อเมซอน อาเธน่า เป็นบริการสืบค้นข้อมูลเชิงโต้ตอบที่ทำให้ง่ายต่อการวิเคราะห์ข้อมูลใน บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (Amazon S3) และแหล่งข้อมูลที่อยู่ใน AWS, ภายในองค์กร หรือระบบคลาวด์อื่นๆ โดยใช้ SQL หรือ Python Athena สร้างขึ้นจากเอนจิ้น Trino และ Presto แบบโอเพ่นซอร์ส และเฟรมเวิร์ก Apache Spark โดยไม่ต้องเตรียมการหรือกำหนดค่าใดๆ Athena เป็นแบบไร้เซิร์ฟเวอร์ ดังนั้นจึงไม่มีโครงสร้างพื้นฐานให้จัดการ และคุณจ่ายเฉพาะการสืบค้นที่คุณเรียกใช้เท่านั้น
ภูเขาน้ำแข็งอาปาเช่ เป็นรูปแบบตารางเปิดสำหรับชุดข้อมูลการวิเคราะห์ขนาดใหญ่มาก โดยจะจัดการคอลเลกชันขนาดใหญ่ของไฟล์เป็นตาราง และสนับสนุนการดำเนินการ Data Lake เชิงวิเคราะห์ที่ทันสมัย เช่น การแทรกระดับเรกคอร์ด อัปเดต ลบ และแบบสอบถามการเดินทางข้ามเวลา Athena รองรับการอ่าน การเดินทางข้ามเวลา การเขียน และการสืบค้น DDL สำหรับตาราง Apache Iceberg ที่ใช้รูปแบบ Apache Parquet สำหรับข้อมูลและ แคตตาล็อกข้อมูลกาว AWS Data สำหรับ metastore ของพวกเขา
วิศวกรรมคุณลักษณะ เป็นกระบวนการระบุและแปลงข้อมูลดิบ (รูปภาพ ไฟล์ข้อความ วิดีโอ และอื่นๆ) ทดแทนข้อมูลที่ขาดหายไป และเพิ่มองค์ประกอบข้อมูลที่มีความหมายอย่างน้อยหนึ่งรายการเพื่อให้บริบทเพื่อให้โมเดลการเรียนรู้ของเครื่อง (ML) สามารถเรียนรู้จากข้อมูลนั้นได้ การติดฉลากข้อมูลจำเป็นสำหรับกรณีการใช้งานต่างๆ รวมถึงการพยากรณ์ คอมพิวเตอร์วิทัศน์ การประมวลผลภาษาธรรมชาติ และการรู้จำเสียง
เมื่อรวมกับความสามารถของ Athena แล้ว Apache Iceberg มอบเวิร์กโฟลว์ที่ง่ายขึ้นสำหรับนักวิทยาศาสตร์ข้อมูลเพื่อสร้างคุณสมบัติข้อมูลใหม่โดยไม่จำเป็นต้องคัดลอกหรือสร้างชุดข้อมูลใหม่ทั้งหมด คุณสามารถสร้างฟีเจอร์โดยใช้ SQL มาตรฐานบน Athena โดยไม่ต้องใช้บริการอื่นใดสำหรับวิศวกรรมฟีเจอร์ นักวิทยาศาสตร์ด้านข้อมูลสามารถลดเวลาที่ใช้ในการเตรียมและคัดลอกชุดข้อมูล และแทนที่จะมุ่งเน้นไปที่วิศวกรรมฟีเจอร์ข้อมูล การทดลอง และการวิเคราะห์ข้อมูลตามขนาด
ในโพสต์นี้ เราจะทบทวนประโยชน์ของการใช้ Athena กับรูปแบบตารางแบบเปิดของ Apache Iceberg และวิธีการลดความซับซ้อนของงานวิศวกรรมคุณลักษณะทั่วไปสำหรับนักวิทยาศาสตร์ข้อมูล เราสาธิตวิธีที่ Athena สามารถแปลงตารางที่มีอยู่ในรูปแบบ Apache Iceberg จากนั้นเพิ่มคอลัมน์ ลบคอลัมน์ และแก้ไขข้อมูลในตารางโดยไม่ต้องสร้างหรือคัดลอกชุดข้อมูลใหม่ และใช้ความสามารถเหล่านี้เพื่อสร้างคุณสมบัติใหม่บนตาราง Apache Iceberg
ภาพรวมโซลูชัน
นักวิทยาศาสตร์ข้อมูลมักจะคุ้นเคยกับการทำงานกับชุดข้อมูลขนาดใหญ่ ชุดข้อมูลมักจะจัดเก็บในรูปแบบ JSON, CSV, ORC หรือ อาปาเช่ปาร์เก้ รูปแบบหรือรูปแบบที่ปรับให้เหมาะสมสำหรับการอ่านที่คล้ายกันเพื่อประสิทธิภาพการอ่านที่รวดเร็ว นักวิทยาศาสตร์ด้านข้อมูลมักจะสร้างคุณลักษณะข้อมูลใหม่ และแทนที่คุณลักษณะข้อมูลดังกล่าวด้วยข้อมูลรวมและข้อมูลเสริม ในอดีต งานนี้สำเร็จได้ด้วยการสร้างมุมมองด้านบนของตารางที่มีข้อมูลพื้นฐานในรูปแบบ Apache Parquet โดยที่คอลัมน์และข้อมูลดังกล่าวถูกเพิ่มในขณะรันไทม์ หรือโดยการสร้างตารางใหม่ที่มีคอลัมน์เพิ่มเติม แม้ว่าเวิร์กโฟลว์นี้จะเหมาะสำหรับกรณีการใช้งานจำนวนมาก แต่ก็ไม่มีประสิทธิภาพสำหรับชุดข้อมูลขนาดใหญ่ เนื่องจากข้อมูลจะต้องถูกสร้างขึ้นที่รันไทม์ มิฉะนั้นชุดข้อมูลจะต้องถูกคัดลอกและแปลง
เอเธน่าได้แนะนำ ธุรกรรม ACID (Atomicity, Consistency, Isolation, Durability) ความสามารถที่เพิ่มการดำเนินการ INSERT, UPDATE, DELETE, MERGE และการเดินทางข้ามเวลา ตาราง Apache Iceberg. ความสามารถเหล่านี้ช่วยให้นักวิทยาศาสตร์ข้อมูลสามารถสร้างคุณลักษณะข้อมูลใหม่และวางคุณลักษณะข้อมูลที่มีอยู่ลงในชุดข้อมูลที่มีอยู่โดยไม่ต้องกังวลเกี่ยวกับการคัดลอกหรือแปลงชุดข้อมูลหรือทำให้เป็นนามธรรมด้วยมุมมอง นักวิทยาศาสตร์ด้านข้อมูลสามารถมุ่งเน้นไปที่งานด้านวิศวกรรมคุณลักษณะและหลีกเลี่ยงการคัดลอกและแปลงชุดข้อมูล
การดำเนินการ Athena Iceberg UPDATE เขียนไฟล์ลบตำแหน่ง Apache Iceberg และแถวที่อัปเดตใหม่เป็นไฟล์ข้อมูลในธุรกรรมเดียวกัน คุณสามารถแก้ไขบันทึกได้โดยใช้คำสั่ง UPDATE คำสั่งเดียว
ด้วยการเปิดตัว Athena engine เวอร์ชัน 3 ความสามารถของตาราง Apache Iceberg ได้รับการปรับปรุงด้วยการสนับสนุนสำหรับการดำเนินการต่างๆ เช่น สร้างตารางเป็นเลือก (CTAS) และคำสั่ง MERGE ที่ปรับปรุงการจัดการวงจรชีวิตของข้อมูล Iceberg ของคุณ CTAS ช่วยให้สร้างตารางจากรูปแบบอื่นๆ เช่น Apache Paquet ได้อย่างรวดเร็วและมีประสิทธิภาพ รวมเข้า การอัปเดตแบบมีเงื่อนไข ลบ หรือแทรกแถวลงในตาราง Iceberg คำสั่งเดียวสามารถรวมการดำเนินการปรับปรุง ลบ และแทรก
เบื้องต้น
ตั้งค่า Athena workgroup ด้วย Athena engine เวอร์ชัน 3 เพื่อใช้คำสั่ง CTAS และ MERGE กับตาราง Apache Iceberg หากต้องการอัปเกรดเอนจิ้น Athena ที่มีอยู่เป็นเวอร์ชัน 3 ในเวิร์กกรุ๊ป Athena ให้ทำตามคำแนะนำใน อัปเกรดเป็น Athena engine เวอร์ชัน 3 เพื่อเพิ่มประสิทธิภาพการสืบค้นและเข้าถึงฟีเจอร์การวิเคราะห์เพิ่มเติม หรืออ้างถึง การเปลี่ยนเวอร์ชันเครื่องยนต์ในคอนโซล Athena.
ชุด
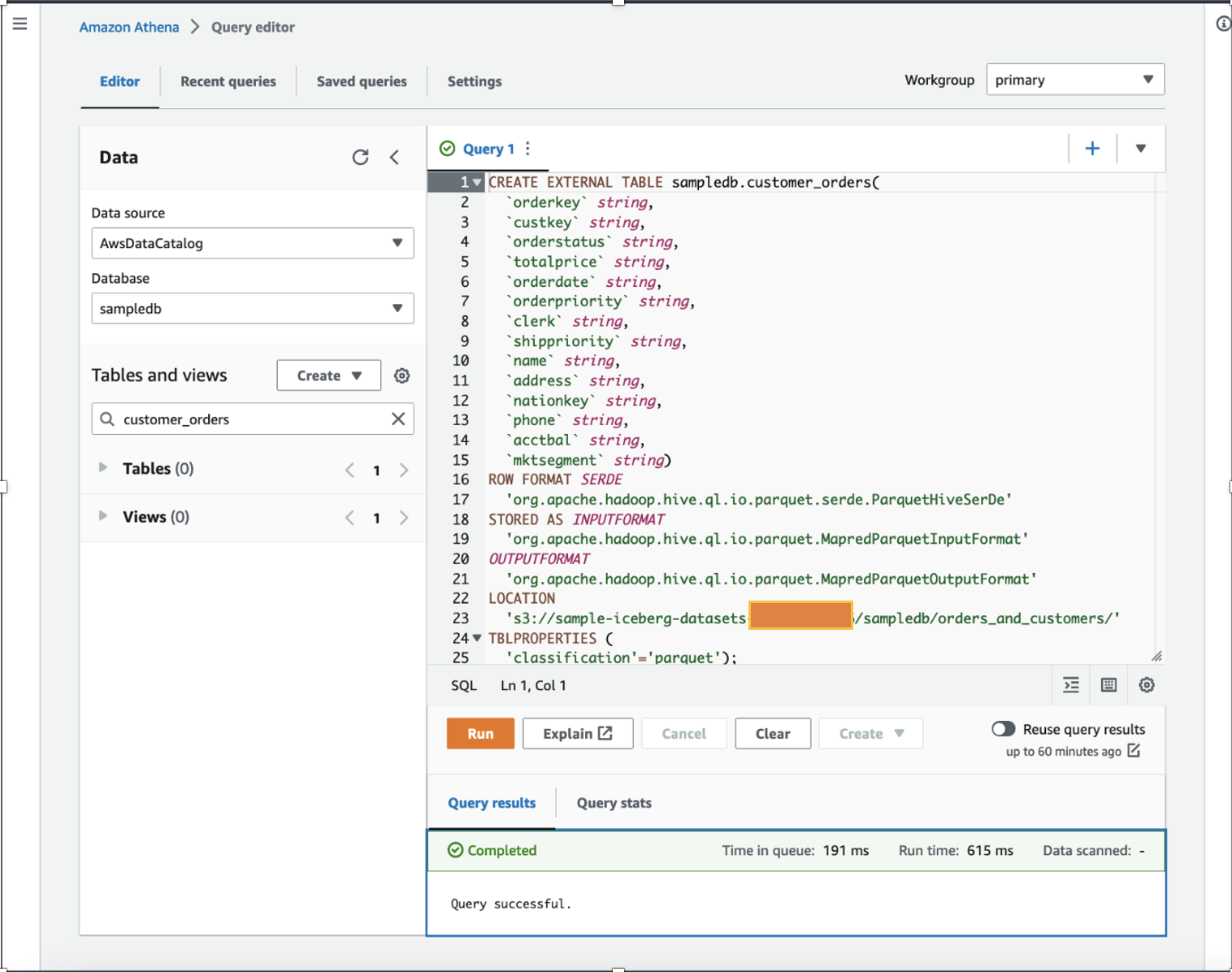
สำหรับการสาธิต เราใช้ตาราง Apache Parquet ที่มีข้อมูลการขายสมมติที่กระจายแบบสุ่มหลายล้านรายการจากหลายปีที่ผ่านมาซึ่งจัดเก็บไว้ในบัคเก็ต S3 ดาวน์โหลด ชุดข้อมูล เปิดเครื่องรูดไปยังเครื่องคอมพิวเตอร์ของคุณ และอัปโหลดไปยังบัคเก็ต S3 ของคุณ ในโพสต์นี้ เราอัปโหลดชุดข้อมูลของเราไปที่ s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/.
ตารางต่อไปนี้แสดงเค้าโครงสำหรับตาราง customer_orders.
| ชื่อคอลัมน์ | ประเภทข้อมูล | รายละเอียด |
| คีย์คำสั่ง | เชือก | หมายเลขคำสั่งซื้อสำหรับการสั่งซื้อ |
| คุ้กกี้ | เชือก | หมายเลขประจำตัวลูกค้า |
| สถานะการสั่งซื้อ | เชือก | สถานะของการสั่งซื้อ |
| ราคารวม | เชือก | ราคารวมของการสั่งซื้อ |
| วันสั่ง | เชือก | วันที่ของการสั่งซื้อ |
| ลำดับความสำคัญ | เชือก | ลำดับความสำคัญของการสั่งซื้อ |
| เสมียน | เชือก | ชื่อพนักงานที่ดำเนินการตามคำสั่งซื้อ |
| ลำดับความสำคัญของเรือ | เชือก | ลำดับความสำคัญในการจัดส่ง |
| ชื่อ | เชือก | ชื่อลูกค้า |
| ที่อยู่ | เชือก | ที่อยู่ลูกค้า |
| เนชั่นคีย์ | เชือก | รหัสประเทศของลูกค้า |
| โทรศัพท์ | เชือก | เบอร์โทรลูกค้า |
| บัญชี | เชือก | ยอดเงินในบัญชีลูกค้า |
| mktsegment | เชือก | ส่วนตลาดลูกค้า |
ดำเนินการวิศวกรรมคุณลักษณะ
ในฐานะนักวิทยาศาสตร์ข้อมูล เราต้องการดำเนินการ วิศวกรรมคุณลักษณะ ในข้อมูลการสั่งซื้อของลูกค้าโดยเพิ่มยอดซื้อรวมหนึ่งปีที่คำนวณได้และยอดซื้อเฉลี่ยหนึ่งปีสำหรับลูกค้าแต่ละรายในชุดข้อมูลที่มีอยู่ เพื่อวัตถุประสงค์ในการสาธิต เราได้สร้าง customer_orders ตารางใน sampledb ฐานข้อมูลโดยใช้ Athena ดังแสดงในคำสั่ง DDL ต่อไปนี้ (คุณสามารถใช้ชุดข้อมูลที่มีอยู่แล้วทำตามขั้นตอนที่กล่าวถึงในโพสต์นี้) customer_orders ชุดข้อมูลถูกสร้างขึ้นและจัดเก็บไว้ในตำแหน่งบัคเก็ต S3 s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/ ในรูปแบบไม้ปาร์เก้ ตารางนี้ไม่ใช่ตาราง Apache Iceberg
![]()
ตรวจสอบข้อมูลในตารางโดยการเรียกใช้แบบสอบถาม:
![]()
เราต้องการเพิ่มคุณสมบัติใหม่ให้กับตารางนี้เพื่อทำความเข้าใจการขายของลูกค้าให้ลึกซึ้งยิ่งขึ้น ซึ่งอาจส่งผลให้การฝึกโมเดลเร็วขึ้นและได้ข้อมูลเชิงลึกที่มีค่ามากขึ้น หากต้องการเพิ่มคุณสมบัติใหม่ให้กับชุดข้อมูล ให้แปลงไฟล์ customer_orders ตาราง Athena ไปยังตาราง Apache Iceberg บน Athena ฉบับ ก CTAS คำสั่งแบบสอบถามเพื่อสร้างตารางใหม่ด้วยรูปแบบ Apache Iceberg จาก customer_orders โต๊ะ. ในขณะที่ทำเช่นนั้น คุณลักษณะใหม่จะถูกเพิ่มเพื่อรับยอดซื้อทั้งหมดในปีที่ผ่านมา (ปีสูงสุดของชุดข้อมูล) จากลูกค้าแต่ละราย
ในแบบสอบถาม CTAS ต่อไปนี้ คอลัมน์ใหม่ชื่อ one_year_sales_aggregate โดยมีค่าเริ่มต้นเป็น 0.0 ของประเภทข้อมูล double ถูกเพิ่มและ table_type ถูกตั้งค่าเป็น ICEBERG:
![]()
ใช้แบบสอบถามต่อไปนี้เพื่อตรวจสอบข้อมูลในตาราง Apache Iceberg ด้วยคอลัมน์ใหม่ one_year_sales_aggregate ค่าเป็น 0.0:
![]()
เราต้องการเติมค่าสำหรับคุณสมบัติใหม่ one_year_sales_aggregate ในชุดข้อมูลเพื่อรับยอดซื้อทั้งหมดสำหรับลูกค้าแต่ละรายตามการซื้อในปีที่ผ่านมา (ปีสูงสุดของชุดข้อมูล) ออกคำสั่งแบบสอบถาม MERGE ไปยังตาราง Apache Iceberg โดยใช้ Athena เพื่อเติมค่าสำหรับ one_year_sales_aggregate คุณสมบัติ:
![]()
ใช้แบบสอบถามต่อไปนี้เพื่อตรวจสอบมูลค่าที่อัปเดตสำหรับการใช้จ่ายทั้งหมดโดยลูกค้าแต่ละรายในปีที่ผ่านมา:
![]()
เราตัดสินใจเพิ่มคุณลักษณะอื่นลงในตาราง Apache Iceberg ที่มีอยู่เพื่อคำนวณและจัดเก็บยอดซื้อเฉลี่ยในปีที่ผ่านมาโดยลูกค้าแต่ละราย ออกคำสั่งแบบสอบถาม ALTER เพื่อเพิ่มคอลัมน์ใหม่ให้กับตารางที่มีอยู่สำหรับคุณสมบัติ one_year_sales_average:
![]()
ก่อนเติมค่าให้กับฟีเจอร์ใหม่นี้ คุณสามารถตั้งค่าเริ่มต้นสำหรับฟีเจอร์ได้ one_year_sales_average ไปยัง 0.0. ใช้ตาราง Apache Iceberg เดียวกันกับ Athena ออกคำสั่งการสืบค้น UPDATE เพื่อเติมค่าสำหรับคุณสมบัติใหม่เป็น 0.0:
![]()
ใช้แบบสอบถามต่อไปนี้เพื่อตรวจสอบมูลค่าที่อัปเดตสำหรับการใช้จ่ายเฉลี่ยโดยลูกค้าแต่ละรายในปีที่ผ่านมา ตั้งค่าเป็น 0.0:
![]()
ตอนนี้เราต้องการเติมค่าสำหรับคุณสมบัติใหม่ one_year_sales_average ในชุดข้อมูลเพื่อรับยอดซื้อเฉลี่ยสำหรับลูกค้าแต่ละรายตามการซื้อในปีที่ผ่านมา (ปีสูงสุดของชุดข้อมูล) ออกคำสั่งแบบสอบถาม MERGE ไปยังตาราง Apache Iceberg ที่มีอยู่บน Athena โดยใช้เครื่องมือ Athena เพื่อเติมค่าสำหรับคุณลักษณะ one_year_sales_average:
![]()
ใช้แบบสอบถามต่อไปนี้เพื่อตรวจสอบค่าที่อัปเดตสำหรับการใช้จ่ายโดยเฉลี่ยของลูกค้าแต่ละราย:
![]()
เมื่อเพิ่มฟีเจอร์ข้อมูลเพิ่มเติมลงในชุดข้อมูลแล้ว นักวิทยาศาสตร์ข้อมูลมักจะดำเนินการฝึกโมเดล ML และทำการอนุมานโดยใช้ Amazon Sagemaker หรือชุดเครื่องมือที่เทียบเท่า
สรุป
ในโพสต์นี้ เราได้สาธิตวิธีดำเนินการวิศวกรรมคุณลักษณะโดยใช้ Athena กับ Apache Iceberg นอกจากนี้ เรายังสาธิตการใช้แบบสอบถาม CTAS เพื่อสร้างตาราง Apache Iceberg บน Athena จากชุดข้อมูลที่มีอยู่ในรูปแบบ Apache Parquet การเพิ่มคุณสมบัติใหม่ในตาราง Apache Iceberg ที่มีอยู่บน Athena โดยใช้แบบสอบถาม ALTER และใช้คำสั่งแบบสอบถาม UPDATE และ MERGE เพื่ออัปเดต ค่าคุณลักษณะของคอลัมน์ที่มีอยู่
เราสนับสนุนให้คุณใช้การสืบค้น CTAS เพื่อสร้างตารางอย่างรวดเร็วและมีประสิทธิภาพ และใช้คำสั่งการสืบค้น MERGE เพื่อซิงโครไนซ์ตารางในขั้นตอนเดียว เพื่อลดความซับซ้อนของการเตรียมข้อมูลและอัปเดตงานเมื่อแปลงคุณสมบัติโดยใช้ Athena กับ Apache Iceberg หากคุณมีความคิดเห็นหรือข้อเสนอแนะ โปรดทิ้งไว้ในส่วนความคิดเห็น
เกี่ยวกับผู้เขียน
![]() วิเวก โกตัม เป็นสถาปนิกข้อมูลที่มีความเชี่ยวชาญด้าน Data Lake ที่ AWS Professional Services เขาทำงานร่วมกับลูกค้าองค์กรที่สร้างผลิตภัณฑ์ข้อมูล แพลตฟอร์มการวิเคราะห์ และโซลูชันบน AWS เมื่อไม่ได้สร้างและออกแบบแพลตฟอร์มข้อมูลสมัยใหม่ Vivek เป็นผู้ชื่นชอบอาหารที่ชอบสำรวจสถานที่ท่องเที่ยวใหม่ๆ และเดินป่า
วิเวก โกตัม เป็นสถาปนิกข้อมูลที่มีความเชี่ยวชาญด้าน Data Lake ที่ AWS Professional Services เขาทำงานร่วมกับลูกค้าองค์กรที่สร้างผลิตภัณฑ์ข้อมูล แพลตฟอร์มการวิเคราะห์ และโซลูชันบน AWS เมื่อไม่ได้สร้างและออกแบบแพลตฟอร์มข้อมูลสมัยใหม่ Vivek เป็นผู้ชื่นชอบอาหารที่ชอบสำรวจสถานที่ท่องเที่ยวใหม่ๆ และเดินป่า
![]() มิคาอิล ไวน์สเตน เป็น Solutions Architect กับ Amazon Web Services Mikhail ทำงานร่วมกับลูกค้าด้านการดูแลสุขภาพและชีววิทยาศาสตร์เพื่อสร้างโซลูชันที่ช่วยปรับปรุงผลลัพธ์ของผู้ป่วย มิคาอิลเชี่ยวชาญด้านบริการวิเคราะห์ข้อมูล
มิคาอิล ไวน์สเตน เป็น Solutions Architect กับ Amazon Web Services Mikhail ทำงานร่วมกับลูกค้าด้านการดูแลสุขภาพและชีววิทยาศาสตร์เพื่อสร้างโซลูชันที่ช่วยปรับปรุงผลลัพธ์ของผู้ป่วย มิคาอิลเชี่ยวชาญด้านบริการวิเคราะห์ข้อมูล
![]() นเรศ เกาตัม เป็นผู้นำด้านการวิเคราะห์ข้อมูลและ AI/ML ที่ AWS ด้วยประสบการณ์ 20 ปี ผู้ชื่นชอบการช่วยลูกค้าออกแบบโซลูชันการวิเคราะห์ข้อมูลและ AI/ML ที่พร้อมใช้งานสูง ประสิทธิภาพสูง และคุ้มค่า เพื่อเพิ่มศักยภาพให้ลูกค้าด้วยการตัดสินใจที่ขับเคลื่อนด้วยข้อมูล . เวลาว่างชอบทำสมาธิและทำอาหาร
นเรศ เกาตัม เป็นผู้นำด้านการวิเคราะห์ข้อมูลและ AI/ML ที่ AWS ด้วยประสบการณ์ 20 ปี ผู้ชื่นชอบการช่วยลูกค้าออกแบบโซลูชันการวิเคราะห์ข้อมูลและ AI/ML ที่พร้อมใช้งานสูง ประสิทธิภาพสูง และคุ้มค่า เพื่อเพิ่มศักยภาพให้ลูกค้าด้วยการตัดสินใจที่ขับเคลื่อนด้วยข้อมูล . เวลาว่างชอบทำสมาธิและทำอาหาร
![]() ฮารชา ทาดิปาร์ตี เป็นผู้เชี่ยวชาญ Principal Solutions Architect, Analytics ที่ AWS เขาสนุกกับการแก้ปัญหาลูกค้าที่ซับซ้อนในฐานข้อมูลและการวิเคราะห์ และส่งมอบผลลัพธ์ที่ประสบความสำเร็จ นอกเวลางาน เขาชอบที่จะใช้เวลากับครอบครัว ดูหนัง และท่องเที่ยวทุกครั้งที่ทำได้
ฮารชา ทาดิปาร์ตี เป็นผู้เชี่ยวชาญ Principal Solutions Architect, Analytics ที่ AWS เขาสนุกกับการแก้ปัญหาลูกค้าที่ซับซ้อนในฐานข้อมูลและการวิเคราะห์ และส่งมอบผลลัพธ์ที่ประสบความสำเร็จ นอกเวลางาน เขาชอบที่จะใช้เวลากับครอบครัว ดูหนัง และท่องเที่ยวทุกครั้งที่ทำได้
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- การเงิน EVM ส่วนต่อประสานแบบครบวงจรสำหรับการเงินแบบกระจายอำนาจ เข้าถึงได้ที่นี่.
- กลุ่มสื่อควอนตัม IR/PR ขยาย เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. ข้อมูลอัจฉริยะ Web3 ขยายความรู้ เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/accelerate-data-science-feature-engineering-on-transactional-data-lakes-using-amazon-athena-with-apache-iceberg/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 10
- 100
- 12
- 17
- 20
- 23
- 27
- 7
- a
- เกี่ยวกับเรา
- เร่งความเร็ว
- เข้า
- คล่องแคล่ว
- ลงชื่อเข้าใช้
- การปฏิบัติ
- เพิ่ม
- ที่เพิ่ม
- เพิ่ม
- เพิ่มเติม
- ที่อยู่
- AI / ML
- ด้วย
- แม้ว่า
- อเมซอน
- อเมซอน อาเธน่า
- อเมซอน SageMaker
- Amazon Web Services
- จำนวน
- an
- วิเคราะห์
- วิเคราะห์
- การวิเคราะห์
- วิเคราะห์
- วิเคราะห์
- และ
- อื่น
- ใด
- อาปาเช่
- Apache Spark
- เป็น
- AS
- At
- ใช้ได้
- เฉลี่ย
- หลีกเลี่ยง
- AWS
- บริการระดับมืออาชีพของ AWS
- ตาม
- BE
- เพราะ
- รับ
- ประโยชน์ที่ได้รับ
- สร้าง
- การก่อสร้าง
- สร้าง
- by
- คำนวณ
- CAN
- ความสามารถในการ
- กรณี
- การจัดหมวดหมู่
- เมฆ
- คอลเลกชัน
- คอลัมน์
- คอลัมน์
- รวมกัน
- ความคิดเห็น
- ร่วมกัน
- ซับซ้อน
- คำนวณ
- คอมพิวเตอร์
- วิสัยทัศน์คอมพิวเตอร์
- องค์ประกอบ
- มี
- สิ่งแวดล้อม
- แปลง
- การปรุงอาหาร
- การทำสำเนา
- การแก้ไข
- ค่าใช้จ่ายที่มีประสิทธิภาพ
- สร้าง
- ที่สร้างขึ้น
- การสร้าง
- ลูกค้า
- ลูกค้า
- ข้อมูล
- วิเคราะห์ข้อมูล
- ดาต้าเลค
- วิทยาศาสตร์ข้อมูล
- นักวิทยาศาสตร์ข้อมูล
- ที่ขับเคลื่อนด้วยข้อมูล
- ฐานข้อมูล
- ฐานข้อมูล
- ชุดข้อมูล
- วันที่
- ตัดสินใจ
- การตัดสินใจ
- ลึก
- ค่าเริ่มต้น
- การส่งมอบ
- มอบ
- สาธิต
- แสดงให้เห็นถึง
- การออกแบบ
- สถานที่ท่องเที่ยว
- กระจาย
- การทำ
- สอง
- หล่น
- ความทนทาน
- แต่ละ
- ง่าย
- ที่มีประสิทธิภาพ
- อย่างมีประสิทธิภาพ
- ความพยายาม
- ทั้ง
- องค์ประกอบ
- ให้อำนาจ
- ทำให้สามารถ
- ส่งเสริม
- เครื่องยนต์
- ชั้นเยี่ยม
- เครื่องยนต์
- ที่เพิ่มขึ้น
- Enterprise
- ลูกค้าองค์กร
- คนที่กระตือรือร้น
- ทั้งหมด
- เท่ากัน
- อีเธอร์ (ETH)
- ที่มีอยู่
- ประสบการณ์
- สำรวจ
- ภายนอก
- เท็จ
- ครอบครัว
- FAST
- เร็วขึ้น
- ลักษณะ
- คุณสมบัติ
- ข้อเสนอแนะ
- ไฟล์
- โฟกัส
- ปฏิบัติตาม
- ดังต่อไปนี้
- อาหาร
- สำหรับ
- รูป
- กรอบ
- ฟรี
- ราคาเริ่มต้นที่
- โดยทั่วไป
- สร้าง
- ได้รับ
- Go
- บัญชีกลุ่ม
- Hadoop
- มี
- he
- การดูแลสุขภาพ
- ช่วย
- การช่วยเหลือ
- ประสิทธิภาพสูง
- อย่างสูง
- เดินป่า
- ของเขา
- อดีต
- รัง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTML
- HTTPS
- ประจำตัว
- ระบุ
- if
- ภาพ
- ปรับปรุง
- in
- รวมทั้ง
- เพิ่ม
- ไม่มีประสิทธิภาพ
- โครงสร้างพื้นฐาน
- แทรก
- ข้อมูลเชิงลึก
- แทน
- คำแนะนำการใช้
- การโต้ตอบ
- เข้าไป
- แนะนำ
- ความเหงา
- ปัญหา
- IT
- jpg
- JSON
- การติดฉลาก
- ทะเลสาบ
- ภาษา
- ใหญ่
- ชื่อสกุล
- แบบ
- ผู้นำ
- เรียนรู้
- การเรียนรู้
- ทิ้ง
- ชีวิต
- วิทยาศาสตร์สิ่งมีชีวิต
- วงจรชีวิต
- LIMIT
- ในประเทศ
- ที่ตั้ง
- รัก
- เครื่อง
- เรียนรู้เครื่อง
- ทำ
- ทำให้
- จัดการ
- การจัดการ
- จัดการ
- หลาย
- ตลาด
- จับคู่
- แม็กซ์
- มีความหมาย
- การทำสมาธิ
- กล่าวถึง
- ผสาน
- ล้าน
- หายไป
- ML
- แบบ
- โมเดล
- ทันสมัย
- แก้ไข
- ข้อมูลเพิ่มเติม
- Movies
- ชื่อ
- ที่มีชื่อ
- ประเทศชาติ
- โดยธรรมชาติ
- ภาษาธรรมชาติ
- ประมวลผลภาษาธรรมชาติ
- จำเป็นต้อง
- ต้อง
- ใหม่
- คุณลักษณะใหม่
- คุณสมบัติใหม่
- ใหม่
- ไม่
- จำนวน
- of
- มักจะ
- on
- ONE
- เพียง
- เปิด
- โอเพนซอร์ส
- การดำเนินการ
- การดำเนินการ
- or
- คำสั่งซื้อ
- อื่นๆ
- ของเรา
- ผลลัพธ์
- ด้านนอก
- อดีต
- ชำระ
- ดำเนินการ
- การปฏิบัติ
- โทรศัพท์
- แพลตฟอร์ม
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- กรุณา
- ตำแหน่ง
- เป็นไปได้
- โพสต์
- การเตรียมความพร้อม
- ราคา
- หลัก
- ปัญหาที่เกิดขึ้น
- กระบวนการ
- การประมวลผล
- การประมวลผล
- ผลิตภัณฑ์
- มืออาชีพ
- ให้
- ซื้อ
- การซื้อสินค้า
- วัตถุประสงค์
- หลาม
- คำสั่ง
- อย่างรวดเร็ว
- ดิบ
- ข้อมูลดิบ
- อ่าน
- การรับรู้
- ระเบียน
- บันทึก
- ลด
- ปล่อย
- จำเป็นต้องใช้
- ผล
- ทบทวน
- แถว
- วิ่ง
- วิ่ง
- sagemaker
- ขาย
- เดียวกัน
- ขนาด
- วิทยาศาสตร์
- วิทยาศาสตร์
- นักวิทยาศาสตร์
- นักวิทยาศาสตร์
- Section
- serverless
- บริการ
- บริการ
- ชุด
- หลาย
- แสดง
- แสดงให้เห็นว่า
- คล้ายคลึงกัน
- ง่าย
- ที่เรียบง่าย
- ลดความซับซ้อน
- เดียว
- So
- โซลูชัน
- การแก้
- แหล่งที่มา
- จุดประกาย
- ผู้เชี่ยวชาญ
- ความเชี่ยวชาญ
- การพูด
- การรู้จำเสียง
- ใช้จ่าย
- การใช้จ่าย
- SQL
- มาตรฐาน
- คำแถลง
- งบ
- ขั้นตอน
- ขั้นตอน
- การเก็บรักษา
- จัดเก็บ
- เก็บไว้
- เพรียวลม
- เชือก
- ที่ประสบความสำเร็จ
- อย่างเช่น
- สนับสนุน
- รองรับ
- ระบบ
- ตาราง
- งาน
- งาน
- ที่
- พื้นที่
- การผสาน
- ของพวกเขา
- พวกเขา
- แล้วก็
- ที่นั่น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- นี้
- เวลา
- การเดินทางข้ามเวลา
- ไปยัง
- ด้านบน
- รวม
- รถไฟ
- การฝึกอบรม
- การทำธุกรรม
- ธุรกรรม
- เปลี่ยน
- การเปลี่ยนแปลง
- การเดินทาง
- ชนิด
- พื้นฐาน
- ความเข้าใจ
- บันทึก
- ให้กับคุณ
- การปรับปรุง
- อัพเกรด
- อัปโหลด
- ใช้
- การใช้
- มักจะ
- ตรวจสอบความถูกต้อง
- มีคุณค่า
- ความคุ้มค่า
- ความคุ้มค่า
- ต่างๆ
- ตรวจสอบ
- รุ่น
- มาก
- ผ่านทาง
- วิดีโอ
- รายละเอียด
- วิสัยทัศน์
- ต้องการ
- คือ
- นาฬิกา
- we
- เว็บ
- บริการเว็บ
- คือ
- เมื่อ
- เมื่อไรก็ตาม
- ที่
- ในขณะที่
- WHO
- กับ
- ไม่มี
- งาน
- เวิร์กโฟลว์
- กลุ่มงาน
- การทำงาน
- โรงงาน
- จะ
- เขียน
- ปี
- ปี
- เธอ
- ของคุณ
- ลมทะเล
- รหัสไปรษณีย์