Beskrivning
Sammanslagningen av artificiell intelligens (AI) och konstnärskap avslöjar nya vägar inom kreativ digital konst, framträdande genom spridningsmodeller. Dessa modeller sticker ut i den kreativa AI-konstgenerationen och erbjuder ett distinkt tillvägagångssätt från konventionella neurala nätverk. Den här artikeln tar dig med på en utforskande resa in i djupet av diffusionsmodeller, och belyser deras unika mekanism för att skapa visuellt fantastiska och kreativt rika konstverk. Förstå nyanserna av diffusionsmodeller och få insikt i deras roll i att omdefiniera konstnärliga uttryck genom linsen av avancerad AI-teknik.

Inlärningsmål
- Förstå de grundläggande koncepten för diffusionsmodeller i AI.
- Utforska skillnaden mellan diffusionsmodeller och traditionella neurala nätverk i konstgenerering.
- Analysera processen att skapa konst med hjälp av diffusionsmodeller.
- Utvärdera de kreativa och estetiska implikationerna av AI i digital konst.
- Diskutera de etiska övervägandena i AI-genererade konstverk.
Denna artikel publicerades som en del av Data Science Blogathon.
Innehållsförteckning
Förstå diffusionsmodeller

Diffusionsmodeller revolutionerar generativ AI och presenterar en unik metod för bildskapande som skiljer sig från konventionella tekniker som Generative Adversarial Networks (GAN). Dessa modeller börjar med slumpmässigt brus och förfinar det successivt och liknar en konstnär som finjusterar en målning, vilket resulterar i intrikata och sammanhängande bilder.
Denna inkrementella förfiningsprocess speglar diffusionens metodiska natur. Här förändrar varje iteration subtilt bruset, och kantar det närmare den slutliga konstnärliga visionen. Resultatet är inte bara en produkt av slumpmässighet utan ett utvecklat konstverk, distinkt i sin progression och finish.
Kodning för diffusionsmodeller kräver ett djupt grepp om neurala nätverk och ramverk för maskininlärning som TensorFlow eller PyTorch. Den resulterande koden är intrikat och kräver omfattande utbildning i expansiva datamängder för att uppnå de nyanserade effekterna som observeras i AI-genererad konst.
Tillämpning av stabil diffusion i art
Tillkomsten av AI-konstgeneratorer som stabila diffusionsmodeller kräver sofistikerad kodning inom plattformar som TensorFlow eller PyTorch. Dessa modeller sticker ut för sin förmåga att metodiskt omvandla slumpmässighet till struktur, ungefär som en konstnär som finslipar en preliminär skiss till ett levande mästerverk.
Stabila diffusionsmodeller omformar AI-konstscenen genom att skulptera ordnade bilder från slumpmässighet, och undviker den konkurrenskraftiga dynamiken som är karakteristisk för GAN:er. De utmärker sig i att tolka konceptuella uppmaningar till bildkonst, och främjar en synergistisk dans mellan AI-kapacitet och mänsklig uppfinningsrikedom. Genom att utnyttja PyTorch observerar vi hur dessa modeller iterativt förfinar kaos till klarhet, och speglar konstnärens resa från en begynnande idé till en polerad skapelse.
Experimentera med AI-genererad konst
Denna demonstration fördjupar sig i den fascinerande världen av AI-genererad konst med hjälp av ett konvolutionellt neuralt nätverk som kallas ConvDiffusionModel. Den här modellen är tränad på olika konstbilder, som omfattar teckningar, målningar, skulpturer och gravyrer, hämtade från denna Kaggle-datauppsättning. Vårt mål är att utforska modellens förmåga att fånga och reproducera den komplexa estetiken hos dessa konstverk.
Modellarkitektur och utbildning
Arkitektonisk design
ConvDiffusionModel, i sin kärna, är ett under av neural ingenjörskonst, med en sofistikerad kodar-avkodararkitektur skräddarsydd för kraven från konstgenerering. Modellens struktur är ett komplext neuralt nätverk, som integrerar raffinerade kodare-avkodarmekanismer speciellt finslipade för konstgenerering. Med ytterligare faltningslager och överhoppningskopplingar som efterliknar konstnärlig intuition, kan modellen dissekera och återsätta konst med en skarp förståelse för komposition och stil.
- Encoder: Kodaren är modellens analytiska öga, som granskar varje ingångsbilds små detaljer. När bilder passerar genom kodarens faltningslager komprimeras de successivt till ett latent utrymme – en kompakt, kodad representation av det ursprungliga konstverket. Vår kodare granskar inte bara ingående bilder utan gör det nu med ett förstärkt djup av perception, tack vare ytterligare lager och batchnormaliseringstekniker. Denna utökade undersökning möjliggör en rikare, förtätad representation inom det latenta rummet, som speglar en konstnärs djupa kontemplation av ett ämne.
- Avkodare: Däremot fungerar avkodaren som modellens kreativa hand, tar de abstrakta skisserna från kodaren och blåser liv i dem. Den rekonstruerar konstverket från det latenta utrymmet, lager för lager, detalj för detalj, tills en komplett bild framträder. Vår dekoder drar nytta av hoppkopplingar och kan rekonstruera konstverk med större precision. Den återvänder till den abstraherade essensen av input och förskönar den gradvis och uppnår en återgivning som är mer trogen källmaterialet. De förbättrade lagren samverkar för att säkerställa att den slutliga bilden är en levande, intrikat del som återspeglar ingångens konstnärskap.
Utbildningsprocess
Utbildningen av ConvDiffusionModel är en resa genom ett konstnärligt landskap som sträcker sig över 150 epoker. Varje epok representerar en fullständig passage genom hela datamängden, där modellen strävar efter att förfina sin förståelse och förbättra troheten hos sina genererade bilder.
- Hybridförlustfunktion: I hjärtat av träningen ligger förlustfunktionen för medelkvadratfel (MSE). Denna funktion kvantifierar skillnaden mellan det ursprungliga mästerverket och modellens rekreation, vilket ger ett tydligt mått att minimera. Vi kommer att introducera en perceptuell förlustkomponent härledd från ett förtränat VGG-nätverk som kompletterar mätvärdet för medelkvadratfel (MSE). Denna strategi med dubbla förluster driver modellen att hedra originalens konstnärliga integritet samtidigt som den perfekta den tekniska återgivningen av deras detaljer.
- Optimerare: Med sin inlärningshastighet dynamiskt justerad av en schemaläggare vägleder Adam-optimeraren modellens inlärning med ökad klokhet. Detta adaptiva tillvägagångssätt säkerställer att modellens framsteg när det gäller att lära sig att replikera och förnya konst är både stadiga och robusta.
- Iteration och förfining: Träningsupprepningarna är en dans mellan att bevara konstnärlig väsen och sträva efter teknisk replikering. Med varje cykel kommer modellen närmare en syntes av trohet och kreativitet.
- Visualisering av framsteg: Bilder sparas med jämna mellanrum under träning för att visualisera modellens framsteg. Dessa ögonblicksbilder ger ett fönster in i modellens inlärningskurva, och visar hur dess genererade konst utvecklas, blir tydligare, mer detaljerad och mer konstnärligt sammanhängande med varje epok.



Ovanstående demonstreras med följande kodbit:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision.models import vgg16
from PIL import Image
# Defining a function to check for valid images
def is_valid_image(image_path):
try:
with Image.open(image_path) as img:
img.verify()
return True
except (IOError, SyntaxError) as e:
# Printing out the names of all corrupt files
print(f'Bad file:', image_path)
return False
# Defining the neural network
class ConvDiffusionModel(nn.Module):
def __init__(self):
super(ConvDiffusionModel, self).__init__()
# Encoder
self.enc1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc2 = nn.Sequential(nn.Conv2d(64, 128,
kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3,
padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2,
stride=2))
# Decoder
self.dec1 = nn.Sequential(nn.ConvTranspose2d(256, 128,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(128))
self.dec2 = nn.Sequential(nn.ConvTranspose2d(128, 64,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(64))
self.dec3 = nn.Sequential(nn.ConvTranspose2d(64, 3,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid())
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
# Decoder with skip connections
dec1 = self.dec1(enc3) + enc2
dec2 = self.dec2(dec1) + enc1
dec3 = self.dec3(dec2)
return dec3
# Using a pre-trained VGG16 model to compute perceptual loss
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
self.vgg = vgg16(pretrained=True).features[:16].cuda()
.eval() # Only the first 16 layers
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, input, target):
input_vgg = self.vgg(input)
target_vgg = self.vgg(target)
loss = torch.nn.functional.mse_loss(input_vgg,
target_vgg)
return loss
# Checking if CUDA is available and set device to GPU if it is.
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# Initializing the model and perceptual loss
model = ConvDiffusionModel().to(device)
vgg_loss = VGGLoss().to(device)
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30,
gamma=0.1)
# Dataset and DataLoader setup
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(root='/content/Images',
transform=transform, is_valid_file=is_valid_image)
dataloader = DataLoader(dataset, batch_size=32,
shuffle=True)
# Training loop
num_epochs = 150
for epoch in range(num_epochs):
for i, (inputs, _) in enumerate(dataloader):
inputs = inputs.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Calculate losses
mse = mse_loss(outputs, inputs)
perceptual = vgg_loss(outputs, inputs)
loss = mse + perceptual
# Backward pass and optimize
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}],
Step [{i+1}/{len(dataloader)}], Loss: {loss.item()},
Perceptual Loss: {perceptual.item()}, MSE Loss:
{mse.item()}')
# Saving the generated image for visualization
save_image(outputs, f'output_epoch_{epoch+1}
_step_{i+1}.png')
# Updating the learning rate
scheduler.step()
# Saving model checkpoints
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(),
f'/content/model_epoch_{epoch+1}.pth')
print('Training Complete')
Visualisera det genererade konstverket
Manifesterar AI-Crafted Artistry
Med ConvDiffusionModel nu fullt utbildad skiftar fokus från det abstrakta till det konkreta – från potentialen till att förverkliga AI-skapad konst. Det efterföljande kodavsnittet materialiserar modellens inlärda konstnärliga förmågor och omvandlar indata till en digital duk av uttryck.
import os
import matplotlib.pyplot as plt
# Loading the trained model
model = ConvDiffusionModel().to(device)
model.load_state_dict(torch.load('/content/model_epoch_150.pth'))
model.eval() # Set the model to evaluation mode
# Transforming for the input image
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Function to de-normalize the image for viewing
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).
to(device).view(-1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).
to(device).view(-1, 1, 1)
tensor = tensor * std + mean # De-normalize
tensor = tensor.clamp(0, 1) # Clamp to the valid image range
return tensor
# Loading and transforming the image
input_image_path = '/content/Validation/0006.jpg'
input_image = Image.open(input_image_path).convert('RGB')
input_tensor = transform(input_image).unsqueeze(0).to(device)
# Adding a batch dimension
# Generating the image
with torch.no_grad():
generated_tensor = model(input_tensor)
# Converting the generated image tensor to an image
generated_image = denormalize(generated_tensor.squeeze(0))
# Removing the batch dimension and de-normalizing
generated_image = generated_image.cpu() # Move to CPU
# Saving the generated image
save_image(generated_image, '/content/generated_image.png')
print("Generated image saved to '/content/generated_image.png'")
# Displaying the generated image using matplotlib
plt.figure(figsize=(8, 8))
plt.imshow(generated_image.permute(1, 2, 0))
# Rearrange the channels for plotting
plt.axis('off') # Hide the axes
plt.show()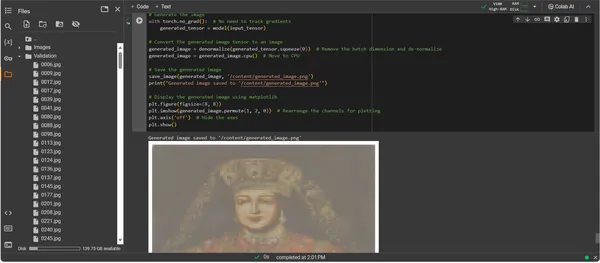

Konstverk Generation Code Walkthrough
- Modell Resurrection: Det första steget i konstverksgenereringen är att återuppliva vår utbildade ConvDiffusionModel. Modellens inlärda vikter laddas och förs in i utvärderingsläge, vilket sätter scenen för skapandet utan att ytterligare ändra dess parametrar.
- Bildomvandling: För att säkerställa överensstämmelse med träningsregimen, bearbetas indatabilder genom samma sekvens av transformationer. Detta inkluderar storleksändring för att matcha modellens indatadimensioner, tensorkonvertering för PyTorch-kompatibilitet och normalisering baserat på träningsdatas statistiska profil.
- Denormaliseringsverktyg: En anpassad funktion vänder på förbehandlingseffekterna och skalar om tensorn till originalbildens färgområde. Detta steg är viktigt för att göra den genererade utdatan till en visuellt korrekt representation.
- Ingångsförberedelse: En bild laddas och utsätts för de tidigare nämnda omvandlingarna. Det är viktigt att notera att den här bilden fungerar som musan från vilken AI kommer att hämta inspiration – den tysta viskningen tänder modellens syntetiska fantasi.
- Konstverkssyntes: I en delikat dans av framåtriktad fortplantning tolkar modellen ingångstensorn, vilket gör att dess lager kan samarbeta för att producera en ny konstnärlig vision. Utför den här processen utan att spåra gradienter, eftersom vi nu är i tillämpningsområdet, inte träning.
- Bildkonvertering: Tensorutgången av modellen, som nu håller det digitalt födda konstverket, denormaliseras, vilket översätter modellens skapelse tillbaka till det välbekanta utrymmet av färg och ljus som våra ögon kan uppskatta.
- Konstverksuppenbarelse: Den transformerade tensorn läggs ut på en digital duk, som kulminerar i en sparad bildfil. Den här filen är ett fönster in i AI:s kreativa själ, ett statiskt eko av den dynamiska process som gav den liv.
- Konstverkshämtning: Skriptet avslutas med att spara den genererade bilden på en angiven sökväg och meddela att den är klar. Den sparade bilden, en syntes av inlärda konstnärliga principer och framväxande kreativitet, är redo för visning och kontemplation.
Analysera output
ConvDiffusionModels resultat presenterar en figur med en tydlig nick till historisk konst. Draperad i utarbetad klädsel, den AI-renderade bilden ekar storheten hos klassiska porträtt men ändå med en distinkt, modern touch. Ämnets klädsel är rik på textur och blandar modellens inlärda mönster med en ny tolkning. Fina ansiktsdrag och ett subtilt samspel av ljus och skugga visar upp AI:s nyanserade förståelse för traditionella konsttekniker. Detta konstverk är ett bevis på modellens sofistikerade träning, som återspeglar en elegant syntes av historiskt konstnärskap genom prismat av avancerad maskininlärning. I huvudsak är det en digital hyllning till det förflutna, skapad med nutidens algoritmer.
Utmaningar och etiska överväganden
Att implementera diffusionsmodeller för konstgenerering för med sig flera utmaningar och etiska överväganden som du bör överväga:
- Datahärkomst: Utbildningsdatauppsättningarna måste kureras ansvarsfullt. Det är viktigt att verifiera att data som används för att träna spridningsmodeller inte innehåller upphovsrättsskyddade eller skyddade verk utan lämplig auktorisation.
- Bias och representation: AI-modeller kan vidmakthålla fördomar i sina träningsdata. Att säkerställa olika och inkluderande datauppsättningar är viktigt för att undvika att förstärka stereotyper i AI-genererad konst.
- Kontroll över utgång: Eftersom spridningsmodeller kan generera ett brett utbud av utdata är det nödvändigt att sätta gränser för att förhindra skapandet av olämpligt eller stötande innehåll.
- Juridiskt ramverk: Bristen på en robust rättslig ram för att ta itu med nyanserna av AI i den kreativa processen utgör en utmaning. Lagstiftningen måste utvecklas för att skydda rättigheterna för alla inblandade parter.
Slutsats
Framväxten av diffusionsmodeller inom AI och konst markerar en transformativ era, där beräkningsprecision förenas med estetisk utforskning. Deras resa i konstvärlden belyser betydande innovationspotential men kommer med komplexitet. Att balansera originalitet, inflytande, etiskt skapande och respekt för befintliga verk är en integrerad del av den konstnärliga processen.
Key Takeaways
- Diffusionsmodeller är i framkant av ett transformativt skifte inom konstskapande. De erbjuder nya digitala verktyg som utökar det konstnärliga uttryckets duk bortom traditionella gränser.
- Inom den AI-förbättrade konsten är det absolut nödvändigt att prioritera den etiska insamlingen av träningsdata och respektera kreatörernas immateriella rättigheter för att upprätthålla integriteten i digitalt konstnärskap.
- Konvergensen av konstnärlig vision och teknisk innovation öppnar dörrar till ett symbiotiskt förhållande mellan konstnärer och AI-utvecklare. Främja en samarbetsmiljö som kan ge upphov till banbrytande konst.
- Det är viktigt att se till att AI-genererad konst representerar ett brett spektrum av perspektiv. Inkludera ett varierat utbud av data som återspeglar rikedomen hos olika kulturer och synpunkter, vilket främjar inkludering.
- Det växande intresset för konst skapad av AI kräver inrättandet av robusta rättsliga ramar. Dessa ramverk bör klargöra upphovsrättsfrågor, erkänna bidrag och styra den kommersiella användningen av AI-genererade konstverk.
Gryningen av denna konstnärliga utveckling erbjuder en väg full av kreativ potential men kräver medveten vårdnad. Det åligger oss att odla ett landskap där fusionen av AI och konst frodas, styrt av ansvarsfulla och kulturellt känsliga metoder.
Vanliga frågor
A. Diffusionsmodeller är generativa ML-algoritmer som skapar bilder genom att börja med ett mönster av slumpmässigt brus och gradvis forma det till en sammanhängande bild. Denna process liknar en konstnär som börjar med en tom duk och långsamt lägger till lager av detaljer.
A. GAN:er, diffusionsmodeller kräver inte ett separat nätverk för att bedöma resultatet. De fungerar genom att lägga till och ta bort brus iterativt, vilket ofta resulterar i mer detaljerade och nyanserade bilder.
S. Ja, diffusionsmodeller kan generera originalkonstverk genom att lära sig från en datauppsättning av bilder. Originaliteten påverkas dock av mångfalden och omfattningen av träningsdata. Det pågår en debatt om etiken i att använda befintliga konstverk för att träna dessa modeller.
S. Etiska problem omfattar undvikande av AI-genererad upphovsrättsintrång. Respektera mänskliga konstnärers originalitet, förhindra bias-perpetuation och säkerställa transparens i AI:s kreativa process.
S. Framtiden för AI-genererad konst ser lovande ut, med spridningsmodeller som erbjuder nya verktyg för konstnärer och kreatörer. Vi kan förvänta oss att se mer sofistikerade och intrikata konstverk när tekniken utvecklas. Den kreativa gemenskapen måste dock navigera i etiska överväganden och arbeta mot tydliga riktlinjer och bästa praxis.
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
Relaterad
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2023/12/implementing-diffusion-models-for-creative-ai-art-generation/
- :är
- :inte
- :var
- 001
- 1
- 10
- 100
- 11
- 12
- 15%
- 150
- 16
- 19
- 224
- 225
- 8
- 9
- a
- förmåga
- Om Oss
- ovan
- SAMMANDRAG
- exakt
- Uppnå
- uppnå
- Adam
- adaptiv
- tillsats
- Annat
- adress
- justerat
- avancerat
- framsteg
- första advent
- kontradiktoriskt
- AI
- ai konst
- besläktad
- algoritmer
- Alla
- tillåta
- tillåter
- an
- Analytisk
- analytics
- Analys Vidhya
- och
- Vi presenterar
- Ansökan
- uppskatta
- tillvägagångssätt
- arkitektur
- ÄR
- Konst
- Artikeln
- konstnär
- konstnärliga
- konstnärligt
- artisteri
- Artister
- konstverk
- konstverk
- AS
- At
- augmented
- tillstånd
- tillgänglig
- vägar
- undvika
- undvika
- AXLAR
- tillbaka
- Badrum
- balansering
- baserat
- BE
- passande
- Fördelarna
- BÄST
- bästa praxis
- mellan
- Bortom
- förspänning
- förspänner
- blank
- blandning
- bloggaton
- födda
- båda
- gränser
- andas
- full
- Bringar
- bred
- fört
- spirande
- men
- by
- beräkna
- kallas
- KAN
- canvas
- kapacitet
- kapacitet
- fånga
- utmanar
- utmaningar
- kanaler
- Kaos
- karakteristiska
- ta
- kontroll
- klämma
- klarhet
- klass
- klar
- klarare
- närmare
- koda
- Kodning
- SAMMANHÄNGANDE
- samarbeta
- samarbete
- färg
- kommer
- kommersiella
- samfundet
- kompakt
- kompatibilitet
- konkurrenskraftig
- fullborda
- fullbordan
- komplex
- komplexiteter
- komponent
- sammansättning
- beräkningar
- Compute
- Begreppen
- begreppsmässig
- oro
- konsert
- avslutar
- Anslutningar
- Tänk
- överväganden
- innehålla
- innehåll
- Däremot
- bidrag
- konventionell
- Konvergens
- Konvertering
- omvandling
- convolutional neuralt nätverk
- upphovsrätt
- upphovsrättsintrång
- Kärna
- korrupta
- CPU
- tillverkad
- skapa
- Skapa
- skapande
- Kreativ
- Kreativt
- kreativitet
- skaparna
- avgörande
- kulminerade
- Odla
- kulturellt
- kurerad
- kurva
- beställnings
- cykel
- dansa
- datum
- datauppsättningar
- diskussion
- djup
- definierande
- krav
- demonstreras
- djup
- Djup
- Härledd
- betecknad
- detalj
- detaljerad
- detaljer
- utvecklare
- anordning
- skilja sig
- Skillnaden
- olika
- Diffusion
- digital
- digital konst
- digitalt
- Dimensionera
- dimensioner
- diskretion
- Visa
- visning
- distinkt
- skillnad
- flera
- Mångfald
- do
- gör
- Dörrarna
- dra
- Ritningar
- under
- dynamisk
- dynamiskt
- Dynamiken
- e
- varje
- missar
- ekon
- effekter
- Utveckla
- annars
- framträder
- kodade
- omfatta
- encompassing
- Teknik
- förbättrad
- säkerställa
- säkerställer
- säkerställa
- Hela
- Miljö
- epok
- epoker
- Era
- fel
- huvudsak
- väsentlig
- etablering
- Eter (ETH)
- etisk
- etik
- utvärdering
- Varje
- Utvecklingen
- utvecklas
- utvecklats
- utvecklas
- undersökning
- excel
- Utom
- befintliga
- Bygga ut
- expansiv
- förvänta
- utforskning
- utforska
- Uttrycket
- förlängas
- omfattande
- ögat
- Ögon
- ansikts
- trogna
- falsk
- bekant
- fascinerande
- Funktioner
- Med
- trohet
- Figur
- Fil
- Filer
- slutlig
- slut
- Förnamn
- Fokus
- efter
- För
- förgrunden
- Framåt
- Foster
- främja
- Ramverk
- ramar
- från
- fullständigt
- fungera
- funktionella
- grundläggande
- ytterligare
- sammansmältning
- framtida
- Få
- GAN
- samla
- gav
- generera
- genereras
- generera
- generering
- generativ
- generativa adversariella nätverk
- Generativ AI
- generatorer
- Ge
- Målet
- GPU
- gradienter
- gradvis
- magnitud
- grepp
- större
- banbrytande
- guidad
- riktlinjer
- Guider
- sidan
- Utnyttja
- Hjärta
- här.
- Dölja
- höjdpunkter
- historisk
- innehav
- hyllning
- ära
- Hur ser din drömresa ut
- Men
- HTTPS
- humant
- i
- Tanken
- if
- tänds
- bild
- bilder
- fantasi
- nödvändigt
- genomföra
- implikationer
- importera
- med Esport
- förbättra
- in
- innefattar
- Inkludering
- inclusivity
- införliva
- ökat
- steg
- Sittande
- påverka
- påverkas
- överträdelse
- uppfinningsrikedom
- förnya
- Innovation
- ingång
- ingångar
- insikt
- integrerad
- Integrera
- integritet
- intellektuella
- immateriella rättigheter
- intresse
- tolkning
- in
- invecklad
- införa
- intuition
- involverade
- problem
- IT
- iteration
- iterationer
- DESS
- resa
- jpg
- Domaren
- Brist
- liggande
- lager
- skikt
- lärt
- inlärning
- Adress
- juridiskt ramverk
- Lagstiftning
- Lins
- ligger
- livet
- ljus
- tycka om
- läser in
- UTSEENDE
- förlust
- förluster
- Maskinen
- maskininlärning
- bibehålla
- förundras
- mästerverk
- Match
- Materialet
- matplotlib
- betyda
- mekanism
- mekanismer
- Media
- endast
- sammanslagning
- metod
- metodisk
- metriska
- minimera
- minut
- spegling
- ML
- ML-algoritmer
- Mode
- modell
- modeller
- Modern Konst
- modul
- mer
- flytta
- mycket
- MUSE
- måste
- namn
- begynnande
- Natur
- Navigera
- nödvändigt för
- behov
- nät
- nätverk
- neural
- Neural ingenjörskonst
- neurala nätverk
- neurala nätverk
- Nya
- Brus
- Notera
- roman
- nu
- nyanser
- observera
- observerad
- of
- sänkt
- offensiv
- erbjudanden
- erbjuda
- Erbjudanden
- Ofta
- on
- pågående
- endast
- öppnas
- Optimera
- or
- ursprungliga
- originalitet
- Originals
- OS
- Övriga
- vår
- ut
- produktion
- utgångar
- över
- ägd
- målning
- målningar
- parameter
- parametrar
- del
- parter
- passera
- Tidigare
- bana
- Mönster
- mönster
- varseblivning
- fullända
- utföra
- perspektiv
- Bild
- bit
- bitar
- Plattformar
- plato
- Platon Data Intelligence
- PlatonData
- porträtt
- potentiell
- praxis
- Precision
- preliminära
- presentera
- presenterar
- konservering
- förhindra
- förebyggande
- Principerna
- tryckning
- prioritering
- process
- bearbetade
- producerande
- Produkt
- Profil
- djupgående
- Framsteg
- progression
- progressivt
- lovande
- främja
- prompter
- förökning
- rätt
- egenskapen
- skydda
- skyddad
- härkomst
- tillhandahålla
- publicerade
- fullfölja
- pytorch
- kvantifierar
- slumpmässig
- slumpmässighet
- område
- Betygsätta
- redo
- rike
- känner igen
- omdefiniera
- förfina
- raffinerade
- reflekterande
- Reflekterar
- regim
- regelbunden
- relation
- bort
- rendering
- replikation
- representation
- representerar
- reproduktion
- kräver
- Kräver
- liknar
- omforma
- avseende
- respektera
- ansvarig
- ansvarsfullt
- resulterande
- avkastning
- uppenbarelse
- Revive
- revolutionera
- RGB
- Rik
- rättigheter
- Rise
- robusta
- Roll
- Samma
- sparade
- sparande
- scen
- Vetenskap
- omfattning
- skript
- se
- SJÄLV
- känslig
- separat
- Sekvens
- serverar
- in
- inställning
- inställning
- flera
- skugga
- formning
- skifta
- Skift
- skall
- visa
- visa upp
- visas
- signifikant
- eftersom
- Långsamt
- kodavsnitt
- So
- sofistikerade
- Själ
- Källa
- kommer från
- Utrymme
- spänning
- specifikt
- Spektrum
- squared
- stabil
- Etapp
- stå
- Starta
- statistisk
- stadig
- Steg
- Strategi
- strävan
- struktur
- Bedövning
- stil
- ämne
- senare
- sådana
- Symbiotisk
- synergistisk
- syntes
- syntetisk
- skräddarsydd
- tar
- tar
- Målet
- Teknisk
- tekniker
- teknisk
- Tekniken
- Teknologi
- tensorflow
- testament
- den där
- Smakämnen
- Framtiden
- källan
- deras
- Dem
- Där.
- Dessa
- de
- detta
- Trivs
- Genom
- Således
- till
- verktyg
- brännaren
- Torchvision
- Rör
- mot
- Spårning
- traditionell
- Tåg
- tränad
- Utbildning
- Förvandla
- Transformation
- transformationer
- transformativ
- transformerad
- omvandla
- transformer
- Öppenhet
- sann
- prova
- förstå
- förståelse
- unika
- tills
- presenterar
- uppdatering
- på
- us
- användning
- Begagnade
- med hjälp av
- verktyg
- giltigt
- verifiera
- via
- visning
- synpunkter
- syn
- visuell
- visuell konst
- visualisering
- visualisera
- visuellt
- avgörande
- var
- we
- webp
- Vad
- Vad är
- som
- medan
- Viska
- VEM
- bred
- Brett utbud
- kommer
- fönster
- med
- inom
- utan
- Arbete
- fungerar
- världen
- X
- ja
- ännu
- dig
- zephyrnet
- noll-