AWS Lim Studio är ett grafiskt gränssnitt som gör det enkelt att skapa, köra och övervaka extrahera, transformera och ladda (ETL) jobb i AWS-lim. Det låter dig visuellt komponera arbetsflöden för datatransformation med hjälp av noder som representerar olika datahanteringssteg, som senare automatiskt omvandlas till kod för att köras.
AWS Lim Studio Nyligen släppt 10 fler visuella transformationer för att skapa mer avancerade jobb på ett visuellt sätt utan kodningsförmåga. I det här inlägget diskuterar vi potentiella användningsfall som återspeglar vanliga ETL-behov.
De nya transformationerna som kommer att demonstreras i det här inlägget är: Sammanfoga, Dela sträng, Array till kolumner, Lägg till aktuell tidsstämpel, Pivot rader till kolumner, Unpivot kolumner till rader, Lookup, Explodera matris eller mappa till kolumner, härledd kolumn och autobalansering. .
Lösningsöversikt
I det här användningsfallet har vi några JSON-filer med aktieoptionsoperationer. Vi vill göra några transformationer innan vi lagrar data för att göra det lättare att analysera, och vi vill också ta fram en separat datamängdssammanfattning.
I denna datauppsättning representerar varje rad en handel med optionskontrakt. Optioner är finansiella instrument som ger rätten – men inte skyldigheten – att köpa eller sälja aktieaktier till ett fast pris (kallad strejkpris) före ett definierat utgångsdatum.
Indata
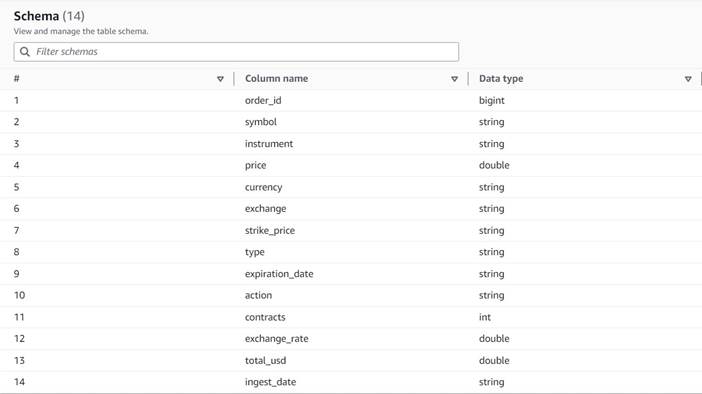
Uppgifterna följer följande schema:
- order_id – Ett unikt ID
- Symbolen – En kod som vanligtvis baseras på några bokstäver för att identifiera det företag som sänder ut de underliggande aktieaktierna
- Instrumentet – Namnet som identifierar det specifika alternativet som köps eller säljs
- valutan – ISO-valutakoden som priset uttrycks i
- pris – Det belopp som betalades för köpet av varje optionskontrakt (på de flesta börser tillåter ett kontrakt dig att köpa eller sälja 100 aktieaktier)
- utbyta – Koden för det börscenter eller handelsplats där optionen handlades
- säljs – En lista över antalet kontrakt som tilldelats för att fylla säljordern när detta är en säljaffär
- köpt – En lista över antalet kontrakt som tilldelats för att fylla köpordern när detta är köphandel
Följande är ett exempel på den syntetiska data som genereras för detta inlägg:
ETL krav
Denna data har ett antal unika egenskaper, som ofta finns på äldre system, som gör data svårare att använda.
Följande är ETL-kraven:
- Instrumentnamnet har värdefull information som är avsedd för människor att förstå; vi vill normalisera det i separata kolumner för enklare analys.
- Attributen
boughtochsoldutesluter varandra; vi kan konsolidera dem i en enda kolumn med kontraktsnumren och ha en annan kolumn som anger om kontrakten köptes eller såldes i denna ordning. - Vi vill behålla informationen om de individuella kontraktstilldelningarna men som enskilda rader istället för att tvinga användare att hantera en rad siffror. Vi skulle kunna lägga ihop siffrorna, men vi skulle förlora information om hur ordern fylldes (vilket indikerar marknadslikviditet). Istället väljer vi att avnormalisera tabellen så att varje rad har ett enda antal kontrakt, och delar upp order med flera nummer i separata rader. I ett komprimerat kolumnformat är den extra datauppsättningsstorleken för denna upprepning ofta liten när komprimering tillämpas, så det är acceptabelt att göra datauppsättningen lättare att fråga.
- Vi vill generera en sammanfattande tabell över volymer för varje optionstyp (call and put) för varje aktie. Detta ger en indikation på marknadssentimentet för varje aktie och marknaden i allmänhet (girighet kontra rädsla).
- För att möjliggöra övergripande handelssammanfattningar vill vi för varje operation tillhandahålla totalsumman och standardisera valutan till amerikanska dollar, med hjälp av en ungefärlig omräkningsreferens.
- Vi vill lägga till datumet när dessa omvandlingar ägde rum. Detta kan till exempel vara användbart för att ha en referens om när valutaomvandlingen gjordes.
Baserat på dessa krav kommer jobbet att ge två utgångar:
- En CSV-fil med en sammanfattning av antalet kontrakt för varje symbol och typ
- En katalogtabell för att hålla en historik över beställningen, efter att ha gjort de angivna omvandlingarna
Förutsättningar
Du behöver din egen S3-hink för att följa med i detta användningsfall. För att skapa en ny hink, se Skapa en hink.
Generera syntetisk data
För att följa med i det här inlägget (eller experimentera med den här typen av data på egen hand), kan du generera denna datauppsättning syntetiskt. Följande Python-skript kan köras i en Python-miljö med Boto3 installerat och tillgång till Amazon enkel lagringstjänst (Amazon S3).
Utför följande steg för att generera data:
- På AWS Glue Studio skapar du ett nytt jobb med alternativet Python-skalskriptredigerare.
- Ge jobbet ett namn och på Jobb detaljer fliken, välj en lämplig roll och ett namn för Python-skriptet.
- I Jobb detaljer avsnitt, expandera Avancerade egenskaper och bläddra ner till Jobbparametrar.
- Ange en parameter med namnet
--bucketoch tilldela som värde namnet på den hink du vill använda för att lagra exempeldata. - Ange följande skript i AWS Glue shell editor:
- Kör jobbet och vänta tills det visas som framgångsrikt slutfört på fliken Körningar (det bör ta bara några sekunder).
Varje körning genererar en JSON-fil med 1,000 XNUMX rader under den angivna hinken och prefixet transformsblog/inputdata/. Du kan köra jobbet flera gånger om du vill testa med fler indatafiler.
Varje rad i den syntetiska datan är en datarad som representerar ett JSON-objekt som följande:
Skapa AWS Glue visuella jobb
För att skapa AWS Glue visuella jobb, slutför följande steg:
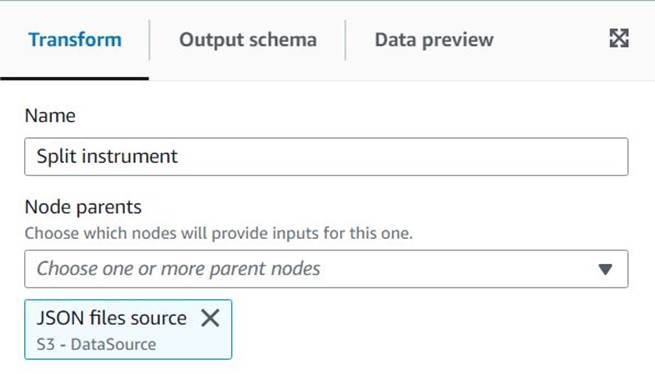
- Gå till AWS Glue Studio och skapa ett jobb med alternativet Visual med en tom duk.
- Redigera
Untitled jobatt ge den ett namn och tilldela den en roll som lämpar sig för AWS Glue på Jobb detaljer fliken. - Lägg till en S3-datakälla (du kan namnge den
JSON files source) och ange S3-URL under vilken filerna lagras (till exempel,s3://<your bucket name>/transformsblog/inputdata/), välj sedan JSON som dataformat. - Välja Härleda schema så det ställer in utdataschemat baserat på data.
Från den här källnoden fortsätter du att kedja transformeringar. När du lägger till varje transform, se till att den valda noden är den sista som läggs till så att den tilldelas som förälder, om inte annat anges i instruktionerna.
Om du inte valde rätt förälder kan du alltid redigera föräldern genom att välja den och välja en annan förälder i konfigurationsfönstret.
För varje nod som läggs till kommer du att ge den ett specifikt namn (så att nodens syfte visas i grafen) och konfiguration på Förvandla fliken.
Varje gång en transformation ändrar schemat (till exempel lägg till en ny kolumn), måste utmatningsschemat uppdateras så att det är synligt för nedströmstransformationerna. Du kan redigera utdataschemat manuellt, men det är mer praktiskt och säkrare att göra det med förhandsgranskningen av data.
På så sätt kan du dessutom verifiera att omvandlingen fungerar så långt som förväntat. För att göra det, öppna Förhandsgranskning av data med omvandlingen vald och starta en förhandsgranskningssession. När du har verifierat att de transformerade data ser ut som förväntat, gå till Utgångsschema fliken och välj Använd schema för förhandsgranskning av data för att uppdatera schemat automatiskt.
När du lägger till nya typer av transformationer kan förhandsgranskningen visa ett meddelande om ett saknat beroende. När detta händer, välj Avsluta session och starta en ny, så förhandsgranskningen tar upp den nya typen av nod.
Extrahera instrumentinformation
Låt oss börja med att ta itu med informationen om instrumentnamnet för att normalisera den till kolumner som är lättare att komma åt i den resulterande utdatatabellen.
- Lägg till Delad sträng nod och namnge den
Split instrument, som kommer att tokenisera instrumentkolumnen med ett blankstegsregex:s+(ett enda utrymme skulle göra i det här fallet, men det här sättet är mer flexibelt och visuellt tydligare). - Vi vill behålla den ursprungliga instrumentinformationen som den är, så ange ett nytt kolumnnamn för den delade arrayen:
instrument_arr.
- Lägg till en Array till kolumner nod och namnge den
Instrument columnsför att konvertera den nyss skapade arraykolumnen till nya fält, förutomsymbol, som vi redan har en kolumn för. - Välj kolumnen
instrument_arr, hoppa över den första token och be den att extrahera utdatakolumnernamonth, day, year, strike_price, typemed hjälp av index2, 3, 4, 5, 6(mellanslagen efter kommatecken är för läsbarhet, de påverkar inte konfigurationen).
Årtalet som extraheras uttrycks endast med två siffror; låt oss sätta ett stopp för att anta att det är i detta århundrade om de bara använder två siffror.
- Lägg till Härledd kolumn nod och namnge den
Four digits year. - ange
yearsom den härledda kolumnen så att den åsidosätter den och ange följande SQL-uttryck:CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
För bekvämlighets skull bygger vi en expiration_date fält som en användare kan ha som referens för det sista datum optionen kan utnyttjas.
- Lägg till Sammanfoga kolumner nod och namnge den
Build expiration date. - Ge den nya kolumnen ett namn
expiration_date, välj kolumnernayear,monthochday(i den ordningen), och ett bindestreck som spacer.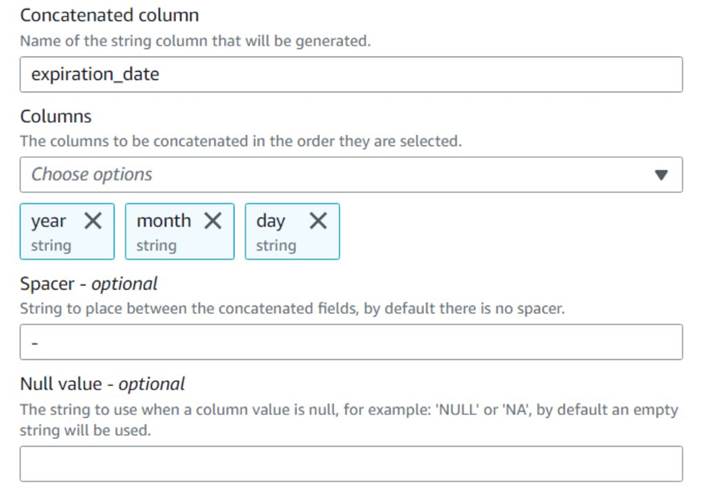
Diagrammet hittills bör se ut som följande exempel.
![]()
Dataförhandsgranskningen av de nya kolumnerna hittills bör se ut som följande skärmdump.
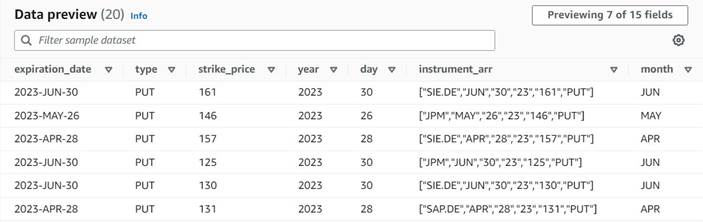
Normalisera antalet kontrakt
Var och en av raderna i data anger antalet kontrakt för varje option som köptes eller såldes och de partier som beställningarna fylldes på. Utan att förlora informationen om de enskilda partierna vill vi ha varje belopp på en enskild rad med ett enda beloppsvärde, medan resten av informationen replikeras i varje producerad rad.
Låt oss först slå samman beloppen till en enda kolumn.
- Lägg till en Lossa kolumner i rader nod och namnge den
Unpivot actions. - Välj kolumner
boughtochsoldför att avpivotera och lagra namnen och värdena i namngivna kolumneractionochcontracts, Respektive.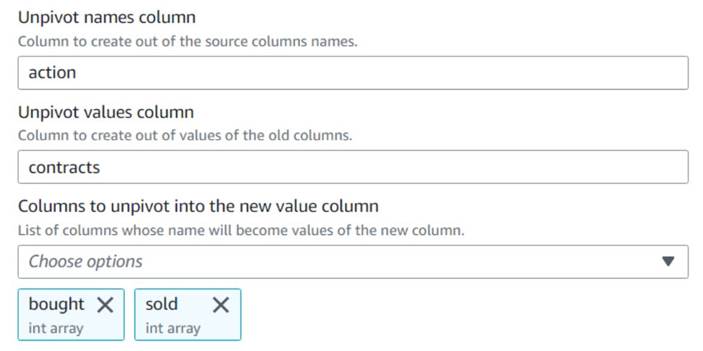
Lägg märke till i förhandsgranskningen att den nya kolumnencontractsär fortfarande en uppsättning siffror efter denna transformation.
- Lägg till en Explodera array eller mappa i rader rad namngiven
Explode contracts. - Välj
contractskolumn och skriv incontractssom den nya kolumnen för att åsidosätta den (vi behöver inte behålla den ursprungliga arrayen).
Förhandsgranskningen visar nu att varje rad har en singel contracts mängd, och resten av fälten är desamma.
Detta betyder också det order_id är inte längre en unik nyckel. För dina egna användningsfall måste du bestämma hur du ska modellera dina data och om du vill avnormalisera eller inte.
Följande skärmdump är ett exempel på hur de nya kolumnerna ser ut efter transformationerna hittills.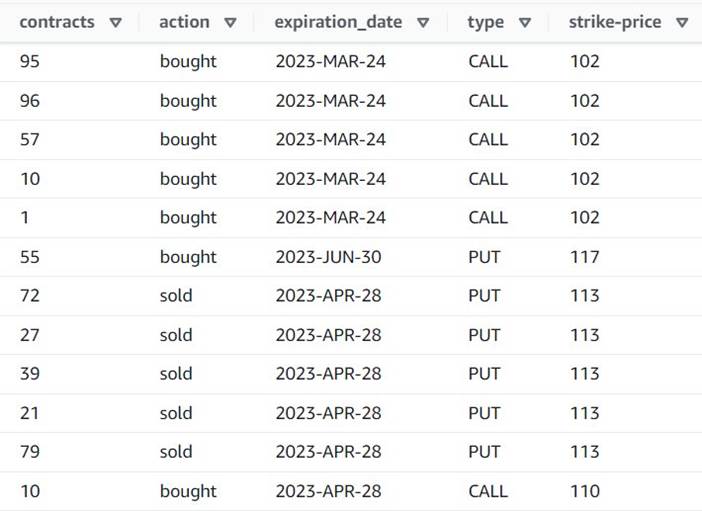
Skapa en sammanfattningstabell
Nu skapar du en sammanfattningstabell med antalet handlade kontrakt för varje typ och varje aktiesymbol.
Låt oss i illustrationssyfte anta att filerna som behandlas tillhör en enskild dag, så denna sammanfattning ger affärsanvändarna information om vad marknadsintresset och sentimentet är den dagen.
- Lägg till Välj fält nod och välj följande kolumner att behålla för sammanfattningen:
symbol,typeochcontracts.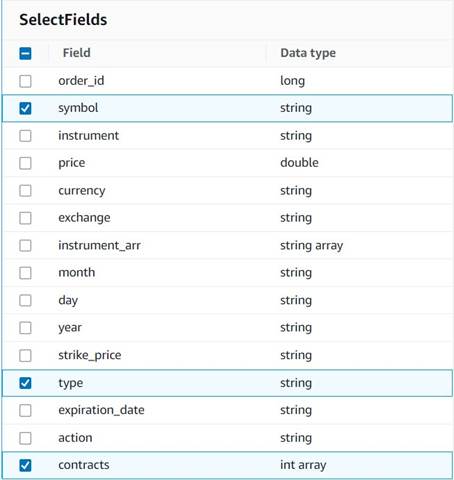
- Lägg till Pivotera rader till kolumner nod och namnge den
Pivot summary. - Aggregera på
contractskolumn medsumoch väljer att konverteratypekolonn.
Normalt skulle du lagra det på någon extern databas eller fil för referens; i det här exemplet sparar vi den som en CSV-fil på Amazon S3.
- Lägg till en Autobalansering nod och namnge den
Single output file. - Även om den transformeringstypen normalt används för att optimera parallelliteten, använder vi den här för att reducera utdata till en enda fil. Ange därför
1i antal partitionskonfigurationer.
- Lägg till ett S3-mål och namnge det
CSV Contract summary. - Välj CSV som dataformat och ange en S3-sökväg där jobbrollen tillåts lagra filer.
Den sista delen av jobbet ska nu se ut som i följande exempel.![]()
- Spara och kör jobbet. Använd Körs fliken för att kontrollera när den är klar.
Du hittar en fil under den sökvägen som är en CSV, trots att den inte har det tillägget. Du måste förmodligen lägga till tillägget efter att du har laddat ner det för att öppna det.
På ett verktyg som kan läsa CSV:en bör sammanfattningen se ut ungefär som följande exempel.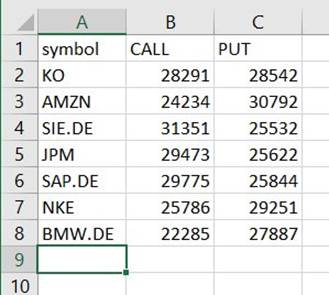
Rensa upp tillfälliga kolumner
Som förberedelse för att spara beställningarna i en historisk tabell för framtida analys, låt oss rensa upp några tillfälliga kolumner som skapats längs vägen.
- Lägg till Släpp fält nod med
Explode contractsnod vald som sin förälder (vi förgrenar datapipelinen för att generera en separat utdata). - Välj de fält som ska tas bort:
instrument_arr,month,dayochyear.
Resten vill vi behålla så att de sparas i den historiska tabellen som vi skapar senare.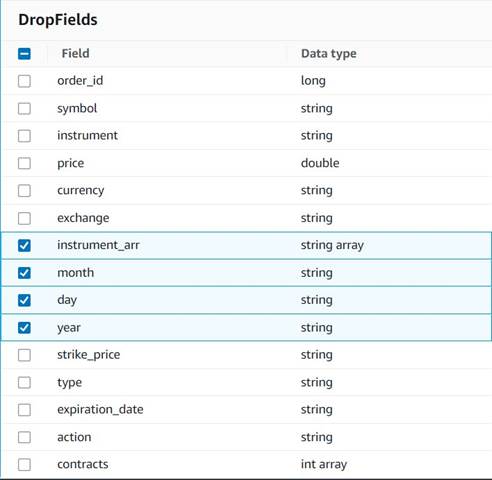
Standardisering av valuta
Denna syntetiska data innehåller fiktiva operationer på två valutor, men i ett riktigt system kan du få valutor från marknader över hela världen. Det är användbart att standardisera de valutor som hanteras till en enda referensvaluta så att de enkelt kan jämföras och aggregeras för rapportering och analys.
Vi använder Amazonas Athena att simulera en tabell med ungefärliga valutaomvandlingar som uppdateras med jämna mellanrum (här antar vi att vi behandlar beställningarna i tid nog att omvandlingen är en rimlig representation för jämförelsesyften).
- Öppna Athena-konsolen i samma region där du använder AWS Glue.
- Kör följande fråga för att skapa tabellen genom att ställa in en S3-plats där både dina Athena- och AWS Glue-roller kan läsa och skriva. Du kanske också vill lagra tabellen i en annan databas än
default(om du gör det, uppdatera det tabellkvalificerade namnet i enlighet med exemplen). - Ange några exempel på konverteringar i tabellen:
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - Du bör nu kunna se tabellen med följande fråga:
SELECT * FROM default.exchange_rates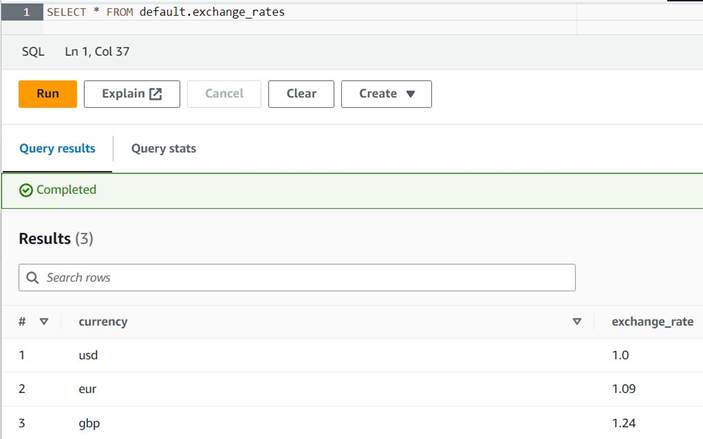
- Tillbaka på AWS Glue visuella jobb, lägg till en Lookup nod (som ett barn till
Drop Fields) och namnge detExchange rate. - Ange det kvalificerade namnet på tabellen du just skapade med
currencysom tangent och väljexchange_ratefält att använda.
Eftersom fältet heter samma namn i både data och uppslagstabell kan vi bara ange namnetcurrencyoch behöver inte definiera en mappning.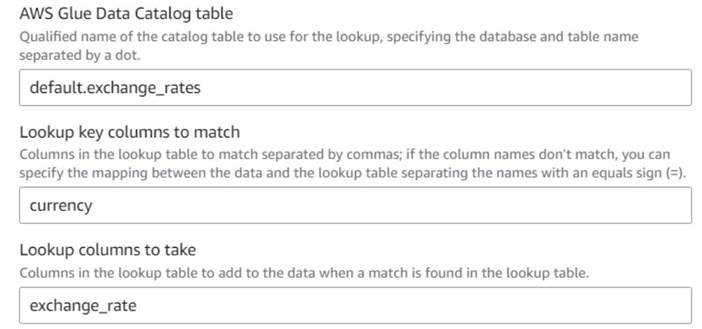
När detta skrivs stöds inte Lookup-transformen i dataförhandsgranskningen och den kommer att visa ett felmeddelande om att tabellen inte existerar. Detta är endast för förhandsgranskningen av data och hindrar inte jobbet från att köras korrekt. De få återstående stegen i inlägget kräver inte att du uppdaterar schemat. Om du behöver köra en dataförhandsgranskning på andra noder kan du ta bort uppslagsnoden tillfälligt och sedan lägga tillbaka den. - Lägg till Härledd kolumn nod och namnge den
Total in usd. - Namnge den härledda kolumnen
total_usdoch använd följande SQL-uttryck:round(contracts * price * exchange_rate, 2)
- Lägg till Lägg till aktuell tidsstämpel nod och namnge kolumnen
ingest_date. - Använd formatet
%Y-%m-%dför din tidsstämpel (i demonstrationssyfte använder vi bara datumet; du kan göra det mer exakt om du vill).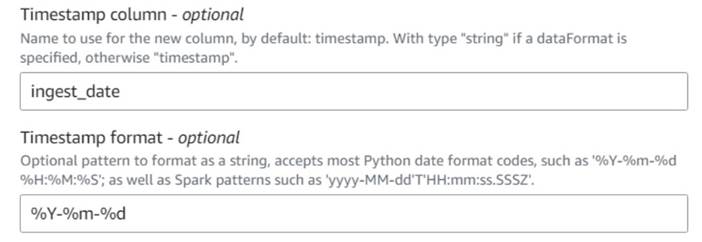
Spara den historiska ordertabellen
För att spara den historiska ordertabellen, utför följande steg:
- Lägg till en S3-målnod och namnge den
Orders table. - Konfigurera Parkettformat med snabb komprimering och tillhandahåll en S3-målväg under vilken du kan lagra resultaten (separat från sammanfattningen).
- Välja Skapa en tabell i datakatalogen och vid efterföljande körningar, uppdatera schemat och lägg till nya partitioner.
- Ange en måldatabas och ett namn för den nya tabellen, till exempel:
option_orders.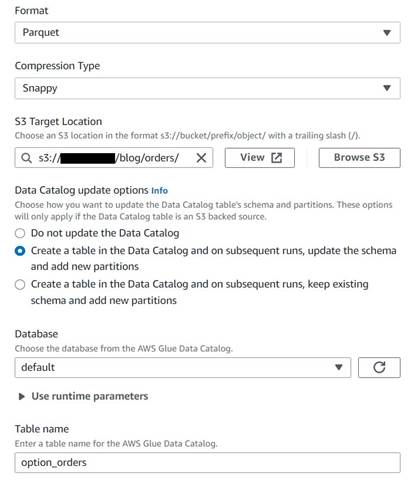
Den sista delen av diagrammet bör nu se ut som följande, med två grenar för de två separata utgångarna.![]()
När du har kört jobbet framgångsrikt kan du använda ett verktyg som Athena för att granska data som jobbet har producerat genom att fråga den nya tabellen. Du kan hitta tabellen på Athena-listan och välja Förhandsgranska tabellen eller kör bara en SELECT-fråga (uppdatera tabellnamnet till namnet och katalogen du använde):
SELECT * FROM default.option_orders limit 10
Ditt tabellinnehåll bör se ut som på följande skärmdump.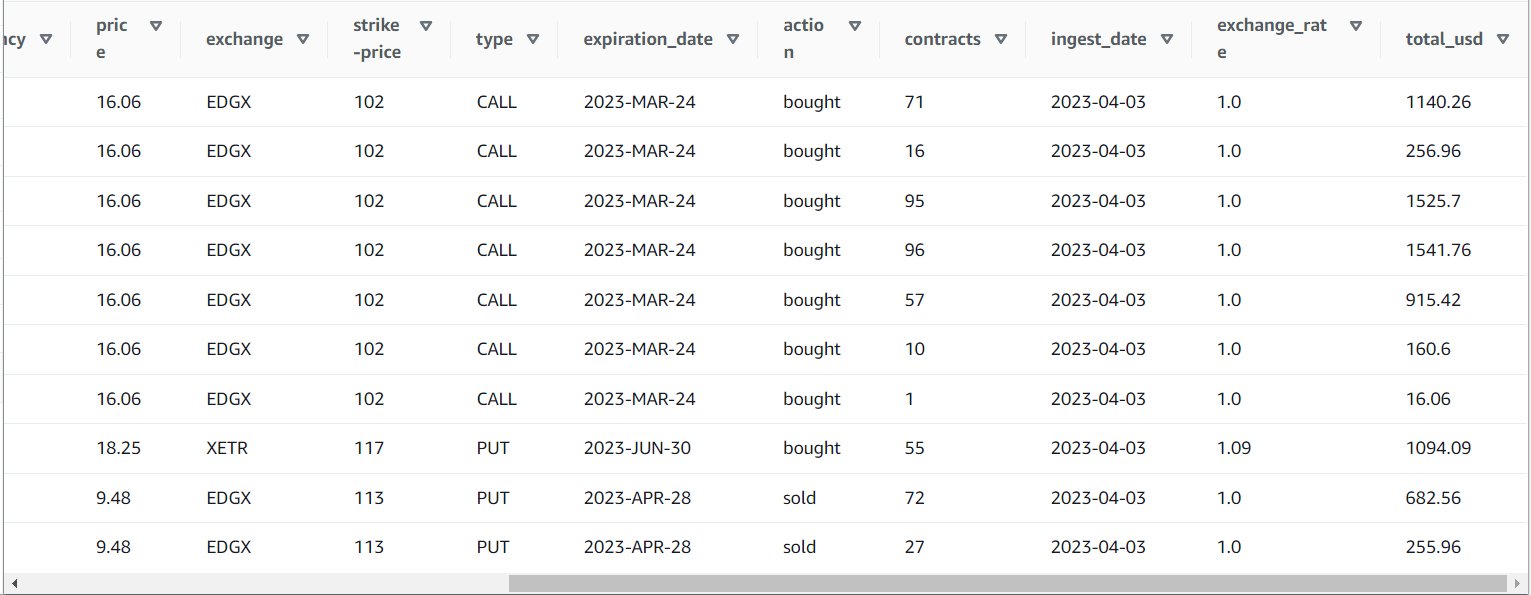
Städa upp
Om du inte vill behålla det här exemplet, radera de två jobben du skapade, de två tabellerna i Athena och S3-vägarna där in- och utdatafilerna lagrades.
Slutsats
I det här inlägget visade vi hur de nya transformationerna i AWS Glue Studio kan hjälpa dig att göra mer avancerad transformation med minimal konfiguration. Detta innebär att du kan implementera fler ETL-användningsfall utan att behöva skriva och underhålla någon kod. De nya transformationerna är redan tillgängliga på AWS Glue Studio, så du kan använda de nya transformationerna idag i dina visuella jobb.
Om författaren
![]() Gonzalo herreros är Senior Big Data Architect på AWS Glue-teamet.
Gonzalo herreros är Senior Big Data Architect på AWS Glue-teamet.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Minting the Future med Adryenn Ashley. Tillgång här.
- Köp och sälj aktier i PRE-IPO-företag med PREIPO®. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/
- : har
- :är
- :inte
- :var
- $UPP
- 000
- 1
- 10
- 100
- 102
- 11
- 12
- 13
- 14
- 15%
- 20
- 23
- 24
- 26
- 28
- 30
- 49
- 67
- 7
- 8
- 9
- 937
- 98
- a
- Able
- Om oss
- godtagbart
- tillgång
- i enlighet med detta
- lägga till
- lagt till
- tillsats
- avancerat
- Efter
- Alla
- allokeras
- tilldelningar
- tillåter
- tillåter
- längs
- redan
- också
- alltid
- amason
- mängd
- mängder
- an
- analys
- analysera
- och
- Annan
- vilken som helst
- tillämpas
- ungefärlig
- april
- ÄR
- Argumentet
- array
- AS
- delad
- At
- attribut
- automatiskt
- tillgänglig
- AWS
- AWS-lim
- tillbaka
- baserat
- BE
- innan
- Där vi får lov att vara utan att konstant prestera,
- Stor
- Stora data
- blank
- BMW
- båda
- köpt
- grenar
- SLUTRESULTAT
- företag
- men
- Köp
- by
- Ring
- KAN
- Vid
- fall
- katalog
- Centrum
- Århundrade
- Förändringar
- egenskaper
- ta
- barn
- Välja
- välja
- klarare
- koda
- Kodning
- Kolumn
- Kolonner
- Gemensam
- jämfört
- jämförelse
- fullborda
- Avslutade
- konfiguration
- Konsol
- konsolidera
- innehåller
- innehåll
- kontrakt
- kontrakt
- bekvämlighet
- Konvertering
- omvandlingar
- konvertera
- konverterad
- FÖRETAG
- kunde
- skapa
- skapas
- Skapa
- valutor
- Valuta
- Aktuella
- DAG
- datum
- Databas
- Datum
- Datum
- datum Tid
- dag
- behandla
- som handlar om
- beslutar
- Standard
- definierade
- demonstreras
- Dependency
- Härledd
- Trots
- detaljer
- olika
- siffror
- diskutera
- do
- inte
- gör
- dollar
- inte
- dubbla
- ner
- Drop
- tappade
- varje
- lättare
- lätt
- lätt
- redaktör
- möjliggöra
- tillräckligt
- ange
- Miljö
- fel
- Eter (ETH)
- EUR
- exempel
- exempel
- Utom
- utbyta
- Utbyten
- Exklusiv
- existerar
- Bygga ut
- förväntat
- experimentera
- utgångs
- uttryckt
- förlängning
- extern
- extra
- extrahera
- långt
- rädsla
- få
- fiktiva
- fält
- Fält
- Fil
- Filer
- fylla
- fyllda
- finansiella
- Finansiella instrument
- hitta
- Förnamn
- fixerad
- flexibel
- följer
- efter
- följer
- För
- format
- hittade
- från
- framtida
- GBP
- Allmänt
- allmänhet
- generera
- genereras
- skaffa sig
- Ge
- ger
- Go
- diagram
- Girighet
- Arbetsmiljö
- händer
- Har
- har
- hjälpa
- här.
- historisk
- historia
- Hur ser din drömresa ut
- How To
- html
- http
- HTTPS
- Människa
- i
- identifierar
- identifiera
- if
- Inverkan
- genomföra
- importera
- in
- index
- indikerade
- pekar på
- indikerar
- indikation
- individuellt
- informationen
- ingång
- exempel
- istället
- instruktioner
- Instrumentet
- instrument
- intresse
- Gränssnitt
- in
- ISO
- IT
- DESS
- Jobb
- Lediga jobb
- jpg
- json
- bara
- Ha kvar
- Nyckel
- Snäll
- Efternamn
- senare
- tycka om
- BEGRÄNSA
- linje
- Likviditet
- Lista
- läsa in
- läge
- längre
- se
- ser ut som
- UTSEENDE
- slå upp
- förlorar
- förlora
- gjord
- bibehålla
- göra
- GÖR
- manuellt
- karta
- kartläggning
- marknad
- marknadssentiment
- Marknader
- Maj..
- betyder
- Sammanfoga
- meddelande
- kanske
- minsta
- saknas
- modell
- Övervaka
- mer
- mest
- multipel
- ömsesidigt
- namn
- Som heter
- namn
- Behöver
- behov
- Nya
- Nej
- nod
- noder
- normalt
- nu
- antal
- nummer
- objektet
- of
- Ofta
- on
- ONE
- endast
- öppet
- drift
- Verksamhet
- Optimera
- Alternativet
- Tillbehör
- or
- beställa
- ordrar
- ursprungliga
- Övriga
- annat
- produktion
- över
- övergripande
- åsidosätta
- egen
- betalas
- panelen
- parameter
- del
- bana
- Picks
- rörledning
- pivot
- Plats
- plato
- Platon Data Intelligence
- PlatonData
- Inlägg
- potentiell
- Praktisk
- exakt
- förhindra
- Förhandsvisning
- pris
- förmodligen
- process
- bearbetning
- producera
- producerad
- ge
- förutsatt
- ger
- inköp
- Syftet
- syfte
- sätta
- Python
- kvalificerad
- höja
- slumpmässig
- Läsa
- verklig
- rimlig
- minska
- reflektera
- region
- Återstående
- ta bort
- replikeras
- Rapportering
- representerar
- representativ
- representerar
- representerar
- kräver
- Krav
- Kräver
- respektive
- REST
- resulterande
- Resultat
- översyn
- Roll
- roller
- RAD
- Körning
- rinnande
- säkrare
- Samma
- SAP
- Save
- sparande
- rulla
- sekunder
- vald
- väljer
- sälja
- senior
- känsla
- separat
- session
- uppsättningar
- inställning
- aktier
- Shell
- skall
- show
- Visar
- liknande
- Enkelt
- enda
- Storlek
- färdigheter
- Small
- So
- än så länge
- säljs
- några
- något
- Källa
- Utrymme
- utrymmen
- specifik
- specificerade
- delas
- kalkylblad
- SQL
- starta
- Steg
- Fortfarande
- lager
- förvaring
- lagra
- lagras
- Sträng
- studio
- senare
- Framgångsrikt
- lämplig
- SAMMANFATTNING
- Som stöds
- Symbolen
- syntetisk
- syntetiska data
- syntetiskt
- system
- System
- bord
- Ta
- Målet
- grupp
- tala
- temporär
- tio
- testa
- än
- den där
- Smakämnen
- Grafen
- den information
- världen
- Dem
- sedan
- därför
- Dessa
- de
- detta
- de
- tid
- gånger
- tidsstämpel
- till
- i dag
- token
- symbolisera
- tog
- verktyg
- Totalt
- handla
- handlas
- Förvandla
- Transformation
- transformationer
- transformerad
- två
- Typ
- under
- underliggande
- förstå
- unika
- tills
- Uppdatering
- uppdaterad
- uppdatering
- URL
- us
- Kronor
- USD
- användning
- användningsfall
- Begagnade
- Användare
- användare
- med hjälp av
- Värdefulla
- Värdefull information
- värde
- Värden
- Mötesplats
- verifierade
- verifiera
- utsikt
- synlig
- volym
- vs
- vänta
- vill
- var
- Sätt..
- we
- były
- Vad
- när
- som
- medan
- kommer
- med
- utan
- arbetsflöden
- arbetssätt
- världen
- skulle
- skriva
- skrivning
- år
- dig
- Din
- zephyrnet











