Beskrivning
I det snabbt utvecklande landskapet för generativ AI har vektordatabasernas centrala roll blivit alltmer uppenbar. Den här artikeln dyker ner i den dynamiska synergin mellan vektordatabaser och generativa AI-lösningar, och utforskar hur dessa tekniska grundstenar formar framtiden för kreativitet med artificiell intelligens. Följ med oss på en resa genom den här kraftfulla alliansens krångligheter, och lås upp insikter om den transformativa inverkan som vektordatabaser ger till framkanten av innovativa AI-lösningar.
Inlärningsmål
Den här artikeln hjälper dig att förstå aspekterna av vektordatabasen nedan.
- Betydelsen av vektordatabaser och dess nyckelkomponenter
- Detaljerad studie av vektordatabasjämförelse med traditionell databas
- Utforskning av vektorinbäddningar från en applikationssynpunkt
- Vektor databas byggnad med Pincone
- Implementering av Pinecone Vector-databas med hjälp av langchain LLM-modell
Denna artikel publicerades som en del av Data Science Blogathon.
Innehållsförteckning
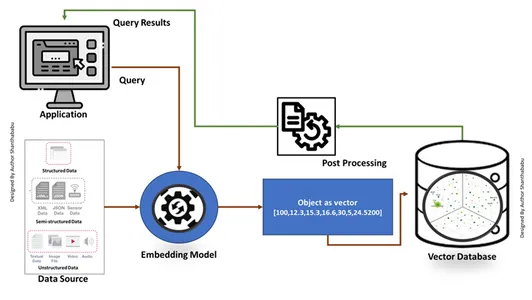
Vad är Vector Database?
En vektordatabas är en form av datainsamling som lagras i rymden. Ändå, här lagras det i matematiska representationer eftersom formatet som lagras i databaserna gör det lättare för öppna AI-modeller att memorera indata och tillåter vår öppna AI-applikation att använda kognitiv sökning, rekommendationer och textgenerering för olika användningsfall i de digitalt transformerade industrierna. Lagring av data och hämtning kallas "Vektorinbäddningar" eller "Inbäddningar." Dessutom är detta representerat i ett numeriskt matrisformat. Att söka är mycket enklare än traditionella databaser som används för AI-perspektiv med enorma, indexerade möjligheter.
Egenskaper för vektordatabaser
- Det drar nytta av kraften i dessa vektorinbäddningar, vilket leder till indexering och sökning i en enorm datauppsättning.
- Kompakt med alla dataformat (bilder, text eller data).
- Eftersom den anpassar inbäddningstekniker och mycket indexerade funktioner kan den erbjuda en komplett lösning för att hantera data och indata för det givna problemet.
- En vektordatabas organiserar data genom högdimensionella vektorer som innehåller hundratals dimensioner. Vi kan konfigurera dem mycket snabbt.
- Varje dimension motsvarar en specifik egenskap eller egenskap hos dataobjektet som den representerar.
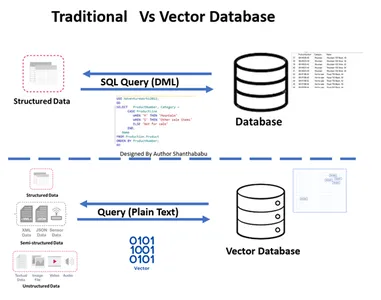
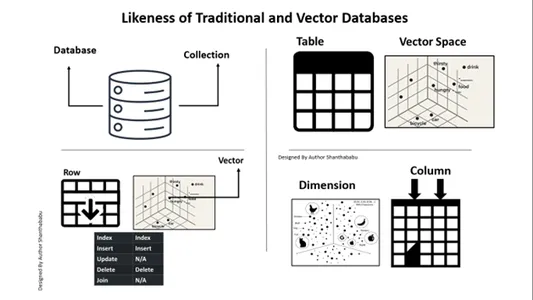
Traditionell vs. Vektor databas
- Bilden visar det traditionella arbetsflödet och vektordatabasen på hög nivå
- Formella databasinteraktioner sker genom SQL uttalanden och data lagrade i radbas- och tabellformat.
- I Vector-databasen sker interaktioner genom vanlig text (t.ex. engelska) och data som lagras i matematiska representationer.
Likhet med traditionella och vektordatabaser
Vi måste överväga hur Vector-databaser skiljer sig från traditionella. Låt oss diskutera detta här. En snabb skillnad jag kan ge är den i konventionella databaser. Data lagras exakt som de är; vi skulle kunna lägga till lite affärslogik för att justera data och slå samman eller dela upp data baserat på affärskrav eller krav. Vektordatabasen har dock en massiv transformation, och data blir en komplex vektorrepresentation.
Här är en karta för din förståelse och tydlighet relationella databaser mot vektordatabaser. Bilden nedan är självförklarande för att förstå vektordatabaser med traditionella databaser. Kort sagt, vi kan exekvera infogning och borttagning i vektordatabaser, inte uppdatera uttalanden.
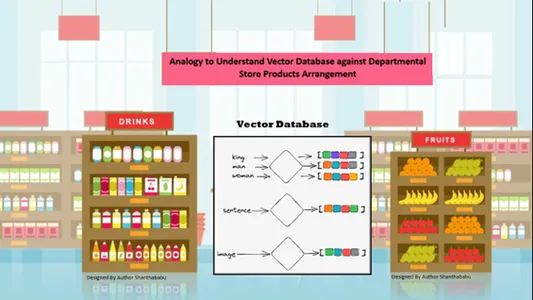
Enkel analogi för att förstå vektordatabaser
Data ordnas automatiskt rumsligt av innehållslikheten i den lagrade informationen. Så låt oss överväga varuhuset för vektordatabasanalogi; alla produkter är ordnade på hyllan utifrån natur, syfte, tillverkning, användning och kvantitetsbas. I ett liknande beteende är uppgifterna
automatiskt ordnade i vektordatabasen på liknande sätt, även om genren inte var väldefinierad under lagring eller åtkomst av data.
Vektordatabaserna tillåter en framträdande granularitet och dimensioner på de specifika likheterna, så att kunden söker efter önskad produkt, tillverkare och kvantitet och behåller varan i varukorgen. Vektordatabas lagrar all data i en perfekt lagringsstruktur; här behöver maskininlärnings- och AI-ingenjörer inte märka eller tagga det lagrade innehållet manuellt.
Väsentliga teorier bakom vektordatabaser
- Vektorinbäddningar och deras omfattning
- Indexeringskrav
- Förstå semantisk och likhetssökning
Vektorinbäddning och deras omfattning
En vektorinbäddning är en vektorrepresentation i termer av de numeriska värdena. I ett komprimerat format fångar inbäddningar de inneboende egenskaperna och associationerna för originaldata, vilket gör dem till en häftklammer i användningsfallen för artificiell intelligens och maskininlärning. Att designa inbäddningar för att koda relevant information om originaldata till ett utrymme med lägre dimensioner säkerställer hög hämtningshastighet, beräkningseffektivitet och effektiv lagring.
Att fånga essensen av data på ett mer identiskt strukturerat sätt är processen för vektorinbäddning, som bildar en "inbäddningsmodell." I slutändan tar dessa modeller hänsyn till alla dataobjekt, extraherar meningsfulla mönster och relationer inom datakällan och omvandlar dem till vektorinbäddningar. . Därefter utnyttjar algoritmer dessa vektorinbäddningar för att utföra olika uppgifter. Många högutvecklade inbäddningsmodeller, tillgängliga online som antingen gratis eller betalbara, underlättar genomförandet av vektorinbäddning.
Omfattning av vektorinbäddningar från en applikationssynpunkt
Dessa inbäddningar är kompakta, innehåller komplex information, ärver relationer mellan data som lagras i en vektordatabas, möjliggör en effektiv databehandlingsanalys för att underlätta förståelse och beslutsfattande, och bygger dynamiskt olika innovativa dataprodukter i alla organisationer.
Vektorinbäddningstekniker är viktiga för att koppla ihop gapet mellan läsbar data och komplexa algoritmer. Med datatyper som numeriska vektorer kunde vi låsa upp potentialen för ett stort antal generativa AI-applikationer tillsammans med tillgängliga Open AI-modeller.
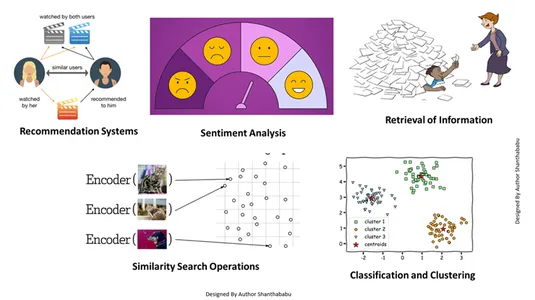
Flera jobb med vektorinbäddning
Denna vektorinbäddning hjälper oss att utföra flera jobb:
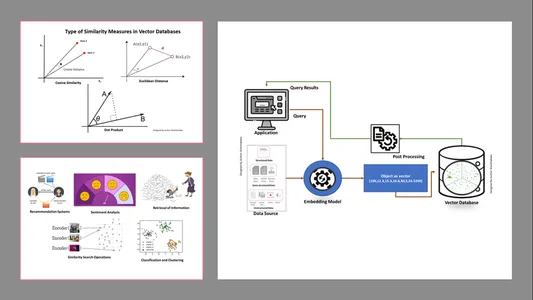
- Hämtning av information: Med hjälp av dessa kraftfulla tekniker kan vi bygga inflytelserika sökmotorer som kan hjälpa oss att hitta svar baserat på användarfrågor från lagrade filer, dokument eller media
- Likhetssökningsoperationer: Detta är välorganiserat och indexerat; det hjälper oss att hitta likheten mellan olika förekomster i vektordata.
- Klassificering och klustring: Med hjälp av dessa inbäddningstekniker kan vi utföra dessa modeller för att träna relevanta maskininlärningsalgoritmer och gruppera och klassificera dem.
- Rekommendationssystem: Eftersom inbäddningsteknikerna är korrekt organiserade leder det till rekommendationssystem som korrekt relaterar produkter, media och artiklar baserat på historiska data.
- Sentimentanalys: Denna inbäddningsmodell hjälper oss att kategorisera och härleda sentimentlösningar.
Indexeringskrav
Som vi vet kommer indexet att förbättra sökdata från tabellen i traditionella databaser, liknande vektordatabaser, och tillhandahålla indexeringsfunktionerna.
Vektordatabaser tillhandahåller "Platta index", som är den direkta representationen av vektorinbäddningen. Sökförmågan är omfattande, och denna använder inte förutbildade kluster. Den utför frågevektorn utförs över varje enskild vektorinbäddning, och K avstånd beräknas för varje par.
- På grund av det enkla med detta index krävs minimal beräkning för att skapa de nya indexen.
- Ett platt index kan faktiskt hantera frågor effektivt och ge snabba hämtningstider.
Förstå semantisk och likhetssökning
Vi gör två olika sökningar i vektordatabaser: semantiska och likhetssökningar.
- Semantisk sökning: När du söker efter information, istället för att söka efter nyckelord, kan du hitta dem baserat på meningsfull konversationsmetodik. Snabb ingenjörskonst spelar en viktig roll för att överföra input till systemet. Denna sökning tillåter utan tvekan sökningar och resultat av högre kvalitet som kan matas för innovativa applikationer, SEO, textgenerering och sammanfattning.
- Likhetssökning: Alltid i dataanalys möjliggör likhetssökningen ostrukturerade, mycket bättre givna datamängder. När det gäller vektordatabaser måste vi fastställa närheten mellan två vektorer och hur de liknar varandra: tabeller, text, dokument, bilder, ord och ljudfiler. I processen att förstå avslöjas likheten mellan vektorer som likheten mellan dataobjekten i den givna datamängden. Den här övningen hjälper oss att förstå interaktion, identifiera mönster, extrahera insikter och fatta beslut ur tillämpningsperspektiv. Semantic and Similarity-sökningen skulle hjälpa oss att bygga applikationerna nedan för branschfördelar.
- Informationsinhämtning: Med hjälp av öppna AI- och vektordatabaser skulle vi bygga sökmotorer för informationshämtning med hjälp av företagsanvändares eller slutanvändares frågor och indexerade dokument i vektor-DB.
- Klassificering och klustring:Att klassificera eller gruppera liknande datapunkter eller grupper av objekt innebär att de tilldelas flera kategorier baserat på delade egenskaper.
- Anomalidetektering: Upptäcka avvikelser från vanliga mönster genom att mäta likheten mellan datapunkter och upptäcka oregelbundenheter.
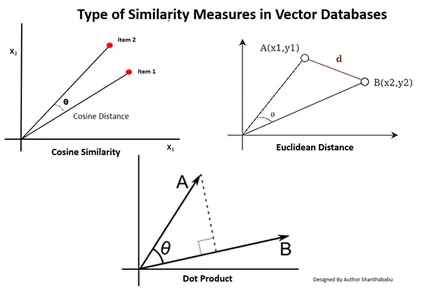
Typer av likhetsmått i vektordatabaser
Mätmetoderna beror på typen av data och den specifika applikationen. Vanligtvis används tre metoder för att mäta likheten och förtrogenheten med Machine Learning.
Euklidisk avstånd
Enkelt uttryckt är avståndet mellan de två vektorerna det raka avståndet mellan de två vektorpunkterna som mäter st.
Punkt produkt
Detta hjälper oss att förstå inriktningen mellan två vektorer, vilket indikerar om de pekar i samma riktning, motsatta riktningar eller är vinkelräta mot varandra.
Cosine likhet
Den bedömer likheten mellan två vektorer genom att använda vinkeln mellan dem, som visas i figuren. I detta fall är värdena och storleken på vektorerna obetydliga och påverkar inte resultaten; endast vinkeln beaktas i beräkningen.
Traditionella databaser Sök efter exakta SQL-satsmatchningar och hämta data i tabellformat. Samtidigt hanterar vi vektordatabaser som söker efter den vektor som liknar indatafrågan på vanlig engelska med hjälp av promptteknik. Databasen använder sökalgoritmen Approximate Nearest Neighbour (ANN) för att hitta liknande data. Ge alltid någorlunda exakta resultat med hög prestanda, noggrannhet och svarstid.
Arbetsmekanism
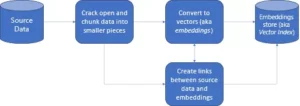
- Vektordatabaser konverterar först data till inbäddningsvektorer, lagrar dem i vektordatabaser och skapar indexering för snabbare sökning.
- En fråga från applikationen kommer att interagera med inbäddningsvektorn, söka efter närmaste granne eller liknande data i vektordatabasen med hjälp av ett index och hämta resultaten som skickas till applikationen.
- Baserat på affärskraven skulle den hämtade informationen finjusteras, formateras och visas för slutanvändarsidan eller fråge- eller åtgärdsflödet.
Skapa en vektordatabas
Låt oss få kontakt med Pinecone.
Du kan ansluta till Pinecone med Google, GitHub eller Microsoft ID.
Skapa en ny användarinloggning för din användning.
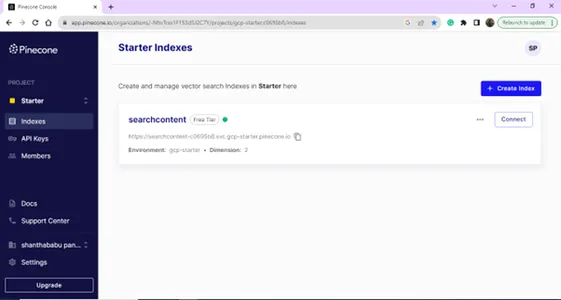
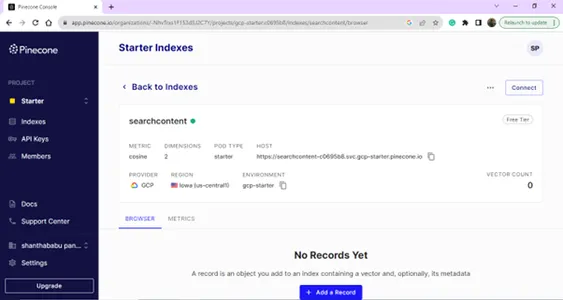
Efter lyckad inloggning kommer du att landa på indexsidan; du kan skapa ett index för din vektordatabas. Klicka på knappen Skapa index.
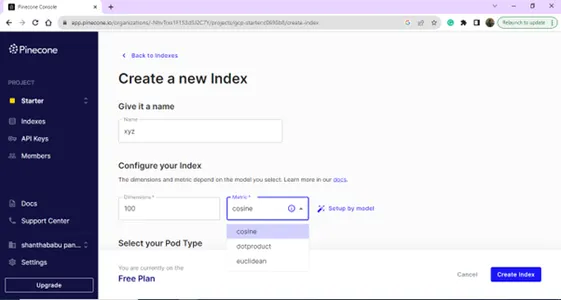
Skapa ditt nya index genom att ange namn och mått.
Index listsida,
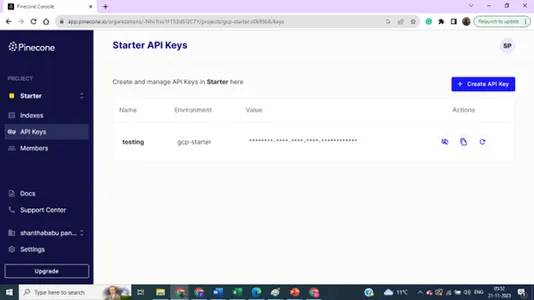
Indexdetaljer – Namn, Region och Miljö – Vi behöver alla dessa detaljer för att koppla ihop vår vektordatabas från modellbyggkoden.
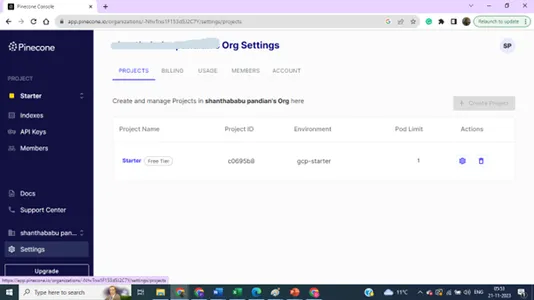
Projektinställningar detaljer,
Du kan uppgradera dina inställningar för flera index och nycklar för projektändamål.
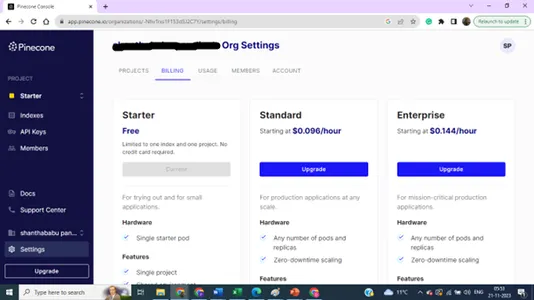
Hittills har vi diskuterat att skapa vektordatabasens index och inställningar i Pinecone.
Vektordatabasimplementering med Python
Låt oss göra lite kodning nu.
Importerar bibliotek
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
from langchain.vectorstores import Pinecone
from langchain.document_loaders import TextLoader
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAITillhandahåller API-nyckel för OpenAI och Vector-databas
import os
os.environ["OPENAI_API_KEY"] = "xxxxxxxx"
PINECONE_API_KEY = os.environ.get('PINECONE_API_KEY', 'xxxxxxxxxxxxxxxxxxxxxxx')
PINECONE_API_ENV = os.environ.get('PINECONE_API_ENV', 'gcp-starter')
api_keys="xxxxxxxxxxxxxxxxxxxxxx"
llm = OpenAI(OpenAI=api_keys, temperature=0.1)Initierar LLM
llm=OpenAI(openai_api_key=os.environ["OPENAI_API_KEY"],temperature=0.6)Initierar Pinecone
import pinecone
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
index_name = "demoindex" Laddar .csv-fil för att bygga vektordatabas
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="/content/drive/My Drive/Colab_Notebooks/cereal.csv"
,source_column="name")
data = loader.load()Dela upp texten i bitar
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=20)
text_chunks = text_splitter.split_documents(data)Hitta texten i text_chunk
text_chunksProduktion
[Document(page_content='name: 100% Brannmfr: Nntyp: Cncalories: 70nprotein: 4nfett: 1natrium: 130nfiber: 10ncarbo: 5nsockers: 6npotass: 280nvitaminer: 25nnatrium: 3n1cups: 0.33n68.402973cups: 100n0nnatt: XNUMXnXNUMXn: XNUMXnXNUMXn XNUMXnrekommendation: Barns, metadata={ 'källa': 'XNUMX % kli', 'rad': XNUMX}), , …..
Bygga inbäddning
embeddings = OpenAIEmbeddings()Skapa en Pinecone-instans för vektordatabas från "data"
vectordb = Pinecone.from_documents(text_chunks,embeddings,index_name="demoindex")Skapa en retriever för att fråga vektordatabasen.
retriever = vectordb.as_retriever(score_threshold = 0.7)Hämtar data från vektordatabasen
rdocs = retriever.get_relevant_documents("Cocoa Puffs")
rdocsAnvänd Fråga och hämta data
from langchain.prompts import PromptTemplate
prompt_template = """Given the following context and a question,
generate an answer based on this context only.
,Please state "I don't know." Don't try to make up an answer.
CONTEXT: {context}
QUESTION: {question}"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
input_key="query",
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs)
Låt oss fråga uppgifterna.
chain('Can you please provide cereal recommendation for Kids?')Utdata från Query
{'query': 'Can you please provide cereal recommendation for Kids?',
'result': [Document(page_content='name: Crispixnmfr: Kntype: Cncalories: 110nprotein: 2nfat: 0nsodium: 220nfiber: 1ncarbo: 21nsugars: 3npotass: 30nvitamins: 25nshelf: 3nweight: 1ncups: 1nrating: 46.895644nrecommendation: Kids', metadata={'row': 21.0, 'source': '/content/drive/My Drive/Colab_Notebooks/cereal.csv'}), ..]Slutsats
Hoppas du kan förstå hur vektordatabaser fungerar, deras komponenter, arkitektur och egenskaper hos vektordatabaser i generativa AI-lösningar. Förstå hur vektordatabasen skiljer sig från traditionell databas och jämförelse med konventionella databaselement. Faktum är att analogin hjälper dig att bättre förstå vektordatabasen. Pinecone vektordatabas och indexeringssteg skulle hjälpa dig att skapa en vektordatabas och ta med nyckeln för följande kodimplementering.
Key Takeaways
- Kompakt med strukturerad, ostrukturerad och semistrukturerad data.
- Den anpassar inbäddningstekniker och mycket indexerade funktioner.
- Interaktionerna sker genom vanlig text med en prompt (t.ex. engelska). Och data lagrad i matematiska representationer.
- Likhet kalibreras i vektordatabaser genom – Euklidiskt avstånd, Cosinuslikhet och Punktprodukt.
Vanliga frågor
A. En vektordatabas lagrar en samling data i rymden. Det håller data i matematiska representationer. eftersom formatet som lagras i databaserna gör det lättare för öppna AI-modeller att memorera tidigare indata och låter vår öppna AI-applikation använda kognitiv sökning, rekommendationer och exakt textgenerering för olika användningsfall i digitalt transformerade industrier.
S. Några av egenskaperna är: 1. Det utnyttjar kraften i dessa vektorinbäddningar, vilket leder till indexering och sökning i en enorm datauppsättning. 2. Kompakt med strukturerad, ostrukturerad och semistrukturerad data. 3. En vektordatabas organiserar data genom högdimensionella vektorer som innehåller hundratals dimensioner
A. Databas ==> Samlingar
Tabell==> Vektorutrymme
Rad==>Cector
Kolumn==>Dimension
Infoga och ta bort är möjliga i Vector-databaser, precis som i en traditionell databas.
Uppdatering och gå med är inte i omfattning.
– Hämtning av information för massiv datainsamling snabbt.
– Semantiska och likhetssökningar från de enorma dokumenten.
– Klassificering och klustertillämpning.
– System för rekommendation och sentimentanalys.
A5: Nedan följer de tre metoderna för att mäta likheten:
– Euklidiskt avstånd
– Cosinuslikhet
- Punkt produkt
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
Relaterad
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2023/12/vector-databases-in-generative-ai-solutions/
- : har
- :är
- :inte
- $UPP
- 1
- 10
- 12
- 13
- 46
- 7
- 8
- 9
- a
- Able
- Om oss
- åtkomst
- noggrannhet
- exakt
- exakt
- tvärs
- anpassar sig
- lägga till
- påverka
- AI
- AI-modeller
- algoritm
- algoritmer
- uppriktning
- Alla
- Alliance
- tillåter
- tillåter
- längs
- alltid
- bland
- an
- analys
- analytics
- Analys Vidhya
- och
- svara
- vilken som helst
- api
- skenbar
- Ansökan
- applikationsspecifik
- tillämpningar
- ungefärlig
- arkitektur
- ÄR
- anordnad
- array
- Artikeln
- artiklar
- konstgjord
- artificiell intelligens
- Konstgjord intelligens och maskininlärning
- AS
- aspekter
- utvärderar
- föreningar
- At
- audio
- automatiskt
- tillgänglig
- baserat
- BE
- blir
- blir
- beteende
- bakom
- Där vi får lov att vara utan att konstant prestera,
- nedan
- Fördelarna
- Bättre
- mellan
- bloggaton
- föra
- SLUTRESULTAT
- Byggnad
- företag
- Knappen
- by
- beräknat
- beräkning
- kallas
- KAN
- kapacitet
- kapacitet
- fånga
- Vid
- fall
- kategorier
- kedja
- kedjor
- egenskaper
- klarhet
- klassificering
- klassificera
- klick
- klustring
- koda
- Kodning
- kognitiv
- samling
- vanligen
- kompakt
- jämföra
- jämförelse
- fullborda
- komplex
- komponenter
- omfattande
- beräkning
- beräkningar
- Kontakta
- Anslutning
- Tänk
- anses
- innehålla
- innehåll
- sammanhang
- konventionell
- Konversation
- konvertera
- motsvarar
- kunde
- skapa
- Skapa
- kreativitet
- kund
- datum
- dataanalys
- datapunkter
- databehandling
- Databas
- databaser
- datauppsättningar
- behandla
- Beslutsfattande
- beslut
- krav
- härleda
- design
- önskas
- detaljer
- Detektering
- utvecklade
- skilja sig
- Skillnaden
- olika
- digitalt
- Dimensionera
- dimensioner
- rikta
- riktning
- riktningar
- upptäcka
- diskretion
- diskutera
- diskuteras
- visas
- avstånd
- do
- dokument
- gör
- donation
- DOT
- dynamisk
- dynamiskt
- e
- varje
- lätta
- lättare
- effektivt
- effektivitet
- effektiv
- antingen
- element
- inbäddning
- möjliggöra
- änden
- Teknik
- Ingenjörer
- Motorer
- Engelska
- säkerställer
- Miljö
- huvudsak
- väsentlig
- Eter (ETH)
- Även
- utvecklas
- exekvera
- Motionera
- Utforska
- extrahera
- främja
- Förtrogenhet
- långt
- Leverans
- Funktioner
- Fed
- Figur
- Fil
- Filer
- hitta
- Förnamn
- platta
- efter
- För
- förgrunden
- formen
- format
- Fri
- från
- framtida
- spalt
- generera
- generering
- generativ
- Generativ AI
- snäll
- GitHub
- Ge
- ges
- Grupp
- Gruppens
- hantera
- hända
- Har
- hjälpa
- hjälper
- här.
- Hög
- högnivå
- höggradigt
- historisk
- Hur ser din drömresa ut
- Men
- HTTPS
- stor
- Hundratals
- i
- ID
- identifiera
- if
- bilder
- Inverkan
- genomförande
- importera
- förbättra
- in
- alltmer
- index
- indexeras
- index
- indikerar
- index
- industrier
- industrin
- Inflytelserik
- informationen
- inneboende
- innovativa
- ingång
- ingångar
- Insert
- inuti
- insikter
- exempel
- istället
- Intelligens
- interagera
- interaktion
- interaktioner
- in
- intrikat
- innebär
- IT
- DESS
- Lediga jobb
- delta
- Följ med oss
- resa
- bara
- Nyckel
- nycklar
- nyckelord
- barn
- Vet
- etikett
- land
- liggande
- Large
- ledande
- Leads
- inlärning
- Hävstång
- hävstångs
- tycka om
- Lista
- Lastaren
- Logiken
- logga in
- Maskinen
- maskininlärning
- större
- göra
- GÖR
- Framställning
- hantera
- sätt
- manuellt
- Tillverkare
- karta
- massiv
- tändstickor
- matematisk
- meningsfull
- mäta
- åtgärder
- mätning
- mekanism
- Media
- Sammanfoga
- Metodik
- metoder
- Microsoft
- minimum
- modell
- modeller
- mer
- Dessutom
- mest
- mycket
- multipel
- måste
- namn
- Natur
- Behöver
- Nya
- nu
- talrik
- objektet
- objekt
- of
- erbjudanden
- on
- ONE
- ettor
- nätet
- endast
- öppet
- OpenAI
- Verksamhet
- motsatt
- or
- organisation
- Organiserad
- organiserar
- ursprungliga
- OS
- Övriga
- vår
- ägd
- sida
- par
- del
- Godkänd
- Förbi
- mönster
- perfekt
- utföra
- prestanda
- utfört
- utför
- perspektiv
- perspektiv
- Bild
- svängbara
- Enkel
- plato
- Platon Data Intelligence
- PlatonData
- spelar
- snälla du
- Punkt
- poäng
- möjlig
- potentiell
- kraft
- den mäktigaste
- Praktisk
- Praktiska tillämpningar
- exakt
- exakt
- preferenser
- föregående
- Problem
- process
- Produkt
- Produkter
- projektet
- framträdande
- prompter
- ordentligt
- egenskaper
- egenskapen
- ge
- tillhandahålla
- tillhandahållande
- publicerade
- puffs
- Syftet
- syfte
- mängd
- sökfrågor
- fråga
- Snabbt
- snabbare
- snabbt
- snabbt
- Rekommendation
- rekommendationer
- om
- region
- relationer
- Förhållanden
- relevanta
- representation
- representerade
- representerar
- Obligatorisk
- Krav
- respons
- svar
- resultera
- Resultat
- avslöjade
- Roll
- RAD
- s
- Samma
- Vetenskap
- omfattning
- Sök
- Sökmotorer
- sök
- söka
- känsla
- SEO
- inställningar
- Forma
- formning
- delas
- Hylla
- Kort
- visas
- Visar
- sida
- liknande
- Likheterna
- Enkelt
- eftersom
- enda
- Storlek
- So
- lösning
- Lösningar
- några
- Källa
- Utrymme
- specifik
- fart
- delas
- spotting
- SQL
- Ange
- .
- uttalanden
- Steg
- Fortfarande
- förvaring
- lagra
- lagras
- lagrar
- struktur
- strukturerade
- Läsa på
- Senare
- framgångsrik
- synergi
- system
- System
- T
- bord
- MÄRKA
- uppgifter
- tekniker
- teknisk
- villkor
- text
- textgenerering
- än
- den där
- Smakämnen
- Framtiden
- deras
- Dem
- Dessa
- de
- detta
- tre
- Genom
- tid
- gånger
- till
- traditionell
- Tåg
- Förvandla
- Transformation
- transformativ
- transformerad
- prova
- två
- typer
- Ytterst
- förstå
- förståelse
- otvivelaktigt
- låsa
- upplåsning
- Uppdatering
- uppgradera
- us
- Användning
- användning
- Begagnade
- Användare
- användningar
- med hjälp av
- vanliga
- Värden
- mängd
- olika
- mycket
- avgörande
- vs
- var
- we
- webp
- väldefinierad
- były
- Vad
- Vad är
- om
- som
- medan
- kommer
- med
- inom
- ord
- Arbete
- arbetssätt
- skulle
- dig
- Din
- zephyrnet