Med tillkomsten av generativ AI kan dagens grundmodeller (FM), som de stora språkmodellerna (LLM) Claude 2 och Llama 2, utföra en rad generativa uppgifter som att svara på frågor, sammanfatta och skapa innehåll på textdata. Men verklig data finns i flera modaliteter, såsom text, bilder, video och ljud. Ta till exempel ett PowerPoint-bildspel. Den kan innehålla information i form av text eller inbäddad i grafer, tabeller och bilder.
I det här inlägget presenterar vi en lösning som använder multimodala FM:er som Amazon Titan multimodala inbäddningar modell och LLaVA 1.5 och AWS-tjänster inklusive Amazonas berggrund och Amazon SageMaker att utföra liknande generativa uppgifter på multimodala data.
Lösningsöversikt
Lösningen tillhandahåller en implementering för att svara på frågor med hjälp av information som finns i texten och visuella element i ett bildspel. Designen bygger på konceptet Retrieval Augmented Generation (RAG). Traditionellt har RAG associerats med textdata som kan bearbetas av LLM:er. I det här inlägget utökar vi RAG till att även inkludera bilder. Detta ger en kraftfull sökfunktion för att extrahera kontextuellt relevant innehåll från visuella element som tabeller och diagram tillsammans med text.
Det finns olika sätt att designa en RAG-lösning som innehåller bilder. Vi har presenterat ett tillvägagångssätt här och kommer att följa upp med ett alternativt tillvägagångssätt i det andra inlägget i denna tredelade serie.
Denna lösning innehåller följande komponenter:
- Amazon Titan Multimodal Embeddings modell – Denna FM används för att generera inbäddningar för innehållet i bildspelet som används i det här inlägget. Som en multimodal modell kan denna Titan-modell bearbeta text, bilder eller en kombination som input och generera inbäddningar. Titan Multimodal Embeddings-modellen genererar vektorer (inbäddningar) med 1,024 XNUMX dimensioner och nås via Amazon Bedrock.
- Stor språk- och synassistent (LLaVA) – LLaVA är en multimodal modell med öppen källkod för visuell och språkförståelse och används för att tolka data i bilderna, inklusive visuella element som grafer och tabeller. Vi använder 7-miljarder parameterversionen LLaVA 1.5-7b i denna lösning.
- Amazon SageMaker – LLaVA-modellen distribueras på en SageMaker-slutpunkt med SageMaker-värdtjänster, och vi använder den resulterande slutpunkten för att köra slutsatser mot LLaVA-modellen. Vi använder även SageMaker-anteckningsböcker för att orkestrera och demonstrera denna lösning från början.
- Amazon OpenSearch Serverlös – OpenSearch Serverless är en on-demand serverlös konfiguration för Amazon OpenSearch Service. Vi använder OpenSearch Serverless som en vektordatabas för att lagra inbäddningar genererade av Titan Multimodal Embeddings-modellen. Ett index skapat i OpenSearch Serverless-samlingen fungerar som vektorlager för vår RAG-lösning.
- Amazon OpenSearch Ingestion (OSI) – OSI är en helt hanterad, serverlös datainsamlare som levererar data till OpenSearch Service-domäner och OpenSearch Serverless-samlingar. I det här inlägget använder vi en OSI-pipeline för att leverera data till OpenSearch Serverless vektorlager.
Lösningsarkitektur
Lösningsdesignen består av två delar: intag och användarinteraktion. Under intag bearbetar vi inmatningsbildspelet genom att konvertera varje bild till en bild, genererar inbäddningar för dessa bilder och fyller sedan i vektordatalagret. Dessa steg slutförs före stegen för användarinteraktion.
I användarinteraktionsfasen konverteras en fråga från användaren till inbäddningar och en likhetssökning körs på vektordatabasen för att hitta en bild som potentiellt kan innehålla svar på användarens fråga. Vi tillhandahåller sedan denna bild (i form av en bildfil) till LLaVA-modellen och användarfrågan som en uppmaning för att generera ett svar på frågan. All kod för detta inlägg finns tillgänglig i GitHub repa.
Följande diagram illustrerar intagsarkitekturen.
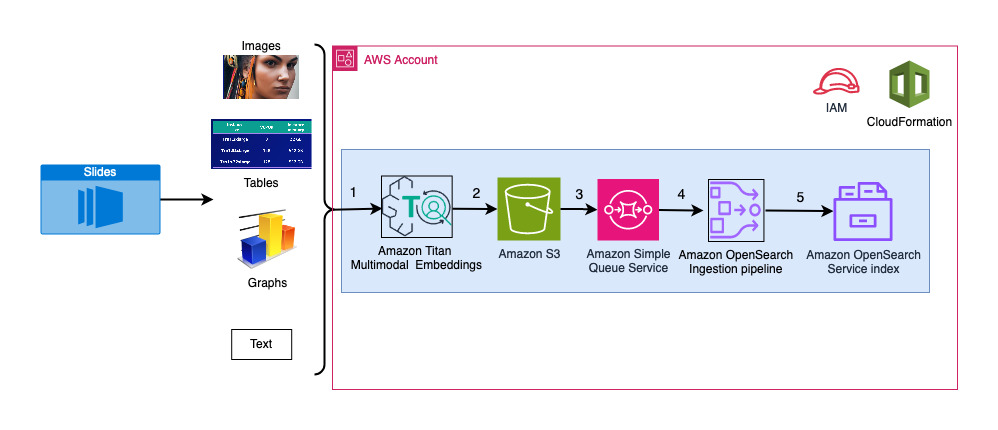
Arbetsflödesstegen är följande:
- Slides konverteras till bildfiler (en per bild) i JPG-format och skickas till Titan Multimodal Embeddings-modellen för att generera inbäddningar. I det här inlägget använder vi bildspelet med titeln Träna och distribuera Stabil Diffusion med AWS Trainium & AWS Inferentia från AWS Summit i Toronto, juni 2023, för att demonstrera lösningen. Provdäcket har 31 bilder, så vi genererar 31 uppsättningar av vektorinbäddningar, var och en med 1,024 XNUMX dimensioner. Vi lägger till ytterligare metadatafält till dessa genererade vektorinbäddningar och skapar en JSON-fil. Dessa ytterligare metadatafält kan användas för att utföra omfattande sökfrågor med OpenSearchs kraftfulla sökfunktioner.
- De genererade inbäddningarna sätts ihop i en enda JSON-fil som laddas upp till Amazon enkel lagringstjänst (Amazon S3).
- Via Amazon S3-händelsemeddelanden, en händelse läggs i en Amazon enkel kötjänst (Amazon SQS) kö.
- Denna händelse i SQS-kön fungerar som en trigger för att köra OSI-pipeline, som i sin tur matar in data (JSON-fil) som dokument till OpenSearch Serverless-index. Observera att OpenSearch Serverless-index är konfigurerat som sink för denna pipeline och skapas som en del av OpenSearch Serverless-samlingen.
Följande diagram illustrerar arkitekturen för användarinteraktion.
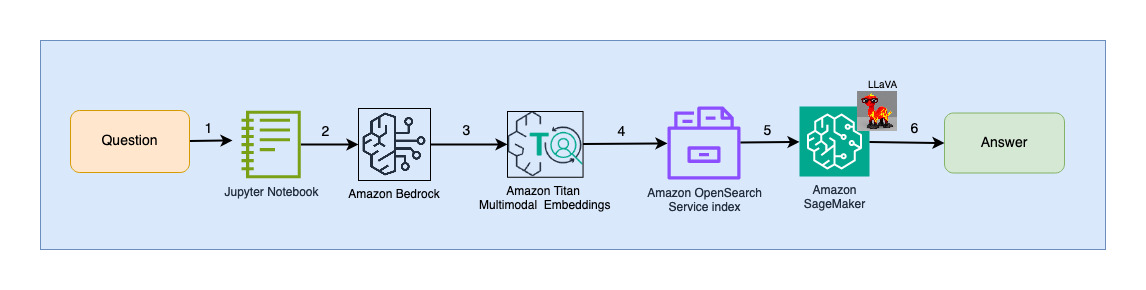
Arbetsflödesstegen är följande:
- En användare skickar en fråga relaterad till bildspelet som har tagits in.
- Användarinmatningen konverteras till inbäddningar med Titan Multimodal Embeddings-modellen som nås via Amazon Bedrock. En OpenSearch-vektorsökning utförs med dessa inbäddningar. Vi utför en k-närmaste granne (k=1) sökning för att hämta den mest relevanta inbäddningen som matchar användarens fråga. Inställningen k=1 hämtar den mest relevanta bilden till användarfrågan.
- Metadata för svaret från OpenSearch Serverless innehåller en sökväg till bilden som motsvarar den mest relevanta bilden.
- En prompt skapas genom att kombinera användarfrågan och bildsökvägen och tillhandahålls till LLaVA på SageMaker. LLaVA-modellen kan förstå användarfrågan och svara på den genom att undersöka data i bilden.
- Resultatet av denna slutledning returneras till användaren.
Dessa steg diskuteras i detalj i följande avsnitt. Se den Resultat avsnitt för skärmdumpar och detaljer om utgången.
Förutsättningar
För att implementera lösningen som tillhandahålls i det här inlägget bör du ha en AWS-konto och förtrogenhet med FMs, Amazon Bedrock, SageMaker och OpenSearch Service.
Denna lösning använder Titan Multimodal Embeddings-modellen. Se till att denna modell är aktiverad för användning i Amazon Bedrock. Välj på Amazon Bedrock-konsolen Modellåtkomst i navigeringsfönstret. Om Titan Multimodal Embeddings är aktiverat kommer åtkomststatus att anges Tillgång beviljad.
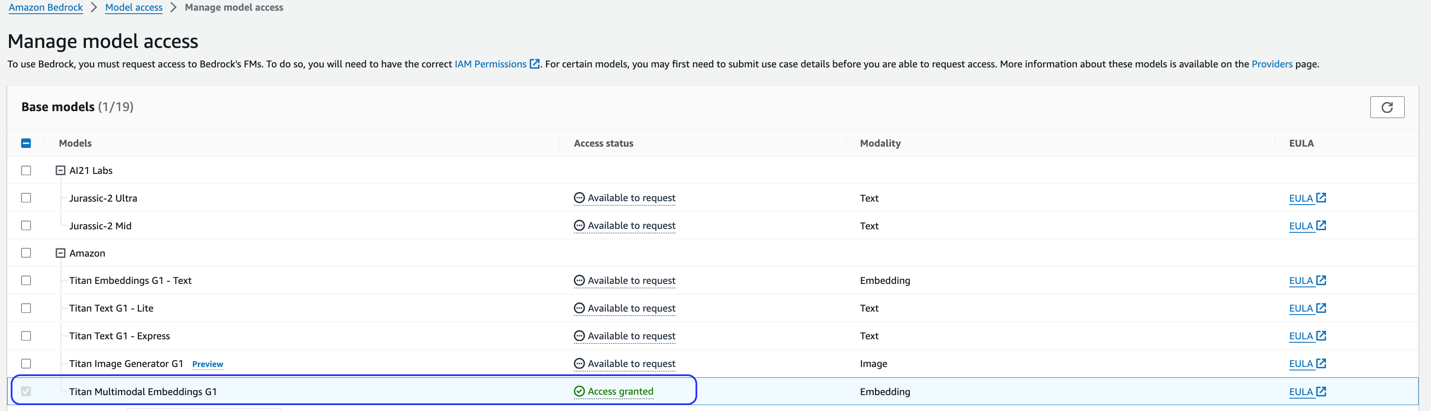
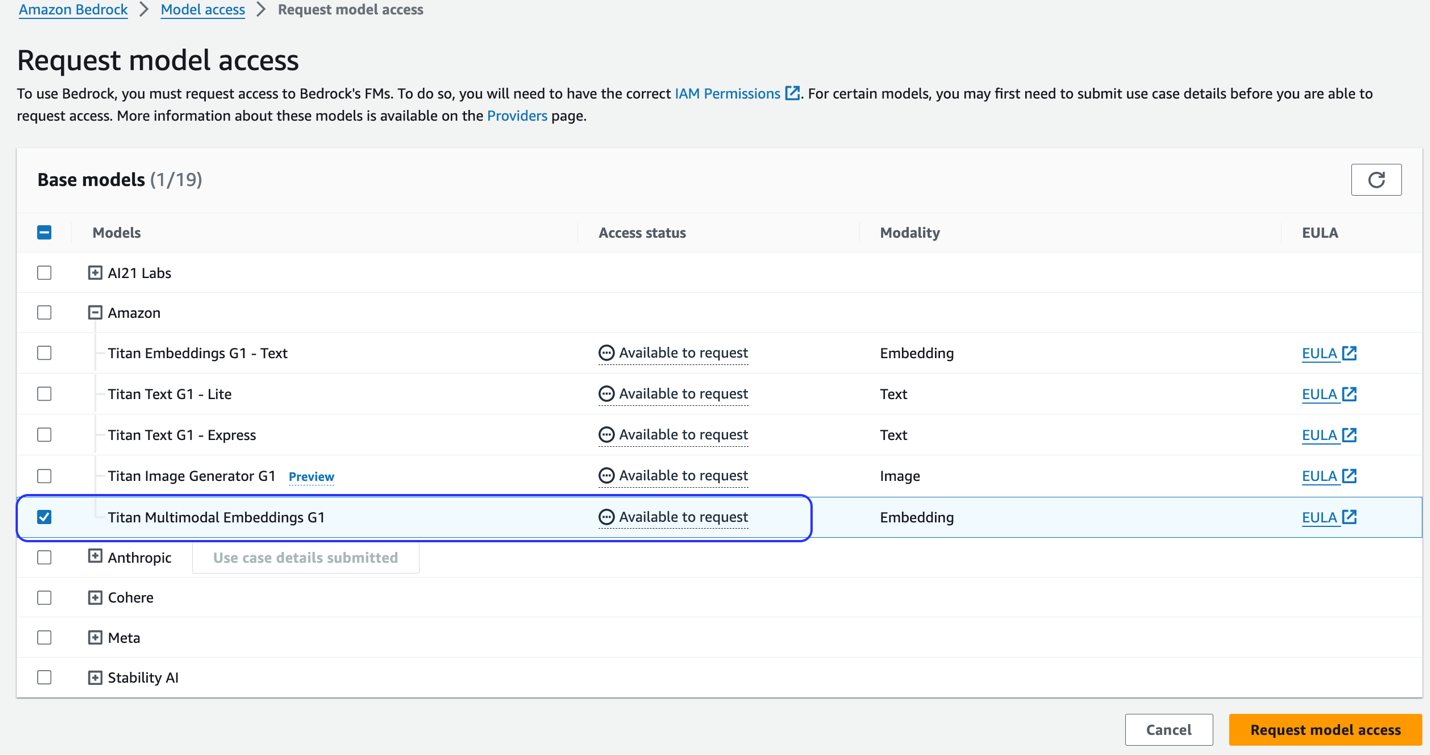
Om modellen inte är tillgänglig, aktivera åtkomst till modellen genom att välja Hantera modellåtkomst, väljer Titan Multimodal Embeddings G1, och välja Begär modellåtkomst. Modellen är aktiverad för användning omedelbart.
Använd en AWS CloudFormation-mall för att skapa lösningsstacken
Använd något av följande AWS molnformation mallar (beroende på din region) för att lansera lösningsresurserna.
| AWS-regionen | Länk |
|---|---|
us-east-1 |
|
us-west-2 |
När stacken har skapats framgångsrikt, navigera till stackens Utgångarna fliken på AWS CloudFormation-konsolen och notera värdet för MultimodalCollectionEndpoint, som vi använder i efterföljande steg.
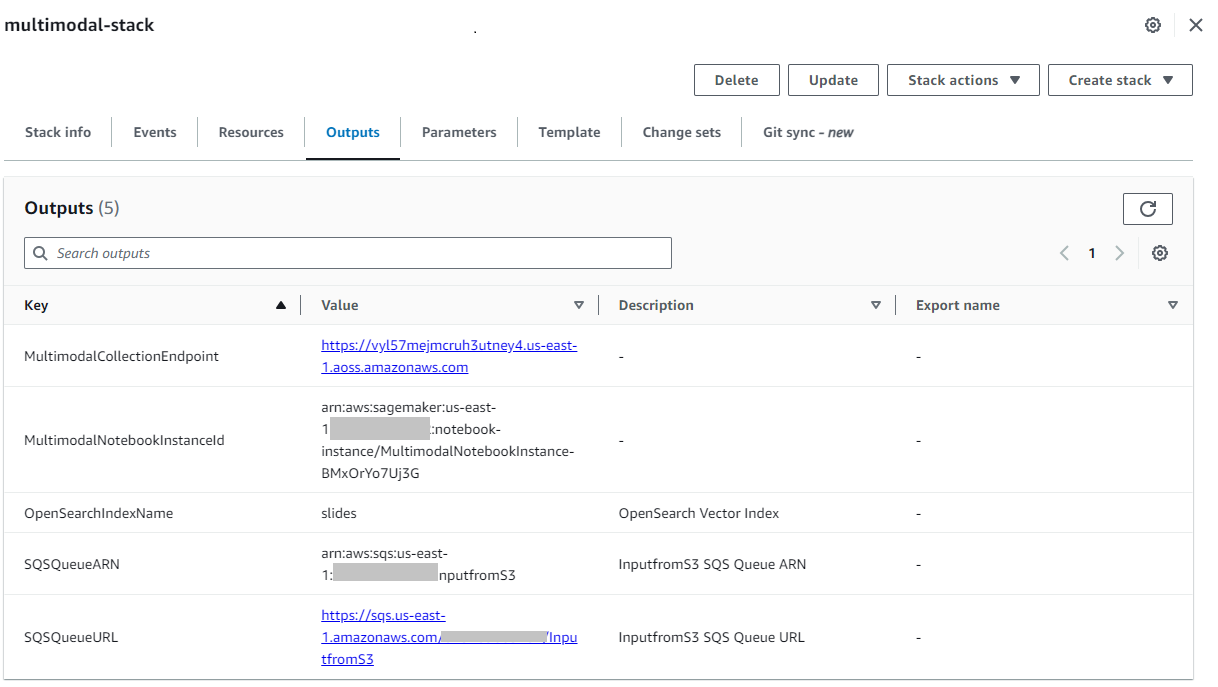
CloudFormation-mallen skapar följande resurser:
- IAM-roller - Det följande AWS identitets- och åtkomsthantering (IAM)-roller skapas. Uppdatera dessa roller för att ansöka minsta behörigheter.
SMExecutionRolemed Amazon S3, SageMaker, OpenSearch Service och Bedrock full åtkomst.OSPipelineExecutionRolemed tillgång till specifika Amazon SQS och OSI-åtgärder.
- SageMaker anteckningsbok – All kod för det här inlägget körs via den här anteckningsboken.
- OpenSearch Serverlös samling – Det här är vektordatabasen för att lagra och hämta inbäddningar.
- OSI pipeline – Det här är pipelinen för att mata in data till OpenSearch Serverless.
- S3 hink – All data för detta inlägg lagras i denna hink.
- SQS-kö – Händelserna för att trigga OSI-pipelinekörningen placeras i denna kö.
CloudFormation-mallen konfigurerar OSI-pipeline med Amazon S3 och Amazon SQS-bearbetning som källa och ett OpenSearch Serverless-index som sink. Alla objekt som skapats i den angivna S3-hinken och prefixet (multimodal/osi-embeddings-json) kommer att utlösa SQS-meddelanden, som används av OSI-pipeline för att mata in data till OpenSearch Serverless.
CloudFormation-mallen skapar också nät, krypteringoch datatillgång policyer som krävs för OpenSearch Serverless-samlingen. Uppdatera dessa policyer för att tillämpa minsta behörigheter.
Observera att CloudFormations mallnamn hänvisas till i SageMakers anteckningsböcker. Om standardmallnamnet ändras, se till att du uppdaterar detsamma i globals.py
Testa lösningen
När de nödvändiga stegen är klara och CloudFormation-stacken har skapats framgångsrikt är du nu redo att testa lösningen:
- Välj på SageMaker-konsolen bärbara datorer i navigeringsfönstret.
- Välj
MultimodalNotebookInstanceanteckningsbok instans och välj Öppna JupyterLab.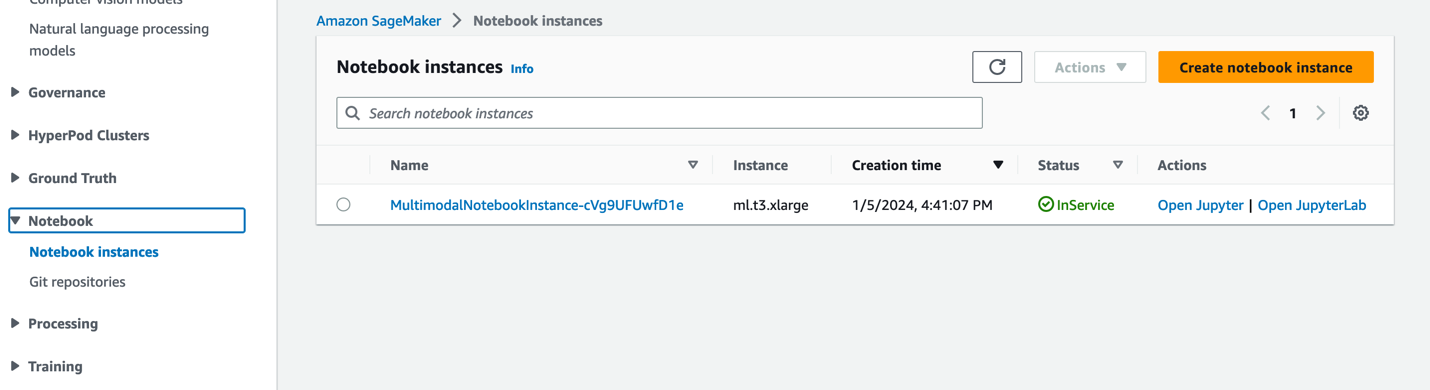
- In File Browser, gå till mappen anteckningsböcker för att se anteckningsböckerna och stödfilerna.
Anteckningsböckerna numreras i den ordning de körs. Instruktioner och kommentarer i varje anteckningsbok beskriver de åtgärder som utförs av den anteckningsboken. Vi kör dessa anteckningsböcker en efter en.
- Välja 0_deploy_llava.ipynb för att öppna den i JupyterLab.
- På Körning meny, välj Kör alla celler för att köra koden i den här anteckningsboken.
Den här bärbara datorn distribuerar LLaVA-v1.5-7B-modellen till en SageMaker-slutpunkt. I den här anteckningsboken laddar vi ner LLaVA-v1.5-7B-modellen från HuggingFace Hub, ersätter inference.py-skriptet med llava_inference.py, och skapa en model.tar.gz-fil för denna modell. Filen model.tar.gz laddas upp till Amazon S3 och används för att distribuera modellen på SageMaker-slutpunkten. De llava_inference.py skriptet har ytterligare kod för att tillåta att läsa en bildfil från Amazon S3 och köra slutledning om den.
- Välja 1_data_prep.ipynb för att öppna den i JupyterLab.
- På Körning meny, välj Kör alla celler för att köra koden i den här anteckningsboken.
Den här anteckningsboken laddar ner skjutdäck, konverterar varje bild till JPG-filformat och laddar upp dessa till S3-hinken som används för det här inlägget.
- Välja 2_data_ingestion.ipynb för att öppna den i JupyterLab.
- På Körning meny, välj Kör alla celler för att köra koden i den här anteckningsboken.
Vi gör följande i den här anteckningsboken:
- Vi skapar ett index i OpenSearch Serverless-samlingen. Detta index lagrar inbäddningsdata för bildspelet. Se följande kod:
- Vi använder Titan Multimodal Embeddings-modell för att konvertera JPG-bilderna som skapats i föregående anteckningsbok till vektorinbäddningar. Dessa inbäddningar och ytterligare metadata (som bildfilens S3-sökväg) lagras i en JSON-fil och laddas upp till Amazon S3. Observera att en enda JSON-fil skapas, som innehåller dokument för alla bilder (bilder) som konverterats till inbäddningar. Följande kodsnutt visar hur en bild (i form av en Base64-kodad sträng) konverteras till inbäddningar:
- Den här åtgärden utlöser OpenSearch Ingestion-pipeline, som bearbetar filen och matar in den i OpenSearch Serverless-index. Följande är ett exempel på den skapade JSON-filen. (En vektor med fyra dimensioner visas i exempelkoden. Titan Multimodal Embeddings-modellen genererar 1,024 XNUMX dimensioner.)
- Välja 3_rag_inference.ipynb för att öppna den i JupyterLab.
- På Körning meny, välj Kör alla celler för att köra koden i den här anteckningsboken.
Den här anteckningsboken implementerar RAG-lösningen: vi konverterar användarfrågan till inbäddningar, hittar en liknande bild (slide) från vektordatabasen och tillhandahåller den hämtade bilden till LLaVA för att generera ett svar på användarfrågan. Vi använder följande promptmall:
Följande kodavsnitt tillhandahåller RAG-arbetsflödet:
Resultat
Följande är en sammanställning av några användarfrågor och svar som genererats av vår implementering. De Fråga kolumnen fångar användarfrågan och Svar kolumn är textsvaret som genereras av LLaVA. Bild är den k-närmaste (k=1) bildmatchningen som returneras av OpenSearch Serverless vektorsökning. Denna bild tolkas av LLaVA för att ge svaret.
Multimodala RAG-resultat
| Fråga | Svar | Bild |
|---|---|---|
| Hur jämförs Inf2 i prestanda med jämförbara EC2-instanser? Jag behöver siffror. | Enligt bildspelet erbjuder Inf2-instanser av AWS Inferentia2 upp till 4x högre genomströmning och 10x lägre latens jämfört med jämförbara EC2-instanser. |  |
| Enligt AI/ML-svänghjulet, vad tillhandahåller AWS AI/ML-tjänsterna? | AWS AI/ML-tjänster ger bättre $/perfer-kapacitet, nya möjligheter och investeringar i innovation. | 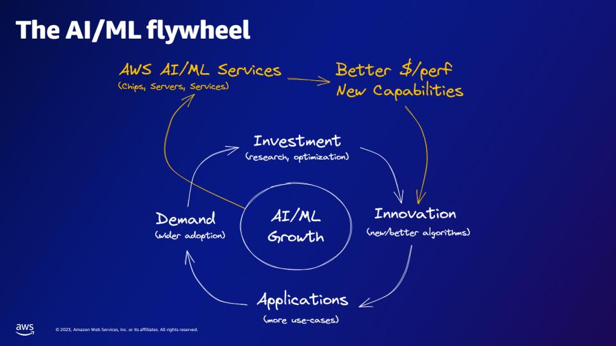 |
| Jämfört med GPT-2, hur många fler parametrar har GPT-3? Vad är den numeriska skillnaden mellan parameterstorleken för GPT-2 och GPT-3? | Enligt bilden har GPT-3 175 miljarder parametrar, medan GPT-2 har 1.5 miljarder parametrar. Den numeriska skillnaden mellan parameterstorleken för GPT-2 och GPT-3 är 173.5 miljarder. | 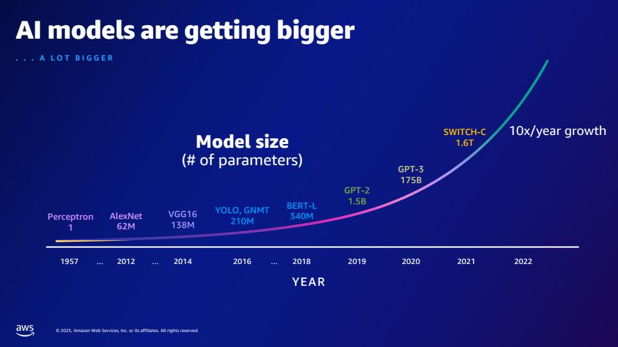 |
| Vad är kvarkar i partikelfysik? | Jag hittade inte svaret på denna fråga i slide-decket. |  |
Utvidga gärna denna lösning till dina rutschbanor. Uppdatera helt enkelt variabeln SLIDE_DECK i globals.py med en URL till ditt bildspel och kör inmatningsstegen som beskrivs i föregående avsnitt.
Tips
Du kan använda OpenSearch Dashboards för att interagera med OpenSearch API för att köra snabba tester på ditt index och intagna data. Följande skärmdump visar ett GET-exempel på OpenSearch-instrumentpanelen.
Städa upp
Ta bort resurserna du skapade för att undvika framtida avgifter. Du kan göra detta genom att ta bort stacken via CloudFormation-konsolen.

Ta dessutom bort SageMaker slutpunkten för slutpunkten som skapats för LLaVA-inferencing. Du kan göra detta genom att avkommentera rensningssteget 3_rag_inference.ipynb och kör cellen, eller genom att ta bort slutpunkten via SageMaker-konsolen: välj Slutledning och endpoints i navigeringsfönstret, välj sedan slutpunkten och ta bort den.
Slutsats
Företag genererar nytt innehåll hela tiden, och bildspel är en vanlig mekanism som används för att dela och sprida information internt med organisationen och externt med kunder eller på konferenser. Med tiden kan rik information förbli begravd och dold i icke-textbaserade modaliteter som grafer och tabeller i dessa bildspel. Du kan använda den här lösningen och kraften i multimodala FM:er som Titan Multimodal Embeddings-modellen och LLaVA för att upptäcka ny information eller avslöja nya perspektiv på innehåll i bildspel.
Vi uppmuntrar dig att lära dig mer genom att utforska Amazon SageMaker JumpStart, Amazon Titan-modeller, Amazon Bedrock och OpenSearch Service, och bygga en lösning med hjälp av exempelimplementeringen i det här inlägget.
Håll utkik efter ytterligare två inlägg som en del av den här serien. Del 2 tar upp ett annat tillvägagångssätt som du kan använda för att prata med din bildlek. Detta tillvägagångssätt genererar och lagrar LLaVA-slutledningar och använder de lagrade slutledningarna för att svara på användarfrågor. Del 3 jämför de två tillvägagångssätten.
Om författarna
 Amit Arora är en AI- och ML-specialistarkitekt på Amazon Web Services, som hjälper företagskunder att använda molnbaserade maskininlärningstjänster för att snabbt skala sina innovationer. Han är också adjungerad lektor i MS datavetenskap och analysprogrammet vid Georgetown University i Washington DC
Amit Arora är en AI- och ML-specialistarkitekt på Amazon Web Services, som hjälper företagskunder att använda molnbaserade maskininlärningstjänster för att snabbt skala sina innovationer. Han är också adjungerad lektor i MS datavetenskap och analysprogrammet vid Georgetown University i Washington DC
 Manju Prasad är Senior Solutions Architect inom Strategic Accounts på Amazon Web Services. Hon fokuserar på att tillhandahålla teknisk vägledning inom en mängd olika domäner, inklusive AI/ML till en marquee M&E-kund. Innan hon började på AWS designade och byggde hon lösningar för företag inom finanssektorn och även för en startup.
Manju Prasad är Senior Solutions Architect inom Strategic Accounts på Amazon Web Services. Hon fokuserar på att tillhandahålla teknisk vägledning inom en mängd olika domäner, inklusive AI/ML till en marquee M&E-kund. Innan hon började på AWS designade och byggde hon lösningar för företag inom finanssektorn och även för en startup.
 Archana Inapudi är Senior Solutions Architect på AWS som stödjer strategiska kunder. Hon har över tio års erfarenhet av att hjälpa kunder att designa och bygga dataanalys- och databaslösningar. Hon brinner för att använda teknik för att ge värde till kunder och uppnå affärsresultat.
Archana Inapudi är Senior Solutions Architect på AWS som stödjer strategiska kunder. Hon har över tio års erfarenhet av att hjälpa kunder att designa och bygga dataanalys- och databaslösningar. Hon brinner för att använda teknik för att ge värde till kunder och uppnå affärsresultat.
 Antara Raisa är en AI och ML Solutions Architect på Amazon Web Services som stödjer strategiska kunder baserade från Dallas, Texas. Hon har också tidigare erfarenhet av att arbeta med stora företagspartners på AWS, där hon arbetat som Partner Success Solutions Architect för digitala inbyggda kunder.
Antara Raisa är en AI och ML Solutions Architect på Amazon Web Services som stödjer strategiska kunder baserade från Dallas, Texas. Hon har också tidigare erfarenhet av att arbeta med stora företagspartners på AWS, där hon arbetat som Partner Success Solutions Architect för digitala inbyggda kunder.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-1/
- : har
- :är
- :inte
- :var
- $UPP
- 1
- 10
- 100
- 13
- 15%
- 16
- 173
- 20
- 2023
- 26
- 29
- 31
- 8
- 9
- a
- Able
- Om Oss
- tillgång
- Accessed
- konton
- Uppnå
- Handling
- åtgärder
- handlingar
- lägga till
- Annat
- tillägg
- första advent
- mot
- AI
- AI / ML
- Alla
- tillåter
- längs
- också
- amason
- Amazon SageMaker
- Amazon Web Services
- an
- analytics
- och
- Annan
- svara
- svar
- svar
- vilken som helst
- api
- Ansök
- tillvägagångssätt
- tillvägagångssätt
- arkitektur
- ÄR
- AS
- be
- Assistent
- associerad
- At
- audio
- augmented
- Auth
- tillgänglig
- undvika
- AWS
- AWS molnformation
- baserat
- BE
- varit
- Bättre
- mellan
- Miljarder
- kropp
- SLUTRESULTAT
- Byggnad
- byggt
- företag
- by
- KAN
- kapacitet
- kapacitet
- fångar
- cellen
- ändrats
- avgifter
- Välja
- välja
- klient
- koda
- samling
- samlingar
- Kollektorn
- Kolumn
- kombination
- kombinera
- kommentarer
- Gemensam
- Företag
- jämförbar
- jämföra
- jämfört
- fullborda
- Avslutade
- komponenter
- begrepp
- konferenser
- konfiguration
- konfigurerad
- består
- Konsol
- innehålla
- innehöll
- innehåller
- innehåll
- innehållsskapande
- konvertera
- konverterad
- omvandling
- Motsvarande
- kunde
- omfattar
- skapa
- skapas
- skapar
- Skapa
- skapande
- referenser
- kund
- Kunder
- Dallas
- instrumentbräda
- instrumentpaneler
- datum
- Data Analytics
- datavetenskap
- Databas
- årtionde
- däck
- Standard
- leverera
- levererar
- demonstrera
- beroende
- distribuera
- utplacerade
- utplacera
- vecklas ut
- beskriva
- Designa
- utformade
- detalj
- detaljerad
- detaljer
- Diagrammet
- DICT
- DID
- Skillnaden
- olika
- Diffusion
- digital
- Dimensionera
- dimensioner
- Upptäck
- diskuteras
- Visa
- do
- dokument
- gör
- domäner
- ladda ner
- Nedladdningar
- under
- e
- varje
- element
- inbäddade
- inbäddning
- möjliggöra
- aktiverad
- kodade
- uppmuntra
- änden
- Slutpunkt
- Motor
- säkerställa
- Företag
- företagskunder
- fel
- Eter (ETH)
- händelse
- händelser
- Granskning
- exempel
- Utom
- undantag
- finns
- erfarenhet
- Utforska
- förlänga
- externt
- extrahera
- Förtrogenhet
- Fält
- Fil
- Filer
- finansiella
- finansiella tjänster
- hitta
- fokuserar
- följer
- efter
- följer
- För
- formen
- format
- fundament
- fyra
- Fri
- från
- full
- fullständigt
- framtida
- generera
- genereras
- genererar
- generering
- generativ
- Generativ AI
- george
- skaffa sig
- GitHub
- kommer
- grafer
- vägleda
- Har
- he
- hjälp
- hjälpa
- här.
- dold
- högre
- träffar
- värd
- värd
- värd
- värdar
- Hur ser din drömresa ut
- Men
- html
- http
- HTTPS
- Nav
- Kramar ansikte
- i
- IAM
- Identitet
- if
- illustrerar
- bild
- bilder
- blir omedelbart
- genomföra
- genomförande
- redskap
- in
- innefattar
- innefattar
- Inklusive
- index
- index
- informationen
- Innovation
- innovationer
- ingång
- exempel
- instanser
- instruktioner
- interagera
- interaktion
- invändigt
- in
- investering
- IT
- sammanfogning
- jpg
- json
- juni
- språk
- Large
- Latens
- lansera
- LÄRA SIG
- inlärning
- föreläsare
- tycka om
- LINK
- Lama
- lokal
- lägre
- Maskinen
- maskininlärning
- göra
- hantera
- förvaltade
- många
- Match
- matchande
- mekanism
- Meny
- metadata
- metod
- ML
- modaliteter
- modell
- modeller
- mer
- mest
- MS
- multipel
- namn
- nativ
- Navigera
- Navigering
- Behöver
- Nya
- Ingen
- Notera
- anteckningsbok
- bärbara datorer
- anmälningar
- nu
- numrerad
- nummer
- objekt
- of
- erbjudanden
- on
- On-Demand
- ONE
- endast
- öppet
- öppen källkod
- or
- organisation
- OS
- vår
- ut
- utfall
- produktion
- över
- panelen
- parameter
- parametrar
- del
- partikel
- partnern
- partner
- reservdelar till din klassiker
- Godkänd
- brinner
- bana
- för
- utföra
- prestanda
- utfört
- behörigheter
- perspektiv
- fas
- Fysik
- Bilder
- rörledning
- plato
- Platon Data Intelligence
- PlatonData
- Strategier
- Inlägg
- inlägg
- potentiellt
- kraft
- den mäktigaste
- Predictor
- presentera
- presenteras
- föregående
- Innan
- process
- bearbetade
- processer
- bearbetning
- Program
- egenskaper
- ge
- förutsatt
- ger
- tillhandahålla
- sätta
- kvarkar
- sökfrågor
- fråga
- fråga
- frågor
- Snabbt
- trasa
- område
- snabbt
- Läsning
- redo
- verkliga världen
- mottagna
- refererade
- region
- relaterad
- relevanta
- förblir
- ersätta
- begära
- Obligatorisk
- Resurser
- Svara
- respons
- svar
- resultera
- resulterande
- Resultat
- hämtning
- avkastning
- Rik
- roller
- Körning
- rinnande
- sagemaker
- SageMaker Inference
- Samma
- säga
- Skala
- Vetenskap
- skärmdumpar
- skript
- Sök
- Andra
- §
- sektioner
- sektor
- se
- välj
- väljer
- senior
- Sekvens
- Serier
- Server
- serverar
- service
- Tjänster
- session
- uppsättningar
- inställning
- inställningar
- Dela
- hon
- skall
- visas
- Visar
- liknande
- Enkelt
- helt enkelt
- enda
- Storlek
- Skjut
- Diabilder
- kodavsnitt
- So
- lösning
- Lösningar
- några
- Källa
- specialist
- specifik
- specificerade
- stabil
- stapel
- start
- Ange
- status
- Steg
- Steg
- förvaring
- lagra
- lagras
- lagrar
- Strategisk
- Sträng
- senare
- framgång
- Framgångsrikt
- sådana
- Summit
- Stödjande
- säker
- bord
- Ta
- Diskussion
- uppgifter
- Teknisk
- Teknologi
- mall
- mallar
- testa
- tester
- texas
- text
- text-
- den där
- Smakämnen
- den information
- deras
- sedan
- Dessa
- detta
- de
- genomströmning
- tid
- titan
- betitlad
- till
- dagens
- tillsammans
- toronto
- traditionellt
- korsa
- utlösa
- trigg
- sann
- prova
- SVÄNG
- två
- Typ
- avslöja
- förstå
- förståelse
- universitet
- Uppdatering
- uppladdad
- URL
- användning
- Begagnade
- Användare
- användningar
- med hjälp av
- värde
- variabel
- mängd
- version
- via
- Video
- utsikt
- syn
- visuell
- washington
- sätt
- we
- webb
- webbservice
- VÄL
- Vad
- Vad är
- som
- medan
- kommer
- med
- inom
- arbetade
- arbetsflöde
- arbetssätt
- dig
- Din
- zephyrnet