
När AI migrerar från molnet till Edge ser vi att tekniken används i ett ständigt växande antal användningsfall – allt från avvikelsedetektering till applikationer inklusive smart shopping, övervakning, robotik och fabriksautomation. Därför finns det ingen lösning som passar alla. Men med den snabba tillväxten av kameraaktiverade enheter har AI använts mest för att analysera videodata i realtid för att automatisera videoövervakning för att öka säkerheten, förbättra drifteffektiviteten och ge bättre kundupplevelser, vilket i slutändan får en konkurrensfördel i sina branscher . För att bättre stödja videoanalys måste du förstå strategierna för att optimera systemprestanda i Edge AI-distributioner.
- Välja beräkningsmotorer av rätt storlek för att möta eller överträffa de erforderliga prestandanivåerna. För en AI-applikation måste dessa beräkningsmotorer utföra funktionerna för hela visionpipelinen (dvs videoför- och efterbearbetning, neurala nätverksinferencing).
En dedikerad AI-accelerator, oavsett om den är diskret eller integrerad i en SoC (i motsats till att köra AI-inferencing på en CPU eller GPU) kan behövas.
- Förstå skillnaden mellan genomströmning och latens; varvid genomströmning är den hastighet som data kan bearbetas i ett system och latens mäter databehandlingsfördröjningen genom systemet och är ofta associerad med känslighet i realtid. Till exempel kan ett system generera bilddata med 100 bilder per sekund (genomströmning) men det tar 100 ms (latens) för en bild att gå igenom systemet.
- Med tanke på möjligheten att enkelt skala AI-prestanda i framtiden för att tillgodose växande behov, förändrade krav och utvecklande teknologier (t.ex. mer avancerade AI-modeller för ökad funktionalitet och precision). Du kan uppnå prestandaskalning med AI-acceleratorer i modulformat eller med ytterligare AI-acceleratorchips.
De faktiska prestandakraven är applikationsberoende. Vanligtvis kan man förvänta sig att för videoanalys måste systemet behandla dataströmmar som kommer in från kameror med 30-60 bilder per sekund och med en upplösning på 1080p eller 4k. En AI-aktiverad kamera skulle behandla en enda ström; en kantapparat skulle behandla flera strömmar parallellt. I båda fallen måste edge AI-systemet stödja förbehandlingsfunktionerna för att omvandla kamerans sensordata till ett format som matchar ingångskraven för AI-inferensavsnittet (Figur 1).
Förbearbetningsfunktioner tar in rådata och utför uppgifter som storleksändring, normalisering och färgrymdskonvertering innan indata matas in i modellen som körs på AI-acceleratorn. Förbehandling kan använda effektiva bildbehandlingsbibliotek som OpenCV för att minska förbehandlingstiderna. Efterbehandling innebär att man analyserar resultatet av slutsatsen. Den använder uppgifter som icke-maximal undertryckning (NMS tolkar utdata från de flesta objektdetekteringsmodeller) och bildvisning för att generera handlingsbara insikter, såsom begränsningsrutor, klassetiketter eller konfidenspoäng.

Figur 1. För AI-modellinferencing utförs för- och efterbehandlingsfunktionerna vanligtvis på en applikationsprocessor.
AI-modellens slutledning kan ha den extra utmaningen att bearbeta flera neurala nätverksmodeller per ram, beroende på applikationens kapacitet. Computer vision-applikationer involverar vanligtvis flera AI-uppgifter som kräver en pipeline av flera modeller. Dessutom är en modells utdata ofta nästa modells input. Med andra ord, modeller i en applikation är ofta beroende av varandra och måste exekveras sekventiellt. Den exakta uppsättningen av modeller som ska köras kanske inte är statisk och kan variera dynamiskt, även på en ram för bildruta.
Utmaningen att köra flera modeller dynamiskt kräver en extern AI-accelerator med dedikerat och tillräckligt stort minne för att lagra modellerna. Ofta kan den integrerade AI-acceleratorn inuti en SoC inte hantera arbetsbelastningen för flera modeller på grund av begränsningar som åläggs av delsystem för delat minne och andra resurser i SoC.
Till exempel förlitar sig rörelseprediktionsbaserad objektspårning på kontinuerliga detekteringar för att bestämma en vektor som används för att identifiera det spårade objektet vid en framtida position. Effektiviteten av detta tillvägagångssätt är begränsad eftersom det saknar verklig återidentifieringsförmåga. Med rörelseprediktion kan ett objekts spår gå förlorade på grund av missade upptäckter, ocklusioner eller att objektet lämnar synfältet, till och med tillfälligt. När du har tappat bort, finns det inget sätt att återassociera objektets spår. Att lägga till återidentifiering löser denna begränsning men kräver inbäddning av ett visuellt utseende (dvs. ett bildfingeravtryck). Utseendeinbäddningar kräver ett andra nätverk för att generera en egenskapsvektor genom att bearbeta bilden som finns inuti begränsningsrutan för objektet som detekteras av det första nätverket. Denna inbäddning kan användas för att identifiera objektet igen, oavsett tid eller rum. Eftersom inbäddningar måste genereras för varje objekt som upptäcks i synfältet, ökar bearbetningskraven när scenen blir livligare. Objektspårning med omidentifiering kräver noggrant övervägande mellan att utföra detektering med hög noggrannhet/hög upplösning/hög bildhastighet och att reservera tillräckligt med overhead för inbäddningsskalbarhet. Ett sätt att lösa bearbetningskravet är att använda en dedikerad AI-accelerator. Som nämnts tidigare kan SoC:s AI-motor lida av bristen på delade minnesresurser. Modelloptimering kan också användas för att sänka bearbetningskravet, men det kan påverka prestanda och/eller noggrannhet.
I en smart kamera eller edge-apparat förvärvar den integrerade SoC (dvs. värdprocessorn) videoramarna och utför de förbehandlingssteg som vi beskrev tidigare. Dessa funktioner kan utföras med SoC:s CPU-kärnor eller GPU (om en sådan finns tillgänglig), men de kan också utföras av dedikerade hårdvaruacceleratorer i SoC (t.ex. bildsignalprocessor). Efter att dessa förbearbetningssteg har slutförts kan AI-acceleratorn som är integrerad i SoC direkt komma åt denna kvantiserade indata från systemminnet, eller i fallet med en diskret AI-accelerator, inmatningen levereras sedan för slutledning, vanligtvis över USB- eller PCIe-gränssnitt.
En integrerad SoC kan innehålla en rad beräkningsenheter, inklusive CPU:er, GPU:er, AI-accelerator, visionprocessorer, videokodare/avkodare, bildsignalprocessor (ISP) och mer. Dessa beräkningsenheter delar alla samma minnesbuss och får följaktligen åtkomst till samma minne. Dessutom kan CPU och GPU också behöva spela en roll i slutsatsen och dessa enheter kommer att vara upptagna med att köra andra uppgifter i ett utplacerat system. Detta är vad vi menar med systemnivå overhead (Figur 2).
Många utvecklare utvärderar felaktigt prestandan hos den inbyggda AI-acceleratorn i SoC utan att överväga effekten av systemnivåoverhead på den totala prestandan. Som ett exempel, överväg att köra ett YOLO-riktmärke på en 50 TOPS AI-accelerator integrerad i en SoC, som kan få ett benchmark-resultat på 100 slutsatser/sekund (IPS). Men i ett utrullat system med alla dess andra beräkningsenheter aktiva, skulle dessa 50 TOPS kunna minska till ungefär 12 TOPS och den totala prestandan skulle bara ge 25 IPS, förutsatt en generös 25% utnyttjandefaktor. Systemoverhead är alltid en faktor om plattformen kontinuerligt bearbetar videoströmmar. Alternativt, med en diskret AI-accelerator (t.ex. Kinara Ara-1, Hailo-8, Intel Myriad X), kan utnyttjandet på systemnivå vara större än 90 %, eftersom när värd-SoC initierar slutledningsfunktionen och överför AI-modellens indata data, kör acceleratorn autonomt och använder sitt dedikerade minne för att komma åt modellvikter och parametrar.
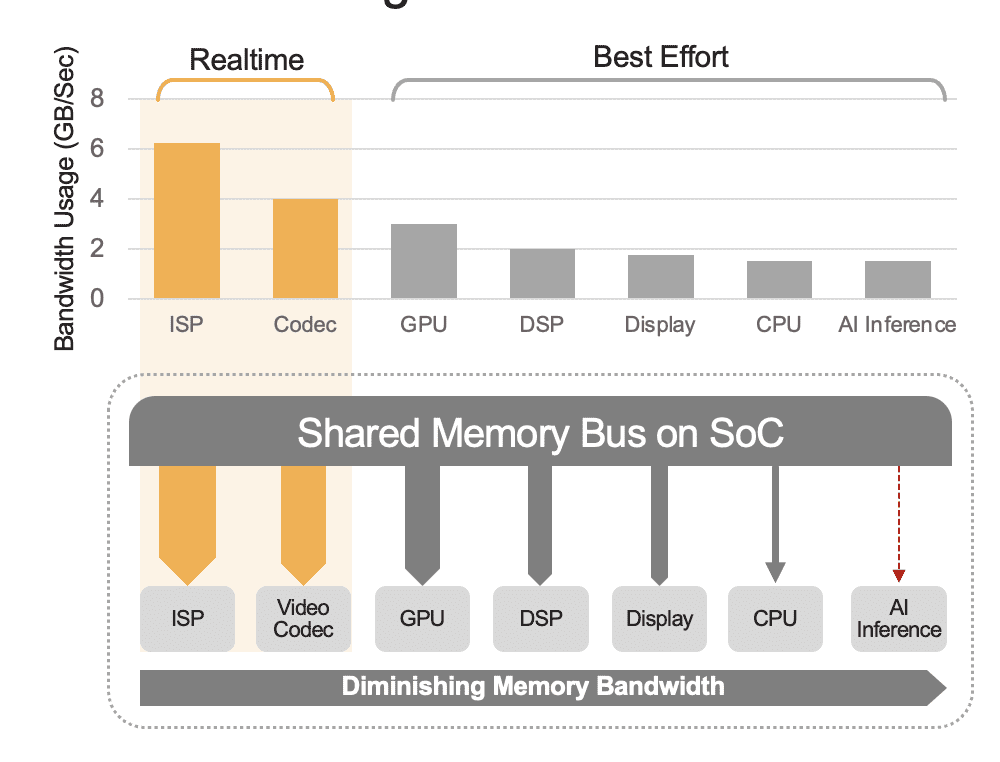
Figur 2. Den delade minnesbussen kommer att styra prestanda på systemnivå, som visas här med uppskattade värden. Verkliga värden kommer att variera beroende på din applikationsanvändningsmodell och SoC:s beräkningsenhetskonfiguration.
Fram till denna punkt har vi diskuterat AI-prestanda i termer av bilder per sekund och TOPS. Men låg latens är ett annat viktigt krav för att leverera ett systems lyhördhet i realtid. Till exempel inom spel är låg latens avgörande för en sömlös och lyhörd spelupplevelse, särskilt i rörelsestyrda spel och virtuella verklighetssystem (VR). I autonoma körsystem är låg latens avgörande för objektdetektering i realtid, igenkänning av fotgängare, fildetektering och igenkänning av trafikmärken för att undvika att äventyra säkerheten. Autonoma körsystem kräver vanligtvis en fördröjning från ända till ända på mindre än 150 ms från upptäckt till den faktiska åtgärden. På samma sätt, inom tillverkning, är låg latens avgörande för detektering av defekter i realtid, avvikelseigenkänning och robotstyrning är beroende av videoanalyser med låg latens för att säkerställa effektiv drift och minimera produktionsstopp.
I allmänhet finns det tre komponenter för latens i en videoanalysapplikation (Figur 3):
- Datainsamlingsfördröjning är tiden från det att kamerasensorn fångar en videobild till bildrutans tillgänglighet för analyssystemet för bearbetning. Du kan optimera denna latens genom att välja en kamera med en snabb sensor och processor med låg latens, välja optimala bildhastigheter och använda effektiva videokomprimeringsformat.
- Dataöverföringslatens är tiden för infångad och komprimerad videodata att färdas från kameran till edge-enheter eller lokala servrar. Detta inkluderar nätverksbehandlingsfördröjningar som uppstår vid varje slutpunkt.
- Databehandlingslatens hänvisar till tiden för edge-enheterna att utföra videobearbetningsuppgifter såsom ramdekompression och analytiska algoritmer (t.ex. rörelseförutsägelsebaserad objektspårning, ansiktsigenkänning). Som påpekats tidigare är behandlingslatens ännu viktigare för applikationer som måste köra flera AI-modeller för varje videobildruta.
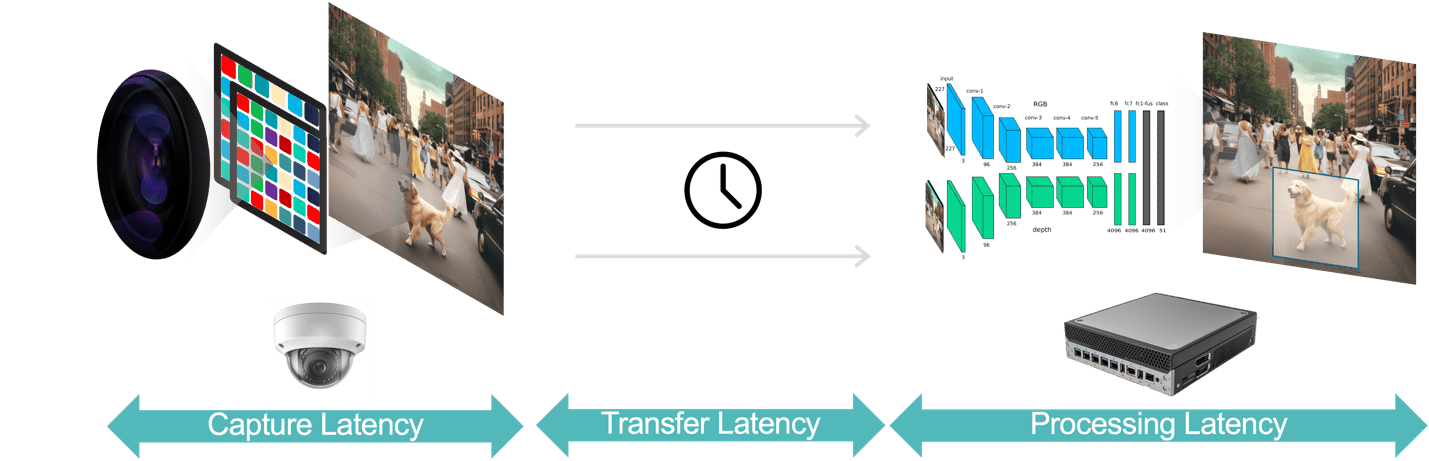
Figur 3. Videoanalyspipelinen består av datafångst, dataöverföring och databehandling.
Databehandlingslatensen kan optimeras med hjälp av en AI-accelerator med en arkitektur utformad för att minimera datarörelser över chippet och mellan datorer och olika nivåer i minneshierarkin. Dessutom, för att förbättra latensen och effektiviteten på systemnivå, måste arkitekturen stödja noll (eller nära noll) växlingstid mellan modeller, för att bättre stödja flermodellapplikationerna som vi diskuterade tidigare. En annan faktor för både förbättrad prestanda och latens relaterar till algoritmisk flexibilitet. Med andra ord är vissa arkitekturer designade för optimalt beteende endast på specifika AI-modeller, men med den snabbt föränderliga AI-miljön dyker nya modeller för högre prestanda och bättre noggrannhet upp i vad som verkar vara varannan dag. Välj därför en edge AI-processor utan praktiska begränsningar för modelltopologi, operatörer och storlek.
Det finns många faktorer som måste beaktas för att maximera prestanda i en edge AI-apparat, inklusive prestanda- och latenskrav och systemoverhead. En framgångsrik strategi bör överväga en extern AI-accelerator för att övervinna minnes- och prestandabegränsningarna i SoC:s AI-motor.
CH Chee är en erfaren produktmarknadsförings- och ledningschef, Chee har lång erfarenhet av att marknadsföra produkter och lösningar inom halvledarindustrin, med fokus på vision-baserad AI, anslutningsmöjligheter och videogränssnitt för flera marknader inklusive företag och konsumenter. Som entreprenör var Chee med och grundade två nystartade videohalvledarföretag som förvärvades av ett offentligt halvledarföretag. Chee ledde produktmarknadsföringsteam och tycker om att arbeta med ett litet team som fokuserar på att uppnå fantastiska resultat.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- : har
- :är
- :inte
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- förmåga
- accelerator
- acceleratorer
- tillgång
- åtkomst
- rymma
- åstadkomma
- noggrannhet
- uppnå
- förvärvade
- förvärvar
- tvärs
- Handling
- aktiv
- faktiska
- tillsats
- Annat
- antagen
- avancerat
- Efter
- igen
- AI
- AI-motor
- AI-modeller
- algoritmisk
- algoritmer
- Alla
- också
- alltid
- an
- analys
- analytics
- analys
- och
- avvikelse av anomali
- Annan
- Ansökan
- tillämpningar
- tillvägagångssätt
- arkitektur
- ÄR
- AS
- associerad
- At
- automatisera
- Automation
- autonom
- autonomt
- tillgänglighet
- tillgänglig
- undvika
- baserat
- grund
- BE
- därför att
- blir
- varit
- innan
- Där vi får lov att vara utan att konstant prestera,
- riktmärke
- Bättre
- mellan
- båda
- Box
- boxar
- inbyggd
- Bussen
- upptagen
- men
- by
- rum
- kameror
- KAN
- kapacitet
- kapacitet
- fånga
- fångas
- Fångande
- noggrann
- Vid
- fall
- utmanar
- byte
- chip
- Pommes frites
- välja
- klass
- cloud
- färg
- kommande
- företag
- konkurrenskraftig
- Avslutade
- komponenter
- komprometterande
- beräkning
- beräkningar
- Compute
- dator
- Datorsyn
- Datorseende applikationer
- förtroende
- konfiguration
- Anslutningar
- Följaktligen
- Tänk
- övervägande
- anses
- med tanke på
- består
- begränsningar
- Konsumenten
- innehålla
- innehöll
- kontinuerlig
- kontinuerligt
- Konvertering
- kunde
- CPU
- kritisk
- kund
- datum
- databehandling
- dag
- dedicerad
- fördröja
- fördröjningar
- leverera
- levereras
- beroende
- beroende
- utplacerade
- distributioner
- beskriven
- utformade
- detekterad
- Detektering
- Bestämma
- utvecklare
- enheter
- Skillnaden
- direkt
- diskuteras
- Visa
- stilleståndstid
- drivande
- grund
- dynamiskt
- e
- varje
- Tidigare
- lätt
- kant
- effekt
- effektivitet
- effektiviteter
- effektivitet
- effektiv
- antingen
- inbäddning
- änden
- början till slut
- Motor
- Motorer
- förbättra
- säkerställa
- Företag
- Hela
- Entrepreneur
- Miljö
- väsentlig
- beräknad
- utvärdera
- Även
- Varje
- utvecklas
- exempel
- överstiga
- exekvera
- exekveras
- verkställande
- förvänta
- erfarenhet
- Erfarenheter
- omfattande
- Omfattande erfarenhet
- extern
- Ansikte
- ansiktsigenkänning
- faktor
- faktorer
- fabrik
- SNABB
- Leverans
- matning
- fält
- Figur
- fingeravtryck
- Förnamn
- Flexibilitet
- fokuserar
- fokusering
- För
- format
- RAM
- från
- fungera
- funktionalitet
- funktioner
- Vidare
- framtida
- få
- Games
- Gaming
- spelupplevelse
- Allmänt
- generera
- genereras
- generös
- Go
- GPU
- GPUs
- stor
- större
- Odling
- Tillväxt
- vägleda
- hårdvara
- Har
- därav
- här.
- hierarkin
- Hög
- högre
- värd
- HTTPS
- i
- identifiera
- if
- bild
- Inverkan
- med Esport
- ålagts
- förbättra
- förbättras
- in
- I andra
- innefattar
- Inklusive
- Öka
- ökat
- industrier
- industrin
- initierar
- ingång
- inuti
- insikter
- integrerade
- Intel
- Gränssnitt
- gränssnitt
- in
- engagera
- innebär
- oavsett
- ISP
- IT
- DESS
- KDnuggets
- Etiketter
- Brist
- Lane
- Large
- Latens
- lämnar
- Led
- mindre
- nivåer
- bibliotek
- tycka om
- begränsning
- begränsningar
- Begränsad
- lokal
- förlorat
- Låg
- lägre
- hantera
- ledning
- Produktion
- många
- Marknadsföring
- Marknader
- Maximera
- maximera
- Maj..
- betyda
- åtgärder
- Möt
- Minne
- nämnts
- kanske
- missade
- modell
- modeller
- modul
- övervakning
- mer
- mest
- rörelse
- rörelse
- multipel
- måste
- myriad
- Nära
- behov
- nät
- neural
- neurala nätverk
- Nya
- Nästa
- Nej
- objektet
- Objektdetektion
- inträffa
- of
- Ofta
- on
- gång
- ONE
- endast
- OpenCV
- drift
- operativa
- operatörer
- motsatt
- optimala
- optimering
- Optimera
- optimerad
- optimera
- or
- Övriga
- ut
- produktion
- över
- övergripande
- Övervinna
- Parallell
- parametrar
- särskilt
- för
- utföra
- prestanda
- utfört
- utför
- utför
- rörledning
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- Spela
- Punkt
- placera
- efterbehandling
- Praktisk
- förutsägelse
- process
- bearbetade
- bearbetning
- Processorn
- processorer
- Produkt
- Produktion
- Produkter
- främja
- ge
- allmän
- område
- som sträcker sig
- snabb
- snabbt
- Betygsätta
- rates
- Raw
- rådata
- verklig
- realtid
- Verkligheten
- erkännande
- minska
- hänvisar
- kräver
- Obligatorisk
- krav
- Krav
- Kräver
- Upplösning
- Resurser
- mottaglig
- begränsningar
- resultera
- Resultat
- robotik
- Roll
- Körning
- rinnande
- kör
- Säkerhet
- Samma
- skalbarhet
- Skala
- skala ai
- skalning
- scen
- poäng
- sömlös
- Andra
- §
- se
- verkar
- väljer
- halvledare
- in
- Dela
- delas
- Gå och Handla
- skall
- visas
- signera
- Signal
- Liknande
- eftersom
- enda
- Storlek
- Small
- smarta
- lösning
- Lösningar
- LÖSA
- Löser
- några
- något
- Utrymme
- specifik
- nystartade företag
- Steg
- lagra
- strategier
- Strategi
- ström
- strömmar
- framgångsrik
- sådana
- tillräcklig
- stödja
- undertryckande
- övervakning
- system
- System
- Ta
- tar
- uppgifter
- grupp
- lag
- Tekniken
- Teknologi
- villkor
- än
- den där
- Smakämnen
- Framtiden
- deras
- sedan
- Där.
- därför
- Dessa
- de
- detta
- de
- tre
- Genom
- genomströmning
- tid
- gånger
- till
- Överdelar
- Totalt
- spår
- Spårning
- trafik
- överföring
- överföringar
- Förvandla
- färdas
- sann
- två
- typiskt
- Ytterst
- oförmögen
- förstå
- enhet
- enheter
- Användning
- usb
- användning
- Begagnade
- användningar
- med hjälp av
- vanligen
- Använda
- Värden
- mängd
- olika
- Video
- utsikt
- Virtuell
- Virtual reality
- syn
- avgörande
- vr
- Sätt..
- we
- były
- Vad
- om
- som
- brett
- kommer
- med
- utan
- ord
- arbetssätt
- skulle
- X
- Avkastning
- Yolo
- dig
- Din
- zephyrnet
- noll-







