In 2021 och 2020, berättade vi om de nya funktionerna i Amazon RedShift som gör det enklare, snabbare och mer kostnadseffektivt att analysera all din data och hitta rika och kraftfulla insikter. Under 2022 är vi glada att kunna rapportera att Amazon Redshift-teamet arbetade hårt. Vi arbetade bakåt från kundernas krav och tillkännagav flera nya funktioner för att göra det enklare, snabbare och mer kostnadseffektivt att analysera all din data. Det här inlägget täcker några av dessa nya funktioner.
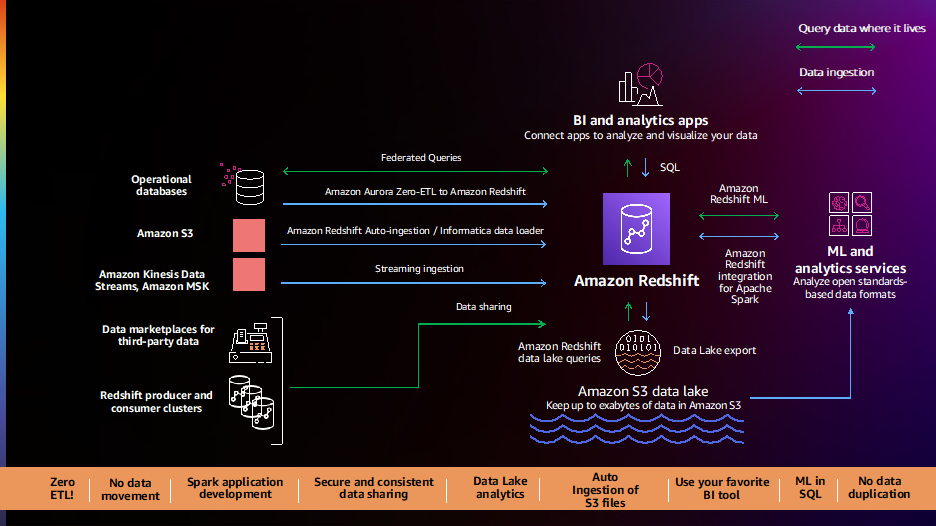
På AWS, för data och analys, är vår strategi att ge dig en modern dataarkitektur som hjälper dig att bryta dig loss från datasilos; ha specialbyggda data, analyser, maskininlärning (ML) och tjänster för artificiell intelligens för att använda rätt verktyg för rätt jobb; och har öppna, styrda, säkra och helt hanterade tjänster för att göra analyser tillgänglig för alla. Inom AWS moderna dataarkitektur förblir Amazon Redshift som molndatalager en nyckelkomponent, vilket gör att du kan köra komplex SQL-analys i skala och prestanda på terabyte till petabyte av strukturerad och ostrukturerad data, och göra insikterna allmänt tillgängliga genom populär affärsintelligens ( BI) och analysverktyg. Vi fortsätter att arbeta bakåt från kundernas krav och lanserade 2022 över 40 funktioner i Amazon Redshift för att hjälpa kunder med deras bästa användningsfall för datalager, inklusive:
- Självbetjäningsanalys
- Enkel dataintag
- Datadelning och samarbete
- Datavetenskap och maskininlärning
- Säker och pålitlig analys
- Bästa prisprestandaanalys
Låt oss dyka djupare och diskutera de nya Amazon Redshift-funktionerna i dessa områden.
Självbetjäningsanalys
Kunder fortsätter att berätta för oss att data och analys blir allestädes närvarande, och alla i deras organisation behöver analyser. Vi meddelade Amazon Redshift Serverlös (i förhandsvisning) 2021 för att göra det enkelt att köra och skala analyser på några sekunder utan att behöva tillhandahålla och hantera datalagerinfrastruktur. I juli 2022 tillkännagav vi allmän tillgänglighet för Redshift Serverless, och sedan dess har tusentals kunder, inklusive Peloton, Broadridge Financials och NextGen Healthcare, använt det för att snabbt och enkelt analysera sina data. Amazon Redshift Serverless tillhandahåller automatiskt och skalar datalagerkapaciteten på ett intelligent sätt för att leverera hög prestanda för all din analys, och du betalar bara för den beräkning som används under hela arbetsbelastningen per sekund. Sedan GA har vi lagt till funktioner som resurstaggning, förenklad övervakning och tillgänglighet i ytterligare AWS-regioner för att ytterligare förenkla fakturering och utöka räckvidden över fler regioner över hela världen.
2021 lanserade vi Amazon Redshift Query Editor V2, som är ett gratis webbaserat verktyg för dataanalytiker, datavetare och utvecklare att utforska, analysera och samarbeta kring data i Amazon Redshifts datalager och datasjöar. 2022 fick Query Editor V2 ytterligare förbättringar som t.ex stöd för bärbara datorer för förbättrat samarbete för att skriva, organisera och kommentera frågor; användaråtkomst genom identitetsleverantörsuppgifter (IdP). för enkel inloggning; och möjligheten att köra flera frågor samtidigt för att förbättra utvecklarens produktivitet.
Autonomics är ett annat område där vi aktivt arbetar med att använda ML-baserade optimeringar och ge kunderna ett självlärande och självoptimerande datalager. Under 2022 tillkännagav vi den allmänna tillgängligheten för Automatiserade materialiserade vyer (AutoMVs) för att förbättra prestandan för frågor (minska den totala körtiden) utan användaransträngning genom att automatiskt skapa och underhålla materialiserade vyer. AutoMVs, i kombination med automatisk uppdatering, inkrementell uppdatering och automatisk frågeomskrivning för materialiserade vyer, gjorde materialiserade vyer underhållsfria, vilket ger dig snabbare prestanda automatiskt. Dessutom har automatisk tabelloptimering (ATO) förmåga för schemaoptimering och automatisk arbetsbelastningshantering (auto WLM) förmåga för arbetsbelastningsoptimering fick ytterligare förbättringar för bättre frågeprestanda.
Enkel dataintag
Kunder berättar att de har sin data distribuerad över flera datakällor som transaktionsdatabaser, datalager, datasjöar och big data-system. De vill ha flexibiliteten att integrera denna data med no-code/low-code, noll-ETL datapipelines eller analysera denna data på plats utan att flytta den. Kunder berättar att deras nuvarande datapipelines är komplexa, manuella, stela och långsamma, vilket resulterar i ofullständiga, inkonsekventa och inaktuella datavyer, vilket begränsar insikterna. Kunder har bett oss om en bättre väg framåt, och vi är glada att kunna presentera ett antal nya funktioner för att förenkla och automatisera datapipelines.
Amazon Aurora noll-ETL-integration med Amazon Redshift (förhandsvisning) gör att du kan köra nästan realtidsanalys och ML på petabyte av transaktionsdata. Det erbjuder en kodlös lösning för att skapa transaktionsdata från flera Amazon-Aurora databaser tillgängliga i Amazon Redshifts datalager inom några sekunder efter att de skrivits till Aurora, vilket eliminerar behovet av att bygga och underhålla komplexa datapipelines. Med den här funktionen kan Aurora-kunder också få tillgång till Amazon Redshift-funktioner som komplex SQL-analys, inbyggd ML, datadelning och federerad åtkomst till flera datalagrar och datasjöar. Den här funktionen är nu tillgänglig i förhandsvisning för Amazon Aurora MySQL-kompatibel utgåva version 3 (med MySQL 8.0-kompatibilitet), och du kan begär åtkomst till förhandsvisningen.
Amazon Redshift stöder nu autokopiera från Amazon S3 (förhandsgranskning) för att förenkla dataladdning från Amazon enkel lagringstjänst (Amazon S3) till Amazon Redshift. Du kan nu ställa in regler för kontinuerlig filinmatning (kopieringsjobb) för att spåra dina Amazon S3-sökvägar och automatiskt ladda nya filer utan behov av ytterligare verktyg eller anpassade lösningar. Kopieringsjobb kan övervakas genom systemtabeller och de håller automatiskt reda på tidigare laddade filer och exkluderar dem från inmatningsprocessen för att förhindra dataduplicering. Den här funktionen är nu tillgänglig i förhandsvisning; du kan prova den här funktionen genom att skapa ett nytt kluster med förhandsgranskningsspåret.
Kunder fortsätter att berätta för oss att de behöver omedelbar, i ögonblicket, realtidsanalys, och vi är glada att kunna meddela att allmän tillgång till stöd för streamingintag i Amazon Redshift för Amazon Kinesis dataströmmar och Amazon Managed Streaming för Apache Kafka (Amazon MSK). Den här funktionen eliminerar behovet av att iscensätta strömmande data i Amazon S3 innan den matas in i Amazon Redshift, vilket gör att du kan uppnå låg latens, mätt i sekunder, samtidigt som du matar in hundratals megabyte strömmande data per sekund i dina datalager. Du kan använda SQL inom Amazon Redshift för att ansluta till och direkt mata in data från flera Kinesis-dataströmmar eller MSK-ämnen, skapa automatiskt uppdaterade strömmande materialiserade vyer med transformationer ovanpå strömmar direkt för att komma åt strömmande data och kombinera realtidsdata med historiska data för bättre insikter. Till exempel har Adobe integrerat Amazon Redshift-strömningsintag som en del av deras Adobe Experience Platform för att inta och analysera, i realtid, webben och applikationsklickströmmar och sessionsdata för olika applikationer som CRM och kundsupportapplikationer.
Kunder har berättat för oss att de vill ha enkel, out-of-the-box integration mellan Amazon Redshift, BI och ETL (extrahera, transformera och ladda) verktyg och affärsapplikationer som Salesforce och Marketo. Vi är glada att kunna meddela den allmänna tillgängligheten för Informatica Data Loader för Amazon Redshift, som gör att du kan använda Informatica Data Loader för höghastighets- och volymdataladdning till Amazon Redshift gratis. Du kan helt enkelt välja alternativet Informatica Data Loader på Amazon Redshift-konsolen. Väl i Informatica Data Loader kan du ansluta till källor som Salesforce eller Marketo, välja Amazon Redshift som mål och börja ladda din data.
Datadelning och samarbete
Kunder fortsätter att berätta för oss att de vill analysera all sin förstaparts- och tredjepartsdata och göra de rika datadrivna insikterna tillgängliga för sina kunder, partners och leverantörer. Vi lanserade nya funktioner 2021, som t.ex Datadelning och AWS Data Exchange integration, för att göra det enklare för dig att analysera all din data och dela den inom och utanför dina organisationer.
Ett bra exempel på en kund som använder datadelning är Orion. Orion tillhandahåller realtidsdata as a service-lösningar (DaaS) för kunder inom finansbranschen, såsom förmögenhetsförvaltning, kapitalförvaltning och leverantörer av investeringsförvaltning. De har över 2,500 XNUMX datakällor som i första hand är SQL Server-databaser som sitter både i lokaler och i AWS. Data strömmas med Kafka-anslutningar till Amazon Redshift. De har ett producentkluster som tar emot all denna data och sedan använder Data Sharing för att dela data i realtid för samarbete. Detta är en arkitektur med flera hyresgäster som betjänar flera kunder. Med tanke på känsligheten hos deras data är datadelning ett sätt att ge arbetsbelastningsisolering mellan kluster och även säkert dela denna data till slutanvändare.
Under 2022 fortsatte vi att investera i detta område för att förbättra prestanda, styrning och utvecklarproduktivitet med nya funktioner för att göra det enklare, enklare och snabbare att dela och samarbeta kring data.
När kunder bygger storskaliga datadelningskonfigurationer har de bett om förenklad styrning och säkerhet för delad data, och vi lägger till centraliserad passerkontroll med AWS Lake Formation för Amazon Redshift-datadelning för att möjliggöra delning av livedata över flera Amazon Redshift-datalager. Med den här funktionen stöder nu Amazon Redshift förenklad styrning av Amazon Redshift-datadelning genom att använda AWS Lake Formation som en enda ruta för att centralt hantera data eller behörigheter för datadelning. Du kan visa, ändra och granska behörigheter, inklusive säkerhet på rad- och kolumnnivå i tabellerna och vyerna i Amazon Redshift-datadelningarna, med hjälp av Lake Formation API:er och AWS Management Console, och tillåta Amazon Redshift-datadelningarna att upptäckas och konsumeras av andra Amazon Redshift-datalager.
Datavetenskap och maskininlärning
Kunder fortsätter att berätta för oss att de vill att deras data- och analyssystem ska hjälpa dem att svara på ett brett spektrum av frågor, från vad som händer i deras verksamhet (beskrivande analys) till varför det händer (diagnostisk analys) och vad som kommer att hända i framtiden (prediktiv analys). Amazon Redshift tillhandahåller funktioner som komplex SQL-analys, datasjöanalys och Amazon Redshift ML för kunder att analysera sin data och upptäcka kraftfulla insikter. Rödförskjutning ML integrerar Amazon Redshift med Amazon SageMaker, en helt hanterad ML-tjänst, som gör att du kan skapa, träna och distribuera ML-modeller med bekanta SQL-kommandon.
Kunder har också bett oss om bättre integration mellan Amazon Redshift och Apache Spark, så vi är glada att kunna meddela Amazon Redshift-integration för Apache Spark för att göra datalager lättillgängliga för Spark-baserade applikationer. Nu använder utvecklare AWS-analys och ML-tjänster som t.ex Amazon EMR, AWS-lim, och SageMaker kan enkelt bygga Apache Spark-applikationer som läser från och skriver till deras Amazon Redshift-datalager. Amazon EMR och AWS Glue paketerar Redshift-Spark-kontakten så att du enkelt kan ansluta till ditt datalager från dina Spark-baserade applikationer. Du kan använda flera pushdown-funktioner för operationer som sorterings-, aggregerings-, limit-, join- och skalärfunktioner så att endast relevant data flyttas från ditt Amazon Redshift-datalager till den konsumerande Spark-applikationen. Du kan också göra dina applikationer säkrare genom att använda AWS identitets- och åtkomsthantering (IAM)-uppgifter för att ansluta till Amazon Redshift.
Säker och pålitlig analys
Kunder fortsätter att berätta att deras datalager är verksamhetskritiska system som behöver hög tillgänglighet, tillförlitlighet och säkerhet. Vi lanserade ett antal nya funktioner under 2022 inom detta område.
Amazon Redshift stöder nu Multi-AZ-distributioner (i förhandsvisning) för RA3-instansbaserade kluster, vilket gör det möjligt att köra ditt datalager i flera AWS-tillgänglighetszoner samtidigt och kontinuerlig drift i oförutsedda scenarier för felscenarier för tillgänglighetszon. Multi-AZ-stöd är redan tillgängligt för Redshift Serverless. En Amazon Redshift Multi-AZ-distribution låter dig återställa i händelse av Availability Zone-fel utan något användaringripande. Ett Amazon Redshift Multi-AZ-datalager nås som ett enda datalager med en slutpunkt och hjälper dig att maximera prestanda genom att distribuera arbetsbelastningsbearbetning över flera tillgänglighetszoner automatiskt. Inga applikationsändringar behövs för att upprätthålla kontinuiteten i verksamheten under oförutsedda avbrott.
Under 2022 lanserade vi funktioner som rollbaserad åtkomstkontroll, säkerhet på radnivå och datamaskering (i förhandsvisning) för att göra det enklare för dig att hantera åtkomst och bestämma vem som har åtkomst till vilken data, inklusive fördunkla personligt identifierbar information (PII) ) som kreditkortsnummer.
Du kan använda rollbaserad åtkomstkontroll (RBAC) för att kontrollera slutanvändarens åtkomst till data på en bred eller granulär nivå baserat på en slutanvändares jobbroll och behörigheter. Med RBAC kan du skapa en roll med SQL, ge en samling granulära behörigheter till rollen och sedan tilldela den rollen till slutanvändare. Roller kan beviljas behörigheter på objektnivå, kolumnnivå och systemnivå. Dessutom introducerar RBAC out-of-box systemroller för DBA:er, operatörer, säkerhetsadministratörer eller anpassade roller.
Säkerhet på radnivå (RLS) förenklar design och implementering av finkornig åtkomst till raderna i tabeller. Med RLS kan du begränsa åtkomsten till en delmängd av rader i en tabell baserat på användarnas jobbroll eller behörigheter med SQL.
Amazon Redshift-stöd för dynamisk datamaskering (DDM), som nu är tillgänglig i förhandsvisning, låter dig förenkla skyddet av PII som personnummer, kreditkortsnummer och telefonnummer i ditt Amazon Redshift-datalager. Med dynamisk datamaskering styr du åtkomsten till dina data genom enkla SQL-baserade maskeringspolicyer som avgör hur Amazon Redshift returnerar känslig data till användaren vid frågetillfället. Du kan skapa maskeringspolicyer för att definiera konsekventa, formatbevarande och irreversibla maskerade datavärden. Du kan tillämpa en maskeringspolicy på en specifik kolumn eller lista med kolumner i en tabell. Du har också flexibiliteten att välja hur du vill visa maskerade data. Du kan till exempel helt dölja data, ersätta partiella reella värden med jokertecken eller definiera ditt eget sätt att maskera data med hjälp av SQL-uttryck, Python eller AWS Lambda användardefinierade funktioner. Dessutom kan du tillämpa en villkorlig maskeringspolicy baserad på andra kolumner, som selektivt skyddar kolumndata i en tabell baserat på värdena i en eller flera olika kolumner.
Vi tillkännagav också förbättringar av granskningsloggning, infödd integration med Microsoft Azure Active Directory, och stöd för standard IAM-roller i ytterligare regioner för att ytterligare förenkla säkerhetshanteringen.
Bästa prisprestandaanalys
Kunder fortsätter att berätta för oss att de behöver snabba och kostnadseffektiva datalager som levererar hög prestanda i alla skala samtidigt som kostnaderna hålls låga. Från dag 1 sedan dess Amazon Redshift lanserades 2012, vi har använt ett datadrivet tillvägagångssätt och använt fleettelemetri för att bygga en molndatalagertjänst som ger dig bästa prisprestanda oavsett skala. Genom åren har vi utvecklats Amazon Redshifts arkitektur och lanserade funktioner som t.ex Redshift Managed Storage (RMS) för separation av lagring och beräkning, Amazon Redshift Spectrum för datasjöfrågor, automatisk tabelloptimering för fysisk schemaoptimering, automatisk arbetsbelastningshantering att prioritera arbetsbelastningar och allokera rätt dator och minne, kluster ändra storlek att skala beräkning och lagring vertikalt, och samtidighetsskalning för att dynamiskt skala beräkna ut eller in. Vår prestanda riktmärken fortsätt att visa Amazon Redshifts ledarskap i prisprestanda.
Under 2022 lade vi till nya funktioner som den allmänna tillgängligheten av samtidighetsskalning för skrivoperationer som COPY, INSERT, UPDATE och DELETE för att stödja praktiskt taget obegränsat antal samtidiga användare och frågor. Vi introducerade också prestandaförbättringar för strängbaserad databehandling genom vektoriserade skanningar över lätta, CPU-effektiva, ordbokskodade strängkolumner, vilket gör att databasmotorn kan arbeta direkt över komprimerad data.
Vi lade även till stöd för SQL-operatorer som t.ex SAMMANFOGA (enkel operatör för inlägg eller uppdateringar); CONNECY_BY (för hierarkiska frågor); GRUPPERINGSSET, ROLLUP och KUB (för multidimensionell rapportering); och ökade storleken på datatypen SUPER till 16 MB för att göra det lättare för dig att migrera från äldre datalager till Amazon Redshift.
Slutsats
Våra kunder fortsätter att berätta för oss att data och analys förblir en högsta prioritet för dem och behovet av att kostnadseffektivt extrahera mer affärsvärde från deras data under dessa tider är mer uttalat än någon annan tid tidigare. Amazon Redshift som ditt molndatalager gör att du kan köra komplex SQL-analys med skala och prestanda på terabyte till petabyte av strukturerad och ostrukturerad data och göra insikterna allmänt tillgängliga genom populära BI- och analysverktyg.
Även om vi lanserade över 40 funktioner 2022 och innovationstakten fortsätter att accelerera, är det dag 1 kvar och vi ser fram emot att höra från dig om hur dessa funktioner hjälper dig att skapa mer värde för dina organisationer. Vi inbjuder dig att prova dessa nya funktioner och kontakta oss via ditt AWS-kontoteam om du har ytterligare kommentarer.
Om författaren
 Manan Goel är Product Go-To-Market Leader för AWS Analytics Services inklusive Amazon Redshift på AWS. Han har mer än 25 års erfarenhet och är väl insatt i databaser, datalagring, business intelligence och analys. Manan har en MBA från Duke University och en kandidatexamen i elektronik- och kommunikationsteknik.
Manan Goel är Product Go-To-Market Leader för AWS Analytics Services inklusive Amazon Redshift på AWS. Han har mer än 25 års erfarenhet och är väl insatt i databaser, datalagring, business intelligence och analys. Manan har en MBA från Duke University och en kandidatexamen i elektronik- och kommunikationsteknik.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/whats-new-in-amazon-redshift-2022-a-year-in-review/
- 1
- 100
- 2021
- 2022
- a
- förmåga
- Om oss
- accelerera
- tillgång
- Tillgång till data
- Accessed
- tillgänglig
- Konto
- Uppnå
- tvärs
- aktiv
- aktivt
- lagt till
- Dessutom
- Annat
- Dessutom
- Adobe
- Alla
- tillåter
- redan
- amason
- Amazon EMR
- analytiker
- analytics
- analysera
- analys
- och
- Meddela
- meddelade
- Annan
- svara
- Apache
- Apache Spark
- API: er
- Ansökan
- tillämpningar
- Ansök
- tillvägagångssätt
- arkitektur
- OMRÅDE
- områden
- konstgjord
- artificiell intelligens
- tillgång
- Kapitalförvaltning
- revision
- aurora
- Författaren
- bil
- automatisera
- Automat
- automatiskt
- tillgänglighet
- tillgänglig
- AWS
- AWS-lim
- Azure
- baserat
- grund
- passande
- innan
- Där vi får lov att vara utan att konstant prestera,
- BÄST
- Bättre
- mellan
- Stor
- Stora data
- fakturering
- Ha sönder
- bred
- Broadridge
- SLUTRESULTAT
- Byggnad
- inbyggd
- företag
- Business Applications
- kontinuitet i verksamheten
- business intelligence
- kapacitet
- Kapacitet
- kortet
- Vid
- fall
- Förändringar
- tecken
- Välja
- välja
- klienter
- cloud
- kluster
- samarbeta
- samverkan
- samling
- Kolumn
- Kolonner
- kombinera
- kombinerad
- kommentarer
- Trygghet i vårdförloppet
- kompatibilitet
- fullständigt
- komplex
- komponent
- Compute
- konkurrent
- Kontakta
- konsekvent
- Konsol
- konsumeras
- fortsätta
- fortsatte
- fortsätter
- kontinuerlig
- kontroll
- kostnadseffektiv
- Kostar
- omfattar
- skapa
- Skapa
- referenser
- kredit
- kreditkort
- krediter
- CRM
- Aktuella
- beställnings
- kund
- Helpdesk
- Kunder
- kundanpassad
- datum
- Datautbyte
- datasjö
- databehandling
- datadeling
- datalagret
- datalager
- data driven
- Databas
- databaser
- dag
- djupare
- leverera
- demonstrera
- distribuera
- utplacering
- Designa
- Bestämma
- Utvecklare
- utvecklare
- olika
- direkt
- Upptäck
- upptäckt
- diskutera
- distribueras
- fördelnings
- Duke
- hertig universitet
- under
- dynamisk
- lättare
- lätt
- redaktör
- ansträngning
- Elektronik
- eliminerar
- eliminera
- möjliggöra
- möjliggör
- möjliggör
- Slutpunkt
- Motor
- Teknik
- Eter (ETH)
- alla
- utvecklats
- exempel
- utbyta
- exciterade
- Bygga ut
- erfarenhet
- utforska
- uttryck
- extrahera
- Misslyckande
- bekant
- SNABB
- snabbare
- Leverans
- Funktioner
- Fil
- Filer
- finansiella
- finansiella tjänster
- ekonomi
- hitta
- FLOTTA
- Flexibilitet
- bildning
- Framåt
- Fri
- från
- fullständigt
- funktioner
- ytterligare
- framtida
- Allmänt
- skaffa sig
- gif
- Ge
- ges
- ger
- Ge
- glas
- Gå till marknaden
- styrning
- bevilja
- beviljats
- stor
- hända
- lyckligt
- Hård
- har
- hälso-och sjukvård
- hörsel
- hjälpa
- hjälper
- Dölja
- Hög
- historisk
- innehar
- Hur ser din drömresa ut
- How To
- html
- HTTPS
- Hundratals
- IAM
- Identitet
- genomförande
- förbättra
- förbättras
- förbättringar
- in
- Inklusive
- ökat
- industrin
- informationen
- Infrastruktur
- Innovation
- Insert
- insikter
- integrera
- integrerade
- integrerar
- integrering
- Intelligens
- ingripande
- introducerade
- Introducerar
- Invest
- investering
- bjuda in
- isolering
- IT
- Jobb
- Lediga jobb
- delta
- Juli
- kafka
- Ha kvar
- hålla
- Nyckel
- Kinesis dataströmmar
- sjö
- storskalig
- Latens
- lansera
- lanserades
- ledare
- Ledarskap
- inlärning
- Legacy
- Nivå
- lättvikt
- BEGRÄNSA
- Lista
- lever
- livedata
- läsa in
- Lastaren
- läser in
- se
- Låg
- Maskinen
- maskininlärning
- gjord
- bibehålla
- underhåll
- göra
- Framställning
- hantera
- förvaltade
- ledning
- manuell
- Marketo
- mask
- Maximera
- Minne
- migrera
- ML
- modeller
- Modern Konst
- modifiera
- övervakas
- övervakning
- mer
- rörliga
- multipel
- MySQL
- nativ
- Behöver
- behövs
- behov
- Nya
- Nya funktioner
- antal
- nummer
- Erbjudanden
- ONE
- öppet
- driva
- drift
- Verksamhet
- Operatören
- operatörer
- optimering
- Alternativet
- organisation
- organisationer
- Övriga
- avbrott
- utanför
- egen
- Fred
- paket
- panelen
- del
- partner
- Tidigare
- Betala
- klungan
- prestanda
- behörigheter
- Personligen
- telefon
- fysisk
- pii
- Plats
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- nöjd
- Strategier
- policy
- Populära
- Inlägg
- den mäktigaste
- Predictive Analytics
- förhindra
- Förhandsvisning
- tidigare
- pris
- primärt
- Prioritera
- prioritet
- process
- bearbetning
- producent
- Produkt
- produktivitet
- skydda
- ge
- leverantör
- leverantörer
- ger
- tillhandahållande
- Python
- frågor
- snabbt
- område
- nå
- Läsa
- verklig
- realtid
- data i realtid
- erhåller
- Recover
- minska
- regioner
- relevanta
- tillförlitlighet
- pålitlig
- resterna
- ersätta
- rapport
- Rapportering
- Krav
- begränsa
- resulterande
- återgår
- översyn
- omskrivning
- Rik
- styv
- Roll
- roller
- rulla upp
- regler
- Körning
- rinnande
- sagemaker
- Salesforce
- Skala
- skalor
- skalning
- scenarier
- Vetenskap
- vetenskapsmän
- Andra
- sekunder
- säkra
- säkert
- säkerhet
- känslig
- Känslighet
- Server
- serverar
- service
- Tjänster
- session
- in
- uppsättningar
- flera
- Dela
- delas
- delning
- show
- Enkelt
- förenklade
- förenkla
- helt enkelt
- samtidigt
- eftersom
- enda
- Sittande
- Storlek
- långsam
- So
- Social hållbarhet
- lösning
- Lösningar
- några
- Källor
- Gnista
- specifik
- SQL
- Etapp
- förvaring
- lagrar
- Strategi
- strömmas
- streaming
- strömmar
- strukturerade
- strukturerade och ostrukturerade data
- sådana
- super
- leverantörer
- stödja
- Stöder
- system
- System
- bord
- Målet
- grupp
- Smakämnen
- Framtiden
- deras
- tredje part
- tusentals
- Genom
- tid
- gånger
- till
- verktyg
- verktyg
- topp
- ämnen
- Totalt
- Rör
- spår
- Tåg
- transaktion
- Förvandla
- transformationer
- allmänt förekommande
- oförutsedd
- universitet
- obegränsat
- låsa
- Uppdatering
- Uppdateringar
- us
- användning
- Användare
- användare
- Använda
- värde
- Värden
- olika
- version
- utsikt
- visningar
- praktiskt taget
- Warehouse
- Lagring
- Rikedom
- förmögenhetsförvaltning
- webb
- Webb-baserad
- Vad
- Vad är
- som
- medan
- VEM
- bred
- Brett utbud
- brett
- kommer
- inom
- utan
- Arbete
- arbetade
- arbetssätt
- inom hela sverige
- skriva
- skriven
- år
- år
- Din
- zephyrnet
- zoner