Geospatial data är data om specifika platser på jordens yta. Det kan representera ett geografiskt område som helhet eller det kan representera en händelse associerad med ett geografiskt område. Analys av geospatial data är eftertraktad i ett fåtal branscher. Det handlar om att förstå var data finns ur ett rumsligt perspektiv och varför det finns där.
Det finns två typer av geospatiala data: vektordata och rasterdata. Rasterdata är en matris av celler representerade som ett rutnät, som mest representerar fotografier och satellitbilder. I det här inlägget fokuserar vi på vektordata, som representeras som geografiska koordinater för latitud och longitud samt linjer och polygoner (områden) som förbinder eller omfattar dem. Vektordata har en mängd användningsfall för att härleda mobilitetsinsikter. Användarmobildata är en sådan komponent av det, och det härrör mestadels från den geografiska positionen för mobila enheter som använder GPS eller apputgivare som använder SDK:er eller liknande integrationer. I detta inlägg hänvisar vi till denna data som mobilitetsdata.
Detta är en serie i två delar. I det här första inlägget introducerar vi mobilitetsdata, dess källor och ett typiskt schema för denna data. Vi diskuterar sedan de olika användningsfallen och utforskar hur du kan använda AWS-tjänster för att rensa data, hur maskininlärning (ML) kan hjälpa till i detta arbete, och hur du kan använda data etiskt för att generera bilder och insikter. Det andra inlägget kommer att vara mer tekniskt och täcka dessa steg i detalj tillsammans med exempelkoden. Det här inlägget har ingen exempeldatauppsättning eller exempelkod, utan det täcker snarare hur man använder data efter att den har köpts från en dataaggregator.
Du kan använda Amazon SageMaker geospatiala funktioner att lägga över mobilitetsdata på en baskarta och tillhandahålla skiktvis visualisering för att göra samarbetet enklare. Den GPU-drivna interaktiva visualizern och Python-datorer ger ett sömlöst sätt att utforska miljontals datapunkter i ett enda fönster och dela insikter och resultat.
Källor och schema
Det finns få källor till mobilitetsdata. Förutom GPS-pingar och apputgivare används andra källor för att utöka datamängden, såsom Wi-Fi-åtkomstpunkter, budströmsdata som erhålls via visning av annonser på mobila enheter och specifika hårdvaru-sändare placerade av företag (till exempel i fysiska butiker) ). Det är ofta svårt för företag att samla in denna data själva, så de kan köpa den från datainsamlare. Dataaggregatorer samlar in mobilitetsdata från olika källor, rengör dem, lägger till brus och gör data tillgänglig dagligen för specifika geografiska regioner. På grund av själva uppgifternas natur och eftersom de är svåra att få fram, kan noggrannheten och kvaliteten på denna data variera avsevärt, och det är upp till företagen att bedöma och verifiera detta genom att använda mätvärden som dagliga aktiva användare, totala dagliga ping, och genomsnittliga dagliga pingar per enhet. Följande tabell visar hur ett typiskt schema för ett dagligt dataflöde som skickas av dataaggregatorer kan se ut.
| Attribut | Beskrivning |
| ID eller MAID | Mobile Advertising ID (MAID) för enheten (hashat) |
| lat | Enhetens latitud |
| lng | Enhetens longitud |
| geohash | Geohash plats för enheten |
| enhetstyp | Enhetens operativsystem = IDFA eller GAID |
| horisontell_noggrannhet | Noggrannhet för horisontella GPS-koordinater (i meter) |
| tidsstämpel | Tidsstämpel för händelsen |
| ip | IP-adress |
| alt | Enhetens höjd (i meter) |
| fart | Enhetens hastighet (i meter/sekund) |
| land | ISO tvåsiffrig kod för ursprungslandet |
| tillstånd | Koder som representerar staten |
| stad | Koder som representerar stad |
| postnummer | Postnummer för var enhets-ID visas |
| bärare | Bärare för enheten |
| device_manufacturer | Tillverkare av enheten |
Användningsfall
Mobilitetsdata har utbredda tillämpningar i olika branscher. Följande är några av de vanligaste användningsfallen:
- Densitetsmått – Analys av fottrafik kan kombineras med befolkningstäthet för att observera aktiviteter och besök på intressanta platser (POI). Dessa mätvärden ger en bild av hur många enheter eller användare som aktivt stannar och engagerar sig i ett företag, vilket kan användas ytterligare för att välja plats eller till och med analysera rörelsemönster kring ett evenemang (till exempel personer som reser för en speldag). För att få sådana insikter går inkommande rådata igenom en extrahera, transformation och laddningsprocess (ETL) för att identifiera aktiviteter eller engagemang från den kontinuerliga strömmen av enhetsplatspingningar. Vi kan analysera aktiviteter genom att identifiera stopp gjorda av användaren eller mobilenheten genom att klustra pingar med ML-modeller i Amazon SageMaker.
- Resor och banor – En enhets dagliga platsflöde kan uttryckas som en samling aktiviteter (stopp) och resor (rörelse). Ett par aktiviteter kan representera en resa mellan dem, och att spåra resan med den rörliga enheten i geografiskt utrymme kan leda till kartläggning av den faktiska banan. Banmönster för användarrörelser kan leda till intressanta insikter som trafikmönster, bränsleförbrukning, stadsplanering med mera. Den kan också tillhandahålla data för att analysera rutten från reklamplatser som en skylt, identifiera de mest effektiva leveransvägarna för att optimera driften i leveranskedjan eller analysera evakueringsvägar vid naturkatastrofer (till exempel orkanevakuering).
- Upptagningsområdesanalys - En upptagningsområde hänvisar till platser varifrån ett visst område drar sina besökare, som kan vara kunder eller potentiella kunder. Detaljhandelsföretag kan använda denna information för att bestämma den optimala platsen för att öppna en ny butik, eller avgöra om två butiksplatser ligger för nära varandra med överlappande upptagningsområden och hindrar varandras verksamhet. De kan också ta reda på var de faktiska kunderna kommer ifrån, identifiera potentiella kunder som passerar området och reser till jobbet eller hemmet, analysera liknande besöksstatistik för konkurrenter och mer. Marketing Tech (MarTech) och Advertisement Tech (AdTech) företag kan också använda denna analys för att optimera marknadsföringskampanjer genom att identifiera målgruppen nära ett varumärkes butik eller för att rangordna butiker efter prestanda för reklam utanför hemmet.
Det finns flera andra användningsfall, inklusive att generera platsintelligens för kommersiella fastigheter, utöka satellitbildsdata med antal besökare, identifiera leveransnav för restauranger, fastställa sannolikheten för evakuering av grannskapet, upptäcka människors rörelsemönster under en pandemi och mer.
Utmaningar och etiskt bruk
Etisk användning av mobilitetsdata kan leda till många intressanta insikter som kan hjälpa organisationer att förbättra sin verksamhet, utföra effektiv marknadsföring eller till och med uppnå en konkurrensfördel. För att använda dessa data etiskt måste flera steg följas.
Det börjar med själva insamlingen av data. Även om de flesta mobilitetsdata förblir fri från personligt identifierbar information (PII) såsom namn och adress, måste datainsamlare och aggregatorer ha användarens samtycke för att samla in, använda, lagra och dela deras data. Datasekretesslagar som GDPR och CCPA måste följas eftersom de ger användare möjlighet att avgöra hur företag kan använda deras data. Detta första steg är ett betydande steg mot etisk och ansvarsfull användning av mobilitetsdata, men mer kan göras.
Varje enhet tilldelas ett hashat Mobile Advertising ID (MAID), som används för att förankra de individuella pingarna. Detta kan fördunklas ytterligare genom att använda Amazon Macie, Amazon S3 Object Lambda, Amazon Comprehend, eller till och med AWS Lim Studio Upptäck PII-transformation. För mer information, se Vanliga tekniker för att upptäcka PHI- och PII-data med hjälp av AWS Services.
Bortsett från PII bör överväganden göras för att maskera användarens hemplats såväl som andra känsliga platser som militärbaser eller platser för tillbedjan.
Det sista steget för etisk användning är att endast härleda och exportera aggregerade mätvärden från Amazon SageMaker. Detta innebär att få mätvärden som genomsnittligt antal eller totalt antal besökare i motsats till individuella resemönster; få dagliga, veckovisa, månatliga eller årliga trender; eller indexera mobilitetsmönster över allmänt tillgängliga data som folkräkningsdata.
Lösningsöversikt
Som nämnts tidigare är AWS-tjänsterna som du kan använda för analys av mobilitetsdata Amazon S3, Amazon Macie, AWS Glue, S3 Object Lambda, Amazon Comprehend och Amazon SageMaker geospatiala funktioner. Amazon SageMakers geospatiala funktioner gör det enkelt för datavetare och ML-ingenjörer att bygga, träna och distribuera modeller med hjälp av geospatial data. Du kan effektivt transformera eller berika storskaliga geospatiala datauppsättningar, accelerera modellbyggandet med förutbildade ML-modeller och utforska modellförutsägelser och geospatiala data på en interaktiv karta med hjälp av 3D-accelererad grafik och inbyggda visualiseringsverktyg.
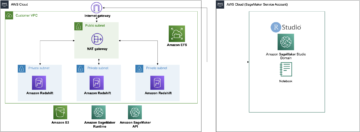
Följande referensarkitektur visar ett arbetsflöde som använder ML med geospatiala data.
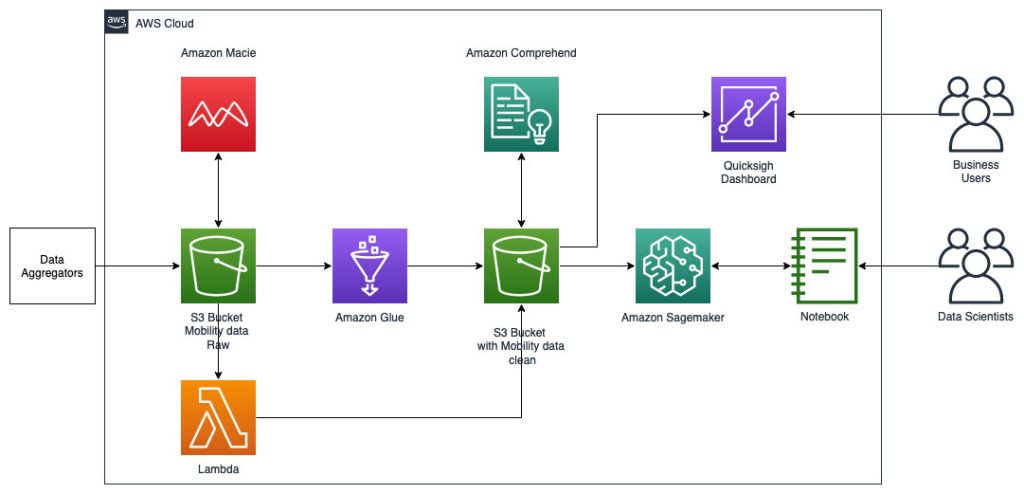
I detta arbetsflöde aggregeras rådata från olika datakällor och lagras i en Amazon enkel lagringstjänst (S3) hink. Amazon Macie används på denna S3-hink för att identifiera och redigera och PII. AWS Glue används sedan för att rengöra och omvandla rådata till önskat format, sedan lagras den modifierade och rensade datan i en separat S3-hink. För de datatransformationer som inte är möjliga via AWS Glue använder du AWS Lambda för att ändra och rensa rådata. När data är rensade kan du använda Amazon SageMaker för att bygga, träna och distribuera ML-modeller på förberedd geospatial data. Du kan också använda geospatial Processing jobb funktionen hos Amazon SageMakers geospatiala möjligheter för att förbearbeta data – till exempel genom att använda en Python-funktion och SQL-satser för att identifiera aktiviteter från rå mobilitetsdata. Dataforskare kan åstadkomma denna process genom att ansluta via Amazon SageMaker-anteckningsböcker. Du kan också använda Amazon QuickSight för att visualisera affärsresultat och andra viktiga mätvärden från data.
Amazon SageMaker geospatiala funktioner och geospatiala bearbetningsjobb
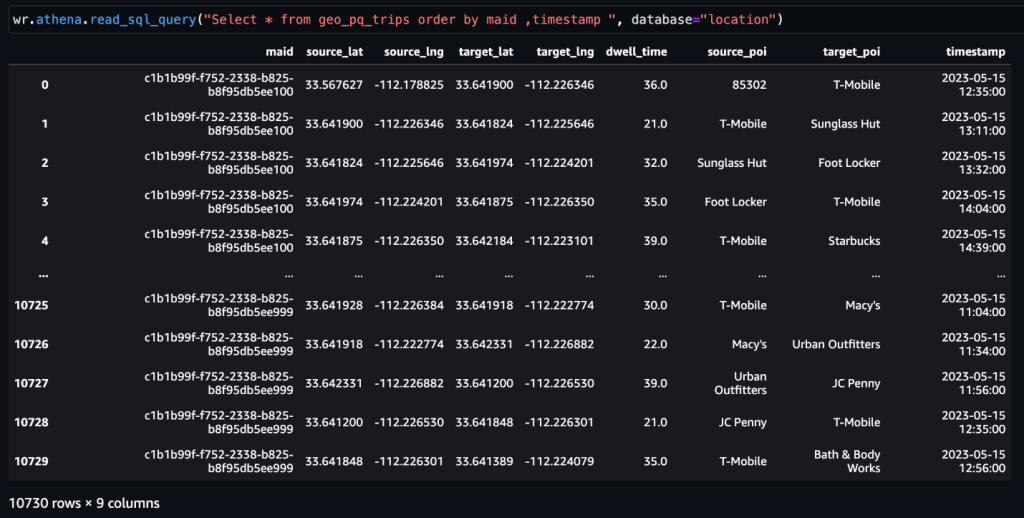
Efter att data har erhållits och matats in i Amazon S3 med ett dagligt flöde och rengjorts för eventuella känsliga data, kan de importeras till Amazon SageMaker med en Amazon SageMaker Studio anteckningsbok med en geospatial bild. Följande skärmdump visar ett exempel på dagliga enhetspingar som laddas upp till Amazon S3 som en CSV-fil och sedan laddas i en pandas dataram. Amazon SageMaker Studio-anteckningsboken med geospatial bild är förladdad med geospatiala bibliotek som GDAL, GeoPandas, Fiona och Shapely, och gör det enkelt att bearbeta och analysera denna data.
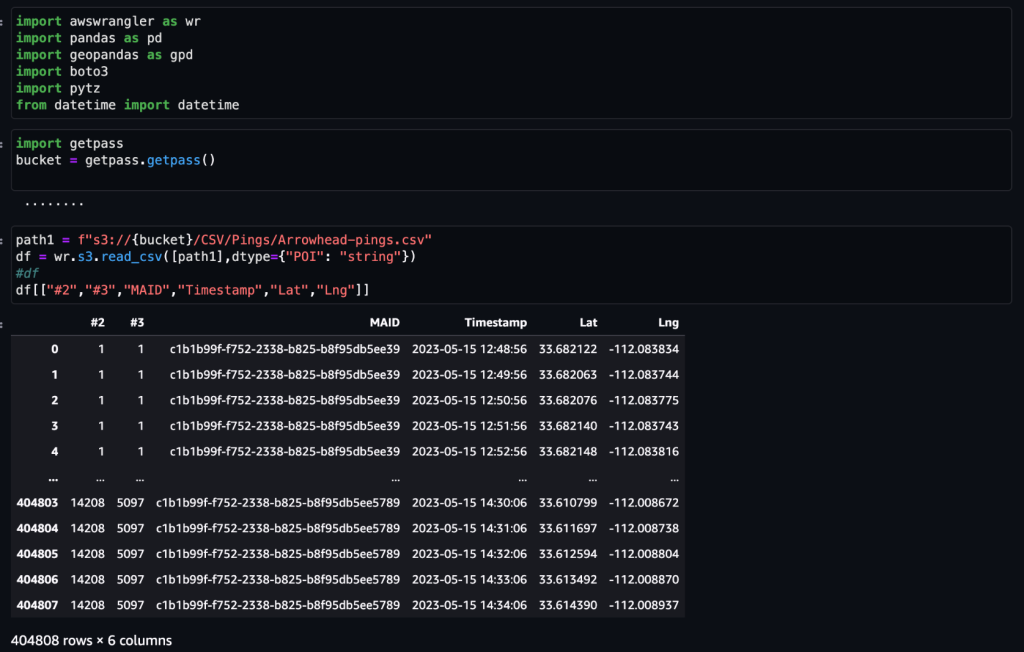
Denna exempeldatauppsättning innehåller cirka 400,000 5,000 dagliga enhetspingar från 14,000 15 enheter från 2023 XNUMX unika platser inspelade från användare som besöker Arrowhead Mall, ett populärt köpcentrumkomplex i Phoenix, Arizona, den XNUMX maj XNUMX. Den föregående skärmdumpen visar en undergrupp av kolumner i dataschema. De MAID kolumnen representerar enhets-ID, och varje MAID genererar ping varje minut som vidarebefordrar enhetens latitud och longitud, registrerat i exempelfilen som Lat och Lng kolumner.
Följande är skärmdumpar från kartvisualiseringsverktyget för Amazon SageMakers geospatiala funktioner som drivs av Foursquare Studio, som visar layouten av pingar från enheter som besöker köpcentret mellan 7:00 och 6:00.
Följande skärmdump visar ping från köpcentret och omgivande områden.

Följande visar plingar inifrån olika butiker i köpcentret.
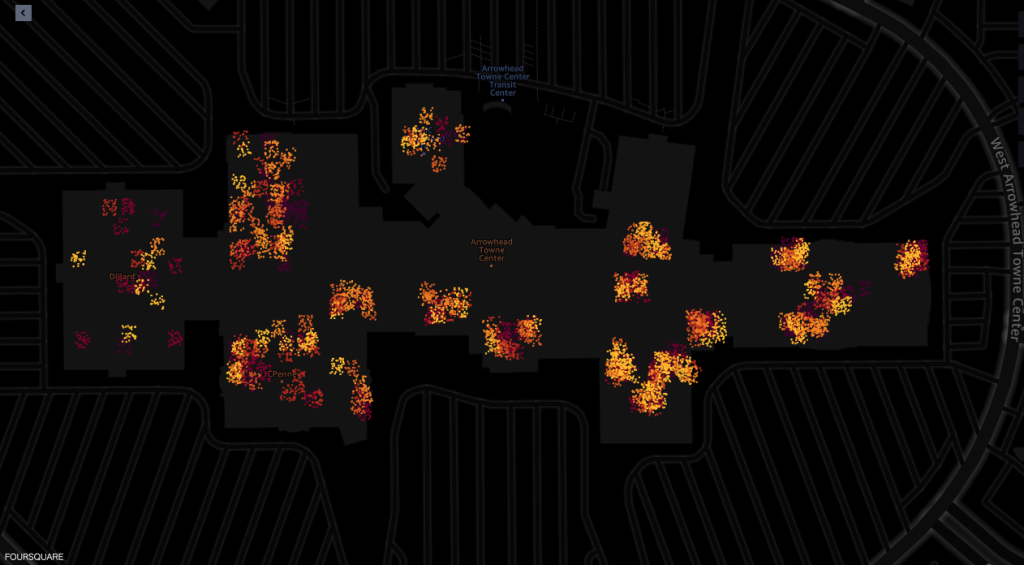
Varje prick i skärmdumparna visar en ping från en given enhet vid en given tidpunkt. Ett kluster av pingar representerar populära platser där enheter samlades eller stannade, till exempel butiker eller restauranger.
Som en del av den initiala ETL kan denna rådata laddas in i tabeller med AWS Glue. Du kan skapa en AWS Glue-crawler för att identifiera schemat för data och formulärtabeller genom att peka på rådataplatsen i Amazon S3 som datakälla.

Som nämnts ovan kommer rådata (de dagliga enhetspingarna), även efter initial ETL, att representera en kontinuerlig ström av GPS-pingar som indikerar enhetens positioner. För att extrahera praktiska insikter från denna data måste vi identifiera stopp och resor (banor). Detta kan uppnås med hjälp av geospatial Processing jobb egenskap hos SageMakers geospatiala funktioner. Amazon SageMaker-bearbetning använder en förenklad, hanterad upplevelse på SageMaker för att köra arbetsbelastningar för databehandling med den specialbyggda geospatiala behållaren. Den underliggande infrastrukturen för ett SageMaker Processing-jobb hanteras helt av SageMaker. Den här funktionen gör att anpassad kod kan köras på geospatial data lagrad på Amazon S3 genom att köra en geospatial ML-behållare på ett SageMaker Processing-jobb. Du kan köra anpassade operationer på öppen eller privat geospatial data genom att skriva anpassad kod med öppen källkodsbibliotek och köra operationen i skala med SageMaker Processing-jobb. Det containerbaserade tillvägagångssättet löser behov kring standardisering av utvecklingsmiljö med vanliga bibliotek med öppen källkod.
För att köra sådana storskaliga arbetsbelastningar behöver du ett flexibelt beräkningskluster som kan skalas från tiotals instanser för att bearbeta ett stadskvarter, till tusentals instanser för bearbetning i planetarisk skala. Att manuellt hantera ett DIY-datorkluster är långsamt och dyrt. Den här funktionen är särskilt användbar när mobilitetsdatasetet omfattar mer än ett fåtal städer till flera stater eller till och med länder och kan användas för att köra en tvåstegs ML-metod.
Det första steget är att använda densitetsbaserad rumslig klustring av applikationer med brus (DBSCAN) algoritm för att klustra stopp från pingar. Nästa steg är att använda metoden för stödvektormaskiner (SVM) för att ytterligare förbättra noggrannheten hos de identifierade stoppen och även för att särskilja stopp med engagemang med en POI jämfört med stopp utan en (som hem eller arbete). Du kan också använda SageMaker Processing-jobb för att generera resor och banor från de dagliga enhetspingarna genom att identifiera på varandra följande stopp och kartlägga vägen mellan källan och destinationsstoppen.
Efter att ha bearbetat rådata (dagliga enhetspingningar) i skala med geospatiala bearbetningsjobb, bör den nya datamängden som kallas stops ha följande schema.
| Attribut | Beskrivning |
| ID eller MAID | Mobile Advertising ID för enheten (hashat) |
| lat | Latitud för tyngdpunkten för stoppklustret |
| lng | Longitud för tyngdpunkten för stoppklustret |
| geohash | Geohash plats för POI |
| enhetstyp | Enhetens operativsystem (IDFA eller GAID) |
| tidsstämpel | Starttid för stopp |
| uppehållstid | Uppehållstid för stopp (i sekunder) |
| ip | IP-adress |
| alt | Enhetens höjd (i meter) |
| land | ISO tvåsiffrig kod för ursprungslandet |
| tillstånd | Koder som representerar staten |
| stad | Koder som representerar stad |
| postnummer | Postnummer för var enhets-ID visas |
| bärare | Bärare för enheten |
| device_manufacturer | Tillverkare av enheten |
Stoppar konsolideras genom att klustera pingarna per enhet. Densitetsbaserad klustring kombineras med parametrar som att stopptröskeln är 300 sekunder och minsta avstånd mellan stopp är 50 meter. Dessa parametrar kan justeras enligt ditt användningsfall.
Följande skärmdump visar ungefär 15,000 400,000 stopp identifierade från XNUMX XNUMX pingar. En delmängd av det föregående schemat finns också, där kolumnen Dwell Time representerar stopptiden och Lat och Lng kolumner representerar latitud och longitud för tyngdpunkterna i stoppklustret per enhet och plats.
Post-ETL lagras data i filformatet Parquet, vilket är ett kolumnformat lagringsformat som gör det lättare att bearbeta stora datamängder.
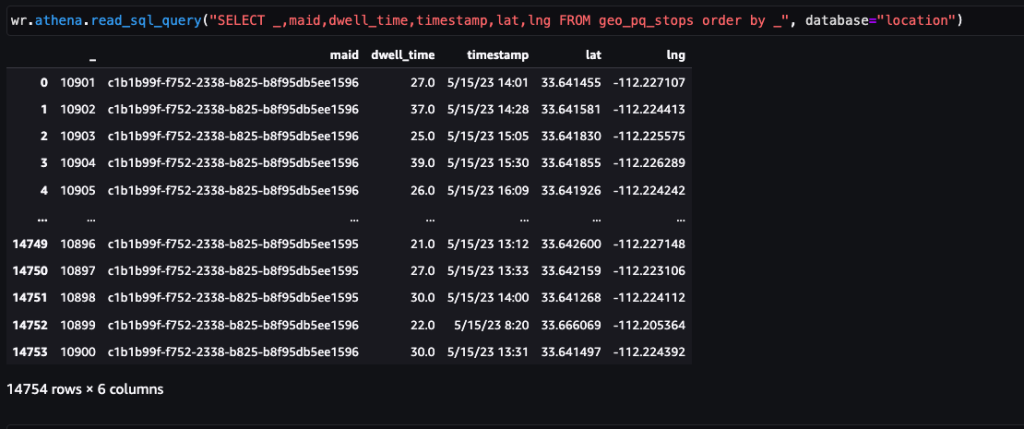
Följande skärmdump visar hållplatserna konsoliderade från pingar per enhet i köpcentret och omgivande områden.

Efter att ha identifierat stopp kan denna datauppsättning sammanfogas med allmänt tillgängliga POI-data eller anpassade POI-data som är specifika för användningsfallet för att identifiera aktiviteter, såsom engagemang med varumärken.
Följande skärmdump visar hållplatserna som identifierats vid stora POIs (butiker och varumärken) i Arrowhead Mall.
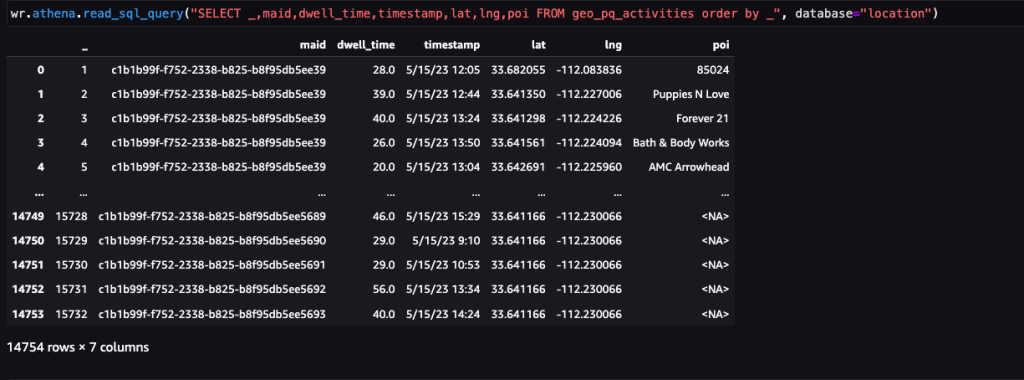
Hempostnummer har använts för att maskera varje besökares hemplats för att upprätthålla integriteten om det är en del av deras resa i datamängden. Latitud och longitud i sådana fall är respektive koordinater för postnumrets tyngdpunkt.
Följande skärmdump är en visuell representation av sådana aktiviteter. Den vänstra bilden kartlägger hållplatserna till butikerna och den högra bilden ger en uppfattning om själva gallerians layout.

Denna resulterande datamängd kan visualiseras på ett antal sätt, som vi diskuterar i följande avsnitt.
Densitetsmått
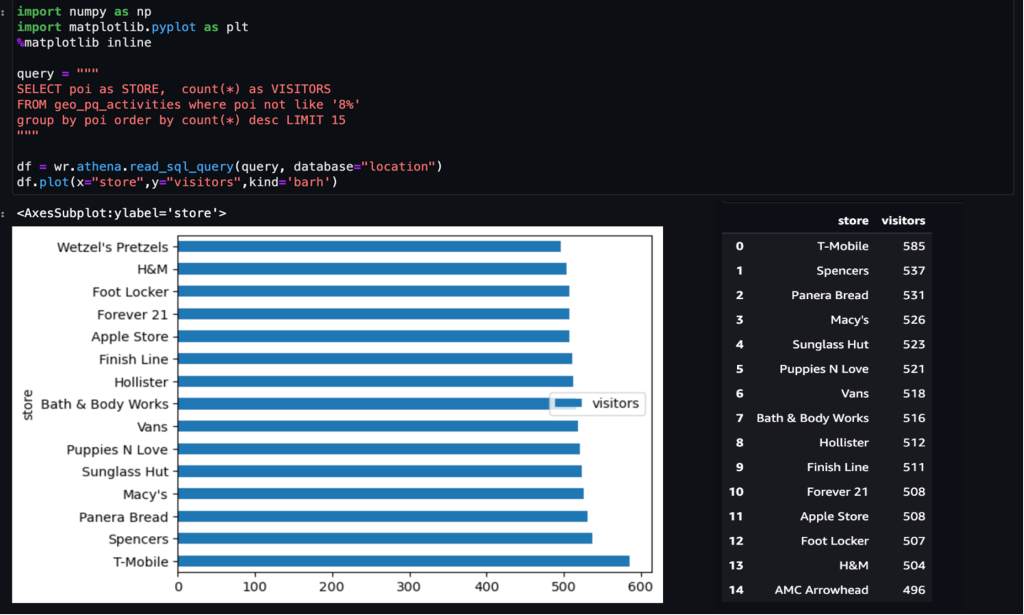
Vi kan beräkna och visualisera tätheten av aktiviteter och besök.
Exempelvis 1 – Följande skärmdump visar topp 15 besökta butiker i köpcentret.
Exempelvis 2 – Följande skärmdump visar antalet besök på Apple Store per timme.

Resor och banor
Som nämnts tidigare representerar ett par på varandra följande aktiviteter en resa. Vi kan använda följande tillvägagångssätt för att härleda resor från aktivitetsdata. Här används fönsterfunktioner med SQL för att generera trips tabell, som visas på skärmdumpen.

Efter trips tabell genereras, resor till en POI kan fastställas.
Exempel 1 - Följande skärmdump visar de 10 bästa butikerna som leder fottrafik mot Apple Store.

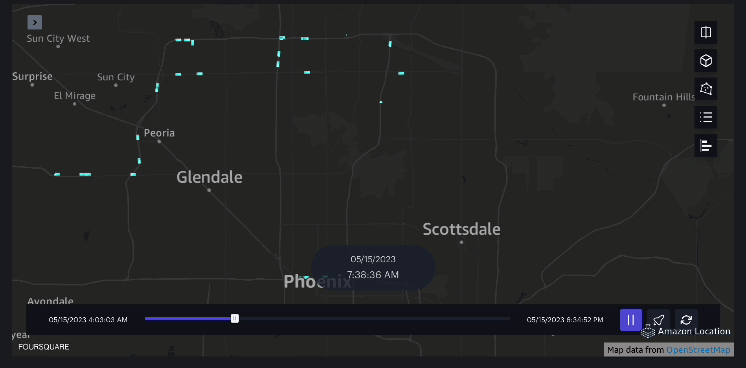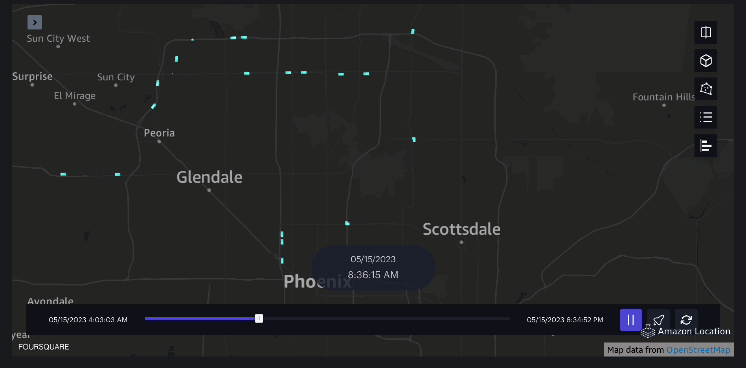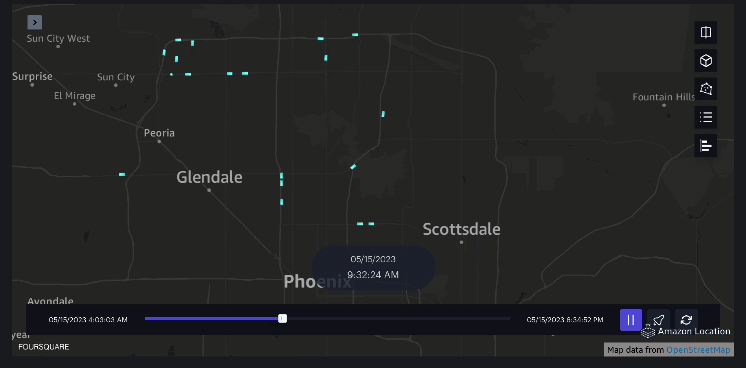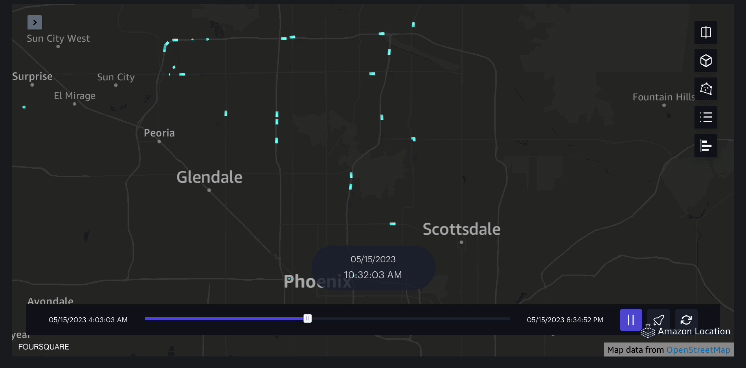
Exempelvis 2 – Följande skärmdump visar alla resor till Arrowhead Mall.

Exempelvis 3 – Följande video visar rörelsemönstren inne i köpcentret.

Exempelvis 4 – Följande video visar rörelsemönstren utanför köpcentret.
Upptagningsområdesanalys
Vi kan analysera alla besök på en POI och bestämma upptagningsområdet.
Exempel 1 - Följande skärmdump visar alla besök i Macy's-butiken.

Exempelvis 2 – Följande skärmdump visar de 10 vanligaste postnumren för hemområdet (gränser markerade) varifrån besöken inträffade.

Kontroll av datakvalitet
Vi kan kontrollera det dagliga inkommande dataflödet för kvalitet och upptäcka anomalier med hjälp av QuickSights instrumentpaneler och dataanalyser. Följande skärmdump visar ett exempel på instrumentpanelen.

Slutsats
Mobilitetsdata och dess analys för att få kundinsikter och få konkurrensfördelar förblir ett nischområde eftersom det är svårt att få en konsekvent och korrekt datauppsättning. Dessa data kan dock hjälpa organisationer att lägga till sammanhang till befintlig analys och till och med producera nya insikter kring kunders rörelsemönster. Amazon SageMakers geospatiala funktioner och geospatiala bearbetningsjobb kan hjälpa till att implementera dessa användningsfall och få insikter på ett intuitivt och tillgängligt sätt.
I det här inlägget demonstrerade vi hur man använder AWS-tjänster för att rensa mobilitetsdata och sedan använder Amazon SageMakers geospatiala kapaciteter för att generera härledda datamängder som stopp, aktiviteter och resor med ML-modeller. Sedan använde vi derivatdatauppsättningarna för att visualisera rörelsemönster och generera insikter.
Du kan komma igång med Amazon SageMakers geospatiala funktioner på två sätt:
Om du vill veta mer, besök Amazon SageMaker geospatiala funktioner och Komma igång med Amazon SageMaker geospatial. Besök även vår GitHub repo, som har flera exempel på bärbara datorer på Amazon SageMakers geospatiala funktioner.
Om författarna
 Jimy Matthews är en AWS Solutions Architect, med expertis inom AI/ML-teknik. Jimy är baserad i Boston och arbetar med företagskunder när de förändrar sin verksamhet genom att ta till sig molnet och hjälper dem att bygga effektiva och hållbara lösningar. Han brinner för sin familj, bilar och mixed martial arts.
Jimy Matthews är en AWS Solutions Architect, med expertis inom AI/ML-teknik. Jimy är baserad i Boston och arbetar med företagskunder när de förändrar sin verksamhet genom att ta till sig molnet och hjälper dem att bygga effektiva och hållbara lösningar. Han brinner för sin familj, bilar och mixed martial arts.
 Girish Keshav är en lösningsarkitekt på AWS och hjälper kunder i deras molnmigreringsresa att modernisera och köra arbetsbelastningar säkert och effektivt. Han arbetar med ledare för teknikteam för att vägleda dem om applikationssäkerhet, maskininlärning, kostnadsoptimering och hållbarhet. Han är baserad i San Francisco och älskar att resa, vandra, titta på sport och utforska hantverksbryggerier.
Girish Keshav är en lösningsarkitekt på AWS och hjälper kunder i deras molnmigreringsresa att modernisera och köra arbetsbelastningar säkert och effektivt. Han arbetar med ledare för teknikteam för att vägleda dem om applikationssäkerhet, maskininlärning, kostnadsoptimering och hållbarhet. Han är baserad i San Francisco och älskar att resa, vandra, titta på sport och utforska hantverksbryggerier.
 Ramesh Jetty är en senior ledare för Solutions Architecture fokuserad på att hjälpa AWS företagskunder att tjäna pengar på sina datatillgångar. Han råder chefer och ingenjörer att designa och bygga mycket skalbara, pålitliga och kostnadseffektiva molnlösningar, speciellt inriktade på maskininlärning, data och analys. På fritiden tycker han om att vara utomhus, cykla och vandra med sin familj.
Ramesh Jetty är en senior ledare för Solutions Architecture fokuserad på att hjälpa AWS företagskunder att tjäna pengar på sina datatillgångar. Han råder chefer och ingenjörer att designa och bygga mycket skalbara, pålitliga och kostnadseffektiva molnlösningar, speciellt inriktade på maskininlärning, data och analys. På fritiden tycker han om att vara utomhus, cykla och vandra med sin familj.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/use-mobility-data-to-derive-insights-using-amazon-sagemaker-geospatial-capabilities/
- : har
- :är
- :inte
- :var
- $UPP
- 000
- 1
- 10
- 100
- 14
- 15%
- 2023
- 300
- 361
- 3d
- 400
- 50
- 7
- 9
- a
- Om oss
- ovan
- accelerera
- accelererad
- tillgång
- tillgänglig
- åstadkomma
- noggrannhet
- exakt
- uppnås
- aktiv
- aktivt
- aktiviteter
- faktiska
- lägga till
- adress
- följt
- justerat
- Anta
- annonser
- Fördel
- Annons
- reklam
- Efter
- Aggregator
- Sammanställare
- AI / ML
- Stöd
- algoritm
- Alla
- vid sidan av
- också
- Även
- am
- amason
- Amazon Comprehend
- Amazon SageMaker
- Amazon SageMaker geospatial
- Amazon SageMaker Studio
- Amazon Web Services
- mängder
- an
- analyser
- analys
- analytics
- analysera
- analys
- Ankare
- och
- vilken som helst
- isär
- app
- Apple
- Ansökan
- applikationssäkerhet
- tillämpningar
- tillvägagångssätt
- cirka
- arkitektur
- ÄR
- OMRÅDE
- områden
- arizona
- runt
- konst
- AS
- Tillgångar
- delad
- associerad
- At
- uppnå
- publik
- förstärka
- tillgänglig
- genomsnitt
- AWS
- AWS-lim
- bas
- baserat
- grund
- BE
- därför att
- varit
- Där vi får lov att vara utan att konstant prestera,
- mellan
- bud
- Blockera
- boston
- gränser
- varumärken
- SLUTRESULTAT
- Byggnad
- inbyggd
- företag
- företag
- men
- by
- beräkna
- kallas
- Kampanjer
- KAN
- Kan få
- kapacitet
- bilar
- Vid
- fall
- CCPA
- Celler
- Folkräkningen
- folkräkning data
- kedja
- ta
- Städer
- Stad
- rena
- Stäng
- cloud
- kluster
- klustring
- koda
- koder
- samverkan
- samla
- samling
- samlare
- Kolumn
- Kolonner
- kombinerad
- kommer
- kommande
- kommersiella
- kommersiella fastigheter
- Gemensam
- vanligen
- Företag
- konkurrenskraftig
- konkurrenter
- komplex
- komponent
- förstå
- Compute
- Anslutning
- i följd
- samtycke
- överväganden
- konsekvent
- konsumtion
- Behållare
- innehåller
- sammanhang
- kontinuerlig
- Pris
- länder
- land
- täcka
- omfattar
- farkoster
- sökrobot
- skapa
- beställnings
- kund
- Kunder
- dagligen
- instrumentbräda
- instrumentpaneler
- datum
- datapunkter
- dataintegritet
- databehandling
- datauppsättningar
- dag
- leverans
- demonstreras
- densitet
- skildrar
- distribuera
- derivat
- härleda
- Härledd
- Designa
- destinationer
- detalj
- upptäcka
- Bestämma
- bestämd
- bestämmande
- Utveckling
- anordning
- enheter
- svårt
- rikta
- katastrofer
- upptäcka
- diskutera
- avstånd
- skilja på
- diy
- gör
- gjort
- DOT
- drar
- grund
- varaktighet
- under
- varje
- Tidigare
- lättare
- lätt
- Effektiv
- effektiv
- effektivt
- ansträngning
- ge
- möjliggör
- encompassing
- ingrepp
- uppdrag
- engagerande
- Ingenjörer
- berika
- Företag
- företagskunder
- Miljö
- speciellt
- fastigheter
- Eter (ETH)
- etisk
- Även
- händelse
- Varje
- exempel
- befattningshavare
- befintliga
- finns
- dyra
- erfarenhet
- expertis
- utforska
- Utforska
- export
- uttryckt
- extrahera
- familj
- Leverans
- Fed
- få
- Fil
- slutlig
- hitta
- fiona
- Förnamn
- flexibel
- Fokus
- fokuserade
- följt
- efter
- Fot
- För
- formen
- format
- fyrkant
- RAM
- Francisco
- Fri
- från
- Bränsle
- fullständigt
- fungera
- funktioner
- ytterligare
- få
- lek
- samlade ihop
- GDPR
- generera
- genereras
- genererar
- generera
- geografisk
- geografisk
- Geospatial ML
- skaffa sig
- få
- gif
- ges
- ger
- Går
- gps
- grafik
- stor
- Bra utomhus
- Rutnät
- styra
- hårdvara
- hashade
- Har
- he
- hjälpa
- hjälp
- hjälpa
- hjälper
- här.
- Markerad
- höggradigt
- vandring
- hans
- Hem
- Horisontell
- timme
- Hur ser din drömresa ut
- How To
- Men
- html
- http
- HTTPS
- hubbar
- orkan
- ID
- Tanken
- identifierade
- identifiera
- identifiera
- IDFA
- if
- bild
- genomföra
- med Esport
- förbättra
- in
- Inklusive
- Inkommande
- indikerar
- individuellt
- industrier
- informationen
- Infrastruktur
- inledande
- inuti
- insikter
- instanser
- integrationer
- Intelligens
- interaktiva
- intresse
- intressant
- in
- införa
- intuitiv
- innebär
- IT
- DESS
- sig
- Jobb
- Lediga jobb
- fogade
- resa
- jpg
- Large
- storskalig
- latitud
- Lagar
- skiktad
- Layout
- leda
- ledare
- ledare
- LÄRA SIG
- inlärning
- vänster
- bibliotek
- tycka om
- sannolikhet
- rader
- läsa in
- läge
- platser
- se
- ser ut som
- älskar
- Maskinen
- maskininlärning
- Maskiner
- gjord
- bibehålla
- större
- göra
- GÖR
- förvaltade
- hantera
- manuellt
- många
- karta
- kartläggning
- kartor
- Marknadsföring
- Marknadsföringskampanjer
- marknadsföringsteknik
- MarTech
- krigisk
- mask
- Matris
- Maj..
- betyder
- nämnts
- metod
- Metrics
- migration
- Militär
- miljoner
- minsta
- minut
- blandad
- ML
- Mobil
- mobilenhet
- Mobil enheter
- mobilitet
- modell
- modeller
- modernisera
- modifierad
- modifiera
- tjäna pengar
- månad
- mer
- mest
- för det mesta
- flytta
- rörelse
- rörelser
- rörliga
- multipel
- mängd
- måste
- namn
- Natural
- Natur
- Behöver
- behov
- Nya
- Nästa
- nisch
- Brus
- anteckningsbok
- bärbara datorer
- antal
- nummer
- objektet
- observera
- få
- erhållna
- erhållande
- inträffade
- of
- Ofta
- on
- ONE
- endast
- öppet
- öppen källkod
- drift
- Verksamhet
- motsatt
- optimala
- optimering
- Optimera
- or
- organisationer
- Övriga
- vår
- ut
- utfall
- utomhus
- utanför
- över
- par
- pandor
- pandemi
- parametrar
- del
- särskilt
- passera
- brinner
- bana
- mönster
- Personer
- för
- utföra
- prestanda
- Personligen
- perspektiv
- Phoenix
- Fotografierna
- fysisk
- Bild
- pii
- ping
- placeras
- platser
- planering
- plato
- Platon Data Intelligence
- PlatonData
- pm
- Punkt
- poäng
- Populära
- befolkning
- placera
- möjlig
- Inlägg
- potentiell
- potentiella kunder
- drivs
- föregående
- Förutsägelser
- presentera
- privatpolicy
- sekretesslagar
- privat
- process
- bearbetning
- producera
- ge
- publicly
- förlag
- inköp
- köpt
- Syftet
- Python
- kvalitet
- rangordna
- snarare
- Raw
- rådata
- verklig
- fastigheter
- registreras
- hänvisa
- referens
- hänvisar
- regioner
- pålitlig
- resterna
- representerar
- representation
- representerade
- representerar
- representerar
- Obligatorisk
- att
- ansvarig
- restauranger
- resulterande
- Resultat
- detaljhandeln
- höger
- Rutt
- rutter
- Körning
- rinnande
- sagemaker
- Exempeldatauppsättning
- San
- San Francisco
- satellit
- satellitbilder
- skalbar
- Skala
- vetenskapsmän
- skärmdumpar
- sdks
- sömlös
- Andra
- sekunder
- sektioner
- säkert
- säkerhet
- Val
- senior
- känslig
- skickas
- separat
- Serier
- Tjänster
- portion
- flera
- Dela
- Gå och Handla
- skall
- visas
- Visar
- liknande
- Enkelt
- förenklade
- enda
- webbplats
- långsam
- So
- Lösningar
- Löser
- några
- eftersträvas
- Källa
- Källor
- Utrymme
- rumsliga
- specifik
- Sporter
- fläckar
- SQL
- standardisering
- igång
- startar
- uttalanden
- Stater
- Steg
- Steg
- Sluta
- slutade
- stoppa
- Stoppar
- förvaring
- lagra
- lagras
- lagrar
- okomplicerad
- ström
- studio
- väsentlig
- sådana
- leverera
- leveranskedjan
- stödja
- yta
- kring
- Hållbarhet
- hållbart
- system
- bord
- tagen
- lag
- tech
- Teknisk
- tekniker
- Teknologi
- tiotals
- än
- den där
- Smakämnen
- Området
- källan
- deras
- Dem
- sig själva
- sedan
- Där.
- Dessa
- de
- detta
- de
- tusentals
- tröskelvärde
- Genom
- tid
- till
- alltför
- verktyg
- verktyg
- topp
- Top 10
- Totalt
- mot
- spåra
- trafik
- Tåg
- bana
- Förvandla
- transformationer
- sändare
- färdas
- Traveling
- Trender
- tur
- två
- typer
- typisk
- underliggande
- förståelse
- unika
- uppladdad
- användning
- användningsfall
- Begagnade
- Användare
- användare
- användningar
- med hjälp av
- utnyttja
- olika
- verifiera
- via
- Video
- Besök
- besökta
- besökare
- Besök
- visuell
- visualisering
- visualisera
- visuella
- vs
- tittar
- Sätt..
- sätt
- we
- webb
- webbservice
- vecka
- VÄL
- Vad
- när
- som
- VEM
- Hela
- varför
- Wi-fi
- utbredd
- kommer
- fönster
- med
- utan
- Arbete
- arbetsflöde
- fungerar
- skrivning
- årlig
- dig
- Din
- zephyrnet
- Postnummer