Ett nyskapat artificiell intelligens (AI)-system baserat på djup förstärkningsinlärning (DRL) kan reagera på angripare i en simulerad miljö och blockera 95 % av cyberattackerna innan de eskalerar.
Det säger forskarna från Department of Energy's Pacific Northwest National Laboratory som byggde en abstrakt simulering av den digitala konflikten mellan angripare och försvarare i ett nätverk och tränade fyra olika DRL-neurala nätverk för att maximera belöningar baserat på att förhindra kompromisser och minimera nätverksavbrott.
De simulerade angriparna använde en rad taktiker baserade på MITER ATT & CK ramverkets klassificering för att gå från den initiala åtkomst- och spaningsfasen till andra attackfaser tills de nådde sitt mål: nedslags- och exfiltrationsfasen.
Den framgångsrika träningen av AI-systemet i den förenklade attackmiljön visar att defensiva svar på attacker i realtid kan hanteras av en AI-modell, säger Samrat Chatterjee, en datavetare som presenterade teamets arbete vid årsmötet i Association for the Association Framstegen för artificiell intelligens i Washington, DC den 14 februari.
"Du vill inte flytta in i mer komplexa arkitekturer om du inte ens kan visa vad de här teknikerna lovar", säger han. "Vi ville först visa att vi faktiskt kan träna en DRL framgångsrikt och visa några bra testresultat, innan vi går vidare."
Tillämpningen av maskininlärning och artificiell intelligens på olika områden inom cybersäkerhet har blivit en het trend under det senaste decenniet, från den tidiga integrationen av maskininlärning i e-postsäkerhetsgateways i de tidiga 2010-erna till nyare ansträngningar att använd ChatGPT för att analysera kod eller göra kriminaltekniska analyser. Nu, de flesta säkerhetsprodukter har — eller hävdar att de har — några funktioner som drivs av maskininlärningsalgoritmer tränade på stora datamängder.
Men att skapa ett AI-system som kan proaktivt försvar fortsätter att vara ambitiöst snarare än praktiskt. Medan en mängd olika hinder kvarstår för forskare, visar PNNL-forskningen att en AI-försvarare kan vara möjlig i framtiden.
"Att utvärdera flera DRL-algoritmer som tränats under olika kontradiktoriska miljöer är ett viktigt steg mot praktiska autonoma cyberförsvarslösningar," forskargruppen från PNNL uppgav i deras tidning. "Våra experiment tyder på att modellfria DRL-algoritmer effektivt kan tränas under attackprofiler i flera steg med olika skicklighets- och uthållighetsnivåer, vilket ger gynnsamma försvarsresultat i omtvistade miljöer."
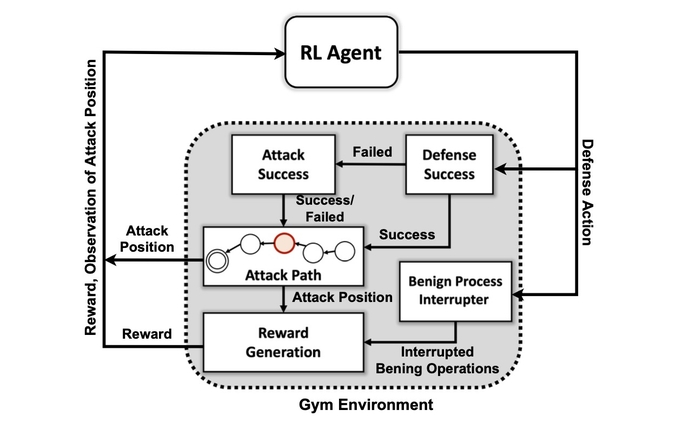
Hur systemet använder MITER ATT&CK
Det första målet för forskargruppen var att skapa en anpassad simuleringsmiljö baserad på en öppen källkodsverktygslåda som kallas Öppna AI Gym. Med hjälp av den miljön skapade forskarna angriparenheter med olika skicklighets- och uthållighetsnivåer med förmågan att använda en delmängd av 7 taktiker och 15 tekniker från MITER ATT&CK-ramverket.
Målen för angriparagenterna är att gå igenom de sju stegen i attackkedjan, från initial åtkomst till utförande, från uthållighet till kommando och kontroll och från insamling till nedslag.
För angriparen kan det vara komplext att anpassa sin taktik till omgivningens tillstånd och försvararens nuvarande handlingar, säger PNNL:s Chatterjee.
"Motståndaren måste navigera sig från ett initialt rekonditionstillstånd hela vägen till något exfiltrations- eller nedslagstillstånd", säger han. "Vi försöker inte skapa en sorts modell för att stoppa en motståndare innan de kommer in i miljön - vi antar att systemet redan är äventyrat."
Forskarna använde fyra metoder för neurala nätverk baserade på förstärkningsinlärning. Reinforcement learning (RL) är en maskininlärningsmetod som efterliknar den mänskliga hjärnans belöningssystem. Ett neuralt nätverk lär sig genom att stärka eller försvaga vissa parametrar för individuella neuroner för att belöna bättre lösningar, mätt med en poäng som indikerar hur väl systemet presterar.
Förstärkningsinlärning gör det i huvudsak möjligt för datorn att skapa ett bra, men inte perfekt, förhållningssätt till det aktuella problemet, säger Mahantesh Halappanavar, en PNNL-forskare och författare till artikeln.
"Utan att använda någon förstärkningsinlärning skulle vi fortfarande kunna göra det, men det skulle vara ett riktigt stort problem som inte kommer att ha tillräckligt med tid för att faktiskt komma på någon bra mekanism", säger han. "Vår forskning ... ger oss den här mekanismen där djup förstärkningsinlärning i viss mån efterliknar en del av det mänskliga beteendet i sig, och det kan utforska detta mycket stora utrymme mycket effektivt."
Inte redo för Prime Time
Experimenten fann att en specifik förstärkningsinlärningsmetod, känd som ett Deep Q Network, skapade en stark lösning på det defensiva problemet, fånga 97% av angriparna i testdatauppsättningen. Men forskningen är bara början. Säkerhetspersonal bör inte leta efter en AI-kompanjon för att hjälpa dem att göra incidentrespons och kriminalteknik när som helst snart.
Bland de många problem som återstår att lösa är att få förstärkningsinlärning och djupa neurala nätverk för att förklara faktorerna som påverkade deras beslut, ett forskningsområde som kallas förklaringsbar förstärkningsinlärning (XRL).
Dessutom är robustheten hos AI-algoritmerna och att hitta effektiva sätt att träna de neurala nätverken båda problem som måste lösas, säger PNNL:s Chatterjee.
"Att skapa en produkt - det var inte huvudmotivet för den här forskningen", säger han. "Det här handlade mer om vetenskapliga experiment och algoritmisk upptäckt."
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://www.darkreading.com/emerging-tech/researchers-create-ai-cyber-defender-that-reacts-to-attackers
- 7
- 95%
- a
- förmåga
- Om Oss
- SAMMANDRAG
- tillgång
- Enligt
- åtgärder
- faktiskt
- Dessutom
- befordran
- kontradiktoriskt
- medel
- AI
- AI-powered
- algoritmisk
- algoritmer
- Alla
- tillåter
- redan
- analys
- analysera
- och
- årsringar
- Ansökan
- tillvägagångssätt
- tillvägagångssätt
- OMRÅDE
- konstgjord
- artificiell intelligens
- Konstgjord intelligens (AI)
- Förening
- attackera
- Attacker
- Författaren
- autonom
- baserat
- blir
- innan
- Bättre
- mellan
- Stor
- Blockera
- Hjärna
- byggt
- kallas
- kan inte
- kapabel
- vissa
- kedja
- ChatGPT
- patentkrav
- klassificering
- samling
- komma
- komplex
- Äventyras
- dator
- Genomför
- konflikt
- fortsätter
- kontroll
- kunde
- skapa
- skapas
- Skapa
- Aktuella
- beställnings
- cyber
- cyberattack
- Cybersäkerhet
- datum
- datavetare
- datauppsättning
- datauppsättningar
- dc
- årtionde
- Beslutet
- beslut
- djup
- djupa neurala nätverk
- Försvararna
- Försvar
- defensiv
- demonstrera
- demonstrerar
- Avdelning
- Department of Energy
- olika
- digital
- Upptäckten
- Störningar
- flera
- HIND
- Tidig
- effektivt
- effektiv
- effektivt
- ansträngningar
- e-postsäkerhet
- energi
- tillräckligt
- enheter
- Miljö
- väsentligen
- Eter (ETH)
- utvärdering
- Även
- utförande
- exfiltrering
- Förklara
- utforska
- faktorer
- Funktioner
- få
- Fält
- finna
- Förnamn
- flöda
- Forensic
- kriminalteknik
- Framåt
- hittade
- Ramverk
- från
- framtida
- skaffa sig
- få
- ger
- Målet
- Mål
- god
- sidan
- hjälpa
- HET
- Hur ser din drömresa ut
- HTTPS
- humant
- häck
- Inverkan
- med Esport
- in
- incident
- incidentrespons
- indikerar
- individuellt
- påverkas
- inledande
- integrering
- Intelligens
- IT
- sig
- Snäll
- känd
- laboratorium
- Large
- inlärning
- nivåer
- se
- Maskinen
- maskininlärning
- Huvudsida
- många
- max-bredd
- Maximera
- mekanism
- möte
- metod
- minimerande
- modell
- mer
- Motivation
- flytta
- rörliga
- multipel
- nationell
- Navigera
- Behöver
- nät
- nätverk
- neural
- neurala nätverk
- neurala nätverk
- nervceller
- öppet
- öppen källkod
- Övriga
- stilla havet
- Papper
- parametrar
- Tidigare
- perfekt
- utför
- persistens
- fas
- plato
- Platon Data Intelligence
- PlatonData
- möjlig
- drivs
- Praktisk
- presenteras
- förebyggande
- Prime
- Proaktiv
- Problem
- problem
- Produkter
- yrkesmän/kvinnor
- Profiler
- löfte
- RE
- kommit fram till
- Reagera
- reagerar
- redo
- verklig
- realtid
- senaste
- förstärkning lärande
- förblir
- forskning
- forskaren
- forskare
- respons
- Belöna
- Belöningar
- robusthet
- säger
- Forskare
- säkerhet
- Serier
- in
- inställningar
- sju
- skall
- show
- Visar
- förenklade
- simulering
- skicklighet
- lösning
- Lösningar
- några
- Alldeles strax
- Källa
- Utrymme
- specifik
- starta
- Ange
- Steg
- Steg
- Fortfarande
- Sluta
- förstärkning
- stark
- framgångsrik
- Framgångsrikt
- system
- taktik
- grupp
- tekniker
- Testning
- Smakämnen
- Framtiden
- Staten
- deras
- Genom
- tid
- till
- toolkit
- mot
- Tåg
- tränad
- Utbildning
- Trend
- under
- us
- användning
- mängd
- Omfattande
- ville
- washington
- sätt
- medan
- VEM
- kommer
- inom
- utan
- Arbete
- skulle
- vilket gav
- zephyrnet











