
Bild från Adobe Firefly
"Vi var för många. Vi hade tillgång till för mycket pengar, för mycket utrustning, och så småningom blev vi galna."
Francis Ford Coppola gjorde inte en metafor för AI-företag som spenderar för mycket och går vilse, men han kunde ha varit det. Apokalyps nu var episkt men också ett långt, svårt och dyrt projekt att göra, ungefär som GPT-4. Jag skulle föreslå att utvecklingen av LLM har blivit för mycket pengar och för mycket utrustning. Och en del av "vi uppfann just allmän intelligens"-hypen är lite galen. Men nu är det open source-gemenskapernas tur att göra det de är bäst på: att leverera gratis konkurrerande programvara med mycket mindre pengar och utrustning.
OpenAI har tagit över $11 miljarder i finansiering och det uppskattas att GPT-3.5 kostar $5-$6m per träningskörning. Vi vet väldigt lite om GPT-4 eftersom OpenAI inte är talande, men jag tror att det är säkert att anta att det inte är mindre än GPT-3.5. Det finns för närvarande en världsomspännande brist på GPU och – för en förändring – det beror inte på det senaste kryptomyntet. Generativa AI-start-ups landar $100m+ Serie A-omgångar till enorma värderingar när de inte äger någon av IP:en för LLM som de använder för att driva sin produkt. LLM-tåget är på högvarv och pengarna flödar.
It had looked like the die was cast: only deep-pocketed companies like Microsoft/OpenAI, Amazon, and Google could afford to train hundred-billion parameter models. Bigger models were assumed to be better models. GPT-3 got something wrong? Just wait until there's a bigger version and it’ll all be fine! Smaller companies looking to compete had to raise far more capital or be left building commodity integrations in the ChatGPT marketplace. Academia, with even more constrained research budgets, was relegated to the sidelines.
Lyckligtvis tog ett gäng smarta människor och projekt med öppen källkod detta som en utmaning snarare än en begränsning. Forskare vid Stanford släppte Alpaca, en 7-miljarder parametermodell vars prestanda kommer nära GPT-3.5:s 175-miljarder parametermodell. Eftersom de saknade resurserna för att bygga en träningsuppsättning av den storlek som används av OpenAI, valde de smart att ta en utbildad öppen källkod LLM, LLaMA, och finjustera den på en serie GPT-3.5-uppmaningar och utgångar istället. Modellen lärde sig i huvudsak vad GPT-3.5 gör, vilket visar sig vara en mycket effektiv strategi för att replikera dess beteende.
Alpaca är licensierad för icke-kommersiell användning endast i både kod och data eftersom den använder den icke-kommersiella LLaMA-modellen med öppen källkod, och OpenAI förbjuder uttryckligen all användning av dess API:er för att skapa konkurrerande produkter. Det skapar den lockande möjligheten att finjustera en annan öppen källkod LLM på uppmaningar och utdata från Alpaca... skapa en tredje GPT-3.5-liknande modell med olika licensmöjligheter.
Det finns ytterligare ett lager av ironi här, i det att alla de stora LLM:erna utbildades på upphovsrättsskyddad text och bilder tillgängliga på Internet och de betalade inte ett öre till rättighetsinnehavarna. Företagen hävdar undantaget "fair use" enligt amerikansk upphovsrättslagstiftning med argumentet att användningen är "transformativ". Men när det kommer till produktionen av modellerna de bygger med gratis data, vill de verkligen inte att någon ska göra samma sak mot dem. Jag förväntar mig att detta kommer att förändras när rättighetsinnehavarna blir kloka, och kan hamna i domstol någon gång.
Detta är en separat och distinkt punkt till den som tagits upp av författare till restriktivt licensierad öppen källkod som, för generativ AI för kodprodukter som CoPilot, motsätter sig att deras kod används för utbildning med motiveringen att licensen inte följs. Problemet för enskilda författare med öppen källkod är att de måste visa upp sig – reell kopiering – och att de har ådragit sig skador. Och eftersom modellerna gör det svårt att länka utdatakod till indata (raderna med källkod av författaren) och det inte finns någon ekonomisk förlust (det är tänkt att vara gratis), är det mycket svårare att göra ett ärende. Detta är till skillnad från vinstdrivande skapare (t.ex. fotografer) vars hela affärsmodell är att licensiera/sälja sitt arbete, och som representeras av aggregatorer som Getty Images som kan visa innehållsmässig kopiering.
En annan intressant sak med LLaMA är att den kom från Meta. Det släpptes ursprungligen bara till forskare och läckte sedan ut via BitTorrent till världen. Meta är i en fundamentalt annorlunda verksamhet än OpenAI, Microsoft, Google och Amazon genom att den inte försöker sälja molntjänster eller mjukvara till dig, och har därför väldigt olika incitament. Den har tidigare använt sina datordesigner med öppen källkod (OpenCompute) och sett communityn förbättra dem – den förstår värdet av öppen källkod.
Meta kan visa sig vara en av de viktigaste AI-bidragsgivarna med öppen källkod. Det har inte bara enorma resurser, men det gynnar om det finns en spridning av fantastisk generativ AI-teknik: det kommer att finnas mer innehåll för den att tjäna pengar på sociala medier. Meta har släppt tre andra AI-modeller med öppen källkod: ImageBind (multidimensionell dataindexering), DINOv2 (datorseende) och Segment Anything. Den senare identifierar unika objekt i bilder och släpps under den mycket tillåtande Apache-licensen.
Slutligen hade vi också det påstådda läckaget av ett internt Google-dokument "We Have No Moat, and Nother Does OpenAI" som tar en svag syn på slutna modeller kontra innovationen av samhällen som producerar mycket mindre, billigare modeller som presterar nära eller bättre än deras motsvarigheter med sluten källa. Jag säger påstås eftersom det inte finns något sätt att verifiera källan till artikeln som intern hos Google. Den innehåller dock denna övertygande graf:
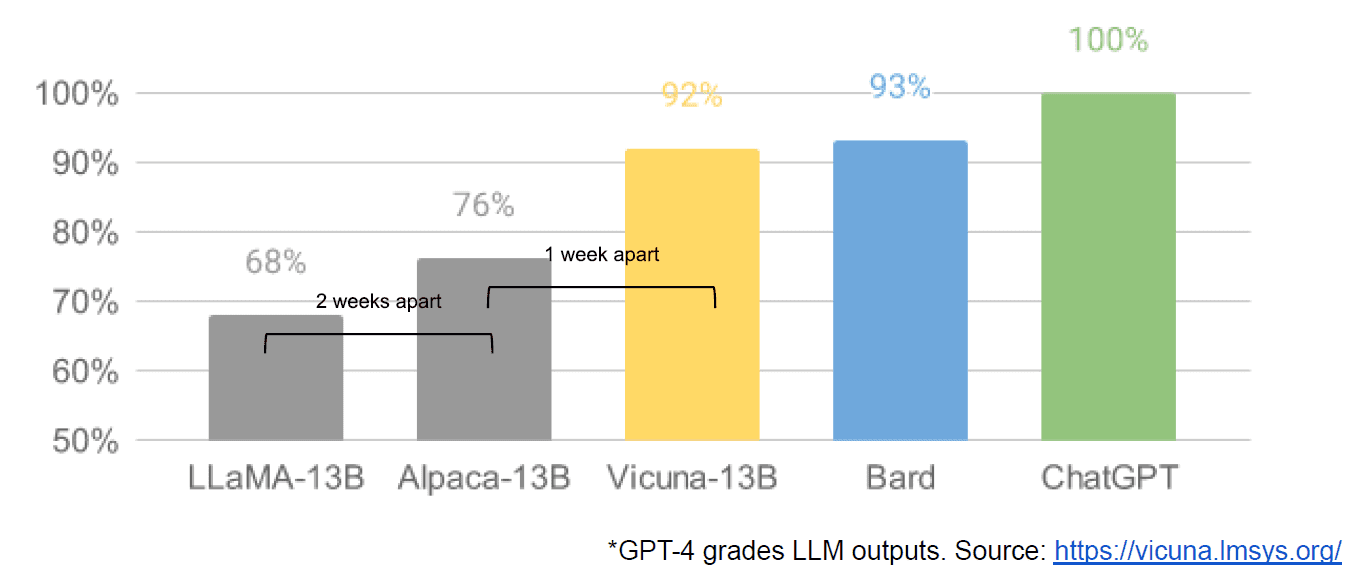
Den vertikala axeln är graderingen av LLM-utgångarna av GPT-4, för att vara tydlig.
Stable Diffusion, som syntetiserar bilder från text, är ett annat exempel på där generativ AI med öppen källkod har kunnat avancera snabbare än proprietära modeller. En ny upprepning av det projektet (ControlNet) har förbättrat det så att det har överträffat Dall-E2:s kapacitet. Detta kom från en hel del pysslande över hela världen, vilket resulterade i en framstegstakt som är svår för en enskild institution att matcha. Några av dessa pysslar kom på hur man gör Stable Diffusion snabbare att träna och köra på billigare hårdvara, vilket möjliggör kortare iterationscykler av fler människor.
Och så har vi kommit en runda. Att inte ha för mycket pengar och för mycket utrustning har inspirerat till en listig innovationsnivå av en hel gemenskap av vanliga människor. Vilken tid att vara en AI-utvecklare.
Mathew Lodge är VD för Diffblue, en AI For Code-startup. Han har 25+ års mångsidig erfarenhet av produktledarskap på företag som Anaconda och VMware. Lodge sitter för närvarande i styrelsen för Good Law Project och är vice ordförande i styrelsen för Royal Photographic Society.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Minting the Future med Adryenn Ashley. Tillgång här.
- Köp och sälj aktier i PRE-IPO-företag med PREIPO®. Tillgång här.
- Källa: https://www.kdnuggets.com/2023/05/llm-apocalypse-revenge-open-source-clones.html?utm_source=rss&utm_medium=rss&utm_campaign=llm-apocalypse-now-revenge-of-the-open-source-clones
- : har
- :är
- :inte
- :var
- $UPP
- 9
- a
- Able
- Om oss
- Akademin
- tillgång
- Adobe
- avancera
- Sammanställare
- AI
- Alla
- påstådda
- påstås
- också
- amason
- an
- och
- Annan
- vilken som helst
- någon
- något
- Apache
- API: er
- ÄR
- Argumentet
- Artikeln
- AS
- antas
- At
- Författaren
- Författarna
- tillgänglig
- Axis
- BE
- därför att
- varit
- Där vi får lov att vara utan att konstant prestera,
- Fördelarna
- BÄST
- Bättre
- större
- BitTorrent
- ombord
- båda
- budgetar
- SLUTRESULTAT
- Byggnad
- Bunch
- företag
- affärsmodell
- men
- by
- kom
- KAN
- kapacitet
- kapital
- Vid
- VD
- Ordförande
- utmanar
- byta
- ChatGPT
- billigare
- valde
- Circle
- patentkrav
- klar
- Stänga
- stängt
- cloud
- molntjänster
- koda
- komma
- kommer
- råvara
- samhällen
- samfundet
- Företag
- övertygande
- konkurrera
- tävlande
- Compute
- dator
- Datorsyn
- innehåll
- contributors
- kopiering
- upphovsrätt
- Kostar
- kunde
- Domstol
- skapa
- Skapa
- skaparna
- kryptokoin
- För närvarande
- cykler
- datum
- leverera
- biträdande
- mönster
- Utvecklare
- Utveckling
- den
- olika
- svårt
- Diffusion
- distinkt
- flera
- do
- dokumentera
- gör
- inte
- e
- Ekonomisk
- Effektiv
- möjliggör
- änden
- Hela
- EPISK
- Utrustning
- väsentligen
- beräknad
- Även
- exempel
- förvänta
- dyra
- erfarenhet
- långt
- snabbare
- figured
- Strömmande
- följt
- För
- ford
- Fri
- från
- full
- fundamentalt
- finansiering
- Gear
- Allmänt
- generativ
- Generativ AI
- god
- GPU
- diagram
- stor
- hade
- Hård
- hårdvara
- Har
- har
- he
- här.
- Hög
- höggradigt
- hållare
- Hur ser din drömresa ut
- How To
- Men
- HTTPS
- stor
- Hype
- i
- identifierar
- if
- bilder
- med Esport
- förbättra
- förbättras
- in
- incitament
- individuellt
- Innovation
- ingång
- SINNESSJUK
- inspirerat
- istället
- Institution
- integrationer
- intressant
- inre
- Internet
- uppfann
- IP
- ironi
- IT
- iteration
- DESS
- bara
- KDnuggets
- Vet
- landning
- senaste
- Lag
- lager
- Ledarskap
- lärt
- vänster
- mindre
- Nivå
- Licens
- Licensierade
- Licens
- tycka om
- rader
- LINK
- liten
- Lama
- Lång
- såg
- du letar
- förlorar
- förlust
- Lot
- större
- göra
- Framställning
- många
- marknadsplats
- massiv
- Match
- Maj..
- Media
- meta
- Microsoft
- modell
- modeller
- tjäna pengar
- pengar
- mer
- mest
- mycket
- Behöver
- Varken
- Nej
- icke-kommersiell
- nu
- objektet
- objekt
- of
- on
- ONE
- endast
- öppet
- öppen källkod
- open source-projekt
- OpenAI
- or
- vanlig
- ursprungligen
- Övriga
- ut
- produktion
- över
- egen
- Fred
- parameter
- Tidigare
- Betala
- Personer
- utföra
- prestanda
- plato
- Platon Data Intelligence
- PlatonData
- Punkt
- Möjligheterna
- kraft
- Problem
- Produkt
- Produkter
- projektet
- projekt
- proprietary
- utsikter
- höja
- insamlat
- snarare
- verkligen
- senaste
- frigörs
- representerade
- forskning
- forskare
- Resurser
- begränsning
- resulterande
- rättigheter
- omgångar
- kungliga
- Körning
- s
- säker
- Samma
- säga
- sett
- segmentet
- sälja
- separat
- Serier
- Serie A
- serverar
- Tjänster
- in
- brist
- show
- eftersom
- enda
- Storlek
- mindre
- smarta
- So
- Social hållbarhet
- sociala medier
- Samhället
- Mjukvara
- några
- något
- Källa
- källkod
- spendera
- stabil
- stanford
- nystartade företag
- start
- Strategi
- sådana
- föreslå
- förment
- överträffade
- Ta
- tagen
- tar
- Teknologi
- än
- den där
- Smakämnen
- källan
- världen
- deras
- Dem
- sedan
- Där.
- de
- sak
- tror
- Tredje
- detta
- de
- tre
- tid
- till
- alltför
- tog
- Tåg
- tränad
- Utbildning
- SVÄNG
- vänder
- under
- förstår
- unika
- till skillnad från
- tills
- us
- användning
- Begagnade
- användningar
- med hjälp av
- värderingar
- värde
- verifiera
- version
- vertikal
- mycket
- via
- utsikt
- syn
- vmware
- vs
- vänta
- vill
- var
- Sätt..
- we
- begav sig
- były
- Vad
- när
- som
- VEM
- Hela
- vars
- kommer
- KLOK
- med
- Arbete
- världen
- Fel
- dig
- zephyrnet









