Key Takeaways
- Tankespridning (TP) är en ny metod som förbättrar de komplexa resonemangsförmågan hos stora språkmodeller (LLM).
- TP utnyttjar analoga problem och deras lösningar för att förbättra resonemang, snarare än att få LLM:er att resonera från grunden.
- Experiment med olika uppgifter visar att TP överträffar baslinjemetoderna avsevärt, med förbättringar som sträcker sig från 12 % till 15 %.
TP uppmanar först LLM:er att föreslå och lösa en uppsättning analoga problem som är relaterade till ingången. Sedan återanvänder TP resultaten av analoga problem för att direkt ge en ny lösning eller ta fram en kunskapsintensiv plan för utförande för att ändra den initiala lösningen som erhållits från grunden.
Mångsidigheten och beräkningskraften hos stora språkmodeller (LLM) är obestridliga, men de är inte obegränsade. En av de mest betydande och konsekventa utmaningarna för LLM:er är deras allmänna inställning till problemlösning, som består av resonemang från första principer för varje ny uppgift som möter. Detta är problematiskt, eftersom det möjliggör en hög grad av anpassningsförmåga, men också ökar sannolikheten för fel, särskilt i uppgifter som kräver flerstegsresonemang.
Utmaningen att "resonera från grunden" är särskilt uttalad i komplexa uppgifter som kräver flera steg av logik och slutledning. Till exempel, om en LLM uppmanas att hitta den kortaste vägen i ett nätverk av sammankopplade punkter, skulle den vanligtvis inte utnyttja förkunskaper eller liknande problem för att hitta en lösning. Istället skulle det försöka lösa problemet isolerat, vilket kan leda till suboptimala resultat eller till och med direkta fel. Stiga på Tankeförökning (TP), en metod utformad för att utöka resonemangsförmågan hos LLM:er. TP syftar till att övervinna de inneboende begränsningarna hos LLM genom att låta dem dra från en reservoar av analoga problem och deras motsvarande lösningar. Detta innovativa tillvägagångssätt förbättrar inte bara noggrannheten hos LLM-genererade lösningar utan förbättrar också avsevärt deras förmåga att hantera komplexa resonemangsuppgifter i flera steg. Genom att utnyttja kraften i analogi tillhandahåller TP ett ramverk som förstärker LLMs medfödda resonemangsförmåga, vilket tar oss ett steg närmare förverkligandet av verkligt intelligenta artificiella system.
Tankeförökning innefattar två huvudsteg:
- Först uppmanas LLM att föreslå och lösa en uppsättning analoga problem relaterade till ingångsproblemet
- Därefter används lösningarna på dessa analoga problem för att antingen direkt ge en ny lösning eller för att ändra den ursprungliga lösningen
Processen att identifiera analoga problem gör det möjligt för LLM att återanvända problemlösningsstrategier och lösningar, och därigenom förbättra dess resonemangsförmåga. TP är kompatibel med befintliga promptmetoder, vilket ger en generaliserbar lösning som kan integreras i olika uppgifter utan betydande uppgiftsspecifik ingenjörskonst.
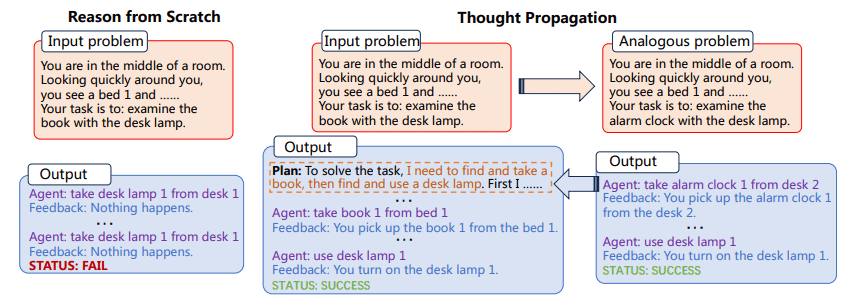
Figur 1: Tankeförökningsprocessen (Bild från papper)
Dessutom bör TP:s anpassningsförmåga inte underskattas. Dess kompatibilitet med befintliga uppmaningsmetoder gör det till ett mycket mångsidigt verktyg. Detta innebär att TP inte är begränsad till någon specifik typ av problemlösningsdomän. Detta öppnar upp spännande vägar för uppgiftsspecifik finjustering och optimering, och höjer därigenom användbarheten och effektiviteten hos LLM i ett brett spektrum av applikationer.
Implementeringen av Thought Propagation kan integreras i arbetsflödet för befintliga LLM:er. Till exempel, i en Shortest-path Reasoning-uppgift, skulle TP först kunna lösa en uppsättning enklare, analoga problem för att förstå olika möjliga vägar. Den skulle sedan använda dessa insikter för att lösa det komplexa problemet och därigenom öka sannolikheten för att hitta den optimala lösningen.
Exempelvis 1
- uppgift: Kortaste vägen Resonemang
- Analoga problem: Kortaste vägen mellan punkt A och B, Kortaste vägen mellan punkt B och C
- Slutgiltig lösning: Optimal väg från punkt A till C med tanke på lösningarna av analoga problem
Exempelvis 2
- uppgift: Kreativt skrivande
- Analoga problem: Skriv en kort berättelse om vänskap, Skriv en novell om tillit
- Slutgiltig lösning: Skriv en komplex novell som integrerar teman om vänskap och förtroende
Processen innebär att först lösa dessa analoga problem och sedan använda insikterna för att ta itu med den komplexa uppgiften. Den här metoden har visat sin effektivitet över flera uppgifter och visat upp avsevärda förbättringar i prestandamått.
Thought Propagation's implikationer går utöver att bara förbättra befintliga mätvärden. Denna uppmaningsteknik har potential att förändra hur vi förstår och distribuerar LLM:er. Metodiken understryker en förändring från isolerad, atomär problemlösning till en mer holistisk, sammankopplad strategi. Det uppmanar oss att överväga hur LLM:er kan lära sig inte bara av data, utan från själva problemlösningsprocessen. Genom att kontinuerligt uppdatera sin förståelse genom lösningar på analoga problem, är LLM:er utrustade med TP bättre förberedda för att hantera oförutsedda utmaningar, vilket gör dem mer motståndskraftiga och anpassningsbara i snabbt utvecklande miljöer.
Tankespridning är ett lovande tillägg till verktygslådan med uppmaningsmetoder som syftar till att förbättra kapaciteten hos LLM. Genom att låta LLM:er utnyttja analoga problem och deras lösningar, ger TP en mer nyanserad och effektiv resonemangsmetod. Experiment bekräftar dess effektivitet, vilket gör den till en kandidatstrategi för att förbättra prestandan för LLM:er över en mängd olika uppgifter. TP kan i slutändan representera ett betydande steg framåt i sökandet efter mer kapabla AI-system.
Matthew Mayo (@mattmayo13) har en magisterexamen i datavetenskap och en examen i datautvinning. Som chefredaktör för KDnuggets strävar Matthew efter att göra komplexa datavetenskapliga koncept tillgängliga. Hans yrkesintressen inkluderar naturlig språkbehandling, maskininlärningsalgoritmer och att utforska framväxande AI. Han drivs av ett uppdrag att demokratisera kunskap inom datavetenskapssamhället. Matthew har kodat sedan han var 6 år gammal.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.kdnuggets.com/thought-propagation-an-analogical-approach-to-complex-reasoning-with-large-language-models?utm_source=rss&utm_medium=rss&utm_campaign=thought-propagation-an-analogical-approach-to-complex-reasoning-with-large-language-models
- : har
- :är
- :inte
- $UPP
- 15%
- 8
- a
- förmågor
- förmåga
- Om Oss
- tillgänglig
- noggrannhet
- tvärs
- Dessutom
- AI
- AI-system
- syftar
- Syftet
- algoritmer
- tillåta
- tillåter
- också
- förstärker
- an
- och
- vilken som helst
- tillämpningar
- tillvägagångssätt
- ÄR
- konstgjord
- AS
- At
- försök
- förstärka
- vägar
- b
- Baslinje
- BE
- varit
- Bättre
- mellan
- Bortom
- Föra
- bred
- men
- by
- KAN
- kandidat
- kapacitet
- kapabel
- utmanar
- utmaningar
- närmare
- Kodning
- samfundet
- kompatibilitet
- kompatibel
- komplex
- beräkningar
- beräkningskraft
- dator
- Datavetenskap
- Begreppen
- Bekräfta
- Tänk
- med tanke på
- konsekvent
- Bestående
- kontinuerligt
- Motsvarande
- kunde
- Kreativ
- datum
- data mining
- datavetenskap
- Examen
- Efterfrågan
- DEMOKRATISERA
- demonstreras
- distribuera
- utformade
- direkt
- domän
- dra
- driven
- Editor-in-chief
- Effektiv
- effektivitet
- effektivitet
- antingen
- upplyft
- smärgel
- Teknik
- Förbättrar
- förbättra
- ange
- miljöer
- utrustad
- fel
- speciellt
- Även
- Varje
- utvecklas
- exempel
- spännande
- utförande
- befintliga
- experiment
- Utforska
- hitta
- finna
- Förnamn
- För
- Framåt
- Ramverk
- Vänskap
- från
- vunnits
- Allmänt
- Go
- uppgradera
- sidan
- he
- Hög
- höggradigt
- hans
- innehar
- helhetssyn
- Hur ser din drömresa ut
- HTTPS
- identifiera
- if
- bild
- genomförande
- implikationer
- förbättra
- förbättringar
- förbättrar
- förbättra
- in
- innefattar
- Inkorporerad
- Ökar
- ökande
- inneboende
- inledande
- medfödd
- innovativa
- ingång
- insikter
- istället
- integrerade
- integrerar
- Intelligent
- sammankopplade
- intressen
- in
- innebär
- isolerat
- isolering
- IT
- DESS
- sig
- jpg
- bara
- KDnuggets
- Snäll
- kunskap
- språk
- Large
- leda
- LÄRA SIG
- inlärning
- Hävstång
- hävstångs
- hävstångs
- sannolikhet
- BEGRÄNSA
- begränsningar
- Begränsad
- Logiken
- Maskinen
- maskininlärning
- Huvudsida
- göra
- GÖR
- Framställning
- Master
- Matthew
- Maj..
- betyder
- endast
- metod
- Metodik
- metoder
- Metrics
- Gruvdrift
- Mission
- modeller
- mer
- mest
- multipel
- Natural
- Naturligt språk
- Naturlig språkbehandling
- nät
- Nya
- ny lösning
- roman
- erhållna
- of
- Gamla
- on
- ONE
- endast
- öppnas
- optimala
- optimering
- or
- utklassar
- rent ut
- Övervinna
- Papper
- särskilt
- bana
- prestanda
- Planen
- plato
- Platon Data Intelligence
- PlatonData
- Punkt
- poäng
- möjlig
- potentiell
- kraft
- beredd
- Principerna
- Innan
- Problem
- problemlösning
- problem
- process
- bearbetning
- professionell
- lovande
- uttalad
- förökning
- föreslå
- ger
- tillhandahålla
- som sträcker sig
- snabbt
- snarare
- insikt
- Anledningen
- relaterad
- rendering
- representerar
- kräver
- elastisk
- Resultat
- återanvända
- s
- Vetenskap
- repa
- Sök
- in
- skifta
- Kort
- skall
- show
- visa upp
- signifikant
- signifikant
- eftersom
- lösning
- Lösningar
- LÖSA
- Lösa
- specifik
- Spektrum
- Steg
- Steg
- Historia
- strategier
- Strategi
- väsentlig
- väsentligen
- System
- tackla
- uppgift
- uppgifter
- Tekniken
- än
- den där
- Smakämnen
- deras
- Dem
- teman
- sedan
- vari
- Dessa
- de
- detta
- trodde
- Genom
- till
- verktyg
- Verktygslåda
- mot
- tp
- verkligen
- Litar
- två
- typiskt
- Ytterst
- obestridlig
- understryker
- förstå
- förståelse
- oförutsedd
- uppdatering
- us
- användning
- Begagnade
- med hjälp av
- verktyg
- mängd
- olika
- mångsidig
- mångsidighet
- var
- we
- som
- med
- utan
- arbetsflöde
- skulle
- skriva
- skrivning
- år
- ännu
- Avkastning
- zephyrnet