Experter vid bordet: Semiconductor Engineering satte sig ner för att prata om vägen framåt för minnet i allt mer heterogena system, med Frank Ferro, koncernchef, produktledning på Kadens; Steven Woo, kollega och framstående uppfinnare vid Rambus; Jongsin Yun, minnestekniker vid Siemens EDA; Randy White, programansvarig för minneslösningar på Nyckelsikt; och Frank Schirrmeister, vice vd för lösningar och affärsutveckling på Arteris. Det som följer är utdrag ur det samtalet. Del ett av denna diskussion kan hittas här..
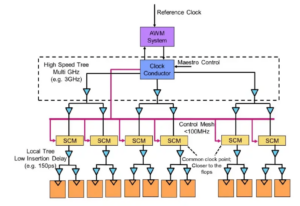
![[L-R]: Frank Ferro, Cadence; Steven Woo, Rambus; Jongsin Yun, Siemens EDA; Randy White, Keysight; och Frank Schirrmeister, Arteris.](https://platoaistream.com/wp-content/uploads/2024/01/rethinking-memory.png)
[L-R]: Frank Ferro, Cadence; Steven Woo, Rambus; Jongsin Yun, Siemens EDA; Randy White, Keysight; och Frank Schirrmeister, Arteris
SE: När vi kämpar med AI/ML och kraftkrav, vilka konfigurationer behöver tänkas om? Kommer vi att se en förskjutning bort från Von Neumann-arkitekturen?
Uppvakta: När det gäller systemarkitekturer pågår det en bifurkation i branschen. De traditionella applikationerna som är de dominerande arbetshästarna, som vi kör i molnet på x86-baserade servrar, försvinner inte. Det finns årtionden av mjukvara som har byggts upp och utvecklats, och som kommer att förlita sig på den arkitekturen för att fungera bra. Däremot är AI/ML en ny klass. Människor har tänkt om arkitekturerna och byggt väldigt domänspecifika processorer. Vi ser att ungefär två tredjedelar av energin går åt till att bara flytta data mellan en processor och en HBM-enhet, medan bara ungefär en tredjedel går åt till att faktiskt komma åt bitarna i DRAM-kärnorna. Datarörelsen är nu mycket mer utmanande och dyrare. Vi kommer inte att bli av med minnet. Vi behöver det eftersom datamängderna blir större. Så frågan är, ’Vad är rätt väg framåt?’ Det har varit mycket diskussion om stapling. Om vi skulle ta det minnet och lägga det direkt ovanpå processorn gör det två saker för dig. För det första är bandbredden idag begränsad av kusten eller chipets omkrets. Det är dit I/O:erna går. Men om du skulle stapla den direkt ovanpå processorn kan du nu använda hela kretsens yta för distribuerade sammankopplingar, och du kan få mer av bandbredden i själva minnet, och det kan matas direkt ner i processorn. Länkarna blir mycket kortare och strömeffektiviteten går förmodligen upp i storleksordningen 5X till 6X. För det andra ökar mängden bandbredd som du kan få på grund av den mera arraysammankopplingen till minnet också med flera heltalsfaktorer. Att göra dessa två saker tillsammans kan ge mer bandbredd och göra det mer energieffektivt. Branschen utvecklas till vad behoven än är, och det är definitivt ett sätt vi kommer att se minnessystem börja utvecklas i framtiden för att bli mer energieffektiva och ge mer bandbredd.
Järn: När jag först började arbeta på HBM runt 2016 frågade några av de mer avancerade kunderna om det kunde staplas. De har tittat på hur man staplar DRAM på toppen ganska länge eftersom det finns tydliga fördelar. Från det fysiska lagret blir PHY i princip försumbar, vilket sparar mycket kraft och effektivitet. Men nu har du en processor på flera 100W som har ett minne ovanpå. Minnet tål inte värmen. Det är förmodligen den svagaste länken i värmekedjan, vilket skapar ytterligare en utmaning. Det finns fördelar, men de måste fortfarande ta reda på hur de ska hantera termiken. Det finns mer incitament nu att flytta den typen av arkitektur framåt, eftersom det verkligen sparar dig totalt sett när det gäller prestanda och kraft, och det kommer att förbättra din beräkningseffektivitet. Men det finns vissa fysiska designutmaningar som måste hanteras. Som Steve sa, vi ser alla typer av arkitekturer som kommer ut. Jag håller helt med om att GPU/CPU-arkitekturerna inte kommer någonstans, de kommer fortfarande att vara dominerande. Samtidigt försöker alla företag på planeten komma på en bättre råttfälla för att göra sin AI. Vi ser on-chip SRAM och kombinationer av minne med hög bandbredd. LPDDR har höjt huvudet ganska mycket nu för tiden när det gäller hur man drar fördel av LPDDR i datacentret på grund av kraften. Vi har till och med sett GDDR användas i vissa AI-inferensapplikationer, såväl som alla gamla minnessystem. De försöker nu pressa så många DDR5:or på ett fotavtryck som möjligt. Jag har sett alla arkitekturer du kan tänka dig, oavsett om det är DDR, HBM, GDDR eller andra. Det beror på din processorkärna i termer av vad ditt totala mervärde är, och sedan hur du kan bryta igenom just din arkitektur. Minnessystemet som följer med det, så att du kan skulptera din CPU och din minnesarkitektur, beroende på vad som är tillgängligt.
Och ett: En annan fråga är icke-volatiliteten. Om AI:n måste hantera kraftintervallet mellan att köra en IoT-baserad AI, till exempel, behöver vi mycket ström av och på, och all denna information för AI-träningen måste rotera om och om igen. Om vi har någon typ av lösningar där vi kan lagra dessa vikter i chippet så att vi inte alltid behöver röra oss fram och tillbaka för samma vikt, då kommer det att bli mycket energibesparingar, speciellt för IoT-baserad AI. Det kommer att finnas en annan lösning för att hjälpa dessa kraftbehov.
Schirrmeister: Vad jag tycker är fascinerande, ur ett NoC-perspektiv, är där du måste optimera dessa vägar från en processor som går genom en NoC, åtkomst till ett minnesgränssnitt med en styrenhet som potentiellt går genom UCIe för att skicka en chiplet till en annan chiplet, som sedan har minne i Det. Det är inte så att Von Neumann-arkitekturer är döda. Men det finns så många varianter nu, beroende på vilken arbetsbelastning du vill beräkna. De måste betraktas i minnessammanhang, och minnet är bara en aspekt. Var du får data från datalokaliteten, hur är det ordnat i detta DRAM? Vi arbetar igenom alla dessa saker, som prestandaanalys av minnen och sedan optimerar systemarkitekturen på det. Det sporrar till mycket innovation för nya arkitekturer, vilket jag aldrig tänkte på när jag var på universitetet och lärde mig om Von Neumann. I den yttersta andra änden har du saker som maskor. Det finns en hel del fler arkitekturer nu emellan att överväga, och det drivs av minnesbandbredden, beräkningskapaciteten och så vidare, som inte växer i samma takt.
Vit: Det finns en trend som involverar disaggregerad beräkning eller distribuerad beräkning, vilket innebär att arkitekten behöver ha fler verktyg till sitt förfogande. Minneshierarkin har utökats. Det finns semantik med, liksom CXL och olika hybridminnen, som finns för flash och i DRAM. En parallell applikation till datacentret är bilindustrin. Automotive hade alltid denna sensor att beräkna med ECU:er (elektroniska styrenheter). Jag är fascinerad av hur det har utvecklats till datacentret. Snabbspolning framåt, och idag har vi distribuerat beräkningsnoder, så kallade domänkontrollanter. Det är samma sak. Det försöker ta itu med att makt kanske inte är så stor sak eftersom omfattningen av datorer inte är lika stor, men latens är verkligen en stor sak med bilindustrin. ADAS behöver superhög bandbredd, och du har olika avvägningar. Och så har du fler mekaniska sensorer, men liknande begränsningar i ett datacenter. Du har kalllagring som inte behöver ha låg latens, och sedan har du andra applikationer med hög bandbredd. Det är fascinerande att se hur mycket verktygen och alternativen för arkitekten har utvecklats. Branschen har gjort ett riktigt bra jobb med att svara, och vi tillhandahåller alla olika lösningar som kommer in på marknaden.
SE: Hur har verktyg för minnesdesign utvecklats?
Schirrmeister: När jag började med mina första par chips på 90-talet var det mest använda systemverktyget Excel. Sedan dess har jag alltid hoppats att det kan gå sönder vid ett tillfälle för de saker vi gör på systemnivå, minne, bandbreddsanalys och så vidare. Detta påverkade mina lag ganska mycket. På den tiden var det väldigt avancerade grejer. Men till Randys poäng, nu måste vissa komplexa saker simuleras på en nivå av trohet som tidigare inte var möjlig utan datorn. För att ge ett exempel, att anta en viss latens för en DRAM-åtkomst kan leda till dåliga arkitekturbeslut och potentiellt felaktig design av datatransportarkitekturer på chip. Baksidan är också sant. Om du alltid antar det värsta fallet, kommer du att överdesigna arkitekturen. Att låta verktyg utföra DRAM- och prestandaanalysen, och att ha de rätta modellerna tillgängliga för kontrollerna gör det möjligt för en arkitekt att simulera allt, det är en fascinerande miljö att vara i. Min förhoppning från 90-talet att Excel vid ett tillfälle kan gå sönder som en Verktyg på systemnivå kan faktiskt bli verklighet, eftersom vissa av de dynamiska effekterna du inte kan göra i Excel längre eftersom du behöver simulera dem - speciellt när du lägger in ett die-to-die-gränssnitt med PHY-egenskaper och sedan länkar lager egenskaper som att kontrollera om allt var korrekt och eventuellt skicka om data. Att inte ha dessa simuleringar gjorda kommer att resultera i suboptimal arkitektur.
Järn: Det första steget i de flesta utvärderingar vi gör är att ge dem minnestestbänken för att börja titta på DRAM-effektiviteten. Det är ett stort steg, till och med att göra saker så enkla som att köra lokala verktyg för att göra DRAM-simulering, men sedan gå in i fullskaliga simuleringar. Vi ser att fler kunder efterfrågar den typen av simulering. Att se till att din DRAM-effektivitet är uppe på 90-talet är ett mycket viktigt första steg i varje utvärdering.
Uppvakta: En del av anledningen till att du ser uppkomsten av kompletta systemsimuleringsverktyg är att DRAM-minnen har blivit mycket mer komplicerade. Det är väldigt svårt nu att vara jämn i ribban för vissa av dessa komplexa arbetsbelastningar genom att använda enkla verktyg som Excel. Om du tittar på databladet för DRAM på 90-talet var dessa datablad som 40 sidor. Nu är de hundratals sidor. Det talar bara om enhetens komplexitet för att få ut de höga bandbredderna. Du kopplar det till det faktum att minnet är en sådan drivkraft i systemkostnad, såväl som bandbredd och latens relaterad till processorns prestanda. Det är också en stor drivkraft, så att du behöver simulera på en mycket mer detaljerad nivå nu. När det gäller verktygsflöde förstår systemarkitekter att minnet är en enorm drivkraft. Så verktygen måste vara mer sofistikerade, och de måste ha ett mycket bra gränssnitt mot andra verktyg så att systemarkitekten får den bästa globala överblicken över vad som händer - särskilt med hur minnet påverkar systemet.
Och ett: När vi går till AI-eran används många flerkärniga system, men vi vet inte vilken data som går vart. Det går också mer parallellt med chippet. Storleken på minnet är mycket större. Om vi använder ChatGPT-typ av AI, så kräver datahanteringen för modellerna cirka 350 MB data, vilket är en enorm mängd data bara för en vikt, och den faktiska input/output är mycket större. Den ökningen av mängden data som krävs betyder att det finns många probabilistiska effekter som vi inte har sett tidigare. Det är ett extremt utmanande test att se alla fel relaterade till denna stora mängd minne. Och ECC används överallt, även i SRAM, som inte traditionellt använde ECC, men nu är det väldigt vanligt för de största systemen. Att testa allt detta är mycket utmanande och behöver stödjas av EDA-lösningar för att testa alla dessa olika tillstånd.
SE: Vilka utmaningar möter ingenjörsteam på en daglig basis?
Vit: Vilken dag som helst hittar du mig i labbet. Jag kavlar upp ärmarna och har blivit smutsiga på händerna, sticker i kablar, löder och sånt. Jag tänker mycket på post-silikonvalidering. Vi pratade om tidig simulering och on-die-verktyg – BiST och sådana saker. I slutet av dagen, innan vi skickar, vill vi göra någon form av systemvalidering eller tester på enhetsnivå. Vi pratade om hur man kan övervinna minnesväggen. Vi samlokaliserar minne, HBM, sådana saker. Om vi tittar på utvecklingen av förpackningsteknik började vi med blyförsedda förpackningar. De var inte särskilt bra för signalintegritet. Decennier senare gick vi över till optimerad signalintegritet, som ball grid arrays (BGAs). Vi kunde inte komma åt det, vilket innebar att du inte kunde testa det. Så vi kom på det här konceptet som kallas en enhetsinterposer - en BGA-interposer - och som gjorde det möjligt för oss att lägga en speciell fixtur som dirigerade ut signaler. Sedan kunde vi koppla den till testutrustningen. Snabbspola fram till idag, och nu har vi HBM och chiplets. Hur lägger jag in min armatur på mellanlägget av kisel? Vi kan inte, och det är kampen. Det är en utmaning som håller mig vaken på natten. Hur utför vi felanalys i fält med en OEM- eller systemkund, där de inte får 90 % effektivitet. Det finns fler fel i länken, de kan inte initieras ordentligt och utbildningen fungerar inte. Är det ett systemintegritetsproblem?
Schirrmeister: Skulle du inte hellre göra detta hemifrån med ett virtuellt gränssnitt än att gå till labbet? Är inte svaret mer analys du bygger in i chippet? Med chiplets integrerar vi allt ytterligare. Att få in din lödkolv där är inte riktigt ett alternativ, så det måste finnas ett sätt för on-chip-analys. Vi har samma problem för NoC. Folk tittar på NoC, och du skickar data och sedan är den borta. Vi behöver analyserna att lägga in där så att folk kan göra felsökning, och det sträcker sig till tillverkningsnivån, så att du äntligen kan arbeta hemifrån och göra allt baserat på chipanalys.
Järn: Speciellt med minne med hög bandbredd kan du inte fysiskt komma in där. När vi licensierar PHY har vi också en produkt som går med det så att du kan se varenda en av dessa 1,024 3 bitar. Du kan börja läsa och skriva DRAM från verktyget så att du inte behöver komma in där fysiskt. Jag gillar mellanläggsidén. Vi tar med några stift ur interposern under testning, vilket du inte kan göra i systemet. Det är verkligen en utmaning att komma in i dessa 2.5D-system. Även ur designverktygsflödessynpunkt verkar det som att de flesta företag gör sitt eget individuella flöde på många av dessa 2.5D-verktyg. Vi börjar sätta ihop ett mer standardiserat sätt att bygga ett XNUMXD-system, från signalintegritet, kraft, hela hela flödet.
Vit: När saker och ting går vidare hoppas jag att vi fortfarande kan behålla samma nivå av noggrannhet. Jag är med i UCIe form factor compliance group. Jag tittar på hur man karakteriserar en känd bra tärning, en gyllene tärning. Så småningom kommer detta att ta mycket mer tid, men vi kommer att hitta ett lyckligt medium mellan prestandan och noggrannheten i testningen som vi behöver, och den flexibilitet som är inbyggd.
Schirrmeister: Om jag tittar på chiplets och deras användning i en mer öppen produktionsmiljö är testning en av de större utmaningarna för att få det att fungera rätt. Om jag är ett stort företag och jag kontrollerar alla sidor av det, då kan jag begränsa saker på lämpligt sätt så att tester och så vidare blir genomförbara. Om jag vill gå till UCIe-sloganen att UCI bara är en bokstav bort från PCI, och jag föreställer mig en framtid där UCIe-montering, ur ett tillverkningsperspektiv, blir som PCI-slots i en PC idag, så är testaspekterna för det verkligen utmanande. Vi måste hitta en lösning. Det finns mycket arbete att göra.
Relaterade artiklar
Minnets framtid (Del 1 av ovan kan rundas)
Från försök att lösa värme- och energiproblem till rollerna som CXL och UCIe, framtiden har ett antal möjligheter för minne.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://semiengineering.com/rethinking-memory/
- : har
- :är
- :inte
- :var
- $UPP
- 1
- 2016
- 3d
- 40
- a
- Om oss
- ovan
- tillgång
- åtkomst
- noggrannhet
- faktiska
- faktiskt
- ADA:er
- lägga till
- adress
- Antagande
- avancerat
- Fördel
- fördelar
- igen
- AI
- AI-utbildning
- AI / ML
- Alla
- tillåts
- tillåter
- också
- alltid
- mängd
- an
- analys
- analytics
- och
- Annan
- svara
- vilken som helst
- längre
- var som helst
- Ansökan
- tillämpningar
- lämpligt
- arkitekter
- arkitektur
- ÄR
- OMRÅDE
- runt
- anordnad
- array
- AS
- be
- aspekt
- aspekter
- Montage
- utgå ifrån
- At
- Försök
- fordonsindustrin
- tillgänglig
- bort
- tillbaka
- Badrum
- boll
- Bandbredd
- bar
- baserat
- I grund och botten
- grund
- BE
- därför att
- blir
- blir
- varit
- innan
- Där vi får lov att vara utan att konstant prestera,
- Fördelarna
- BÄST
- Bättre
- mellan
- Stor
- större
- Bit
- Ha sönder
- föra
- SLUTRESULTAT
- byggt
- företag
- affärsutveckling
- men
- by
- Kadens
- kallas
- kom
- KAN
- Kan få
- kapacitet
- Vid
- Centrum
- vissa
- säkerligen
- kedja
- utmanar
- utmaningar
- utmanande
- egenskaper
- karakterisera
- kontroll
- chip
- Pommes frites
- klass
- klar
- cloud
- förkylning
- Kylförvaring
- kombinationer
- komma
- kommande
- Gemensam
- Företag
- företag
- komplex
- Komplexiteten
- Efterlevnad
- komplicerad
- Compute
- datorer
- databehandling
- begrepp
- villkor
- Kontakta
- anses
- begränsningar
- sammanhang
- Däremot
- kontroll
- styrenhet
- Konversation
- Kärna
- korrekt
- Pris
- kunde
- Par
- CPU
- skapar
- kund
- Kunder
- datum
- Data Center
- datauppsättningar
- dag
- dag för dag
- Dagar
- döda
- behandla
- årtionden
- beslut
- definitivt
- krav
- beroende
- beror
- Designa
- design
- detaljerad
- Utveckling
- anordning
- den
- olika
- svårt
- direkt
- Direktör
- diskussion
- förfogande
- Distingerad
- distribueras
- distribuerad databehandling
- do
- gör
- inte
- gör
- domän
- dominerande
- gjort
- inte
- ner
- driven
- chaufför
- under
- dynamisk
- Tidig
- effekter
- effektivitet
- effektiv
- Elektronisk
- änden
- energi
- Teknik
- Hela
- Miljö
- Utrustning
- Era
- fel
- speciellt
- Eter (ETH)
- utvärdering
- utvärderingar
- Även
- så småningom
- Varje
- allt
- överallt
- Utvecklingen
- utvecklas
- utvecklats
- utvecklas
- exempel
- excel
- expanderade
- dyra
- sträcker
- extrem
- extremt
- Ögon
- Ansikte
- Faktum
- faktor
- Misslyckande
- fascinerande
- SNABB
- möjlig
- Kompis
- trohet
- fält
- Figur
- Slutligen
- hitta
- Förnamn
- Blixt
- Flexibilitet
- Flip
- flöda
- följer
- Fotavtryck
- För
- formen
- vidare
- Framåt
- hittade
- Frank
- från
- full
- ytterligare
- framtida
- skaffa sig
- få
- Ge
- ges
- Välgörenhet
- Go
- Går
- kommer
- Golden
- borta
- god
- bra jobb
- fick
- Rutnät
- Grupp
- Odling
- hade
- Arbetsmiljö
- händer
- lyckligt
- Har
- har
- huvud
- hjälpa
- hierarkin
- Hög
- innehar
- Hem
- hoppas
- Hur ser din drömresa ut
- How To
- html
- HTTPS
- stor
- Hundratals
- Hybrid
- i
- Tanken
- if
- bild
- påverkade
- slag
- med Esport
- förbättra
- in
- Incitament
- ingår
- felaktigt
- Öka
- alltmer
- individuellt
- industrin
- informationen
- Innovation
- inuti
- integrera
- integritet
- sammankopplingar
- Gränssnitt
- in
- involverar
- fråga
- problem
- IT
- DESS
- sig
- Jobb
- bara
- Vet
- känd
- lab
- Large
- större
- största
- Latens
- senare
- lager
- leda
- inlärning
- brev
- Nivå
- Licens
- tycka om
- Begränsad
- LINK
- länkar
- lokal
- se
- du letar
- Lot
- Föremål
- Låg
- bibehålla
- göra
- Framställning
- ledning
- chef
- Produktion
- många
- marknad
- max-bredd
- kanske
- me
- betyder
- menas
- mekanisk
- Medium
- Minnen
- Minne
- kanske
- modeller
- mer
- mest
- flytta
- rörd
- rörelse
- rörliga
- mycket
- my
- Behöver
- behov
- aldrig
- Nya
- natt
- noder
- nu
- antal
- of
- sänkt
- Gamla
- on
- ONE
- endast
- öppet
- möjligheter
- Optimera
- optimerad
- optimera
- Alternativet
- Tillbehör
- or
- beställa
- Övriga
- Övrigt
- ut
- övergripande
- Övervinna
- egen
- paket
- förpackning
- sidor
- Parallell
- del
- särskilt
- passera
- bana
- banor
- PC
- Personer
- utföra
- prestanda
- perspektiv
- fysisk
- Fysiskt
- tall
- planet
- plato
- Platon Data Intelligence
- PlatonData
- Punkt
- möjlig
- potentiellt
- kraft
- VD
- tidigare
- förmodligen
- Problem
- Processorn
- processorer
- Produkt
- produktledning
- Produktion
- Program
- rätt
- ordentligt
- ge
- sätta
- fråga
- ganska
- höja
- Betygsätta
- snarare
- Läsning
- verkligen
- relaterad
- förlita
- Obligatorisk
- Kräver
- Lös
- reagera
- resultera
- Befria
- höger
- Rise
- roller
- Rulla
- Körning
- rinnande
- Samma
- Save
- Besparingar
- säger
- Skala
- Andra
- se
- se
- verkar
- sett
- semantik
- halvledare
- sända
- givare
- sensor
- servrar
- flera
- ark
- skifta
- skickas
- sida
- Sidor
- siemens
- Signal
- signaler
- Kisel
- liknande
- Enkelt
- simulering
- simuleringar
- eftersom
- enda
- Storlek
- spelautomater
- So
- Mjukvara
- lösning
- Lösningar
- några
- sofistikerade
- talar
- speciell
- spent
- Squeeze
- stapel
- staplade
- stapling
- standardiserad
- ståndpunkt
- starta
- igång
- Starta
- Steg
- Steve
- steven
- Fortfarande
- förvaring
- lagra
- Kamp
- sådana
- Som stöds
- säker
- system
- System
- bord
- Ta
- Diskussion
- lag
- teknolog
- Teknologi
- villkor
- testa
- Testning
- tester
- än
- den där
- Smakämnen
- Framtiden
- deras
- Dem
- sedan
- Där.
- termisk
- Dessa
- de
- sak
- saker
- tror
- Tredje
- detta
- de
- trodde
- Genom
- tid
- till
- i dag
- tillsammans
- verktyg
- verktyg
- topp
- TOTALT
- kompromisser
- traditionell
- traditionellt
- Utbildning
- transport
- Trend
- sann
- försöker
- två
- två tredjedelar
- Typ
- förstå
- enheter
- universitet
- us
- användning
- Begagnade
- med hjälp av
- godkännande
- värde
- variationer
- olika
- mycket
- vice
- Vice President
- utsikt
- Virtuell
- av
- gående
- Vägg
- vill
- var
- Sätt..
- we
- vikt
- VÄL
- były
- Vad
- oberoende
- när
- om
- som
- medan
- vit
- Hela
- varför
- kommer
- med
- utan
- woo
- Arbete
- arbeta hemifrån
- arbetssätt
- värsta
- skrivning
- dig
- Din
- zephyrnet