Det här inlägget är skrivet tillsammans med Pramod Nayak, LakshmiKanth Mannem och Vivek Aggarwal från Low Latency Group of LSEG.
Transaktionskostnadsanalys (TCA) används i stor utsträckning av handlare, portföljförvaltare och mäklare för analys före och efter handel, och hjälper dem att mäta och optimera transaktionskostnader och effektiviteten i deras handelsstrategier. I det här inlägget analyserar vi alternativ bud-fråga-spreadar från LSEG Tick History – PCAP dataset med hjälp av Amazon Athena för Apache Spark. Vi visar dig hur du kommer åt data, definierar anpassade funktioner att tillämpa på data, frågar och filtrerar datasetet och visualiserar resultaten av analysen, allt utan att behöva oroa dig för att sätta upp infrastruktur eller konfigurera Spark, även för stora datamängder.
Bakgrund
Options Price Reporting Authority (OPRA) fungerar som en viktig värdepappersinformationsprocessor, som samlar in, konsoliderar och sprider senaste försäljningsrapporter, offerter och relevant information för amerikanska optioner. Med 18 aktiva amerikanska optionsbörser och över 1.5 miljoner kvalificerade kontrakt spelar OPRA en avgörande roll för att tillhandahålla omfattande marknadsdata.
Den 5 februari 2024 kommer Securities Industry Automation Corporation (SIAC) att uppgradera OPRA-flödet från 48 till 96 multicast-kanaler. Denna förbättring syftar till att optimera symboldistribution och linjekapacitetsutnyttjande som svar på eskalerande handelsaktivitet och volatilitet på den amerikanska optionsmarknaden. SIAC har rekommenderat att företag förbereder sig för maximala datahastigheter på upp till 37.3 GBit per sekund.
Trots att uppgraderingen inte omedelbart ändrar den totala volymen publicerad data, gör den det möjligt för OPRA att sprida data i en betydligt snabbare takt. Denna övergång är avgörande för att möta kraven från den dynamiska optionsmarknaden.
OPRA framstår som en av de mest omfattande flödena, med en topp på 150.4 miljarder meddelanden på en enda dag under tredje kvartalet 3 och ett kapacitetsbehov på 2023 miljarder meddelanden under en dag. Att fånga upp varje enskilt meddelande är avgörande för analys av transaktionskostnader, marknadslikviditetsövervakning, utvärdering av handelsstrategi och marknadsundersökningar.
Om uppgifterna
LSEG Tick History – PCAP är ett molnbaserat arkiv som överstiger 30 PB och innehåller global marknadsdata av ultrahög kvalitet. Dessa data fångas noggrant direkt i utbytesdatacentren, med hjälp av redundanta fångstprocesser strategiskt placerade i stora primära datacenter och backup-datacenter över hela världen. LSEG:s fångstteknik säkerställer förlustfri datafångst och använder en GPS-tidskälla för nanosekunders tidsstämpelprecision. Dessutom används sofistikerade dataarbitragetekniker för att sömlöst fylla eventuella dataluckor. Efter fångst genomgår data noggrann bearbetning och skiljedom och normaliseras sedan till parkettformat med LSEG:s Real Time Ultra Direct (RTUD) foderhanterare.
Normaliseringsprocessen, som är integrerad för att förbereda data för analys, genererar upp till 6 TB komprimerade parkettfiler per dag. Den enorma mängden data tillskrivs OPRA:s omfattande karaktär, som sträcker sig över flera utbyten och innehåller många optionskontrakt som kännetecknas av olika attribut. Ökad marknadsvolatilitet och marknadsskapande aktivitet på optionsbörserna bidrar ytterligare till mängden data som publiceras på OPRA.
Attributen av Tick History – PCAP gör det möjligt för företag att utföra olika analyser, inklusive följande:
- Analys före handel – Utvärdera potentiell handelspåverkan och utforska olika utförandestrategier baserat på historiska data
- Utvärdering efter handel – Mät faktiska genomförandekostnader mot riktmärken för att bedöma genomförandet av strategier
- optimerad utförande – Finjustera exekveringsstrategier baserade på historiska marknadsmönster för att minimera marknadspåverkan och minska de totala handelskostnaderna
- Riskhantering – Identifiera glidmönster, identifiera extremvärden och proaktivt hantera risker förknippade med handelsaktiviteter
- Prestandatillskrivning – Separera effekten av handelsbeslut från investeringsbeslut när portföljens prestanda analyseras
LSEG Tick History – PCAP-datauppsättningen är tillgänglig i AWS datautbyte och kan nås på AWS Marketplace. Med AWS Data Exchange för Amazon S3, kan du komma åt PCAP-data direkt från LSEG:s Amazon enkel lagringstjänst (Amazon S3) hinkar, vilket eliminerar behovet för företag att lagra sin egen kopia av data. Detta tillvägagångssätt effektiviserar datahantering och lagring, vilket ger kunderna omedelbar tillgång till högkvalitativ PCAP eller normaliserad data med enkel användning, integration och betydande datalagringsbesparingar.
Athena för Apache Spark
För analytiska ansträngningar, Athena för Apache Spark erbjuder en förenklad notebook-upplevelse tillgänglig via Athena-konsolen eller Athena API:er, så att du kan bygga interaktiva Apache Spark-applikationer. Med en optimerad Spark-körtid hjälper Athena analysen av petabyte data genom att dynamiskt skala antalet Spark-motorer på mindre än en sekund. Dessutom är vanliga Python-bibliotek som pandor och NumPy sömlöst integrerade, vilket möjliggör skapandet av invecklad applikationslogik. Flexibiliteten sträcker sig till import av anpassade bibliotek för användning i bärbara datorer. Athena for Spark rymmer de flesta öppna dataformat och är sömlöst integrerat med AWS-lim Datakatalog.
dataset
För denna analys använde vi datauppsättningen LSEG Tick History – PCAP OPRA från 17 maj 2023. Denna datauppsättning består av följande komponenter:
- Bästa bud och erbjudande (BBO) – Rapporterar det högsta budet och det lägsta budet för ett värdepapper vid en given börs
- Nationellt bästa bud och erbjudande (NBBO) – Rapporterar det högsta budet och det lägsta budet för en säkerhet på alla börser
- Handel – Registrerar genomförda affärer på alla börser
Datauppsättningen omfattar följande datavolymer:
- Handel – 160 MB fördelat på cirka 60 komprimerade parkettfiler
- BBO – 2.4 TB fördelat på cirka 300 komprimerade parkettfiler
- NBBO – 2.8 TB fördelat på cirka 200 komprimerade parkettfiler
Analysöversikt
Att analysera OPRA Tick History-data för Transaction Cost Analysis (TCA) innebär att granska marknadsnoteringar och affärer kring en specifik handelshändelse. Vi använder följande mätvärden som en del av denna studie:
- Citerad spridning (QS) – Beräknas som skillnaden mellan BBO-budet och BBO-budet
- Effektiv spridning (ES) – Beräknas som skillnaden mellan handelspriset och mittpunkten för BBO (BBO bud + (BBO ask – BBO bud)/2)
- Effektiv/noterad spread (EQF) – Beräknat som (ES / QS) * 100
Vi beräknar dessa spreadar före handeln och dessutom med fyra intervaller efter handeln (strax efter, 1 sekund, 10 sekunder och 60 sekunder efter handeln).
Konfigurera Athena för Apache Spark
För att konfigurera Athena för Apache Spark, utför följande steg:
- På Athena-konsolen, under KOM IGÅNG, Välj Analysera dina data med PySpark och Spark SQL.
- Om det här är första gången du använder Athena Spark, välj Skapa arbetsgrupp.

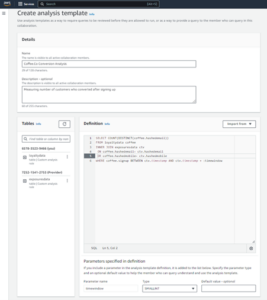
- För Arbetsgruppens namn¸ ange ett namn för arbetsgruppen, t.ex
tca-analysis. - I Analytics-motor avsnitt, välj Apache Spark.
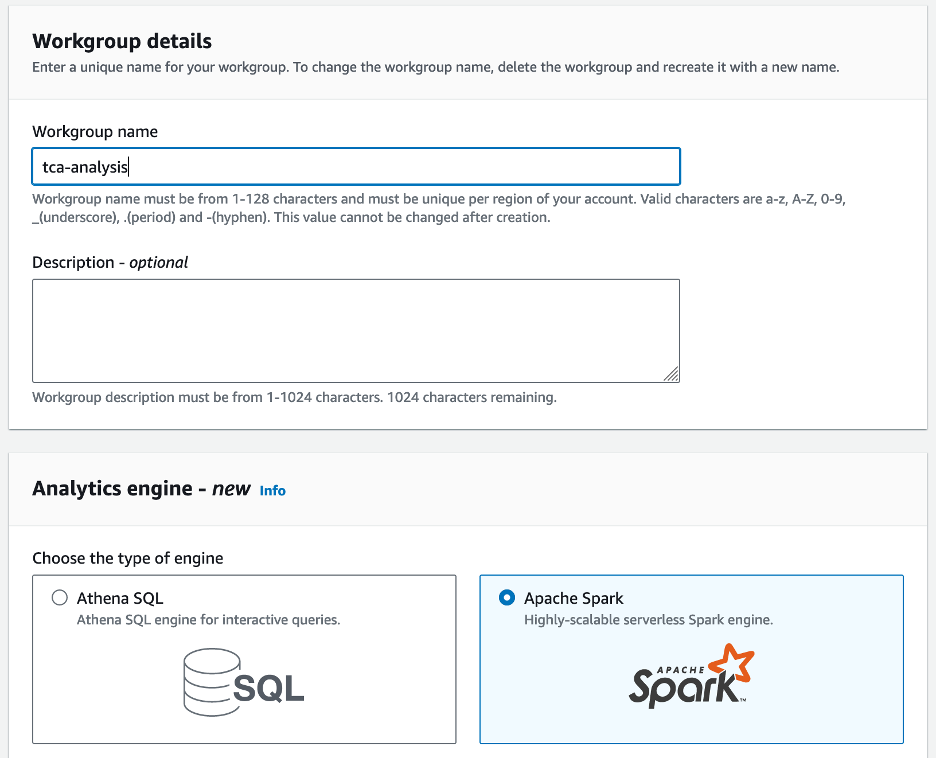
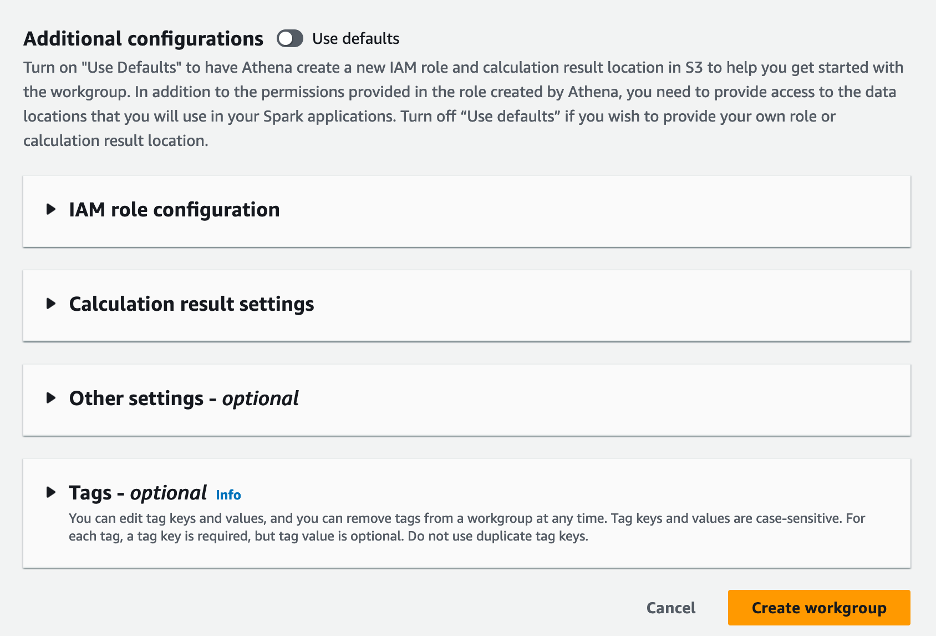
- I Ytterligare konfigurationer avsnitt kan du välja Använd standardinställningar eller tillhandahålla en anpassad AWS identitets- och åtkomsthantering (IAM) roll och Amazon S3-plats för beräkningsresultat.
- Välja Skapa arbetsgrupp.
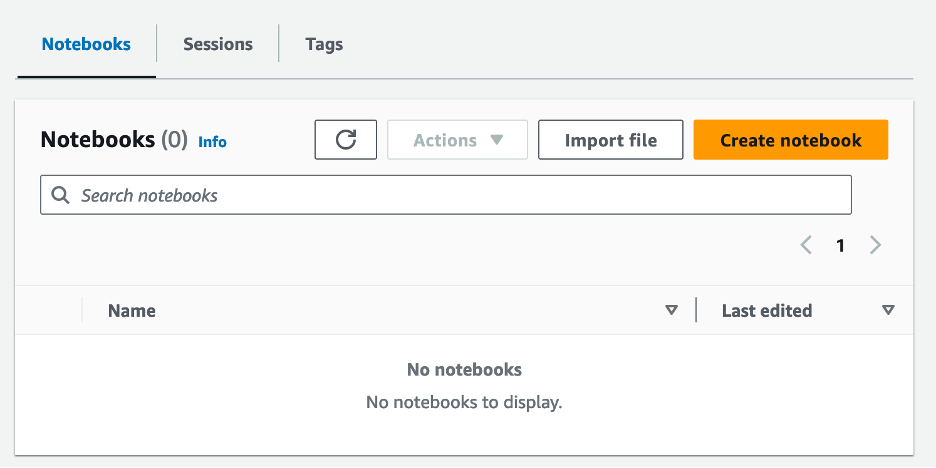
- När du har skapat arbetsgruppen, navigera till bärbara datorer fliken och välj Skapa anteckningsbok.
- Ange ett namn för din anteckningsbok, t.ex
tca-analysis-with-tick-history. - Välja Skapa för att skapa din anteckningsbok.
Starta din anteckningsbok
Om du redan har skapat en Spark-arbetsgrupp väljer du Starta anteckningsbokredigeraren under KOM IGÅNG.
![]()
När din anteckningsbok har skapats omdirigeras du till den interaktiva anteckningsbokredigeraren.
![]()
Nu kan vi lägga till och köra följande kod till vår anteckningsbok.
Skapa en analys
Utför följande steg för att skapa en analys:
- Importera vanliga bibliotek:
- Skapa våra dataramar för BBO, NBBO och affärer:
- Nu kan vi identifiera en handel att använda för transaktionskostnadsanalys:
Vi får följande utdata:
Vi använder den markerade handelsinformationen framöver för handelsprodukten (tp), handelspris (tpr) och handelstid (tt).
- Här skapar vi ett antal hjälpfunktioner för vår analys
- I följande funktion skapar vi datasetet som innehåller alla citat före och efter handeln. Athena Spark bestämmer automatiskt hur många DPU:er som ska startas för bearbetning av vår datauppsättning.
- Låt oss nu kalla TCA-analysfunktionen med informationen från vår utvalda handel:
Visualisera analysresultaten
Låt oss nu skapa dataramarna vi använder för vår visualisering. Varje dataram innehåller citat för ett av de fem tidsintervallen för varje dataflöde (BBO, NBBO):
I följande avsnitt tillhandahåller vi exempelkod för att skapa olika visualiseringar.
Rita QS och NBBO före handeln
Använd följande kod för att plotta den noterade spreaden och NBBO före handeln:
![]()
Rita QS för varje marknad och NBBO efter handeln
Använd följande kod för att plotta den noterade spreaden för varje marknad och NBBO omedelbart efter handeln:
![]()
Rita QS för varje tidsintervall och varje marknad för BBO
Använd följande kod för att plotta den noterade spreaden för varje tidsintervall och varje marknad för BBO:
![]()
Rita ES för varje tidsintervall och marknad för BBO
Använd följande kod för att plotta den effektiva spridningen för varje tidsintervall och marknad för BBO:
Rita EQF för varje tidsintervall och marknad för BBO
Använd följande kod för att plotta den effektiva/noterade spridningen för varje tidsintervall och marknad för BBO:
Athena Spark beräkningsprestanda
När du kör ett kodblock bestämmer Athena Spark automatiskt hur många DPU:er som krävs för att slutföra beräkningen. I det sista kodblocket, där vi kallar tca_analysis funktion, instruerar vi faktiskt Spark att bearbeta data, och vi konverterar sedan de resulterande Spark-dataramarna till Pandas-dataramar. Detta utgör den mest intensiva bearbetningsdelen av analysen, och när Athena Spark kör detta block visar det förloppsindikatorn, förfluten tid och hur många DPU:er som bearbetar data för närvarande. Till exempel, i följande beräkning, använder Athena Spark 18 DPU:er.
![]()
När du konfigurerar din Athena Spark-anteckningsbok har du möjlighet att ställa in det maximala antalet DPU:er som den kan använda. Standard är 20 DPU:er, men vi testade den här beräkningen med 10, 20 och 40 DPU:er för att visa hur Athena Spark automatiskt skalas för att köra vår analys. Vi observerade att Athena Spark skalas linjärt och tog 15 minuter och 21 sekunder när den bärbara datorn konfigurerades med maximalt 10 DPU:er, 8 minuter och 23 sekunder när den bärbara datorn konfigurerades med 20 DPU:er och 4 minuter och 44 sekunder när den bärbara datorn var konfigurerad med 40 DPU:er. Eftersom Athena Spark tar betalt baserat på DPU-användning, med en granularitet per sekund, är kostnaden för dessa beräkningar liknande, men om du ställer in ett högre maximalt DPU-värde kan Athena Spark returnera resultatet av analysen mycket snabbare. För mer information om priserna på Athena Spark klicka här..
Slutsats
I det här inlägget demonstrerade vi hur du kan använda high-fidelity OPRA-data från LSEG:s Tick History-PCAP för att utföra transaktionskostnadsanalyser med Athena Spark. Tillgången till OPRA-data i rätt tid, kompletterad med tillgänglighetsinnovationer från AWS Data Exchange för Amazon S3, minskar strategiskt tiden till analys för företag som vill skapa handlingskraftiga insikter för viktiga handelsbeslut. OPRA genererar cirka 7 TB normaliserade parkettdata varje dag, och det är en utmaning att hantera infrastrukturen för att tillhandahålla analyser baserade på OPRA-data.
Athenas skalbarhet vid hantering av storskalig databehandling för Tick History – PCAP för OPRA-data gör det till ett övertygande val för organisationer som söker snabba och skalbara analyslösningar i AWS. Det här inlägget visar den sömlösa interaktionen mellan AWS-ekosystemet och Tick History-PCAP-data och hur finansinstitutioner kan dra fördel av denna synergi för att driva datadrivet beslutsfattande för kritiska handels- och investeringsstrategier.
Om författarna
![]() Pramod Nayak är direktör för produkthantering för Low Latency Group på LSEG. Pramod har över 10 års erfarenhet inom finansteknikbranschen, med fokus på mjukvaruutveckling, analys och datahantering. Pramod är en före detta mjukvaruingenjör och brinner för marknadsdata och kvantitativ handel.
Pramod Nayak är direktör för produkthantering för Low Latency Group på LSEG. Pramod har över 10 års erfarenhet inom finansteknikbranschen, med fokus på mjukvaruutveckling, analys och datahantering. Pramod är en före detta mjukvaruingenjör och brinner för marknadsdata och kvantitativ handel.
![]() LakshmiKanth Mannem är produktchef i LSEG-gruppen för låg latens. Han fokuserar på data- och plattformsprodukter för marknadsdataindustrin med låg latens. LakshmiKanth hjälper kunder att bygga de mest optimala lösningarna för deras marknadsdatabehov.
LakshmiKanth Mannem är produktchef i LSEG-gruppen för låg latens. Han fokuserar på data- och plattformsprodukter för marknadsdataindustrin med låg latens. LakshmiKanth hjälper kunder att bygga de mest optimala lösningarna för deras marknadsdatabehov.
![]() Vivek Aggarwal är Senior Data Engineer i Low Latency Group av LSEG. Vivek arbetar med att utveckla och underhålla datapipelines för bearbetning och leverans av infångade marknadsdataflöden och referensdataflöden.
Vivek Aggarwal är Senior Data Engineer i Low Latency Group av LSEG. Vivek arbetar med att utveckla och underhålla datapipelines för bearbetning och leverans av infångade marknadsdataflöden och referensdataflöden.
![]() Alket Memushaj är huvudarkitekt i Financial Services Market Development-teamet på AWS. Alket ansvarar för teknisk strategi och arbetar med partners och kunder för att distribuera även de mest krävande arbetsbelastningarna på kapitalmarknaden till AWS-molnet.
Alket Memushaj är huvudarkitekt i Financial Services Market Development-teamet på AWS. Alket ansvarar för teknisk strategi och arbetar med partners och kunder för att distribuera även de mest krävande arbetsbelastningarna på kapitalmarknaden till AWS-molnet.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- : har
- :är
- :inte
- :var
- $UPP
- 1
- 10
- 100
- 12
- 15%
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- Om oss
- tillgång
- Accessed
- tillgänglighet
- tillgänglig
- tvärs
- aktiv
- aktivitet
- faktiska
- faktiskt
- lägga till
- Dessutom
- adresse
- Fördel
- Efter
- mot
- Aggarwal
- Syftet
- Alla
- tillåta
- redan
- amason
- Amazonas Athena
- Amazon Web Services
- an
- analyser
- analys
- Analytisk
- analytics
- analysera
- analys
- och
- vilken som helst
- Apache
- Apache Spark
- API: er
- Ansökan
- tillämpningar
- Ansök
- tillvägagångssätt
- cirka
- arbitrage
- skiljedom
- ÄR
- runt
- AS
- be
- bedöma
- associerad
- At
- attribut
- myndighet
- automatiskt
- Automation
- tillgänglighet
- tillgänglig
- AWS
- säkerhetskopiering
- bar
- baserat
- BE
- därför att
- innan
- riktmärken
- BÄST
- mellan
- bud
- Miljarder
- Blockera
- mäklare
- SLUTRESULTAT
- men
- by
- beräkna
- beräknat
- beräkning
- Ring
- KAN
- Kapacitet
- kapital
- Kapitalmarknader
- fånga
- fångas
- Fångande
- katalog
- Centers
- utmanande
- kanaler
- känne
- avgifter
- val
- Välja
- klienter
- cloud
- koda
- Samla
- Gemensam
- övertygande
- fullborda
- Avslutade
- komponenter
- omfattande
- innefattar
- Genomför
- konfigurerad
- konfigurering
- Konsol
- konsolidera
- innehåller
- kontrakt
- bidra
- konvertera
- FÖRETAG
- Pris
- Kostar
- samskriven
- skapa
- skapas
- skapande
- kritisk
- avgörande
- För närvarande
- beställnings
- Kunder
- Dash
- datum
- datacenter
- dataingenjör
- Datautbyte
- datahantering
- databehandling
- datalagring
- data driven
- datauppsättningar
- dag
- Beslutsfattande
- beslut
- Standard
- definiera
- leverans
- krävande
- krav
- demonstrera
- demonstreras
- distribuera
- detaljer
- bestämd
- utveckla
- Utveckling
- utvecklingsteam
- Skillnaden
- olika
- direkt
- Direktör
- distribueras
- fördelning
- flera
- dubbla
- driv
- dynamisk
- dynamiskt
- Dynamiken
- varje
- lätta
- enkel användning
- ekosystemet
- redaktör
- Effektiv
- effektivitet
- berättigad
- eliminera
- anställd
- utnyttjande
- möjliggöra
- möjliggör
- encompassing
- strävanden
- Motor
- ingenjör
- Motorer
- förbättring
- säkerställer
- ange
- eskalerande
- Eter (ETH)
- utvärdera
- utvärdering
- Även
- händelse
- Varje
- exempel
- utbyta
- Utbyten
- utförande
- erfarenhet
- utforska
- uttrycker
- sträcker
- snabbare
- Med
- Februari
- Fig.
- Filer
- fylla
- filtrera
- finansiella
- Finansiella institut
- finansiella tjänster
- finansiell teknik
- företag
- Förnamn
- första gången
- fem
- Flexibilitet
- fokuserar
- fokusering
- efter
- För
- format
- Tidigare
- Framåt
- fyra
- RAM
- från
- fungera
- funktioner
- ytterligare
- luckor
- genererar
- skaffa sig
- ges
- Välgörenhet
- global marknad
- Go
- kommer
- gps
- Grupp
- Arbetsmiljö
- Har
- har
- he
- fri höjd
- hjälper
- hög kvalitet
- högre
- högsta
- Markerad
- historisk
- historia
- bostäder
- Hur ser din drömresa ut
- How To
- http
- HTTPS
- IAM
- identifiera
- Identitet
- if
- omedelbar
- blir omedelbart
- Inverkan
- importera
- in
- Inklusive
- ökat
- industrin
- informationen
- Infrastruktur
- innovationer
- insikter
- institutioner
- integrerad
- integrerade
- integrering
- interaktion
- interaktiva
- in
- invecklad
- investering
- innebär
- IT
- jpg
- bara
- Large
- storskalig
- Efternamn
- Latens
- lansera
- mindre
- bibliotek
- linje
- Likviditet
- läge
- Logiken
- du letar
- Låg
- lägst
- upprätthålla
- större
- GÖR
- Framställning
- hantera
- ledning
- chef
- chefer
- hantera
- sätt
- många
- marknad
- Market Data
- marknadspåverkan
- marknadsundersökning
- Marknadsvolatilitet
- marknadsskapande
- Marknader
- massiv
- Mastering
- maximal
- Maj..
- mäta
- meddelande
- meddelanden
- noggrann
- noggrant
- Metrics
- miljon
- minimera
- minuter
- övervakning
- mer
- Dessutom
- mest
- mycket
- multipel
- namn
- Natur
- Navigera
- Behöver
- behov
- Ingen
- anteckningsbok
- bärbara datorer
- antal
- talrik
- numpy
- observerad
- of
- erbjudanden
- Erbjudanden
- on
- ONE
- optimala
- Optimera
- optimerad
- Alternativet
- Tillbehör
- or
- organisationer
- vår
- ut
- produktion
- över
- övergripande
- egen
- pandor
- del
- partner
- brinner
- mönster
- Topp
- för
- utföra
- prestanda
- svängbara
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- spelar
- snälla du
- komplott
- portfölj
- portföljförvaltare
- placerad
- Inlägg
- efter handel
- potentiell
- Precision
- Förbered
- förbereda
- pris
- prissättning
- primär
- Principal
- process
- processer
- bearbetning
- Processorn
- Produkt
- produktledning
- produktchef
- Produkter
- Framsteg
- ge
- tillhandahålla
- publicerade
- Python
- Q3
- kvantitativ
- mängd
- fråga
- citat
- Betygsätta
- rates
- Läsa
- verklig
- realtid
- rekommenderas
- register
- Red
- minska
- minskar
- referens
- refinitiv
- Rapportering
- Rapport
- Repository
- krav
- Kräver
- forskning
- respons
- ansvarig
- resultera
- resulterande
- Resultat
- avkastning
- risker
- Roll
- Körning
- kör
- Till Salu
- skalbarhet
- skalbar
- skalor
- skalning
- sömlös
- sömlöst
- Andra
- sekunder
- §
- sektioner
- Värdepapper
- säkerhet
- söker
- välj
- vald
- senior
- separat
- serverar
- Tjänster
- in
- inställning
- show
- Visar
- signifikant
- liknande
- Enkelt
- förenklade
- enda
- glidning
- Mjukvara
- mjukvaruutveckling
- Programvara ingenjör
- Lösningar
- sofistikerade
- spänning
- Gnista
- specifik
- spridning
- Sprider
- står
- Steg
- förvaring
- lagra
- Strategiskt
- strategier
- Strategi
- strömlinjer
- Läsa på
- senare
- sådana
- SWIFT
- Symbolen
- synergi
- Ta
- tar
- grupp
- Teknisk
- tekniker
- Teknologi
- testade
- än
- den där
- Smakämnen
- den information
- deras
- Dem
- sedan
- Dessa
- detta
- Genom
- tick
- tid
- tid
- tidsstämpel
- Titel
- till
- Totalt
- tp
- TPR
- handla
- handlare
- handel
- Handel
- Trading Strategies
- handelsstrategi
- transaktion
- transaktionskostnader
- omvandla
- övergång
- Ultra
- under
- genomgår
- uppgradera
- us
- Användning
- användning
- Begagnade
- användningar
- med hjälp av
- Använda
- värde
- olika
- visualisering
- visualisera
- Volatilitet
- volym
- volymer
- var
- we
- webb
- webbservice
- när
- som
- brett
- kommer
- med
- inom
- utan
- arbetsgrupp
- arbetssätt
- fungerar
- inom hela sverige
- oro
- X
- år
- dig
- Din
- zephyrnet