I dagens digitala tidsålder är data kärnan i varje organisations framgång. Ett av de mest använda formaten för att utbyta data är XML. Att analysera XML-filer är avgörande av flera anledningar. För det första används XML-filer i många branscher, inklusive finans, sjukvård och myndigheter. Att analysera XML-filer kan hjälpa organisationer att få insikter i sina data, så att de kan fatta bättre beslut och förbättra sin verksamhet. Att analysera XML-filer kan också hjälpa till med dataintegration, eftersom många applikationer och system använder XML som standarddataformat. Genom att analysera XML-filer kan organisationer enkelt integrera data från olika källor och säkerställa konsistens över sina system. Däremot innehåller XML-filer semistrukturerade, mycket kapslade data, vilket gör det svårt att komma åt och analysera information, särskilt om filen är stor och har komplext, mycket kapslat schema.
XML-filer är väl lämpade för applikationer, men de kanske inte är optimala för analysmotorer. För att förbättra frågeprestanda och möjliggöra enkel åtkomst i nedströms analysmotorer som t.ex Amazonas Athena, är det avgörande att förbehandla XML-filer till ett kolumnformat som Parquet. Denna transformation möjliggör förbättrad effektivitet och användbarhet i analysarbetsflöden. I det här inlägget visar vi hur man bearbetar XML-data med hjälp av AWS-lim och Athena.
Lösningsöversikt
Vi utforskar två distinkta tekniker som kan effektivisera ditt arbetsflöde för bearbetning av XML-filer:
- Teknik 1: Använd en AWS Glue crawler och AWS Glue visuella editor – Du kan använda AWS Glue-användargränssnittet tillsammans med en sökrobot för att definiera tabellstrukturen för dina XML-filer. Detta tillvägagångssätt ger ett användarvänligt gränssnitt och är särskilt lämpligt för individer som föredrar ett grafiskt tillvägagångssätt för att hantera sina data.
- Teknik 2: Använd AWS Glue DynamicFrames med antagna och fasta scheman – Sökroboten har en begränsning när det gäller att bearbeta en enda rad i XML-filer större än 1 MB. För att övervinna denna begränsning använder vi en AWS Glue-anteckningsbok för att konstruera AWS Glue
DynamicFrames, med användning av både härledda och fasta scheman. Denna metod säkerställer effektiv hantering av XML-filer med rader som är större än 1 MB.
I båda tillvägagångssätten är vårt slutmål att konvertera XML-filer till Apache Parquet-format, vilket gör dem lättillgängliga för frågor med Athena. Med dessa tekniker kan du förbättra bearbetningshastigheten och tillgängligheten för dina XML-data, vilket gör att du enkelt kan få värdefulla insikter.
Förutsättningar
Innan du börjar den här handledningen, fyll i följande förutsättningar (dessa gäller båda teknikerna):
- Ladda ner XML-filerna teknik1.xml och teknik2.xml.
- Ladda upp filerna till en Amazon enkel lagringstjänst (Amazon S3) hink. Du kan ladda upp dem till samma S3-hink i olika mappar eller till olika S3-hinkar.
- Skapa ett AWS identitets- och åtkomsthantering (IAM) roll för ditt ETL-jobb eller anteckningsbok enligt instruktionerna i Ställ in IAM-behörigheter för AWS Glue Studio.
- Lägg till en integrerad policy till din roll med redan: PassRole verkan:
- Lägg till en behörighetspolicy för rollen med åtkomst till din S3-bucket.
Nu när vi är klara med förutsättningarna, låt oss gå vidare till att implementera den första tekniken.
Teknik 1: Använd en AWS Glue-crawler och den visuella redigeraren
Följande diagram illustrerar den enkla arkitekturen som du kan använda för att implementera lösningen.
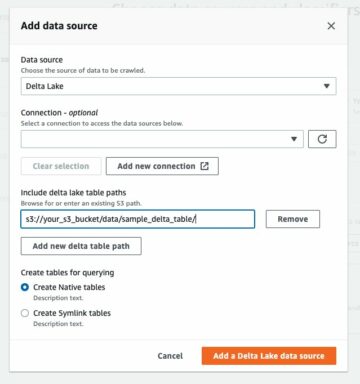
För att analysera XML-filer lagrade i Amazon S3 med AWS Glue och Athena genomför vi följande steg på hög nivå:
- Skapa en AWS Glue-sökrobot för att extrahera XML-metadata och skapa en tabell i AWS Glue Data Catalog.
- Bearbeta och omvandla XML-data till ett format (som Parkett) som är lämpligt för Athena med hjälp av ett AWS-limextraherande, transformera och ladda (ETL) jobb.
- Ställ in och kör ett AWS Glue-jobb via AWS Glue-konsolen eller AWS-kommandoradsgränssnitt (AWS CLI).
- Använd bearbetade data (i parkettformat) med Athena-tabeller, vilket möjliggör SQL-frågor.
- Använd det användarvänliga gränssnittet i Athena för att analysera XML-data med SQL-frågor på dina data lagrade i Amazon S3.
Denna arkitektur är en skalbar, kostnadseffektiv lösning för att analysera XML-data på Amazon S3 med hjälp av AWS Glue och Athena. Du kan analysera stora datamängder utan komplex infrastrukturhantering.
Vi använder AWS Glue-sökroboten för att extrahera XML-filmetadata. Du kan välja standard AWS Glue-klassificerare för generell XML-klassificering. Den upptäcker automatiskt XML-datastruktur och -schema, vilket är användbart för vanliga format.
Vi använder också en anpassad XML-klassificerare i denna lösning. Den är designad för specifika XML-scheman eller -format, vilket möjliggör exakt extrahering av metadata. Detta är idealiskt för icke-standardiserade XML-format eller när du behöver detaljerad kontroll över klassificeringen. En anpassad klassificerare säkerställer att endast nödvändig metadata extraheras, vilket förenklar nedströms bearbetning och analysuppgifter. Detta tillvägagångssätt optimerar användningen av dina XML-filer.
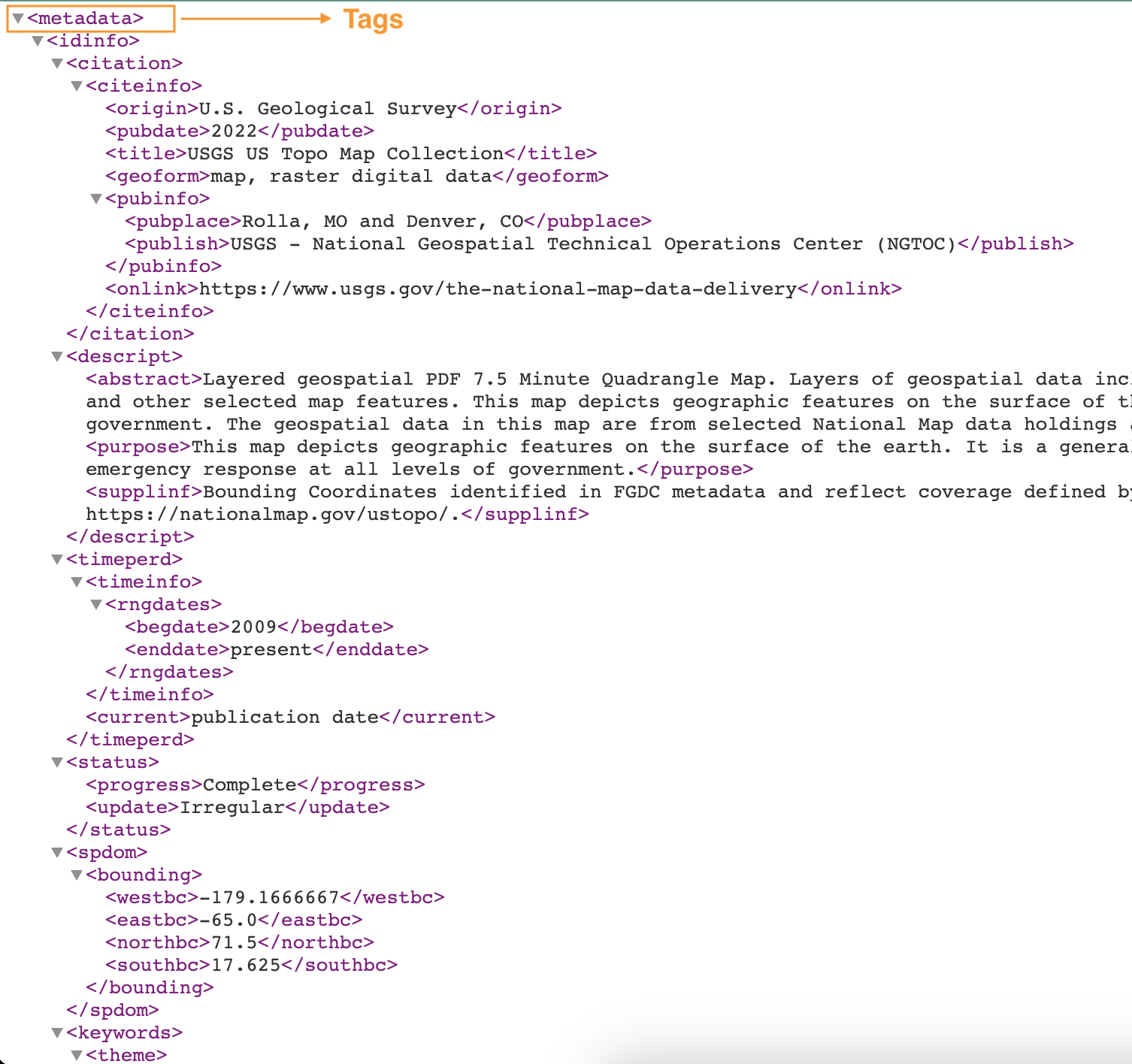
Följande skärmdump visar ett exempel på en XML-fil med taggar.
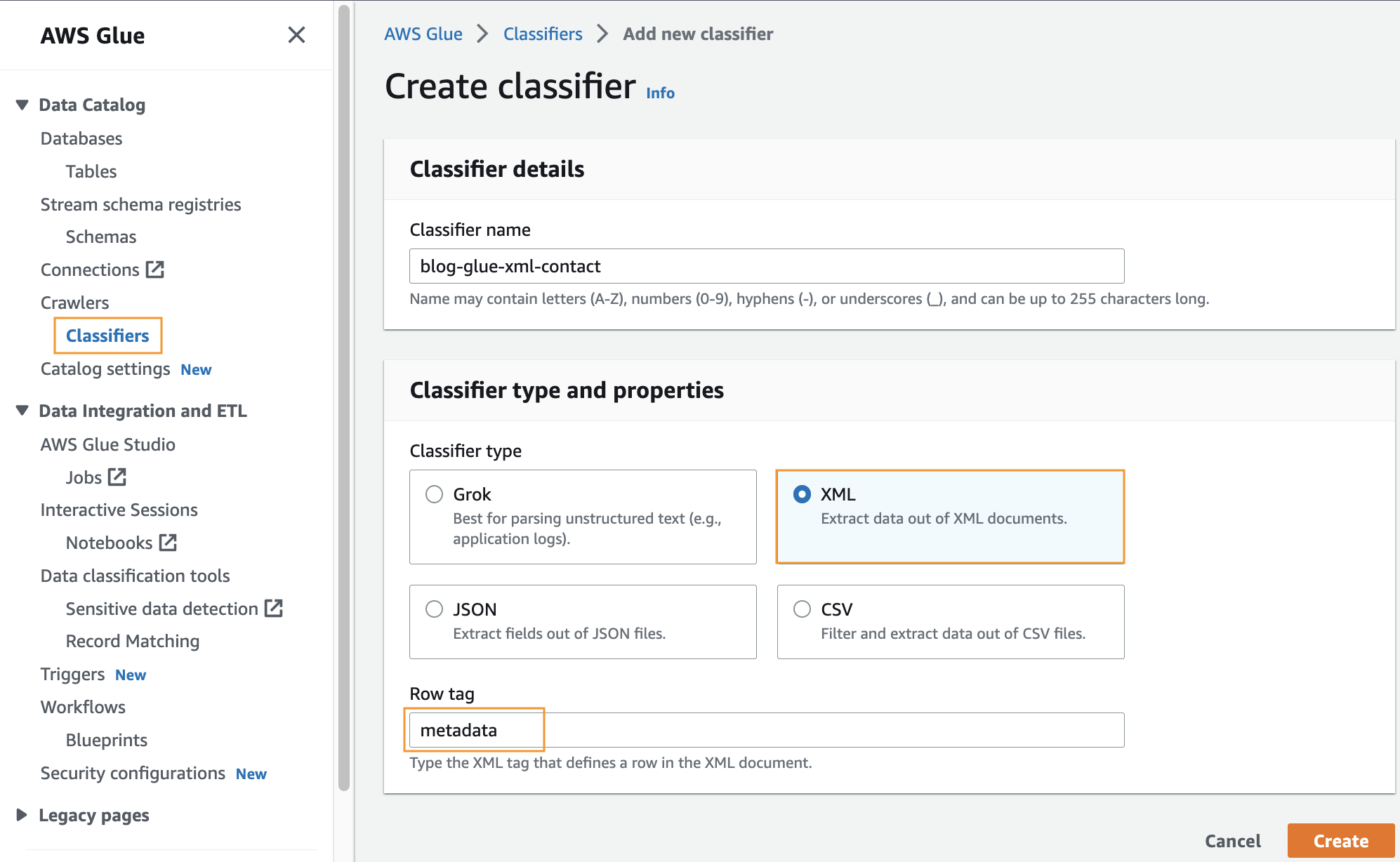
Skapa en anpassad klassificerare
I det här steget skapar du en anpassad AWS Glue-klassificerare för att extrahera metadata från en XML-fil. Slutför följande steg:
- På AWS Lim-konsolen, under crawlers välj i navigeringsfönstret klassificerare.
- Välja Lägg till klassificerare.
- Välja XML som klassificeringstyp.
- Ange ett namn för klassificeraren, t.ex
blog-glue-xml-contact. - För Radtagg, ange namnet på rottaggen som innehåller metadata (t.ex.
metadata). - Välja Skapa.
Skapa en AWS Glue Crawler för att genomsöka xml-fil
I det här avsnittet skapar vi en Glue Crawler för att extrahera metadata från XML-filen med hjälp av kundklassificeraren som skapades i föregående steg.
Skapa en databas
- Gå till AWS Limkonsolväljer Databaser i navigeringsfönstret.
- Klicka på Lägg till databas.
- Ange ett namn som t.ex
blog_glue_xml - Välja Skapa Databas
Skapa en sökrobot
Utför följande steg för att skapa din första sökrobot:
- Välj på AWS Lim-konsolen crawlers i navigeringsfönstret.
- Välja Skapa sökrobot.
- På Ställ in sökrobotegenskaper sida, ange ett namn för den nya sökroboten (t.ex
blog-glue-parquet), sedan Välj Nästa. - På Välj datakällor och klassificerare sida, välj Inte än under Konfiguration av datakälla.
- Välja Lägg till ett datalager.
- För S3 väg, bläddra till
s3://${BUCKET_NAME}/input/geologicalsurvey/.
Se till att du väljer XML-mappen istället för filen i mappen.
- Lämna resten av alternativen som standard och välj Lägg till en S3-datakälla.
- Bygga ut Anpassade klassificerare – valfritt, välj blog-lim-xml-contact och välj sedan Nästa och behåll resten av alternativen som standard.
- Välj din IAM-roll eller välj Skapa ny IAM-roll, lägg till suffixet
glue-xml-contact(till exempel,AWSGlueServiceNotebookRoleBlog) och välj Nästa. - På Ställ in utdata och schemaläggning sida, under Konfiguration av utdataväljer
blog_glue_xmlför Måldatabas. - ange
console_som prefix som lagts till i tabeller (valfritt) och under Crawler-schema, behåll frekvensen inställd på På begäran. - Välja Nästa.
- Granska alla parametrar och välj Skapa sökrobot.
Kör sökroboten
När du har skapat sökroboten utför du följande steg för att köra den:
- Välj på AWS Lim-konsolen crawlers i navigeringsfönstret.
- Öppna sökroboten du skapade och välj Körning.
Sökroboten tar 1–2 minuter att slutföra.
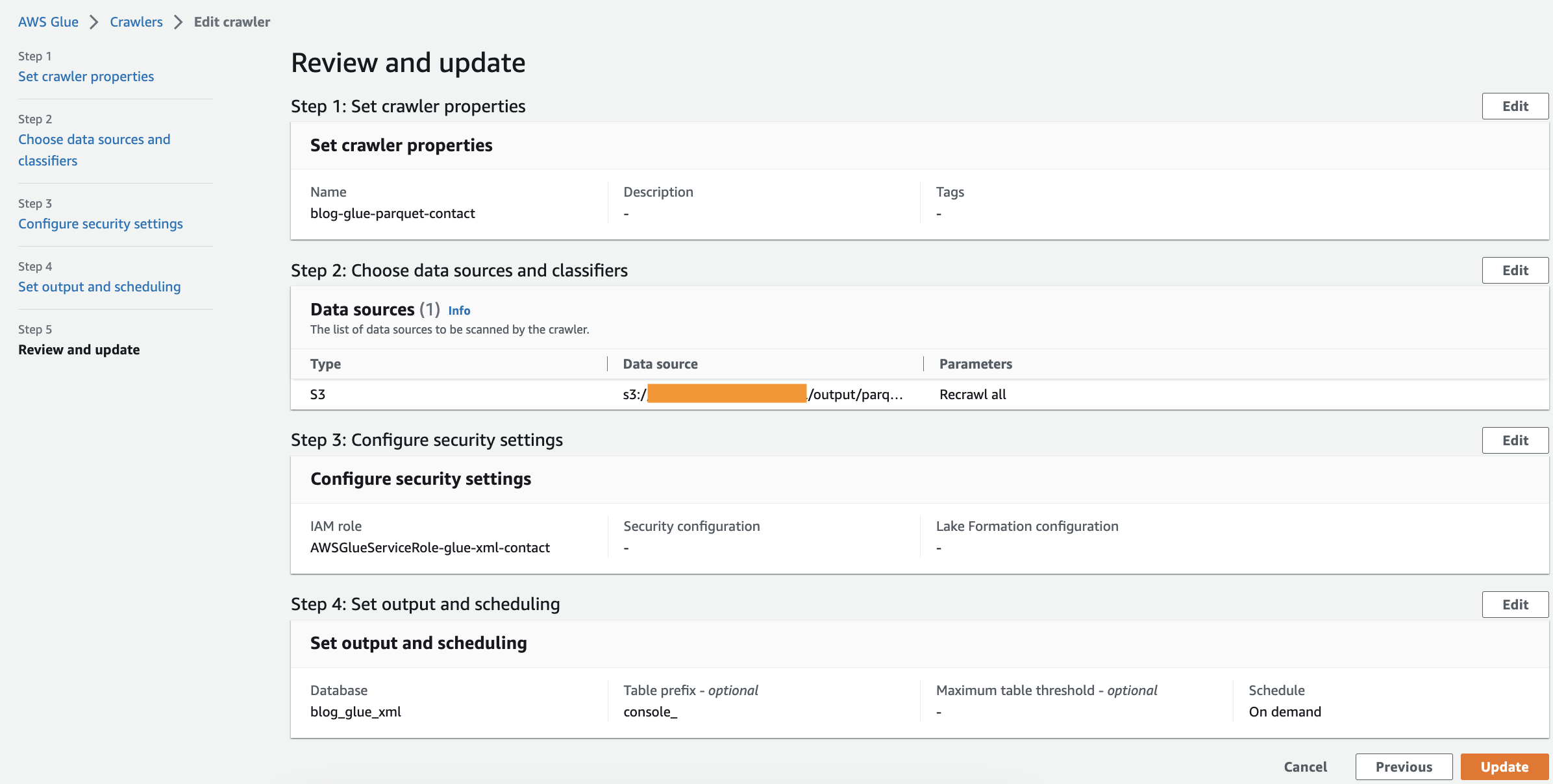
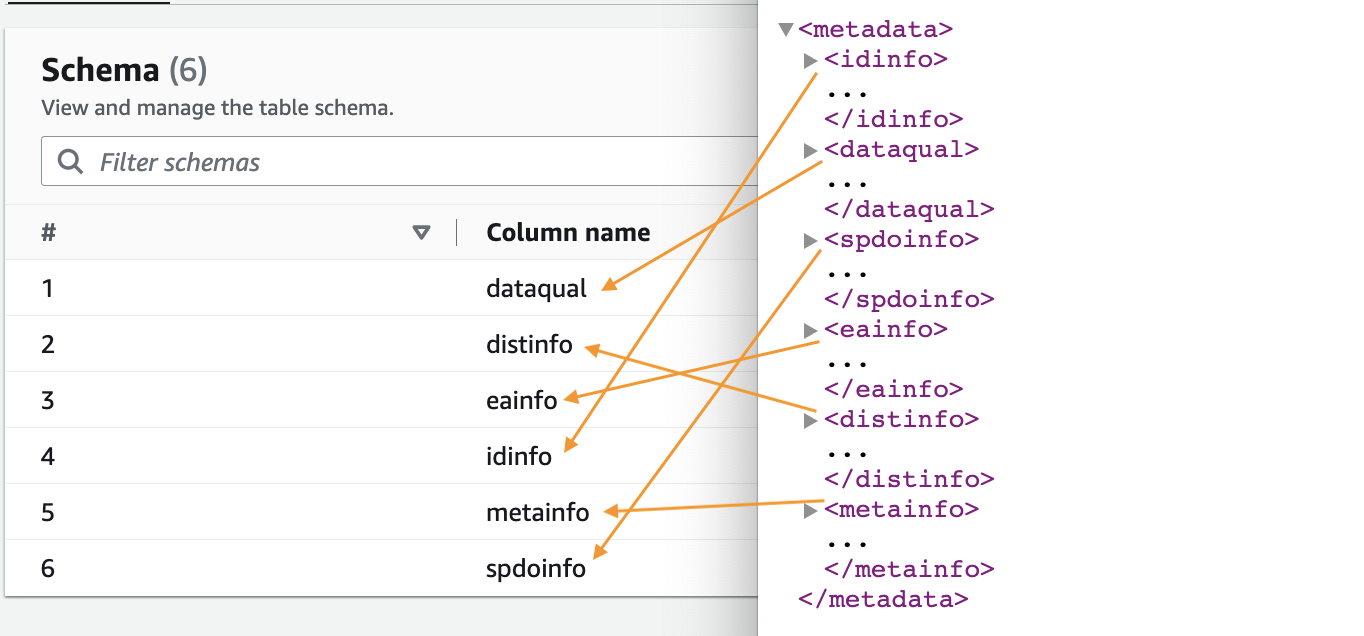
- När sökroboten är klar väljer du Databaser i navigeringsfönstret.
- Välj databasen du skapade och välj tabellnamnet för att se schemat extraherat av sökroboten.
Skapa ett AWS-limjobb för att konvertera XML till parkettformat
I det här steget skapar du ett AWS Glue Studio-jobb för att konvertera XML-filen till en Parkett-fil. Slutför följande steg:
- Välj på AWS Lim-konsolen Lediga jobb i navigeringsfönstret.
- Enligt Skapa jobb, Välj Visual med en tom duk.
- Välja Skapa.
- Byt namn på jobbet till
blog_glue_xml_job.
Nu har du en tom AWS Glue Studio visuell jobbredigerare. Överst i redigeraren finns flikarna för olika vyer.
- Välj Script fliken för att se ett tomt skal av AWS Glue ETL-skriptet.
När vi lägger till nya steg i den visuella redigeraren kommer skriptet att uppdateras automatiskt.
- Välj Jobb detaljer fliken för att se alla jobbkonfigurationer.
- För IAM-rollväljer
AWSGlueServiceNotebookRoleBlog. - För Limversionväljer Lim 4.0 – Support Spark 3.3, Scala 2, Python 3.
- uppsättning Begärt antal arbetare till 2.
- uppsättning Antal återförsök till 0.
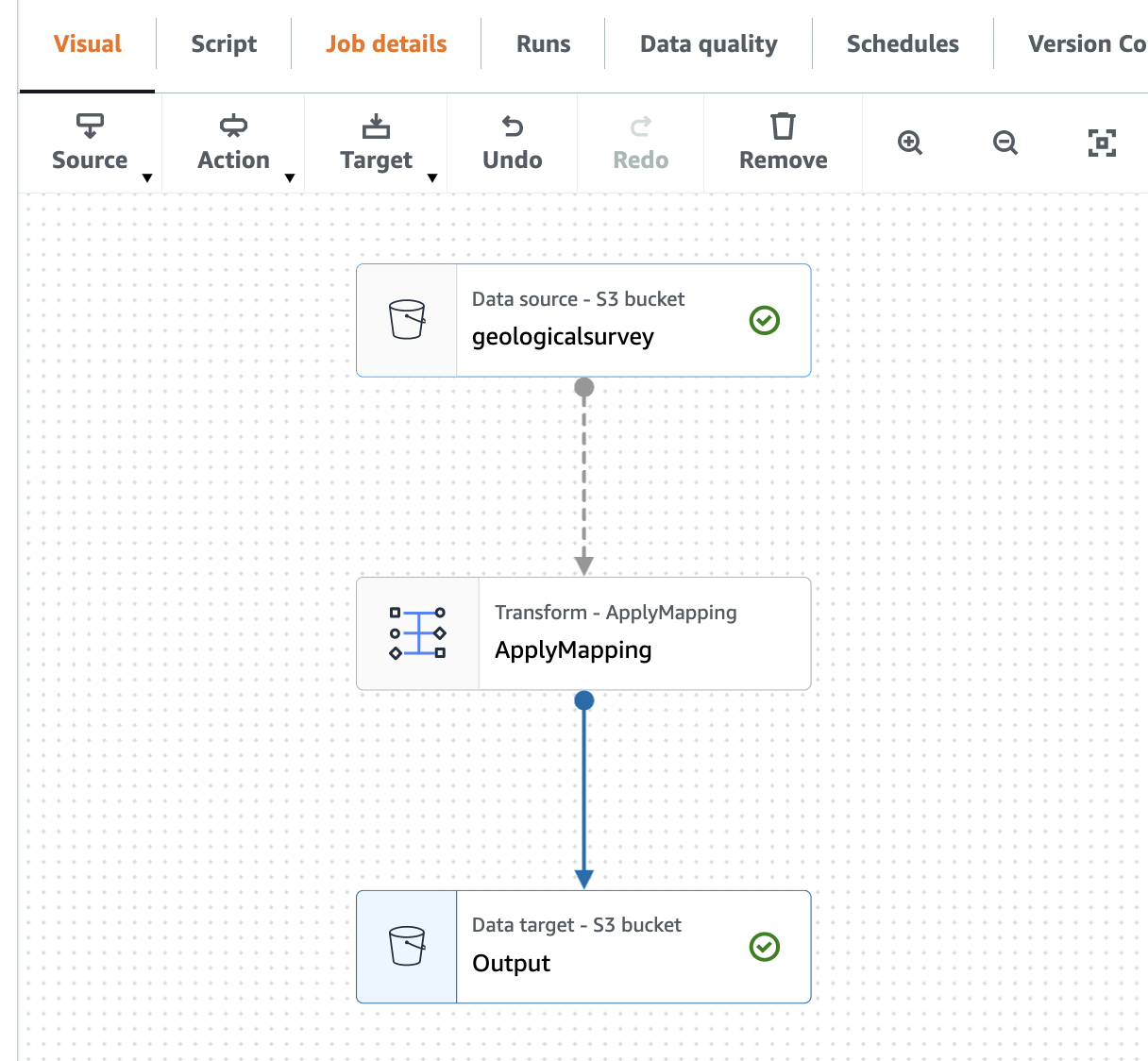
- Välj Visuell för att gå tillbaka till den visuella redigeraren.
- På Källa rullgardinsmeny, välj AWS limdatakatalog.
- På Datakällans egenskaper – Datakatalog fliken, ange följande information:
- För Databasväljer
blog_glue_xml. - För Bord, välj tabellen som börjar med namnet console_ som sökroboten skapade (till exempel,
console_geologicalsurvey).
- För Databasväljer
- På Nodegenskaper fliken, ange följande information:
- byta Namn till
geologicalsurveydatasätt. - Välja Handling och förvandlingen Ändra schema (tillämpa mappning).
- Välja Nodegenskaper och ändra namnet på transformationen från Change Schema (Apply Mapping) till
ApplyMapping. - På Målet meny, välj S3.
- byta Namn till
- På Datakällegenskaper - S3 fliken, ange följande information:
- För bildad, Välj Parkett.
- För Komprimeringstyp, Välj Okomprimerad.
- För S3 källtyp, Välj S3-plats.
- För S3 URL, stiga på
s3://${BUCKET_NAME}/output/parquet/. - Välja Nodegenskaper och ändra namnet till
Output.
- Välja Save för att rädda jobbet.
- Välja Körning att köra jobbet.
Följande skärmdump visar jobbet i den visuella redigeraren.
Skapa en AWS Gue Crawler för att genomsöka Parkett-filen
I det här steget skapar du en AWS Glue-crawler för att extrahera metadata från den parkettfil du skapade med ett AWS Glue Studio-jobb. Den här gången använder du standardklassificeraren. Slutför följande steg:
- Välj på AWS Lim-konsolen crawlers i navigeringsfönstret.
- Välja Skapa sökrobot.
- På Ställ in sökrobotegenskaper sida, ange ett namn för den nya sökroboten, till exempel blogg-lim-parkett-kontakt, och välj sedan Nästa.
- På Välj datakällor och klassificerare sida, välj Inte än för Konfiguration av datakälla.
- Välja Lägg till ett datalager.
- För S3 väg, bläddra till
s3://${BUCKET_NAME}/output/parquet/.
Se till att du väljer parquet mappen i stället för filen i mappen.
- Välj din IAM-roll som skapades under förutsättningsavsnittet eller välj Skapa ny IAM-roll (till exempel,
AWSGlueServiceNotebookRoleBlog) och välj Nästa. - På Ställ in utdata och schemaläggning sida, under Konfiguration av utdataväljer
blog_glue_xmlför Databas. - ange
parquet_som prefix som lagts till i tabeller (valfritt) och under Crawler-schema, behåll frekvensen inställd på På begäran. - Välja Nästa.
- Granska alla parametrar och välj Skapa sökrobot.
Nu kan du köra sökroboten, som tar 1–2 minuter att slutföra.

Du kan förhandsgranska det nyskapade schemat för Parquet-filen i AWS Glue Data Catalog, som liknar schemat för XML-filen.
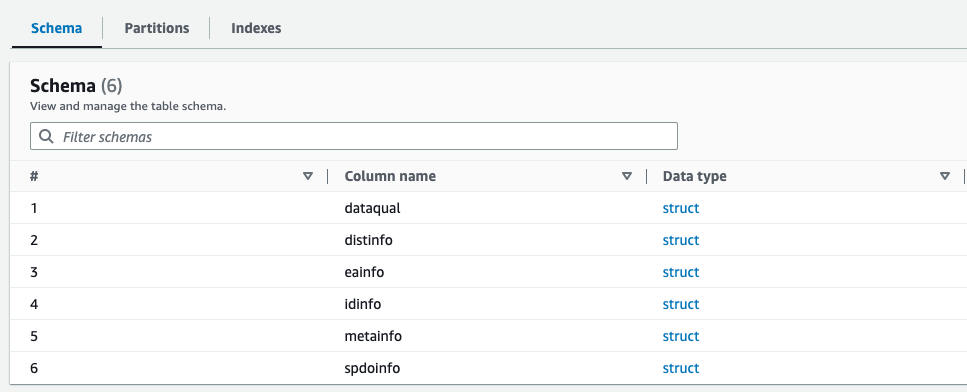
Vi har nu data som är lämpliga att använda med Athena. I nästa avsnitt utför vi datafrågor med Athena.
Fråga efter Parkett-filen med Athena
Athena stöder inte fråga om XML-filformat, vilket är anledningen till att du konverterade XML-filen till Parquet för effektivare dataförfrågningar och användning punktnotation för att fråga komplexa typer och kapslade strukturer.
Följande exempelkod använder punktnotation för att fråga efter kapslade data:
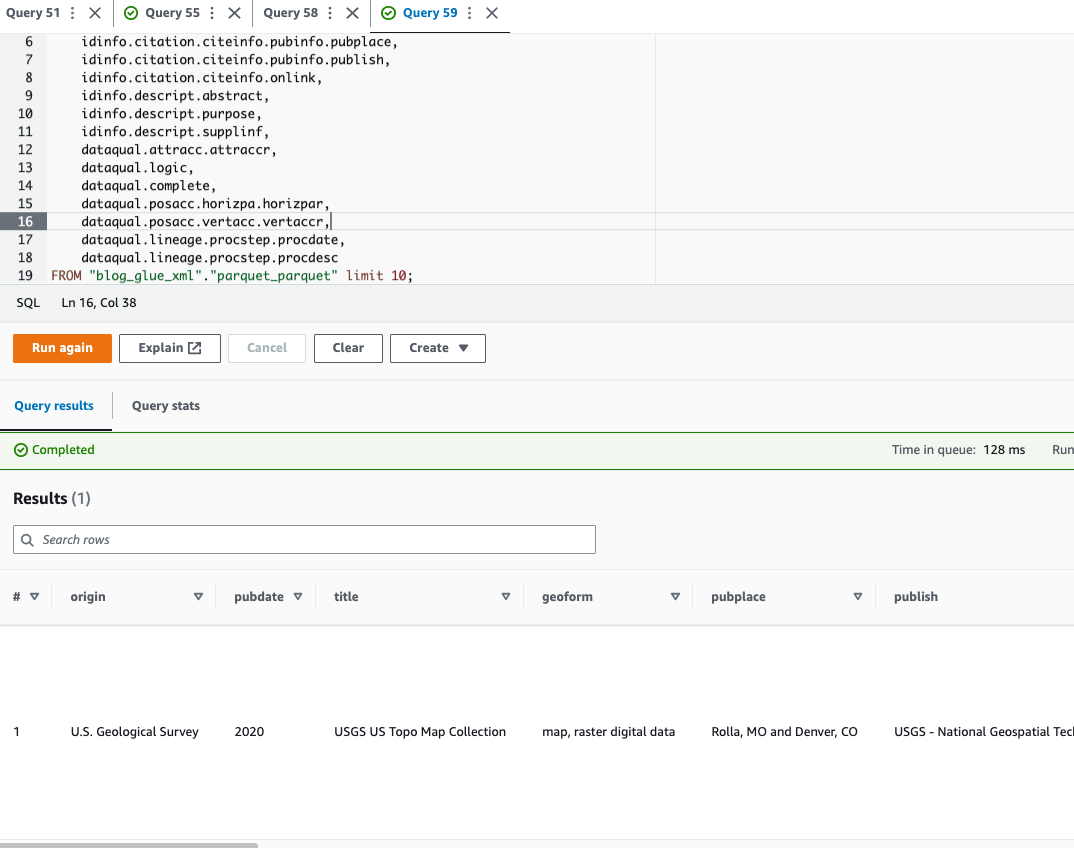
Nu när vi har slutfört teknik 1, låt oss gå vidare för att lära oss om teknik 2.
Teknik 2: Använd AWS Glue DynamicFrames med antagna och fasta scheman
I föregående avsnitt behandlade vi processen att hantera en liten XML-fil med hjälp av en AWS Glue-crawler för att generera en tabell, ett AWS Glue-jobb för att konvertera filen till Parkett-format och Athena för att komma åt Parkettdata. Sökroboten stöter dock på begränsningar när det gäller att bearbeta XML-filer som överskrider 1 MB i storlek. I det här avsnittet fördjupar vi oss i ämnet batchbearbetning av större XML-filer, vilket kräver ytterligare analys för att extrahera enskilda händelser och utföra analyser med Athena.
Vårt tillvägagångssätt innebär att läsa XML-filerna genom AWS Glue DynamicFrames, som använder både härledda och fasta scheman. Sedan extraherar vi de enskilda händelserna i parkettformat med hjälp av relationalisera transformation, vilket gör att vi kan fråga och analysera dem sömlöst med Athena.
För att implementera den här lösningen genomför du följande steg på hög nivå:
- Skapa en AWS Glue-anteckningsbok för att läsa och analysera XML-filen.
- Använda
DynamicFramesmedInferSchemaför att läsa XML-filen. - Använd relationsfunktionen för att avnesta alla arrayer.
- Konvertera data till parkettformat.
- Fråga efter parkettdata med Athena.
- Upprepa de föregående stegen, men den här gången skicka ett schema till
DynamicFramesistället för att användaInferSchema.
XML-filen för befolkningsdata för elfordon har en response taggen på sin rotnivå. Den här taggen innehåller en array av row taggar, som är kapslade i den. Radtaggen är en array som innehåller en uppsättning andra radtaggar, som ger information om ett fordon, inklusive dess märke, modell och andra relevanta detaljer. Följande skärmdump visar ett exempel.

Skapa en AWS Glue Notebook
För att skapa en AWS Glue-anteckningsbok, slutför följande steg:
- Öppna AWS Lim Studio konsol, välj Lediga jobb i navigeringsfönstret.
- Välja Jupyter Notebook Och välj Skapa.
- Ange ett namn för ditt AWS-limjobb, t.ex
blog_glue_xml_job_Jupyter. - Välj rollen som du skapade i förutsättningarna (
AWSGlueServiceNotebookRoleBlog).
AWS Glue-anteckningsboken kommer med ett redan existerande exempel som visar hur man frågar en databas och skriver utdata till Amazon S3.
- Justera timeout (i minuter) som visas i följande skärmdump och kör cellen för att skapa den interaktiva AWS Glue-sessionen.
Skapa grundläggande variabler
När du har skapat den interaktiva sessionen, i slutet av anteckningsboken, skapar du en ny cell med följande variabler (ange ditt eget hinknamn):
Läs XML-filen som härleder schemat
Om du inte skickar ett schema till DynamicFrame, kommer det att härleda schemat för filerna. För att läsa data med en dynamisk ram kan du använda följande kommando:
Skriv ut DynamicFrame Schema
Skriv ut schemat med följande kod:
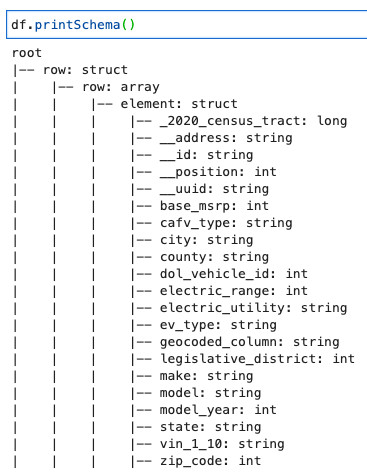
Schemat visar en kapslad struktur med en row array som innehåller flera element. För att ta bort den här strukturen i linjer kan du använda AWS-limmet relationalisera omvandling:
Vi är bara intresserade av informationen i radmatrisen, och vi kan se schemat genom att använda följande kommando:
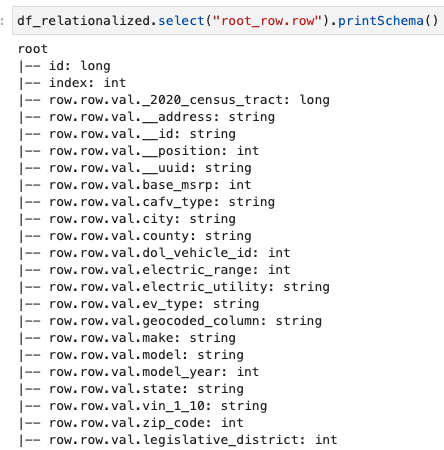
Kolumnnamnen innehåller row.row, som motsvarar arraystrukturen och arraykolumnen i datamängden. Vi byter inte namn på kolumnerna i det här inlägget; för instruktioner för att göra det, se Automatisera dynamisk mappning och byta namn på kolumnnamn i datafiler med AWS Glue: Del 1. Sedan kan du konvertera data till parkettformat och skapa AWS Glue-tabellen med följande kommando:
AWS-lim DynamicFrame tillhandahåller funktioner som du kan använda i ditt ETL-skript för att skapa och uppdatera ett schema i datakatalogen. Vi använder updateBehavior parameter för att skapa tabellen direkt i datakatalogen. Med detta tillvägagångssätt behöver vi inte köra en AWS Glue-crawler efter att AWS Glue-jobbet är klart.

Läs XML-filen genom att ställa in ett schema
Ett alternativt sätt att läsa filen är att fördefiniera ett schema. För att göra detta, slutför följande steg:
- Importera AWS Glue-datatyperna:
- Skapa ett schema för XML-filen:
- Skicka schemat när du läser XML-filen:
- Ta bort datamängden som tidigare:
- Konvertera datasetet till Parkett och skapa AWS Glue-tabellen:
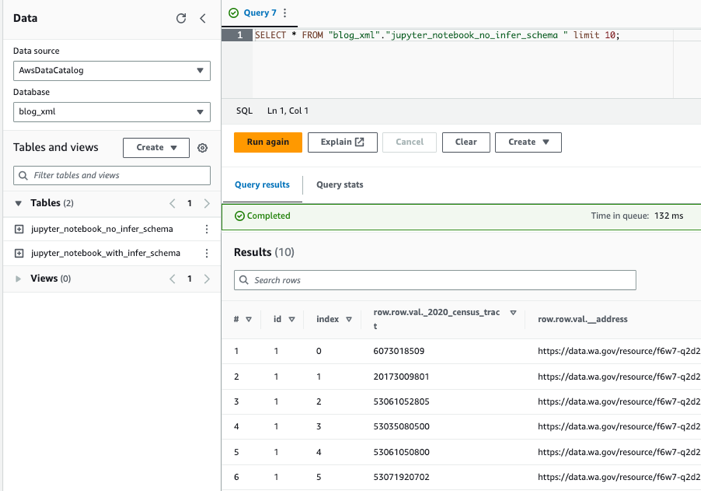
Fråga tabellerna med Athena
Nu när vi har skapat båda tabellerna kan vi fråga tabellerna med Athena. Vi kan till exempel använda följande fråga:
Clean Up
I det här inlägget skapade vi en IAM-roll, en AWS Glue Jupyter-anteckningsbok och två tabeller i AWS Glue Data Catalog. Vi laddade också upp några filer till en S3-hink. Utför följande steg för att rensa upp dessa objekt:
- Ta bort rollen du skapade på IAM-konsolen.
- Ta bort den anpassade klassificeraren, sökroboten, ETL-jobben och Jupyter-anteckningsboken på AWS Glue Studio-konsolen.
- Navigera till AWS Glue Data Catalog och ta bort tabellerna du skapade.
- På Amazon S3-konsolen, navigera till hinken du skapade och ta bort de namngivna mapparna
temp,infer_schemaochno_infer_schema.
Key Takeaways
I AWS Glue finns det en funktion som heter InferSchema i AWS Glue DynamicFrames. Den räknar automatiskt ut strukturen för en dataram baserat på data den innehåller. Däremot innebär att definiera ett schema att uttryckligen ange hur dataramens struktur ska vara innan data laddas.
XML, som är ett textbaserat format, begränsar inte datatyperna i dess kolumner. Detta kan orsaka problem med InferSchema-funktionen. Till exempel, i den första körningen, resulterar en fil med kolumn A med värdet 2 i en parkettfil med kolumn A som ett heltal. I den andra körningen har en ny fil kolumn A med värdet C, vilket leder till en Parkettfil med kolumn A som en sträng. Nu finns det två filer på S3, var och en med en kolumn A med olika datatyper, vilket kan skapa problem nedströms.
Samma sak händer med komplexa datatyper som kapslade strukturer eller arrayer. Till exempel, om en fil har en taggpost som kallas transaction, antas det som en struktur. Men om en annan fil har samma tagg, antas den vara en array
Trots dessa datatypproblem, InferSchema är användbart när du inte känner till schemat eller att definiera ett manuellt är opraktiskt. Det är dock inte idealiskt för stora eller ständigt föränderliga datauppsättningar. Att definiera ett schema är mer exakt, särskilt med komplexa datatyper, men har sina egna problem, som att kräva manuell ansträngning och att vara oflexibel med dataändringar.
InferSchema har begränsningar, som felaktig datatyp slutledning och problem med att hantera nollvärden. Att definiera ett schema har också begränsningar, som manuell ansträngning och potentiella fel.
Att välja mellan att sluta och definiera ett schema beror på projektets behov. InferSchema är utmärkt för snabb utforskning av små datauppsättningar, medan definition av ett schema är bättre för större, komplexa datauppsättningar som kräver noggrannhet och konsekvens. Tänk på avvägningarna och begränsningarna för varje metod för att välja vad som passar ditt projekt bäst.
Slutsats
I det här inlägget utforskade vi två tekniker för att hantera XML-data med AWS Glue, var och en skräddarsydd för att möta specifika behov och utmaningar du kan stöta på.
Teknik 1 erbjuder en användarvänlig väg för dem som föredrar ett grafiskt gränssnitt. Du kan använda en AWS Glue-sökrobot och den visuella redigeraren för att enkelt definiera tabellstrukturen för dina XML-filer. Detta tillvägagångssätt förenklar datahanteringsprocessen och är särskilt tilltalande för dem som letar efter ett enkelt sätt att hantera sin data.
Vi inser dock att sökroboten har sina begränsningar, särskilt när det gäller XML-filer som har rader större än 1 MB. Det är här teknik 2 kommer till undsättning. Genom att utnyttja AWS Glue DynamicFrames med både indikerade och fasta scheman, och med en AWS Glue-anteckningsbok, kan du effektivt hantera XML-filer av alla storlekar. Denna metod ger en robust lösning som säkerställer sömlös bearbetning även för XML-filer med rader som överskrider begränsningen på 1 MB.
När du navigerar i datahanteringens värld ger dessa tekniker i din verktygslåda dig möjlighet att fatta välgrundade beslut baserat på de specifika kraven i ditt projekt. Oavsett om du föredrar enkelheten i teknik 1 eller skalbarheten i teknik 2, ger AWS Glue den flexibilitet du behöver för att hantera XML-data effektivt.
Om författarna
 Navnit Shuklafungerar som AWS Specialist Solution Architect med fokus på Analytics. Han har en stark entusiasm för att hjälpa kunder att upptäcka värdefulla insikter från deras data. Genom sin expertis konstruerar han innovativa lösningar som gör det möjligt för företag att komma fram till informerade, datadrivna val. Noterbart är Navnit Shukla den fulländade författaren till boken med titeln "Data Wrangling on AWS.
Navnit Shuklafungerar som AWS Specialist Solution Architect med fokus på Analytics. Han har en stark entusiasm för att hjälpa kunder att upptäcka värdefulla insikter från deras data. Genom sin expertis konstruerar han innovativa lösningar som gör det möjligt för företag att komma fram till informerade, datadrivna val. Noterbart är Navnit Shukla den fulländade författaren till boken med titeln "Data Wrangling on AWS.
 Patrick Muller arbetar som Senior Data Lab Architect på AWS. Hans huvudansvar är att hjälpa kunderna att omvandla sina idéer till en produktionsklar dataprodukt. På fritiden tycker Patrick om att spela fotboll, titta på film och resa.
Patrick Muller arbetar som Senior Data Lab Architect på AWS. Hans huvudansvar är att hjälpa kunderna att omvandla sina idéer till en produktionsklar dataprodukt. På fritiden tycker Patrick om att spela fotboll, titta på film och resa.
 Amogh Gaikwad är senior lösningsutvecklare på Amazon Web Services. Han hjälper globala kunder att bygga och distribuera AI/ML-lösningar på AWS. Hans arbete är främst inriktat på datorseende och naturlig språkbehandling och att hjälpa kunder att optimera sina AI/ML-arbetsbelastningar för hållbarhet. Amogh har tagit sin magisterexamen i datavetenskap med inriktning mot maskininlärning.
Amogh Gaikwad är senior lösningsutvecklare på Amazon Web Services. Han hjälper globala kunder att bygga och distribuera AI/ML-lösningar på AWS. Hans arbete är främst inriktat på datorseende och naturlig språkbehandling och att hjälpa kunder att optimera sina AI/ML-arbetsbelastningar för hållbarhet. Amogh har tagit sin magisterexamen i datavetenskap med inriktning mot maskininlärning.
 Sheela Sonone är Senior Resident Architect på AWS. Hon hjälper AWS-kunder att göra välgrundade val och avvägningar om att accelerera deras data, analyser och AI/ML-arbetsbelastningar och implementeringar. På fritiden umgås hon gärna med sin familj – oftast på tennisbanor.
Sheela Sonone är Senior Resident Architect på AWS. Hon hjälper AWS-kunder att göra välgrundade val och avvägningar om att accelerera deras data, analyser och AI/ML-arbetsbelastningar och implementeringar. På fritiden umgås hon gärna med sin familj – oftast på tennisbanor.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- : har
- :är
- :inte
- :var
- $UPP
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- Om oss
- SAMMANDRAG
- accelererande
- tillgång
- tillgänglighet
- åstadkommit
- noggrannhet
- tvärs
- Handling
- lägga till
- lagt till
- Annat
- adress
- Efter
- ålder
- AI / ML
- Alla
- tillåter
- tillåta
- tillåter
- också
- alternativ
- amason
- Amazonas Athena
- Amazon Web Services
- an
- analys
- analytics
- analysera
- analys
- och
- Annan
- vilken som helst
- Apache
- lockande
- tillämpningar
- Ansök
- tillvägagångssätt
- tillvägagångssätt
- arkitektur
- ÄR
- array
- AS
- bistå
- bistå
- At
- Författaren
- automatiskt
- tillgänglig
- AWS
- AWS-lim
- tillbaka
- baserat
- grundläggande
- BE
- därför att
- innan
- börja
- Där vi får lov att vara utan att konstant prestera,
- BÄST
- Bättre
- mellan
- blank
- boken
- båda
- SLUTRESULTAT
- företag
- men
- by
- kallas
- KAN
- katalog
- Orsak
- cellen
- utmaningar
- byta
- Förändringar
- byte
- val
- Välja
- Stad
- klassificering
- klienter
- koda
- Kolumn
- Kolonner
- COM
- kommer
- Gemensam
- vanligen
- fullborda
- Avslutade
- komplex
- dator
- Datavetenskap
- Datorsyn
- tillstånd
- Genomför
- förening
- Tänk
- Konsol
- ständigt
- begränsningar
- konstruera
- innehålla
- innehöll
- innehåller
- Däremot
- kontroll
- konvertera
- konverterad
- kostnadseffektiv
- kostnadseffektiv lösning
- län
- Domstolar
- omfattas
- sökrobot
- skapa
- skapas
- Skapa
- avgörande
- beställnings
- kund
- Kunder
- datum
- dataintegration
- datahantering
- data driven
- Databas
- datauppsättningar
- som handlar om
- beslut
- Standard
- definiera
- definierande
- gräva
- demonstrerar
- beror
- distribuera
- utformade
- detaljerad
- detaljer
- Utvecklare
- olika
- svårt
- digital
- digital ålder
- direkt
- upptäcka
- distinkt
- do
- inte
- gjort
- inte
- DOT
- under
- dynamisk
- varje
- lätta
- lätt
- lätt
- redaktör
- effekt
- effektivt
- effektivitet
- effektiv
- effektivt
- ansträngning
- enkelt
- elektriska
- elbil
- element
- utnyttjande
- ge
- bemyndigar
- tom
- möjliggöra
- möjliggör
- råka ut för
- änden
- Motorer
- förbättra
- säkerställa
- säkerställer
- ange
- entusiasm
- inträde
- fel
- speciellt
- Eter (ETH)
- Även
- händelser
- Varje
- exempel
- överstiga
- utbyte
- expertis
- utforskning
- utforska
- utforskas
- extrahera
- extraktion
- familj
- Leverans
- Funktioner
- siffror
- Fil
- Filer
- finansiering
- Förnamn
- fixerad
- Flexibilitet
- Fokus
- fokuserade
- efter
- För
- format
- RAM
- Fri
- Frekvens
- från
- fungera
- Få
- generell mening
- generera
- Välgörenhet
- Go
- Målet
- Regeringen
- stor
- hantera
- Arbetsmiljö
- händer
- Utnyttja
- Har
- har
- he
- hälso-och sjukvård
- Hjärta
- hjälpa
- hjälpa
- hjälper
- här
- högnivå
- höggradigt
- hans
- Hur ser din drömresa ut
- How To
- Men
- html
- http
- HTTPS
- IAM
- idealisk
- idéer
- Identitet
- if
- illustrerar
- genomföra
- implementeringar
- genomföra
- importera
- förbättra
- förbättras
- in
- Inklusive
- individuellt
- individer
- industrier
- informationen
- informeras
- Infrastruktur
- innovativa
- inuti
- insikter
- istället
- instruktioner
- integrera
- integrering
- interaktiva
- intresserad
- Gränssnitt
- in
- innebär
- problem
- IT
- DESS
- Jobb
- Lediga jobb
- jpg
- json
- Jupyter Notebook
- Ha kvar
- Vet
- lab
- språk
- Large
- större
- ledande
- LÄRA SIG
- inlärning
- Nivå
- tycka om
- BEGRÄNSA
- begränsning
- begränsningar
- linje
- rader
- läsa in
- läser in
- Logiken
- du letar
- Maskinen
- maskininlärning
- Huvudsida
- huvudsakligen
- göra
- Framställning
- ledning
- hantera
- manuell
- manuellt
- många
- kartläggning
- master
- Maj..
- betyder
- Meny
- metadata
- metod
- minuter
- modell
- mer
- mer effektiv
- mest
- flytta
- Filmer
- multipel
- namn
- Som heter
- namn
- Natural
- Naturligt språk
- Naturlig språkbehandling
- Navigera
- Navigering
- nödvändigt för
- Behöver
- behov
- Nya
- nytt
- Nästa
- i synnerhet
- anteckningsbok
- nu
- antal
- objekt
- of
- Erbjudanden
- on
- ONE
- endast
- Verksamhet
- optimala
- Optimera
- optimerar
- Tillbehör
- or
- beställa
- organisationer
- Ursprung
- Övriga
- vår
- ut
- produktion
- över
- Övervinna
- egen
- sida
- panelen
- parameter
- parametrar
- del
- särskilt
- passera
- bana
- patrick
- utföra
- prestanda
- behörigheter
- plocka
- plato
- Platon Data Intelligence
- PlatonData
- i
- policy
- befolkning
- besitter
- Inlägg
- potentiell
- exakt
- föredra
- förutsättningar
- Förhandsvisning
- föregående
- problem
- process
- bearbetade
- bearbetning
- Produkt
- projektet
- projekt
- egenskaper
- ge
- ger
- publicera
- Syftet
- Python
- sökfrågor
- Snabbt
- snarare
- Läsa
- lätt
- Läsning
- skäl
- mottagna
- känner igen
- hänvisa
- relevanta
- Krav
- rädda
- resurs
- respons
- ansvaret
- REST
- begränsa
- begränsning
- Resultat
- robusta
- Roll
- rot
- RAD
- Körning
- Samma
- Save
- Skala
- skalbarhet
- skalbar
- Vetenskap
- skript
- sömlös
- sömlöst
- Andra
- §
- se
- senior
- Tjänster
- session
- in
- inställning
- flera
- hon
- Shell
- skall
- show
- visas
- Visar
- liknande
- Enkelt
- enkelhet
- förenkla
- enda
- Storlek
- Small
- So
- Fotboll
- lösning
- Lösningar
- några
- Källa
- Källor
- Gnista
- specialist
- specialiserat
- specifik
- specifikt
- fart
- Spendera
- SQL
- standard
- startar
- Ange
- .
- anger
- Steg
- Steg
- förvaring
- lagras
- okomplicerad
- effektivisera
- Sträng
- stark
- struktur
- strukturer
- studio
- framgång
- sådana
- lämplig
- stödja
- säker
- Hållbarhet
- System
- bord
- MÄRKA
- skräddarsydd
- Ta
- tar
- uppgifter
- tekniker
- tennis
- än
- den där
- Smakämnen
- den information
- världen
- deras
- Dem
- sedan
- Där.
- Dessa
- de
- detta
- de
- Genom
- tid
- Titel
- betitlad
- till
- dagens
- toolkit
- topp
- ämne
- Förvandla
- Transformation
- Traveling
- Vrida
- handledning
- två
- Typ
- typer
- slutliga
- under
- Uppdatering
- uppdaterad
- uppladdad
- us
- användbarhet
- användning
- Begagnade
- Användare
- Användargränssnitt
- användarvänligt
- användningar
- med hjälp av
- vanligen
- Använda
- Värdefulla
- värde
- Värden
- vehikel
- version
- via
- utsikt
- visningar
- syn
- tittar
- Sätt..
- we
- webb
- webbservice
- Vad
- när
- medan
- om
- som
- VEM
- varför
- kommer
- med
- inom
- utan
- Arbete
- arbetsflöde
- arbetsflöden
- fungerar
- världen
- skriva
- XML
- dig
- Din
- zephyrnet