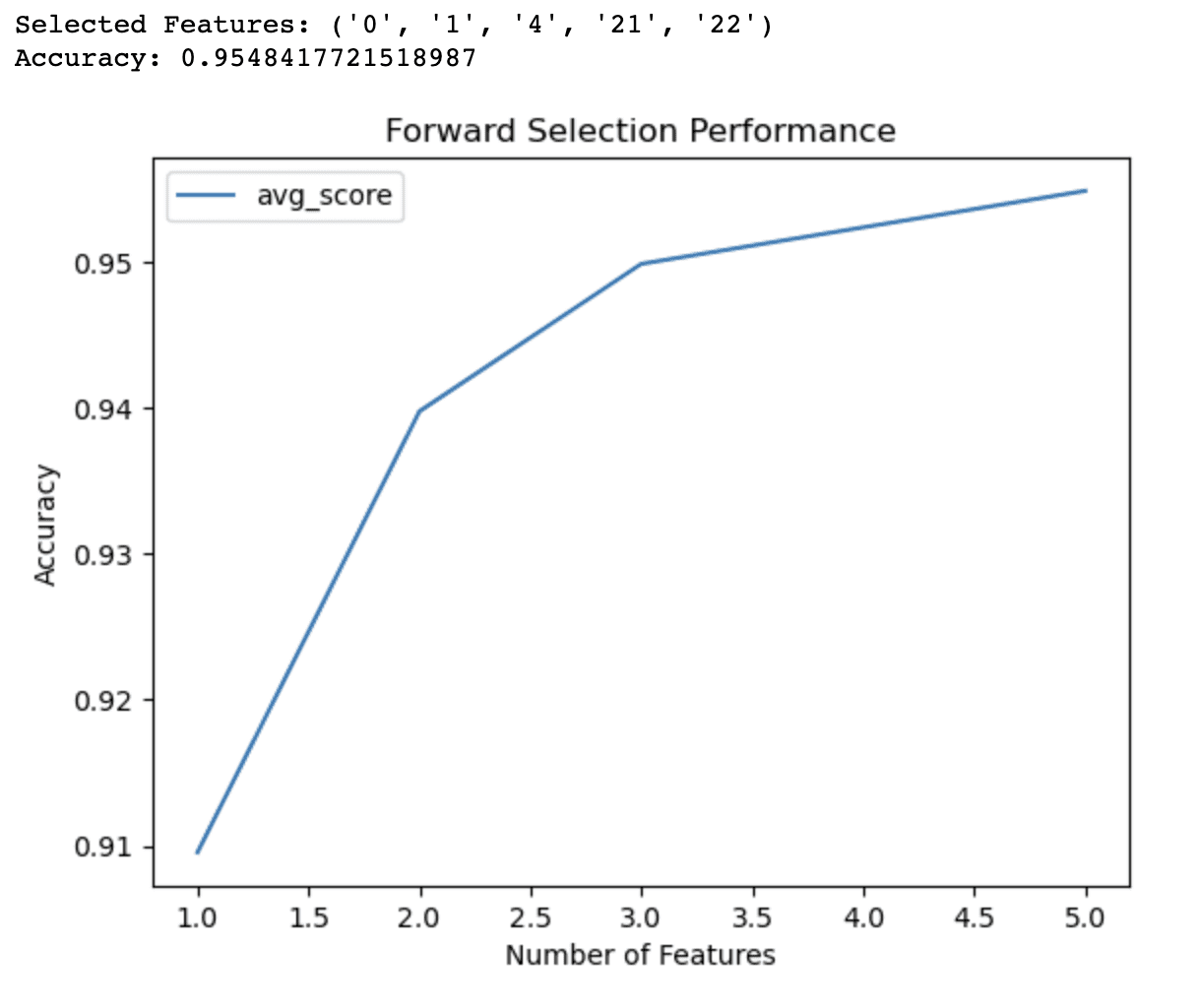
ผลลัพธ์ของรหัสการเลือกไปข้างหน้าแสดงให้เห็นว่าอัลกอริทึมได้ระบุชุดย่อยของคุณลักษณะ 5 ประการที่ให้ความแม่นยำสูงสุด (0.9548) สำหรับแบบจำลองการถดถอยลอจิสติกบนชุดข้อมูลมะเร็งเต้านม คุณสมบัติที่เลือกเหล่านี้จะถูกระบุโดยดัชนี: 0, 1, 4, 21 และ 22
กราฟเส้นให้ข้อมูลเชิงลึกเพิ่มเติมเกี่ยวกับประสิทธิภาพของโมเดลพร้อมฟีเจอร์ต่างๆ มากมาย มันแสดงให้เห็นว่า:
- ด้วยคุณสมบัติเพียง 1 อย่าง โมเดลนี้จึงมีความแม่นยำประมาณ 91%
- การเพิ่มคุณสมบัติที่สองเพิ่มความแม่นยำเป็น 94%
- ด้วยคุณสมบัติ 3 ประการ ความแม่นยำจึงเพิ่มขึ้นถึง 95%
- รวม 4 คุณสมบัติทำให้ความแม่นยำสูงกว่า 95% เล็กน้อย
นอกเหนือจากคุณสมบัติทั้ง 4 ประการแล้ว การปรับปรุงความแม่นยำก็มีความสำคัญน้อยลง ข้อมูลนี้สามารถช่วยให้คุณมีข้อมูลประกอบการตัดสินใจเกี่ยวกับข้อดีข้อเสียระหว่างความซับซ้อนของโมเดลและประสิทธิภาพเชิงคาดการณ์ จากผลลัพธ์เหล่านี้ คุณอาจตัดสินใจใช้คุณลักษณะเพียง 3 หรือ 4 รายการในแบบจำลองของคุณเพื่อสร้างสมดุลระหว่างความแม่นยำและความเรียบง่าย
การเลือกแบบย้อนกลับ
สิ่งที่ตรงกันข้ามกับการเลือกไปข้างหน้าคือการเลือกแบบย้อนกลับ คุณเริ่มต้นด้วยชุดคุณลักษณะทั้งหมดและค่อยๆ ตัดคุณลักษณะต่างๆ ออกไป
ในแต่ละเฟส คุณจะวัดประสิทธิภาพของโมเดลด้วยชุดคุณลักษณะปัจจุบัน ลบคุณลักษณะที่จะลบ
คุณลักษณะที่ทำให้ประสิทธิภาพลดลงน้อยที่สุดจะถูกตัดออกจากชุด
ขั้นตอนนี้จะทำซ้ำจนกว่าจะไม่มีการเพิ่มประสิทธิภาพอย่างมีนัยสำคัญหรือถึงจำนวนคุณสมบัติที่กำหนดไว้ล่วงหน้า
การเลือกย้อนกลับและไปข้างหน้าจัดหมวดหมู่เป็นการเลือกคุณสมบัติตามลำดับ คุณสามารถเรียนรู้เพิ่มเติมได้ โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม.
การเลือกคุณสมบัติที่ครบถ้วนสมบูรณ์
การเลือกคุณลักษณะอย่างละเอียดถี่ถ้วนจะเปรียบเทียบประสิทธิภาพของชุดย่อยคุณลักษณะที่เป็นไปได้ทั้งหมด และเลือกชุดย่อยที่มีประสิทธิภาพดีที่สุด แนวทางนี้เป็นที่ต้องการในการคำนวณ โดยเฉพาะอย่างยิ่งสำหรับชุดข้อมูลขนาดใหญ่ แต่ก็รับประกันว่าจะมีคุณลักษณะย่อยที่ดีที่สุด
การกำจัดคุณสมบัติแบบเรียกซ้ำ
การกำจัดคุณสมบัติแบบเรียกซ้ำเริ่มต้นด้วยชุดคุณสมบัติทั้งหมด และกำจัดคุณสมบัติซ้ำๆ ขึ้นอยู่กับความเกี่ยวข้องตามที่ตัดสินโดยอัลกอริธึมการเรียนรู้ คุณลักษณะที่สำคัญน้อยที่สุดจะถูกลบออกในแต่ละขั้นตอน และแบบจำลองจะได้รับการฝึกใหม่ วิธีนี้จะถูกทำซ้ำจนกว่าจะบรรลุคุณสมบัติตามจำนวนที่กำหนดไว้
1.3 แนวทางแบบฝัง
วิธีการเลือกคุณสมบัติแบบฝังรวมถึงกระบวนการเลือกคุณสมบัติซึ่งเป็นส่วนหนึ่งของอัลกอริทึมการเรียนรู้
นี่หมายความว่าตลอดขั้นตอนการฝึกอบรม อัลกอริธึมการเรียนรู้ไม่เพียงแต่ปรับพารามิเตอร์โมเดลให้เหมาะสม แต่ยังเลือกคุณลักษณะที่สำคัญที่สุดอีกด้วย วิธีการฝังตัวอาจมีประสิทธิผลมากกว่าวิธี wrapper เนื่องจากไม่ต้องการขั้นตอนการเลือกคุณสมบัติภายนอก
ภาพโดยผู้เขียน
การทำให้สม่ำเสมอ
การทำให้เป็นมาตรฐานเป็นวิธีการที่เพิ่มเงื่อนไขการลงโทษให้กับฟังก์ชันการสูญเสีย เพื่อป้องกันไม่ให้มีการติดตั้งมากเกินไปในโมเดลแมชชีนเลิร์นนิง
วิธีการทำให้เป็นมาตรฐาน เช่น lasso (การทำให้เป็นมาตรฐาน L1) และสัน (การทำให้เป็นมาตรฐาน L2) สามารถใช้ร่วมกับการเลือกคุณลักษณะเพื่อลดค่าสัมประสิทธิ์ของคุณลักษณะที่มีนัยสำคัญน้อยกว่าให้เป็นศูนย์ ดังนั้นจึงเลือกชุดย่อยของคุณลักษณะที่เกี่ยวข้องมากที่สุด
ความสำคัญของป่าแบบสุ่ม
Random Forest เป็นวิธีการเรียนรู้แบบทั้งมวลที่ผสมผสานการทำนายแผนผังการตัดสินใจหลายแบบ ฟอเรสต์สุ่มคำนวณคะแนนนัยสำคัญของคุณลักษณะสำหรับแต่ละคุณลักษณะโดยเป็นส่วนหนึ่งของกระบวนการสร้างแผนภูมิ ซึ่งอาจใช้เพื่อเรียงลำดับคุณลักษณะตามความเกี่ยวข้อง แบบจำลองนี้ถือว่าคุณลักษณะที่มีการให้คะแนนที่มีนัยสำคัญสูงกว่าจะมีนัยสำคัญมากกว่า
หากคุณต้องการเรียนรู้เพิ่มเติมเกี่ยวกับป่าสุ่ม นี่คือบทความ “แผนผังการตัดสินใจและอัลกอริทึมฟอเรสต์แบบสุ่ม” ซึ่งอธิบายอัลกอริธึมแผนผังการตัดสินใจด้วย
ตัวอย่างต่อไปนี้ใช้ชุดข้อมูล Covertype ซึ่งประกอบด้วยข้อมูลเกี่ยวกับการปกคลุมฟอเรสต์ประเภทต่างๆ
จุดมุ่งหมายของชุดข้อมูล Covertype คือการคาดการณ์ประเภทป่าปกคลุม (พันธุ์ไม้ที่โดดเด่น) ภายในป่าสงวนแห่งชาติ Roosevelt ทางตอนเหนือของโคโลราโด
เป้าหมายหลักของโค้ดด้านล่างคือการกำหนดความสำคัญของฟีเจอร์โดยใช้ตัวแยกประเภทฟอเรสต์แบบสุ่ม ด้วยการประเมินการมีส่วนร่วมของแต่ละคุณลักษณะต่อประสิทธิภาพการจำแนกโดยรวม วิธีการนี้จะช่วยระบุคุณลักษณะที่เกี่ยวข้องมากที่สุดสำหรับการสร้างแบบจำลองเชิงคาดการณ์
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt # Load the Covertype dataset
data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.data.gz", header=None) # Assign column names
cols = ["Elevation", "Aspect", "Slope", "Horizontal_Distance_To_Hydrology", "Vertical_Distance_To_Hydrology", "Horizontal_Distance_To_Roadways", "Hillshade_9am", "Hillshade_Noon", "Hillshade_3pm", "Horizontal_Distance_To_Fire_Points"] + ["Wilderness_Area_"+str(i) for i in range(1,5)] + ["Soil_Type_"+str(i) for i in range(1,41)] + ["Cover_Type"] data.columns = cols
จากนั้น เราสร้างออบเจ็กต์ RandomForestClassifier และปรับให้เข้ากับข้อมูลการฝึก จากนั้นจะแยกความสำคัญของฟีเจอร์ออกจากโมเดลที่ได้รับการฝึกและเรียงลำดับจากมากไปหาน้อย คุณสมบัติ 10 อันดับแรกจะถูกเลือกตามคะแนนความสำคัญและแสดงในการจัดอันดับ
# Split the dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # Create a random forest classifier object
rfc = RandomForestClassifier(n_estimators=100, random_state=42) # Fit the model to the training data
rfc.fit(X_train, y_train) # Get feature importances from the trained model
importances = rfc.feature_importances_ # Sort the feature importances in descending order
indices = np.argsort(importances)[::-1] # Select the top 10 features
num_features = 10
top_indices = indices[:num_features]
top_importances = importances[top_indices] # Print the top 10 feature rankings
print("Top 10 feature rankings:")
for f in range(num_features): # Use num_features instead of 10 print(f"{f+1}. {X_train.columns[indices[f]]}: {importances[indices[f]]}")
นอกจากนี้ โค้ดยังแสดงภาพความสำคัญของคุณลักษณะ 10 อันดับแรกโดยใช้แผนภูมิแท่งแนวนอน
# Plot the top 10 feature importances in a horizontal bar chart
plt.barh(range(num_features), top_importances, align='center')
plt.yticks(range(num_features), X_train.columns[top_indices])
plt.xlabel("Feature Importance")
plt.ylabel("Feature")
plt.show()
การแสดงภาพนี้ช่วยให้เปรียบเทียบคะแนนความสำคัญได้ง่าย และช่วยในการตัดสินใจโดยมีข้อมูลครบถ้วนว่าคุณลักษณะใดที่จะรวมหรือแยกออกจากการวิเคราะห์ของคุณ
ด้วยการตรวจสอบผลลัพธ์และแผนภูมิ คุณสามารถเลือกคุณลักษณะที่เกี่ยวข้องมากที่สุดสำหรับแบบจำลองการคาดการณ์ของคุณ ซึ่งสามารถช่วยปรับปรุงประสิทธิภาพ ลดการทำงานมากเกินไป และเร่งเวลาการฝึกอบรมได้
นี่คือรหัสทั้งหมด
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt # Load the Covertype dataset
data = pd.read_csv( "https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.data.gz", header=None,
) # Assign column names
cols = ( [ "Elevation", "Aspect", "Slope", "Horizontal_Distance_To_Hydrology", "Vertical_Distance_To_Hydrology", "Horizontal_Distance_To_Roadways", "Hillshade_9am", "Hillshade_Noon", "Hillshade_3pm", "Horizontal_Distance_To_Fire_Points", ] + ["Wilderness_Area_" + str(i) for i in range(1, 5)] + ["Soil_Type_" + str(i) for i in range(1, 41)] + ["Cover_Type"]
) data.columns = cols # Split the dataset into features and target
X = data.iloc[:, :-1]
y = data.iloc[:, -1] # Split the dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=42
) # Create a random forest classifier object
rfc = RandomForestClassifier(n_estimators=100, random_state=42) # Fit the model to the training data
rfc.fit(X_train, y_train) # Get feature importances from the trained model
importances = rfc.feature_importances_ # Sort the feature importances in descending order
indices = np.argsort(importances)[::-1] # Select the top 10 features
num_features = 10
top_indices = indices[:num_features]
top_importances = importances[top_indices] # Print the top 10 feature rankings
print("Top 10 feature rankings:")
for f in range(num_features): # Use num_features instead of 10 print(f"{f+1}. {X_train.columns[indices[f]]}: {importances[indices[f]]}")
# Plot the top 10 feature importances in a horizontal bar chart
plt.barh(range(num_features), top_importances, align="center")
plt.yticks(range(num_features), X_train.columns[top_indices])
plt.xlabel("Feature Importance")
plt.ylabel("Feature")
plt.show()
นี่คือผลลัพธ์
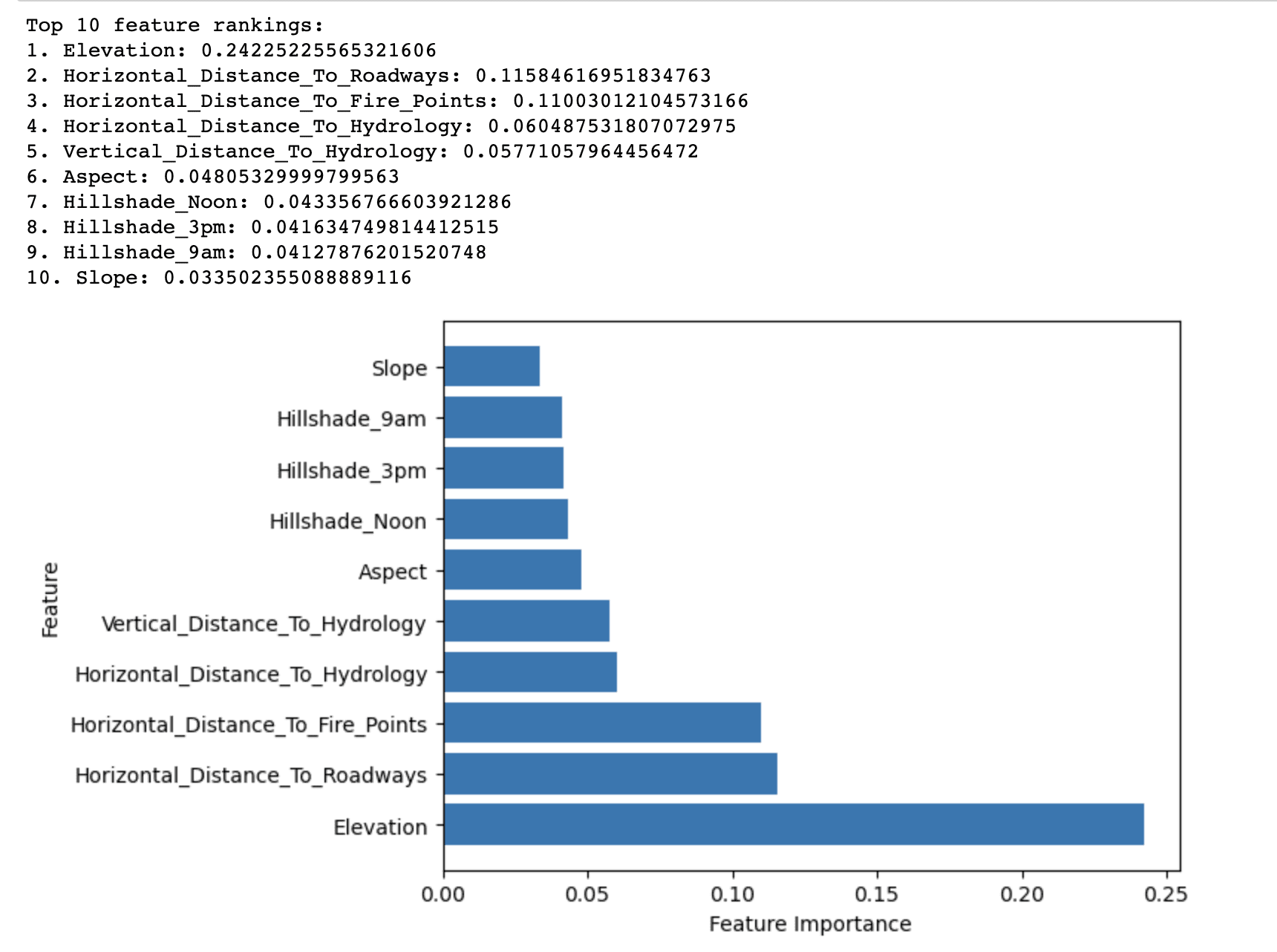
ผลลัพธ์ของวิธี Random Forest Importance จะแสดงคุณสมบัติ 10 อันดับแรกที่จัดอันดับตามความสำคัญในการทำนายประเภทการปกคลุมของฟอเรสต์ในชุดข้อมูล Covertype
โดยพบว่าระดับความสูงมีคะแนนความสำคัญสูงสุด (0.2423) ในบรรดาคุณลักษณะทั้งหมดในการทำนายประเภทป่าปกคลุม สิ่งนี้ชี้ให้เห็นว่าระดับความสูงมีบทบาทสำคัญในการกำหนดพันธุ์ไม้ที่โดดเด่นในป่าสงวนแห่งชาติรูสเวลต์
คุณสมบัติอื่น ๆ ที่มีคะแนนความสำคัญค่อนข้างสูง ได้แก่ Horizongal_Distance_To_Roadways (0.1158) และ Horizional_Distance_To_Fire_Points (0.1100) สิ่งเหล่านี้บ่งชี้ว่าความใกล้ชิดกับถนนและจุดจุดไฟยังส่งผลกระทบอย่างมีนัยสำคัญต่อประเภทพื้นที่ป่า
คุณลักษณะที่เหลือในรายการ 10 อันดับแรกมีคะแนนความสำคัญค่อนข้างต่ำกว่า แต่ยังคงมีส่วนช่วยในประสิทธิภาพการคาดการณ์โดยรวมของโมเดล ลักษณะเหล่านี้ส่วนใหญ่เกี่ยวข้องกับปัจจัยทางอุทกวิทยา ความชัน ลักษณะกว้างไกล และดัชนีร่มเงาเนินเขา
โดยสรุป ผลลัพธ์ที่ได้เน้นถึงปัจจัยที่สำคัญที่สุดที่ส่งผลต่อการกระจายของประเภทป่าปกคลุมในป่าสงวนแห่งชาติ Roosevelt ซึ่งสามารถนำมาใช้เพื่อสร้างแบบจำลองการทำนายที่มีประสิทธิภาพและประสิทธิผลมากขึ้นสำหรับการจำแนกประเภทของป่าปกคลุม
เมื่อไม่มีตัวแปรเป้าหมาย สามารถใช้แนวทางการเลือกคุณลักษณะแบบไม่มีผู้ดูแลเพื่อลดมิติของชุดข้อมูลในขณะที่ยังคงรักษาโครงสร้างพื้นฐานไว้ได้ วิธีการเหล่านี้มักจะรวมถึงการเปลี่ยนพื้นที่คุณลักษณะเริ่มต้นเป็นพื้นที่มิติล่างใหม่ ซึ่งคุณลักษณะที่เปลี่ยนแปลงจะบันทึกการเปลี่ยนแปลงส่วนใหญ่ของข้อมูล

ภาพโดยผู้เขียน
2.1 การวิเคราะห์องค์ประกอบหลัก (PCA)
PCA เป็นวิธีการลดขนาดเชิงเส้นที่จะแปลงพื้นที่คุณลักษณะดั้งเดิมให้เป็นพื้นที่ตั้งฉากใหม่ที่กำหนดโดยส่วนประกอบหลัก ส่วนประกอบเหล่านี้เป็นการผสมผสานเชิงเส้นของคุณลักษณะดั้งเดิมที่เลือกไว้เพื่อบันทึกความแปรปรวนระดับสูงสุดในข้อมูล
PCA อาจถูกนำมาใช้เพื่อเลือกองค์ประกอบหลัก k อันดับแรกที่แสดงถึงการเปลี่ยนแปลงส่วนใหญ่ ซึ่งจะช่วยลดมิติของชุดข้อมูลลง
เพื่อแสดงให้คุณเห็นว่าสิ่งนี้ทำงานอย่างไรในทางปฏิบัติ เราจะทำงานร่วมกับชุดข้อมูล Wine นี่เป็นชุดข้อมูลที่ใช้กันอย่างแพร่หลายสำหรับงานจำแนกประเภทและการเลือกคุณสมบัติในแมชชีนเลิร์นนิง และประกอบด้วยตัวอย่าง 178 ตัวอย่าง ซึ่งแต่ละตัวอย่างเป็นตัวแทนของไวน์ที่แตกต่างกันซึ่งมีต้นกำเนิดจากสามสายพันธุ์ที่แตกต่างกันในภูมิภาคเดียวกันในอิตาลี
เป้าหมายของการทำงานกับชุดข้อมูลไวน์โดยปกติคือการสร้างแบบจำลองการคาดการณ์ที่สามารถจำแนกตัวอย่างไวน์ให้เป็นหนึ่งในสามสายพันธุ์ได้อย่างแม่นยำโดยพิจารณาจากคุณสมบัติทางเคมีของตัวอย่าง
รหัสต่อไปนี้สาธิตการประยุกต์ใช้ Principal Component Analysis (PCA) ซึ่งเป็นเทคนิคการเลือกคุณสมบัติที่ไม่ได้รับการดูแลบนชุดข้อมูล Wine
ส่วนประกอบเหล่านี้ (ส่วนประกอบหลัก) จับความแปรปรวนของข้อมูลได้มากที่สุดในขณะที่ลดการสูญเสียข้อมูลให้เหลือน้อยที่สุด
โค้ดเริ่มต้นด้วยการโหลดชุดข้อมูล Wine ซึ่งประกอบด้วยคุณสมบัติ 13 ประการที่อธิบายคุณสมบัติทางเคมีของตัวอย่างไวน์ต่างๆ
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler # Load the Wine dataset
wine = load_wine()
X = wine.data
y = wine.target
feature_names = wine.feature_names
จากนั้นคุณสมบัติเหล่านี้จะได้รับมาตรฐานโดยใช้ StandardScaler เพื่อให้แน่ใจว่า PCA จะไม่ได้รับผลกระทบจากคุณสมบัติอินพุตที่มีขนาดต่างกัน
# Standardize the features
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
จากนั้น PCA จะดำเนินการกับข้อมูลมาตรฐานโดยใช้คลาส PCA จากโมดูล sklearn.decomposition
# Perform PCA
pca = PCA()
X_pca = pca.fit_transform(X_scaled)
อัตราส่วนความแปรปรวนที่อธิบายไว้สำหรับแต่ละองค์ประกอบหลักได้รับการคำนวณ ซึ่งระบุสัดส่วนของความแปรปรวนทั้งหมดในข้อมูลที่แต่ละองค์ประกอบอธิบาย
# Calculate the explained variance ratio
explained_variance_ratio = pca.explained_variance_ratio_
ในที่สุด จะมีการสร้างแปลงสองแปลงเพื่อแสดงภาพอัตราส่วนความแปรปรวนที่อธิบายไว้ และความแปรปรวนที่อธิบายสะสมตามองค์ประกอบหลัก
โครงเรื่องแรกแสดงอัตราส่วนความแปรปรวนที่อธิบายไว้สำหรับองค์ประกอบหลักแต่ละรายการ ในขณะที่โครงเรื่องที่สองแสดงให้เห็นว่าความแปรปรวนที่อธิบายสะสมเพิ่มขึ้นอย่างไรเมื่อมีการรวมส่วนประกอบหลักเพิ่มเติม
แผนผังเหล่านี้ช่วยกำหนดจำนวนองค์ประกอบหลักที่เหมาะสมที่สุดที่จะใช้ในแบบจำลอง โดยสร้างสมดุลระหว่างการลดขนาดและการเก็บรักษาข้อมูล
# Create a 2x1 grid of subplots
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16, 8)) # Plot the explained variance ratio in the first subplot
ax1.bar(range(1, len(explained_variance_ratio) + 1), explained_variance_ratio)
ax1.set_xlabel('Principal Component')
ax1.set_ylabel('Explained Variance Ratio')
ax1.set_title('Explained Variance Ratio by Principal Component') # Calculate the cumulative explained variance
cumulative_explained_variance = np.cumsum(explained_variance_ratio) # Plot the cumulative explained variance in the second subplot
ax2.plot(range(1, len(cumulative_explained_variance) + 1), cumulative_explained_variance, marker='o')
ax2.set_xlabel('Number of Principal Components')
ax2.set_ylabel('Cumulative Explained Variance')
ax2.set_title('Cumulative Explained Variance by Principal Components') # Display the figure
plt.tight_layout()
plt.show()
มาดูโค้ดทั้งหมดกัน
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler # Load the Wine dataset
wine = load_wine()
X = wine.data
y = wine.target
feature_names = wine.feature_names # Standardize the features
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # Perform PCA
pca = PCA()
X_pca = pca.fit_transform(X_scaled) # Calculate the explained variance ratio
explained_variance_ratio = pca.explained_variance_ratio_ # Create a 2x1 grid of subplots
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16, 8)) # Plot the explained variance ratio in the first subplot
ax1.bar(range(1, len(explained_variance_ratio) + 1), explained_variance_ratio)
ax1.set_xlabel("Principal Component")
ax1.set_ylabel("Explained Variance Ratio")
ax1.set_title("Explained Variance Ratio by Principal Component") # Calculate the cumulative explained variance
cumulative_explained_variance = np.cumsum(explained_variance_ratio) # Plot the cumulative explained variance in the second subplot
ax2.plot( range(1, len(cumulative_explained_variance) + 1), cumulative_explained_variance, marker="o",
)
ax2.set_xlabel("Number of Principal Components")
ax2.set_ylabel("Cumulative Explained Variance")
ax2.set_title("Cumulative Explained Variance by Principal Components") # Display the figure
plt.tight_layout()
plt.show()
นี่คือผลลัพธ์
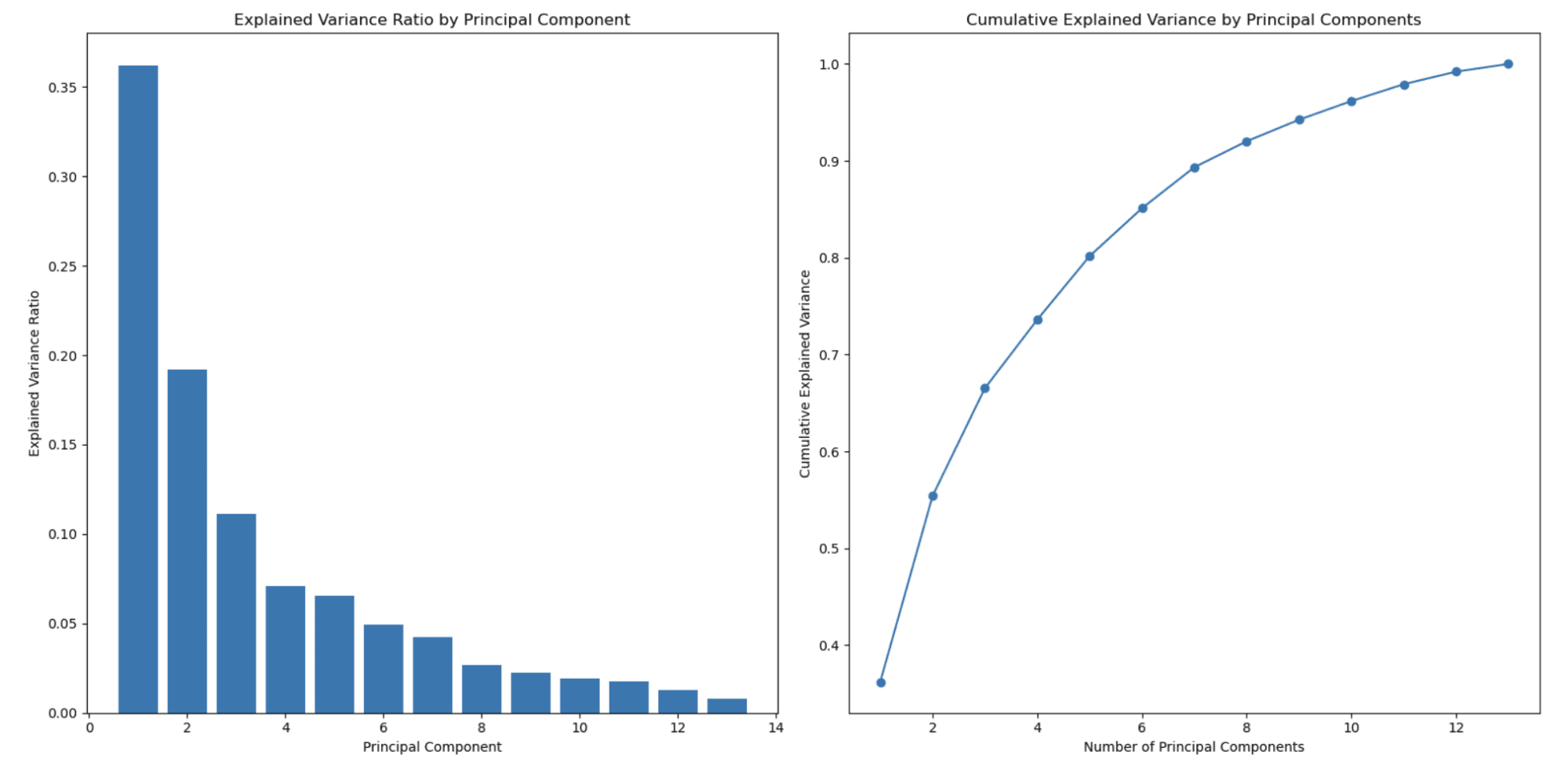
กราฟทางด้านซ้ายแสดงให้เห็นว่าอัตราส่วนความแปรปรวนที่อธิบายไว้จะลดลงเมื่อจำนวนองค์ประกอบหลักเพิ่มขึ้น นี่เป็นพฤติกรรมทั่วไปที่พบใน PCA เนื่องจากองค์ประกอบหลักเรียงลำดับตามจำนวนความแปรปรวนที่อธิบาย
องค์ประกอบหลักแรก (คุณลักษณะ) จะจับค่าความแปรปรวนสูงสุด องค์ประกอบหลักที่สองจะจับจำนวนสูงสุดเป็นอันดับสอง และอื่นๆ เป็นผลให้อัตราส่วนผลต่างที่อธิบายลดลงตามองค์ประกอบหลักแต่ละรายการที่ตามมา
นี่เป็นหนึ่งในเหตุผลหลักที่ใช้ PCA ในการลดขนาด
กราฟที่สองทางด้านขวาแสดงความแปรปรวนที่อธิบายสะสม และช่วยคุณกำหนดจำนวนองค์ประกอบหลัก (คุณลักษณะ) ที่จะเลือกเพื่อแสดงเปอร์เซ็นต์ของข้อมูลของคุณ แกน x แสดงถึงจำนวนขององค์ประกอบหลัก และแกน y แสดงความแปรปรวนที่อธิบายสะสม เมื่อคุณเคลื่อนที่ไปตามแกน x คุณจะเห็นว่าความแปรปรวนรวมยังคงอยู่ได้มากเพียงใดเมื่อคุณรวมองค์ประกอบหลักหลายๆ ส่วนเข้าไป
ในตัวอย่างนี้ คุณจะเห็นว่าการเลือกองค์ประกอบหลักประมาณ 3 หรือ 4 องค์ประกอบจับความแปรปรวนได้มากกว่า 80% แล้ว และองค์ประกอบหลักประมาณ 8 องค์ประกอบจับมากกว่า 90% ของความแปรปรวนทั้งหมด
คุณสามารถเลือกจำนวนส่วนประกอบหลักโดยพิจารณาจากการแลกเปลี่ยนที่คุณต้องการระหว่างการลดขนาดและความแปรปรวนที่คุณต้องการคงไว้
ในตัวอย่างนี้ เราใช้ Sci-kit เพื่อเรียนรู้การใช้ PCA และคุณจะพบเอกสารอย่างเป็นทางการที่นี่
2.2 การวิเคราะห์องค์ประกอบอิสระ (ICA)
ICA เป็นวิธีการแบ่งสัญญาณหลายมิติออกเป็นส่วนประกอบต่างๆ
ในบริบทของการเลือกคุณลักษณะ ICA สามารถใช้ในการแปลงพื้นที่คุณลักษณะดั้งเดิมให้เป็นพื้นที่ใหม่ที่มีคุณลักษณะเฉพาะด้วยส่วนประกอบที่เป็นอิสระทางสถิติ คุณอาจลดมิติของชุดข้อมูลในขณะที่ยังคงรักษาโครงสร้างพื้นฐานไว้โดยเลือกส่วนประกอบอิสระ k อันดับแรก
2.3 การแยกตัวประกอบเมทริกซ์ที่ไม่เป็นลบ (NMF)
ปัจจัยเมทริกซ์ที่ไม่เป็นลบ (NMF) เป็นวิธีการลดขนาดที่ประมาณเมทริกซ์ข้อมูลที่ไม่เป็นลบเป็นผลคูณของเมทริกซ์ที่ไม่เป็นลบที่มีมิติต่ำกว่าสองตัว
NMF สามารถใช้ในบริบทของการเลือกคุณลักษณะเพื่อแยกคุณลักษณะพื้นฐานชุดใหม่ที่จับโครงสร้างที่สำคัญของข้อมูลต้นฉบับ คุณสามารถลดมิติของชุดข้อมูลให้เหลือน้อยที่สุดในขณะที่ยังคงรักษาข้อจำกัดที่ไม่ใช่เชิงลบโดยการเลือกคุณลักษณะพื้นฐาน k สูงสุด
2.4 การฝัง Stochastic Neighbor แบบกระจาย t (t-SNE)
t-SNE เป็นวิธีการลดขนาดแบบไม่เชิงเส้นที่พยายามรักษาโครงสร้างของชุดข้อมูลโดยการลดความแตกต่างระหว่างการแจกแจงความน่าจะเป็นแบบคู่ในตำแหน่งที่มีมิติสูงและต่ำ
t-SNE อาจนำไปใช้ในการเลือกคุณลักษณะเพื่อฉายพื้นที่คุณลักษณะดั้งเดิมลงในพื้นที่มิติที่ต่ำกว่าซึ่งจะรักษาโครงสร้างของข้อมูล ทำให้มีการแสดงภาพและการประเมินผลที่ดียิ่งขึ้น
คุณสามารถค้นหาข้อมูลเพิ่มเติมเกี่ยวกับอัลกอริธึมที่ไม่ได้รับการดูแลและ t-SNE ได้ที่นี่ “อัลกอริทึมการเรียนรู้ที่ไม่มีผู้ดูแล"
2.5 ตัวเข้ารหัสอัตโนมัติ
โปรแกรมเข้ารหัสอัตโนมัติซึ่งเป็นโครงข่ายประสาทเทียมชนิดหนึ่ง เรียนรู้ที่จะเข้ารหัสข้อมูลอินพุตให้เป็นการนำเสนอในมิติที่ต่ำกว่า แล้วถอดรหัสกลับไปเป็นเวอร์ชันดั้งเดิม การแสดงมิติที่ต่ำกว่าของตัวเข้ารหัสอัตโนมัติสามารถใช้เพื่อสร้างชุดคุณลักษณะอื่นที่จับโครงสร้างพื้นฐานของข้อมูลต้นฉบับได้
โดยสรุป การเลือกคุณสมบัติมีความสำคัญในการเรียนรู้ของเครื่อง ช่วยลดมิติข้อมูล ลดความเสี่ยงในการติดตั้งมากเกินไป และปรับปรุงประสิทธิภาพโดยรวมของแบบจำลอง การเลือกวิธีการเลือกคุณสมบัติที่เหมาะสมจะขึ้นอยู่กับปัญหาเฉพาะ ชุดข้อมูล และข้อกำหนดด้านการสร้างแบบจำลอง
บทความนี้ครอบคลุมเทคนิคการเลือกคุณสมบัติที่หลากหลาย รวมถึงวิธีการแบบมีผู้ดูแลและไม่ได้รับการดูแล
เทคนิคที่ได้รับการดูแล เช่น วิธีการแบบอิงตัวกรอง แบบ Wrapper และแบบฝัง จะใช้ความสัมพันธ์ระหว่างคุณลักษณะและตัวแปรเป้าหมายเพื่อระบุคุณลักษณะที่สำคัญที่สุด
เทคนิคที่ไม่ได้รับการดูแล เช่น PCA, ICA, NMF, t-SNE และตัวเข้ารหัสอัตโนมัติ มุ่งเน้นไปที่โครงสร้างภายในของข้อมูลเพื่อลดมิติข้อมูลโดยไม่คำนึงถึงตัวแปรเป้าหมาย
เมื่อเลือกวิธีการเลือกคุณลักษณะที่เหมาะสมสำหรับโมเดลของคุณ สิ่งสำคัญคือต้องพิจารณาคุณลักษณะของข้อมูล สมมติฐานพื้นฐานของแต่ละเทคนิค และความซับซ้อนในการคำนวณที่เกี่ยวข้อง
ด้วยการเลือกและใช้เทคนิคการเลือกคุณสมบัติที่เหมาะสมอย่างรอบคอบ คุณจะสามารถเพิ่มประสิทธิภาพได้อย่างมาก นำไปสู่ข้อมูลเชิงลึกและการตัดสินใจที่ดีขึ้น
เนท โรซิดิ เป็นนักวิทยาศาสตร์ข้อมูลและในกลยุทธ์ผลิตภัณฑ์ เขายังเป็นผู้ช่วยศาสตราจารย์สอนการวิเคราะห์และเป็นผู้ก่อตั้ง StrataScratchซึ่งเป็นแพลตฟอร์มที่ช่วยให้นักวิทยาศาสตร์ด้านข้อมูลเตรียมพร้อมสำหรับการสัมภาษณ์ด้วยคำถามสัมภาษณ์จริงจากบริษัทชั้นนำ เชื่อมต่อกับเขาที่ ทวิตเตอร์: StrataScratch or LinkedIn.
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- การเงิน EVM ส่วนต่อประสานแบบครบวงจรสำหรับการเงินแบบกระจายอำนาจ เข้าถึงได้ที่นี่.
- กลุ่มสื่อควอนตัม IR/PR ขยาย เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. ข้อมูลอัจฉริยะ Web3 ขยายความรู้ เข้าถึงได้ที่นี่.
- ที่มา: https://www.kdnuggets.com/2023/06/advanced-feature-selection-techniques-machine-learning-models.html?utm_source=rss&utm_medium=rss&utm_campaign=advanced-feature-selection-techniques-for-machine-learning-models
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- 1
- 10
- 11
- 12
- 13
- 15%
- 16
- 20
- 22
- 27
- 7
- 8
- 9
- 95%
- a
- ความสามารถ
- เกี่ยวกับเรา
- ข้างบน
- เร่งความเร็ว
- ยอมรับได้
- ตาม
- ตาม
- ลงชื่อเข้าใช้
- ความถูกต้อง
- แม่นยำ
- บรรลุ
- ประสบความสำเร็จ
- ประสบความสำเร็จ
- เพิ่ม
- ที่เพิ่ม
- เพิ่มเติม
- เพิ่ม
- สูง
- น่าสงสาร
- อายุ
- เอดส์
- จุดมุ่งหมาย
- ขั้นตอนวิธี
- อัลกอริทึม
- ทั้งหมด
- การอนุญาต
- ช่วยให้
- คนเดียว
- ตาม
- แล้ว
- ด้วย
- เสมอ
- ในหมู่
- จำนวน
- an
- การวิเคราะห์
- การวิเคราะห์
- วิเคราะห์
- วิเคราะห์
- และ
- อื่น
- คำตอบ
- การใช้งาน
- ประยุกต์
- ใช้
- การประยุกต์ใช้
- เข้าใกล้
- วิธีการ
- เหมาะสม
- เป็น
- รอบ
- บทความ
- เทียม
- AS
- แง่มุม
- ประเมินผล
- การประเมิน
- สมมติฐาน
- At
- แอตทริบิวต์
- ใช้ได้
- เฉลี่ย
- กลับ
- กระดูกสันหลัง
- ยอดคงเหลือ
- สมดุล
- บาร์
- ตาม
- ขั้นพื้นฐาน
- รากฐาน
- BE
- เพราะ
- กลายเป็น
- ก่อน
- เริ่ม
- การเริ่มต้น
- ด้านล่าง
- ที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- Black
- เลือด
- ความดันโลหิต
- ค่าดัชนีมวลกาย
- ร่างกาย
- กล้า
- ทั้งสอง
- BP
- โรคมะเร็งเต้านม
- สร้าง
- การก่อสร้าง
- แต่
- by
- คำนวณ
- คำนวณ
- คำนวณ
- CAN
- โรคมะเร็ง
- จับ
- จับ
- รอบคอบ
- กรณี
- ก่อให้เกิด
- สาเหตุที่
- ศูนย์
- บาง
- การเปลี่ยนแปลง
- การเปลี่ยนแปลง
- เปลี่ยนแปลง
- ลักษณะเฉพาะ
- ลักษณะ
- ลักษณะ
- แผนภูมิ
- chatbots
- ChatGPT
- สารเคมี
- สารเคมี
- ทางเลือก
- Choose
- เลือก
- เลือก
- ชั้น
- ชั้นเรียน
- การจัดหมวดหมู่
- แยกประเภท
- ซีเอ็นเอ็น
- รหัส
- โคโลราโด
- คอลัมน์
- คอลัมน์
- COM
- รวม
- รวม
- อย่างธรรมดา
- บริษัท
- เปรียบเทียบ
- การเปรียบเทียบ
- การแข่งขัน
- ความซับซ้อน
- ส่วนประกอบ
- ส่วนประกอบ
- พลังการคำนวณ
- คำนวณ
- ข้อสรุป
- ร่วม
- เชื่อมต่อ
- ดังนั้น
- พิจารณา
- ถือว่า
- พิจารณา
- พิจารณา
- ประกอบ
- มี
- สิ่งแวดล้อม
- อย่างต่อเนื่อง
- ต่อเนื่องกัน
- สนับสนุน
- ผลงาน
- แปลง
- ความสัมพันธ์
- ราคา
- แพง
- ค่าใช้จ่าย
- ได้
- หน้าปก
- ปกคลุม
- สร้าง
- วิกฤติ
- ปัจจุบัน
- ประจำวัน
- ข้อมูล
- นักวิทยาศาสตร์ข้อมูล
- ชุดข้อมูล
- ตัดสินใจ
- กำลังตัดสินใจ
- การตัดสินใจ
- การตัดสินใจ
- ต้นไม้ตัดสินใจ
- การตัดสินใจ
- ลดลง
- ลดลง
- กำหนด
- การส่งมอบ
- เรียกร้อง
- แสดงให้เห็นถึง
- ทั้งนี้ขึ้นอยู่กับ
- ขึ้นอยู่กับ
- ที่ต้องการ
- กำหนด
- การกำหนด
- โรคเบาหวาน
- DID
- แตกต่าง
- ความแตกต่าง
- ต่าง
- แยก
- ค้นพบ
- สนทนา
- การสนทนา
- แสดง
- แสดง
- การกระจาย
- การกระจาย
- แบ่งออก
- do
- เอกสาร
- เด่น
- e
- แต่ละ
- อย่างง่ายดาย
- ง่าย
- ขอบ
- มีประสิทธิภาพ
- ที่มีประสิทธิภาพ
- ทั้ง
- กำจัด
- ตัดออก
- ขจัด
- ที่ฝัง
- การฝัง
- พนักงาน
- เสริม
- ที่เพิ่มขึ้น
- ทำให้มั่นใจ
- เพื่อให้แน่ใจ
- ทั้งหมด
- ยุค
- โดยเฉพาะอย่างยิ่ง
- อีเธอร์ (ETH)
- ประเมินค่า
- การประเมินการ
- การประเมินผล
- เผง
- การตรวจสอบ
- ตัวอย่าง
- ตัวอย่าง
- ดำเนินการ
- อธิบาย
- อธิบาย
- อธิบาย
- ภายนอก
- สารสกัด
- สารสกัดจาก
- ที่หน้า
- การจดจำใบหน้า
- ปัจจัย
- ปัจจัย
- คุ้นเคย
- เร็วขึ้น
- ลักษณะ
- คุณสมบัติ
- ข้อเสนอแนะ
- หญิง
- มะเดื่อ
- รูป
- กรอง
- หา
- ธรรมชาติ
- ชื่อจริง
- พอดี
- ลอย
- โฟกัส
- ปฏิบัติตาม
- ดังต่อไปนี้
- ดังต่อไปนี้
- สำหรับ
- ป่า
- รูปแบบ
- ข้างหน้า
- ผู้สร้าง
- ราคาเริ่มต้นที่
- ฟังก์ชัน
- ต่อไป
- ได้รับ
- เพศ
- General
- สร้าง
- ได้รับ
- ให้
- กำหนด
- เป้าหมาย
- เป้าหมาย
- ดี
- ค่อยๆ
- กราฟ
- ยิ่งใหญ่
- มากขึ้น
- ตะแกรง
- จัดการ
- อันตราย
- มี
- มี
- he
- ความสูง
- ช่วย
- เป็นประโยชน์
- การช่วยเหลือ
- จะช่วยให้
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- จุดสูง
- สูงกว่า
- ที่สูงที่สุด
- เน้น
- พระองค์
- ตามแนวนอน
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTTPS
- ใหญ่
- เป็นมนุษย์
- i
- ICS
- ความคิด
- ในอุดมคติ
- ระบุ
- แยกแยะ
- การเผาไหม้
- แสดงให้เห็นถึง
- ส่งผลกระทบ
- ผลกระทบ
- นำเข้า
- ความสำคัญ
- สำคัญ
- ด้านที่สำคัญ
- ปรับปรุง
- การปรับปรุง
- การปรับปรุง
- การปรับปรุง
- ช่วยเพิ่ม
- การปรับปรุง
- in
- ประกอบด้วย
- รวม
- รวมถึง
- รวมทั้ง
- เพิ่ม
- เพิ่มขึ้น
- เพิ่มขึ้น
- ขึ้น
- อิสระ
- ดัชนี
- แสดง
- การแสดง
- ดัชนี
- เป็นรายบุคคล
- มีอิทธิพล
- ข้อมูล
- แจ้ง
- แรกเริ่ม
- อินพุต
- ข้อมูลเชิงลึก
- แทน
- สำคัญ
- ปฏิสัมพันธ์
- สัมภาษณ์
- คำถามในการสัมภาษณ์
- บทสัมภาษณ์
- เข้าไป
- แท้จริง
- ร่วมมือ
- ปัญหา
- IT
- อิตาลี
- ITS
- การสัมภาษณ์
- ตัดสิน
- เพียงแค่
- KD นักเก็ต
- การเก็บรักษา
- ชนิด
- ทราบ
- ที่รู้จักกัน
- l2
- ป้ายกำกับ
- ใหญ่
- ชั้นนำ
- เรียนรู้
- การเรียนรู้
- น้อยที่สุด
- ซ้าย
- น้อยลง
- ชั้น
- การใช้ประโยชน์
- ห้องสมุด
- ห้องสมุด
- กดไลก์
- การ จำกัด
- Line
- LINK
- รายการ
- ชีวิต
- ll
- โหลด
- โหลด
- วันหยุด
- ดู
- ปิด
- ลด
- ลด
- เครื่อง
- เรียนรู้เครื่อง
- หลัก
- ส่วนใหญ่
- การบำรุงรักษา
- รักษา
- สำคัญ
- ส่วนใหญ่
- ทำ
- ทำให้
- การทำ
- หลาย
- มวล
- matplotlib
- มดลูก
- อาจ..
- ความหมาย
- วัด
- การวัด
- วัด
- มาตรการ
- วิธี
- วิธีการ
- เมตริก
- อาจ
- การลด
- หายไป
- แบบ
- การสร้างแบบจำลอง
- โมเดล
- ปานกลาง
- โมดูล
- ข้อมูลเพิ่มเติม
- มากที่สุด
- ย้าย
- มาก
- ซึ่งกันและกัน
- ชื่อ
- แห่งชาติ
- จำเป็นต้อง
- เครือข่าย
- เครือข่าย
- ประสาท
- เครือข่ายประสาท
- เครือข่ายประสาทเทียม
- ใหม่
- ถัดไป
- ไม่
- จำนวน
- ตัวเลข
- มึน
- วัตถุ
- วัตถุประสงค์
- ตั้งข้อสังเกต
- of
- เป็นทางการ
- มักจะ
- on
- ONE
- เพียง
- ตรงข้าม
- ดีที่สุด
- เพิ่มประสิทธิภาพ
- or
- ใบสั่ง
- เป็นต้นฉบับ
- มีต้นกำเนิด
- อื่นๆ
- ของเรา
- ออก
- แนะ
- เอาท์พุต
- เกิน
- ทั้งหมด
- ภาพรวม
- คู่
- หมีแพนด้า
- พารามิเตอร์
- ส่วนหนึ่ง
- ในสิ่งที่สนใจ
- โดยเฉพาะ
- เปอร์เซ็นต์
- ดำเนินการ
- การปฏิบัติ
- ดำเนินการ
- ระยะ
- เลือก
- คัดสรร
- เวที
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- เล่น
- จุด
- ยอดนิยม
- เป็นไปได้
- ที่มีศักยภาพ
- ที่อาจเกิดขึ้น
- อำนาจ
- ขับเคลื่อน
- การปฏิบัติ
- คาดการณ์
- ทำนาย
- การคาดการณ์
- เตรียมการ
- การมี
- ความดัน
- ป้องกัน
- ประถม
- หลัก
- พิมพ์
- ความน่าจะเป็น
- ปัญหา
- ปัญหาที่เกิดขึ้น
- กระบวนการ
- ก่อ
- ผลิตภัณฑ์
- ศาสตราจารย์
- ในอาชีพ
- โครงการ
- โครงการ
- คุณสมบัติ
- สัดส่วน
- ให้
- การให้
- คำถาม
- คำถาม
- สุ่ม
- พิสัย
- ตั้งแต่
- จัดอันดับ
- อันดับ
- อันดับ
- การให้คะแนน
- อัตราส่วน
- ถึง
- อ่าน
- จริง
- ดินแดน
- เหตุผล
- การรับรู้
- ซ้ำ
- ลด
- ลดลง
- ลด
- การลดลง
- ภูมิภาค
- ถดถอย
- การเรียนรู้การเสริมแรง
- ที่เกี่ยวข้อง
- ความสัมพันธ์
- ญาติ
- สัมพัทธ์
- ความสัมพันธ์กัน
- ตรงประเด็น
- ที่เหลืออยู่
- ลบออก
- ลบ
- ซ้ำแล้วซ้ำอีก
- ซ้ำแล้วซ้ำเล่า
- แสดง
- การแสดง
- เป็นตัวแทนของ
- แสดงให้เห็นถึง
- ต้องการ
- ความต้องการ
- แหล่งข้อมูล
- ผล
- ผลสอบ
- รักษา
- การรักษา
- ความจำ
- เผย
- ขวา
- ความเสี่ยง
- บทบาท
- s
- ประโยชน์
- เดียวกัน
- ตาชั่ง
- นักวิทยาศาสตร์
- นักวิทยาศาสตร์
- คะแนน
- คะแนน
- ที่สอง
- เห็น
- แสวงหา
- เลือก
- การเลือก
- การเลือก
- เซรุ่ม
- ชุด
- ชุดอุปกรณ์
- หลาย
- เพศ
- น่า
- โชว์
- การแสดง
- แสดงให้เห็นว่า
- สัญญาณ
- ความสำคัญ
- สำคัญ
- อย่างมีความหมาย
- ความง่าย
- ตั้งแต่
- หก
- ลาด
- So
- ช่องว่าง
- โดยเฉพาะ
- ที่ระบุไว้
- การพูด
- การรู้จำเสียง
- แยก
- สี่เหลี่ยม
- ดาว
- เริ่มต้น
- เริ่มต้น
- ทางสถิติ
- สถิติ
- สถิติ
- ขั้นตอน
- ขั้นตอน
- ยังคง
- ร้านค้า
- ซื่อตรง
- กลยุทธ์
- กลยุทธ์
- แข็งแกร่ง
- โครงสร้าง
- ภายหลัง
- เป็นกอบเป็นกำ
- อย่างเช่น
- ชี้ให้เห็นถึง
- เหมาะสม
- สรุป
- เหนือกว่า
- การเรียนรู้ภายใต้การดูแล
- ที่สนับสนุน
- การ
- คุย
- เป้า
- งาน
- งาน
- การเรียนการสอน
- เทคนิค
- เทคโนโลยี
- ระยะ
- เงื่อนไขการใช้บริการ
- ทดสอบ
- การทดสอบ
- กว่า
- ที่
- พื้นที่
- ข้อมูล
- ของพวกเขา
- พวกเขา
- แล้วก็
- ที่นั่น
- ดังนั้น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- นี้
- สาม
- ธรณีประตู
- ตลอด
- ครั้ง
- ไปยัง
- ในวันนี้
- เกินไป
- ด้านบน
- สูงสุด 10
- หัวข้อ
- หัวข้อ
- รวม
- ไปทาง
- รถไฟ
- ผ่านการฝึกอบรม
- การฝึกอบรม
- ต้นไม้
- ต้นไม้
- สอง
- ชนิด
- ชนิด
- ตามแบบฉบับ
- เป็นปกติ
- ในที่สุด
- ความไม่แน่นอน
- พื้นฐาน
- เข้าใจ
- จนกระทั่ง
- ใช้
- มือสอง
- ใช้
- การใช้
- มักจะ
- มีคุณค่า
- ความคุ้มค่า
- ความคุ้มค่า
- ความหลากหลาย
- ต่างๆ
- รุ่น
- การสร้างภาพ
- จำเป็น
- ต้องการ
- we
- น้ำหนัก
- ดี
- อะไร
- เมื่อ
- ที่
- ในขณะที่
- ทั้งหมด
- กว้าง
- ช่วงกว้าง
- อย่างกว้างขวาง
- จะ
- ไวน์
- วิสคอนซิน
- กับ
- ภายใน
- ไม่มี
- งาน
- การทำงาน
- โรงงาน
- X
- ปี
- ยัง
- ผล
- เธอ
- ของคุณ
- ด้วยตัวคุณเอง
- ลมทะเล
- เป็นศูนย์




