Forskare fortsätter att utveckla nya modellarkitekturer för vanliga maskininlärningsuppgifter (ML). En sådan uppgift är bildklassificering, där bilder accepteras som input och modellen försöker klassificera bilden som en helhet med objektetikettutdata. Med många tillgängliga modeller idag som utför denna bildklassificeringsuppgift, kan en ML-utövare ställa frågor som: "Vilken modell ska jag finjustera och sedan distribuera för att uppnå bästa prestanda på min datauppsättning?" Och en ML-forskare kan ställa frågor som: "Hur kan jag skapa min egen rättvisa jämförelse av flera modellarkitekturer mot en specificerad datauppsättning samtidigt som jag kontrollerar träningshyperparametrar och datorspecifikationer, såsom GPU:er, CPU:er och RAM?" Den förra frågan tar upp modellval över modellarkitekturer, medan den senare frågan gäller benchmarking av tränade modeller mot en testdatauppsättning.
I det här inlägget kommer du att se hur TensorFlow bildklassificering algoritm för Amazon SageMaker JumpStart kan förenkla de implementeringar som krävs för att ta itu med dessa frågor. Tillsammans med genomförandet detaljerna i en motsvarande exempel Jupyter anteckningsbok, kommer du att ha tillgängliga verktyg för att utföra modellval genom att utforska pareto-gränser, där det inte är möjligt att förbättra ett prestandamått, såsom noggrannhet, utan att försämra ett annat mätvärde, såsom genomströmning.
Lösningsöversikt
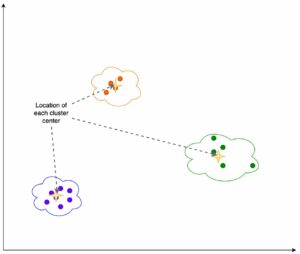
Följande figur illustrerar avvägningen mellan modellvalet för ett stort antal bildklassificeringsmodeller finjusterade på Caltech-256 dataset, som är en utmanande uppsättning av 30,607 256 verkliga bilder som spänner över XNUMX objektkategorier. Varje punkt representerar en enda modell, punktstorlekar skalas med avseende på antalet parametrar som ingår i modellen, och punkterna är färgkodade baserat på deras modellarkitektur. Till exempel representerar de ljusgröna punkterna EfficientNet-arkitekturen; varje ljusgrön punkt är en annan konfiguration av denna arkitektur med unika finjusterade modellprestandamätningar. Figuren visar förekomsten av en pareto-gräns för modellval, där högre noggrannhet byts ut mot lägre genomströmning. I slutändan beror valet av en modell längs pareto-gränsen, eller uppsättningen av pareto-effektiva lösningar, på prestandakraven för din modelldistribution.
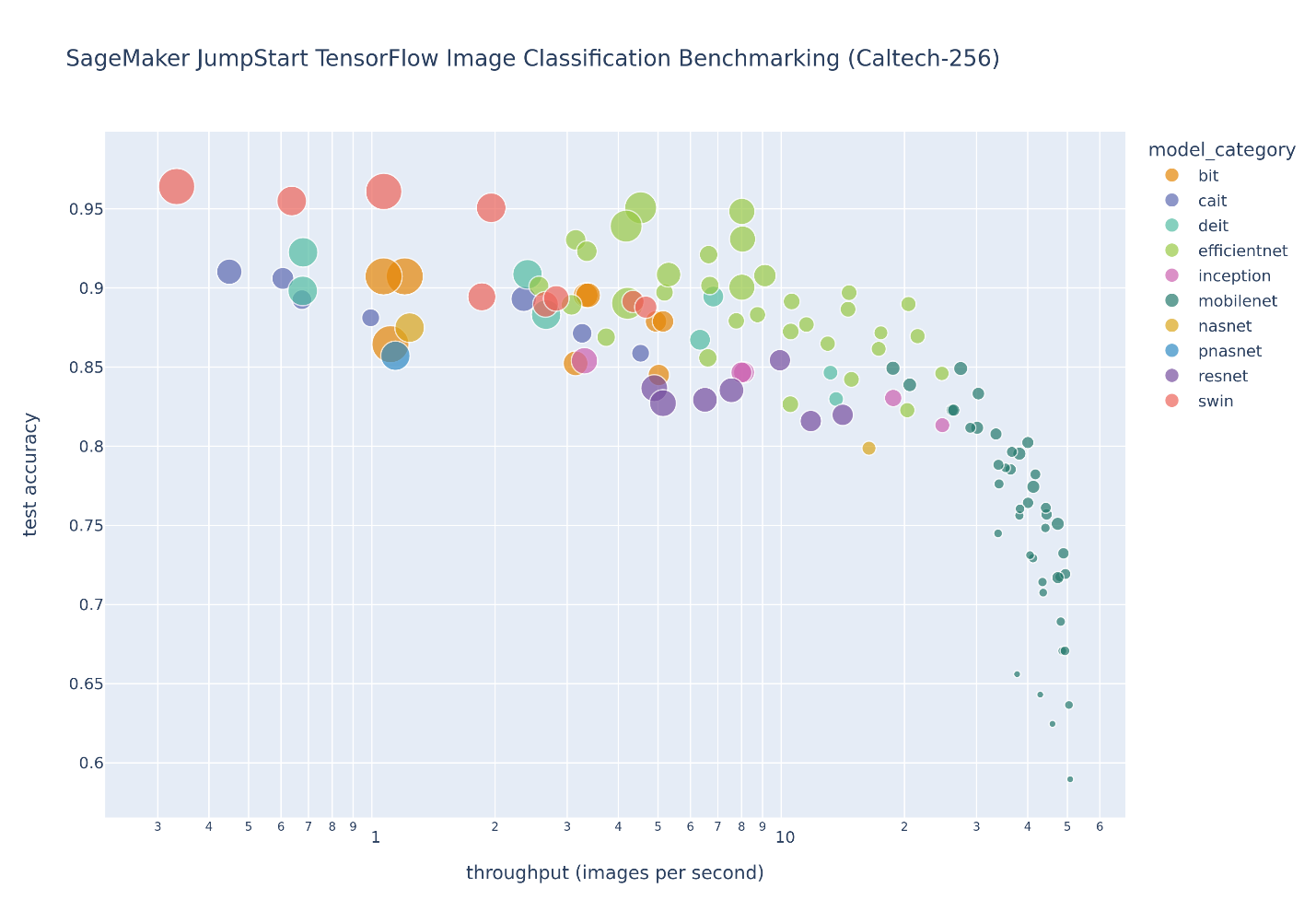
Om du observerar testnoggrannhet och testar genomströmningsgränser av intresse, extraheras uppsättningen av pareto-effektiva lösningar på föregående figur i följande tabell. Rader sorteras så att testgenomströmningen ökar och testnoggrannheten minskar.
| Modellnamn | Antal parametrar | Testnoggrannhet | Testa topp 5 noggrannhet | Genomströmning (bilder/er) | Varaktighet per epok(er) |
| swin-large-patch4-window12-384 | 195.6M | 96.4% | 99.5% | 0.3 | 2278.6 |
| swin-large-patch4-window7-224 | 195.4M | 96.1% | 99.5% | 1.1 | 698.0 |
| efficientnet-v2-imagenet21k-ft1k-l | 118.1M | 95.1% | 99.2% | 4.5 | 1434.7 |
| efficientnet-v2-imagenet21k-ft1k-m | 53.5M | 94.8% | 99.1% | 8.0 | 769.1 |
| efficientnet-v2-imagenet21k-m | 53.5M | 93.1% | 98.5% | 8.0 | 765.1 |
| efficientnet-b5 | 29.0M | 90.8% | 98.1% | 9.1 | 668.6 |
| efficientnet-v2-imagenet21k-ft1k-b1 | 7.3M | 89.7% | 97.3% | 14.6 | 54.3 |
| efficientnet-v2-imagenet21k-ft1k-b0 | 6.2M | 89.0% | 97.0% | 20.5 | 38.3 |
| efficientnet-v2-imagenet21k-b0 | 6.2M | 87.0% | 95.6% | 21.5 | 38.2 |
| mobilenet-v3-large-100-224 | 4.6M | 84.9% | 95.4% | 27.4 | 28.8 |
| mobilenet-v3-large-075-224 | 3.1M | 83.3% | 95.2% | 30.3 | 26.6 |
| mobilenet-v2-100-192 | 2.6M | 80.8% | 93.5% | 33.5 | 23.9 |
| mobilenet-v2-100-160 | 2.6M | 80.2% | 93.2% | 40.0 | 19.6 |
| mobilenet-v2-075-160 | 1.7M | 78.2% | 92.8% | 41.8 | 19.3 |
| mobilenet-v2-075-128 | 1.7M | 76.1% | 91.1% | 44.3 | 18.3 |
| mobilenet-v1-075-160 | 2.0M | 75.7% | 91.0% | 44.5 | 18.2 |
| mobilenet-v1-100-128 | 3.5M | 75.1% | 90.7% | 47.4 | 17.4 |
| mobilenet-v1-075-128 | 2.0M | 73.2% | 90.0% | 48.9 | 16.8 |
| mobilenet-v2-075-96 | 1.7M | 71.9% | 88.5% | 49.4 | 16.6 |
| mobilenet-v2-035-96 | 0.7M | 63.7% | 83.1% | 50.4 | 16.3 |
| mobilenet-v1-025-128 | 0.3M | 59.0% | 80.7% | 50.8 | 16.2 |
Det här inlägget ger detaljer om hur man implementerar storskalighet Amazon SageMaker benchmarking och modellvalsuppgifter. Först introducerar vi JumpStart och de inbyggda TensorFlow-bildklassificeringsalgoritmerna. Vi diskuterar sedan implementeringsöverväganden på hög nivå, såsom JumpStart hyperparameterkonfigurationer, metrisk extrahering från Amazon CloudWatch-loggar, och starta asynkrona hyperparameterjusteringsjobb. Slutligen täcker vi implementeringsmiljön och parametrering som leder till de pareto-effektiva lösningarna i föregående tabell och figur.
Introduktion till JumpStart TensorFlow-bildklassificering
JumpStart tillhandahåller finjustering och distribution med ett klick av en mängd olika förtränade modeller över populära ML-uppgifter, samt ett urval av helhetslösningar som löser vanliga affärsproblem. Dessa funktioner tar bort de tunga lyften från varje steg i ML-processen, vilket gör det lättare att utveckla högkvalitativa modeller och minskar tiden till implementering. De JumpStart API:er låter dig programmera distribuera och finjustera ett stort urval av förtränade modeller på dina egna datamängder.
JumpStart-modellhubben ger tillgång till ett stort antal TensorFlow bildklassificeringsmodeller som möjliggör överföringsinlärning och finjustering av anpassade datauppsättningar. När detta skrivs innehåller JumpStart-modellhubben 135 TensorFlow-bildklassificeringsmodeller över en mängd populära modellarkitekturer från TensorFlow Hub, för att inkludera kvarvarande nätverk (ResNet), MobileNet, EfficientNet, Start, Neural Architecture Search Networks (NASNet), Stor överföring (Bit), skiftat fönster (Swin) transformatorer, klassuppmärksamhet i bildtransformatorer (CaiT), och dataeffektiva bildtransformatorer (DeiT).
Väldigt olika interna strukturer omfattar varje modellarkitektur. Till exempel använder ResNet-modeller överhoppningsanslutningar för att möjliggöra väsentligt djupare nätverk, medan transformatorbaserade modeller använder självuppmärksamhetsmekanismer som eliminerar den inneboende lokaliteten för faltningsoperationer till förmån för mer globala mottagliga fält. Förutom de olika funktionsuppsättningarna som dessa olika strukturer tillhandahåller, har varje modellarkitektur flera konfigurationer som justerar modellens storlek, form och komplexitet inom den arkitekturen. Detta resulterar i hundratals unika bildklassificeringsmodeller som finns tillgängliga på JumpStart-modellhubben. I kombination med inbyggd överföringsinlärning och slutledningsskript som omfattar många SageMaker-funktioner, är JumpStart API en bra startpunkt för ML-utövare för att snabbt komma igång med utbildning och implementering av modeller.
Hänvisa till Överför lärande för TensorFlow-bildklassificeringsmodeller i Amazon SageMaker och följande exempel anteckningsbok för att lära dig mer om SageMaker TensorFlow-bildklassificering på djupet, inklusive hur man kör inferens på en förtränad modell samt finjusterar den förtränade modellen på en anpassad datauppsättning.
Storskaliga modellvalsöverväganden
Modellval är processen att välja den bästa modellen från en uppsättning kandidatmodeller. Denna process kan tillämpas på modeller av samma typ med olika parametervikter och över modeller av olika typer. Exempel på modellval mellan modeller av samma typ inkluderar att anpassa samma modell med olika hyperparametrar (till exempel inlärningshastighet) och tidigt stopp för att förhindra överanpassning av modellvikter till tåguppsättningen. Modellval mellan modeller av olika typer inkluderar att välja den bästa modellarkitekturen (till exempel Swin vs. MobileNet) och välja de bästa modellkonfigurationerna inom en enskild modellarkitektur (till exempel, mobilenet-v1-025-128 vs mobilenet-v3-large-100-224).
Övervägandena som beskrivs i detta avsnitt möjliggör alla dessa modellvalsprocesser på en valideringsdatauppsättning.
Välj hyperparameterkonfigurationer
TensorFlow bildklassificering i JumpStart har ett stort antal tillgängliga hyperparametrar som kan justera scriptbeteendena för överföringsinlärning enhetligt för alla modellarkitekturer. Dessa hyperparametrar hänför sig till dataförstärkning och förbearbetning, optimeringsspecifikation, överanpassningskontroller och inlärningsbara lagerindikatorer. Du uppmuntras att justera standardvärdena för dessa hyperparametrar efter behov för din applikation:
För denna analys och den tillhörande anteckningsboken är alla hyperparametrar inställda på standardvärden utom inlärningshastighet, antal epoker och specifikationer för tidig stopp. Inlärningshastigheten justeras som en kategorisk parameter genom att SageMaker automatisk modelljustering jobb. Eftersom varje modell har unika standardvärden för hyperparameter, inkluderar den diskreta listan över möjliga inlärningshastigheter standardinlärningshastigheten såväl som en femtedel av standardinlärningshastigheten. Detta startar två träningsjobb för ett enda hyperparameterjusteringsjobb, och det träningsjobb som har bäst rapporterad prestanda på valideringsdatauppsättningen väljs. Eftersom antalet epoker är inställt på 10, vilket är större än standardinställningen för hyperparametern, motsvarar det valda bästa träningsjobbet inte alltid standardinlärningshastigheten. Slutligen används ett kriterium för tidig stopp med ett tålamod, eller antalet epoker för att fortsätta träningen utan förbättring, på tre epoker.
En standard hyperparameterinställning av särskild betydelse är train_only_on_top_layer, var, om inställd på True, är modellens funktionsextraktionslager inte finjusterade på den tillhandahållna träningsdatauppsättningen. Optimeraren tränar bara parametrar i det översta fullt anslutna klassificeringsskiktet med utdatadimensionalitet lika med antalet klassetiketter i datamängden. Som standard är denna hyperparameter inställd på True, som är en inställning som är inriktad för överföring av lärande på små datamängder. Du kan ha en anpassad datauppsättning där funktionsextraktionen från förutbildningen på ImageNet-datauppsättningen inte är tillräcklig. I dessa fall bör du ställa in train_only_on_top_layer till False. Även om den här inställningen kommer att öka träningstiden, kommer du att extrahera mer meningsfulla funktioner för ditt problem och därigenom öka noggrannheten.
Extrahera mätvärden från CloudWatch-loggar
JumpStart TensorFlow bildklassificeringsalgoritm loggar tillförlitligt en mängd olika mätvärden under träning som är tillgängliga för SageMaker Estimator och HyperparameterTuner-objekt. Konstruktören av en SageMaker Estimator har en metric_definitions nyckelordsargument, som kan användas för att utvärdera träningsjobbet genom att tillhandahålla en lista över ordböcker med två nycklar: Namn för namnet på måtten, och Regex för det reguljära uttrycket som används för att extrahera måtten från loggarna. Den medföljande anteckningsbok visar implementeringsdetaljerna. Följande tabell listar tillgängliga mätvärden och associerade reguljära uttryck för alla JumpStart TensorFlow-bildklassificeringsmodeller.
| Metriskt namn | Vanligt uttryck |
| antal parametrar | "- Antal parametrar: ([0-9\.]+)" |
| antal träningsbara parametrar | "- Antal träningsbara parametrar: ([0-9\.]+)" |
| antal icke-träningsbara parametrar | "- Antal icke-träningsbara parametrar: ([0-9\.]+)" |
| tåguppsättningsmått | f"- {metrisk}: ([0-9\.]+)" |
| valideringsdatametrik | f"- val_{metrisk}: ([0-9\.]+)" |
| testdatauppsättningsmått | f"- Testa {metrisk}: ([0-9\.]+)" |
| tågets varaktighet | "- Total träningslängd: ([0-9\.]+)" |
| tåglängd per epok | "- Genomsnittlig träningslängd per epok: ([0-9\.]+)" |
| test utvärdering latens | "- Latens för testutvärdering: ([0-9\.]+)" |
| testlatens per prov | "- Genomsnittlig testlatens per prov: ([0-9\.]+)" |
| testa genomströmning | "- Genomsnittlig testgenomströmning: ([0-9\.]+)" |
Det inbyggda transferinlärningsskriptet tillhandahåller en mängd olika mätvärden för träning, validering och testdatauppsättning inom dessa definitioner, som representeras av f-strängsersättningsvärdena. De exakta mätvärdena som är tillgängliga varierar beroende på vilken typ av klassificering som utförs. Alla kompilerade modeller har en loss metrisk, som representeras av en korsentropiförlust för antingen ett binärt eller kategoriskt klassificeringsproblem. Den förra används när det finns en klassetikett; den senare används om det finns två eller flera klassetiketter. Om det bara finns en enskild klassetikett beräknas, loggas och extraheras följande mätvärden via f-strängens reguljära uttryck i föregående tabell: antal sanna positiva (true_pos), antal falska positiva (false_pos), antal sanna negativa (true_neg), antal falsknegativa (false_neg), precision, recall, område under mottagarens operationskarakteristik (ROC) kurva (auc), och området under precisions-återkallningskurvan (PR) (prc). På samma sätt, om det finns sex eller fler klassetiketter, ett topp-5-noggrannhetsmått (top_5_accuracy) kan också beräknas, loggas och extraheras via de föregående reguljära uttrycken.
Under utbildningen specificerades mätvärden till en SageMaker Estimator sänds ut till CloudWatch-loggar. När utbildningen är klar kan du åberopa SageMaker DescribeTrainingJob API och inspektera FinalMetricDataList nyckel i JSON-svaret:
Detta API kräver att endast jobbnamnet ges till frågan, så när det är klart kan mätvärden erhållas i framtida analyser så länge som utbildningsjobbets namn är korrekt loggat och återställbart. För denna modellvalsuppgift lagras jobbnamn för hyperparameterinställning och efterföljande analyser bifogar igen en HyperparameterTuner objekt med namnet på inställningsjobbet, extrahera det bästa träningsjobbnamnet från den bifogade hyperparametertunern och anropa sedan DescribeTrainingJob API som beskrivits tidigare för att få mätvärden förknippade med det bästa träningsjobbet.
Starta asynkrona hyperparameterjusteringsjobb
Se motsvarande anteckningsbok för implementeringsdetaljer om asynkron start av hyperparameterjusteringsjobb, som använder Python-standardbibliotekets samtidiga futures modul, ett gränssnitt på hög nivå för att asynkront köra anropsbara telefoner. Flera SageMaker-relaterade överväganden implementeras i denna lösning:
- Varje AWS-konto är anslutet till SageMaker tjänstekvoter. Du bör se dina nuvarande gränser för att utnyttja dina resurser fullt ut och eventuellt begära resursgränshöjningar vid behov.
- Frekventa API-anrop för att skapa många samtidiga hyperparameterjusteringsjobb kan överskrider Python SDK-hastigheten och ger undantag för strypning. En lösning på detta är att skapa en SageMaker Boto3-klient med en anpassad försökskonfiguration.
- Vad händer om ditt skript stöter på ett fel eller om skriptet stoppas innan det är klart? För ett så stort modellval eller benchmarkingstudie kan du logga inställningsjobbnamn och tillhandahålla bekvämlighetsfunktioner för återanslut hyperparameterjusteringsjobb som redan finns:
Analysdetaljer och diskussion
Analysen i detta inlägg utför överföringsinlärning för modell-ID i JumpStart TensorFlow-bildklassificeringsalgoritmen på Caltech-256-datauppsättningen. Alla träningsjobb utfördes på SageMaker-utbildningsinstansen ml.g4dn.xlarge, som innehåller en enda NVIDIA T4 GPU.
Testdatauppsättningen utvärderas på träningsinstansen i slutet av utbildningen. Modellval utförs före utvärderingen av testdatauppsättningen för att ställa in modellvikter till den epok med bästa prestanda för valideringsuppsättningen. Testgenomströmningen är inte optimerad: datasetets batchstorlek är inställd på standardinställningen för träningshyperparameterbatchstorleken, som inte justeras för att maximera GPU-minnesanvändningen; rapporterad testgenomströmning inkluderar dataladdningstid eftersom datamängden inte är pre-cache; och distribuerad slutledning över flera GPU:er används inte. Av dessa skäl är denna genomströmning ett bra relativt mått, men den faktiska genomströmningen skulle i hög grad bero på dina slutpunktsutbyggnadskonfigurationer för den tränade modellen.
Även om JumpStart-modellhubben innehåller många bildklassificeringsarkitekturtyper, domineras denna pareto-gräns av utvalda Swin-, EfficientNet- och MobileNet-modeller. Swin-modeller är större och relativt mer exakta, medan MobileNet-modeller är mindre, relativt mindre exakta och lämpliga för resursbegränsningar för mobila enheter. Det är viktigt att notera att denna gräns är beroende av en mängd olika faktorer, inklusive den exakta datamängden som används och de valda finjusterande hyperparametrarna. Du kanske upptäcker att din anpassade datauppsättning producerar en annan uppsättning pareto-effektiva lösningar, och du kanske önskar längre träningstider med olika hyperparametrar, såsom mer dataökning eller finjustering av mer än bara det översta klassificeringsskiktet i modellen.
Slutsats
I det här inlägget visade vi hur man kör storskaligt modellval eller benchmarkinguppgifter med hjälp av JumpStart-modellhubben. Denna lösning kan hjälpa dig att välja den bästa modellen för dina behov. Vi uppmuntrar dig att prova och utforska detta lösning på din egen datauppsättning.
Referensprojekt
Mer information finns på följande resurser:
Om författarna
 Dr Kyle Ulrich är en tillämpad vetenskapsman med Amazon SageMaker inbyggda algoritmer team. Hans forskningsintressen inkluderar skalbara maskininlärningsalgoritmer, datorseende, tidsserier, Bayesianska icke-parametriska och Gaussiska processer. Hans doktorsexamen är från Duke University och han har publicerat artiklar i NeurIPS, Cell och Neuron.
Dr Kyle Ulrich är en tillämpad vetenskapsman med Amazon SageMaker inbyggda algoritmer team. Hans forskningsintressen inkluderar skalbara maskininlärningsalgoritmer, datorseende, tidsserier, Bayesianska icke-parametriska och Gaussiska processer. Hans doktorsexamen är från Duke University och han har publicerat artiklar i NeurIPS, Cell och Neuron.
 Dr Ashish Khetan är senior tillämpad forskare med Amazon SageMaker inbyggda algoritmer och hjälper till att utveckla maskininlärningsalgoritmer. Han tog sin doktorsexamen från University of Illinois Urbana Champaign. Han är en aktiv forskare inom maskininlärning och statistisk slutledning och har publicerat många artiklar i NeurIPS, ICML, ICLR, JMLR, ACL och EMNLP-konferenser.
Dr Ashish Khetan är senior tillämpad forskare med Amazon SageMaker inbyggda algoritmer och hjälper till att utveckla maskininlärningsalgoritmer. Han tog sin doktorsexamen från University of Illinois Urbana Champaign. Han är en aktiv forskare inom maskininlärning och statistisk slutledning och har publicerat många artiklar i NeurIPS, ICML, ICLR, JMLR, ACL och EMNLP-konferenser.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/image-classification-model-selection-using-amazon-sagemaker-jumpstart/
- 10
- 100
- 9
- a
- Om oss
- tillgång
- tillgänglig
- Konto
- noggrannhet
- exakt
- Uppnå
- tvärs
- aktiv
- Dessutom
- adress
- adresser
- justerat
- Ansluten
- mot
- algoritm
- algoritmer
- Alla
- redan
- Även
- alltid
- amason
- Amazon SageMaker
- Amazon SageMaker JumpStart
- analys
- och
- Annan
- api
- Ansökan
- tillämpas
- lämpligt
- arkitektur
- OMRÅDE
- Argumentet
- associerad
- bifoga
- Försök
- Automat
- tillgänglig
- genomsnitt
- AWS
- baserat
- Bayesian
- därför att
- innan
- Där vi får lov att vara utan att konstant prestera,
- BÄST
- Stor
- inbyggd
- företag
- Samtal
- kandidat
- fall
- kategorier
- utmanande
- karakteristiska
- Välja
- klass
- klassificering
- klassificera
- klient
- kombinerad
- Gemensam
- jämförelse
- fullborda
- Avslutade
- fullbordan
- Komplexiteten
- dator
- Datorsyn
- oro
- konferenser
- konfiguration
- anslutna
- Anslutningar
- överväganden
- begränsningar
- innehåller
- fortsätta
- styrning
- kontroller
- bekvämlighet
- Motsvarande
- täcka
- skapa
- Aktuella
- kurva
- beställnings
- datum
- datauppsättningar
- djupare
- Standard
- beror
- distribuera
- utplacera
- utplacering
- djup
- beskriven
- beskrivning
- detaljer
- utveckla
- enheter
- olika
- diskutera
- distribueras
- flera
- inte
- Duke
- hertig universitet
- under
- varje
- Tidigare
- Tidig
- lättare
- effektiv
- antingen
- eliminera
- möjliggöra
- uppmuntra
- uppmuntras
- början till slut
- Slutpunkt
- Miljö
- epok
- epoker
- fel
- Eter (ETH)
- utvärdera
- utvärderade
- utvärdering
- exempel
- exempel
- Utom
- utforska
- Utforska
- uttryck
- extrahera
- extraktion
- faktorer
- verkligt
- gynna
- Leverans
- Funktioner
- Fält
- Figur
- Slutligen
- hitta
- Förnamn
- montering
- efter
- Tidigare
- från
- Frontier
- Gränser
- fullständigt
- funktioner
- framtida
- Futures
- generera
- skaffa sig
- ges
- Välgörenhet
- god
- GPU
- GPUs
- stor
- större
- Grön
- händer
- kraftigt
- hjälpa
- hjälper
- högnivå
- hög kvalitet
- högre
- Hur ser din drömresa ut
- How To
- html
- HTTPS
- Nav
- Hundratals
- Inställning av hyperparameter
- ICLR
- Illinois
- bild
- Bildklassificering
- IMAGEnet
- bilder
- genomföra
- genomförande
- genomföras
- vikt
- med Esport
- förbättring
- förbättra
- in
- innefattar
- innefattar
- Inklusive
- Öka
- Ökar
- ökande
- indikatorer
- informationen
- ingång
- exempel
- intresse
- intressen
- Gränssnitt
- inre
- inneboende
- införa
- IT
- Jobb
- Lediga jobb
- json
- Nyckel
- nycklar
- etikett
- Etiketter
- Large
- storskalig
- större
- Latens
- lanserar
- lansera
- lager
- skikt
- ledande
- LÄRA SIG
- inlärning
- lyft
- ljus
- BEGRÄNSA
- gränser
- Lista
- listor
- läser in
- Lång
- längre
- förlust
- Maskinen
- maskininlärning
- Framställning
- många
- Maximera
- meningsfull
- mätningar
- Minne
- metriska
- Metrics
- ML
- Mobil
- Mobil enheter
- modell
- modeller
- modul
- mer
- multipel
- namn
- namn
- nödvändigt för
- behövs
- behov
- nätverk
- neural
- NeurIPS
- Nya
- anteckningsbok
- antal
- Nvidia
- objektet
- objekt
- observera
- få
- erhållna
- ONE
- drift
- Verksamhet
- optimerad
- skisse
- egen
- papper
- parameter
- parametrar
- särskilt
- Tålamod
- utföra
- prestanda
- utför
- plato
- Platon Data Intelligence
- PlatonData
- Punkt
- poäng
- Populära
- möjlig
- Inlägg
- potentiellt
- pr
- förhindra
- Innan
- Problem
- problem
- process
- processer
- ge
- förutsatt
- ger
- tillhandahålla
- publicerade
- Python
- fråga
- frågor
- snabbt
- RAM
- Betygsätta
- rates
- verkliga världen
- skäl
- reducerande
- regelbunden
- relativt
- ta bort
- Rapporterad
- representerar
- representerade
- representerar
- begära
- Obligatorisk
- Krav
- Kräver
- forskning
- forskaren
- Upplösning
- resurs
- Resurser
- respons
- Resultat
- Körning
- rinnande
- sagemaker
- Samma
- skalbar
- Forskare
- skript
- sDK
- Sök
- §
- vald
- väljer
- Val
- senior
- Serier
- service
- session
- in
- uppsättningar
- inställning
- flera
- Forma
- skall
- Visar
- Liknande
- förenkla
- samtidig
- enda
- SEX
- Storlek
- storlekar
- Small
- mindre
- So
- lösning
- Lösningar
- LÖSA
- specifikation
- specifikationer
- specificerade
- standard
- igång
- statistisk
- Steg
- slutade
- stoppa
- lagras
- Läsa på
- senare
- väsentligen
- sådana
- tillräcklig
- lämplig
- bord
- riktade
- uppgift
- uppgifter
- grupp
- tensorflow
- testa
- Smakämnen
- deras
- vari
- tre
- genomströmning
- tid
- Tidsföljder
- gånger
- till
- i dag
- tillsammans
- verktyg
- topp
- topp 5
- Totalt
- Tåg
- tränad
- Utbildning
- överföring
- transformatorer
- sann
- typer
- Ytterst
- under
- unika
- universitet
- Användning
- användning
- utnyttja
- utnyttjas
- godkännande
- Värden
- mängd
- Omfattande
- via
- utsikt
- syn
- som
- medan
- bred
- kommer
- inom
- utan
- skulle
- skrivning
- Din
- zephyrnet