Detta är ett gästinlägg skrivet av Alex Naumov, huvuddataarkitekt på smava.
smava GmbH är ett av de ledande företagen för finansiella tjänster i Tyskland, som gör personliga lån transparenta, rättvisa och överkomliga för konsumenter. Baserat på digitala processer jämför smava låneerbjudanden från fler än 20 banker. På så sätt kan låntagare välja de affärer som är mest fördelaktiga för dem på ett snabbt, digitaliserat och effektivt sätt.
smava tror på och utnyttjar datadrivna beslut för att bli marknadsledande. Dataplattformsteamet ansvarar för att stödja datadrivna beslut på smava genom att tillhandahålla dataprodukter över alla avdelningar och grenar av företaget. Avdelningarna omfattar team från teknik till försäljning och marknadsföring. Filialer varierar efter produkter, nämligen B2C-lån, B2B-lån och tidigare även B2C-bolån. Dataprodukterna som används inom företaget inkluderar bland annat insikter från användarresor, verksamhetsrapporter och marknadsföringskampanjresultat. Dataplattformen betjänar i genomsnitt 60 tusen frågor per dag. Datavolymen är i tvåsiffriga tuberkulos med stadig tillväxt i takt med att verksamheten och datakällorna utvecklas.
smavas dataplattformsteam stod inför utmaningen att leverera data till intressenter med olika SLA:er, samtidigt som flexibiliteten att skala upp och ner samtidigt som de förblir kostnadseffektiva bibehålls. Det tog upp till 3 timmar att generera daglig rapportering, vilket påverkade affärsbeslut när omberäkningar behövde ske under dagen. För att påskynda självbetjäningsanalysen och främja innovation baserad på data behövdes en lösning för att ge alla team möjlighet att skapa dataprodukter på egen hand på ett decentraliserat sätt. För att skapa och hantera dataprodukterna använder smava Amazon RedShift, ett molndatalager.
I det här inlägget visar vi hur smava optimerade sin dataplattform genom att använda Amazon Redshift Serverlös och Amazon Redshift datadelning för att övervinna utmaningar med rätt storlek för oförutsägbara arbetsbelastningar och ytterligare förbättra pris-prestanda. Genom optimeringarna uppnådde smava upp till 50 % kostnadsbesparingar och upp till tre gånger snabbare rapportgenerering jämfört med den tidigare analysinfrastrukturen.
Översikt över lösningen
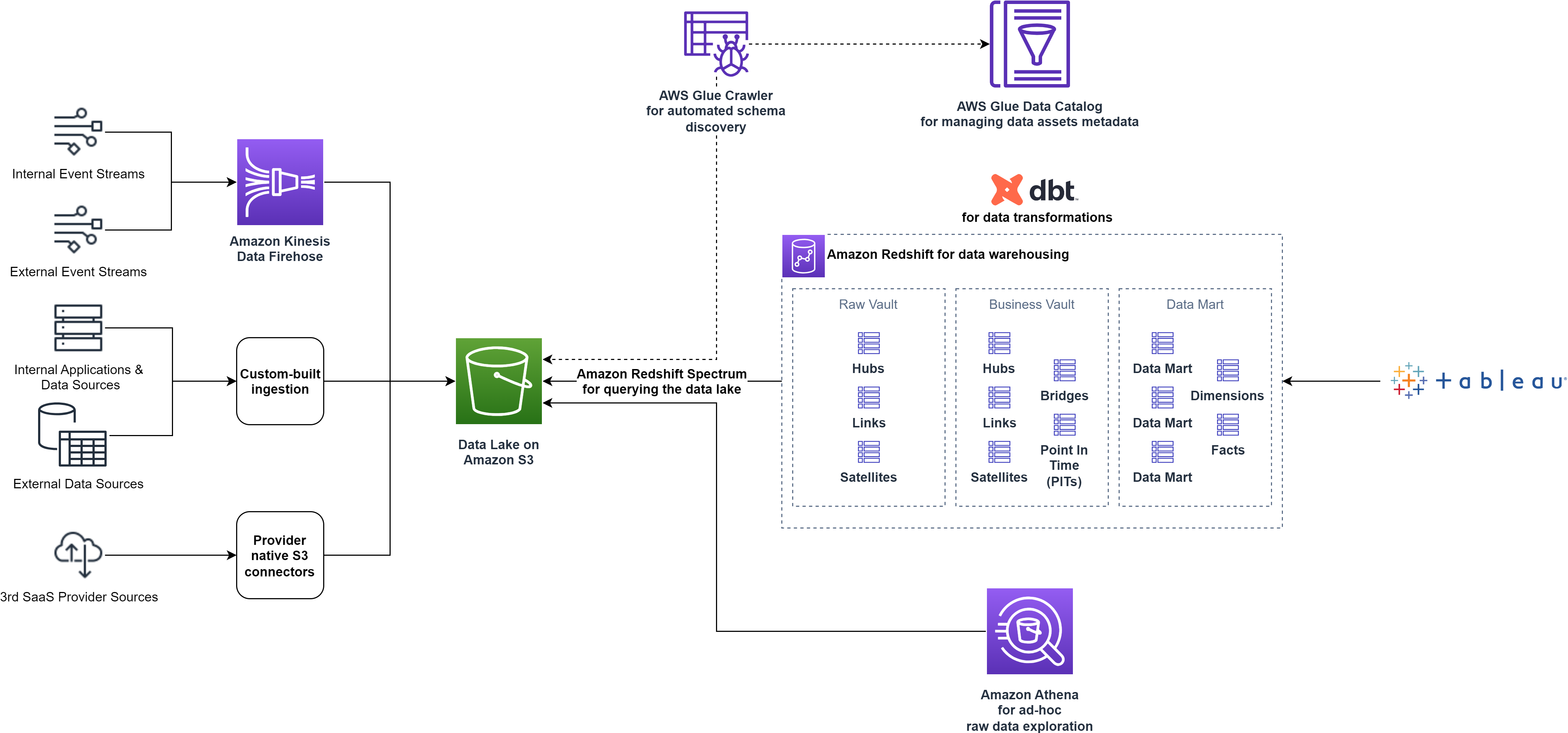
Som ett datadrivet företag förlitar sig smava på AWS Cloud för att driva sina analytiska användningsfall. För att ge sina kunder de bästa erbjudandena och användarupplevelsen följer smava modern dataarkitektur principer med en datasjö som ett skalbart, hållbart datalager och specialbyggda datalager för analytisk bearbetning och datakonsumtion.
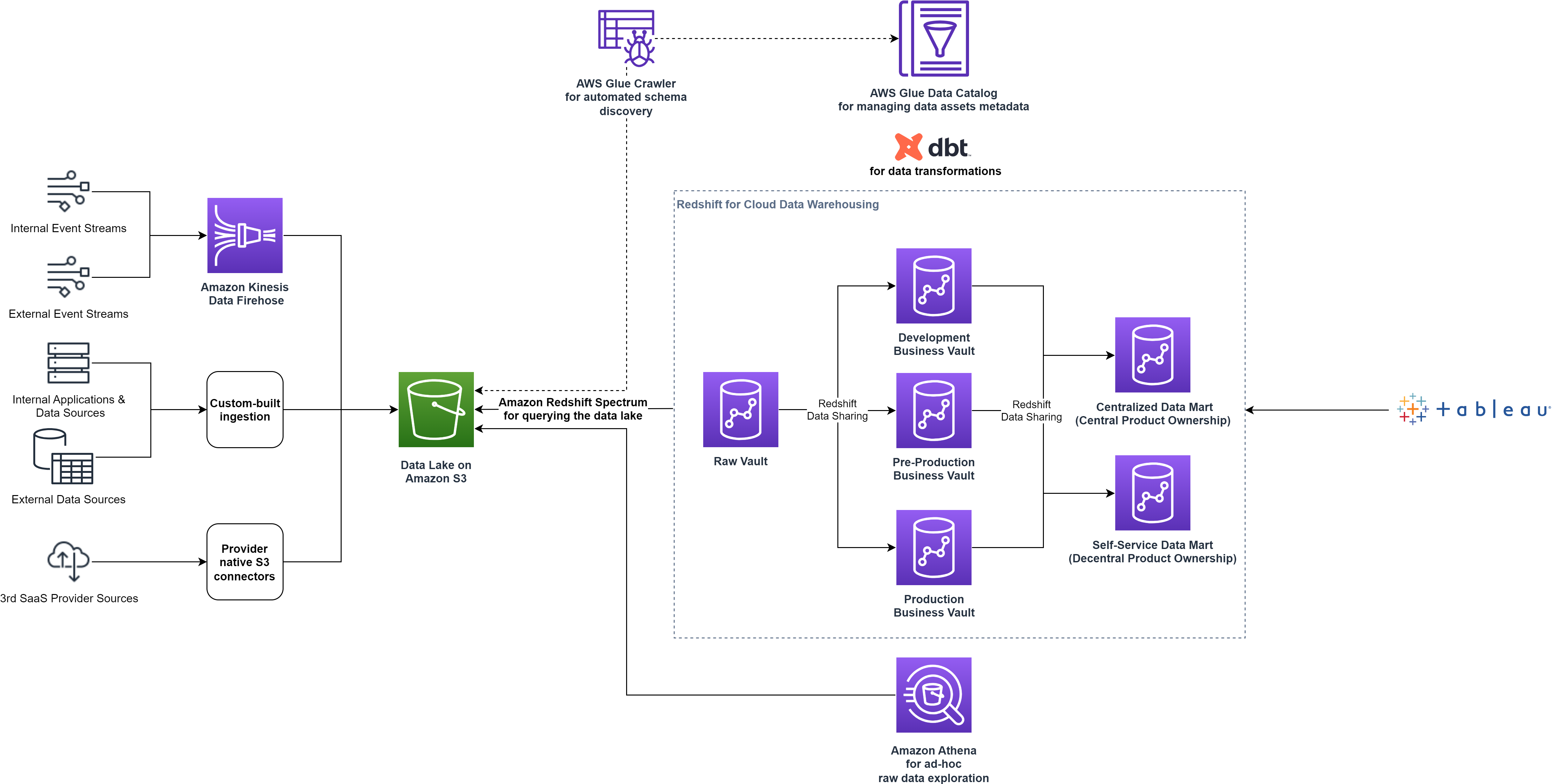
smava får in data från olika externa och interna datakällor till ett landningssteg på datasjön baserat på Amazon enkel lagringstjänst (Amazon S3). För att få in data använder smava en uppsättning populära tredjeparts kunddataplattformar kompletterade med anpassade skript.
Efter att data landar i Amazon S3 använder smava AWS-lim Datakatalog och sökrobotar för att automatiskt katalogisera tillgänglig data, fånga metadata och tillhandahålla ett gränssnitt som gör det möjligt att söka efter alla datatillgångar.
Dataanalytiker som behöver tillgång till råtillgångarna på datasjön använder Amazonas Athena, en serverlös, interaktiv analystjänst för utforskning med ad hoc-frågor. För nedströmskonsumtion av alla avdelningar i organisationen, förbereder smavas dataplattformsteam kurerade dataprodukter efter extrahera, ladda och transformera (ELT) mönster. smava använder Amazon Redshift som deras molndatalager för att transformera, lagra och analysera data och användningar Amazon Redshift Spectrum för att effektivt söka efter och hämta strukturerad och semistrukturerad data från datasjön med hjälp av SQL.
smava följer modellering av datavalv metodik med Raw Vault-, Business Vault- och Data Mart-stadierna för att förbereda dataprodukterna för slutkonsumenter. Raw Vault beskriver objekt som laddas direkt från datakällorna och representerar en kopia av landningsstadiet i datasjön. Business Vault fylls i med data som kommer från Raw Vault och omvandlas enligt affärsreglerna. Slutligen aggregeras data till specifika dataprodukter orienterade mot en specifik affärslinje. Det här är Data Mart skede. Dataprodukterna från Business Vault- och Data Mart-stadierna är nu tillgängliga för konsumenter. smava bestämde sig för att använda Tableau för affärsintelligens, datavisualisering och ytterligare analyser. Datatransformationerna hanteras med DBT för att förenkla arbetsflödesstyrningen och teamsamarbete.
Följande diagram visar dataplattformsarkitekturen på hög nivå före optimeringarna.
Utveckling av kraven på dataplattformen
smava började med ett enda Redshift-kluster för att vara värd för alla tre datasteg. De valde provisionerade klusternoder för RA3 typ med Reserverade instanser (RI) för kostnadsoptimering. Eftersom datavolymerna ökade med 53 % från år till år, ökade komplexiteten och kraven från olika analytiska arbetsbelastningar.
smava åtgärdade snabbt de växande datavolymerna genom att anpassa klustret i rätt storlek och använda Amazon Redshift Concurrency Scaling för toppbelastningar. Dessutom ville smava ge alla team möjlighet att skapa sina egna dataprodukter på ett självbetjäningssätt för att öka innovationstakten. För att undvika störningar av de centralt hanterade dataprodukterna behövde de decentraliserade produktutvecklingsmiljöerna vara strikt isolerade. Samma krav tillämpades också för isolering av olika produktsteg som kurerats av dataplattformsteamet.
Optimera arkitekturen med datadelning och Redshift Serverless
För att möta de utvecklade kraven, bestämde sig smava för att separera arbetsbelastningen genom att dela upp det enda tillhandahållna Redshift-klustret i flera datalager, där varje lager betjänar ett annat steg. Dessutom lade smava till nya iscensättningsmiljöer i Business Vault för att utveckla nya dataprodukter utan risk för att störa befintliga produktpipelines. För att undvika störningar med dataplattformsteamets centralt hanterade dataprodukter introducerade smava ytterligare ett Redshift-kluster som isolerade de decentraliserade arbetsbelastningarna.
smava letade efter en färdig lösning för att uppnå arbetsbelastningsisolering utan att hantera en komplex datareplikeringspipeline.
Direkt efter lanseringen av Redshift datadelning kapacitet 2021, insåg Data Platform-teamet att detta var lösningen de hade letat efter. smava använde datadelningsfunktionen för att ha data från producentkluster tillgängliga för läsåtkomst på olika konsumentkluster, där vart och ett av dessa konsumentkluster betjänar ett annat steg.
Redshift-datadelning möjliggör omedelbar, detaljerad och snabb dataåtkomst över Redshift-kluster utan att behöva kopiera data. Det ger liveåtkomst till data så att användarna alltid ser den mest uppdaterade och konsekventa informationen när den uppdateras i datalagret. Med datadelning kan du säkert dela livedata med Redshift-kluster i samma eller olika AWS-konton och över regioner.
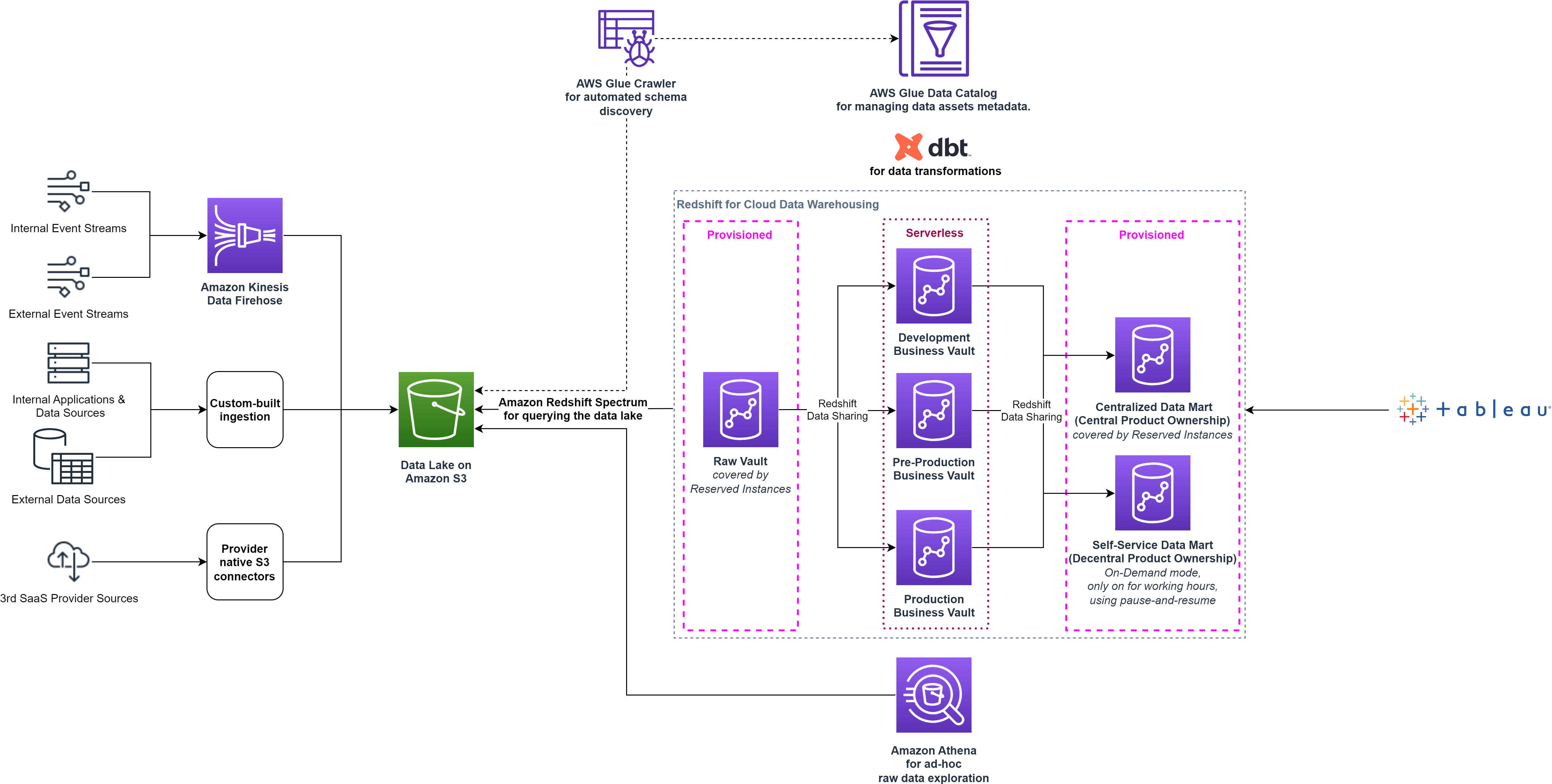
Med Redshift-datadelning kunde smava optimera dataarkitekturen genom att separera dataarbetsbelastningarna till enskilda konsumentkluster utan att behöva replikera data. Följande diagram illustrerar dataplattformsarkitekturen på hög nivå efter uppdelning av det enda Redshift-klustret i flera kluster.
Genom att tillhandahålla en datamart med självbetjäning ökade smava datademokratiseringen genom att ge användarna tillgång till alla aspekter av datan. De försåg också teamen med en uppsättning anpassade verktyg för dataupptäckt, ad hoc-analys, prototypframställning och drift av mogna dataprodukters hela livscykel.
Efter att ha samlat in driftsdata från de individuella klustren identifierade dataplattformsteamet ytterligare potentiella optimeringar: Raw Vault-klustret var under konstant belastning 24/7, men Business Vault-klustren uppdaterades bara varje natt. För att optimera för kostnader använde smava pausa och återuppta funktioner av Redshift-förberedda kluster. Dessa funktioner är användbara för kluster som måste vara tillgängliga vid specifika tidpunkter. Medan klustret är pausat stängs fakturering på begäran av. Endast klustrets lagring medför avgifter.
Pausa och återuppta-funktionen hjälpte smava att optimera för kostnaden, men det krävde ytterligare driftskostnader för att utlösa klusteroperationerna. Dessutom förblev utvecklingsklustren utsatta för lediga tider under arbetstid. Dessa utmaningar löstes slutligen genom att anta Redshift Serverless 2022. Dataplattformsteamet beslutade att flytta Business Data Vault-stegklustren till Redshift Serverless, vilket tillåter dem att betala för datalagret endast när det används, tillförlitligt och effektivt.
Redshift Serverless är idealiskt för fall där det är svårt att förutsäga beräkningsbehov såsom varierande arbetsbelastningar, periodiska arbetsbelastningar med vilotid och steady-state arbetsbelastningar med toppar. Dessutom, eftersom användningsefterfrågan utvecklas med nya arbetsbelastningar och fler samtidiga användare, tillhandahåller Redshift Serverless automatiskt rätt beräkningsresurser, och datalagret skalas sömlöst och automatiskt, utan behov av manuellt ingripande. Datadelning stöds i båda riktningarna mellan Redshift Serverless och provisionerade Redshift-kluster med RA3-noder, så inga ändringar i smava-arkitekturen behövdes. Följande diagram visar arkitekturinställningen på hög nivå efter övergången till Redshift Serverless.
smava kombinerade fördelarna med Redshift Serverless och dbt genom en sömlös CI/CD-pipeline, med en trunkbaserad utvecklingsmetodik. Ändringar på Git-förvaret distribueras automatiskt till ett teststeg och valideras med hjälp av automatiserade integrationstester. Detta tillvägagångssätt ökade effektiviteten hos utvecklarna och minskade den genomsnittliga tiden till produktion från dagar till minuter.
smava antog en arkitektur som använder både provisionerade och serverlösa Redshift-datalager, tillsammans med datadelningskapaciteten för att isolera arbetsbelastningarna. Genom att välja rätt arkitektoniska mönster för deras behov kunde smava åstadkomma följande:
- Förenkla datapipelines och minska driftskostnader
- Minska släpptiden för funktioner från dagar till minuter
- Öka pris-prestanda genom att minska lediga tider och anpassa arbetsbelastningen i rätt storlek
- Uppnå upp till tre gånger snabbare rapportgenerering (snabbare beräkningar och högre parallellisering) till 50 % av de ursprungliga installationskostnaderna
- Öka smidigheten för alla avdelningar och stödja datadrivet beslutsfattande genom att demokratisera tillgången till data
- Öka innovationshastigheten genom att exponera självbetjäningsdatakapacitet för team över alla avdelningar och stärka A/B-testkapaciteten för att täcka hela kundresan
Nu använder alla avdelningar på smava de tillgängliga dataprodukterna för att fatta datadrivna, korrekta och smidiga beslut.
Framtidsvision
För framtiden planerar smava att fortsätta att optimera dataplattformen baserat på operativa mätvärden. De överväger att byta ut fler tillhandahållna kluster som Self-Service Data Mart-klustret till serverlösa. Dessutom optimerar smava ELT-orkestreringsverktygskedjan för att öka antalet parallella datapipelines som ska köras. Detta kommer att öka utnyttjandet av reserverade Redshift-resurser och möjliggöra kostnadsminskningar.
Med introduktionen av den decentraliserade självbetjäningen för att skapa dataprodukter tog smava ett steg framåt mot en datanätsarkitektur. I framtiden planerar Data Platform-teamet att ytterligare utvärdera behoven hos sina tjänstanvändare och etablera ytterligare datanätprinciper som federerad datastyrning.
Slutsats
I det här inlägget visade vi hur smava optimerade sin dataplattform genom att isolera miljöer och arbetsbelastningar med hjälp av Redshift Serverless och datadelningsfunktioner. Dessa Redshift-miljöer är väl integrerade med sin infrastruktur, flexibla i skalning på efterfrågan och högt tillgängliga, och de kräver minimala administrationsinsatser. Sammantaget har smava ökat prestandan med tre gånger samtidigt som de har minskat de totala plattformskostnaderna med 50 %. Dessutom reducerade de driftskostnader till ett minimum samtidigt som de bibehöll de befintliga SLA:erna för rapportgenereringstider. Dessutom har smava stärkt innovationskulturen genom att tillhandahålla självbetjäningsdataproduktfunktioner för att snabba upp deras tid till marknaden.
Om du är intresserad av att lära dig mer om Amazon Redshift-funktioner rekommenderar vi att du tittar på den senaste Vad är nytt med Amazon Redshift-session i AWS Events-kanalen för att få en överblick över de funktioner som nyligen lagts till tjänsten. Du kan också utforska självbetjäning, praktiska Amazon Redshift-labb att experimentera med Amazon Redshift-funktionaliteter på ett guidat sätt.
Du kan också dyka djupare in i Redshift Serverless användningsfall och användningsfall för datadelning. Kolla dessutom in bästa praxis för datadelning och upptäck hur andra kunder optimerade för kostnad och prestanda med Redshift-datadelning för att bli inspirerad för din egen arbetsbelastning.
Om du föredrar böcker, kolla in Amazon Redshift: The Definitive Guide av O'Reilly, där författarna beskriver funktionerna hos Amazon Redshift och ger dig insikter om motsvarande mönster och tekniker.
Om författarna
 Alex Naumov är huvuddataarkitekt på smava GmbH och leder transformationsprojekten på dataavdelningen. Alex har tidigare arbetat 10 år som konsult och data-/lösningsarkitekt inom en mängd olika domäner, såsom telekommunikation, bank, energi och finans, med hjälp av olika teknikstackar och i många olika länder. Han har en stor passion för data och att transformera organisationer till att bli datadrivna och bäst på det de gör.
Alex Naumov är huvuddataarkitekt på smava GmbH och leder transformationsprojekten på dataavdelningen. Alex har tidigare arbetat 10 år som konsult och data-/lösningsarkitekt inom en mängd olika domäner, såsom telekommunikation, bank, energi och finans, med hjälp av olika teknikstackar och i många olika länder. Han har en stor passion för data och att transformera organisationer till att bli datadrivna och bäst på det de gör.
 Lingli Zheng arbetar som affärsutvecklingschef i AWS världsomspännande specialistorganisation och stödjer kunder i DACH-regionen för att få ut det bästa värdet av Amazons analystjänster. Med över 12 års erfarenhet inom energi, automation och mjukvaruindustrin med fokus på dataanalys, AI och ML, är hon dedikerad till att hjälpa kunder att uppnå konkreta affärsresultat genom digital transformation.
Lingli Zheng arbetar som affärsutvecklingschef i AWS världsomspännande specialistorganisation och stödjer kunder i DACH-regionen för att få ut det bästa värdet av Amazons analystjänster. Med över 12 års erfarenhet inom energi, automation och mjukvaruindustrin med fokus på dataanalys, AI och ML, är hon dedikerad till att hjälpa kunder att uppnå konkreta affärsresultat genom digital transformation.
 Alexander Spivak är Senior Startup Solutions Architect på AWS, med fokus på B2B ISV-kunder över hela EMEA North. Före AWS arbetade Alexander som konsult inom finansiella tjänster, inklusive olika roller inom mjukvaruutveckling och arkitektur. Han brinner för dataanalys, serverlösa arkitekturer och att skapa effektiva organisationer.
Alexander Spivak är Senior Startup Solutions Architect på AWS, med fokus på B2B ISV-kunder över hela EMEA North. Före AWS arbetade Alexander som konsult inom finansiella tjänster, inklusive olika roller inom mjukvaruutveckling och arkitektur. Han brinner för dataanalys, serverlösa arkitekturer och att skapa effektiva organisationer.
Det här inlägget granskades för teknisk noggrannhet av David Greenshtein, Senior Analytics Solutions Architect.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/how-smava-makes-loans-transparent-and-affordable-using-amazon-redshift-serverless/
- : har
- :är
- :var
- $UPP
- 10
- 100
- 12
- 125
- 20
- 2021
- 2022
- 60
- a
- Able
- Om oss
- tillgång
- Tillgång till data
- åstadkomma
- Enligt
- konton
- noggrannhet
- exakt
- Uppnå
- uppnås
- tvärs
- Ad
- lagt till
- Dessutom
- Annat
- Dessutom
- adresserad
- administrering
- antagen
- Anta
- Fördel
- prisvärd
- Efter
- smidig
- AI
- alex
- Alexander
- Alla
- tillåter
- tillåter
- också
- alltid
- amason
- Amazon Web Services
- bland
- an
- analys
- analytiker
- Analytisk
- Analytisk
- analytics
- analysera
- och
- vilken som helst
- tillämpas
- tillvägagångssätt
- arkitektoniska
- arkitektur
- ÄR
- AS
- aspekter
- Tillgångar
- At
- Författaren
- Författarna
- Automatiserad
- automatiskt
- Automation
- tillgänglig
- genomsnitt
- undvika
- AWS
- B2B
- B2C
- Banking
- Banker
- baserat
- BE
- blir
- varit
- innan
- tror
- Fördelarna
- BÄST
- mellan
- fakturering
- Blogg
- Böcker
- låntagare
- båda
- grenar
- föra
- företag
- affärsutveckling
- business intelligence
- men
- by
- Kampanj
- KAN
- kapacitet
- kapacitet
- fånga
- fall
- katalog
- utmanar
- utmaningar
- Förändringar
- avgifter
- ta
- Välja
- välja
- valde
- cloud
- kluster
- samverkan
- Samla
- kombinerad
- Företag
- företag
- jämfört
- fullborda
- komplex
- Komplexiteten
- Compute
- konkurrent
- med tanke på
- konsekvent
- konsult
- Konsumenten
- konsumenter
- konsumtion
- fortsätta
- Motsvarande
- Pris
- kostnadsbesparingar
- Kostar
- länder
- täcka
- skapa
- Skapa
- skapande
- kultur
- kurerad
- beställnings
- kund
- konsument data
- Kunder
- dagligen
- datum
- datatillgång
- Data Analytics
- datasjö
- Dataplattform
- datadeling
- datavisualisering
- datalagret
- datalager
- data driven
- David
- dag
- Dagar
- Erbjudanden
- decentraliserad
- beslutade
- Beslutsfattande
- beslut
- minskade
- dedicerad
- djupare
- slutgiltig
- leverera
- Efterfrågan
- demokratisering
- demokrati
- Avdelning
- avdelningar
- utplacerade
- detalj
- utveckla
- utvecklare
- Utveckling
- DID
- olika
- svårt
- digital
- digital Transformation
- riktningar
- direkt
- Upptäck
- Upptäckten
- Dyk
- do
- domäner
- ner
- under
- varje
- effektivitet
- effektiv
- effektivt
- ansträngningar
- EMEA
- möjliggör
- änden
- energi
- uppdrag
- Teknik
- miljöer
- etablera
- Eter (ETH)
- utvärdera
- händelser
- utvecklas
- utvecklats
- utvecklas
- befintliga
- erfarenhet
- experimentera
- utforskning
- utforska
- extern
- inför
- verkligt
- SNABB
- snabbare
- gynnsam
- Leverans
- Funktioner
- Slutligen
- finansiering
- finansiella
- finansiella tjänster
- Flexibilitet
- flexibel
- Fokus
- fokusering
- efter
- följer
- För
- För konsumenterna
- förr
- Framåt
- Foster
- från
- full
- funktionaliteter
- ytterligare
- Vidare
- framtida
- generera
- generering
- Tyskland
- skaffa sig
- gå
- Ge
- GmBH
- styrning
- stor
- växte
- Odling
- Tillväxt
- Gäst
- gäst inlägg
- styra
- guidad
- hade
- praktisk
- hända
- Har
- har
- he
- hjälpte
- hjälpa
- högnivå
- högre
- höggradigt
- värd
- ÖPPETTIDER
- Hur ser din drömresa ut
- html
- HTTPS
- idealisk
- identifierade
- Idle
- illustrerar
- påverkade
- förbättra
- in
- innefattar
- Inklusive
- Öka
- ökat
- individuellt
- industrin
- informationen
- Infrastruktur
- Innovation
- inuti
- insikter
- inspirerat
- instanser
- omedelbar
- integrerade
- integrering
- Intelligens
- interaktiva
- intresserad
- Gränssnitt
- störningar
- interfererande
- inre
- ingripande
- in
- introducerade
- införa
- Beskrivning
- isolerat
- isolering
- ISV
- IT
- Journeys
- Nyckel
- sjö
- landning
- landar
- lansera
- ledare
- ledande
- Leads
- inlärning
- livscykel
- tycka om
- linje
- lever
- livedata
- läsa in
- lån
- Lån
- du letar
- gjord
- upprätthålla
- göra
- GÖR
- Framställning
- hantera
- förvaltade
- chef
- hantera
- sätt
- manuell
- många
- marknad
- Marknadsledare
- Marknadsföring
- mogen
- Möt
- maska
- metadata
- Metodik
- Metrics
- minsta
- minuter
- ML
- mer
- Dessutom
- hypotekslån
- mest
- flytta
- multipel
- nämligen
- Behöver
- behövs
- behov
- Nya
- Nej
- noder
- Nord
- nu
- antal
- objekt
- of
- Erbjudanden
- on
- On-Demand
- ONE
- endast
- drift
- operativa
- Verksamhet
- optimering
- Optimera
- optimerad
- optimera
- Alternativet
- or
- orkestrering
- beställa
- organisation
- organisationer
- ursprungliga
- Övriga
- Övrigt
- ut
- över
- övergripande
- Övervinna
- Översikt
- egen
- Fred
- Parallell
- brinner
- brinner
- Mönster
- mönster
- paus
- pausad
- Betala
- Topp
- för
- prestanda
- periodisk
- personlig
- Personliga lån
- rörledning
- planer
- plattform
- Plattformar
- plato
- Platon Data Intelligence
- PlatonData
- Populära
- befolkad
- Inlägg
- potentiell
- kraft
- förutse
- föredra
- Förbered
- förbereder
- föregående
- tidigare
- Principal
- Principerna
- Innan
- processer
- bearbetning
- producent
- Produkt
- produktutveckling
- Produktion
- Produkter
- projekt
- prototyping
- ge
- förutsatt
- ger
- tillhandahålla
- sökfrågor
- snabbt
- område
- Raw
- Läsa
- senaste
- nyligen
- erkänt
- rekommenderar
- minska
- Minskad
- reducerande
- minskningar
- region
- regioner
- frigöra
- förblev
- replikation
- rapport
- Rapportering
- Rapport
- Repository
- representerar
- kräver
- Obligatorisk
- krav
- Krav
- Resurser
- ansvarig
- Resultat
- Fortsätt
- Granskad
- höger
- Risk
- roller
- regler
- Körning
- försäljning
- Försäljning och marknadsföring
- Samma
- Besparingar
- skalbar
- Skala
- skalor
- skalning
- skript
- sömlös
- sömlöst
- säkert
- se
- Självbetjäning
- senior
- separat
- separerande
- Server
- serverar
- service
- Tjänster
- portion
- session
- in
- inställning
- Dela
- delning
- hon
- show
- visade
- Visar
- Enkelt
- förenkla
- enda
- So
- Mjukvara
- mjukvaruutveckling
- lösning
- Lösningar
- löst
- kommer från
- Källor
- specialist
- specifik
- fart
- spikar
- SQL
- Stacks
- Etapp
- stadier
- staging
- intressenter
- igång
- start
- vistas
- stadig
- Steg
- förvaring
- lagra
- lagrar
- förstärkt
- förstärkning
- strukturerade
- ämne
- sådana
- stödja
- Som stöds
- Stödjande
- suspenderades
- Tableau
- tar
- påtaglig
- grupp
- lag
- tech
- Teknisk
- tekniker
- telekommunikationer
- testa
- tester
- än
- den där
- Smakämnen
- Framtiden
- deras
- Dem
- Dessa
- de
- tredje part
- detta
- de
- tusen
- tre
- Genom
- tid
- gånger
- till
- tillsammans
- tog
- verktyg
- Totalt
- mot
- Förvandla
- Transformation
- transformationer
- transformerad
- omvandla
- transparent
- utlösa
- under
- oförutsägbar
- TIDSENLIG
- uppdaterad
- Användning
- användning
- Begagnade
- Användare
- Användarupplevelse
- användare
- användningar
- med hjälp av
- Återvinnare
- validerade
- värde
- variabel
- mängd
- olika
- Valv
- visualisering
- volym
- volymer
- ville
- Warehouse
- var
- tittar
- Sätt..
- sätt
- we
- webb
- webbservice
- VÄL
- były
- Vad
- när
- som
- medan
- VEM
- bred
- wikipedia
- kommer
- med
- utan
- arbetade
- arbetsflöde
- arbetssätt
- Arbetstid
- fungerar
- Workshops
- inom hela sverige
- år
- år
- dig
- Din
- Youtube
- zephyrnet