Amazon RedShift, ett flitigt använt molndatalager, har utvecklats avsevärt för att möta prestandakraven för de mest krävande arbetsbelastningarna. Det här inlägget täcker en sådan ny funktion - sorteringsnyckeln för flerdimensionell datalayout.
Amazon Redshift förbättrar nu din frågeprestanda genom att stödja sorteringsnycklar för flerdimensionell datalayout, vilket är en ny typ av sorteringsnyckel som sorterar en tabells data efter filterpredikat istället för fysiska kolumner i tabellen. Multidimensionella datalayoutsorteringsnycklar förbättrar avsevärt prestandan för tabellgenomsökningar, särskilt när din frågebelastning innehåller repetitiva genomsökningsfilter.
Amazon Redshift ger redan möjligheten att automatisk tabelloptimering (ATO), som automatiskt optimerar designen av tabeller genom att använda sorterings- och distributionsnycklar utan behov av administratörsingripande. I det här inlägget introducerar vi flerdimensionella datalayoutsorteringsnycklar som en extra funktion som erbjuds av ATO och förstärkt av Amazon Redshifts sorteringsnyckelrådgivares algoritm.
Multidimensionella datalayoutsorteringsnycklar
När du definierar en tabell med AUTO-sorteringsnyckeln kommer Amazon Redshift ATO att analysera din frågehistorik och automatiskt välja antingen en enkolumns sorteringsnyckel eller flerdimensionell datalayoutsorteringsnyckel för din tabell, baserat på vilket alternativ som är bäst för din arbetsbelastning. När flerdimensionell datalayout är vald kommer Amazon Redshift att konstruera en flerdimensionell sorteringsfunktion som samlokaliserar rader som vanligtvis nås av samma frågor, och sorteringsfunktionen används sedan under frågekörningar för att hoppa över datablock och till och med hoppa över att skanna det individuella predikatet kolumner.
Tänk på följande användarfråga, som är ett dominerande frågemönster i användarens arbetsbelastning:
Amazon Redshift lagrar data för varje kolumn i 1 MB diskblock och lagrar minimi- och maxvärdena i varje block som en del av tabellens metadata. Om en fråga använder en räckviddsbegränsat predikat, Amazon Redshift kan använda lägsta och högsta värden för att snabbt hoppa över ett stort antal block under tabellskanningar. Den här frågans filter på underregionkolumnen kan dock inte användas för att bestämma vilka block som ska hoppa över baserat på lägsta och maxvärden, och som ett resultat avsöker Amazon Redshift alla rader från rubriktabellen:
När användarens fråga kördes med titles med en enkolumns sorteringsnyckel på subregion, resultatet av den föregående frågan är följande:
Detta visar att tabellskanningen läste 2,164,081,640 XNUMX XNUMX XNUMX rader.
För att förbättra skanningar på titles tabell kan Amazon Redshift automatiskt välja att använda en sorteringsnyckel för flerdimensionell datalayout. Alla rader som uppfyller lower(subregion) like '%United States%' predikatet skulle vara samlokaliserat till en dedikerad region av tabellen, och därför kommer Amazon Redshift endast att skanna datablock som uppfyller predikatet.
När användarens fråga körs med titles använda en flerdimensionell datalayoutsorteringsnyckel som inkluderar lower(subregion) like '%United States%' som ett predikat, resultatet av sys_query_detail frågan är som följer:
Detta visar att tabellskanningen läste 152,324,046 7 XNUMX rader, vilket bara är XNUMX % av originalet, och den använde sorteringsnyckeln för flerdimensionell datalayout.
Observera att det här exemplet använder en enda fråga för att visa upp den flerdimensionella datalayoutfunktionen, men Amazon Redshift kommer att överväga alla frågor som körs mot tabellen och kan skapa flera regioner för att uppfylla de vanligaste körda predikaten.
Låt oss ta ett annat exempel, med mer komplexa predikat och flera frågor den här gången.
Tänk dig att ha ett bord items (cost int, available int, demand int) med fyra rader som visas i följande exempel.
| #id | kosta | tillgänglig | Efterfrågan |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
Din dominerande arbetsbelastning består av två frågor:
- 70 % frågemönster:
- 20 % frågemönster:
Med traditionella sorteringstekniker kan du välja att sortera tabellen över kostnadskolumnen, så att utvärderingen av cost > 3 kommer att dra nytta av den sorten. Så, objekten tabellen efter sortering med en singel cost kolumnen kommer att se ut så här.
| #id | kosta | tillgänglig | Efterfrågan |
| Region #1, med kostnad <= 3 | |||
| Region #2, med kostnad > 3 | |||
| #id | kosta | tillgänglig | Efterfrågan |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
Genom att använda denna traditionella sortering kan vi omedelbart utesluta de två översta (blå) raderna med ID 4 och ID 2, eftersom de inte uppfyller cost > 3.
Å andra sidan, med en flerdimensionell datalayoutsorteringsnyckel, kommer tabellen att sorteras baserat på en kombination av de två vanligt förekommande predikaten i användarens arbetsbelastning, som är cost > 3 och available < demand. Som ett resultat sorteras tabellens rader i fyra regioner.
| #id | kosta | tillgänglig | Efterfrågan |
| Region #1, med kostnad <= 3 och tillgänglig < efterfrågan | |||
| Region #2, med kostnad <= 3 och tillgänglig >= efterfrågan | |||
| Region #3, med kostnad > 3 och tillgänglig < efterfrågan | |||
| Region #4, med kostnad > 3 och tillgänglig >= efterfrågan | |||
| #id | kosta | tillgänglig | Efterfrågan |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
Detta koncept är ännu mer kraftfullt när det tillämpas på hela block istället för enstaka rader, när det tillämpas på komplexa predikat som använder operatorer som inte är lämpliga för traditionella sorteringstekniker (som t.ex. like), och när de tillämpas på mer än två predikat.
Systemtabeller
Följande Amazon Redshift-systemtabeller visar användare om flerdimensionella datalayouter används i deras tabeller och frågor:
- För att avgöra om en viss tabell använder en flerdimensionell datalayoutsorteringsnyckel kan du kontrollera om
sortkey1in svv_tabellinfo är lika medAUTO(SORTKEY(padb_internal_mddl_key_col)). - För att avgöra om en viss fråga använder flerdimensionell datalayout för att påskynda tabellsökningar kan du kontrollera
step_attributei sys_query_detail se. Värdet kommer att vara lika medmulti-dimensionalom tabellens flerdimensionella datalayoutsorteringsnyckel användes under skanningen.
Prestanda riktmärken
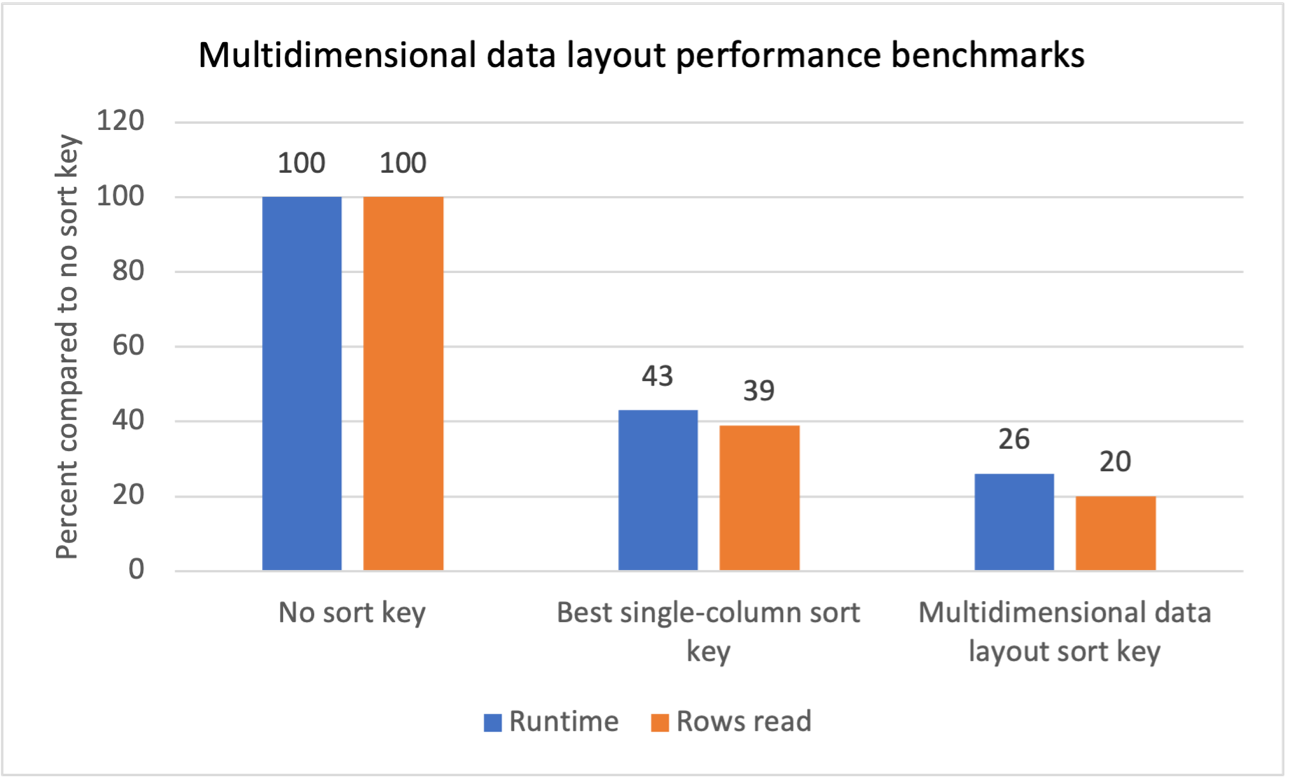
Vi utförde interna benchmark-tester för flera arbetsbelastningar med repetitiva skanningsfilter och ser att införandet av flerdimensionella datalayoutsorteringsnycklar gav följande resultat:
- En total minskning av körtiden med 74 % jämfört med att inte ha någon sorteringsnyckel.
- En total minskning av körtiden med 40 % jämfört med att ha den bästa sorteringsnyckeln med en kolumn på varje tabell.
- En 80 % minskning av det totala antalet rader som läses från tabeller jämfört med att inte ha någon sorteringsnyckel.
- En 47 % minskning av det totala antalet rader som läses från tabeller jämfört med att ha den bästa sorteringsnyckeln med en kolumn i varje tabell.
Funktionsjämförelse
Med introduktionen av flerdimensionella sorteringsnycklar för datalayout kan dina tabeller nu sorteras efter uttryck baserade på de vanligt förekommande filterpredikaten i din arbetsbelastning. Följande tabell ger en jämförelse av funktioner för Amazon Redshift med två konkurrenter.
| Leverans | Amazon RedShift | Konkurrent A | Konkurrent B |
| Stöd för sortering på kolumner | Ja | Ja | Ja |
| Stöd för sortering efter uttryck | Ja | Ja | Nej |
| Automatiskt kolumnval för sortering | Ja | Nej | Ja |
| Automatiskt val av uttryck för sortering | Ja | Nej | Nej |
| Automatiskt val mellan kolumnsortering eller uttryckssortering | Ja | Nej | Nej |
| Automatisk användning av sorteringsegenskaper för uttryck under skanningar | Ja | Nej | Nej |
Överväganden
Tänk på följande när du använder en flerdimensionell datalayout:
- Flerdimensionell datalayout är aktiverad när du ställer in din tabell som SORTKEY AUTO.
- Amazon Redshift Advisor kommer automatiskt att välja antingen en enkolumns sorteringsnyckel eller flerdimensionell datalayout för tabellen genom att analysera din historiska arbetsbelastning.
- Amazon Redshift ATO justerar sorteringsresultaten för flerdimensionell datalayout baserat på det sätt på vilket pågående frågor interagerar med arbetsbelastningen.
- Amazon Redshift ATO upprätthåller flerdimensionella datalayoutsorteringsnycklar på samma sätt som för närvarande gör för befintliga sorteringsnycklar. Hänvisa till Arbetar med automatisk tabelloptimering för mer information om ATO.
- Multidimensionella datalayoutsorteringsnycklar fungerar med både provisionerade kluster och serverlösa arbetsgrupper.
- Multidimensionella datalayoutsorteringsnycklar fungerar med dina befintliga data så länge som AUTO SORTKEY är aktiverad på din tabell och en arbetsbelastning med repetitiva skanningsfilter upptäcks. Tabellen kommer att omorganiseras baserat på resultaten av flerdimensionell sorteringsfunktion.
- För att inaktivera sorteringsnycklar för flerdimensionell datalayout för en tabell, använd alter table:
ALTER TABLE table_name ALTER SORTKEY NONE. Detta inaktiverar AUTO-sorteringsnyckelfunktionen på tabellen. - Multidimensionella datalayoutsorteringsnycklar bevaras när du återställer eller migrerar ditt provisionerade kluster till ett serverlöst kluster eller vice versa.
Slutsats
I det här inlägget visade vi att flerdimensionella datalayoutsorteringsnycklar avsevärt kan förbättra prestandan för frågekörning för arbetsbelastningar där dominerande frågor har repetitiva skanningsfilter.
För att skapa ett förhandsvisningskluster från Amazon Redshift-konsolen, navigera till kluster sida och välj Skapa förhandsgranskningskluster. Du kan skapa ett kluster i regionerna Östra USA (Ohio), Östra USA (N. Virginia), Västra USA (Oregon), Stillahavsområdet (Tokyo), Europa (Irland) och Europa (Stockholm) och testa dina arbetsbelastningar.
Vi vill gärna höra din feedback om den här nya funktionen och ser fram emot dina kommentarer på det här inlägget.
Om författarna
 Milind Oke är en Data Warehouse Specialist Solutions Architect baserad i New York. Han har byggt datalagerlösningar i över 15 år och är specialiserad på Amazon Redshift.
Milind Oke är en Data Warehouse Specialist Solutions Architect baserad i New York. Han har byggt datalagerlösningar i över 15 år och är specialiserad på Amazon Redshift.
 Jialin Ding är en tillämpad vetenskapsman i Learned Systems Group, specialiserad på att tillämpa maskininlärning och optimeringstekniker för att förbättra prestandan hos datasystem som Amazon Redshift.
Jialin Ding är en tillämpad vetenskapsman i Learned Systems Group, specialiserad på att tillämpa maskininlärning och optimeringstekniker för att förbättra prestandan hos datasystem som Amazon Redshift.
 Yanzhu Ji är produktchef i Amazon Redshift-teamet. Hon har erfarenhet av produktvision och strategi inom branschledande dataprodukter och plattformar. Hon har enastående skicklighet i att bygga betydande mjukvaruprodukter med hjälp av webbutveckling, systemdesign, databas och distribuerade programmeringstekniker. I sitt personliga liv gillar Yanzhu att måla, fotografera och spela tennis.
Yanzhu Ji är produktchef i Amazon Redshift-teamet. Hon har erfarenhet av produktvision och strategi inom branschledande dataprodukter och plattformar. Hon har enastående skicklighet i att bygga betydande mjukvaruprodukter med hjälp av webbutveckling, systemdesign, databas och distribuerade programmeringstekniker. I sitt personliga liv gillar Yanzhu att måla, fotografera och spela tennis.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- : har
- :är
- :inte
- :var
- 1
- 100
- 15 år
- 15%
- 152
- 7
- 8
- 9
- a
- accelerera
- Accessed
- Annat
- rådgivare
- Efter
- mot
- algoritm
- Alla
- redan
- amason
- Amazon Web Services
- an
- analysera
- analys
- och
- Annan
- tillämpas
- Tillämpa
- ÄR
- AS
- asien
- Asiens pacific
- bil
- Automat
- automatiskt
- tillgänglig
- AWS
- baserat
- BE
- därför att
- varit
- riktmärke
- fördel
- BÄST
- Bättre
- mellan
- Blockera
- Block
- Blå
- båda
- Byggnad
- men
- by
- KAN
- kapacitet
- ta
- Välja
- cloud
- kluster
- Kolumn
- Kolonner
- kombination
- kommentarer
- vanligen
- jämfört
- jämförelse
- konkurrenter
- komplex
- begrepp
- Tänk
- består
- Konsol
- konstruera
- innehåller
- Pris
- omfattar
- skapa
- För närvarande
- datum
- datalagret
- Databas
- beslutar
- dedicerad
- definiera
- Efterfrågan
- krävande
- Designa
- detaljer
- detekterad
- Bestämma
- Utveckling
- distribueras
- fördelning
- gör
- dominerande
- inte
- under
- varje
- öster
- antingen
- aktiverad
- Hela
- lika
- speciellt
- Eter (ETH)
- Europa
- utvärdering
- Även
- utvecklats
- exempel
- befintliga
- erfarenhet
- uttryck
- Leverans
- återkoppling
- filtrera
- filter
- efter
- följer
- För
- Framåt
- fyra
- från
- fungera
- Grupp
- sidan
- Har
- har
- he
- höra
- här
- historisk
- historia
- Men
- html
- HTTPS
- ID
- if
- blir omedelbart
- förbättra
- förbättrar
- in
- innefattar
- individuellt
- branschledande
- istället
- interagera
- inre
- ingripande
- in
- införa
- införa
- Beskrivning
- irland
- IT
- artikel
- Nyckel
- nycklar
- Large
- Layout
- lärt
- inlärning
- livet
- tycka om
- gillar
- Lång
- se
- ser ut som
- älskar
- Maskinen
- maskininlärning
- upprätthåller
- chef
- sätt
- maximal
- Möt
- metadata
- kanske
- migrerande
- emot
- minsta
- mer
- mest
- multipel
- Navigera
- Behöver
- Nya
- ny funktion
- New York
- Nej
- nu
- nummer
- förekommande
- of
- sänkt
- erbjuds
- Ohio
- on
- ONE
- pågående
- endast
- operatörer
- optimering
- optimerar
- Alternativet
- or
- beställa
- Oregon
- ursprungliga
- Övriga
- ut
- utestående
- över
- stilla havet
- målning
- del
- särskilt
- Mönster
- prestanda
- utfört
- personlig
- fotografi
- fysisk
- Plattformar
- plato
- Platon Data Intelligence
- PlatonData
- i
- Inlägg
- den mäktigaste
- bevarad
- Förhandsvisning
- producerad
- Produkt
- produktchef
- Produkter
- Programmering
- egenskaper
- ger
- sökfrågor
- snabbt
- Läsa
- reduktion
- hänvisa
- region
- regioner
- repetitiva
- Krav
- återställa
- resultera
- Resultat
- Körning
- rinnande
- kör
- Samma
- scanna
- scanning
- skannar
- Forskare
- Säsong
- se
- välj
- vald
- Val
- Server
- Tjänster
- in
- hon
- show
- visa
- visade
- visas
- Visar
- signifikant
- enda
- skicklighet
- So
- Mjukvara
- Lösningar
- specialist
- specialiserat
- specialiserat
- lagrar
- Strategi
- Senare
- väsentlig
- sådana
- lämplig
- Stödjande
- system
- System
- bord
- Ta
- grupp
- tekniker
- tennis
- testa
- Testning
- än
- den där
- Smakämnen
- deras
- därför
- de
- detta
- tid
- titlar
- till
- Tokyo
- topp
- Totalt
- traditionell
- två
- Typ
- typiskt
- us
- användning
- Begagnade
- Användare
- användare
- användningar
- med hjälp av
- värde
- Värden
- vice
- utsikt
- Virginia
- syn
- Warehouse
- var
- Sätt..
- we
- webb
- Webbutveckling
- webbservice
- väster
- när
- om
- som
- brett
- kommer
- med
- utan
- Arbete
- skulle
- år
- york
- dig
- Din
- zephyrnet