
Bild skapad med DALL-E3
Artificiell intelligens har varit en fullständig revolution inom teknikvärlden.
Dess förmåga att härma mänsklig intelligens och utföra uppgifter som en gång betraktades som enbart mänskliga domäner förvånar fortfarande de flesta av oss.
Men oavsett hur bra dessa sena AI-språng framåt har varit, finns det alltid utrymme för förbättringar.
Och det är just här snabb ingenjörskonst börjar!
Gå in i det här fältet som avsevärt kan förbättra produktiviteten för AI-modeller.
Låt oss upptäcka allt tillsammans!
Prompt engineering är en snabbt växande domän inom AI som fokuserar på att förbättra effektiviteten och effektiviteten hos språkmodeller. Det handlar om att skapa perfekta uppmaningar för att vägleda AI-modeller för att producera våra önskade resultat.
Se det som att lära sig att ge bättre instruktioner till någon för att säkerställa att de förstår och utför en uppgift korrekt.
Varför snabb teknik är viktigt
- Förbättrad produktivitet: Genom att använda uppmaningar av hög kvalitet kan AI-modeller generera mer exakta och relevanta svar. Detta innebär att mindre tid spenderas på korrigeringar och mer tid att utnyttja AI:s kapacitet.
- Kostnadseffektivitet: Att träna AI-modeller är resurskrävande. Snabb ingenjörskonst kan minska behovet av omskolning genom att optimera modellens prestanda genom bättre uppmaningar.
- Mångsidighet: En välgjord uppmaning kan göra AI-modeller mer mångsidiga, vilket gör att de kan hantera ett bredare utbud av uppgifter och utmaningar.
Innan vi dyker in i de mest avancerade teknikerna, låt oss komma ihåg två av de mest användbara (och grundläggande) snabba ingenjörsteknikerna.
Sekventiellt tänkande med "Låt oss tänka steg för steg"
Idag är det välkänt att LLM-modellers noggrannhet förbättras avsevärt när man lägger till ordsekvensen "Låt oss tänka steg för steg".
Varför... undrar du kanske?
Tja, detta beror på att vi tvingar modellen att dela upp alla uppgifter i flera steg, och på så sätt se till att modellen har tillräckligt med tid för att bearbeta var och en av dem.
Till exempel skulle jag kunna utmana GPT3.5 med följande prompt:
Om John har 5 päron, sedan äter 2, köper 5 till och ger sedan 3 till sin vän, hur många päron har han?
Modellen ger mig ett svar direkt. Men om jag lägger till det sista "Låt oss tänka steg för steg", tvingar jag modellen att generera en tankeprocess med flera steg.
Uppmaning till få skott
Medan Zero-shot-prompten hänvisar till att be modellen att utföra en uppgift utan att tillhandahålla något sammanhang eller förkunskaper, innebär få-shot-prompttekniken att vi presenterar LLM med några exempel på vår önskade output tillsammans med någon specifik fråga.
Till exempel, om vi vill komma på en modell som definierar vilken term som helst med hjälp av en poetisk ton, kan det vara ganska svårt att förklara. Höger?
Däremot kan vi använda följande få-shot-uppmaningar för att styra modellen i den riktning vi vill.
Din uppgift är att svara i en konsekvent stil i linje med följande stil.
: Lär mig om motståndskraft.
: Spänst är som ett träd som böjer sig med vinden men aldrig går sönder.
Det är förmågan att studsa tillbaka från motgångar och fortsätta framåt.
: Din input här.
Om du inte har provat det än kan du gå och utmana GPT.
Men eftersom jag är ganska säker på att de flesta av er redan kan dessa grundläggande tekniker, kommer jag att försöka utmana er med några avancerade tekniker.
1. Tankekedja (CoT) Prompting
Introducerad av Google 2022, innebär denna metod att instruera modellen att genomgå flera resonemangssteg innan den levererar det ultimata svaret.
Låter väl bekant? I så fall har du helt rätt.
Det är som att slå samman både Sequential Thinking och Few-Shot Prompting.
Hur?
I huvudsak dirigerar CoT-uppmaning LLM att behandla information sekventiellt. Detta innebär att vi exemplifierar hur man löser ett första problem med flerstegsresonemang och sedan skickar till modellen vår verkliga uppgift, och förväntar oss att den ska efterlikna en jämförbar tankekedja när vi svarar på den faktiska frågan vi vill att den ska lösa.
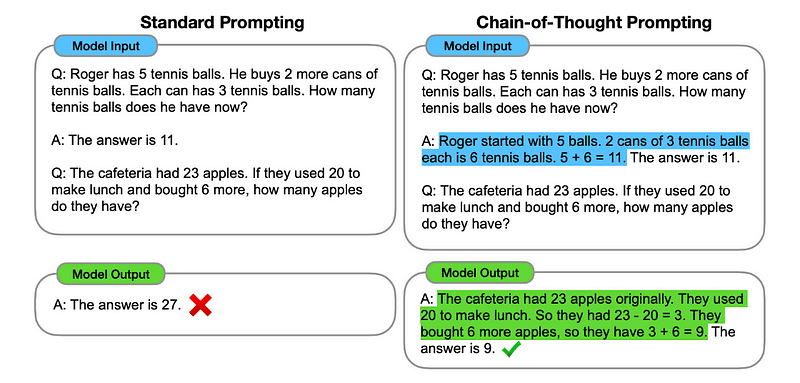
Bild tagen från papper.
Så, efter det allra första exemplet, kan vi ge en prompt med det första problemet och en sekventiell förklaring av hur man löser det. Sedan kan vi skicka in vår input och se hur magi händer!
Om John har 5 päron, sedan äter 2, köper 5 till och ger sedan 3 till sin vän, hur många päron har han? Låt oss tänka steg för steg.
Låt oss gå steg för steg. John börjar med 5 päron. Han äter 2 päron, så han har 5–2 = 3 päron kvar. Sedan köper han 5 päron till. Så han har nu 3 + 5 = 8 päron. Till sist ger han 3 päron till sin vän. Därför har han 8–3 = 5 päron kvar. Så efter alla dessa steg har John 5 päron.
Din input här.
Men de flesta av er måste tänka... Måste jag tänka på ett sekventiellt sätt att lösa några problem när jag vill fråga något på ChatGPT?
Tja... du är inte den första! Och detta leder oss till...
2. Automatisk tankekedja (Auto-CoT)
2022, Zhang och kollegor introducerade en metod för att undvika denna manuella process. Det finns två huvudskäl att undvika manuella uppgifter:
- Det kan vara tråkigt.
- Det kan ge dåliga resultat – till exempel när vår mentala process är fel.
De föreslog att man skulle använda LLMs kombinerat med "Låt oss tänka steg för steg"-uppmaningen för att sekventiellt producera resonemangskedjor för varje demonstration.
Detta innebär att man frågar ChatGPT hur man löser alla problem i följd och sedan använder samma exempel för att träna hur man löser alla andra problem.
3. Självständighet
Självkonsekvens är en annan intressant promptteknik som syftar till att förbättra tankekedjan för mer komplexa resonemangsproblem.
Så... vad är den största skillnaden?
Huvudtanken under Self-Consistency är att vara medveten om att vi kan träna modellen med ett felaktigt exempel. Föreställ dig bara att jag löser det tidigare problemet med en felaktig mental process:
Om John har 5 päron, sedan äter 2, köper 5 till och ger sedan 3 till sin vän, hur många päron har han? Låt oss tänka steg för steg.
Börja med 5 päron. John äter 2 päron. Sedan ger han 3 päron till sin vän. Dessa åtgärder kan kombineras: 2 (äts) + 3 (givna) = 5 päron totalt påverkade. Subtrahera nu det totala antalet påverkade päron från de första 5 päronen: 5 (initial) – 5 (påverkade) = 0 päron kvar.
Då blir alla andra uppgifter jag skickar till modellen fel.
Det är därför Self-Consistency involverar provtagning från olika resonemangsvägar, var och en av dem innehåller en tankekedja, och sedan låter LLM välja den bästa och mest konsekventa vägen för att lösa problemet.
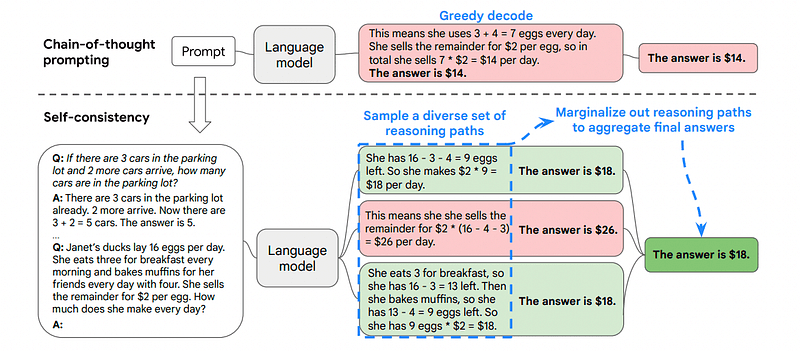
Bild tagen från papper
I det här fallet, och efter det allra första exemplet igen, kan vi visa modellen olika sätt att lösa problemet.
Om John har 5 päron, sedan äter 2, köper 5 till och ger sedan 3 till sin vän, hur många päron har han?
Börja med 5 päron. John äter 2 päron och lämnar honom med 5–2 = 3 päron. Han köper 5 päron till, vilket ger summan 3 + 5 = 8 päron. Till sist ger han 3 päron till sin kompis, så han har 8–3 = 5 päron kvar.
Om John har 5 päron, sedan äter 2, köper 5 till och ger sedan 3 till sin vän, hur många päron har han?
Börja med 5 päron. Han köper sedan 5 päron till. John äter 2 päron nu. Dessa åtgärder kan kombineras: 2 (ätit) + 5 (köpt) = 7 päron totalt. Subtrahera päronet som Jon har ätit från den totala mängden päron 7 (total mängd) – 2 (ätit) = 5 päron kvar.
Din input här.
Och här kommer den sista tekniken.
4. Allmän kunskapsfråga
En vanlig praxis för prompt engineering är att utöka en fråga med ytterligare kunskap innan det slutliga API-anropet skickas till GPT-3 eller GPT-4.
Enligt Jiacheng Liu och Co, vi kan alltid lägga till lite kunskap till varje begäran så att LLM vet bättre om frågan.
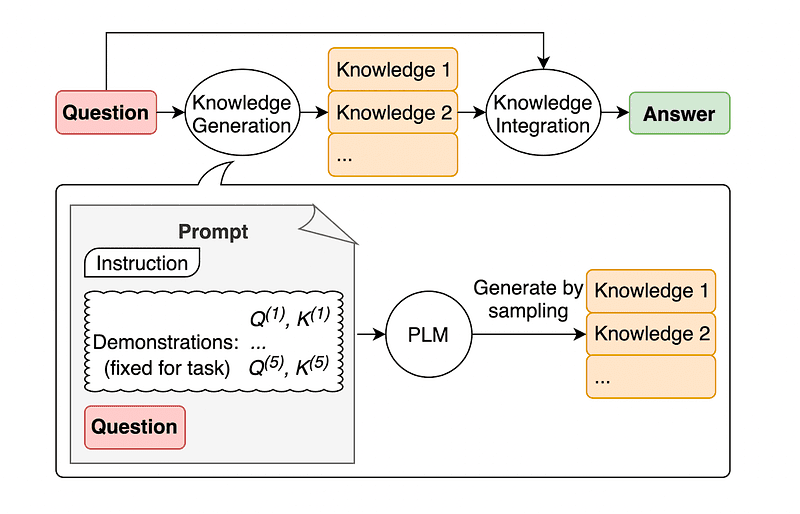
Bild tagen från papper.
Så till exempel, när du frågar ChatGPT om en del av golf försöker få en högre poängsumma än andra, kommer det att validera oss. Men huvudmålet med golf är det motsatta. Det är därför vi kan lägga till lite tidigare kunskaper som säger att "Spelaren med lägre poäng vinner".

Så .. vad är det roliga om vi berättar exakt svaret för modellen?
I det här fallet används denna teknik för att förbättra hur LLM interagerar med oss.
Så i stället för att hämta kompletterande sammanhang från en extern databas rekommenderar uppsatsens författare att låta LLM producera sin egen kunskap. Denna självgenererade kunskap integreras sedan i uppmaningen för att stärka sunt förnuft och ge bättre resultat.
Så detta är hur LLM:er kan förbättras utan att öka dess utbildningsdatauppsättning!
Snabb ingenjörskonst har dykt upp som en avgörande teknik för att förbättra förmågan hos LLM. Genom att iterera och förbättra uppmaningar kan vi kommunicera på ett mer direkt sätt till AI-modeller och på så sätt få mer exakta och kontextuellt relevanta utdata, vilket sparar både tid och resurser.
För både teknikentusiaster, datavetare och innehållsskapare kan förståelse och behärskning av snabb ingenjörskonst vara en värdefull tillgång för att utnyttja AIs fulla potential.
Genom att kombinera noggrant utformade inmatningsuppmaningar med dessa mer avancerade tekniker kommer du utan tvekan att ge dig ett försprång under de kommande åren att ha kompetensen inom snabb ingenjörskonst.
Josep Ferrer är en analysingenjör från Barcelona. Han tog examen i fysikteknik och arbetar för närvarande inom datavetenskapsområdet tillämpat på mänsklig rörlighet. Han är en innehållsskapare på deltid med fokus på datavetenskap och teknologi. Du kan kontakta honom på LinkedIn, Twitter or Medium.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.kdnuggets.com/some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models?utm_source=rss&utm_medium=rss&utm_campaign=some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models
- : har
- :är
- :inte
- :var
- $UPP
- 10
- 11
- 2022
- 29
- 7
- 8
- a
- förmåga
- Om oss
- noggrannhet
- exakt
- åtgärder
- faktiska
- lägga till
- tillsats
- Annat
- avancerat
- Efter
- igen
- AI
- AI-modeller
- Syftet
- Justerat
- lika
- Alla
- tillåta
- längs
- redan
- alltid
- am
- mängd
- an
- analytics
- och
- Annan
- svara
- vilken som helst
- api
- tillämpas
- ÄR
- AS
- be
- be
- tillgång
- Författarna
- Automat
- undvika
- medveten
- bort
- tillbaka
- Badrum
- Barcelona
- grundläggande
- BE
- därför att
- varit
- innan
- Där vi får lov att vara utan att konstant prestera,
- BÄST
- Bättre
- stödja
- lyft
- Boring
- båda
- köpt
- Studsa
- Ha sönder
- raster
- Bringar
- bredare
- men
- buys
- by
- Ring
- KAN
- kapacitet
- försiktigt
- Vid
- kedja
- kedjor
- utmanar
- utmaningar
- ChatGPT
- Välja
- kollegor
- kombinerad
- kombinera
- komma
- kommer
- kommande
- Gemensam
- kommunicera
- jämförbar
- fullborda
- komplex
- anses
- konsekvent
- kontakta
- innehåll
- innehållsskapare
- sammanhang
- Korrigeringar
- korrekt
- kunde
- skapas
- skaparen
- skaparna
- För närvarande
- datum
- datavetenskap
- Databas
- definierar
- leverera
- utformade
- önskas
- Skillnaden
- olika
- rikta
- riktning
- Upptäck
- dykning
- do
- gör
- domän
- domäner
- ner
- varje
- kant
- effektivitet
- effektivitet
- dykt
- ingenjör
- Teknik
- förbättra
- förbättra
- tillräckligt
- säkerställa
- entusiaster
- exakt
- exempel
- exempel
- exekvera
- väntar
- Förklara
- förklaring
- bekant
- få
- fält
- slutlig
- Slutligen
- Förnamn
- fokuserade
- fokuserar
- efter
- För
- tvingar
- Framåt
- vän
- från
- full
- rolig
- Allmänt
- generera
- skaffa sig
- Ge
- ges
- ger
- Go
- Målet
- golf
- god
- styra
- Hård
- Utnyttja
- Har
- har
- he
- här.
- hög kvalitet
- högre
- honom
- hans
- Hur ser din drömresa ut
- How To
- Men
- HTTPS
- humant
- mänsklig intelligens
- i
- Tanken
- if
- bild
- förbättra
- förbättras
- förbättring
- förbättra
- in
- ökande
- informationen
- inledande
- ingång
- exempel
- instruktioner
- integrerade
- Intelligens
- interagerar
- intressant
- in
- introducerade
- innebär
- IT
- DESS
- John
- jon
- bara
- KDnuggets
- Ha kvar
- sparka
- Kicks
- Vet
- kunskap
- vet
- språk
- Efternamn
- Sent
- Leads
- Språng
- inlärning
- lämnar
- vänster
- mindre
- Låt
- uthyrning
- hävstångs
- tycka om
- lägre
- magi
- Huvudsida
- göra
- Framställning
- sätt
- manuell
- många
- Mastering
- Materia
- me
- betyder
- mentala
- sammanslagning
- metod
- kanske
- mobilitet
- modell
- modeller
- mer
- mest
- rörliga
- multipel
- måste
- Behöver
- aldrig
- Nej
- nu
- få
- of
- on
- gång
- motsatt
- optimera
- or
- Övriga
- Övrigt
- vår
- ut
- produktion
- utgångar
- utanför
- egen
- Papper
- del
- bana
- perfekt
- utföra
- prestanda
- Fysik
- svängbara
- plato
- Platon Data Intelligence
- PlatonData
- Spelaren
- Punkt
- potentiell
- praktiken
- exakt
- presentera
- pretty
- föregående
- Problem
- problem
- process
- producera
- produktivitet
- ge
- tillhandahålla
- dra
- fråga
- ganska
- område
- snarare
- verklig
- skäl
- rekommenderar
- minska
- hänvisar
- relevanta
- begära
- motståndskraft
- Resursintensiv
- Resurser
- reagera
- respons
- svar
- Resultat
- omskolning
- Rotation
- höger
- Rum
- s
- Samma
- sparande
- Vetenskap
- Vetenskap och teknik
- vetenskapsmän
- göra
- se
- sända
- skicka
- Sekvens
- in
- flera
- show
- signifikant
- skicklighet
- So
- enbart
- LÖSA
- Lösa
- några
- någon
- något
- specifik
- spent
- stadier
- starta
- startar
- styra
- Steg
- Steg
- Fortfarande
- stil
- säker
- tackla
- tagen
- uppgift
- uppgifter
- tech
- Tekniken
- tekniker
- Teknologi
- tala
- termin
- än
- den där
- Smakämnen
- Dem
- sedan
- Där.
- därför
- Dessa
- de
- tror
- Tänkande
- detta
- trodde
- Genom
- Således
- tid
- till
- TON
- Totalt
- TOTALT
- Tåg
- Utbildning
- träd
- försökte
- prova
- försöker
- två
- slutliga
- under
- genomgå
- förstå
- förståelse
- otvivelaktigt
- us
- användning
- Begagnade
- med hjälp av
- BEKRÄFTA
- Värdefulla
- olika
- mångsidig
- mycket
- vill
- Sätt..
- sätt
- we
- ALLBEKANT
- były
- när
- som
- varför
- kommer
- vind
- med
- inom
- utan
- ord
- arbetssätt
- världen
- Fel
- år
- ännu
- Avkastning
- dig
- Din
- zephyrnet







